

Enhancing Decision-Making and Data Management in Healthcare: A Hybrid Ensemble Learning and Blockchain Approach


Abstract
1. Introduction
1.1. Motivation and Objective
1.2. Contribution
- Integrating the learning method with a secure mechanism in order to detect the malicious behavior of the communicating devices along with improving the accuracy of the proposed mechanism.
- The boosting ensemble learning mechanism is used to validate the data sampling while recording and generating the information from intelligent devices in order to provide accurate decision-making.
- Blockchain mechanism is used for identifying the malicious activities and continuous surveillance of heterogeneous information recorded by several intelligent devices while processing and communicating the information in the network.
2. Related Work
Research Gap
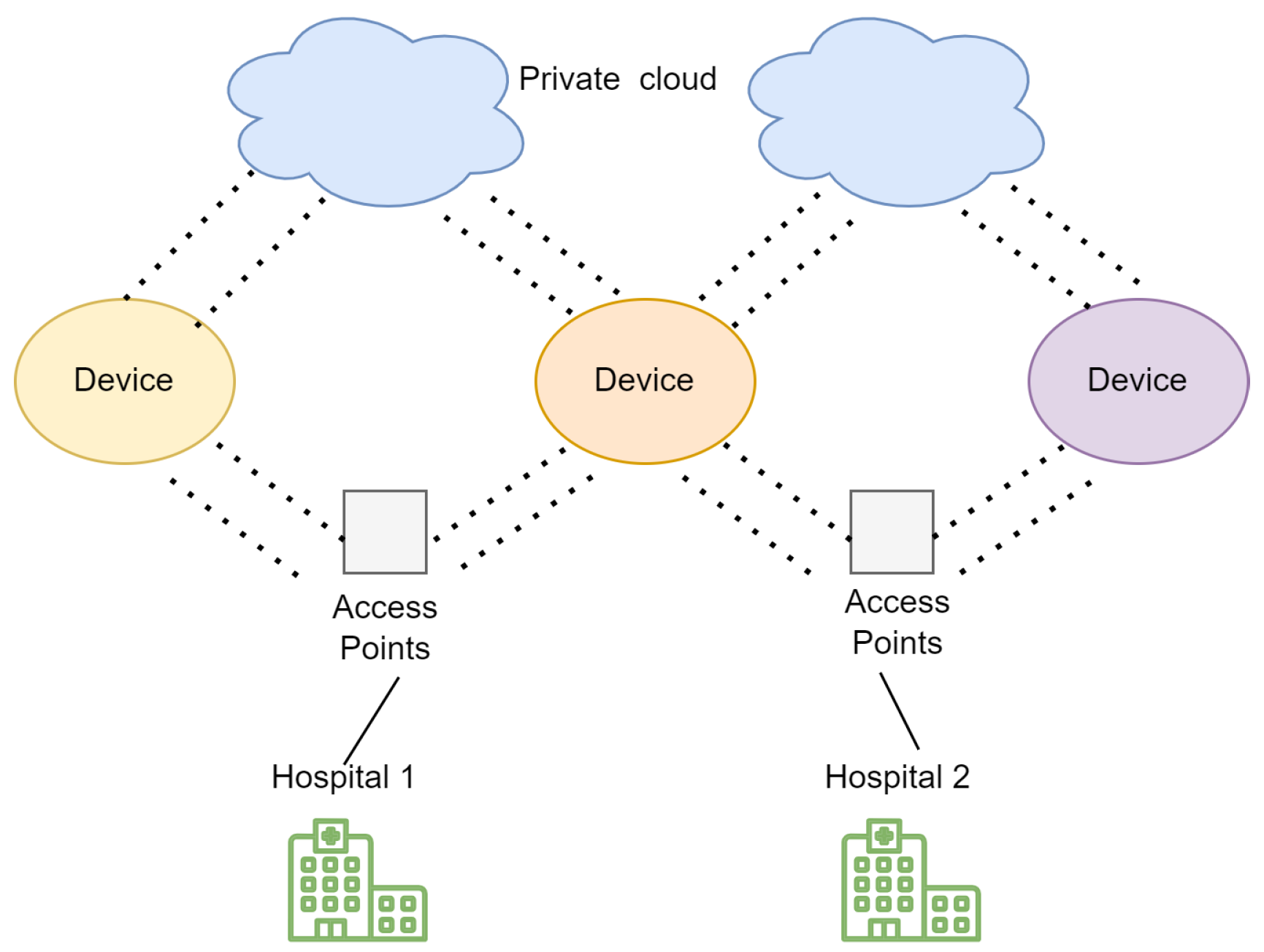
3. Proposed Approach
| Algorithm 1: Data sampling |
 |
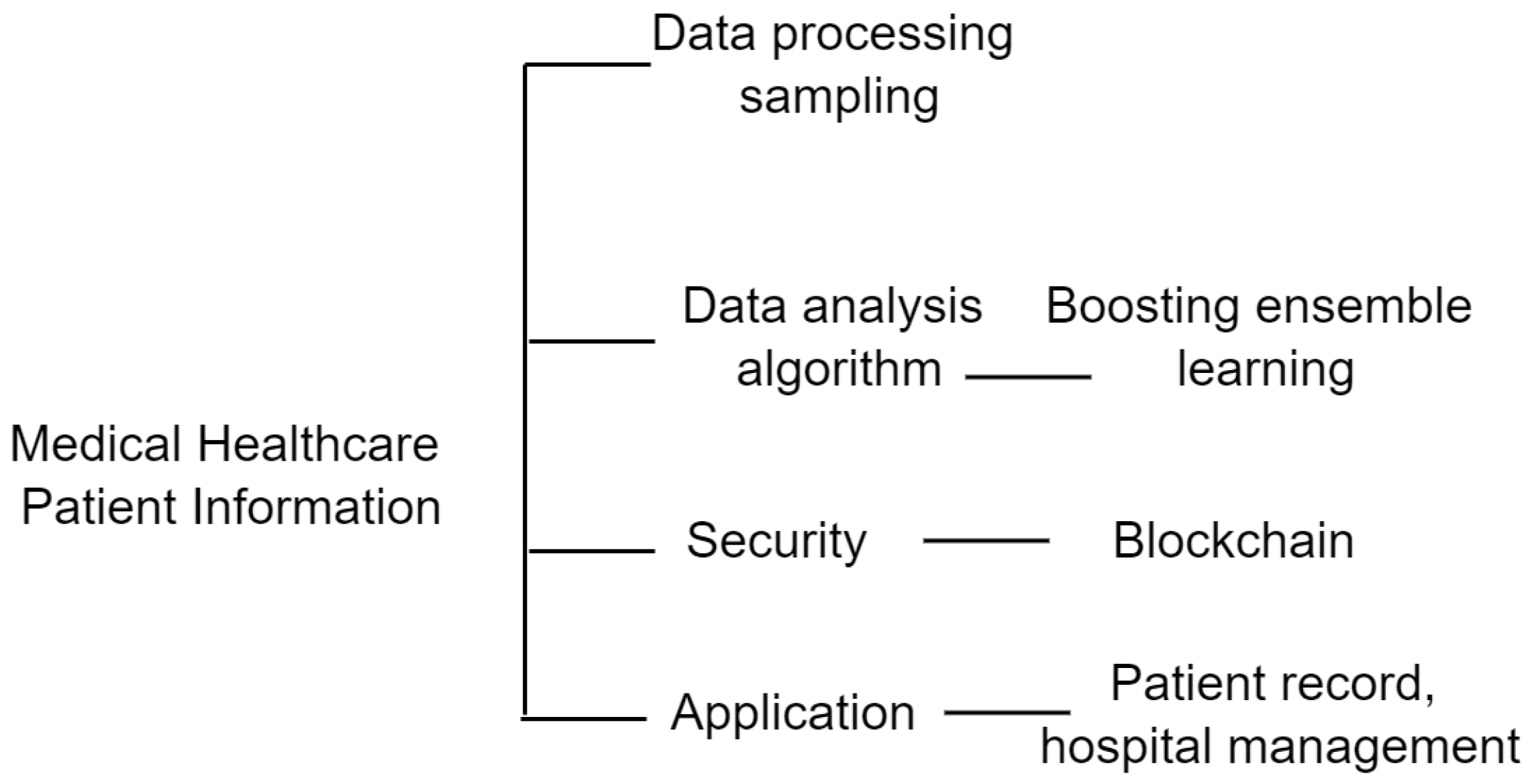
3.1. Ensemble Learning
3.1.1. Data Processing
3.1.2. Boosting Algorithm
| Algorithm 2: Sequential boosting ensemble learning |
Input: N number of data samples, n number of learners, n number of models Output: final prediction of the samples and instances Step 1: train the initial dataset d on first learner and generate the misclassification of samples Step 2: new dataset d2 is generated from the d1 by prioritizing the misclassified data instances from first learner model Step 3: by prioritizing the second learners misclassified dataset instances Repeat n times Step 4: Combines and weights all the learners in to obtain the final prediction |
3.1.3. Blockchain Network
3.1.4. Block Addition
3.1.5. Block Updation
4. Performance Analysis
4.1. Methodology
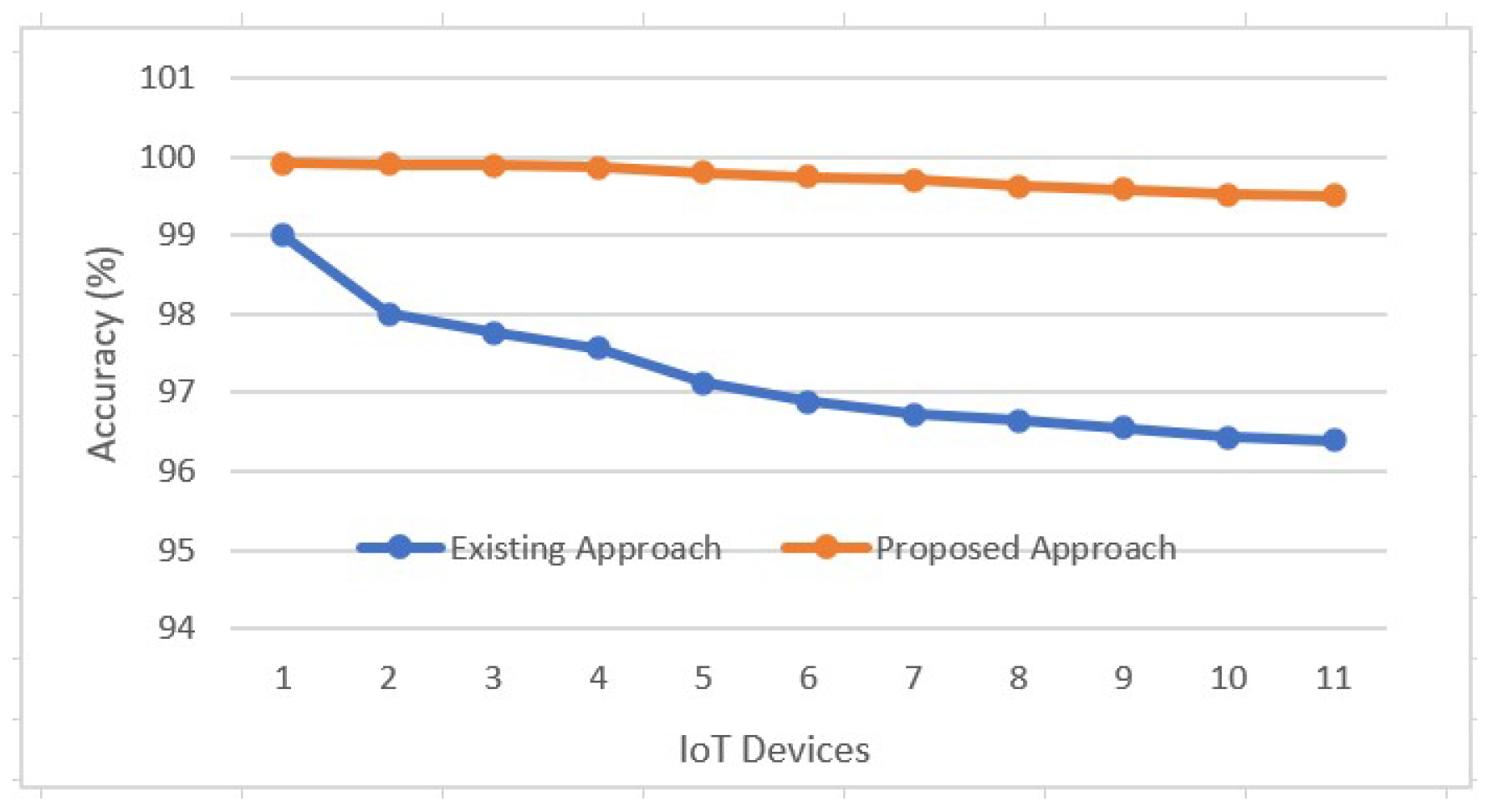
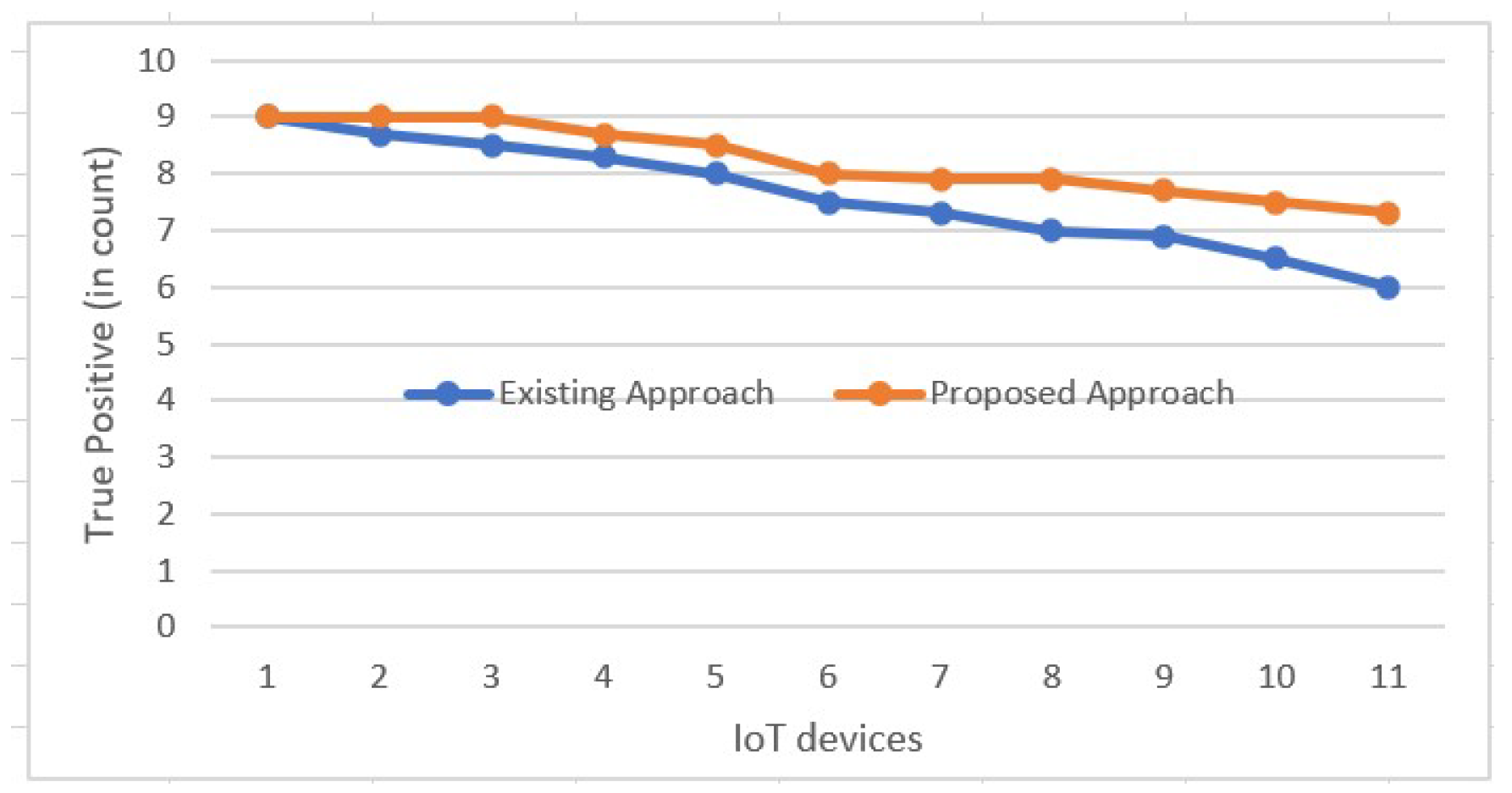
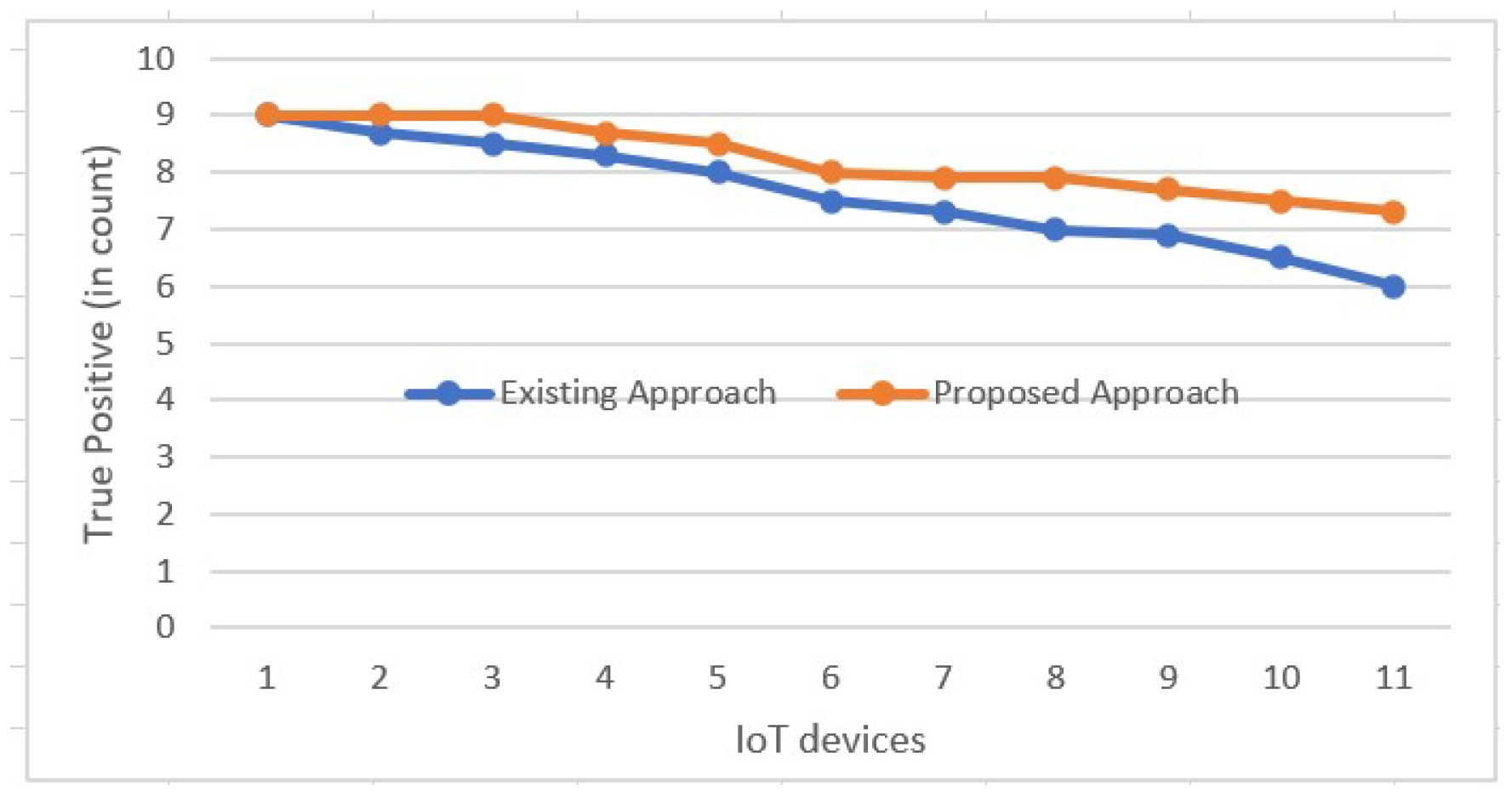
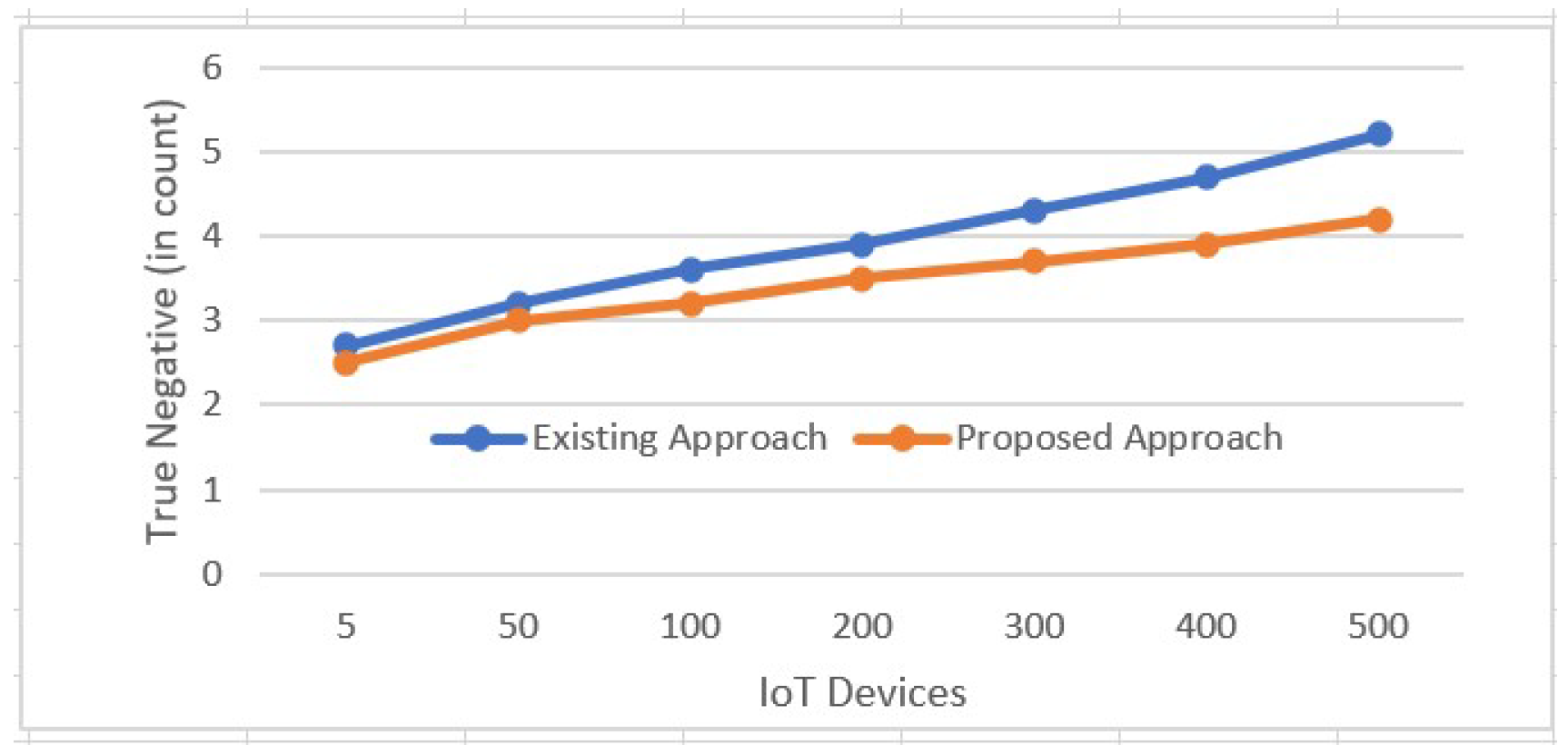
4.2. Results and Discussion
Results Analysis
4.3. Summary
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pereira, P.; Cunha, J.; Fernandes, J.P. On understanding data scientists. In Proceedings of the 2020 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), Dunedin, New Zealand, 11–14 August 2020; pp. 1–5. [Google Scholar]
- Zhang, Z.; Kouzani, A.Z. Implementation of DNNs on IoT devices. Neural Comput. Appl. 2020, 32, 1327–1356. [Google Scholar] [CrossRef]
- Badar, M.S.; Shamsi, S.; Haque, M.M.U.; Aldalbahi, A.S. Applications of AI and ML in IoT. In Integration of WSNs into Internet of Things; CRC Press: Boca Raton, FL, USA, 2021; pp. 273–290. [Google Scholar]
- Alajlan, N.N.; Ibrahim, D.M. TinyML: Enabling of inference deep learning models on ultra-low-power IoT edge devices for AI applications. Micromachines 2022, 13, 851. [Google Scholar] [CrossRef] [PubMed]
- Qiu, J.; Wu, Q.; Ding, G.; Xu, Y.; Feng, S. A survey of machine learning for big data processing. EURASIP J. Adv. Signal Process. 2016, 2016, 67. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Malokani, A.S.; Sodhro, G.H.; Muzammal, M.; Zongwei, L. An adaptive QoS computation for medical data processing in intelligent healthcare applications. Neural Comput. Appl. 2020, 32, 723–734. [Google Scholar] [CrossRef]
- Ma, F.; Ye, M.; Luo, J.; Xiao, C.; Sun, J. Advances in mining heterogeneous healthcare data. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 4050–4051. [Google Scholar]
- Wang, M.; Li, S.; Zheng, T.; Li, N.; Shi, Q.; Zhuo, X.; Ding, R.; Huang, Y. Big data health care platform with multisource heterogeneous data integration and massive high-dimensional data governance for large hospitals: Design, development, and application. JMIR Med. Inform. 2022, 10, e36481. [Google Scholar] [CrossRef] [PubMed]
- Thakur, A.; Molaei, S.; Nganjimi, P.C.; Soltan, A.; Schwab, P.; Branson, K.; Clifton, D.A. Knowledge abstraction and filtering based federated learning over heterogeneous data views in healthcare. NPJ Digit. Med. 2024, 7, 283. [Google Scholar] [CrossRef] [PubMed]
- Kasban, H.; El-Bendary, M.A.M.; Salama, D.H. A comparative study of medical imaging techniques. Int. J. Inf. Sci. Intell. Syst. 2015, 4, 37–58. [Google Scholar]
- Suetens, P. Fundamentals of Medical Imaging; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef]
- Hammi, M.T.; Bellot, P.; Serhrouchni, A. BCTrust: A decentralized authentication blockchain-based mechanism. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Ma, H.; Huang, E.X.; Lam, K.Y. Blockchain-based mechanism for fine-grained authorization in data crowdsourcing. Future Gener. Comput. Syst. 2020, 106, 121–134. [Google Scholar] [CrossRef]
- Pelekoudas-Oikonomou, F.; Zachos, G.; Papaioannou, M.; de Ree, M.; Ribeiro, J.C.; Mantas, G.; Rodriguez, J. Blockchain-based security mechanisms for IoMT Edge networks in IoMT-based healthcare monitoring systems. Sensors 2022, 22, 2449. [Google Scholar] [CrossRef]
- Parsaeian, M.; Mahdavi, M.; Saadati, M.; Mehdipour, P.; Sheidaei, A.; Khatibzadeh, S.; Farzadfar, F.; Shahraz, S. Introducing an efficient sampling method for national surveys with limited sample sizes: Application to a national study to determine quality and cost of healthcare. BMC Public Health 2021, 21, 1414. [Google Scholar] [CrossRef]
- Lu, R.; Jin, X.; Zhang, S.; Qiu, M.; Wu, X. A study on big knowledge and its engineering issues. IEEE Trans. Knowl. Data Eng. 2018, 31, 1630–1644. [Google Scholar] [CrossRef]
- Salloum, S.; Huang, J.Z.; He, Y.; Chen, X. An asymptotic ensemble learning framework for big data analysis. IEEE Access 2018, 7, 3675–3693. [Google Scholar] [CrossRef]
- Shang, T.; Zhang, F.; Chen, X.; Liu, J.; Lu, X. Identity-based dynamic data auditing for big data storage. IEEE Trans. Big Data 2019, 7, 913–921. [Google Scholar] [CrossRef]
- Yu, T.; Wang, X.; Shami, A. Recursive principal component analysis-based data outlier detection and sensor data aggregation in IoT systems. IEEE Internet Things J. 2017, 4, 2207–2216. [Google Scholar] [CrossRef]
- Sanyal, S.; Zhang, P. Improving quality of data: IoT data aggregation using device to device communications. IEEE Access 2018, 6, 67830–67840. [Google Scholar] [CrossRef]
- Lin, R.; Ye, Z.; Wang, H.; Wu, B. Chronic diseases and health monitoring big data: A survey. IEEE Rev. Biomed. Eng. 2018, 11, 275–288. [Google Scholar] [CrossRef]
- Emara, T.Z.; Huang, J.Z. Distributed data strategies to support large-scale data analysis across geo-distributed data centers. IEEE Access 2020, 8, 178526–178538. [Google Scholar] [CrossRef]
- Ding, X.; Wang, H.; Li, G.; Li, H.; Li, Y.; Liu, Y. IoT data cleaning techniques: A survey. Intell. Converg. Netw. 2022, 3, 325–339. [Google Scholar] [CrossRef]
- Tsogbaatar, E.; Bhuyan, M.H.; Taenaka, Y.; Fall, D.; Gonchigsumlaa, K.; Elmroth, E.; Kadobayashi, Y. DeL-IoT: A deep ensemble learning approach to uncover anomalies in IoT. Internet Things 2021, 14, 100391. [Google Scholar] [CrossRef]
- Jatoth, C.; Jain, R.; Fiore, U.; Chatharasupalli, S. Improved classification of blockchain transactions using feature engineering and ensemble learning. Future Internet 2021, 14, 16. [Google Scholar] [CrossRef]
- Al-Utaibi, K.A.; El-Alfy, E.S.M. Intrusion detection taxonomy and data preprocessing mechanisms. J. Intell. Fuzzy Syst. 2018, 34, 1369–1383. [Google Scholar] [CrossRef]
- Wang, S.; Celebi, M.E.; Zhang, Y.-D.; Yu, X.; Lu, S.; Yao, X.; Zhou, Q.; Miguel, M.-G.; Tian, Y.; Gorriz, J.M.; et al. Advances in data preprocessing for biomedical data fusion: An overview of the methods, challenges, and prospects. Inf. Fusion 2021, 76, 376–421. [Google Scholar] [CrossRef]
- Lashkari, B.; Musilek, P. A comprehensive review of blockchain consensus mechanisms. IEEE Access 2021, 9, 43620–43652. [Google Scholar] [CrossRef]
- Yawalkar, P.M.; Paithankar, D.N.; Pabale, A.R.; Kolhe, R.V.; William, P. Integrated identity and auditing management using blockchain mechanism. Meas. Sensors 2023, 27, 100732. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author Name | Description | Silent Features of Literature Discussion |
|---|---|---|
| Lu et al. [17] | concept of big knowledge system | presented the definition by checking the engineering projects |
| Salloum et al. [18] | distributed data parallel mechanism | developed a prototype using frameworks Hadoop distributed file system |
| Shang et al. [18] | identity-based dynamic data auditing mechanism | achieved an efficient operation using data structures of Merkle Hash tree |
| Yu et al. [20] | cluster-based data analysis framework | defined the abnormal squared prediction error by adapting and updating the changes |
| Sanyal et al. [21] | data aggregation scheme | achieved the aforementioned tasks by determining the uncensored information |
| Lin et al. [22] | reviewed the recent research efforts | focused on data processing and data visualization issues |
| Emara et al. [23] | data distribution strategies | used random partition data model in order to analyses the entire information |
| Ding et al. [24] | data cleaning survey | error detection and repairing schemes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rathee, G.; Iqbal, R. Enhancing Decision-Making and Data Management in Healthcare: A Hybrid Ensemble Learning and Blockchain Approach. Technologies 2025, 13, 43. https://doi.org/10.3390/technologies13020043
Rathee G, Iqbal R. Enhancing Decision-Making and Data Management in Healthcare: A Hybrid Ensemble Learning and Blockchain Approach. Technologies. 2025; 13(2):43. https://doi.org/10.3390/technologies13020043
Chicago/Turabian StyleRathee, Geetanjali, and Razi Iqbal. 2025. "Enhancing Decision-Making and Data Management in Healthcare: A Hybrid Ensemble Learning and Blockchain Approach" Technologies 13, no. 2: 43. https://doi.org/10.3390/technologies13020043
APA StyleRathee, G., & Iqbal, R. (2025). Enhancing Decision-Making and Data Management in Healthcare: A Hybrid Ensemble Learning and Blockchain Approach. Technologies, 13(2), 43. https://doi.org/10.3390/technologies13020043