2. Related Work
Abdel-Salam and Rafea [
10] performed a series of investigations to determine the impact of several versions of a Bidirectional Encoder Representation from Transformers (BERT)-based model on text summarization and proposed SqueezeBERTSum, a trained summarization model improved using the SqueezeBERT encoder modification. Their model achieved comparable ROUGE scores with 49% fewer trainable variables while retaining 98% of the BERTSum baseline system efficacy
Conventional approaches often select top-weighted tweets continuously and ignore the relationships between messages to construct a summary. This process was investigated by Chellal and Boughanem [
11], who recommended an innovative method that generated an efficiency problem model using integer linear programming to provide the summary. The success of their approach was demonstrated through trials using the TREC RTF 2015 and TREC RTS 2016 datasets.
Geng et al. [
12] examined query-focused summarizing and presented a novel summary architecture capable of producing historical summaries of any length of time as well as tailored online summaries. Their approach’s efficacy and efficiency were demonstrated via extensive trials conducted on real microblogs.
Keswani and Celis [
13] presented a method that used a traditional summarization technique as a black box and generated a summary that was comparatively more dialect-diverse from a small group of phrases to account for that bias. They demonstrated the effectiveness of their method on Twitter, collecting tweets written in dialects spoken by individuals belonging to various social categories classified by gender, race, or location; in every instance, their method improved dialect diversity compared to conventional summarizing methods.
Integrity-Aware Extractive–Abstractive (IAEA) real-time occurrence summarization is a unique framework for real-time event summarization offered by Lin et al. [
14]. They showed experimentally that IAEA could produce more consistent and better summaries than the most advanced methods.
Zhang et al. [
15] proposed pre-training a large Transformer-based encoder–decoder model with a novel self-supervised aim on large text corpora. Their model performed surprisingly well on low-resource summarization, outperforming previous state-of-the-art (SOTA) outcomes on six datasets with a mere 1000 samples.
Goyal et al. [
16] presented a brand-new method called Mythos that finds events, identifies subevents within an event, and creates an abstract synopsis and plot to offer several perspectives on the event. It performed better in both cases than baseline methods. The summaries produced were compared to summaries from other reference materials, such as
Wikipedia and
The Guardian.
In an investigation by Wang and Ren, the summary-aware attention weight [
17] was computed using attended summary vectors and source hidden states. The results of assessments conducted by humans and computers equally demonstrate that their model operated significantly better than high baselines.
Through the simultaneous consideration of subject feelings and topic aspects, a solution was identified in an investigation by Ali et al. [
18]. Their approach could outperform current approaches on standard metrics like ROUGE-1, as demonstrated by their comparison with SOTA Twitter summarizing techniques.
Wu et al. [
19] presented an Ortony–Clore–Collins (OCC) model and an opinion summary approach for Chinese microblogging platforms based on convolutional neural networks (CNNs). Experimental findings from the analysis of three real-world microblog databases showed the effectiveness of their proposed strategy.
Although the TREC Incident Streams track dataset was not meant to be used for automated summarization, as evaluated by Dusart et al. [
20], the suggested dataset was used to test a number of popular current techniques for automatic text summarization, some of which were tailored specifically to Twitter summarization and some of which were not.
Garg et al. [
21] proposed a real-time Twitter summation system for incidents called ontology-based real-time Twitter summarization (OntoRealSumm), which is built on ontologies and produces an overview of disaster-related tweets with limited assistance from humans. OntoRealSumm’s efficacy was confirmed by contrasting its performance against cutting-edge methods on ten disaster datasets.
The task of compiling pertinent tweets was addressed by Saini et al. [
22], who examined efficiency by maximizing various aspects of the summary using a multi-objective binary differential evolution (MOBDE) search algorithm to choose a portion of tweets. In comparison to current methods, their best-proposed solution (MOOST3) enhanced ROUGE−2 and ROUGE−L by 8.5% and 3.1%, respectively, and the t-test was used to confirm the statistical significance of these improvements.
Li and Zhang [
23] investigated two extraction methods for Twitter event summaries. Comparisons demonstrated that these two strategies work better than others.
Table 1 lists the methods, outcomes, and datasets used to automatically summarize brief texts.
3. Methodology
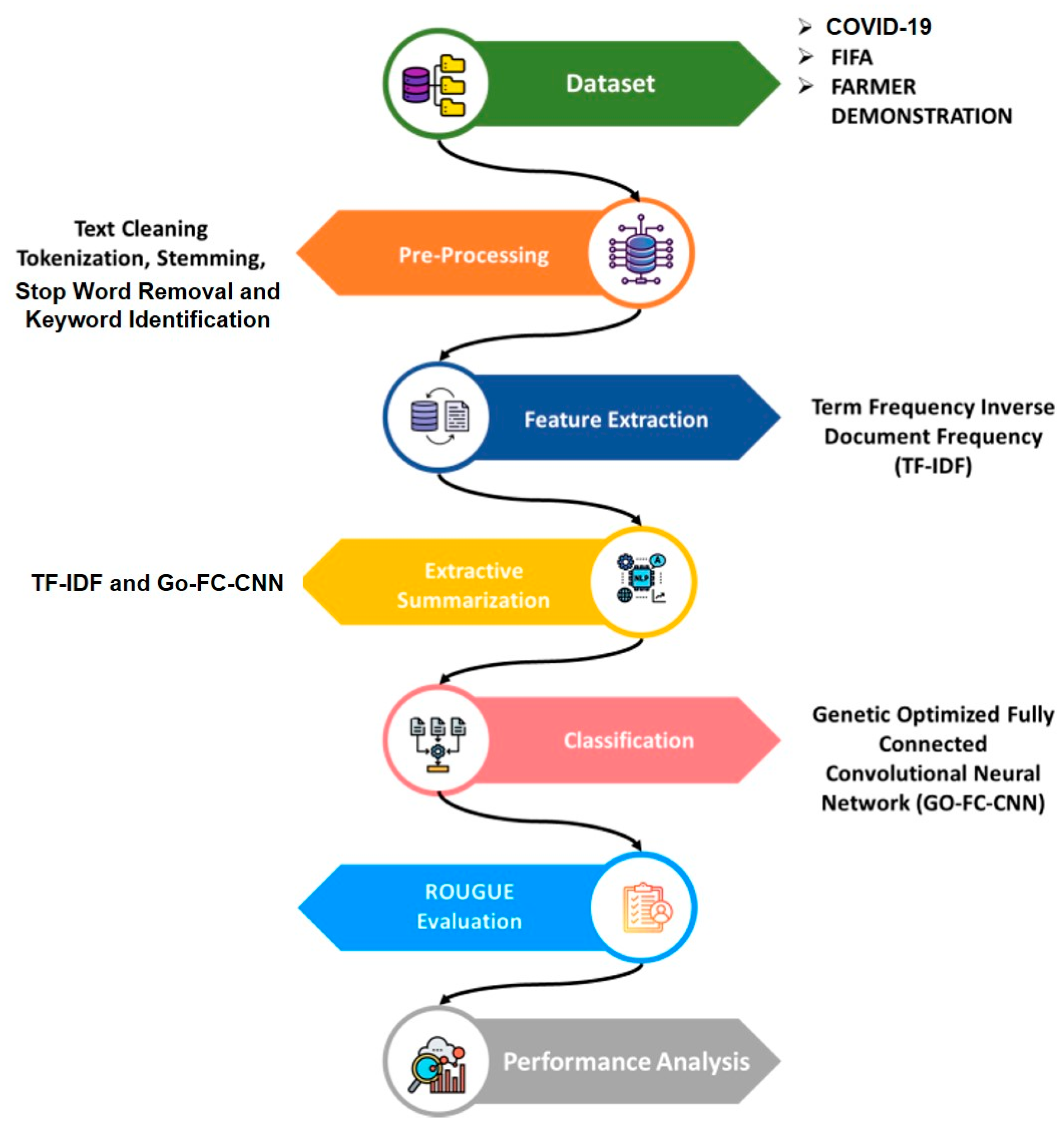
We obtained a Twitter dataset from Kaggle which covered a range of subjects, including COVID-19, FIFA, and farmer demonstrations. Preprocessing Twitter data using stop word removal, tokenization, stemming, and keyword identification comprised part of the methodology [
28]. The initial feature extraction process used TF–IDF. Redundancy was decreased and summary accuracy increased with a GO-FC-CNN. Using ROUGE measures, the model’s performance was assessed in comparison with current techniques. An overview of the procedure is shown in
Figure 1.
3.1. Datasets
We gathered tweets related to the datasets FIFA, FARMER PROTEST, and COVID-19 taken from Kaggle sources.
Several attributes are included in the FIFA World Cup 2022 tweet dataset: an index, the date and time each tweet was created, the number of likes it received, the source platform, the text content, and the mood of the tweet. Public responses to the incident were captured by the sentiment attribute, which has three classes: neutral (2574 tweets), negative (1804 tweets), and positive (2622 tweets).
https://www.kaggle.com/datasets/tirendazacademy/fifa-world-cup-2022-tweets (accessed on 28 August 2024).
The following attributes are part of the FARMER DEMONSTRATIONS dataset: source, medium, retweeted tweet, quoted tweet, mentioned users, sentiment, reply count, retweet count, like count, and user ID. The distribution was as follows: 3034 neutral, 1886 negative, and 2080 positive sentiments. This extensive dataset gathers the necessary information for assessing Twitter activity and attitudes around farmer demonstrations.
https://www.kaggle.com/datasets/prathamsharma123/farmers-protest-tweets-dataset-csv (accessed on 28 August 2024).
The COVID-19 Twitter Dataset (April–June 2021) includes various attributes such as Tweet ID, creation date and time, source platform, text content, language, favorite and retweet counts, original author, hashtags, user mentions, location, cleaned tweet text, and the classes (compound, negative, neutral, and positive). The dataset classifies tweets into neutral (3134), negative (1686), and positive (2180) sentiments.
https://www.kaggle.com/datasets/arunavakrchakraborty/covid19-X-dataset/data (accessed on 28 August 2024).
3.2. Data Preprocessing
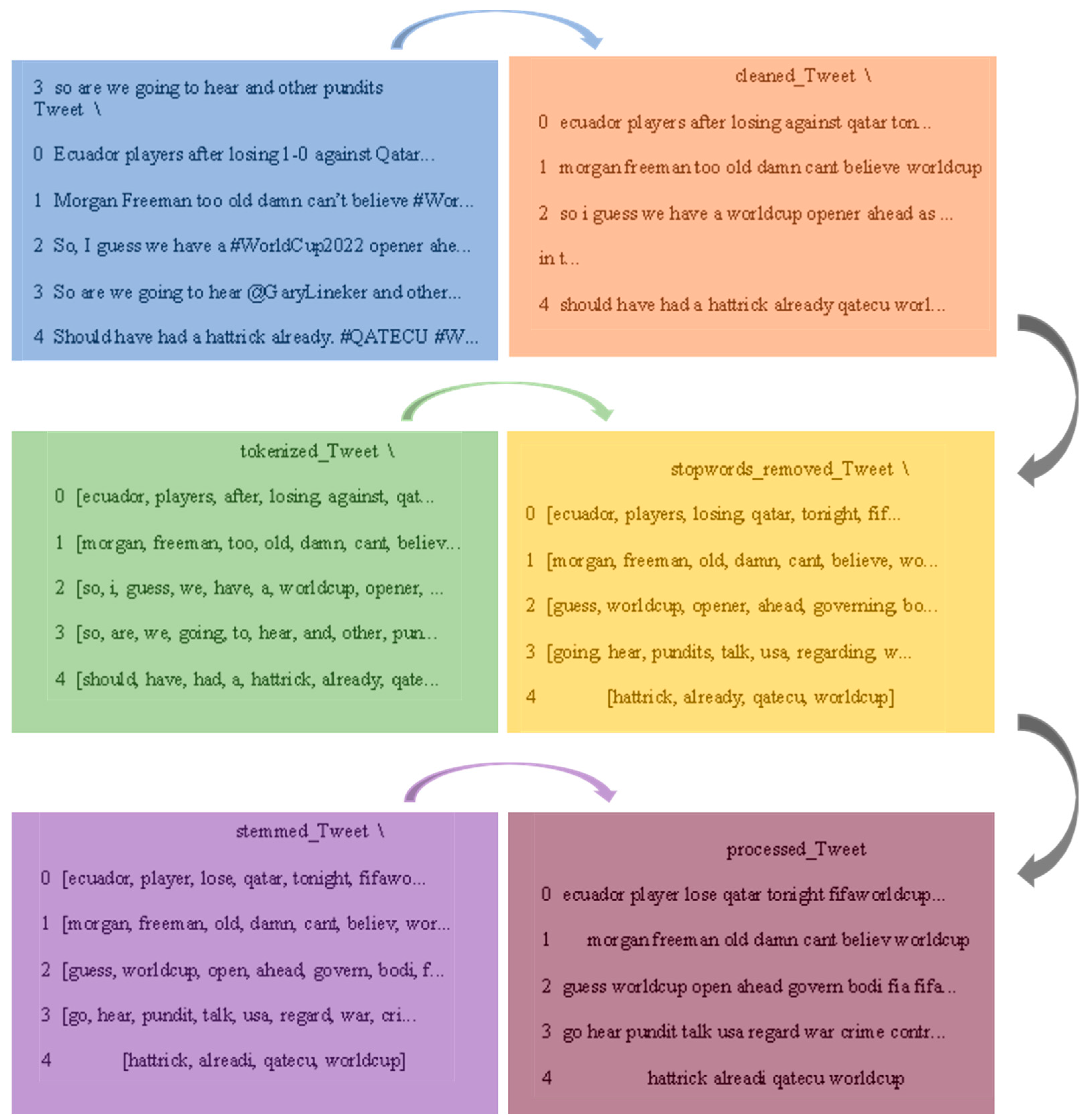
Stop word removal, tokenization, stemming, and keyword recognition are all used to standardize terminology. Enhancing the efficacy and precision of summarization algorithms may also require eliminating redundant data, managing absent values, and guaranteeing uniform formatting.
A crucial step in the NLP process is text preprocessing. The importance of NLP preprocessing is demonstrated by the following [
28,
29].
Tokenization: Sentence segmentation divides text into meaningful components known as tokens, such as words, characters, and phrases.
Stemming: Stemming eliminates suffixes and prefixes from words to return them to their root form. Word presentation is reduced to its fundamental form.
Stop word removal: This stage involves removing frequently used words which lack semantic content, including this, and, a, and the, from textual material.
Keyword identification: This method identifies words or phrases that are important for the topic or setting of the text. Keywords are vital for understanding the primary content and for other activities like indexing, categorizing, and summing.
Figure 2 shows the preprocessed output.
3.3. Feature Extraction Using TF–IDF
To measure importance, methods such as TF–IDF are employed to assist in identifying the most pertinent details to condense and summarize original text while maintaining its meaning. The TF–IDF weight assesses the significance of a word to a document inside a collection [
30]. The frequency of a word in the corpus balances out the importance, as shown in Equation (1), which increases in direct proportion to the number of times it is found in the document. In a specific document,
, the term frequency is
where the denominator is the total number of occurrences of every phrase in the document
, and
is the number of instances of the examined term (
) in
.
The amount of every document divided by the number of documents including a word generates the inverse document frequency, which is a measure of a phrase’s overall relevance. The logarithm of the quotient is calculated in Equation (2).
where the denominator is the number of documents in which
appears, and
is the overall number of documents in the gathering shown in Equation (3).
This technique has a limitation in that it cannot be applied to a single document without any additional documents for comparison because it selects keywords based on phrase frequency.
Figure 3 shows the feature extraction output.
3.4. Extractive Summarization
Our approach to extractive text summarization incorporates an FC-CNN and GO. The process is broken down into the following key steps:
- Step 1.
Initial summaries: The GO first generates initial summary candidates by selecting sentences from the input text based on their TF–IDF scores.
- Step 2.
Evolution: The initial summaries undergo an evolutionary process. The algorithm applies selection, crossover, and mutation operations to enhance the quality of the summaries.
- Step 3.
Iterative improvement: This evolutionary process is repeated across multiple generations, with each generation producing better summary candidates.
- Step 4.
Refinement using an FC-CNN: Once GO produces a set of high-quality summaries, the FC-CNN model further refines them to achieve the best possible extract, ensuring that the final summaries are both concise and informative.
- Step 5.
Final output: The final output is a set of optimized summaries that effectively represent the original text, achieved by combining the strengths of both the GO and the FC-CNN model. As an example,
Figure 4 shows one of the high-quality summaries generated by our approach for the twitter_red dataset.
3.5. Classification Using GO-FC-CNN
The process of summarizing is improved using classifying techniques to separate important information from unimportant details. This method efficiently removes noise and highlights important data from social media networks by utilizing the GO-FC-CNN model. This improvement ensures the accuracy of the summary by emphasizing important information and lessening the influence of unimportant details. Advanced classification approaches are used to improve overall content relevance and clarity through more accurate and efficient data summarization.
3.5.1. GO-FC-CNN
The GO-FC-CNN model is a hybrid approach designed for text classification and summarization. It enhances the standard FC-CNN architecture by adding fully connected layers and optimizing the convolutional layers using a genetic algorithm (GO). These additional layers and optimization improve the model’s ability to handle various text formats and classification tasks. The genetic optimization fine-tunes the model, making it more adaptable and accurate. After training, the model categorizes texts into topics and generates concise summaries based on the classified data. This approach efficiently handles short-text classification and summarization.
3.5.2. FC-CNN
The FC-CNN can be used to gather textual patterns and for deep feature integration. Because of this feature, this architecture can be used to produce accurate and efficient summaries of brief texts by eliminating material that can be removed and extracting significant information. An FCNN includes an input layer (IL) and multiple hidden layers (HLs) culminating in an output layer (OL). The input vectors which contain early features of the text are processed in the HLs, the IL generates a numerical vector of preprocessed text data, and the OL holds the summarized text result [
31]. For an enhanced understanding of the structure and work of FCNNs, we describe a five-layered neural network in
Figure 5. This FCNN has three parallel HLs with seven neurons each, which are independent of the others, five neurons in the IL, and three elements in the OL, which is the final layer.
Each concealed layer in
Figure 5 represents a summarizing layer, and every white ellipse with factors w or
z characterizes a summary component. The key points in a document are comparable to the data. In the downstream summarizing layer, they can propagate via connections between summary nodes. All summary nodes process the signals throughout this procedure. Additionally, the output value (OV) of each neuron in HL 1 may be found using Equations (4) and (5).
where
is the
OV of the
HL in the summarization strategy, and w
1 and w
2 are features that show the frequency of significant words in the U and V axes directions, while w
3 and w
4 are decentering variables facing the X and Y axes. The entire length of the text is indicated by the feature
w5. The weight of the
output
relates to the
ith neuron’s preceding layer in the
jth HL significance of each text feature. The
bias term of the
pth HL is represented by
. The training network is an efficient method for adjusting the weight and bias coefficients to increase the summarization quality. When the final estimated summary is reasonably close to the theoretical significance, the network has been accomplished effectively. The initial and second HLs’ equations can be expressed in comparable matrix forms. As a result, the equation for the second HL can be summarized as in Equation (6).
Not all Ovs can be moved to the following concealed layer. In actuality, a summarization model must process every OV. The model’s goal is to extract the most important details and remove any unnecessary material to produce a summary that is clear and educational. This extractive summarization method is illustrated in Equation (7).
Assume that after a summarization method has been used, each OV of the text’s upper layer can be moved to the next layer. The output is summarized via the second HL in Equation (8).
We can obtain
by spreading
over the levels of the summarization framework up to the third HL. Features of the input elements are summed in the Ovs of the final HL. The weighted summation of features derived from the input data yields a summary score evaluated via a loss function. This summary score is utilized as the final summarized output if it meets the root mean square value judgment criteria of the loss function shown in Equation (9). The following equation can be used to represent the loss function used to assess summarization quality:
Here, is a summary of the material and is the actual content.
The resultant summary will be an immediate output if it satisfies the selection requirements of the loss function. If not, the HLs’ weights will be continuously changed until the value satisfies the criteria for selection. This process, which takes place during the network’s training stage, is sometimes referred to as neural network backward transmission.
It will be a direct output if the resulting summary fulfills the loss function decision. If not, the HL weights will be adjusted once more until the chosen value is reached. This phenomenon, referred to as neural network reverse transmission, typically takes place during the network training phase. Each HL contains one thousand neurons. The network produces five estimated values, each of which represents an angle of view, the tilt mistake of the and axes, and the essential elements of the summary of the and axes. The architecture and parameters of an FCNN for automatic short-text summarization are enhanced using genetic algorithms. This procedure entails mutation, crossover, and selection altering neural network configuration populations to improve summarization performance. The intention is to enhance the performance and efficiency of writing concise and useful text summaries.
3.5.3. GO
To improve the quality of applicant summaries based on a fitness function, GO will repeatedly choose, alter, and reassemble them. By giving priority to readability and relevance, this approach develops succinct, coherent summaries, and via evolutionary progress, it finally yields the ideal summary.
A population-centered meta-heuristic approach forms the basis of GO, and every member of the population provides an acceptable response [
32]. Following crossing, mutation, and selection, the individuals in GO are modified. Two individuals are chosen at random during the selection process, which improves the population’s variability. The crossover mechanism then exchanges values between the chosen individuals (parents) to create new individuals. Next, mutation is used to swap out a randomly chosen person for a randomly chosen value from the search space. Finally, the most exceptional individuals are selected to comprise the emerging and current populations depending on the fitness characteristics of the newly formed individuals and their parents. These three GO processes, selection, crossover, and mutation, are then repeated until the end requirements are met, updating the population.
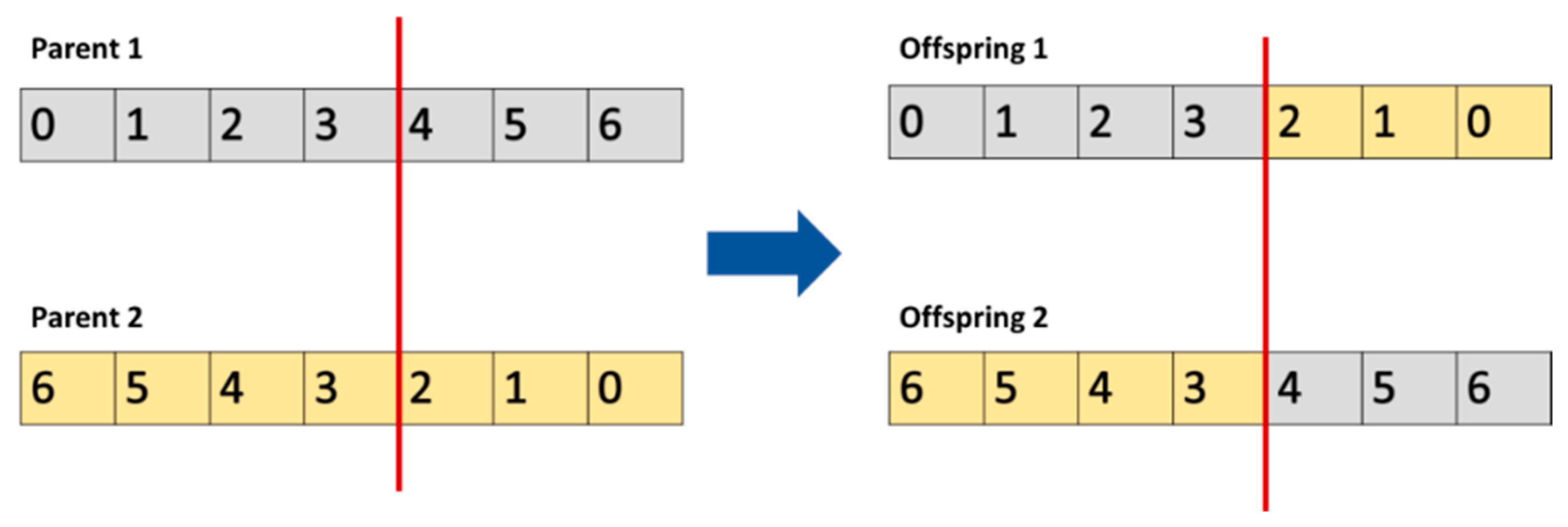
The crossover operator is a fundamental operator in various GO modifications. The single-point approach is the most straightforward crossover; it comprises the two required parents, which are chosen at random from the general population. By singly dividing the information within them to a single point, the parents are employed to create offspring. New solutions are produced by switching the values among the two parents after they use a single point. By merging the best features of two-parent solutions into one potentially better offspring solution, the crossover approach improves the summarization process. The operation of the single-point (S-P) crossover is illustrated graphically in
Figure 6.
Although the S-P crossover is a solid alternative, using a different version is preferable for real-world code applications.
, commonly referred to as the blend crossover, is an actual coded operator. As with the single-point crossover, two parents,
, must be selected from the population. This procedure uses GO to optimize the network’s parameters to improve the efficiency and accuracy of producing succinct and helpful text summaries. A component of
is retrieved from each using the parents. For
, Equation (10) offers a satisfactory explanation.
where
is a positive number set to 0.5
elements extracted from the text segment.
A mutation is an operator that aids in exploring the surroundings of a particular solution. Regarding the crossover, there are various methods for carrying out a mutation. For this type of mutation, an element from the population must be taken and changed using a random variable (RV) produced using a Gaussian distribution (GD). This helps the network escape local minima, improves its overall performance, and improves the text summarization quality. The altered solution, which is a mutated individual, is calculated using the formula in Equation (11).
A Gaussian () is an RV initiator that employs a GD with a standard deviation of to create unpredictability in the summarization procedure. From Equation (11), is the summary individual determined from the population.
The selection operator plays a crucial role in identifying the population components that crossover and mutation will affect. While there are a variety of systems of this type, the roulette wheel is the most widely used. This approach, which is based on fitness, operates by giving each person in the population a probability
. The population is then divided into many regions, which are represented by individuals. If an element
in a population of
potential solutions
has the fitness value
, the probability that
will be chosen can be calculated as in Equation (12).
4. Results
The experimental environment and setup, as well as the effectiveness of the suggested approach displayed in
Table 2, are described in this section. Table 6 shows the overall performances. Multi-Feature Maximal Marginal Relevance Bidirectional Encoder Representations from Transformers (MFMMR-Bert Sum) [
24], using ROUGE metrics, is compared with the existing approaches: MTLTS [
25], Deep Classification and Batch Real-Time Summarization (DCBRTS) [
26], Convolutional Neural Network—Robustly optimized (RoBERTa), and Bidirectional Gated Recurrent Unit Attention (CNN-BiGRU (Att)) [
27].
4.1. Summarization Findings
The ROUGE-L metric, which assesses the quality of text summaries by contrasting them with reference summaries, is used in
Table 3 to compare how well various summarization algorithms perform on a particular assignment. The algorithms LSA Summarizer, TextRank, Tweet Ranking, LexRank, and Luhn Summarizer are compared. The effectiveness of these algorithms is evaluated in comparison to the TF-IDF-GO-FC-CNN model.
The efficacy of the TF-IDF-GO-FC-CNN algorithm for each summarization technique is shown using percentages. Greater percentages indicate improved results. From
Table 3, the results indicate that the TF-IDF-GO-FC-CNN algorithm outperforms traditional summarization models like LexRank at 90.91%, TextRank at 87.87%, and so on, with ROUGE-L performing the lowest at 74.94%. This suggests that the proposed model excels in producing summaries that retain the core information of the original text.
Figure 7 shows a comparison of various summarization algorithms.
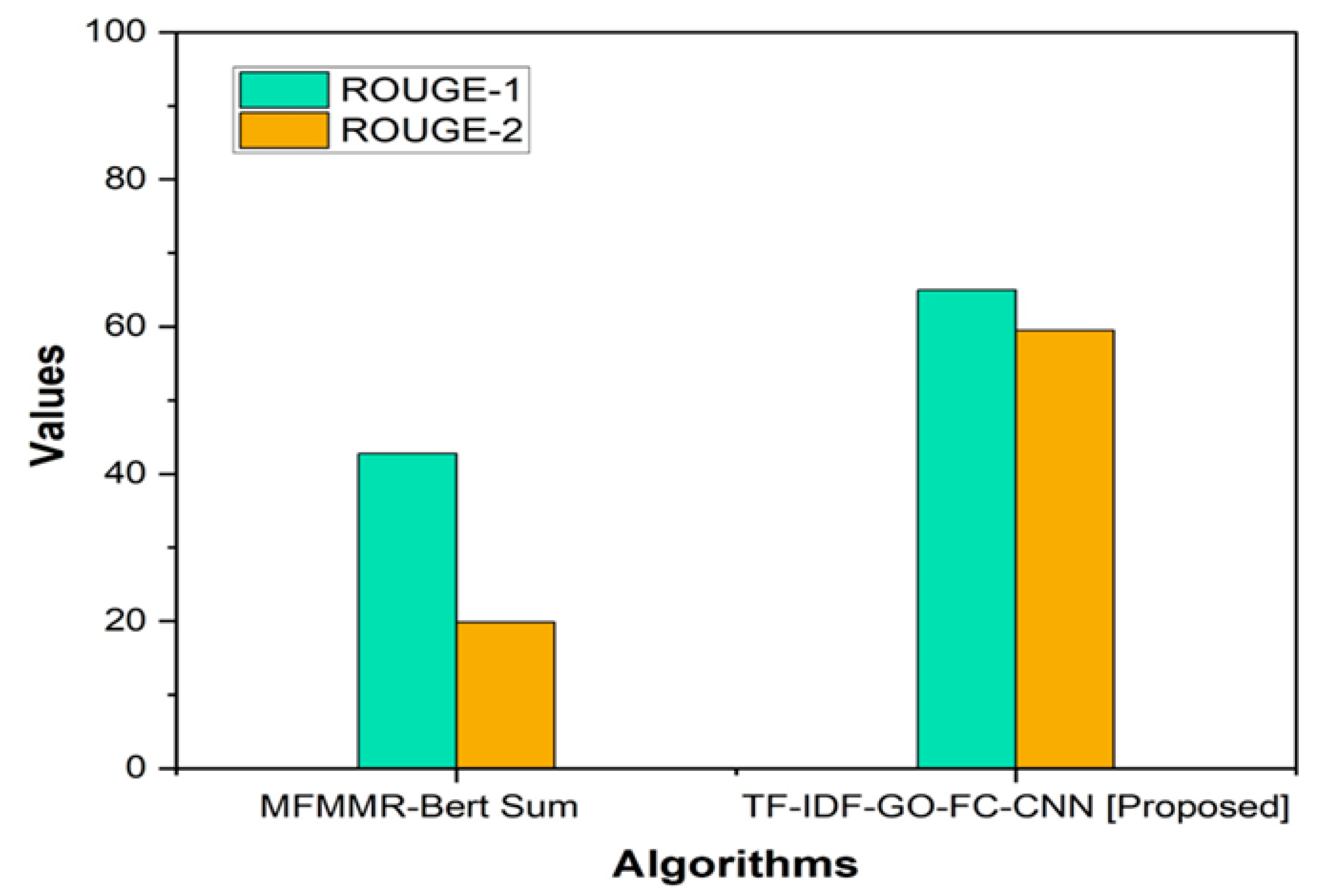
ROUGE-1: This statistic determines the number of unigrams of single words that the summary and the reference text contain. ROUGE-2: This metric calculates how many bigrams two words that follow the summary and the reference text share. Examining the word order assesses the summary’s coherence and fluency. The ROGUE score is displayed in
Table 4. In comparison, the TF-IDF-GO-FC-CNN has greater scores for both ROUGE-1 (64.95) and ROUGE-2 (59.5) than MFMMR-Bert Sum, which achieved a ROUGE-1 score of 42.74 and a ROUGE-2 score of 59.5; this indicates that TF-IDF-GO-FC-CNN generates summaries with superior word and phrase matching to the reference text. Higher ROUGE-1 and ROUGE-2 scores demonstrate that the TF-IDF-GO-FC-CNN algorithm works better than the MFMMR-Bert Sum method in producing accurate and coherent summaries.
Figure 8 provides a ROGUE score diagram.
The ROUGE-L measure is used in
Table 5 to compare the efficiency of several summarization techniques at different breakpoints. The algorithms evaluated include TextRank, LSA Summarizer, LexRank, Tweet Ranking, and Luhn Summarizer. Performance is measured for three distinct breakpoint ranges: up to 2000, from 2000 to 5000, and from 5000 to 7000.
Table 5 compares the performance of the summarization algorithms.
Table 5 demonstrates the performance variations of different summarization algorithms across various text length ranges. The tweet ranking shows the highest ROUGE-L score (69.87%) for texts up to 2000 words. Text rank performs better (61.23%) for texts between 2000 and 5000 words, while tweet ranking performs the best (58.65%) for texts between 5000 and 7000 words. Based on the length of the text being summarized, these outcomes suggest that summarizing algorithms can differ greatly in their efficacy.
Figure 9 shows the summarization algorithms across different breakpoints.
4.2. Classification Findings
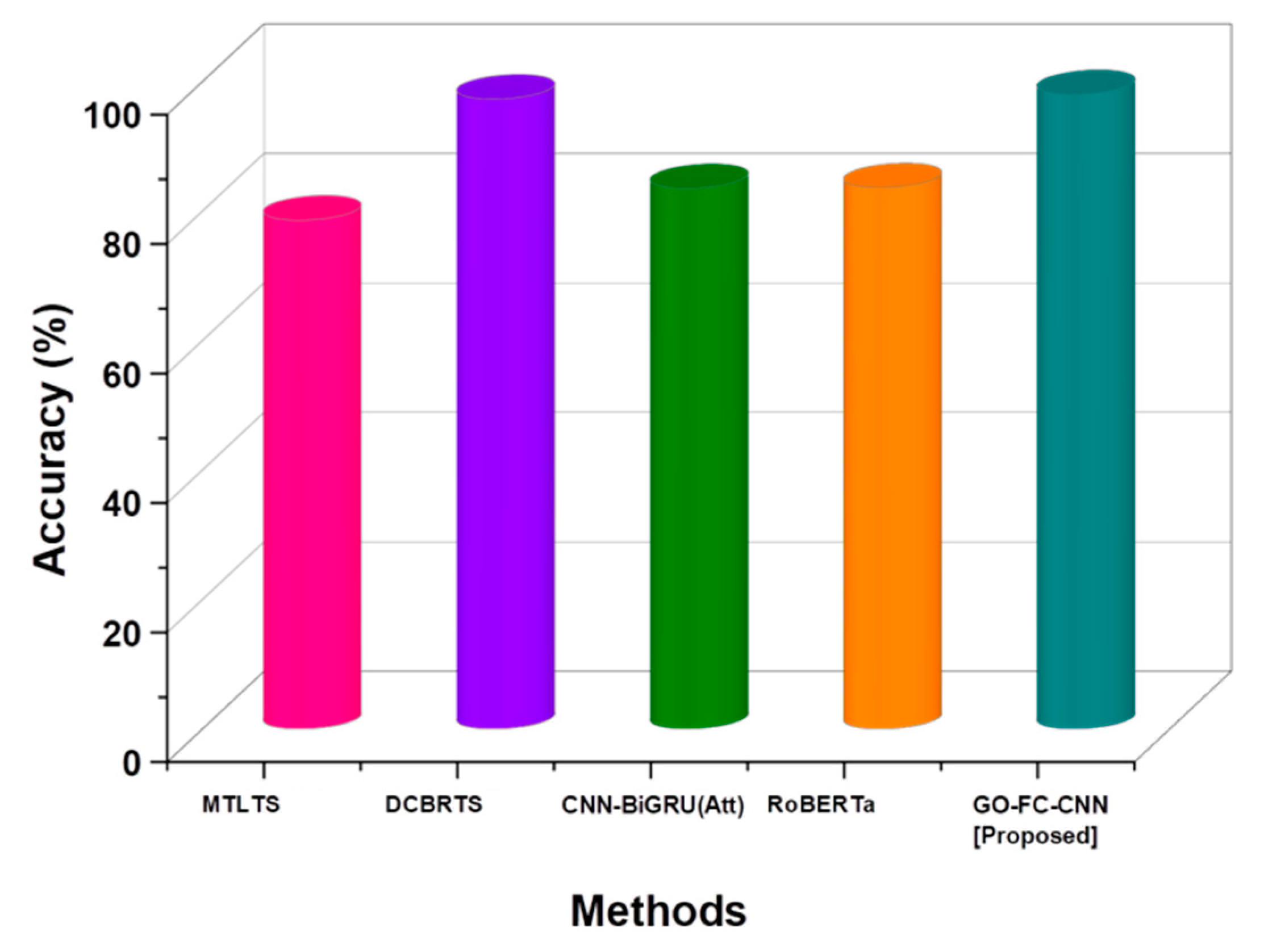
Accuracy evaluates coherence and informativeness, guaranteeing that the summary retains important details and clarity.
Figure 10 provides a comparative examination of accuracy. While the existing methods MTLTS, DCBRTS, CNN-BiGRU (Att), and RoBERTa achieved 78.6%, 97.30%, 83.5%, and 83.6%, respectively, our proposed GO-FC-CNN methodology achieved 98.00%. The findings demonstrate that our suggested approach substantially outperforms existing methods (
Table 6).
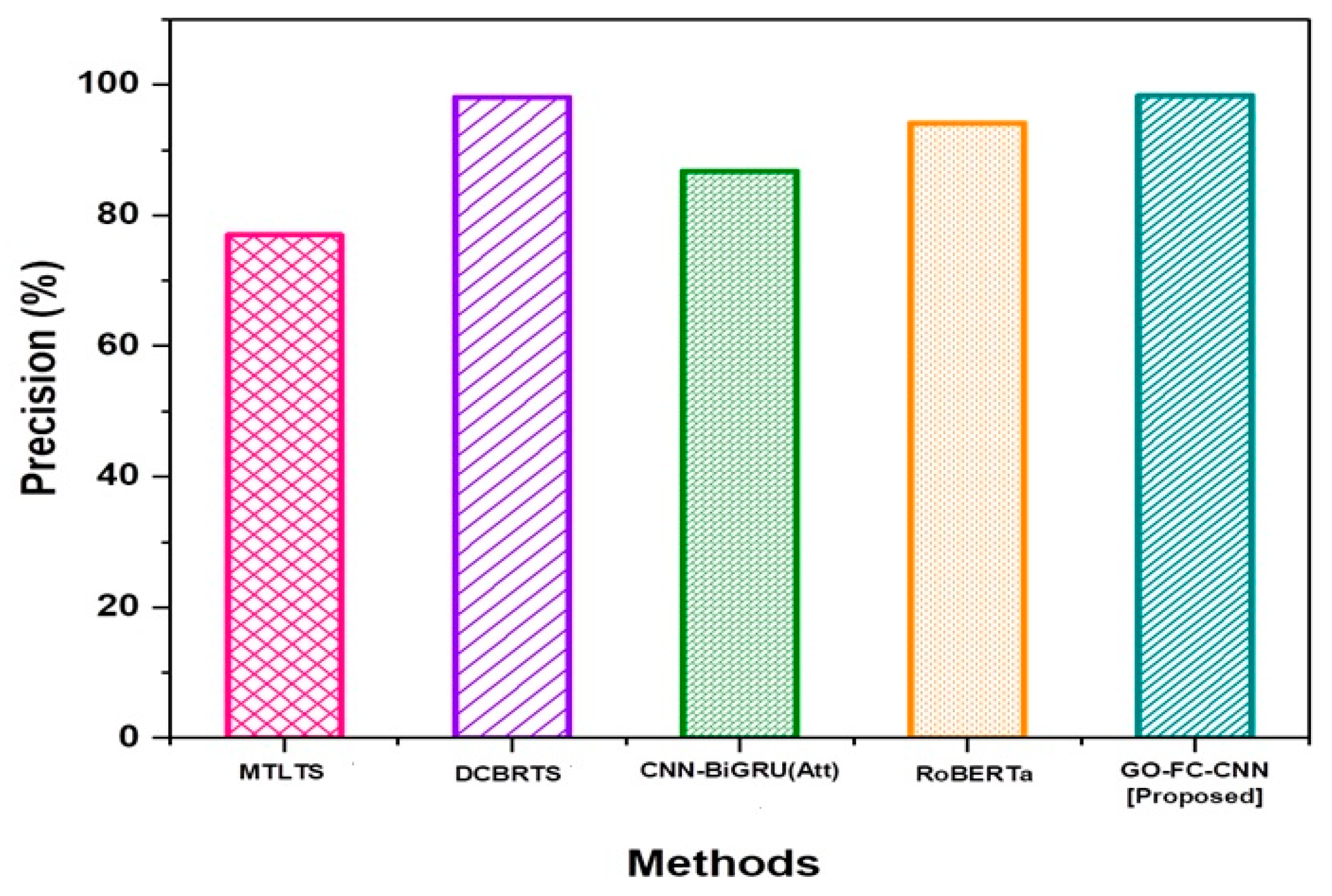
Precision evaluates how well a summary maintains the primary concepts of the original text while removing any unnecessary information.
Figure 11 illustrates a precision output.
The GO-FC-CNN technique accomplished a precision of 98.30%, which is admirable in comparison to the traditional methods MTLTS, DCBRTS, CNN-BiGRU (Att) and RoBERTa, which achieved precision values of 77%, 98.10%, 86.8%, and 94.1%, respectively. The findings indicate that our suggested method outperforms current techniques by a significant margin in terms of precision.
Recall assesses how well a summary covers all important features, demonstrating the model’s capacity to cover necessary material.
Figure 12 shows a comparable recall result.
The GO-FC-CNN technique accomplished a recall of (98.72%), which is admirable compared to the memory of the traditional methods MTLTS, DCBRTS, CNN-BiGRU (Att) and RoBERTa achieved 76.6%, 98.63%, 84.2% and 73.1%. The findings indicate that our suggested method outperforms the current techniques by a significant margin in terms of recall.
The F-score is the harmonic mean of these metrics, indicating the completeness and correctness of the summary’s ability to capture the main information.
Figure 13 provides a comparative exploration of the F1-score.
The GO-FC-CNN strategy we propose achieved an F1-score of 98.61%, which is superior to the memory of the existing techniques MTLTS, DCBRTS, CNN-BiGRU (Att), and RoBERTa, which achieved 76.8%, 98.41%, 83.3%, and 82.3%, respectively. These outcomes demonstrate that our suggested approach outperforms traditional techniques by a substantial margin in regard to the F1-score.
5. Discussion
The MFMMR-BERT Sum approach, which leverages multiple features and BERT to predict sentiment, offers a powerful methodology for short-text summarization. However, its strength comes with several challenges. The model’s reliance on BERT and multiple feature inputs makes it resource-intensive, demanding significant computational power and memory. This can create bottlenecks, especially when applied to larger datasets or when real-time processing is required. Furthermore, the model’s performance can vary based on the specificity of the text. For instance, MFMMR-BERT Sum may excel in summarizing short texts with fewer features, but it might struggle when the text is dense with intricate details or contains numerous diverse features. Such variability in performance raises concerns about its generalizability across different types of texts.
Moreover, the approach faces potential inefficiencies in balancing its management of multiple tasks, as seen in models like MTLTS (Multi-Task Learning for Text Summarization). The complexity of handling multiple tasks simultaneously can result in suboptimal performance if the model fails to adequately manage these tasks. This complexity also increases the training time and resource demands, making it less feasible for deployment in resource-constrained environments. Additionally, MTLTS may struggle with texts that do not conform to clear patterns or standards, leading to less accurate summaries. This issue is compounded by the need for batch processing, which can introduce delays in real-time applications. Such delays may be unacceptable in scenarios in which rapid summarization is critical.
A significant risk associated with deep learning models, including MFMMR-BERT Sum, is the potential to generate shallow or superficial summaries. While deep classification can be effective in identifying key points, it may sometimes fail to capture the nuances and subtleties of a text. This is particularly problematic for short texts, where every word can carry substantial meaning. If the model focuses too much on broader themes, it may miss important contextual details, resulting in summaries that lack depth or relevance. The demand for high computational resources during training and deployment only adds to the complexity, making this approach challenging to scale without substantial infrastructure.
Given these challenges, we propose an alternative approach: automatic short-text summarization using the Genetic Optimized Fully Connected Convolutional Neural Network (GO-FC-CNN). The GO-FC-CNN approach seeks to address the limitations of existing models by optimizing the network structure through a genetic algorithm, allowing for more efficient training and improved generalization. By focusing on short-text summarization, GO-FC-CNN is designed to handle the specific challenges associated with concise text, such as the need to capture subtle nuances without overwhelming computational demands.
One of the key advantages of GO-FC-CNN is its ability to optimize network architecture dynamically, enabling it to perform well across a range of different texts without the need for excessive resource allocation. Unlike MFMMR-BERT Sum, which relies heavily on BERT’s pre-trained embeddings and requires significant memory, GO-FC-CNN is more lightweight and adaptable. This makes it more suitable for real-time applications in which speed and efficiency are paramount. Furthermore, the use of genetic optimization helps refine the model architecture, ensuring that it can effectively balance the need for depth in summaries with the computational constraints typical of real-world deployments.
In addition to addressing resource constraints, GO-FC-CNN also improves upon the challenge of handling texts with unclear or ambiguous features. By leveraging convolutional layers optimized through genetic algorithms, the model can better capture the underlying structure of the text, even when the features are not immediately apparent. This makes it particularly effective for summarizing short texts with which traditional models might struggle due to a lack of clear patterns.
Despite the promising results of the GO-FC-CNN model compared to existing methods, there is potential for enhancement in handling dense or complex text. As shown in
Table 5, a performance drop occurs for texts longer than 5000 words, indicating that the model’s effectiveness may vary across different datasets, especially those with varying levels of complexity. Although GO-FC-CNN is designed to be more efficient than models like BERT, it still demands considerable computational resources during the training phase. Additionally, the model may encounter challenges with dynamic datasets that evolve over time, requiring continuous updates or retraining to maintain its effectiveness.
In summary, while existing models like MFMMR-BERT Sum and MTLTS offer valuable approaches to text summarization, they are not without their limitations. Their resource-intensive nature, potential for shallow summaries, and challenges in handling complex or ambiguous texts make them less ideal for all applications. The GO-FC-CNN approach provides a promising alternative by offering a more efficient and adaptable solution for automatic short-text summarization. Through the use of genetic optimization and a fully connected convolutional architecture, GO-FC-CNN can achieve high-quality summaries without the need for excessive computational resources, making it a more viable option for a wide range of practical applications. This model could be particularly useful in applications requiring summarization, such as summarizing breaking news articles or condensing social media texts, where both speed and accuracy are critical. The lightweight architecture, combined with its high performance, positions it as a viable tool for practical applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}