
Cross-Encoder-Based Semantic Evaluation of Extractive and Generative Question Answering in Low-Resourced African Languages

 ,
,  and
and
Abstract
1. Introduction
- An automatic text labelling technique for custom and generalized semantic textual analysis tasks is proposed.
- The automatic text labelling technique is deployed to enhance the efficiency of the semantic answer similarity (SAS) method in QA evaluation proposed in [9]. The resulting enhanced technique is dubbed SAS+.
- This study demonstrates the efficiency and robustness of the SAS+ pipeline in evaluating underserved low-resourced languages, compared to conventional methods used by encoder–decoder and decoder-only models.
- This study shows that the proposed SAS+ evaluation pipeline is a more natural and befitting estimator for QA model performance relative to the prevailing F1 and EM metrics.
2. Related Works
2.1. Question Answering in African Languages
2.2. Cross-Lingual Language Resources
2.3. Cross-Lingual QA Performance Evaluation Metrics
3. Proposed QA Evaluation Pipeline
3.1. Dataset
3.2. Cross-Encoder for SAS+
3.3. Automatic Answer Labelling
| Algorithm 1: Pseudocode for the proposed pipeline with automatic answer labelling for SAS enhancement |
| Input: Question (Q), Context (C) Output: Performance score (ρ) Initialize bi-encoder (β), answer prediction model ()
|
4. Experimental Design
5. Results and Discussion
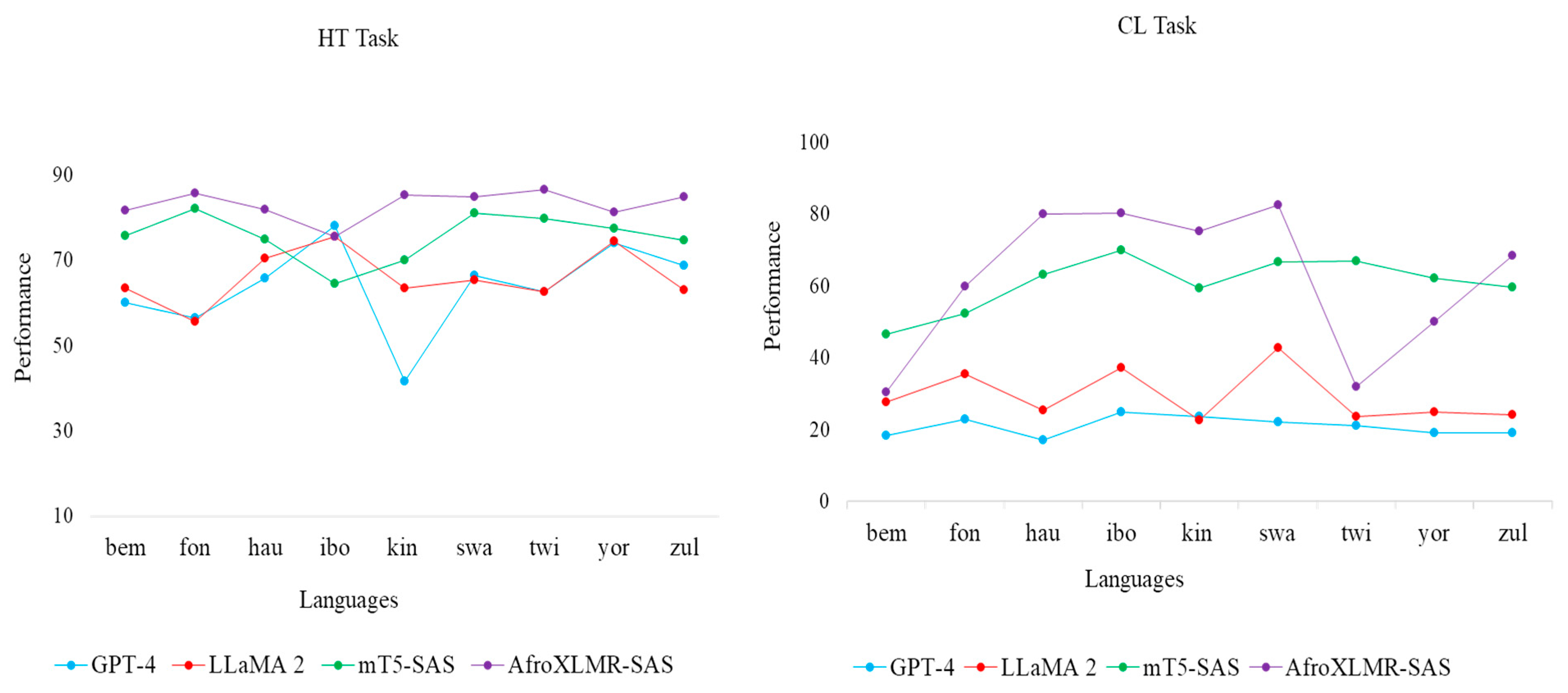
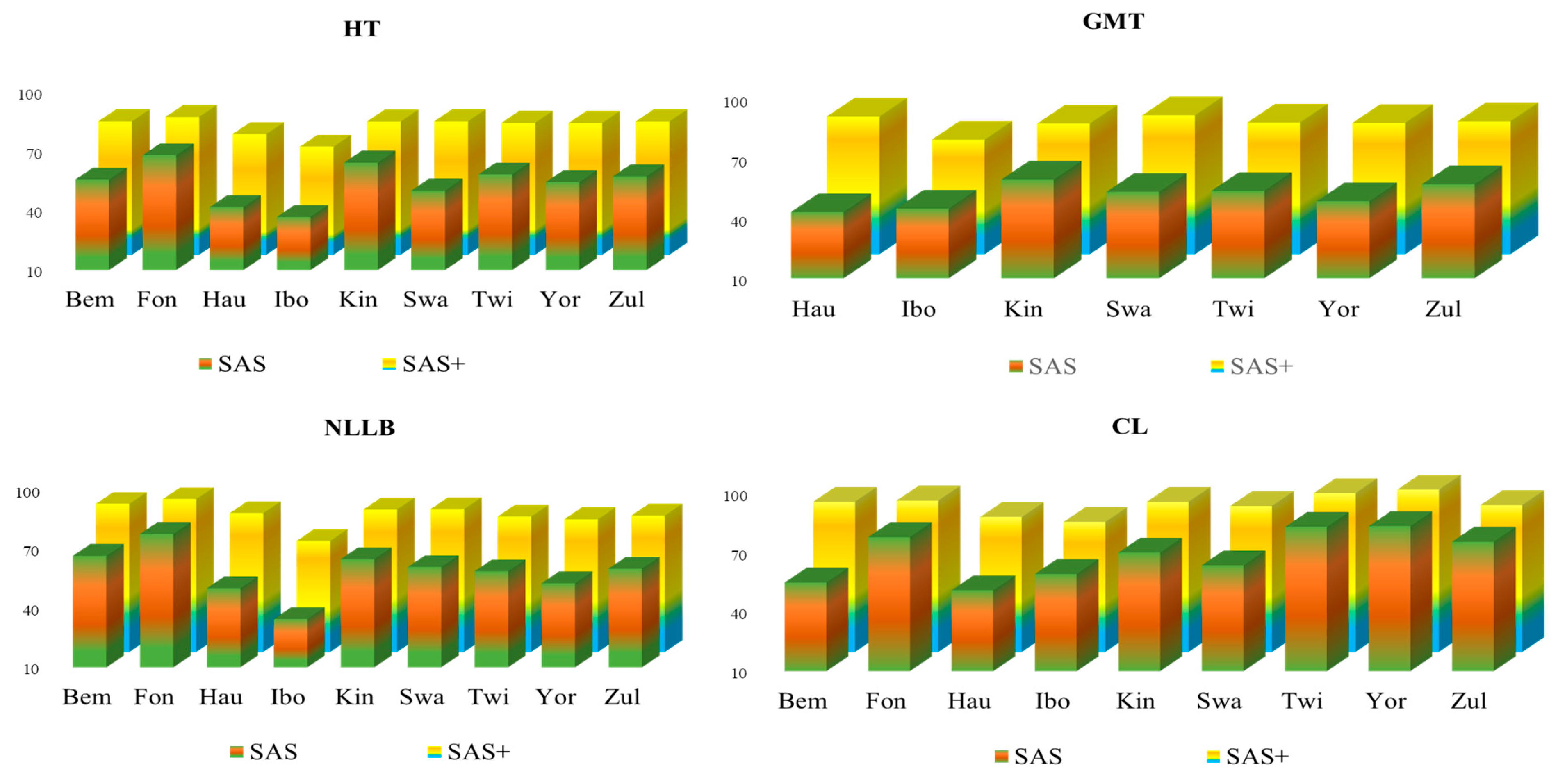
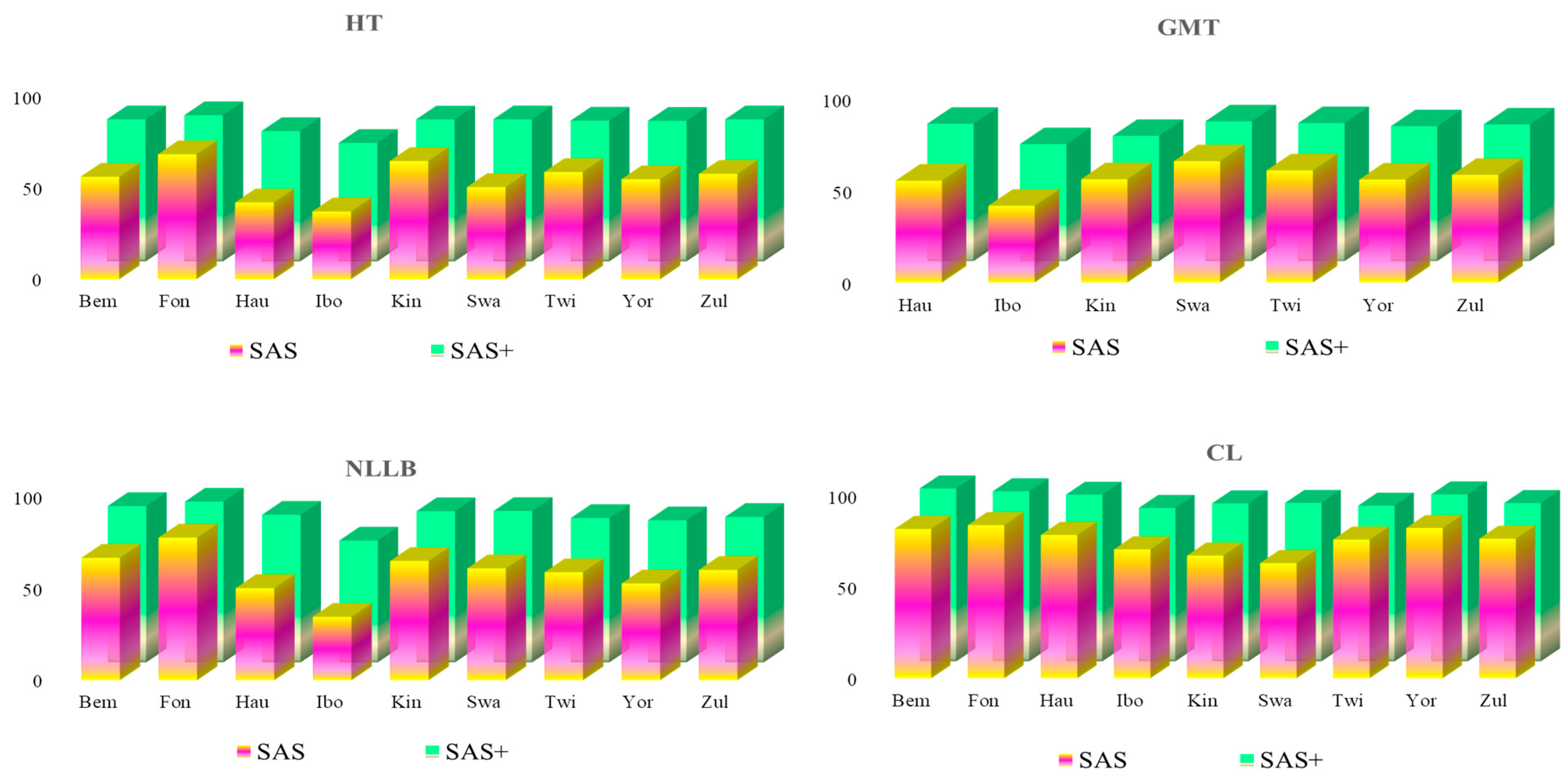
5.1. SAS+ Performance Compared to F1- and EM-Based Baselines
5.2. SAS+’s Performance Compared to F1-Bassed Generative QA Models
5.3. SAS+ Analysis of Dissimilar Answer Pairs from the F1 Assessment
5.4. Comparing SAS+ and SAS Performances in the Downstream Task
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rasool, Z.; Kurniawan, S.; Balugo, S.; Barnett, S.; Vasa, R.; Chesser, C.; Hampstead, B.M.; Belleville, S.; Mouzakis, K.; Bahar-Fuchs, A. Evaluating LLMs on Document-Based QA: Exact Answer Selection and Numerical Extraction Using CogTale Dataset. Nat. Lang. Process. J. 2024, 8, 100083. [Google Scholar] [CrossRef]
- Asai, A.; Kasai, J.; Clark, J.; Lee, K.; Choi, E.; Hajishirzi, H. XOR QA: Cross-Lingual Open-Retrieval Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Bangkok, Thailand, 2021; pp. 547–564. [Google Scholar]
- Do, J.; Lee, J.; Hwang, S. ContrastiveMix: Overcoming Code-Mixing Dilemma in Cross-Lingual Transfer for Information Retrieval. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Mexico City, Mexico, 2024; pp. 197–204. [Google Scholar]
- Guo, P.; Hu, Y.; Cao, Y.; Ren, Y.; Li, Y.; Huang, H. Query in Your Tongue: Reinforce Large Language Models with Retrievers for Cross-Lingual Search Generative Experience. In Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; ACM: Singapore, 2024; pp. 1529–1538. [Google Scholar]
- Adelani, D.I.; Ojo, J.; Azime, I.A.; Zhuang, J.Y.; Alabi, J.O.; He, X.; Ochieng, M.; Hooker, S.; Bukula, A.; Lee, E.-S.A.; et al. IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models. arXiv 2025, arXiv:2406.03368. [Google Scholar]
- Adebara, I.; Abdul-Mageed, M. Towards Afrocentric NLP for African Languages: Where We Are and Where We Can Go. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 3814–3841. [Google Scholar]
- Ogundepo, O.; Zhang, X.; Sun, S.; Duh, K.; Lin, J. AfriCLIRMatrix: Enabling Cross-Lingual Information Retrieval for African Languages. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 8721–8728. [Google Scholar]
- Ogundepo, O.; Gwadabe, T.; Rivera, C.; Clark, J.; Ruder, S.; Adelani, D.; Dossou, B.; Diop, A.; Sikasote, C.; Hacheme, G.; et al. Cross-Lingual Open-Retrieval Question Answering for African Languages. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Association for Computational Linguistics: Singapore, 2023; pp. 14957–14972. [Google Scholar]
- Risch, J.; Möller, T.; Gutsch, J.; Pietsch, M. Semantic Answer Similarity for Evaluating Question Answering Models. In Proceedings of the 3rd Workshop on Machine Reading for Question Answering, Punta Cana, Dominican Republic, 3 June 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 149–157. [Google Scholar]
- Ijebu, F.F.; Liu, Y.; Sun, C.; Usip, P.U. Soft Cosine and Extended Cosine Adaptation for Pre-Trained Language Model Semantic Vector Analysis. Appl. Soft Comput. 2024, 169, 112551. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-Trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Bangkok, Thailand, 2021; pp. 483–498. [Google Scholar]
- Alabi, J.O.; Adelani, D.I.; Mosbach, M.; Klakow, D. Adapting Pre-Trained Language Models to African Languages via Multilingual Adaptive Fine-Tuning. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C.-R., Kim, H., Pustejovsky, J., Wanner, L., Choi, K.-S., Ryu, P.-M., Chen, H.-H., Donatelli, L., Ji, H., et al., Eds.; International Committee on Computational Linguistics: Gyeongju, Republic of Korea, 2022; pp. 4336–4349. [Google Scholar]
- Usip, P.U.; Ijebu, F.F.; Udo, I.J.; Ollawa, I.K. Text-Based Emergency Alert Framework for Under-Resourced Languages in Southern Nigeria. In Semantic AI in Knowledge Graphs; CRC Press: Boca Raton, FL, USA, 2023; pp. 111–126. ISBN 978-1-00-331326-7. [Google Scholar]
- Inyang, U.G.; Ijebu, F.F.; Osang, F.B.; Afoluronsho, A.A.; Udoh, S.S.; Eyoh, I.J. A Dataset-Driven Parameter Tuning Approach for Enhanced K-Nearest Neighbour Algorithm Performance. Int. J. Adv. Sci. Eng. Inf. Technol. 2023, 13, 380–391. [Google Scholar] [CrossRef]
- Vázquez-Enríquez, M.; Alba-Castro, J.L.; Docío-Fernández, L.; Rodríguez-Banga, E. SWL-LSE: A Dataset of Health-Related Signs in Spanish Sign Language with an ISLR Baseline Method. Technologies 2024, 12, 205. [Google Scholar] [CrossRef]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Benchmarking Large Language Models in Retrieval-Augmented Generation. AAAI 2024, 38, 17754–17762. [Google Scholar] [CrossRef]
- Li, S.; Sun, C.; Liu, B.; Liu, Y.; Ji, Z. Modeling Extractive Question Answering Using Encoder-Decoder Models with Constrained Decoding and Evaluation-Based Reinforcement Learning. Mathematics 2023, 11, 1624. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 2383–2392. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1870–1879. [Google Scholar]
- Harris, S.; Hadi, H.J.; Ahmad, N.; Alshara, M.A. Fake News Detection Revisited: An Extensive Review of Theoretical Frameworks, Dataset Assessments, Model Constraints, and Forward-Looking Research Agendas. Technologies 2024, 12, 222. [Google Scholar] [CrossRef]
- Wu, C.-S.; Madotto, A.; Liu, W.; Fung, P.; Xiong, C. QAConv: Question Answering on Informative Conversations. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 5389–5411. [Google Scholar]
- Huang, J.; Wang, M.; Cui, Y.; Liu, J.; Chen, L.; Wang, T.; Li, H.; Wu, J. Layered Query Retrieval: An Adaptive Framework for Retrieval-Augmented Generation in Complex Question Answering for Large Language Models. Appl. Sci. 2024, 14, 11014. [Google Scholar] [CrossRef]
- Chen, J.; Wang, H.; Shang, J. Chaomurilige Interpretable Embeddings for Next Point-of-Interest Recommendation via Large Language Model Question–Answering. Mathematics 2024, 12, 3592. [Google Scholar] [CrossRef]
- Hernández, A.; Ortega-Mendoza, R.M.; Villatoro-Tello, E.; Camacho-Bello, C.J.; Pérez-Cortés, O. Natural Language Understanding for Navigation of Service Robots in Low-Resource Domains and Languages: Scenarios in Spanish and Nahuatl. Mathematics 2024, 12, 1136. [Google Scholar] [CrossRef]
- Gaim, F.; Yang, W.; Park, H.; Park, J. Question-Answering in a Low-Resourced Language: Benchmark Dataset and Models for Tigrinya. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 11857–11870. [Google Scholar]
- Wanjawa, B.W.; Wanzare, L.D.A.; Indede, F.; Mconyango, O.; Muchemi, L.; Ombui, E. KenSwQuAD—A Question Answering Dataset for Swahili Low-Resource Language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–20. [Google Scholar] [CrossRef]
- Bayes, E.; Azime, I.A.; Alabi, J.O.; Kgomo, J.; Eloundou, T.; Proehl, E.; Chen, K.; Khadir, I.; Etori, N.A.; Muhammad, S.H.; et al. Uhura: A Benchmark for Evaluating Scientific Question Answering and Truthfulness in Low-Resource African Languages. arXiv 2024, arXiv:2412.00948. [Google Scholar]
- Ojo, J.; Ogueji, K.; Stenetorp, P.; Adelani, D.I. How Good Are Large Language Models on African Languages? arXiv 2024, arXiv:2311.07978v2. [Google Scholar]
- Lewis, P.; Oguz, B.; Rinott, R.; Riedel, S.; Schwenk, H. MLQA: Evaluating Cross-Lingual Extractive Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Bangkok, Thailand, 2020; pp. 7315–7330. [Google Scholar]
- Longpre, S.; Lu, Y.; Daiber, J. MKQA: A Linguistically Diverse Benchmark for Multilingual Open Domain Question Answering. Trans. Assoc. Comput. Linguist. 2021, 9, 1389–1406. [Google Scholar] [CrossRef]
- Asai, A.; Yu, X.; Kasai, J.; Hajishirzi, H. One Question Answering Model for Many Languages with Cross-Lingual Dense Passage Retrieval. arXiv 2021, arXiv:2107.11976. [Google Scholar]
- NLLB Team; Costa-jussà, M.R.; Cross, J.; Çelebi, O.; Elbayad, M.; Heafield, K.; Heffernan, K.; Kalbassi, E.; Lam, J.; Licht, D.; et al. Scaling Neural Machine Translation to 200 Languages. Nature 2024, 630, 841–846. [Google Scholar] [CrossRef]
- Adelani, D.I.; Alabi, J.O.; Fan, A.; Kreutzer, J.; Shen, X.; Reid, M.; Ruiter, D.; Klakow, D.; Nabende, P.; Chang, E.; et al. A Few Thousand Translations Go a Long Way! Leveraging Pre-Trained Models for African News Translation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; Carpuat, M., de Marneffe, M.-C., Meza Ruiz, I.V., Eds.; Association for Computational Linguistics: Seattle, WA, USA, 2022; pp. 3053–3070. [Google Scholar]
- Clark, J.H.; Choi, E.; Collins, M.; Garrette, D.; Kwiatkowski, T.; Nikolaev, V.; Palomaki, J. TyDi QA: A Benchmark for Information-Seeking Question Answering in Ty Pologically Di Verse Languages. Trans. Assoc. Comput. Linguist. 2020, 8, 454–470. [Google Scholar] [CrossRef]
- Wang, L.; Yu, K.; Wumaier, A.; Zhang, P.; Yibulayin, T.; Wu, X.; Gong, J.; Maimaiti, M. Genre: Generative Multi-Turn Question Answering with Contrastive Learning for Entity–Relation Extraction. Complex Intell. Syst. 2024, 10, 3429–3443. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Jin, J.; Wang, H. Select High-Quality Synthetic QA Pairs to Augment Training Data in MRC under the Reward Guidance of Generative Language Models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; Calzolari, N., Kan, M.-Y., Hoste, V., Lenci, A., Sakti, S., Xue, N., Eds.; ELRA and ICCL: Torino, Italia, 2024; pp. 14543–14554. [Google Scholar]
- Inyang, U.G.; Robinson, S.A.; Ijebu, F.F.; Udo, I.J.; Nwokoro, C.O. Optimality Assessments of Classifiers on Single and Multi-Labelled Obstetrics Outcome Classification Problems. IJACSA 2021, 12. [Google Scholar] [CrossRef]
- Sellam, T.; Das, D.; Parikh, A. BLEURT: Learning Robust Metrics for Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Bangkok, Thailand, 2020; pp. 7881–7892. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the Eighth International Conference on Learning Representations, ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Feng, F.; Yang, Y.; Cer, D.; Arivazhagan, N.; Wang, W. Language-Agnostic BERT Sentence Embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 878–891. [Google Scholar]
- Usip, P.U.; Ijebu, F.F.; Dan, E.A. A Spatiotemporal Knowledge Bank from Rape News Articles for Decision Support. In Knowledge Graphs and Semantic Web: Second Iberoamerican Conference and First Indo-American Conference, KGSWC 2020, Mérida, Mexico, 26–27 November 2020; Villazón-Terrazas, B., Ortiz-Rodríguez, F., Tiwari, S.M., Shandilya, S.K., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 147–157. [Google Scholar]
- Xiong, K.; Ding, X.; Cao, Y.; Liu, T.; Qin, B. Examining Inter-Consistency of Large Language Models Collaboration: An In-Depth Analysis via Debate. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 7572–7590. [Google Scholar]
- Wang, Z.; Mao, S.; Wu, W.; Ge, T.; Wei, F.; Ji, H. Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Mexico City, Mexico, 2024; pp. 257–279. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lang. | HT | GMT | NLLB | CL | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SAS+ | F1 | EM | SAS+ | F1 | EM | SAS+ | F1 | EM | SAS+ | F1 | EM | |
| bem | 81.64 | 38.20 | 29.50 | - | - | - | 82.29 | 30.00 | 21.90 | 30.45 | 0.40 | 0.40 |
| fon | 85.77 | 53.80 | 40.40 | - | - | - | 77.95 | 37.50 | 26.70 | 59.86 | 13.40 | 6.00 |
| hau | 81.85 | 60.90 | 52.70 | 82.67 | 54.40 | 47.70 | 82.00 | 50.90 | 43.70 | 80.22 | 27.70 | 23.70 |
| ibo | 75.54 | 68.20 | 60.60 | 80.66 | 62.10 | 55.00 | 71.71 | 62.80 | 56.20 | 80.23 | 29.20 | 24.70 |
| kin | 85.31 | 56.80 | 38.90 | 84.55 | 50.80 | 36.00 | 82.78 | 51.30 | 36.60 | 75.42 | 22.70 | 17.90 |
| swa | 84.80 | 45.20 | 37.90 | 83.85 | 44.60 | 37.90 | 84.62 | 45.20 | 38.10 | 82.55 | 31.60 | 24.60 |
| twi | 86.67 | 51.20 | 41.80 | 86.10 | 39.20 | 31.10 | 86.12 | 34.30 | 30.00 | 31.98 | 3.40 | 2.50 |
| yor | 81.38 | 45.10 | 38.60 | 84.42 | 36.00 | 31.70 | 81.97 | 32.30 | 28.00 | 50.00 | 6.00 | 3.80 |
| zul | 84.90 | 59.10 | 49.20 | 83.50 | 56.00 | 48.60 | 82.39 | 53.60 | 45.80 | 68.60 | 17.00 | 13.50 |
| Lang. | HT | GMT | NLLB | CL | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SAS+ | F1 | EM | SAS+ | F1 | EM | SAS+ | F1 | EM | SAS+ | F1 | EM | |
| bem | 75.77 | 48.80 | 41.70 | - | - | - | 84.68 | 38.50 | 32.00 | 46.52 | 2.90 | 1.10 |
| fon | 82.12 | 41.40 | 28.50 | - | - | - | 83.67 | 23.40 | 15.30 | 52.44 | 5.10 | 2.30 |
| hau | 74.92 | 58.50 | 49.00 | 80.87 | 53.50 | 45.70 | 82.99 | 50.90 | 42.70 | 63.29 | 25.80 | 22.30 |
| ibo | 64.48 | 66.60 | 59.20 | 68.82 | 59.80 | 53.30 | 73.94 | 60.20 | 53.30 | 70.00 | 41.70 | 34.70 |
| kin | 70.07 | 60.80 | 43.80 | 75.59 | 57.30 | 40.90 | 79.34 | 58.80 | 42.90 | 59.49 | 25.50 | 20.20 |
| swa | 81.01 | 52.30 | 42.60 | 82.56 | 48.90 | 40.80 | 83.97 | 49.20 | 41.20 | 66.78 | 29.40 | 23.50 |
| twi | 79.72 | 55.40 | 45.30 | 86.30 | 42.00 | 33.70 | 86.82 | 40.10 | 33.10 | 67.04 | 5.30 | 3.50 |
| yor | 77.57 | 54.90 | 49.80 | 82.02 | 48.90 | 45.10 | 83.61 | 47.90 | 43.00 | 62.19 | 11.90 | 7.80 |
| zul | 74.80 | 60.20 | 50.80 | 76.97 | 57.40 | 48.90 | 79.45 | 55.60 | 46.50 | 59.75 | 24.70 | 20.90 |
| Lang | F1 | AfroXLMR | mT5 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Value | HT | GMT | NLLB | CL | HT | GMT | NLLB | CL | |
| bem | F1 = 0 | 32.16 | - | 30.84 | 9.38 | 36.77 | - | 44.56 | 6.91 |
| F1 ≠ 0 | 56.00 | - | 66.60 | 54.77 | 47.66 | - | 55.64 | 81.60 | |
| fon | F1 = 0 | 26.01 | - | 7.37 | 5.90 | 53.94 | - | 27.05 | 9.46 |
| F1 ≠ 0 | 68.30 | - | 77.61 | 77.69 | 64.90 | - | 76.61 | 83.70 | |
| hau | F1 = 0 | 18.20 | 13.17 | 17.89 | 13.87 | 35.86 | 25.58 | 38.70 | 4.48 |
| F1 ≠ 0 | 42.01 | 43.35 | 50.13 | 50.84 | 49.26 | 55.39 | 58.35 | 78.34 | |
| ibo | F1 = 0 | 18.20 | 13.17 | 17.89 | 13.87 | 41.89 | 49.63 | 43.73 | 27.41 |
| F1 ≠ 0 | 37.06 | 45.12 | 34.53 | 59.12 | 51.01 | 41.74 | 53.57 | 70.44 | |
| kin | F1 = 0 | 24.01 | 27.84 | 30.54 | 18.56 | 33.76 | 36.04 | 45.14 | 20.96 |
| F1 ≠ 0 | 64.60 | 59.67 | 64.89 | 69.91 | 55.33 | 56.16 | 63.57 | 67.05 | |
| swa | F1 = 0 | 36.92 | 27.16 | 31.89 | 18.86 | 27.94 | 20.89 | 39.83 | 15.38 |
| F1 ≠ 0 | 50.41 | 53.47 | 60.87 | 63.50 | 60.14 | 66.00 | 64.24 | 62.92 | |
| twi | F1 = 0 | 34.70 | 27.75 | 28.97 | 0.00 | 17.85 | 29.02 | 29.07 | 24.67 |
| F1 ≠ 0 | 58.62 | 54.04 | 58.75 | 82.89 | 57.75 | 60.96 | 59.04 | 75.82 | |
| yor | F1 = 0 | 25.75 | 24.52 | 18.23 | 2.02 | 22.62 | 19.23 | 24.89 | 19.54 |
| F1 ≠ 0 | 54.67 | 48.73 | 52.67 | 83.20 | 52.84 | 55.98 | 63.64 | 82.13 | |
| zul | F1 = 0 | 31.97 | 25.04 | 25.79 | 6.43 | 48.03 | 36.40 | 33.81 | 0.00 |
| F1 ≠ 0 | 57.60 | 57.32 | 60.06 | 75.38 | 60.06 | 58.51 | 60.74 | 76.27 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ijebu, F.F.; Liu, Y.; Sun, C.; Jere, N.; Mienye, I.D.; Inyang, U.G. Cross-Encoder-Based Semantic Evaluation of Extractive and Generative Question Answering in Low-Resourced African Languages. Technologies 2025, 13, 119. https://doi.org/10.3390/technologies13030119
Ijebu FF, Liu Y, Sun C, Jere N, Mienye ID, Inyang UG. Cross-Encoder-Based Semantic Evaluation of Extractive and Generative Question Answering in Low-Resourced African Languages. Technologies. 2025; 13(3):119. https://doi.org/10.3390/technologies13030119
Chicago/Turabian StyleIjebu, Funebi Francis, Yuanchao Liu, Chengjie Sun, Nobert Jere, Ibomoiye Domor Mienye, and Udoinyang Godwin Inyang. 2025. "Cross-Encoder-Based Semantic Evaluation of Extractive and Generative Question Answering in Low-Resourced African Languages" Technologies 13, no. 3: 119. https://doi.org/10.3390/technologies13030119
APA StyleIjebu, F. F., Liu, Y., Sun, C., Jere, N., Mienye, I. D., & Inyang, U. G. (2025). Cross-Encoder-Based Semantic Evaluation of Extractive and Generative Question Answering in Low-Resourced African Languages. Technologies, 13(3), 119. https://doi.org/10.3390/technologies13030119