1. Introduction
What distinguishes a tiger from a bird? A king from a lawyer? And success from victory? Unlike the lexical items
bird,
lawyer, and
victory, the lexical items
tiger,
king, and
success are all cognates with their Danish translation equivalents (respectively
tiger,
konge, and
succes). Bilingual processing of translation equivalents with a high degree of cross-language overlap at the orthographic level is frequently examined to address two pertinent theoretical issues regarding the bilingual language system: The question of language selectivity during bilingual language processing, and the related question of how lexical representations are stored in the bilingual’s mental lexicon (
Dijkstra and Van Heuven 2002). One hypothesis—the language selective access hypothesis—proposes that bilingual language processing activates lexical candidates from the target language only, in effect resulting in bilinguals being equipped with two distinct lexicons devoid of interaction. While some evidence supporting the language selective access hypothesis has been provided (
Gerard and Scarborough 1989;
Macnamara and Kushner 1971;
Scarborough et al. 1984), a surge of evidence countering this hypothesis has amounted from studies on spoken word production (see
Kroll et al. (
2006) for a review), spoken word recognition (
Marian and Spivey 2003), visual word recognition (see
Dijkstra (
2005) for a review), and studies investigating cross-language interference through the use of nonwords resembling the nontarget language (
Altenberg and Cairns 1983;
Nas 1983). As a result, most researchers today subscribe to the language nonselective access hypothesis in which a bilingual’s two languages are assumed to be integrated in a shared lexicon with cross-language interactions during language processing.
A great deal of the research supporting language nonselectivity during visual word recognition has investigated how cognates may be facilitated or inhibited (depending on the experimental setting) compared to noncognates. Such cognate effects are typically explained by language nonselective activation of words from the two languages with this convergent cross-lingual activation speeding up or hindering recognition. Studies presenting cognates out of context include various versions of the visual priming task (
Bowers et al. 2000;
Davis et al. 2010;
De Groot and Nas 1991;
Gollan et al. 1997;
Lee et al. 2018;
Lijewska et al. 2018;
Voga and Grainger 2007), progressive demasking tasks (
Dijkstra et al. 2010), picture naming tasks (
Hoshino and Kroll 2008), word association tasks (
Van Hell and Dijkstra 2002), and various translation-based tasks (
De Groot 1992;
De Groot et al. 1994). The cognate effects commonly found in studies investigating single-word processing have been replicated in more natural, sentence-like contexts using rapid serial visual presentation tasks (
Dijkstra et al. 2015;
Gullifer et al. 2013;
Schwartz and Kroll 2006), self-paced reading tasks (
Bultena et al. 2014), variations of lexical decision tasks and translation tasks embedded in sentential contexts (
Van Hell and De Groot 2008), as well as eye-tracking when reading sentences (
Balling 2013;
Bultena et al. 2014;
Duyck et al. 2007;
Libben and Titone 2009;
Van Assche et al. 2009,
2011) or entire novels (
Cop et al. 2017). The results from such behavioral studies have also been replicated with neuroscientific methods; for instance,
Peeters et al. (
2013) compared behavioral and electrophysiological data and found cognate effects in the behavioral data to be mirrored at the neurological level (see
Van Heuven and Dijkstra (
2010) for a review of other studies using neuroscientific methods).
The most widely used paradigm to study cognate facilitation effects, however, is arguably lexical decision tasks. In a lexical decision task, participants are asked to indicate whether or not a word conforms to certain criteria (e.g., if it belongs to a specific language). Studies using lexical decision tasks have found a number of factors that influence the processing of cognates such as phonology (
Dijkstra et al. 1999;
Lemhöfer and Dijkstra 2004), task demands (
Dijkstra et al. 2010;
Mulder et al. 2015;
Poort and Rodd 2017;
Vanlangendonck et al. 2020 (see also
Peeters et al. (
2019) for an fMRI-counterpart to the study by Vanlangendonck et al.)), and frequencies in each of the languages (
Peeters et al. 2013). Additionally, orthographic overlap, that is, whether a cognate is identical or nonidentical, has been found to play a role in processing with identical cognates being more prone to cognate effects than nonidentical cognates (
Dijkstra et al. 2010;
Duyck et al. 2007;
Mulder et al. 2015;
Vanlangendonck et al. 2020).
Despite the extensive research on cognate effects using lexical decision tasks, some questions remain largely unanswered. One such question is how foreign language knowledge influences native language performance since most studies tend to focus on cognate processing in L2 tasks. An exception is
Van Hell and Dijkstra’s (
2002) study using L1 lexical decision tasks to test trilinguals speaking Dutch (L1), English (L2), and French (L3). This study found L1 words that had corresponding L2 cognates to be processed faster than noncognates. Notably, L1 words that had corresponding L3 cognates were processed faster by high-proficiency L3 speakers only, thereby indicating that a certain level of language proficiency is required to see an effect of the nontarget language on L1 processing. By presenting words in the dominant language to naïve participants, Van Hell and Dijkstra’s study thus supports the hypothesis that lexical access is profoundly language nonselective. On the other hand, a study like
De Groot et al. (
2002), which compared performance on L1 and L2 lexical decision tasks in a between-subjects design controlling 18 different variables, only found cognate status to affect L2 lexical decision, not L1 lexical decision. Notably, however, the bilinguals tested in this experiment appear to be less balanced than the trilinguals tested by
Van Hell and Dijkstra (
2002).
The overarching goal of this paper is to add to the literature on how cognates are represented in the bilingual lexicon and accessed during word recognition. This is done by reporting results from a study using visual lexical decision tasks with the somewhat under-researched language pair Danish-English. Whereas findings from studies investigating language pairs like Dutch-English or Spanish-English may hypothetically be extended to other language pairs, this cannot necessarily be assumed a priori, thereby meriting the continued study of cognate effects. More importantly, this study benefits from applying a within-subjects research design testing the processing of cognates in L1 and L2 tasks as well as in pure and mixed language conditions (respectively including words from one or both languages in the lexical decision tasks). A within-subjects design examining performance in both languages is of interest for two reasons. First, it makes it possible to control extraneous participant variables and thereby reduce noise in the data. Second, the simultaneous testing of performance on both L1 and L2 tasks allows for more informed interpretations of the data. This study thus distinguishes itself from other studies on cognate processing, which tend to only test performance on L2 tasks or employ a between-subjects design to test performance on both L1 and L2 tasks.
2. The BIA+ Model as an Architecture of the Bilingual Word Recognition System
The connectionist Bilingual Interactive Activation + Model (BIA+;
Dijkstra and Van Heuven 2002) remains among the most influential models of word recognition. The model posits that the visual presentation of a word to a bilingual reader will activate stored orthographic representations corresponding to the input, which in turn activate associated semantic and phonological representations in a cyclical activation and inhibition flow. The language membership of the orthographic representations is likewise activated, but building on findings from numerous studies (
De Groot et al. 2000;
Dijkstra et al. 1998,
1999,
2000b), the activation of language membership is believed to happen at a relatively late stage in lexical access. As a result, language membership is believed to only impose minor selection constraints on word recognition compared to orthography, phonology, and semantics. Once the input has been deciphered, information is sent from the word identification system to a task/decision system that specifies a task schema required to successfully complete a given task.
Implicit in the BIA+ model is the presumption that lexical representations have differing resting level activations, that is, different starting points for reaching the recognition threshold. The resting level activation of an item is contingent on multiple factors such as recency of use and subjective frequency. As a result, a lexical candidate with a high resting level activation may be activated quicker than other candidates that are otherwise equally similar to the visual input (
Dijkstra 2005). The inclusion of resting level activations as a parameter influencing word recognition is thus crucial in explaining differences in L1 and L2 processing. Since bilinguals are typically less exposed to L2 representations, potential asymmetrical processing dominated by the L1 is explained by the slower activation of L2 lexical representations (
Dijkstra and Van Heuven 2002). Consequently, visual word recognition is based on the parallel activation of lexical candidates depending not only on their similarity to the input string but also on the resting level activations of the individual candidates.
Language-ambiguous words have traditionally posed issues for models of the bilingual word recognition system due to the models’ inability to account for processing differences of language-ambiguous words compared to language-specific words. However, by assigning two distinct lexical representations to language-ambiguous words, the BIA+ model can simulate the diverging findings—facilitatory, null, or inhibitory effects—of studies using language-ambiguous words under different conditions. Empirical evidence for both interlingual homographs (e.g.,
De Groot et al. 2000;
Dijkstra et al. 1998;
Thomas and Allport 2000) and cognates (e.g.,
Dijkstra et al. 2010;
Vanlangendonck et al. 2020) supports the hypothesis of two distinct lexical representations in an integrated lexicon. Consequently, cognates are represented in two lexical representations—one for each of a bilingual’s languages—with (near)identical orthography and shared semantic information. When processing a cognate word in a pure language condition, both orthographic representations are simultaneously activated and send converging activation to a shared semantic representation, thereby leading to strong activation and the commonly found cognate facilitation effect (
Dijkstra et al. 2019).
How, then, can the BIA+ model be used to explain the cognate inhibition effects often found in mixed language conditions? The task/decision system of the BIA+ model is of vital importance in explaining such effects. Although
Dijkstra and Van Heuven (
2002) provide no detailed account of the task/decision system, later accounts by Dijkstra and colleagues shed further light on the path from word identification to decision with the notion of stimulus–response binding playing a crucial role (
Dijkstra 2005;
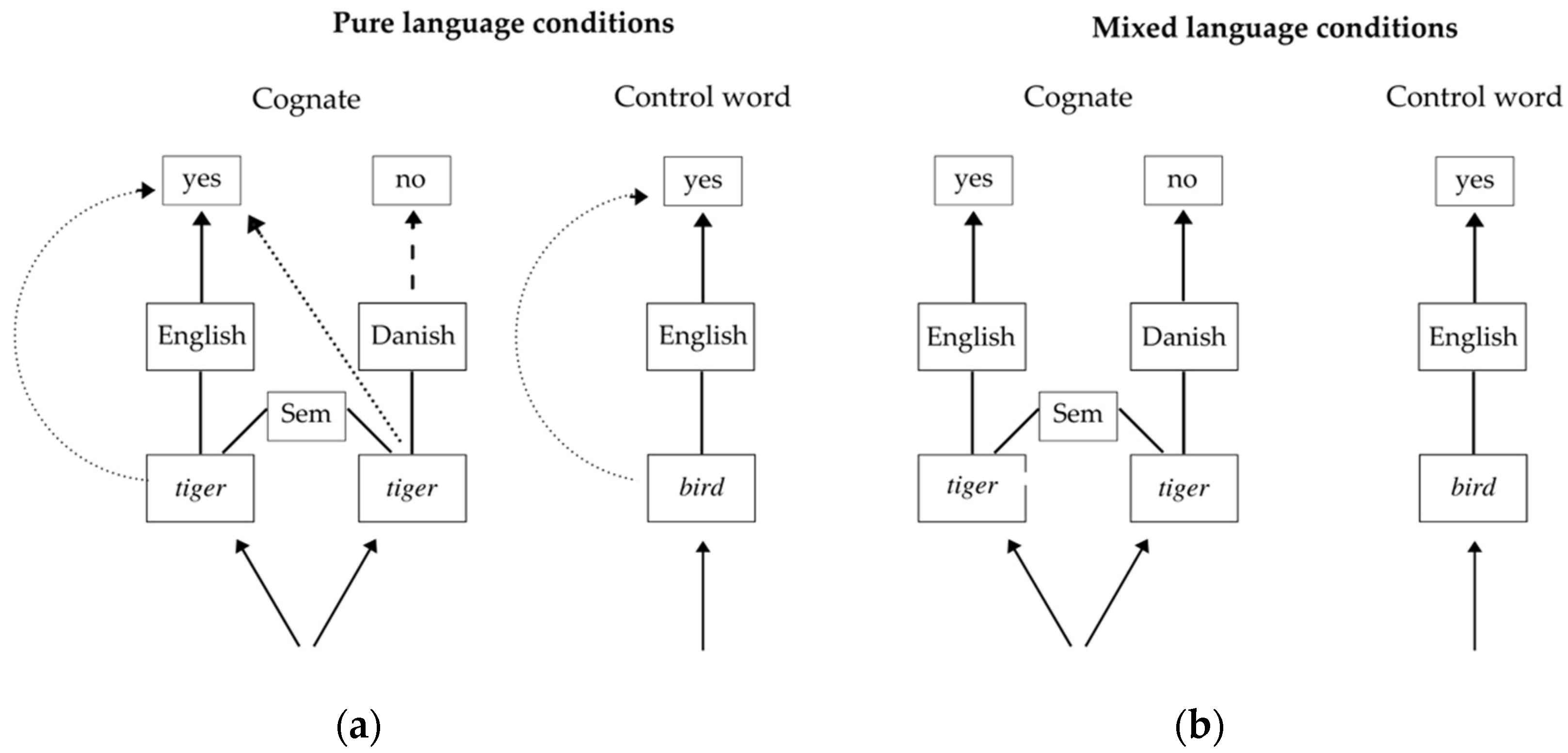
Vanlangendonck et al. 2020). Stimulus–response binding refers to the relationship between an identified word and its related response, thereby being contingent on task demands. See
Figure 1, which illustrates the process from word identification to lexical decision for cognates and control words in pure and mixed language conditions. The lexical decision tasks illustrated require participants to distinguish English words (YES-response) from non-English words (NO-response).
In an English lexical decision task consisting solely of English words and nonwords (a pure language condition), English words are bound to the YES-response, and nonwords are bound to the NO-response. However, for a Danish-English bilingual, different routes from word identification to response are available depending on the type of stimuli. Language-specific control words (see
Figure 1a) either follow a route from the English lexical representation
bird via an English language membership check to the YES-response or take a shortcut (indicated by a dotted line) from the lexical representation to the YES-response. Such shortcuts from the lexical representation to the YES-response allow responses based solely on activated orthography without a language membership check. In other words, participants may respond to the presence of a word rather than an
English word because language membership checks are not necessary to perform the task at hand (
Dijkstra 2005).
Cognates in a pure language condition (see
Figure 1a) may follow the same routes as control words. However, given that both English and Danish orthographic representations are activated due to language nonselective access, an additional shortcut from the Danish lexical representation to the YES-response is likewise available. Furthermore, the shared semantic representation across cognates may give rise to additional facilitatory effects (
Vanlangendonck et al. 2020). While cognates may in principle induce a NO-response resulting from a Danish reading of
tiger (indicated by dashed lines), this is unlikely as Danish words occur only infrequently and are generally irrelevant for the task. Phrased differently, Danish lexical representations are only weakly bound to the NO-response in contrast to the task-induced strong binding between nonwords and the NO-response.
While pure language conditions often reveal facilitatory effects for cognates, bilinguals’ processing of cognates tends to be inhibited in mixed language conditions such as an English lexical decision task interspersed with Danish words. In this task, English words are still bound to the YES-response, but this time both nonwords and Danish words are bound to the NO-response. This is because the task remains the same as in the pure language condition: To identify English words with a YES-response and all non-English words with a NO-response. Responses in mixed language conditions therefore depend on language membership, thereby eliminating any shortcuts circumventing language membership checks. Although participant performance would benefit from consciously “turning off” the Danish language and solely focus on English lexical representations given the task demands, the robust findings of inhibitory effects in the literature indicate that this is not possible. In other words, it is impossible to suppress parallel bottom-up activation of lexical candidates from both English and Danish, thus implying that nonlinguistic context like task demands does not impact word recognition itself but rather a later stage in the lexical decision process. Such an observation lends further support to the language nonselective hypothesis (
Dijkstra and Van Heuven 2002).
Zooming in on the processing of different stimulus types, the impact of task demands becomes clear. While target language control words (see
Figure 1b) such as
bird may be slightly affected by the lack of shortcuts with an increase in reaction times as a result, the path from word identification to response remains otherwise uninterrupted. In contrast, the introduction of nontarget language control words reinforces the binding between Danish words and the NO-response and therefore complicates the identification of cognates (
Vanlangendonck et al. 2020; see
Figure 1b). When encountering a cognate, the English and Danish lexical representations activate their corresponding language memberships, contributing to the task/decision system receiving conflicting information. As a result, mixed language conditions often produce longer reaction times for cognates, which reflect the response competition arising due to converging formal and semantic information from English and Danish lexical representations.
Based on the predictions of the BIA+ model and findings from previous studies, two sets of hypotheses regarding the influence of task demands on cognate processing were empirically tested in this study. The first hypothesis (H1) predicts that the processing of cognates will be facilitated in pure language conditions compared to the processing of control words. Conversely, the second hypothesis (H2) predicts that the processing of cognates will be inhibited in mixed language conditions compared to the processing of control words. The alternative hypotheses of H1 and H2 predict no significant differences in the processing of cognates compared to control words. While the hypotheses tested are not novel, this study distinguishes itself by employing a within-subjects research design to test differences between L1 and L2 tasks. The ability to compare participants’ L1 and L2 performance makes it possible to implicitly address the role of language proficiency on cognate processing, a somewhat uncharted territory given that most previous research has had a tendency to focus on cognate processing in L2 tasks. While knowledge of the L1′s influence on the L2 is valuable, language transfer is likely a bidirectional phenomenon, thus warranting increased attention to the L2′s influence on the L1.
3. Method
Two Danish lexical decision tasks (L1_pure and L1_mixed) and two English lexical decision tasks (L2_pure and L2_mixed) were used to test the hypotheses. Danish-English bilinguals (with Danish as L1 and English as L2) were randomly assigned one of two experimental conditions; either they first performed the two Danish lexical decision tasks followed by the two English lexical decision tasks, or vice versa. In L1_pure and L2_pure, half of the stimuli were target language-derived nonwords requiring a NO-response, while the other half of the stimuli requiring a YES-response consisted of cognates and target language control words. In L1_mixed and L2_mixed, half of the nonwords were replaced by nontarget language control words. Regardless of whether the first two tasks were in Danish or English, participants always encountered the pure stimulus list first (L1_pure or L2_pure) followed by the mixed stimulus list (L1_mixed or L1_mixed).
3.1. Participants
A total of 26 Danish-English bilingual students living in an L1 dominant environment volunteered to participate in the experiment. All participants were right-handed and had normal or corrected-to-normal vision. Given that all data from two participants were subsequently excluded due to exceptionally high overall error rates on the four tasks, the study will focus solely on the characteristics of and data from the 24 remaining participants.
Of these 24 participants, 16 women and 8 men with a mean age of 24.7 (standard deviation = 2.6) participated. Ten participants were undergraduate students and fourteen were graduate students. All participants reported high average exposure to English and had received at least 8 years of formal instruction in English, resulting in all but one evaluating themselves as fluent in the language. While the participants formed a rather heterogeneous group in terms of age, study program, and linguistic background, they may all be considered upper-intermediate to advanced users of English due to their extensive formal instruction in the language. This presumption is supported by participants’ generally high scores (mean = 87.4, standard deviation = 9.5) on the Lexical Test for Advanced Learners of English (LexTALE;
Lemhöfer and Broersma 2012). In comparison, Lemhöfer and Broersma reported considerably lower scores for a comparable group of Dutch students (mean = 75.5, standard deviation = 12.5). The high LexTALE scores of the participants in this study further correlate with participants’ high self-ratings of their L2 proficiency: ability to read English, mean = 8.33/10; ability to speak English: mean = 8.21; ability to understand spoken English: mean = 8.75.
3.2. Stimuli
The stimulus set consisted of 84 nonwords and 140 Danish-English translation pairs, all of which were nouns. Danish nonwords were created by replacing, deleting, or adding one letter in an existing Danish noun with one to three syllables and a length of four to six characters. English nonwords were drawn from
Dijkstra et al. (
2010) and
Vanlangendonck et al. (
2020), who employed the same method in creating nonwords. Care was taken to ensure that none of the Danish nonwords were letter strings that formed a valid word in English, and vice versa.
Translation pairs belonged to one of two categories: cognates or target/nontarget language control words. Inspiration for the translation pairs was found in the Dutch-English stimuli used by
Dijkstra et al. (
2010) and
Vanlangendonck et al. (
2020) as well as in a list of the 1000 most frequent singular nouns in English generated from the Corpus of Contemporary American English (COCA;
Davies 2008;
The COCA Corpus 2020). Several factors were considered when selecting the translation pairs.
In terms of orthographic considerations, the first exclusion criterion for a translation pair was the presence of the letters
æ,
ø, or
å in the Danish word to avoid sublexical language membership information affecting word recognition (
Van Kesteren et al. 2012). Second, only words with a range of one to three syllables and three to seven letters were kept based on the findings by
New et al. (
2006) and
De Groot et al. (
2002), which highlights the necessity of such control. Lastly, the Levenshtein distance was employed to quantify the degree of cross-linguistic orthographic overlap between words in a translation pair (see
Schepens et al. (
2012) on the use of the Levenshtein distance to reliably define bilingual orthographic similarity). In this experiment, target/nontarget language control word translation pairs had a Levenshtein distance of 4 or higher. Cognate translation pairs were either identical cognates (Levenshtein distance of 0) or nonidentical cognates (Levenshtein distance of 1 or 2). Danish has many more nonidentical cognates than identical cognates, and a mix of the two types was thus used to obtain a sufficiently large stimulus set.
To avoid unbalanced activation of distinct semantic representations stemming from polysemy and lexical ambiguity, the semantics of each word in a translation pair was carefully controlled by consulting dictionaries (
Gyldendal n.d.;
Oxford English Dictionary n.d.). This resulted in the removal of all interlingual and intralingual homographs except for homographs that were semantically related but belonged to different parts of speech. Finally, word and lemma
1 frequencies were controlled using COCA and the largest corpus of the Danish language KORPUS-DK (
Asmussen 2012–,
2015,
2020), since frequency has consistently been found to have considerable impact on L1 and L2 lexical decision tasks (
Connine et al. 1990;
Duyck et al. 2008;
Forster and Chambers 1973;
Rubenstein et al. 1970;
Scarborough et al. 1977). While it is impossible to make definitive claims based on the frequencies found in the two corpora due to differences in corpus compilations and search options, they nevertheless provide reasonably valid grounds for comparison. Within-language
t-tests revealed no differences in word or lemma frequencies between the selected cognates and target language control words. Cross-language
t-tests were not deemed feasible given the different corpus compilations.
Following the identification of the stimuli, translation pairs and nonwords were allocated to the four tasks based on word length, Levenshtein distance, and word/lemma frequencies. Crucially, each task had an equal number of identical and nonidentical cognates. See
Table 1 for examples of translation pairs and information about stimuli characteristics in each of the categories. Note that participants were only exposed to one of the two words in a translation pair to avoid priming effects. The entire stimulus set can be found in the
Supplementary Materials. Finally, the lists of stimuli were randomized so that no two participants were exposed to the same order of stimuli.
3.3. Procedure
The lexical decision tasks were run on a computer using the software E-Prime 3.0 (
Psychology Software Tools 2016). Participants were seated in a normally lit room approximately 60 cm from the computer screen. YES-responses were given by pressing “K” on the keyboard with the right index finger, NO-responses were given by pressing “D” on the keyboard with the left index finger. The keys “K” and “D” were chosen due to their central position on the keyboard, thereby ensuring optimal dexterity and ergonomic positioning of the hands with the keys still being sufficiently spaced to avoid erroneous responses.
At the start of each experimental session, participants gave written informed consent. Subsequently, they were given general written instructions in Danish asking them to indicate as quickly as possible whether a presented letter string was a word in the target language (Danish in L1_pure and L1_mixed, English in L2_pure and L2_mixed) by pressing a button. Each task was preceded by specific instructions in the target language of the task as well as eight practice trials reflecting the proportion of stimuli in the task at hand. Participants were given supplementary oral instructions in Danish as needed, e.g., to ensure participant awareness of some words existing in both Danish and English. The decision to inform participants of the presence of language-ambiguous words rested on the findings by
Dijkstra et al. (
2000a), who found no significant effects of instruction-based expectancies in lexical decision tasks involving interlingual homographs.
Each of the four tasks consisted of 56 trials. Every trial began with the presentation of a fixation cross for 500 ms to guide participants’ attention to the center of the screen. After an additional 500 ms with a blank screen, the stimulus was presented in black 18-point Consolas font in the center of the screen. The stimulus remained visible until the participant responded, or until the maximum response time of 2500 ms was reached. Intertrial intervals were 1000 ms and consisted of a blank screen. Participants’ accuracy and reaction times in ms were recorded by the computer.
To minimize confounding effects like fatigue, task order was counterbalanced with participants being randomly assigned to one of the two experimental conditions; either they first completed L1_pure and L1_mixed followed by L2_pure and L2_mixed, or they began by completing L2_pure and L2_mixed followed by L1_pure and L1_mixed. Regardless of task order, a short break was included after the first two tasks during which the participant was engaged in a few minutes of light conversation with the experimenter to divert their attention from the previous tasks. Each of the four lexical decision tasks took approximately 5 min.
Following the completion of all four tasks, participants filled in a modified pencil-and-paper version of the Language Experience and Proficiency Questionnaire (LEAP-Q;
Marian et al. 2007) in English with information about their language background and self-reported language proficiencies. Finally, all participants completed the LexTALE online to obtain an objective assessment of their English vocabulary knowledge. Given that some participants finished with an English lexical decision task and others with a Danish lexical decision task, the rationale behind choosing an English version of the LEAP-Q was to somewhat equalize participants’ resting level activations for English lexical representations prior to completing the LexTALE. The entire experiment (i.e., the four lexical decision tasks, the LEAP-Q, and the LexTALE) took 30–40 min.
3.4. Data Preparation and Statistical Analysis
As noted in
Section 3.1, an inspection of participant error rates revealed two participants with very high overall error rates across the four lexical decision tasks (respectively 19% and 47%), resulting in the exclusion of all data from these two participants. Of the remaining 24 participants, an additional 2 participants indicated halfway through the experiment that they had misunderstood their second task. A comparison of the participants’ error rates and reaction times in the given tasks with their performance on the other three tasks supported this, and data from the two tasks in question were excluded. Furthermore, two stimulus items—the nonword
trouse in L2_pure and the identical cognate
grin in L2_mixed—elicited error rates substantially higher than other items (respectively error rates of 50% and 39%). Responses to these two words were therefore removed. Next, outliers (responses < 300 ms; responses = 2500 ms) as well as datapoints more than three standard deviations from an item’s or participant’s mean reaction time were removed to further refine the dataset. In total, the data loss amounted to 5.34%. However, since responses reaching 2500 ms, i.e., the maximum response time, may be considered errors, they are included as incorrect responses in the analysis.
The mean accuracy rate was 97.07% across the four tasks. Because incorrect responses made up less than 3% of the dataset with the majority being given to nonwords, incorrect responses will only be considered sparingly. See
Table 2 for mean reaction times with standard deviations and error rates for each item category across the four tasks.
Analyses of reaction time data were conducted in the R statistical computing environment (
R Core Team 2020) using the lmerTest package (
Kuznetsova et al. 2017) to compute two linear mixed-effects regression (LMER) models, one model for each language. Since the use of LMER models presumes normally distributed data, reaction times were logarithmically transformed to reduce any skewing in their distribution (
Baayen 2009). The fixed effects were item category (cognate or target language control) and condition (pure or mixed language condition). Following
Barr et al.’s (
2013) “keep it maximal approach”, the models included by-item and by-participant random intercepts as well as by-participant random slopes for fixed effects and interactions. All categorical predictors were sum-coded. Results of the two LMER models are reported in
Table 3 and
Table 4. The relevant contrasts were evaluated using the emmeans package (
Lenth 2022) in R, and
p-values were adjusted with Holm’s method. Results of the comparison of cognate vs. cognate across pure and mixed language conditions are reported in
Table 5, and results of the comparison of cognate vs. target language control words within the different tasks are reported in
Table 6.
5. Discussion
5.1. Cognate Processing in L1 Tasks
The results do not support H1 and H2 for the L1 tasks as no significant cognate effects were found neither for the combined participant sample nor for the low- or high-proficiency groups. The null results preclude definitive conclusions regarding the L1 pure and mixed language conditions, but a few comments are nevertheless in order.
In the L1 pure language condition, mean reaction times to cognates and target language control words were almost identical across the combined participant sample as well as within the low- and high-proficiency groups in the post-hoc analysis. The null effects in this task align with those of
De Groot et al. (
2002) but not those in
Van Hell and Dijkstra’s (
2002) study of trilinguals. Because participants in the study by De Groot et al. are described as unbalanced bilinguals, a comparison will only be made to Van Hell and Dijkstra’s study.
As mentioned in the introduction, Van Hell and Dijkstra found foreign language knowledge to influence native language performance when participants had a certain level of proficiency in the foreign language. Thus, trilinguals with comparable levels of English (L2) and French (L3) performed better on words that were cognates in either language, whereas trilinguals with lower L3 proficiencies only exhibited cognate facilitation effects for L2 cognates. The lack of cognate facilitation effects in the L1 pure language condition in the present experiment could therefore be interpreted as participants not having sufficiently high L2 proficiencies for cognate effects to surface. However, such a conclusion seems unwarranted for at least two reasons. First, participants in the present study and those in the study by Van Hell and Dijkstra have comparable histories of formal instruction in English. Second, participants in the present study have high LexTALE scores and high self-ratings of their L2 proficiency. Unfortunately, a direct comparison with the proficiency tests used by Van Hell and Dijkstra is not possible as they utilized lexical decision tasks constructed for that particular study. Nothing thus points to the lack of cognate effects in the L1 pure language condition being rooted in participants having too low L2 proficiencies. Add to this the prominent role English has acquired on the Internet and social media since the publication of Van Hell and Dijkstra’s study, and it is even harder to imagine the participants of this study having markedly lower L2 proficiencies given the sheer amount of possible exposure to English.
Although nonsignificant, the L1 mixed language condition did induce longer mean reaction times in the direction predicted by H2 with cognates taking longer to process than target language control words. This was the case for the combined participant sample as well as for both low- and high-proficiency groups. Native language performance thus seemed to be more impressionable to foreign language knowledge in the L1 mixed language condition than in the L1 pure language condition. This is not surprising since the task in the mixed language condition is harder than in the pure language condition. Whereas the nontarget language in the pure language condition had only been activated indirectly through the presentation of cognates and hence only weakly bound to a NO-response, the nontarget language occurred more frequently in the mixed language condition. This time, however, it was strongly bound to a NO-response due to task demands, resulting in increased response competition. The L1 mixed language condition thus differed from the L1 pure language condition in that the mere detection of a word was not sufficient to make a response; rather, the language membership of a lexical representation had to be retrieved to determine whether a YES- or NO-response was appropriate. To the best of the present author’s knowledge, no studies involving tasks comparable to the L1 mixed language condition exist, thus making it impossible to contrast it with existing research.
5.2. Cognate Processing in L2 Tasks
H1 and H2 received more support from the results of the L2 tasks. Beginning with the L2 mixed language condition, increased response competition due to the introduction of nontarget language control words is reflected in overall longer mean reaction times and—in line with the prediction of H2—significant inhibition effects for cognates compared to target language control words. Notably, these cognate inhibition effects were found for the combined participant sample as well as for the low- and high-proficiency groups. As predicted by the BIA+ model (cf.
Figure 1), the findings of the L2 mixed language condition may be ascribed to the task/decision system receiving conflicting information from the word identification system through the concurrent activation of English and Danish lexical representations for cognates. The results of the L2 mixed language condition resemble the findings of
Poort and Rodd (
2017) and
Vanlangendonck et al. (
2020), although the inhibition effects found in the present experiment were markedly higher.
H1 received partial support from the results of the present study. When considering the entire participant sample, only near-significant cognate facilitation effects were found in the L2 pure language condition, thus diverging from the findings of previous studies (
Dijkstra et al. 1999,
2010;
Lemhöfer and Dijkstra 2004;
Mulder et al. 2015;
Poort and Rodd 2017;
Vanlangendonck et al. 2020). However, an exploratory analysis dividing participants into two groups revealed differential cognate processing originating in different L2 proficiencies; significant cognate facilitation effects surfaced for the low-proficiency group but remained absent for the high-proficiency group. Cognate processing in the L2 pure language condition was thus susceptible to differences in L2 proficiency.
The observed differences in cognate facilitation effects in the L2 pure language condition can be accounted for within the BIA+ model. The cognate facilitation effects found for the low-proficiency group may be explained by the maximal co-activation of L1 and L2 orthographic representations, resulting in cognate lexical representations reaching the recognition threshold faster than lexical representations for target language control words. In contrast, the high-proficiency group’s lack of significant cognate facilitation effects suggests that the higher L2 proficiencies have minimized the gap between L1 and L2 resting level activations and, by implication, the potential to benefit from converging activation of L1 and L2 lexical representations in L2 pure language conditions.
Summing up, L2 proficiency modulated participant performance in the L2 pure language condition but not in the L2 mixed language condition. Such asymmetry not only underscores the importance of task demands when investigating cognate processing, it also suggests that highly proficient bilinguals may reach a ceiling effect when it comes to cognate processing in certain tasks.
5.3. Bottom-Up and Top-Down Influences
The tenet of the BIA+ model is the hypothesis of language nonselective access, that is, bilingual word recognition is believed to automatically engage both languages. As such, any differential processing of language ambiguous words like cognates is believed to be fueled by converging bottom-up input rather than top-down influences like global language activation. Various lines of research have found evidence for and against the exclusively bottom-up predictions of the BIA+ model. The following will briefly consider the present study in light of two such strands of research.
2One approach to varying global language activation has been to modify the stimulus list composition, e.g., by systematically manipulating the proportion of identical and nonidentical cognates (e.g.,
Arana et al. 2022;
Comesaña et al. 2015). Arana et al. conducted four lexical decision tasks in L2 pure language conditions with varying ratios of identical and nonidentical cognates (50–50, 25–75, 12–88, and 0–100) and report decreasing cognate facilitation effects that correlate with a decrease in the number of identical cognates. The authors ascribe the varying degrees of cognate facilitation effects in the four lexical decision tasks to differences in lexical representations; while identical cognates have shared orthographic representations, nonidentical cognates have distinct orthographic representations competing for selection. As a result, the authors conclude that cognate processing is not exclusively a bottom-up process but may be modulated by overall stimulus list composition. However,
Van Hell and Dijkstra’s (
2002) study on trilinguals provides evidence that cognate facilitation effects may surface even when the stimulus list is largely comprised of nonidentical cognates (respectively 85% and 75% of the L1 words were nonidentical cognates with the L2 and the L3). With an equal number of identical and nonidentical cognates in all four tasks of the present study, it does not seem viable to attribute the observed pattern of cognate effects to top-down influences rooted in stimulus list composition.
A second approach to varying global language activation is related to the “language mode” established in the experimental session (see
Wu and Thierry (
2010) for a review). For example,
Elston-Güttler et al. (
2005) investigated how the processing of German-English homographs in L2 sentences was affected by pre-experimental exposure to a 20-min film narrated in either German or English. The authors found that pre-experimental L2 priming eliminated measurable influences of the L1 on the L2, thereby suggesting that the English film had boosted L2 resting level activations. In the present study, the order of L1 and L2 tasks was counterbalanced across participants to avoid effects of fatigue, thus posing a potential risk of asymmetrical task order effects on cognate processing. More specifically, participants performing the L2 tasks first may have had boosted L2 resting level activations that affected their performance on the subsequent L1 tasks. Any such effect would likely be unidirectional (L2 affecting L1) rather than bidirectional given that participants lived in an L1-dominant environment. However, post-hoc analyses including task order as a fixed effect in the LMER models did not reveal reliable effects of task order. This does not necessarily counter the findings of Elston-Güttler et al. but at least suggests that a certain amount of L2 priming is needed to adequately boost L2 resting level activations (cp. watching an L2-narrated 20-min film vs. performing two lexical decision tasks with a total of 56 L2 words).
In sum, the pattern of cognate effects observed in this study does not seem to depend on global language activation induced by neither stimulus list composition nor an experimentally induced language mode. Rather, the most convincing account of the results relies on bottom-up processing as advocated by the BIA+ model with L2 language proficiency—that is, differences in relative L1 and L2 resting level activations—as a determining factor.
5.4. Limitations and Future Research
While this study differentiates itself from other studies on cognate processing by investigating performance on both L1 and L2 tasks, it is nevertheless marked by some limitations. One such limitation is inherent in the choice of experimental design. The within-subjects design increases the validity of any cross-language performance comparisons, but it also prevents the inclusion of both words of a translation pair in the stimulus set due to the risk of undesirable priming effects. In principle, participants may thus have had markedly different subjective L1 and L2 resting level activations for the lexical items investigated, which would not have been captured by the present results.
Another limitation of the study pertains to the stimuli selection. Studies on bilingual language processing often rely on existing databases to select stimuli matched on various lexical properties such as word frequency and phonemes. However, since no such database of the Danish language exists, all stimuli were selected manually, which necessarily makes the selection of stimuli more prone to uncontrolled variables. Additionally, lexical properties that have elsewhere been proven to influence word recognition such as phonological overlap (
Dijkstra et al. 1999;
Lemhöfer and Dijkstra 2004) and orthographic neighborhoods (
Van Heuven et al. 1998) were not controlled. Thus, one of the strengths of the study—that it surveys the relatively under-researched language pair English–Danish—at the same time presents obstacles for the generalizability of the results.
Other future avenues of research include going beyond this particular stimulus type and contrasting results with other subject populations. In terms of stimulus type, most studies have hitherto focused on the processing of nouns, and research on cognate effects for verbs or adjectives remains scarce (notable exceptions include
Balling (
2013),
Bultena et al. (
2013,
2014), and
Van Assche et al. (
2013)). It cannot be assumed a priori that cognate effects extend to other parts of speech; in fact,
Bultena et al. (
2014) found cognate effects to be smaller for verbs than for nouns. Similarly, the results of the present study emphasize the need to contrast various subject populations with different L2 backgrounds.
6. Conclusions
This study had Danish-English bilinguals with upper-intermediate to advanced L2 proficiencies perform four lexical decision tasks in which the target language (L1 or L2) and stimulus composition (pure or mixed language condition) were varied. Cognate facilitation effects were predicted to surface in the pure language conditions due to converging activation of formal and semantic information from the two languages while increased response competition in the mixed language conditions were predicted to result in cognate inhibition effects. Curiously, only the L2 mixed language condition produced significant cognate effects when considering the entire participant sample. A post-hoc analysis dividing participants into two groups based on L2 proficiency additionally found significant cognate effects in the L2 pure language condition for the group with lower L2 proficiency.
The findings of the L2 tasks were interpreted within the BIA+ model, and the observed differences between the low- and high-proficiency groups in the L2 pure language condition were argued to reflect variations in participants’ relative L1 and L2 resting level activations. Altogether, the significant cognate effects of the L2 tasks thus support the hypothesis of language nonselective access during bilingual word recognition. If lexical access was language-specific, cognates should not be processed differently than control words under any circumstances. At the same time, the nature of the results stresses the need for nuanced interpretations that consider the impact of task demands and L2 proficiency on L2 cognate processing.
The absence of significant effects in the L1 tasks was remarkable. Given the small number of comparable studies investigating the impact of a foreign language on native language performance, future studies ought to address this gap in the literature. Any attempt to characterize the bilingual lexicon and word recognition system is necessarily untenable if it relies primarily on conclusions regarding just one of a bilingual’s two languages.



{kind=link}