Abstract
Financial sentiment analysis is crucial for making informed decisions in the financial markets, as it helps predict trends, guide investments, and assess economic conditions. Traditional methods for financial sentiment classification, such as Support Vector Machines (SVM), Random Forests, and Logistic Regression, served as our baseline models. While somewhat effective, these conventional approaches often struggled to capture the complexity and nuance of financial language. Recent advancements in deep learning, particularly transformer-based models like GPT and BERT, have significantly enhanced sentiment analysis by capturing intricate linguistic patterns. In this study, we explore the application of deep learning for financial sentiment analysis, focusing on fine-tuning GPT-4o, GPT-4o-mini, BERT, and FinBERT, alongside comparisons with traditional models. To ensure optimal configurations, we performed hyperparameter tuning using Bayesian optimization across 100 trials. Using a combined dataset of FiQA and Financial PhraseBank, we first apply zero-shot classification and then fine tune each model to improve performance. The results demonstrate substantial improvements in sentiment prediction accuracy post-fine-tuning, with GPT-4o-mini showing strong efficiency and performance. Our findings highlight the potential of deep learning models, particularly GPT models, in advancing financial sentiment classification, offering valuable insights for investors and financial analysts seeking to understand market sentiment and make data-driven decisions.
1. Introduction
Financial sentiment analysis has emerged as a pivotal area in financial technology, offering valuable insights into market trends, investor decisions and economic indicators. The ability to accurately classify sentiment in financial texts can significantly enhance decision-making processes, from predicting stock price movements to shaping investment strategies (Du et al., 2024). Given the high-stakes nature of financial markets, leveraging advanced Natural Language Processing (NLP) techniques to extract meaningful sentiment from financial documents, news articles, and social media discussions is of paramount importance.
Unlike general sentiment analysis, which often deals with product reviews, movie ratings, or social opinions, financial sentiment analysis involves interpreting domain-specific language rich with technical jargon, abbreviations, and market-specific terms. Financial texts often carry ambiguous or nuanced meanings that are highly context-dependent—what may seem positive in a general context could imply risk or instability in a financial one. Moreover, financial sentiment is frequently influenced by macroeconomic events, requiring models to account for temporal dynamics and intertextual references. These characteristics make financial sentiment analysis uniquely challenging and demand models capable of understanding subtle shifts in tone and intent that are not typically encountered in general sentiment analysis tasks.
Traditionally, sentiment analysis in finance has relied on lexicon-based approaches and classical machine learning models, such as support vector machines (SVM) and logistic regression (Du et al., 2023; Malo et al., 2014). While these techniques have demonstrated some success, they often require extensive feature engineering and domain-specific customizations to handle the complexity of financial language, which is characterized by technical jargon, contextual ambiguity, and frequent shifts in meaning due to economic fluctuations. Moreover, rule-based systems and conventional models struggle to generalize across different financial contexts, leading to suboptimal performance in real-world applications.
The advent of deep learning, particularly transformer-based architectures, has revolutionized NLP tasks, including financial sentiment analysis (Du et al., 2024). NLP models such as Bidirectional Encoder Representations from Transformers (BERT) and Large Language Models (LLMs) such as Generative Pre-trained Transformers (GPT) have demonstrated remarkable capabilities in understanding nuanced language structures (Roumeliotis et al., 2025). These models, pre-trained on vast corpora of text, can capture intricate linguistic patterns, making them highly effective for sentiment classification tasks without the need for extensive manual feature engineering. A noteworthy example is the work of (Liu et al., 2020; Y. Yang et al., 2020b), which fine-tuned the BERT model using both the FiQA and PhraseBank sentiment datasets, leading to the introduction of the FinBERT model (GitHub (Y. Yang et al., 2020a)). This model has been instrumental in advancing fine-grained sentiment analysis in financial applications. Numerous other studies have built on FinBERT to perform financial tasks, such as extracting information from financial texts (Huang et al., 2023), forecasting the S&P 500 Index (Arami et al., 2023), and sentiment analysis and prediction of stock prices (Baghavathi Priya et al., 2025; Shobayo et al., 2024).
Recent studies have explored the application of transformer models in financial sentiment analysis, with findings suggesting that fine-tuning these models on domain-specific datasets enhances their classification accuracy (Roumeliotis et al., 2024; B. Zhang et al., 2023). While BERT-based models have been widely adopted for financial sentiment tasks, the emergence of advanced GPT variants, such as GPT-4o and its lightweight counterpart GPT-4o-mini, presents new opportunities for improving sentiment classification in financial texts. These models leverage extensive contextual understanding, enabling more precise sentiment classification in complex financial narratives.
This study aims to conduct a comparative analysis of fine-tuned transformer models for financial sentiment classification, directly comparing them with traditional models such as SVM, Random Forests, and Logistic Regression. Specifically, we evaluate the performance of GPT-4o, GPT-4o-mini, a fine-tuned BERT model, a further fine-tuned version of FinBERT, as well as the aforementioned traditional models, using a combined dataset comprising FiQA and Financial PhraseBank (Sbhatti, 2021), two widely recognized financial sentiment datasets.
The core objectives of this study are threefold: (1) to assess the classification accuracy of state-of-the-art transformer-based models compared to traditional machine learning approaches in the context of financial sentiment analysis; (2) to evaluate the efficiency and scalability of these models—particularly in comparing the lightweight GPT-4o-mini with its larger counterpart, GPT-4o; and (3) to explore the application of zero-shot and fine-tuned transformer models in financial sentiment classification tasks using domain-specific datasets. By explicitly comparing these models under both zero-shot and fine-tuned scenarios, we aim to better understand their strengths, limitations, and practical applicability in real-world financial analysis settings.
By comparing the performance of these models, this research contributes to the growing body of literature on financial sentiment analysis and transformer-based NLP applications in finance. Our findings provide valuable insights into the effectiveness of fine-tuning LLMs for financial sentiment classification, highlighting the potential of GPT-4o models as efficient and accurate tools for financial market analysis. The results of this study hold significant implications for researchers, investors, and financial analysts seeking to leverage AI-driven sentiment analysis for better market understanding and decision-making.
2. Literature Review
Financial Sentiment Analysis (FSA) has become an essential tool for investors, policymakers, and financial analysts to interpret market trends and inform decision-making processes. While traditional NLP models have demonstrated success in extracting sentiment from financial texts, the advent of LLMs has greatly expanded capabilities through zero-shot and few-shot learning. Nonetheless, challenges persist in domain adaptation, explainability, adversarial robustness, and computational efficiency. This section reviews recent research aimed at addressing these challenges, with a focus on transformer-based approaches (e.g., BERT, FinBERT, GPT variants) and other techniques applied to FSA. A summary of these studies is provided in Table 1, followed by a more detailed discussion.

Table 1.
Summary of key findings from selected papers on financial sentiment analysis.
2.1. Transformer-Based Models for Financial Sentiment Analysis
The introduction of transformer-based architectures has significantly elevated the accuracy of FSA, primarily by capturing nuanced contexts and fine-grained language features. Dmonte et al. (2024) compared GPT-like architectures (in-context learning) with BERT-based models, revealing that while transformer-based models effectively deciphered complex financial terminology, they struggled in cases of data sparsity and ambiguous sentiment. Meanwhile, Fatouros et al. (2023) reported that ChatGPT, prompted effectively, achieved a 35% boost in performance relative to FinBERT in forex sentiment tasks, underscoring the value of prompt engineering. Sidogi et al. (2021) found that leveraging a domain-specific variant such as FinBERT for stock price prediction via news headlines greatly outperformed generic BERT models. Farimani et al. (2021) similarly demonstrated how BERT-derived financial sentiment features reduced error rates compared to standard machine learning models. Together, these studies illustrate the centrality of transformer-based approaches for FSA and highlight the necessity of domain-focused adjustments—ranging from specialized pre-training to tailored prompts.
2.2. Retrieval-Augmented and Instruction-Tuned Approaches
To address data scarcity and enhance contextual understanding, several researchers have turned to retrieval-augmented models and instruction tuning. B. Zhang et al. (2023) introduced a retrieval-augmented LLM framework that integrates external knowledge sources for sentiment classification, achieving a 15–48% accuracy advantage over baseline models. They further proposed Instruct-FinGPT, which instruction-tunes a general-purpose LLM using financial datasets. L. Zhao et al. (2021) utilized structured financial documents alongside news sentiment for retrieval-based augmentation, emphasizing how curated external sources can enrich LLM-based classifiers. Mathebula et al. (2024) extended the retrieval approach through a Retrieval-Augmented Generation (RAG) framework, adeptly handling idiomatic expressions and informal reviews. Agarwal and Gupta (2024) employed Parameter-Efficient Fine-Tuning (PEFT) on LLaMA 2 LLM within a retrieval-augmented setup, reaching 89% accuracy. These efforts collectively demonstrate that retrieval-augmented and instruction-tuned paradigms help bridge domain gaps and increase model adaptability.
2.3. Domain-Specific Fine-Tuning and Lexicon-Based Methods
Given the specialized lexicon and jargon in financial domains, leveraging domain-focused corpora or expert-developed dictionaries yields more robust FSA. Gutiérrez-Fandiño et al. (2021) showed that FinEAS, a financial embedding model, consistently outperformed generic BERT in sentiment tasks by capturing market-specific phrasing. Consoli et al. (2022) introduced Fine-Grained Aspect-based Sentiment (FiGAS), combining lexicon rules with specialized semantics to achieve improved interpretability and accuracy over conventional lexicon-based methods. Yekrangi and Abdolvand (2021) further highlighted the superiority of tailored dictionaries for financial market sentiment extracted from Twitter data, while Štrimaitis et al. (2021) demonstrated that domain-specific adaptation can be effectively extended to non-English settings—e.g., Lithuanian-language financial news—reinforcing the importance of linguistic nuances in various markets.
2.4. Semantic and Syntactic Enhancements
Beyond vocabulary alignment, some researchers incorporate higher-level linguistic structures and discourse contexts to refine sentiment classification. Xiang et al. (2022) proposed the Semantic and Syntactic Enhanced Neural Model (SSENM), leveraging dependency graphs and self-attention to refine sentiment predictions, resulting in a 2–3% performance improvement over baselines. Daudert (2021) explored sentiment “contagion” across textual sources, finding that intertextual relationships considerably improved predictive accuracy. These approaches underscore that purely lexical analysis may overlook crucial syntactic and discursive signals, and that integrating structural insights yields more comprehensive sentiment interpretations.
2.5. Multi-Agent and Hybrid Frameworks
In recognition of the multi-faceted nature of financial sentiment, researchers have begun to combine specialized agents or integrate multiple model types. Xing (2024) presented a multi-agent paradigm rooted in Minsky’s “Society of Mind” theory, wherein multiple LLM agents collaborate to leverage both linguistic and financial expertise, surpassing single-model results. J. Yang et al. (2022) combined sentiment features with technical indicators in a hybrid LASSO-LSTM model, achieving an 8.53% improvement for stock price prediction. Similarly, Duan et al. (2024) fused topic extraction and fine-tuned transformers with enhanced attention, boosting both stability and interpretability. Collectively, these multi-agent and hybrid methods capture a broader array of signals—linguistic, contextual, and market-driven—resulting in more robust FSA systems.
2.6. Multimodal and Social Media–Focused Approaches
Given the explosion of user-generated financial discussions online, a parallel line of research has examined sentiment analysis of social media data and corporate communications. Qian et al. (2022), for instance, analyzed Twitter sentiment within cryptocurrency and NFT discussions, highlighting key emotional drivers such as trust and anticipation. Deng et al. (2023) used semi-supervised LLMs for deriving weak labels on Reddit—where rapidly evolving slang poses a significant challenge. Todd et al. (2024) expanded beyond text-only data by incorporating speech emotion recognition from corporate earnings calls, enhancing sentiment forecasting. Hajek and Munk (2023) similarly explored managerial tone in speech, finding that embedding emotion signals into textual sentiment predictions boosted the detection of financial distress. Meanwhile, Sy et al. (2025) developed an ensemble BERT architecture that blends argument mining features with social media data, obtaining improvements in argument unit identification. These studies demonstrate that multimodal fusion, alongside the flexibility of LLMs to adapt to informal, dynamic platforms, can sharpen FSA performance.
2.7. Adversarial Attacks and Model Robustness
As LLM-driven sentiment predictions gain traction in real-world financial applications, researchers have turned their attention to adversarial robustness. Leippold (2023) revealed that GPT-3–based adversarial examples can subvert financial sentiment predictions, exposing vulnerabilities in general-purpose keyword-based models. Nevertheless, domain-specific transformers like FinBERT showed greater resilience, likely thanks to more context-aware embeddings. This work highlights the need for continual improvements in robust training methods, adversarial detection, and domain-tailored approaches to safeguard FSA insights.
2.8. Synthesis and Future Directions
Collectively, these investigations confirm that transformer-based models excel at capturing the nuances of financial language, provided they are augmented and adapted to the sector’s unique characteristics. Retrieval-augmented and instruction-tuned strategies mitigate data limitations and better align model inferences with finance-specific contexts. Domain-specific embeddings, lexicon-based refinements, and semantic or syntactic enhancements deliver further gains in interpretability and precision, while multi-agent and multimodal approaches integrate a rich tapestry of complementary signals. Nevertheless, challenges remain in ensuring model robustness to adversarial manipulation and in providing transparent explanations to stakeholders. Future directions likely include specialized adversarial defense techniques—fine-tuned for finance—as well as expansions of topic-aware transformer architectures. These refinements promise to enhance the reliability, explainability, and performance of FSA systems in increasingly complex market environments.
Overall, the convergence of transformer-based methods, domain-tailored modifications, and dynamic multi-agent or multimodal systems suggests a promising trajectory for financial sentiment analysis. As research continues to address enduring challenges of generalizability, computational efficiency, and interpretability, the tools facilitating automated sentiment insights in finance will become both more potent and more trusted.
3. Materials and Methods
To systematically evaluate the effectiveness of transformer-based models for financial sentiment classification, we adopt a structured experimental approach. Our methodology encompasses both zero-shot and few-shot classification after fine-tuning on domain-specific datasets to assess model performance under different conditions. The comparative analysis features state-of-the-art models such as GPT-4o and GPT-4o-mini, a fine-tuned BERT model, and FinBERT. Traditional machine learning models—SVM, Random Forest, and Logistic Regression—are also included as baselines.
While there are open-source LLMs such as LLaMA, Qwen, and others available via frameworks like Ollama, which allow for local deployment and fine-tuning, we selected an API-based GPT model for this task. Although open-source models provide flexibility and control, leveraging them typically requires access to multiple high-performance GPUs or TPUs and considerable time and computational resources for effective fine-tuning. In contrast, the OpenAI API offers immediate access to a highly capable model with state-of-the-art language understanding, optimized infrastructure, and robust performance in both zero-shot and few-shot scenarios. This choice ensures a more practical and scalable solution within our resource and time constraints while maintaining high accuracy and generalization capabilities in financial sentiment analysis.
In this section, we outline the data preprocessing steps, model-training procedures, evaluation metrics, and experimental setup used to measure classification accuracy and efficiency across these approaches.
3.1. Data Preprocessing Phase
3.1.1. Understanding the Dataset
For this study, the Financial Sentiment Analysis dataset was selected to advance research in financial sentiment analysis (Sbhatti, 2021). This dataset comprises two well-established sources, FiQA and Financial PhraseBank, which were merged into a single CSV file. It contains financial sentences annotated with sentiment labels and is publicly available under a CC0: Public Domain license via the Kaggle repository. The Financial PhraseBank was created by Malo et al. (2014) as part of the study “Good Debt or Bad Debt: Detecting Semantic Orientations in Economic Texts” published in the Journal of the Association for Information Science and Technology (Malo et al., 2014; Malo & Sinha, 2024). This dataset is original and human-annotated, not synthetic, as the sentiment labels were assigned by 16 individual annotators, with a reported average pairwise agreement of 74.9%. The dataset includes two columns: Sentence, containing the financial text, and Sentiment, labeling each sentence as positive, negative, or neutral. The selection of this dataset was motivated by its high usability rating (scored 10 by users), as well as its completeness and diversity.
Prior to preprocessing, a rigorous feature engineering phase was undertaken to gain deeper insights into the dataset. The original dataset consists of 5842 rows and two columns: “Sentence” and “Sentiment”. The maximum length of the “Sentence” column is 315 characters, while the minimum and average lengths are 9 and 117 characters, respectively. The “Sentiment” column contains three distinct labels: negative, positive, and neutral. Of the total samples, 3130 are labeled as neutral, 1852 as positive, and 860 as negative. Although the dataset is valuable, this imbalance in sentiment distribution poses a potential bias in model training, as models may disproportionately favor the majority class. Consequently, an under-sampling strategy was deemed necessary to mitigate this issue.
3.1.2. Dataset Preprocessing
The data preprocessing phase followed a structured and iterative methodology, implemented through a well-designed class to ensure data quality, consistency, and suitability for predictive modeling. The process encompassed several key steps, including handling missing values, standardizing textual data, employing stratified sampling, and partitioning the dataset into training, validation, and test subsets.
Initially, an exploratory data analysis was conducted to examine the distribution of sentiment labels. This analysis involved extracting unique sentiment values and their respective frequencies to assess class balance. A dedicated method was invoked to load the dataset and quantify the sentiment labels.
Next, missing values were addressed to maintain data integrity. Rows containing empty values in crucial columns, such as “Sentence” and “Sentiment”, were identified and removed using a predefined function. This function loaded the dataset into a Pandas DataFrame, detected missing values in specified columns, and eliminated the corresponding rows. To ensure traceability, the original dataset was preserved under a new filename before saving the cleaned version as a CSV file.
Following data cleaning, the textual data were standardized to enhance consistency and interpretability for modeling. A text normalization method was applied, which involved converting text to lowercase, removing special characters, and eliminating redundant whitespace. This function ensured uniform formatting across the dataset. As with previous steps, the original dataset was retained under a modified filename before saving the standardized version.
Subsequent to preprocessing, an additional exploratory check was performed to verify that sentiment distribution remained unchanged. This validation ensured that preprocessing operations had not inadvertently altered label proportions.
In probability theory, a fair coin refers to a situation where the outcomes of a coin toss are equally likely, meaning there is a 50/50 chance of landing heads or tails. An unfair (biased) coin, on the other hand, is one where the outcomes are not equally likely, with one side having a higher probability of landing face up than the other. This bias could be due to the coin’s physical properties or the way it is tossed.
Similarly, in machine learning, a biased or imbalanced dataset is like an unfair coin: one class (like positive sentiment) is more prevalent than the other, creating a disproportionate distribution. Just as an unfair coin tends to land on one side more frequently, an imbalanced dataset causes the model to favor the majority class, making it less effective at predicting the minority class.
To address label imbalance, a stratified sampling approach was employed. This method ensures that each sentiment category in the dataset is represented equally, just as a fair coin would give an equal chance to both heads and tails. A specialized function was created to partition the dataset by selecting an equal number of instances for each sentiment class. The total number of rows was distributed proportionally across the labels to maintain balance. The function then iteratively sampled instances from each class, incorporating random selections to achieve the specified total count. Finally, the resulting subset was shuffled to prevent any ordering biases before being saved as a new CSV file.
Once the stratified subset was prepared, the dataset was divided into training, validation, and test sets while maintaining the original sentiment distribution. Initially, 20% of the data was allocated to the test set, while the remaining portion was further split into training and validation subsets. Stratified sampling ensured that the sentiment balance was preserved across all three partitions. The final datasets were saved as separate CSV files—train_set.csv, validation_set.csv, and test_set.csv—for subsequent modeling phases. The final dataset distributions included 516 samples in the test set, 516 in the validation set, and 1548 in the training set, all equally distributed among the three sentiment labels.
It is also important to consider that some machine learning algorithms can process string labels directly, while others require numerical encoding. In this study, SVM and BERT models necessitated numerical label encoding, whereas LLMs could handle categorical string labels. For low-dimensional datasets, label encoding is a practical choice, whereas high-dimensional datasets may benefit more from one-hot encoding. In this study, label encoding was applied, converting categorical sentiment labels into numerical values: negative (0), positive (1), and neutral (2). This transformation created a new column within the test set file, facilitating model evaluation in subsequent phases.
3.2. Fine-Tuning and Sentiment Analysis Phase
With the data prepared for the predictive modeling classification task, we proceeded with the training and fine-tuning phase. This process began with an evaluation of the performance of traditional machine learning algorithms—SVM, Random Forest, and Logistic Regression—accompanied by extensive hyperparameter tuning. A similar hyperparameter tuning strategy was applied to the pre-trained BERT and FinBERT models, incorporating a variety of optimization techniques. Additionally, we conducted fine-tuning on OpenAI’s flagship model, GPT-4o, as well as its smaller variant, GPT-4o-mini.
Initially, we considered using a grid search approach to identify the optimal hyperparameters for each model. However, grid search, which involves exhaustively training models across all possible hyperparameter combinations, can lead to a combinatorial explosion—especially when dealing with multiple transformer-based models and traditional algorithms. To overcome these limitations, we adopted a more probabilistic approach: Bayesian optimization.
Leveraging the Optuna library, we performed a broad search across a range of hyperparameter combinations using 100 trials per model. To improve training efficiency and prevent overfitting, we integrated early stopping and pruning techniques, halting training if a model showed no improvement over a specified number of epochs. Following Bayesian optimization, the best-performing models—selected based on their validation accuracy—were used to make predictions on the same test set.
3.2.1. SVM Sentiment Classification with Hyperparameter Optimization
As highlighted in the introduction, SVMs have been widely utilized for classification tasks, often requiring extensive feature engineering, domain-specific adaptations, and careful hyperparameter tuning to achieve optimal performance. In this study, Bayesian optimization was employed using the Optuna framework to fine tune an SVM model for financial sentiment classification. The entire procedure was conducted on Google Colab using a single CPU.
The optimization process explored a comprehensive hyperparameter space to improve both the TF-IDF text vectorization and the performance of the SVM classifier. For the TF-IDF component, max_features was selected from 5,000, 10,000, 15,000, or unlimited; ngram_range was chosen from unigrams, bigrams, or trigrams ((1,1), (1,2), (1,3)); and stop_words was toggled between None and “english”. The SVM classifier was tuned across several critical hyperparameters: the regularization parameter C was sampled logarithmically between 0.01 and 100.0; the kernel was selected from ‘linear’, ‘rbf’, or ‘poly’; and class_weight was optionally set to “balanced” to handle class imbalances. Additionally, for non-linear kernels, the gamma parameter was optimized with values of ‘scale’ or ‘auto’.
Each trial in the optimization involved constructing a pipeline that combined TF-IDF and SVM, training it on the training set, and evaluating it on a validation set using accuracy and hinge loss. The results of every trial were logged, enabling detailed performance tracking and identification of the best configuration. The core of the approach involved optimizing an SVM classifier for the task of financial sentiment classification. To ensure optimal model performance, the Optuna framework was employed for hyperparameter tuning, leveraging Bayesian optimization across 100 trials.
The best-performing model emerged from trial no. 81, achieving a validation accuracy of 0.6899. This model used a linear kernel, placed no restriction on maximum features, considered unigrams, bigrams, and trigrams, did not remove stop words, and applied a regularization parameter C of approximately 0.787. Importantly, no class weighting was applied, as the dataset was already balanced across class distributions.
A total of 100 optimization trials were conducted over a span of 8.65 min. The lowest-performing trial, Trial 48, yielded a validation accuracy of 0.3236. Compared to this worst-case baseline, the best trial showed a 113.17% relative improvement. The average trial accuracy was 0.6134, with the best trial outperforming the average by 12.48%.
An analysis of parameter importance indicated that the kernel type had the highest impact on model performance, with an importance score of 0.5439. This was followed by the maximum number of features used in TF-IDF (0.2078), the n-gram range (0.1591), the regularization parameter C (0.0597), class weighting (0.0236), and stop word removal (0.0059), suggesting that text representation and model type had significantly more influence than regularization or class balancing.
Final model evaluation on the validation set revealed a validation loss of 0.9668 and a balanced classification report, with macro and weighted F1-scores both at 0.69. Class-wise, the model performed best in identifying classes 0 and 1, with precision and recall scores in the high 60s to low 70s. Class 2 had slightly lower precision but higher recall, resulting in comparable F1 performance.
When evaluated on the test set, the model achieved an accuracy of 0.6453. The classification report showed a consistent pattern: classes 0 and 1 maintained a good precision-recall balance, while class 2, though slightly less precise, achieved the highest recall (0.77), likely capturing more positive sentiments. The macro and weighted average F1-scores on the test set remained around 0.64, demonstrating stable generalization from validation to test data. The average prediction time per sample was 0.001777 s, confirming the suitability of the model for real-time or low-latency inference settings.
3.2.2. Random Forest Optimization and Evaluation
Following the same hyperparameter tuning methodology, we trained a Random Forest model for the same classification task using the same training and validation sets. The Optuna framework was again employed to explore a wide range of hyperparameter combinations in order to maximize validation accuracy.
The best trial for the Random Forest model was trial number 70, which achieved the highest validation accuracy of 0.6725.
For the hyperparameters, the optimal configuration included a maximum feature count of 15,000 for the TF-IDF vectorizer, with a unigrams-only n-gram range and no stop words filtering. For the Random Forest classifier, the best parameters were 151 estimators, a maximum tree depth of 40, and a minimum sample split of 7. Additionally, the model utilized a log2 feature selection method, and bootstrap sampling was disabled, with no class weight adjustment.
In terms of the optimization process, 100 trials were completed in a total of 6.98 min. The worst-performing trial achieved an accuracy of 0.4981, while the best trial showed an improvement of 0.1744 (35.02%) over this worst result. The average trial accuracy was 0.6257, and the best trial outperformed this by 0.0468 (7.48%).
Regarding the parameter importance, the most significant factors influencing the model’s performance were the rf_max_features parameter, which contributed the most to the final model’s accuracy (0.5500), followed by the min_samples_leaf parameter (0.1573), and the bootstrap setting (0.1486).
On the validation set, the Random Forest model achieved an accuracy of 0.6725, with a classification report showing that the model was fairly balanced across the three sentiment classes. Specifically, class 0 (negative sentiment) had a precision of 0.72, class 1 (neutral sentiment) had a precision of 0.65, and class 2 (positive sentiment) had a precision of 0.66. The weighted average across all classes was 0.67 for precision, recall, and F1-score.
For the test set, the model achieved a test accuracy of 0.6531, with similar performance across the sentiment classes. The F1-scores for all classes ranged from 0.63 to 0.67, and the weighted average was again 0.65, showing that the model generalizes well to unseen data. Finally, the average prediction time for each sample was 0.042986 s.
The most important features in the model were mostly common words and financial terminology. The top 20 most important features included terms such as “the”, “down”, “and”, and “up”, with the word “the” having the highest importance (0.020174). This suggests that common words in the text, possibly related to market movements, played a significant role in the model’s predictions.
3.2.3. Logistic Regression Optimization and Evaluation
The Logistic Regression model was also trained using the same hyperparameter tuning methodology as outlined for the other models. The results from this optimization process are as follows:
The best trial was trial number 34, achieving a validation accuracy of 0.6899. The hyperparameters selected for this best-performing model included a maximum of 1000 features for the TF-IDF vectorizer, the use of 1-g and 2-g features, and no stop words. Additionally, the regularization parameter C was optimized to 1.21398, and the model utilized balanced class weights to account for potential class imbalances. The penalty and solver combo was chosen as ‘l2’, ‘liblinear’, with a maximum of 200 iterations.
In terms of performance, a total of 100 trials were completed during the optimization. The optimization process took 0.78 min, with the worst-performing trial achieving an accuracy of 0.0000. This led to an absolute improvement of 0.6899 over the worst trial. On average, the accuracy across all trials was 0.5385, with an improvement of 0.1514 (or 28.12%) over this average.
The parameter importance analysis revealed that the penalty_solver_combo had the highest importance score at 0.9638, indicating that the choice of regularization method and solver had a significant impact on model performance. Other parameters, such as max_features, C, and stop_words, were less influential.
The final evaluation on the validation set showed a validation accuracy of 0.6899 and a loss of 0.8885. The classification report on the validation set indicated that the model performed reasonably well across all classes, with a balanced precision, recall, and F1-score close to 0.69 for each class.
On the test set, the model achieved an accuracy of 0.6492, with a classification report showing slightly lower performance compared to the validation set. The average prediction time per sample was 0.000828 s.
3.2.4. Fine-Tuning and Predictive Analysis of BERT Model
With the advent of transformer-based models, traditional approaches such as SVM have been largely abandoned in favor of pre-trained models like BERT. A similar methodology used for traditional models was applied to the fine-tuning of the BERT-based model. The process was also conducted on Google Colab, utilizing an A100 GPU (Tesla V100-SXM2-16 GB).
Bayesian optimization was also employed to efficiently search the complex hyperparameter space of the BERT model. The search space included batch size ranging from 4 to 64, learning rate from 5 × 10−6 to 1 × 10−4, number of epochs from 2 to 10, optimizer type (Adam vs. AdamW), weight decay from 1 × 10−6 to 1 × 10−2, warmup ratio from 0 to 0.2, and dropout rate from 0.1 to 0.5.
The implementation utilized the BERT base uncased model (Hugging Face, 2025) with specific configurations for sequence classification, with dropout probabilities adjusted based on optimization trials.
The training procedure for each trial included tokenization with appropriate padding and truncation, batch preparation through custom dataset and dataloader classes, training with loss tracking and gradient updates, evaluation on validation data after each epoch, and early stopping based on validation accuracy trends to prevent overfitting.
The optimization process revealed that learning rate had the highest impact on model performance (importance score: 0.5785), followed by dropout rate (0.2006), warmup ratio (0.1139), weight decay (0.0586), number of epochs (0.0294), optimizer choice (0.0157), and batch size (0.0033). This aligns with general understanding that learning rate is critical for neural network training.
The best trial (number 82) achieved a validation accuracy of 0.8372 with hyperparameters: batch size of 4, learning rate of 3.63e-05, 3 epochs, Adam optimizer, weight decay of 0.0009, warmup ratio of 0.031, and dropout rate of 0.121. This represented a 3.35% improvement over the worst-performing trial and a 1.76% improvement over the average trial accuracy.
3.2.5. Fine-Tuning and Predictive Analysis of FinBERT Model
The same procedure was applied using the FinBERT pre-trained model, a domain-specific variant of BERT that has been trained on financial communications and is optimized for sentiment classification within the financial domain.
Hyperparameter tuning involved evaluating batch sizes of 4, 8, 16, 32, and 64. The learning rate was sampled continuously within the range of 5 × 10−6 to 1 × 10−4. Training durations varied from 2 to 10 epochs. The choice of optimizer was limited to Adam and AdamW. Weight decay was sampled logarithmically between 1 × 10−6 and 1 × 10−2. The warmup ratio ranged continuously from 0.0 to 0.2, while the dropout rate varied from 0.1 to 0.5. Across all experiments, the maximum sequence length was fixed at 512 tokens, and CUDA acceleration was utilized when available.
A total of 100 optimization trials were scheduled, of which 24 completed successfully. The optimal hyperparameter configuration achieved a validation accuracy of 0.8275. This configuration included a batch size of 16, a learning rate of 4.99 × 10−5, 3 training epochs, the Adam optimizer, a weight decay of 0.00131, a warmup ratio of 0.156, and a dropout rate of 0.120.
An importance analysis identified dropout rate as the most influential hyperparameter, accounting for 47.57% of the performance variation. Batch size and learning rate followed with contributions of 17.71% and 17.69%, respectively. Other hyperparameters had comparatively lower influence: warmup ratio (6.19%), weight decay (5.22%), number of epochs (2.82%), and optimizer choice (2.79%).
The optimal configuration outperformed the worst-performing trial (validation accuracy of 0.7888) by 4.91% and exceeded the average trial performance (validation accuracy of 0.7998) by 3.46%. The final model, trained with these optimal hyperparameters, achieved a validation accuracy of 0.8004.
The full optimization process required approximately 136 min of computational time.
3.2.6. Fine-Tuning and Predictive Analysis of GPT Models
Unlike SVM, Random Forest, Logistic Regression, and BERT models—which were trained on Google Colab using a dedicated CPU/GPU—GPT models, being closed-source, were fine-tuned and deployed for predictions via the OpenAI API. A specialized class was implemented to manage API connectivity, construct prompts, process model responses, and generate JSONL files necessary for the fine-tuning process.
For a LLM to generate meaningful text, an appropriately structured prompt must be designed to effectively guide the model while optimizing token usage and minimizing costs. To achieve this, well-established prompt engineering strategies were employed (K. Zhang et al., 2024), including the following:
- Model-Agnostic Content Design: The prompt was formulated to be adaptable across different LLM architectures, ensuring that it was not reliant on any specific model framework. This approach enabled seamless integration with multiple LLMs by emphasizing clear task communication with contextually relevant instructions.
- Structured Output for Enhanced Accessibility: To ensure both human readability and machine interpretability, the response format adhered to standardized coding and accessibility principles. The output was structured in compliance with the JSON standard, facilitating logical organization and seamless processing by automated systems.
Following iterative testing and refinement across various LLMs, a final prompt was developed that consistently yielded outputs in the desired format. This optimized prompt structure enhanced both human comprehension and model efficiency. The finalized version is presented in Listing 1.
| Listing 1. Model-agnostic prompt. | |||
| conversation.append({ | (1) | ||
| ‘role’: ’user’, ‘content’: | |||
| ‘You are an AI assistant specializing in financial sentiment classification. Your task is to analyze each financial sentence and classify it as negative, positive, or neutral. Provide your final classification in the following JSON format without explanations: {“Sentiment”: “sentiment_tag”}}. \nFinancial sentence: …’ | |||
| }) | |||
With the finalized prompt, an iterative process was conducted in which both the GPT-4o and GPT-4o-mini models were prompted to generate predictions for the test set. These predictions were made solely based on the models’ pre-existing knowledge acquired during their pre-training phase, without additional task-specific fine-tuning at this stage. The models performed zero-shot classification, assigning sentiment labels to each sentence in the test set based on its inferred sentiment polarity. The predictions were returned in JSON format, processed using a dedicated method, and stored in a separate column within the test set file. Additionally, the response time for each prediction was measured and recorded in a distinct column for each model.
Following this initial prediction phase, the base models underwent fine-tuning using the same labeled training and validation datasets previously employed for the SVM and BERT models. However, unlike the earlier models, which utilized encoded sentiment labels (0 for negative, 1 for positive, and 2 for neutral), the GPT models were fine-tuned using the actual sentiment text labels (“negative”, “positive”, and “neutral”).
To facilitate the fine-tuning process, two JSONL-formatted files were generated by iterating through the training and validation sets to create prompt-response pairs. These structured pairs were stored within the same JSONL files, as illustrated in Listing 2. Once the files were prepared, they were uploaded to OpenAI’s user interface, where the desired models were selected for fine-tuning.
| Listing 2. Prompt and completion pairs—JSONL files. | ||
| {“messages”: [ | (2) | |
| {“role”: “system”,”content”: “You are an AI assistant specializing in financial sentiment classification.”}, {“role”: “user”, “content”: “You are an AI assistant specializing in financial sentiment classification. Your task is to analyze each financial sentence and classify it as negative, positive, or neutral. Provide your final classification in the following JSON format without explanations: {\”Sentiment\”: \”sentiment_tag\”}}. \nFinancial sentence: …”}, {“role”: “assistant”, “content”: “{\”Sentiment\”: \”neutral\”}”} | ||
| ]} | ||
While OpenAI offers users the flexibility to manually configure hyperparameters during the fine-tuning process, our study opted to use the default hyperparameter settings provided by the platform. This decision was driven by practical considerations, including time and resource constraints, which made exhaustive hyperparameter tuning unfeasible. The default configuration included training for three epochs, utilizing a batch size of three, and applying a learning rate multiplier of 1.8. These defaults, while seemingly generic, are likely the product of OpenAI’s internal optimization processes. It is plausible that OpenAI employs an initial warm-up or adaptive tuning phase—without requiring user intervention—to identify baseline hyperparameter values that are effective across a range of datasets and tasks. As such, the defaults are not arbitrary, but rather informed choices that can serve as a solid starting point for many applications.
For production-level implementations or research demanding higher performance, users may still benefit from conducting dedicated hyperparameter optimization tailored to their specific datasets and objectives.
The fine-tuning process for the GPT-4o model took 3621 s and incurred a training cost of $12.83, resulting in a training loss of 0.0016 and a validation loss of 0.0014. In comparison, fine-tuning the GPT-4o-mini model took 2054 s at a cost of $1.54, with a training loss of 0.0002 and a validation loss of 0.0053.
Upon completing the fine-tuning process, the newly fine-tuned models were employed to generate predictions for the test set. Similar to the initial predictions, both the sentiment classifications and the response times were recorded in the test set file for further analysis.
To uphold our dedication to open science and impartial research, we have released our entire codebase as an open-source project on GitHub under the MIT license (Nasiopoulos et al., 2025). This enables researchers and developers to reproduce, build upon, and expand our work freely.
4. Results
In Section 3, a comprehensive examination of the methodology used to implement and fine tune the transformer models GPT and BERT was conducted, along with the hyperparameter tuning strategies employed for training the SVM, Random Forest, and Logistic Regression algorithms in the context of financial sentiment analysis. This section provides a comparative analysis of all six models, focusing on their performance metrics, prediction time, and computational cost. The evaluation metrics for the predictions, both before and after fine-tuning, are summarized in Table 2.
Table 2.
Comparison of model performance metrics.
4.1. Zero-Shot Evaluation of GPT-4o and GPT-4o-Mini
Both GPT-4o and GPT-4o-mini initially underwent a zero-shot evaluation—that is, they were tested on the financial sentiment classification task without any domain-specific fine-tuning. GPT-4o achieved an accuracy of 0.7984, a precision of 0.8171, a recall of 0.7984, and an F1-score of 0.7997. GPT-4o-mini attained slightly lower but still robust results: 0.7752 for accuracy, 0.7909 for precision, 0.7752 for recall, and 0.7766 for F1.
These findings suggest that, even in a zero-shot setting, large language models pre-trained on general data can successfully infer context and domain-specific indicators for sentiment classification. However, the observed disparity in performance between GPT-4o and GPT-4o-mini likely reflects the diminished parameter capacity of GPT-4o-mini and, consequently, a slightly less comprehensive general understanding of the language intricacies in the financial domain. Nonetheless, both models showed strong baseline capabilities, highlighting the benefits of extensive pre-training on diverse language tasks.
4.2. Post Fine-Tuning Evaluation
After the zero-shot evaluation, GPT-4o and GPT-4o-mini were fine-tuned on a financial sentiment dataset. Both models exhibited substantial performance improvements. GPT-4o improved its accuracy from 0.7984 to 0.8779 (a 9.96% improvement), increasing its precision, recall, and F1-score to around the 0.88 range. GPT-4o-mini’s accuracy improvement was even greater, rising from 0.7752 to 0.8779 (a 13.25% improvement), and its precision, recall, and F1-scores also converged around 0.8770–0.8780.
These outcomes demonstrate that domain-specific fine-tuning can effectively augment language models’ capacity to contextualize specialized terminology and sentiment cues within financial texts.
In parallel, BERT-based models (BERT and FinBERT) and traditional machine learning algorithms (SVM, Random Forest, and Logistic Regression) were intensively optimized through Bayesian hyperparameter tuning. Among the BERT-based models, BERT achieved 0.812 accuracy (precision = 0.815, recall = 0.812, F1 = 0.8116), slightly outperforming FinBERT’s 0.8004 across all metrics. The gap between BERT and FinBERT may reflect differences in how each model’s pretraining interacts with this particular dataset.
Furthermore, the traditional algorithms recorded lower performance, with accuracies in the 0.64–0.65 range, underscoring the relative difficulty of capturing nuanced sentiment cues without deeper language modeling or more training data. (It is important to note that this was a few-shot scenario with only 1,500 training samples and 516 validation samples.).
Finally, it is crucial to compare the results of the LLMs with those of the BERT models. Specifically, the fine-tuned LLMs are 8.11% more accurate than the fine-tuned BERT model and 9.68% more accurate than the fine-tuned FinBERT model. This suggests that generative models may have an advantage over BERT for this specific sentiment classification task, likely due to their higher parameter count. BERT is pre-trained on approximately 110 million parameters (Pretrained models, 2025), while GPT-4o is assumed to have been pre-trained on a significantly larger number of parameters—8 billion for GPT-4o Mini and 1.8 trillion for GPT-4o (Howarth, 2025)—which likely contributes to its superior performance.
4.2.1. GPT-4o vs. GPT-4o-Mini
Post fine-tuning, GPT-4o and GPT-4o-mini achieved virtually identical accuracies (0.8779 each), highlighting GPT-4o-mini’s strong potential to match its larger counterpart despite its reduced parameter count and lower computational cost. This comparable performance suggests that, within the domain of financial sentiment classification, smaller architectures can effectively learn domain-specific knowledge when supported by high-quality training data and well-optimized hyperparameter settings.
The near-identical performance metrics (accuracy, precision, recall, and F1 score) also indicate a similar distribution of misclassifications between the two models, implying that GPT-4o-mini was capable of capturing class-specific cues related to financial sentiment.
When examining class-specific F1 scores, GPT-4o-mini’s smaller parameter capacity may result in narrower margins for detecting subtle sentiments, leading to minor misclassification differences—particularly in borderline cases such as neutral statements exhibiting faintly positive or negative traits.
Finally, comparing the accuracy improvement after fine-tuning, we observed a 9.96% increase for GPT-4o and an even greater improvement of 13.25% for GPT-4o-mini. This could suggest that the larger model, GPT-4o, may begin to exhibit signs of overfitting beyond a certain point, whereas the smaller model continues to benefit more significantly from fine-tuning.
4.2.2. BERT vs. Finbert
A notable observation is that BERT surpassed FinBERT, despite the latter having been pretrained explicitly on financial corpora. Several factors might explain this outcome:
- Dataset size and diversity: BERT’s pretraining on a massive corpus of general text may give it robust semantic coverage, which can be advantageous for recognizing nuanced linguistic structures present in financial texts.
- Quality of financial pretraining: Although FinBERT is adapted for financial language, the specific pretraining corpus and domain coverage may not align perfectly with the style or topics in the fine-tuning dataset, leading to less benefit than expected.
- Adaptability limitations: BERT’s broader pretraining might enable greater flexibility and generalization during fine-tuning, whereas FinBERT, though domain-specific, may have overemphasized certain financial phraseologies that do not generalize fully to the test set.
Interestingly, FinBERT’s metrics (accuracy, precision, recall, and F1 of 0.8004) are all identical, indicating that its probability thresholds or label distributions yielded an even classification performance across each of the three sentiment classes. Identical metrics could suggest that the model is not disproportionately overfitting one class at the expense of another; nonetheless, it also indicates that while FinBERT performed evenly, it did not achieve the higher peaks in class-specific performance that BERT reached.
4.2.3. Traditional Machine Learning Algorithms
Among classical algorithms, SVM, Random Forest, and Logistic Regression provided accuracies around 0.6453–0.6531. Although these models benefited from rigorous Bayesian hyperparameter tuning, they lagged behind deep learning approaches. This discrepancy likely stems from the inability of simpler algorithms to capture complex semantic and contextual features present in financial text—especially in few-shot scenarios with limited training data. Moreover, feature engineering for sentiment classification in financial contexts can be challenging, and deeper architectures inherently learn more nuanced representations. Consequently, while these traditional methods present lower computational cost and interpretability advantages, they fall short in accuracy and other performance metrics relative to LLMs and BERT-based models in this domain.
4.3. Additional Insights
4.3.1. Performance Differences Across Sentiment Classes
Although the overall metrics suggest consistently high performance for GPT-4o and GPT-4o-mini, class-specific analysis (from precision and recall values across positive, negative, and neutral) reveal minor divergences in how each model handles borderline cases. Typically, neutral classes in financial text can be harder to label, as subtle positive or negative indicators might be context dependent. The results here imply that fine-tuning resolves many of these ambiguities effectively.
4.3.2. Model Robustness and Class Balance
Both GPT-4o variants showed robust handling of the three sentiment categories. The fine-tuning data, as mentioned in the Materials and Methods section, were balanced, mitigating the risk of skewing toward a dominant class. Neither SVM nor Logistic Regression proved as resilient, highlighting the importance of nuanced feature extraction for imbalanced or subtle sentiment distinctions.
4.3.3. Overfitting and Underfitting Considerations
The significant jump in performance between zero-shot and fine-tuned states for GPT-4o and GPT-4o-mini underscores the value of domain-specific adaptation. The sustained high accuracy and F1-scores (near 0.88) also suggest that neither model displayed obvious overfitting in this context; similarly, stable Bayesian-optimized performance for BERT and FinBERT indicates suitable hyperparameter configurations that balance learned representations of multiple sentiment classes.
4.3.4. Computational Trade-Offs
An important practical advantage of GPT-4o-mini is that it achieves nearly the same performance as GPT-4o at reduced computational overhead. Organizations with limited computational resources or real-time inference constraints may find GPT-4o-mini more suitable. However, in contexts where the marginal gains in performance are paramount, GPT-4o (or another large-scale LLM) may be preferable, especially if future fine-tuning or domain expansions are anticipated.
In summary, the results highlight the efficacy and adaptability of large language models and, unexpectedly, the general BERT model over FinBERT in the domain of financial sentiment classification. The comparable performance of GPT-4o-mini and GPT-4o underscores the value of parameter-efficient architectures, whereas the relatively modest scores of traditional ML methods confirm the advantages of deep contextualized embeddings for complex sentiment analysis tasks.
4.4. Prediction Time and Computational Cost Analysis
The evaluation of prediction time and computational cost is critical in assessing the practicality of deploying these models in real-world financial sentiment analysis applications. The mean prediction time, total processing time for 516 sentences, and associated prediction costs provide a comprehensive perspective on models’ efficiency. The documented time and cost results during the prediction process are presented in Table 3.
Table 3.
Predictions: Time and Cost.
The base GPT-4o model exhibited a mean prediction time of 1.26 s per sentence, resulting in a total processing time of 650.92 s for the entire dataset, with a prediction cost of 0.17. The fine-tuned GPT-4o model (ft:gpt-4o) had a slightly longer mean prediction time of 1.89 s, leading to a total processing time of 976.28 s and a higher prediction cost of 0.25. The increased time and cost for the fine-tuned GPT-4o model suggest that while fine-tuning improves performance metrics, it also increases computational demands, likely due to the additional parameters and optimizations introduced during training.
GPT-4o-mini, designed for efficiency, demonstrated significantly faster prediction times and lower costs. The base version (base:gpt-4o-mini) achieved a mean prediction time of 0.73 s, with a total processing time of 374.83 s and a minimal cost of 0.02. The fine-tuned version (ft:gpt-4o-mini) had a slightly longer mean prediction time of 0.78 s and a total processing time of 404.15 s, with only a marginal increase in prediction cost to 0.03. The fine-tuned GPT-4o-mini model achieved a balance between efficiency and performance, making it a viable option for applications requiring lower latency and cost-effective processing.
The fine-tuned BERT and FinBERT models exhibited significantly lower prediction times compared to the GPT-based models. Both models had an average prediction time of 0.01 s per sentence, resulting in a total processing time of approximately 5.94 and 6.05 s, respectively. Notably, these models incurred no significant prediction costs, making them highly efficient for large-scale financial sentiment analysis tasks where cost and time constraints are critical. However, despite their efficiency, their performance metrics remained lower than those of the fine-tuned GPT-4o models, indicating a trade-off between predictive power and computational efficiency.
Logistic Regression was the fastest model (mean prediction time: 0.0008 s), followed by the SVM classifier (0.002 s) and Random Forest (0.04 s). The Logistic Regression model achieved accuracy comparable to the other models, completing sentiment analysis predictions for 516 sentences in just 0.43 s. Like the BERT models, the traditional models incurred no prediction cost, making them the most computationally efficient option. However, their significantly lower accuracy, precision, recall, and F1-score indicate that this speed comes at the cost of reduced effectiveness in sentiment classification.
Overall, the results highlight that while fine-tuned GPT-4o models deliver the highest accuracy, they come with increased computational time and cost. GPT-4o-mini offers a compelling alternative with competitive performance and lower resource consumption. The BERT models present a highly efficient and cost-effective solution but do not reach the same level of predictive performance as the fine-tuned GPT models. Traditional models remain the most lightweight option but are not suitable for high-accuracy sentiment classification tasks. The choice of model ultimately depends on the balance between accuracy, efficiency, and cost considerations required for a given financial application.
5. Discussion
In the preceding sections, we explored the financial sentiment analysis and classification capabilities of two LLMs from the Omni family, alongside a BERT model and FinBERT NLP models, as well as traditional models such as SVM, Random Forest, and Logistic Regression. We first evaluated the base GPT models in a zero-shot framework, where they predicted the sentiment of test set sentences—positive, negative, or neutral—without any prior task-specific training. Following this, we fine-tuned the models using few-shot learning, optimizing them on dedicated training and validation sets. For the NLP and traditional models, we performed hyperparameter tuning, selecting the best configurations after 100 trials. Once fine-tuned, the models were prompted to make sentiment predictions on the same test set, and their performance was analyzed in detail. In this section, we leverage these classification outcomes to derive insights from our research findings.
5.1. Heatmap Analysis of Sentiment Classification
To better understand the classification results, visualizations were deemed necessary to highlight the strengths and limitations of each model across different sentiment categories. For this purpose, heatmaps were generated (Figure 1 and Figure 2). Heatmaps are powerful visualization tools that facilitate classification analysis by providing an intuitive and comprehensive representation of model performance. Heatmaps effectively depict data distributions, feature correlations, and classification outcomes using color gradients, enabling researchers to identify complex patterns more easily (S. Zhao et al., 2014). In classification tasks, heatmaps are commonly used for confusion matrices, feature importance analysis, and activation mapping in deep learning models, assisting in the identification of misclassifications, feature relevance, and decision boundaries. The diagonal line in these heatmaps represents correct classifications, where the predicted sentiment matches the actual sentiment. In the context of confusion matrices, this diagonal is commonly referred to as the “True Positives” for each category.
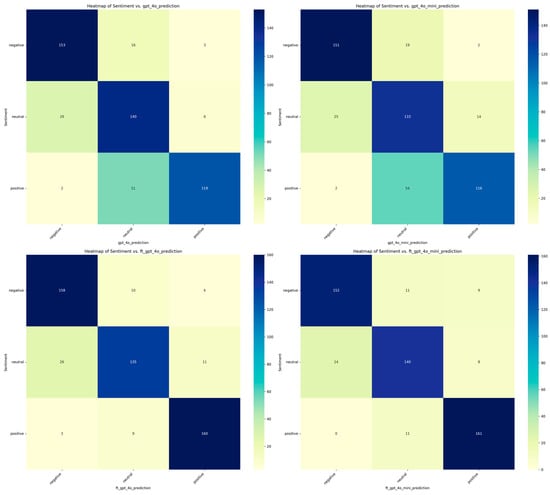
Figure 1.
Comparison of GPT model predictions before and after fine-tuning with actual categories using heatmaps.

Figure 2.
Comparison of BERT, FinBERT and traditional model predictions with actual categories using heatmaps.
Examining the results of both the base and fine-tuned GPT models (Figure 1), we observe a recurring challenge in accurately identifying neutral sentiment, with higher misclassification rates concentrated in this category. Notably, the fine-tuned GPT-4o model misclassified 26 neutral samples as negative, indicating a tendency to interpret ambiguous or balanced language with a pessimistic bias. Interestingly, the smaller fine-tuned GPT-4o-mini model performed better in this regard, misclassifying only 24 neutral instances as negative. This suggests that, despite having fewer parameters, GPT-4o-mini may have learned to generalize more effectively in certain nuanced cases.
In contrast, the base GPT models, operating in a zero-shot setting, exhibited a different pattern of misclassification—struggling primarily with positive sentiment detection. These models frequently mislabeled more than 50 positive samples as neutral, reflecting their limited contextual understanding without task-specific fine-tuning. This result highlights the importance of domain adaptation in improving sentiment classification performance.
As discussed in Section 4.3.1, neutral sentiment in financial texts poses unique challenges due to its often-subtle and context-dependent nature. Statements that appear neutral on the surface may contain implicit positive or negative cues, which can easily be overlooked without deep contextual comprehension. This complexity may explain why both base and fine-tuned models, despite their differences, consistently showed higher error rates when classifying neutral examples. These findings reinforce the need for more sophisticated modeling techniques or richer annotation strategies when dealing with nuanced financial sentiment.
Figure 2 presents confusion matrix heatmaps comparing the predicted versus actual sentiment categories—negative (0), positive (1), and neutral (2)—for five fine-tuned models: BERT, FinBERT, SVM, Random Forest, and Logistic Regression. These visualizations help us understand how well each model performs in capturing the nuanced emotional tone within financial texts.
Starting with the fine-tuned BERT model, we observe strong overall classification performance, with 147 negative, 144 positive, and 128 neutral samples correctly predicted. However, a notable source of error lies in the misclassification of neutral sentiment. Specifically, BERT incorrectly classified 28 neutral instances as negative, reflecting a possible sensitivity to cautious or reserved language often found in financial texts. Additionally, 12 positive samples were predicted as neutral, and 14 negative samples were labeled as positive. While these errors are relatively limited, they highlight the model’s occasional difficulty in distinguishing between moderate and strongly polarized sentiments—particularly when subtle linguistic cues are involved.
The FinBERT model, fine-tuned on the same dataset, performs slightly better in managing these ambiguities. As a financial-domain-specific transformer, FinBERT correctly identified 134 negative, 140 positive, and 139 neutral samples. Compared to BERT, it made fewer mistakes when handling neutral sentiment, misclassifying 23 neutral samples as negative and 19 positive samples as neutral. Interestingly, 17 negative samples were also predicted as neutral, suggesting that FinBERT occasionally underestimates the polarity of clearly negative expressions. Nonetheless, its improved handling of neutral sentiment suggests that domain-specific pretraining helps reduce confusion in more context-dependent categories.
Moving on to the SVM model, we see a noticeable drop in performance, particularly with regard to sentiment separation. SVM correctly predicted only 98 negative and 103 positive samples, while neutral classification fared better with 132 correct predictions. However, the model frequently confused sentiment classes: 47 positive samples were labeled as neutral, and 47 negative instances were labeled as neutral. Additionally, 27 negative samples were predicted as positive, and 25 neutral samples were misclassified as negative. These results suggest that the SVM struggled with more complex, non-linear relationships in the data, especially when tasked with discerning sentiment in balanced or indirect phrasing.
The Random Forest classifier offers slightly improved results over SVM, with 107 negative, 110 positive, and 120 neutral predictions made correctly. Despite this improvement, the confusion between neutral and the other sentiment classes remains evident. For example, 32 neutral samples were labeled as negative, while 38 negative samples were misclassified as neutral. Likewise, 34 positive samples were wrongly classified as neutral, showing that, while the ensemble approach improves robustness, it still lacks the semantic depth to accurately parse the subtle cues of financial sentiment—particularly in edge cases where polarity is implied rather than directly stated.
Lastly, Logistic Regression, a simpler linear model, shows the most significant struggles with sentiment classification. It correctly predicted 96 negative, 107 positive, and 132 neutral samples, but made extensive misclassifications in the negative and positive categories. Specifically, 49 negative and 42 positive samples were labeled as neutral, while 27 negative samples were misclassified as positive. This suggests that the model tends to default to neutral when faced with uncertainty, reflecting its limited expressive capacity for handling complex sentence structures or implied sentiment.
In summary, these findings highlight a consistent trend across models: neutral sentiment remains the most difficult category to classify accurately. This difficulty is particularly pronounced in models not specifically trained on financial data, as subtle expressions or hedged language common in finance often blur the line between neutrality and mild polarity. FinBERT’s performance reinforces the value of domain-specific pretraining, while traditional machine learning models like SVM and Logistic Regression illustrate the limitations of less context-aware architectures in capturing sentiment nuance.
5.2. Research Findings and Limitations
The findings presented in Section 4 strongly indicate the superiority of transformer-based models over traditional classifiers. Specifically, transformer-based models (BERT and FinBERT) demonstrated a mean higher accuracy by 24.18% over traditional models (SVM, RF, LR). While the traditional models achieved a mean accuracy of only 64.92%, it is important to contextualize this result. Given that a random classification approach would yield a probability of correct classification at 1/3 (or 30%), the classifiers significantly outperform random selection, confirming its viability despite their inferiority to transformer-based approaches.
Transformer-based models have fundamentally reshaped AI, particularly in NLP. The BERT model has been widely employed across various classification and NLP tasks, consistently demonstrating effectiveness and cost efficiency. However, the advent of generative AI has further advanced the NLP field, with LLMs exhibiting superior or at least comparable efficiency to traditional NLP models. This efficiency is primarily attributed to their extensive pre-training on billions of parameters, enabling them to generalize across diverse tasks. Notably, their true advantage lies not only in this large-scale pre-training but also in their capacity for fine-tuning, allowing them to adapt effectively to tasks beyond their original training scope.
For the purposes of this study, base LLMs were found to be less effective than fine-tuned BERT models. However, after fine-tuning, LLMs surpassed BERT models, achieving a greater mean accuracy of 9%. This performance gain, however, comes at a substantial cost. Fine-tuning the GPT-4o model was found to be 558.26 times more expensive than fine-tuning a BERT model, while fine-tuning GPT-4o-mini was 66.95 times more costly than BERT. Training time is also a critical consideration; the GPT-4o model required 3,621 s for fine-tuning, whereas the BERT model completed fine-tuning 97.39% faster. The discrepancy in training time is even more pronounced when comparing LLMs with classifiers. A similar pattern was observed in the prediction phase, where LLMs incurred higher costs and longer prediction times compared to both BERT and traditional models.
Despite these challenges, LLMs hold significant potential, particularly when optimized through parameter-efficient fine-tuning techniques. In this study, both BERT and traditional models underwent thorough hyperparameter tuning following the Bayesian optimization technique to determine the optimal hyperparameters. However, for LLMs, default hyperparameters were used during fine-tuning. It is highly likely that employing a comparable hyperparameter tuning approach for LLMs would yield even better performance results. Hyperparameter optimization is especially critical for real-world applications, where performance is paramount. However, such optimization incurs substantial costs in LLMs, as each hyperparameter combination requires a separate fine-tuning job. Furthermore, techniques such as early stopping, which can improve efficiency in traditional machine learning models, are often unavailable in closed-source API-based LLMs.
Given their performance and adaptability, the findings of this study have direct implications for real-world applications, especially in the financial technology sector. Transformer-based models like BERT and fine-tuned LLMs can be integrated into fintech platforms to automate sentiment analysis of news headlines, regulatory updates, and earnings announcements. This can provide real-time insights to support risk assessment and investment decisions. Additionally, investor dashboards could leverage these models to highlight key market signals, flag sentiment shifts, or generate automated summary reports, enhancing the decision-making pipeline for both institutional and retail investors. The tradeoff between performance and cost (particularly for LLMs) may guide implementation choices, with smaller platforms favoring BERT variants and larger, resource-rich institutions potentially benefiting from LLMs’ higher accuracy.
While this research offers valuable insights into the comparative performance of traditional classifiers, transformer-based models, and LLMs, it is important to acknowledge its limitations. First, the study is confined to the classification of financial sentiment from textual data, which may not generalize to other NLP tasks or domains. Second, only a specific subset of models and datasets were explored—performance might vary with different architectures (e.g., RoBERTa, T5) or data sources (e.g., social media, full articles). Third, economic constraints played a central role in model selection and tuning, particularly for LLMs, where extensive hyperparameter tuning or exploration of alternative fine-tuning techniques (e.g., LoRA, adapters) was not feasible due to cost and API limitations. Additionally, the use of closed-source models like GPT-4o limits transparency in understanding architectural details and introduces dependencies on external APIs, which may pose challenges in production environments. Finally, ethical and regulatory implications of using LLMs in financial decision-making—such as explainability and data privacy—were not addressed and remain areas for future exploration.
6. Conclusions
Our research findings highlight the evolving landscape of sentiment classification in the financial domain, with each model class offering unique strengths and trade-offs. Transformer-based models, particularly FinBERT, demonstrated a notable advantage in handling neutral sentiments, making them especially useful for nuanced financial text where neutrality often carries significant meaning. Traditional classifiers, while outperformed by modern architectures in terms of accuracy, remain viable alternatives in scenarios where larger training datasets are available. Their lower computational costs and faster training and inference times make them attractive options for real-time or large-scale deployment under budget constraints.
On the other hand, LLMs, especially fine-tuned versions of GPT-4o, consistently achieved the highest accuracy, outperforming all other models by a substantial margin. Their strength is particularly evident in few-shot learning scenarios, where data are scarce and generalization is crucial. However, this performance comes at a high price—LLMs incur significant computational costs and are subject to multiple limitations, including API restrictions, lack of transparency, and limited support for efficient training strategies.
Overall, these findings suggest a tiered model selection strategy depending on application context: traditional models for cost-sensitive, high-volume tasks; transformer-based models like BERT and FinBERT for balanced performance and interpretability; and LLMs for high-stakes, data-scarce environments where accuracy is paramount. Future research should explore parameter-efficient fine-tuning techniques and cost-aware optimization strategies to bridge the performance-efficiency gap and enable broader adoption of LLMs in production-grade financial applications.
Author Contributions
Conceptualization, D.K.N., K.I.R., D.P.S., K.T. and P.R.; methodology, D.K.N., K.I.R. and D.P.S.; software, K.I.R.; validation, D.K.N., K.I.R., D.P.S., K.T. and P.R.; formal analysis, D.K.N., K.I.R., D.P.S. and K.T.; investigation, D.K.N., K.I.R. and D.P.S.; resources, D.K.N., K.I.R., D.P.S., K.T. and P.R.; data curation, D.K.N., K.I.R., D.P.S. and K.T.; writing—original draft preparation, D.K.N., K.I.R. and D.P.S.; writing—review and editing, D.K.N., K.I.R., D.P.S., K.T. and P.R.; visualization, D.K.N., K.I.R. and D.P.S.; supervision, D.K.N., K.I.R., D.P.S. and K.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Agarwal, P., & Gupta, A. (2024, April 24–26). Strategic business insights through enhanced financial sentiment analysis: A fine-tuned llama 2 approach. 7th International Conference on Inventive Computation Technologies, ICICT 2024 (pp. 1446–1453), Kathmandu, Nepal. [Google Scholar] [CrossRef]
- Arami, M., Balina, S., Chang, V., Kim, J., Kim, H.-S., & Choi, S.-Y. (2023). Forecasting the S&P 500 index using mathematical-based sentiment analysis and deep learning models: A FinBERT transformer model and LSTM. Axioms, 12(9), 835. [Google Scholar] [CrossRef]
- Baghavathi Priya, S., Kumar, M., Nitheesh Prakash, J. D., & Krithika, N. (2025, February 5–7). Advanced financial sentiment analysis using FinBERT to explore sentiment dynamics. 3rd International Conference on Intelligent Data Communication Technologies and Internet of Things, IDCIoT 2025 (pp. 889–897), Bengaluru, India. [Google Scholar] [CrossRef]
- Consoli, S., Barbaglia, L., & Manzan, S. (2022). Fine-grained, aspect-based sentiment analysis on economic and financial lexicon. Knowledge-Based Systems, 247, 108781. [Google Scholar] [CrossRef]
- Daudert, T. (2021). Exploiting textual and relationship information for fine-grained financial sentiment analysis. Knowledge-Based Systems, 230, 107389. [Google Scholar] [CrossRef]
- Deng, X., Bashlovkina, V., Han, F., Baumgartner, S., & Bendersky, M. (2023, April 30–May 4). LLMs to the moon? Reddit market sentiment analysis with large language models. ACM Web Conference 2023—Companion of the World Wide Web Conference, WWW 2023 (pp. 1014–1019), New York, NY, USA. [Google Scholar] [CrossRef]
- Dmonte, A., Ko, E., & Zampieri, M. (2024, December 15–18). An evaluation of large language models in financial sentiment analysis. 2024 IEEE international Conference on Big Data (BigData) (pp. 4869–4874), Washington DC, USA. [Google Scholar] [CrossRef]
- Du, K., Xing, F., & Cambria, E. (2023). Incorporating multiple knowledge sources for targeted aspect-based financial sentiment analysis. ACM Transactions on Management Information Systems, 14(3), 23. [Google Scholar] [CrossRef]
- Du, K., Xing, F., Mao, R., & Cambria, E. (2024). Financial Sentiment analysis: Techniques and applications. ACM Computing Surveys, 56(9), 220. [Google Scholar] [CrossRef]
- Duan, G., Yan, S., & Zhang, M. (2024). A hybrid neural network model for sentiment analysis of financial texts using topic extraction, pre-trained model, and enhanced attention mechanism methods. IEEE Access, 12, 98207–98224. [Google Scholar] [CrossRef]
- Farimani, S. A., Jahan, M. V., Fard, A. M., & Haffari, G. (2021, October 6–9). Leveraging latent economic concepts and sentiments in the news for market prediction. 2021 IEEE 8th International Conference on Data Science and Advanced Analytics, DSAA 2021, Porto, Portugal. [Google Scholar] [CrossRef]
- Fatouros, G., Soldatos, J., Kouroumali, K., Makridis, G., & Kyriazis, D. (2023). Transforming sentiment analysis in the financial domain with ChatGPT. Machine Learning with Applications, 14, 100508. [Google Scholar] [CrossRef]
- Gutiérrez-Fandiño, A., Kolm, P. N., Alonso, M. N. I., & Armengol-Estapé, J. (2021). FinEAS: Financial embedding analysis of sentiment. Journal of Financial Data Science, 4(3), 45–53. [Google Scholar] [CrossRef]
- Hajek, P., & Munk, M. (2023). Speech emotion recognition and text sentiment analysis for financial distress prediction. Neural Computing and Applications, 35(29), 21463–21477. [Google Scholar] [CrossRef]
- Howarth, J. (2025). Number of parameters in GPT-4 (latest data). Available online: https://explodingtopics.com/blog/gpt-parameters (accessed on 20 April 2025).
- Huang, A. H., Wang, H., & Yang, Y. (2023). FinBERT: A large language model for extracting information from financial text. Contemporary Accounting Research, 40(2), 806–841. [Google Scholar] [CrossRef]
- Hugging Face. (2025). bert-base-uncased hugging face. Available online: https://huggingface.co/bert-base-uncased (accessed on 20 April 2025).
- Leippold, M. (2023). Sentiment spin: Attacking financial sentiment with GPT-3. Finance Research Letters, 55, 103957. [Google Scholar] [CrossRef]
- Liu, Z., Huang, D., Huang, K., Li, Z., & Zhao, J. (2020, July 11–17). FinBERT: A pre-trained financial language representation model for financial text mining. Twenty-Ninth International Joint Conference on Artificial Intelligence Special Track on AI in FinTech, Yokohama, Japan. Available online: https://dl.acm.org/doi/abs/10.5555/3491440.3492062 (accessed on 20 April 2025).
- Malo, P., & Sinha, A. (2024). takala/financial_phrasebank datasets at hugging face. Available online: https://huggingface.co/datasets/takala/financial_phrasebank (accessed on 20 April 2025).
- Malo, P., Sinha, A., Korhonen, P., Wallenius, J., & Takala, P. (2014). Good debt or bad debt: Detecting semantic orientations in economic texts. Journal of the Association for Information Science and Technology, 65(4), 782–796. [Google Scholar] [CrossRef]
- Mathebula, M., Modupe, A., & Marivate, V. (2024). Fine-tuning retrieval-augmented generation with an auto-regressive language model for sentiment analysis in financial reviews. Applied Sciences, 14(23), 10782. [Google Scholar] [CrossRef]
- Nasiopoulos, D., Roumeliotis, K., Sakas, D., Toudas, K., & Reklitis, P. (2025). GitHub—Applied-AI-research-lab/financial-sentiment-analysis-and-classification-deep-learning-models. Available online: https://github.com/Applied-AI-Research-Lab/Financial-Sentiment-Analysis-and-Classification-Deep-Learning-Models (accessed on 20 April 2025).
- Pretrained models. (2025). Pretrained models—transformers 3.3.0 documentation. Available online: https://huggingface.co/transformers/v3.3.1/pretrained_models.html (accessed on 20 April 2025).
- Qian, C., Mathur, N., Zakaria, N. H., Arora, R., Gupta, V., & Ali, M. (2022). Understanding public opinions on social media for financial sentiment analysis using AI-based techniques. Information Processing & Management, 59(6), 103098. [Google Scholar] [CrossRef]
- Roumeliotis, K. I., Tselikas, N. D., & Nasiopoulos, D. K. (2024). LLMs and NLP models in cryptocurrency sentiment analysis: A comparative classification study. Big Data and Cognitive Computing, 8(6), 63. [Google Scholar] [CrossRef]
- Roumeliotis, K. I., Tselikas, N. D., & Nasiopoulos, D. K. (2025). Fake news detection and classification: A comparative study of convolutional neural networks, large language models, and natural language processing models. Future Internet, 17(1), 28. [Google Scholar] [CrossRef]
- Sbhatti. (2021). Financial sentiment analysis. Available online: https://www.kaggle.com/datasets/sbhatti/financial-sentiment-analysis (accessed on 20 April 2025).
- Shobayo, O., Adeyemi-Longe, S., Popoola, O., & Ogunleye, B. (2024). Innovative sentiment analysis and prediction of stock price using FinBERT, GPT-4 and logistic regression: A data-driven approach. Big Data and Cognitive Computing, 8(11), 143. [Google Scholar] [CrossRef]
- Sidogi, T., Mbuvha, R., & Marwala, T. (2021, October 17–20). Stock price prediction using sentiment analysis. Conference Proceedings—IEEE International Conference on Systems, Man and Cybernetics (pp. 46–51), Melbourne, Australia. [Google Scholar] [CrossRef]
- Sy, E., Peng, T.-C., Lin, H.-Y., Huang, S.-H., Chang, Y.-C., & Chung, C.-P. (2025). Ensemble BERT techniques for financial sentiment analysis and argument understanding with linguistic features in social media Analytics. Journal of Information Science and Engineering, 41(3), 579–599. [Google Scholar] [CrossRef]
- Štrimaitis, R., Stefanovič, P., Ramanauskaitė, S., & Slotkienė, A. (2021). Financial context news sentiment analysis for the lithuanian language. Applied Sciences, 11(10), 4443. [Google Scholar] [CrossRef]
- Todd, A., Bowden, J., & Moshfeghi, Y. (2024). Text-based sentiment analysis in finance: Synthesising the existing literature and exploring future directions. Intelligent Systems in Accounting, Finance and Management, 31(1), e1549. [Google Scholar] [CrossRef]
- Xiang, C., Zhang, J., Li, F., Fei, H., & Ji, D. (2022). A semantic and syntactic enhanced neural model for financial sentiment analysis. Information Processing & Management, 59(4), 102943. [Google Scholar] [CrossRef]
- Xing, F. (2024). Designing heterogeneous LLM agents for financial sentiment analysis. ACM Transactions on Management Information Systems, 16(5), 24. [Google Scholar] [CrossRef]
- Yang, J., Wang, Y., & Li, X. (2022). Prediction of stock price direction using the LASSO-LSTM model combines technical indicators and financial sentiment analysis. PeerJ Computer Science, 8, e1148. [Google Scholar] [CrossRef]
- Yang, Y., Christopher, M., UY, S., & Huang, A. (2020a). GitHub—yya518/FinBERT: A pretrained BERT model for financial communications. Available online: https://github.com/yya518/FinBERT (accessed on 20 April 2025).
- Yang, Y., Christopher, M., Uy, S., & Huang, A. (2020b, July 11–17). FinBERT: A pretrained language model for financial communications. Twenty-Ninth International Joint Conference on Artificial Intelligence Special Track on AI in FinTech, Yokohama, Japan. Available online: https://arxiv.org/abs/2006.08097v2 (accessed on 20 April 2025).
- Yekrangi, M., & Abdolvand, N. (2021). Financial markets sentiment analysis: Developing a specialized Lexicon. Journal of Intelligent Information Systems, 57(1), 127–146. [Google Scholar] [CrossRef]
- Zhang, B., Yang, H., & Liu, X.-Y. (2023). Instruct-FinGPT: Financial sentiment analysis by instruction tuning of general-purpose large language models. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Zhang, K., Zhou, F., Wu, L., Xie, N., & He, Z. (2024). Semantic understanding and prompt engineering for large-scale traffic data imputation. Information Fusion, 102, 102038. [Google Scholar] [CrossRef]
- Zhao, L., Li, L., Zheng, X., & Zhang, J. (2021, May 5–7). A BERT based sentiment analysis and key entity detection approach for online financial texts. 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design, CSCWD 2021 (pp. 1233–1238), Dalian, China. [Google Scholar] [CrossRef]
- Zhao, S., Guo, Y., Sheng, Q., & Shyr, Y. (2014). Advanced heat map and clustering analysis using Heatmap3. BioMed Research International, 2014(1), 986048. [Google Scholar] [CrossRef]
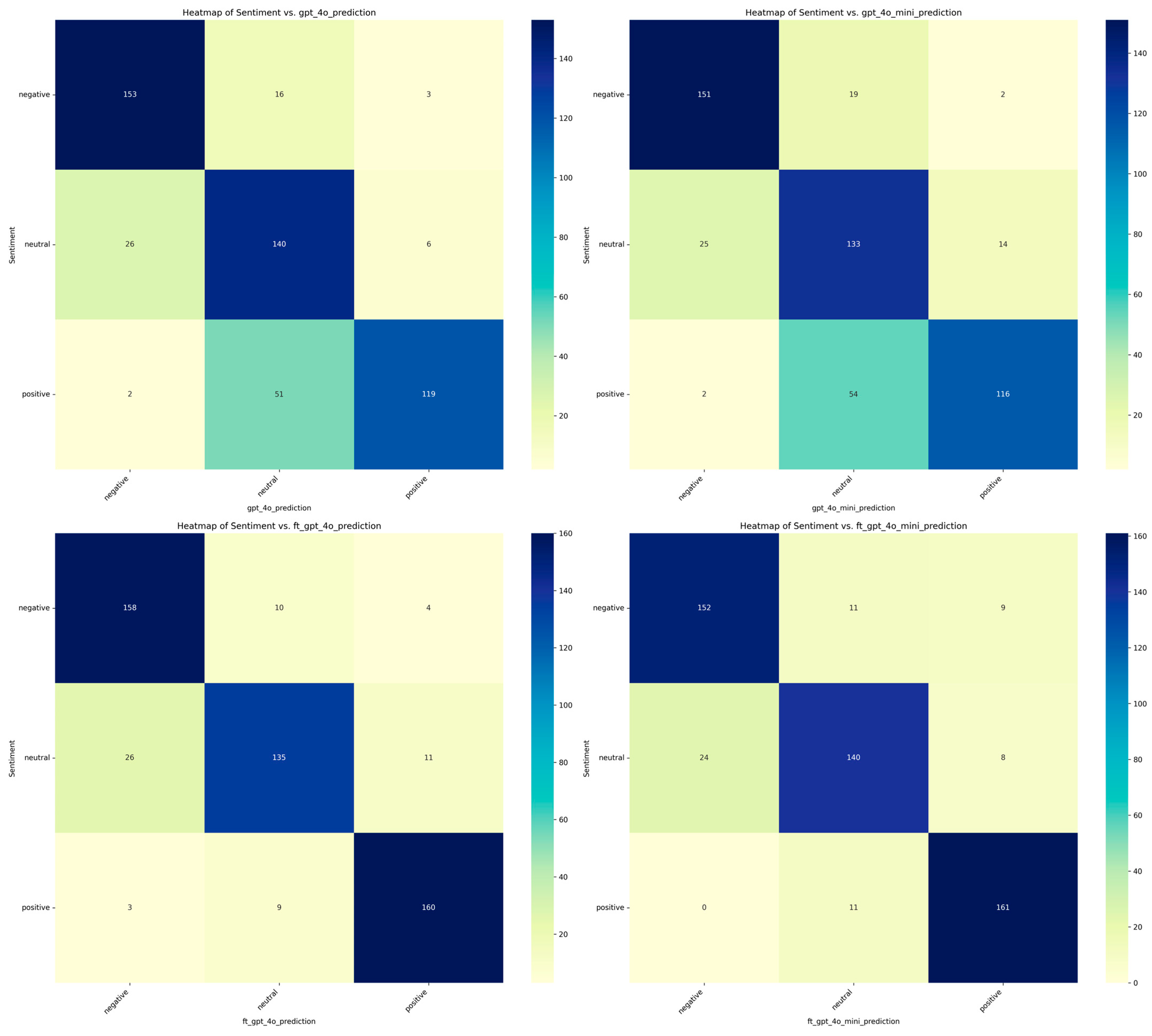

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).