

Quantitative Methods for Analyzing Second Language Lexical Tone Production


Abstract
:1. Introduction
1.1. Perceptual Approaches to L2 Tone Analysis
1.2. Acoustic Approaches to L2 Tone Analysis
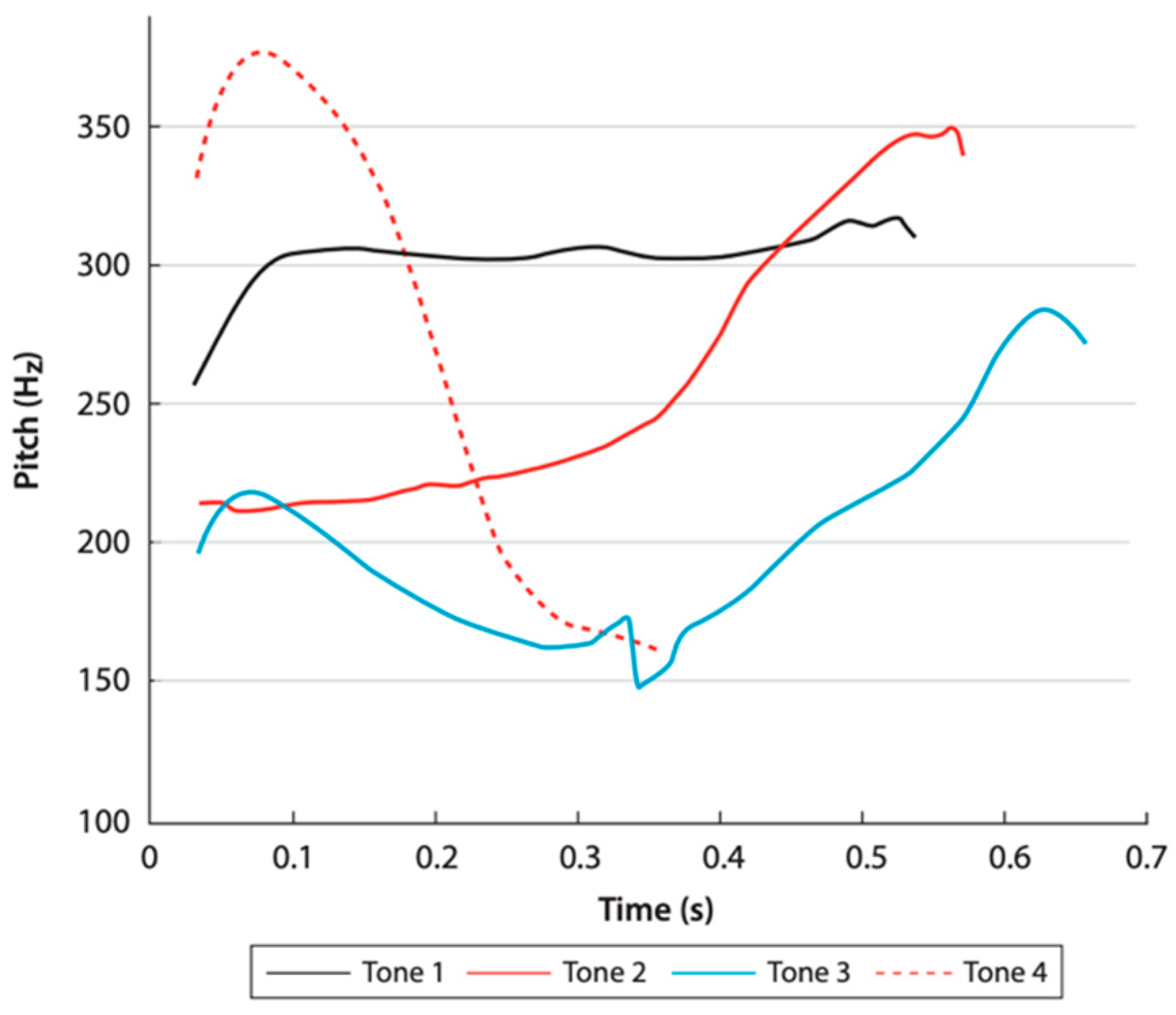
1.3. Defined Region Approach
1.4. Measures for Time Series Data
1.5. The Current Study
2. Materials and Methods
2.1. Datasets
2.2. Data Pre-Processing
2.2.1. Data Resampling and Curve Fitting
2.2.2. Time Normalization
2.2.3. F0 Normalization
2.3. Analyses
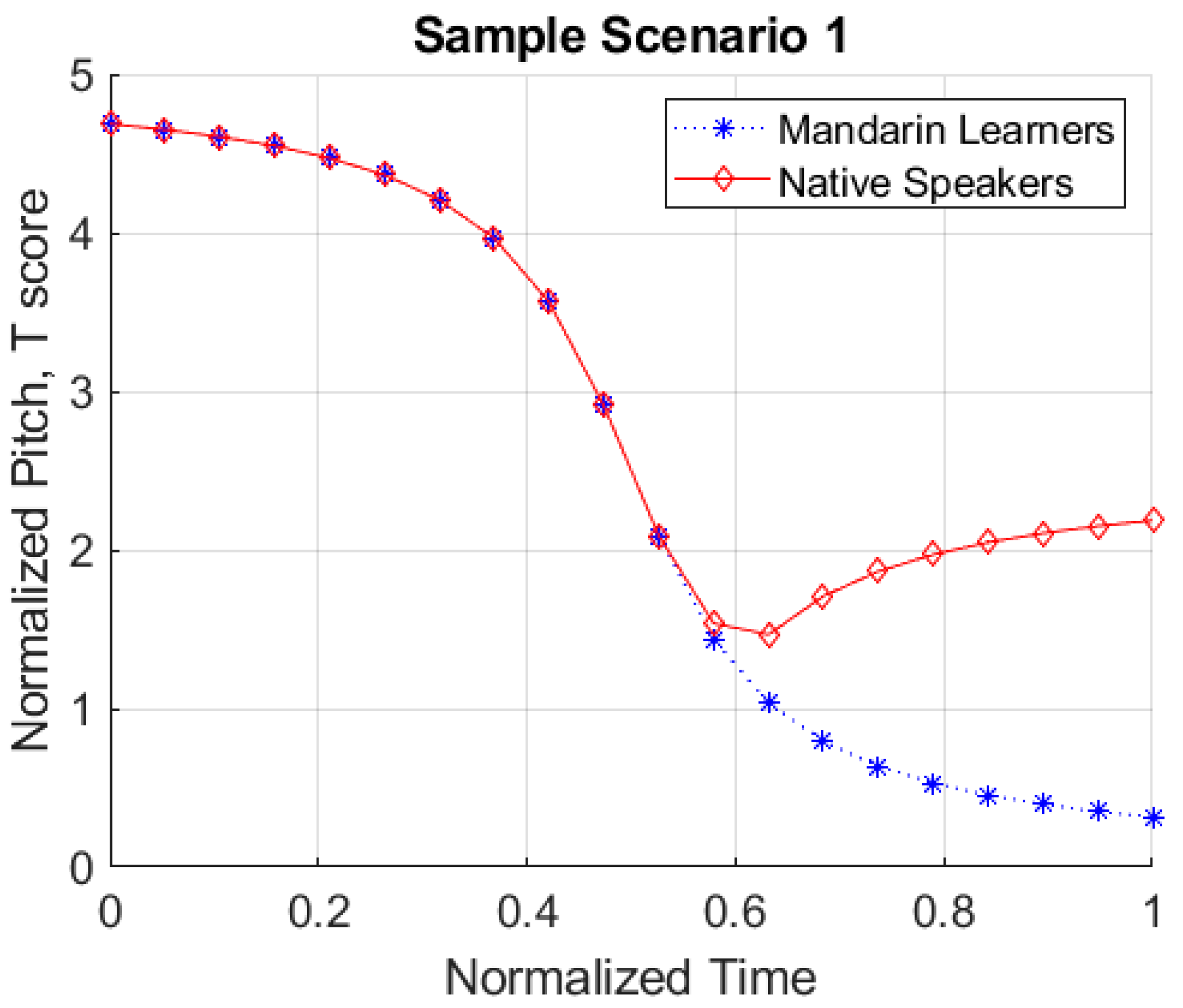
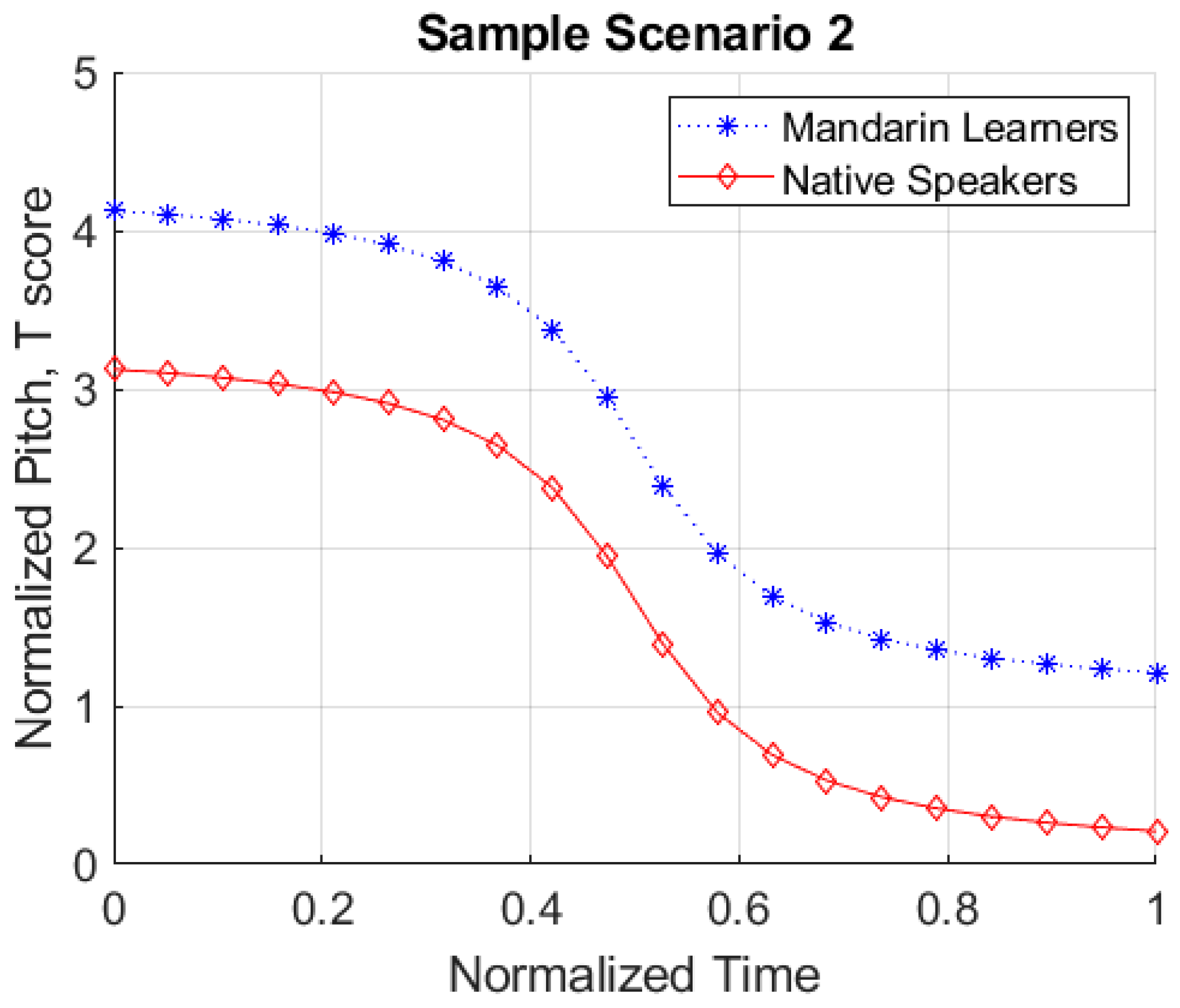
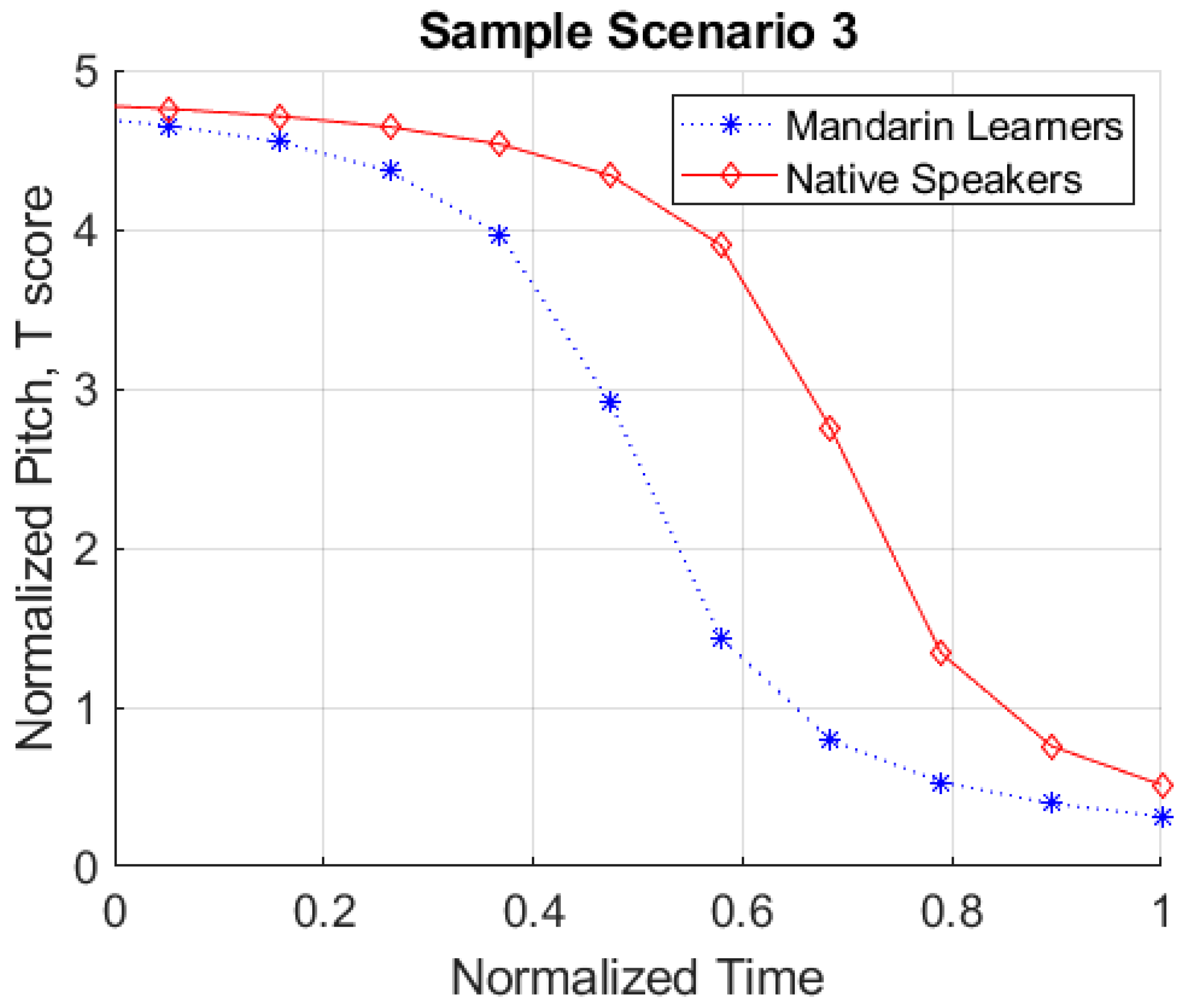
2.3.1. Deviation Score Analysis
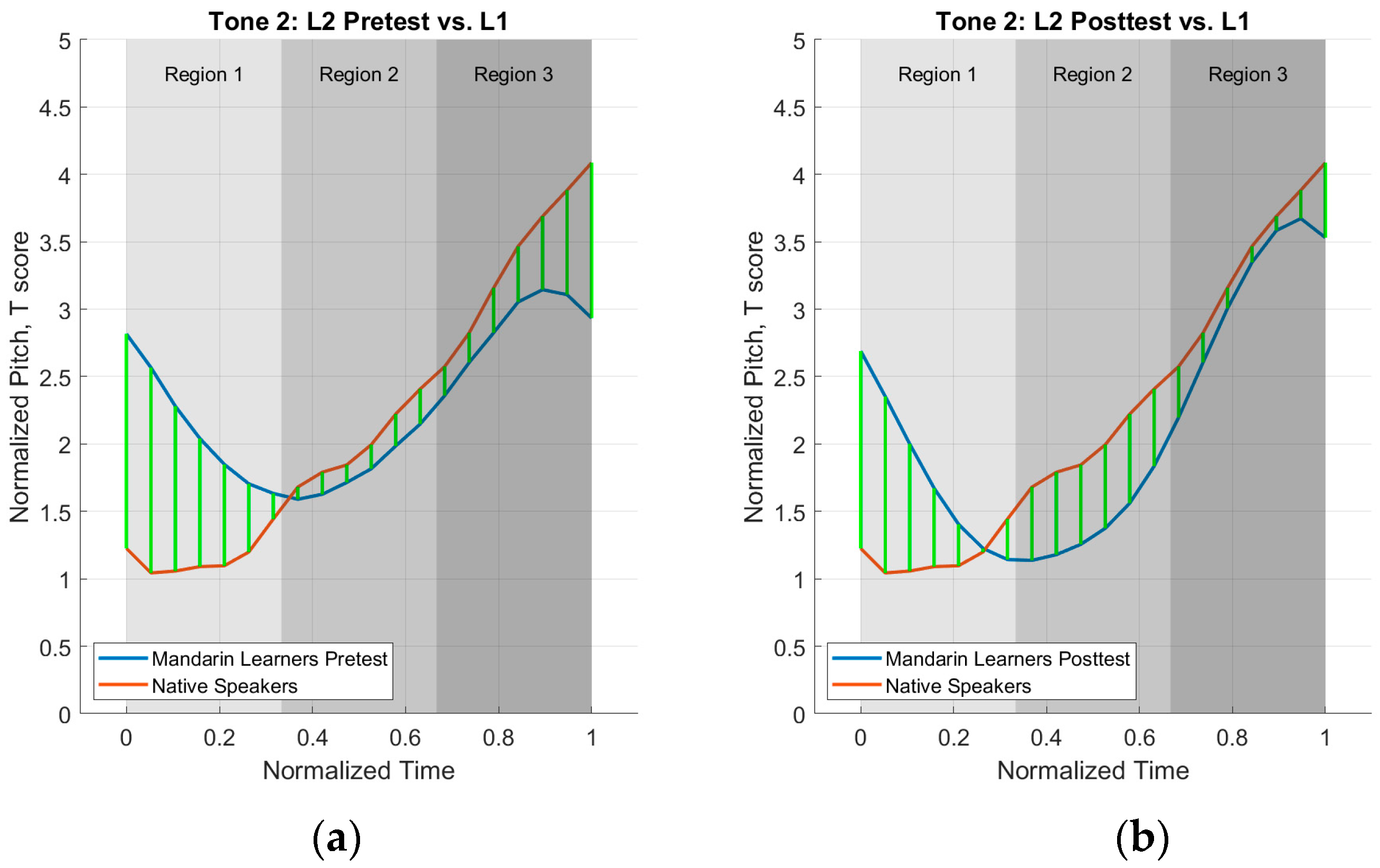
2.3.2. Defined Region Analysis
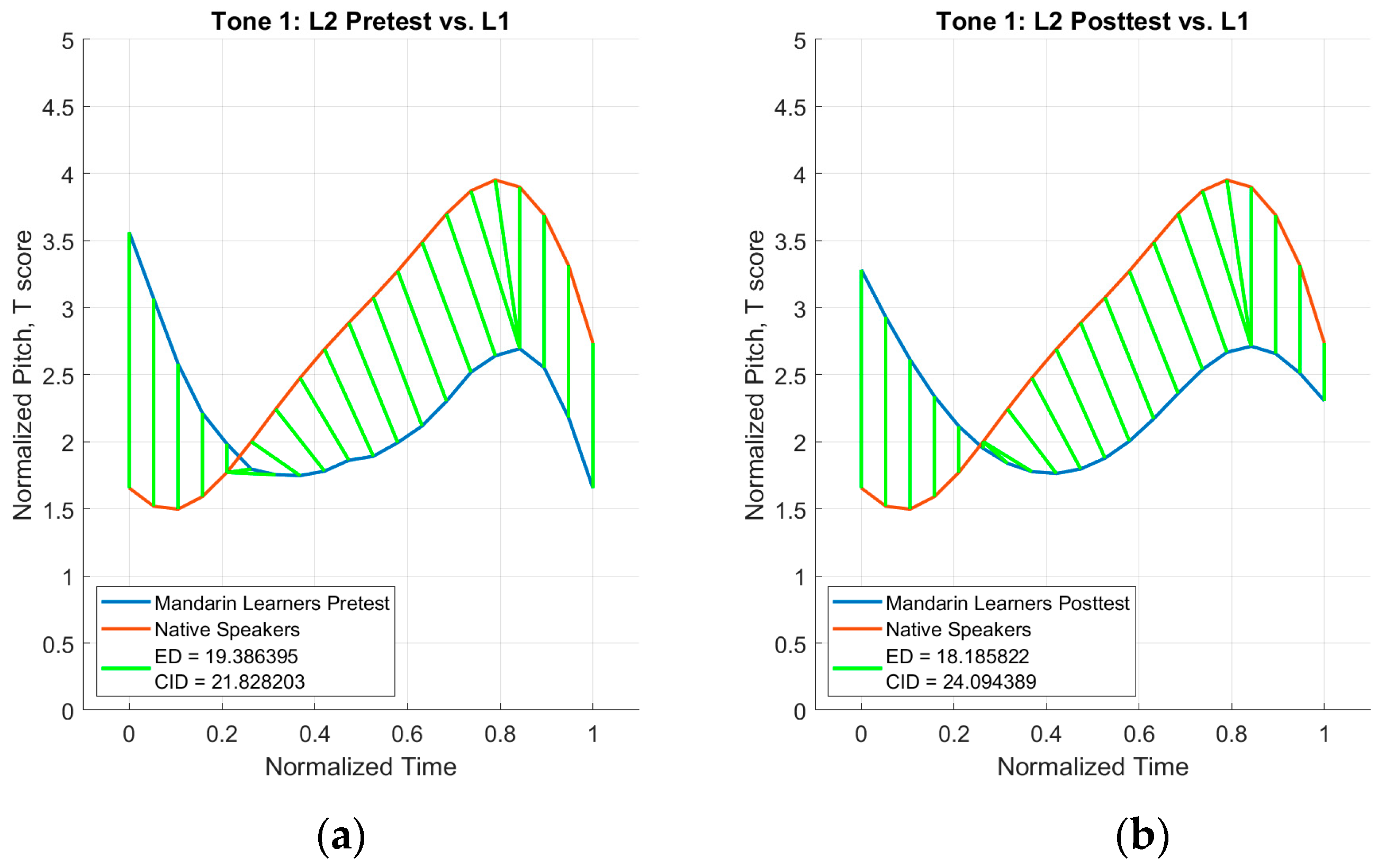
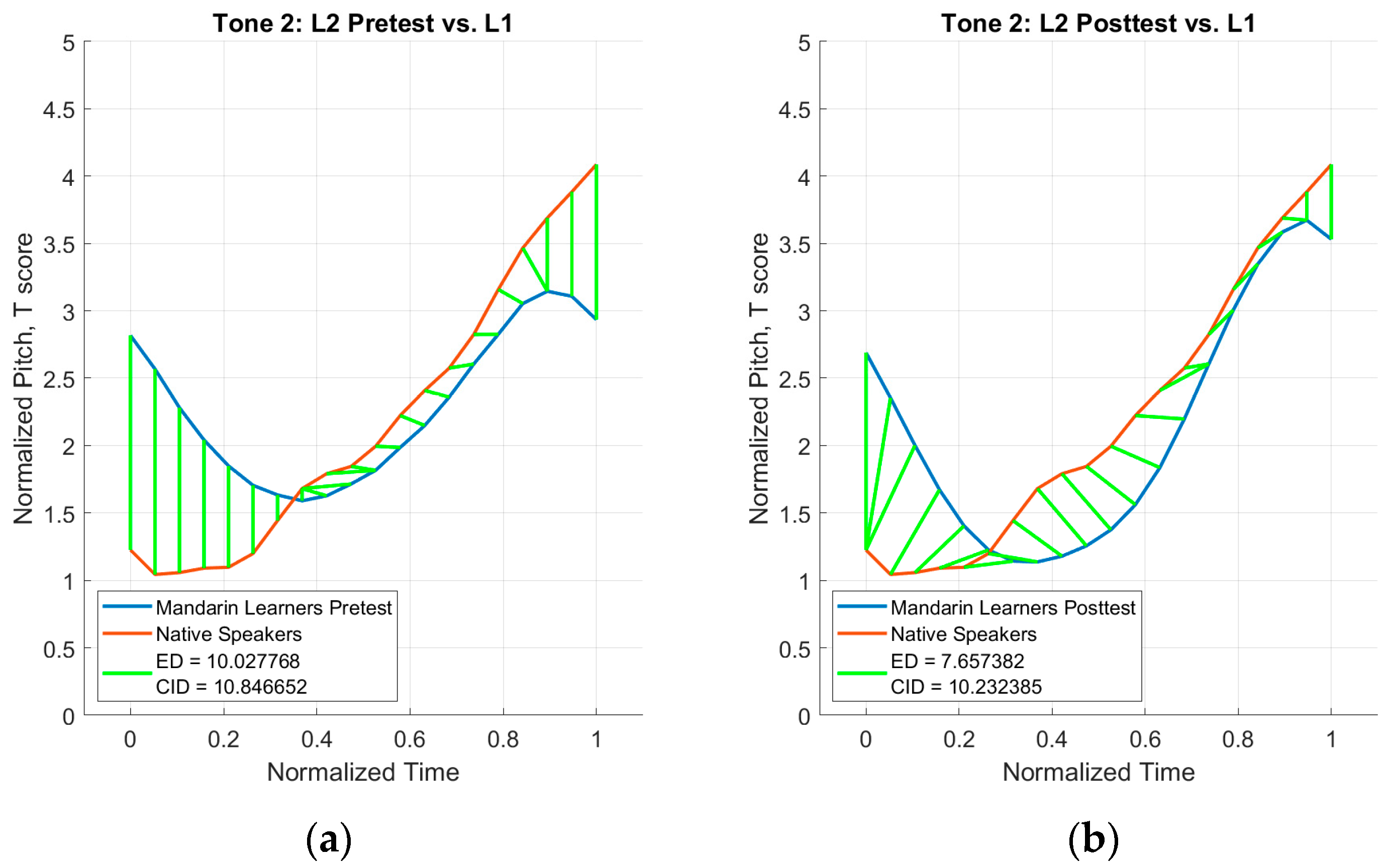
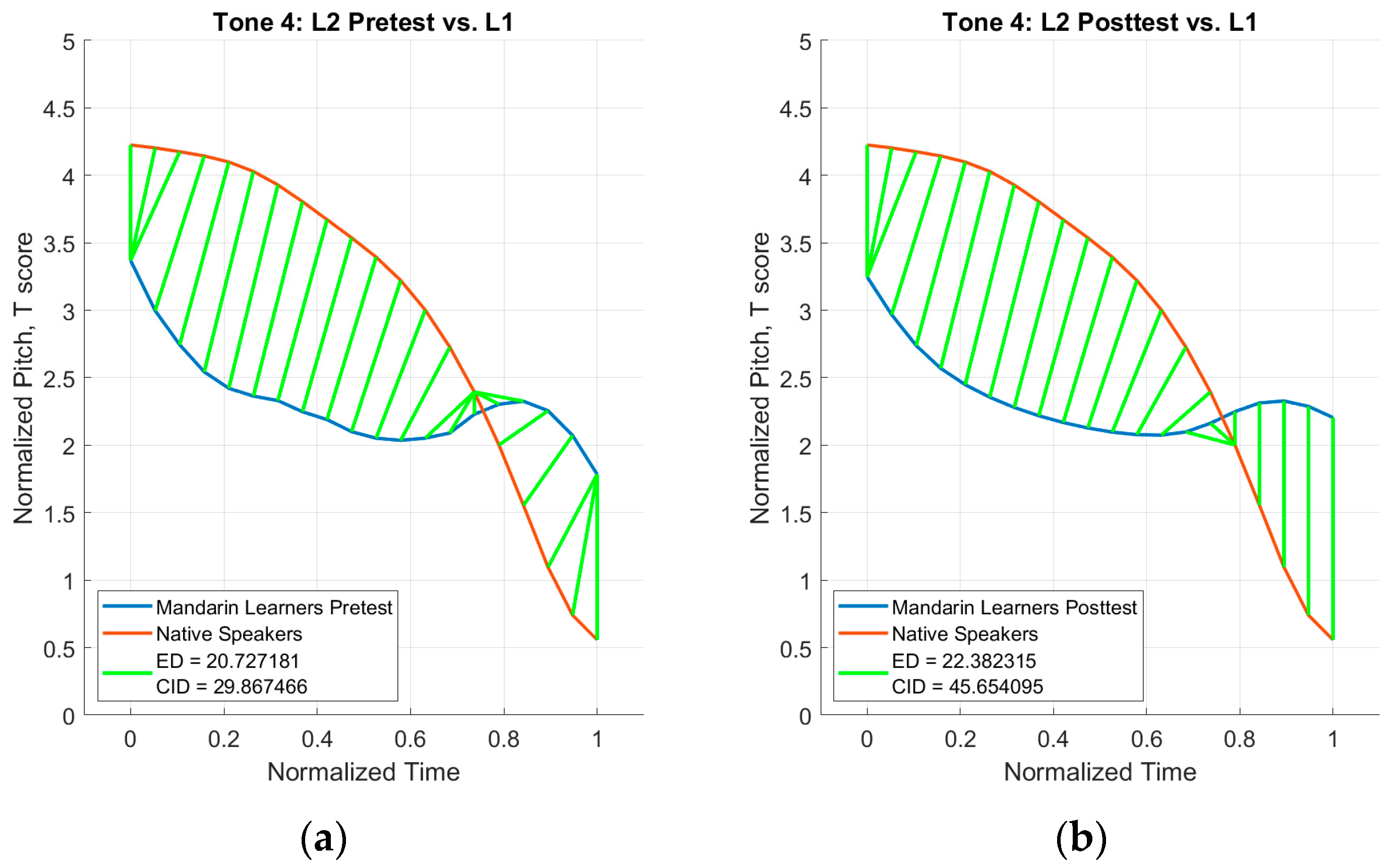
2.3.3. CID Measure Analysis
3. Results
3.1. Deviation Score Analysis Results
3.2. Defined Region Analysis Results
3.3. CID Measure Analysis Results
4. Discussion
4.1. Exploration of the Analyses
4.2. Conclusions from the Current Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | Also, it is worth noting emerging research on L2 tone evaluations via machine learning. This research has mainly focused on the development of networks or models for identifying mispronounced L2 tone (e.g., Cheng 2012; Li et al. 2019). |
| 2 | Although both prior analyses and those examined in the current paper use native speaker productions as a benchmark for L2 comparisons, it should be noted intelligibility and comprehensibility (for a discussion, see Munro and Derwing 1995) rather than native-like production should be the aim for most L2 learners. |
| 3 | Data from four speakers was previously presented in Zhou and Olson (2023). |
References
- Amato, Federico, Mohamed Laib, Fabian Guignard, and Mikhail Kanevski. 2020. Analysis of air pollution time series using complexity-invariant distance and information measures. Physica A: Statistical Mechanics and Its Applications 547: 1–9. [Google Scholar] [CrossRef]
- Batista, Gustavo E. A. P. A., Eamonn Keogh, Oben M. Tataw, and Vinicius M. A. de Souza. 2014. CID: An efficient complexity-invariant distance for time series. Data Mining and Knowledge Discovery 28: 634–69. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2022. Praat–Doing Phonetics by Computer (Version 6.2.23). [Computer Program]. Available online: www.praat.org (accessed on 15 May 2023).
- Chao, Yuen R. 1948. Mandarin Primer. Cambridge: Harvard University Press. [Google Scholar]
- Chen, Gwang-tsai. 1974. The pitch range of English and Chinese speakers. Journal of Chinese Linguistics 2: 159–71. [Google Scholar]
- Chen, Mengtian. 2022. Computer-aided feedback on the pronunciation of Mandarin Chinese tones: Using Praat to promote multimedia foreign language learning. Computer Assisted Language Learning 35: 1–26. [Google Scholar] [CrossRef]
- Cheng, Jian. 2012. Automatic tone assessment of non-native Mandarin speakers. Paper presented at 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, September 9–13; Baixas: International Speech Communication Association (ISCA), pp. 1299–302. [Google Scholar] [CrossRef]
- Chun, Dorothy M. 1989. Teaching tone and intonation with microcomputers. CALICO Journal 7: 21–46. [Google Scholar] [CrossRef]
- Chun, Dorothy M., Yan Jiang, Justine Meyr, and Rong Yang. 2015. Acquisition of L2 Mandarin Chinese tones with learner-created tone visualizations. Journal of Second Language Pronunciation 1: 86–114. [Google Scholar] [CrossRef]
- Ding, Hui, Goce Trajcevski, Peter Scheuermann, Wang Xiaoyue, and Eamonn Keogh. 2008. Querying and mining of time series data: Experimental comparison of representations and distance measures. Proceedings of the VLDB Endowment 1: 1542–52. [Google Scholar] [CrossRef]
- Esling, Philippe, and Carlos Agon. 2012. Time-series data mining. ACM Computing Surveys 45: 1–34. [Google Scholar] [CrossRef]
- He, Yunjuan, Qian Wang, and Ratree Wayland. 2016. Effects of different teaching methods on the production of Mandarin tone 3 by English-speaking learners. Chinese as a Second Language 51: 252–65. [Google Scholar] [CrossRef]
- Keogh, Eamonn, Li Wei, Xiaopeng Xi, Michail Vlachos, Sang-Hee Lee, and Pavlos Protopapas. 2009. Supporting exact indexing of arbitrarily rotated shapes and periodic time series under Euclidean and warping distance measures. The VLDB Journal 18: 611–30. [Google Scholar] [CrossRef]
- Li, Man, and Robert DeKeyser. 2017. Perception practice, production practice, and musical ability in L2 Mandarin tone-word learning. Studies in Second Language Acquisition 39: 593–620. [Google Scholar] [CrossRef]
- Li, Wei, Nancy F. Chen, Sabato M. Siniscalchi, and Chin-Hui Lee. 2019. Improving mispronunciation detection of Mandarin tones for non-native learners with soft-target tone labels and BLSTM-based deep tone models. IEEE/ACM Transactions on Audio, Speech, and Language Processing 27: 2012–24. [Google Scholar] [CrossRef]
- Liao, Hsien-Cheng, Jiang-Chun Chen, Sen-Chia Chang, Ying-Hua Guan, and Chin-Hui Lee. 2010. Decision tree-based tone modeling with corrective feedback for automatic Mandarin tone assessment. Paper presented at 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, September 26–30; Baixas: International Speech Communication Association (ISCA), pp. 602–5. [Google Scholar] [CrossRef]
- Munro, Murray J., and Tracey M. Derwing. 1995. Foreign accent, comprehensibility, and intelligibility in the speech of second language learners. Language Learning 45: 73–97. [Google Scholar] [CrossRef]
- Offerman, Heather M., and Daniel J. Olson. 2016. Visual feedback and second language segmental production: The generalizability of pronunciation gains. System 59: 45–60. [Google Scholar] [CrossRef]
- Olson, Daniel J. 2014. Benefits of visual feedback on segmental production in the L2 classroom. Language Learning & Technology 18: 173–92. Available online: https://llt.msu.edu/issues/october2014/olson.pdf (accessed on 23 May 2023).
- Olson, Daniel J., and Heather M. Offerman. 2021. Maximizing the effect of visual feedback for pronunciation instruction: A comparative analysis of three approaches. Journal of Second Language Pronunciation 7: 89–115. [Google Scholar] [CrossRef]
- Rose, Phil. 1987. Considerations in the normalization of the fundamental frequency of linguistic tone. Speech Communication 6: 343–51. [Google Scholar] [CrossRef]
- Schmidt, Richard. 1995. Consciousness and foreign language learning: A tutorial on the role of attention and awareness in learning. In Attention and Awareness in Foreign Language Learning. Edited by Richard Schmidt. Honolulu: University of Hawai’i Press, pp. 1–63. [Google Scholar]
- Shang, Du, Pengjian Shang, and Liu Liu. 2019. Multidimensional scaling method for complex time series feature classification based on generalized complexity-invariant distance. Nonlinear Dynamics 95: 2875–92. [Google Scholar] [CrossRef]
- Shen, Xiaonan S. 1989. Toward a register approach in teaching Mandarin tones. Journal of the Chinese Language Teachers Association 24: 27–47. [Google Scholar]
- Singh, Leher, and Charlene S. L. Fu. 2016. A new view of language development: The acquisition of lexical tone. Child Development 87: 834–54. [Google Scholar] [CrossRef]
- Souza, Vinicius M. A. 2018. Asphalt pavement classification using smartphone accelerometer and complexity invariant distance. Engineering Applications of Artificial Intelligence 74: 198–211. [Google Scholar] [CrossRef]
- The MathWorks Inc. 2023. Matlab Version 9.14.0 (R2023a). [Computer Program]. Available online: www.mathworks.com (accessed on 23 May 2023).
- Wang, Xinchun. 2012. Auditory and visual training on Mandarin tones: A pilot study on phrases and sentences. International Journal of Computer-Assisted Language Learning and Teaching 2: 16–29. [Google Scholar] [CrossRef]
- Wang, Yue, Allard Jongman, and Joan A. Sereno. 2003. Acoustic and perceptual evaluation of Mandarin tone productions before and after perceptual training. The Journal of the Acoustical Society of America 113: 1033–43. [Google Scholar] [CrossRef] [PubMed]
- Wiener, Seth, Marjorie K. M. Chan, and Kiwako Ito. 2020. Do explicit instruction and high variability phonetic training improve nonnative speakers’ Mandarin tone productions? The Modern Language Journal 104: 152–68. [Google Scholar] [CrossRef]
- Woodward, James. 2000. Explanation and invariance in the special sciences. The British Journal for the Philosophy of Science 51: 197–254. Available online: https://www.jstor.org/stable/3541803 (accessed on 1 April 2023). [CrossRef]
- Yang, Chunsheng, and Marjorie K. M. Chan. 2010. The perception of Mandarin Chinese tones and intonation by American learners. Journal of the Chinese Language Teachers Association 45: 7–36. [Google Scholar]
- Yip, Moira. 2002. Tone. Cambridge: Cambridge University Press. [Google Scholar]
- Zhang, Hang. 2017. The effect of theoretical assumptions on pedagogical methods: A case study of second language Chinese tones. International Journal of Applied Linguistics 27: 363–82. [Google Scholar] [CrossRef]
- Zheng, Annie, Yukari Hirata, and Spencer D. Kelly. 2018. Exploring the effects of imitating hand gestures and head nods on L1 and L2 Mandarin tone production. Journal of Speech, Language, and Hearing Research 61: 2179–95. [Google Scholar] [CrossRef]
- Zhou, Alexis, and Daniel Olson. 2023. The use of visual feedback to train L2 lexical tone: Evidence from Mandarin phonetic acquisition. In Proceedings of the 13th Pronunciation in Second Language Learning and Teaching Conference. Edited by R. I. Thomson, T. M. Derwing, J. M. Levis and K. Hiebert. St. Catharines: Brock University. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tone Combination | Chinese Characters | Pinyin | Translation |
|---|---|---|---|
| T1-T0 | 心思 | xīnsi | thoughts |
| T1-T1 | 开工 | kāigōng | go into operation |
| T1-T2 | 天文 | tiānwén | astronomy |
| T1-T3 | 经理 | jīnglǐ | manager |
| T1-T4 | 医院 | yīyuàn | hospital |
| Pretest | Posttest | |
|---|---|---|
| Tone 1 | −0.52 | −0.46 |
| Tone 2 | 0.10 | −0.05 |
| Tone 3 | −0.14 | −0.21 |
| Tone 4 | −0.70 | −0.67 |
| Region 1 | Region 2 | Region 3 | ||||
|---|---|---|---|---|---|---|
| Pretest | Posttest | Pretest | Posttest | Pretest | Posttest | |
| Tone 1 | 0.67 | 0.69 | −1.05 | −1.03 | −1.23 | −1.06 |
| Tone 2 | 0.96 | 0.62 | −0.14 | −0.54 | −0.52 | −0.25 |
| Tone 3 | −1.24 | −1.19 | −0.60 | −0.80 | 1.42 | 1.37 |
| Tone 4 | −1.43 | −1.46 | −1.27 | −1.27 | 0.57 | 0.65 |
| Magnitude | Phase | |||
|---|---|---|---|---|
| Pretest | Posttest | Pretest | Posttest | |
| Tone 1 | 8.58 | 7.69 | 48.84 | 78.63 |
| Tone 2 | 3.63 | 2.82 | 113.04 | 96.68 |
| Tone 3 | 17.65 | 17.94 | 44.00 | 43.17 |
| Tone 4 | 18.37 | 19.91 | 62.99 | 46.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, A.; Olson, D.J. Quantitative Methods for Analyzing Second Language Lexical Tone Production. Languages 2023, 8, 209. https://doi.org/10.3390/languages8030209
Zhou A, Olson DJ. Quantitative Methods for Analyzing Second Language Lexical Tone Production. Languages. 2023; 8(3):209. https://doi.org/10.3390/languages8030209
Chicago/Turabian StyleZhou, Alexis, and Daniel J. Olson. 2023. "Quantitative Methods for Analyzing Second Language Lexical Tone Production" Languages 8, no. 3: 209. https://doi.org/10.3390/languages8030209
APA StyleZhou, A., & Olson, D. J. (2023). Quantitative Methods for Analyzing Second Language Lexical Tone Production. Languages, 8(3), 209. https://doi.org/10.3390/languages8030209