
Improving Effectiveness of a Coaching System through Preference Learning †



Abstract
:1. Introduction
2. Related Work
3. Adapting Coaching to User’s Preferences
3.1. The SAAM Coaching System
3.2. Preference Learning Targets
- Coaching action.
- Selecting a coaching action based on user’s preference is only feasible in situations where several coaching actions are valid and appropriate. This requires that the coaching action decision model is probabilistic and a coaching action is selected stochastically according to some probability distribution.
- Persuasion strategy.
- The coaching actions used during the SAAM project were designed according to two persuasion strategies, i.e., suggestion and self monitoring, under the hypothesis that different persuasion strategies can be more effective for different users. The persuasion strategy is selected using the coaching rendering model.
- Interaction target.
- One of the defining ideas of SAAM is that coaching actions can be delivered through the primary user’s social circle, that is, their assigned secondary users (SU). As people differ, some of the primary users might prefer this approach, while to others might prefer direct delivery of coaching messages (PU). As such, this preference is a natural fit for personalization. In the context of the SAAM system, each user decides whether the coaching messages should be delivered to them directly, through secondary users or both.
3.3. Integration in the Coaching System
- Collection of the learning data.
- When we first start employing the coaching system, we have no data that would contain information about user’s preferences and that we could use for learning, i.e., we encounter the cold start problem. Therefore, we need to collect such data, and we can achieve this by using the coaching system with any applicable preferences being selected by random. Preferably, this random selection should follow a uniform probability distribution in order to cover the entire space of possible preferences, that is, we want all the possible options to occur so we can better assess the preferences and improve the acceptance of the coaching actions. Such a uniformly distributed learning dataset also eases model learning and typically results in a more accurate model.
- Learning of the acceptance model.
- Once enough learning data has been collected, we can learn a model that predicts user’s acceptance of the received coaching actions in the particular context which they received it in. As we will see later, this model can provide an assessment of the likelihood that each possible coaching action (with a selected rendering) will be accepted by the user. These probability estimates are then used in the next step.
- Using predictions of the acceptance model.
- The predicted probabilities from the acceptance model can then be used to instantiate the probability distributions for each of the PLTs mentioned above in Section 3.2. Consequently, coaching actions and their renderings should then be adapted to be closer to the user’s actual preferences. Particular implementation details will be presented in Section 4.2.
4. Preference Learning
4.1. Learning Data
4.2. The Learning Approach
4.3. Preference Model for Sleep Quality Coaching
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Žnidaršič, M.; Osojnik, A.; Rupnik, P.; Ženko, B. Improving Effectiveness of a Coaching System Through Preference Learning. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 459–465. [Google Scholar] [CrossRef]
- Luce, R.D.; Raiffa, H. Games and Decisions: Introduction and Critical Survey; Publications of the Bureau of Applied Social Research of the Columbia University; Wiley: New York, NY, USA, 1957. [Google Scholar]
- Fürnkranz, J.; Hüllermeier, E. (Eds.) Preference Learning; Springer: Berlin, Germany, 2010; Available online: https://link.springer.com/book/10.1007/978-3-642-14125-6 (accessed on 31 January 2021).
- Fürnkranz, J.; Hüllermeier, E.; Rudin, C.; Slowinski, R.; Sanner, S. Preference Learning (Dagstuhl Seminar 14101); Dagstuhl Reports; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2014; Volume 4. [Google Scholar]
- Greco, S.; Figueira, J.; Ehrgott, M. Multiple Criteria Decision Analysis, 2nd ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Keeney, R.L.; Raiffa, H.; Meyer, R.F. Decisions with Multiple Objectives: Preferences and Value Trade-Offs; Cambridge University Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Farquhar, P.H.; Keller, R.L. Preference intensity measurement. Ann. Oper. Res. 1989, 19, 205–217. [Google Scholar] [CrossRef]
- Braziunas, D.; Boutilier, C. Elicitation of factored utilities. AI Mag. 2008, 29, 79. [Google Scholar] [CrossRef] [Green Version]
- Salo, A.A.; Hamalainen, R.P. Preference ratios in multiattribute evaluation (PRIME)-elicitation and decision procedures under incomplete information. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 2001, 31, 533–545. [Google Scholar] [CrossRef] [Green Version]
- Siskos, Y.; Grigoroudis, E.; Matsatsinis, N.F. UTA methods. In Multiple Criteria Decision Analysis; Springer: Berlin/Heidelberg, Germany, 2016; pp. 315–362. [Google Scholar]
- Bous, G.; Pirlot, M. Learning multicriteria utility functions with random utility models. In International Conference on Algorithmic Decision Theory; Springer: Berlin/Heidelberg, Germany, 2013; pp. 101–115. [Google Scholar]
- Yang, J.B.; Sen, P. Preference modelling by estimating local utility functions for multiobjective optimization. Eur. J. Oper. Res. 1996, 95, 115–138. [Google Scholar] [CrossRef]
- Siskos, Y.; Spyridakos, A.; Yannacopoulos, D. Using artificial intelligence and visual techniques into preference disaggregation analysis: The MIIDAS system. Eur. J. Oper. Res. 1999, 113, 281–299. [Google Scholar] [CrossRef]
- Branke, J.; Greco, S.; Słowiński, R.; Zielniewicz, P. Learning value functions in interactive evolutionary multiobjective optimization. IEEE Trans. Evol. Comput. 2014, 19, 88–102. [Google Scholar] [CrossRef] [Green Version]
- Cruz-Reyes, L.; Fernandez, E.; Rangel-Valdez, N. A metaheuristic optimization-based indirect elicitation of preference parameters for solving many-objective problems. Int. J. Comput. Intell. Syst. 2017, 10, 56–77. [Google Scholar] [CrossRef] [Green Version]
- Fürnkranz, J.; Hüllermeier, E. Preference Learning and Ranking by Pairwise Comparison. In Preference Learning; Fürnkranz, J., Hüllermeier, E., Eds.; Springer: Berlin, Germany, 2010; pp. 65–82. [Google Scholar]
- Jannach, D.; Zanker, M.; Felfernig, A.; Friedrich, G. Recommender Systems: An Introduction; Cambridge University Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Baier, D. Bayesian Methods for Conjoint Analysis-Based Predictions: Do We Still Need Latent Classes? In German-Japanese Interchange of Data Analysis Results; Springer: Berlin/Heidelberg, Germany, 2014; pp. 103–113. [Google Scholar]
- Todd, D.S.; Sen, P. Directed multiple objective search of design spaces using genetic algorithms and neural networks. In Proceedings of the 1st Annual Conference on Genetic and Evolutionary Computation, Orlando, FL, USA, 13–17 July 1999; Morgan Kaufmann: San Francisco, CA, USA, 1999; Volume 2, pp. 1738–1743. [Google Scholar]
- Misitano, G. Interactively Learning the Preferences of a Decision Maker in Multi-objective Optimization Utilizing Belief-rules. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; IEEE: New York, NY, USA, 2020; pp. 133–140. [Google Scholar]
- Lete, N.; Beristain, A.; García-Alonso, A. Survey on virtual coaching for older adults. Health Inform. J. 2020, 26, 3231–3249. [Google Scholar] [CrossRef] [PubMed]
- Dimitrov, Y.; Gospodinova, Z.; Wheeler, R.; Žnidaršič, M.; Ženko, B.; Veleva, V.; Miteva, N. Social Activity Modelling and Multimodal Coaching for Active Aging. In Proceedings of the 12th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 5–7 June 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 608–615. [Google Scholar]
- Žnidaršič, M.; Ženko, B.; Osojnik, A.; Bohanec, M.; Panov, P.; Burger, H.; Matjačić, Z.; Debeljak, M. Multi-criteria Modelling Approach for Ambient Assisted Coaching of Senior Adults. In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Vienna, Austria, 17–19 September 2019; INSTICC, SciTePress: Vienna, Austria, 2019; Volume 2, pp. 87–93. [Google Scholar]
- Hüllermeier, E.; Fürnkranz, J. Preference learning and ranking. Mach. Learn. 2013, 93, 185–189. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; The Morgan Kaufmann Series in Data Management Systems; Elsevier Science: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Quinlan, R.J. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
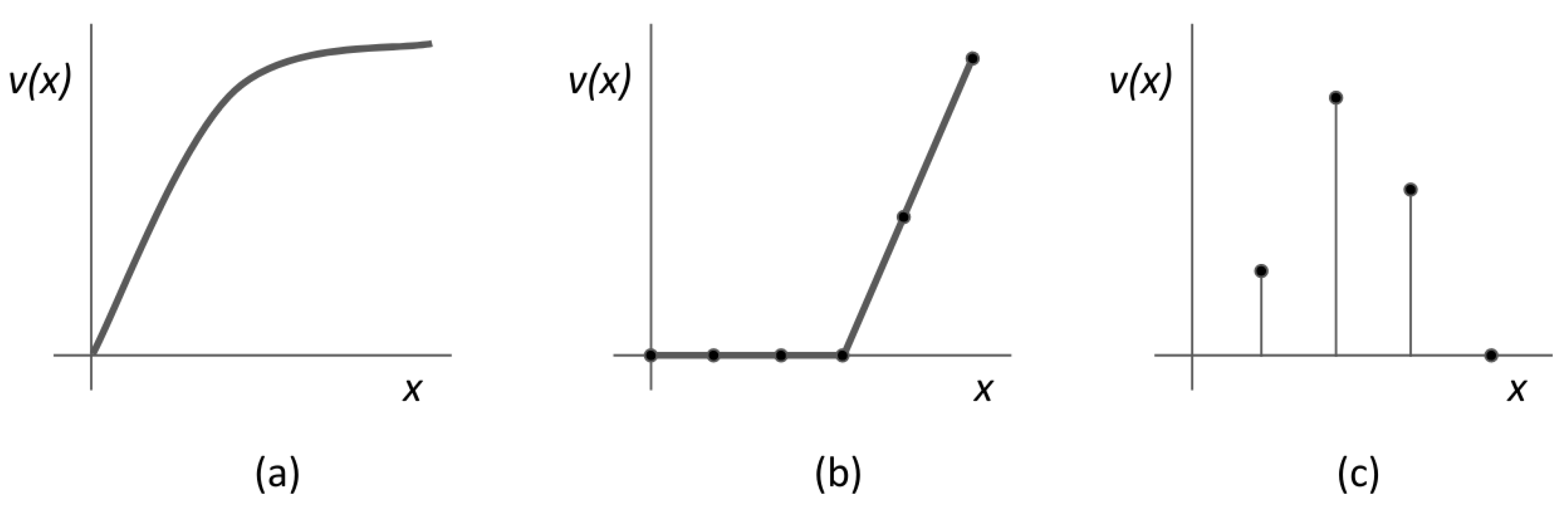



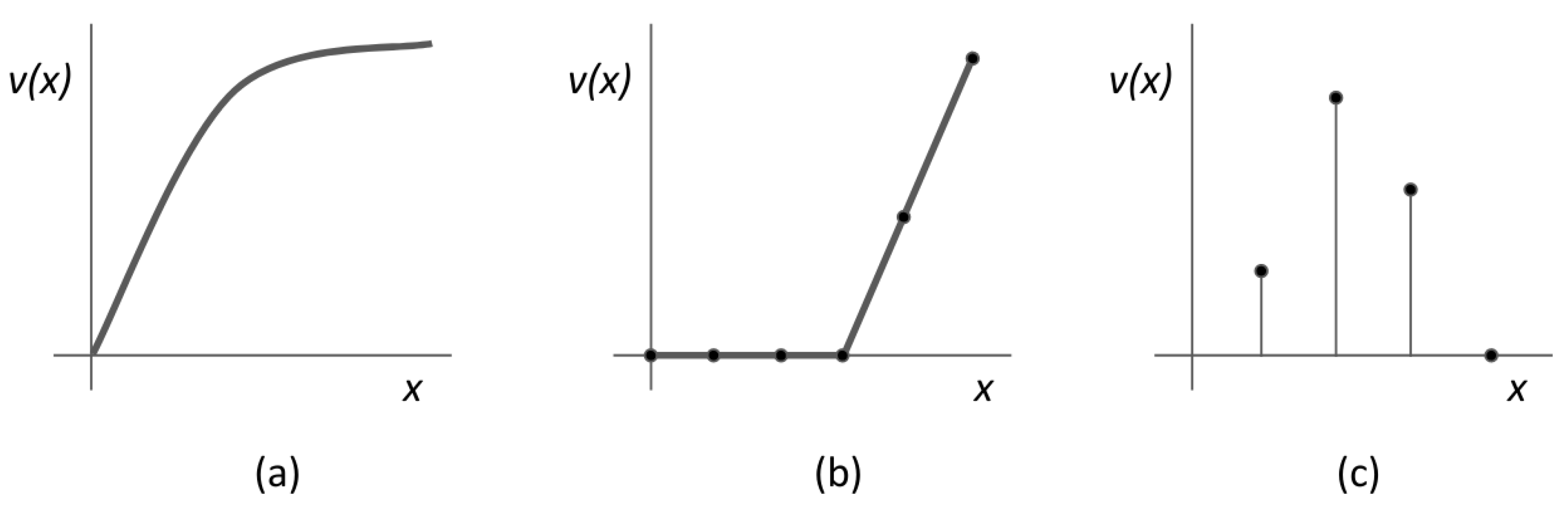{kind=link}
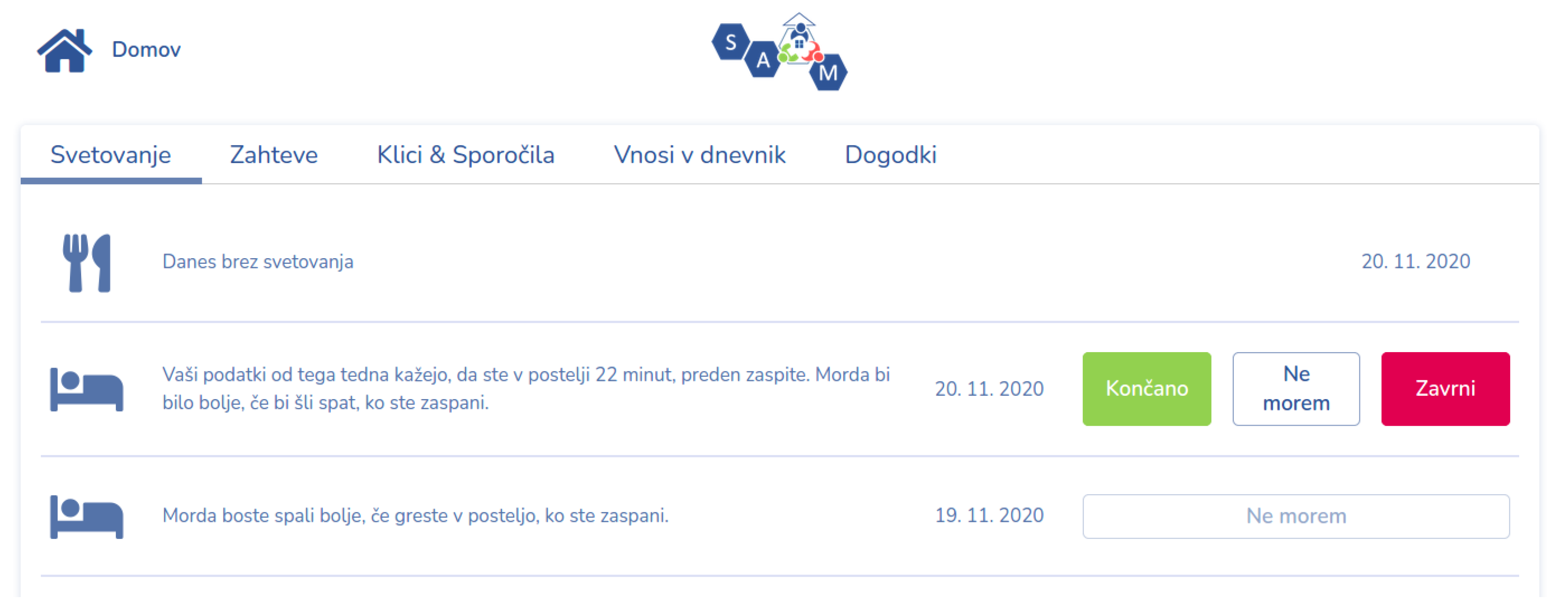
{kind=link}
{kind=link}
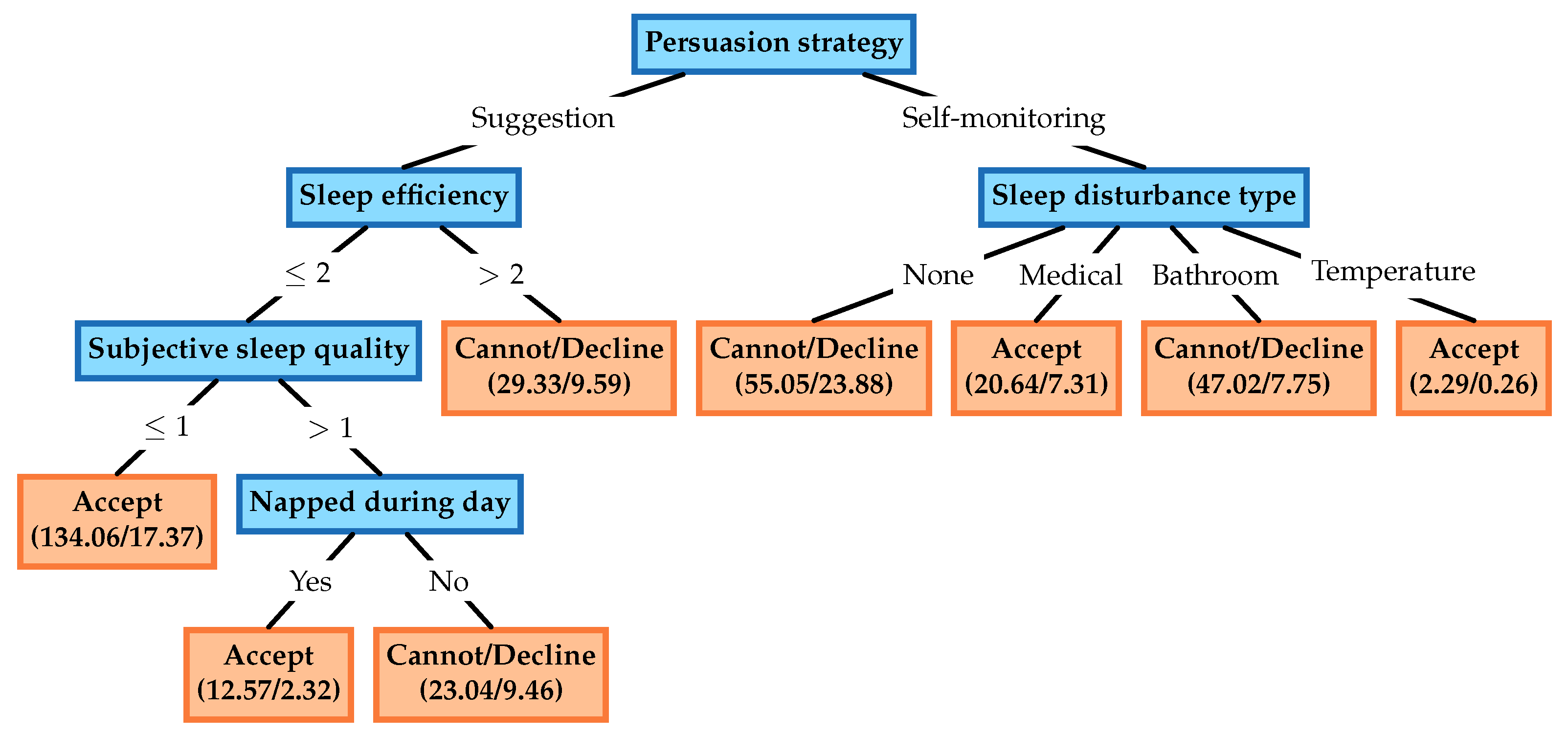{kind=link}
| Attribute Name | Possible Values | Missing | Role |
|---|---|---|---|
| Coaching Action | Get up from bed if awake, Go to bed only if sleepy, See your doctor, Adjust bedroom temperature, Avoid drinking 2 h before sleep | 0% | PLT |
| Persuasion Strategy | Suggestion, Self-monitoring | 0% | PLT |
| Interaction Target | PU, SU | 0% | PLT |
| Predicted Cooking Activity | None, Once, Twice or more | 91% | Context |
| Recorded Cooking Activity | None, Once, Twice or more | 91% | Context |
| Cooking Activity Situation | Usual cooking, Less cooking | 91% | Context |
| Subjective Sleep Quality | Numeric (0–3) | 8% | Context |
| Sleep Disturbance Type | None, Medical, Bathroom, Temperature | 8% | Context |
| Napping During Day | Yes, No | 8% | Context |
| Sleep Efficiency | Numeric | 8% | Context |
| Sleep Latency | Numeric | 8% | Context |
| User Feedback | Accept, Cannot or decline | 0% | Target |
| Ranking Score | Input Variable |
|---|---|
| 0.19 | Subjective Sleep Quality |
| 0.17 | Persuasion Strategy |
| 0.17 | Napping During Day |
| 0.16 | Interaction Target |
| 0.16 | Sleep Latency |
| 0.16 | Sleep Disturbance Type |
| 0.14 | Sleep Efficiency |
| 0.08 | Coaching Action |
| 0.04 | Recorded Cooking Activity |
| 0.03 | Predicted Cooking Activity |
| 0.02 | Cooking Activity Situation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Žnidaršič, M.; Osojnik, A.; Rupnik, P.; Ženko, B. Improving Effectiveness of a Coaching System through Preference Learning. Technologies 2022, 10, 24. https://doi.org/10.3390/technologies10010024
Žnidaršič M, Osojnik A, Rupnik P, Ženko B. Improving Effectiveness of a Coaching System through Preference Learning. Technologies. 2022; 10(1):24. https://doi.org/10.3390/technologies10010024
Chicago/Turabian StyleŽnidaršič, Martin, Aljaž Osojnik, Peter Rupnik, and Bernard Ženko. 2022. "Improving Effectiveness of a Coaching System through Preference Learning" Technologies 10, no. 1: 24. https://doi.org/10.3390/technologies10010024
APA StyleŽnidaršič, M., Osojnik, A., Rupnik, P., & Ženko, B. (2022). Improving Effectiveness of a Coaching System through Preference Learning. Technologies, 10(1), 24. https://doi.org/10.3390/technologies10010024