
A Longitudinal Study of Speech Acoustics in Older French Females: Analysis of the Filler Particle euh across Utterance Positions


Abstract
1. Introduction
1.1. Filler Particles in Connected Speech
1.1.1. Definition
1.1.2. Filler Particles in Discourse: Frequency and Location
1.1.3. Acoustic Characteristics of Filler Particles
1.2. Aging Effects on Speech Anatomy, Physiology, and Acoustics
1.2.1. Respiratory System
1.2.2. Upper Vocal Tract
1.2.3. Larynx
1.3. Research Questions and Predictions
- No increase in euh usage with age.
- Lower f0 in utterance-final positions.
- Lower F1 with age, but no effect of position.
- Greater noise and steeper spectral tilt with aging; greater aperiodicity and flatter spectral tilt in utterance-final position.
2. Materials and Methods
2.1. Database
2.2. Speakers
2.3. Instrumentation
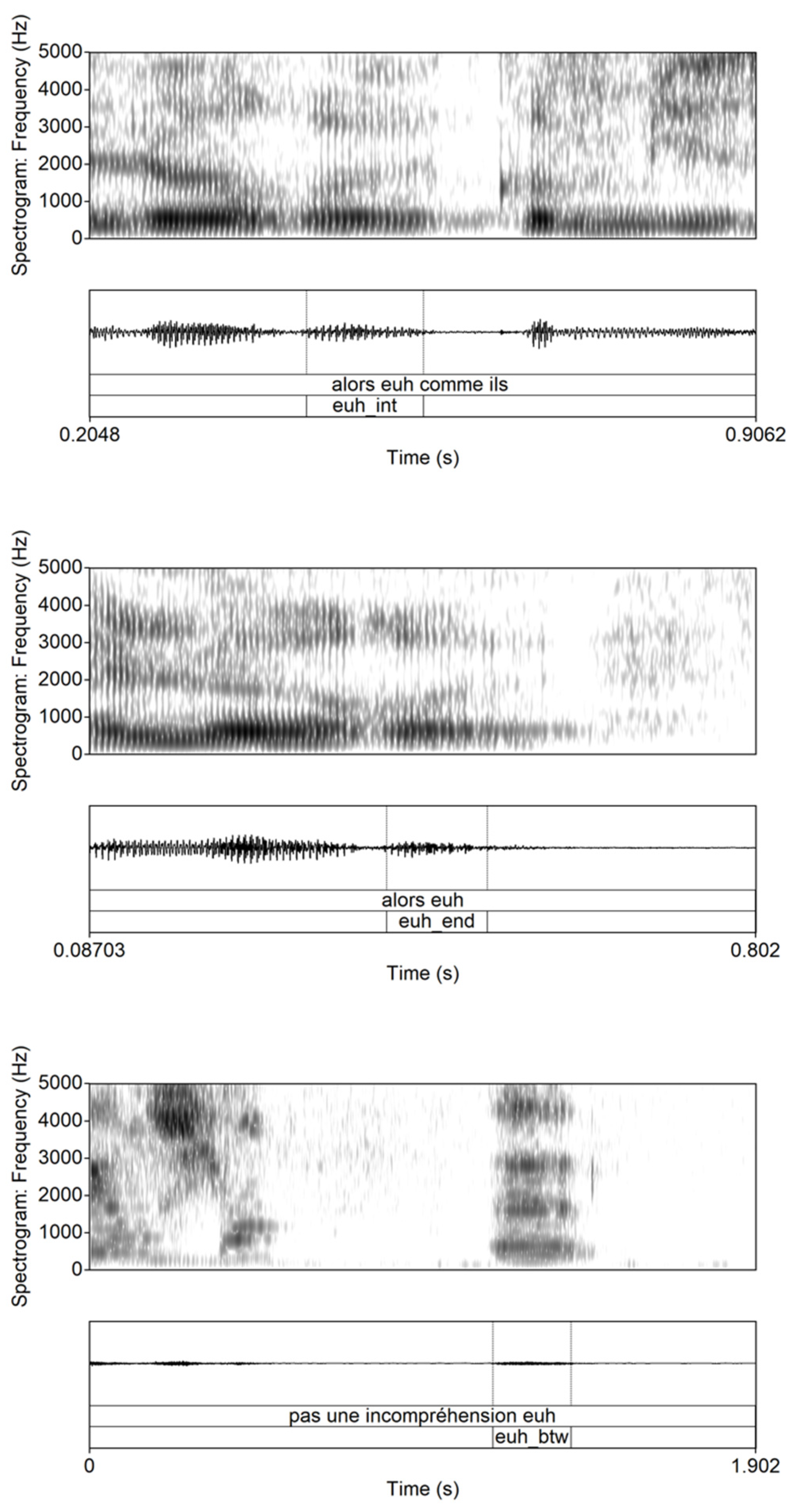
2.4. Utterances Analyzed
2.5. Processing
2.6. Measures
2.7. Statistics and Exclusions
3. Results
3.1. Frequency of euh
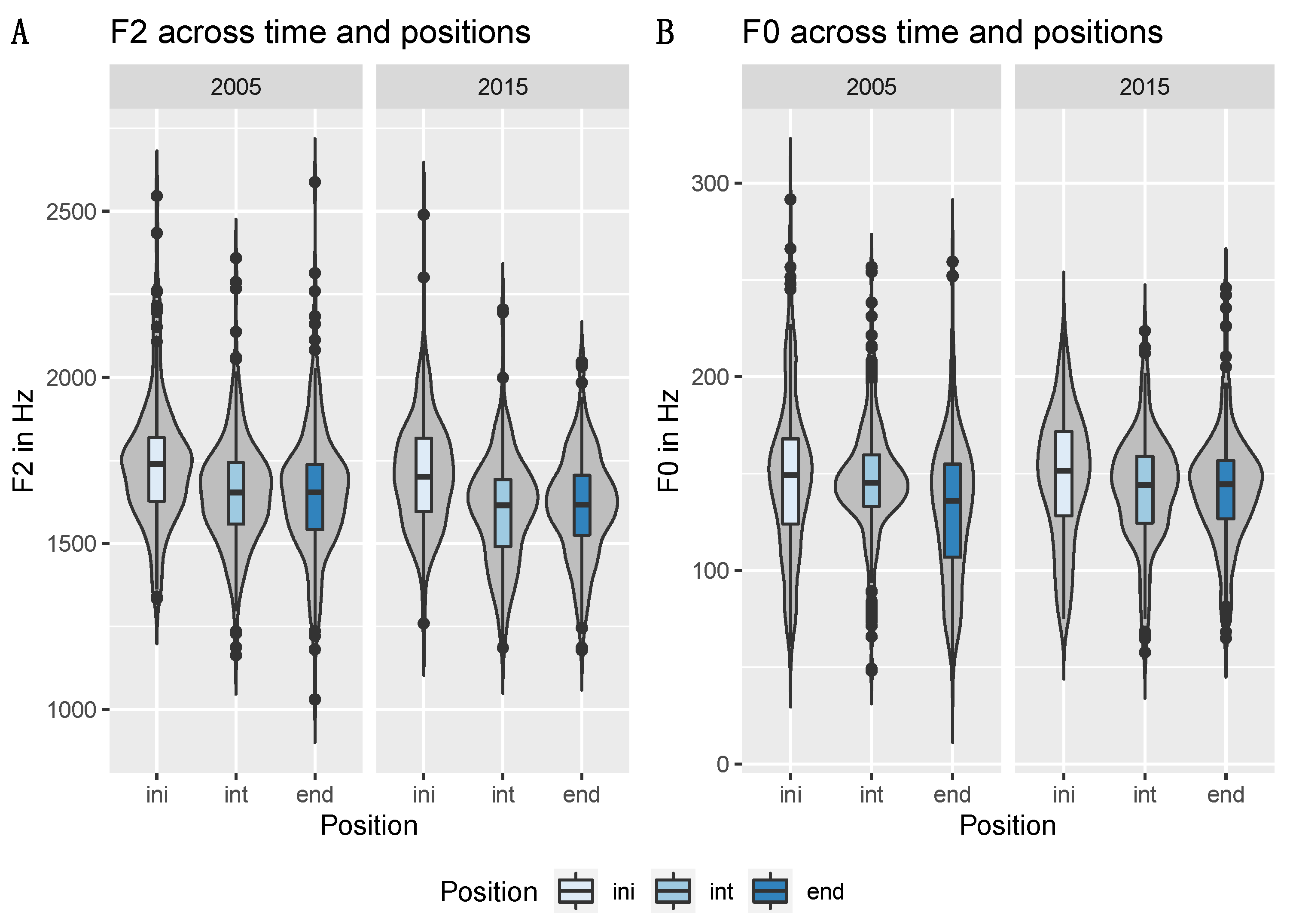
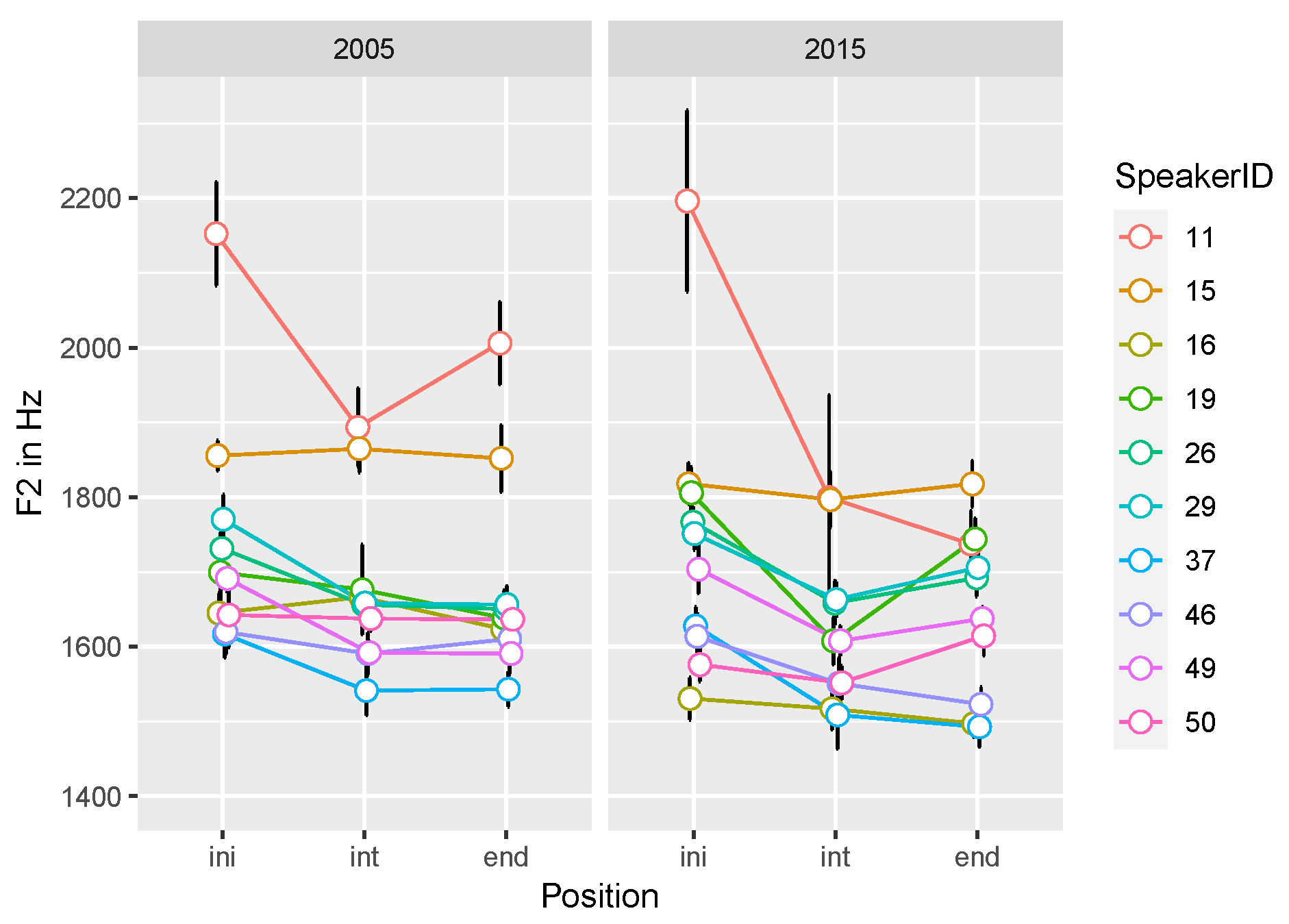
3.2. Formants
3.3. Fundamental Frequency
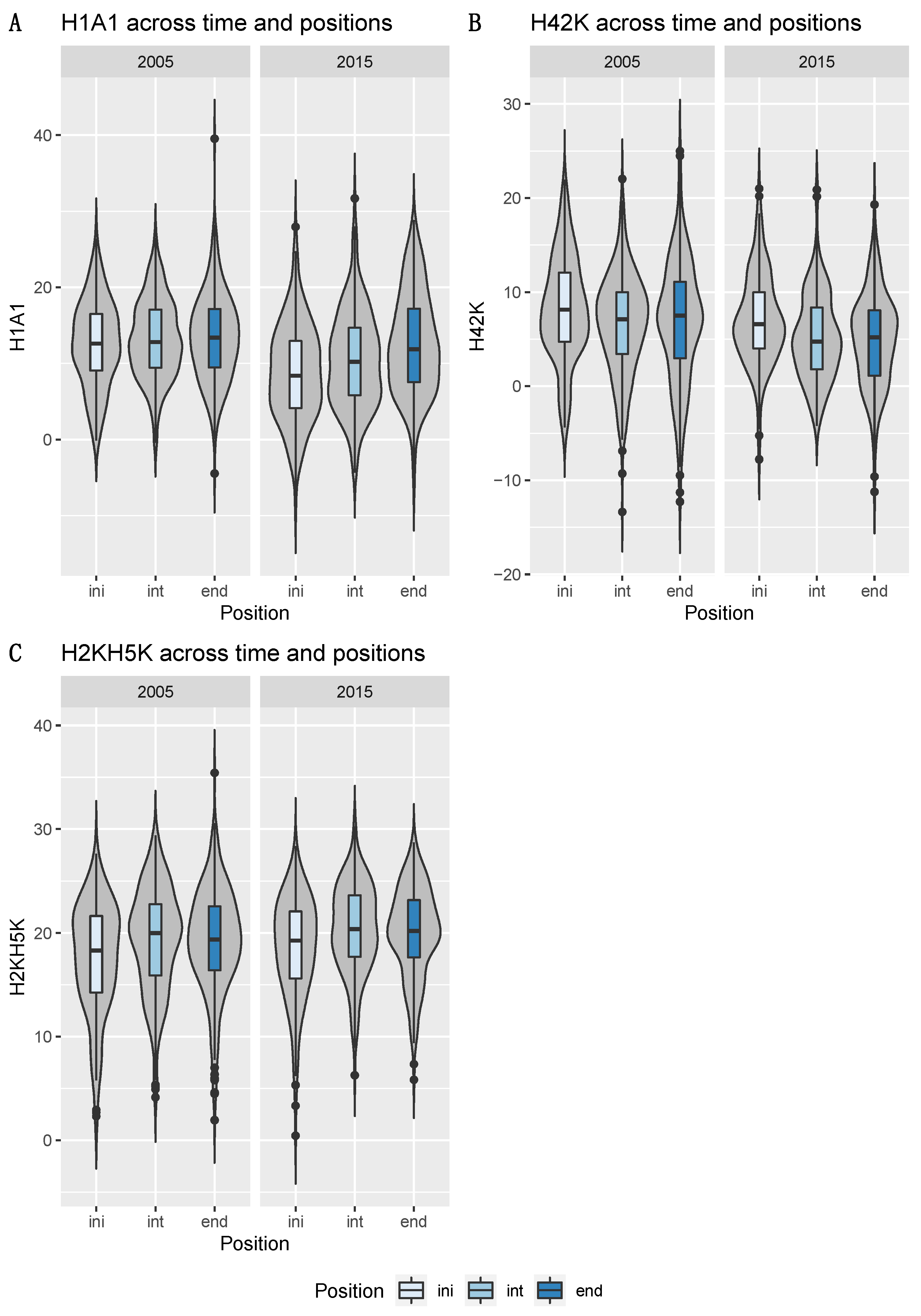
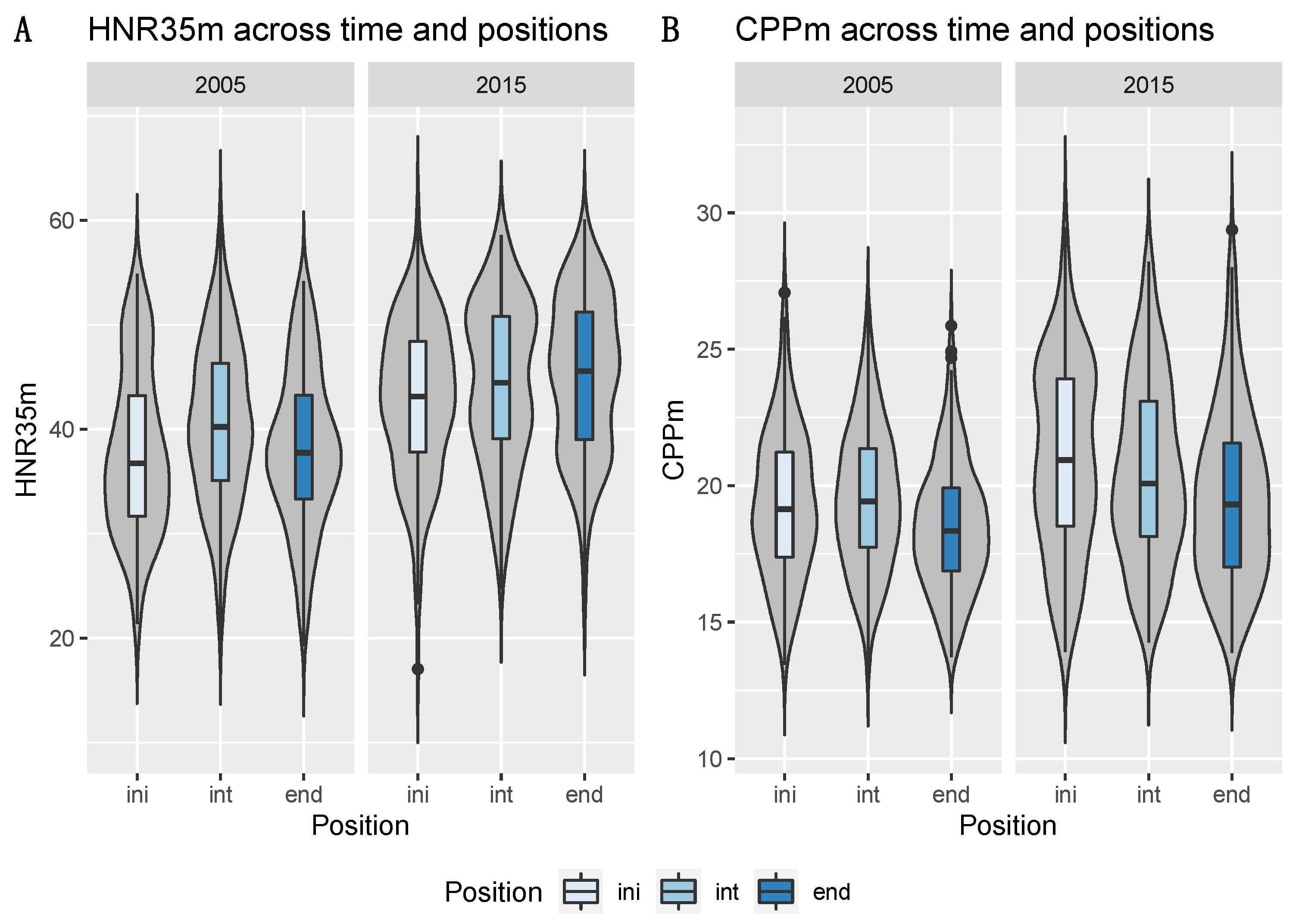
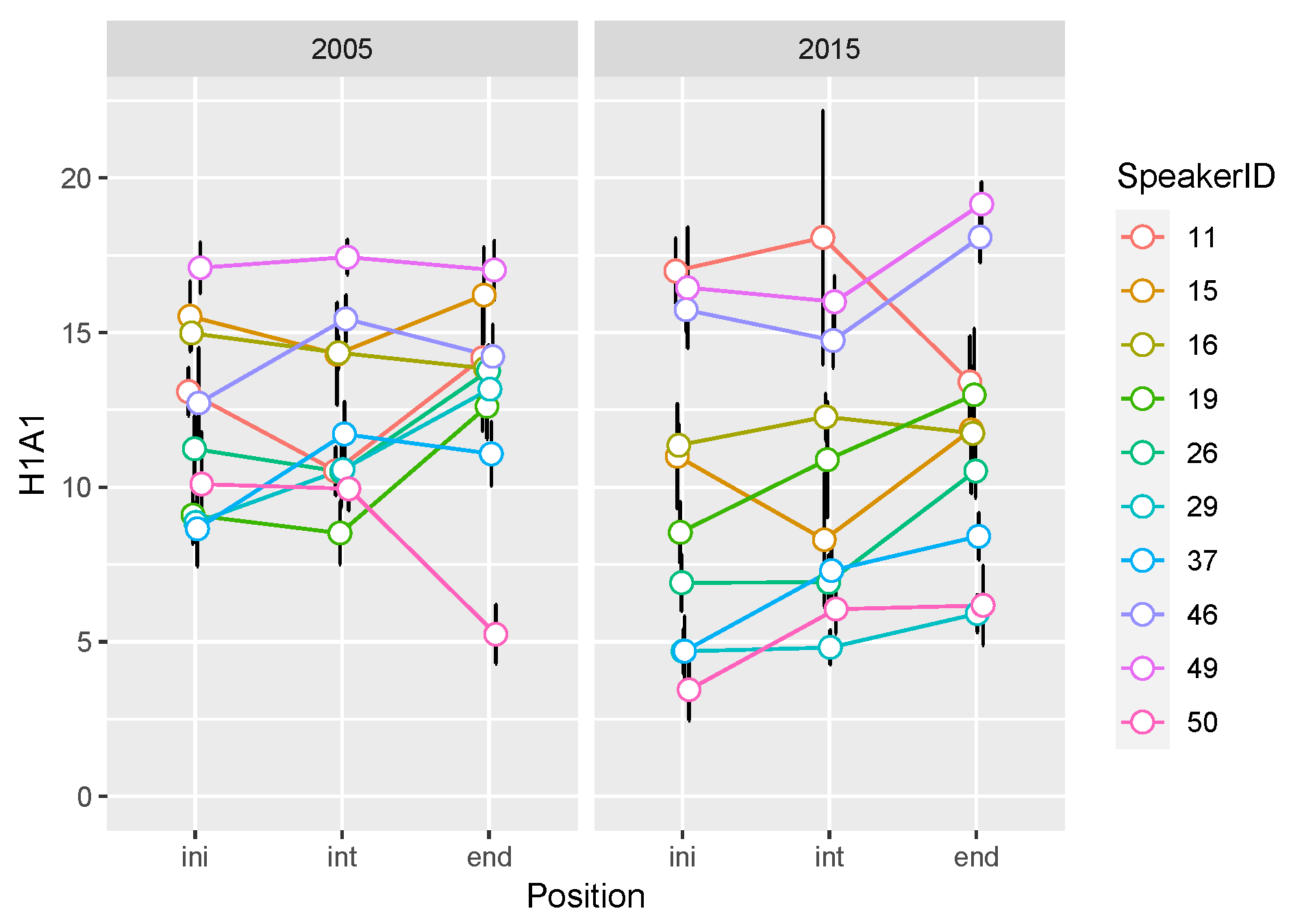
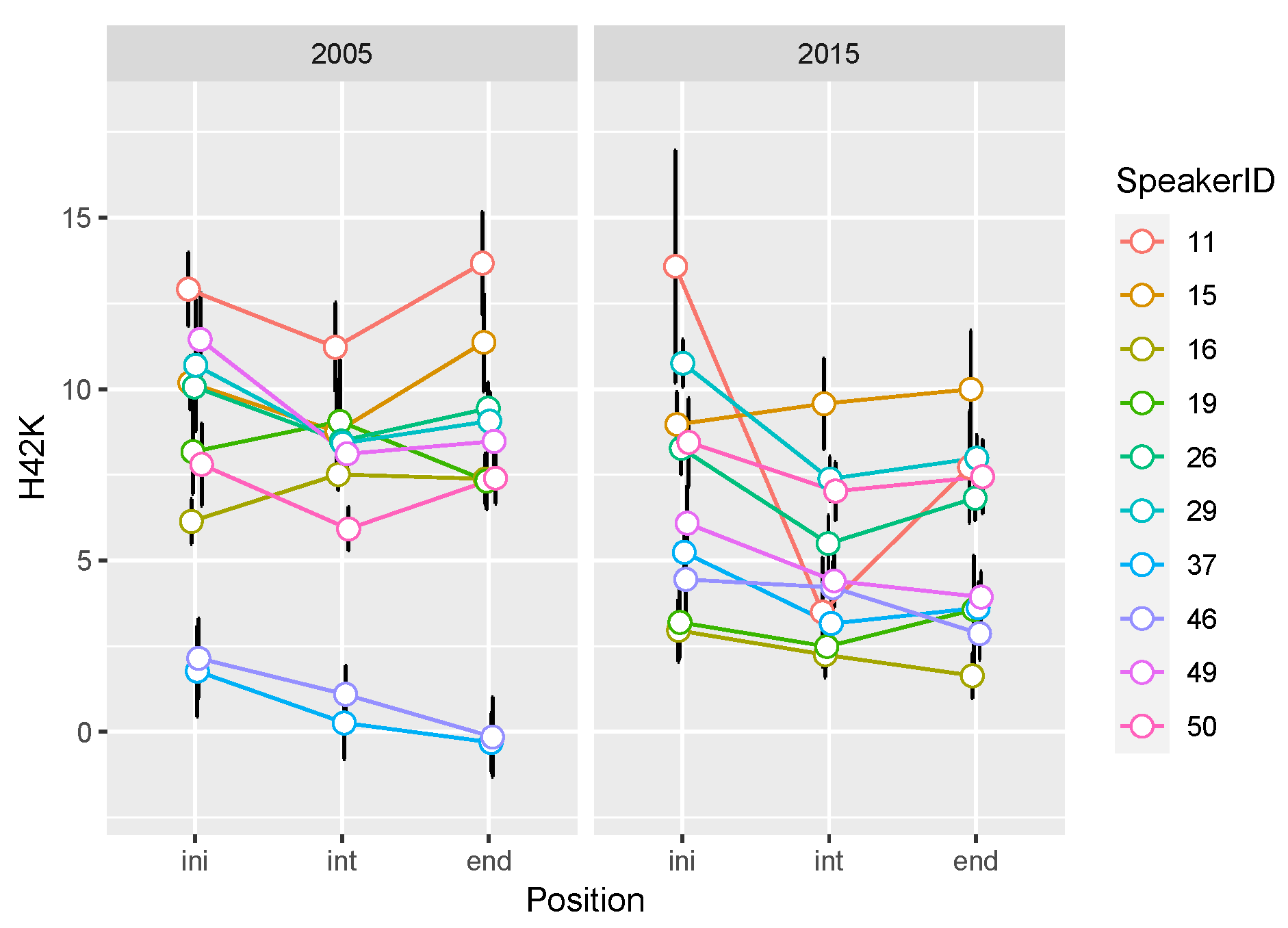
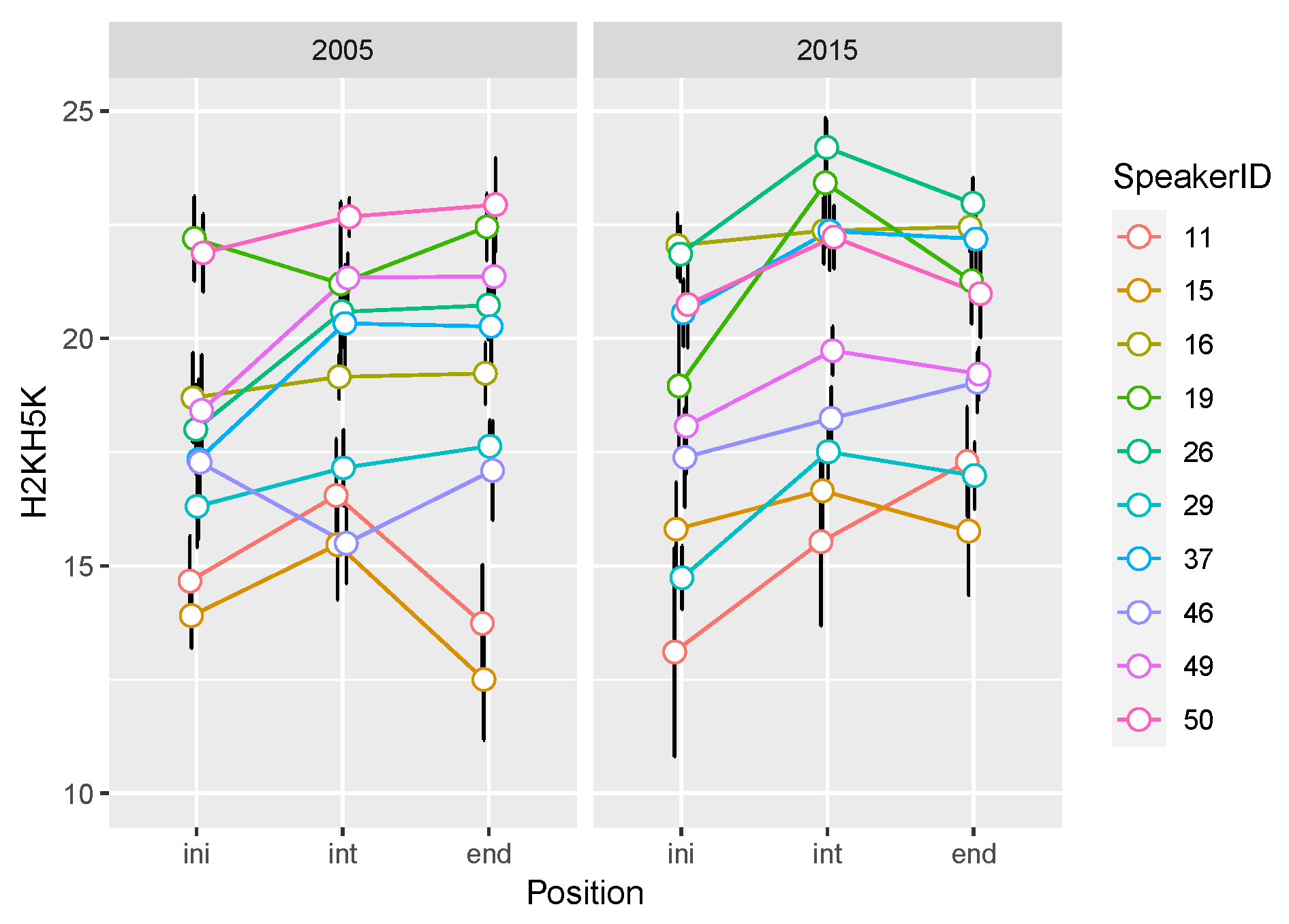
3.4. Voice Quality Parameters
4. Discussion
4.1. Frequency of euh
4.2. Effects of Age and Position
4.2.1. Age
4.2.2. Utterance Position: Main Effects and Interactions
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sp | Age | No. Tokens | No. All euh | No. euh/1000 Tokens | No. Analyzed euh | Pct (%) Analyzed euh | No. btwPaus | No. ini | No. int | No. End |
|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 86 | 8990 | 100 | 11.1 | 48 | 48 | 1 | 12 | 19 | 17 |
| 15 | 78 | 5923 | 106 | 17.9 | 61 | 58 | 6 | 35 | 15 | 11 |
| 16 | 71 | 6068 | 252 | 41.5 | 105 | 42 | 4 | 25 | 57 | 23 |
| 19 | 76 | 4545 | 99 | 21.8 | 62 | 63 | 3 | 16 | 12 | 34 |
| 26 | 78 | 7369 | 183 | 24.8 | 85 | 46 | 3 | 31 | 20 | 34 |
| 29 | 67 | 5059 | 148 | 29.3 | 76 | 51 | 7 | 31 | 38 | |
| 37 | 79 | 5438 | 170 | 31.3 | 74 | 44 | 2 | 17 | 22 | 35 |
| 46 | 74 | 5931 | 221 | 37.3 | 72 | 33 | 4 | 11 | 37 | 24 |
| 49 | 72 | 9865 | 304 | 30.8 | 96 | 32 | 12 | 58 | 26 | |
| 50 | 63 | 6018 | 247 | 41 | 62 | 25 | 12 | 43 | 7 | |
| 11 | 96 | 9817 | 87 | 8.9 | 19 | 22 | 4 | 4 | 11 | |
| 15 | 88 | 5725 | 61 | 10.7 | 36 | 59 | 6 | 16 | 11 | 9 |
| 16 | 81 | 3914 | 246 | 62.9 | 64 | 26 | 4 | 12 | 27 | 25 |
| 19 | 86 | 7134 | 88 | 12.3 | 26 | 30 | 1 | 15 | 5 | 6 |
| 26 | 88 | 6429 | 113 | 17.6 | 76 | 67 | 6 | 29 | 21 | 26 |
| 29 | 77 | 5571 | 175 | 31.4 | 94 | 54 | 33 | 29 | 32 | |
| 37 | 89 | 6307 | 174 | 27.6 | 72 | 41 | 14 | 24 | 12 | 36 |
| 46 | 84 | 4259 | 195 | 45.8 | 92 | 47 | 9 | 25 | 34 | 33 |
| 49 | 82 | 6857 | 156 | 22.8 | 103 | 66 | 5 | 10 | 40 | 53 |
| 50 | 74 | 4051 | 115 | 28.4 | 60 | 52 | 1 | 10 | 35 | 15 |
References
- Aare, Kätlin, Pärtel Lippus, Marcin Włodarczak, and Mattias Heldner. 2018. Creak in the Respiratory Cycle. Paper presented at the Interspeech, Hyderabad, India, September 2–6; pp. 1408–12. [Google Scholar] [CrossRef]
- Albuquerque, Luciana, Catarina Oliveira, António Teixeira, Pedro Sa-Couto, and Daniela Figueiredo. 2020. A comprehensive analysis of age and gender effects in European Portuguese oral vowels. Journal of Voice. in press. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Benjamin M. Bolker, and Steven Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Belz, Malte. 2020. Acoustic Vowel Quality of Filler Particles in German. Paper presented at the Laughter and Other Non-Verbal Vocalisations Workshop, Bielefeld, Germany, October 5; pp. 7–10. [Google Scholar] [CrossRef]
- Belz, Malte. 2021. Die Phonetik von äh und ähm. Akustische Variation von Füllpartikeln im Deutschen. Stuttgart: Metzler. [Google Scholar]
- Benjamin, Barbaranne J. 1981. Frequency variability in the aged voice. Journal of Gerontology 36: 722–26. [Google Scholar] [CrossRef]
- Biever, Dawn M., and Diane M. Bless. 1989. Vibratory characteristics of the vocal folds in young adult and geriatric women. Journal of Voice 3: 120–31. [Google Scholar] [CrossRef]
- Bolly, Catherine T., George Christodoulides, and Anne Catherine Simon. 2016. Disfluences et vieillissement langagier. De la base de données Valibel aux corpus outillés en français parlé. Corpus 15: 1–13. [Google Scholar] [CrossRef]
- Bortfeld, Heather, Silvia D. Leon, Jonathan E. Bloom, Michael F. Schober, and Susan E. Brennan. 2001. Disfluency rates in conversation: Effects of age, relationship, topic, role, and gender. Language and Speech 44: 123–47. [Google Scholar] [CrossRef]
- Brown, W. S., Richard J. Morris, and John F. Michel. 1989. Vocal jitter in young adult and aged female voices. Journal of Voice 3: 113–19. [Google Scholar] [CrossRef]
- Candea, Maria, Ioana Vasilescu, and Martine Adda-Decker. 2005. Inter- and Intra-Language Acoustic Analysis of Autonomous Fillers. Paper presented at the Disfluency in Spontaneous Speech Workshop, Aix-en-Provence, France, September 10–12; pp. 47–51. Available online: https://www.isca-speech.org/archive_open/diss_05/dis5_047.html (accessed on 15 December 2021).
- Candea, Maria. 2000. Contribution à l’Etude des Pauses Silencieuses et des Phénomènes dits ‘d’Hésitation’ en Français Oral Spontané. Ph.D. dissertation, Université Paris, Paris, France. [Google Scholar]
- Childers, Donald G., and Ke Wu. 1991. Gender recognition from speech. Part II: Fine analysis. The Journal of the Acoustical Society of America 90: 1841–56. [Google Scholar] [CrossRef]
- Cole, Jennifer. 2015. Prosody in context: A review. Language, Cognition and Neuroscience 30: 1–31. [Google Scholar] [CrossRef]
- de Jong, Nivja H., and Hans Rutger Bosker. 2013. Choosing a Threshold for Silent Pauses to Measure Second Language Fluency. Paper presented at the Disfluency in Spontaneous Speech Workshop, Stockholm, Sweden, August 21–23; pp. 17–20. Available online: http://hdl.handle.net/11858/00-001M-0000-0015-0FB8-8 (accessed on 15 December 2021).
- Decoster, Wivine, and Frans Debruyne. 1997. Changes in spectral measures and voice-onset time with age: A cross-sectional and a longitudinal study. Folia Phoniatrica et Logopaedica 49: 269–80. [Google Scholar] [CrossRef] [PubMed]
- Dehquan, Ali, Ronald C. Scherer, Gholamali Dashti, Alireza Ansari-Moghaddam, and Sepideh Fanaie. 2012. The effects of aging on acoustic parameters of voice. Folia Phoniatrica et Logopaedica 64: 265–70. [Google Scholar] [CrossRef] [PubMed]
- Duez, Danielle. 2001. Acoustico-phonetic Characteristics of Filled Pauses in Spontaneous French Speech: Preliminary Results. Paper presented at the Disfluency in Spontaneous Speech Workshop, Edinburgh, Scotland, UK, August 29–31; pp. 41–44. Available online: https://www.isca-speech.org/archive_open/diss_01/dis1_041.html (accessed on 15 December 2021).
- Eichhorn, Julie T., Raymond D. Kent, Diane Austin, and Houri K. Vorperian. 2018. Effects of aging on vocal fundamental frequency and vowel formants in men and women. Journal of Voice 32: 644.e1–644.e9. [Google Scholar] [CrossRef]
- Endres, Werner, W. Bambach, and G. Flösser. 1971. Voice spectrograms as a function of age, voice disguise, and voice imitation. The Journal of the Acoustical Society of America 49: 1842–48. [Google Scholar] [CrossRef]
- Estenne, Marc, Jean-Claude Yernault, and André de Troyer. 1985. Rig cage and diaphragm-abdomen compliance in humans: Effects of age and posture. Journal of Applied Psychology 59: 1842–48. [Google Scholar] [CrossRef]
- Ferrand, Carole T. 2002. Harmonics-to-Noise Ratio: An index of vocal aging. Journal of Voice 16: 480–87. [Google Scholar] [CrossRef]
- Ferreira, Fernanda, and Karl G. D. Bailey. 2004. Disfluencies and human language comprehension. Trends in Cognitive Sciences 8: 231–37. [Google Scholar] [CrossRef] [PubMed]
- Fougeron, Cécile, Fanny Guitard-Ivent, and Véronique Delvaux. 2021. Multi-dimensional variation in adult speech as a function of age. Languages 6: 176. [Google Scholar] [CrossRef]
- Frank, N. Robert, Jere Mead, and Benjamin G. Ferris, Jr. 1957. The mechanical behavior of the lungs in healthy elderly persons. The Journal of Clinical Investigation 36: 1680–87. [Google Scholar] [CrossRef]
- Gall, Juliane. 2019. Disfluencies im Laufe des höheren Lebensalters. Eine individuenzentrierte Längsschnittstudie. Göttingen: Verlag für Gesprächsforschung. [Google Scholar]
- Gendrot, Cédric, and Carolin Schmid. 2011. F0 Declination in French: Broadcast News versus Spontaneous Speech. Paper presented at the Nijmegen Workshop in Production and Comprehension of Conversational Speech, Nijmegen, The Netherlands, December 12–13; pp. 15–17. Available online: https://hal.archives-ouvertes.fr/halshs-00691494/ (accessed on 15 December 2021).
- Gerstenberg, Annette. 2005–2021. LangAge Collection of Biographical Interviews. Potsdam: Department of Romance Studies. Available online: www.langage-corpora.org (accessed on 15 December 2021).
- Gerstenberg, Annette. 2011. Generation und Sprachprofile im höheren Lebensalter: Untersuchungen zum Französischen auf der Basis eines Korpus biographischer Interviews. Frankfurt am Main: Vittorio Klostermann. [Google Scholar]
- Gerstenberg, Annette. 2015. A sociolinguistic perspective on vocabulary richness in a seven-year comparison of older adults. In Language Development: The Lifespan Perspective. Edited by Annette Gerstenberg and Anja Voeste. Amsterdam: Benjamins, pp. 109–27. [Google Scholar] [CrossRef]
- Gerstenberg, Annette. 2020. Pragmatic development in the (middle and) later stages of life. In Developmental and Clinical Pragmatics (HOPS 13). Edited by Klaus P. Schneider and Elly Ifantidou. Berlin and Boston: De Gruyter Mouton, pp. 209–34. [Google Scholar] [CrossRef]
- Gerstenberg, Annette, Susanne Fuchs, Julie Kairet, Johannes Schroeder, and Claudia Frankenberg. 2018. A Cross-linguistic, Longitudinal Case Study of Pauses and Interpausal Units in Spontaneous Speech Corpora of Older Speakers of German and French. Paper presented at the 9th International Conference on Speech Prosody, Poznań, Poland, June 13–16; pp. 211–15. [Google Scholar]
- Goozée, Justine V., Bruce E. Murdoch, Deborah G. Theodoros, and Elizabeth C. Thompson. 1998. The effects of age and gender on laryngeal aerodynamics. International Journal of Language and Communication Disorders 33: 221–38. [Google Scholar] [CrossRef]
- Gósy, Mária, and Vered Silber-Varod. 2021. Attached Filled Pauses: Occurrences and Durations. Paper presented at the Disfluency in Spontaneous Speech Workshop, Paris, France, August 25–26; pp. 71–76. [Google Scholar]
- Gósy, Mária, Judit Bóna, András Beke, and Viktória Horváth. 2014. Phonetic Characteristics of Filled Pauses: The Effects of Speakers’ Age. Paper presented at the 10th International Seminar on Speech Production, Köln, Germany, May 5–8; pp. 150–53. Available online: http://www.issp2014.uni-koeln.de/wp-content/uploads/2014/Proceedings_ISSP_revised.pdf (accessed on 22 November 2021).
- Grosman, Iulia, Anne Catherine Simon, and Liesbeth Degand. 2018. Variation de la durée des pauses silencieuses: Impact de la syntaxe, du style de parole et des disfluences. Langages 111: 13–40. [Google Scholar] [CrossRef]
- Hammond, Thomas H., Steven D. Gray, John Butler, Ruixia Zhou, and Elizabeth Hammond. 1998. Age-and gender-related elastin distribution changes in human vocal folds. Otolaryngology—Head and Neck Surgery 4: 314–22. [Google Scholar] [CrossRef]
- Hammond, Thomas H., Steven D. Gray, and John E. Butler. 2000. Age- and gender-related collagen distribution in human vocal folds. Annals of Otology, Rhinology & Laryngology 109: 913–20. [Google Scholar] [CrossRef]
- Hanson, Helen M. 1997. Glottal characteristics of female speakers: Acoustic correlates. The Journal of the Acoustical Society of America 101: 466–81. [Google Scholar] [CrossRef]
- Harrington, Jonathan, Sallyanne Palethorpe, and Catherine I. Watson. 2000. Does the Queen speak the Queen’s English? Nature 408: 927–28. [Google Scholar] [CrossRef]
- Higgins, Maureen B., and John H. Saxman. 1991. A comparison of selected phonatory behaviors of healthy aged and young adults. Journal of Speech and Hearing Research 34: 1000–10. [Google Scholar] [CrossRef] [PubMed]
- Hirano, Minoru, Shigejiro Kurita, and Teruyuki Nakashima. 1983. Growth, development, and aging of human vocal folds. In Vocal Fold Physiology: Contemporary Research and Clinical Issues. Edited by Diane M. Bless and James H. Abbs. San Diego: College-Hill Press, pp. 22–43. [Google Scholar]
- Hoit, Jeannette D., and Thomas J. Hixon. 1987. Age and speech breathing. Journal of Speech and Hearing Research 30: 351–66. [Google Scholar] [CrossRef] [PubMed]
- Honjo, Iwao, and Nobuhiko Isshiki. 1980. Laryngoscopic and voice characteristics of aged persons. Archives of Otolaryngology 106: 149–50. [Google Scholar] [CrossRef] [PubMed]
- Horton, William S., Daniel H. Spieler, and Elizabeth Shriberg. 2010. A corpus analysis of patterns of age-related change in conversational speech. Psychology and Aging 25: 708–13. [Google Scholar] [CrossRef]
- Iseli, Markus, Yen-Liang Shue, and Abeer Alwan. 2007. Age, sex, and vowel dependencies of acoustic measures related to the voice source. The Journal of the Acoustical Society of America 121: 2283–95. [Google Scholar] [CrossRef] [PubMed]
- Israel, Harry. 1973. Age factor and the pattern of change in craniofacial structures. American Journal of Physical Anthropology 39: 111–28. [Google Scholar] [CrossRef] [PubMed]
- Kahane, Joel C. 1987a. Connective tissue changes in the larynx and their effects on voice. Journal of Voice 1: 27–30. [Google Scholar] [CrossRef]
- Kahane, Joel C. 1987b. Developmental changes in the articular cartilage of the human cricoarytenoid joint. In Laryngeal Function in Phonation and Respiration. Edited by Thomas Baer, Clarence Sasaki and Katherine S. Harris. Boston: Little, Brown and Company, pp. 14–28. [Google Scholar]
- Kahane, Joel C. 1988. Age related changes in the human cricoarytenoid joint. In Vocal Physiology: Voice Production, Mechanisms and Functions. Edited by Osamu Fujimura. New York: Raven Press, pp. 145–57. [Google Scholar]
- Karlsson, Fredrik, and Lena Hartelius. 2021. On the primary influences of age on articulation and phonation in maximum performance tasks. Languages 6: 174. [Google Scholar] [CrossRef]
- Karpiński, Maciej. 2013. Acoustic features of filled pauses in Polish task-oriented dialogues. Archives of Acoustics 38: 63–73. [Google Scholar] [CrossRef]
- Kassambara, Alboukadel. 2020. ggpubr: ‘ggplot2’ Based Publication Ready Plots, Version 0.4.0, 2020-06-27. R-Project: Package ggplot2. Available online: https://cran.r-project.org/web/packages/ggpubr/index.html (accessed on 15 December 2021).
- Keszler, Borbála, and Judit Bóna. 2019. Pausing and Disfluencies in Elderly Speech: Longitudinal Case Studies. Paper presented at the 9th Workshop on Disfluency in Spontaneous Speech, Budapest, Hungary, September 12–13; pp. 67–70. [Google Scholar] [CrossRef]
- Koenig, Laura L., Susanne Fuchs, Annette Gerstenberg, and Moriah Rastegar. 2020. Formant and Voice Quality Changes as a Function of Age in Women. Paper presented at the 179th Meeting of the Acoustical Society of America, Acoustics Virtually Everywhere, Online, December 7–11. [Google Scholar]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Lasker, Gabrial W. 1953. The age factor in bodily measurements of adult male and female Mexicans. Human Biology 25: 50–63. [Google Scholar] [PubMed]
- Lenell, Charles, Mary J. Sandage, and Aaron M. Johnson. 2019. A tutorial of the effects of sex hormones on laryngeal senescence and neuromuscular response to exercise. Journal of Speech, Language, and Hearing Research 62: 602–10. [Google Scholar] [CrossRef]
- Lenth, Russell. 2021. Emmeans: Estimated Marginal Means, Aka Least-Squares Means. R Package Version 1.6.2-1. Available online: https://cran.r-project.org/web/packages/emmeans/index.html (accessed on 22 November 2021).
- Linville, Sue Ellen. 1992. Glottal gap configurations in two age groups of women. Journal of Speech and Hearing Research 35: 1209–15. [Google Scholar] [CrossRef]
- Linville, Sue Ellen, and Hilda B. Fisher. 1985. Acoustic characteristics of women’s voices with advancing age. Journal of Gerontology 40: 324–30. [Google Scholar] [CrossRef]
- Linville, Sue Ellen, and Jennifer Rens. 2001. Vocal tract resonance analysis of aging voice using long-term average spectra. Journal of Voice 15: 323–30. [Google Scholar] [CrossRef]
- Lundy, Donna S., Carlos Silva, Roy R. Casiano, F. Ling Lu, and Jun Wu Xue. 1998. Cause of hoarseness in elderly patients. Otolaryngology—Head and Neck Surgery 118: 481–85. [Google Scholar] [CrossRef]
- MATLAB. 2018. Version R2018b. Natick: The MathWorks Inc. [Google Scholar]
- Maxim, Jane, Karen Bryan, and Ian Thompson. 1994. Language of the Elderly: A Clinical Perspective. San Diego: Singular. [Google Scholar]
- Michel, John F., W. S. Brown, Wojtek Chodzko-Zajko, Harry Hollien, Ruth Huntley, Joel C. Kahane, Sue Ellen Linville, and Robert L. Ringel. 1987. Aging voice: Panel 1. Journal of Voice 1: 53–61. [Google Scholar] [CrossRef]
- Morel, Mary-Annick, and Laurent Danon-Boileau. 1998. Grammaire de l’Intonation: L’Exemple du Français Oral. Paris: Ophrys. [Google Scholar]
- Ogden, Richard. 2001. Turn transition, creak and glottal stop in Finnish talk-in-interaction. Journal of the International Phonetic Association 31: 139–52. [Google Scholar] [CrossRef]
- Oyer, Herbert J., and Leo V. Deal. 1985. Temporal aspects of speech and the aging process. Folia Phoniatrica 37: 109–12. [Google Scholar] [CrossRef]
- Paulsen, Friedrich P., and Bernhard N. Tillmann. 1998. Degenerative changes in the human cricoarytenoid joint. Archives of Otolaryngology–Head & Neck Surgery 124: 903–6. [Google Scholar] [CrossRef][Green Version]
- Pontes, Paulo, Alcione Brasolotto, and Mara Behlau. 2005. Glottic characteristics and voice complaint in the elderly. Journal of Voice 19: 84–94. [Google Scholar] [CrossRef]
- Pressman, Joel J., and George Kelemen. 1955. Physiology of the larynx. Physiological Review 35: 506–54. [Google Scholar] [CrossRef]
- Ramig, Lorraine A., and Robert L. Ringel. 1983. Effects of physiological aging on selected acoustic characteristics of voice. Journal of Speech and Hearing Research 26: 22–30. [Google Scholar] [CrossRef]
- Reubold, Ulrich, Jonathan Harrington, and Felicitas Kleber. 2010. Vocal aging effects on f0 and the first formant: A longitudinal analysis in adult speakers. Speech Communication 52: 638–51. [Google Scholar] [CrossRef]
- Ringel, Robert L., and Wojtek J. Chodzko-Zajko. 1987. Vocal indices of biological age. Journal of Voice 1: 31–37. [Google Scholar] [CrossRef]
- Rochet-Capellan, Amélie, and Susanne Fuchs. 2013. The Interplay of Linguistic Structure and Breathing in German Spontaneous Speech. Paper presented at the 14th Annual Conference of the International Speech Communication Association, Lyon, France, August 25–29, vol. 14, pp. 2014–18. Available online: https://hal.archives-ouvertes.fr/hal-00871600/ (accessed on 15 December 2021).
- Russell, Alison, Lynda Penny, and Cecilia Pemberton. 1995. Speaking fundamental frequency changes over time in women: A longitudinal study. Journal of Speech and Hearing Research 38: 101–9. [Google Scholar] [CrossRef] [PubMed]
- Schönle, Paul-Walter, and Bastian Conrad. 1985. Hesitation vowels: A motor speech respiration hypothesis. Neuroscience Letters 55: 293–96. [Google Scholar] [CrossRef]
- Schötz, Susanne. 2006. Perception, Analysis and Synthesis of Speaker Age. Travaux de l’Institut de Linguistique de Lund 47. Lund: Lund University. [Google Scholar]
- Schultz, Benjamin G., Sandra Rojas, Miya St. John, Elaina Kefalianos, and Adam P. Vogel. 2021. A cross-sectional study of perceptual and acoustic voice characteristics in healthy aging. Journal of Voice. in press. [Google Scholar] [CrossRef] [PubMed]
- Scukanec, Gail P., Linda Petrosino, and Kevin Squibb. 1991. Formant frequency characteristics of children, young adult, and aged female speakers. Perceptual and Motor Skills 73: 203–8. [Google Scholar] [CrossRef]
- Searl, Jeffrey P., Rodney M. Gabel, and J.Steven Fulks. 2002. Speech disfluency in centenarians. Journal of Communication Disorders 35: 383–92. [Google Scholar] [CrossRef]
- Segre, Renato. 1971. Senescence of the voice. The Eye, Ear, Nose and Throat Monthly 50: 223–27. [Google Scholar]
- Shriberg, Elizabeth. 2001. To ‘errrr’ is human: Ecology and acoustics of speech disfluencies. Journal of the International Phonetic Association 31: 153–69. [Google Scholar] [CrossRef]
- Shriberg, Elizabeth E., and Robin J. Lickley. 1993. Intonation of clause-internal filled pauses. Phonetica 50: 172–79. [Google Scholar] [CrossRef] [PubMed]
- Smorenburg, Laura, and Willemijn Heeren. 2020. The distribution of speaker information in Dutch fricatives /s/ and /x/ from telephone dialogues. The Journal of the Acoustical Society of America 147: 949–60. [Google Scholar] [CrossRef] [PubMed]
- Sperry, Elizabeth E., and Richard J. Klich. 1992. Speech breathing in senescent and younger women during oral reading. Journal of Speech and Hearing Research 35: 1246–55. [Google Scholar] [CrossRef]
- Stathopoulos, Elaine T., Jessica E. Huber, and Joan E. Sussman. 2011. Changes in acoustic characteristics of the voice across the life span: Measures from individuals 4–93 years of age. Journal of Speech, Language, and Hearing Research 54: 1011–21. [Google Scholar] [CrossRef]
- Stoicheff, Margaret L. 1981. Speaking fundamental frequency characteristics of nonsmoking female adults. Journal of Speech and Hearing Research 24: 437–41. [Google Scholar] [CrossRef] [PubMed]
- Tabain, Marija. 2003. Effects of prosodic boundary on /aC/ sequences: Acoustic results. The Journal of the Acoustical Society of America 113: 516–31. [Google Scholar] [CrossRef]
- Taschenberger, Linda, Outi Tuomainen, and Valerie Hazan. 2019. Disfluencies in Spontaneous Speech in Easy and Adverse Communicative Situations: The Effect of Age. Paper presented at the Disfluency in Spontaneous Speech Workshop, Budapest, Hungary, September 12–14, vol. 9, pp. 55–58. [Google Scholar] [CrossRef]
- Turk, L. Munir, and David A. Hogg. 1993. Age changes in the human laryngeal cartilages. Clinical Anatomy 6: 154–62. [Google Scholar] [CrossRef]
- Vayra, Mario, and Carol A. Fowler. 1992. Declination of supralaryngeal gestures in spoken Italian. Phonetica 49: 48–60. [Google Scholar] [CrossRef] [PubMed]
- Wagner, Anita, and Angelika Braun. 2003. Is Voice Quality Language-Dependent? Acoustic Analyses Based on Speakers of Three Different Languages. Paper presented at the 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9; pp. 651–54. Available online: https://www.internationalphoneticassociation.org/icphs-proceedings/ICPhS2003/papers/p15_0651.pdf (accessed on 26 July 2021).
- Weirich, Melanie. 2012. The Influence of NATURE and NURTURE on Speaker-Specific Parameters in Twins’ speech: Articulation, Acoustics and Perception. Ph.D. dissertation, Humboldt University of Berlin, Berlin, Germany. [Google Scholar]
- Wickham, Hadley. 2016. Ggplot2: Elegant Graphics for Data Analysis, 2nd ed. Dordrecht: Springer International Publishing. [Google Scholar] [CrossRef]
- Wolk, Lesley, Nassima B. Abdelli-Beruh, and Dianne Slavin. 2012. Habitual use of vocal fry in young adult female speakers. Journal of Voice 26: e111–e116. [Google Scholar] [CrossRef]
- Xue, Steve An, and Dimitar Deliyski. 2001. Effects of aging on selected acoustic voice parameters: Preliminary normative data and educational implications. Educational Gerontology 27: 159–68. [Google Scholar] [CrossRef]
- Xue, Steve An, and Grace Jianping Hao. 2003. Changes in the human vocal tract due to aging and the acoustic correlates of speech production: A pilot study. Journal of Speech, Language, and Hearing Research 46: 689–701. [Google Scholar] [CrossRef]
- Xue, Steve An, Jack Jiang, Emily Lin, Raymond Glassenberg, and Peter B. Mueller. 1999. Age-related changes in human vocal tract configurations and the effects on speakers’ vowel formant frequencies: A pilot study. Logopedics Phoniatrics Vocology 24: 132–37. [Google Scholar] [CrossRef]
- Yamauchi, Akihito, Hisayuki Yokonishi, Hiroshi Imagawa, Ken-Ichi Sakakibara, Takaharu Nito, Niro Tayama, and Tatsuya Yamasoba. 2014. Age-and gender-related difference of vocal fold vibration and glottal configuration in normal speakers: Analysis with glottal area waveform. Journal of Voice 28: 525–31. [Google Scholar] [CrossRef]
- Yuasa, Ikuko Patricia. 2010. Creaky voice: A new feminine voice quality for young urban-oriented upwardly mobile American women? American Speech 85: 315–37. [Google Scholar] [CrossRef]
- Zhang, Zhaoyan. 2016a. Cause-effect relationship between vocal fold physiology and voice production in a three-dimensional phonation model. The Journal of the Acoustical Society of America 139: 1493–507. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Zhaoyan. 2016b. Respiratory laryngeal coordination in airflow conservation and reduction of respiratory effort of phonation. Journal of Voice 30: e7–e13. [Google Scholar] [CrossRef] [PubMed]



| System Level | Acoustic Parameters |
|---|---|
| Supralaryngeal resonances | •First formant (F1) •Second formant (F2) |
| Phonation | •Fundamental frequency (f0) |
| Voice quality | Low-frequency spectral tilt (up to about 1000 Hz): •H1H2 (amplitudes of first and second harmonics) •H2H4 (amplitudes of second and fourth harmonics) •H1A1 (amplitudes of first harmonic and F1) |
| Higher-frequency spectral tilt (up to about 5000 Hz): •H1A2 (amplitudes of first harmonic and F2) •H1A3 (amplitudes of first harmonic and F3) •H42K (amplitudes of fourth harmonic and that at ca. 2 kHz) •H2K5K (amplitudes of second harmonic and that at ca. 5 kHz) | |
| Noise, aperiodicity: •HNR35 •CPP |
| Speakers | 11 | 15 | 16 | 19 | 26 | 29 | 37 | 46 | 49 | 50 | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2005 | 3.5 | 4.4 | 7.6 | 4.5 | 6.1 | 5.5 | 5.4 | 5.2 | 6.9 | 4.5 | 53.6 |
| 2015 | 1.4 | 2.6 | 4.6 | 1.9 | 5.5 | 6.8 | 5.2 | 6.7 | 7.4 | 4.3 | 46.4 |
| Total | 4.8 | 7.0 | 12.2 | 6.4 | 11.6 | 12.3 | 10.6 | 11.9 | 14.4 | 8.8 |
| Parameter | TIME | POSITION | Interaction |
|---|---|---|---|
| F2 | ini > int, end | ini > int, end in 2015 | |
| f0 | ini > end | ini, int > end in 2005 | |
| H1A1 | 2005 > 2015 | ini, int < end in 2015 | |
| H42K | ini > int | ini > end, ini > int (p = 0.06) in 2015 | |
| H2KH5K | ini < int, end | ini < int, end in 2015 | |
| HNR35 | 2005 < 2015 | ||
| CPP | ini > end | ini, int > end in 2005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuchs, S.; Koenig, L.L.; Gerstenberg, A. A Longitudinal Study of Speech Acoustics in Older French Females: Analysis of the Filler Particle euh across Utterance Positions. Languages 2021, 6, 211. https://doi.org/10.3390/languages6040211
Fuchs S, Koenig LL, Gerstenberg A. A Longitudinal Study of Speech Acoustics in Older French Females: Analysis of the Filler Particle euh across Utterance Positions. Languages. 2021; 6(4):211. https://doi.org/10.3390/languages6040211
Chicago/Turabian StyleFuchs, Susanne, Laura L. Koenig, and Annette Gerstenberg. 2021. "A Longitudinal Study of Speech Acoustics in Older French Females: Analysis of the Filler Particle euh across Utterance Positions" Languages 6, no. 4: 211. https://doi.org/10.3390/languages6040211
APA StyleFuchs, S., Koenig, L. L., & Gerstenberg, A. (2021). A Longitudinal Study of Speech Acoustics in Older French Females: Analysis of the Filler Particle euh across Utterance Positions. Languages, 6(4), 211. https://doi.org/10.3390/languages6040211