
Reinforcement Learning for Fail-Operational Systems with Disentangled Dual-Skill Variables



Abstract
1. Introduction
2. Related Works
2.1. Safe Reinforcement Learning
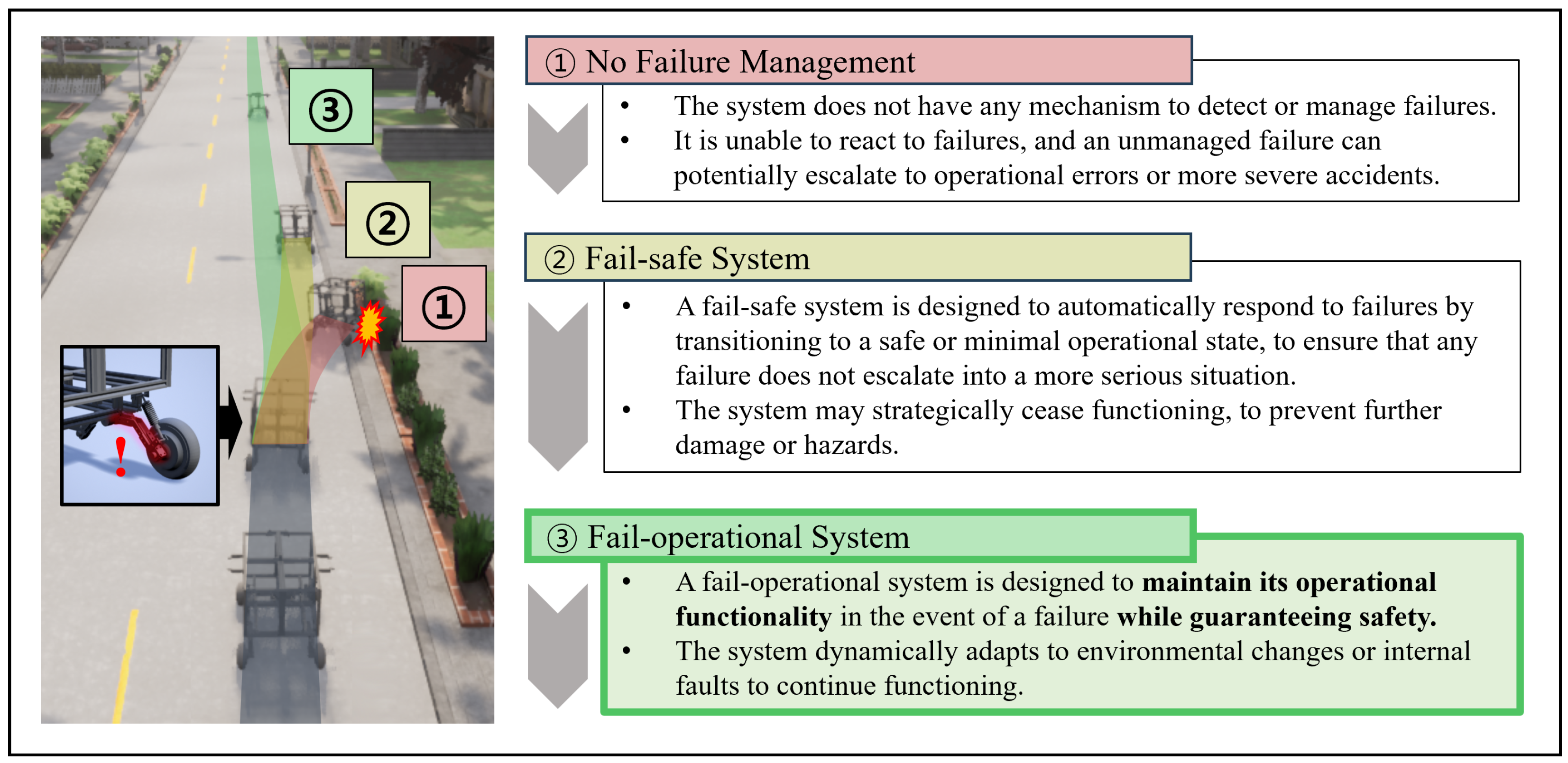
2.2. Fail-Operational Systems
2.3. Skill-Based Reinforcement Learning
2.4. Disentangled Skill Discovery
3. Methodology
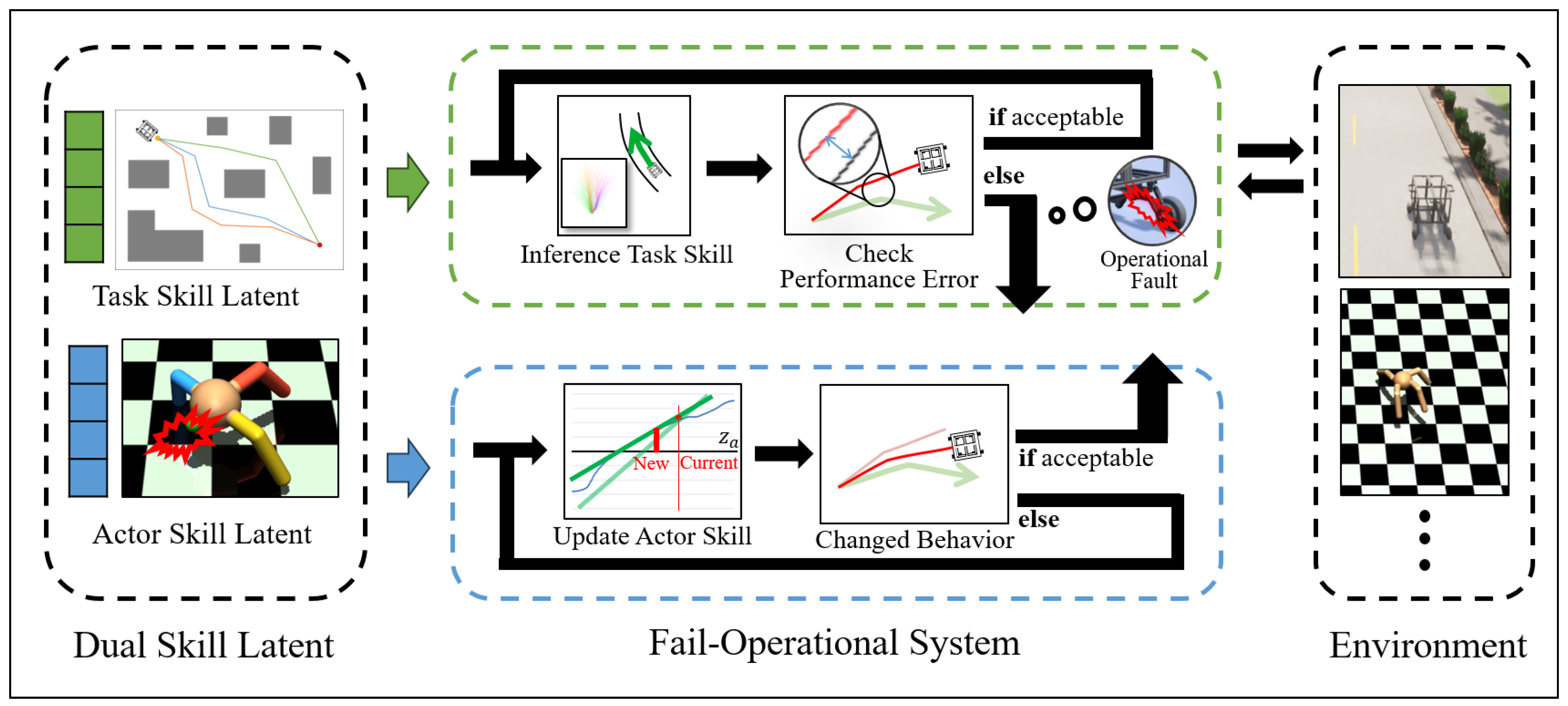
3.1. Skill-Based Fail-Operational System
3.2. Dual Skill Latents
3.2.1. Task Skill Learner and Sampler
3.2.2. Actor Skill Learner
3.3. Skill Inferencing
3.3.1. Task Skill
3.3.2. Actor Skill
| Algorithm 1 Skill inference algorithm |
|
4. Experiments
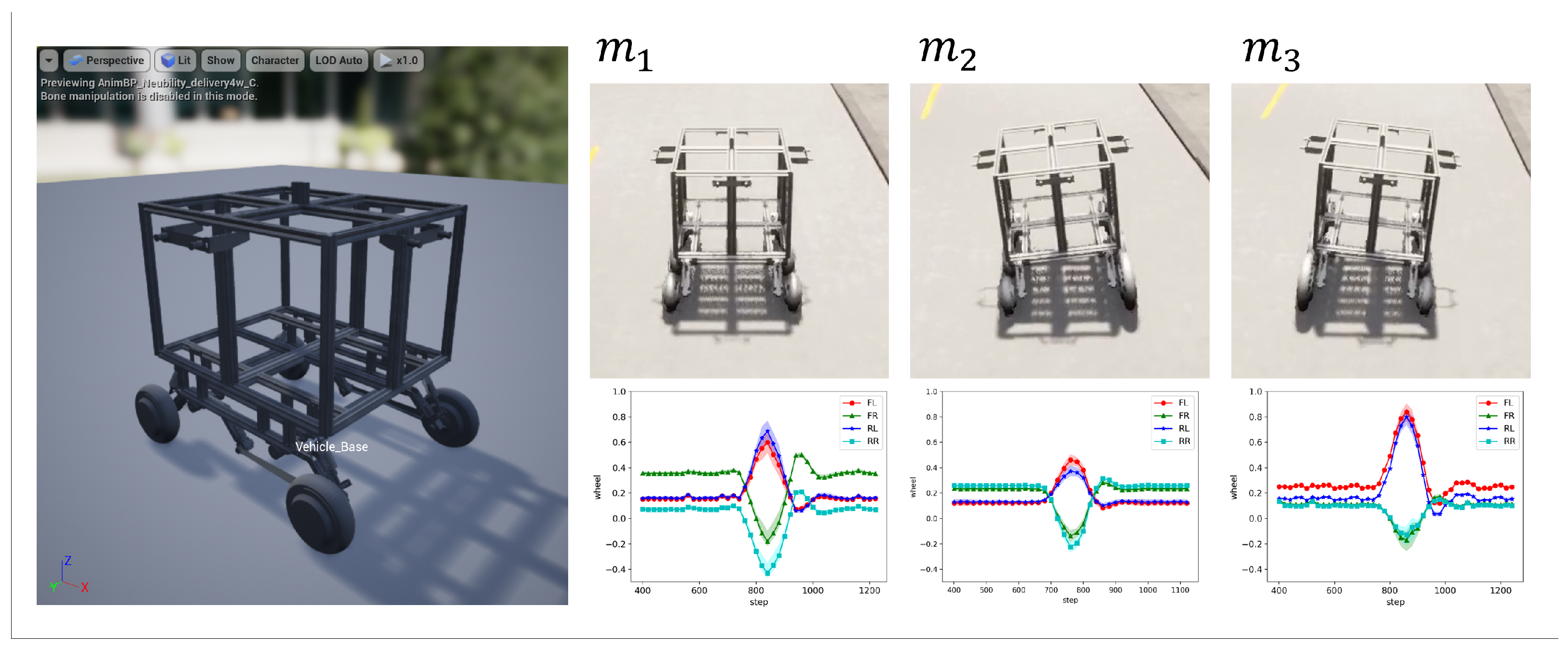
4.1. Skill Discovery from Predefined Models
4.2. Visualization of Skill Latent Space
4.2.1. Task Skill Latent
4.2.2. Actor Skill Latent
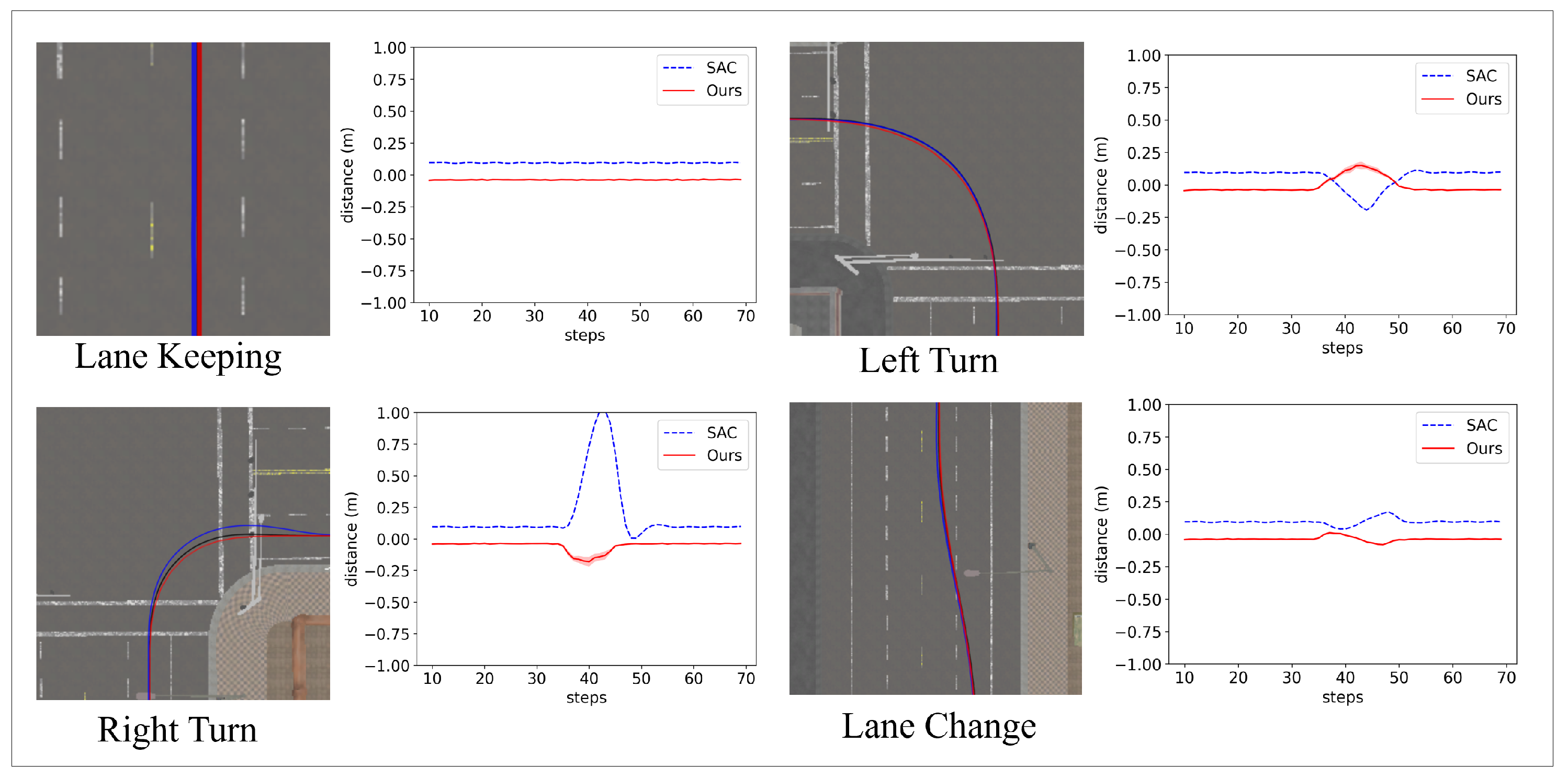
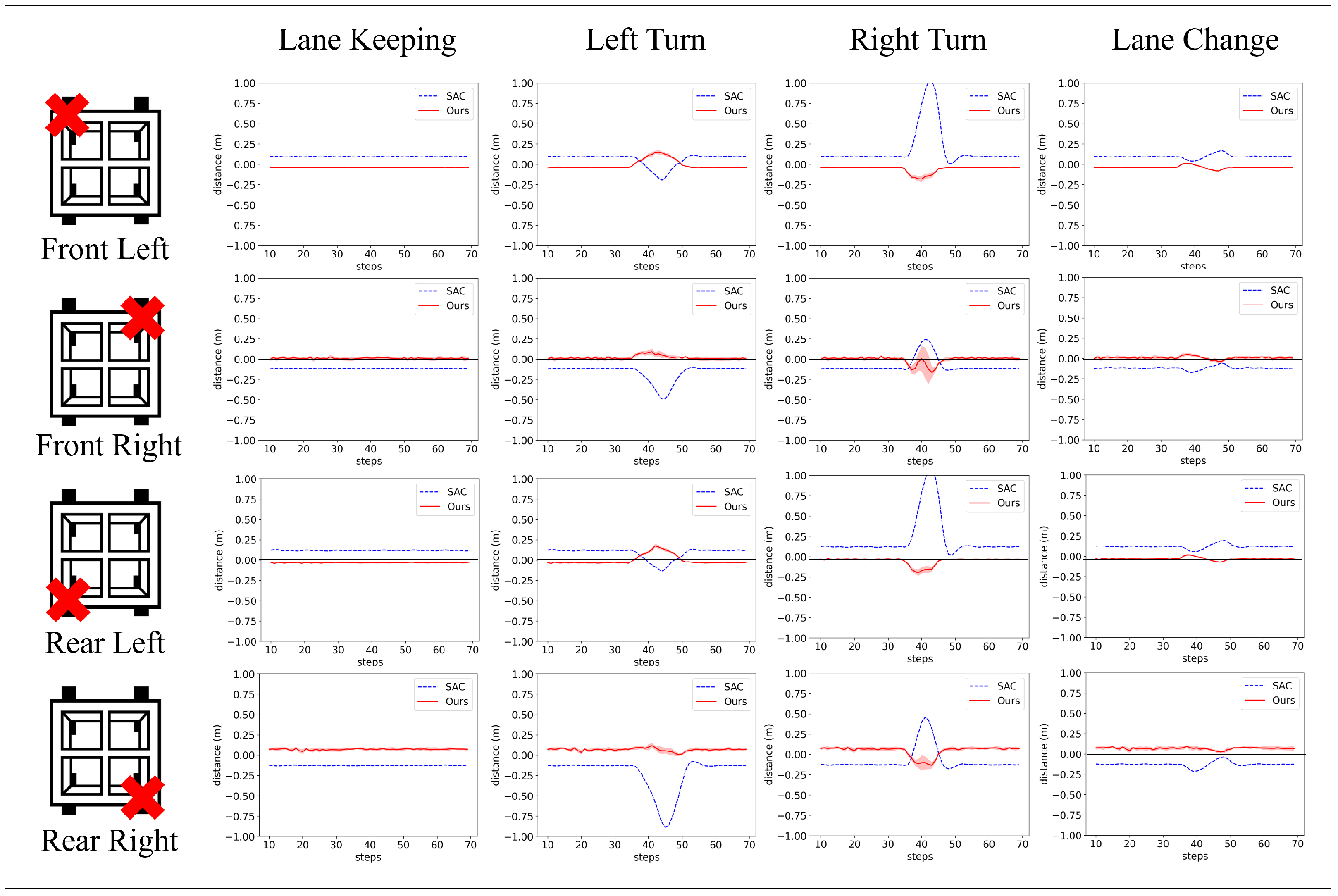
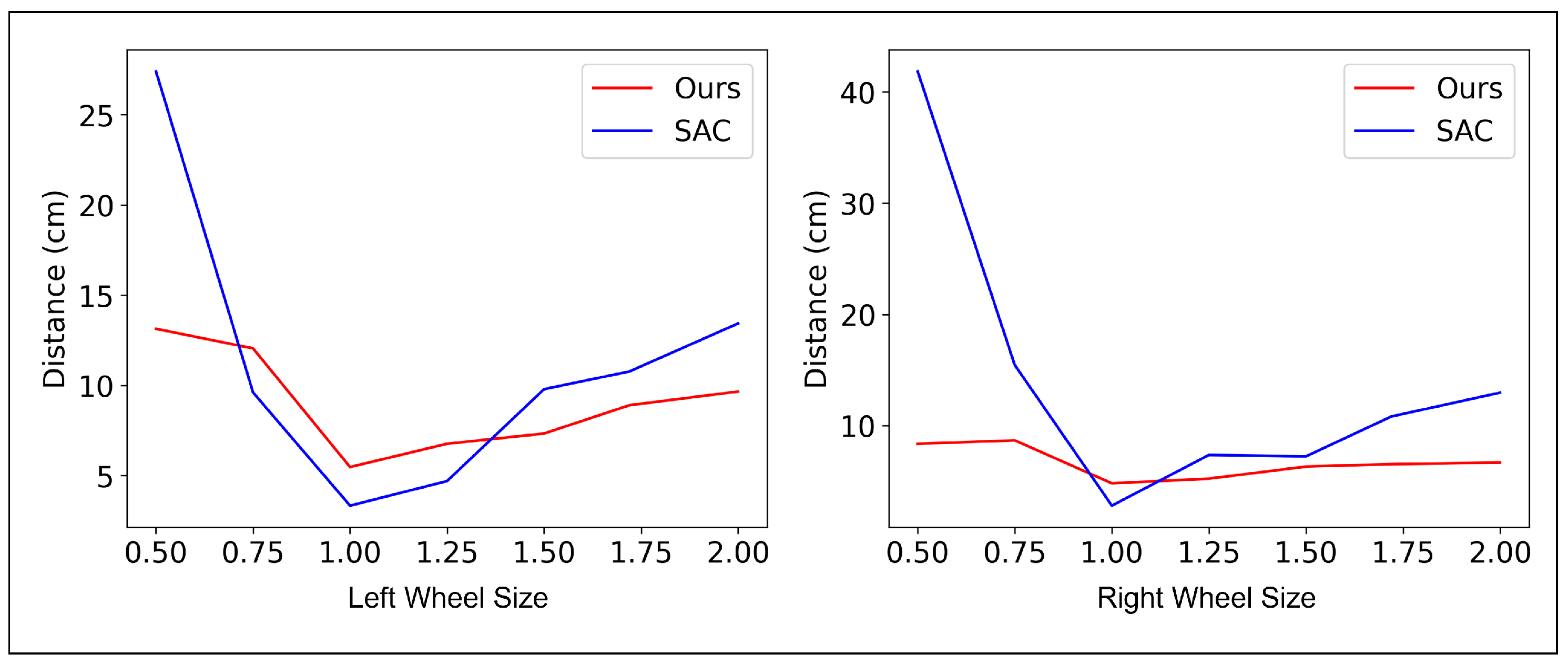
4.3. Evaluation of Robustness in Static Environment Changes
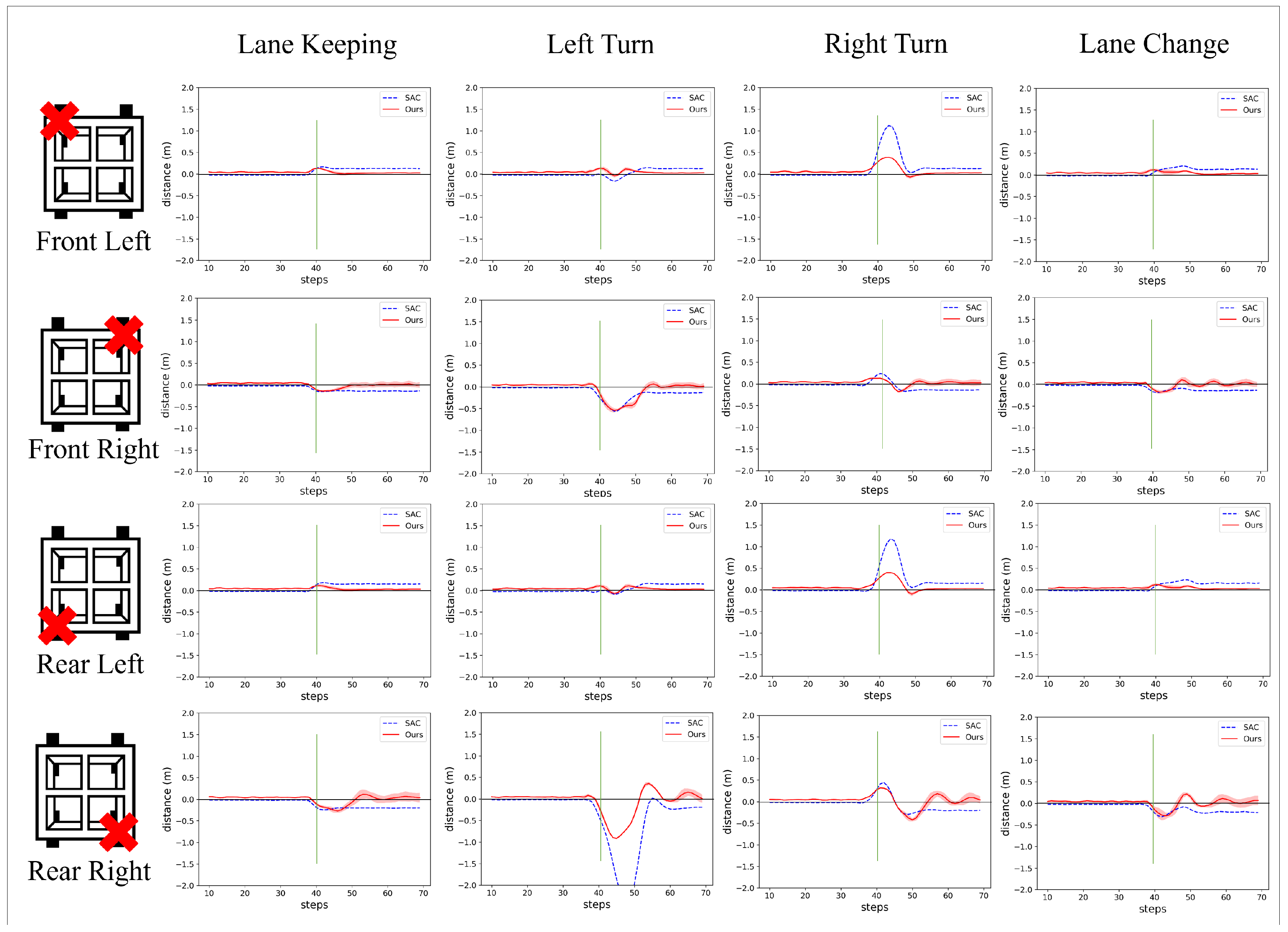
4.4. Evaluation of Fail-Operational System
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Technical Detail
Appendix A.1. Environment Setting
- State Vector: The state vector consists of a total of 10 elements. All values are given as coordinates relative to the geometric state at the starting point of the trajectory.
- −
- Position (x, y): the relative coordinates of the vehicle’s current position (m)
- −
- Speed (x, y): instantaneous speed along the x and y axes (m/s).
- −
- Acceleration (x, y): acceleration components of the vehicle (m/s2).
- −
- Vehicle orientation (unit vector x, y): this unit vector represents the orientation of the vehicle in a two-dimensional plane.
- −
- Vehicle pose (roll and pitch): these quantify the angular orientation of the vehicle in terms of roll and pitch (degree).
- Action Vector: The action vector consists of four unique values ranging from −1 to 1, each value corresponding to a control input provided to each wheel of the vehicle. Positive values indicate acceleration, and negative values represent deceleration.
Appendix A.2. Implementation Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Encoder 1 | [256, 256] |
| Decoder 1 | [256, 256] |
| 2 | 0.001 |
| Learning rate | 0.0001 |
| 2 | 0.02 |
| 2 | 0.01 |
| 3 | 0.25 |
| 3 | 0.9 |
| Parameter | Value |
|---|---|
| Decoder 1 | [256, 256] |
| 2 | 0.001 |
| Learning rate | 0.0001 |
| 2 | 0.02 |
| 2 | 0.01 |
| Parameter | Value |
|---|---|
| Value Network 1 | [256, 256] |
| Policy Network 1 | [256, 256] |
| 2 | 0.95 |
| Initial Entropy 2 | 0.1 |
| Target Entropy 2 | |
| Learning rate | 0.0001 |
| Policy Update rate 2 | 0.05 |
Appendix B. Experiment Settings
Appendix B.1. Training
Appendix B.2. Scenario Experiments
References
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Aradi, S. Survey of deep reinforcement learning for motion planning of autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 23, 740–759. [Google Scholar] [CrossRef]
- Coraluppi, S.P.; Marcus, S.I. Risk-sensitive and minimax control of discrete-time, finite-state Markov decision processes. Automatica 1999, 35, 301–309. [Google Scholar] [CrossRef]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Garcıa, J.; Fernández, F. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- The Tesla Team. A Tragic Loss; The Tesla Team: Austin, TX, USA, 2016. [Google Scholar]
- Wanner, D.; Trigell, A.S.; Drugge, L.; Jerrelind, J. Survey on fault-tolerant vehicle design. World Electr. Veh. J. 2012, 5, 598–609. [Google Scholar] [CrossRef]
- Wood, M.; Robbel, P.; Maass, M.; Tebbens, R.D.; Meijs, M.; Harb, M.; Reach, J.; Robinson, K.; Wittmann, D.; Srivastava, T. Safety first for automated driving. Aptiv, Audi, BMW, Baidu, Continental Teves, Daimler, FCA, HERE, Infineon Technologies, Intel, Volkswagen 2019. Available online: https://group.mercedes-benz.com/documents/innovation/other/safety-first-for-automated-driving.pdf (accessed on 11 October 2024).
- Stolte, T.; Ackermann, S.; Graubohm, R.; Jatzkowski, I.; Klamann, B.; Winner, H.; Maurer, M. Taxonomy to unify fault tolerance regimes for automotive systems: Defining fail-operational, fail-degraded, and fail-safe. IEEE Trans. Intell. Veh. 2021, 7, 251–262. [Google Scholar] [CrossRef]
- ISO 26262-1:2018; Road Vehicles–Functional Safety. International Organization for Standardization: Geneva, Switzerland, 2018.
- Kain, T.; Tompits, H.; Müller, J.S.; Mundhenk, P.; Wesche, M.; Decke, H. FDIRO: A general approach for a fail-operational system design. In Proceedings of the 30th European Safety and Reliability Conference and 15th Probabilistic Safety Assessment and Management Conference, Venice, Italy, 1–5 November 2020; Research Publishing Services: Singapore, 2020. [Google Scholar] [CrossRef]
- Polleti, G.; Santana, M.; Del Sant, F.S.; Fontes, E. Hierarchical Fallback Architecture for High Risk Online Machine Learning Inference. arXiv 2025, arXiv:2501.17834. [Google Scholar]
- Simonik, P.; Snasel, V.; Ojha, V.; Platoš, J.; Mrovec, T.; Klein, T.; Suganthan, P.N.; Ligori, J.J.; Gao, R.; Gruenwaldt, M. Steering Angle Estimation for Automated Driving on Approach to Analytical Redundancy for Fail-Operational Mode. 2024. Available online: https://ssrn.com/abstract=4938200 (accessed on 11 October 2024).
- Kim, T.; Yadav, P.; Suk, H.; Kim, S. Learning unsupervised disentangled skill latents to adapt unseen task and morphological modifications. Eng. Appl. Artif. Intell. 2022, 116, 105367. [Google Scholar] [CrossRef]
- Thananjeyan, B.; Balakrishna, A.; Nair, S.; Luo, M.; Srinivasan, K.; Hwang, M.; Gonzalez, J.E.; Ibarz, J.; Finn, C.; Goldberg, K. Recovery rl: Safe reinforcement learning with learned recovery zones. IEEE Robot. Autom. Lett. 2021, 6, 4915–4922. [Google Scholar] [CrossRef]
- Gu, S.; Yang, L.; Du, Y.; Chen, G.; Walter, F.; Wang, J.; Yang, Y.; Knoll, A. A review of safe reinforcement learning: Methods, theory and applications. arXiv 2022, arXiv:2205.10330. [Google Scholar] [CrossRef]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained policy optimization. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 22–31. [Google Scholar]
- Kim, D.; Oh, S. TRC: Trust region conditional value at risk for safe reinforcement learning. IEEE Robot. Autom. Lett. 2022, 7, 2621–2628. [Google Scholar] [CrossRef]
- Geibel, P.; Wysotzki, F. Risk-sensitive reinforcement learning applied to control under constraints. J. Artif. Intell. Res. 2005, 24, 81–108. [Google Scholar] [CrossRef]
- Tessler, C.; Mankowitz, D.J.; Mannor, S. Reward constrained policy optimization. arXiv 2018, arXiv:1805.11074. [Google Scholar]
- Srinivasan, K.; Eysenbach, B.; Ha, S.; Tan, J.; Finn, C. Learning to be safe: Deep rl with a safety critic. arXiv 2020, arXiv:2010.14603. [Google Scholar]
- Chow, Y.; Nachum, O.; Duenez-Guzman, E.; Ghavamzadeh, M. A lyapunov-based approach to safe reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Chow, Y.; Nachum, O.; Faust, A.; Duenez-Guzman, E.; Ghavamzadeh, M. Lyapunov-based safe policy optimization for continuous control. arXiv 2019, arXiv:1901.10031. [Google Scholar]
- Lee, J.; Hwangbo, J.; Hutter, M. Robust recovery controller for a quadrupedal robot using deep reinforcement learning. arXiv 2019, arXiv:1901.07517. [Google Scholar]
- Fisac, J.F.; Akametalu, A.K.; Zeilinger, M.N.; Kaynama, S.; Gillula, J.; Tomlin, C.J. A general safety framework for learning-based control in uncertain robotic systems. IEEE Trans. Autom. Control 2018, 64, 2737–2752. [Google Scholar] [CrossRef]
- Gillula, J.H.; Tomlin, C.J. Guaranteed safe online learning via reachability: Tracking a ground target using a quadrotor. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 2723–2730. [Google Scholar]
- Li, S.; Bastani, O. Robust model predictive shielding for safe reinforcement learning with stochastic dynamics. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 7166–7172. [Google Scholar]
- Garcia, C.E.; Prett, D.M.; Morari, M. Model predictive control: Theory and practice—A survey. Automatica 1989, 25, 335–348. [Google Scholar] [CrossRef]
- Sadigh, D.; Kapoor, A. Safe control under uncertainty with probabilistic signal temporal logic. In Proceedings of the Robotics: Science and Systems XII, Ann Arbor, MI, USA, 12–14 July 2016. [Google Scholar]
- Berkenkamp, F.; Turchetta, M.; Schoellig, A.; Krause, A. Safe Model-based Reinforcement Learning with Stability Guarantees. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Rosolia, U.; Borrelli, F. Learning model predictive control for iterative tasks. a data-driven control framework. IEEE Trans. Autom. Control 2017, 63, 1883–1896. [Google Scholar] [CrossRef]
- Bastani, O.; Li, S.; Xu, A. Safe Reinforcement Learning via Statistical Model Predictive Shielding. In Proceedings of the Robotics: Science and Systems, Virtually, 12–16 July 2021; pp. 1–13. [Google Scholar]
- Pertsch, K.; Lee, Y.; Lim, J. Accelerating reinforcement learning with learned skill priors. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 188–204. [Google Scholar]
- Nam, T.; Sun, S.H.; Pertsch, K.; Hwang, S.J.; Lim, J.J. Skill-based meta-reinforcement learning. arXiv 2022, arXiv:2204.11828. [Google Scholar]
- Thrun, S.; Schwartz, A. Finding structure in reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; Volume 7. [Google Scholar]
- Pickett, M.; Barto, A.G. Policyblocks: An algorithm for creating useful macro-actions in reinforcement learning. In Proceedings of the ICML, Sydney, Australia, 8–12 July 2002; Volume 19, pp. 506–513. [Google Scholar]
- Li, A.C.; Florensa, C.; Clavera, I.; Abbeel, P. Sub-policy adaptation for hierarchical reinforcement learning. arXiv 2019, arXiv:1906.05862. [Google Scholar]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef]
- Bacon, P.L.; Harb, J.; Precup, D. The option-critic architecture. In Proceedings of the AAAI Conference on Artificial Intelligence 2017, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Plappert, M.; Andrychowicz, M.; Ray, A.; McGrew, B.; Baker, B.; Powell, G.; Schneider, J.; Tobin, J.; Chociej, M.; Welinder, P.; et al. Multi-goal reinforcement learning: Challenging robotics environments and request for research. arXiv 2018, arXiv:1802.09464. [Google Scholar]
- Mandlekar, A.; Ramos, F.; Boots, B.; Savarese, S.; Fei-Fei, L.; Garg, A.; Fox, D. Iris: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4414–4420. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Hausman, K.; Springenberg, J.T.; Wang, Z.; Heess, N.; Riedmiller, M. Learning an embedding space for transferable robot skills. In Proceedings of the International Conference on Learning Representation, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lynch, C.; Khansari, M.; Xiao, T.; Kumar, V.; Tompson, J.; Levine, S.; Sermanet, P. Learning latent plans from play. In Proceedings of the Conference on Robot Learning, Virtual, 16–18 November 2020; pp. 1113–1132. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a deep embedding model for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2021–2030. [Google Scholar]
- Jiang, Z.; Gao, J.; Chen, J. Unsupervised skill discovery via recurrent skill training. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 39034–39046. [Google Scholar]
- Park, S.; Lee, K.; Lee, Y.; Abbeel, P. Controllability-Aware Unsupervised Skill Discovery. arXiv 2023, arXiv:2302.05103. [Google Scholar]
- Gregor, K.; Rezende, D.J.; Wierstra, D. Variational intrinsic control. arXiv 2016, arXiv:1611.07507. [Google Scholar]
- Achiam, J.; Edwards, H.; Amodei, D.; Abbeel, P. Variational option discovery algorithms. arXiv 2018, arXiv:1807.10299. [Google Scholar]
- Eysenbach, B.; Gupta, A.; Ibarz, J.; Levine, S. Diversity is all you need: Learning skills without a reward function. arXiv 2018, arXiv:1802.06070. [Google Scholar]
- Kim, J.; Park, S.; Kim, G. Unsupervised skill discovery with bottleneck option learning. arXiv 2021, arXiv:2106.14305. [Google Scholar]
- Sharma, A.; Gu, S.; Levine, S.; Kumar, V.; Hausman, K. Dynamics-aware unsupervised discovery of skills. arXiv 2019, arXiv:1907.01657. [Google Scholar]
- Park, S.; Choi, J.; Kim, J.; Lee, H.; Kim, G. Lipschitz-constrained unsupervised skill discovery. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Warde-Farley, D.; de Wiele, T.; Kulkarni, T.; Ionescu, C.; Hansen, S.; Mnih, V. Unsupervised control through non-parametric discriminative rewards. arXiv 2018, arXiv:1811.11359. [Google Scholar]
- Pitis, S.; Chan, H.; Zhao, S.; Stadie, B.; Ba, J. Maximum entropy gain exploration for long horizon multi-goal reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7750–7761. [Google Scholar]
- Kim, H.; Kim, J.; Jeong, Y.; Levine, S.; Song, H.O. Emi: Exploration with mutual information. arXiv 2018, arXiv:1810.01176. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]



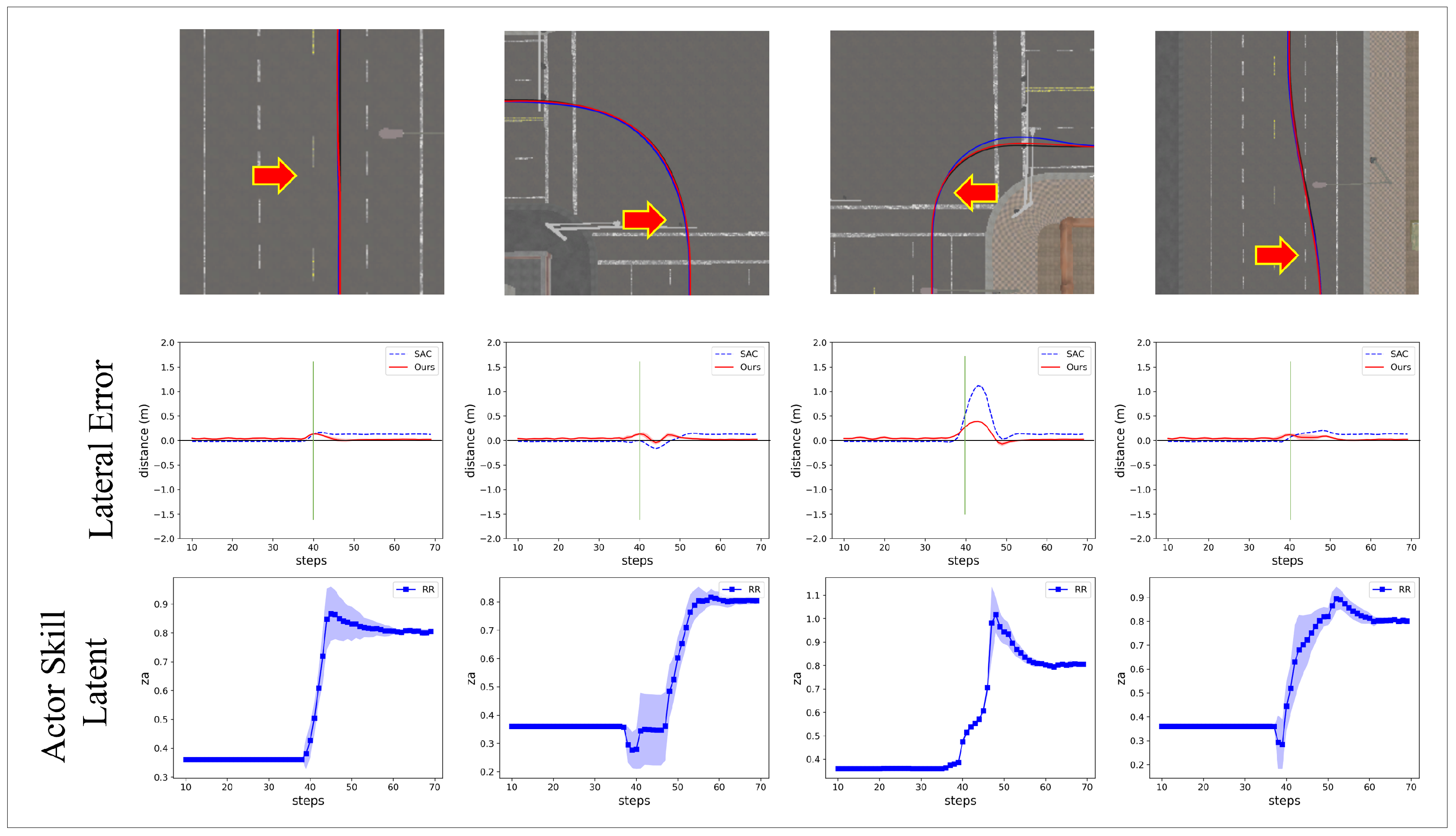
| Shape | Algorithm | Velocity (m/s) | Error (cm) | |
|---|---|---|---|---|
| Ours | 0.37 | 3.22 | 2.52 | |
| SAC | N/A | 2.41 | 0.47 | |
| Ours | −0.18 | 3.57 | 1.94 | |
| SAC | N/A | 2.28 | 1.32 | |
| Ours | 1.01 | 2.69 | 1.05 | |
| SAC | N/A | 2.46 | 0.84 |
| Disconn. Wheel | Algorithm | Lane Keeping | Turn Left | Turn Right | Lane Change (Left) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error (cm) | Vel (m/s) | Error (cm) | Vel (m/s) | Error (cm) | Vel (m/s) | Error (cm) | Vel (m/s) | |||||||
| Name | Avg | Max | Avg | Avg | Max | Avg | Avg | Max | Avg | Avg | Max | Avg | ||
| Front Left | Ours | 1.19 | 3.8 | 4.16 | 2.5 | 5.71 | 14.95 | 2.51 | 5.71 | 18.06 | 2.41 | 4.1 | 8.11 | 2.5 |
| SAC | N/A | 9.43 | 9.85 | 2.34 | 9.32 | 19.41 | 2.33 | 23.97 | 102.1 | 2.25 | 9.92 | 17.09 | 2.33 | |
| Front Right | Ours | −0.37 | 0.97 | 1.67 | 2.45 | 2.01 | 9.25 | 2.38 | 2.33 | 16.11 | 2.47 | 1.29 | 4.25 | 2.45 |
| SAC | N/A | 11.75 | 12.18 | 3.47 | 18.98 | 49.02 | 3.32 | 12.62 | 24.44 | 3.36 | 11.51 | 16.79 | 3.46 | |
| Rear Left | Ours | 1.13 | 3.26 | 3.69 | 2.49 | 5.52 | 17.39 | 2.49 | 5.5 | 19.35 | 2.39 | 3.53 | 7.33 | 2.48 |
| SAC | N/A | 12.04 | 12.54 | 2.39 | 9.96 | 13.42 | 2.37 | 27.07 | 105.4 | 2.3 | 12.28 | 19.88 | 2.37 | |
| Rear Right | Ours | −0.73 | 7.23 | 7.88 | 2.44 | 6.54 | 11.72 | 2.25 | 7.41 | 13.42 | 2.48 | 6.6 | 8.17 | 2.44 |
| SAC | N/A | 12.69 | 12.98 | 3.18 | 28.54 | 88.79 | 3.03 | 16.22 | 45.79 | 3.11 | 12.53 | 21.35 | 3.19 | |
| Size of Left Wheel | 50% | 75% | 100% | 125% | 150% | 175% | 200% | |
|---|---|---|---|---|---|---|---|---|
| Dist (cm) | SAC | 27.4 | 9.613 | 3.338 | 4.7 | 9.795 | 10.78 | 13.44 |
| Ours | 13.14 | 12.05 | 5.477 | 6.768 | 7.336 | 8.905 | 9.664 | |
| Vel (m/s) | SAC | 1.51 | 2.166 | 2.511 | 2.748 | 2.524 | 2.517 | 2.546 |
| Ours | 0.792 | 2.502 | 3.007 | 3.067 | 3.181 | 3.187 | 3.249 | |
| Ours | −0.72 | −0.095 | 0.37 | 0.525 | 0.9 | 1.027 | 1.136 | |
| Time to recovery (s) | SAC | X | 1.25 | - | 0.9 | 0.7 | 1.55 | 1.85 |
| Ours | 1.05 | 0.9 | - | 0.65 | 0.6 | 0.95 | 1.4 | |
| Size of Right Wheel | 50% | 75% | 100% | 125% | 150% | 175% | 200% | |
|---|---|---|---|---|---|---|---|---|
| Dist (cm) | SAC | 41.84 | 15.44 | 2.797 | 7.355 | 7.23 | 10.82 | 12.96 |
| Ours | 8.361 | 8.667 | 4.805 | 5.223 | 6.312 | 6.524 | 6.674 | |
| Vel (m/s) | SAC | 1.151 | 2.119 | 2.255 | 2.362 | 2.608 | 2.868 | 2.864 |
| Ours | 0.632 | 2.538 | 2.962 | 3.077 | 3.181 | 3.189 | 3.244 | |
| Ours | 1.803 | 1.078 | 0.37 | 0.083 | −0.119 | −0.363 | −0.429 | |
| Time to recovery (s) | SAC | X | 1.35 | - | 0.5 | 0.85 | 1 | 1.3 |
| Ours | 1.8 | 0.75 | - | 0.4 | 0.6 | 0.85 | 0.8 | |
| Disconn. Wheel | Algorithm | Lane Keeping | Turn Left | Turn Right | Lane Change (Left) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error (cm) | Vel (m/s) | Error (cm) | Vel (m/s) | Error (cm) | Vel (m/s) | Error (cm) | Vel (m/s) | |||||||
| Name | Avg | Max | Avg | Avg | Max | Avg | Avg | Max | Avg | Avg | Max | Avg | ||
| Front Left | Ours | 1.19 | 3.81 | 13.51 | 2.74 | 4.93 | 13.41 | 2.83 | 9.05 | 38.54 | 2.56 | 4.51 | 11.74 | 2.7 |
| SAC | - | 10.29 | 16.65 | 2.5 | 8.6 | 16.8 | 2.5 | 23.4 | 112 | 2.41 | 10.68 | 20.51 | 2.5 | |
| Front Right | Ours | −0.37 | 4.19 | 14.1 | 3.38 | 14.32 | 54.18 | 3.13 | 5.67 | 17.88 | 3.25 | 5.31 | 17.89 | 3.36 |
| SAC | - | 11.01 | 15.58 | 2.46 | 17.82 | 55.95 | 2.37 | 11.49 | 23.94 | 2.47 | 10.96 | 18.9 | 2.46 | |
| Rear Left | Ours | 1.13 | 4 | 11.31 | 2.74 | 4.82 | 10.84 | 2.85 | 9.27 | 39.85 | 2.56 | 4.58 | 12.03 | 2.71 |
| SAC | - | 11.76 | 18.33 | 2.49 | 8.64 | 16.39 | 2.49 | 25.11 | 117.6 | 2.39 | 12.36 | 23.46 | 2.48 | |
| Rear Right | Ours | −0.73 | 8.29 | 27.13 | 3.11 | 24.1 | 91.57 | 2.75 | 11.63 | 34.82 | 3.05 | 8.65 | 31.29 | 3.14 |
| SAC | - | 15.95 | 24.47 | 2.39 | 57.09 | 238.7 | 2.1 | 17.71 | 44.44 | 2.45 | 15.4 | 30.73 | 2.4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.; Kim, S. Reinforcement Learning for Fail-Operational Systems with Disentangled Dual-Skill Variables. Technologies 2025, 13, 156. https://doi.org/10.3390/technologies13040156
Kim T, Kim S. Reinforcement Learning for Fail-Operational Systems with Disentangled Dual-Skill Variables. Technologies. 2025; 13(4):156. https://doi.org/10.3390/technologies13040156
Chicago/Turabian StyleKim, Taewoo, and Shiho Kim. 2025. "Reinforcement Learning for Fail-Operational Systems with Disentangled Dual-Skill Variables" Technologies 13, no. 4: 156. https://doi.org/10.3390/technologies13040156
APA StyleKim, T., & Kim, S. (2025). Reinforcement Learning for Fail-Operational Systems with Disentangled Dual-Skill Variables. Technologies, 13(4), 156. https://doi.org/10.3390/technologies13040156