
Efficient Supervised Machine Learning Network for Non-Intrusive Load Monitoring



Abstract
1. Introduction
- An efficient non-parametric supervised machine learning network (ENSML) was proposed with fast inference speed and low storage requirements. The proposed method was used to create a realistic and adaptable NILM formulation model, with the parameter values following a supervised learning strategy.
- The proposed ENSML has a lowered learning parameter; therefore, it takes up less space while performing as well as other state-of-the-art NILM systems.
- The suggested ENSML methodology with the NILM system could recognise newly installed appliances, filling a critical research need.
- A public dataset was used to validate the provided model and approach. All of the hypothesised potentials have been shown to be genuine, in addition to the high precision of load disaggregation.
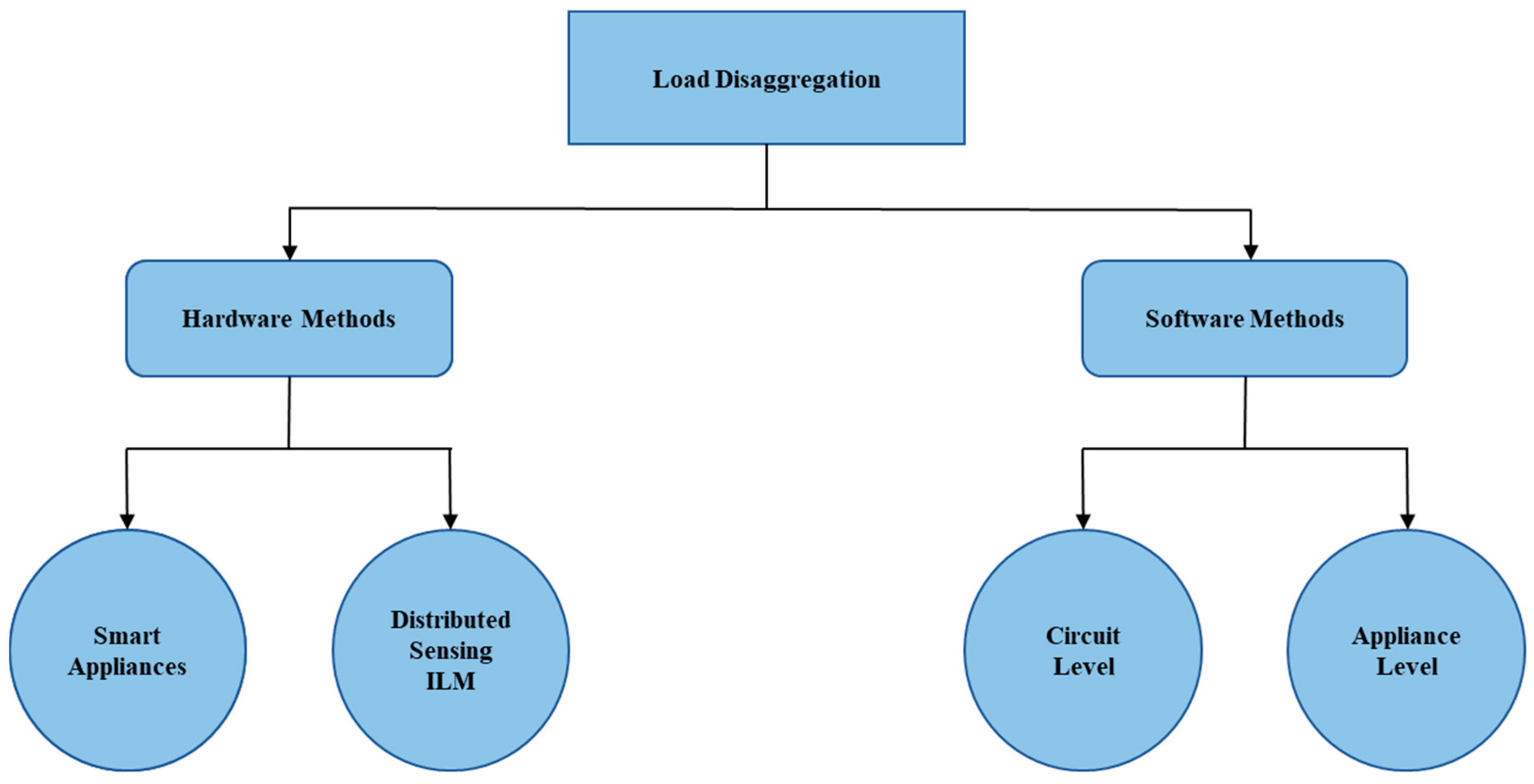
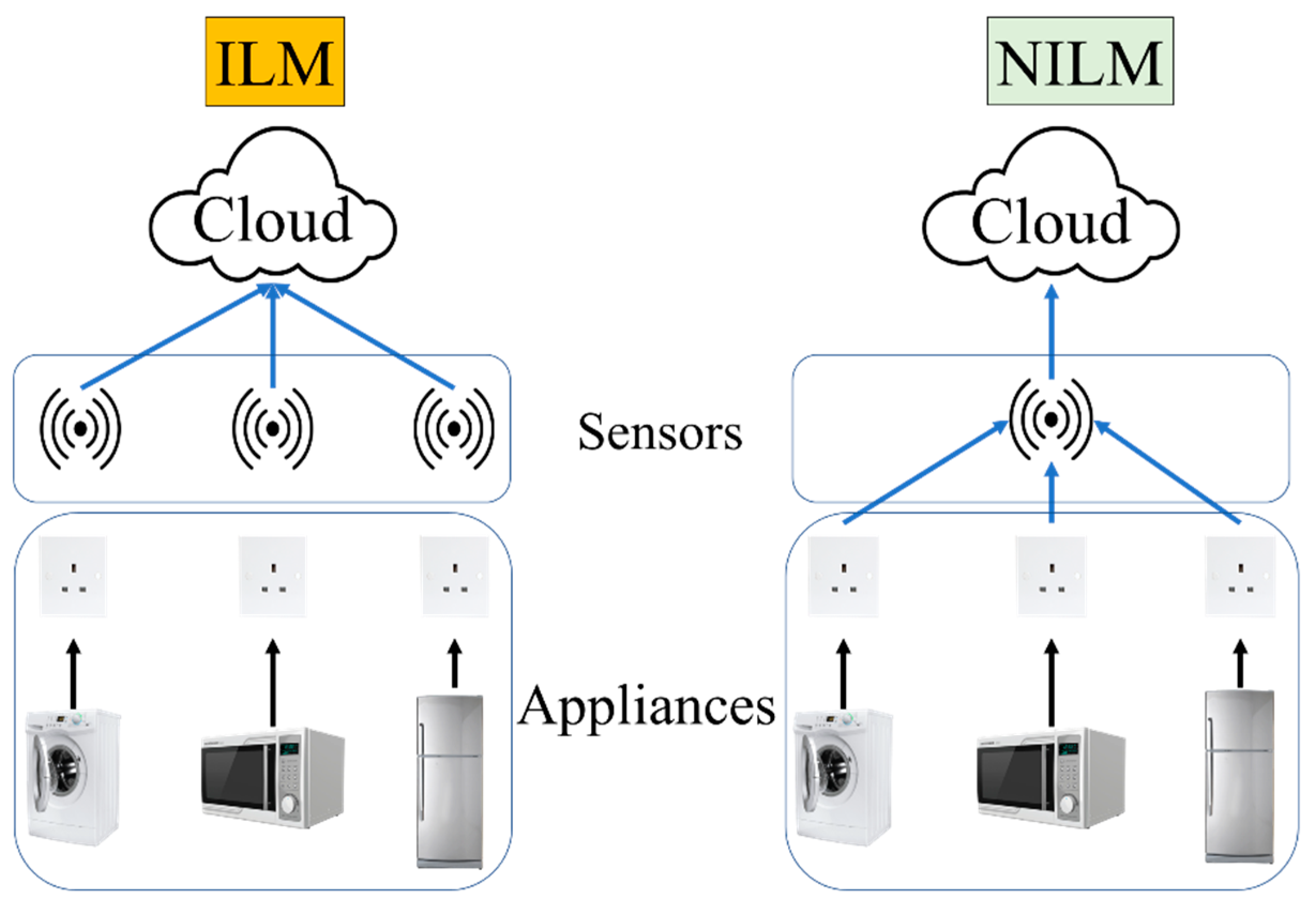
2. Literature Review
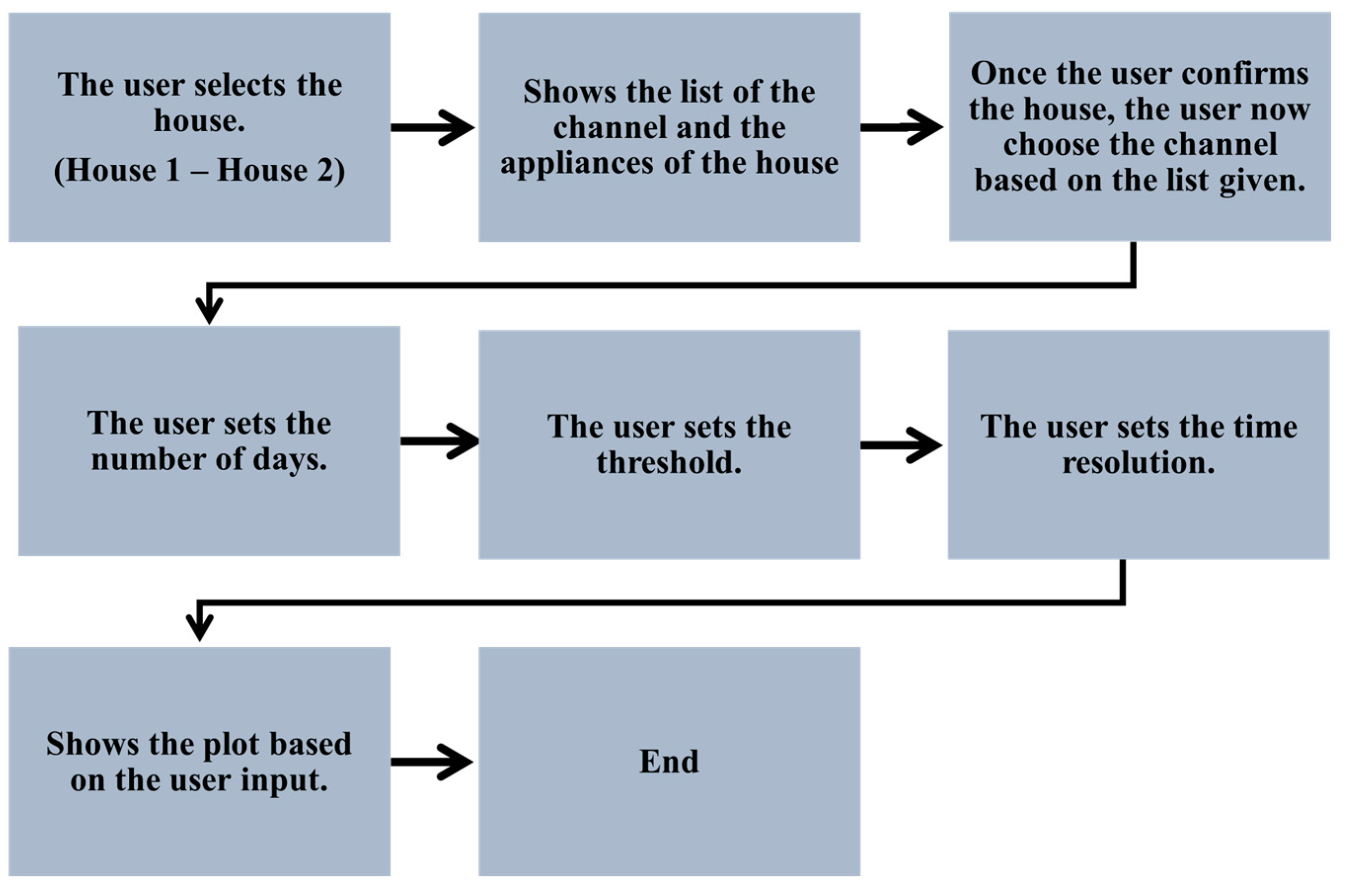
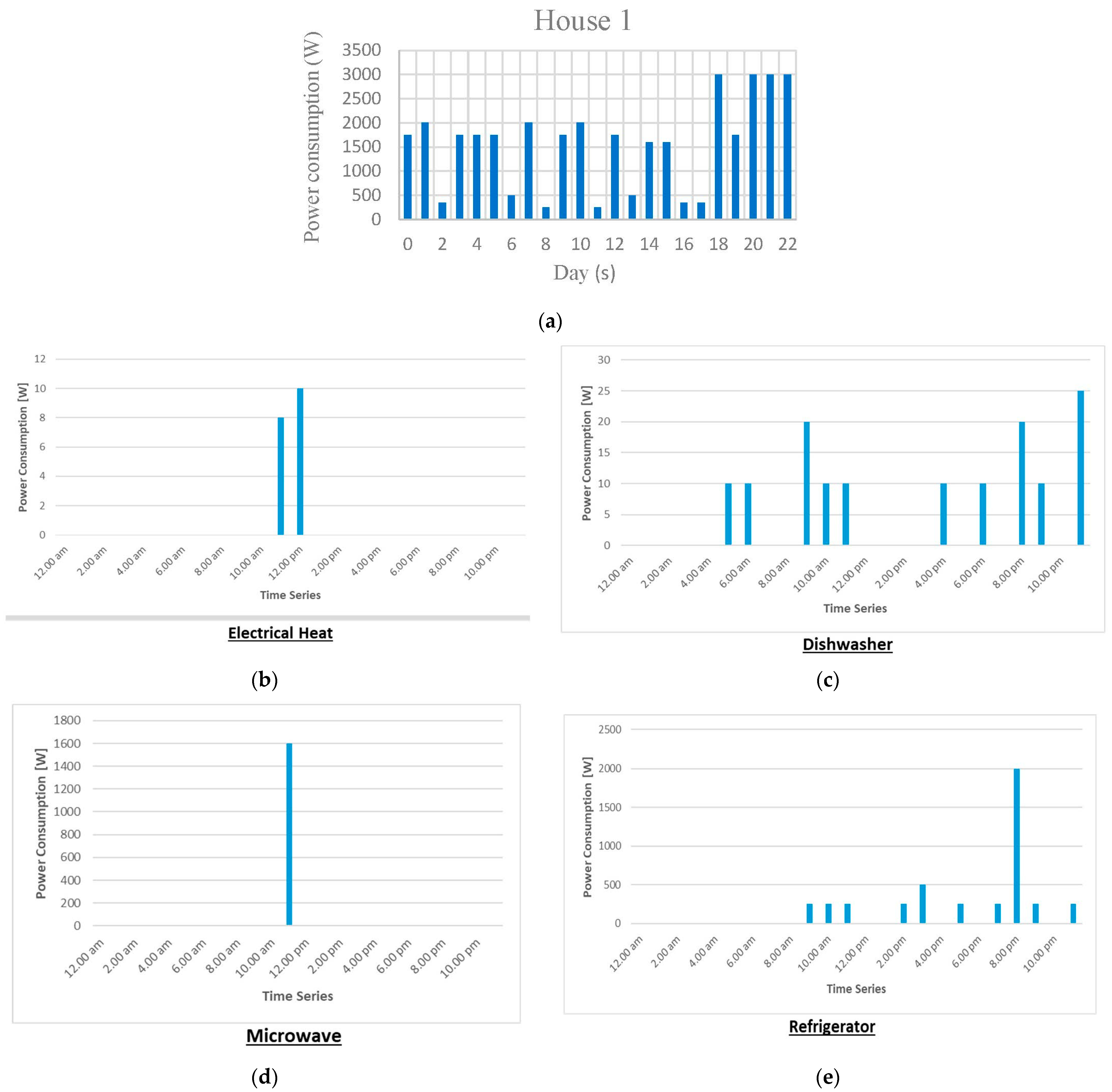
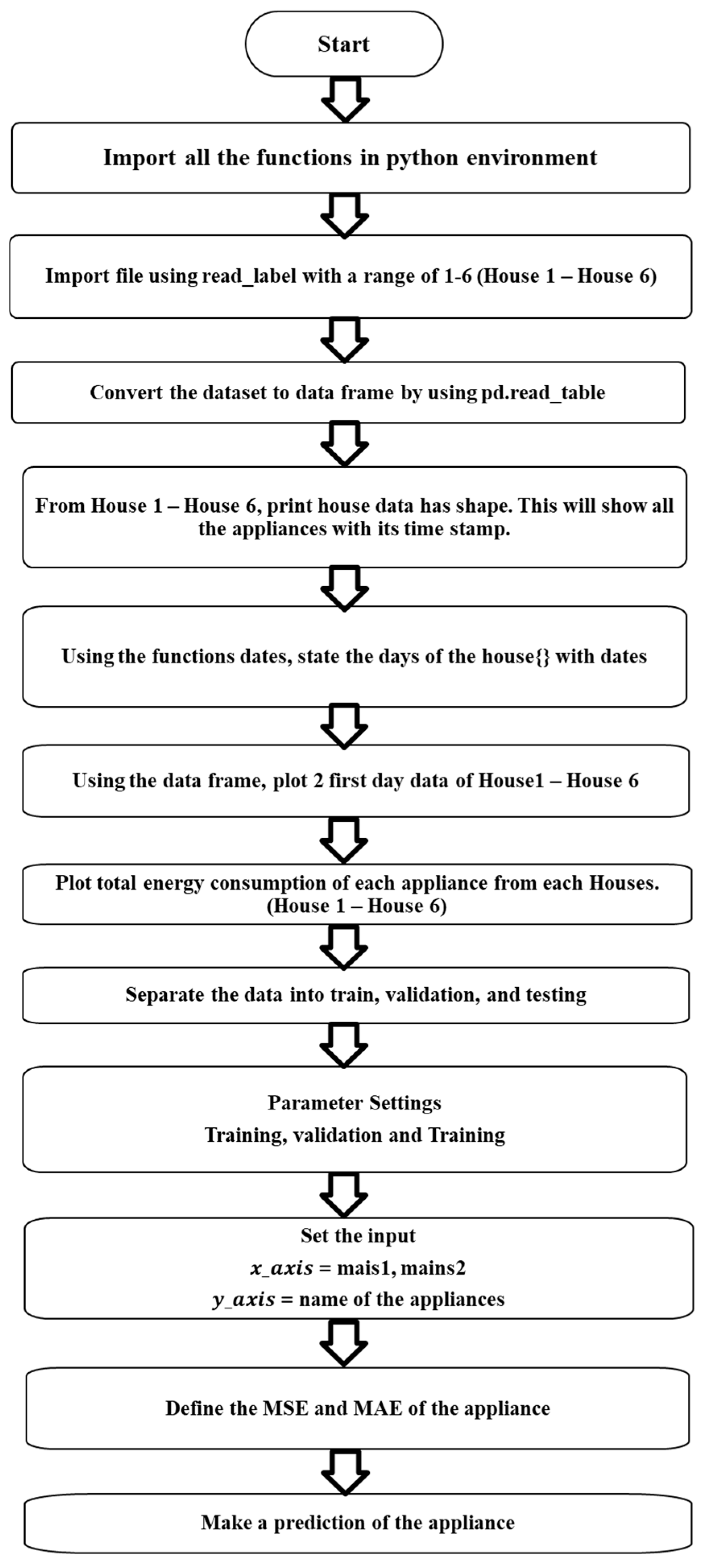
3. Visualisation of Dataset
4. Efficient Non-Parametric Supervised Machine Learning (ENSML) Network as a Predictive Agent
| Algorithm 1 ENSML Algorithm |
 |
Advantages and Disadvantages
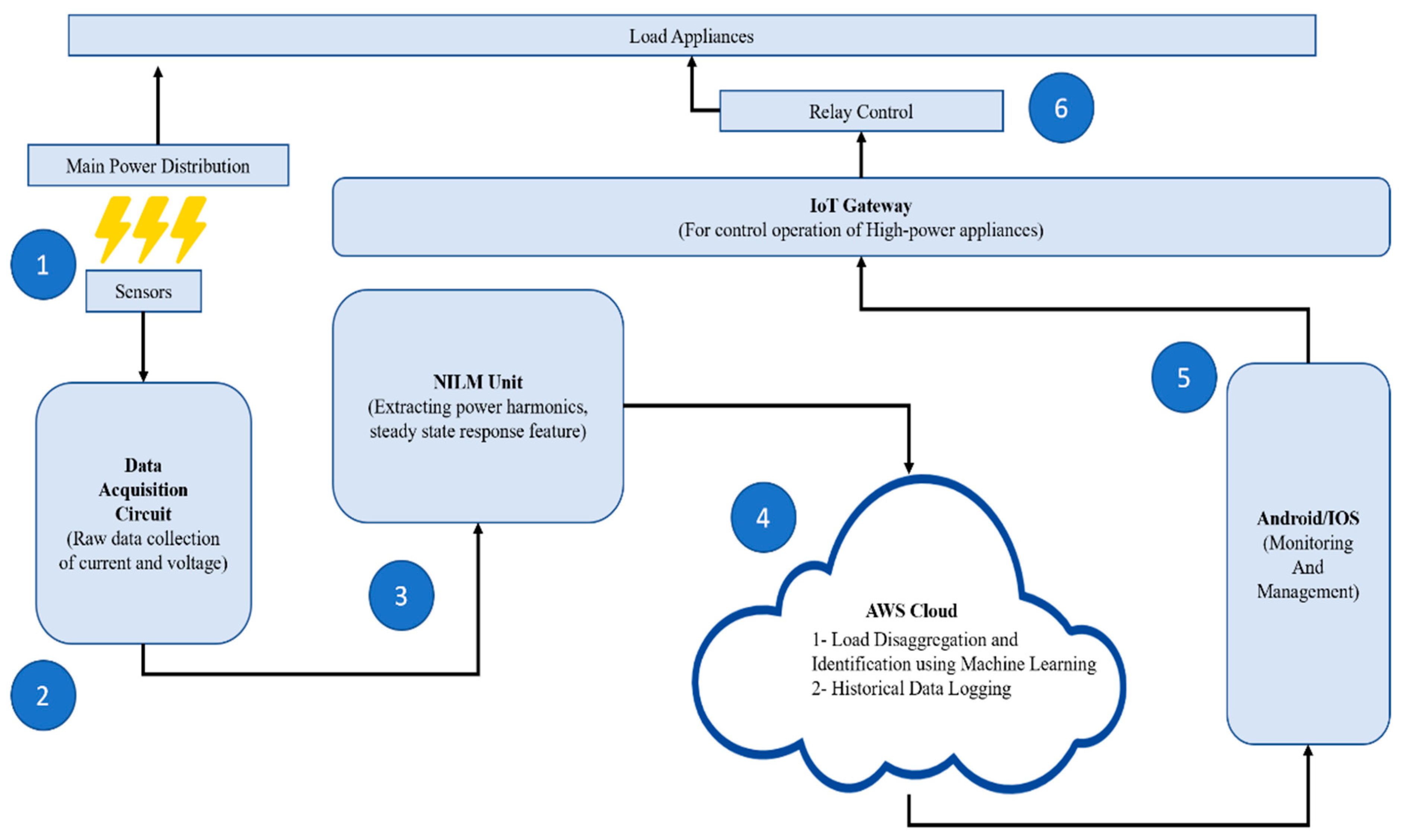
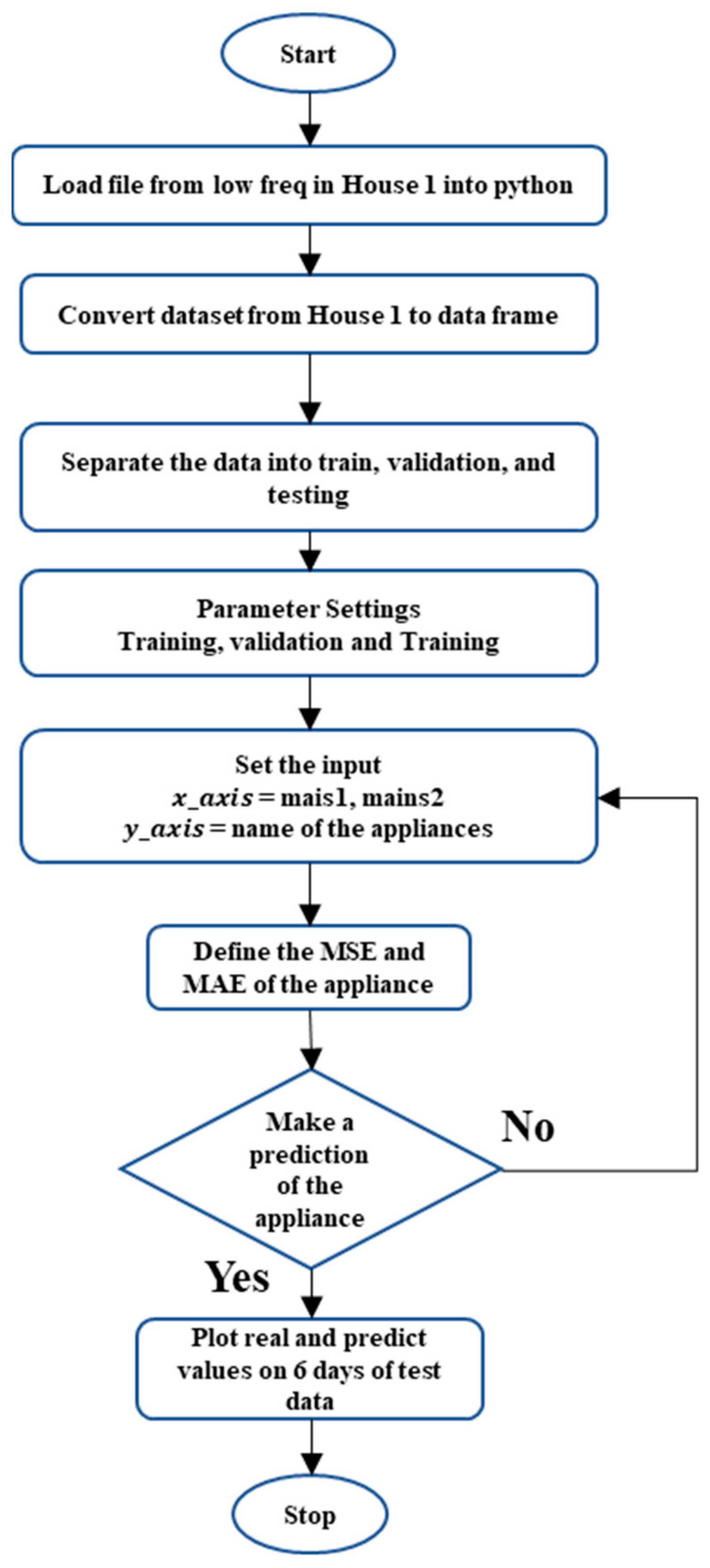
5. Setup Experiment
5.1. ENSML Regression Model for Prediction
5.2. Performance Metrics
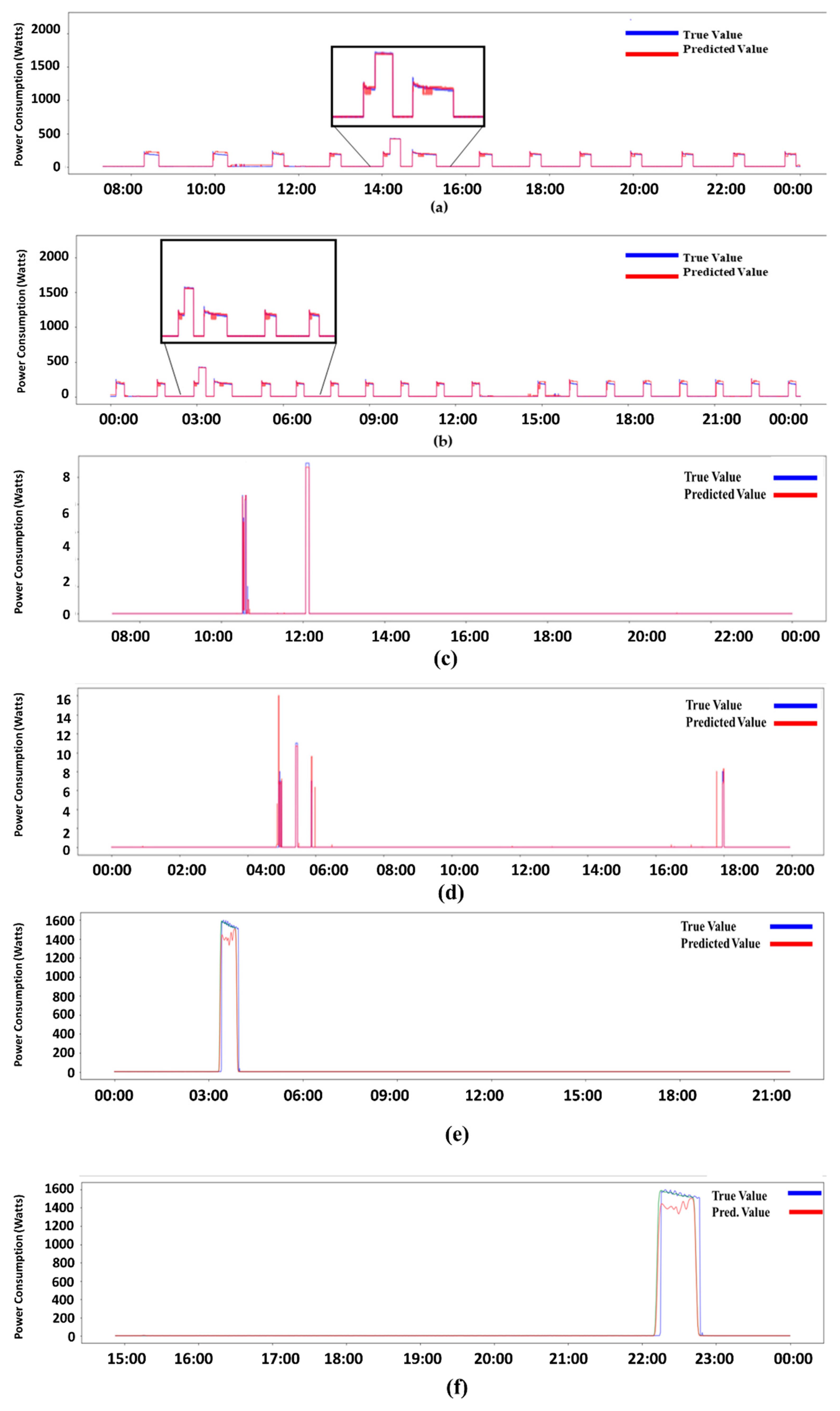
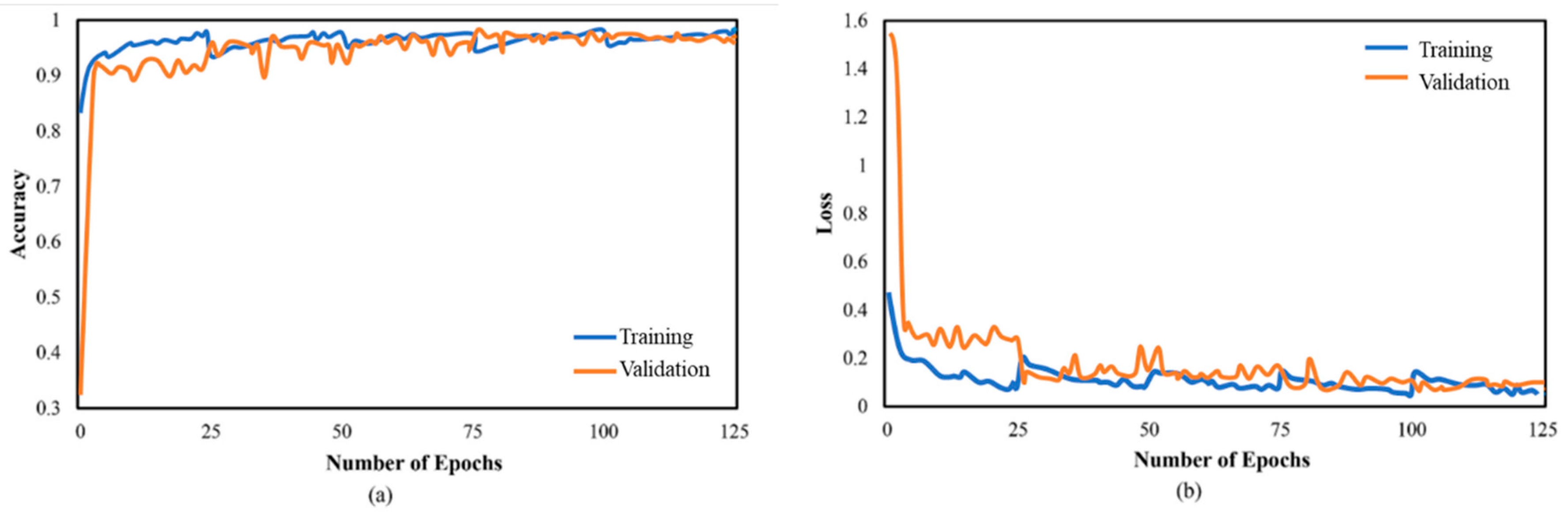
6. Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Osuwa, A.A.; Ekhoragbon, E.B.; Fat, L.T. Application of Artificial Intelligence in Internet of Things. In Proceedings of the 2017 9th International Conference on Computational Intelligence and Communication Networks, Girne, Cyprus, 16–17 September 2017. [Google Scholar]
- Subbulakshmi, V.; Aiswarya, D.; Arulselvi, A. Monitoring and controlling energy consumption using IOT and blockchain. Int. J. Adv. Netw. Appl. 2016, 1, 317–321. [Google Scholar]
- Garcia, F.D.; Souza, W.A.; Diniz, I.S.; Marafão, F.P. NILM-based approach for energy efficiency assessment of household appliances. Energy Inform. 2020, 3, 10. [Google Scholar] [CrossRef]
- Chang, H.; Wiratha, P.W.; Chen, N. A Non-intrusive Load Monitoring System Using an Embedded System for Applications to Unbalanced Residential Distribution Systems. Energy Procedia 2014, 61, 146–150. [Google Scholar] [CrossRef][Green Version]
- Nalmpantis, C.; Vrakas, D. On time series representations for multi-label NILM. Neural Comput. Appl. 2020, 32, 17275–17290. [Google Scholar] [CrossRef]
- Sankar, L.; Rajagopalan, S.R.; Mohajer, S.; Poor, H.V. Smart Meter Privacy: A Theoretical Framework. IEEE Trans. Smart Grid 2013, 4, 837–846. [Google Scholar] [CrossRef]
- Carrie Armel, K.; Gupta, A.; Shrimali, G.; Albert, A. Is disaggregation the holy grail of energy efficiency? The case of electricity. Energy Policy 2013, 52, 213–234. [Google Scholar] [CrossRef]
- Devlin, M.A.; Hayes, B.P. Non-Intrusive Load Monitoring and Classification of Activities of Daily Living Using Residential Smart Meter Data. IEEE Trans. Consum. Electron. 2019, 65, 339–348. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Klemenjak, C.; Makonin, S.; Elmenreich, W. Towards comparability in non-intrusive load monitoring: On data and performance evaluation. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020. [Google Scholar]
- Virtsionis-Gkalinikis, N.; Nalmpantis, C.; Vrakas, D. SAED: Self-attentive energy disaggregation. Mach. Learn. 2021, 1–20. [Google Scholar] [CrossRef]
- Kelly, D.G. Disaggregation of Domestic Smart Meter Energy Data; London University: London, UK, 2016. [Google Scholar]
- Batra, N.; Kukunuri, R.; Pandey, A.; Malakar, R.; Kumar, R.; Krystalakos, O.; Zhong, M.; Meira, P.; Parson, O. Towards reproducible state-of-the-art energy disaggregation. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; pp. 193–202. [Google Scholar]
- Jiang, J.; Kong, Q.; Plumbley, M.D.; Gilbert, N.; Hoogendoorn, M.; Roijers, D.M. Deep Learning-Based Energy Disaggregation and On/Off Detection of Household Appliances. ACM Trans. Knowl. Discov. Data 2021, 15, 1–21. [Google Scholar] [CrossRef]
- He, K.; Stankovic, L.; Liao, J.; Stankovic, V. Non-intrusive load disaggregation using graph signal processing. IEEE Trans. Smart Grid 2018, 9, 1739–1747. [Google Scholar] [CrossRef]
- Liu, Q.; Kamoto, K.M.; Liu, X.; Sun, M.; Linge, N. Low-complexity non-intrusive load monitoring using unsupervised learning and generalized appliance models. IEEE Trans. Consum. Electron. 2019, 65, 28–37. [Google Scholar] [CrossRef]
- Kong, S.; Kim, Y.; Ko, R.; Joo, S. Home appliance load disaggregation using cepstrum-smoothing-based method. IEEE Trans. Consum. Electron. 2015, 61, 24–30. [Google Scholar] [CrossRef]
- Bhotto, M.Z.A.; Makonin, S.; Bajic, I.V. Load disaggregation based on aided linear integer programming. IEEE Trans. Circuits Syst. II Express Briefs 2017, 64, 792–796. [Google Scholar] [CrossRef]
- Wittmann, F.M.; Lopez, J.C.; Rider, M.J. Nonintrusive load monitoring algorithm using mixed-integer linear programming. IEEE Trans. Consum. Electron. 2018, 64, 180–187. [Google Scholar] [CrossRef]
- Net2grid. 2019. Available online: http://www.net2grid.com (accessed on 19 March 2022).
- Smappee. 2019. Available online: https://www.smappee.com/been/homepage (accessed on 19 March 2022).
- SmartB Energy Management. 2019. Available online: http://www.smartb.de/ (accessed on 19 March 2022).
- Watty. 2019. Available online: https://watty.io/ (accessed on 21 March 2022).
- Bidgely. 2019. Available online: http://www.bidgely.com (accessed on 19 March 2022).
- Verv. 2019. Available online: https://verv.energy/ (accessed on 19 March 2022).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Kelly, J.; Knottenbelt, W. Neural NILM. In: ACM, 55–64. (4 November 2015). Available online: http://dl.acm.org/citation.cfm?id=2821672 (accessed on 19 March 2022).
- Barsim, K.S.; Yang, B. Toward a semi-supervised non-intrusive load monitoring system for event-based energy disaggregation. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 58–62. Available online: https://ieeexplore.ieee.org/document/7418156 (accessed on 19 March 2022).
- Biansoongnern, S.; Plangklang, B. Nonintrusive load monitoring (NILM) using an Artificial Neural Network in embedded system with low sampling rate. In Proceedings of the 2016 13th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Mai, Thailand, 28 June–1 July 2016; pp. 1–4. [Google Scholar]
- Faustine, A.; Pereira, L.; Bousbiat, H.; Kulkarni, S. UNet-NILM: A Deep Neural Network for Multi-Tasks Appliances State Detection and Power Estimation in NILM. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, NILM’20, Virtual Event, Japan, 18 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 84–88. [Google Scholar]
- Zeifman, M.; Roth, K. Nonintrusive appliance load monitoring: Review and outlook. IEEE Trans. Consum. Electron. 2011, 57, 76–84. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, G. Residential Appliances Identification and Monitoring by a Nonintrusive Method. IEEE Trans. Smart Grid 2012, 3, 80–92. [Google Scholar]
- Weiss, M.; Helfenstein, A.; Mattern, F.; Staake, T. Leveraging smart meter data to recognize home appliances. In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications, Lugano, Switzerland, 19–23 March 2012; pp. 190–197. [Google Scholar]
- Makriyiannis, M.; Lung, T.; Craven, R.; Toni, F.; Kelly, J. Smarter electricity and argumentation theory. In Proceedings of the Smart Innovation, Systems and Technologies; Springer Science and Business Media Deutschland GmbH: Berlin, Germany, 2016; Volume 46, pp. 79–95. [Google Scholar]
- Hadi, M.U.; Murtaza, G. Enhancing distributed feedback-standard single mode fiber-radio over fiber links performance by neural network digital predistortion. Microw. Opt. Technol. Lett. 2021, 63, 1558–1565. [Google Scholar] [CrossRef]
- Chang, H.H.; Lin, L.S.; Chen, N.; Lee, W.J. Particle-swarm-optimization-based nonintrusive demand monitoring and load identification in smart meters. IEEE Trans. Ind. Appl. 2013, 49, 2229–2236. [Google Scholar]
- Kolter, J.Z.; Jaakkola, T. Approximate inference in additive factorial hmms with application to energy disaggregation. In Proceedings of the Machine Learning Research, Volume 22: Artificial Intelligence and Statistics, La Palma, Canary Islands, Spain, 21–23 April 2012; pp. 1472–1482. [Google Scholar]
- Hadi, M.U.; Awais, M.; Raza, M.; Khurshid, K.; Jung, H. Neural Network DPD for Aggrandizing SM-VCSEL-SSMF-Based Radio over Fiber Link Performance. Photonics 2021, 8, 19. [Google Scholar] [CrossRef]
- Hadi, M.U. Practical Demonstration of 5G NR Transport Over-Fiber System with Convolutional Neural Network. Telecom 2022, 3, 103–117. [Google Scholar] [CrossRef]
- Egarter, D.; Bhuvana, V.P.; Elmenreich, W. PALDi: Online Load Disaggregation via Particle Filtering. IEEE Trans. Instrum. Meas. 2015, 64, 467–477. [Google Scholar] [CrossRef]
- Ferrández-Pastor, F.J.; Mora-Mora, H.; Sánchez-Romero, J.L.; Nieto-Hidalgo, M.; García-Chamizo, J.M. Interpreting human activity from electrical consumption data using reconfigurable hardware and hidden Markov models. J. Ambient. Intell. Humaniz. Comput. 2016, 8, 469–483. [Google Scholar] [CrossRef]
- Khurshid, K.; Khan, A.A.; Siddiqui, H.; Rashid, I.; Hadi, M.U. Big Data Assisted CRAN Enabled 5G SON Architecture. J. ICT Res. Appl. 2019, 13, 93–106. [Google Scholar] [CrossRef]
- Hadi, M.U.; Awais, M.; Raza, M.; Ashraf, M.I.; Song, J. Experimental Demonstration and Performance Enhancement of 5G NR Multiband Radio over Fiber System Using Optimized Digital Predistortion. Appl. Sci. 2021, 11, 11624. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Deng, J.; Sheng, W.; Tan, P. Non-Intrusive Load Monitoring Based on Unsupervised Optimization Enhanced Neural Network Deep Learning. Front. Energy Res. 2021, 9, 718916. [Google Scholar] [CrossRef]
- Wang, K.; Zhong, H.; Yu, N.; Xia, Q. Nonintrusive Load Monitoring Based on Sequence-To-Sequence Model with Attention Mechanism. Proc. CSEE 2019, 39, 75–83. [Google Scholar]
- Liu, L.; Ding, J.; Zhong, J.; Fu, X.; Lv, Y. An unsupervised model for classification and recognition of household appliances. J. Comput. Inf. Syst. 2014, 10, 403–410. [Google Scholar]
- Athanasiadis, C.; Doukas, D.; Papadopoulos, T.; Chrysopoulos, A. A Scalable Real-Time Non-Intrusive Load Monitoring System for the Estimation of Household Appliance Power Consumption. Energies 2021, 14, 767. [Google Scholar] [CrossRef]
- Athanasiadis, C.L.; Papadopoulos, T.A.; Doukas, D.I. Real-time non-intrusive load monitoring: A light-weight and scalable approach. Energy Build. 2021, 253, 111523. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | House Number | Channels | Appliances |
|---|---|---|---|
| 1 | House 1 | 20 | 4 kitchen outlets, 3 lightings, 3 washer dryer, 2 mains, 2 ovens, 1 refrigerator, 1 dishwasher, 1 microwave, 1 electric heat, 1 stove, 1-bathroom. |
| 2 | House 2 | 11 | 2 mains, 2 kitchen outlets, 1 lighting, 1 stove, 1 microwave, 1 washer dryer, 1 refrigerator, 1 dishwasher, 1 disposal. |
| 3 | House 3 | 22 | 5 lightings, 3 unknown outlets, 2 mains, 2 washer dryer, 2 kitchen outlets, 1 electronic, 1 refrigerator, 1 dishwasher, 1 disposal, 1 microwave, 1 furnace, 1 smoke alarm, 1-bathroom. |
| 4 | House 4 | 20 | 4 lightings, 3 air-conditioner, 2 mains, 2-bathroom, 2 kitchen outlets, 1 unknown outlet, 1 washer dryer, 1 stove, 1 smoke alarm, 1 dishwasher, 1 miscellaneous, 1 furnace. |
| 5 | House 5 | 26 | 5 lightings, 4 unknown outlets, 2 mains, 2 washer dryers, 2 subpanel, 2 electric heat, 2 kitchen outlets, 1 microwave, 1 furnace, 1-bathroom, 1 dishwasher, 1 disposal, 1 electronics, 1 refrigerator. |
| 6 | House 6 | 17 | 3 air-conditioner, 2 mains, 2 kitchen outlets, 2 unknown outlets, 1 washer dryer, 1 stove, 1 electronics, 1 electrical heat, 1-bathroom, 1 refrigerator, 1 dishwasher, 1 lighting. |
| No | Author | Method | Advantage | Disadvantage |
|---|---|---|---|---|
| 1 | Kelly, Jack, Knottenbelt, Willian [27] | LSTM | Work best for two state appliances | Does not perform well when it comes to multi-state appliances such as washing machine and dish washer |
| 2 | Somchai, Boonyang [28] | ANN | With incomplete information, the data may still produce output. | Provides a probing solution, but it does not specify the why or how. |
| 3 | Barsim, Karim Said; Bin Yang [29] | SSL | It estimates the structure of the unlabelled data from its own predictions rather than relying on additional clustering components for this purpose. | Error propagation occurs when misclassified observations are chosen for an iteration, causing the prediction function to be increasingly skewed in subsequent iterations |
| 4 | Faustine, Anthony; Pereira, Lucas; Bousbiat, Hafsa and Kulkarni, Shridhar [30] | DNN | To be able to estimate the prediction’s uncertainty by combining appliance states and power consumption values. | Single target regression, which ignores any correlations between targets, yielding a single model for each. |
| 5 | Jiang, Jie; Kong, Qiuqiang; Plumbley, Mark D; Gilbert, Nigel; Hoogendoorn, Mark and Roijers, Diederik M [31] | WaveNet | A reduction in filter sizes is achieved by reducing the size of the convolution filters as compared to conventional CNN(s). | Must minimise the loss with an optimizer with a learning rate of 0.001 |
| No | Terminology | Explanation |
|---|---|---|
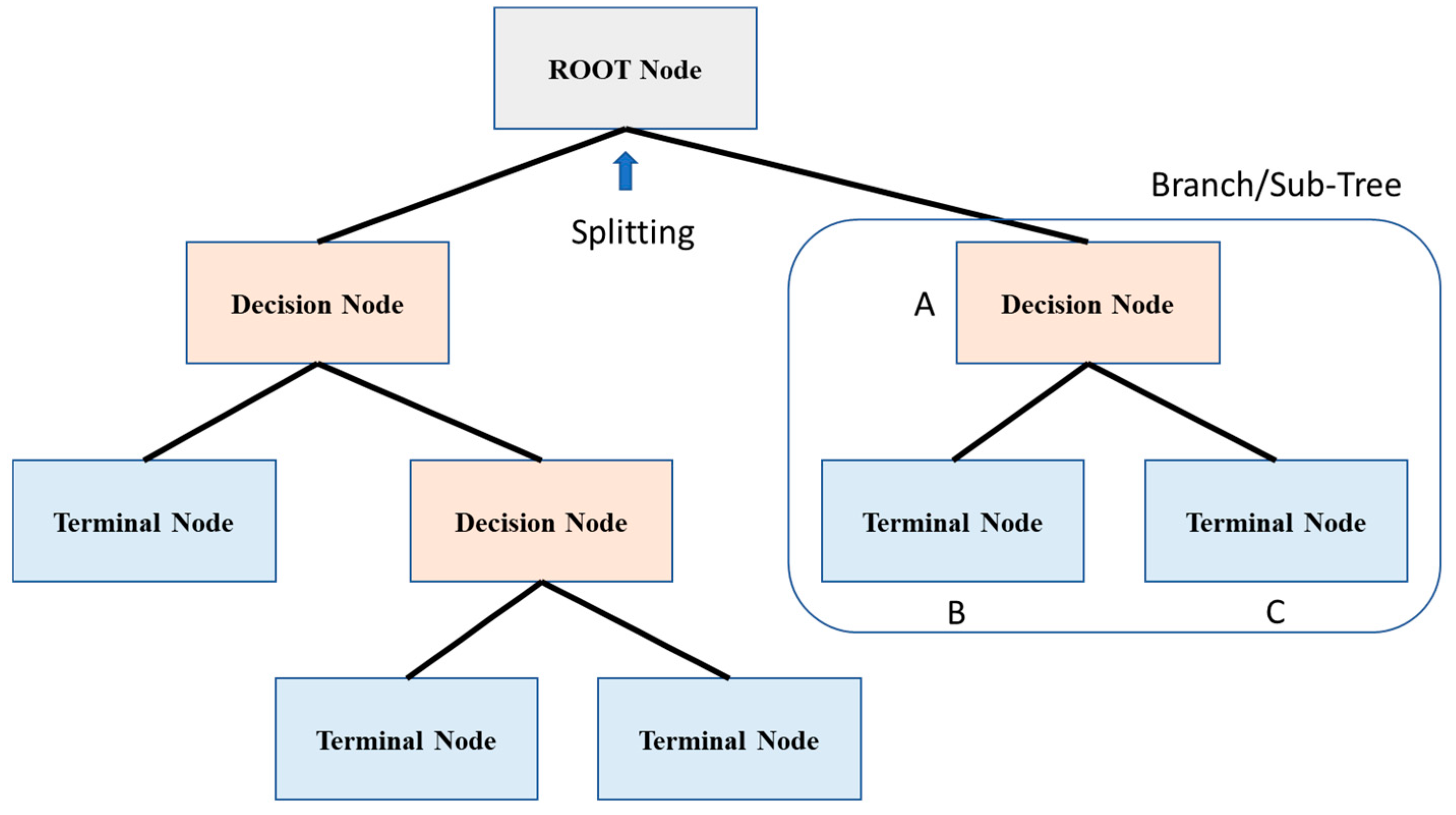
| 1 | Root Node | This is a sample of an entire population that is divided into two or more homogeneous groups. |
| 2 | Splitting | A process in which a node is divided into two or more sub-nodes |
| 3 | Decision Node | In a decision network, each subnode splits into further subnodes |
| 4 | Leaf/Terminal Node | Nodes that do not split are known as Leaf or Terminal nodes. |
| 5 | Prunning | Pruning is opposite to splitting. It is removing sub-nodes of a decision node |
| 6 | Branch/Sub-Tree | An individual branch or sub-tree is a part of an entire tree. |
| 7 | Parent and Child Node | Usually, the parent node of subnodes is referred to as the parent node, whereas subnodes are its children. |
| No | Benefits | Shortcomings |
|---|---|---|
| 1 | The model can be applied to both classification and regression. | Prone to overfitting. |
| 2 | Understanding, interpreting and visualising are easy. | No way to extrapolate. |
| 3 | There is no constraint on data type. | Regression can be unstable. |
| Class | Accuracy (%) | Recall Rate (%) | Precision (%) | F1-Score (%) | MAE (%) |
|---|---|---|---|---|---|
| Refrigerator | 99.556 | 99.667 | 99.336 | 99.501 | 0.64 |
| Microwave | 98.752 | 99.54 | 99.145 | 99.46 | 0.98 |
| Electrical Heat | 99.454 | 99.14 | 99.556 | 99.75 | 0.35 |
| Contribution | Methods/Techniques | Number of Appliances | Precision [%] |
|---|---|---|---|
| [42] | Factorial hidden Markov models | REDD | 82 |
| [43] | Deep Learning Approach | REDD | 76 |
| [44] | Back propagation neural network | REDD | 45 |
| [45] | K-means clustering algorithm | REDD | 62 |
| [46] | Unsupervised Linear Discrimination Method | REDD | 81 |
| [47] | CNN binary classifier | private | 97 |
| [48] | Deep CNN and a KNN classifier | private | 93.8 |
| Present Work | Efficient Non-parametric Supervised Machine Learning Network | REDD | 99.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadi, M.U.; Suhaimi, N.H.N.; Basit, A. Efficient Supervised Machine Learning Network for Non-Intrusive Load Monitoring. Technologies 2022, 10, 85. https://doi.org/10.3390/technologies10040085
Hadi MU, Suhaimi NHN, Basit A. Efficient Supervised Machine Learning Network for Non-Intrusive Load Monitoring. Technologies. 2022; 10(4):85. https://doi.org/10.3390/technologies10040085
Chicago/Turabian StyleHadi, Muhammad Usman, Nik Hazmi Nik Suhaimi, and Abdul Basit. 2022. "Efficient Supervised Machine Learning Network for Non-Intrusive Load Monitoring" Technologies 10, no. 4: 85. https://doi.org/10.3390/technologies10040085
APA StyleHadi, M. U., Suhaimi, N. H. N., & Basit, A. (2022). Efficient Supervised Machine Learning Network for Non-Intrusive Load Monitoring. Technologies, 10(4), 85. https://doi.org/10.3390/technologies10040085