The Role of Acoustic Similarity and Non-Native Categorisation in Predicting Non-Native Discrimination: Brazilian Portuguese Vowels by English vs. Spanish Listeners


Abstract
1. Introduction
The Present Study
2. Cross-Language Acoustic Comparisons
2.1. Participants
2.2. Stimuli and Procedure
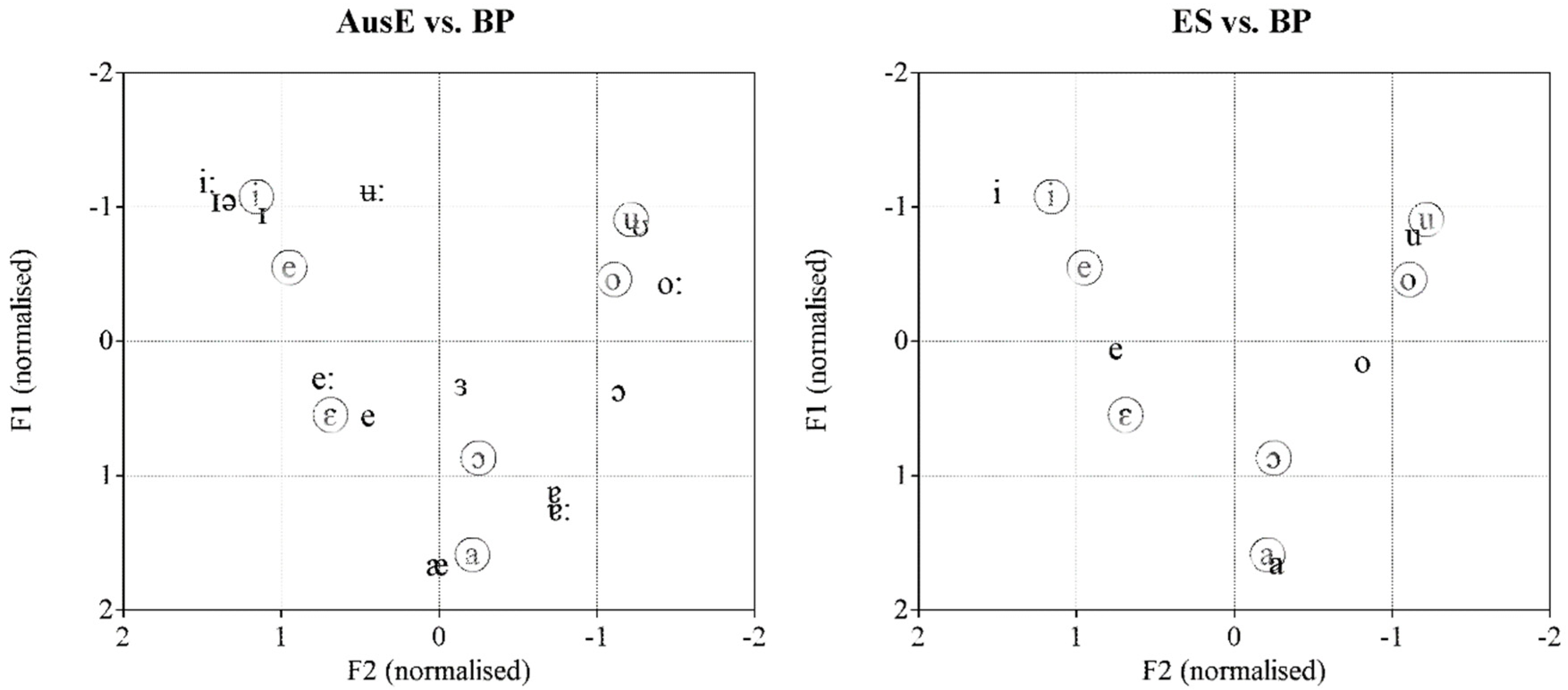
2.3. Results: Cross-Language Acoustic Comparisons
2.4. L2LP Predictions for Non-Native Categorisation
2.5. L2LP Predictions for Non-Native Discrimination
3. Non-Native Categorisation
3.1. Participants
3.2. Stimuli and Procedure
3.3. Results
3.4. Discussion
Predictions for Discrimination Accuracy
4. Non-Native Discrimination
4.1. Participants
4.2. Stimuli and Procedure
4.3. Results
4.4. Acoustic vs. Perceptual Similarity as a Predictor of Non-Native Discrimination
5. General Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alispahic, S., K. E. Mulak, and P. Escudero. 2017. Acoustic properties predict perception of unfamiliar Dutch vowels by adult Australian English and Peruvian Spanish listeners. Frontiers in Psychology 8: 52. [Google Scholar] [CrossRef]
- Alispahic, S., P. Escudero, and K. E. Mulak. 2014. Difficulty in discriminating non-native vowels: Are Dutch vowels easier for Australian English than Spanish listeners? Paper presented at Annual Conference of the International Speech Communication Association, INTERSPEECH, (SEPTEMBER), Singapore, September 14–18; pp. 1293–96. [Google Scholar] [CrossRef]
- Antoniou, M., and P. C. Wong. 2015. Poor phonetic perceivers are affected by cognitive load when resolving talker variability. The Journal of the Acoustical Society of America 138: 571–74. [Google Scholar] [CrossRef]
- Bassetti, B., P. Escudero, and R. Hayes-Harb. 2015. Second language phonology at the interface between acoustic and orthographic input. Applied Psycholinguistics 36: 1–6. [Google Scholar] [CrossRef]
- Benders, T., P. Escudero, and M. J. Sjerps. 2012. The interrelation between acoustic context effects and available response categories in speech sound categorisation. The Journal of the Acoustical Society of America 131: 3079–87. [Google Scholar] [CrossRef]
- Best, C. T. 1994. The Emergence of Native-Language Phonological Influences in Infants: A Perceptual Assimilation Model. The Development of Speech Perception: The Transition from Speech Sounds to Spoken Words 167: 167–224. [Google Scholar]
- Best, C. T. 1995. A direct realist perspective on cross-language speech perception. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by W. Strange. Timonium: York Press, pp. 171–204. [Google Scholar]
- Best, C. T., and M. D. Tyler. 2007. Non-native and second-language speech perception: Commonalities and complementarities. In Language Experience in Second-Language Speech Learning: In Honor of James Emil Flege. Edited by O. Bohn and M. J. Munro. Amsterdam: John Benjamins, pp. 13–34. [Google Scholar]
- Best, C. T., C. Avesani, M. D. Tyler, and M. Vayra. 2019. Perceiving non-native consonants that utilize articulators not employed contrastively in the native language: Revisiting PAM and the Articulatory Organ Hypothesis. In A Sound Approach to Language Matters: In Honor of Ocke-Schwen Bohn. Edited by A. M. Nyvad, M. Hejná, A. Højen, A. B. Jespersen and M. H. Sørensen. Aarhus: Aarhus University Press, pp. 13–40. [Google Scholar] [CrossRef]
- Blackwood Ximenes, A., J. A. Shaw, and C. Carignan. 2017. A comparison of acoustic and articulatory methods for analyzing vowel differences across dialects: Data from American and Australian English. The Journal of the Acoustical Society of America 142: 363–77. [Google Scholar] [CrossRef]
- Bohn, O. S., C. T. Best, C. Avesani, and M. Vayra. 2011. Perceiving through the lens of native phonetics: Italian and Danish listenerś perception of English consonant contrasts. Paper presented at XVII International Congress of Phonetic Sciences, Hong Kong, China, August 17–21; pp. 336–39. [Google Scholar]
- Bohn, O., and J. E. Flege. 1990. Interlingual identification and the role of foreign language experience in L2 vowel perception. Applied Psycholinguistics 11: 303–28. [Google Scholar] [CrossRef]
- Broersma, M. 2002. Comprehension of non-native speech: Inaccurate phoneme processing and activation of lexical competitors. Paper presented at the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, September 16–20; pp. 261–64. [Google Scholar]
- Brysbaert, M., and M. Stevens. 2018. Power analysis and effect size in mixed effects models: A tutorial. Journal of Cognition 1: 9. [Google Scholar] [CrossRef]
- Chládková, Kateřina, and Paola Escudero. 2012. Comparing vowel perception and production in Spanish and Portuguese: European versus Latin American dialects. The Journal of the Acoustical Society of America 131: EL119–25. [Google Scholar] [CrossRef] [PubMed]
- Colantoni, L., J. Steele, and P. Escudero. 2015. Second Language Speech. Cambridge: Cambridge Univ Press. [Google Scholar]
- Cox, F. 2006. The Acoustic Characteristics of/hVd/Vowels in the Speech of some Australian Teenagers. Australian Journal of Linguistics 26: 147–79. [Google Scholar] [CrossRef]
- Curtin, S., C. Fennell, and P. Escudero. 2009. Weighting of vowel cues explains patterns of word—Object associative learning. Developmental Science 12: 725–31. [Google Scholar] [CrossRef]
- Diaz Granado, M. 2011. L2 and L3 Acquisition of the Portuguese Stressed Vowel Inventory by Native Speakers of English. Ph.D. disstertation, The University of Arizona, Tucson, AZ, USA. [Google Scholar]
- Díaz, B., H. Mitterer, M. Broersma, and N. Sebastian-Gallés. 2012. Individual differences in late bilinguals’ L2 phonological processes: From acoustic-phonetic analysis to lexical access. Learning and Individual Differences 22: 680–89. [Google Scholar] [CrossRef]
- Elvin, J. 2016. The Role of the Native Language in Non-Native Perception and Spoken Word Recognition: English vs. Spanish Learners of Portuguese. Ph.D. dissertation, Western Sydney University, Sydney, NSW, Australia. [Google Scholar]
- Elvin, J., and P. Escudero. 2019. Cross-Linguistic Influence in Second Language Speech: Implications for Learning and Teaching. In Cross-Linguistic Influence: From Empirical Evidence to Classroom Practice. Cham: Springer, pp. 1–20. [Google Scholar]
- Elvin, J., D. Williams, and P. Escudero. 2016. Dynamic acoustic properties of monophthongs and diphthongs in Western Sydney Australian English. The Journal of the Acoustical Society of America 140: 576–81. [Google Scholar] [CrossRef] [PubMed]
- Elvin, J., P. Escudero, and P. Vasiliev. 2014. Spanish is better than English for discriminating Portuguese vowels: Acoustic similarity versus vowel inventory. Frontiers in Psychology 5: 1–8. [Google Scholar] [CrossRef]
- Escudero, P. 2001. The role of the input in the development of L1 and L2 sound contrasts: Language-specific cue weighting for vowels. In Proceedings of the 25th Annual Boston University Conference on Language Development. Somerville: Cascadilla Press, pp. 250–61. [Google Scholar]
- Escudero, P. 2005. Linguistic Perception and Second Language Acquisition: Explaining the Attainment of Optimal Phonological Categorization. Amsterdam: Netherlands Graduate School of Linguistics. [Google Scholar]
- Escudero, P. 2009. The linguistic perception of similar L2 sounds. Phonology in Perception 15: 152–90. [Google Scholar]
- Escudero, P., and D. Williams. 2011. Perceptual assimilation of Dutch vowels by Peruvian Spanish listeners. The Journal of the Acoustical Society of America 129: EL1–7. [Google Scholar] [CrossRef]
- Escudero, P., and D. Williams. 2012. Native dialect influences second-language vowel perception: Peruvian versus Iberian Spanish learners of Dutch. The Journal of the Acoustical Society of America 131: EL406–12. [Google Scholar] [CrossRef]
- Escudero, P., and K. Chládková. 2010. Spanish listeners’ perception of American and Southern British English vowels. The Journal of the Acoustical Society of America 128: EL254–9. [Google Scholar] [CrossRef]
- Escudero, P., and K. Wanrooij. 2010. The Effect of L1 Orthography on Non-native Vowel Perception. Language and Speech 53: 343–65. [Google Scholar] [CrossRef]
- Escudero, P., and P. Boersma. 2002. The Subset Problem in L2 Perceptual Development: Multiple-Category Assimilation by Dutch Learners of Spanish. Paper presented at 26th annual Boston University conference on language development, Boston, MA, USA, November 5–7; pp. 208–19. [Google Scholar]
- Escudero, P., and P. Boersma. 2004. Bridging the gap between L2 speech perception research and phonological theory. Studies in Second Language Acquisition 26: 551–85. [Google Scholar] [CrossRef]
- Escudero, P., and P. Vasiliev. 2011. Cross-language acoustic similarity predicts perceptual assimilation of Canadian English and Canadian French vowels. The Journal of the Acoustical Society of America 130: EL277–83. [Google Scholar] [CrossRef]
- Escudero, P., and R. A. H. Bion. 2007. Modeling Vowel Normalization and Sound Perception as Sequential Processes. Available online: http://icphs2007.de/conference/Papers/1313/1313.pdf (accessed on 22 February 2021).
- Escudero, P., B. Sisinni, and M. Grimaldi. 2014. The effect of vowel inventory and acoustic properties in Salento Italian learners of Southern British English vowels. The Journal of the Acoustical Society of America 135: 1577–84. [Google Scholar] [CrossRef] [PubMed]
- Escudero, P., K. E. Mulak, J. Elvin, and N. M. Traynor. 2018. “Mummy, keep it steady”: Phonetic variation shapes word learning at 15 and 17 months. Developmental Science 21: e12640. [Google Scholar] [CrossRef]
- Escudero, P., M. Broersma, and E. Simon. 2013. Learning words in a third language: Effects of vowel inventory and language proficiency. Language and Cognitive Processes, 1–16. [Google Scholar] [CrossRef]
- Escudero, P., P. Boersma, A. S. Rauber, and H. R. Bion. 2009. A cross-dialect acoustic description of vowels: Brazilian and European Portuguese. The Journal of the Acoustical Society of America 126: 1379–93. [Google Scholar] [CrossRef] [PubMed]
- Escudero, P., R. Hayes-Harb, and H. Mitterer. 2008. Novel second-language words and asymmetric lexical access. Journal of Phonetics 36: 345–60. [Google Scholar] [CrossRef]
- Faris, M. M., C. T. Best, and M. D. Tyler. 2016. An examination of the different ways that non-native phones may be perceptually assimilated as uncategorized. The Journal of the Acoustical Society of America 139: 1–5. [Google Scholar] [CrossRef] [PubMed]
- Flege, J. E. 1995. Second language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Timonium: York Press, pp. 233–76. [Google Scholar]
- Flege, J. E., I. R. A. Mackay, and D. Meador. 1999. Native Italian speakers ’ perception and production of English vowels. The Journal of the Acoustical Society of America 106: 2973–87. [Google Scholar] [CrossRef] [PubMed]
- Flege, J. E., M. J. Munro, and I. R. A. Mackay. 1995. Factors affecting strength of perceived foreign accent in a second language. The Journal of the Acoustical Society of America 97: 3125. [Google Scholar] [CrossRef] [PubMed]
- Flege, J. E., O.-S. Bohn, and S. Jang. 1997. Effects of experience on non-native speakers’ production and perception of English vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef]
- Gilichinskaya, Y. D., and W. Strange. 2010. Perceptual assimilation of American English vowels by inexperienced Russian listeners. The Journal of the Acoustical Society of America 128: EL80–5. [Google Scholar] [CrossRef] [PubMed]
- Gordon, L. S. 2008. Factors Affecting English Speakers’ Perception of L2 Vowels. ProQuest. Washington: Georgetown University. [Google Scholar]
- Green, P., and C. J. MacLeod. 2016. SIMR: An R package for power analysis of generalized linear mixed models by simulation. Methods in Ecology and Evolution 7: 493–98. [Google Scholar] [CrossRef]
- Iverson, P., and B. G. Evans. 2007. Learning English vowels with different first-language vowel systems: Perception of formant targets, formant movement, and duration. The Journal of the Acoustical Society of America 122: 2842–54. [Google Scholar] [CrossRef] [PubMed]
- Iverson, P., and B. G. Evans. 2009. Learning English vowels with different first-language vowel systems II: Auditory training for native Spanish and German speakers. The Journal of the Acoustical Society of America 126: 866–77. [Google Scholar] [CrossRef]
- Jin, Y., B. Díaz, M. Colomer, and N. Sebastián-Gallés. 2014. Oscillation encoding of individual differences in speech perception. PLoS ONE 9. [Google Scholar] [CrossRef] [PubMed]
- Kisler, T., F. Schiel, and H. Sloetjes. 2012. Signal processing via webservices: The use case WebMAUS. Paper presented at Digital Humanities, Hamburg, Germany, July 16–22; pp. 30–34. [Google Scholar]
- Levy, E. S. 2009. On the assimilation-discrimination relationship in American English adults’ French vowel learning. The Journal of the Acoustical Society of America 126: 2670–82. [Google Scholar] [CrossRef]
- Levy, E. S., and F. F. Law. 2010. Production of French vowels by American-English learners of French: Language experience, consonantal context, and the perception-production relationship. The Journal of the Acoustical Society of America 128: 1290–305. [Google Scholar] [CrossRef] [PubMed]
- Lobanov, B. M. 1971. Classification of Russian vowels spoken by different speakers. The Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Mayr, R., and P. Escudero. 2010. Explaining individual variation in L2 perception: Rounded vowels in English learners of German. Bilingualism: Language and Cognition 13: 279–97. [Google Scholar] [CrossRef]
- Morrison, G. S. 2003. Perception and Production of Spanish Vowels by English Speakers. Paper presented at 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9, vol. 2003, pp. 1533–36. [Google Scholar]
- Morrison, G. S. 2009. L1-Spanish Speakers’ Acquisition of the English/i/--//Contrast II: Perception of Vowel Inherent Spectral Change1. Language and Speech 52: 437–62. [Google Scholar] [CrossRef]
- Noiray, A., K. Iskarous, and D. H. Whalen. 2014. Variability in English vowels is comparable in articulation and acoustics. Laboratory phonology 5: 271. [Google Scholar] [CrossRef] [PubMed]
- Pallier, C., A. Colomé, and N. Sebastiáń Gallés. 2001. The influence of native-language phonology on lexical access: Exemplar-based vs. abstract lexical entries. Pyschological Science 12: 445–49. [Google Scholar] [CrossRef] [PubMed]
- Rauber, A. S., P. Escudero, R. A. H. Bion, and B. O. Baptista. 2005. The Interrelation between the Perception and Production of English Vowels by Native Speakers of Brazilian Portuguese Graduate Program in Applied Linguistics. Interspeech 2: 2913–16. [Google Scholar]
- Sebastián-Gallés, N., and B. Díaz. 2012. First and Second Language Speech Perception: Graded Learning. Language Learning 62: 131–47. [Google Scholar] [CrossRef]
- Shaw, J. A., C. T. Best, G. Docherty, B. Evans, P. Foulkes, and J. Hay. 2018. Resilience of English vowel perception across regional accent variation. Laboratory Phonology 9: 11. [Google Scholar] [CrossRef]
- Smith, B. L., and R. Hayes-Harb. 2011. Individual differences in the perception of final consonant voicing among native and non-native speakers of English. Journal of Phonetics 39: 115–20. [Google Scholar] [CrossRef]
- Strange, W., O.-S. Bohn, S. Trent, and K. Nishi. 2004. Acoustic and perceptual similarity of North German and American English vowels. The Journal of the Acoustical Society of America 115: 1791. [Google Scholar] [CrossRef]
- Thomas, E. R., and T. Kendall. 2007. NORM: The Vowel Normalization and Plotting Suite: An Online Tool for Sociophonetic Vowel Normalization. Available online: http://lingtools.uoregon.edu/norm/ (accessed on 22 February 2021).
- Tyler, M. D., C. T. Best, A. Faber, and A. G. Levitt. 2014. Perceptual assimilation and discrimination of non-native vowel contrasts. Phonetica 71: 4–21. [Google Scholar] [CrossRef] [PubMed]
- van Leussen, J.-W., and P. Escudero. 2015. Learning to perceive and recognize a second language: The L2LP model revised. Frontiers in Psychology 6: 1–12. [Google Scholar] [CrossRef]
- Vasiliev, P. 2013. The Initial State for Californian English Learners of Spanish and Portuguese Vowels. Los Angeles: University of California. [Google Scholar]
- Wagenmakers, E.-J. 2007. A practical solution to the perverse problems of p-values. Psychonomic Bulletin and Review 14: 779–804. [Google Scholar] [CrossRef]
- Wanrooij, K., P. Escudero, and M. E. Raijmakers. 2013. What do listeners learn from exposure to a vowel distribution? An analysis of listening strategies in distributional learning. Journal of Phonetics 41: 307–19. [Google Scholar] [CrossRef]
- Watson, C. I., and J. Harrington. 1999. Acoustic evidence for dynamic formant trajectories in Australian English vowels. The Journal of the Acoustical Society of America 106: 458–68. [Google Scholar] [CrossRef] [PubMed]
- Weber, A., and A. Cutler. 2004. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language 50: 1–25. [Google Scholar] [CrossRef]
- Whalen, D. H., W. R. Chen, M. K. Tiede, and H. Nam. 2018. Variability of articulator positions and formants across nine english vowels. Journal of phonetics 68: 1–14. [Google Scholar] [CrossRef]
- Williams, D., and P. Escudero. 2014. A cross-dialectal acoustic comparison of vowels in Northern and Southern British English. The Journal of the Acoustical Society of America 136: 2751–61. [Google Scholar] [CrossRef] [PubMed]
- Williams, D., P. Escudero, and A. Gafos. 2018. Spectral change and duration as cues in Australian English listeners’ front vowel categorisation. The Journal of the Acoustical Society of America 144: EL215–21. [Google Scholar] [CrossRef]
- Yazawa, K., J. Whang, M. Kondo, and P. Escudero. 2020. Language-dependent cue weighting: An investigation of perception modes in L2 learning. Second Language Research 36: 557–81. [Google Scholar] [CrossRef]
- Yu, A. C., and G. Zellou. 2019. Individual differences in language processing: Phonology. Annual Review of Linguistics 5: 131–50. [Google Scholar] [CrossRef]
| 1 | The L2LP terms “NEW” and “SIMILAR” scenarios differ notably from SLM’s use of these terms, and should not be confused with them. The difference in terminology arises from the different foci of the two models: L2LP addresses phonemic contrasts, whereas SLM focuses on individual phones. SLM posits that when listeners are presented with an L2 phone that does not closely resemble any L1 phoneme they form a new phonetic category which should be easier to acquire than an L2 phone that is similar to an existing L1 phoneme, which should be more difficult to acquire despite the phonetic differences (Colantoni et al. 2015). In contrast, in L2LP a NEW scenario requires the listener to establish a new contrast in the L2, which does not exist in the L1, while a SIMILAR scenario reflects a contrast that is similar to one already existing in the L1. SIMILAR scenarios are therefore predicted to be much easier to acquire than NEW scenarios in L2LP. |
| 2 | The /ɪə/ vowel is traditionally considered a diphthong in Australian English. However, recent studies have shown that this vowel is produced as a monophthong when presented in a closed CVC context (see Elvin et al. 2016) as in this study. |
| 3 | We note, however, that there are reasons as to why a listener’s own productions might not be the best predictors of how they perceive other speakers. Part of a listener’s knowledge about vowels includes the ways that different members of their speech community vary (e.g., vocal tract anatomy and social factors). However, we do believe a good way to find symmetry between perception and production is to compare those in the same group of people as in Chládková and Escudero (2012). |
| 4 | Given the fact that the CVCV context is the most common word structure in Spanish, we specifically chose to analyse the /fVfo/ context in the ES native production task. This also prevented the ES participants from producing the target BP stimuli and thereby having an unfair advantage over the AusE participants. We do acknowledge, however, that the post-stressed /e/ in the second syllable of the BP target items is different to the post-stressed /o/ in the second syllable of the Spanish targets, which may have a minor impact on the stressed V acoustic parameters in BP as compared to ES. |
| 5 | See Elvin et al. (2016); Williams et al. (2018) and Escudero et al. (2018) for an overview and visualization of the AusE formant trajectories. |
| 6 | We note that the five participants missing from the non-native categorisation are included in our analyses of non-native discrimination. We do address the issue of the missing data from the categorisation task in our comparison of cross-linguistic acoustic similarity vs. perceptual similarity below. |




{kind=link}
{kind=link}
{kind=link}
| AusE Vowels | BP Vowels | ||||||
|---|---|---|---|---|---|---|---|
| i | e | ɛ | a | ɔ | o | u | |
| iː | 0.22 | 0.13 | |||||
| ɪ | 0.71 | 0.59 | 0.01 | ||||
| ɪə | 0.05 | 0.11 | |||||
| e | 0.01 | 0.63 | 0.16 | ||||
| eː | 0.06 | 0.33 | 0.06 | ||||
| ɜː | 0.02 | 0.05 | 0.06 | ||||
| ɐ | 0.15 | 0.32 | |||||
| ɐː | 0.06 | 0.06 | |||||
| æ | 0.02 | 0.74 | 0.08 | ||||
| ɔ | 0.25 | 0.26 | 0.04 | ||||
| oː | 0.20 | 0.04 | |||||
| ʊ | 0.01 | 0.53 | 0.92 | ||||
| ʉː | 0.02 | 0.10 | |||||
| ES Vowels | BP Vowels | ||||||
|---|---|---|---|---|---|---|---|
| i | e | ɛ | a | o | ɔ | u | |
| i | 0.89 | 0.23 | 0.01 | ||||
| e | 0.11 | 0.77 | 1.00 | 0.27 | |||
| a | 0.99 | 0.07 | |||||
| o | 0.01 | 0.22 | 0.64 | 0.02 | |||
| u | 0.78 | 0.01 | 0.98 | ||||
| Group | BP Vowel Contrast | |||||
|---|---|---|---|---|---|---|
| /a/–/ɔ/ | /a/–/ɛ/ | /i/–/e/ | /o/–/u/ | /e/–/ɛ/ | /o/–/ɔ/ | |
| AusE | 0.34 | 0.04 | 0.79 | 0.61 | 0.08 | 0.26 |
| ES | 0.08 | 0.00 | 0.34 | 0.80 | 0.77 | 0.23 |
| AusE Vowels | BP Vowels | ||||||
|---|---|---|---|---|---|---|---|
| i | e | ɛ | a | o | ɔ | u | |
| iː | 0.43 | 0.23 | 0.05 | 0.01 | |||
| ɪ | 0.43 | 0.20 | 0.02 | ||||
| ɪə | 0.06 | 0.15 | 0.06 | 0.02 | 0.01 | 0.01 | |
| e | 0.06 | 0.14 | 0.14 | ||||
| eː | 0.01 | 0.23 | 0.58 | 0.06 | 0.01 | 0.04 | |
| ɜː | 0.01 | 0.01 | 0.08 | 0.05 | 0.03 | ||
| æ | 0.01 | 0.03 | 0.07 | 0.38 | 0.01 | ||
| ɐː | 0.01 | 0.02 | 0.08 | 0.50 | 0.13 | ||
| ɐ | 0.03 | 0.04 | 0.06 | ||||
| ɔ | 0.09 | 0.15 | 0.07 | ||||
| oː | 0.02 | 0.01 | 0.02 | 0.53 | 0.58 | 0.06 | |
| ʊ | 0.23 | 0.03 | 0.65 | ||||
| ʉː | 0.04 | 0.02 | 0.12 | ||||
| ES Vowels | BP Vowels | ||||||
|---|---|---|---|---|---|---|---|
| i | e | ɛ | a | o | ɔ | u | |
| i | 1.0 | 0.56 | 0.01 | ||||
| e | 0.44 | 0.94 | |||||
| a | 0.05 | 1.00 | 0.02 | ||||
| o | 0.69 | 0.97 | 0.01 | ||||
| u | 0.31 | 0.01 | 0.99 | ||||
| Group | Overlap | BP Contrasts | |||||
|---|---|---|---|---|---|---|---|
| /a/–/ɔ/ | /a/–/ɛ/ | /i/–/e/ | /o/–/u/ | /e/–/ɛ/ | /o/–/ɔ/ | ||
| AusE | Acoustic | 0.34 | 0.04 | 0.79 | 0.61 | 0.08 | 0.26 |
| Perceptual | 0.22 | 0.11 | 0.58 | 0.47 | 0.57 | 0.73 | |
| ES | Acoustic | 0.08 | 0.00 | 0.34 | 0.80 | 0.77 | 0.23 |
| Perceptual | 0.02 | 0.05 | 0.56 | 0.32 | 0.45 | 0.70 | |
| Perceptual Overlap Rank | Acoustic Overlap Rank | |||||||
|---|---|---|---|---|---|---|---|---|
| Group | Individual | Group | Individual | |||||
| BP Contrast | AusE | ES | AusE | ES | AusE | ES | AusE | ES |
| /a/–/ɔ/ | 2.00 | 1.00 | 1.95 | 1.60 | 4.00 | 2.00 | 4.05 | 2.90 |
| /a/–/ɛ/ | 1.00 | 2.00 | 2.00 | 1.87 | 1.00 | 1.00 | 1.48 | 1.17 |
| /i/–/e/ | 5.00 | 5.00 | 4.33 | 4.40 | 6.00 | 4.00 | 5.40 | 4.03 |
| /o/–/u/ | 3.00 | 3.00 | 3.88 | 3.83 | 5.00 | 6.00 | 4.80 | 4.80 |
| /e/–/ɛ/ | 4.00 | 4.00 | 3.88 | 4.17 | 2.00 | 5.00 | 2.18 | 4.30 |
| /o/–/ɔ/ | 6.00 | 6.00 | 4.98 | 5.13 | 3.00 | 3.00 | 3.10 | 3.80 |
| Order of Discrimination Difficulty | ||||||||
| AusE | /a/–/ɛ/>/a/–/ɔ/>/e/–/ɛ/>/o/–/ɔ/>/i/–/e/~/o/–/u/ | |||||||
| ES | /a/–/ɛ/~/a/–/ɔ/>/e/–/ɛ/>/o/–/ɔ/~/i/–/e/~/o/–/u/ | |||||||
| AusE | ES | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Est. | SE | z | p | Est. | SE | z | p | ||
| Perceptual Overlap Group | Intercept | 1.55 | 0.10 | 14.99 | <0.001 | 1.49 | 0.11 | 13.82 | <0.001 |
| Effect | –0.38 | 0.06 | –6.32 | <0.001 | –0.49 | 0.06 | –7.70 | <0.001 | |
| Perceptual Overlap Individual | Intercept | 1.59 | 0.11 | 14.66 | <0.001 | 1.43 | 0.12 | 12.01 | <0.001 |
| Effect | –0.20 | 0.05 | –4.25 | <0.001 | –0.21 | 0.05 | –3.93 | <0.001 | |
| Acoustic Overlap Group | Intercept | 1.62 | 0.11 | 14.70 | <0.001 | 1.49 | 0.12 | 12.26 | <0.001 |
| Effect | –0.36 | 0.07 | –5.28 | <0.001 | –0.30 | 0.06 | –4.92 | <0.001 | |
| Acoustic Overlap Individual | Intercept | 1.59 | 0.12 | 13.36 | <0.001 | 1.38 | 0.12 | 11.85 | <0.001 |
| Effect | –0.19 | 0.06 | –2.98 | 0.003 | –0.11 | 0.04 | –2.85 | 0.004 | |
| Order of Discrimination Difficulty | |
|---|---|
| Elvin et al. 2014 | AusE/ES: /a/–/ɛ/>/a/–/ɔ/~/e/–/ɛ/~/o/–/ɔ/>/i/–/e/~/o/–/u/ |
| The present study | AusE: /a/–/ɛ/>/a/–/ɔ/>/e/–/ɛ/>/o/–/ɔ/>/i/–/e/~/o/–/u/ ES: /a/–/ɛ/~/a/–/ɔ/>/e/–/ɛ/>/o/–/ɔ/~/i/–/e/~/o/–/u/ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elvin, J.; Williams, D.; Shaw, J.A.; Best, C.T.; Escudero, P. The Role of Acoustic Similarity and Non-Native Categorisation in Predicting Non-Native Discrimination: Brazilian Portuguese Vowels by English vs. Spanish Listeners. Languages 2021, 6, 44. https://doi.org/10.3390/languages6010044
Elvin J, Williams D, Shaw JA, Best CT, Escudero P. The Role of Acoustic Similarity and Non-Native Categorisation in Predicting Non-Native Discrimination: Brazilian Portuguese Vowels by English vs. Spanish Listeners. Languages. 2021; 6(1):44. https://doi.org/10.3390/languages6010044
Chicago/Turabian StyleElvin, Jaydene, Daniel Williams, Jason A. Shaw, Catherine T. Best, and Paola Escudero. 2021. "The Role of Acoustic Similarity and Non-Native Categorisation in Predicting Non-Native Discrimination: Brazilian Portuguese Vowels by English vs. Spanish Listeners" Languages 6, no. 1: 44. https://doi.org/10.3390/languages6010044
APA StyleElvin, J., Williams, D., Shaw, J. A., Best, C. T., & Escudero, P. (2021). The Role of Acoustic Similarity and Non-Native Categorisation in Predicting Non-Native Discrimination: Brazilian Portuguese Vowels by English vs. Spanish Listeners. Languages, 6(1), 44. https://doi.org/10.3390/languages6010044