1. Introduction
A growing number of recent sociolinguistic studies have transcended top-down codified definitions of communities and have explored the nuanced differences within predefined groups including ethnic groups. In the context of Jordanian Arabic, for example,
Al-Wer et al. (
2015) show how religious affiliations—which are considered a malleable category and responsive to the sociopolitical environment—could act as a component of a more intricate social construct and covary with linguistic behavior. Similarly,
Habib (
2010) not only explores the relationship between social class and linguistic variation within Arabic-speaking communities but also defines social class in the specific context of her inquiry by highlighting the complexities associated with defining social class. Through exploring language as a marker of social identity, Habib underscores the importance of gaining insights into the social dynamics of specific communities to understand linguistic variation within specific social contexts. In another study,
Habib (
2016) explored the different linguistic behaviors of preadolescent boys and girls in a small Christian village in Syria in reference to social meanings of specific linguistic variants (the [q] and [ʔ] realizations of the variable (q) in Arabic) both in terms of gendered and spatial identities. Habib’s findings showed that preadolescent boys in the village of Oyoun Al-Wadi in Syria used higher rates of the variant that acts as a covert prestige marker—[q]—with its masculinity and non-urban associations in this particular context. In her analysis, Habib treats the community of practice and the speech community as complementary and highlights the importance of both. The top-down speech community approach looks at correlates between predefined categories (e.g., ethnic community) and linguistic forms and features. While “meaningful participation” in the shared “ideological communicative system” has been considered one of the central characteristics of speech communities (
Morgan 2004, p. 3) and some sociolinguists have given some agency to members in constructing speech community boundaries (
Labov 1973), the role of outside authority in defining speech community boundaries has been emphasized in the literature. Morgan, for example, makes it very clear that the emergence of speech communities into public awareness is triggered by either a crisis
1 or researchers’ consideration of the community as a study unit. This centrality of the role of the researcher as the outside authority to define the boundaries of speech communities and the lack of focus on the agency of community members in speech community studies have been the core of criticisms against this approach (e.g.,
Bucholtz 1999b).
Bucholtz (
1999b) also considers the speech community theory’s view of identity as static.
Drawing on practice theory in disciplines like sociology and anthropology, sociolinguists have introduced the community of practice theory in order to emphasize the agency of members and the fluid nature of identity (
Eckert and McConnell-Ginet 1992,
1999;
Bucholtz 1999b). As a result, the bottom-up endogenous community of practice approach (
Eckert 2000) emphasizes the role of community members’ agency in defining the boundaries of the community and in projecting their linguistic markers. The community of practice theory incorporates language into the larger context of common practices (
Bucholtz 1999b), which includes shared beliefs, values, power relations, and language norms (
Eckert and McConnell-Ginet 1992,
1999). In the community of practice theory, identity is a fluid process (
Bucholtz 1999b;
Finnis 2014), and ordinary members and nonmembers (as opposed to the expert outsider with research authority) exercise some agency in defining the boundaries of the community. For example,
Bucholtz (
1999b) defines a community of practice of female students (referred to as “nerds”) in suburban high schools in the US who share the purpose of being uncool (as opposed to the Jocks and Burnouts (
Eckert 1989) who want to be cool) and practice their identity by sending signals based on sartorial choices (e.g., wearing shirts and jeans which are neither tight nor saggy) and their use of language (e.g., using super-standard and hyper-correct phonological and syntactic forms, and avoiding slang).
Although the top-down exogenous speech community perspective seems to precede the bottom-up endogenous community of practice perspective, these two approaches have been treated as contemporaneous by a large body of sociolinguistic research in Europe and North America, which has focused on the development of multi-ethnolects (i.e., immigrant linguistic varieties spoken by speakers from a host of different ethnic and heritage language backgrounds). These studies show a range of ethnic-oriented phonological, syntactic, and lexical variations that are consciously practiced by certain ethnic groups (e.g.,
Cheshire et al. 2015;
Cychosz 2018;
Hoffman and Walker 2010;
Nortier and Dorleijn 2013;
Quist 2008). Drawing on
Agha’s (
2003,
2007) enregisterment processes and
Silverstein’s (
1985) total linguistic fact,
Rampton (
2015) sets the theoretical platform for a collection of such studies on multi-ethnic linguistic variants in Europe and North America (
Nortier and Svendsen 2015). In doing so,
Rampton (
2015) and
Svendsen (
2015) challenge any division between speech community studies and community of practice studies and argue for a contemporaneous relationship between the two approaches. Following
Habib’s (
2010,
2016) and
Al-Wer et al.’s (
2015) sociolinguistic work in Syria and Jordan, I treat speech community and the community of practice approaches not only contemporaneous but also complementary in this paper. An important aspect of the complementary nature of top-down and bottom-up approaches to sociolinguistic communities is visibility (both linguistic and physical). For any sociolinguistic community to be studied, it must first be noticed (either by linguists or non-linguists). The noticeability or visibility of a community is possible only if certain markers indicate the existence of any given community. Linguistic variants that mark ethnic communities must first be noticed —i.e., must be correlated with certain communities—in order for these groups of speakers to be able to consciously practice such variants. In outlining the process of a language regard response, for example,
Preston (
2016) distinguishes between noticing a linguistic feature and classifying or iconizing that linguistic feature. All individuals are constantly drawing on their linguistic competence and sending linguistic signals to add layers of “social meaning to the denotational meaning” (
Eckert 2012, p. 88), which could be noticed based on a hearer’s social, cultural, and ideological classifications (e.g., scholars have explored intersections between language use and social positionings such as masculinity (
Bucholtz 1999a;
Cutler 1999;
Habib 2016), a wealthy elite status (
Zhang 2005,
2008) and social class (
Habib 2010), power (
Kiesling 1998), local attachment (
Reed 2018), urban versus rural status (
Habib 2016), and ethnic attachment (
Fought 2006;
Labov 1972;
Hoffman and Walker 2010). A linguistic signal can only be consciously practiced once it has been noticed and classified in association with certain social, cultural, and ideological meanings. Only after such noticing can language users make the conscious decision whether to use such linguistic markers for the social positioning of themselves and others, and the social positioning of self or others can only be meaningful in the light of the totality of linguistic fact (
Silverstein 1985), which means that the use of linguistic markers is constructed by (and constructs) the dominant ideology in a society.
It is in this framework that
Sheydaei (
2024) explored the linguistic practices of Americans of Southwest Asian or North African descent
2 (SWANA Americans for short) in Dearborn, MI, and treated certain ethno-local markers as features of an ethnolinguistic repertoire for SWANA Americans. Dearborners, and SWANA Americans by extension, use these features in reference to their individual preferences in terms of how they would like to position themselves within certain contexts. Exploring individual and stylistic differences within broadly predefined communities has been well received by sociolinguistic and variationist studies, and more and more studies are looking at language variation and change and stylistic choices within minoritized communities (cf., e.g.,
Poplack 1978;
Bailey 2000;
Carmichael 2017;
Holliday 2019;
Reed 2020;
King 2021). Such studies look at variation across time, space, and different social and personal affiliations (or personae) to explore the complex interaction of linguistic behavior with affiliations and break down predefined linguistic and non-linguistic codifications.
King (
2021), for instance, showed how speakers with different personae within a Black community in Rochester, NY, position themselves in terms of the local and social meanings of the Northern Cities Shift (NCS) features; for example, speakers’ stronger local orientation (i.e., with stronger local personae) correlated with more fronted and raised TRAP vowels, an advanced feature of the NCS.
Within this general framework of treating the speech community and community of practice approaches complementary and emphasizing individual speakers’ stylistic choices, I investigate SWANA Americans’ performative agency in using their linguistic repertoires with certain social meanings and indexical markers. The present paper explores the relationship between the ethnic affiliation and linguistic behaviors of SWANA Americans by looking at their rates of “reracializing” ethnically affiliated lexicon in English that have gone through indexical bleaching (
Squires 2014) (words such as
Ali,
Muslim,
Iraq,
Mohammad, etc.). The results show higher rates of reracializing these words covary with higher ethnic rootedness and specific locality, and with religion in the more careful speech style.
2. Materials and Methods
Data collected for analysis in this paper come from Labovian Sociolinguistic Interviews (I am following
Becker (
2017) in capitalizing the phrase) with 54 SWANA Americans in the Upper Midwest (N = 44) and Southern California (N = 10). The bigger project investigated linguistic practices of SWANA Americans in general and residents of Dearborn, MI, in particular. For the present study, I will focus on SWANA Americans’ reracialization of indexically bleached (
Squires 2014) ethnically affiliated words (i.e., ethnically affiliated words that are pronounced in a neutral way so that original associations in terms of ethnicity are not marked in pronunciation). For this analysis, I took a bottom-up approach; in other words, I did not approach this analysis with a set of predefined words. However, after listening to the very first interview, I noticed my participant’s reracializing of some words by replacing the Americanized pronunciation with the ethnic pronunciation. For example,
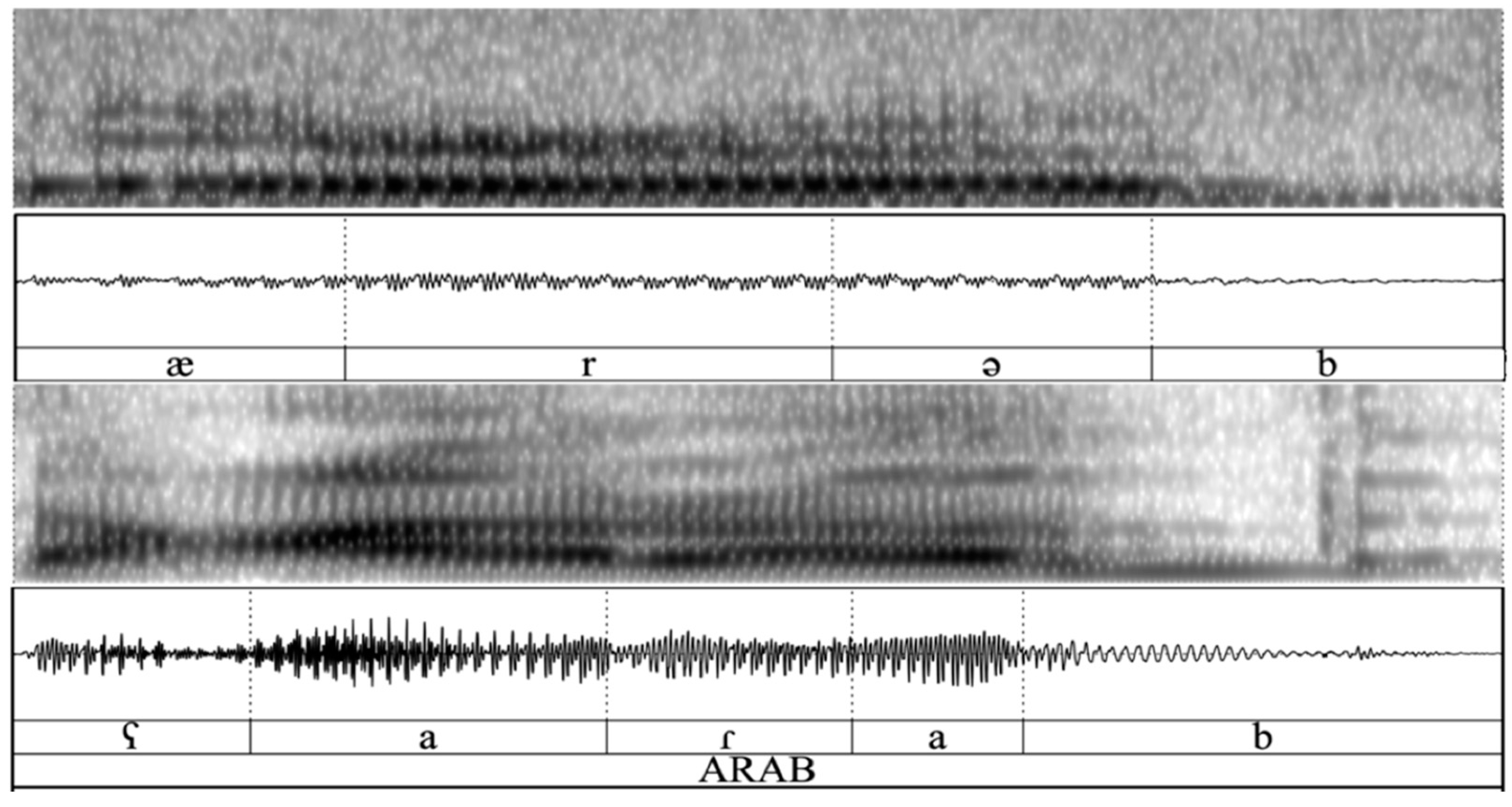
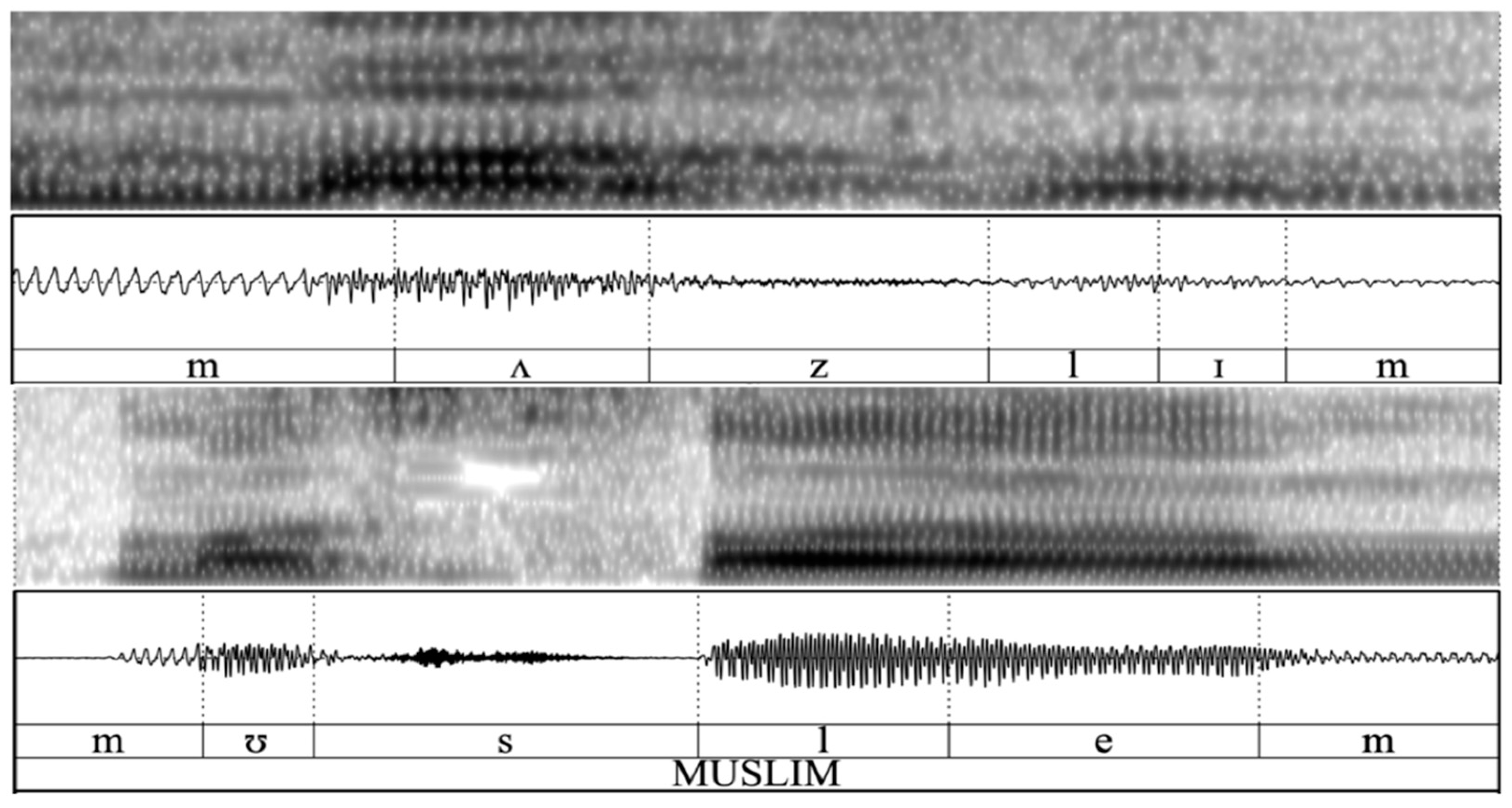
Figure 1 and
Figure 2 show the waveform and spectrogram of the pronunciation of the words
Arab and
Muslim, respectively.
I selected Speaker SEMI10 in
Figure 1 and
Figure 2 to illustrate the ethnic pronunciation of the words
Arab and
Muslim in order to show that these ethnic pronunciations are not necessarily the result of substrate effects of Arabic. The heritage language of Speaker SEMI10 is Dari, a dialect of Persian. As shown in
Figure 1, Speaker SEMI10 inserts the pharyngeal fricative /ʕ/ into the pronunciation of the word
Arab in their English speech, while there are no pharyngeal consonants in the phonological system of Dari, their heritage language. Speaker SEMI10 is not only pronouncing the word
Arab in an Arabic way (the word
Arab is pronounced as [ʕæˈɾæb] in Arabic and as [æˈɾæb] in Persian) but is also pronouncing the word
Muslim [ˈmʊslem] in an Arabic way (the word for Muslim is
Musalman [mosælˈmʌn] in Persian). Such linguistic behavior by Speaker SEMI10 suggests their performative agency rather than substrate effects of Arabic on their English language, because their linguistic behavior in these two instances is not reflecting the phonological system of their heritage language but the phonological system of Arabic, the language spoken by the majority of their community. Therefore, interview protocol and the sentence list were modified to try to elicit ethnically affiliated words from SWANA American participants in the project. In the next section, the materials and methods for this study are described.
2.1. Participants and Their SWANA-Centric Ethnic Rootedness Scores
As described above, Labovian Sociolinguistic Interviews were conducted with 54 SWANA Americans in the Upper Midwest (N = 44) and Southern California (N = 10). The average age of speakers at the time of the interviews was 22, ranging from 18 to 46 (only 4 speakers were over the age of 30). A total of 26 of the speakers self-identified as male and 28 speakers self-identified as female. Thirty-two of the participants were from Dearborn, MI. In terms of religion, 12 participants were Judeo-Christian (10 Christians and 2 Jews), and 42 participants were Muslim. In light of previous research on internal differences within a community in terms of ethnic orientation (
Hoffman and Walker 2010) or local rootedness (
Reed 2018), a SWANA-centric ethnic rootedness scale was also developed to examine the interaction of SWANA Americans’ linguistic behavior (such as their reracialization rates) with the degree of their ethnic orientation/rootedness. The ethnic rootedness scale comprises two broad categories of identity rootedness and practice rootedness, and questions asked during the interviews were used to assign scores on each sub-scale to individual participants. Within each category of identity rootedness, practice rootedness, and overall rootedness, three groups of “Strong”, “Moderate”, and “Weak” were assigned according to rootedness scores.
Table 1 below summarizes the ethnic rootedness scale and the three groups of “Strong”, “Moderate”, and “Weak” within each category.
For the identity rootedness scale, participants were given a score from 1 to 3 in three categories: (1) racial identification in a formal context (such as census and application forms); (2) ethnic identification in an informal setting (such as conversations with an acquaintance or friend); and (3) the language they identified as their native language (the question about native languages was worded along the following lines: “What would you say your native language is?” or “What would you consider your native language to be?”). Within the first category (racial identification in a formal setting), if a participant said they would check white as their race on forms, they would get a score of 1; if they said that they check “Other” as their race or other categories than white (for example, an Egyptian person might check African American), they would get a score of 3; and finally, if they said that they would check both white and another option, they would get a score of 2. Within the second category (ethnic identification in an informal setting), if a participant said they would identify as American only, they would obtain a score of 1; if they identified with their heritage ethnicity only, they would get a score of 3; and if they identified with both their heritage ethnicity and American, they would get a score of 2. Within the last category of identity rootedness scale (native languages), if a participant only identified English as their native language, they would get a score of 1 (all of the participants had at least one parent who was not a native speaker of English, and in some cases, they identified English as their native language even though they would say they grew up with their heritage language from birth up to a certain age, such as four or five); if they identified only the heritage language as their native language, they would get a score of 3; and if they identified both English and their heritage language as their native language, they would get a score of 2.
For the practice rootedness scale, participants were given a score from 1 to 3 in two categories: (1) languages they used to speak with their parents (same scoring style as the native language question above); and (2) visibility, which was subjectively assigned by the author. Skin tone, facial hair, and headcover were the factors based on which visibility scores were assigned. For example, if a female participant had a darker skin tone and wore an Islamic headcover, she would be given a score of 3 for her ethnic visibility, while a participant with a lighter skin tone and no headcover would be given a score of 1. A visibility score of 2 would be given to a participant who was semi-visible; for example, one participant who had a light skin tone shared during the interview that she could pass as a white person because people often ask her whether she had been a convert to Islam (due to her Islamic headcover and her light complexion). In light of previous research (
Hoffman and Walker 2010) and ethnographic evidence (
Sheydaei 2021) that underscore the importance of ethnic visibility, visibility scores were multiplied by 2 for the calculation of practice rootedness scores. The two broad categories of identity rootedness and practice rootedness were combined into an overall ethnic rootedness score. Within each category of identity rootedness, practice rootedness, and overall rootedness, three groups of “Strong”, “Moderate”, and “Weak” were assigned according to rootedness scores—represented by the colors of red (dark shading in black-and-white printouts), orange (light shading in black-and-white printouts), and yellow (lightest or no shading in black-and-white printouts), respectively, in
Table 1.
Overall, Dearborn participants said they felt like a more visible community, which is in line with anthropological research with Arab Detroit communities which describes Dearborn as a “highly visible” community (
Shryock and Lin 2009, p. 58). Dearborn—a suburb adjacent to Detroit in Wayne County, MI, and part of the Detroit metropolitan area—is a city with the largest Muslim population per capita in the US and one of the most visible SWANA American communities in the country. Dearborn was described by some of my participants as the “mini-Middle East” and the “Middle East of the Western world”. All participants were L1 English/English-dominant speakers who were either born in the US (41 speakers) or moved to the US during the critical period for language acquisition (
Lenneberg 1967) (13 speakers). In total, 27 speakers identified English as their first language, 18 speakers identified their heritage language as their first language, and 9 speakers identified both English and their heritage language as their first language. Speakers’ heritage languages included Arabic (n = 36), Armenian (n = 1), Assyrian (n = 6), Chaldean (n = 2), Hebrew (n = 2), Kurdish (n = 1), Persian (n = 5; 2 Dari, and 3 Farsi), and Turkish (n = 1).
Table 2 below shows the number of participants in different overall rootedness groups sorted by religion, Dearborn residency status, and heritage language (binary categories of Arabic and non-Arabic are used in
Table 2 for easier visualization).
Table 2 shows that while the percentages of members of the strong rootedness groups are similar across religion, Dearborn residency, and heritage language categories, there are more Dearborner and Muslim members and members with Arabic as a heritage language in the moderate rootedness group compared to non-Dearborners, Judeo-Christians, and SWANA Americans from a non-Arabic background. The next subsection describes the procedure and words extracted from the interview for analysis in the present paper.
2.2. Procedure and Target Words
The interview procedure consisted of three components: (1) casual speech, which started with questions asking about general demographic information, and then focused on topics of cultural and ethnic identities; (2) a reading passage; and (3) a sentence list. After a few demographic information questions asking, among other things, about the interviewees’ age, places lived in between ages 4 and 12, and acquired and learned languages, the focus of the casual speech section of the interview shifted towards questions about racial and ethnic identities. In the casual speech section of the interviews, interviewees were shown a map of the SWANA region and were asked questions about travel history to the region. The sentence list included target words and target names in the carrier phrase “Please say the … for …”. The target names included ethnically affiliated names (such as
Mohammad), ambiguous words (such as
Ali, which can both be an American name and a Middle Eastern name), and country names that could be pronounced in different Americanized ways or in an ethnically affiliated way (such as
Iran and
Iraq). All interviews were recorded on a solid-state digital voice recorder. The interviews were transcribed using ELAN (
Wittenburg et al. 2006) and force-aligned (with manual correction) using the FAVE-aligner (
Rosenfelder et al. 2022).
Table 3 shows the target words extracted from both the casual speech and sentence list contexts for analysis in the present paper. These target words were manually looked for in Praat and coded according to the corresponding pronunciations in
Table 3. After each word was manually marked in Praat, a Praat script was used to gather the words, pronunciation types, and timestamps for the words.
The different colors in
Table 3 represent the different pronunciations of certain words extracted from the interviews for analysis: red represents the “reraced” pronunciations and yellow represents the “bleached” pronunciations. For the words
Iran and
Iraq, there are two bleached pronunciations—bleached-/a:/ and bleached-/ae/ represented by the colors orange and yellow, respectively—listed in
Table 3 in addition to the reraced pronunciation, while all other words have one bleached and one reraced pronunciation. The next subsection presents the findings of this study in terms of the intersection of reracialization rates and group affiliations.
3. Results
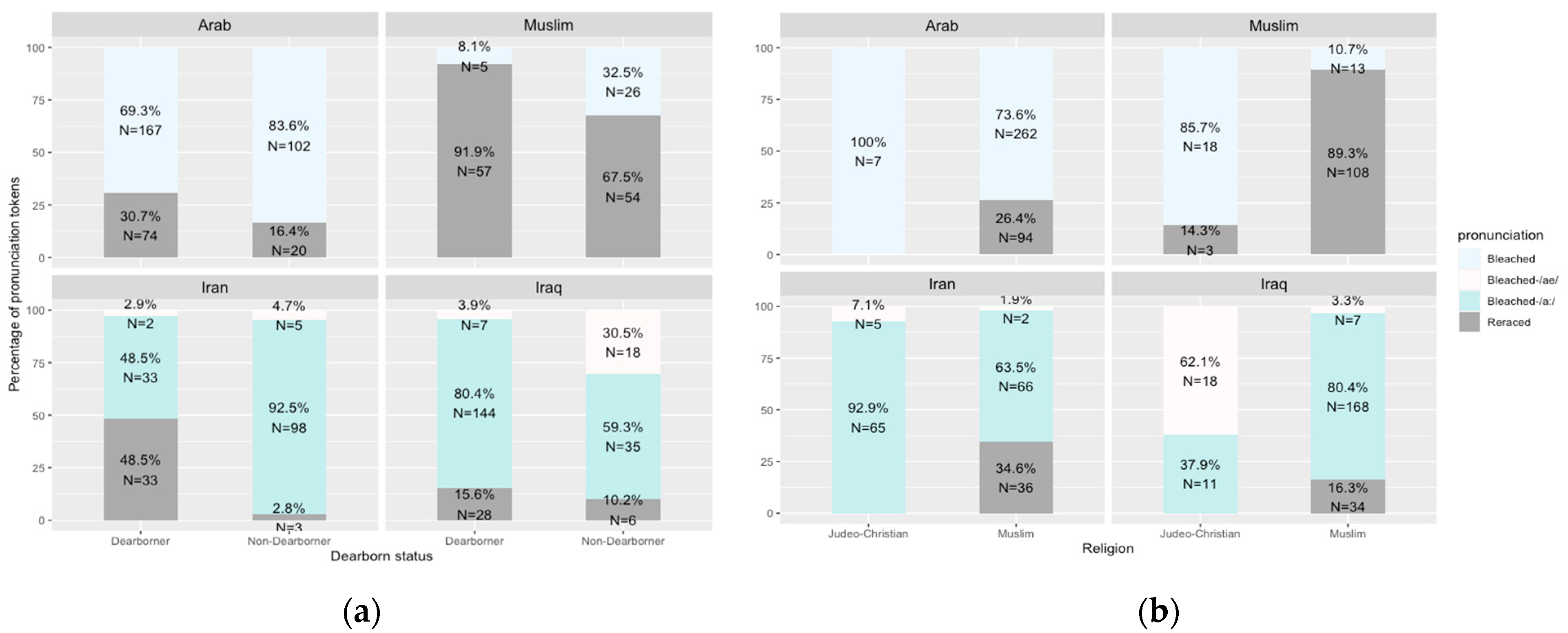
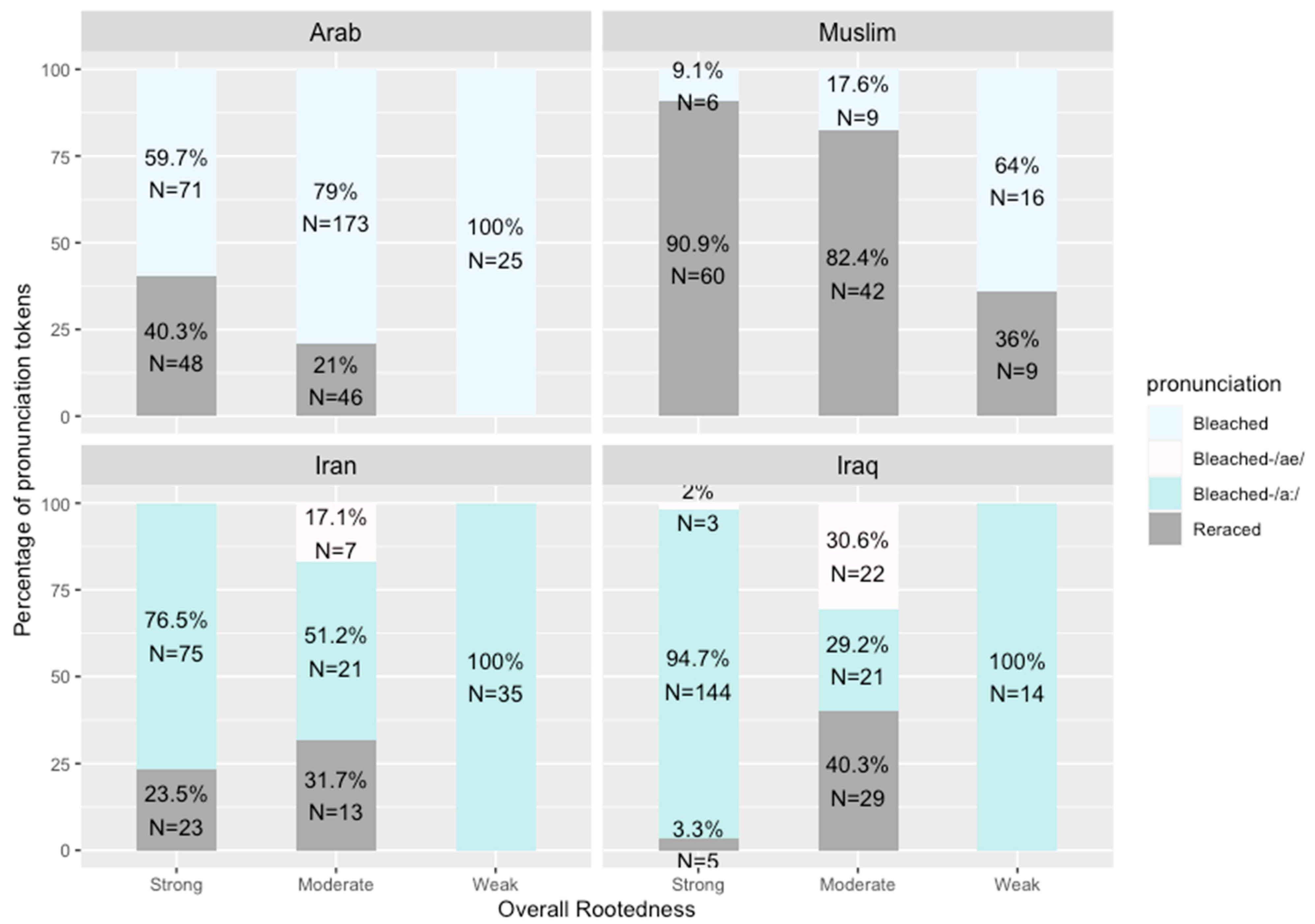
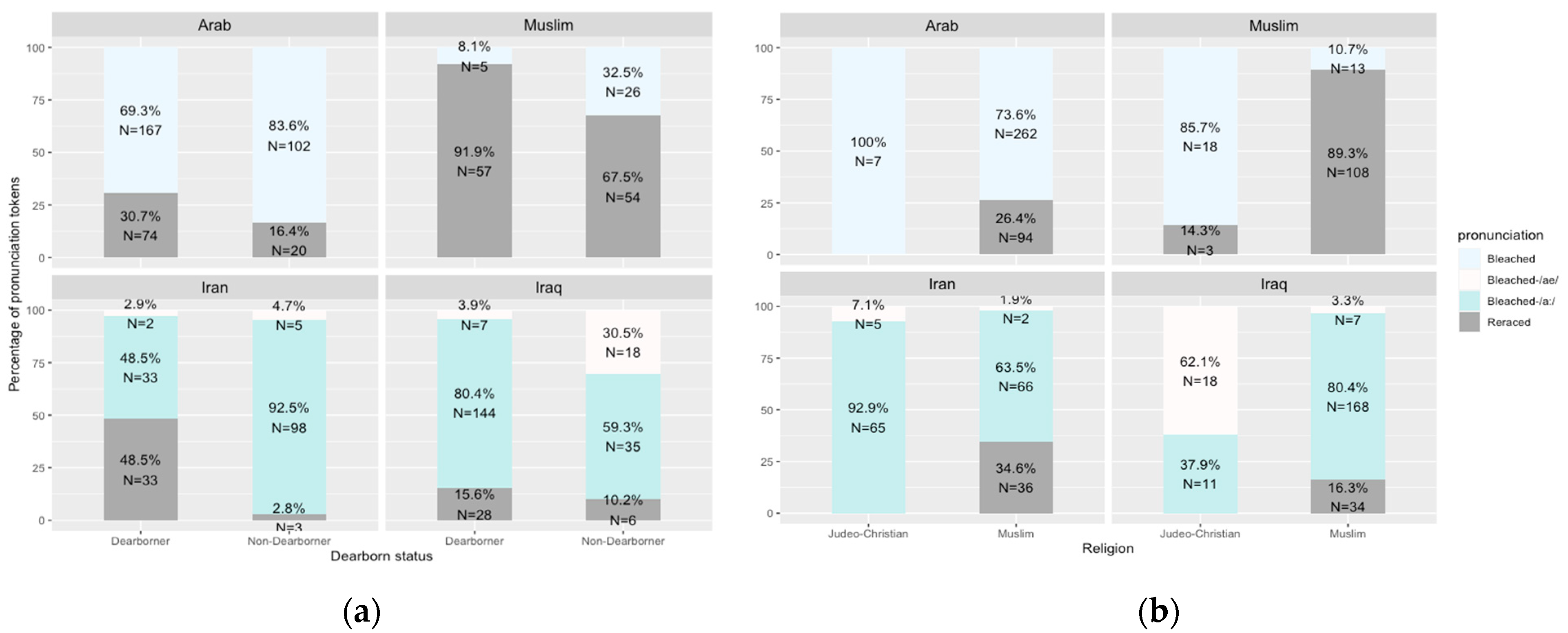
Figure 3 and
Figure 4 show the different pronunciations of ethnically affiliated words in casual speech listed in
Section 2.2 in association with the SWANA American participants’ religion, Dearborn residency, and overall ethnic rootedness scores.
Figure 3 shows that reraced pronunciations of all words are clearly associated with higher ethnic rootedness scores; interestingly, however, while the strong group leads in reracing the words
Arab and
Muslim, the moderate group leads the strong group in reracing the country names
Iran and
Iraq. Also interestingly, while we could expect to see tokens of [aɪ.ˈræn] and [aɪ.ˈræk] produced by the weak group, only the moderate group produced such tokens.
Figure 4a shows that Dearborn residency status covaries with higher rates of reracializing ethnically affiliated words, and in the case of the word
Iraq, it covaries with higher rates of the [ɪˈra:k] pronunciation and fewer tokens of the [aɪ.ˈræk] pronunciation. Similarly, Muslims have higher rates of reracializing ethnically affiliated words, especially for the word
Muslim, and with the word
Iraq, being Muslim is associated with higher rates of the [ɪˈra:k] pronunciation and fewer tokens of the [aɪ.ˈræk] pronunciation. A linear mixed-effects model
3 was run for the words
Iran and
Iraq (because they included three different pronunciations), and another model was run for the rest of the words (which included two pronunciations).
Table 4 shows the results of the linear mixed-effects models.
The results in
Table 4 show that strong ethnic rootedness is a significant predictor of reracializing the words
Arab and
Muslim (the expected direction) and at the same time a significant predictor for the production of bleached /a:/ pronunciations for the country names
Iran and
Iraq. For the moderate group, however, while ethnic rootedness is not a significant predictor of pronunciation types for the country names
Iran and
Iraq and the words
Arab and
Muslim, when we only look at the word
Muslim (informed by the patterns observed in
Figure 3), moderate ethnic rootedness becomes a significant predictor of reracializing
Muslim (estimate = 12.9, z value = 4.4,
p < 0.01) (expected direction).
Table 4 also shows that being a Dearborner is a significant predictor of indexically bleached pronunciations for the words
Muslim and
Arab (unexpected direction, again being driven by the indexically bleached pronunciations of
Arab, estimate = −9.4, z value = −4.4,
p < 0.01); however, if we only look at the word
Muslim, being a Dearborner is a significant predictor of reracialized pronunciations of [ˈmʊslem] (estimate = 14.3, z value = 3.2,
p < 0.01) (the expected direction). Being a Dearborner is also a significant predictor of bleached /a:/ pronunciations for
Iran and
Iraq, as is being a non-Dearborner.
Table 4 also shows that religion is not a significant predictor of pronunciation types for the words
Arab and
Muslim and the country names
Iran and
Iraq; nevertheless, exploring the word
Muslim alone (informed by the patterns observed in
Figure 4b) shows being a Muslim speaker is a significant predictor of reracializing the word
Muslim (estimate = 28.8, z value = 4.3,
p < 0.01). Two separate linear mixed-effects models (for the two sets of words) were also run to investigate the intersection between the predictor variables of ethnic rootedness, religion, and Dearborn status in predicting rates of reracialized pronunciations in the casual speech style; the only significant interaction was found between strong ethnic rootedness and non-Dearborn status (estimate = 4.05, z value = 5.05,
p < 0.01) in predicting higher reracialized pronunciations of the words
Arab and
Muslim. This means that higher ethnic rootedness for non-Dearborners is associated with higher rates of reracialized pronunciations of
Arab and
Muslim.
In order to see how attention to speech style might affect reracialization rates, next, we will look at the pronunciation of ethnically affiliated words in the sentence list speech style.
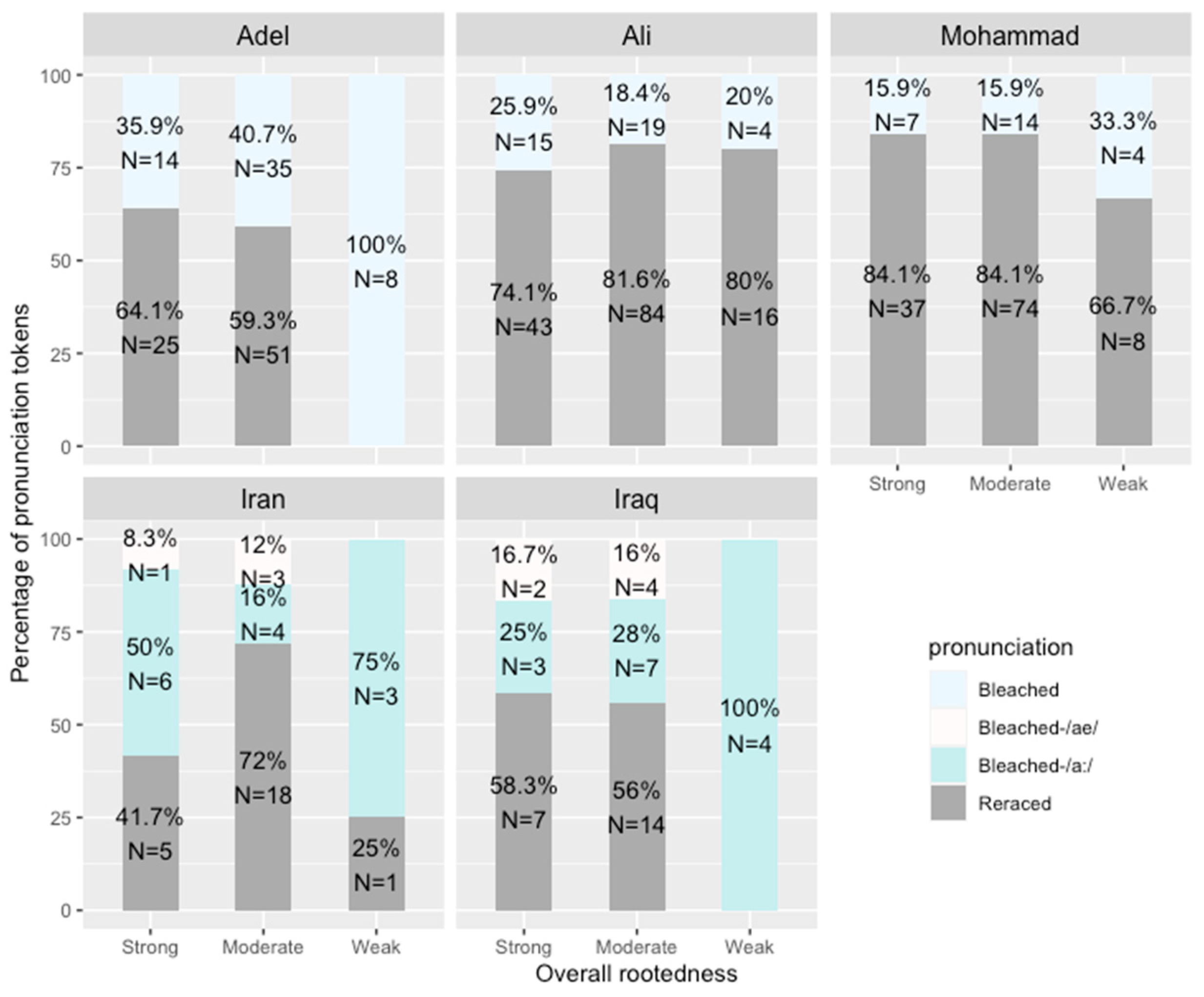
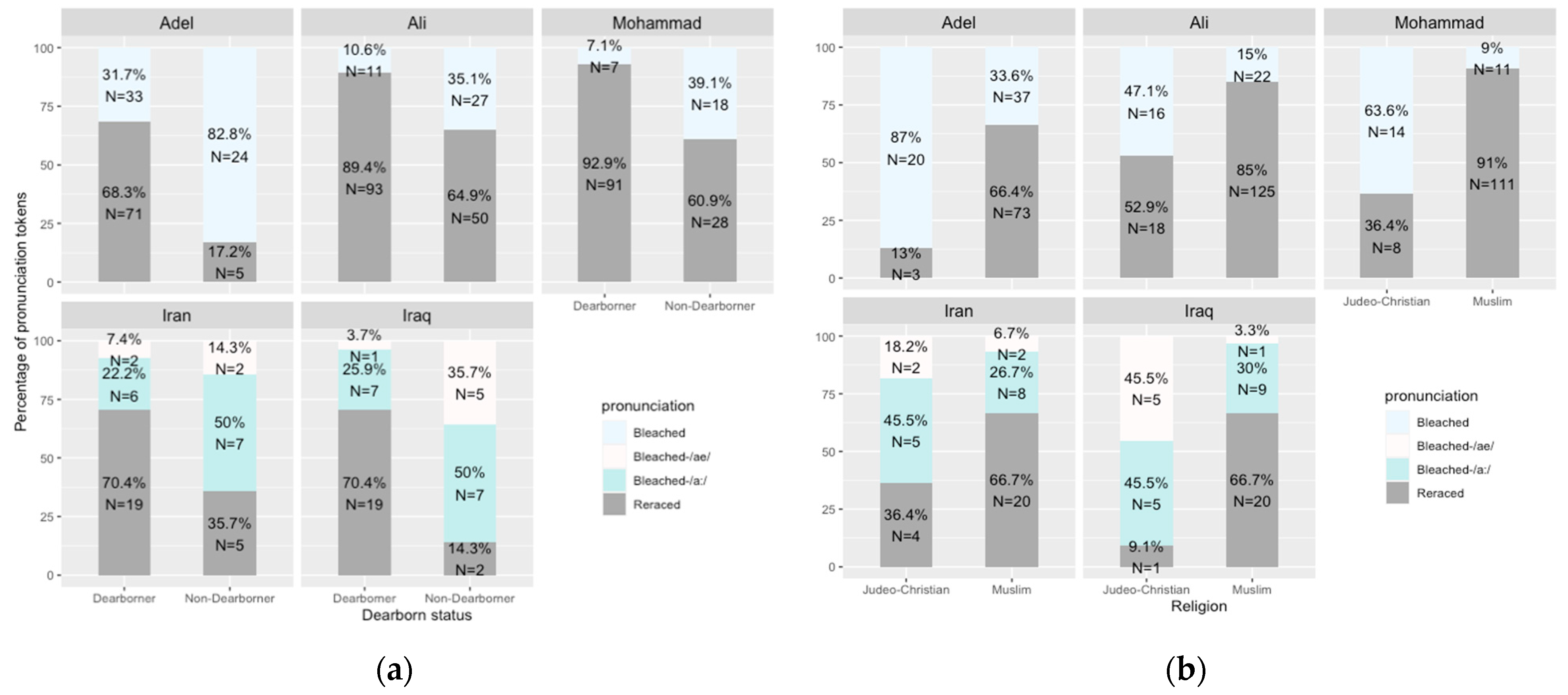
Figure 5 and
Figure 6 show the different pronunciations of ethnically affiliated words in the sentence list reading style listed in
Section 2.2 in association with the SWANA American participants’ religion, Dearborn residency, and overall ethnic rootedness scores.
Figure 5 shows when SWANA Americans pay more attention to their speech style (i.e., reading a sentence list), the reracialization of ethnically affiliated words—especially
Ali and
Mohammad—increases across all ethnic rootedness groups.
Figure 5 also shows that with more attention to style, the country names
Iran and
Iraq get reracialized at higher rates too, and similar to the casual speech context, SWANA Americans in the moderate group tend to lead the strong group in reracializing
Iran and
Iraq, while those in the weak group tend to use higher proportions of the indexically bleached /a:/ pronunciations.
Figure 6a shows that, similar to the casual speech context, Dearborn residency status covaries with higher rates of reracializing ethnically affiliated words, and when Dearborners pay more attention to their speech, they reracialize the country names
Iran and
Iraq at higher rates too. Similarly, Muslims have higher rates of reracializing ethnically affiliated words, especially for the names
Ali and
Mohammad; again, the country names
Iran and
Iraq are more frequently reracialized by Muslims when they pay more attention to their speech. A linear mixed-effects model was run for the words
Iran and
Iraq (because they included three different pronunciations), and another one was run for the rest of the words (which included two pronunciations); the results are presented in
Table 5.
Table 5 shows that moderate ethnic rootedness is a significant predictor of reracializing the names
Adel, Ali, and
Mohammad (the expected direction) and at the same time a significant predictor of reracializing the country names
Iran and
Iraq. Weak ethnic rootedness, on the other hand, is a significant predictor for the indexically bleached /æ/ pronunciation of the country names
Iran and
Iraq. As such, both
Table 4 and
Table 5 (and
Figure 3 and
Figure 5) show that the moderately ethnic rooted group leads the strongly ethnic rooted group when they pay more attention to their speech.
Table 5 also shows that being a Dearborner is a significant predictor of reracialized pronunciations for the names
Adel,
Ali, and
Mohammad and the country names
Iran and
Iraq (expected direction); being a non-Dearborner, on the other hand, is a significant predictor of indexically bleached pronunciations of ethnically affiliated names. Similarly, being a Muslim is a significant predictor of reracialized pronunciations of ethnically affiliated names (but not country names) in the sentence list speech style. In summary, the results from the sentence list speech style confirm our findings from the casual speech style (that higher ethnic rootedness scores and being a Dearborner are associated with higher rates of racializing ethnically affiliated words) and show that with more attention to their speech, the moderate ethnic rootedness group reracializes ethnically affiliated words even more than the strong ethnic rootedness group. These results also show that in the more careful speech style, Muslim speakers show higher rates of reracializing ethnically affiliated names. Two separate linear mixed-effects models (for the two sets of words) did not reveal any significant interactions between the predictor variables (ethnic rootedness, religion, and Dearborn status) in predicting reracialized pronunciations in the sentence list reading style. Additionally, three logistic regression models were run to explore whether speech style (casual speech or sentence list reading) interacted with any of the three predictor variables (ethnic rootedness, religion, or Dearborn status) in predicting reracialized pronunciations or the words
Iran and
Iraq: the only significant interaction was found between strong ethnic rootedness and the sentence list reading style (estimate = 1.72, z value = 2.84,
p < 0.01). This means that with more attention to style (i.e., reading a sentence list), SWANA Americans reracialize
Iran and
Iraq at higher rates.
4. Discussion
An emerging body of studies in sociolinguistics and language variation has explored variation within predefined speech communities including ethnic communities. These studies analyze variation over time, geographical locations, and different social roles to investigate how linguistic behavior interacts with individuals’ different affiliations. For example,
King (
2021) examined Black speakers’ vowel patterning in reference to the local vowel pattern in Rochester, NY, based on their social persona and their orientation towards the local community. Looking at variation across time,
Holliday (
2019), for example, explored prosodic variation among Black speakers in the DC area over two periods: one in the 1960s and the other in the 2010s. Focusing on a specific rural area in north East Tennessee,
Reed (
2018) looked at Appalachians’ use of monophthongal /aɪ/ in intersection with their local rootedness (how strongly they are oriented towards the local community). Extending his analysis to prosodic variation,
Reed (
2020) found significant effects of socio-indexical factors, such as local rootedness, on Appalachian speakers’ intonational patterns in their casual speech, with more rooted speakers showing more frequent L + H* pitch accents and an earlier pitch accent onset. Similarly, in an earlier study,
Carmichael (
2017) found significant associations between New Orleanians’ local orientation and rates of r-lessness in their speech within the specific context of the suburb of Chalmette, showing orientation towards places outside of Chalmette to be significantly associated with lower rates of r-lessness. The present study contributes to this body of emerging literature by studying variation within an underrepresented community in sociolinguistics. This paper explored SWANA Americans’ pronunciation of certain ethnically affiliated words at the intersection with their ethnic rootedness scores, their religion, and their Dearborn residency status.
In the US context, the ethnic category of SWANA (see endnote 3 for a discussion of the terminology) has recently received some attention both from within the community of SWANA Americans (e.g.,
Kahn 2010) and from a governmental perspective (e.g.,
Jones 2017). SWANA Americans are an understudied community in the field of sociolinguistics but could be highly visible in society. SWANA Americans have historically and legally been classified as white despite the social perception that they are not white (
Beydoun 2015;
Khoshneviss 2019;
Maghbouleh 2017). The linguistic analysis in this study showed the social discrepancies between the top-down perspective of assigning all SWANA Americans a statistical race (
Prewitt 2013) category versus the bottom-up perspective of examining the social implications of this community’s nuanced internal composition differences. The results show that higher SWANA-centric ethnic rootedness scores are significant predictors of reracializing ethnically affiliated words such as
Arab, Muslim, Iran, Iraq, and
Mohammad. Similarly, being a Dearborner significantly predicted reracialization of ethnically affiliated words. In this process, however, the word
Muslim was specifically reracialized as [ˈmʊslem] not only by speakers with higher ethnic rootedness and Dearborners but also by Muslim speakers. Additionally, strong ethnic rootedness interacted only with non-Dearborn status in predicting higher rates of reracialized pronunciations of
Arab and
Muslim, which could mean Dearborners tend to reracialize these words at higher rates regardless of the strength of their ethnic rootedness.
These results are specifically important given
Durrani’s (
2018) discussion of the variation in the pronunciations of the word
Muslim and their meanings. Durrani explains that the indexically bleached pronunciation of the word (i.e., with the phonated consonant [ˈmʌzlɪm]) translates to
مظلم (“dark”, “black”, or “very evil”) in Arabic, while the reracialized pronunciation [ˈmʊslem] translates to
مسلم (“one who accepts/submits”). This study also showed that when SWANA Americans pay more attention to their speech by reading a sentence list (in the Labovian sense of careful speech style), our observations are confirmed: higher ethnic rootedness, being a Muslim, and being a Dearborner are strong predictors of reracializing ethnically affiliated words. Additionally, SWANA Americans who are moderately ethnic rooted reracialize ethnically affiliated names and country names at higher rates than strongly ethnic rooted SWANA Americans when they pay more attention to their speech. Such linguistic performance could be interpreted as the mirror image of lower-middle-class speakers’ outperforming their upper-middle-class counterparts in their use of certain overt prestige markers (such as the pronunciation of /r/ in
Labov’s (
1986) New York City study). Similarly, in the more careful speech style of sentence list reading, Muslim participants reracialized ethnically affiliated names at higher rates compared to their own performance in the casual speech style. Exploring the interactions between the different predictors also revealed that strong ethnic rootedness interacted significantly with the sentence list reading style in predicting higher rates of reracializing
Iran and
Iraq, meaning SWANA Americans reracialize these country names at higher rates when they pay more attention to style.
In summary, the results from this study emphasize linguistic variation in connection to social identities (
Suleiman 1999) among individuals of SWANA ancestry in the US. More specifically, SWANA Americans who are more strongly rooted ethnically, are from the city of Dearborn in Michigan, or are Muslim reracialize the pronunciation of ethnically affiliated words (such as
Arab,
Muslim,
Mohammad,
Ali,
Iran, or
Iraq) at higher rates. Future studies could explore similar linguistic practices within other ethno-racially minority communities by applying and modifying the ethnic rootedness scale and considering other factors such as community settlement patterns and perceived internal hierarchies.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}