1. Introduction
Time–frequency distributions (TFDs) are essential tools for capturing the dynamic behavior of non-stationary signals across the time–frequency (TF) domain. While quadratic TFDs (QTFDs) are commonly used, they often introduce unwanted oscillatory artifacts, known as cross-terms, especially in signals with multiple components [
1]. Although suppressing these cross-terms in the ambiguity function (AF) can be effective, it often compromises the quality of auto-terms, which are crucial components of the signal [
1,
2].
To address the drawbacks of conventional TF methods, various advanced and nonlinear methods have been developed, including the synchrosqueezing transform [
3,
4], synchroextracting transform [
5], and sparse TF representations leveraging compressive sensing (CS) [
6,
7]. Among these, sparse TF representation is a commonly used method [
8], with plenty of approaches for solving sparse representation problems [
9,
10]. This work focuses on TFD reconstruction using the AF, which provides a suitable framework to compressively sample non-stationary signals [
7,
11,
12]. Recent studies have demonstrated the effectiveness of such sparse TFDs in achieving high resolution of the auto-terms while mitigating cross-terms and noise across diverse signals [
6,
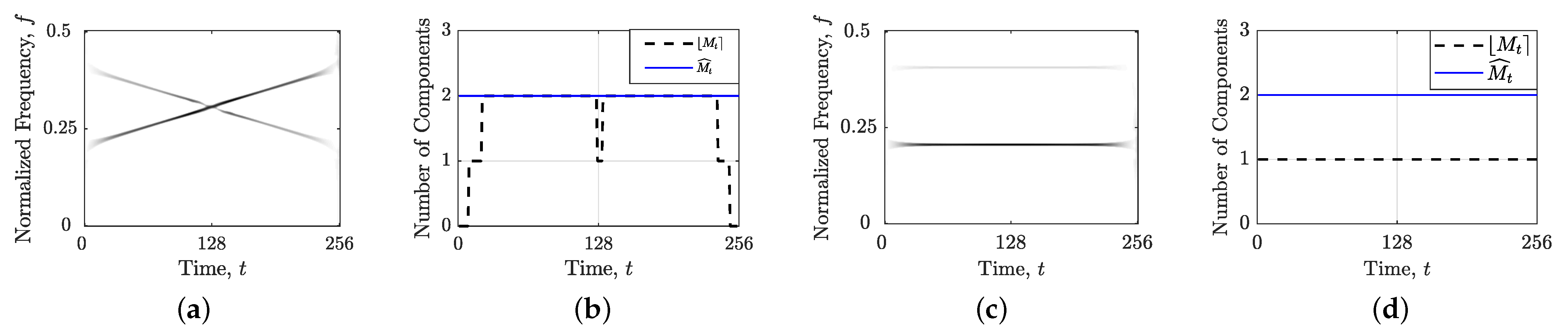
7,
13,
14,
15,
16,
17].
However, selecting the optimal regularization parameter in CS-based TFD reconstruction is a very delicate and computationally expensive task [
7,
11,
15]. The regularization parameter basically needs to clear TFD from unwanted artifacts and leave only the signal’s auto-terms, where too low a value can result in unwanted reconstruction of interference, while too high a value can lead to the loss of auto-terms, i.e., overly sparse auto-term structures [
12,
14,
15,
18,
19,
20,
21,
22]. In practice, the exact positioning and distinction between auto-terms and cross-terms are often unknown, particularly in real-world signals with multiple, unpredictable components and noise. Over many years, the selection of this parameter has been handled manually or experimentally, a process that is subjective, imprecise, and time-consuming [
11,
15,
23,
24].
Recent research has sought to address this issue by developing measures to optimize sparse TFDs [
12,
18,
21]. It has been shown that the loss of signal auto-terms complicates the use of global concentration and sparsity measures for evaluating and optimizing reconstructed TFDs, as they may artificially favor oversparse TFDs [
12,
18,
21]. To be more precise, global measures consider the whole TFD (often vectorized) and fail to account for the local structure of auto-terms, often treating them the same as cross-terms. The limitation of the global approach has been solved in [
18,
19] by using the localized Rényi entropy (LRE) method [
18,
19,
25,
26]. In this method, auto-term reconstruction is evaluated by estimating the local number of components (i.e., auto-terms) before reconstruction and comparing it with estimates from the reconstructed TFD. Moreover, coupling the LRE-based measure with the global energy concentration measure [
27] has led to the formulation of objective functions for multi-objective meta-heuristic optimization algorithms, such as particle swarm optimization (PSO) and the genetic algorithm (GA) [
12,
16,
18,
19]. This has offered a solution for a numerical assessment of reconstruction quality and automatic optimization of sparse TFD reconstruction algorithms.
Despite these advancements, LRE and meta-heuristic methods have limitations. Firstly, The LRE may be inaccurate for signals with significantly different component amplitudes, intersection points, or deviations from the reference component, potentially leading to the absence of auto-terms or the reconstruction of cross-terms and noise. Secondly, meta-heuristic optimizations begin stochastic in nature, do not guarantee finding the global solution, may get stuck in local optima, and often require numerous algorithm executions and evaluations.
To overcome these limitations, this paper aims to investigate the potential of modern deep learning networks (DNNs) for more efficient prediction of the regularization parameter. Although DNNs have not yet been applied to this specific problem, supervised learning methods have shown considerable potential in other signal processing applications. Bilevel learning approaches have been successful in obtaining optimal regularizers across various problems [
28,
29,
30] as they aim to achieve optimal performance on average with respect to the training set. However, since this paper is not focused on a specific application, such approaches are less suitable because a single regularization parameter may not be adequate for diverse signals. Another class of supervised learning methods exploits DNNs such as convolutional neural networks (CNNs) and residual neural networks (ResNets) [
31,
32], which were initially used for post-processing improvements or image classification tasks [
33]. Additionally, deep leaning methods have been employed to learn entire regularization functions [
34,
35,
36] or to train a CNN to map observations to regularization parameters [
37]. One recent approach in [
8] uses a machine learning approach to predict the true quality metric from the approximated metrics obtained from reconstructed images using pre-selected regularization parameters. While this approach is suitable when limited experimental data are available, pre-selecting a regularization parameter may be inaccurate when research is not application-specific. The development of deep learning techniques has also led to several applications in TF signal analysis [
38,
39,
40]. For instance, Jiang et al. [
38] utilized a data-driven U-Net framework to reconstruct TF representation. An et al. [
41] utilized DL for reconstruction of structural vibration responses. Miao et al. [
42] utilized sparse TF representations and DL for classification problems of underwater acoustic signals. The works in [
43,
44], which use sparse TF analysis of seismic data, indicated the need for DL to improve the efficiency of determining regularization parameters.
To position this paper within the current research landscape, this paper presents a novel application of DNNs in CS-based sparse TFD reconstruction. Unlike previous works which focus on specific applications, in this approach, the proposed DNN is trained with a comprehensive set of synthetic signals composed of linear frequency-modulated (LFM) and quadratic FM (QFM) components, exhibiting randomly generated positions, amplitudes, and noise contamination. The choice of LFM and QFM components is motivated by studies indicating that most real-world signals exhibit such modulations [
1,
45,
46]. This allows for the prediction of the regularization parameter for a wide range of signals, especially those with crossing components of different amplitudes, which pose challenges for existing meta-heuristic optimization approaches.
The main contribution of this paper is the development of a DNN-based technique with the following key properties:
The developed DNN predicts regularization parameters for a wide range of signals, both synthetic and real world, exhibiting LFM and QFM components.
For a new signal, the DNN-based regularization parameters can be obtained efficiently in an online phase, requiring only forward propagation through the DNN. This is significantly faster than the existing optimization approach, which may require multiple algorithm executions.
Numerical results show that in synthetic and real-world signal examples, DNN-computed regularization parameters lead to reconstructed TFDs with enhanced auto-term resolution and fewer cross-terms and noise samples compared to the existing optimization approach.
Training the DNN with noise improved the performance of the reconstructed TFDs in noisy conditions.
Note that the proposed DNN requires only the Wigner–Ville distribution (WVD) as input, eliminating the need for meta-heuristic optimization for each signal and addressing the limitations associated with LRE-based and concentration measures as objective functions in optimization. Once trained, the DNN can efficiently obtain regularization parameters through forward propagation.
It is acknowledged that providing the same regularization parameter to different reconstruction algorithms can yield varying quality of reconstructed TFDs [
11,
12]. This variation arises from differences in the algorithms which may also include additional parameters that influence the results. This study focuses on the augmented Lagrangian algorithm for
(YALL1) [
47] due to its slow execution time, which is more pronounced in meta-heuristic optimizations, and its tendency to produce TFDs with discontinuous auto-terms, leading to more cross-terms when optimized using the existing LRE-based approach. Although this research primarily addresses the YALL1 algorithm, it also lays the groundwork for designing DNNs for other reconstruction algorithms and CS-based approaches.
Therefore, this paper includes a comprehensive comparison between several DNNs with different architectures and complexities. The selected DNN model is then used for performance comparison of the TFDs reconstructed using the YALL1 algorithm with the proposed DNN-based regularization parameter versus those obtained using the LRE-based approach described in [
12,
18]. The evaluation covers both synthetic and real-world gravitational and electroencephalogram (EEG) seizure signals embedded in additive white Gaussian noise (AWGN).
The subsequent sections of this paper are organized as follows.
Section 2 provides an overview of sparse TFD reconstruction and existing LRE-based measures, while
Section 3 introduces the proposed methodology based on the DNN.
Section 4 details the experimental simulation results, followed by the conclusion in
Section 5.
2. Sparse Time-Frequency Distributions
Consider a non-stationary signal, denoted as
, which represents the analytic form of a real signal
, mathematically expressed as [
1]:
where
M is the number of signal components,
is the
m-th signal component, while
and
denote the
m-th signal component’s instantaneous amplitude and phase, respectively.
The WVD serves as a fundamental TFD and is defined as [
1]:
where
represents the complex conjugate of
z, and
f is the frequency variable.
Although the WVD provides precise instantaneous frequency estimates for signals with a single LFM component, it suffers from several limitations. This includes the presence of negative values, which complicate energy density interpretation, and the occurrence of interference, referred to as cross-terms. Cross-terms, which emerge as bilinear byproducts in multi-component signals, are positioned between any two components in the TF plane [
1]. Interference can also be caused by noise, which varies depending on its source and type. This study specifically focuses on white noise, which is uniformly distributed across the TF plane. Additionally, noise usually appears as a background interference with no specific structure. Interference suppression is typically handled in the AF,
, given as the 2D Fourier transform of the WVD [
1]:
This leads to the definition of QTFDs, denoted as
:
where
is the low-pass filter kernel in the AF. The operation in (
5) performs a multiplication of the original AF with the filter kernel, which can have various shapes tailored for specific signal types. The rationale behind the low-pass filtering in equation (
5) is the typical positioning of cross-terms in the AF, which are generally located away from the AF origin due to their high oscillatory behavior in the TF plane. In contrast, auto-terms are positioned along trajectories that pass through the AF origin [
1,
46]. While traditional cross-term suppression through filtering, as seen in (
5), helps eliminate cross-terms, it also removes some auto-term samples, often resulting in a reduction in auto-term resolution, which is crucial for accurate signal representation [
1].
To overcome the inherent trade-off, sparsity constraints are introduced using CS, resulting in a sparse TFD,
[
7,
11]. The CS-based approach in this study compressively samples the AF representation of the signal, focusing on a small subset of samples, namely the CS-AF area
, while the rest of the AF is calculated in order to obtain a high-performing sparse TFD. Among QTFDs, the WVD is chosen as the starting point due to its superior auto-term resolution, computational efficiency (requiring no additional tuning parameters), and an AF that includes all signal samples crucial for defining the CS-AF area [
11,
13,
15,
16]. The CS-AF area is usually centered around the AF origin and carefully selected to encompass only signal auto-terms. Ensuring that this area is correctly defined is crucial; otherwise, interference artifacts may reappear in the reconstructed TFD [
14,
15]. In this research, an adaptive rectangular CS-AF area of size
is employed, with
and
being the numbers of lag and Doppler bins, respectively [
11,
14]. This area adaptively positions its boundaries near the first set of cross-terms, maximizing the inclusion of auto-term samples while minimizing computational requirements.
Given the smaller cardinality of
compared to
(
), where
and
are the numbers of time instances and frequency bins, respectively, the system is under-determined, allowing for multiple solutions of
. The reconstruction algorithm seeks the optimal solution as described in [
11,
12]:
where
is the Hermitian transpose of a domain transformation matrix, analogous to the 2D Fourier transform akin to (
3). To achieve this, a regularization function is needed to emphasize the desired attributes of the solution. This leads to an unconstrained optimization problem given as [
14]:
where
is the regularization function, while
is the regularization parameter. To promote sparsity, the
norm is commonly used in the reconstruction process [
2,
7,
11,
13,
14], which leads to the following unconstrained optimization problem [
14]:
where
denotes the user-defined solution tolerance, also referred to as the energy threshold, which governs the reconstruction accuracy by comparing the reconstructed TFDs from the current and previous iterations. The closed-form solution of (
8) can be expressed as [
14]:
where
is a soft-threshold function given as [
14]:
The primary purpose of the parameter in this context is to suppress samples in the filtered TFD associated with interference while enhancing the prominence of the auto-terms. Note that this approach applies a single, uniform parameter consistently across the entire TFD.
Due to the popularity and effectiveness of
-based minimization, a number of algorithms have emerged for solving (
8) [
7,
11]. Considering its wide application and effectiveness in the various optimization problems, this paper focuses on the YALL1 algorithm given for the
-th iteration [
11,
47]:
where
is the penalty parameter, while the parameters
,
, and
are calculated as:
,
, and
. Since the CS-AF filtering tends to reduce the resolution of auto-terms, the primary goal of the YALL1 reconstruction algorithm is to iteratively enhance this resolution while maintaining suppression of interference components. The final reconstructed TFD is obtained when the solution tolerance,
, is met or the maximum number of iterations,
, has been reached [
11,
14].
2.1. Measuring Sparse TFDs: Existing Approaches
The optimal regularization parameter in sparse TFD reconstruction has usually been determined by a quantitative assessment of reconstructed TFD quality. Traditionally, global concentration and entropy measures, which generate a single value representing the entire TFD, have been used since they are computationally effective [
1]. Specifically, one representative is the energy concentration measure,
, which is calculated as [
27]:
with
being recommended [
1,
27]. A lower
indicates better TFD performance. Given that TFDs can be interpreted as two-dimensional probability density functions, the generalized Rényi entropy, denoted as
, is used. It is defined as follows [
48,
49]:
where
is typically an odd integer to mitigate cross-term effects. Lower
R values also indicate better TFD quality. Note that in (
14) and (
15), QTFDs, defined by (
4), are normalized with respect to their total energy [
26,
48]:
However, these global measures can be misleading for sparse TFDs because they may favor TFDs with fewer samples, falsely suggesting better performance by omitting important signal components [
12,
18,
19,
50]. To address this, the LRE method is used to recognize auto-terms, providing information about the local number of signal components. This involves comparing Rényi entropies of signal and reference components within each time and frequency slice, named as the short-term Rényi entropy (STRE) [
26] and narrow-band Rényi entropy (NBRE) [
18,
19]:
where notations
t and
f indicate localization through time or frequency slices, respectively,
and
represent the observed time or frequency slice, respectively, while
is the reference QTFD. The operators
and
set to zero all TFD samples except those near
(or
) [
18,
26]:
where
and
control the window lengths [
18,
26]. Note that the chosen reference signal in the NBRE is perfectly time-localized and covers all frequencies, contrasting with the STRE reference signal [
18,
19,
26].
The authors in [
18] combined mean squared errors (MSEs) between the original and reconstructed TFDs by using the LRE method as [
18]:
and formulated a state-of-the-art measure that can indicate if the TFD is overly sparse and lacks consistent auto-terms. Then, the optimal regularization parameter is determined by using the multi-objective optimization problem formulated as:
where
and MSE are minimized [
18]. However, in the multi-objective optimization, improving one objective often degrades another [
51,
52,
53,
54]. This is also true for this use case, i.e., artificially the best
is connected with the worst
. Thus, the multi-objective algorithm constructs all feasible solutions in the Pareto front [
51,
52,
53].
Meta-heuristic optimization algorithms are effective for non-linear optimization problems, handling non-differentiable, non-continuous, and non-convex objective functions. As in [
18], the multi-objective particle swarm optimization method (MOPSO) [
51,
52,
53] is utilized, which optimizes particle velocities,
, and positions,
, based on individual and global best positions [
51]:
where
w is the inertia coefficient,
and
are random numbers in
, and
and
are cognitive and social components [
51,
52]. MOPSO incorporates Pareto dominance for optimal solutions, stored in the repository. Furthermore, the MOPSO involves an additional mutation operator in each iteration controlled by the mutation rate
[
51,
52]. The final solution is selected using the fuzzy satisfying method [
18]. This approach represents the current state-of-the-art technique for automatically optimizing regularization parameter, applied in various algorithms within CS-based sparse TFD reconstruction [
16,
18,
21].
3. The Proposed Deep Neural Network-Based Approach for Determining Regularization Parameter
In this study, a novel approach is proposed for determining the regularization parameter
by training a neural network to learn a mapping from observations to regularization parameters. The mapping is defined as
, where an input vector
(the observations) is mapped to a vector
(the regularization parameters):
Here, the goal is to estimate the observation-to-regularization mapping function
by approximating it with a neural network and learning its parameters
. DNNs are used for their universal approximation capabilities [
37].
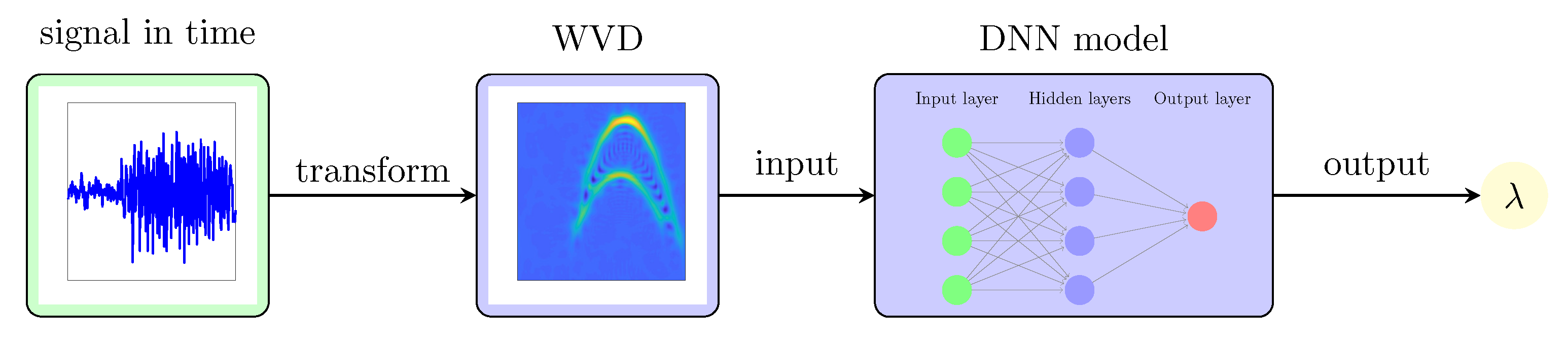
In this work, the DNN takes the WVD, represented in matrix form as
, which is calculated for input signal. Note that the WVD should be presented in its original form, without any post-processing. This choice offers several advantages. Firstly, the WVD can be computed efficiently for any signal and does not include any parameter, making it a straightforward input. Secondly, the WVD clearly delineates the spatial positions and amplitude discrepancies of auto-terms and cross-terms in the TF plane. Thirdly, using the WVD aligns well with the CS-based reconstruction method used in this work, which originates from its AF. A simplified block diagram of the proposed idea is illustrated in
Figure 2.
The output of the DNN, denoted as
, is given by:
For training the DNN, we determine the optimal regularization parameter values, denoted as
, for each provided WVD by minimizing the
norm between the ideal TFD,
, and the reconstructed TFD using the YALL1 algorithm:
The training data, denoted as
, comprises
10,000 synthetic signal examples, both single and multi-component, expressed as a summation of
M finite-duration signals:
where
,
, and
denote the starting time, ending time, and duration of the
m-th signal component, respectively. Here,
is a rectangular function defined as:
Considering the common presence of LFM or QFM behavior in real-world signals [
1,
46,
55], the
m-th component
embodies either an LFM or QFM behavior, expressed as:
where
and
are the starting normalized frequency and amplitude, respectively, and
,
, and
are the frequency modulation rates. These parameters were randomly generated to encapsulate diverse variations of signal components across the entirety of the TFD, including instances of multiple intersections with varying amplitudes. Therefore,
,
.
To account for real-world conditions, randomly selected signals were embedded into AWGN with a signal-to-noise (SNR) ratio as low as 0 dB, covering both noise-free and noisy scenarios. Additionally, the training signals were normalized relative to their maximum amplitude, necessitating the same normalization process when computing reconstructed TFDs for new signals using the regularization parameter predicted by the proposed DNN. As example,
Figure 3 displays the WVDs, ideal TFDs and optimally reconstructed TFDs obtained using the YALL1 with
optimized by (
26) for two synthetic signals from the training set. Note that the WVDs serve as inputs to the DNN, while the optimal
and
are stored in the output vector
.
3.1. DNN Architectures
In this study, four DNN architectures are considered: a fully connected neural network (FCNN), ResNet, DenseNet, and a CNN with attention mechanisms. The FCNN uses a flattened layers, i.e., vectorized WVD as input, which simplifies the data representation and reduces computational complexity. However, this flattening process leads to a loss of spatial relationships of signal auto-terms and cross-terms within the TF plane, potentially hindering the model’s ability to capture patterns that are useful for accurate predictions. ResNets, with their skip connections, offer a solution by preserving spatial hierarchies and preventing the vanishing gradient problem in deep networks, making them highly effective in maintaining performance as the network depth increases. DenseNets further build on this by ensuring that each layer receives direct input from all preceding layers, promoting feature reuse and reducing the risk of overfitting. This architecture is particularly advantageous for tasks where capturing fine-grained spatial details is crucial. CNNs with attention mechanisms, such as Squeeze-and-Excitation (SE) blocks, enhance the model’s ability to focus on the most relevant regions of the matrix, dynamically adjusting to emphasize the most informative features. This makes attention-based CNNs particularly powerful for tasks requiring precise localization and analysis of patterns within large matrices. Overall, while FCNNs offer simplicity and computational efficiency, ResNets, DenseNets, and attention-based CNNs provide more sophisticated approaches that are better suited for capturing the complex spatial dependencies inherent in the TF plane, making them highly advantageous for tasks involving large matrix inputs.
Table 1 outlines the architectures of each DNN used in this study.
The output layer (i.e., predicted ) comprises a single neuron employing the ReLU activation function for regression predictions. To estimate , ADAM optimized with a dynamic learning rate of is utilized with the mean squared error loss function. The DNN models are trained on the input–output pairs for a maximum of 1000 epochs with a batch size of 32 and a validation split of 20%. To mitigate the risk of overfitting and ensure that proposed models generalize well to unseen data, an early stopping criterion is employed during training. Specifically, the early stopping mechanism monitors the validation loss and stops the training process if there is no improvement in the validation loss for 10 epochs. Additionally, it is ensured that the model reverts to the state where it achieved the best validation performance, rather than continuing to train and potentially overfitting to the training data.
3.2. Summary of the Proposed DNN-Based Approach
A general review of the proposed approach is outlined in Algorithm 1. In the offline phase, the training data are used to learn the DNN parameters. This involves computing multiple WVDs and reconstructed TFDs to find
for each synthetic signal. However, once the DNN is trained, forward propagation of the new signals through the network requires only the signal’s WVD. The obtained
using the DNN is finally used in the YALL1 algorithm in order to compute reconstructed TFD.
| Algorithm 1 Reconstructed TFDs obtained via DNN. |
offline phase: generate J training signals, following by their WVDs and ideal TFDs , for obtain using ( 26) use training data to compute DNN’s optimal parameters |
|
online phase: compute WVD of the considered signal propagate through the learned network to get compute the reconstructed TFD using YALL1 |
4. Experimental Results and Discussion
4.1. Experiment Setup
The proposed DNN-based approach performance was assessed on three synthetic signals with
samples. Namely,
composed of three LFM components with different amplitudes:
;
composed of two crossing LFM components embedded in AWGN with
dB:
; and
composed of one LFM and one sinusoidal component embedded in AWGN with
dB:
. Furthermore, the experiment was extended with real-world gravitational (this research has made use of data, software, and/or web tools obtained from the LIGO Open Science Center (
https://losc.ligo.org), a service of LIGO Laboratory and the LIGO Scientific Collaboration. LIGO is funded by the U.S. National Science Foundation),
[
12,
16,
56,
57], and EEG seizure signal,
[
12,
50,
58,
59,
60,
61,
62,
63] as examples. For
, consisting of 3441 samples, downsampling by a factor of 14 resulted in
samples, corresponding to a duration of 0.25 to 0.45 seconds and a frequency range of
Hz. For
, a differentiator filter was applied to enhance its spike signatures as in [
60,
61,
64,
65].
Figure 4 illustrates the WVDs of the analyzed signals, highlighting the presence of cross-terms and noise contamination.
The CS-AF areas,
, for the considered signals
,
,
,
and
were calculated as
,
,
,
, and
, respectively. For the MOPSO, the parameters were configured as follows: a maximum of 50 iterations, a population size of 25, and 25 particles in the repository. The coefficients were set to
, as used in [
18]. The reconstruction algorithm parameters were set as
and
following the recommendations in [
11,
12,
14,
16,
18,
19]. The LRE computation used
and
as recommended in [
12,
21,
26,
66]. The simulations of the algorithms’ execution times, averaged over 1000 independent runs, have been performed on a PC with the Ryzen 7 3700X @ 3.60GHz Base Clock processor and 32GB of DDR4 RAM.
The reconstruction performance has been evaluated using machine learning evaluation metrics [
67]. The use of these metrics has proven effective in image and signal processing, as demonstrated in previous studies [
55,
68,
69,
70]. To apply these metrics, the reconstructed and ideal TFDs were converted into a binary classification framework. Here, the positive class (P) denotes the presence of signal auto-term samples in the TFD, whereas the negative class (N) indicates the absence of signal. The ideal TFD contains true samples that should precisely match their positions and classifications in the reconstructed TFD. Consequently, the following metrics were employed: true positives (TPs)—samples correctly identified as the positive class, true negatives (TNs)—samples correctly identified as the negative class, false positives (FPs)—samples incorrectly categorized in the positive class, and false negatives (FNs)—samples incorrectly categorized in the negative class [
67]. A high FP value suggests the inclusion of noise and/or cross-term-related samples in the reconstruction, while a high FN value indicates missing true signal samples in the reconstructed TFD.
These metrics are visually summarized in a confusion matrix [
67,
71]. Based on the confusion matrix and its components, several statistical measures are calculated [
67]:
All these statistical metrics range from 0 to 1, with higher values indicating better performance.
4.2. Performance of DNN Architectures
Considering the MAE metric provided in
Table 2, the CNN with attention achieves the lowest validation MAE of 0.0956, reflecting its superior ability to generalize to unseen data. In comparison, DenseNet and ResNet follow with validation MAEs of 0.1026 and 0.1011, respectively, demonstrating competitive generalization capabilities. The FCNN, with the highest validation MAE of 0.1318, underperforms due to the loss of spatial information resulting from the input WVD being flattened. Furthermore, the FCNN reached overfitting more quickly, completing training in 90 epochs, while ResNet, DenseNet, and CNN with attention utilized 105, 155, and 170 epochs, respectively. Training times for FCNN, ResNet, DenseNet, and CNN with attention are 2.85, 3.53, 4.56, and 26.73 hours, respectively. For tasks where prediction accuracy is critical and resources are available, the CNN with attention is the best choice due to the best validation MAE. Otherwise, ResNet and DensNet provide better balance between architecture complexity and performance. Consequently, the ResNet (further in the text as the proposed DNN) is selected in this study for further analysis due to its lower training time with competitive training and validation MAEs.
4.3. Comparison with the Current Meta-Heuristic Optimization Approach
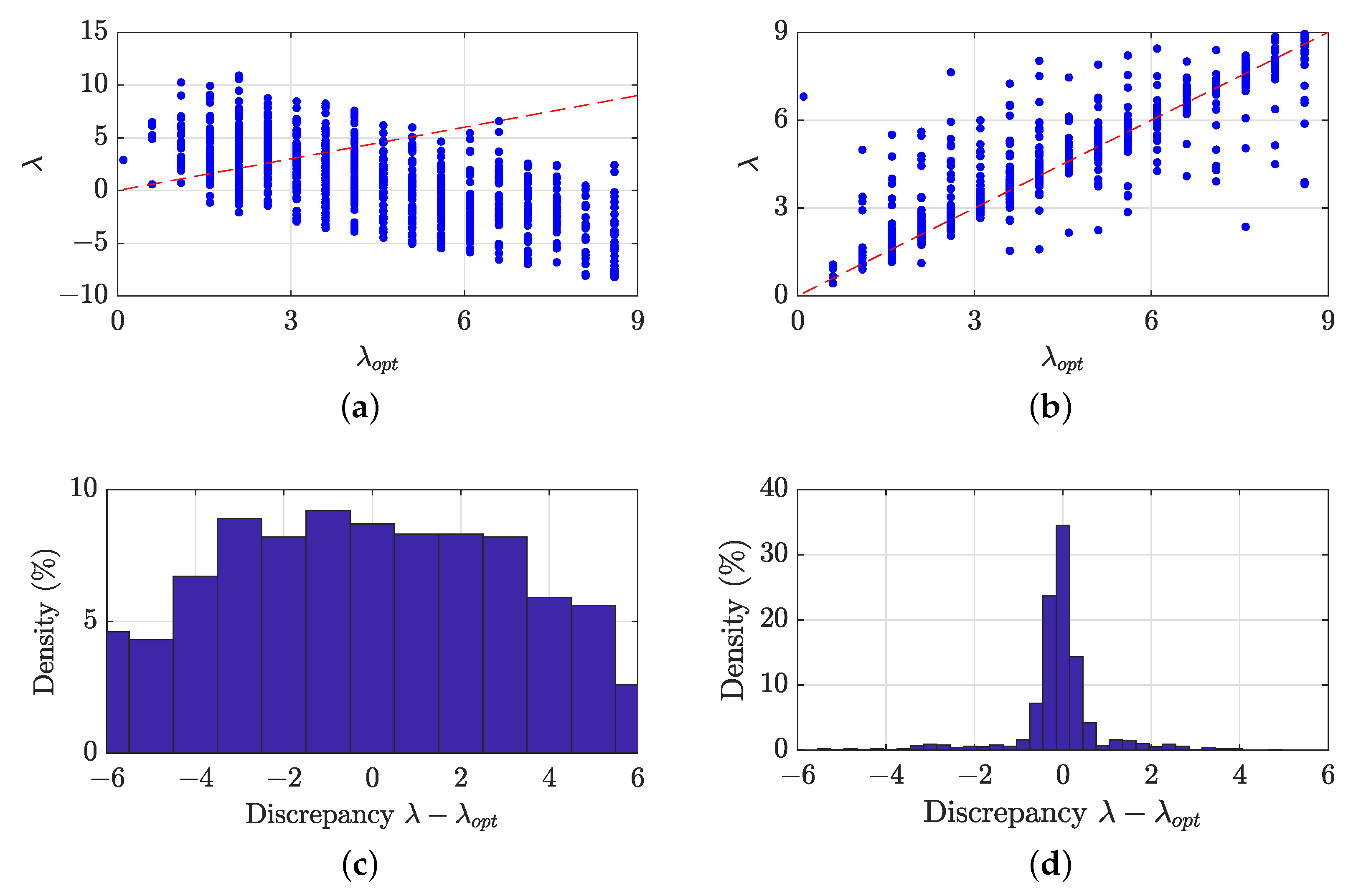
The performance of the DNN in predicting regularization parameters compared to those obtained using the existing MOPSO approach is visualized in
Figure 5. Specifically, the scatter plot for the DNN (see
Figure 5b) indicates a better correlation between the optimal and predicted regularization parameters compared to the MOPSO predictions (see
Figure 5a). This improvement is further illustrated in the density plots for the discrepancy
. The density plot for the DNN, shown in
Figure 5d, reveals that most discrepancies between the optimal and DNN-predicted regularization parameters are within
. In contrast, the density plot for the MOPSO, shown in
Figure 5c, exhibits roughly equal probabilities for discrepancies up to
, with only a slight decrease for discrepancies in continuation. This suggests that MOPSO optimization using the LRE is less reliable, potentially becoming trapped in local optima or converging to a suboptimal TFD reconstruction due to LRE limitations.
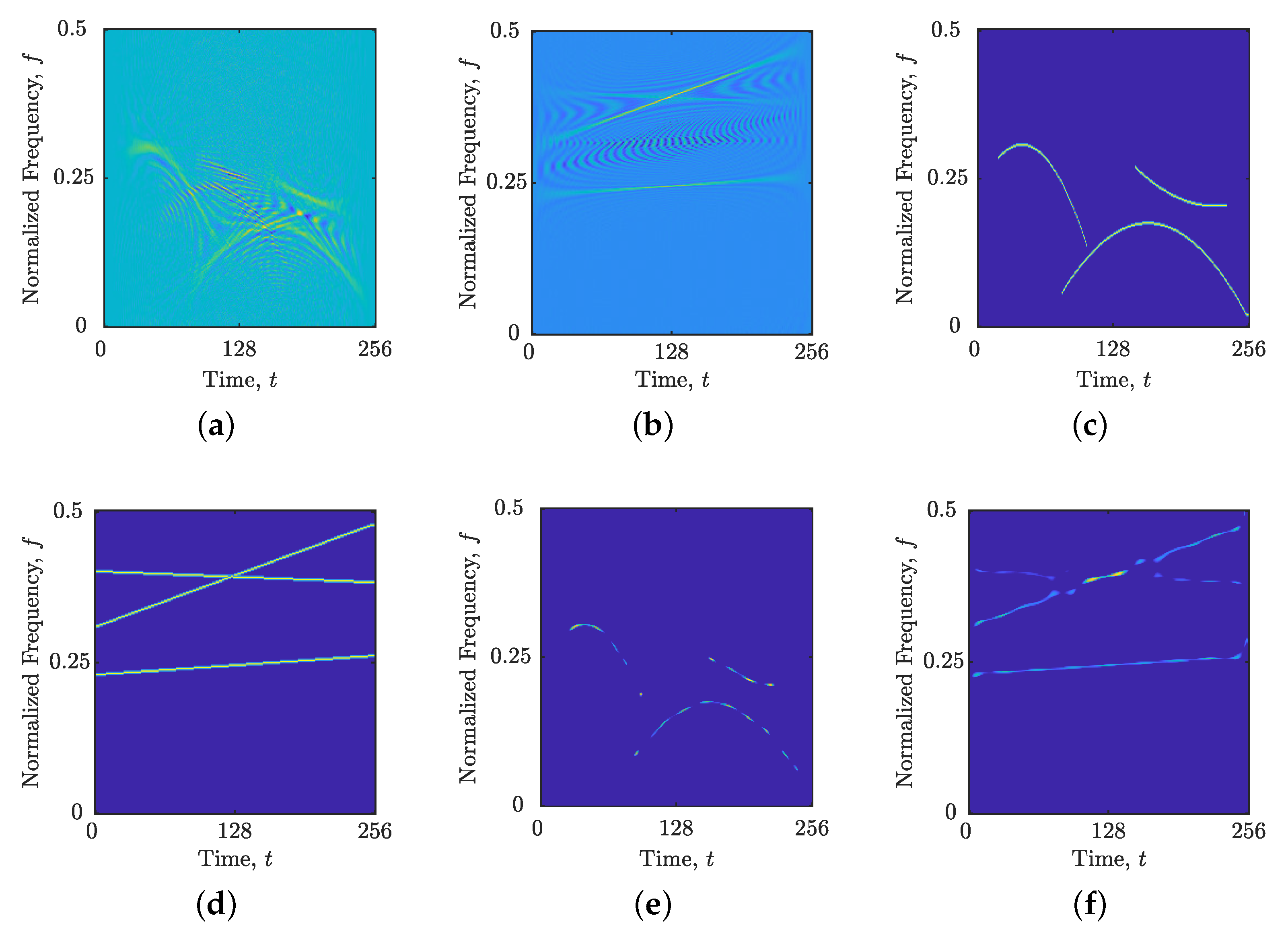
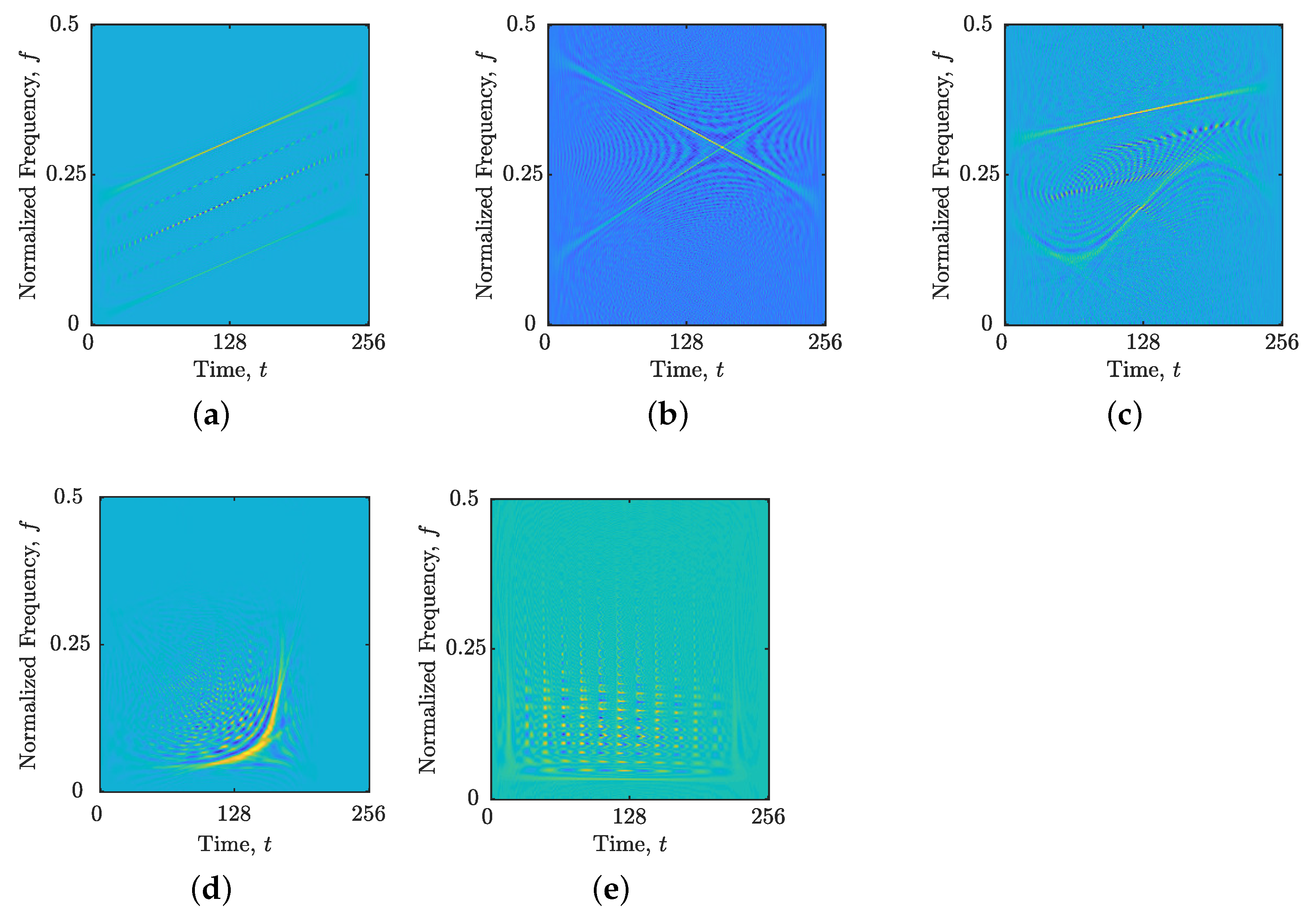
Figure 6 and
Figure 7 present the reconstructed TFDs obtained using the YALL1 with DNN-based versus LRE-based MOPSO
parameter. Across all considered synthetic and real-world signal examples, the DNN-based reconstructed TFDs demonstrate performance competitive with those obtained via MOPSO. Notably, the DNN-based reconstructed TFDs maintain high-resolution auto-terms while effectively suppressing cross-terms and noise, visually outperforming the MOPSO-based reconstructed TFDs. Given that auto-terms reconstructed by the YALL1 often appear discontinuous, the LRE-based MOPSO approach [
18] tends to mitigate this discontinuity but at a cost. To maintain the computed number of components in each time and frequency slice, MOPSO optimization (i) reduces the resolution of auto-terms and (ii) leaves cross-terms or noise samples to fill in the gaps, as illustrated in
Figure 6b,c. Furthermore, when the LRE fails to accurately detect components with low amplitude, the reconstructed TFD does not preserve these components well, as seen in
Figure 6a.
Additionally, the auto-terms of real-world signals
and
are not fully preserved when using MOPSO, as depicted in
Figure 7. This occurs because of two reasons. First, the LRE does not detect auto-terms with lower amplitude. Second, more samples, even those related to auto-terms, artificially degrade the objective
measure, consequently favoring oversparse reconstructed TFDs. By visually inspecting reconstructed TFDs with
predicted by the DNN in
Figure 7, they exhibit better preservation of auto-terms, indicating that the training data used in this study can be used for analyzing unseen real-world signals featuring LFM and/or QFM components, as in
and
.
The numerical performance comparison of the DNN-based and LRE-based MOPSO reconstructed TFDs (shown in
Figure 6) with the ideal TFDs are presented in
Table 3. Overall, the results validate the visual observations mentioned above. For the signal
, the DNN-based reconstructed TFD achieves better preservation of the auto-terms with lower amplitude than the MOPSO-based one. This is indicated by higher TP and lower FN indices in the confusion matrix (and consequently higher recall), as more auto-term samples are correctly predicted with fewer samples falsely set to zero. On the other hand, given a higher
, the MOPSO-based reconstructed TFDs exhibit higher TN and lower FP, achieving higher accuracy and precision metrics.
The opposite behavior can be observed for noise signals and . Reconstruction of cross-term and noise-related samples using the MOPSO is indicated by a significant increase in FP and a decrease in TN indices compared with reconstruction using the DNN-predicted , which is also evident from lower accuracy and precision metrics. Consequently, in this case, the lower obtained using MOPSO preserves more auto-term-related samples, as indicated by higher TP and lower FN indices, and higher recall metric. For all three synthetic signal examples, the DNN-predicted reconstructed TFDs exhibit superior F1 scores.
Some of the reported precision, recall, and F1 scores are relatively low, which can be attributed to several factors. In an ideal TFD that contains only auto-term maxima, positive samples represent a very small proportion of the total, resulting in a highly imbalanced dataset where the majority of samples are zero. This imbalance diminishes the reliability of accuracy as a standalone evaluation metric, highlighting the importance of using precision, recall, and F1 score metrics for a more comprehensive and reliable assessment. Several factors influence the reported metrics. While the YALL1 algorithm significantly enhances auto-term resolution and effectively suppresses interference, the reconstructed auto-term resolution is still less sharp than the ideal, and its trajectory may exhibit discontinuities. These discontinuities, while not affecting the extraction of useful information, can impact classification metrics. Additionally, the reconstruction process and initial interference may introduce slight biases in the positions of auto-term maxima within the reconstructed TFD, leading to deviations from their ideal locations. Another contributing factor is the presence of random TF samples with negligible amplitude in the TFD. If not thresholded, these insignificant samples can artificially lower the evaluation metrics. In this study, the focus has been on evaluating reconstructed TFDs without any post-processing, such as thresholding or over/under-sampling of the data. Future research will explore suitable post-processing methods and metrics to improve the performance and robustness of these classification metrics for this use case.
4.4. Computational Complexity
FCNN, ResNet, DenseNet, and CNN with attention consist 67,544,065, 4,908,673, 206,261, and 34,876,001 parameters, from which 67,540,481, 4,902,913, 201,853 and 34,872,545 are trainable, respectively. Calculating the full computational complexities of neural networks involves considering the number of operations required in each layer. These complexities are typically expressed in terms of the number of floating-point operations (FLOPs), which can be calculated based on the architecture of each network. The FCNN is the least intensive at approximately 67.8 million FLOPs due to its simpler architecture. In contrast, ResNet and DenseNet offer a balance between complexity and performance, with complexities of around 849.3 million FLOPs and 471.8 million FLOPs, respectively, making DenseNet slightly more efficient. The CNN with attention has the highest complexity at approximately 1.227 billion FLOPs due to the additional attention mechanisms.
The main motivation for using the DNN is in reducing the execution time for obtaining
in the online phase, which is significantly lower than performing full meta-heuristic optimization. As reported in
Table 3, obtaining optimal
can take up to 7911 s using MOPSO, while the trained DNN gives its prediction in approximately 0.06 s, which is significantly faster. Indeed, execution time of the MOPSO can be improved by decreasing the numbers of particles and iterations. However, that may lead to more inaccurate
values and consequently reconstructed TFDs with worse performance. As it was intended in [
12,
18,
50], meta-heuristic optimization should be used for offline signal analysis, while the proposed DNN approach is a perspective to be used even for online analysis.
4.5. Noise Sensitivity Analysis
To evaluate the impact of noise on the prediction of the
parameter by the proposed DNN, a comprehensive comparative analysis was conducted using precision, recall, and F1 score metrics. These metrics were derived from the comparison between the ideal TFDs and the noisy reconstructed TFDs obtained using DNN- or MOPSO-predicted
. The synthetic signals were subjected to AWGN across four SNR levels ranging from 9 dB to 0 dB. The results, based on 1000 independent noise realizations, are summarized in
Table 4. The findings underscore the superiority of the DNN reconstructions over the MOPSO reconstructions for all synthetic signal examples. This superiority is discerned through higher F1 scores and precision metrics, particularly notable at lower SNR values.
4.6. Limitations of the Proposed Approach
While the proposed DNN approach exhibits strong predictive capabilities for estimating the regularization parameter in sparse time–frequency distributions of non-stationary signals, it does have certain limitations. The model’s effectiveness is sensitive to the type of noise present in the signals. For instance, in scenarios involving specific noise types such as impulsive or colored noise, retraining the network may be necessary to achieve optimal performance, as the current model is primarily designed for signals corrupted by AWGN. Additionally, the model may experience degraded performance when analyzing real-world signals that do not exhibit LFM or QFM components.
Moreover, although this network has been specifically trained using the YALL1 algorithm for sparse reconstruction, its deep learning architecture is sufficiently flexible to allow for straightforward retraining with other reconstruction algorithms. This adaptability enables the model to incorporate additional parameters beyond the regularization parameter , potentially enhancing its utility across a broader range of applications.
5. Conclusions
This study introduces a novel approach utilizing DNNs for predicting the regularization parameter in CS-based reconstruction of TFDs. By training the DNNs on synthetic signals composed of LFM and QFM components, the proposed method aims to eliminate the need for manual parameter selection or complex optimization procedures, which are often time-consuming, require specialist knowledge, and depend on appropriate objective functions.
The results demonstrate the efficacy of the DNN-based approach in automatically determining the regularization parameter, showing competitive performance compared to existing optimization methods in terms of reconstruction quality. Specifically, the DNN-based reconstructions better preserve auto-terms with low amplitude, exhibit high-resolution auto-terms, and effectively suppress cross-terms and noise. This has also been validated by real-world gravitational signal examples for which the proposed DNN was not specifically trained. Additionally, the DNN-based reconstructions are less sensitive to noise.
Two additional advantages of using DNNs over meta-heuristic optimization are emphasized. First, the end-user only needs to provide the signal’s WVD as input to the network, circumventing the limitations and parameter tuning of additional methods such as LRE and MOPSO. Second, obtaining the parameter using a trained DNN is significantly faster than performing meta-heuristic optimization, suggesting that DNNs can be used for online application purposes.
Overall, this study highlights the potential of DNNs in automating the determination of regularization parameters for TFD reconstruction, paving the way for enhanced signal processing applications in diverse environments. Future research could explore the possibility of constructing the training data with application-specific signal types and noise conditions, as well as applying DNNs across different reconstruction algorithms and approaches. Furthermore, future research will include the development of adaptive regularization parameter using DNNs.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}