

Using Deep Reinforcement Learning with Hierarchical Risk Parity for Portfolio Optimization


Abstract
1. Introduction
- The first, from the financial community, has received great praise and has been used successfully in recent years: Hierarchical Risk Parity (HRP) De Prado (2016) and a variation of it, Hierarchical Equal Risk Contribution (HERC) Raffinot (2018). We use the acronym HC hereon to refer to both of these hierarchical approaches.
- The second one is one of the most advanced machine learning techniques available today: Deep Reinforcement Learning Mnih et al. (2015). It has been used successfully in many domains, from video games to robotics, and has been shown able to learn complex tasks from scratch, without any prior knowledge of the environment. For more details on DRL and its general applications see Li (2017), for DRL in finance see Millea (2021); Mosavi et al. (2020).
- We use HRP and HERC models with much lower covariance estimation periods than used on other markets or than initially designed for Burggraf (2021); De Prado (2016). We use periods as low as 30 and up to 700 h for covariance estimation. These numbers are usually days or even months in the related literature.
- The whole system enables much larger periods for testing, without any retraining. In the literature they usually employ retraining after short periods of testing. In our case the testing periods (or out-of-sample as they are called in the financial community) are as long as the training period or even longer.
- The network architecture and engineering is minimal, as we use a simple feed-forward network with two hidden layers. This makes the whole system very easy to understand and holds the promise for significant enhancements.
2. Related Work
- minimum variance portfolio Bodnar et al. (2017); Clarke et al. (2011) aims at minimizing the variance by finding the minimum weight vector w to minimize
- maximum diversificationChoueifaty and Coignard (2008) defines a diversification ratio
- the risk parity solution Maillard et al. (2010) aims at solving a fixed point problem: with N the number of assets. An alternative formulation is to find w which minimizes
- hierarchical clustering approaches in a series of relatively recent papers. Several works have leveraged the idea of hierarchical clustering which we describe in more detail below.
- (i) if the return predictions deviate by even a small amount from the actual returns then the allocation changes drastically Michaud and Michaud (2007);
- (ii) it requires the inversion of the covariance-matrix, which can be ill-conditioned and thus the inversion is susceptible to numerical errors;
- (iii) correlated investments indicate the need for diversification but this correlation is exactly what makes the solutions unstable (this is known as the Markowitz curse).
2.1. Hierarchical Risk Parity
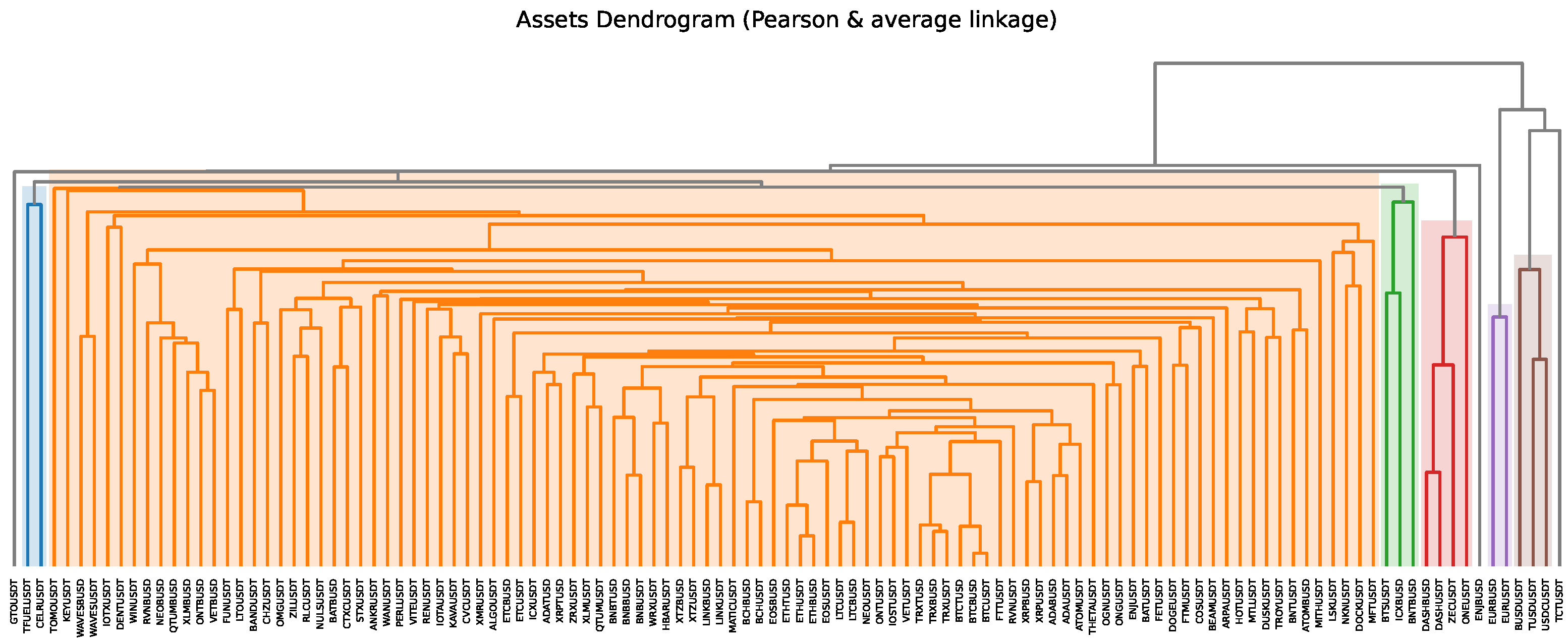
- 1. Computing the dendrogram using hierarchical tree clustering algorithm by using a distance matrix of the asset correlations.
- −
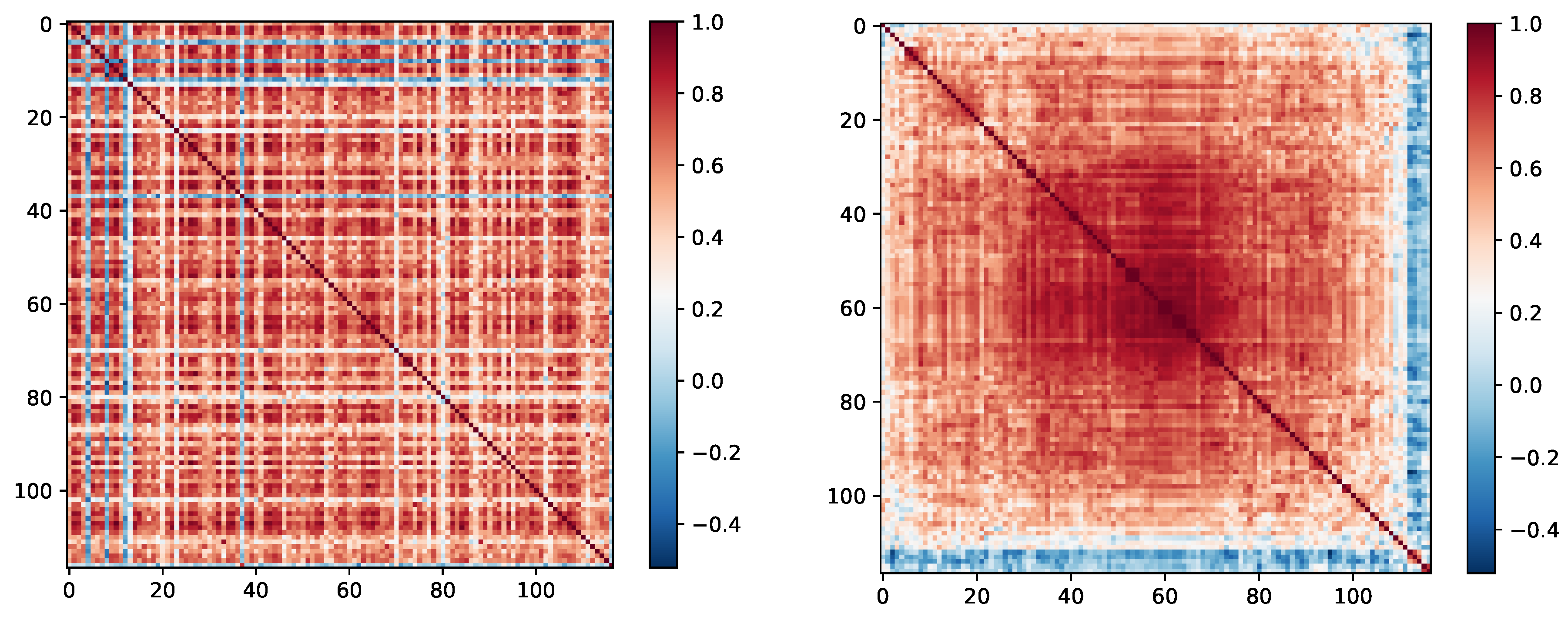
- First we compute the correlation among assets, which produces an matrix we call .
- −
- Then, we convert this to a distance matrix through
- −
- We next devise a new distance matrix which is actually a similarity matrix. It is computed as follows:
- −
- We then start to form clusters as follows:
- −
- We now delete the newly formed cluster assets row and column from the matrix ( and ) and replace them with a single one. Computing distances between this new cluster and the remaining assets can be performed by multiple different criteria, as is the general case with clustering, either single-linkage, average-linkage, etc.
- −
- We repeat the last two steps until we have only one cluster. So we can see this is an agglomerative clustering algorithm. We show its dendrogram (graphical depiction of the hierarchical clustering) on our crypto data in Figure 2.
- 2. Doing matrix seriation. This procedure rearranges data in such a way that larger covariances are closer to the diagonal and that similar values are near. This results in a quasi-diagonal covariance matrix. We show this process on our own crypto dataset Figure 3.
- 3. Recursive bisection. This is the final step which actually assigns weights to the assets using the previous clustering. Looking at the hierarchical tree structure:
- −
- We first set all weights to 1.
- −
- Next, starting from the root, for each cluster we use the following weights to compute the volatilities:This uses the fact that for a diagonal covariance matrix, the inverse-variance allocations are optimal.
- −
- Then for the two branches of each node (a node corresponds to a cluster) we compute the variance: and .
- −
- Finally, we rescale the weights as with and
2.2. Deep Reinforcement Learning
2.3. Model-Based RL
- The interaction with the real environment might be risky, inducing large costs sometimes. Thus having a zero-cost alternative is desirable.
- Having an accurate enough model of the world is necessary for the agent to learn and behave well in the real environment.
- The model is not necessarily a perfect representation of the real world, but it is close enough to be useful.
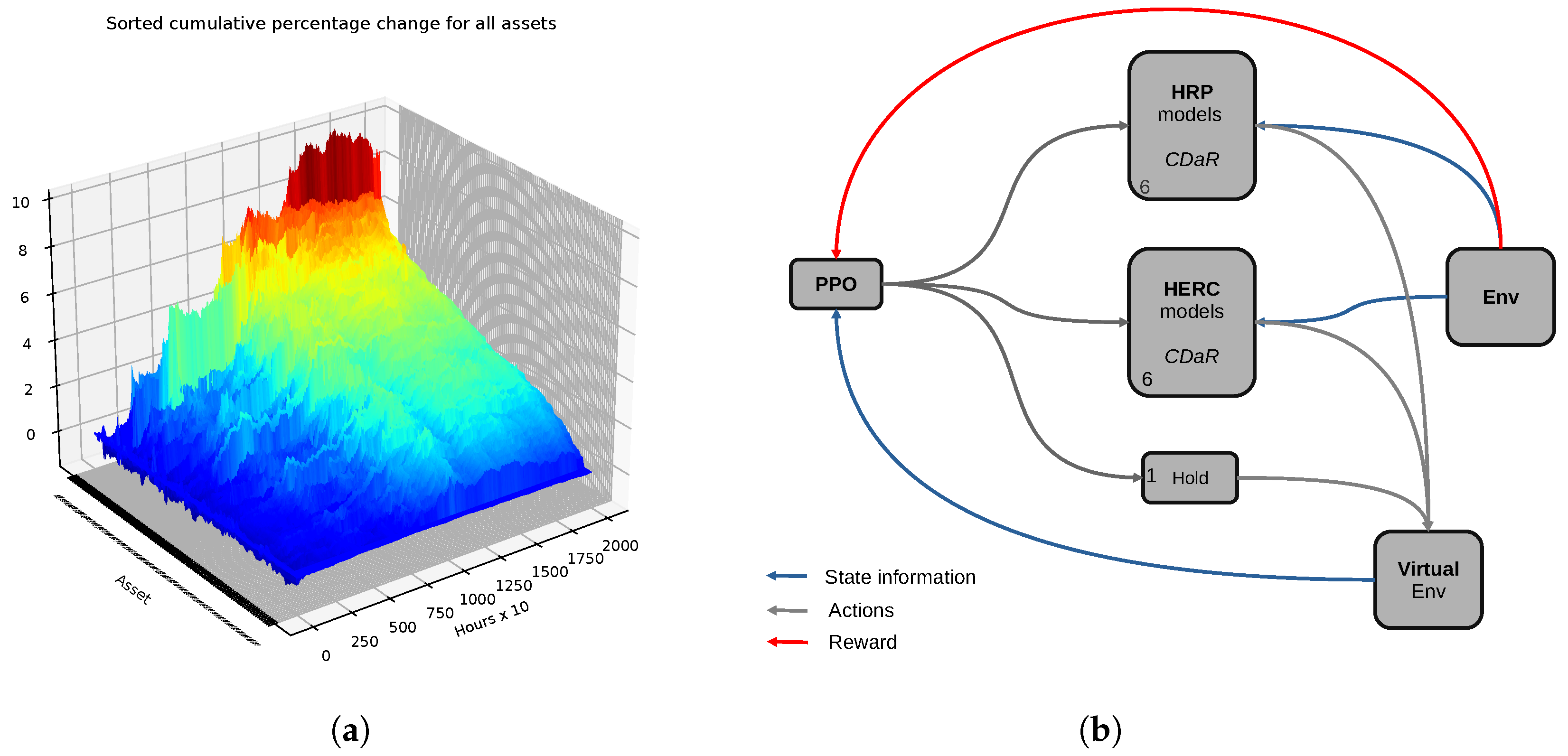
3. System Architecture
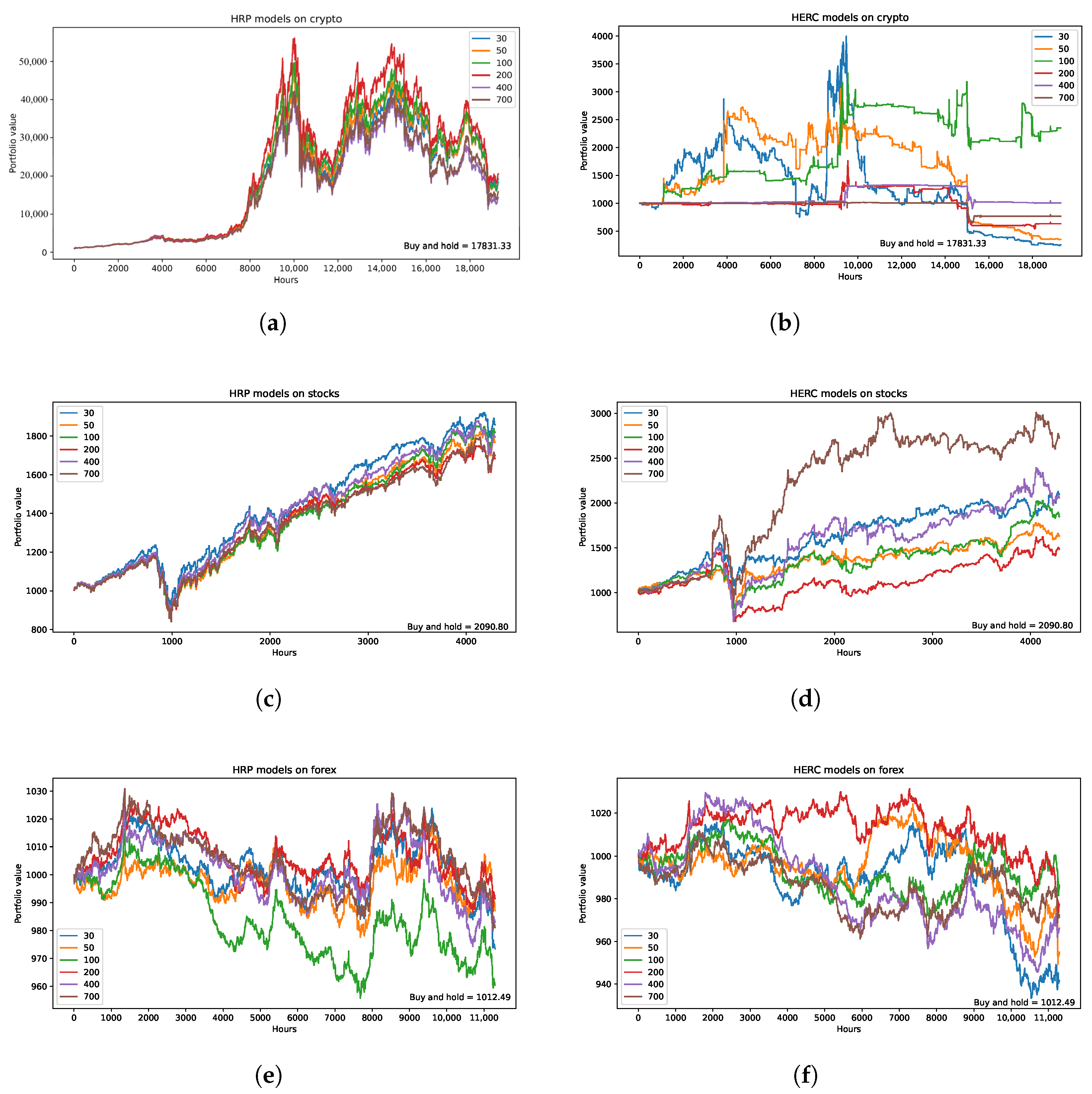
3.1. Performance of Individual HRP Models
3.2. Rewards
3.3. Combining the Models
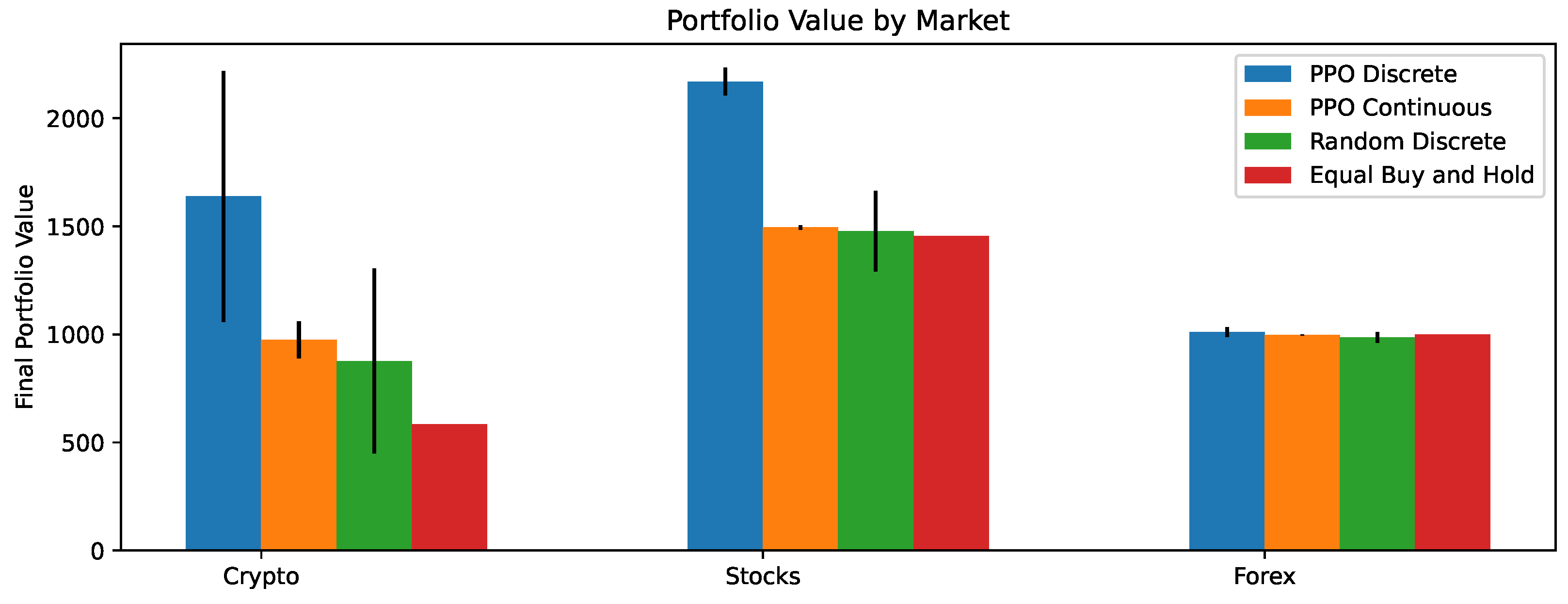
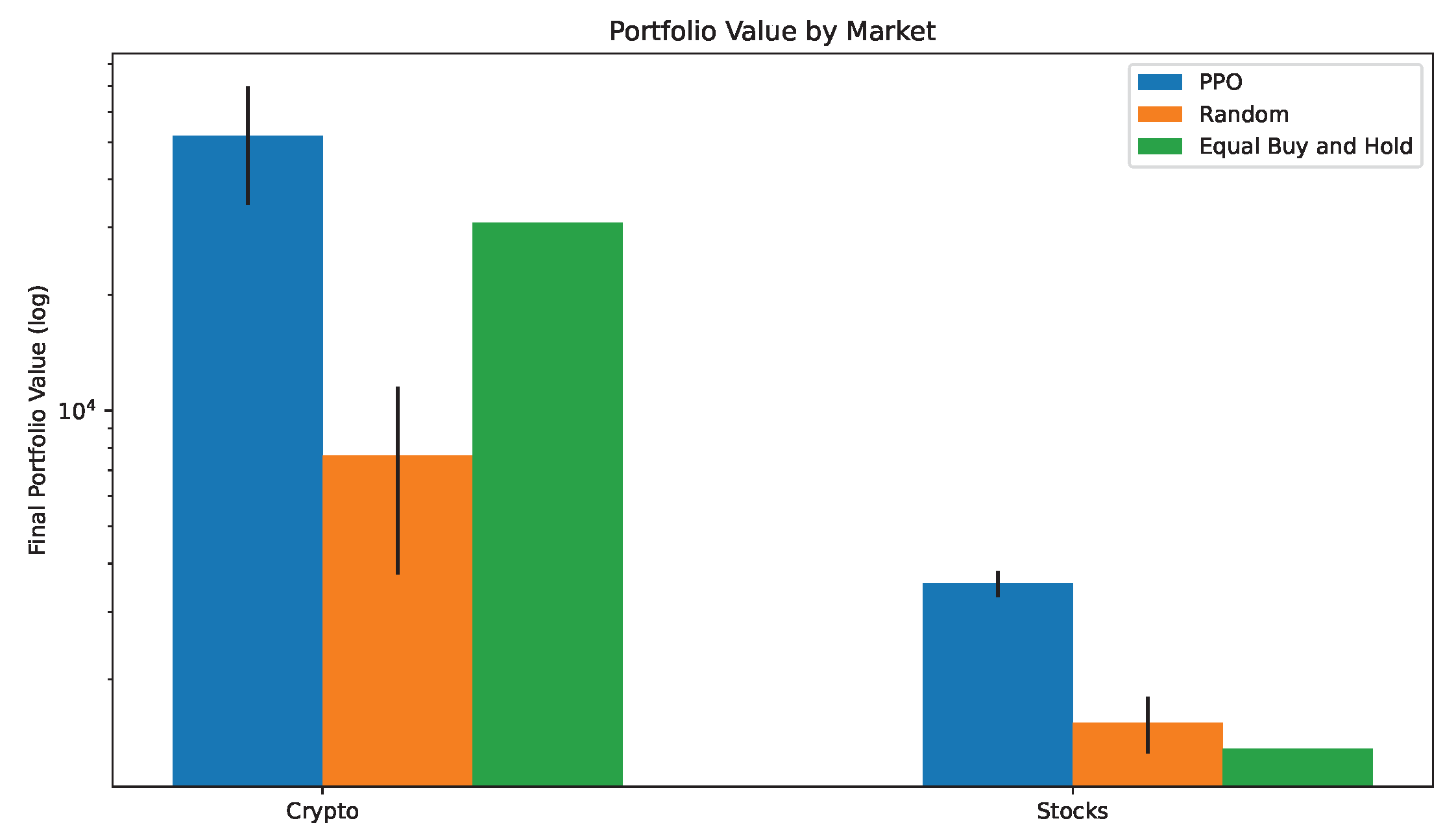
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | https://huggingface.co/blog/deep-rl-ppo (accessed on 20 June 2022). |
| 2 | https://riskfolio-lib.readthedocs.io/en/latest/index.html (accessed on 20 June 2022). |
| 3 | https://docs.ray.io/en/latest/rllib/index.html (accessed on 20 June 2022). |
| 4 | https://github.com/ray-project/ray/blob/master/rllib/algorithms/ddpg/ddpg.py (accessed on 20 June 2022). |
References
- Betancourt, Carlos, and Wen-Hui Chen. 2021. Deep reinforcement learning for portfolio management of markets with a dynamic number of assets. Expert Systems with Applications 164: 114002. [Google Scholar] [CrossRef]
- Black, Fischer, and Robert Litterman. 1992. Global portfolio optimization. Financial Analysts Journal 48: 28–43. [Google Scholar] [CrossRef]
- Bodnar, Taras, Stepan Mazur, and Yarema Okhrin. 2017. Bayesian estimation of the global minimum variance portfolio. European Journal of Operational Research 256: 292–307. [Google Scholar] [CrossRef]
- Burggraf, Tobias. 2021. Beyond risk parity—A machine learning-based hierarchical risk parity approach on cryptocurrencies. Finance Research Letters 38: 101523. [Google Scholar] [CrossRef]
- Choueifaty, Yves, and Yves Coignard. 2008. Toward maximum diversification. The Journal of Portfolio Management 35: 40–51. [Google Scholar] [CrossRef]
- Clarke, Roger, Harindra De Silva, and Steven Thorley. 2011. Minimum-variance portfolio composition. The Journal of Portfolio Management 37: 31–45. [Google Scholar] [CrossRef]
- De Prado, Marcos Lopez. 2016. Building diversified portfolios that outperform out of sample. The Journal of Portfolio Management 42: 59–69. [Google Scholar] [CrossRef]
- Deng, Yue, Feng Bao, Youyong Kong, Zhiquan Ren, and Qionghai Dai. 2016. Deep direct reinforcement learning for financial signal representation and trading. IEEE Transactions on Neural Networks and Learning Systems 28: 653–64. [Google Scholar] [CrossRef]
- Goldberg, Lisa R., and Ola Mahmoud. 2017. Drawdown: From practice to theory and back again. Mathematics and Financial Economics 11: 275–97. [Google Scholar] [CrossRef]
- Hirsa, Ali, Joerg Osterrieder, Branka Hadji-Misheva, and Jan-Alexander Posth. 2021. Deep reinforcement learning on a multi-asset environment for trading. arXiv arXiv:2106.08437. [Google Scholar] [CrossRef]
- Jiang, Zhengyao, and Jinjun Liang. 2017. Cryptocurrency portfolio management with deep reinforcement learning. Paper presented at the 2017 Intelligent Systems Conference (IntelliSys), London, UK, September 7–8; pp. 905–13. [Google Scholar]
- Jiang, Zhengyao, Dixing Xu, and Jinjun Liang. 2017. A deep reinforcement learning framework for the financial portfolio management problem. arXiv arXiv:1706.10059. [Google Scholar]
- Jurczenko, Emmanuel. 2015. Risk-Based and Factor Investing. Amsterdam: Elsevier. [Google Scholar]
- Kolm, Petter N., Reha Tütüncü, and Frank J. Fabozzi. 2014. 60 years of portfolio optimization: Practical challenges and current trends. European Journal of Operational Research 234: 356–71. [Google Scholar] [CrossRef]
- Ledoit, Olivier, and Michael Wolf. 2003. Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. Journal of Empirical Finance 10: 603–21. [Google Scholar] [CrossRef]
- Li, Yang, Wanshan Zheng, and Zibin Zheng. 2019. Deep robust reinforcement learning for practical algorithmic trading. IEEE Access 7: 108014–22. [Google Scholar] [CrossRef]
- Li, Yuxi. 2017. Deep reinforcement learning: An overview. arXiv arXiv:1701.07274. [Google Scholar]
- Lillicrap, Timothy P., Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2015. Continuous control with deep reinforcement learning. arXiv arXiv:1509.02971. [Google Scholar]
- Maillard, Sébastien, Thierry Roncalli, and Jérôme Teïletche. 2010. The properties of equally weighted risk contribution portfolios. The Journal of Portfolio Management 36: 60–70. [Google Scholar] [CrossRef]
- Markowitz, Harry M. 1952. Portfolio Selection. The Journal of Finance 7: 77–91. [Google Scholar]
- Michaud, Richard O., and Robert Michaud. 2007. Estimation Error and Portfolio Optimization: A Resampling Solution. Available online: https://ssrn.com/abstract=2658657 (accessed on 20 September 2022).
- Millea, Adrian. 2021. Deep reinforcement learning for trading—A critical survey. Data 6: 119. [Google Scholar] [CrossRef]
- Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, and et al. 2015. Human-level control through deep reinforcement learning. Nature 518: 529–33. [Google Scholar] [CrossRef]
- Moody, John, and Matthew Saffell. 1998. Reinforcement learning for trading. In Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, vol. 11. [Google Scholar]
- Mosavi, Amirhosein, Yaser Faghan, Pedram Ghamisi, Puhong Duan, Sina Faizollahzadeh Ardabili, Ely Salwana, and Shahab S. Band. 2020. Comprehensive review of deep reinforcement learning methods and applications in economics. Mathematics 8: 1640. [Google Scholar] [CrossRef]
- Raffinot, Thomas. 2017. Hierarchical clustering-based asset allocation. The Journal of Portfolio Management 44: 89–99. [Google Scholar] [CrossRef]
- Raffinot, Thomas. 2018. The Hierarchical Equal Risk Contribution Portfolio. Available online: https://ssrn.com/abstract=3237540 (accessed on 20 September 2022).
- Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv arXiv:1707.06347. [Google Scholar]
- Schulman, John, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. 2015. Trust region policy optimization. Paper presented at the International Conference on Machine Learning, Lille, France, July 6–11; pp. 1889–97. [Google Scholar]
- Théate, Thibaut, and Damien Ernst. 2021. An application of deep reinforcement learning to algorithmic trading. Expert Systems with Applications 173: 114632. [Google Scholar]
- Uryasev, Stanislav. 2000. Conditional value-at-risk: Optimization algorithms and applications. Paper presented at the IEEE/IAFE/INFORMS 2000 Conference on Computational Intelligence for Financial Engineering (CIFEr) (Cat. No. 00TH8520), New York, NY, USA, March 28; pp. 49–57. [Google Scholar]
- Wei, Haoran, Yuanbo Wang, Lidia Mangu, and Keith Decker. 2019. Model-based reinforcement learning for predictions and control for limit order books. arXiv arXiv:1910.03743. [Google Scholar]
- Yang, Hongyang, Xiao-Yang Liu, Shan Zhong, and Anwar Walid. 2020. Deep reinforcement learning for automated stock trading: An ensemble strategy. Paper presented at the First ACM International Conference on AI in Finance, New York, NY, USA, October 15–16; pp. 1–8. [Google Scholar]
- Yu, Pengqian, Joon Sern Lee, Ilya Kulyatin, Zekun Shi, and Sakyasingha Dasgupta. 2019. Model-based deep reinforcement learning for dynamic portfolio optimization. arXiv arXiv:1901.08740. [Google Scholar]
- Zejnullahu, Frensi, Maurice Moser, and Joerg Osterrieder. 2022. Applications of reinforcement learning in finance–trading with a double deep q-network. arXiv arXiv:2206.14267. [Google Scholar]
- Zhang, Zihao, Stefan Zohren, and Stephen Roberts. 2020. Deep reinforcement learning for trading. The Journal of Financial Data Science 2: 25–40. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter—Model | HRP | HERC |
|---|---|---|
| Risk measure | CDaR | CDaR |
| Codependence | Pearson | Pearson |
| Linkage | average | average |
| Max clusters | - | 10 |
| Optimal leaf order | True | True |
| Market | Training Set | Testing Set |
|---|---|---|
| Crypto | 22 March 2020 04:00–13 May 2021 14:00 | 13 May 2021 15:00–1 June 2022 03:00 |
| Stocks | 17 September 2019 15:30–16 December 2020 12:30 | 16 December 2020 13:30–4 February 2022 15:30 |
| Forex | 11 December 2020 01:00–30 September 2021 23:00 | 10 January 2021 00:00–28 September 2022 06:00 |
| Cryptocurrencies | Stocks | Forex | |
|---|---|---|---|
| ADABUSD | LINKBUSD | AAPL | AUDCAD |
| ADATUSD | LINKUSDT | ABT | AUDCHF |
| ADAUSDT | LSKUSDT | ACN | AUDJPY |
| ALGOUSDT | LTCBUSD | ADBE | AUDNZD |
| ANKRUSDT | LTCUSDT | AMD | AUDUSD |
| ARPAUSDT | LTOUSDT | AMZN | CADCHF |
| ATOMBUSD | MATICUSDT | ASML | CADJPY |
| ATOMUSDT | MFTUSDT | AVGO | CHFJPY |
| BANDUSDT | MITHUSDT | BABA | EURAUD |
| BATBUSD | MTLUSDT | BAC | EURCAD |
| BATUSDT | NEOBUSD | BHP | EURCHF |
| BCHBUSD | NEOUSDT | COST | EURGBP |
| BCHUSDT | NKNUSDT | CRM | EURJPY |
| BEAMUSDT | NULSUSDT | CSCO | EURNZD |
| BNBBUSD | OGNUSDT | CVX | EURUSD |
| BNBTUSD | OMGUSDT | DIS | GBPAUD |
| BNBUSDT | ONEUSDT | GOOG | GBPCAD |
| BNTBUSD | ONGUSDT | HD | GBPCHF |
| BNTUSDT | ONTBUSD | INTC | GBPJPY |
| BTCBUSD | ONTUSDT | JNJ | GBPNZD |
| BTCTUSD | PERLUSDT | JPM | GBPUSD |
| BTCUSDT | QTUMBUSD | KO | NZDCAD |
| BTSUSDT | QTUMUSDT | MA | NZDCHF |
| BUSDUSDT | RENUSDT | MCD | NZDJPY |
| CELRUSDT | RLCUSDT | MS | NZDUSD |
| CHZUSDT | RVNBUSD | MSFT | USDCAD |
| COSUSDT | RVNUSDT | NFLX | USDCHF |
| CTXCUSDT | STXUSDT | NKE | USDJPY |
| CVCUSDT | TCTUSDT | NVDA | |
| DASHBUSD | TFUELUSDT | NVS | |
| DASHUSDT | THETAUSDT | ORCL | |
| DENTUSDT | TOMOUSDT | PEP | |
| DOCKUSDT | TROYUSDT | PFE | |
| DOGEUSDT | TRXBUSD | PG | |
| DUSKUSDT | TRXTUSD | PM | |
| ENJBUSD | TRXUSDT | QCOM | |
| ENJUSDT | TUSDUSDT | TM | |
| EOSBUSD | USDCUSDT | TMO | |
| EOSUSDT | VETBUSD | TSLA | |
| ETCBUSD | VETUSDT | TSM | |
| ETCUSDT | VITEUSDT | UNH | |
| ETHBUSD | WANUSDT | UPS | |
| ETHTUSD | WAVESBUSD | V | |
| ETHUSDT | WAVESUSDT | VZ | |
| EURBUSD | WINUSDT | WMT | |
| EURUSDT | WRXUSDT | XOM | |
| FETUSDT | XLMBUSD | ||
| FTMUSDT | XLMUSDT | ||
| FTTUSDT | XMRUSDT | ||
| FUNUSDT | XRPBUSD | ||
| GTOUSDT | XRPTUSD | ||
| HBARUSDT | XRPUSDT | ||
| HOTUSDT | XTZBUSD | ||
| ICXBUSD | XTZUSDT | ||
| ICXUSDT | ZECUSDT | ||
| IOSTUSDT | ZILUSDT | ||
| IOTAUSDT | ZRXUSDT | ||
| IOTXUSDT | KEYUSDT | ||
| KAVAUSDT |
| Hyperparameter—Model | PPO |
|---|---|
| Learning rate | grid_search([0.0001, 0.001, 0.01]) |
| Value function clip | grid_search([1, 10, 100]) |
| Gradient clip | grid_search([0.1, 1, 10]) |
| Network | [1024, 512] |
| Activation function | ReLU |
| KL coeff | 0.2 |
| Clip parameter | 0.3 |
| Uses generalized advantage estimation | True |
| Hyperparameter—Model | DDPG |
|---|---|
| Actor learning rate | grid_search([1 , 1 , 1 ]) |
| Critic learning rate | grid_search([1 , 1 , 1 ]) |
| Network for actor and critic | [1024, 512] |
| Activation function | ReLU |
| Target network update frequency | grid_search([10, 100, 1000]) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Millea, A.; Edalat, A. Using Deep Reinforcement Learning with Hierarchical Risk Parity for Portfolio Optimization. Int. J. Financial Stud. 2023, 11, 10. https://doi.org/10.3390/ijfs11010010
Millea A, Edalat A. Using Deep Reinforcement Learning with Hierarchical Risk Parity for Portfolio Optimization. International Journal of Financial Studies. 2023; 11(1):10. https://doi.org/10.3390/ijfs11010010
Chicago/Turabian StyleMillea, Adrian, and Abbas Edalat. 2023. "Using Deep Reinforcement Learning with Hierarchical Risk Parity for Portfolio Optimization" International Journal of Financial Studies 11, no. 1: 10. https://doi.org/10.3390/ijfs11010010
APA StyleMillea, A., & Edalat, A. (2023). Using Deep Reinforcement Learning with Hierarchical Risk Parity for Portfolio Optimization. International Journal of Financial Studies, 11(1), 10. https://doi.org/10.3390/ijfs11010010