
Multi-Dimensional Variation in Adult Speech as a Function of Age

Abstract
:1. Introduction
2. Materials and Methods
2.1. Population
2.2. Speech Material & Speech Descriptors
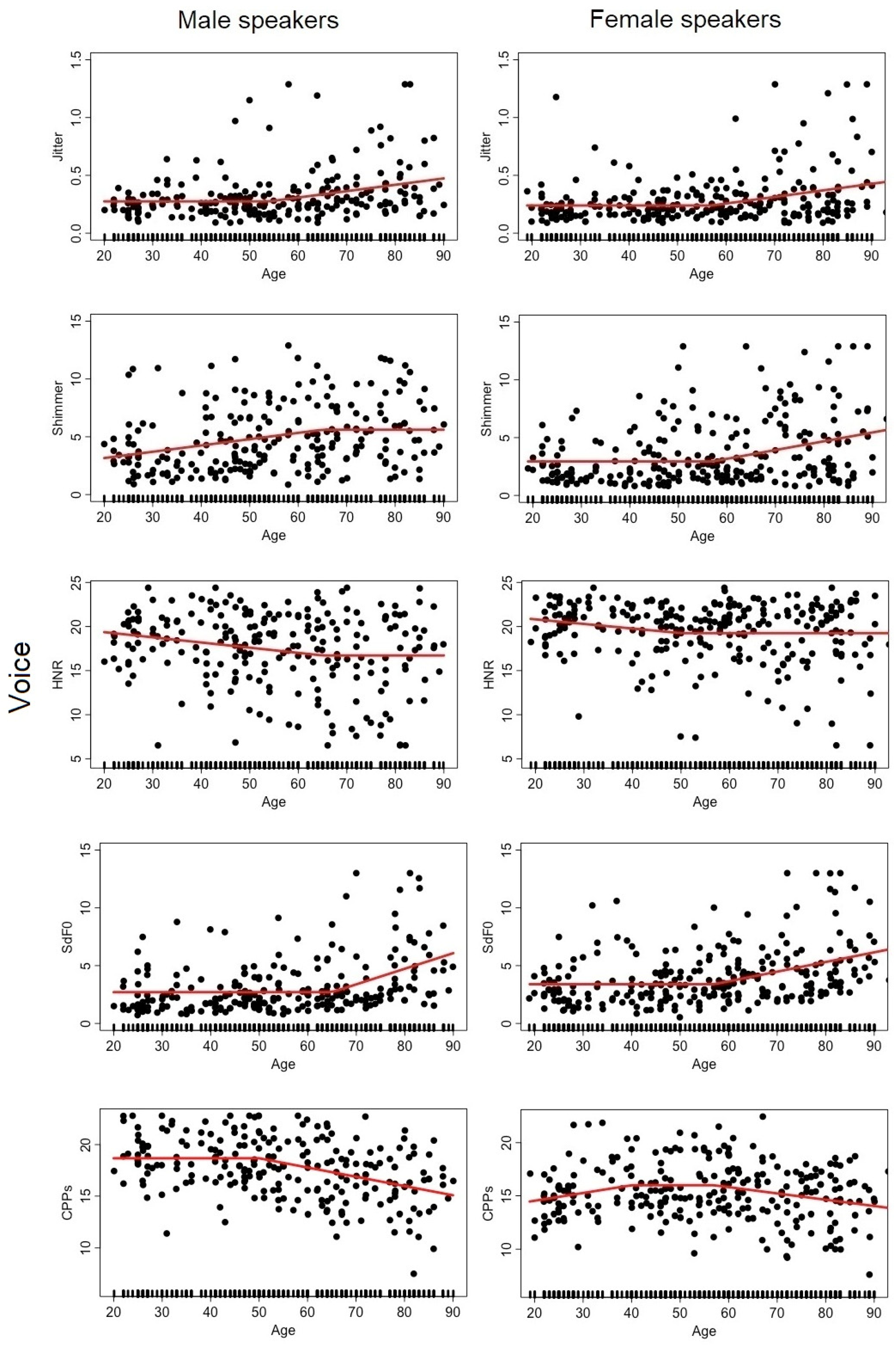
2.2.1. Voice
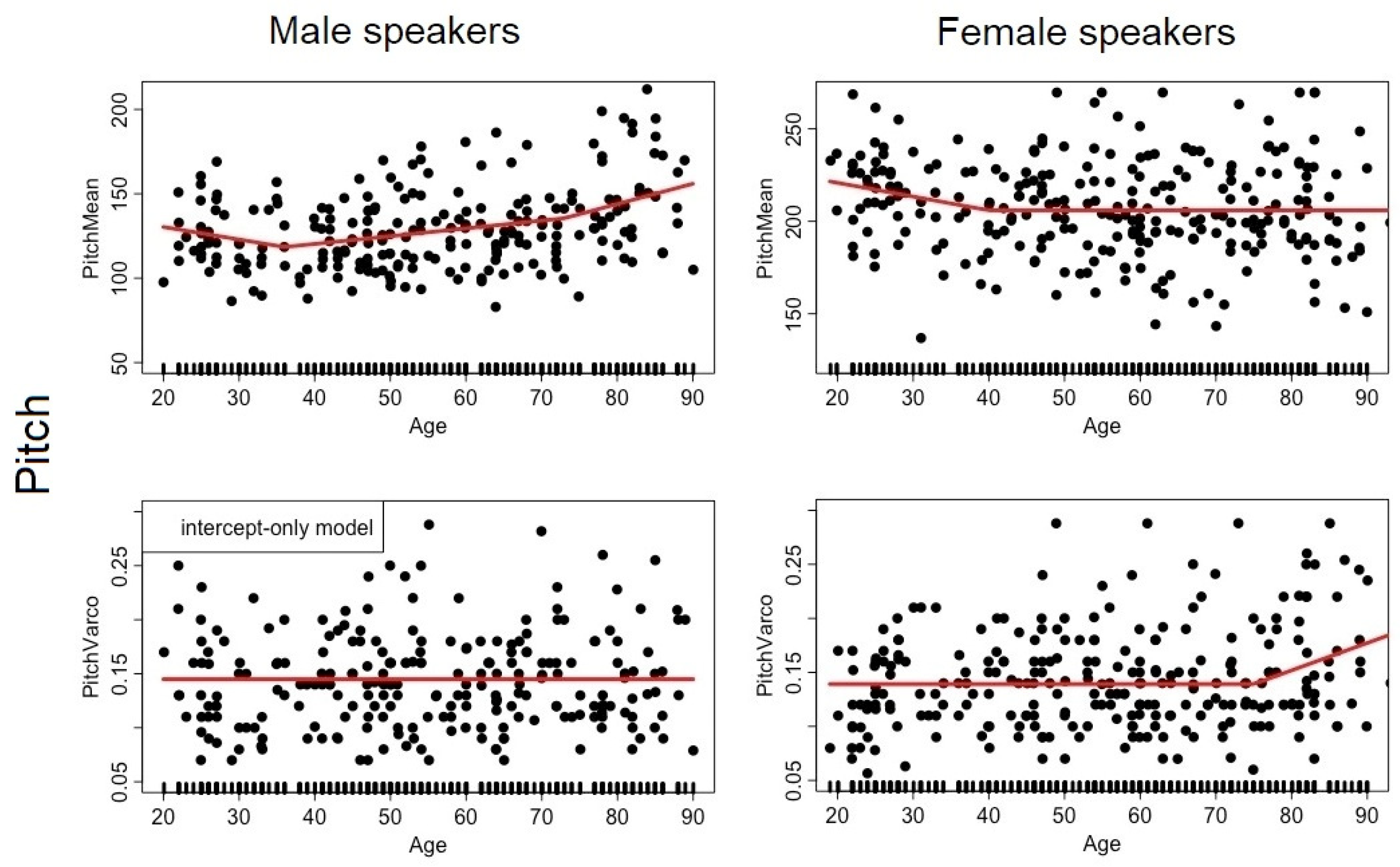
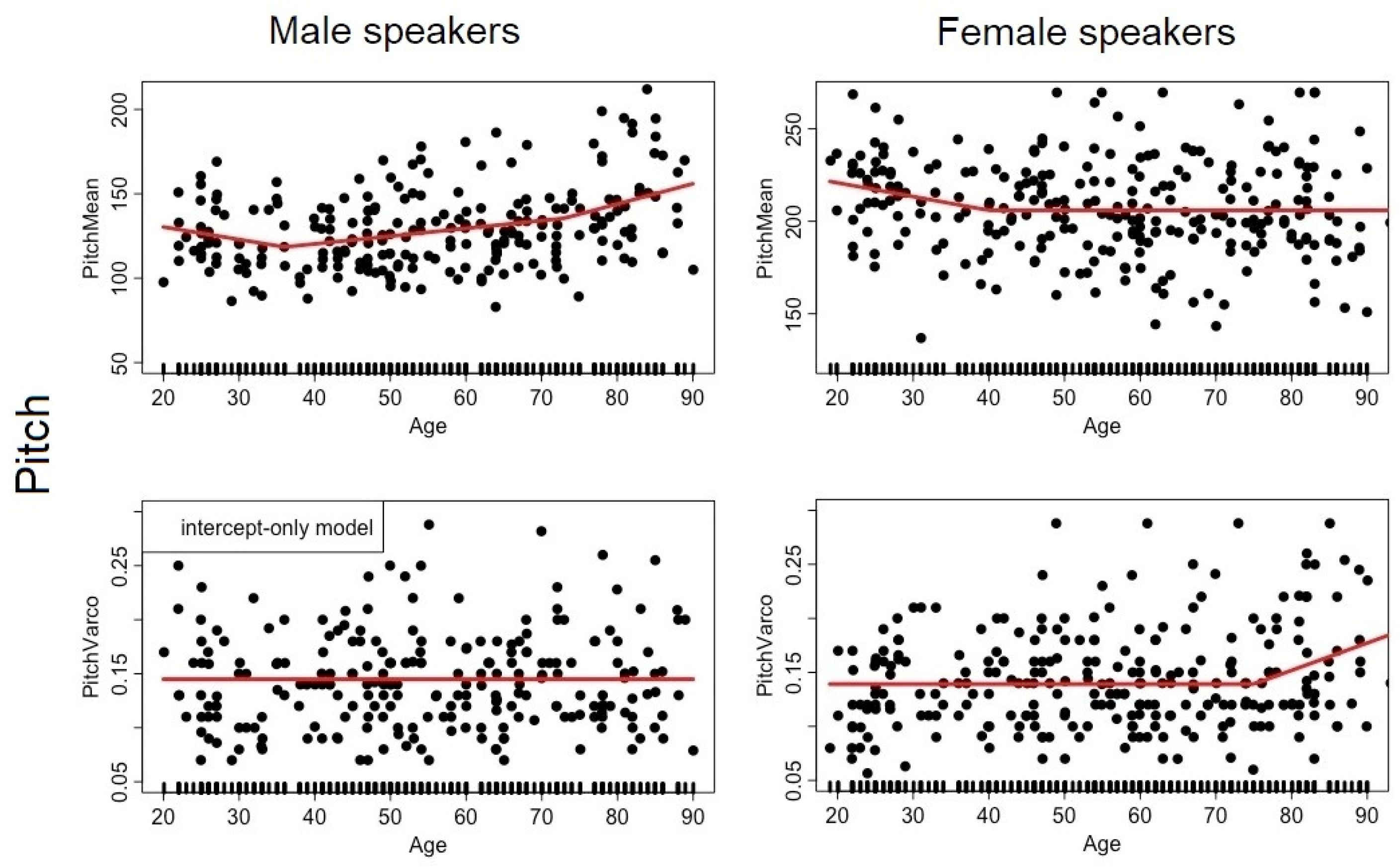
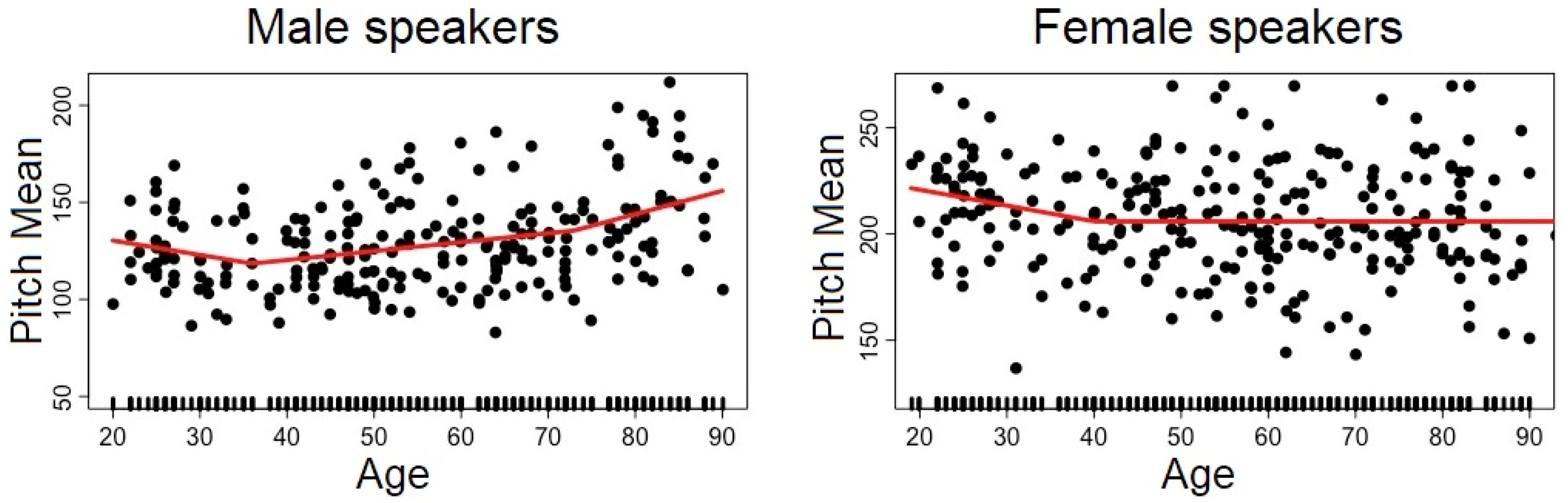
2.2.2. Pitch
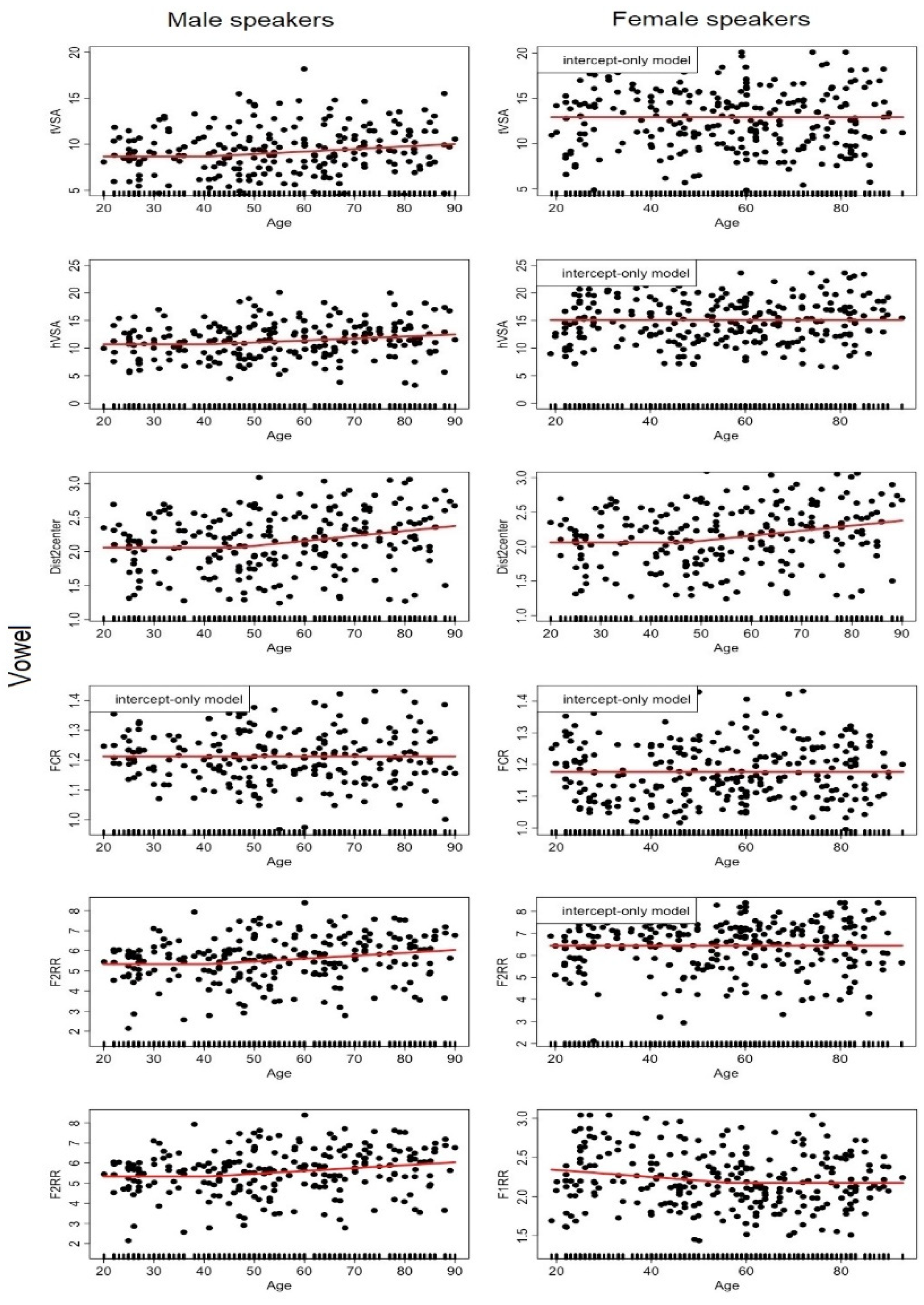
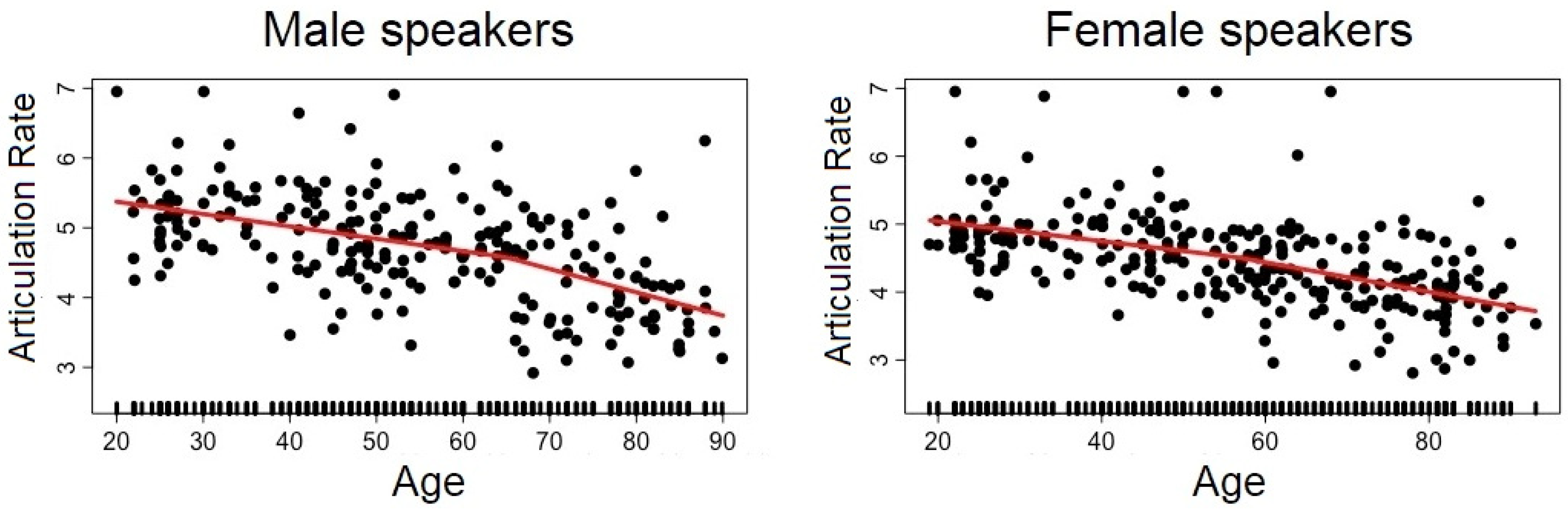
2.2.3. Articulation
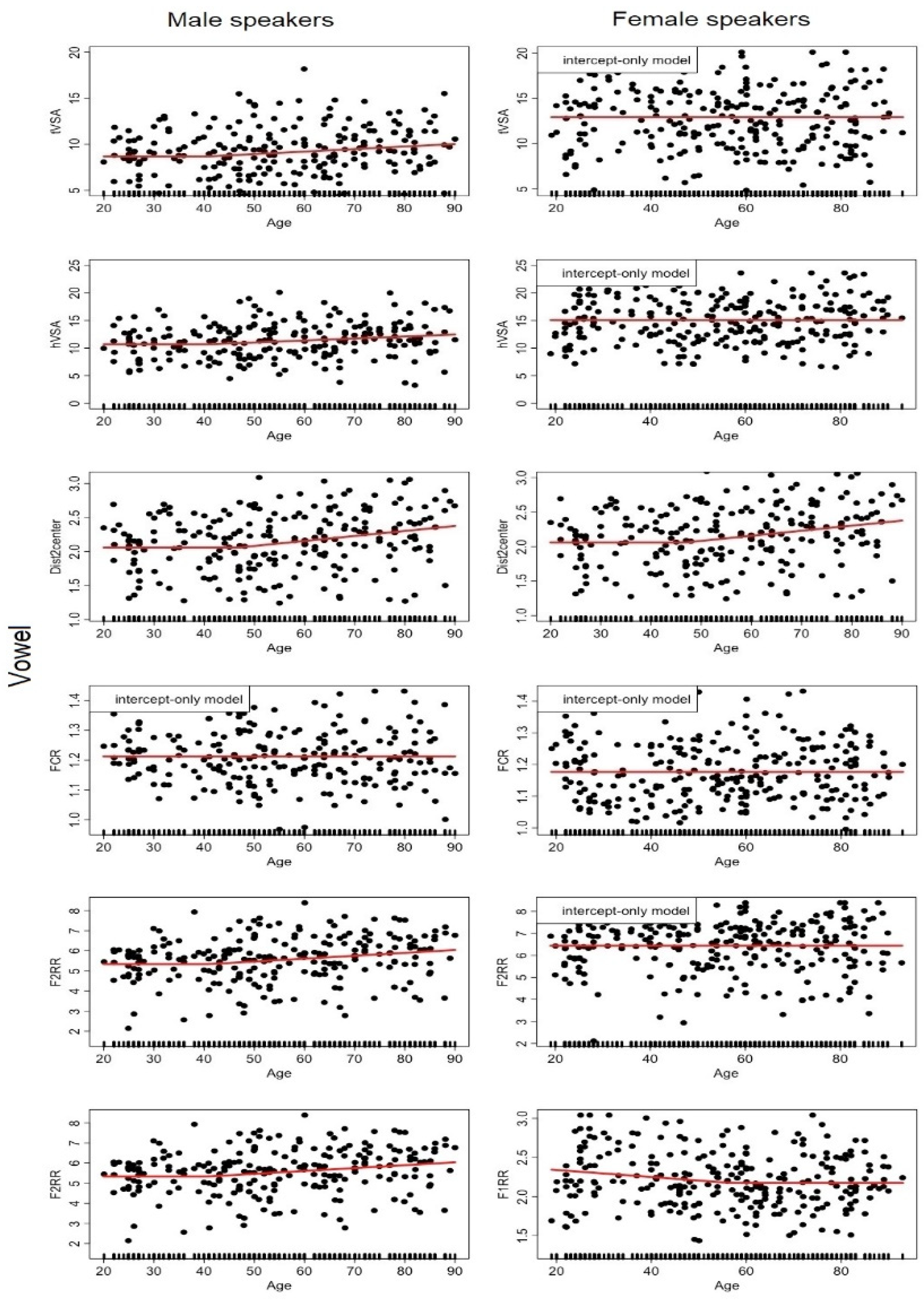
- Vowel space areas: tVSA represents the area of the triangle formed by the 3 peripheral vowels /i-a-u/, and hVSA capture the area of the heptagone formed by the 7 vowels /i, e, ɛ, a, ɔ, o, u/. Areas of the triangles are computed using the formula given below, and the heptagone area is obtained as the sum of the /ieu/, /euo/, /eɛo/, /ɛoɔ/ and /ɛaɔ/ triangles:with x = F1 et y = F2 (e.g., area(iau) = 0.5 × [F1i × (F2a − F2u)+F1a × (F2u − F2i) + F1u × (F2i − F2a)]Area(123) = 0.5 × [x1(y2 − y3) + x2(y3 − y1) + x3(y1 − y2)]
- Distance to the system centroid: In order to get a measure of acoustic dispersion of the vowel tokens relative to the center of the system, an F1–F2 grand mean (the system centroid) is computed over all vowel tokens (5 vowels × 3 repetitions) for each speaker to get the centroid of each speaker vowel space. Then, the Euclidian distances of each vowel token to this grand mean is computed. The degree of dispersion within the speaker’s acoustic space is then expressed as the mean of these individual distances to the centroid (Dist2center).
- Reduction in specific directions: Sapir et al. (2010) developed a series of measures to capture reduction that could occur in particular F1 and/or F2 dimensions according to the vowels. The FCR (formant centralization ratio) is expressed as (F2u + F2a + F1i + F1u)/(F2i + F1a) and rely on the hypothesis that hypoarticulation would result in an increase in the formant values included in the numerator of the fraction, while a decrease is predicted for the items of the denominator. In order to capture potential reduction in the mobility of the tongue, Sapir et al. (2007) also used a measure of reduction in the range of F2 values expressed as F2RR = F2i/F2u. Following the same idea, in Audibert and Fougeron (2012), we used a measure of reduction in the F1 dimension to capture reduction in oral opening, expressed as the F1 range ratio: F1RR = F1a/mean(F1i, F1u).
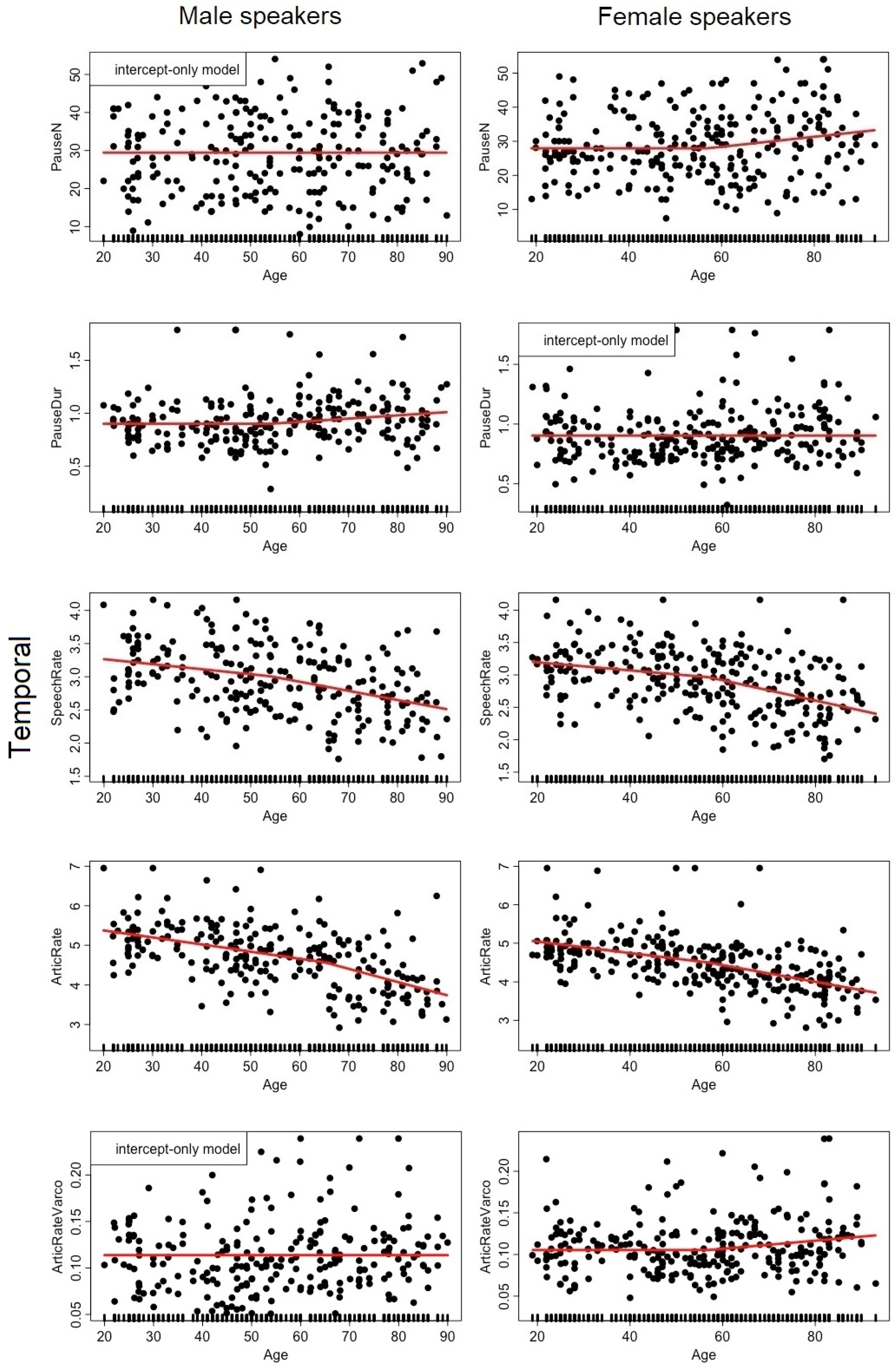
2.2.4. Temporal Organization
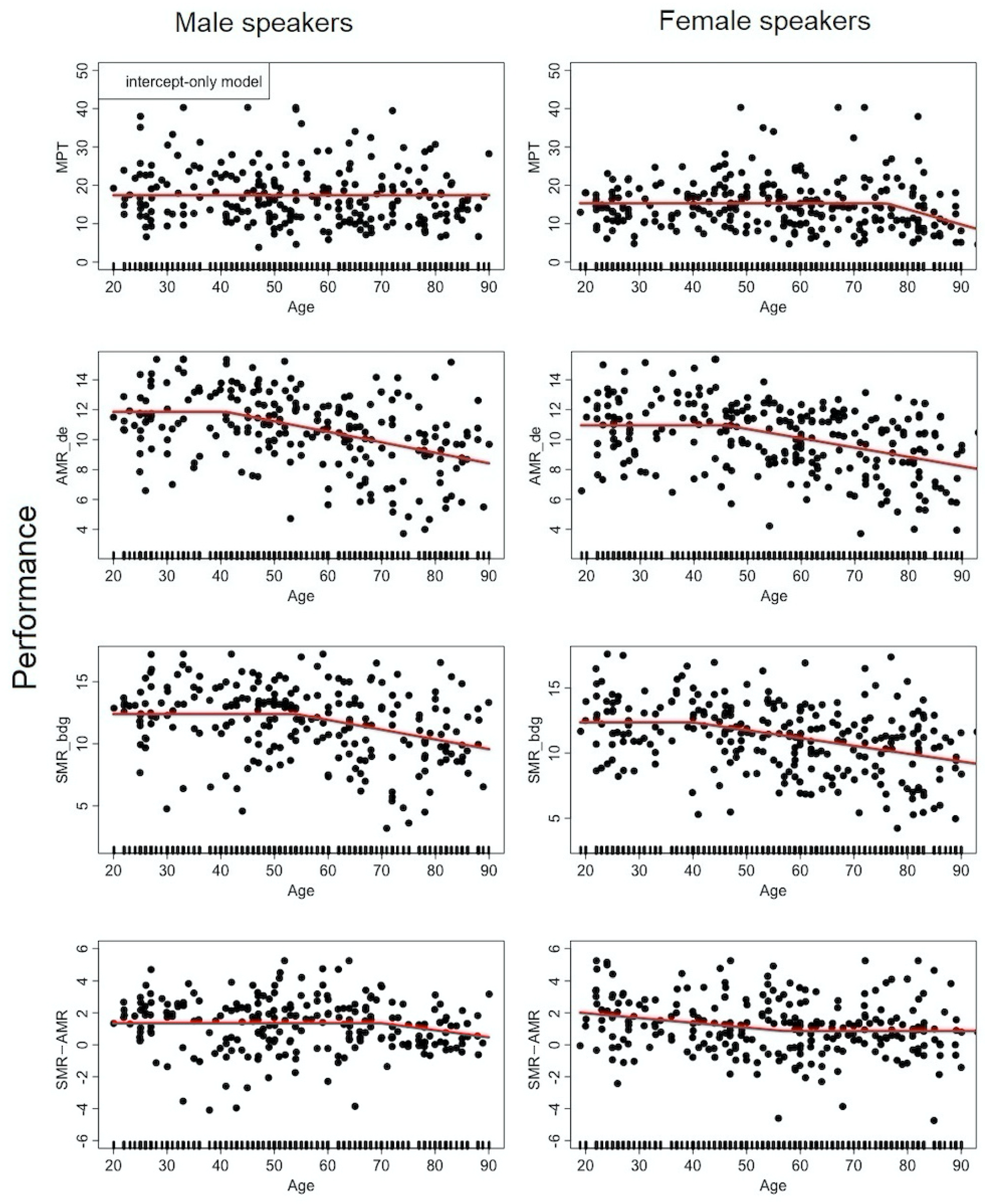
2.2.5. Performances in Speech-Like Tasks
2.3. Statistical Analysis
3. Results
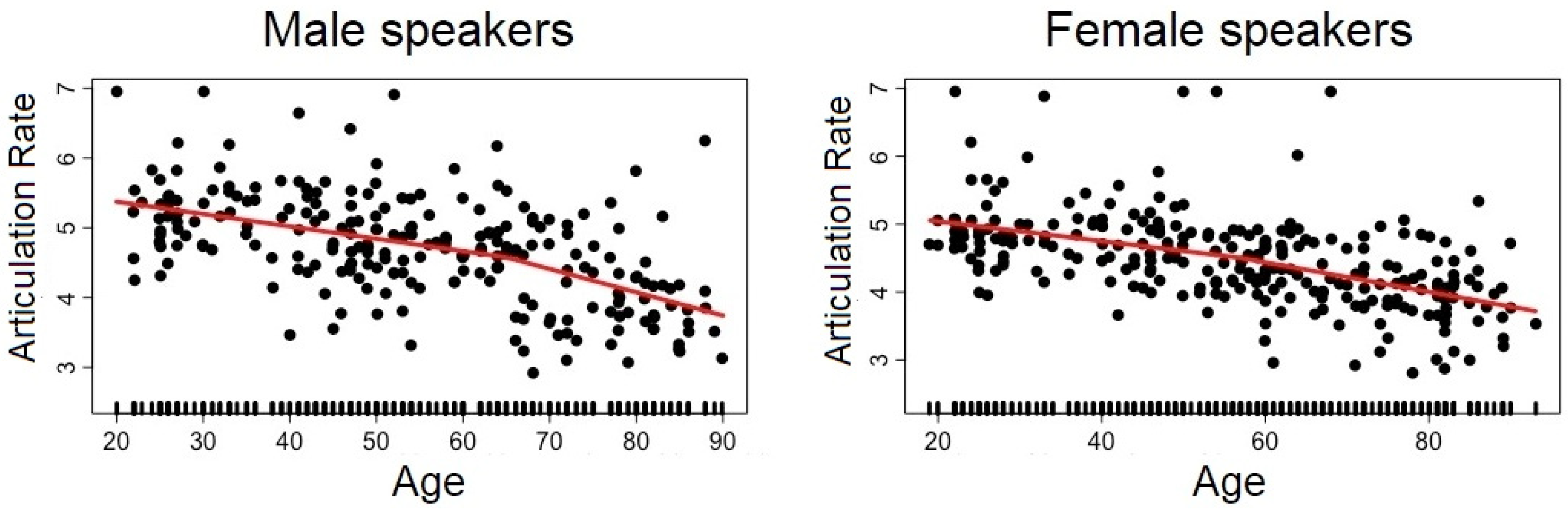
3.1. Analysis #1: How Does Each Speech Descriptor Vary as a Function of Age?
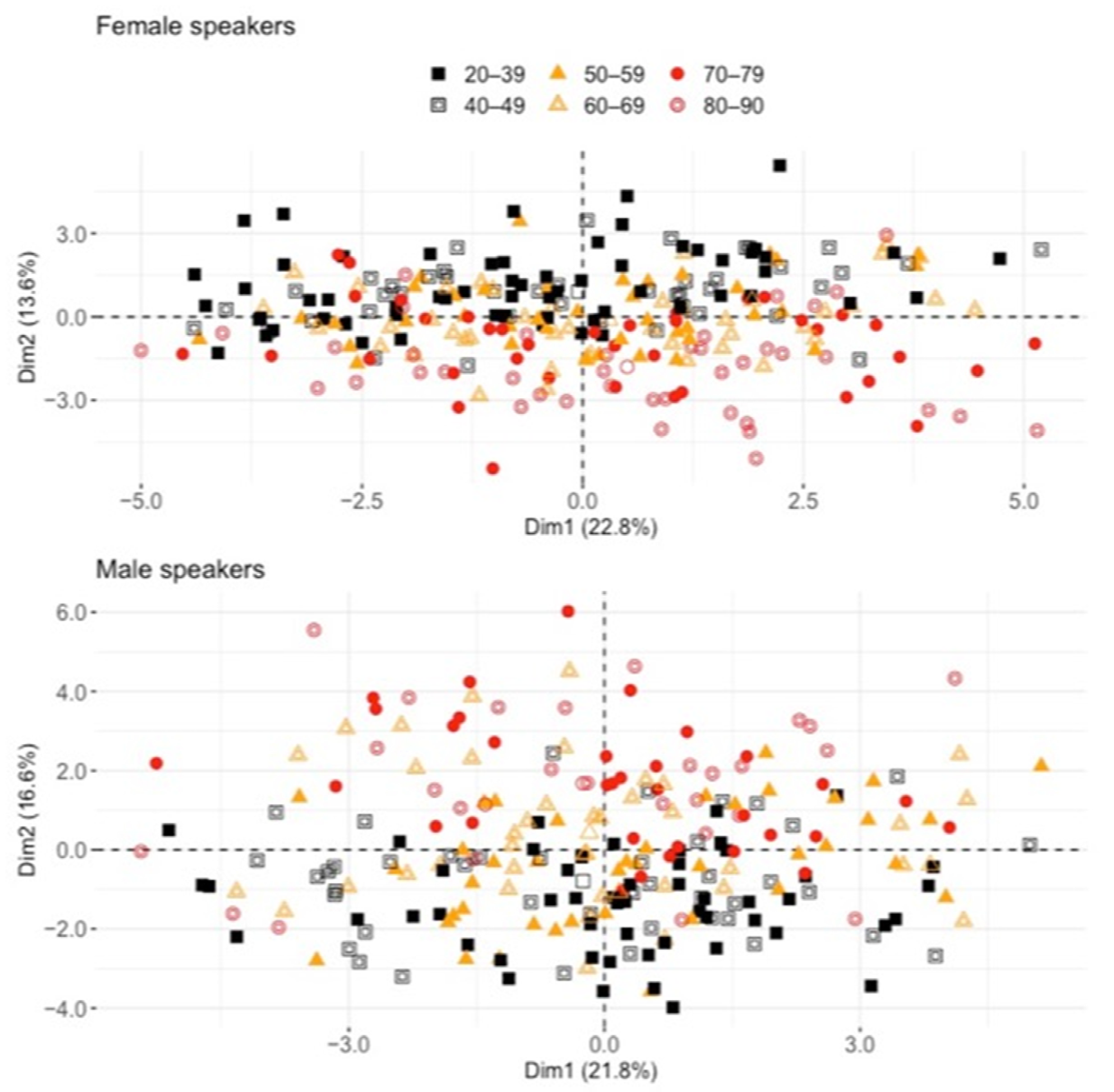
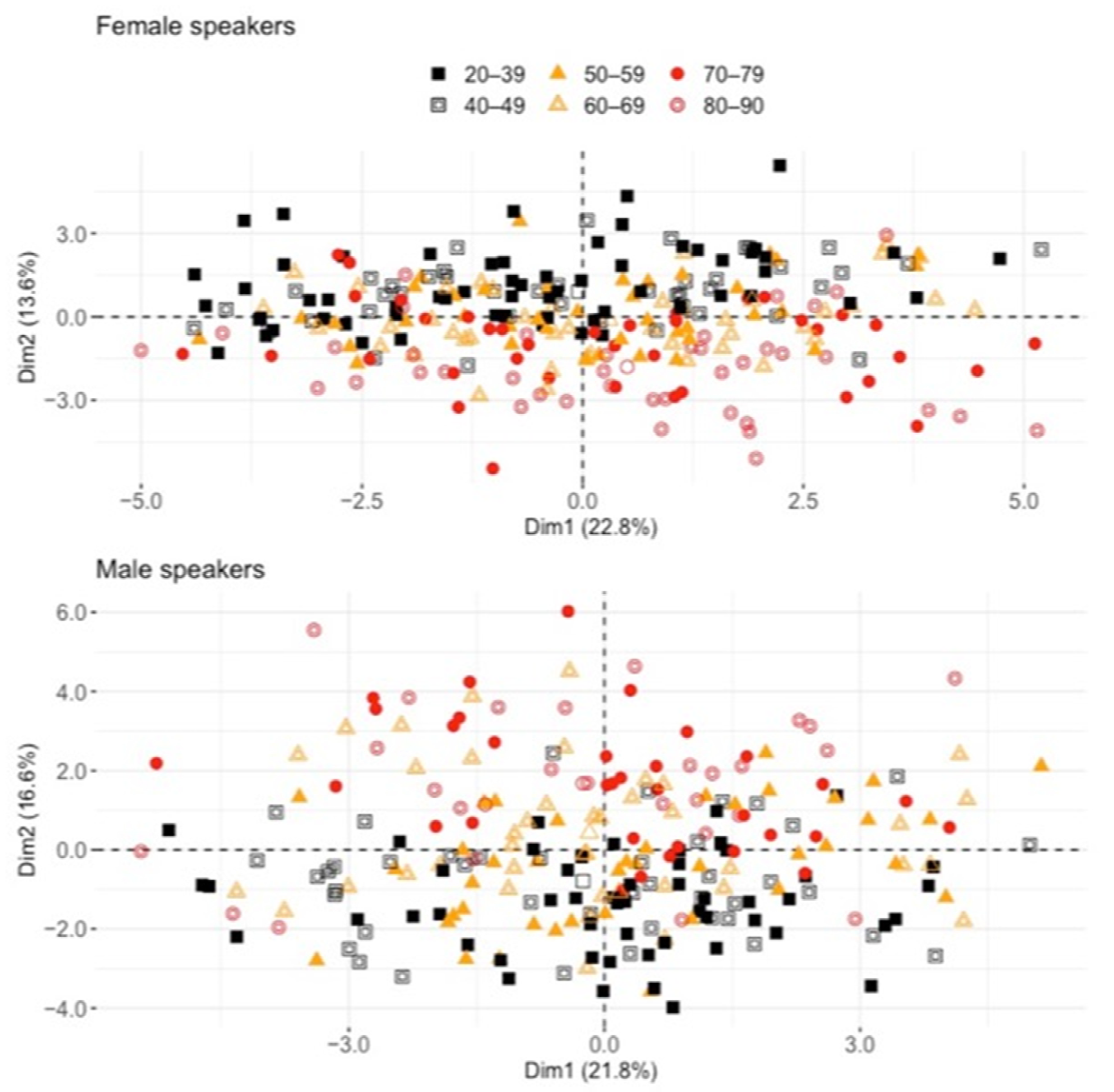
3.2. Analysis #2: How Is Chronological Age Predicted by all Descriptors Combined?
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Female Speakers | Male Speakers | |||||
|---|---|---|---|---|---|---|
| PC1 | PC2 | PC3 | PC1 | PC2 | PC3 | |
| Jitter | 0.08 (0.58) | −0.21 (4.24) | 0.40 (15.80) | −0.06 (0.21) | 0.24 (5.86) | −0.35 (12.45) |
| Shimmer | 0.29 (8.17) | −0.16 (2.56) | 0.26 (6.53) | −0.25 (6.14) | 0.23 (5.07) (6.85) | −0.28 (7.90) |
| HNR | −0.24 (5.51) | 0.16 (2.39) | −0.28 (8.07) | 0.21 (4.21) | −0.26 (6.85) | 0.36 (12.76) |
| SdF0 | 0.03 (0.11) | −0.28 (7.88) | 0.18 (3.12) | −0.01 (0.02) | 0.17 (2.76) | −0.03 (0.11) |
| CPPs | −0.18 (3.22) | 0.20 (0.04) | −0.31 (9.82) | 0.17 (3.02) | −0.24 (5.76) | 0.24 (5.79) |
| PitchMean | 0.02 (0.06) | 0.06 (0.35) | −0.16 (1.09) | −0.04 (0.16) | 0.16 (2.43) | 0.24 (5.84) |
| PitchVarco | 0.00 (0.00) | −0.09 (0.81) | −0.16 (2.48) | 0.04 (0.17) | −0.03 (0.00) | 0.29 (8.53) |
| MPT | −0.04 (0.16) | 0.09 (0.77) | −0.11 (1.18) | 0.07 (0.42) | −0.14 (1.98) | 0.02 (0.05) |
| SMR_bdg | −0.10 (1.09) | 0.35 (12.48) | −0.14 (1.99) | 0.14 (1.89) | −0.33 (11.31) | −0.09 (0.87) |
| AMR_de | −0.10 (0.92) | 0.36 (12.75) | −0.03 (0.12) | 0.11 (1.11) | −0.34 (11.33) | −0.03 (0.07) |
| SMR.AMR | −0.02 (0.07) | −0.21 (4.24) | −0.14 (2.01) | 0.09 (0.81) | −0.18 (3.18) | −0.14 (1.83) |
| PauseN | 0.02 (0.04) | −0.25 (6.12) | −0.33 (10.60) | −0.01 (0.00) | 0.13 (1.72) | 0.42 (17.71) |
| SpeechRate | −0.03 (0.09) | 0.43 (18.73) | 0.39 (15.47) | 0.04 (0.20) | −0.35 (12.38) | −0.38 (14.76) |
| PauseDur | −0.02 (0.03) | −0.10 (0.91) | −0.26 (6.69) | −0.00 (0.00) | 0.14 (1.90) | 0.01 (0.01) |
| Dist2center | −0.35 (12.5) | −0.12 (1.48) | 0.08 (0.70) | 0.37 (11.36) | 0.17 (2.86) | −0.07 (0.55) |
| tVSA | −0.40 (15.7) | −0.11 (1.23) | 0.13 (1.77) | 0.40 (16.15) | 0.18 (3.05) | −0.06 (0.34) |
| hVSA | −0.38 (14.7) | −0.14 (1.85) | 0.08 (0.57) | 0.35 (12.11) | 0.22 (4.78) | −0.09 (0.72) |
| F1RR | −0.31 (9.81) | −0.02 (0.05) | 0.17 (2.75) | 0.31 (9.59) | 0.06 (0.35) | −0.04 (0.17) |
| F2RR | −0.33 (10.76) | −0.13 (1.59) | 0.05 (0.23) | 0.36 (12.79) | 0.15 (2.09) | −0.08 (0.67) |
| FCR | 0.41 (16.38) | 0.08 (0.60) | −0.14 (2.08) | −0.41 (16.90) | −0.09 (0.87) | 0.08 (0.66) |
| ArticRate | −0.03 (0.09) | 0.44 (18.94) | 0.22 (4.80) | 0.05 (0.30) | −0.37 (11.35) | −0.21 (4.54) |
| ArticRateVarco | 0.02 (0.04) | 0.01 (0.05) | 0.15 (2.14) | −0.04 (0.14) | −0.00 (0.00) | −0.19 (3.67) |
References
- Albuquerque, Luciana, Ana Rita Valente, Fábio Barros, António Teixeira, Samuel Silva, Paula Martins, and Catarina Oliveira. 2021. The age effects on EP vowel production: An ultrasound pilot study. IberSPEECH, 245–49. [Google Scholar] [CrossRef]
- Albuquerque, Luciana, Catarina Oliveira, António Teixeira, Predo Sa-Couto, and Daniela Figueiredo. 2019. Age-related changes in European Portuguese vowel acoustics. Paper presented at INTERSPEECH, Graz, Styria, September 15–19. [Google Scholar]
- Albuquerque, Luciana, Catarina Oliveira, António Teixeira, Predo Sa-Couto, and Daniela Figueiredo. 2020. A comprehensive analysis of age and gender effects in European Portuguese oral vowels. Journal of Voice. [Google Scholar] [CrossRef]
- Audibert, Nicolas, and Cécile Fougeron. 2012. Distorsions de l’espace vocalique: Quelles mesures? Application à la dysarthrie. Actes des 29èmes Journées d’Etudes sur la Parole. Paper presented at JEP-TALN-RECITAL 2012, Grenoble, France, June 4–7; pp. 217–24. [Google Scholar]
- Baken, Ronald J. 2005. The aged voice: A new hypothesis. Journal of Voice 19: 317–25. [Google Scholar] [CrossRef]
- Benjamin, Barbaranne J. 1982. Phonological performance in gerontological speech. Journal of Psycholinguistic Research 11: 159–67. [Google Scholar]
- Bier, Stephen D., Catherine I. Watson, and Clare M. McCann. 2017. Dynamic measures of voice stability in young and old adults. Logopedics Phoniatrics Vocology 42: 51–61. [Google Scholar] [CrossRef]
- Boehmke, Brad, and Brandon Greenwell. 2020. Hands-On Machine Learning with R. Boca Raton: CRC Press, ISBN 13: 978-1138495685. [Google Scholar]
- Boersma, Paul, and David Weenink. 2019. Praat: Doing Phonetics by Computer. Version 6.1.02. Available online: http://www.praat.org/ (accessed on 20 October 2021).
- Bourbon, Angélina, and Anne Hermes. 2020. Have a break: Aging effects on sentence production and structuring in French. Paper presented at 12th International Seminar on Speech Production, New Haven, CT, USA, December 14–18. [Google Scholar]
- Caverlé, Maria W. J., and Adam P. Vogel. 2020. Stability, reliability, and sensitivity of acoustic measures of vowel space: A comparison of vowel space area, formant centralization ratio, and vowel articulation index. The Journal of the Acoustical Society of America 148: 1436–44. [Google Scholar] [CrossRef] [PubMed]
- Chicherio, C., T. Genoud-Prachex, F. Assal, and M. Laganaro. 2019. E-GeBAS: Electronic Geneva Bedside Aphasia Scale. Computer Program. Available online: https://www.unige.ch/fapse/logotools/fr/adultes (accessed on 20 October 2021).
- Cox, Violet O., and Mark Selent. 2015. Acoustic and respiratory measures as a function of age in the male voice. Journal of Phonetics and Audiology 1: 105. [Google Scholar] [CrossRef] [Green Version]
- De Jong, Nivja, and Ton Wempe. 2009. Praat script to detect syllable nuclei and measure speech rate automatically. Behavior Research Methods 41: 385–90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dehqan, Ali, and Ronald C. Scherer. 2013. Acoustic analysis of voice: Iranian teachers. Journal of Voice 27: 655. [Google Scholar] [CrossRef] [PubMed]
- Eckert, Penelope. 2017. Age as a sociolinguistic variable. In The Handbook of Sociolinguistics. Hoboken: Wiley, pp. 151–67. [Google Scholar] [CrossRef]
- Eichhorn, Julie T., Raymond D. Kent, Diane Austin, and Houri K. Vorperian. 2018. Effects of aging on vocal fundamental frequency and vowel formants in men and women. Journal of Voice 32: 644. [Google Scholar] [CrossRef]
- Fletcher, Annalise R., Megan J. McAuliffe, Kaitlin L. Lansford, and Julie M. Liss. 2015. The relationship between speech segment duration and vowel centralization in a group of older speakers. The Journal of the Acoustical Society of America 138: 2132–39. [Google Scholar] [CrossRef]
- Folstein, M. F., S. E. Folstein, and P. R. McHugh. 1975. “Mini-mental state”. A practical method for grading the cognitive state of patients for the clinician. Journal of Psychiatric Research 12: 189–98. [Google Scholar] [CrossRef]
- Fougeron, Cécile, Véronique Delvaux, Lucie Menard, and Marina Laganaro. 2018. The MonPaGe_HA database for the documentation of spoken French throughout adulthood. Paper presented at LREC 2018, Miyazaki, Japan, May 7–12; pp. 4301–6. [Google Scholar]
- Foulkes, Paul, and Gerard Docherty. 2006. The social life of phonetics and phonology. Journal of Phonetics 34: 409–38. [Google Scholar] [CrossRef]
- Foulkes, Paul, Gerard Docherty, Ghada Khattab, and Malcah Yaeger-Dror. 2010. Sound judgments: Perception of indexical features in children’s speech. In A Reader in Sociophonetics. New York: De Gruyter Mouton, pp. 327–56. [Google Scholar]
- Fox, Robert Allen, and Ewa Jacewicz. 2017. Reconceptualizing the vowel space in analyzing regional dialect variation and sound change in American English. The Journal of the Acoustical Society of America 142: 444–59. [Google Scholar] [CrossRef] [Green Version]
- Fraile, Rubén, and Juan Ignacio Godino-Llorente. 2014. Cepstral peak prominence: A comprehensive analysis. Biomedical Signal Processing and Control 14: 42–54. [Google Scholar] [CrossRef] [Green Version]
- Friedman, Jérome H. 1991. Multivariate Adaptive Regression Splines. The Annals of Statistics 19: 1–67. [Google Scholar] [CrossRef]
- Fuchs, Susanne, Annette Gerstenberg, and Laura Koening. 2021. Changes in phonetic detail as a matter of discourse and aging: Evidence from a longitudinal study on French. Paper presented at 2nd Workshop on Speech Perception and Production across the Lifespan (SPPL2020), London, UK, December 14–18. [Google Scholar]
- Gahl, Susanne, and R. Harald Baayen. 2019. Twenty-eight years of vowels: Tracking phonetic variation through young to middle age adulthood. Journal of Phonetics 74: 42–54. [Google Scholar] [CrossRef] [Green Version]
- Gerstenberg, Annette, Susanne Fuchs, Julie Marie Kairet, Johannes Schroeder, and Claudia Frankenberg. 2018. A cross-linguistic, longitudinal case study of pauses and interpausal units in spontaneous speech corpora of older speakers of German and French. Speech Prosody 9: 211–15. [Google Scholar]
- Goozée, Justine, Dayna Stephenson, Bruce Murdoch, Ross Darnell, and Leonard Lapointe. 2005. Lingual kinematic strategies used to increase speech rate: Comparison between younger and older adults. Clinical Linguistics & Phonetics 19: 319–34. [Google Scholar]
- Goy, Huiwen, Kathleen M. Pichora-Fuller, Pascal Van Lieshout, and Kathryn Arehart. 2013. Quality of older voices processed by hearing aids: Acoustic factors explaining inter-talker differences. Paper presented at Meetings on Acoustics ICA2013, Narbonne, France, September 18–20; vol. 19, p. 060133. [Google Scholar]
- Harnsberger, James D., Raoul Shrivastav, W. S. Brown Jr., Howard Rothman, and Harry Hollien. 2008. Speaking rate and fundamental frequency as speech cues to perceived age. Journal of Voice 22: 58–69. [Google Scholar] [CrossRef]
- Harrington, Jonathan. 2006. An acoustic analysis of ‘happy-tensing’ in the queen’s Christmas Broadcasts. Journal of Phonetics 34: 439–57. [Google Scholar] [CrossRef] [Green Version]
- Harrington, Jonathan, Sallyane Palethorpe, and Catherine I. Watson. 2007. Age related changes in fundamental frequency and formants: A longitudinal study of four speakers. Paper presented at Interspeech 2007, Antwerp, Belgium, August 27–31; pp. 2753–56. [Google Scholar] [CrossRef]
- Hawkins, Sarah, and Jonathan Midgley. 2005. Formant frequencies of RP monophthongs in four age groups of speakers. Journal of the International Phonetic Association 35: 183–99. [Google Scholar] [CrossRef] [Green Version]
- Hermes, Anne, Jane Mertens, and Doris Mücke. 2018. Age-related Effects on Sensorimotor Control of Speech Production. Paper presented at Interspeech, Hyderabad, India, September 2–6; pp. 1526–30. [Google Scholar]
- Hillenbrand, James, Ronald A. Cleveland, and Robert L. Erickson. 1994. Acoustic correlates of breathy vocal quality. Journal of Speech, Language, and Hearing Research 37: 769–78. [Google Scholar] [CrossRef]
- Horton, William S., Daniel H. Spieler, and Elizabeth Shriberg. 2010. A corpus analysis of patterns of age related change in conversational speech. Psychology and Aging 25: 708. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jacewicz, Ewa, Robert A. Fox, Caitlin O’Neill, and Joseph Salmons. 2009. Articulation rate across dialect, age, and gender. Language Variation and Change 21: 233–56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karlsson, Fredrik, and Jan van Doorn. 2012. Vowel formant dispersion as a measure of articulation proficiency. The Journal of the Acoustical Society of America 132: 2633–41. [Google Scholar] [CrossRef] [Green Version]
- Kassambara, Albukadel, and Fabian Mundt. 2020. ‘factoextra’. Extract and Visualize the Results of Multivariate Data Analyses. Package v. 1.0.7. Available online: https://cran.r-project.org/web/packages/factoextra/index.html (accessed on 20 October 2021).
- Knuijt, Simone, Johanna G. Kalf, Baziel G. van Engelen, Bert J. M. de Swart, and Alexander C. H. Geurts. 2017. The Radboud dysarthria assessment: Development and clinimetric evaluation. Folia Phoniatrica et Logopaedica 69: 143–53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kreiman, Jody, and Diana Sidtis. 2011. Foundations of Voice Studies: An Interdisciplinary Approach to Voice Production and Perception. Hoboken: John Wiley & Sons. [Google Scholar]
- Laganaro, Marina, Cécile Fougeron, Michaela Pernon, Nathalie Levêque, Stéphanie Borel, Maryll Fournet, Sabina Catalano Chiuvé, Ursula Lopez, Roland Trouville, Lucie Ménard, and et al. 2021. Sensitivity and specificity of an acoustic- and perceptual-based tool for assessing motor speech disorders in French: The MonPaGe-screening protocol. Clinical Linguistics & Phonetics, 1–16. [Google Scholar] [CrossRef]
- Linville, Sue Ellen. 2001. Vocal Aging. San Diego: Singular Thomson Learning. [Google Scholar]
- Linville, Sue Ellen, and Jennifer Rens. 2001. Vocal tract resonance analysis of aging voice using long-term average spectra. Journal of Voice 15: 323–30. [Google Scholar] [CrossRef]
- Liss, Julie. M., Garry Weismer, and John C. Rosenbek. 1990. Selected acoustic characteristics of speech production in very old males. Journal of Gerontology 45: 35–45. [Google Scholar] [CrossRef] [PubMed]
- Maslan, Jonathan, Xiaoyan Leng, Catherine Rees, David Blalock, and Susan G. Butler. 2011. Maximum phonation time in healthy older adults. Journal of Voice 25: 709–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Milborrow, Stephen. 2021. Earth: Multivariate Adaptive Regression Splines. R Package version 5.3.1. Available online: https://cran.r-project.org/web/packages/earth/index.html (accessed on 20 October 2021).
- Morris, Richard J., and William S. Brown. 1987. Age-related voice measures among adult women. Journal of Voice 1: 38–43. [Google Scholar] [CrossRef]
- Mücke, Doris, Tabea Thies, Jane Mertens, and Anne Hermes. 2021. 2021 Age-related effects of prosodic prominence in vowel articulation. Paper presented at 12th International Seminar on Speech Production, New Haven, CT, USA, December 14–18. [Google Scholar]
- Neel, Amy T. 2008. Vowel space characteristics and vowel identification accuracy. Journal of Speech Language and Hearing Research 51: 574–85. [Google Scholar] [CrossRef]
- Nishio, Masaki, and Seiji Niimi. 2008. Changes in speaking fundamental frequency characteristics with aging. Folia Phoniatrica et Logopaedica 60: 120–27. [Google Scholar] [CrossRef]
- Oliveira, Caterina, Ana Rita Valente, Luciana Albuquerque, Fábio Barros, Paula Martins, Samuel Silva, and António Teixeira. 2021. The Vox Senes project: A study of segmental changes and rhythm variations on European Portuguese aging voice. IberSPEECH, 135–38. [Google Scholar] [CrossRef]
- Pernon, Michaela, Nathalie Levêque, Véronique Delvaux, Fréderic Assal, Stéphanie Borel, Cécile Fougeron, Roland Trouville, and Marina Laganaro. 2020. MonPaGe, un outil de screening francophone informatise d’évaluation perceptive et acoustique des troubles moteurs de la parole (dysarthries, apraxie de la parole). Rééducation Orthophonique 281: 171–97. [Google Scholar]
- Pierce, John. E., Susan Cotton, and Alison Perry. 2013. Alternating and sequential motion rates in older adults. International Journal of Language & Communication Disorders 48: 257–64. [Google Scholar]
- Quené, Hugo. 2013. Longitudinal trends in speech tempo: The case of Queen Beatrix. The Journal of the Acoustical Society of America 133: EL452–EL457. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. 2021. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, ISBN 3-900051-07-0. Available online: https://www.R-project.org/ (accessed on 20 October 2021).
- Ramig, Lorraine A. 1983. Effects of physiological aging on speaking and reading rates. Journal of Communication Disorders 16: 217–26. [Google Scholar] [CrossRef]
- Ramig, Lorraine A., and Robert L. Ringel. 1983. Effects of physiological aging on selected acoustic characteristics of voice. Journal of Speech Language and Hearing Research 26: 22–30. [Google Scholar] [CrossRef]
- Rastatter, Michael P., Richard A. McGuire, Joseph Kalinowski, and A. Stuart. 1997. Formant frequency characteristics of elderly speakers in contextual speech. Folia Phoniatrica et Logopaedica 49: 1–8. [Google Scholar] [CrossRef] [PubMed]
- Reubold, Ulrich, Jonathan Harrington, and Felicitas Kleber. 2010. Vocal aging effects on F0 and the first formant: A longitudinal analysis in adult speakers. Speech Communication 52: 638–51. [Google Scholar] [CrossRef] [Green Version]
- Sadagopan, Neeraja, and Anne Smith. 2013. Age differences in speech motor performance on a novel speech task. Journal of Speech, Language, and Hearing Research 56: 1552–66. [Google Scholar] [CrossRef]
- Sapir, Shimon, Jennifer L. Spielman, Lorraine O. Ramig, Brad Story, and Cynthia Fox. 2007. Effects of intensive voice treatment (the Lee SilvermanVoice Treatment [LSVT]) on vowel articulation in dysarthric individuals with idiopathic Parkinsondisease: Acoustic and perceptual findings. Journal of Speech-Language and Hearing Research 50: 899–912. [Google Scholar] [CrossRef]
- Sapir, Shimon, Lorraine O. Ramig, Jennifer L. Spielman, and Cynthia Fox. 2010. Formant centralization ratio: A proposal for a new acoustic measure of dysarthric speech. Journal of Speech Language and Hearing Research 53: 114–25. [Google Scholar] [CrossRef]
- Schötz, Susanne. 2007. Acoustic analysis of adult speaker age. In Speaker Classification I. Berlin/Heidelberg: Springer, pp. 88–107. [Google Scholar]
- Signorell, Andri, Ken Aho, Andreas Alfons, Nanina Anderegg, Tomas Aragon, Chandima Arachchige, Antti Arppe, Adrian Baddeley, Kamil Barton, Ben Bolker, and et al. 2021. DescTools: Tools for Descriptive Statistics. R Package Version 0.99.42. Available online: https://cran.r-project.org/package=DescTools (accessed on 20 October 2021).
- Speyer, Renée, Hans Bogaardt, Valéria Lima Passos, Nel Roodenburg, Anne Zumach, Mariëlle Heijnen, Laura Baijens, Stijn Fleskens, and Jan Brunings. 2010. Maximum Phonation Time: Variability and Reliability. Journal of Voice 24: 281–84. [Google Scholar] [CrossRef]
- Stathopoulos, Elaine T., Jessica E. Huber, and Joan E. Sussman. 2011. Changes in acoustic characteristics of the voice across the life span: Measures from individuals 4–93 years of age. Journal of Speech, Language, and Hearing Research 54: 1011–21. [Google Scholar] [CrossRef]
- Story, Brad H., and Kate Bunton. 2017. Vowel space density as an indicator of speech performance. The Journal of the Acoustical Society of America 141: EL458. [Google Scholar] [CrossRef] [Green Version]
- Sweeting, Patricia M., and Ronald J. Baken Ronald. 1982. Voice onset time in a normal-aged population. Journal of Speech Language and Hearing Research 25: 129–34. [Google Scholar] [CrossRef]
- Torre, Peter III, and Jessica A. Barlow. 2009. Age-related changes in acoustic characteristics of adult speech. Journal of Communication Disorders 42: 324–33. [Google Scholar] [CrossRef] [PubMed]
- Trouville, Roland, Véronique Delvaux, Cécile Fougeron, and Marina Laganaro. 2021. Logiciel D’évaluation de la Parole (Version Screening) MonPaGe-2.0.s. Computer Program. Available online: https://lpp.in2p3.fr/monpage/ (accessed on 20 October 2021).
- Walker, Neff, David A. Philbin, and Arthur D. Fisk. 1997. Age-related differences in movement control: Adjusting submovement structure to optimize performance. The Journals of Gerontology Series B: Psychological Sciences and Social Sciences 52: 40–53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Watson, Peter J., and Benjamin Munson. 2007. A comparison of vowel acoustics between older and younger adults. Paper presented at 16th International Congress of Phonetic Sciences, Saarbrücken, Germany, August 6–10; pp. 561–64. [Google Scholar]
- Weismer, Gary. 1984. Acoustic descriptions of dysarthric speech: Perceptual correlates and physiological inferences. Seminars in Speech and Language 5: 293–314. [Google Scholar] [CrossRef]
- Weismer, Gary, and Davida Fromm. 1983. Acoustic analysis of geriatric utterances: Segmental and non-segmental characteristics which relate to laryngeal function. In Vocal Fold Physiology: Contemporary Research and Clinical Issues. Edited by Diane M. Bless and James H. Abbs. San Diego: College-Hill, pp. 317–32. [Google Scholar]
- Wohlert, Amy B., and Anne Smith. 1998. Spatiotemporal stability of lip movements in older adult speakers. Journal of Speech Language and Hearing Research 41: 41–50. [Google Scholar] [CrossRef] [PubMed]
| Decade | N | Chronological Age | ||
|---|---|---|---|---|
| Female | Male | Female | Male | |
| [20–29] | 41 | 30 | 24.8 (2.6) | 25.4 (2.2) |
| [30–39] | 20 | 22 | 34.5 (2.8) | 34 (2.9) |
| [40–49] | 43 | 43 | 44.7 (2.9) | 45 (2.9) |
| [50–59] | 40 | 39 | 54.9 (3) | 53.7 (2.9) |
| [60–69] | 44 | 41 | 63.6 (3) | 64.4 (2.7) |
| [70–79] | 37 | 32 | 74.5 (2.8) | 74.6 (3.1) |
| [80–93] | 40 | 28 | 84.3 (3.3) | 84.3 (3.3) |
| total | 265 | 235 | 55.7 (19.9) | 55 (18.6) |
| Descriptor | Task | Female Speakers | Male Speakers | |||
|---|---|---|---|---|---|---|
| Mean (stdev) | P25–P50–P75 | Mean (stdev) | P25–P50–P75 | |||
| Voice | Jitter (%) | Sustained /a/ (2 s.) | 0.28 (0.20) | 0.17–0.22–0.33 | 0.32 (0.21) | 0.20–0.26–0.36 |
| Shimmer (%) | Sustained /a/ (2 s.) | 3.52 (2.75) | 1.51–2.44–4.83 | 4.86 (2.79) | 2.67–4.2–6.57 | |
| HNR (dB) (Harmonic to Noise Ratio) | Sustained /a/ (2 s.) | 19.56 (3.34) | 18–20.42–21.91 | 17.53 (4.21) | 15.41–18.25–20.72 | |
| SdF0 (Hz) (f0 Standard deviation) | Sustained /a/ (2 s.) | 4.04 (2.4) | 2.4–3.43–4.83 | 3.20 (2.36) | 1.64–2.44–4 | |
| CPPs (dB) smoothed Cepstral Peak Prominence | Sustained /a/ (2 s.) | 15.33 (2.61) | 13.69–15.29–16.99 | 17.73 (2.87) | 15.94–17.92–19.92 | |
| Pitch | PitchMean (Hz) | Read sentence | 208 (25.97) | 190.7–206.8–226.5 | 130.25 (25.67) | 111.77–126.54–141.65 |
| PitchVarco (Pitch Coefficient of Variation) | Read sentence | 0.14 (0.05) | 0.11–0.14–0.17 | 0.15 (0.05) | 0.11–0.14–0.17 | |
| Vowel articulation | tVSA (Bark2) (triangular /iau/ Vowel Space Area) | Read/repeated pseudoword | 12.89 (3.48) | 10.34–12.89–15.38 | 9.14 (2.72) | 7.47–9.09–10.86 |
| hVSA (Bark2) (heptagonal /ieɛaɔou/) Vowel Space Area) | Read/repeated pseudoword | 15.07 (4.01) | 12.16–14.87–18.06 | 11.29 (3.18) | 9.09–11.27–13.34 | |
| Dist2center (Bark) (Distance to centroid) | Read/repeated pseudoword | 2.60 (0.77) | 2.32–2.61–2.86 | 2.15 (0.42) | 1.88–2.17–2.45 | |
| FCR (Bark) (Formant Centralization Ratio) | Read/repeated pseudoword | 1.18 (0.09) | 1.11–1.17–1.24 | 1.21 (0.09) | 1.15–1.21–1.27 | |
| F2RR (Bark) (F2 Range Ratio) | Read/repeated pseudoword | 6.44 (1.13) | 5.77–6.65–7.25 | 5.56 (1.11) | 4.89–5.67–6.31 | |
| F1RR (Bark) (F1 Range Ratio) | Read/repeated pseudoword | 2.21 (0.35) | 1.98–2.18–2.47 | 2.21 (0.29) | 1.91–2.08–2.25 | |
| Temporal | PauseN (Number of Pauses) | Read text | 29.08 (9.79) | 22–29–36 | 29.45 (10.32) | 22–30–37 |
| PauseDur (s) (Duration of Pauses) | Read text | 0.90 (0.22) | 0.75–0.87–1.01 | 0.93 (0.22) | 0.79–0.9–1.04 | |
| SpeechRate (syll/s) | Read text | 2.9 (0.49) | 2.57–2.94–3.25 | 2.95 (0.52) | 2.59–2.94–3.31 | |
| ArticRate (syll/s) (Articulation Rate) | Read text | 4.47 (0.67) | 4.06–4.45–4.85 | 4.7 (0.76) | 4.22–4.73–5.18 | |
| ArticRateVarco (Articiulation Rate Coefficient of Variation) | Read text | 0.11 (0.32) | 0.09–0.11–0.12 | 0.11 (0.04) | 0.09–0.11–0.13 | |
| Max performances | MPT (s) (Maximum Phonation Time) | Sustained /a/ (max) | 14.80 (6.37) | 10.48–14.12–18.04 | 17.41 (7.36) | 11.95–16.14–21.39 |
| AMR_de (syll/s) (Alternative Motion Rate) | Fast repetition task | 10.08 (2.28) | 8.55–10.42–11.57 | 10.69 (2.46) | 9.31–10.84–12.37 | |
| SMR_bdg (syll/s) (Sequencial Motion Rate) | Fast repetition task | 11.25 (2.63) | 9.47–11.50–13 | 11.74 (2.86) | 9.45–12.02–13.56 | |
| SMR-AMR (syll/s) | Fast repetition task | 1.14 (1.71) | −0.01–1.06–2.11 | 1.25 (1.60) | 0.24–1.34–2.28 | |
| Descriptor | Female Speakers | Male Speakers | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | Hinge Fun | Intercept | β | R2 | Hinge Fun | Intercept | β | ||
| voice | Jitter | 0.08 | h(x − 57) | 0.24 | 0.006 | 0.08 | h(x − 54) | 0.28 | 0.005 |
| Shimmer | 0.08 | h(x − 57) | 2.94 | 0.08 | 0.08 | h(65 − x) | 5.61 | −0.05 | |
| HNR | 0.02 | h(50 − x) | 19.25 | 0.05 | 0.04 | h(65 − x) | 16.72 | 0.06 | |
| SdF0 | 0.13 | h(x − 57) | 3.39 | 0.08 | 0.15 | h(x − 65) | 2.71 | 0.14 | |
| CPPs | 0.05 | h(40 − x) h(x − 57) | 15.99 | −0.07 −0.06 | 0.15 | h(x − 50) | 18.67 | −0.09 | |
| Pitch | PitchMean | 0.03 | h(40 − x) | 205.93 | 0.75 | 0.12 | h(73 − x) h(x − 36) | 90.97 | 0.74 1.20 |
| PitchVarco | 0.04 | h(75 − x) | 0.14 | 0.00 | 0.00 | - | 0.15 | - | |
| Vowel articulation | tVSA | 0.00 | - | 12.90 | - | 0.02 | h(x − 41) | 8.69 | 0.03 |
| hVSA | 0.00 | - | 15.09 | - | 0.03 | h(x − 41) | 10.69 | 0.04 | |
| Dist2center | 0.00 | - | 2.60 | - | 0.06 | h(x − 47) | 2.06 | 0.007 | |
| FCR | 0.00 | - | 1.18 | 0.00 | - | 1.21 | - | ||
| F2RR | 0.00 | - | 6.44 | - | 0.04 | h(x − 41) | 5.34 | 0.01 | |
| F1RR | 0.02 | h(57 − x) | 2.17 | 0.004 | 0.00 | - | 2.10 | - | |
| temporal | PauseN | 0.02 | h(x − 57) | 27.94 | 0.15 | 0.00 | - | 29.45 | - |
| PauseDur | 0.00 | - | 0.90 | - | 0.02 | h(x − 54) | 0.90 | 0.00 | |
| SpeechRate | 0.19 | h(x − 57) h(57 − x) | 2.96 | −0.02 0.01 | 0.16 | h(x − 54) h(54 − x) | 3.01 | −0.01 0.01 | |
| ArticRate | 0.28 | h(x − 57) h(57 − x) | 4.50 | −0.02 0.02 | 0.30 | h(x − 65) h(65 − x) | 4.58 | −0.03 0.02 | |
| ArticRateVarco | 0.02 | h(x − 57) | 0.11 | 0.00 | 0.00 | - | 0.12 | - | |
| performances | MPT | 0.04 | h(x − 76) | 15.32 | −0.40 | 0.00 | - | 17.41 | - |
| AMR_de | 0.15 | h(x − 46) | 10.96 | −0.06 | 0.19 | h(x − 41) | 11.86 | −0.07 | |
| SMR_bdg | 0.14 | h(x − 40) | 12.36 | −0.06 | 0.09 | hx − 54) | 12.39 | −0.08 | |
| SMR-AMR | 0.05 | h(x − 57) | 0.86 | 0.03 | 0.01 | h(x − 70) | 1.35 | −0.04 | |
| Female Speakers (R2 = 0.55|Intercept = 55.31) | Male Speakers (R2 = 0.47|Intercept = 51.4) | ||||
|---|---|---|---|---|---|
| Fun Nb | Hinge Functions | β | Fun Nb | hinge functions | β |
| 1 | h(ArticRate-5.08) | 25.20 | 1 | h(ArticRate-4.73) | −7.99 |
| 2 | h(4.63-SdF0) | −3.39 | 2 | h(4.73-ArticRate) | 16.18 |
| 3 | h(14.35-SMR_bdg) | 1.25 | 3 | h(2.43-SdF0) | −6.00 |
| 4 | h(Dist2center-2.95) | 31.71 | 4 | PauseN*h(0.11-ArticRateVarco) | −5.63 |
| 5 | h(tVSA-16.90) | −9/82 | 5 | h(Shimmer-4.2)*SdF0 | 0.36 |
| 6 | h(16.90-tVSA) | 1.82 | 6 | HNR*h(Dist2center-2.17) | 1.07 |
| 7 | h(hVSA-21.24) | 7.95 | |||
| 8 | h(21.24-hVSA) | −1.46 | |||
| 9 | h(Shimmer-1.46) | 1.58 | |||
| 10 | h(MPT-13.01 | 0.39 | |||
| 11 | h(13.01-MPT) | 1.21 | |||
| 12 | h(ArticRate-4.13) | −22.19 | |||
| 13 | h(F2RR-5.23) | 3.29 | |||
| Female Speakers | Male Speakers | ||
|---|---|---|---|
| Meaningful Descriptor | Significance (%) | Meaningful Descriptor | Significance (%) |
| ArticRate | 100 | ArticRate | 100 |
| SdF0 | 62.2 | Shimmer | 62.1 |
| SMR_bdg | 50.9 | SdF0 | 62.1 |
| Dist2center | 49.8 | HNR | 53.2 |
| tVSA | 49.8 | Dist2center | 53.2 |
| hVSA | 39.3 | PauseN | 30.7 |
| Shimmer | 34.6 | ArticRateVarco | 30.7 |
| F2RR | 21.9 | ||
| MPT | 17.5 | ||
| PC 1 | PC 2 | PC 3 | ||
|---|---|---|---|---|
| F | Variance | 2.24 | 1.73 | 1.43 |
| Variance (%) | 22.76 | 13.56 | 9.24 | |
| Cumulative Variance (%) | 22.76 | 36.33 | 45.57 | |
| M | Variance | 2.19 | 1.91 | 1.43 |
| Variance (%) | 21.83 | 16.67 | 9.26 | |
| Cumulative Variance (%) | 21.83 | 38.48 | 47.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fougeron, C.; Guitard-Ivent, F.; Delvaux, V. Multi-Dimensional Variation in Adult Speech as a Function of Age. Languages 2021, 6, 176. https://doi.org/10.3390/languages6040176
Fougeron C, Guitard-Ivent F, Delvaux V. Multi-Dimensional Variation in Adult Speech as a Function of Age. Languages. 2021; 6(4):176. https://doi.org/10.3390/languages6040176
Chicago/Turabian StyleFougeron, Cécile, Fanny Guitard-Ivent, and Véronique Delvaux. 2021. "Multi-Dimensional Variation in Adult Speech as a Function of Age" Languages 6, no. 4: 176. https://doi.org/10.3390/languages6040176
APA StyleFougeron, C., Guitard-Ivent, F., & Delvaux, V. (2021). Multi-Dimensional Variation in Adult Speech as a Function of Age. Languages, 6(4), 176. https://doi.org/10.3390/languages6040176