Abstract
Nowadays, video is a common social media in our lives. Video summarisation has become an interesting task for information extraction, where the challenge of high redundancy of key scenes leads to difficulties in retrieving important messages. To address this challenge, this work presents a novel approach called the Graph Attention (GAT)-based bi-directional content-adaptive recurrent unit model for video summarisation. The model makes use of the graph attention approach to transform the visual features of interesting scene(s) from a video. This transformation is achieved by a mechanism called Adaptive Feature-based Transformation (AFT), which extracts the visual features and elevates them to a higher-level representation. We also introduce a new GAT-based attention model that extracts major features from weight features for information extraction, taking into account the tendency of humans to pay attention to transformations and moving objects. Additionally, we integrate the higher-level visual features obtained from the attention layer with the semantic features processed by Bi-CARU. By combining both visual and semantic information, the proposed work enhances the accuracy of key-scene determination. By addressing the issue of high redundancy among major information and using advanced techniques, our method provides a competitive and efficient way to summarise videos. Experimental results show that our approach outperforms existing state-of-the-art methods in video summarisation.
1. Introduction
Video summarisation is a challenging task for rapid review and content comprehension, with the aim of generating concise representations from original videos. Compared to surveillance video content, people tend to watch more frequent views or events rather than static content. Therefore, an effective summarisation technique often results in high key-frame redundancy when dealing with user-interest content. This study presents a bi-CARU model for summarising user-interesting videos, which has been adapted using an attention mechanism for content encoding and decoding [1].
The powerful architecture of encoder–decoder is based on the neural network; it enables the neural system to extract the information from a sequence input and produce new sequence features for representing output. The work of [2] initially adapted a classical attention-based encoder–decoder structure for supervised video summarisation [3,4,5]. This structure aimed to highlight the major information from images, which could further be used for key-frame discovery. However, the limited output length of the encoder in such an encoder–decoder framework resulted in the abandonment of salient features, leading to a decrease in accuracy for key-frame selection and prediction. To alleviate this limitation, an attention mechanism was incorporated into the encoder–decoder framework [6]. This attention mechanism efficiently alleviated the issues arising from the limited encoder output length, but a lack of high-quality human-annotated labels is still faced, restricting the performance of video summarisation. Consequently, unsupervised-based models gained popularity, as they did not depend on annotated labels for training. One such unsupervised method was proposed by [7], who utilised dictionary selection for video summarisation [8]. Following this, Ref. [9] introduced a variational auto-encoder with Generative Adversarial Networks (GANs) to summarise videos [10]. Another noteworthy approach was presented by [11] that applied reinforcement learning techniques to achieve video representations. They proposed an end-to-end LSTM-based unsupervised learning method for video summarisation [12]. These methods incorporated an advanced feedback reward mechanism that combined diversity and representativeness. To further enhance unsupervised video summarisation, Ref. [13] proposed an unsupervised (Cycle-LSTM), which integrated a frame selector and a cycle-consistent learning-based evaluator to achieve better performance. Overall, these unsupervised methods addressed the challenges posed by the lack of human-annotated labels, resulting in more efficient video summarisation [14,15].
In practice, the use of Graph Attention Networks (GATs) in video representation is a promising approach within the end-to-end framework. The GAT approach works by transforming the features of a node in a graph into higher-level features, taking into account the influence of neighbouring nodes that are related to the target node [16,17,18]. Differing from other models, such as Graph Convolutional Network (GCN), which uses predetermined non-parametric weights [19], or GraphSage, which employs identical weights [20], GAT allocates variable (trainable) weights to the neighbouring nodes based on their contribution to the target node, which is achieved through an attention mechanism [21]. By considering variable weights, GAT can capture more fine-grained information about the relationships between nodes in the graph, thus improving the overall capabilities for feature extraction [22]. Moreover, by combining the effects of related neighbouring nodes through attentional mechanisms, GAT allows for more flexibility and adaptability in dealing with different types of graphs and tasks [23].
2. Related Works
Video summarisation has become an interesting task in computer vision and multimedia content analysis, aiming to condense a full-length video into a brief and comprehensive summary. In practice, the Content-Aware Video Summarisation (CAVS) approach performs well for video summarisation [24]. CAVS focuses on diversity, representativeness, and interestingness to create a summary of the received content. It extracts and encodes the main features and decodes the high-level textual information to select the most semantically representative summaries [25]. In recent years, attention-based video summarisation methods have become popular due to the CAVS approach and have produced highly competitive results [14,26,27].
Recently, there has been an increasing amount of research on predicate summarisation by integrating semantic information from videos. A query-centred video summary extraction technique was proposed in [28], which treats each frame as equally important and searches a given video to select key frames related to predefined events or interesting scenes [14]. Also, Refs. [29,30] proposed a text-based evaluation method to assess the extent to which the summary preserves the semantic information of the original video. This text-based approach uses Natural Language Processing (NLP) metrics to measure the semantic distance between human-related summaries and the behavioural performance of the generated summaries. In practice, these approaches are efficient and easy to implement but do not take into account the visual quality of the generated summaries. In a different approach, Ref. [31] developed a Semantic Attended Video Summarisation Network (SASUM) that focuses on extracting features from a keyframe that are semantically related to the given textual description. The SASUM consists of a frame selector and a video descriptor, where the frame selector is an LSTM-based model and the event descriptor is an LSTM-based encoder–decoder model. Further, Ref. [32] extended SASUM with two separate modules for video summarisation and moment localisation. Each module estimates a frame-by-frame importance map to indicate keyframes or moments. To further enhance the semantic content of the output summary, Ref. [33] replaced the RNN by a CARU layer with an attention mechanism approach, allowing different input frames to be assigned different importance weights. These methods effectively establish a connection between textual information and a summary determined by multi-behaviour within the video scene.
Recent developments have shown that attention mechanisms are highly effective in video summarisation. The attention mechanism enables the assignment of different weights to input sequences and the capture of global temporal dependencies. Ref. [34] proposed an efficient visual attention model that incorporates both static and dynamic visual detection. Also, Ref. [35] presented a minimalist transformer-based model for temporal action localisation that combines multi-scale feature representations with local self-attention and uses a lightweight decoder to classify and predict each moment in time. These two visual attention models were non-linearly combined to summarise videos [36]. Similarly, Ref. [37] designed a multimodal feature fusion module that fuses frame features with attention-based query features to achieve retrieval-driven video summarisation. These approaches mainly rely on the underlying features and do not consider the temporal dependency between video frames. Furthermore, Ref. [38] further enhanced attention by performing weighted score filtering on the input frame sequence to focus on a subset of video frames from various scenes [39,40].
Inspired by the context of the video representation, the GAT enables the model to capture the relationships between different sequences or scenes of a video, which can be crucial for accurate video classification. The contributions of this work are reported as follows:
- This work presents two CNN models for processing the visual and audio components of a video. Both models utilise a spatial CNN layer to account for the time series input by employing the VGGreNet architecture. A Spatial Attention Module (SAM) is also considered to attend and weight the extracted features, and a subnet is introduced to combine the received features.
- In the Graph Attention Network (GAT) approach, a comprehensive graph is constructed from features derived from the Self-Attention Mechanism (SAM). The attention mechanism is then applied to the edges of the GAT to extract interesting content from the features.
- Next, an Adaptive Feature-based Transformation (AFT) is then introduced. This transformation is used to improve the calculation of weights, thereby increasing the overall effectiveness of the process. The AFT is then integrated into a multi-headed approach. This integration facilitates the identification of events, thereby enabling a more comprehensive understanding and interpretation of the video content.
- Bi-CARU is recommended for decoding and extracting contextual information using its context-adaptive gate. It also improves the accuracy of the similarity module by combining the forward and backward features of CARU, taking into account the hidden features and attention to generate detailed sentences for fine-grained prediction.
This approach highlights the potential of combining GAT with AFT within a multi-headed framework to enhance the analysis and interpretation of video content. It represents a significant advance in the field of video content understanding and demonstrates the power of attentional mechanisms to extract meaningful information from complex data structures. Overall, this work investigates the combination of GAT and Bi-CARU to enhance accuracy in key-scene selection for video summarisation. These contributions improve the overall performance of video summarisation algorithms, resulting in better outcomes and increased efficiency in video analysis.
3. Proposed Model
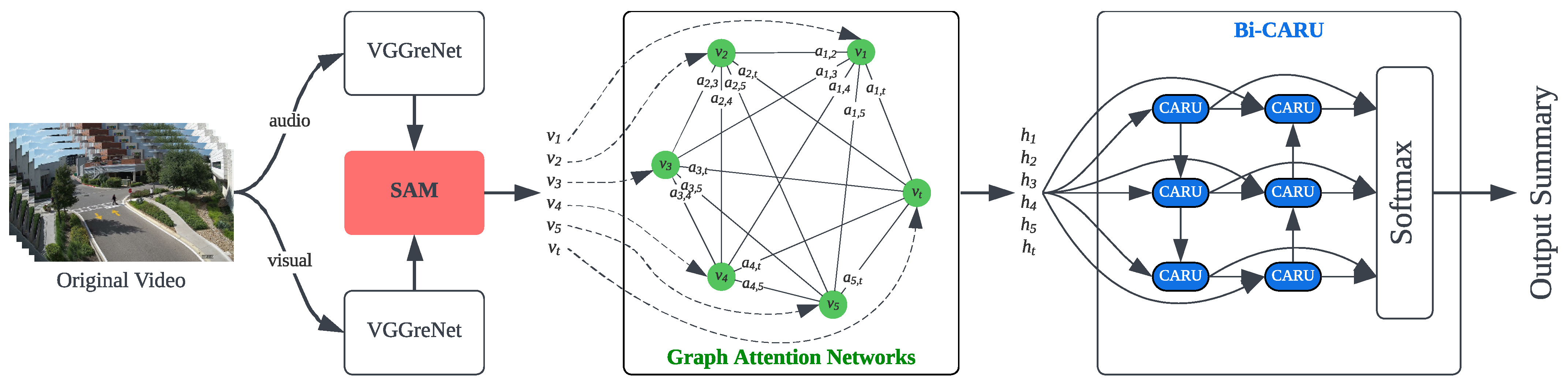
To improve the discrimination between images by efficiently using both visual and audio features, a novel GAT-based Bi-CARU model is developed that effectively discriminates between images by integrating coded features. The proposed model is able to discover the connection between the interested objects within the sequence of frames, addressing the relationship determination from the hidden feature, as illustrated in Figure 1. The model consists of several major components:
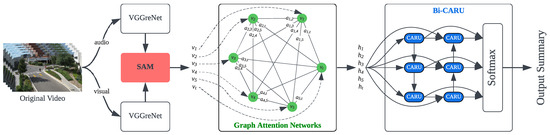
Figure 1.
Framework of the proposed GAT-based bi-CARU for video summarisation.
- Spatial Attention Module (SAM). This module takes the visual features as input to predict the spatial information of the frame(s) and determines the coordinate of the current frame to compute their relative spatial information and perform consistent coordinate projections. By applying the 3D transformation algorithm, the model can be focused on a consistent projective space to compute the acquisition of the relevant regional information of the image.
- Graph Attention Transformer (GAT). The visual features of the nodes are transformed using the Adaptive Feature-based Transformation (AFT) mechanism. This process enhances the representation of visual features in the model. These visual features are then processed by a Bi-CARU network, also employing the multi-headed approaches for the key-frame determination.
- Bi-CARU Layer. An advanced bi-directional RNN architecture with CARU is combined with the GAT attention score generated by the GAT. This bi-CARU architecture enables simultaneous forward and backward feature searching from the input feature.
Moreover, we make use of the reinforcement network to optimise for loss by backpropagating, which performs the training model by iteratively adjusting the attention mechanism. The proposed model is conducted to improve and discover the relationship between interested objects in the middle of the encoding and decoding side. This design provides a clear connection and discards some noise when more objects are extracted within the same scene, making the decoding module perform better by applying this design. By incorporating these components, our proposed model demonstrates better discrimination between images, as it can effectively use both audio and visual features from the original video.
3.1. Spatial Attention Module (SAM)
The proposed SAM performs spatial attention in a convolutional layer. In practice, since the work proposes to receive video sequences for analysis, scalable feature inputs and outputs are required, which are not good for extraction when using traditional CNN networks. Therefore, VGGreNet has the advantage of being able to receive inputs of non-fixed length while still providing the performance of VGGnet. It first receives and concatenates (audio and video) features from VGGreNet [41], adjusting inter-spatial features related to behaviours and their relationships. Different from the colour in the 2D domain, the spatial attention is mainly focused on motion feature extraction and also discards noisy information on the time-axis from the frame sequence. The proposed SAM for spatial feature extraction consists of Chebyshev-pooling [42] and max-pooling layers to produce weighted features (w) as follows:
here, an advanced pooling is recommended to project the feature f into a probability domain that can be used as a weighting feature. It makes use of the Chebyshev theory, whereby the output feature can be projected to a stable range without the need for a sigmoid function, which provides a readable probabilistic result for subsequent processing. Next, an extractor concatenates these weighted features and projects them into a spatial attention that can be expressed as:
where is the sigmoid activation function that ensures the output range in . These are then convolved by a convolutional layer with the filter and kernel sizes of and , respectively. In practice, each can be seen as an interesting scene within a video that needs to be extracted. This enables the extraction of objects or behaviours from the target, effectively eliminating most meaningless content and allowing subsequent procedures to be analysed in more detail.
3.2. Graph Attention Transformer (GAT)
After receiving the scenes extracted by SAM, GAT discovers potential relationships between these features v from them. As illustrated in the graph attention networks in Figure 1, there is a complete graph consisting of nodes, each connected by edge weights . In our study, represents the attention scores that reflect the relationship between node and . The GAT computes normalised coefficients across pairs of and for every received scene in the set . The injected graph structure, which only allows a node to attend over nodes in its neighbourhood, can be expressed as follows:
here, it involves learning the parameters of the two linear projections and corresponding to the paired video scenes and , respectively. To ensure gradient contribution, is used to scale the attention value and normalise their output instead of directly, which can contribute more gradients to enhance convergence, rather than using an activation function of [43]. The pairwise attention matrix shows the temporal relation between frame pairs in . The resulting pairwise attention weights are then converted to the corresponding normalised weights using the Softmax function. This approach also provides gradients without scaling and allows training parameters to be shared with the rest of the network during backpropagation.
To discover events from these , it is necessary to summarise all potential features in these scenes. This work introduces Adaptive Feature-based Transformation (AFT), which focuses on identifying scenes in a video that are significantly different from others, effectively capturing and representing the global diversity between different video scenes. These weights can be adaptably considered by the multi-headed approach [44] to identify and transform interesting events for further decoding. In practice, a LINEAR layer is used to concatenate the dissimilarity between each with from the multi-headed approach. This operation is repeated K times while updating these parameters during each backpropagation as follows:
here is initial to from (4), are derived by the k-th time, and serves as a weight matrix specifying a linear transformation containing N event features.
3.3. Bi-CARU Decoder
Linear RNNs are effective in NLP decoding tasks, but they struggle with long-term dependency and convergence issues. Variants like LSTM and GRU aim to tackle these problems. Our work uses the advanced RNN unit, CARU, which introduces two gates (the context-adaptive gate and the update gate) with fewer parameters than other units. The context-adaptive gate in CARU weighs the input based only on the current feature, allowing for a better combination of weights, unlike the reset gate in GRU, which depends on the entire sequence. This procedure is similar to a tagging task, connecting weights and parts of speech, filtering noise, and highlighting major features in the current input. The complete procedure is as follows:
The CARU processes involve assigning weights to words and gates, and multiplying them by content weights, taking into account both words and content. It allows for precise contextual sentence prediction by accurately predicting individual words and analysing their content based on their current parts of speech. Corresponding to Bi-CARU in Figure 1, bidirectional structures enhance context awareness by considering the previous and next hidden features. Let and denote the feature by concatenated forward and backward CARU. The word probabilities can be obtained through the decoding process as follows:
A Feed-Forward Network (FFN) is used to decode the word-feature. Each update contains sub-updates corresponding to individual FFN parameter vectors. These vectors promote comprehensible concepts, which are often easy for humans to understand. The model is trained using word-level cross-entropy loss and uses the Adam optimiser [45].
4. Experimental Analysis
The model’s performance was evaluated on two datasets: TVSum [46] and SumMe [47]. TVSum is a collection of 50 videos that have been carefully selected from the vast amount of content available on YouTube. SumMe consists of 25 user-created videos covering a diverse range of topics, mostly from sports to vacation experiences. These videos are divided into categories, making it more complex for our model to navigate. The duration of the videos ranges from 1 to 6 min. To understand user behaviour and preferences, it involves over 15 users in creating human-generated summaries. The users also provide attention scores at the frame level, which offers valuable insight and data for this work.
In addition, we evaluate the similarity of the generated summaries to human-annotated summaries following the configuration in [6]. The evaluation metric used is the F-score, which is the harmonic mean of precision (P) and recall (R). The correct parts are identified by overlapping word features between human-generated and model-generated summaries. The F-score is then calculated as:
where P is defined as , and R is defined as .
Table 1 provides a comprehensive overview, showing that on the SumMe dataset, the proposed method achieves competitive results with other methods. It can be found that our proposed method obtained the second-best and best F-scores in TVSum and SumMe, respectively. In practice, our method outperforms those of the baseline studies that use LSTM structures, such as Bi-LSTM [48] and DPP-LSTM [6]. These methods require the temporal feature from the forget gate in LSTM, which can often cause the long-term dependency problem and perturb the attention weights produced by GAT. Our proposed approach achieves superior performance on the SumMe dataset and second-best performance on the TVSum dataset compared to advanced approaches. Our proposed method uses the features received from SAM and applies the attention mechanism to the edges of GAT to discover interesting content. Bi-CARU can adaptively select the long-term feature field through its content-adaptive gate. The AFT enhances the weight calculation and is integrated into the multi-headed approach to determine the event for a more comprehensive understanding of the video.

Table 1.
Comparison with state-of-the-art methods in F-score (%); the best scores are in bold.
As shown in Table 2, this analysis highlights the interesting scenes identified by humans and two advanced methods in this work. This work has selected interesting scenes that cover the human (ground truth) and accurately represent the time period of the video. It is worth noting that most of the comparison algorithms on the SumMe dataset have relatively low F-scores compared to the TVSum dataset. This observation proves that these comparison algorithms perform poorly when dealing with raw or simply edited videos. However, our method’s effectiveness and potential for practical applications are further enhanced by the high score of 58.4% on the TVSum dataset, demonstrating the successful alleviation of these shortcomings.
Table 2.
Visualisation of interesting scenes from the “Paper Wasp Removal|From the Ground Up” video in TVSum dataset. From top to bottom, the highlighted scenes are determined by human annotation, SUM-FCN [49], SUM-DeepLab [49], and this work.
Feature Visualisation by Video Descriptions
To provide the weighting of extracted features, this section displays the relationship between the attention scores and the relevant objects. This allows for post-processing of the significant messages generated by the video description by the study [55]. This technique aims to represent a heatmap covering the interesting scene(s) based on the information extracted from the selected frames. The objective is to indicate the various intervals and their dynamics that affect the viewer’s attention and understanding of the video content. As highlighted in Figure 2, the heatmap focuses primarily on the human face or the moving object within a sequence. When considering the whole video, the video description generated by the proposed AFT can better describe the interesting objects and their connections. Therefore, the saliency of the video description generated by Bi-CARU accurately represents the main content of the textual description. The video summaries generated by our model are consistent with the video descriptions, which further proves the effectiveness of our approach.

Figure 2.
Heatmap visualisation of the “Reuben Sandwich with Corned Beef & Sauerkraut” video in TVSum dataset.
5. Conclusions
To present more accuracy for video summarisation, this work introduces a GAT-based Bi-CARU model that enhances the feature extraction between interesting frames by capturing visual and audio features. The SAM module first takes the visual features as input to predict the spatial information of the frame(s) and then determines the coordinate of the current frame to compute their relative spatial information and perform consistent coordinate projections. Also, the redundancy frames can be discarded by the proposed AFT selection, caused by the low attention calculated from the weight feature(s). Moreover, the Bi-CARU is adapted to decode the summary for the interesting scene(s) predicted by the GAT module. The experiments report that the proposed GAT-based Bi-CARU model achieves competitive results from the advanced methods. In future work, we will integrate spatial analysis into our model and explore the feasibility of reconstructing 3D space to make better use of the video structure. We will also improve the encoding to represent fine-grained features from a global sequence perspective.
Author Contributions
Conceptualization, K.-H.C. and S.-K.I.; methodology, K.-H.C. and S.-K.I.; software, K.-H.C.; validation, S.-K.I.; formal analysis, K.-H.C. and S.-K.I.; investigation, K.-H.C.; resources, K.-H.C. and S.-K.I.; data curation, K.-H.C. and S.-K.I.; writing—original draft preparation, K.-H.C.; writing—review and editing, S.-K.I.; visualization, K.-H.C.; supervision, S.-K.I.; project administration, S.-K.I.; funding acquisition, S.-K.I. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Macao Polytechnic University (Research Project RP/FCA-06/2023).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- de Santana Correia, A.; Colombini, E.L. Attention, please! A survey of neural attention models in deep learning. Artif. Intell. Rev. 2022, 55, 6037–6124. [Google Scholar] [CrossRef]
- Ji, Z.; Xiong, K.; Pang, Y.; Li, X. Video Summarization With Attention-Based Encoder–Decoder Networks. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1709–1717. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Zhong, S.H.; Lin, J.; Lu, J.; Fares, A.; Ren, T. Deep Semantic and Attentive Network for Unsupervised Video Summarization. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–21. [Google Scholar] [CrossRef]
- Zhang, K.; Chao, W.L.; Sha, F.; Grauman, K. Video Summarization with Long Short-Term Memory. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 766–782. [Google Scholar] [CrossRef]
- Touati, R.; Mignotte, M.; Dahmane, M. Anomaly Feature Learning for Unsupervised Change Detection in Heterogeneous Images: A Deep Sparse Residual Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 588–600. [Google Scholar] [CrossRef]
- Shang, R.; Chang, J.; Jiao, L.; Xue, Y. Unsupervised feature selection based on self-representation sparse regression and local similarity preserving. Int. J. Mach. Learn. Cybern. 2017, 10, 757–770. [Google Scholar] [CrossRef]
- He, X.; Hua, Y.; Song, T.; Zhang, Z.; Xue, Z.; Ma, R.; Robertson, N.; Guan, H. Unsupervised Video Summarization with Attentive Conditional Generative Adversarial Networks. In Proceedings of the 27th ACM International Conference on Multimedia, ACM, 2019, MM ’19, Nice, France, 21–25 October 2019. [Google Scholar] [CrossRef]
- Apostolidis, E.; Adamantidou, E.; Metsai, A.I.; Mezaris, V.; Patras, I. Unsupervised Video Summarization via Attention-Driven Adversarial Learning. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 492–504. [Google Scholar] [CrossRef]
- Chandak, Y.; Theocharous, G.; Kostas, J.; Jordan, S.; Thomas, P.S. Learning Action Representations for Reinforcement Learning. arXiv 2019, arXiv:1902.00183. [Google Scholar]
- Hu, M.; Hu, R.; Wang, Z.; Xiong, Z.; Zhong, R. Spatiotemporal two-stream LSTM network for unsupervised video summarization. Multimed. Tools Appl. 2022, 81, 40489–40510. [Google Scholar] [CrossRef]
- Yuan, L.; Tay, F.E.H.; Li, P.; Feng, J. Unsupervised Video Summarization With Cycle-Consistent Adversarial LSTM Networks. IEEE Trans. Multimed. 2020, 22, 2711–2722. [Google Scholar] [CrossRef]
- Saini, P.; Kumar, K.; Kashid, S.; Saini, A.; Negi, A. Video summarization using deep learning techniques: A detailed analysis and investigation. Artif. Intell. Rev. 2023, 56, 12347–12385. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Yang, M.; Zhang, L.; Zhang, Z.; Liu, Y.; Xie, X.; Que, X.; Wang, W. View while Moving: Efficient Video Recognition in Long-untrimmed Videos. In Proceedings of the 31st ACM International Conference on Multimedia. ACM, 2023, MM ’23, Ottawa, ON, Canada, 29 October–3 November 2023. [Google Scholar] [CrossRef]
- Chami, I.; Ying, R.; Ré, C.; Leskovec, J. Hyperbolic Graph Convolutional Neural Networks. arXiv 2019, arXiv:1910.12933. [Google Scholar]
- Spinelli, I.; Scardapane, S.; Uncini, A. Adaptive Propagation Graph Convolutional Network. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4755–4760. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Chen, Z.; Jiang, H.; Song, S.; Han, Y.; Huang, G. Adaptive Focus for Efficient Video Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscatway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Liu, X.; Yan, M.; Deng, L.; Li, G.; Ye, X.; Fan, D. Sampling Methods for Efficient Training of Graph Convolutional Networks: A Survey. IEEE/CAA J. Autom. Sin. 2022, 9, 205–234. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2017, arXiv:1706.02216. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous Graph Attention Network. In Proceedings of the World Wide Web Conference, ACM, 2019, WWW ’19, Austin, TX, USA, 30 April–4 May 2023. [Google Scholar] [CrossRef]
- Brody, S.; Alon, U.; Yahav, E. How Attentive are Graph Attention Networks? arXiv 2021, arXiv:2105.14491. [Google Scholar]
- Bo, D.; Wang, X.; Shi, C.; Shen, H. Beyond Low-frequency Information in Graph Convolutional Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3950–3957. [Google Scholar] [CrossRef]
- Khan, A.A.; Shao, J.; Ali, W.; Tumrani, S. Content-Aware Summarization of Broadcast Sports Videos: An Audio–Visual Feature Extraction Approach. Neural Process. Lett. 2020, 52, 1945–1968. [Google Scholar] [CrossRef]
- Mehta, N.; Murala, S. Image Super-Resolution With Content-Aware Feature Processing. IEEE Trans. Artif. Intell. 2024, 5, 179–191. [Google Scholar] [CrossRef]
- Naik, B.T.; Hashmi, M.F.; Bokde, N.D. A Comprehensive Review of Computer Vision in Sports: Open Issues, Future Trends and Research Directions. Appl. Sci. 2022, 12, 4429. [Google Scholar] [CrossRef]
- Nugroho, M.A.; Woo, S.; Lee, S.; Kim, C. Audio-Visual Glance Network for Efficient Video Recognition. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Piscatway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Yasmin, G.; Chowdhury, S.; Nayak, J.; Das, P.; Das, A.K. Key moment extraction for designing an agglomerative clustering algorithm-based video summarization framework. Neural Comput. Appl. 2021, 35, 4881–4902. [Google Scholar] [CrossRef]
- Wang, D.; Guo, X.; Tian, Y.; Liu, J.; He, L.; Luo, X. TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis. Pattern Recognit. 2023, 136, 109259. [Google Scholar] [CrossRef]
- Xu, B.; Liang, H.; Liang, R. Video summarisation with visual and semantic cues. IET Image Process. 2020, 14, 3134–3142. [Google Scholar] [CrossRef]
- Wei, H.; Ni, B.; Yan, Y.; Yu, H.; Yang, X.; Yao, C. Video Summarization via Semantic Attended Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–8 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Jiang, H.; Mu, Y. Joint Video Summarization and Moment Localization by Cross-Task Sample Transfer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscatway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Im, S.K.; Chan, K.H. Context-Adaptive-Based Image Captioning by Bi-CARU. IEEE Access 2023, 11, 84934–84943. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-End Object Detection with Dynamic Attention. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; IEEE: Piscatway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Zhang, C.L.; Wu, J.; Li, Y. ActionFormer: Localizing Moments of Actions with Transformers. In Computer Vision, Proceedings of the ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 492–510. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, L.; Wang, Y.; Zhang, M.; He, L.; Huang, G.; Li, F. Dynamic Spatial Focus for Efficient Compressed Video Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 695–708. [Google Scholar] [CrossRef]
- Lin, Z.; Zhao, Z.; Zhang, Z.; Zhang, Z.; Cai, D. Moment Retrieval via Cross-Modal Interaction Networks With Query Reconstruction. IEEE Trans. Image Process. 2020, 29, 3750–3762. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Zhong, S.h.; Fares, A. Deep hierarchical LSTM networks with attention for video summarization. Comput. Electr. Eng. 2022, 97, 107618. [Google Scholar] [CrossRef]
- Liu, Y.T.; Li, Y.J.; Wang, Y.C.F. Transforming Multi-concept Attention into Video Summarization. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 498–513. [Google Scholar] [CrossRef]
- Li, P.; Tang, C.; Xu, X. Video summarization with a graph convolutional attention network. Front. Inf. Technol. Electron. Eng. 2021, 22, 902–913. [Google Scholar] [CrossRef]
- Chan, K.H.; Im, S.K.; Ke, W. VGGreNet: A Light-Weight VGGNet with Reused Convolutional Set. In Proceedings of the 2020 IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC), Leicester, UK, 7–10 December 2020; IEEE: Piscatway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Chan, K.H.; Pau, G.; Im, S.K. Chebyshev Pooling: An Alternative Layer for the Pooling of CNNs-Based Classifier. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13–15 August 2021; IEEE: Piscatway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- lashin, V.; Rahtu, E. Multi-modal Dense Video Captioning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscatway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Song, Y.; Vallmitjana, J.; Stent, A.; Jaimes, A. TVSum: Summarizing web videos using titles. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscatway, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Gygli, M.; Grabner, H.; Riemenschneider, H.; Van Gool, L. Creating Summaries from User Videos. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 505–520. [Google Scholar] [CrossRef]
- Zhong, W.; Xiong, H.; Yang, Z.; Zhang, T. Bi-directional long short-term memory architecture for person re-identification with modified triplet embedding. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscatway, NJ, USA, 2017; pp. 1562–1566. [Google Scholar] [CrossRef]
- Rochan, M.; Ye, L.; Wang, Y. Video Summarization Using Fully Convolutional Sequence Networks. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 358–374. [Google Scholar] [CrossRef]
- Zhou, K.; Qiao, Y.; Xiang, T. Deep Reinforcement Learning for Unsupervised Video Summarization With Diversity-Representativeness Reward. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Yan, L.; Wang, Q.; Cui, Y.; Feng, F.; Quan, X.; Zhang, X.; Liu, D. GL-RG: Global-Local Representation Granularity for Video Captioning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, International Joint Conferences on Artificial Intelligence Organization, IJCAI-2022, Vienna, Austria, 23–29 July 2022. [Google Scholar] [CrossRef]
- Gao, Y.; Hou, X.; Suo, W.; Sun, M.; Ge, T.; Jiang, Y.; Wang, P. Dual-Level Decoupled Transformer for Video Captioning. In Proceedings of the 2022 International Conference on Multimedia Retrieval, ACM, 2022, ICMR’22, Newark, NJ, USA, 27–30 June 2022. [Google Scholar] [CrossRef]
- Li, P.; Ye, Q.; Zhang, L.; Yuan, L.; Xu, X.; Shao, L. Exploring global diverse attention via pairwise temporal relation for video summarization. Pattern Recognit. 2021, 111, 107677. [Google Scholar] [CrossRef]
- Zhu, W.; Han, Y.; Lu, J.; Zhou, J. Relational Reasoning Over Spatial-Temporal Graphs for Video Summarization. IEEE Trans. Image Process. 2022, 31, 3017–3031. [Google Scholar] [CrossRef] [PubMed]
- Ramanishka, V.; Das, A.; Zhang, J.; Saenko, K. Top-Down Visual Saliency Guided by Captions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscatway, NJ, USA, 2017. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).