1. Introduction
More than half of the world’s population is multilingual (
Crystal 2007;
Grosjean 2021), meaning that people speak and understand more than one language (
Aronin and Singleton 2012;
Cenoz 2013;
Grosjean 2021;
Kemp 2009). Within the large body of research on multilingual language processing (e.g.,
Aronin and Singleton 2012;
Kroll and Stewart 1994;
Lin and Lei 2020;
Pavlenko 2011), a particularly influential theoretical framework is the Revised Hierarchical Model (RHM) proposed by
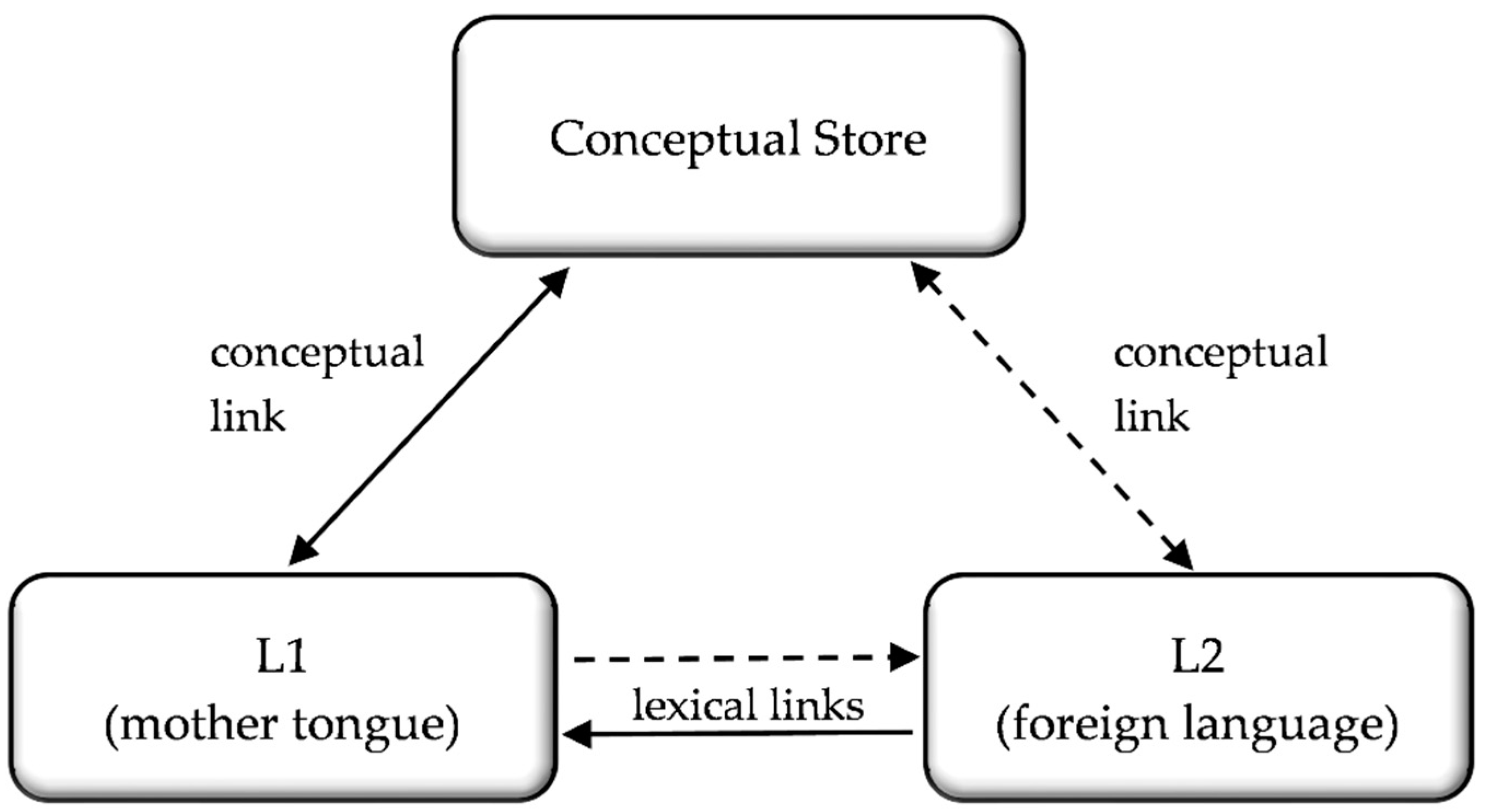
Kroll and Stewart (
1994). This model describes the mental processing of several languages by late multilinguals, i.e., individuals who learnt a foreign language after early childhood (
Kroll et al. 2010). It suggests that two lexical items which carry the same meaning in different languages, for example
apple in English and
Apfel in German, are stored cognitively in distinct lexical stores (
French and Jacquet 2004;
Heredia 1997;
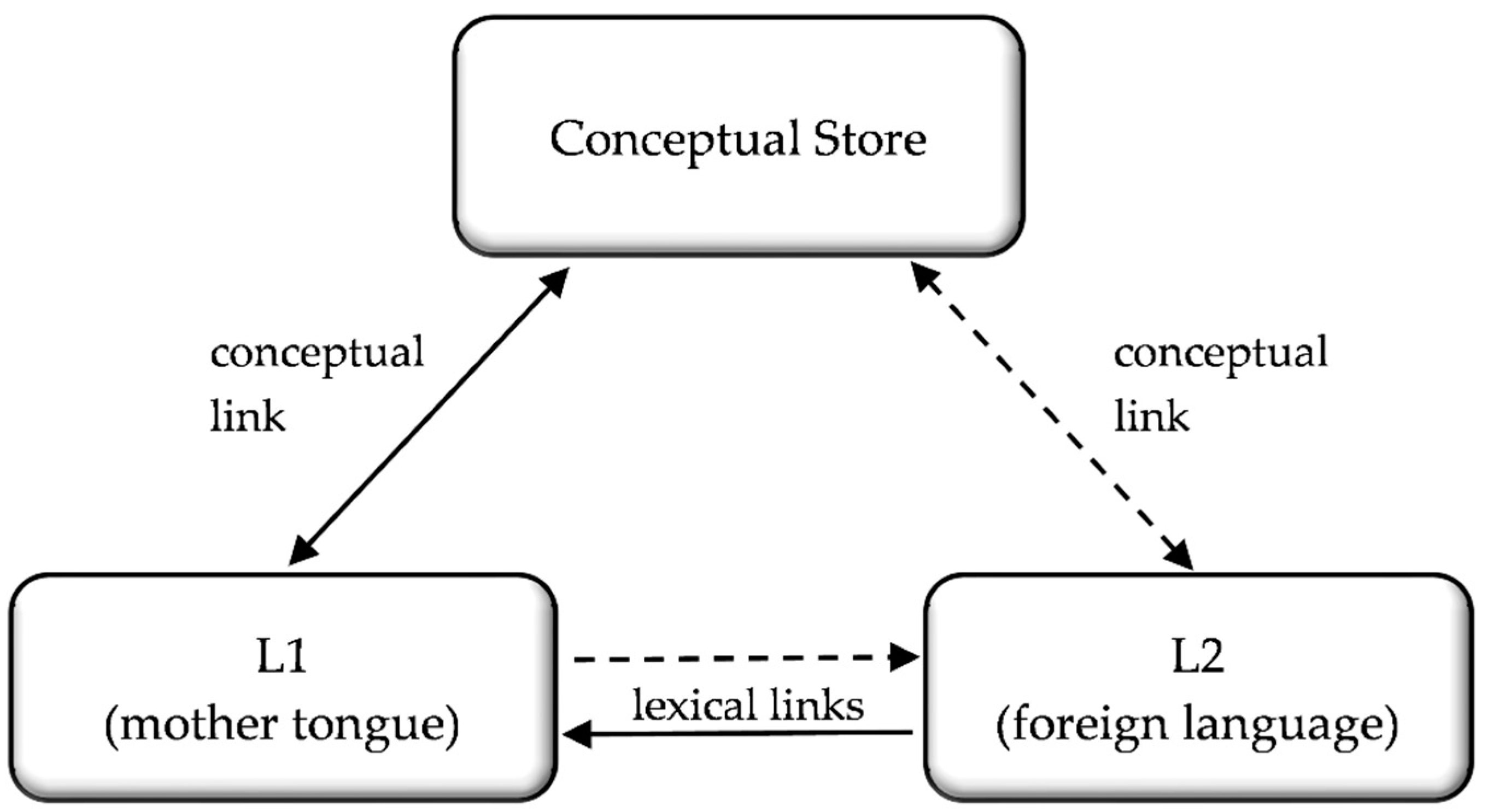
Kroll et al. 2010), while the shared meaning of both words resides within a common, language-independent conceptual store (
Gürel 2004;
Kroll and Tokowicz 2001). Importantly, bidirectional connections exist between the separate lexical stores of the native (L1) and subsequently acquired foreign language (L2) (
Broersma and Bot 2006;
Brown and Gullberg 2008;
Degani et al. 2011;
Kroll and Stewart 1994;
Lagrou et al. 2011). However, the connections differ in strength and are therefore
asymmetrical: translation from L2 to L1 tends to be faster and more accurate compared to that in the reverse direction (
Kroll et al. 2002;
Kroll and Sholl 1992;
Kroll and Stewart 1994;
Palmer et al. 2010;
Potter et al. 1984;
Sperl et al. 2023;
Zheng et al. 2020). The model explains this phenomenon by suggesting that the preferred pathway from the L1 word (e.g.,
apple) to the corresponding word in L2 (
Apfel) is mediated via its equivalent representation in the conceptual store. In contrast, as depicted in
Figure 1, translation from L2 to L1 is possible directly, without requiring the conceptual store.
In addition to proposing bidirectional asymmetrical routes for translation,
Kroll and Stewart (
1994) discussed the phenomenon of
category interference, which means that participants’ performance depends on whether stimuli are presented in semantically structured lists (e.g., containing only birds) or mixed lists (e.g., a list containing a mixture of semantic categories: birds, vehicles, furniture, fruit, etc.). Interestingly, participants were slower to respond when translating from categorically organized lists than from mixed lists, but only when the answer was required in L2 (i.e., in the direction where the cognitive route was assumed to be conceptually mediated). This is attributed to the activation of an entire category, resulting in an increased number of competing lexical entries (e.g.,
dove vs.
sparrow). Consequently, the complexity of the language processing task is heightened, requiring participants to select between similar entries. In turn, this means that they respond more slowly and make more errors than with mixed lists. At the same time, this deeper processing yields a benefit in terms of improved subsequent recall (
Kroll and Stewart 1994). In sum, the RHM is based on three key findings, namely, (1) an
asymmetry effect, whereby translation into L1 is faster and more accurate than into L2; (2)
category interference, which results in slower response times and reduced accuracy for semantically organized lists compared to mixed lists; and (3)
category facilitation, with enhanced recall of words from organized lists compared to mixed lists. These findings shed light on the dynamics of language processing, where the activation of category information can both impede and enhance cognitive performance, offering valuable insights into the mechanisms underlying multilingual cognition.
In the 30 years since its publication, the RHM has been intensively questioned and refined by numerous studies (
Heredia 1997;
Kroll and Tokowicz 2001;
Kroll et al. 2010;
Palmer et al. 2010). Recently,
Sperl et al. (
2023) investigated the applicability of the RHM to non-native multilingual speakers. Their Experiment 2 resembled
Kroll and Stewart’s (
1994) Experiment 3, but instead of comparing participants’ native language to a second language, they compared asymmetry and category effects for two different foreign languages (e.g., L2 and L3). Surprisingly, an asymmetry resembling the one seen between L1 and L2 was also present between L2 and L3, instead of being less pronounced or even absent for non-native languages. This unexpected finding prompts a reconsideration of the RHM as proposed by
Kroll and Stewart (
1994). Originally developed to explain the relationship between L1 and L2 regardless of their identity, the model appears to apply more broadly to relationships among multiple non-native languages. It may be that any of an individual’s foreign languages can, under certain conditions, assume the role typically played by the L1. This ‘pseudo-native’ language could potentially manifest similar effects to a true L1 in its interactions with other languages.
However, understanding such differences between foreign languages requires us to identify which factors affect the relative status of two or more foreign languages. Proficiency and age of acquisition are often reported in this context. However, a recent study by
Sperl et al. (
2023) showed that a language learned later in life can still be superior in status compared to one learned earlier (in their case German, which was on average learned at an age of 16.5 years, compared to English, with 8.2 years). In addition, participants in this study exhibited a highly similar proficiency level regarding the two experimental languages (
M = 4.5 on a scale from 1—A2 to 6—C2 level). Nonetheless, asymmetries were clearly evident between the two languages. One plausible factor that could also play a role in determining the relative status of an individual’s foreign languages could be the
language context surrounding the multilingual speaker.
On the one hand, this could be the immediate
experimental context, i.e., the language of the current investigation (
Grosjean 1989;
Wu and Thierry 2010). For instance, recruiting for, introducing, and conducting an experiment in German could potentially make German particularly salient (
Elston-Güttler et al. 2005;
Wu and Thierry 2010) and facilitate its processing, leading to enhanced asymmetry and category effects. Essentially, a German experimental language context could strengthen the activation of German due to its immediate contextual presence, thereby activating its vocabulary. On the other hand, the relative status of two foreign languages might also be influenced by the surrounding language context in everyday life as a more long-term factor reflecting the
language environment of the individual. This type of context would be expected to shape a person’s language habits and influence the frequency of both active language use and passive language exposure (
see also Wigdorowitz et al. 2022,
2023). Recent research has indeed demonstrated an influence of the linguistic context on both lexical access in different languages and general cognitive control abilities (
Beatty-Martínez et al. 2020).
Here, a person’s language competence may also be profoundly affected by
immersion experiences i.e., the intense act of learning a language implicitly by immerging oneself into the respective culture and context (
Dewey 2007;
Juan-Garau and Lyster 2018;
Wilkinson 1998). Studies have found that acquiring a language implicitly, which occurs by being surrounded constantly by the language in the respective country, may lead to a higher and more efficient, almost mother-tongue-like, language gain (
Freed et al. 2004;
Morgan-Short et al. 2012). This method of acquisition is similar to learning one’s native language, taking place naturalistic and “accidentally”, without actively studying grammar or vocabulary (
Juan-Garau and Lyster 2018;
Kearney 2010). A foreign context facilitates learning opportunities which a classroom is not able to provide. It provides interactions with native speakers. These improve language skills significantly, especially if conversations go beyond small talk and into a deeper level (
Baker-Smemoe et al. 2014). A study by
Morgan-Short et al. (
2012) even found native-like brain activation patterns in participants who learned the foreign language implicitly, while no differences were found in participants who were taught explicitly (e.g., using a grammar-focused classroom method). This finding supports the idea that the conditions of learning a language play a critical role and that certain circumstances, e.g., an immersion experience compared to studying purely in a classroom, may lead to the acquisition of a ‘pseudo-native’ language.
To summarize, both short-term exposure to an
experimental language context or long-term exposure to a certain
environmental language context (potentially associated with a certain degree of
immersion experience) could activate the corresponding vocabulary and render this particular language salient (
Montrul 2015;
Treffers-Daller 2019), leading to differential asymmetries and category effects between several foreign languages.
The Current Study
In order to identify how short- vs. long-term contextual factors affect the relative status of two (or more) foreign languages, three online experiments were conducted with foreign language speakers. These experiments were loosely based on
Kroll and Stewart’s (
1994) theoretical framework. Specifically, Experiment 1 followed up on the unexpected findings of
Sperl et al. (
2023), replicating and establishing the paradigm in an online format and focusing on individual differences between speakers’ language biographies. Next, two further experiments manipulated and compared two distinct types of language context: Experiment 2 investigated the short-term role of the experimental language by varying the language of the instructions, while Experiment 3 targeted the wider long-term language environment by contrasting participants living in countries where different societal languages are spoken. It seems plausible that either or both types of language context could highlight one foreign language over another, giving it a (temporarily) similar status to the L1 in the classic RHM. As in
Kroll and Stewart (
1994), this should be visible in the form of asymmetry effects, category interference, and category facilitation, based on the two dependent variables response time (RT) and accuracy.
All three experiments were conducted online and in parallel, with data acquisition taking place between July 2021 and December 2022. Personal networks and social media postings were used to recruit an exclusive expert sample of late-multilingual speakers who were proficient in both experimental languages (German and English), although neither language was their L1. This approach allows for a meaningful comparison with the RHM, while also enabling us to identify conditions which lead foreign languages to achieve ‘pseudo-native’ status. It compares two foreign languages (instead of a native and a foreign language) in order to examine the salience of a language under different contextual conditions. The key manipulation consisted of highlighting the German language in different ways, potentially giving it a ‘pseudo-native’ status via either the short-term experimental context (Experiment 2) or the longer-term environmental context (Experiment 3).
2. Experiment 1: Online Replication and Immersion Experiences
Experiment 1 examined the applicability of the RHM (
Kroll and Stewart 1994) to subsequent languages (L2, L3 and so forth: note that, in the interest of readability, we will always refer to the two foreign target languages of this study as L2 and L3 for all participants, irrespective of their order of acquisition). This experiment was conducted online due to pandemic restrictions on lab studies. At the same time, it allowed us to test a form of data acquisition that would make it possible to assess a rather exclusive sample of multilingual participants in different locations. In this experiment, participants were late multilinguals currently living in German-speaking countries (i.e., individuals who acquired their L2 only after entering school).
Hypotheses. As already mentioned, we expected
asymmetry effects, with faster RT and higher accuracy for answers in German than in English. In other words, although both languages are assumed to be connected bidirectionally (connections from L2 to L3 and vice versa), participants should respond faster and more precisely in their more salient foreign language (here: German), as they would in their L1, compared to their less salient language (here: English). Such a finding would suggest varying strengths of mental pathways between lexical stores. Furthermore, we expected
category interference effects, where participants would respond slower and less accurately when completing tasks with semantically organized lists rather than mixed lists. However, analogously to
Kroll and Stewart (
1994), these effects were only anticipated in the less salient language. Therefore, we predicted that participants would experience category interference, particularly in English. Lastly, we predicted
category facilitation, whereby more items would be correctly recalled from organized lists due to more in-depth processing during longer response times (
Kroll and Stewart 1994).
In addition to an online replication of
Sperl et al. (
2023), Experiment 1 also looked at the role played by
immersion experiences. We predicted that the language of immersion, in this case German, would be highlighted and therefore assume the role of a pseudo-native language. Moreover, participants with a deeper immersion were supposed to show a stronger asymmetry effect, with faster RT and higher accuracy for answers in German than in English. In other words, we hypothesized that the asymmetry effect would grow stronger with deeper immersion into the German language due to it becoming more salient in comparison to English. In an exploratory manner, Experiment 1 also investigated whether category interference and recall facilitation were associated with the strength of immersion.
2.1. Methods
2.1.1. Participants
Participants were non-German and non-English native speakers who had been living at the time of the experiment in Germany for a minimum of three months and had advanced knowledge of both German and English as foreign languages.
Initially, 60 people participated in the experiment. However, a total of 15 participants had to be excluded due to technical problems (N = 4), an accuracy below 50% (N = 5), for being early multilinguals (N = 3), or because their L1 was German (N = 3). The final sample of 45 participants was on average 38 years old (M = 38.02 years; SD = 11.29, range: 20–59, with 35 females and 10 males). The recruitment strategy consisted of using personal and social media contacts and language teachers. Psychology students were rewarded with course credits.
On average, participants spoke four different languages (
M = 4.11;
SD = 1.17; range: 3–7), including German, English, and their native language, which could be Spanish (
N = 15), Serbian (
N = 5), Portuguese (
N = 5), French (
N = 3), Turkish (
N = 2), Arabic (
N = 1), Armenian (
N = 1), Basque (
N = 1), Bulgarian (
N = 1), Catalan (
N = 1), Chinese (
N = 1), Croatian (
N = 1), Georgian (
N = 1), Greek (
N = 1), Italian/Albanian (
N = 1), Kurdish (
N = 1), Norwegian (
N = 1), Romanian (
N = 1), Serbo-Croatian (
N = 1), or Swedish (
N = 1). For a full overview of the languages participants reported being able to speak, see
Table S1 in the Supplemental Materials.
Contextual usage of languages. On average, participants had been living in Germany for about 12 years, with a wide range between 9 months and 32 years (SD = 8.71). Consequently, although German was not their native language, most participants (69%) used German in everyday life; 33% of participants used their native language; and 22% used English (total responses exceeded 100% as they could name more than one option). A similar distribution was found for the language used at work (69% German, 40% native language, and 27% English). Nonetheless, most participants reported usually thinking in their native language (78%, with 40% German and 13% English).
Age of acquisition. On average, participants started learning German during early adulthood at the age of 20 years (M = 19.84, SD = 8.53; range: 7–39) and English at the age of 11 years (M = 10.6, SD = 4.68, range: 5–30), making them late multilinguals in both languages. In total, they had been using German for about 18 years (M = 18.09, SD = 10.78; range: 2–39) and English for about 27 years (M = 27.48, SD = 10.31, range: 7–49) at the time of the experiment.
Proficiency. On a scale from 1 to 6, with 1 representing an A1 proficiency level and 6 representing a C2 proficiency level according to the definitions of the
Council of Europe (
2001; described in detail in
Table S2 in the Supplemental Materials), participants indicated an overall proficiency of 4.98 in German (
SD = 0.89, range: 3–6) and 4.44 in English (
SD = 1.01, range: 2–6). The average proficiency in German therefore corresponded to C1, which is an advanced level, allowing most participants to understand and use a wide range of complex language and express themselves effectively, even in academic or professional contexts. Average proficiency in English was slightly lower, between B2 and C1, where B2 represents an upper-intermediate level, allowing speakers to express their thoughts spontaneously and without much difficulty (
Council of Europe 2001).
Receptive and productive use. When distinguishing between proficiency skills, on a scale from 1 (“never”) to 7 (“very often”), participants reported using German very often both receptively (reading and listening; M = 6.00, SD = 0.79, range: 4–7) and productively (writing and speaking; M = 5.91, SD = 0.97, range: 4–7). English was reported as being used slightly less (receptively: t(76.88) = 4.27, p < .001; productively: t(76.77) = 5.45, p < .001), though it was still employed frequently by most participants (receptively: M = 5.09, SD = 1.18, range: 1–7; productively: M = 4.49, SD = 1.46, range: 1–7).
2.1.2. Materials
Experiment 1 consisted of two questionnaires (language and immersion), two types of experimental task (translation and picture naming), and a recall task. The questionnaires and task instructions were all presented in written form in German.
Language questionnaire. Aside from assessing demographic data (age, gender, country of residence, time living in Germany, native language, and occupation), this questionnaire assessed participants’ language experience regarding German and English, as described in
Table S3 in the Supplemental Materials. It comprised the age of acquisition for German and English, as well as self-assessments of proficiency in German and English according to the criteria described in the Common European Framework of Reference for Languages (
Council of Europe 2001), an official framework for describing language abilities (for further details, see
Table S2 in the Supplemental Materials). This scale categorizes language abilities as A, B, and C, indicating elementary, intermediate, and proficient language use, respectively. Each category is further subdivided into specific levels: A1, A2, B1, B2, C1, and C2. These correspond to different proficiency levels, ranging from a beginner’s proficiency to approximately that of a native speaker. While self-assessments are necessarily subjective, the scale and the corresponding descriptions provide a standardized reference for evaluating productive and receptive language skills across different languages and contexts. Further questions assessed the native language and other languages spoken by the participant. Also, participants were asked about how frequently they used German, English, and their native language during their occupation, in everyday life, and in their thoughts. Finally, they reported how often they used these three languages for reading and listening (comprehension) vs. writing and speaking (production).
Immersion questionnaire. The degree of immersion was assessed with a specifically constructed immersion questionnaire. This questionnaire was based on the validated Sojourner Adjustment Measure (SAM) designed by
Pedersen et al. (
2011), which measures adjustment in people living abroad temporarily. Hence, the immersion questionnaire assessed immersion regarding German, the environmental language context participants were currently living in. The original version of the SAM identified six factors, which included items about language and culture, from which we extracted three language-specific aspects of immersion relevant for this study. These were (1)
social interaction with host nationals, (2)
language development and use, and (3)
social interaction with co-nationals. The respective items were adapted and translated by the authors into German. An additional fourth aspect,
subjective integration, was added based on literature research (
Dewey 2007;
Kinginger 2008;
Knight and Schmidt-Rinehart 2002) and included questions about the motivation and interest participants felt towards integrating themselves in Germany. The resulting immersion questionnaire, available in
Table S4 in the Supplemental Materials, was presented to participants after completing the experimental tasks and consisted of 24 items with 7-point scales ranging from 1 =
strongly disagree to 7 =
strongly agree, or from 1 =
never to 7 =
always.
Translation and picture-naming task. The experimental lists and items used for the translation and picture-naming tasks were identical to those used by
Sperl et al. (
2023). These could be words in German or English or pictures of various objects, such as buildings and vehicles, such as those listed in
Table S5 in the Supplemental Materials. The items were deemed to be easy or of intermediate difficulty to answer and avoided cognates that look and sound similar in the two languages (e.g.,
Tomate and
tomato). In total, 100 stimuli were organized into 10 lists—each containing either mixed, semantically organized (according to the categories
vehicles,
buildings,
fruits,
vegetables,
furniture,
kitchenware,
stationery, and
clothing), or abstract words (e.g., sadness). Abstract lists (used for translation tasks only) were included in accordance with the work of
Sperl et al. (
2023), who were interested in whether the effects of the RHM might also hold true for words that lack a clear pictorial representation in the conceptual store. However, abstract lists are not the primary focus of the current study, and their inclusion is solely to ensure methodological consistency within the established design. Most of the pictures used in the semantically organized and mixed picture-naming lists were originally from the BOSS inventory (
Brodeur et al. 2010), supplemented by additional internet searches. To minimize the influence of potential differences in stimulus difficulty, two alternate versions of the experiment were created. Each mixed list of stimuli consisted of words drawn from the semantically organized and abstract word lists in the parallel version. The experiment was implemented in E-Prime 3.0 Go (
Psychology Software Tools Inc. 2020).
2.1.3. Design
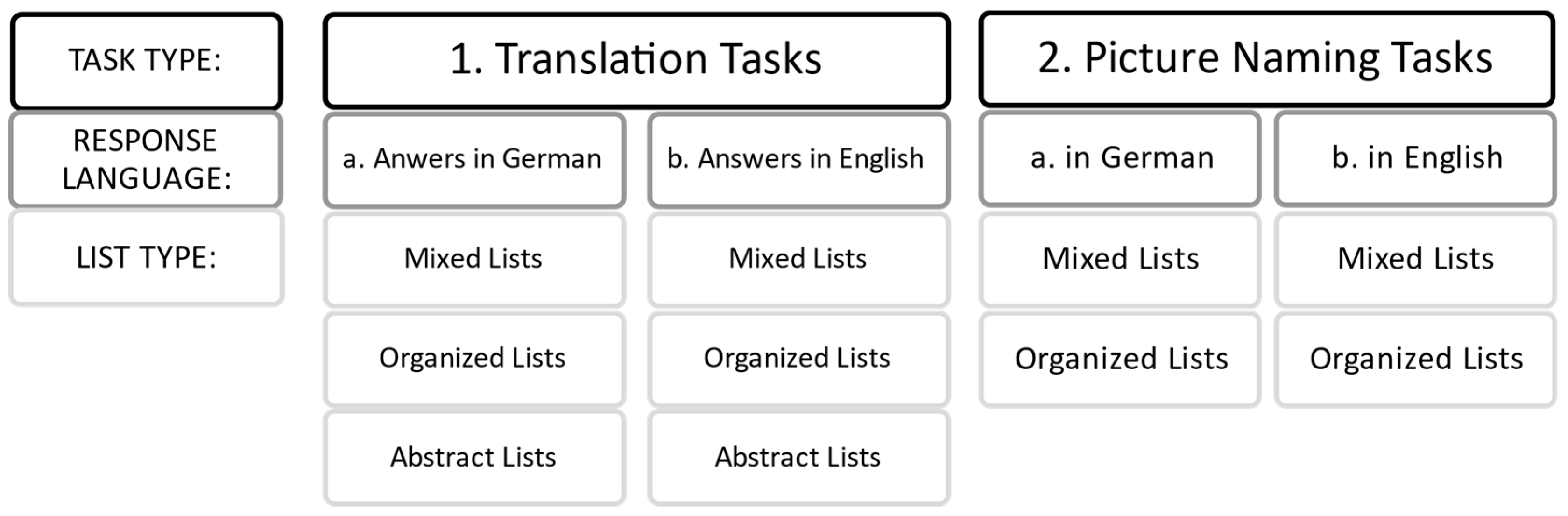
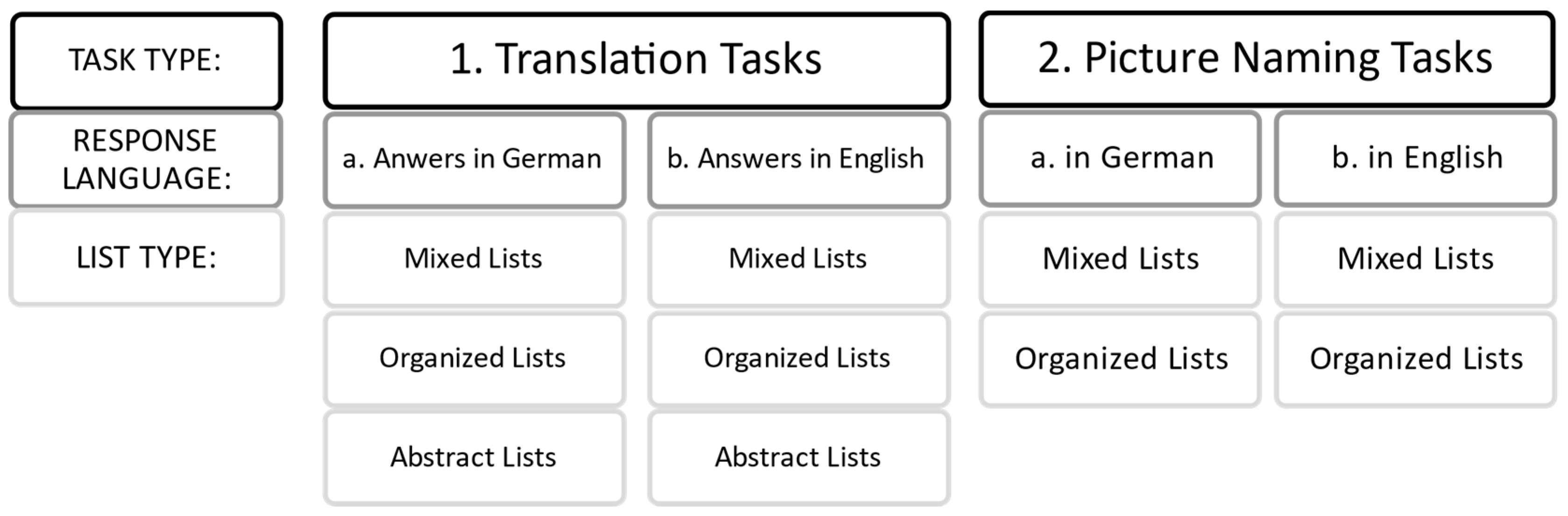
The experimental part of the study consisted of two types of task. First, participants translated words from English into German, and then vice versa (translation tasks). In the second section, they named a depicted object out loud, first in English and then in German (picture-naming tasks). As depicted in
Figure 2, items of the translation tasks were embedded in three types of word list: mixed, semantically organized, and abstract. Since abstract words cannot be depicted well, the picture-naming tasks only consisted of mixed and semantically organized lists. The order of the lists within each task was randomized. However, the order of the items within each list remained the same for all participants, following the precedent of
Kroll and Stewart (
1994). Experiment 1 used a within-participant design, comparing the performance (response times and accuracy) for each participant in relation to response language, list, and task type.
2.1.4. Procedure
Participants received a link to download an E-Prime Go file (
Psychology Software Tools Inc. 2020), which enabled the experiment to run on their personal computers without further supervision or interaction. It began with the language questionnaire (cf.
Table S3 in the Supplemental Materials). Next, participants performed the two translation tasks, followed by the two picture-naming tasks. Each task began with two trial items, followed by three word lists for each translation task and two picture lists for each picture-naming task. Each list consisted of 10 stimuli, meaning that in total participants translated and named 100 items. First, they translated 30 words from three lists into German and then 30 words into English; then, they named 20 pictures from two lists in German and then 20 pictures in English. Participants could take a break after each list of 10 items. Each item began with a black fixation cross, presented for 500 ms in the middle of the screen. Next, the stimulus was presented for 3500 ms, and participants responded by speaking into their headset or internal microphone as fast as possible. The recording of each answer began with the presentation of the stimulus and was saved as an individual .wav file.
After the experimental tasks, participants completed the immersion questionnaire (
Table S4 in the Supplemental Materials). Finally, in the recall task, they were asked to type out as many stimuli as they could remember. They were instructed to write the words in the language in which they remembered the items first. There was no time limit for the recall task. The entire study took approximately 20 min in total, depending on how quickly the participants answered the questionnaires. All data were saved automatically to the E-Prime Go platform (
Psychology Software Tools Inc. 2020).
2.1.5. Data Preparation
After downloading the data of each participant, all relevant variables from the questionnaires were collated into a single table, while the .wav files were processed using
Praat (
Boersma and Weenink 2016) to assess response times and accuracy.
Language questionnaire data. Proficiency levels in German and English were coded on a 6-point scale according to the Common European Framework of Reference for Languages (
Council of Europe 2001), with higher values meaning higher proficiency. The scale ranged from A1 (elementary) to C2 (proficient). The productive and receptive use of German and English were assessed on a 7-point scale from
never to
always, with higher values indicating more frequent use. The use of German and English in the contexts of occupation, daily life, and thought processes was coded binarily: 1 if the respective language was used in the particular context, and 0 otherwise. Participants’ age of acquisition of German and English were assessed in years, while duration of residence was assessed in months.
Response times and accuracy. A Praat script initially detected the response latency of each trial. These speech onsets were manually inspected and adjusted, e.g., when noise or filler words were captured before the answer and not detected automatically. For accuracy, correct answers were coded with a 1 and incorrect answers were coded as 0. Synonyms and grammatical variations of the correct answers were accepted (e.g., “sad” instead of “sadness”). Only correct answers were considered for RT. Data from participants with total accuracy < 50% were not included in the analyses as, with only 10 items per list, this did not leave sufficient items to reliably determine RT for all conditions.
Recall performance. Each correct response in the recall task was classified based on list type (mixed, organized, or abstract), task type (translation or picture-naming task), and response language (translating into/naming in German vs. English) which it had originally occurred in. Statistical analyses considered the proportion of words in each category (e.g., words that appeared in a translation task) compared to the total amount of words recalled per participant. Practice items and words that had not occurred in the experiment at all were not accepted. In total, participants could have recalled a maximum of 100 items.
2.1.6. Statistical Analysis
All statistical analyses were performed in R version 4.2.1 (2022-06-23 ucrt) with a significance level of α = .05. In the interest of readability, we will generally only mention results when they are statistically significant or directly relevant to our hypotheses.
Asymmetry and category effects. We used the
lmer package for R (
Bates et al. 2015) to run separate mixed-effect models (
Baayen et al. 2008;
Brown 2021) for RT using linear mixed-effect models (LME;
Winter 2020), while generalized mixed-effect models (GLMEs;
Whalley 2019) were used to analyze the same effects for the binary outcome of accuracy. These analyses were performed separately for translation and picture-naming tasks since the two tasks differed in complexity. In translation tasks, list type contained three levels of mixed, organized, and abstract word lists, while picture-naming tasks only used mixed and organized lists.
Variables were contrast-coded in all mixed-effects models, as recommended by various researchers (e.g.,
Brehm and Alday (
2022)). This procedure was implemented in the present study to elucidate main effects. As such, the dependent variable (RT or accuracy) was modeled with a response language (translating into/naming in English or German) that had been sum-coded (
Brehm and Alday 2022) using a contrast coding of (−0.5, 0.5), with German as the first and English as the secondary category. List type was also included in the model; however, in a dummy-coded contrast for translation tasks, lists were arranged into mixed, organized, and finally, abstract lists (0, 1, 0 for organized and 0, 0, 1 for abstract lists), so that mixed lists formed a baseline for the other two list types. For picture-naming tasks, a sum-coded contrast of (0.5, −0.5) was used for list type, with mixed lists serving as the first and organized lists as the secondary category. Both independent variables (response language and list type) were defined as fixed effects with by-participant and by-item random intercepts, allowing for interactions; the response language was additionally specified with a by-participant-varying slope.
1 Maximum likelihood (Laplace approximation for GLMEs) was used to estimate parameters. In case of convergence issues with the initial model, an iterative selection process using the
allFit function from the
lme4 R package was used to determine the appropriate optimizers (e.g.,
bobyqa) to facilitate model fit.
Post hoc tests were conducted using estimated marginal means with the R package
emmeans (
Lenth 2023). These post hoc comparisons allowed us to further investigate the main effects of response language and list type, as well as their interaction, while considering the dependencies among the different levels of the grouping variables. In addition to pairwise comparisons between conditions, we specifically tested our key hypothesis about category interference in a combined comparison: responding to semantically organized lists in English should result in lower performance than mixed lists in English as well as organized and mixed lists in German.
Recall. Finally, using the ez package for R, recall performance was examined with two-way within-subject repeated-measures analyses of variance (ANOVA) to analyze the effect of list type and response language. Thus, a 3 (list type: mixed vs. organized vs. abstract word lists) × 2 (response language: translating into German vs. into English) ANOVA was conducted for recall performance from translation tasks, while a 2 (list type: mixed vs. organized lists) × 2 (response language: German vs. English) ANOVA was calculated for picture-naming tasks. In cases of sphericity violations, Greenhouse–Geisser-corrected values are reported. Post hoc analyses used Bonferroni-corrected p-values for multiple comparisons.
Immersion questionnaire data. Data from the immersion questionnaire were extracted as one total immersion score (average value over all questions) and we averaged the scores of the single facets. The total score was used to measure the degree of immersion, i.e., how deeply a person reported being immersed into the German language. Sub-scores were used to understand which specific aspects of immersion contributed most to processing a foreign language similarly to one’s native language. Correlations with language and residence variables were also investigated.
2.2. Results
2.2.1. Language Characteristics
The number of languages spoken by the participants correlated significantly with their proficiency in German (
r = .42;
p = .005) and with using German productively (
r = .35;
p = .02), suggesting that participants who spoke many languages tended to consider themselves more fluent in German, but not necessarily in English. The age of acquisition (AoA) for German correlated negatively with various variables regarding the German language, such as proficiency (
r = −.61;
p < .001), productive use (
r = −.32;
p = .03), receptive use (
r = −.34;
p = .03), thinking in German (
r = −.33;
p = .02), and using German at work (
r = −.52;
p < .001). These links indicate that those who learned German earlier (lower AoA) indicated higher proficiency and the use of the language in various contexts. This was not found for AoA in English, which correlated only with using English at work (
r = −.36;
p = .01). A full overview of correlations between language-use variables with corresponding descriptive statistics is presented in
Table S6 of the Supplemental Materials.
2.2.2. Translation Tasks
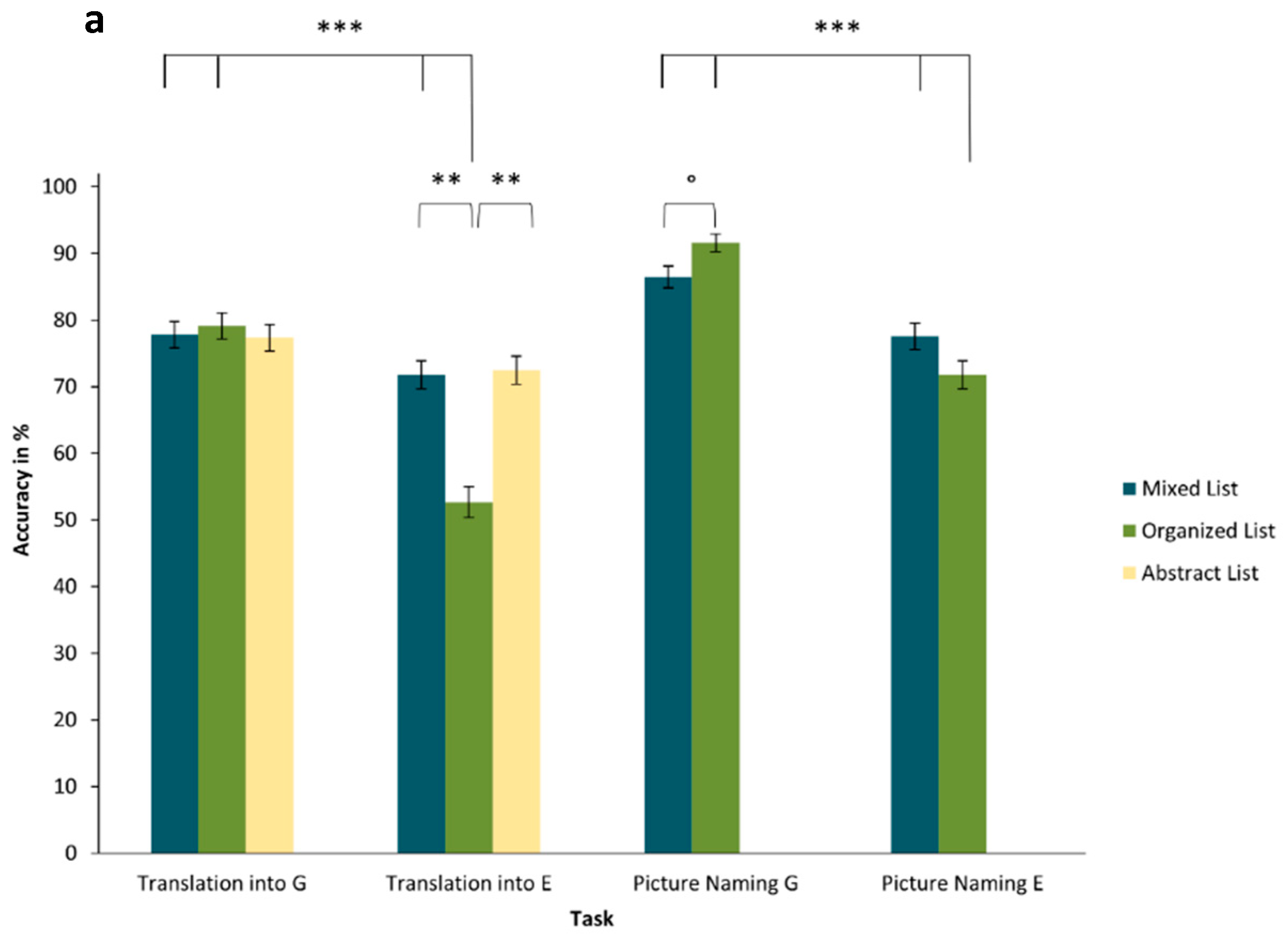
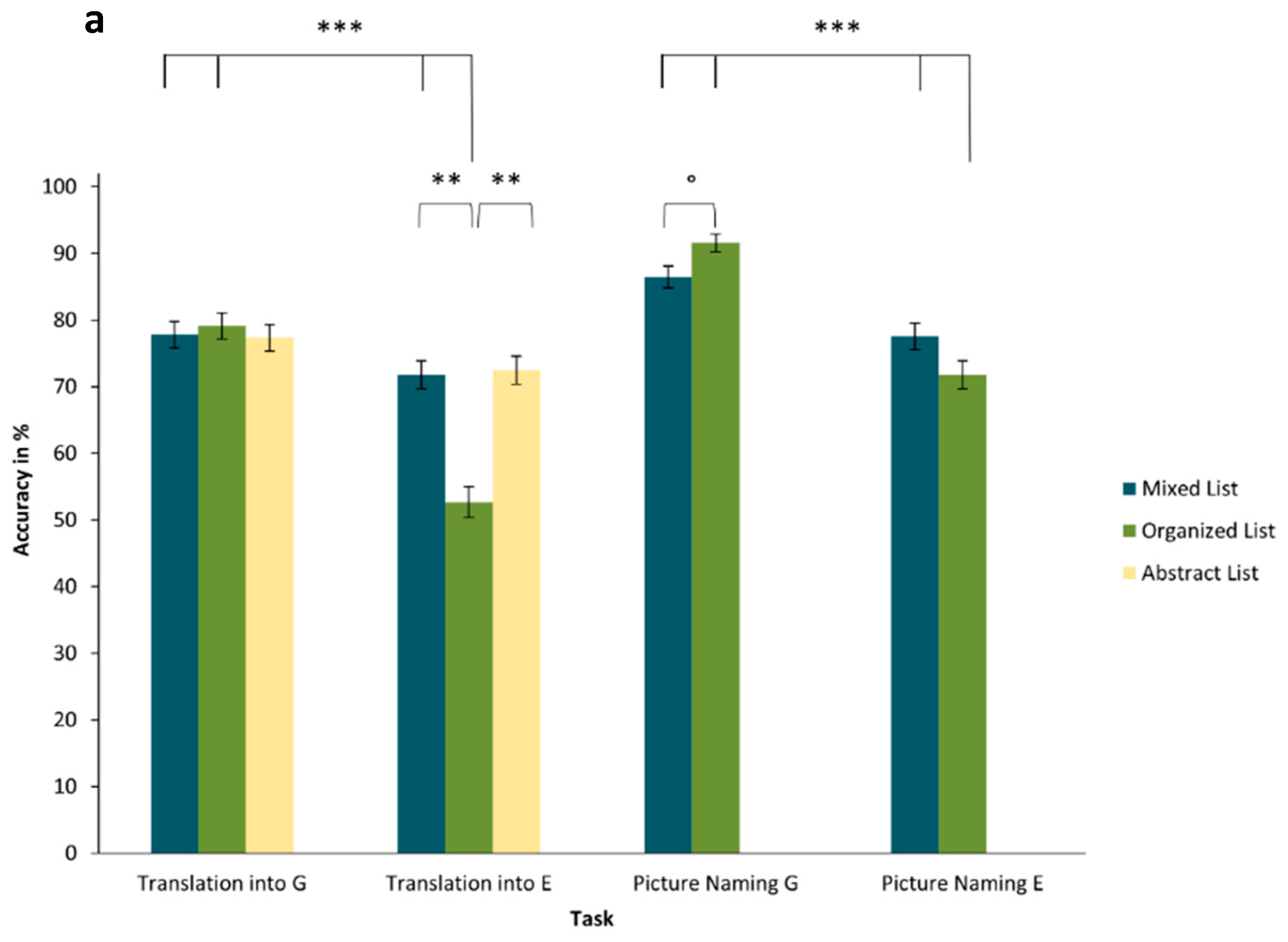
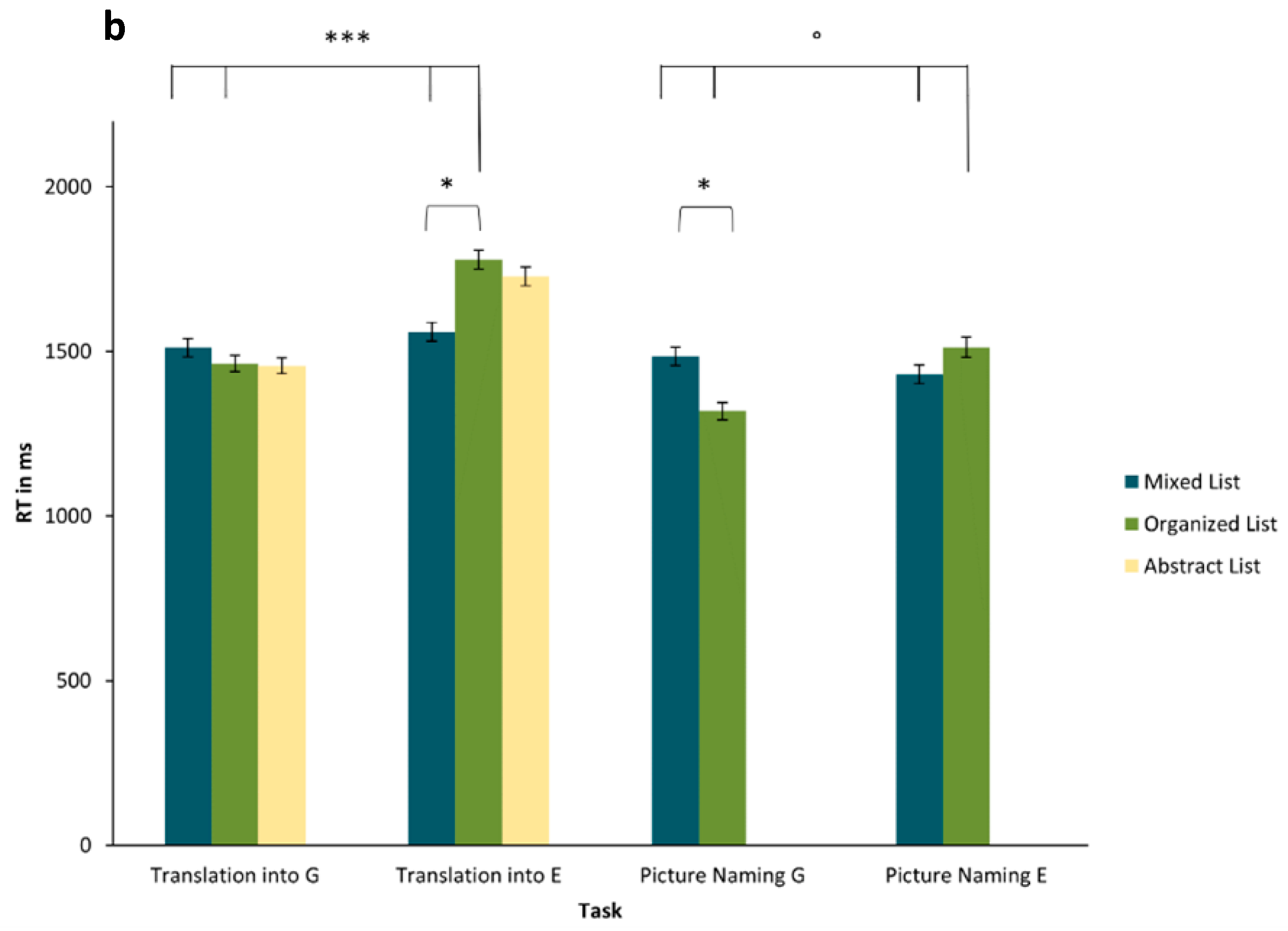
Observing translation tasks overall, participants translated 72% of the presented words correctly (
SD = 0.10) and responded on average after 1585 ms (
SD = 193). Mean performance is depicted in
Figure 3, and further specified in
Table 1, depending on task type, response language, and list type.
Accuracy. The mean accuracy for translation into English was somewhat lower (
M = 0.66,
SD = 0.48) than for translation into German (
M = 0.78,
SD = 0.41). According to the results of the GLME model provided in
Table 2, the odds of accurate answers were higher than 50% (significant intercept), but the effect of the response language was not significant. There was also no significant effect of list type, as the estimates of neither organized nor abstract lists were significant. However, the effect of response language differed for organized lists, with greater accuracy seen when responding in German (emmean = 1.93,
SE = 0.33) than in English (emmean = 0.15,
SE = 0.32;
Table S7 of the Supplemental Materials presents the estimated marginal means for all six possible combinations of response language, and list type, provided separately for accuracy and response times).
Finally, post hoc contrast tests (shown in
Table 3) were conducted to test the key hypotheses that semantically organized lists would result in lower accuracy when translating into English compared to translating mixed lists, and even more specifically, that translating semantically organized lists into English would prove harder than mixed lists into English, mixed lists into German and organized lists into German. Both of these contrasts were significant, as can be seen in the first and bottom lines of
Table 3. In fact, the highest mean probability of success was for translating organized lists into German (emmean = 1.93,
SE = 0.33), the lowest was for translating organized lists into English (emmean = 0.15,
SE = 0.32).
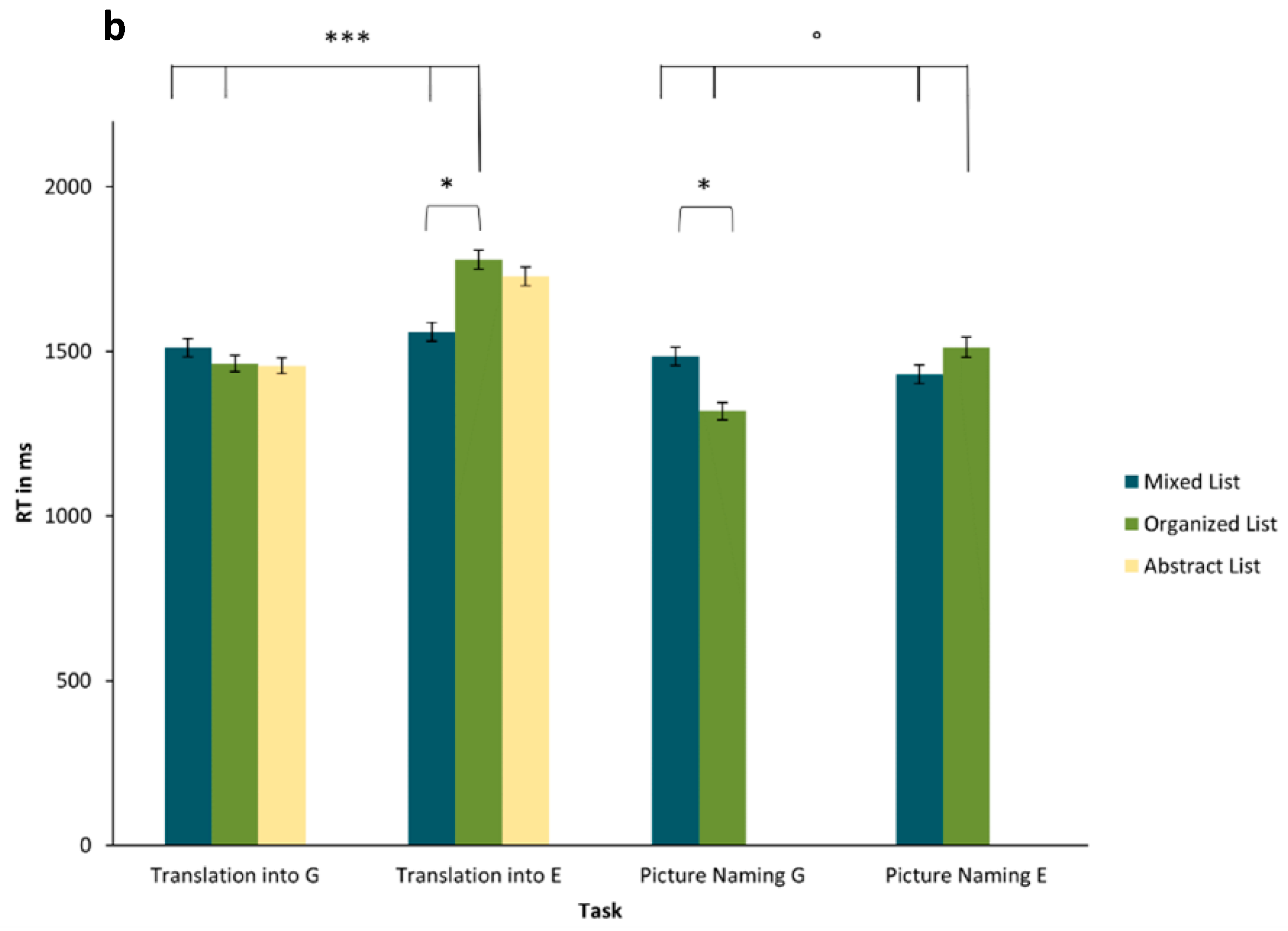
Response time. Correspondingly, translations into English (
M = 1681 ms,
SD = 617 ms) were somewhat slower than translations into German (
M = 1477 ms,
SD = 543 ms). The outcomes of the LME analysis in
Table 2 provide greater detail regarding the interplay of response language and list type. Answering in German or English did not have a significant effect, nor did semantically organized or abstract lists differ from mixed lists per se. Echoing the pattern found for accuracies, the post hoc comparisons presented in
Table 3 show that participants translated organized lists into English slower than mixed lists, as well as translating organized lists into English slower than both mixed lists into English and mixed or organized lists into German.
2.2.3. Picture-Naming Tasks
On average, participants correctly named 82% of pictures overall (
SD = 0.09) and were generally somewhat faster to respond in picture-naming (
M = 1445 ms,
SD = 224) than in translation tasks (
M = 1585 ms;
SD = 193 ms;
t(3126) = 6.72,
p < 0.001).
Figure 3 depicts the mean response accuracy and RT based on task type, response language, and list type; these are further described in
Table 1.
Accuracy. According to the GLME in
Table 4, neither list type nor the interaction between response language and list type were significant. However, response language had a significant effect on its own, with more accurate responses in German than in English. As shown in
Table 5, post hoc comparisons revealed that participants were less accurate when naming semantically organized lists in English (emmean = 1.29,
SE = 0.29) compared to mixed lists in both languages and organized lists in German (full list of emmeans provided in
Table S7 in the Supplemental Materials).
Response times. The results from the LME analysis, presented in
Table 4, show no significant main effects for the response language and list type, but a significant interaction between the two variables. Overall, participants were slowest to name words from semantically organized lists in English (emmean = 1580,
SE = 70), but fastest for organized lists in German (emmean = 1347,
SE = 68). This result is supported by the post hoc test results shown in
Table 5, where the difference observed between naming mixed and organized lists in German is significant, with faster RT for mixed than for semantically organized lists (emmean = 1515,
SE = 68). The main hypothesis, that naming organized lists in English would differ from naming any other list types in English or in German, was only marginally significant (
p = .06).
2.2.4. Recall Performance
After the experiment, participants correctly recalled on average 20 words or items from any of the experimental tasks (M = 19.98; SD = 11.73; range 0–56), with more stimuli recalled from picture-naming (M = 12.09; SD = 6.75, range = 0–27) than from translation tasks (M = 7.84; SD = 6.09, range = 0–29). Cases of falsely recalled items were practically non-existent.
Regarding translation tasks, the two-way ANOVA, analyzing the effect of list type (mixed vs. organized vs. abstract lists) and response language (during the translation task: German vs. English) on the mean number of words recalled, revealed a significant main effect for list type (F [1.95, 85.72] = 4.89, p = .01, Greenhouse–Geisser-corrected). However, subsequent pairwise comparisons using Bonferroni correction yielded only a marginally significant difference (p = .05) between mixed (M = 1.51, SD = 1.29, range = 0–5.5) and abstract (M = 0.97, SD = 1.16, range = 0–4) word lists. There was no significant main effect for the response language and no interaction between the two variables.
For picture-naming tasks on the other hand, the two-way ANOVA showed a main effect for the response language (F [1, 44] = 34.05, p < .001), indicating that participants remembered more items from picture lists they had responded to in English (M = 3.66, SD = 1.92, range = 0–7.5) than in German (M = 2.39, SD = 1.75, range = 0–6). There was no main effect for list type and no interaction.
2.2.5. Immersion
On a scale from one to seven, participants reported an immersion score of 5.16 on average. This score correlated negatively with overall RT (
r = −.31;
p = .03) and positively with overall accuracy (
r = .38;
p = .009). The correlations between total immersion score and asymmetries did not reach significance. An overview of the correlations between asymmetries, interference, and immersion sub-scores can be found in
Table S8 of the Supplemental Materials.
Accuracy. Two of the four sub-scores of immersion, language development and use and subjective integration, correlated positively with the asymmetries in translation (r = .31; p = .037; r = .38; p = .01, respectively) and picture-naming accuracy (r = .29; p = .049; r = .38; p = .009). In all cases, the more participants reported being immersed into the German language and integrated within German culture, the more pronounced their asymmetry between German and English became.
Response times. For RT, only the sub-score language development and use was correlated positively with picture-naming asymmetry (r = .44; p = .002). Again, deeper immersion led to stronger asymmetry effects.
Category interference and recall. Correlations between immersion scores and both category interference and recall performance did not reach significance in any category.
2.3. Discussion
Experiment 1 explored asymmetry effects and category interference in translation and picture-naming tasks. Like
Sperl et al. (
2023), using an online version of the same paradigm, we found an asymmetry effect for accuracies in both translation and picture naming, with more accurate responses produced in German compared to English. Moreover, translations of organized lists into English were produced more slowly and resulted in more errors compared to translations of organized lists into German and mixed lists into both response languages (category interference), even though participants were proficient but non-native speakers of both languages. Of note, even in online experiments where each participant carried out their assessment on their personal computer outside of our experimental control, and with a very heterogeneous sample of non-native speakers, clear differences in response times were measured with millisecond resolution. The only part of the study where the online modality seemed to be problematic was the final recall task, where participants seemed to show less motivation to rack their brains for further items before closing their browser window than when sitting in the lab with paper and a pencil (i.e.,
M = 20 items recalled in the online version vs.
M = 36 (
SD = 10.35) in
Sperl et al. 2023).
While these findings are important from a practical point of view regarding the feasibility of conducting language production experiments remotely, the finding that experimental performance depended on
immersion experience is of theoretical importance. Specifically, the degree of immersion affected accuracy and RT. Asymmetries between German and English responses were more pronounced if a person reported a stronger immersion into the German language and culture, and they were also in general more pronounced for picture naming. This result goes hand in hand with the suggestion that people who are deeply immersed into a language process this language similarly to a native speaker. In fact, the results resemble the pattern found in previous studies with native speakers (e.g.,
Sperl et al. 2023), although the non-native participants show longer response times overall.
Arguably, this finding could suggest that immersion might constitute a driving force for the dynamic aspect postulated by
Kroll and Stewart (
1994). However, in their model, the asymmetry becomes smaller with growing language skills, while the asymmetry in our studies increases for highly immersed speakers of two foreign languages. The rationale behind this important difference is apparent. In the original design, a comparison was made between an L1 and an L2, where strong immersion experiences rendered the L2 more native-like, reducing the difference between the two languages. However, in our study, we investigated
two foreign languages, where intense immersion experiences accentuated the contrast between the target languages by arguably making one of the two relatively more native-like (‘pseudo-native’ status). It also seems reasonable to assume that people who report stronger immersion in German consequently use less English than people reporting weaker immersion. In fact, participants who reported higher English than German language skills showed the opposite asymmetry effect, which is to say negative, instead of positive, correlations with asymmetries (e.g., picture-naming accuracy asymmetry:
r = −.52,
p < .001). However, this trend was not looked at in detail since only immersion into the German language was measured.
In sum, the results suggest that language context, specifically immersion experience, plays an important role in non-native language processing. Hence, it seems that not only the language level, as originally proposed by
Kroll and Stewart (
1994), but also the method of learning influences the performance in language tasks.
2.4. Hypotheses Relating to Language Context (Experiments 2 and 3)
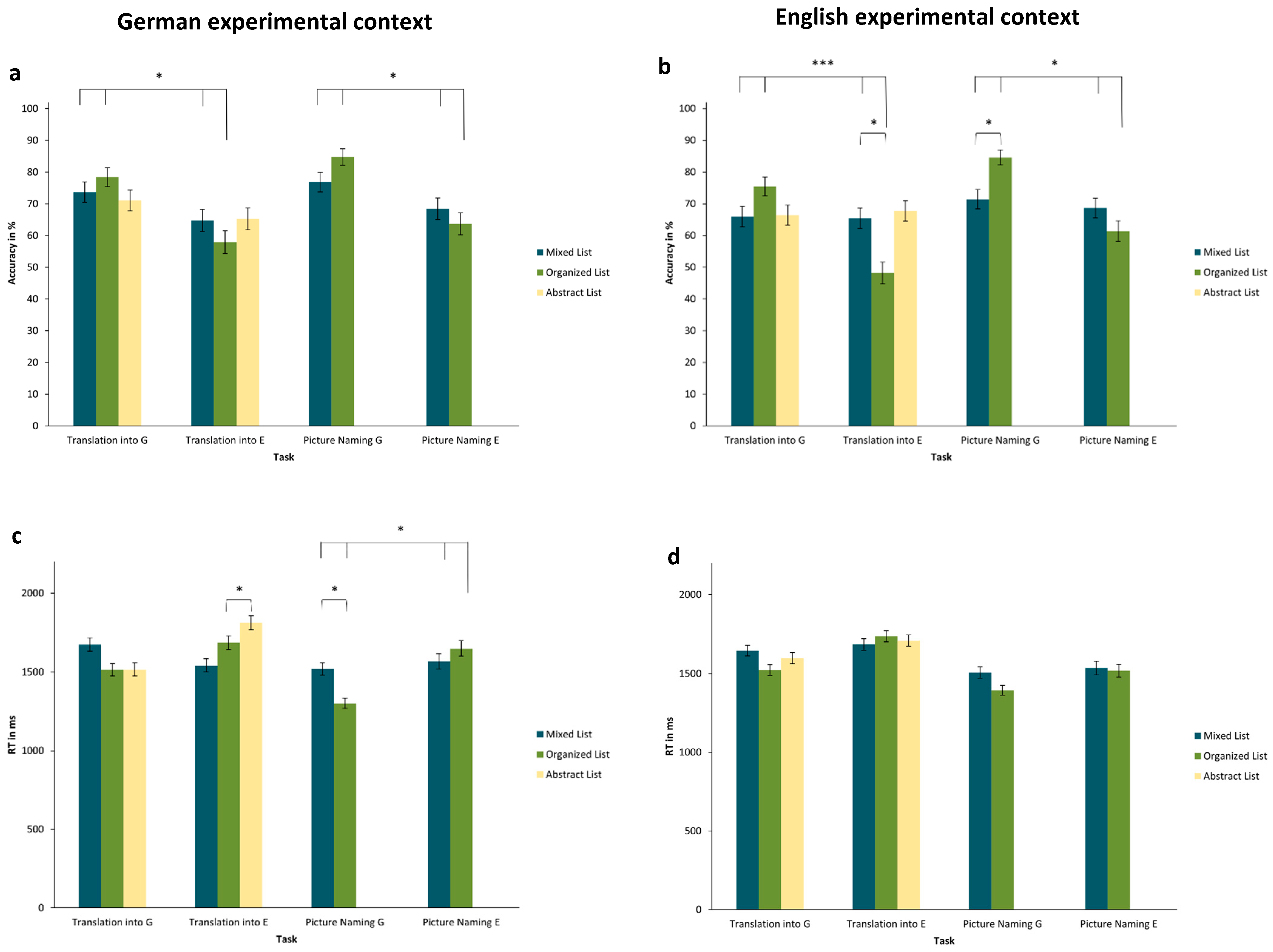
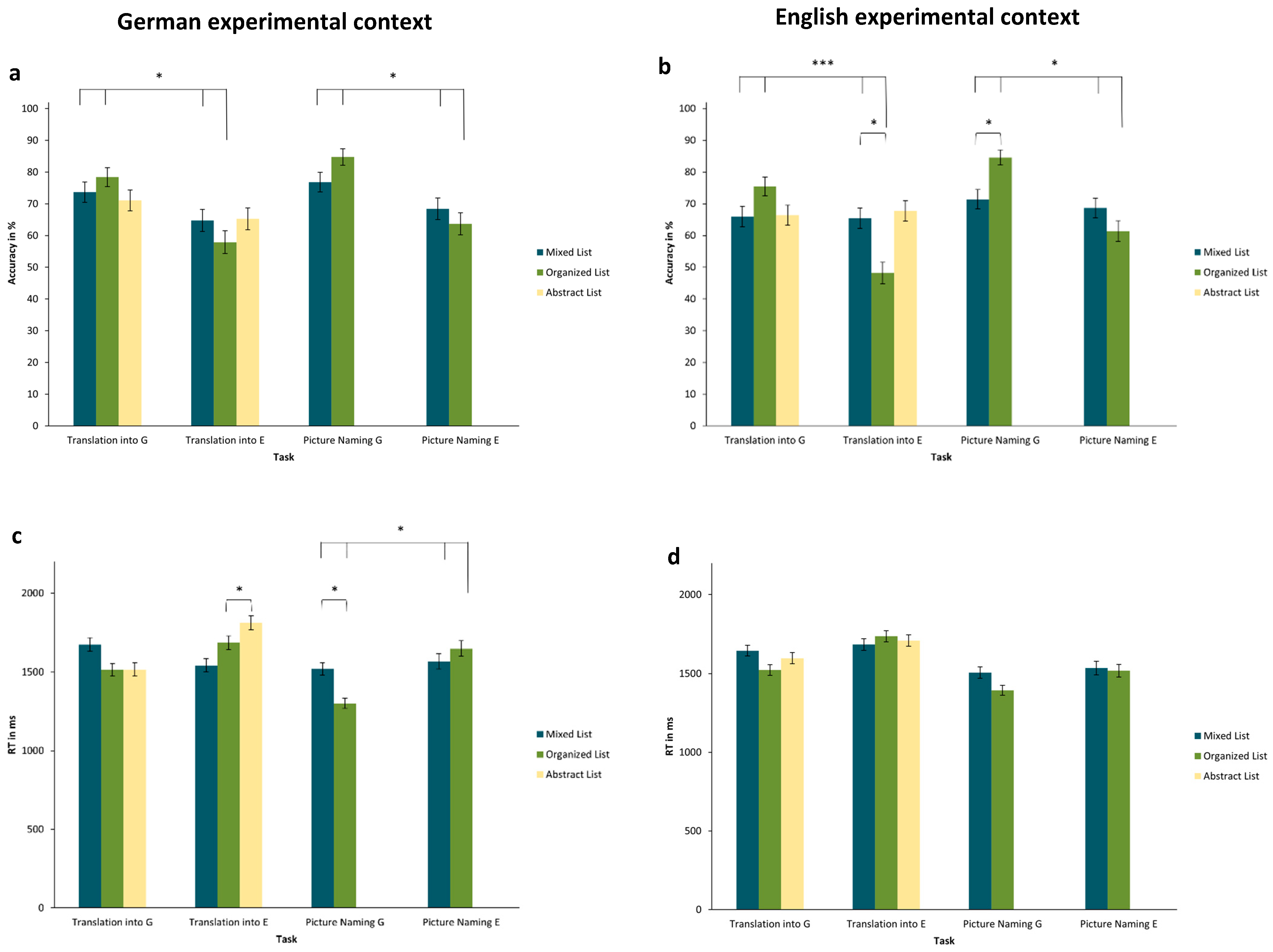
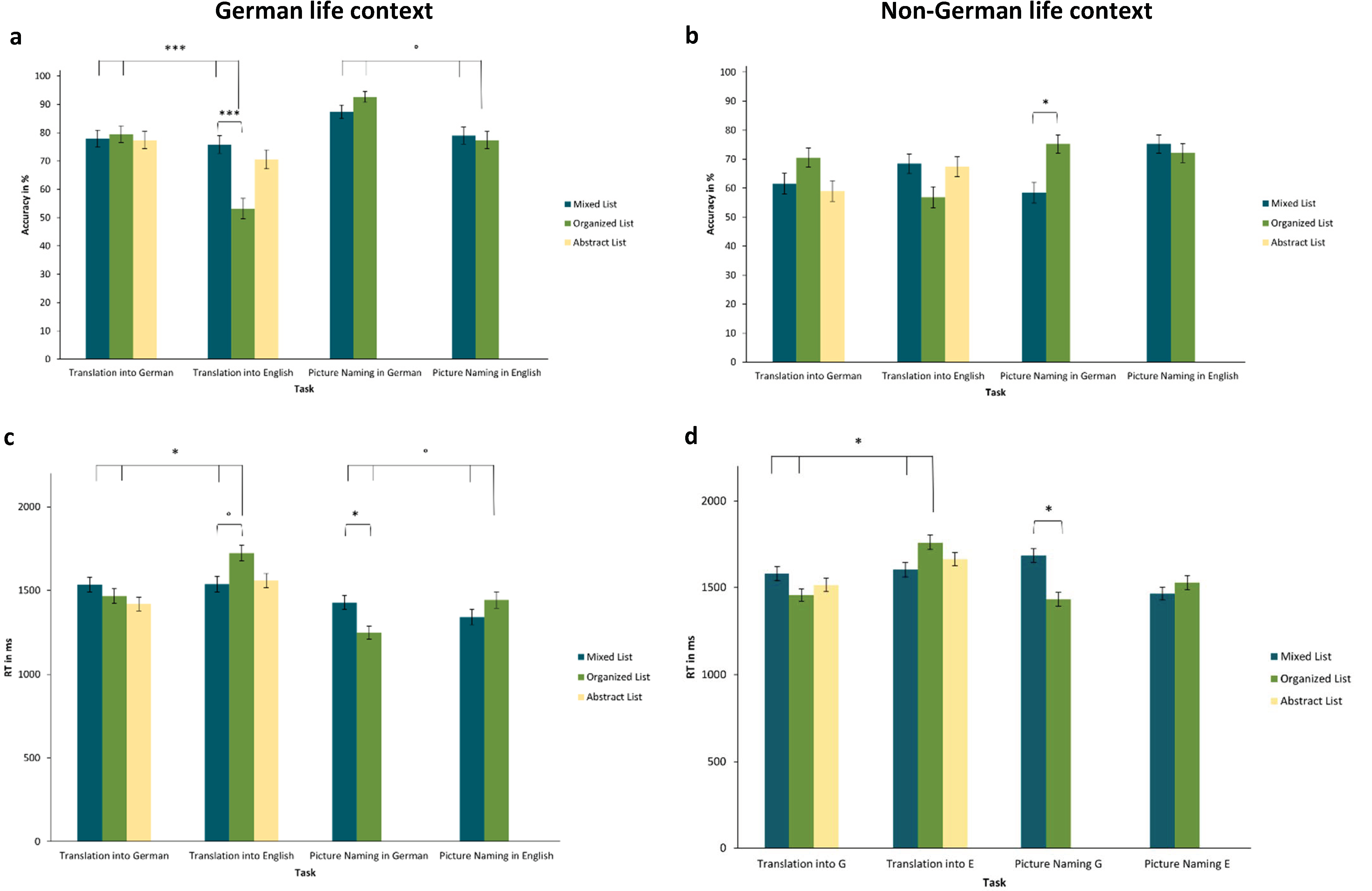
While this suggestion is based purely on correlations with the depth of immersion in Experiment 1, Experiment 2 deliberately manipulated language context, focusing on the experimental language context, and randomly assigning participants to receive either German or English instructions. The complimentary experiment, Experiment 3, varied the environmental language context by assessing individuals living in various non-German and non-English environments compared to those in German-speaking countries. In both cases, if short-term or long-term language contexts influence the relative status of foreign languages, translating into English should take more time and result in more errors compared to translating into German in samples with a German context (German instructions in Experiment 2 and living in German-speaking countries in Experiment 3). In contrast, the group in the non-German context (English instructions in Experiment 2 and living in non-German-speaking countries in Experiment 3) was expected to demonstrate a reverse pattern, where translating into German would take longer and be more prone to errors than translating into English. In other words, we expected to observe an asymmetry effect, as in Experiment 1, and that this effect would be accentuated by the language context. This was also expected for picture-naming tasks, where answers were expected to be faster and more correct in German than in English for participants in German contexts. Additionally, groups in both contexts were expected to translate and name semantically organized lists slower and less accurately compared to mixed lists. This difference was hypothesized to be particularly pronounced when translating from the more salient language (e.g., German in a German context) into the less salient one (English in a German context). In other words, we again expected category interference, as in Experiment 1, and therefore that specifically semantically organized lists would result in longer RT and worse accuracy when translating from German into English in a German context. Importantly, if the experimental context was able to give one of the experimental languages a ‘pseudo-native’ status, then we would expect an analogous, but opposite pattern for English in the English context condition (asymmetry and interference when translating from English into German instead).
5. General Discussion
Three experiments tested predictions derived from the RHM by
Kroll and Stewart (
1994) and replicated the model in an online setting and for two non-native languages, which here were German and English (all participants in all three experiments had other native languages). More specifically, they investigated the role that the current linguistic context may play in rendering one foreign language more salient than the other—in a sense, giving it a ‘pseudo-native’ status relative to other foreign languages, comparable with the L1 in
Kroll and Stewart (
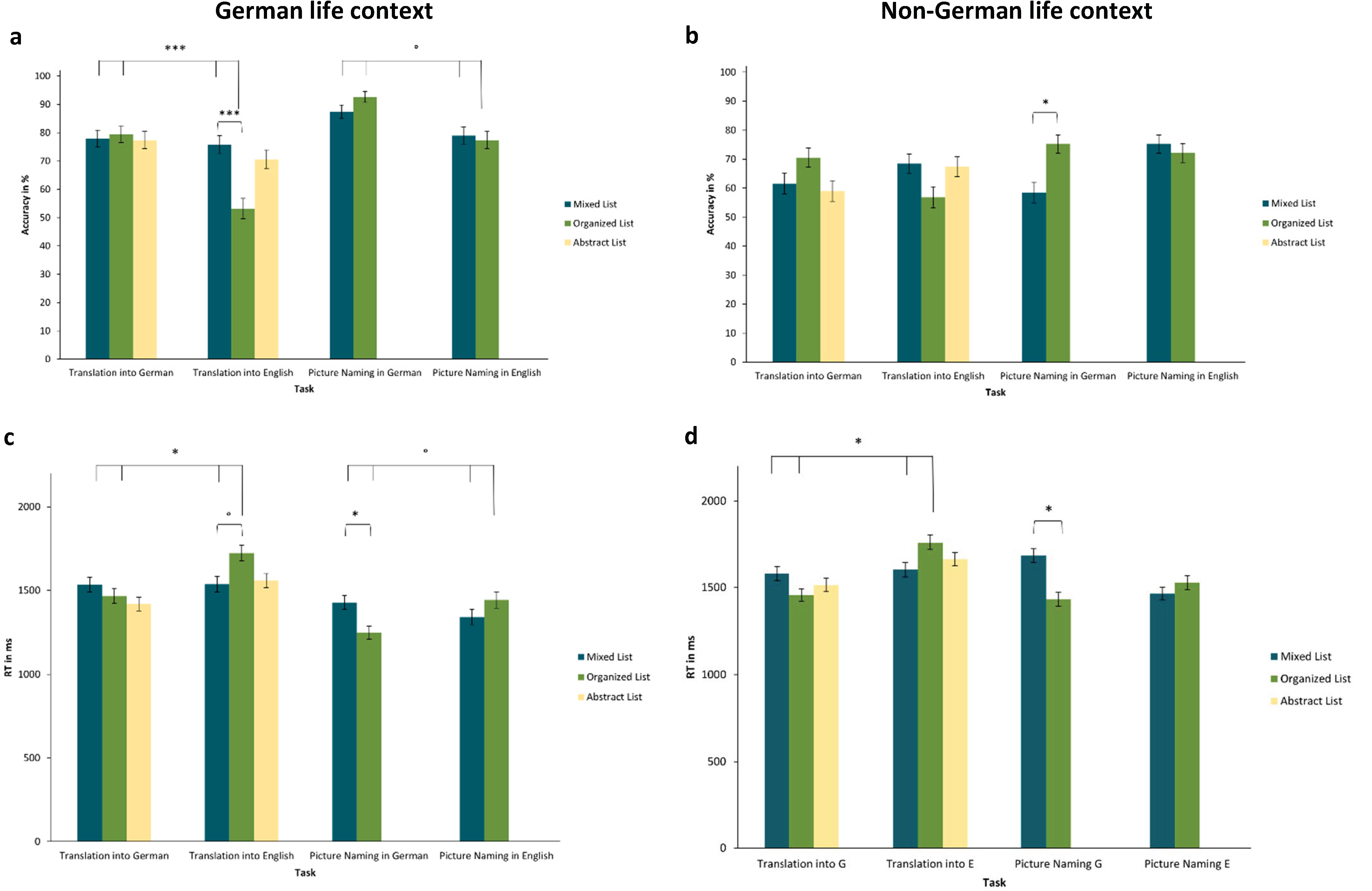
1994). First, the degree of immersion was shown to be significantly associated with the strength of the asymmetry between the two experimental languages (Experiment 1). Hence, profound immersion experiences seem to be able to render one language more native-like. Second, two different forms of current linguistic context were compared regarding asymmetry effects, category interference, and category facilitation: the language highlighted by the instructions of the current experiment (Experiment 2) vs. the language typically spoken in the country the participant is currently living in (Experiment 3). While simple asymmetries between the two languages were not always clear across the three experiments, participants largely showed the predicted category interference, with the processing of organized versus mixed lists depending on the response language. Consistently, the pattern of results for German (as a foreign language) resembled that of the L1 in the RHM. Regarding the linguistic context, the short-term experimental language context in Experiment 2 showed barely any effect, whereas the longer-term context of living in a German (vs. non-German) environment in Experiment 3 affected the size of the results. We will discuss this and other results below.
List effects occurred across all three experiments. Notably, semantically organized lists often interacted with the response language, such that these particular lists led to lower accuracy and slower responses in English, which is the non-prominent foreign language (category interference). Following the original logic of the RHM, this is due to the conceptual mediation that is required for translation into L2 (in this case, the non-prominent language), which means that the activation of a semantic category (through a semantically organized list) interferes with rapid lexical access. Complementing category interference in production,
Kroll and Stewart (
1994) postulated that the associated in-depth processing of the semantically organized lists could result in category facilitation in post-experimental recall. While the recall rates in our online studies were generally low, and while we cannot discount possible recency effects for differences between languages, the recall results of Experiment 3 fit well with this original suggestion, and also with the proposed impact of environmental language context. While, more words were recalled from translations of semantically organized lists into English than into German in the German context, this was not the case in the non-German context (here, more words were recalled from translations of organized lists into German).
In contrast to this relatively frequent interaction of list types and response language, differential effects of linguistic context are less clear. We originally hypothesized a pattern of results favoring German over English within a German context (German instructions or residence in German-speaking countries), and vice versa in the English context of Experiment 2. At least for the short-term experimental context investigated in Experiment 2, context did not significantly impact the effect of list type on RT and accuracy, where both experimental conditions largely showed similar results. In contrast, the non-German context of Experiment 3 was not expected to flip the pattern of results, but rather to reduce it, as it did not highlight either of the two target languages. Hence, in this context, German and English should maintain a similar status as proficient foreign languages. In fact, differences in accuracy were specifically smaller for organized lists in non-German contexts. This is exactly what would be expected if the non-German context reduced the salience differences between German and English. In future research endeavors, it would be an interesting alternative approach to also contrast the German environmental language context with a specific English environmental language context (instead of non-German context here). In such a study, living in an English-speaking environment should actually flip the pattern of results found for the German context, making English the more salient, “pseudo-native” language.
In this context, one notable finding was that German responses were faster and more accurate across most of the tasks and contexts of all three experiments. Thus, we suggest that, even if two foreign languages do not inherently differ in status, when an individual resides within a specific linguistic environment (e.g., Germany or Austria for all participants in Experiments 1 and 2 and for half the sample in Experiment 3), the foreign language spoken in that society may become amplified, receiving a ‘pseudo-native’ status. This may explain why the effects of experimental language context were minimal in Experiment 2, where the daily-life context was German for all participants, and similar asymmetries and categorical interference effects between the response languages were found in both experimental context conditions. In fact, even in the non-German context of Experiment 3, many of the participants are likely to have lived in German-speaking countries previously (they were all proficient in the language and not all places of residence were assessed) and may have invested more personal resources and effort into learning a less frequent foreign language such as German (in contrast to English, which is commonly learnt in school in most countries).
This would lead to a common variable for participants in all three experiments, which was explicitly associated with experimental performance in Experiment 1,
immersion, or in other words, the process of learning and speaking a new language (such as German) while residing in the respective country and its culture (e.g., Germany). Embedded within this environmental context, learners acquire the language implicitly during interactions with native speakers, analogous to learning a native language (
Morgan-Short et al. 2012;
Wigdorowitz et al. 2022,
2023). Consequently, immersion learners often amass vocabulary comparable to that of their native language (
DeKeyser 1986;
Dewey 2007) and are able to articulate the foreign language more naturally (
Collentine and Freed 2004) and fluently than their other foreign languages (
DeKeyser 1986;
Freed et al. 2004). Considering these connections, it appears that the lexicon of the respective language can be accessed more rapidly and easily (
Heredia 1997). This heightened fluency can alter asymmetry and category effects, favoring the corresponding language, similarly to the dynamic aspect suggested by
Kroll and Stewart (
1994), which is mainly based on proficiency. Indeed, the performance seen in the non-German context of Experiment 3 suggests that such changes in language status caused by immersion may well persist even when the individual has left the respective country and no longer encounters the language of immersion on a daily basis.
It is interesting to speculate about the processes causing these long-term effects of acquiring language through immersion. For instance, learning by using different senses (e.g., visually, kinesthetic) or even emotions may enhance learning effects, even in long-term memory (
Li and Deng 2023;
Tyng et al. 2017;
Volpe and Gori 2019). Such situations might occur cumulatively in personal interactions during immersion, linked to cultural experiences that provide an emotional and motivational scaffold for learning processes (
Goldoni 2013). Concluding, we propose that future research should investigate the impact of immersion experiences on translation asymmetries and category effects directly and longitudinally, rather than relying on the purely correlative approach adopted in this study. This would help the field to identify the factors of immersion that may impact short- and long-term language memory and processing.
Methodological Considerations
Before concluding, it is important to mention a number of methodological considerations relevant to our study. Critically, all data were acquired online and were drawn from a very diverse but specifically selected group of participants. Although we believe that both of these aspects actually constitute strengths of the design, they led to a number of practical challenges, including difficulties with recruitment, technical problems due to E-Prime Go not running on all computers, and a lack of communicative interaction between the experimenters and the participants. First, participants only included individuals who were proficient in both German and English, though neither of these were allowed to be their L1. These constraints excluded multilinguals who did not have (sufficient) knowledge of (one of) these specific languages or who were early bilinguals, thereby probably favoring individuals with a certain socio-economic status, academic background, and technical competence. This type of selection also meant that participants had a wide range of different L1s in all experiments, as well as countries of residence in Experiment 3. This deliberate diversity serves as a strength, as it allows for the generalization of our findings across a spectrum of linguistic backgrounds rather than confining their applicability to a single language group. Moreover, the heterogeneity of our sample not only enhances the external validity of our results but also underscores the robustness of our findings.
Nonetheless, a more detailed assessment of participants’ language biographies and their current language context (e.g., using tools as the Contextual and Individual Linguistic Diversity Questionnaire recently developed by
Wigdorowitz et al. 2023) and a more objective measurement of proficiency and immersion would be helpful in clarifying the nature of some of the response patterns. It would also be beneficial to control for participant’s familiarity with vocabulary tests, perhaps by providing standard training before the actual tests. At the same time, we would like to point out that any standardized assessment of proficiency would have substantially increased the time that participants spent on the study, in addition to the challenges of implementing some of the language skill dimensions in an online setting. As a compromise, the
Council of Europe (
2001) criteria constitute clear guidelines for the self-assessment of both productive and receptive language skills. They are also widely familiar in the student populations of European countries which most of our participants were from.
Two potential confounding factors that we cannot discount are possible stimulus effects and effects of the fixed order of experimental tasks. In order to control for stimulus effects, we performed linear mixed model analysis and included item as random effect in the analyses. Moreover, we created two versions of each experiment, assigning items from semantically ordered lists in one version to the mixed lists of the other version. The necessity of avoiding cognates in designing these lists limited the number of available stimuli—there is only a certain number of non-cognate vegetables that non-native speakers can readily name. Nonetheless, in future studies, it would be ideal to match items better in terms of frequency and difficulty. The fixed order of tasks was originally designed to facilitate the coding of correct answers in the lab by
Sperl et al. (
2023). This was actually not primarily relevant for the online version of the tasks used here, but was maintained for replication purposes. One task that was fairly clearly influenced by the fixed order was the recall task, where participants consistently recalled more items from English than German (which was always the first language to be tested), and more items from picture naming than from translation. The latter finding could also be due in part to the pictorial representation of the items in the picture-naming tasks. However, on the basis of the current experiments, it is not possible to tease these two factors apart.
Incidentally, we believe that the overall problematically low word counts per condition in the recall tasks resulted from the online nature of the experiment. This task was not announced prior to starting the study, and so when it appeared right at the end, many participants probably closed their browser window as soon as they needed to think harder. Similarly, a strong manipulation of the experimental language context, as attempted in Experiment 2, would be easier in a lab experiment than online, e.g., by having participants interact with a native speaker of one of the two target languages. At the same time, the successful acquisition of language production data from an online experiment—replicating existing lab studies and uncovering RT differences in millisecond resolution—is a merit in itself, as it makes it more feasible to conduct multilingual research with participants living anywhere on earth, thus massively increasing the range of potential languages and language contexts for investigation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}