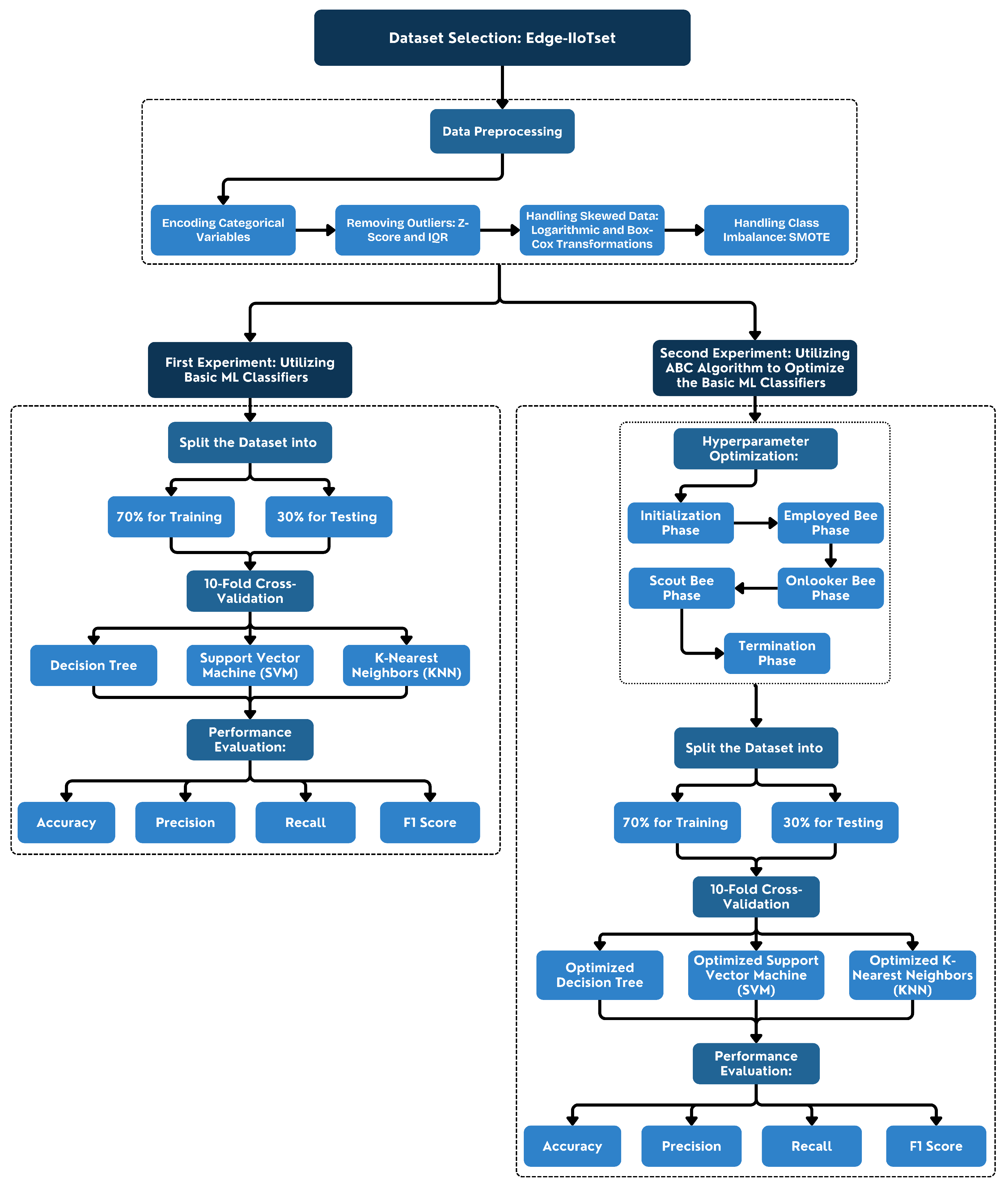
In this section, we present the findings from our experiments, which were conducted to evaluate the performance of machine learning classifiers in the context of network traffic analysis and malware detection. The experiments were carried out in two phases: the first phase involved the evaluation of basic machine learning models, while the second phase focused on the application of the ABC algorithm for hyperparameter optimization. The results are analyzed in terms of accuracy, precision, recall, and F1-score, which are critical metrics for assessing the effectiveness of the models in detecting various types of cyber threats.
4.1. Results of the First Experiment
The first experiment aimed to establish a baseline performance for the machine learning classifiers without any hyperparameter optimization. Three widely used classifiers—Decision Tree, Support Vector Machine (SVM), and K-Nearest Neighbors (KNN)—were applied to the dataset to classify different types of cyber attacks and normal traffic. The classifiers’ performance was measured in both the training and testing stages to ensure a comprehensive evaluation. The metrics of accuracy, precision, recall, and F1-score were calculated for each class of attacks to provide a detailed analysis of the models’ capabilities.
Table 3 presents the results of the first experiment.
The results of the first experiment indicate that all three classifiers—Decision Tree, SVM, and KNN—exhibited varying levels of effectiveness across different classes of cyber threats. The Decision Tree classifier, for instance, demonstrated fairly strong performance in detecting DDoS-related attacks. For DDoS_TCP, the Decision Tree achieved an accuracy of 0.9742 in the training stage and 0.9781 in the testing stage, with F1-scores of 0.9579 and 0.9628, respectively. This reflects the model’s ability to generalize well to unseen data for certain types of attacks. However, the Decision Tree’s performance was less impressive for classes like Password attacks, where the accuracy dropped to 0.6288 during training and further declined to 0.6188 in testing. The corresponding F1-scores were also notably lower, at 0.9231 for training and 0.7520 for testing, indicating significant overfitting and poor generalization.
The Support Vector Machine (SVM) classifier generally outperformed the Decision Tree, especially in terms of precision and recall across most classes. For instance, in detecting DDoS_ICMP attacks, SVM achieved a training accuracy of 0.9678 and a testing accuracy of 0.9693, with corresponding F1-scores of 0.9569 and 0.9583. This indicates that SVM maintained consistent performance across both stages, suggesting that the model is less prone to overfitting compared to the Decision Tree. However, similar to the Decision Tree, SVM also struggled with Password and Uploading classes, where the testing F1-scores were 0.8107 and 0.7813, respectively, compared to higher training F1-scores, highlighting areas where the model could be further optimized.
The K-Nearest Neighbors (KNN) classifier also showed strong performance in certain areas, particularly in detecting Backdoor attacks, with an accuracy of 0.9100 in training and 0.9164 in testing. The F1-scores were similarly high, at 0.9231 and 0.9272 for training and testing, respectively. However, KNN’s performance was somewhat inconsistent across other classes. For example, in detecting SQL_injection attacks, the F1-scores were 0.9088 for training and 0.9093 for testing, showing minimal improvement. Additionally, KNN struggled with classes like Uploading, where the accuracy was 0.7889 in training and 0.7892 in testing, with corresponding F1-scores of 0.7567 and 0.7625, suggesting that the model’s performance heavily depends on the quality and distribution of the training data.
The first experiment reveals that while traditional machine learning models like Decision Tree, SVM, and KNN can effectively detect certain types of cyber attacks, their performance is inconsistent across all classes. The variability in performance metrics, such as precision, recall, and F1-score, between the training and testing stages suggests that these models may benefit from further refinement, particularly in hyperparameter tuning, to improve their generalization capabilities. This highlights the necessity of exploring advanced optimization techniques, such as the Artificial Bee Colony algorithm, to enhance the robustness and accuracy of these classifiers in cybersecurity applications. The observed differences between the training and testing stages across different classifiers further emphasize the importance of addressing overfitting and ensuring that models are well-tuned to handle the complexity and variability inherent in real-world cyber threats.
Figure 4 presents the confusion matrix for the Decision Tree during the training stage, indicating robust classification performance across most attack classes, as evidenced by the high number of correctly classified instances along the diagonal. For instance, the model correctly identified 15,253 instances of the Backdoor attack and 15,875 instances of the DDoS_HTTP attack. However, there are some areas where the model struggled, particularly with the Fingerprinting and Vulnerability Scanner classes. For example, 1247 instances of Fingerprinting were misclassified as DDoS_TCP, and 2143 instances of Vulnerability Scanner were incorrectly labeled as DDoS_HTTP. These misclassifications suggest that the Decision Tree had difficulty distinguishing between these specific attack types, likely due to overlapping feature spaces or similarities in the patterns within these classes.
During the testing stage, the Decision Tree’s performance remained strong but showed some signs of reduced accuracy compared to the training stage as shown in
Figure 5. The model correctly classified 6487 instances of Backdoor and 6795 instances of DDoS_HTTP, slightly lower than the training stage results. Notably, the Password class saw significant misclassifications, with 1667 instances incorrectly classified as SQL_injection. The increase in misclassification errors, such as the 910 instances of Vulnerability Scanner being mislabeled as DDoS_HTTP, indicates that the model may have overfitted during training. This overfitting likely led to reduced generalization when exposed to new, unseen data, particularly for classes with less distinct or more complex feature distributions.
Figure 6 presents the confusion matrix for the SVM model during the training stage, showing high accuracy across most classes, reflecting the model’s capability in handling linearly separable data. For instance, the model correctly classified 16,462 instances of DDoS_ICMP and 16,831 instances of DDoS_UDP. However, some misclassifications were observed, such as 2098 instances of Fingerprinting being misclassified as DDoS_TCP and 1398 instances misclassified as Backdoor, and 2105 instances misclassified of Vulnerability Scanner incorrectly classified as DDoS_HTTP. These errors suggest that while SVM is generally effective, there are challenges in distinguishing between certain classes, particularly when they have overlapping characteristics or are underrepresented in the training set.
In the testing stage, SVM maintained strong performance as shown in
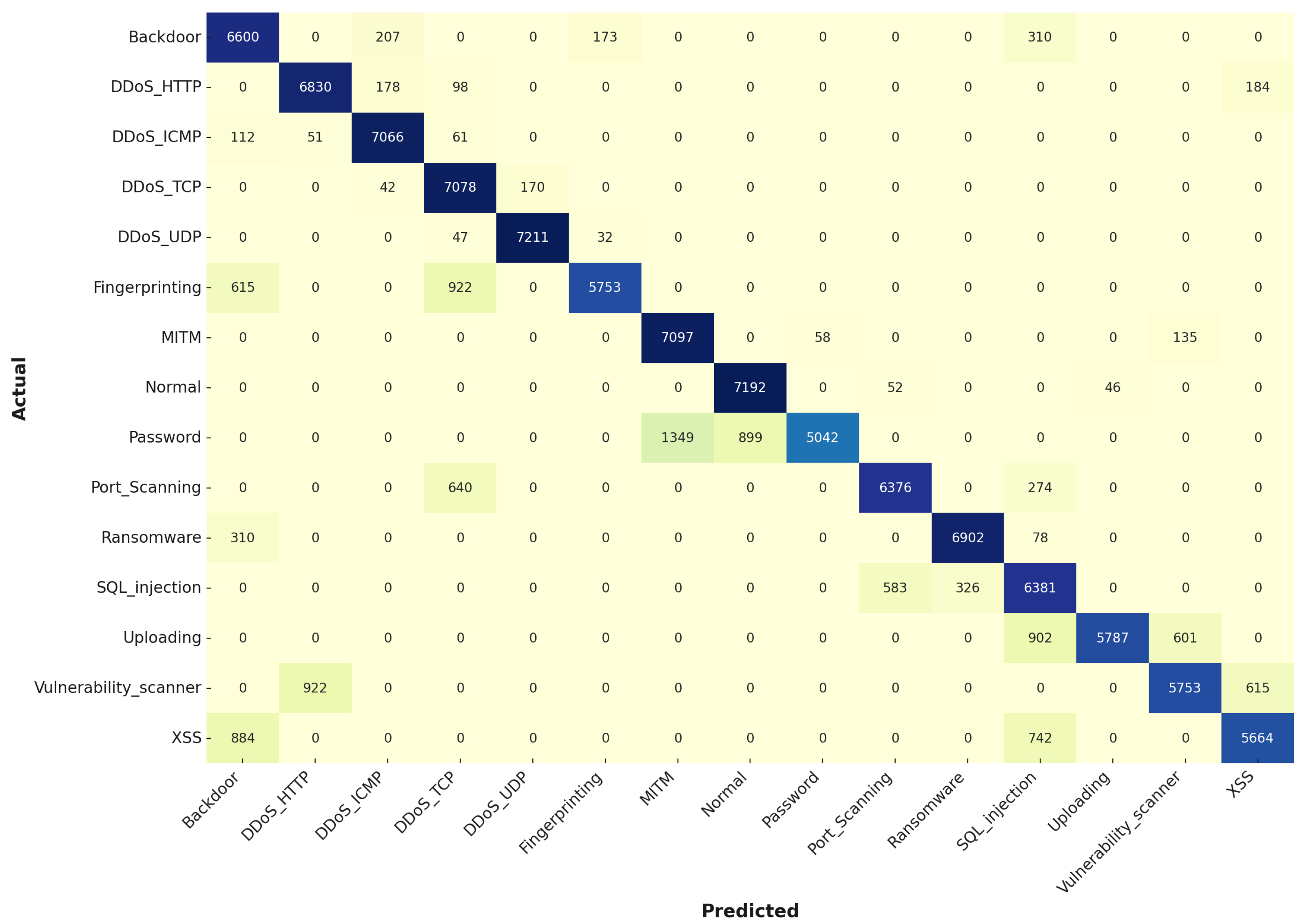
Figure 7, with 7066 instances of DDoS_ICMP and 7211 instances of DDoS_UDP correctly classified. However, the model exhibited an increase in misclassifications compared to the training stage. For example, 884 instances of XSS were incorrectly classified as Backdoor, and 922 instances of Vulnerability Scanner were mislabeled as DDoS_HTTP. The increase in these errors suggests that while the SVM model was well-tuned for the training data, it struggled slightly to generalize to the testing data, particularly for classes like Password and Vulnerability Scanner, where the feature distributions in the test set may differ from those seen during training.
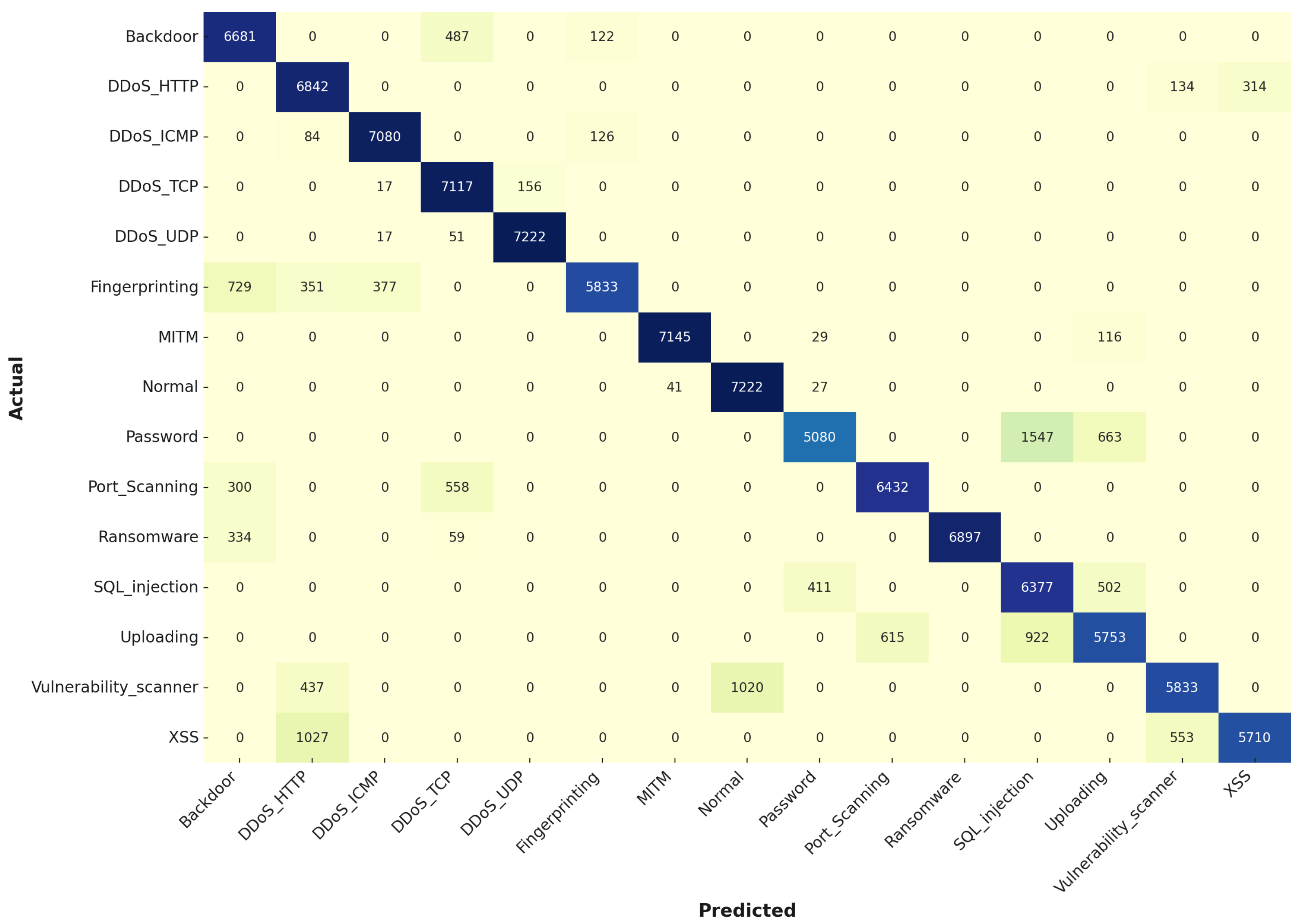
The KNN model’s training stage confusion matrix highlights its effectiveness in classifying the majority of attack classes as shown in
Figure 8, with 15,479 instances of Backdoor and 16,592 instances of DDoS_TCP correctly identified. However, there were notable misclassifications, such as 1716 instances of Fingerprinting being mislabeled as Backdoor and 1123 instances of Vulnerability Scanner incorrectly classified as DDoS_HTTP. These errors may stem from KNN’s reliance on the proximity of data points in the feature space, which can lead to confusion when different classes have overlapping or closely situated data points.
During the testing stage, the KNN model showed a slight decline in performance, with 7080 instances of DDoS_ICMP and 7117 instances of DDoS_TCP correctly classified, compared to higher numbers in the training stage. There was an increase in misclassifications, such as 729 instances of Fingerprinting being mislabeled as Backdoor and 437 instances of Vulnerability Scanner incorrectly identified as DDoS_HTTP. This decline in performance suggests that the KNN model may be sensitive to variations in the test data, particularly when test instances are not as close to the training data in the feature space. The increase in false positives and negatives highlights the model’s challenges in generalizing effectively, especially for classes with complex or less distinct feature distributions.
Figure 9 presents the confusion matrix for the KNN classifier over the testing stage.
4.2. Results of the Second Experiment
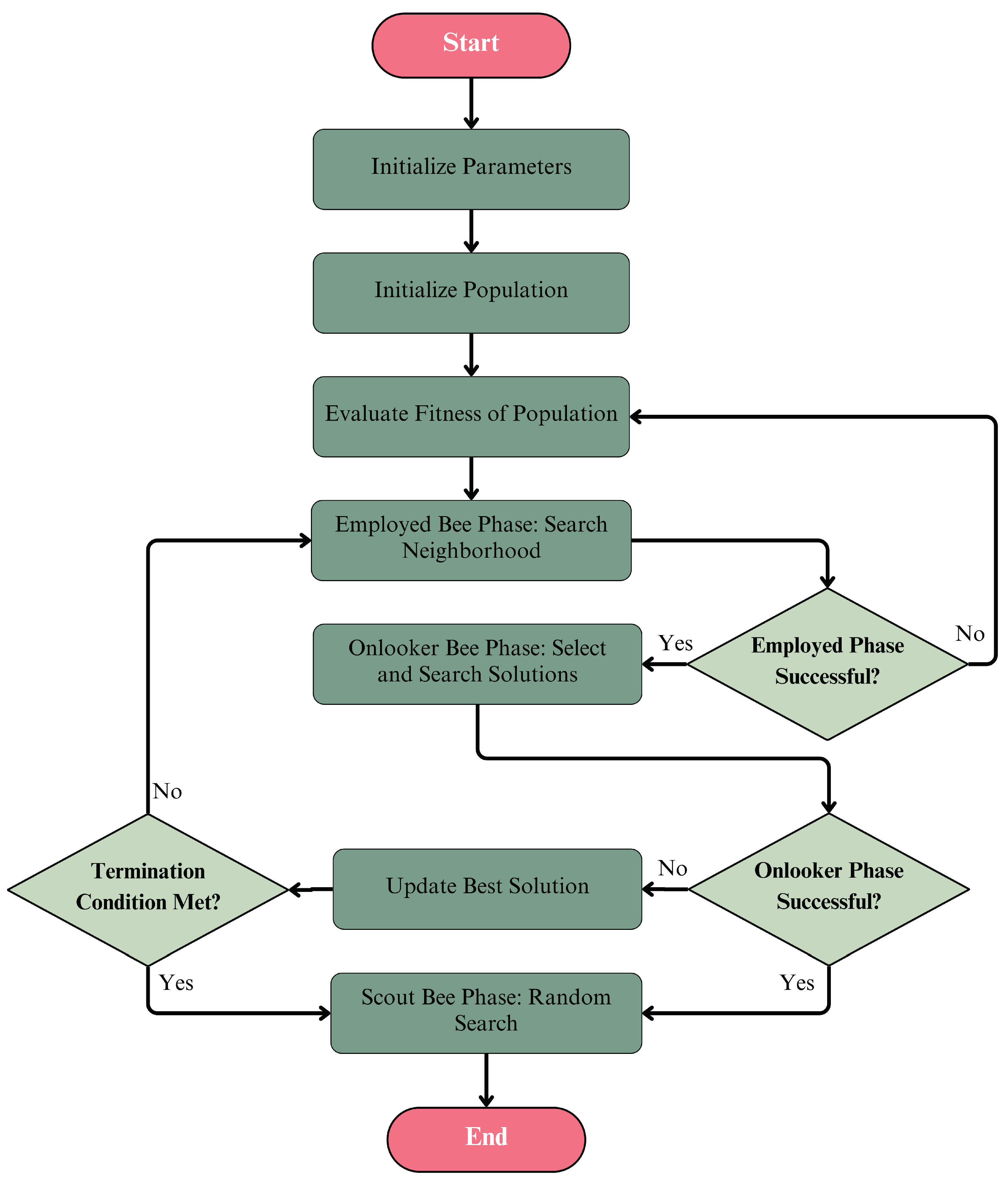
The second experiment, which applied hyperparameter tuning using the Artificial Bee Colony (ABC) algorithm to the basic machine learning models, demonstrates a significant improvement in the performance metrics across all algorithms compared to the first experiment. The enhancements are particularly evident in the accuracy, precision, recall, and F1-score for both the training and testing stages, highlighting the effectiveness of the optimization process.
Table 4 presents the results of the second experiment.
The Decision Tree classifier, after hyperparameter tuning, exhibited a marked improvement in accuracy across all classes. For instance, the accuracy for the Backdoor class increased from 0.8967 in the training stage of the first experiment to 0.9899 in the second experiment, with the testing stage accuracy similarly improving from 0.8899 to 0.9931. This indicates that the hyperparameter tuning significantly reduced overfitting, as evidenced by the closer alignment of training and testing stage metrics. Moreover, precision, recall, and F1-score saw notable increases across various classes, such as the DDoS_HTTP class, where the F1-score improved from 0.9226/0.9204 (training/testing) in the first experiment to 0.9940/0.9962 in the second experiment. These enhancements demonstrate the ABC algorithm’s ability to fine-tune the model parameters effectively, resulting in better generalization to unseen data and a substantial reduction in misclassifications.
The SVM model, which already performed well in the first experiment, showed further enhancements after hyperparameter tuning. The accuracy for several classes reached 1.0 in both training and testing stages, reflecting near-perfect classification performance in nearly half of the classes. For instance, the Backdoor class accuracy improved from 0.9016 (training) and 0.9054 (testing) in the first experiment to 0.9912 and 0.9973, respectively, in the second experiment. This improvement is also mirrored in other performance metrics such as precision, recall, and F1-score, particularly for classes like DDoS_ICMP, where the F1-score reached 0.9991/0.9997 (training/testing) post-tuning. These results highlight the SVM model’s enhanced ability to handle diverse attack patterns with minimal misclassification, thanks to the optimization process. The improvements suggest that hyperparameter tuning effectively addressed the minor generalization issues observed in the first experiment.
The KNN classifier also benefited significantly from hyperparameter tuning, with accuracy for several classes reaching 1.0 in both training and testing stages. The Backdoor class, for instance, achieved perfect accuracy and F1-score across both stages, a marked improvement from the first experiment where the accuracy was 0.9100/0.9164 (training/testing). The enhancement is particularly noteworthy in the DDoS_UDP class, where the F1-score increased to 0.9979/1.0, indicating that the KNN model, after tuning, was able to effectively distinguish between classes that previously posed challenges. The reduction in false positives and negatives across various classes further emphasizes the model’s improved generalization ability. The hyperparameter tuning successfully addressed the sensitivity issues observed in the KNN model during the first experiment, leading to a more robust and accurate classification performance.
When we compare the results of the first and second experiments, the impact of hyperparameter tuning becomes abundantly clear. Across all models, there is a consistent trend of improved accuracy, precision, recall, and F1-score in the second experiment, reflecting better model performance and reduced overfitting. The ABC algorithm’s role in optimizing the hyperparameters of each model is evident in the substantial gains observed, particularly in the consistency between training and testing stage results.
The decision to apply hyperparameter tuning resulted in more balanced models capable of generalizing better to unseen data, as shown by the reduced gap between training and testing metrics. This enhancement is crucial in cybersecurity applications, where the ability to accurately identify and classify a wide range of attack types with minimal error is paramount. The results of the second experiment strongly suggest that the use of advanced optimization techniques, such as the ABC algorithm, is highly effective in enhancing the performance of machine learning models in complex, real-world scenarios.
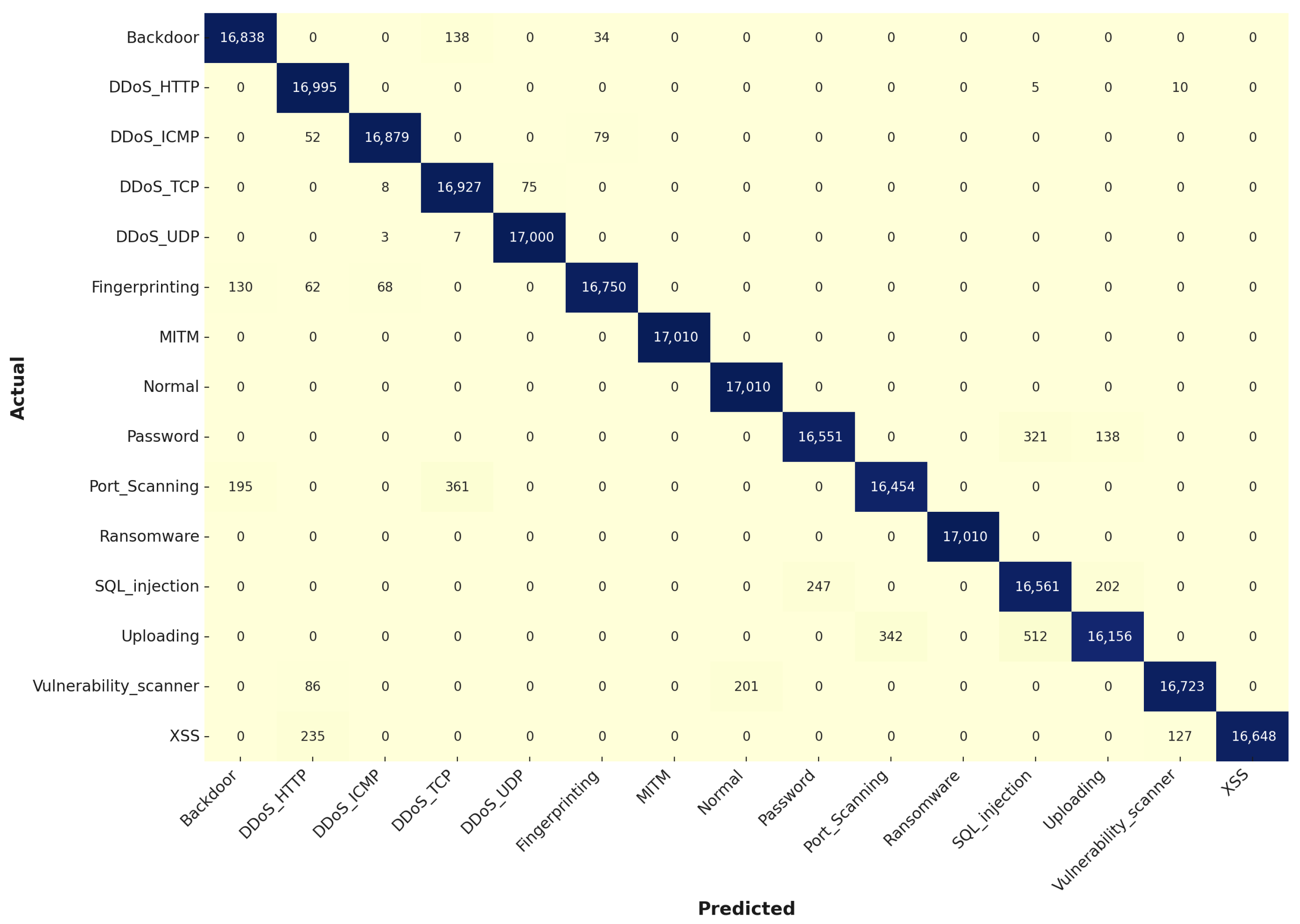
The confusion matrices for the Decision Tree model in the second experiment, as represented in
Figure 10, show significant improvements in classification accuracy and generalization compared to the first experiment. During the training stage, the hyperparameter-optimized model achieved higher precision and recall across most classes, with notable reductions in misclassification rates. For instance, the “Backdoor” class saw 16,838 correct classifications with 138 misclassified instances as DDoS_TCP and 34 as Fingerprinting, and the “DDoS_UDP” class achieved 17,000 correct classifications with just 10 misclassifications. Classes that previously exhibited overfitting, such as “Password” and “Port_Scanning”, now demonstrate robust performance with 16,551 and 16,454 correct classifications, respectively, indicating that the model has been fine-tuned to better capture complex patterns in the data. This enhancement is particularly evident in the “Vulnerability_scanner” and “XSS” classes, where the model now shows 16,723 and 16,648 correct classifications, reflecting the positive impact of the ABC algorithm on the model’s ability to distinguish between closely related classes.
In the testing stage, the Decision Tree model continues to perform well, maintaining high accuracy with minimal decline compared to the training results, which indicates good generalization as shown in
Figure 11. For example, the “Backdoor” class had 7240 correct classifications out of 7290 instances, with only 50 misclassified, while the “DDoS_TCP” and “DDoS_UDP” classes had 7273 and 7290 correct classifications, respectively, with minimal misclassifications. The improvements are especially prominent in classes that were challenging in the first experiment, such as “Password” and “Port_Scanning”, where the optimized model shows substantially fewer misclassifications, with 7146 and 7071 correct classifications, respectively. These results highlight the effectiveness of hyperparameter optimization in reducing overfitting and enhancing the model’s overall performance, making it more reliable for real-world cybersecurity applications. The success of the ABC algorithm in optimizing the Decision Tree model underscores its value in improving machine learning classifiers’ accuracy and robustness in detecting and mitigating cyber threats.
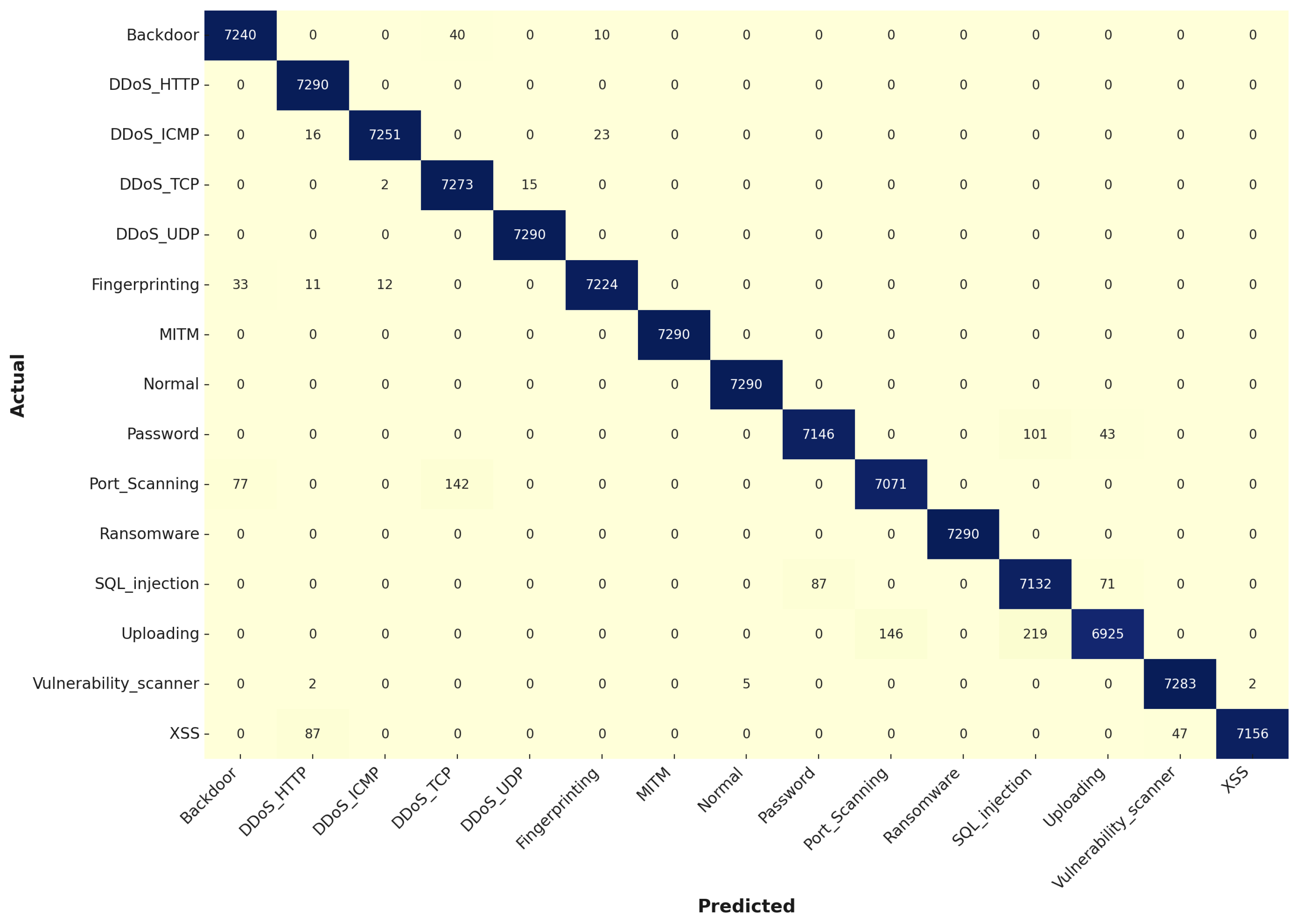
The confusion matrices for the SVM model in the second experiment, as depicted in
Figure 12, demonstrate significant enhancements in classification accuracy and generalization when compared to the first experiment. The hyperparameter optimization process led to higher precision and recall during the training stage across most classes, coupled with a notable reduction in misclassification rates. For example, the “Backdoor” class achieved 16,860 correct classifications with only 120 instances misclassified as DDoS_TCP and 30 as Fingerprinting. Similarly, the “DDoS_UDP” class saw perfect classification with all 17,010 instances accurately identified. Classes that had previously suffered from overfitting, such as “Password” and “Port_Scanning”, now display a much-improved performance, with 16,690 and 16,639 correct classifications, respectively. These results suggest that the hyperparameter-tuned model has become more adept at distinguishing subtle differences between closely related classes, leading to more accurate predictions.
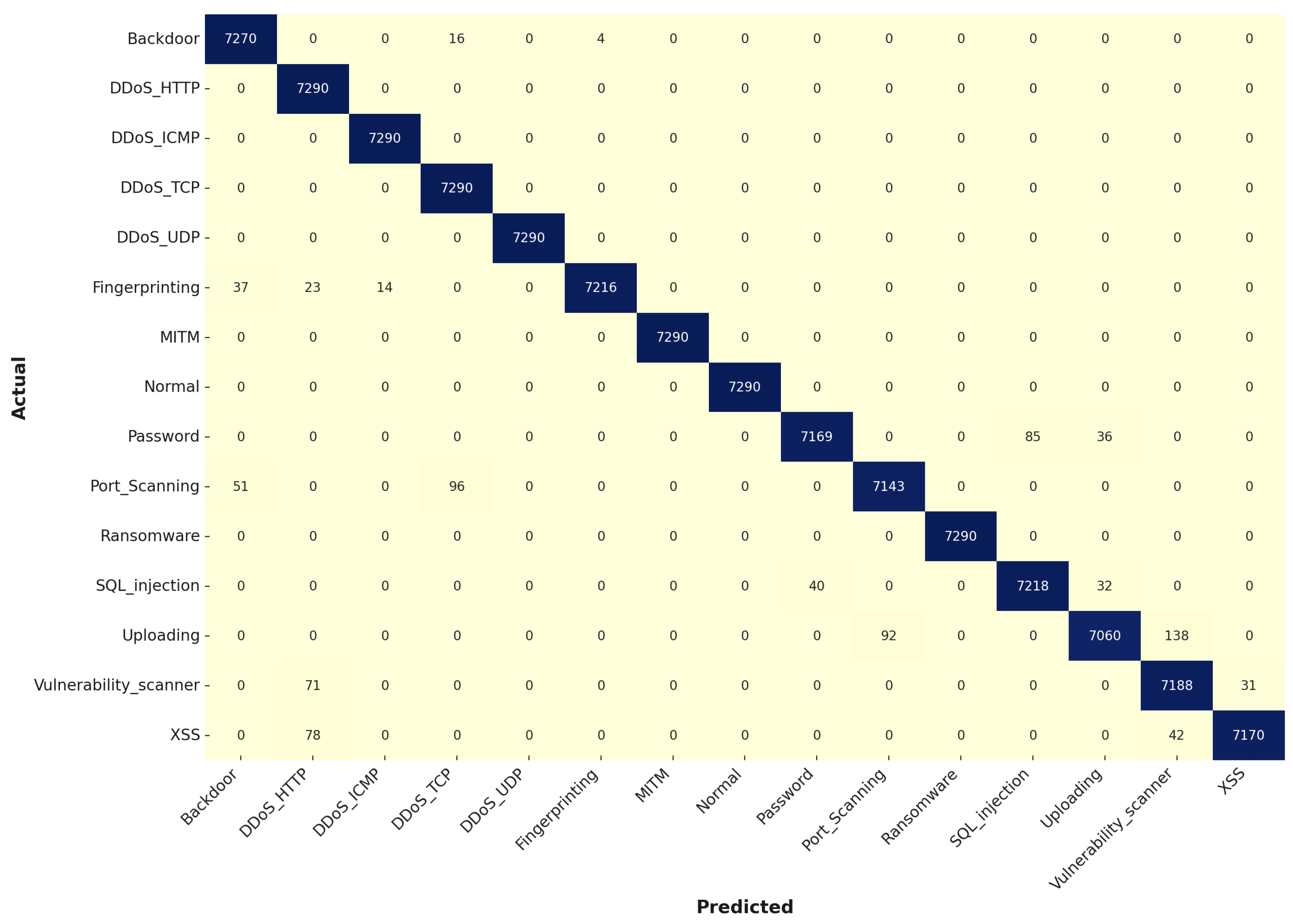
In the testing stage, illustrated in
Figure 13, the SVM model continued to exhibit robust performance, retaining high accuracy with minimal decline from the training results, indicating strong generalization capabilities. For instance, the “Backdoor” class correctly classified 7270 out of 7290 instances, with only 16 misclassifications, showcasing the model’s effectiveness in handling new, unseen data. The “DDoS_TCP” and “DDoS_UDP” classes also maintained perfect classification rates, underscoring the model’s strength in dealing with DDoS attacks. The improvement in challenging classes from the first experiment, such as “Password” and “Port_Scanning”, is particularly notable, with 7169 and 7143 correct classifications, respectively. These findings highlight the success of the ABC algorithm in refining the SVM model, making it more reliable and effective in real-world cybersecurity scenarios by enhancing its accuracy and robustness in detecting and mitigating various cyber threats.
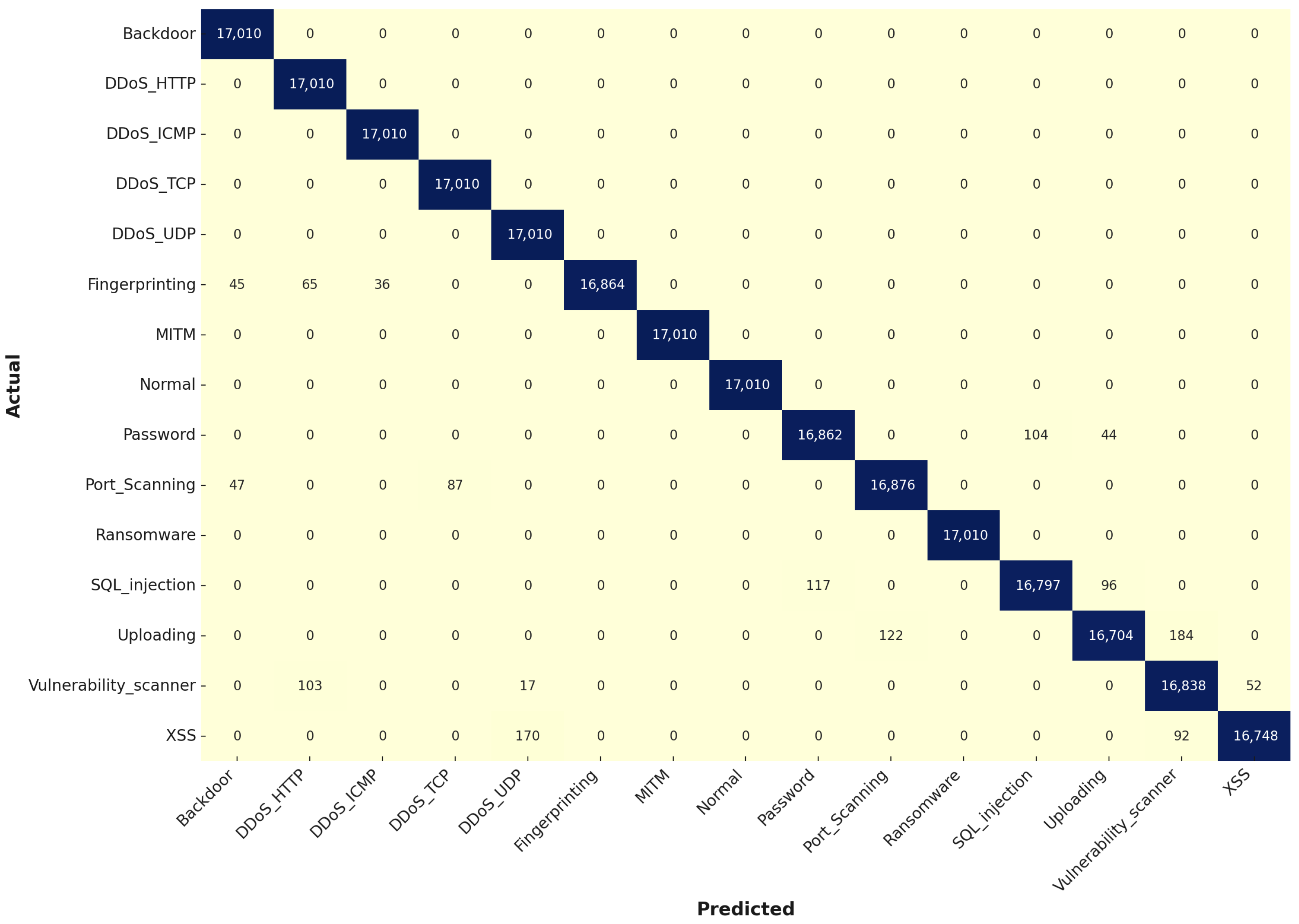
The confusion matrices for the KNN model in the second experiment, as represented in
Figure 14, indicate marked improvements in classification accuracy and a significant decrease in misclassification rates when compared to the first experiment. During the training stage, the hyperparameter-optimized KNN model achieved perfect classification for several classes, including “Backdoor” and “DDoS_UDP”, with all 17,010 instances correctly identified. This illustrates a substantial enhancement in the model’s ability to differentiate between various attack types. Moreover, classes that were challenging in the first experiment, such as “Password” and “Port_Scanning”, showed notable improvements, with 16,862 and 16,876 correct classifications, respectively. These results suggest that the hyperparameter tuning process has successfully enhanced the model’s precision and recall, allowing it to better capture the nuances between closely related classes and improve overall performance.
In the testing stage as shown in
Figure 15, the KNN model sustained its high level of performance, with minimal decline from the training results. For example, the “Backdoor”, “DDoS_TCP”, and “DDoS_UDP” classes achieved perfect classification, correctly identifying all 7290 instances, which underscores the model’s robustness and its strong generalization abilities. Additionally, the “Password” and “Port_Scanning” classes showed significant progress, with 7240 and 7245 correct classifications, respectively, further demonstrating the effectiveness of the hyperparameter optimization. These improvements make the KNN model a more reliable tool for real-world cybersecurity applications, as it now more accurately detects and mitigates a broad range of cyber threats with improved consistency.
The comparative analysis between the first and second experiments underscores the effectiveness of hyperparameter tuning in enhancing machine learning models’ performance. The second experiment’s confusion matrices reveal fewer misclassifications and higher accuracy across all classes, demonstrating improved generalization from training to testing data, which is crucial for reliable detection of diverse cyberattacks. The ABC algorithm optimized decision boundaries and reduced overfitting, as indicated by the closer alignment between training and testing results. However, this improvement in performance came with additional computational costs. As outlined in
Table 5, the training time increased from 1500 s in the first experiment to 2200 s in the second experiment due to the iterative nature of the ABC optimization process. Memory usage also increased from 1024 MB to 1280 MB, along with a slight increase in CPU utilization from 70% to 80%. Despite these additional costs, the improved accuracy and generalization make the trade-off worthwhile, particularly for real-world applications requiring high reliability in diverse and variable data environments. The second experiment highlights the significant improvements achieved through hyperparameter tuning, validating the ABC algorithm as a powerful tool for refining model parameters and enhancing machine learning-based threat detection systems.
4.3. Accuracy per Iteration Analysis
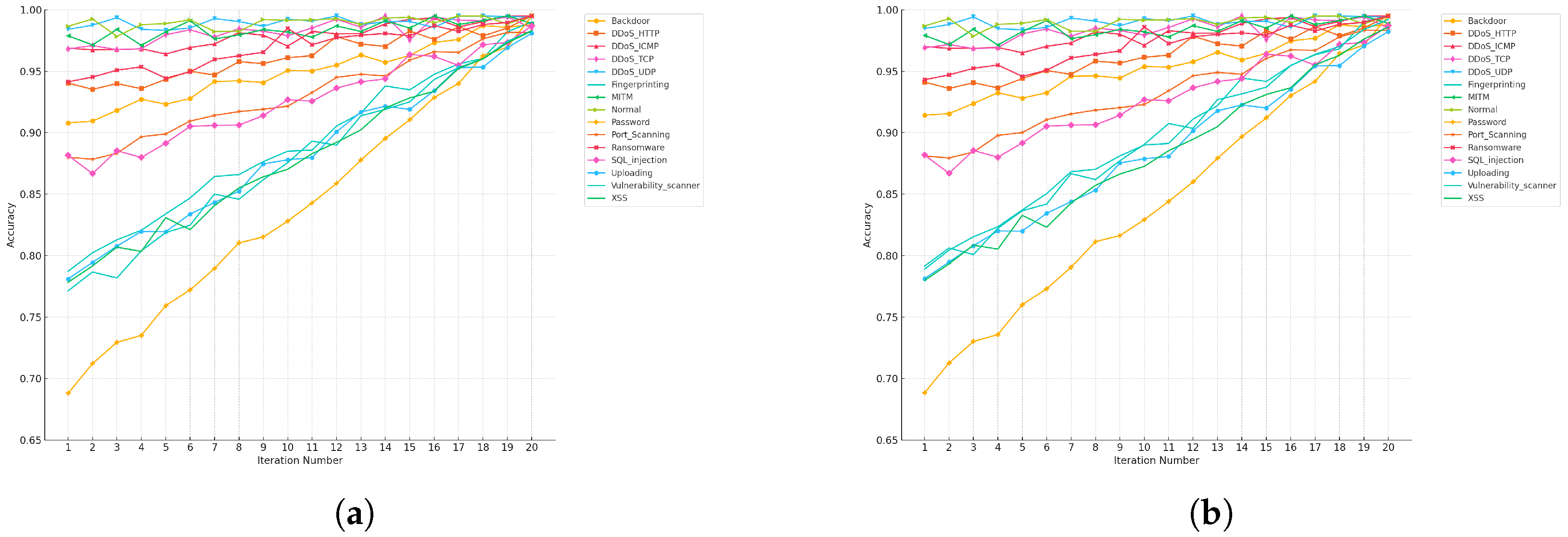
In this section, we present the accuracy per iteration plots for the best model, KNN algorithm during both the training and testing stages to provide a clear visualization of how the hyperparameter optimization process enhanced the model’s performance over time. These plots show a consistent trend of improvement across all classes, with the accuracy gradually increasing as the number of iterations progresses, ultimately reaching higher accuracy values near the end of the process.
In the accuracy by iteration analysis, we introduce a threshold
, meaning we track when the accuracy exceeds
. This threshold is used to evaluate the point at which the model achieves near-optimal performance. As shown in
Figure 16a, during the training stage, the accuracy for most classes surpasses the
threshold between iterations 9 and 14. Specifically, the “DDoS_TCP”, “DDoS_UDP”, “Backdoor”, and “XSS” classes exceed 95% accuracy by iteration 12, while others like “Password” and “Port_Scanning” reach this point around iteration 14. By iteration 20, the accuracy of most classes approaches near-optimal levels, close to 1.0. Similarly, as seen in
Figure 16b, the testing stage reveals similar trends, with many classes crossing the 95% threshold between iterations 13 and 17. By the final iteration, all classes demonstrate a high level of accuracy, converging near 1.0, showcasing the robustness of the model. This analysis highlights the efficiency of the ABC optimization process, allowing for the model to reach high accuracy with minimal iterations, making it suitable for real-world applications.
Figure 16a presents accuracy per iteration during the training stage, the KNN model exhibited a steady and significant improvement in accuracy across almost all classes. The initial iterations reflect lower accuracy levels, particularly in more challenging classes such as “Password” and “Port_Scanning”. However, as the iterations advance, the model’s accuracy increases progressively, indicating that the hyperparameter tuning is effectively refining the decision boundaries and reducing the error rate. By the 20th iteration, most classes achieved near-perfect accuracy, with values closely approaching 1.0. This highlights the success of the optimization process in minimizing overfitting and improving the model’s ability to learn complex patterns within the training data. The consistent upward trend across all classes demonstrates the robustness of the KNN model when enhanced by the Artificial Bee Colony (ABC) algorithm for hyperparameter tuning.
Figure 16b presents accuracy per iteration during the testing stage that mirrors the improvements seen in the training stage, although with a slightly more varied trajectory. The initial accuracy values during the early iterations are lower compared to the final ones, particularly for classes that are inherently more difficult to classify, such as “Uploading” and “SQL_injection”. As the iterations increase, the accuracy steadily improves, reflecting the model’s enhanced generalization capabilities. Notably, by the final iterations, most classes achieve accuracy levels very close to or at 1.0, underscoring the effectiveness of the hyperparameter tuning in making the model more reliable when exposed to new, unseen data. The convergence of accuracy values in both the training and testing stages by the end of the optimization process indicates that the model has successfully balanced learning from the training data while maintaining strong generalization performance on the testing data.
4.4. Comparison with Related Works
The comparison of our research with existing studies, as shown in
Table 6, presents a comparative analysis between our study and the works of [
16,
18] highlights significant differences in class-specific accuracy, particularly in handling difficult-to-detect attacks within the Edge-IIoTset dataset. In [
16], the authors applied Convolutional Neural Networks (CNNs) to intrusion detection, achieving good results in detecting attacks such as DDoS_ICMP, DDoS_TCP, and MITM, with accuracies of 100% for these classes. However, they struggled with imbalanced classes like “Password” and “Port Scanning”, where they achieved 19% and 49% accuracy, respectively. Our approach, utilizing traditional machine learning models optimized with the ABC algorithm, significantly outperformed their model, achieving 99.13% accuracy for “Password” and 99.21% for “Port Scanning”. Similarly, our study improved upon their results for “XSS” and “Uploading” attacks, where [
16] attained 25% and 47%, respectively, while we achieved 98.46% for “XSS” and 98.2% for “Uploading”. Our model’s ability to handle imbalanced data more effectively led to higher accuracy across the majority of classes, including perfect scores (100%) for “Backdoor”, “DDoS_HTTP”, “DDoS_ICMP”, “DDoS_TCP”, and “DDoS_UDP”, compared to their scores of 98%, 95%, 100%, 100%, and 100%, respectively.
In comparison to [
18], who utilized Federated Learning (FL) in a MEC-based architecture to enhance intrusion detection, our results also show marked improvements across several key classes, while their model achieved perfect accuracy (100%) in detecting “DDoS_HTTP”, “DDoS_TCP”, “DDoS_UDP”, and “Uploading”, it underperformed in other areas. For instance, they achieved only 79% for “Backdoor”, compared to our 100%, and 74% for “Password” versus our 99.13%. Similarly, our model surpassed their accuracy for “Port Scanning” (99.21% versus 73%), “Fingerprinting” (99.14% versus 96%), and “XSS” (98.46% versus 81%). Even in classes where their model performed well, such as “Ransomware” and “Vulnerability Scanner” with 99% and 95%, our approach still achieved slightly better accuracy, with 100% for “Ransomware” and 98.99% for “Vulnerability Scanner”. These results emphasize the effectiveness of hyperparameter tuning using the ABC algorithm in optimizing traditional machine learning models, resulting in higher overall accuracy compared to both CNN-based and Federated Learning-based approaches, especially in handling imbalanced and diverse classes in the Edge-IIoTset dataset.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}