
On the Exploration of Automatic Building Extraction from RGB Satellite Images Using Deep Learning Architectures Based on U-Net



Abstract
:1. Introduction
2. Related Work and Motivation for Using RGB Data
3. U-Net-Based Architectures
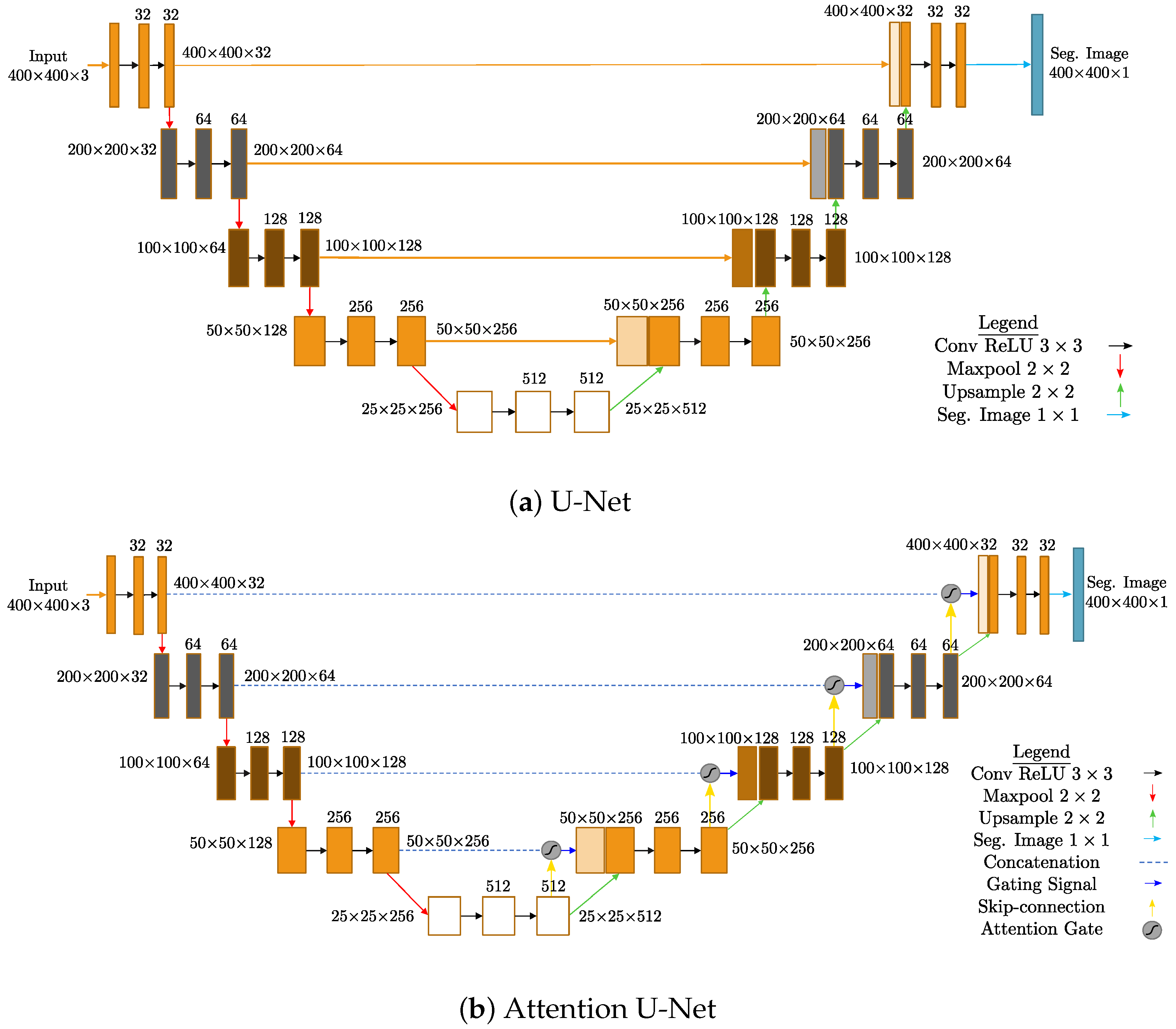
3.1. U-Net
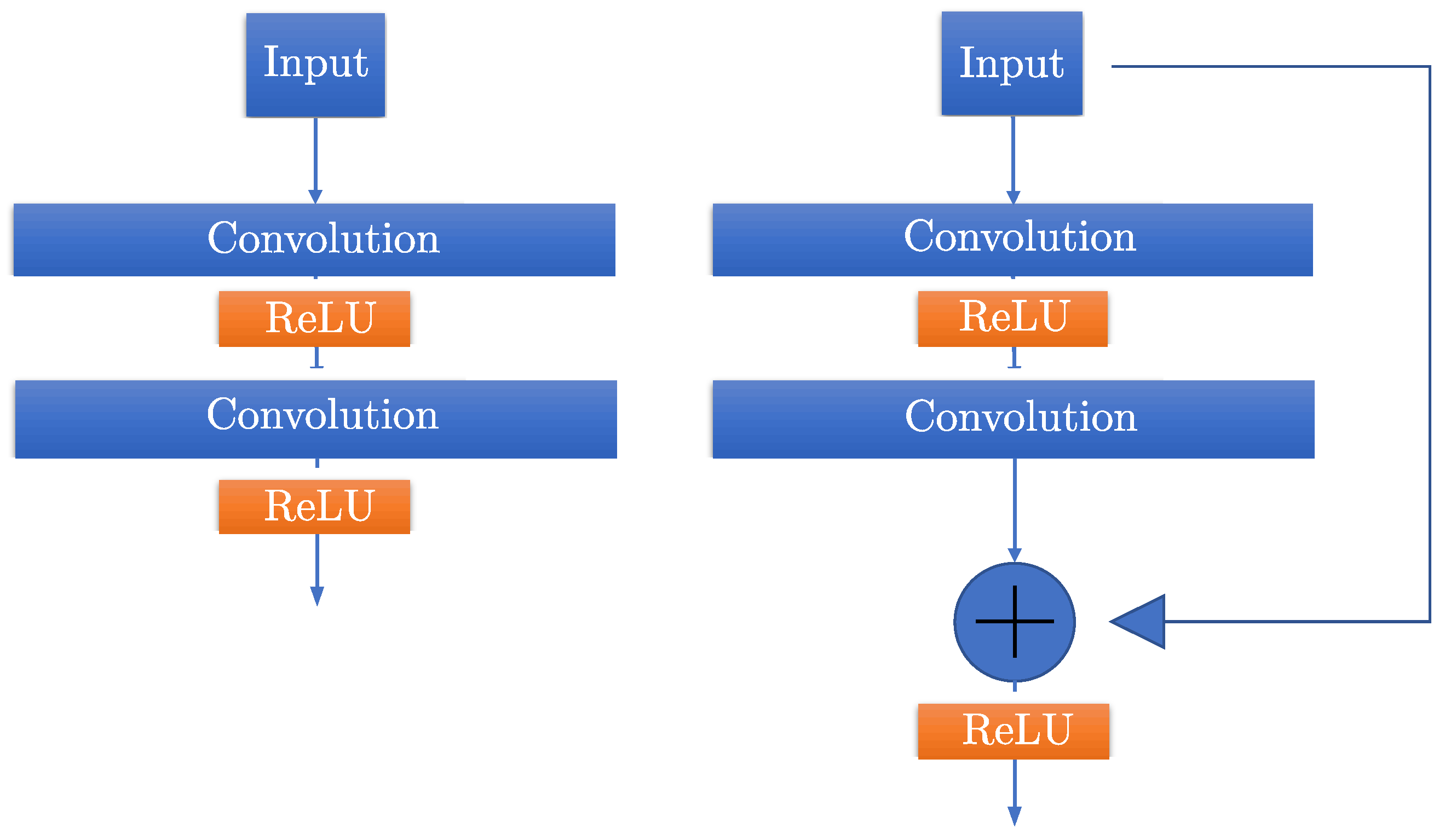
3.2. Residual Block in U-Net
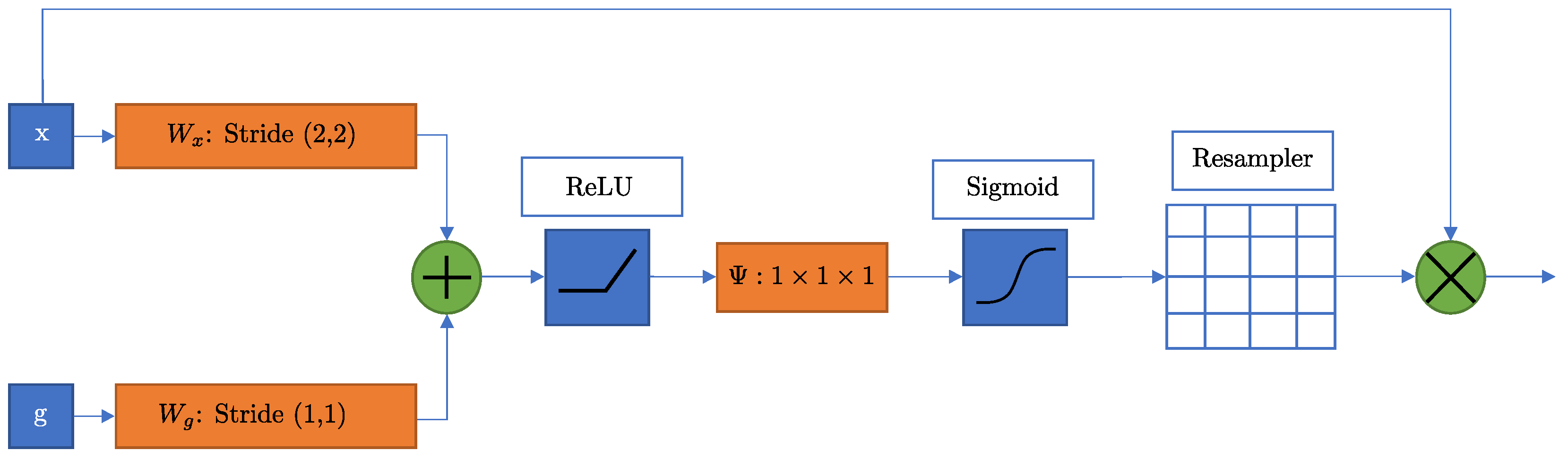
3.3. Attention U-Net
3.4. Attention ResU-Net Architecture
4. Experimental Setup
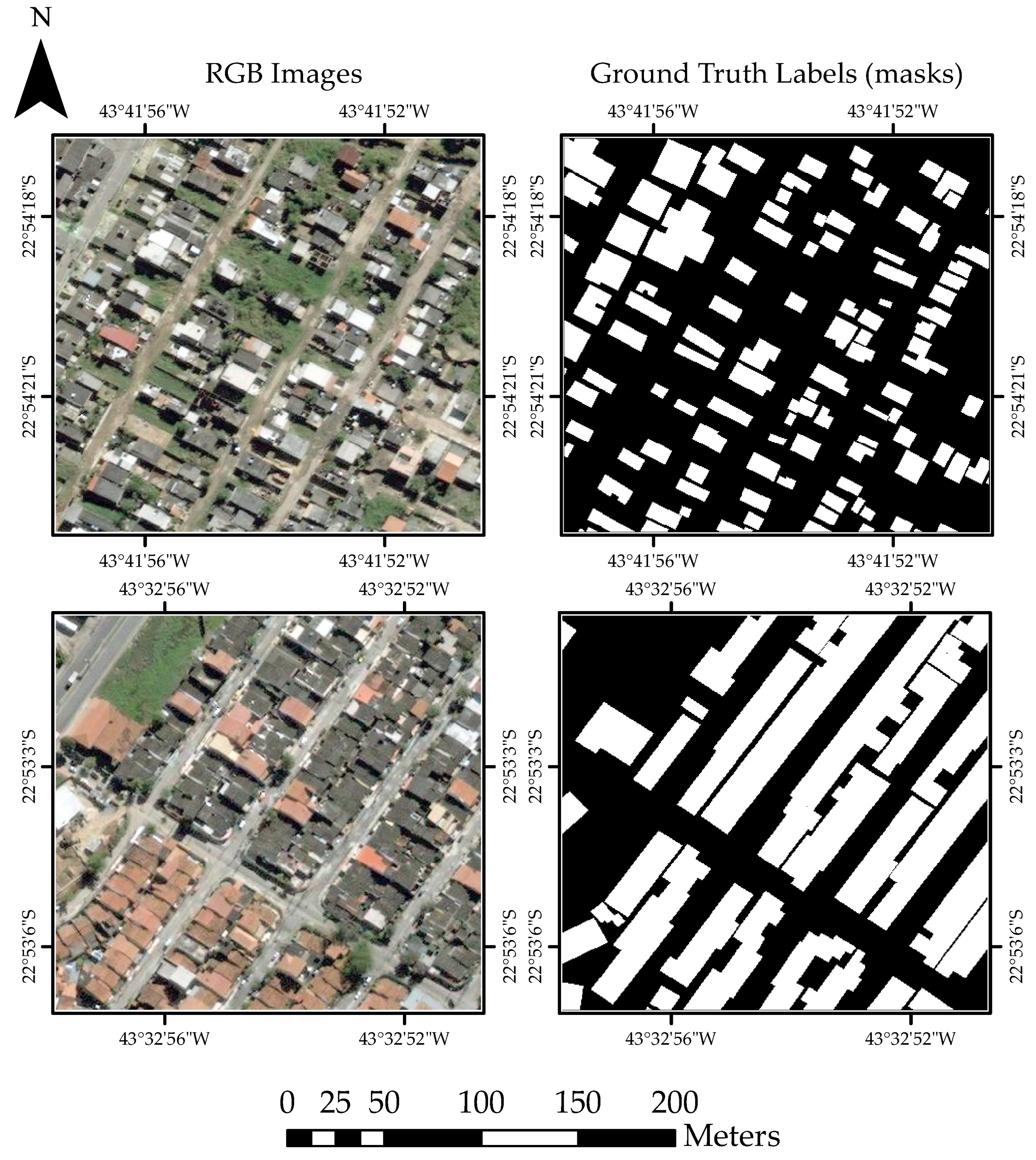
4.1. Dataset Description
4.2. Metrics
4.3. Experimental Results
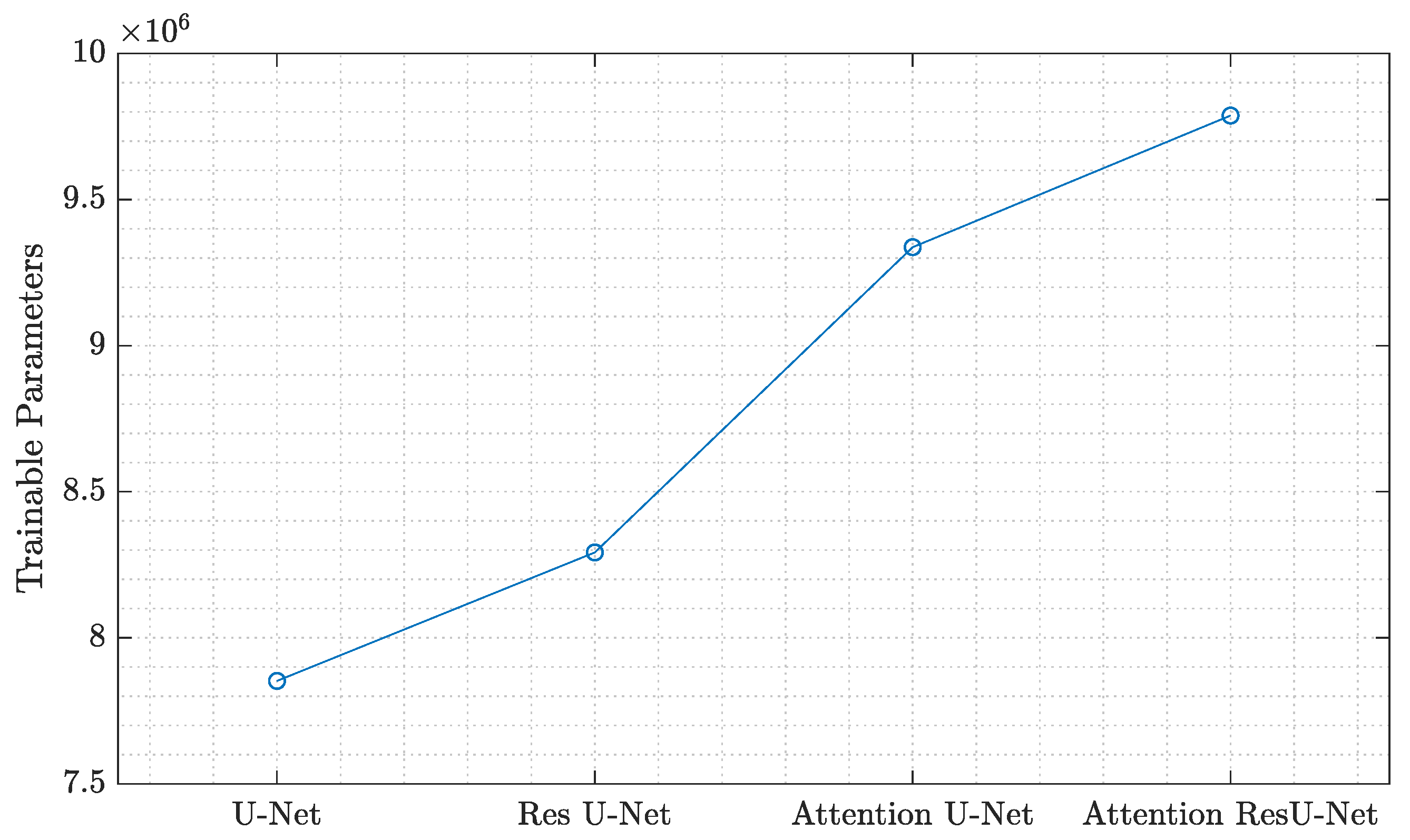
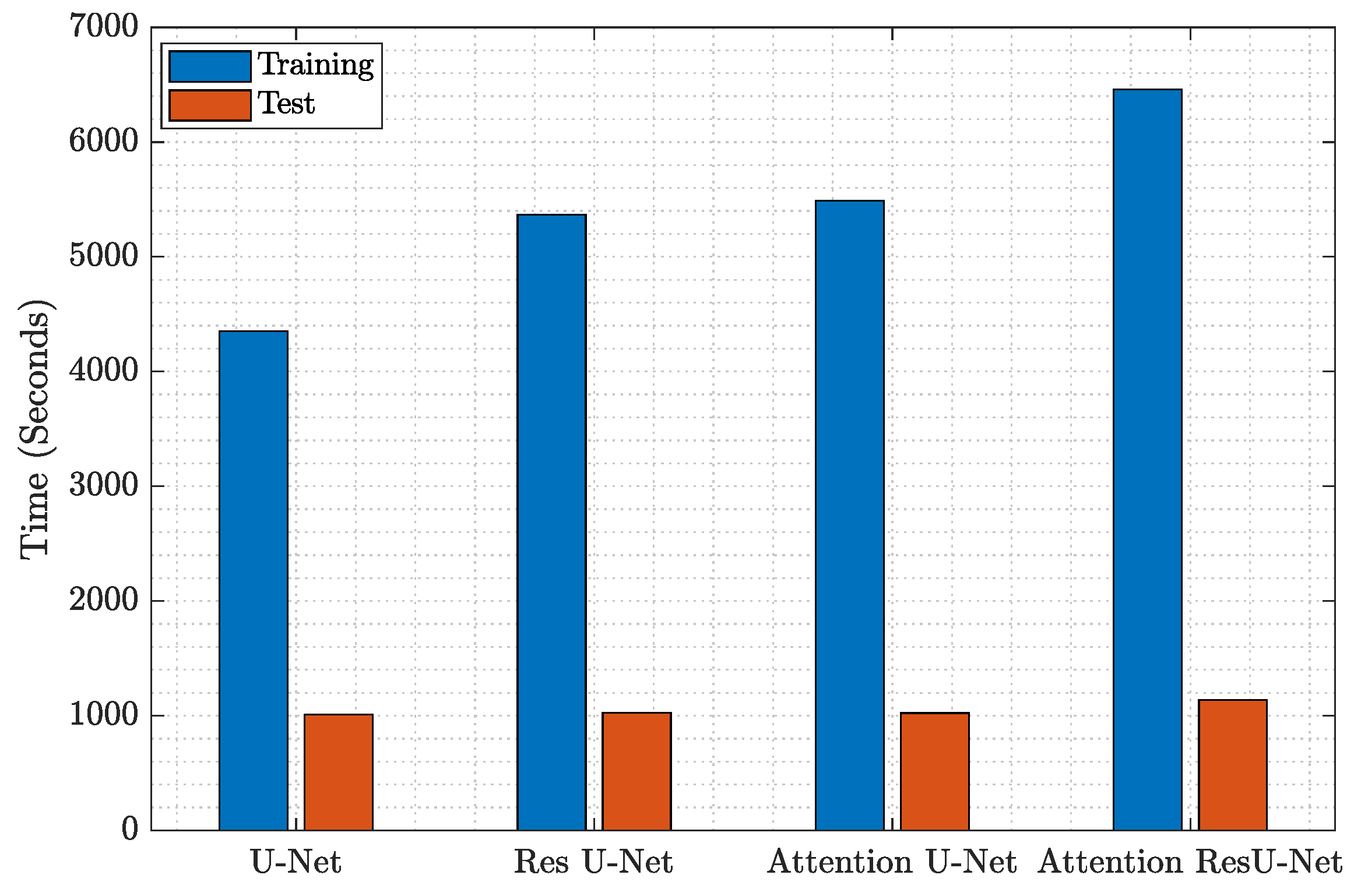
4.4. Model Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Garg, L.; Shukla, P.; Singh, S.; Bajpai, V.; Yadav, U. Land Use Land Cover Classification from Satellite Imagery using mUnet: A Modified Unet Architecture. In Proceedings of the VISIGRAPP (4: VISAPP), Prague, Czech Republic, 25–27 February 2019; pp. 359–365. [Google Scholar]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban land use and land cover classification using novel deep learning models based on high spatial resolution satellite imagery. Sensors 2018, 18, 3717. [Google Scholar] [CrossRef] [Green Version]
- Han, Z.; Dian, Y.; Xia, H.; Zhou, J.; Jian, Y.; Yao, C.; Wang, X.; Li, Y. Comparing fully deep convolutional neural networks for land cover classification with high-spatial-resolution Gaofen-2 images. ISPRS Int. J. -Geo-Inf. 2018, 9, 478. [Google Scholar] [CrossRef]
- Pauleit, S.; Duhme, F. Assessing the environmental performance of land cover types for urban planning. Landsc. Urban Plan. 2000, 52, 1–20. [Google Scholar] [CrossRef]
- Thunig, H.; Wolf, N.; Naumann, S.; Siegmund, A.; Jürgens, C.; Uysal, C.; Maktav, D. Land use/land cover classification for applied urban planning-the challenge of automation. In Proceedings of the 2011 Joint Urban Remote Sensing Event, Munich, Germany, 11–13 April 2011; pp. 229–232. [Google Scholar]
- Rimal, B.; Zhang, L.; Keshtkar, H.; Haack, B.; Rijal, S.; Zhang, P. Land use/land cover dynamics and modeling of urban land expansion by the integration of cellular automata and markov chain. ISPRS Int. J. -Geo-Inf. 2018, 7, 154. [Google Scholar] [CrossRef] [Green Version]
- Beretta, F.; Shibata, H.; Cordova, R.; Peroni, R.; Azambuja, J.; Costa, J. Topographic modelling using UAVs compared with traditional survey methods in mining. REM-Int. Eng. J. 2018, 71, 463–470. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Sirmacek, B.; Unsalan, C. A probabilistic framework to detect buildings in aerial and satellite images. IEEE Trans. Geosci. Remote Sens. 2010, 49, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Vakalopoulou, M.; Bus, N.; Karantzalos, K.; Paragios, N. Integrating edge/boundary priors with classification scores for building detection in very high resolution data. In Proceedings of the 2017 IEEE International Geoscience And Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3309–3312. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Prathap, G.; Afanasyev, I. Deep learning approach for building detection in satellite multispectral imagery. In Proceedings of the 2018 International Conference On Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; pp. 461–465. [Google Scholar]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked autoencoders driven by semi-supervised learning for building extraction from near infrared remote sensing imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Pasquali, G.; Iannelli, G.; Dell’Acqua, F. Building footprint extraction from multispectral, spaceborne earth observation datasets using a structurally optimized U-Net convolutional neural network. Remote Sens. 2019, 11, 2803. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Yang, H.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the united states. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A. Attention to Scale: Scale-aware Semantic Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience And Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing And Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Rakhlin, A.; Davydow, A.; Nikolenko, S. Land cover classification from satellite imagery with u-net and lovász-softmax loss. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 262–266. [Google Scholar]
- Ulmas, P.; Liiv, I. Segmentation of satellite imagery using u-net models for land cover classification. arXiv 2020, arXiv:2003.02899. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In In Proceedings of the IEEE International Conference On Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Temenos, A.; Protopapadakis, E.; Doulamis, A.; Temenos, N. Building Extraction from RGB Satellite Images using Deep Learning: A U-Net Approach. In Proceedings of the 14th PErvasive Technologies Related To Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; pp. 391–395. [Google Scholar]
- Voulodimos, A.; Protopapadakis, E.; Katsamenis, I.; Doulamis, A.; Doulamis, N. Deep learning models for COVID-19 infected area segmentation in CT images. In Proceedings of the 14th PErvasive Technologies Related To Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; pp. 404–411. [Google Scholar]
- Katsamenis, I.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Voulodimos, A. Pixel-level corrosion detection on metal constructions by fusion of deep learning semantic and contour segmentation. In International Symposium on Visual Computing; Springer: Cham, Switzerland, 16 June 2020. [Google Scholar]
- Liu, Y.; Wang, F.; Dobaie, A.; He, G.; Zhuang, Y. Comparison of 2D image models in segmentation performance for 3D laser point clouds. Neurocomputing 2019, 251, 136–144. [Google Scholar] [CrossRef]
- Alom, M.; Yakopcic, C.; Hasan, M.; Taha, T.; Asari, V. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Maltezos, E.; Doulamis, A.; Doulamis, N.; Ioannidis, C. Building extraction from LiDAR data applying deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 16, 155–159. [Google Scholar] [CrossRef]
- Maltezos, E.; Doulamis, N.; Doulamis, A.; Ioannidis, C. Deep convolutional neural networks for building extraction from orthoimages and dense image matching point clouds. J. Appl. Remote Sens. 2017, 11, 042620. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Zhang, L.; Shen, J.; Zhu, B. A research on an improved Unet-based concrete crack detection algorithm. Struct. Health Monit. 2021, 20, 1864–1879. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Evaluation Metrics | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | Jaccard | |
| U-Net [29] | 0.923 | 0.808 | 0.808 | 0.798 | 0.700 |
| ResU-Net | 0.936 | 0.864 | 0.770 | 0.811 | 0.703 |
| Attention U-Net | 0.940 | 0.851 | 0.809 | 0.826 | 0.726 |
| Attention ResU-Net | 0.937 | 0.850 | 0.799 | 0.820 | 0.719 |
| Architecture | Evaluation Metrics | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | Jaccard | |
| SegNet [27] | 0.919 | 0.569 | 0.813 | 0.662 | - |
| SegNet with Sobel filters [10] | 0.923 | 0.596 | 0.722 | 0.667 | - |
| CRF with Sobel filters [10] | 0.931 | 0.632 | 0.763 | 0.675 | - |
| CRF with CNN boundaries [10] | 0.924 | 0.624 | 0.764 | 0.674 | - |
| U-Net [29] | 0.923 | 0.808 | 0.808 | 0.798 | 0.700 |
| ResU-Net | 0.936 | 0.864 | 0.770 | 0.811 | 0.703 |
| Attention U-Net | 0.940 | 0.851 | 0.809 | 0.826 | 0.726 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Temenos, A.; Temenos, N.; Doulamis, A.; Doulamis, N. On the Exploration of Automatic Building Extraction from RGB Satellite Images Using Deep Learning Architectures Based on U-Net. Technologies 2022, 10, 19. https://doi.org/10.3390/technologies10010019
Temenos A, Temenos N, Doulamis A, Doulamis N. On the Exploration of Automatic Building Extraction from RGB Satellite Images Using Deep Learning Architectures Based on U-Net. Technologies. 2022; 10(1):19. https://doi.org/10.3390/technologies10010019
Chicago/Turabian StyleTemenos, Anastasios, Nikos Temenos, Anastasios Doulamis, and Nikolaos Doulamis. 2022. "On the Exploration of Automatic Building Extraction from RGB Satellite Images Using Deep Learning Architectures Based on U-Net" Technologies 10, no. 1: 19. https://doi.org/10.3390/technologies10010019
APA StyleTemenos, A., Temenos, N., Doulamis, A., & Doulamis, N. (2022). On the Exploration of Automatic Building Extraction from RGB Satellite Images Using Deep Learning Architectures Based on U-Net. Technologies, 10(1), 19. https://doi.org/10.3390/technologies10010019