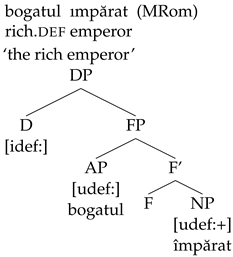
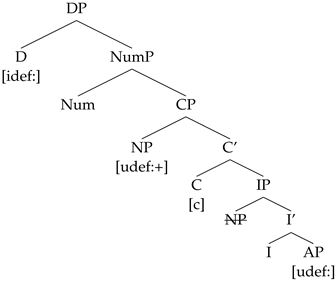
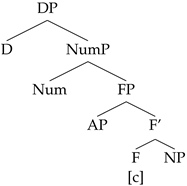
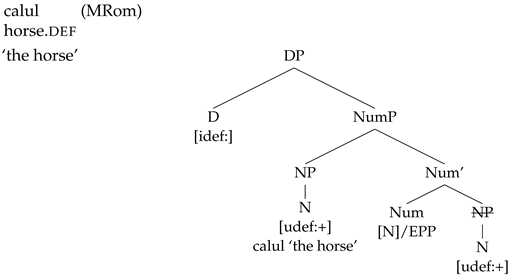
2. Context
The existing generative literature on definiteness in DacRom is focused mainly on Romanian, with few exceptions, such as
Zegrean (
2012a,
2012b), who analyzes Istro-Romanian definite DPs and
Campos (
2005), who focuses on Aromanian.
Three types of analyses have been proposed to account for the occurrence of the definite article as a suffix on the noun in simple definite DPs: N raising, D lowering, and feature agreement. Under the N raising view (
Dobrovie-Sorin (
1994);
Giusti (
2002);
Grosu (
1988), among others for Romanian, (
Zegrean 2012a) for Istro-Romanian, and
Campos (
2005) for Aromanian), the noun moves to D, a complex head is created, and as a result, the definite article is spelled out together with the noun, as a suffix.
As pointed out by
Dobrovie-Sorin and Giurgea (
2006) among others, one argument against a head raising analysis has to do with the expression of the definite article in DPs containing intensional adjectives, which are exclusively pre-nominal in DacRom.
- (2)
| (a) | un | fost | deţinut | (MRom) |
| | a | former | prisoner | |
| | ‘a former prisoner’ |
| (b) | *un | deţinut | fost | (MRom) |
| | a | prisoner | former | |
| | ‘a former prisoner’ |
When a definite DP contains such an adjective, the N-to-D analysis predicts that N should rise in front of the A and form a complex head with the definite D. However, this prediction is not borne out. What we obtain instead is the definite article suffixed to the A.
- (3)
| (a) | *deţinutul | fost | deţinut | (MRom) |
| | prisoner.def | former | prisoner | |
| | ‘the former prisoner’ |
| (b) | fostul | deţinut | (MRom) |
| | former.def | prisoner | |
| | ‘the former prisoner’ |
A different type of analysis that was proposed to account for the suffixation of the definite article in Romanian is one in which D lowers in order to attach to N (
Dobrovie-Sorin and Giurgea (
2006)). This view in fact combines N raising with an additional rule of D lowering.
Dobrovie-Sorin and Giurgea (
2006) assume that N raises in Romanian, but only as high as Num, and in addition, they propose a PF rule according to which the D head lowers to Num. Lowering rules are sensitive to syntactic structure in their view, in the sense that lowering attaches a head to the head of its complement. Thus, D lowering attaches the D head to Num, which contains N, given that N has raised to Num in the syntax.
- (4)
To explain cases in which the definite article is attached to pre-nominal adjectives, rather than to the noun,
Dobrovie-Sorin and Giurgea (
2006) assume that pre-nominal APs raise to SpecNumP and that the Num head, to which D lowers, is an inflectional morpheme that attaches to immediately preceding heads, in this case, the A head. In spite of solving the problems related to the N raising account, the D-lowering analysis cannot explain cases in which the definite article is overtly realized on multiple heads (A
-N
and N
-A
).
Finally, a third type of analysis that has been proposed in the literature in order to account for the overt realization of the definite D as a suffix in Romanian relies on feature agreement.
Cornilescu and Nicolae (
2011a,
2011b) propose that in languages that make use of a suffixal definite determiner, the definite suffix combines with the noun as a reflex of the fact that the noun agrees with D in its definiteness feature.
More specifically,
Cornilescu and Nicolae (
2009,
2011a,
2011b) follow
Pesetsky and Torrego (
2007) in assuming that feature interpretability should be kept distinct from valuation, and therefore, that syntax computes over four types of features, rather than two (as assumed by
Chomsky (
2000,
2001): (a) uninterpretable, valued features [uF: val]
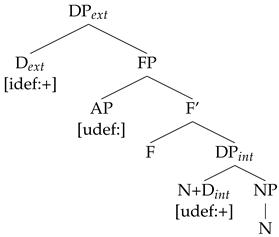
2; (b) interpretable, valued features [iF: val]; (c) uninterpretable, unvalued features [uF: ]; (d) interpretable, unvalued features [iF: ]. D heads bear an unvalued interpretable [def] feature in their view, Ns bear an uninterpretable but valued [def] feature, and As have an uninterpretable, unvalued [def] feature. The only heads that are intrinsically definite in this system are Ns, while Ds and As become definite by agreement.
- (5)
The pronunciation of the definite article depends on Agree in this system, more specifically on the valuation of the [idef:] feature on D. The general rule that
Cornilescu and Nicolae (
2009,
2011a,
2011b) propose is that the definite article is phonologically realized on the head that values the [idef:] feature on D. This head could be in a local relation to D (immediately c-commanded by D), as in the Modern Romanian example in (5), or it could be more distant from D, as in the Old Romanian examples below.
- (6)
| (a) | turcii | mulţii | (Old | Rom, | Iorga | 8) |
| | turks.def | many.def | | | | |
| | ‘the many Turks’ |
| (b) | neştiutor | gândul | omenesc | (ORom, | Cantemir) |
| | ignorant | thought.def | human | | |
| | ‘the ignorant human thinking’ |
The overt realization of the definite article thus depends on the following parameter:
- (7)
Local Agree (LA)): The [+def] GoalP which values [idef] in D must be a [+N] phrase immediately below D.
Long Distance Agree (LDA): The goal that values the probe in D is a c-commanded nominal phrase (NP, AP) which need not be the first (nominal) phrase c-commanded by D.
Notice that LDA subsumes LA, since in LDA languages, the goal that values the [def] feature on D need not be the first nominal phrase c-commanded by D, which leaves open the possibility that it could be such a phrase.
Such an analysis is thus able to account for cases in which the definite article is overtly expressed multiple times, which is an obvious benefit. However, their analysis of multiple definiteness faces some problems. One problem is related to the optionality of the overt realization of the definite article on N in DPs consisting of an A followed by an N (A-N), in languages that display LDA, such as Old Romanian. In
Cornilescu and Nicolae (
2009,
2011a,
2011b)’s view, the alternation between N
-A and N
-A
is due to the fact that As can optionally bear a [def] feature in Old Romanian. However, nouns within definite DPs always bear a valued [def] feature and it is unclear why we also see alternations between A
-N
and A
-N. What is needed is a theory that explains under which conditions this feature is spelled out and when it is silent. Second,
Cornilescu and Nicolae (
2009,
2011a,
2011b)’s analysis leads to the expectation that in a language like Old Romanian, where both local and distant Agree were at work, the definite article should be overt either on a head closest to D, or on a more distant head, or both. However, it is not clear why the only type of definite DP that shows exclusively long distance Agree is A-N
, and why N-A
is not attested. The same is true about other DacRom that seem to behave like Old Romanian, in that they allow A-N
, but not N-A
(Megleno-Romanian and Istro-Romanian). Finally, there are other DacRom that allow double definiteness (Megleno-Romanian, Southern Istro-Romanian, Northern Istro-Romanian, Aromanian, AromanianFG) and are thus expected in this view to display both local Agree and distant Agree. However, some of these languages do confirm this expectation (Megleno-Romanian and Southern Istro-Romanian), but others disallow any pattern involving exclusively long distance Agree (Aromanian, Aromanian FG, and Northern Istro-Romanian). In other words, these languages have neither A-N
, nor N-A
, in spite of the fact that they presumably allow long distance Agree, and this gap is unexplained.
3. My Proposal
3.1. Agree Chains
My proposal shares with
Cornilescu and Nicolae (
2009,
2011a,
2011b) the fact that it relies on Agree, and thus the ability to account for patterns in which the affixal definite article can be overt on more than one head within the DP (A
-N
; N
-A
), which occur in all DacRom languages.
Crucially, following
Pesetsky and Torrego (
2007), I will adopt a view of Agree as feature sharing. In this view, once a probe finds a goal with a matching feature, the probe’s feature is not deleted, but forms instead a link with the goal, which is accessible throughout the derivation. More technically, if some head at a location
has an unvalued, uninterpretable or interpretable, feature F
, it probes for another instance of F in its c-command domain. Once it finds a goal at location
, with an appropriate feature F
, it agrees with it. In the feature-sharing view, Agree consists of replacing F
with F
, so that the same feature is present in both locations.
- (8)
- (a)
An unvalued feature F (a probe) on a head H at syntactic location (F) scans its c-command domain for another instance of F (a goal) at location (F) with which to agree.
- (b)
Replace F with F, so that the same feature is present in both locations.
Several observations are in order with respect to the definition of Agree in (8). First, notice that this definition says nothing about the locality conditions under which Agree is obtained. Most researchers assume that Agree is local (
Bjorkman and Zeijlstra (
2019);
Legate (
2005);
Polinsky and Potsdam (
2001), among others), where locality is established using two criteria: the Phase-Impenetrability Condition (PIC) (
Chomsky 2001) and the closest match condition. PIC establishes the size of the domain that is accessible to any syntactic operation.
- (9)
In a phase with head H, the domain of H is not accessible to operations outside , only H and its edge are accessible to such operations.
The closest match requirement, on the other hand, affects the probe-goal system on the basis of Agree. Agree is an operation that requires feature matching between a probe (a head that has an uninterpretable, unvalued feature) and a goal (a head that has a feature that matches the uninterpretable, unvalued feature of the goal). According to
Chomsky (
2001), not every matching pair of features induces Agree. For Agree to happen, the goal must be in the domain of the probe, i.e., contained in the sister of the probe, and it must be the closest match.
- (10)
- a.
Matching is feature identity.
- b.
D(P) is the sister of P. (the domain of the Probe P is the sister of P)
- c.
Locality reduces to ‘closest c-command’
The view that Agree is local (in the sense that it is constrained by PIC and by the closest match condition) is not shared by all researchers (see, for example,
Bošković (
2007)). However, what is contested is whether Agree is constrained by PIC. In other words, even researchers that argue that Agree is not local assume the closest match condition. I will, therefore, do the same and assume that Agree is established once the closest goal is found.
A second observation related to the definition in (8) has to do with the directionality of Agree. The definition in (8) assumes that Agree is probing downward, in the c-command domain of the probing head. However, I will follow
Carstens (
2016), and I will also allow for directionality-free matching and delayed valuation in cases in which an unvalued feature does not find a valued match in its c-command domain. In particular, an unvalued feature with no match in its c-command domain can be valued either by raising into a position where it is in a local relation with a matching feature, or by remaining in situ and being valued by the closest matching feature within the same phase.
The definition in (8) presupposes that once the probe finds a goal, a chain is created, which contains two links with the same feature.
Crucially, the order of the heads in the Agree chain directly maps onto c-command relations, i.e., if a head X c-commands Y, X will precede Y, regardless of which of the two heads provides the value of the feature.
- (11)
X[F:] … Y[F:val] →Agree→(X[F:val], Y[F:val])
X[F:val] … Y[F:]→Agree→(X[F:val], Y[F:val])
The chain resulting from Agree can be accessed by further derivational processes. One situation is if F is still unvalued after the probe finds a matching goal. In this case, X will re-initiate the search for a matching feature and another operation of Agree will apply if X finds a goal. If the F that is found is valued, then feature sharing will result in a valued feature F present at three locations:
- (12)
(a) X[F:] … Y[F:] →Agree→(X[F:], Y[F:])
(b) (X[F:], Y[F:]) … Z[F:val] →Agree→(X[F:val], Y[F:val], Z[F:val])
The link/chain resulting from Agree could also be accessible when another probe searches for a matching goal. If, for instance, X searches and finds a valued match in Y, a link is created as in (13.a), and this chain could be the goal of another higher probe, Z.
- (13)
(a) X[F:] … Y[F:val] →Agree→(X[F:val], Y[F:val])
(b) Z[F:] … (X[F:val], Y[F:val]) →Agree→(Z[F:val], X[F:val], Y[F:val])
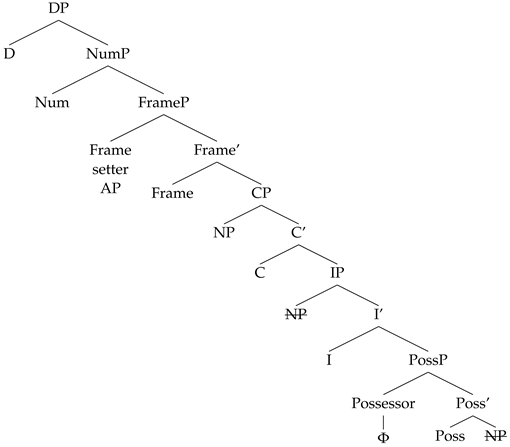
Applying this system to definite DPs in DacRom, the following [def] Agree chains can be created, depending on whether the adjective is merged pre-nominally or post-nominally:
- (14)
(D[idef:+], N[udef:+], A[udef:+])
(D[idef:+], A[udef:+], N[udef:+])
Given that DPs contain an inner phase (NumP), as proposed by
Cornilescu and Nicolae 2009,
2011a,
2011b,
Tănase-Dogaru (
2012), among others, and that Ns and As are merged within this inner phase, the chains in (14) are built incrementally: first the N and the A form a chain and share the value of the [def] feature, and then, when D is merged, it probes for a value for its [def] feature and it finds the closest match. However, given that the closest match is already part of a chain with another head with which it shares a valued [def] feature, the chain that is created when D is added will contain not only D and the closest match but all three heads that share the [def] feature.
3.2. Spell-Out of Agree Chains
Chains created by Agree raise the question of how they are spelled out. There is no reason to assume that Agree chains are any different from this point of view from chains created by movement. One condition that affects the pronunciation of movement chains is Chain Reduction (
Nunes 1999;
Nunes and Uriagereka 2000), a linearization procedure that deletes copies within a given chain. The outcome of Chain Reduction is to delete lower copies of a (movement) chain and pronounce the highest copy unless realizing the highest copy violates some lexical property of the items involved (
Bobaljik 2002;
Bošković 2001,
2002;
Franks 1999;
Landau 2006, among others). The most common situation is one in which the head of the chain is pronounced and the lower copies are deleted.
- (15)
When did you arrive?
Chain output at PF: when did you arrive when
However, under certain circumstances, it is the lower copy that is pronounced and the head of the chain is deleted.
Bošković (
2001) argues that in (16) the the complex head involving the verb and the clitics (
si-mu-gi-dal) moves and left-adjoins to the interrogative particle
li, as in (16b). Deletion of the lower copy of the chain created by this movement yields a grammatical output in Macedonian, but not in Bulgarian. The difference has to do with the nature of the clitics and of the interrogative particle
li in these two languages, lexical properties that cannot be violated when the chain resulting from the movement of the clitics is pronounced. In particular, in Macedonian, clitics are proclitic, while
li is enclitic, but in Bulgarian both the clitics and
li are enclitic. A convergent reduction in the complex head chain in Macedonian will delete the lower copies of the clitics, while in Bulgarian it must, therefore, delete the higher copies of the clitics.
- (16)
| (a) | Dal | li | si | mu | gi | parite? | (Bulgarian) |
| | given | q | are | him.dat | them | money | |
| | ‘Have you given him the money?’ (Rudin et al. 1999) |
| (b) | Chain output at PF (Bošković 2001): si-mu-gi dal li si mu gi dal parite? |
I will propose that Agree chains are also subject to Chain Reduction. In other words, this rule will delete lower copies of an Agree chain and pronounce the highest copy, unless realizing the highest copy violates some lexical property of the items involved.
Since a suffix is a lexical property of individual items, it will clearly play a role in the pronunciation of chains. The suffixal definite article in DacRom cannot be realized on the highest link in the definiteness Agree chain (i.e., the link in D) because suffixes must have a host (
Newton 2008), hence the reduction in this chain will delete the higher copy of the definite article.
- (17)
| (a) | student-ul | (Romanian) |
| | student.def | |
| | ‘the student’ |
| (b) | Chain output at PF: -ul, student-ul |
A second PF restriction on movement chains that can also be assumed to be relevant for Agree chains has to do with locality. In a derivational model in which Spell Out applies multiple times (
Chomsky 2000,
2001;
Epstein et al. 1998;
Franks and Bošković 2001;
Uriagereka 1999), we expect the reduction rule affecting chains to apply progressively after each unit is sent to Spell Out. The current view is that what is sent to spell out is the complement of a phase head (
Chomsky 2001). However, the original proposal in
Chomsky (
2000) was that what is sent to spell out is the phase itself, rather than just the complement of the phasal head. The same view is shared by
Franks and Bošković (
2001,
2007,
2016), etc. Here, I will side with the latter view and assume that what is sent to the phonology is the whole phase XP, but the phonology works only on the complement of the phase head. There are several arguments for this view (see
Bošković (
2016);
Boskovic and Nunes (
2007);
Franks and Bošković (
2001), etc.) but the argument that is relevant here is the one concerning movement chains. Considering a situation in which an XP moves to the Spec of a phasal head, phonology will need to assess whether to pronounce the lower copy of XP or not.
- (18)
[ XP [ Y [ . . . XP ] ] ]
If PF had no access to the higher copy of XP, it would have no way of ‘knowing’ that the lower copy is part of a movement chain, and it would fix its pronunciation. Clearly, this decision will most of the time be unfortunate, since with most movement chains the lower copy of the moved item is not overt. If, however, PF has access to the whole phase, and not only to the complement of the phase head, it will be able to ‘see’ the higher copy of XP, and it will treat the two copies of XP as being part of a chain and will apply Chain Reduction. In other words, the lower copy of XP will be marked for deletion, provided that there is nothing wrong with the phonological realization of the higher copy of XP.
Similarly, the precise choice of the lower link of an Agree chain that is going to be pronounced follows from the same general conditions on multiple Spell Out that apply to movement chains. In particular, links of an Agree chain that are part of a lower phase are processed when the lower phase is sent to PF and are deleted if a higher link exists at the edge of the phase, whose pronunciation would not result in a PF violation.
- (19)
[ XP[def] [ Y [ . . . ZP[def] ] ] ]
Applying this reasoning to [def] Agree chains, and assuming that DPs contain an inner phase–NumP, it follows that links of the [def] chain placed inside the complement of the Num phasal head will never be pronounced, and only instances of [def] placed at the edge of the NumP phase will be overt.
- (20)
[ D[def] [ XP[def] [ Num [ . . . ZP[def] ] ] ] ]
Putting together Chain Reduction and the locality restrictions that result from multiple Spell-Out as applied to definiteness Agree chains, the following rule emerges for the pronunciation of the definite article in DacRom languages:
- (21)
In a [def] Agree chain (D[def], X[def], Y[def]), where [def] is a suffix,
- (a)
lower links that are included in the complement of the Num phasal head are deleted (Chain Reduction applied to the partial chain within the NumP phase)
- (b)
the highest link of the chain (D) is deleted (Chain Reduction applied to the full chain after D is merged)
- (c)
only (lower) links that are at the edge of the NumP phase are pronounced (PIC).
This rule has two possible instantiations, depending on whether a particular language allows the pronunciation of the definite article to spread to multiple heads or not.
- (22)
| (i) | in non-spread languages only the highest (lower) link that satisfies PIC, i.e., only the highest link placed at the edge of the NumP phase, is pronounced. |
| (ii) | in spread languages, all the (lower) links that satisfy PIC, i.e., all the links that are placed at the edge of the NumP phase, are pronounced. |
What is important is that in both types of languages, the overt expression of the definite article is subject to locality restrictions, more specifically it is affected by PIC. The sensitivity of this rule to PIC follows straightforwardly from a multiple Spell-Out system in which a string is sent to Spell-Out in incremental chunks (phases). Notice also, that the pronunciation rule in (21) is also local in the sense that it observes the closest link condition. This is clearly the case in non-spread languages, as the definite article in these languages is pronounced on the closest match that is placed in the same phase as the probe. The closest link condition is also observed in spread languages since the set of all heads that are at the edge of the lower NumP phase includes the head that is closest to the D probe.
4. Implementation
In what follows, I will show how the rule in (21), with the two instantiations along the parameter in (22), can account for the patterns of definiteness observed in DacRom.
Before we start, let me mention another factor that will play a role in the derivations of definite DPs, namely the features of the Num phasal head. I will assume that the Num phasal head bears an optional discourse-related feature, i.e., a [c(ontrastive)] feature. Positing optional features could be seen as problematic, unless the presence of those features is justified by output conditions. In particular, features like [c] on a phase head should be licensed only if their presence triggers some interpretive effect, in keeping with interface economy principles (
Chomsky (
2001);
Fox (
2000);
Reinhart (
1995), etc.). The presence of [c] on Num does indeed trigger such interpretive effects: this feature is assigned to any constituent that opens up a domain of quantification or a set of alternatives (as also proposed by
Büring and Hartmann (
2001);
Rooth (
1985);
Whitehead et al. (
2014), among others). Thus, a NumP marked as [c:+] both introduces a variable (a set of alternatives supplied by the context) and chooses a value for it, i.e., it picks a particular member of the set and places it in contrast with the other members of the set.
Given that nouns are intrinsically definite in our analysis, DPs that contain exclusively a noun cannot introduce any contrast within the DP. This is because the noun does not independently denote a set of individuals that could be set in contrast with the referent picked up by the definite determiner. In fact, Num heads with a [c] feature cannot be merged in such DPs, since the [c] feature on Num is not matched by any of the features on N, and thus the derivation will crash.
However, functional categories that license modifiers (pre-nominal or post-nominal adjectives) do offer a matching [c] feature that could check the EPP associated with the [c] feature on a Num head.
The structure I will assume for post-nominal adjectives follows
Alexiadou (
2001);
Cinque (
2010);
Kayne (
1994), etc., who merge post-nominal adjectives as predicates within in a reduced relative clause inside the NumP, as represented in (23)
- (23)
In this analysis, the C head of the reduced relative clause where the predicative adjective is merged bears attracts the NP to its Spec. More importantly, I will assume that the C head bears a [c] feature, which is related to the predicational and restrictive nature of post-nominal APs in DacRom (see
Cinque 2010;
Cornilescu 2006;
Cornilescu and Nicolae 2016;
Cornilescu and Dinu 2014;
Teodorescu 2006 for Modern Romanian). The adjective DP
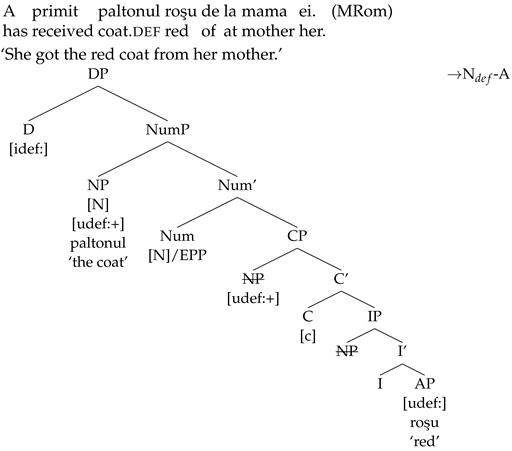
roşu/‘red’ in (24) sets the referent of the DP
paltonul roşu/‘the red red’ in contrast with coats that have different properties, like for instance
paltonul negru/‘the black coat’, or
paltonul de lână/‘the wool coat’.
- (24)
| A | primit | paltonul | roşu | de | la | mama | ei. | (MRom) |
| has | received | coat.def | red | of | at | mother | her. | |
| ‘She got the red coat from her mother.’ |
As for pre-nominal modifiers, I will adopt the standard assumption that they are merged in the Specifier of functional projections inside the nominal.
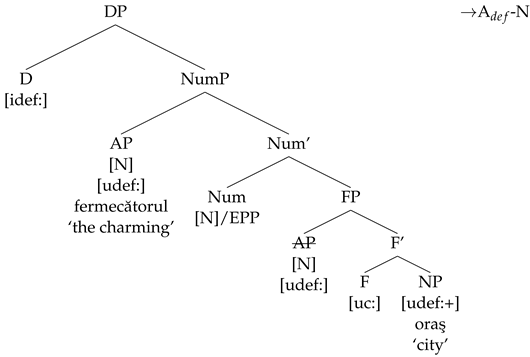
- (25)
Similarly to the C head that licenses post-nominal modifiers, the F head also bears a [c] feature. In other words, fermecatorul oraş/‘the charming city’ in (26) is interpreted as contrasting with cities that have other properties, like liniştitul oraş/‘the calm city’.
- (26)
| fermecatorul | oraş | (MRom) |
| charming.def | city | |
| ‘the charming city’ |
To sum up the [c] feature inside definite DP, only DPs that contain modifiers open up a set of alternatives and may include a Num head with a [c] feature in the derivation. If a [c] feature is present on the Num head, it will be associated with an EPP feature. In other words, Num heads marked as [c] attract constituents with a matching [c] feature to their Specifier. If the Num head lacks [c], the Num head attracts nominal constituents to its Specifier, as proposed by
Cornilescu and Nicolae (
2009,
2011a,
2011b),
Tănase-Dogaru (
2012), etc., hence the EPP feature is associated with a nominal ( [N]) feature on Num. The two types of Num heads that can occur in DacRom definite DPs are given in (27):
- (27)
Types of Num heads:
Num: [N]/EPP
Num: [N]; [c]/EPP
Merging one or the other Num head will yield different PF realizations of the definite article, as will be shown in the remainder of this section.
4.1. D-N Chains
Definite DPs that include only a noun can be found in all DacRom languages. As mentioned above, merging a Num head that bears a [c] feature in such DPs will result in a derivational crash since there is no phrase with a matching [c] feature within the DP that could check the EPP feature associated with the Num head.
On the other hand, merging a Num head that lacks [c] in such DPs will result in the following derivation, where the NP is attracted to SpecNumP, to check the EPP associated with the [N] feature on Num.
- (28)
Given that the NP raises to SpecNumP, a movement chain is created, as in (29a). When the NumP phase is sent to Spell Out, the lower NP copy within the complement of the Num head is deleted, given that the pronunciation of the NP copy at the edge of the NumP phase does not result in a PF violation.
- (29)
(a) NP movement chain: (NP, NP)
(b) Chain output at PF: (NP, NP)
The [def] Agree chain that results when D probes to find a valued match for its [def] feature is given in (30).
- (30)
[def] Agree chain: (D[def], N[def])
The head of this chain cannot be pronounced since it will violate a lexical property of the definite article in DacRom (the definite article is a suffix in these languages), so when the DP phase is sent to Spell Out, it will be the lower instance of [def] that will be pronounced, i.e., the one on N. The resulting string is thus N.
4.2. D-N-A Chains
Modifiers may follow nouns in all DacRom languages. Two patterns may be observed, depending on the overt expression of the definite article. In all DacRom languages, the definite article can be overtly expressed on the noun only. An example for Modern Romanian was provided in (24), and examples for the other DacRom languages are given below.
- (31)
| (f) | au | fîrşit | mănăstirea | mare | (ORom, | Costin | Letopiseţul | 75: | 58) |
| | have | finished | monastery.def | big | | | | | |
| | ‘they finished the big monastery’ |
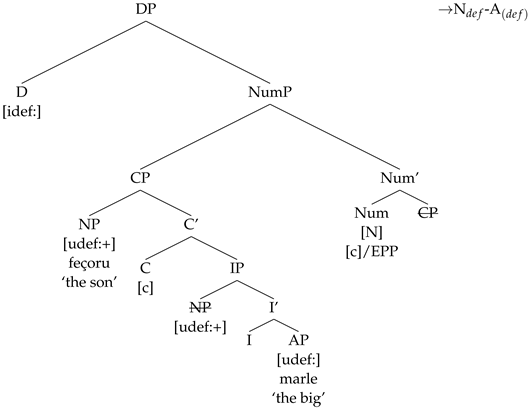
Apart from the N-A pattern, which can be found in all DacRom languages, some of these languages also display the N-A pattern. The languages that allow this pattern are Megleno-Romanian, Southern Istro-Romanian, Northern Istro-Romanian, Northern Aromanian, and Old Romanian.
- (32)
| (b) | Io-m | doi | fečori, | ur | mic | şi | ur | mare | ... | Feçoru | micu | ei | ân | casa, | feçoru | marle | mesa | be | apa |
| | I-have | two | sons, | one | little | and | one | big | ... | Son.def | small.def | is | in | house.def, | son.def | big.def | went | drink | water |
| | ‘I have two sons, a little one and a big one. The little one is in the house, the big one went to drink some water.’ (IstroS, Zegrean 2012a, p. 250) |
| (c) | a | verit | fratele | mai | părvile | (IstroN, | Cantemir 1959, p. 126) |
| | has | come | brother.def | more | first.def | | |
| | ‘the older brother came’ |
| (d) | ş-pórtul | vécl’u | eará | di | gadafeád? |
| | and-clothes.def | old.def | was | of | velvet |
| | ‘and the old clothes were made of velvet?’ (AromN, Saramandu 2007, p. 225) |
| (e) | turcii | mulţii | (Old | Rom, | Iorga | 8) |
| | turks.def | many.def | | | | |
| | ‘the many Turks’ |
As mentioned above, I will assume that post-nominal modifiers are merged as predicates of a reduced relative clause, as in (23). If a Num head without a [c] feature is merged in this structure, the resulting string is N-A, even if A bears [def] and is part of the [def] Agree chain. This is because A is not placed at the edge of the inner phase NumP and is thus inaccessible when D searches. The feature [def] on A becomes, however, valued and checked.
- (33)
Given NP movement to SpecNumP, a movement chain is created, as in (34a). When the NumP phase is sent to Spell Out, the lower NP copies within the complement of the Num head are deleted, given that the pronunciation of the NP copy at the edge of the NumP phase does not result in a PF violation.
- (34)
(a) NP movement chain: (NP, NP, NP)
(b) Chain output at PF: (NP, NP, NP)
When D is probing for a match for its [def] feature, a [def] Agree chain is created that contains D, the higher N copy, and A.
- (35)
[def] Agree chain: (D[def], N[def], A[def])
The pronunciation of this chain proceeds incrementally. First, a partial chain is formed in the NumP phase, that contains only N and A. When A probes to find a valued match for its [def] feature, it fails to find one in its c-command domain, but it does find one in the minimal phase (NumP) that contains the A. Since this match is the [def] feature on N, the partial Agree chain that results is as in (36).
- (36)
(N[udef:+], A[udef:+])
When this partial chain is sent to Spell Out, the lower instance of [def] is deleted since the pronunciation of the higher copy does not lead to a PF violation (the suffixal nature of the definite article can be satisfied by the N host).
When D is merged, D probes for a valued match for its [def] feature, and it finds the [def] feature on N. N is already part of an Agree chain with A, but the [def] instance on A has already been deleted at PF when the NumP phase has been processed. The pronunciation of the newly formed [def] Agree chain will result in a N-A string since pronouncing [def] on D will result in a violation of the suffixal nature of the definite article and N is the only match to the [def] feature on D that is placed at the edge of the NumP phase.
If, on the other hand, a Num with [c] is merged, Num attracts CP to its Spec, since C bears a [c] feature that is able to check the EPP on the Num head.
- (37)
The resulting string is N-A or N-A, depending on whether the respective language allows the spread of the definite article or not. Southern Istro-Romanian is a spread language, and thus the outcome in (37) is N-A. First, a movement chain is created by the movement of the CP to the edge of NumP. Given that the pronunciation of the CP copy at the edge of the NumP phase does not result in a PF violation, the lower copy of the CP is deleted.
- (38)
(a) CP movement chain: (CP, CP)
(b) Chain output at PF: (CP, CP)
The Agree chain that results when D probes for a valued [def] contains D, N, and A. This time, both N and A are placed at the edge of the NumP phase, as both are part of the CP that moves to SpecNumP. In spread languages, the definite article is spelled out on all the heads within CP that bear a [def] feature and the resulting string is N-A, while in non-spread languages the definite article is overt strictly on the closest match, and the resulting string is N-A.
- (39)
[def] Agree chain: (D[def], N[def], A[def])
Chain output at PF in spread languages: (D[def], N[def], A[def])
Chain output at PF in non-spread languages: (D[def], N[def], A[def])
To sum up, on D-N-A definite DPs, two patterns can be observed in DacRom: N
-A and N
-A
, both of which can be accounted for by the proposed analysis. Our analysis correctly predicts that all DacRom languages should display the N
-A pattern, regardless of whether they are spread or non-spread. In non-spread languages, the N
-A pattern can be derived by merging any type of Num head, while in spread languages, this pattern can be derived only if a Num head without a [c] feature is merged. The N
-A
pattern, on the other hand, can be derived only in spread languages that use a Num head with a [c] feature. The picture that emerges is that languages like Megleno-Romanian, Southern and Northern Istro-Romanian, Northern Aromanian, and Old Romanian all of which display the N
-A
pattern, are spread languages, and moreover, that they contain a Num head with a [c] feature in their lexicon. Since these languages also allow the N
-A pattern, they also contain a Num head that lacks a [c] feature in their lexicon. On the other hand, Modern Romanian does not productively display the N
-A
pattern
3, while in Southern Aromanian this pattern is always ungrammatical, which indicates that these languages are non-spread languages. The presence of a Num head marked as [c] is not needed in Modern Romanian and Southern Aromanian since these languages have Ndef-A only and this pattern can be derived by merging a Num head without a [c] feature. I will thus assume that Modern Romanian and Southern Aromanian do not have a Num head marked as [c] in their lexicon. The following table summarizes these results:
| | Spread | Num | N-A
(+/−[c];−Spread)
(−[c];+Spread) | N-A
(+[c]; +Spread) |
| MRom | − | −[c] | ✓ | − |
| ORom | + | +/−[c] | ✓ | ✓ |
| Megl | + | +/−[c] | ✓ | ✓ |
| IstroN | + | +/−[c] | ✓ | ✓ |
| IstroS | + | +/−[c] | ✓ | ✓ |
| AromN | + | +/−[c] | ✓ | ✓ |
| AromS | − | −[c] | ✓ | − |
4.3. D-A-N Chains
Adjectives can occur in pre-nominal position in all DacRom languages, with the exception of Southern Istro-Romanian and Southern Aromanian. All languages in which the A-N order is grammatical, display the A-N pattern, regardless of whether they use Num heads marked as [c] or not, and regardless of whether they allow the spread of the definite article to multiple heads or not.
- (41)
| (a) | fermecătorul | oraş | (MRom) |
| | charming.def | city | |
| | ‘the charming city’ |
| (c) | verit-a | la | marle | iardin | (IstroN, | Cantemir 1959, p. 113) |
| | come-has | to | big.def | garden | | |
| | ‘(S)he arrived at the big garden’ |
| (e) | sfânta | credinţă | (Old | Rom, | Costin | {242}) |
| | holy.def | faith | | | | |
| | ‘the holy faith’ |
The A-N pattern, on the other hand, is grammatical only in Megleno-Romanian, Northern Istro-Romanian, Northern Aromanian, and Old Romanian. These are languages which allow the spread of the definite article to multiple heads,
- (42)
| (c) | íptul | […] | lu̯-ascute̯ám | dit | mărli | pái̯i |
| | wheat.def | […] | it-took.out.1pl | of | big.def | straw.def |
| | ‘The wheat, we would separate it from the big straw.’ |
| | (AromN, Saramandu 2007, p. 70) |
The derivation of A-N orders proceeds from the structure in (25) above, in which the pre-nominal adjective is merged in the Spec of a functional projection inside the DP.
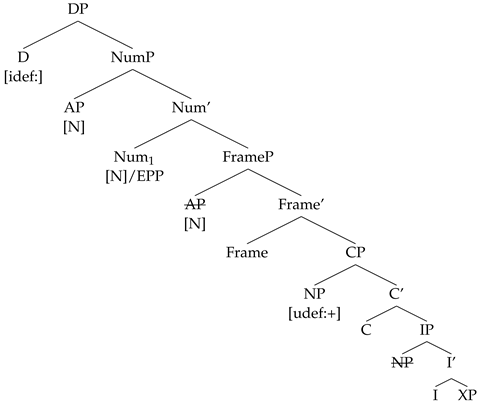
If a Num head without a [c] feature is merged in this structure, it will attract the AP, which bears a matching [N].
- (43)
A movement chain is created by the movement of the AP to SpecNumP, and when the NumP is sent to Spell-out, the lower copy of the AP chain is deleted.
- (44)
(a) AP movement chain: (AP, AP)
(b) Chain output at PF: (AP, AP)
The [def] Agree chain that is formed when D probes for a valued [def] feature contains D, A, and N, all of which Agree with respect to their [def] feature.
- (45)
[def] Agree chain: (D[def], A[def], N[def])
Chain output at PF: (D[def], A[def], N[def])
The pronunciation of this chain is phase-based. First, a partial chain is formed in the NumP phase, that contains only A and N. When the NumP is sent to spell out, the lower [def] instance is deleted, since the pronunciation of the higher [def] copy does not lead to a PF violation (the suffixal nature of the definite article can be satisfied by the A host). When D is merged, D probes for a valued match for its [def] feature, and it finds the [def] feature on A. A is already part of an Agree chain with N, but the [def] instance on N has already been deleted at PF when the NumP phase was processed. The pronunciation of the newly formed [def] Agree chain will result in an A-N string since pronouncing [def] on D will result in a violation of the suffixal nature of the definite article and A is the only match to the [def] feature on D that is placed at the edge of the NumP phase.
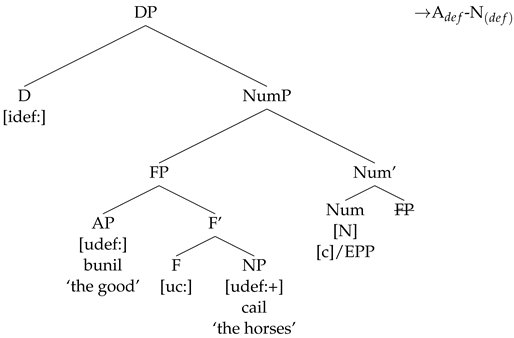
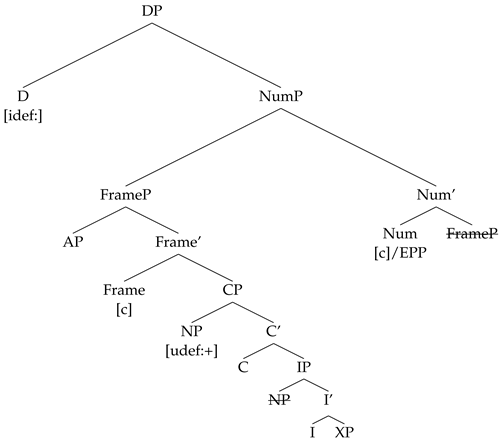
If on the other hand, a Num with [c] is merged, Num attracts FP to its Spec, since F bears a [c] feature that is able to check the EPP on the Num head.
- (46)
The lower copy of the chain resulting from the movement of the FP to SpecNumP is deleted when the FP chain is spelled out.
- (47)
(a) FP movement chain: (FP, FP)
(b) Chain output at PF: (FP, FP)
The Agree chain that results when D probes for a valued [def] contain D, A, and N. Both A and N are placed at the edge of the NumP phase, as both are part of the FP that moves to SpecNumP. In spread languages, the definite article is spelled out on all the heads within FP that bear a [def] feature and the resulting string is A-N, while in non-spread languages the definite article is overt strictly on the closest match, and the resulting string is A-N.
- (48)
[def] Agree chain: (D[def], A[def], N[def])
Chain output at PF in spread languages: (D[def], A[def], N[def])
Chain output at PF in non-spread languages: (D[def], A[def], N[def])
To sum up, on A-N definite DPs, DacRom languages show two patterns: A-N and A-N. The former pattern is available in all DacRom languages with the exception of Southern Istro-Romanian and Southern Aromanian, while the latter pattern is found in all DacRom languages with the exception of Southern Istro-Romanian, Southern Aromanian and Modern Romanian. Notice that Southern Istro-Romanian and Southern Aromanian do not display any of the patterns in which the adjective precedes the noun. I will assume that this is not a consequence of the spread or non-spread nature of these languages, nor of the type of Num head used by these languages, but is simply due to the fact that these two languages do not have pre-nominal adjectives. As for the other DacRom languages, the discussion above showed that A-N patterns can be derived by merging a Num head that lacks a [c] feature, regardless of the spread or non-spread nature of the respective language, and in non-spread languages, it can also be derived by merging a Num head with a [c] feature. As for A-N patterns, we showed that the latter can be derived only in spread languages that have a Num head marked as [c] in their lexicon. The following table summarizes these results:
- (49)
A-N definite DPs
| | Spread | Num | A-N | A-N |
| | | | (+/−[c];−Spread)
(−[c];+Spread) | (+[c]; +Spread) |
| MRom | − | −[c] | ✓ | − |
| ORom | + | +/−[c] | ✓ | ✓ |
| Megl | + | +/−[c] | ✓ | ✓ |
| IstroN | + | +/−[c] | ✓ | ✓ |
| IstroS | + | +/−[c] | − | − |
| AromN | + | +/−[c] | ✓ | ✓ |
| AromS | − | −[c] | − | − |
4.4. Apparently Problematic Cases
There are two types of apparently problematic cases in our analysis above. One is the existence of A-N strings in some of the DacRom, which cannot be derived by the structure we assumed for pre-nominal adjectives, and the other one is the grammaticality of A-N in Modern Romanian in certain restricted contexts, even though Modern Romanian is a language that does not allow the spread of the definite article to multiple heads.
4.4.1. Adef-Ndef Strings in Modern Romanian
Nicolae (
2019) points out that in Modern Romanian the definite article can be doubled in strings like the following, where the noun is followed by a possessive or a demonstrative.
- (50)
| (a) | săracul | băiatul | meu/ | Mariei | (MRom) |
| | poor.def | boy.def | my/ | Mary.gen | |
| | ‘my/Mary’s poor boy’ |
| (b) | săracul | băiatul | ăla | (MRom) |
| | poor.def | boy.def | that | |
| | ‘that poor boy’ |
Nicolae (
2019) proposes that the double definiteness of these strings has two possible sources, depending on the type of XP that follows the noun. For strings like (50a), in which the noun is followed by a possessive,
Nicolae (
2019) proposes that the definite article is realized on the pre-nominal adjective because this item is the closest item to D that bears an [N] feature, and that the realization of the definite article on the lower noun is due to reasons of representational economy (
Chomsky 1995, pp. 150–62). Possessives in Romanian can be introduced by
al or not, and the choice without
al is less costly since it involves a smaller lexical array. Crucially, the option without
al is available only under adjacency with the definite article, as in (51), so the reason why the definite article must be overtly realized on the noun in (50a) is to license the possessive.
- (51)
| (a) | băiatul | (*al) | Mariei | (MRom) |
| | boy.def | al | Mary.gen | |
| | ‘Mary’s boy’ |
| (b) | băiatul | înalt | *(al) | Mariei | (MRom) |
| | boy.def | tall | al | Mary.gen | |
| | ‘Mary’s tall boy’ |
For examples like (50b), including a post-nominal demonstrative,
Nicolae (
2019) proposes a different source for the double definiteness.
Nicolae (
2019) starts from the observation that the class of adjectives that are grammatical in this construction is restricted to evaluative adjectives which are DP level adjectives (
Cornilescu and Nicolae 2016;
Larson and Marušič 2004). These adjectives merge in the periphery of the DP, higher than DP
, and they obtain their [def] feature valued by the higher D head (D
). The noun, on the other hand, moves to D
in
Nicolae’s (
2019) analysis and gets its [def] feature checked by agreement with the adjective.
- (52)
An alternative possible account for the overtness of the lower D is offered in
Cornilescu and Nicolae (
2016): the higher D values only a subset of the features associated with D, while the lower head values the complementary subset, although
Cornilescu and Nicolae (
2016) do not address the issue of double definiteness.
I propose a unified analysis for all the A-N strings that display double definiteness. One important observation is that the type of adjectives that occur in these constructions are restricted to adjectives that express modal subjective evaluation in all of these constructions, not only in those including post-nominal demonstratives (as pointed out by
Nicolae 2019). Second, the noun may be followed not only by a possessive or a demonstrative, but also by a PP modifier or an adjective, and the noun may even lack any modifier at all.
- (53)
| (a) | săracul | băiatul | fără | picioare | (MRom) |
| | poor.def | boy.def | without | legs | |
| | ‘the poor boy missing his legs’ |
| (b) | săracul | băiatul | orfan | (MRom) |
| | poor.def | boy.def | orphan | |
| | ‘the poor orphan boy’ |
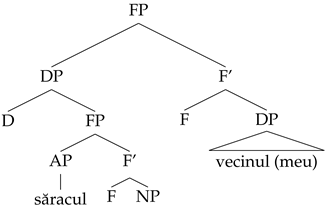
| (c) | săracul | vecinul | (MRom) |
| | poor.def | neighbour.def | |
| | ‘my poor neighbour’ |
This suggests that a split analysis, that depends on the type of modifier that follows the noun, is unlikely. A related point is that the nominal that follows the adjective in these constructions may also contain the adjectival article
cel, which sits in the D
head. This shows that this nominal constituent can be a DP
, rather than a DP
, as proposed by
Nicolae (
2019).
- (54)
| săracul | băiatul | cel | orfan | / | fără | picioare(MRom) |
| poor.def | boy.def | cel | orphan | / | without | legs |
| ‘the poor orphan/legless boy’ |
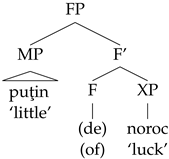
What I suggest is to analyze these examples as instances of pseudo-partitive constructions like the following.
- (55)
| puţin | (de) | noroc | (MRom) |
| little | (of) | luck | |
| ‘a little luck’ |
It is widely accepted that the first constituent of qualitative pseudo-partitives is an emotive modifier that expresses a subjective evaluation of the speaker (
Hulk and Tellier 2000;
Matushansky 2002;
Milner 1978;
Tănase-Dogaru 2012, among others). In other words, these are the same types of modifiers that are allowed in the double definiteness constructions above. The analogy is supported by the fact that the same particle that connects the two constituents in a pseudo-partitive construction (
de) can also occur in strings displaying double definiteness and that this particle is optional in both constructions
4.
- (56)
| săracul | (de) | vecinul | meu | (MRom) |
| poor.def | (of) | neighbour.def | my | |
| ‘my poor neighbour’ |
Moreover, according to
Matushansky (
2002);
Tănase-Dogaru (
2012), among others, the emotive modifier that occurs in qualitative pseudo-partitives is scalar, i.e., it expresses the fact that a certain property is relevant to a certain degree. Similarly, I propose that the emotive adjective that occurs in strings displaying double definiteness in Romanian is also scalar. This property is related to their modal, quantificational nature (
Bouchard 1998;
Demonte 2008, among others).
Building on the scalar nature of the emotive adjective, I propose to assimilate qualitative pseudo-partitives to measure partitives. According to
Cornilescu et al. (
2009);
Schwarzschild (
2006) measure partitives are headed by a functional head that licenses a Measure Phrase (MP) in its Specifier. The complement of this head is an XP that denotes the ‘substance’ that is being measured by the MP.
- (57)
Assuming a similar analysis for the examples in (50) amounts to saying that the adjective is the Measure Phrase and the noun is the ‘substance’ that the adjective quantifies into.
An additional type of support for analyzing such strings as measure partitives is that both strings that display double definiteness and measure partitives allow the inversion of the ‘substance’ noun in front of the modifier.
- (58)
| (noroc) | puţin | (noroc) | (MRom) |
| (luck) | little | (luck) | |
| ‘little luck’ |
- (59)
| (săracul) | vecinul | (săracul) | (MRom) |
| (poor.def) | neighbour.def | (poor.def) | |
| ‘my poor neighbour’ |
The source of the double definiteness in both the inverted and non-inverted structures is the existence of two DPs. As pointed out by
Schwarzschild (
2006), the complement of the F head can be an AP, an NP, or a PP, but it could also be a DP. Crucially, when the complement is a DP, as it is in our constructions, the MP cannot be a modal, quantificational AP, since these adjectives are second-order functions that apply to arguments of the type <e,t>. We will thus assume instead that the AP is not the MP per se, but is embedded into a nominal constituent in which the adjective modifies a null NP.
- (60)
Since this structure contains two DPs, both the modifier within the MP and the DP complement of F can bear a definite article. Notice that this type of double definiteness has a different source than Agree. In other words, the definite article does not spread to multiple heads in a local relation to D as a result of Agree, as it does in other DacRom. The source of double definiteness in this case is the existence of multiple determiners in the syntax.
It is an open question whether in the other languages that display A-N strings (Old Romanian, Megleno-Romanian, Northern Istro-Romanian and Northern Aromanian) this class of adjectives (i.e., modal, intensional adjectives that express subjective evaluation) can also be merged in a similar pseudo-partitive structure, as in modern Romanian. Given that A-N strings can be derived in these languages without assuming this structure, and that the adjectives that occur in this pattern in these languages are not restricted to modal adjectives, I will assume that modern Romanian is the only language in this family that allows adjectives to be merged as part of a Measure Phrase.
4.4.2. A-Ndef
Let us now move on to A-N strings, which are grammatical in Megleno-Romanian, Southern Istro-Romanian, and Old Romanian, but cannot be accounted for by the structure we have assumed above for pre-nominal adjectives.
- (61)
- (62)
- (63)
| neştiutor | gândul | omenesc | (ORom, | Cantemir) |
| ignorant | thought.def | human | | |
| ‘the ignorant human thinking’ |
In order to account for these strings, I propose in these languages there is an additional merge position for pre-nominal adjectives, namely as frame setters (also called ‘scene setters’ by
Lambrecht 1996, ‘limiting topics’ by
Carella 2015, or ‘delimiters’ by
Krifka 2007). Unlike Topics, which indicate ‘aboutness’, frame setters delimit a domain for the evaluation of the truth of the proposition expressed in the utterance (
Krifka 2007). In (64), ‘while writing’ is clearly not what the utterance is about. Rather, the frame setter ‘while writing’ instructs the hearer that the statement that Guillaume makes no mistakes in English should be evaluated along a particular dimension.
- (64)
In the example above, the frame setter ‘while writing’ delimits the set of situations or contexts where the predicate of the main utterance should be evaluated. There are also instances in which the frame setter delimits the type of information that can be provided about an individual.
- (65)
As for his health situation, John had a bypass recently. (
Krifka 2007)
This time, the frame setter ‘as for his health situation’ does not indicate that the predicate ‘had a bypass recently’ is true only with respect to his health situation. Rather, it delimits a subset of possible types of information that can be added about John. Following (
Krifka 2007), I will assume that the two cases can be subsumed under a unitary account and I will adopt the definition that frame setters delimit the type of information that can be provided about an individual. This definition can account for both (64), where ‘while writing’ delimits the types of predicates that are true about the individual Guillaume, and for cases like (65), where the frame setter ‘as for his health situation’ delimits the type of information that can be provided about John. I propose that frame setters can also be active within nominal phases and that pre-nominal adjectives in Megleno-Romanian and Southern Istro-Romanian can be merged as frame setters at the periphery of a nominal phase, parallel to the merge position of frame setters in the clausal domain (
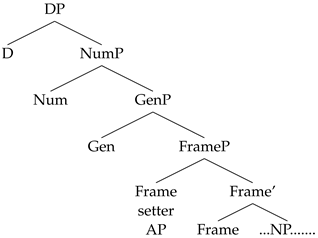
Frascarelli 2017). More specifically, I propose that they are merged in the Specifier of a FrameP at the periphery of the NumP phase, as in (66).
- (66)
This merge position for frame-setting adjectives is very similar to the merge position of regular pre-nominal adjectives in the Spec of FP. Apart from the merge position, another similarity is that just like regular pre-nominal adjectives, frame-setting adjectives are merged in the Specifier of a head that bears a [c] feature. Positing a matching [c] feature on the Frame head is justified by the fact that frame setters imply the existence of an alternative set of frames, where the truth of the proposition does not hold (
Krifka 2007, among others). In (64) for example, the frame setter ‘while writing’ implies that while performing different types of activities, like reading or speaking, Guillaume could make mistakes. In Krifka’s words “If there is no alternative perspective to be considered, then there is no need for an explicit frame setter either” (
Krifka 2007, p. 32). In his view, APs acting as frame setters always contain a variable that spans over possible alternative frames and contains an internal focus.
- (67)
A delimitator
in an expression [
…
Focus ] always comes with a focus within
that generates alternatives
′. (
Krifka 2007)
Despite these similarities, frame setters show properties that set them apart from the other adjectives.
One difference is that frame-setting adjectives lack a specificity ([spec]) feature. This is supported by the inability of frame setters to be resumed by a clitic.
Frascarelli (
2017) points out that the locative frame setter ‘a Casal de’ Pazzi’ in (68a) cannot be resumed by the clitic ‘ci’, in contrast to (68b) where ‘a Casal de’ Pazzi’ is a dislocated locative, in which case it can be resumed by the clitic ‘ci’.
- (68)
| (a) | Io | a | Casal | de’ | Pazzi | non | ci | arrivo. |
| | I | to | Casal | de’ | Pazzi | not | cl.loc | arrive.1sg |
| | ‘I am not going to Casal de’ Pazzi quarter.’ (Italian, Frascarelli 2017, p. 488) |
| (b) | A | Casal | de’ | Pazzi | il | traffico | (*ci) | sembra | scorrevole. |
| | at | Casal | de’ | Pazzi | the | traffic | *cl.loc | seem.3sg | moving |
| | ‘At Casal de’ Pazzi, the traffic flow seems good.’ |
Second, since frame setters function as delimiters of the type of information that can be provided by an individual, we expect frame setters to co-occur with propositions or predicative relations in general, and this is different from regular pre-nominal adjectives, which do not require to scope over a predicative relation. In the case of frame setters that occur at the clausal domain, like (64) or (65), it is obvious that the frame setter scopes over the entire proposition. However, for frame setters that occur in the nominal domain, it looks like in some cases the complement of the Frame head does contain a predication relation, as in the Old Romanian example in (63), but in other cases the complement of the Frame head seems to be a simple NP, as in the Megleno-Romanian and Southern Istro-Romanian examples in (61) and (62), respectively.
In order to understand why this is not actually a problem for our analysis, it is important to notice that the nouns occurring in these strings are relational nouns in both examples, and in our opinion, this is not a coincidence. Relational nouns take a complement, i.e., an internal argument, expressed as a possessor. The structure of the examples in (61) and (62) is, therefore, more complex and contains an implicit PossP embedded as a predicate within a reduced relative clause. This PossP can accommodate a null Possessor in the case of relational nouns.
- (69)
The interpretation of the null Possessor depends on the context. In the context below, for example, from Megleno-Romanian, the possessor is interpreted as the brother who fell.
- (70)
| Unu | di | frats | [. | . | .] | căn | căzú | dighios | ăt’tsi | frănsiră | şamindoauli | pitšoari | [. | . | .]. | Că-l | vizú | [lupu] | ţăl | cu | frănti | pičo̯árili, | căţă | şi | măncă | din | iăl |
| one | of | brothers | [. | . | .] | when | fell | down | his | broke | both | legs | [. | . | .]. | When-him | saw | [wolf.def] | that.one | with | broken | legs.def, | started | and | ate | of | him |
| ‘One of the brothers […] when he fell down, he broke both of his legs […]. When the wolf saw the one with broken legs, he started chewing at him’ |
| (Megl, Saramandu et al. 2017, p. 178) |
This difference between regular pre-nominal adjectives and frame setters regarding the complement of the Frame head is related to a third, interpretive, difference between these two types of adjectives. This interpretive difference can be best expressed by using
Heim (
1982)’s file card model. In this framework, discourse entities are mapped to a set of file cards that identify individuals and record a list of properties for each of them. These properties are semantic predicates that apply to the respective entity. As the discourse progresses, these cards can be updated in various ways, for example, by adding more properties to certain cards. A regular adjective is thus entered directly on the card headed by the noun that it modifies. Frame setters, on the other hand, do not denote the properties of a certain individual, but delimit the type of information that can be provided by an individual. In other words, frame setters break up the list of properties that apply to a certain individual into sublists, they are subheadings that organize the information that is relevant about an individual into domains.
The file card for the noun ‘pičo̯árili’/ ‘the legs’ will include a subfile headed by frănti/ ‘broken’, which delimits the domain within which the possessive predicate should be evaluated. In other words, the predicate ‘belong to the brother that fell’ is true within the domain of broken things.
- (71)
file name: pičo̯árili/ ‘the legs’
subfile: frănti(x)/ ‘broken’ (x), i.e., the domain of broken things
the legs are the brother’s
Similarly, the contribution of the frame setter neştiutor/ ‘ignorant’ to the file card for the noun gândul/ ‘the thinking’ in (63) is to delimit a domain of ‘ignorant things’, and the predicate omenesc/ ‘human’ is recorded to be true in the domain of ignorant things.
- (72)
file name: gândul ‘the thinking’
subfile: neştiutor(x)/ ‘ignorant’ (x), i.e., the domain of ignorant things
gândul e omenesc/ ‘the thinking is human’
Finally, a last difference between regular pre-nominal adjectives and frame setters is that frame setting adjectives lack a [def] feature, as well as a [spec] feature. The lack of a [def] feature is likely related to the fact that frame setters indicate the scope within which other predicates can apply to an individual, and therefore, they always denote (super)sets, rather than identifiable individuals.
Let me now go through the derivations based on the structure in (69), where the adjective is merged as a frame setter. If a Num head without a [c] feature is merged, it will attract the AP to its Spec, to check the [N] feature on Num, which is associated with an EPP. The derivation will crash however, since the [def] feature on D cannot access the only valued match in the structure (the [def] feature on the NP) which is placed within the complement of the NumP phase. Crucially, the AP which sits at the edge of the NumP does not bear a [def] feature in our analysis.
- (73)
If, on the other hand, a Num head bearing a [c] feature is merged, it will attract the FrameP to its Spec. Recall that the Frame head bears a [c] feature in our analysis, a feature that is justified by the fact that frame setters imply the existence of an alternative set of frames. When D searches for a match for its unvalued [def] feature, it finds the def feature on the NP and the definite article is spelled out on N. The resulting string is A-N.
- (74)
To sum up, pre-nominal adjectives in DacRom can be either regular APs merged in the Spec of a functional projection inside the NumP (as part of the main spine of the DP or as part of a measure DP in Spec of a pseudo-partitive projection), or they can be merged as frame setters. If merged in a regular pre-nominal position, APs bear a [def], and if they are merged as frame setters, pre-nominal adjectives lack a [def] feature.
4.5. Language Variation
Not all DacRom languages display all the patterns above. The specific subset of patterns that is grammatical in each language depends on several factors: (i) whether the respective language allows the Num phase head to bear a [c] feature or not; (ii) whether Adjectives can be merged as frame setters in that language; (iii) whether Adjectives can be merged as measure phrases; (iv) whether the respective language is a spread or non-spread language; DacRom languages instantiate the values of the parameters above in the following way: (i) modern Romanian and Southern varieties of Aromanian have Num heads without a [c] feature, while Old Romanian, Megleno-Romanian, Istro-Romanian (both Southern and Northern varieties), and Northern Aromanian allow Num heads to bear a [c] feature; (ii) Adjectives can be merged as frame setters in Old Romanian, Megleno-Romanian and Southern Istro-Romanian, but not in the other languages in this family; (iii) Adjectives can be used as measure phrases in Modern Romanian, but not in the other Daco-Romanian languages. On top of this, there is one lexical restriction that affects Southern Istro-Romanian and Southern Aromanian, in the sense that these two languages lack pre-nominal adjectives altogether. (iv) Modern Romanian is a non-spread language while all the other Daco-Romanian languages are spread languages. Each of these possibilities feeds into the derivation of specific patterns. For example, only a Num head that lacks a [c] feature can generate an N type of DP, while the other patterns can be generated with Num heads that may carry a [c] feature. Similarly, the A-N pattern can be generated only in languages that allow adjectives to be merged as frame setters, but not in others. The table below sums up the patterns that map onto each value of the parameters listed above, as well as how various Daco-Romanian languages instantiate each pattern.
- (75)
| | Spread | Num | AP As | AP As |
| | | | [c] | Frame | MsrP |
| | Single | Multi | no [c] | | Setters | |
| | | N | N-A | A-N | N-A | A-N | A-N | A-N |
| MRom | ✓ | – | ✓ | ✓ | ✓ | – | – | – | ✓ |
| ORom | – | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | – |
| Megl | – | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | – |
| IstroN | – | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | – | – |
| IstroS | – | ✓ | ✓ | ✓ | – | ✓ | – | ✓ | – |
| AromN | – | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | – | – |
| AromS | – | ✓ | ✓ | ✓ | – | – | – | – | – |
A few observations are in order with respect to the table above. One concerns the division of DacRom languages into languages that use a Num head with a [c] feature and languages that use a Num head without such a feature. Some languages, like Modern Romanian and Southern Aromanian exclusively use a Num head without a [c] feature, while others use Num heads that may optionally bear a [c] feature. Also, the patterns that can be obtained with these two types of Num heads overlap to a certain extent. In particular, N-A and A-N patterns can be derived both in languages that use exclusively a Num head without a [c] feature and in those that use a Num head marked as [c]. Other patterns, like N-A and A-N can occur only in languages that use a Num head marked as [c]. Last, but not least, even though Modern Romanian allows A-N patterns, it is not a spread language. Double definiteness in Modern Romanian is not the result of spread, i.e., of an Agree relation involving multiple heads, but rather can be traced back to two D heads, represented as independent of each other in the syntax.