The Role of Task-Essential Training and Working Memory in Offline and Online Morphological Processing



Abstract
1. Introduction
2. Background and Motivation
2.1. Input Processing and Task-Essential Training
2.2. Task-Essential Training and Processing Measures
2.3. Working Memory in L2 Learning and Processing
2.4. The Processing of Verbal Morphology in L2 Spanish, and the Role of Working Memory
3. The Present Study
4. Materials and Methods
4.1. Participants
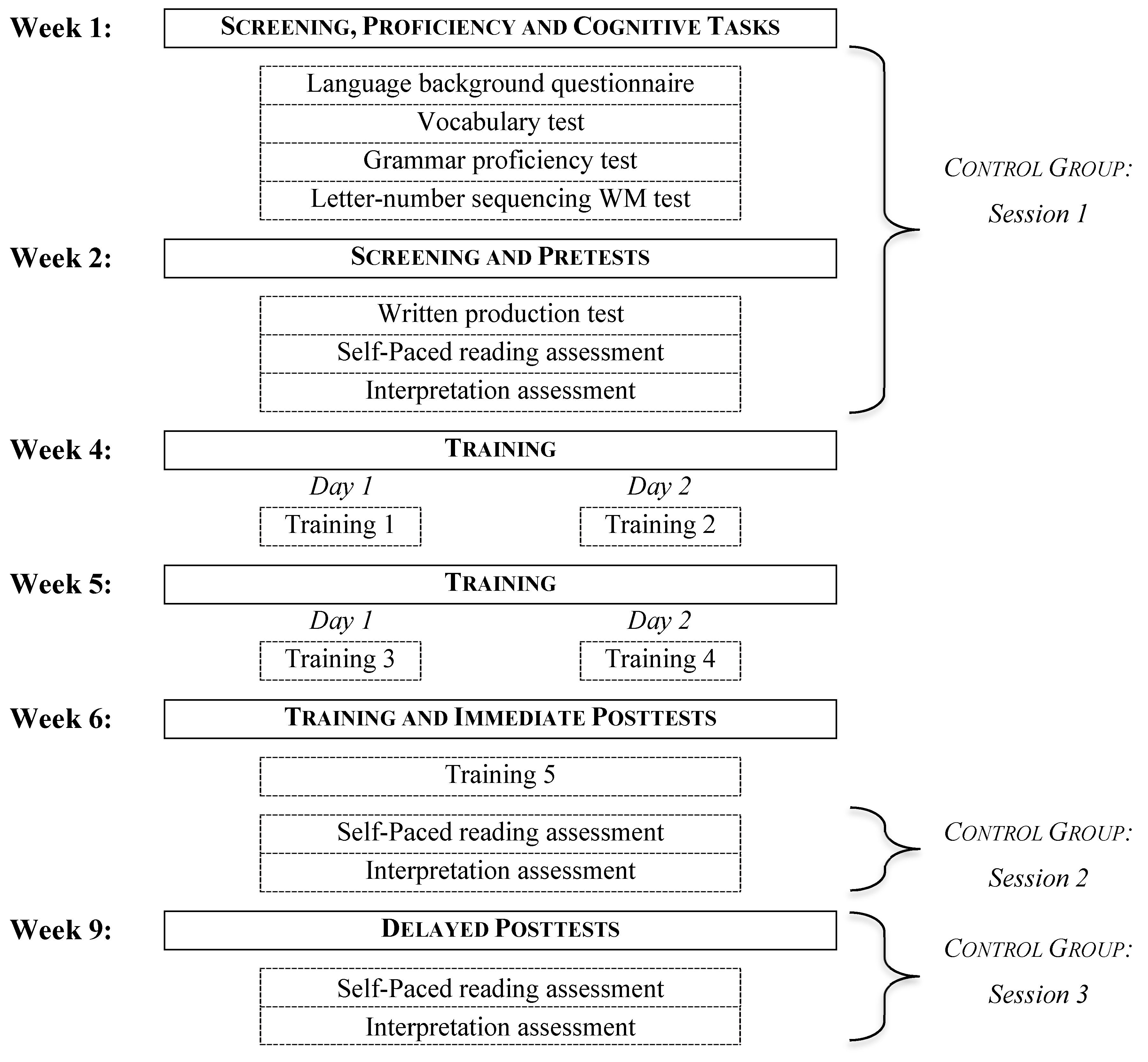
4.2. Experimental Design
4.3. Materials
4.3.1. Background Screening and Proficiency Measures
4.3.2. Working Memory Task
4.3.3. Task-Essential Training
| (1) | Escucho | las | instrucciones | de | la | profesora. |
| listen.prs.1sg | the | instructions | from | the | professor. | |
| I listen to the instructions from the professor. | ||||||
| (2) | Antes | del | partido | comerán | espaguetis. | |
| Before | the | game | eat.fut.3pl | spaghetti. | ||
| Before the game they will eat spaghetti.’ | ||||||
4.3.4. Interpretation Assessment
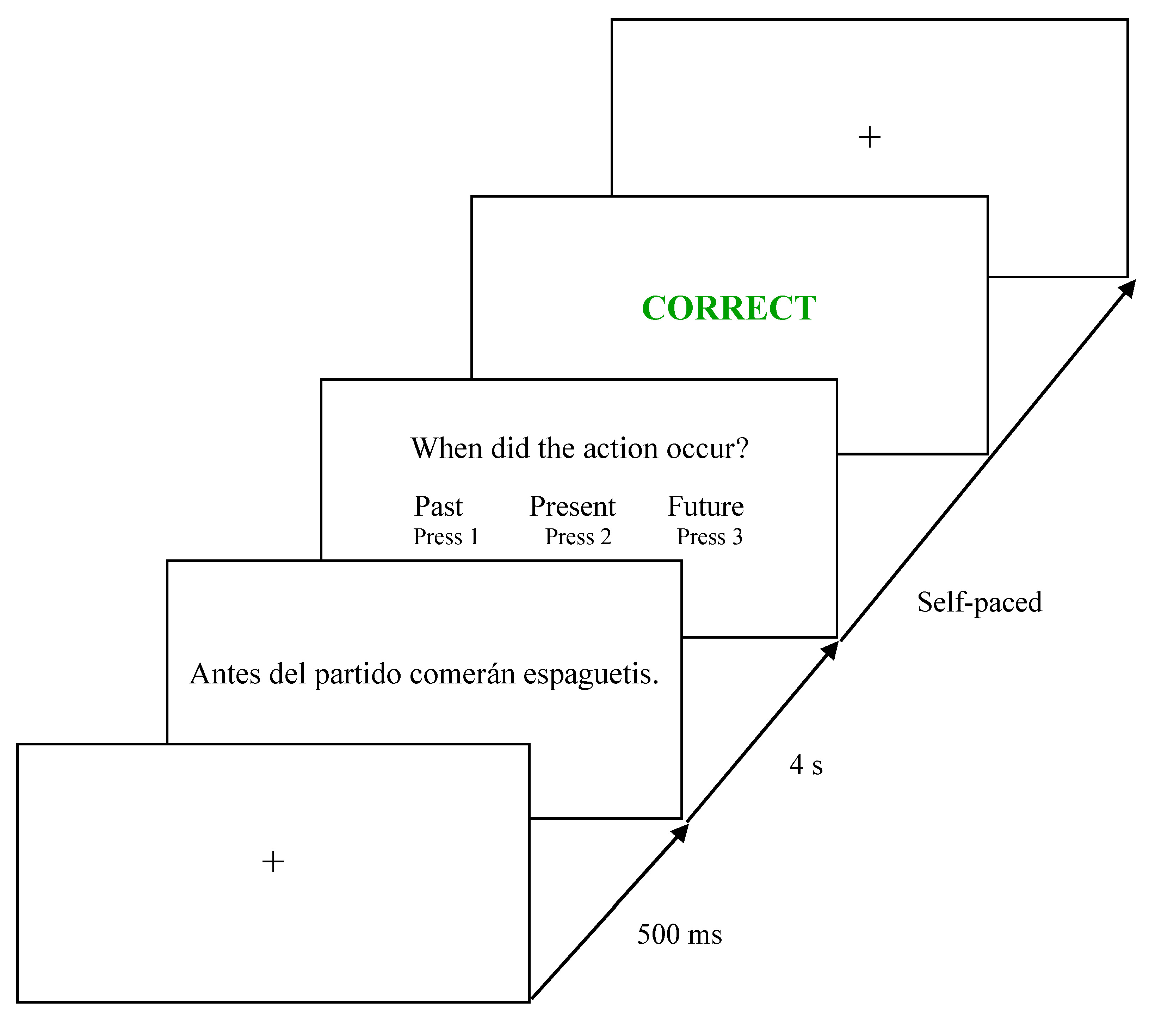
4.3.5. Self-Paced Reading Assessment
5. Results for Interpretation Assessment
5.1. Data Scoring and Statistical Analyses
5.2. Descriptive Statistics
5.3. Model Results
5.3.1. Tense-Preterite Condition
5.3.2. Tense-Future Condition
5.3.3. Subject-Preterite Condition
5.3.4. Subject-Future Condition
6. Results for Self-Paced Reading Assessment
6.1. Data Scoring and Statistical Analyses
6.1.1. Accuracy
6.1.2. Reading Times (RTs)
6.2. Accuracy
6.3. Reading Times
6.3.1. Descriptive Statistics
6.3.2. Model Results
7. Discussion
7.1. RQ1: Offline Interpretation
7.2. RQ2: Online Processing
7.3. RQ 3: The Role of WM
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baddeley, Alan. 2000. The episodic buffer: A new component of working memory? Trends in Cognitive Sciences 4: 417–23. [Google Scholar] [CrossRef]
- Baddeley, Alan, and Graham Hitch. 1974. Working memory. In Recent Advances in Learning and Motivation. Edited by Graham Bower. New York: Academic Press, Vol. 8, pp. 47–89. [Google Scholar]
- Benati, Alessandro. 2001. A comparative study of the effects of processing instruction and output-based instruction on the acquisition of the Italian future tense. Language Teaching Research 5: 95–127. [Google Scholar] [CrossRef]
- Benati, Alessandro. 2005. The effects of processing instruction, traditional instruction and meaning-output instruction on the acquisition of the English past simple tense. Language Teaching Research 9: 67–93. [Google Scholar] [CrossRef]
- Bialystok, Ellen, and Barry Miller. 1999. The problem of age in second-language acquisition: Influences from language, structure, and task. Bilingualism: Language and Cognition 2: 127–45. [Google Scholar] [CrossRef][Green Version]
- Brooks, Patricia J., Vera Kempe, and Ariel Sionov. 2006. The role of learner and input variables in learning inflectional morphology. Applied Psycholinguistics 27: 185–209. [Google Scholar] [CrossRef]
- Cadierno, Teresa. 1995. Formal instruction from a processing perspective: An investigation into the Spanish past tense. The Modern Language Journal 79: 179–93. [Google Scholar] [CrossRef]
- Cameron, Robert D. 2011. Native and Nonnative Processing of Modality and Mood in Spanish. Ph.D. Thesis, Florida State University, Talahassee, FL, USA. [Google Scholar]
- Conway, Andrew, Chris Jarrold, Michael Kane, Akira Miyake, and John Towse, eds. 2008. Variation in Working Memory. New York: Oxford University Press. [Google Scholar]
- Culman, Hillah, Nick Henry, and Bill VanPatten. 2009. The role of explicit information in instructed SLA: An on-line study with Processing Instruction and German accusative case inflections. Die Unterrichtspraxis/Teaching German 42: 19–31. [Google Scholar] [CrossRef]
- Dekydtspotter, Laurent, and Claire Renaud. 2014. On second language processing and grammatical development: The parser in second language acquisition. Linguistic Approaches to Bilingualism 4: 131–65. [Google Scholar] [CrossRef]
- Dracos, Melisa, and Nick Henry. 2018. The effects of task-essential training on L2 processing strategies and the development of Spanish verbal morphology. Foreign Language Annals 51: 344–68. [Google Scholar] [CrossRef]
- Dussias, Paola E., and Pilar Pinar. 2010. Effects of reading span and plausibility in the reanalysis of wh-gaps by Chinese-English second language speakers. Second Language Research 26: 443–72. [Google Scholar] [CrossRef]
- Ellis, Nick C. 2015. Implicit and explicit learning: Their dynamic interface and complexity. In Implicit and Explicit Learning of Languages. Edited by Patrick Rebuschat. Amsterdam: John Benjamins, pp. 3–23. [Google Scholar]
- Ellis, Nick C., and Nuria Sagarra. 2010a. Learned attention effects in L2 temporal reference: The first hour and the next eight semesters. Language Learning 60: 85–108. [Google Scholar] [CrossRef]
- Ellis, Nick C., and Nuria Sagarra. 2010b. The bounds of adult language acquisition. Studies in Second Language Acquisition 32: 553–80. [Google Scholar] [CrossRef]
- Ellis, Nick C., Kausar Hafeez, Katherine Martin, Lillian Chen, Julia Boland, and Nuria Sagarra. 2014. An eye-tracking study of learned attention in second language acquisition. Applied Psycholinguistics 34: 547–79. [Google Scholar] [CrossRef]
- Faretta-Stutenberg, Mandy. 2014. Individual Differences in Context: A Neurolinguistic Investigation of Working Memory and L2 Development. Ph.D. Thesis, University of Illinois at Chicago, Chicago, IL, USA. [Google Scholar]
- Faretta-Stutenberg, Mandy, and Kara Morgan-Short. 2018. The interplay of individual differences and context of learning in behavioral and neurocognitive second language development. Second Language Research 34: 67–101. [Google Scholar] [CrossRef]
- Filgueras-Gomez, Marisa. 2016. The effects of type of feedback, amount of feedback and task-essentialness in a L2 computer-assisted study. Ph.D. Thesis, Georgetown University, Washington, DC, USA. [Google Scholar]
- Fodor, Janet Dean. 1998. Parsing to learn. Journal of Psycholinguistic Research 27: 339–74. [Google Scholar] [CrossRef]
- Foote, Rebecca. 2011. Integrated knowledge of agreement in early and late English–Spanish bilinguals. Applied Psycholinguistics 32: 187–220. [Google Scholar] [CrossRef]
- French, Leif M., and Irena O’Brien. 2008. Phonological memory and children’s second language grammar learning. Applied Psycholinguistics 29: 463–87. [Google Scholar] [CrossRef]
- Grant, Angela M., Shin Yi Fang, and Ping Li. 2015. Second language lexical development and cognitive control: A longitudinal fMRI study. Brain and Language 144: 35–47. [Google Scholar] [CrossRef]
- Grey, Sara, Jessica G. Cox, Ellen J. Serafini, and Christina Sanz. 2015. The role of individual differences in the study Abroad context: Cognitive capacity and language development during short-term intensive language exposure. Modern Language Journal 99: 137–57. [Google Scholar] [CrossRef]
- Harrington, Michael, and Mark Sawyer. 1992. L2 working memory capacity and L2 reading skill. Studies in Second Language Acquisition 14: 25–38. [Google Scholar] [CrossRef]
- Havik, Else, Leah Roberts, Roeland van Hout, Robert Schreuder, and Marco Haverkort. 2009. Processing Subject-Object Ambiguities in the L2: A Self-Paced Reading Study With German L2 Learners of Dutch. Language Learning 59: 73–112. [Google Scholar] [CrossRef]
- Henry, Nick. 2015. Morphosyntactic Processing, Cue Interaction, and the Effects of Instruction: An Investigation of Processing Instruction and the Acquisition of Case Markings in L2 German. Ph.D. Thesis, The Pennsylvania State University, State College, PA, USA. [Google Scholar]
- Henry, Nick, Carrie N. Jackson, and Jack DiMidio. 2017. The role of prosody and explicit instruction in Processing Instruction. Modern Language Journal 101: 1–21. [Google Scholar] [CrossRef]
- Indrarathne, Bimali, and Judit Kormos. 2018. The role of working memory in processing L2 input: Insights from eye-tracking. Bilingualism: Language and Cognition 21: 355–74. [Google Scholar] [CrossRef]
- Issa, Bernard I. 2019. Examining the relationships among attentional allocation, working memory, and second language development: An eye-tracking study. In The Routledge Handbook of Second Language Research in Classroom Learning. Edited by Ronald P. Leow. New York: Routledge, pp. 464–79. [Google Scholar]
- Issa, Bernard I., and Kara Morgan-Short. 2019. Effects of external and internal attentional manipulations on second language grammar development: An eye-tracking study. Studies in Second Language Acquisition 41: 389–417. [Google Scholar] [CrossRef]
- Juffs, Alan. 2004. Representation, processing and working memory in a second language. Transactions of the Philological Society 102: 199–225. [Google Scholar] [CrossRef]
- Juffs, Alan, and Michael Harrington. 2011. Aspects of working memory in L2 learning. Language Teaching 44: 137–66. [Google Scholar] [CrossRef]
- Keating, Gregory. D., and Jill Jegerski. 2015. Experimental Designs in Sentence Processing Research. Studies in Second Language Acquisition 37: 1–32. [Google Scholar] [CrossRef]
- LaBrozzi, Ryan M. 2009. Processing of Lexical and Morphological Cues in a Study Abroad Context. Ph.D. Thesis, The Pennsylvania State Univeristy, State College, PA, USA. [Google Scholar]
- Lardiere, Donna. 1998. Case and Tense in the ‘fossilized’ steady state. Second Language Research 14: 1–26. [Google Scholar] [CrossRef]
- Larson-Hall, Jennifer. 2010. A Guide to Doing Statistics in Second Language Research Using R. New York: Routledge. [Google Scholar]
- Lee, James. F. 2015. The milestones in twenty years of processing instruction research. International Review of Applied Linguistics in Language Teaching 53: 111–26. [Google Scholar] [CrossRef]
- Lee, James F., and Alessandro Benati. 2007. Delivering Processing Instruction in Classrooms and Virtual Contexts: Research and Practice. London: Equinox. [Google Scholar]
- Lee, James F., and Stephen Doherty. 2018. Native and Nonnative Processing of Active and Passive Sentences. Studies in Second Language Acquisition 41: 853–79. [Google Scholar] [CrossRef]
- Legault, Jennifer, Shin Yi Fang, Yu Ju Lan, and Ping Li. 2019. Structural brain changes as a function of second language vocabulary training: Effects of learning context. Brain and Cognition 134: 90–102. [Google Scholar] [CrossRef] [PubMed]
- Linck, Jared A., Peter Osthus, Joel T. Koeth, and Michael F. Bunting. 2014. Working memory and second language comprehension and production: A meta-analysis. Psychonomic Bulletin and Review 21: 861–83. [Google Scholar] [CrossRef] [PubMed]
- Linck, Jared A., and Daniel J. Weiss. 2015. Can working memory and inhibitory control predict second language learning in the classroom? SAGE Open 5: 1–11. [Google Scholar] [CrossRef]
- Loschky, Lester, and Robert Bley-Vroman. 1993. Grammar and task-based methodology. In Tasks and Language Learning: Integrating Theory and Practice. Edited by Graham Crookes and Susan M. Gass. London: Multilingual Matters, pp. 123–67. [Google Scholar]
- Marsden, Emma. 2006. Exploring input processing in the classroom: An experimental comparison of processing instruction and enriched input. Language Learning 56: 507–66. [Google Scholar] [CrossRef]
- Marsden, Emma, and Hsin Ying Chen. 2011. The roles of structured input activities in processing instruction and the kinds of knowledge they promote. Language Learning 61: 1058–98. [Google Scholar] [CrossRef]
- McDonald, Janet L. 2006. Beyond the critical period: Processing-based explanations for poor grammaticality judgment performance by late second language learners. Journal of Memory and Language 55: 381–401. [Google Scholar] [CrossRef]
- McManus, Kevin, and Emma Marsden. 2017. L1 Explicit Instruction Can Improve L2 Online and Offline Performance. Studies in Second Language Acquisition 39: 459–92. [Google Scholar] [CrossRef]
- McManus, Kevin, and Emma Marsden. 2018. Online and Offline Effects of L1 Practice in L2 Grammar Learning. Studies in Second Language Acquisition 40: 459–75. [Google Scholar] [CrossRef]
- McManus, Kevin, and Emma Marsden. 2019. Signatures of automaticity during practice: Explicit instruction about L1 processing routines can improve L2 grammatical processing. Applied Psycholinguistics 40: 205–34. [Google Scholar] [CrossRef]
- Mielicki, Marta, Rebecca H. Koppel, Gabriela Valencia, and Jennifer Wiley. 2018. Measuring working memory capacity with the letter–number sequencing task: Advantages of visual administration. Applied Cognitive Psychology 32: 805–14. [Google Scholar] [CrossRef]
- Miyake, Akira, and Naomi P. Friedman. 1998. Individual differences in second language proficiency: Working memory as language aptitude. In Foreign Language Learning: Psycholinguistic Studies on Training and Retention. Edited by Alice F. Healy and Lyle E. Bourne. Mahwah: Lawrence Erlbaum, pp. 339–64. [Google Scholar]
- Norris, John M., and Lourdes Ortega. 2000. Effectiveness of L2 instruction: A research synthesis and quantitative meta-analysis. Language Learning 50: 417–528. [Google Scholar] [CrossRef]
- Russell, Victoria. 2012. Learning Complex Grammar in the Virtual Classroom: A Comparison of Processing Instruction, Structured Input, Computerized Visual Input Enhancement, and Traditional Instruction. Foreign Language Annals 45: 42–71. [Google Scholar] [CrossRef]
- Sagarra, Nuria. 2007. Working memory and L2 processing of redundant grammatical forms. In Understanding Second Language Process. Edited by Zhaohong Han. Clevedon: Multilingual Matters, pp. 133–47. [Google Scholar]
- Sagarra, Nuria. 2017. Longitudinal effects of working memory on L2 grammar and reading abilities. Second Language Research 33: 341–63. [Google Scholar] [CrossRef]
- Sagarra, Nuria, and Nick C. Ellis. 2013. From Seeing Adverbs To Seeing Verbal Morphology. Studies in Second Language Acquisition 35: 261–90. [Google Scholar] [CrossRef]
- Sagarra, Nuria, and Julia Herschensohn. 2010. The role of proficiency and working memory in gender and number agreement processing in L1 and L2 Spanish. Lingua 120: 2022–39. [Google Scholar] [CrossRef]
- Sagarra, Nuria, and Julia Herschensohn. 2011. Proficiency and animacy effects on L2 gender agreement processes during comprehension. Language Learning 61: 80–116. [Google Scholar] [CrossRef]
- Sagarra, Nuria, and Ryan LaBrozzi. 2018. Benefits of Study Abroad and Working Memory on L2 Morphosyntactic Processing. In The Routledge Handbook of Study Abroad Research and Practice. Edited by Cristina Sanz and Alfonso Morales-Front. New York: Routledge, pp. 149–63. [Google Scholar]
- Santamaria, Kindra, and Gretchen Sunderman. 2015. Working memory in processing instruction: The acquisition of L2 French clitics. In Working Memory in Second Language Acquisition and Processing. Edited by Zhisheng Wen, Mailce Borges Mota and Arthur McNeill. Bristol: NBN International, pp. 205–223. [Google Scholar]
- Sanz, Christina. 2004. Computer delivered implicit vs. explicit feedback in processing instruciton. In Processing Instruction: Theory, Research, and Commentary. Edited by Bill VanPatten. Mahwah: Lawrence Erlbaum, pp. 33–67. [Google Scholar]
- Sanz, Christina, and Kara Morgan-Short. 2004. Positive evidence versus explicit rule presentation and explicit negative feedback: A computer-assisted study. Language Learning 54: 35–78. [Google Scholar] [CrossRef]
- Sanz, Cristina, Hui-Ju Lin, Beatriz Lado, Catherine A. Stafford, and Harriet W. Bowden. 2016. One Size Fits All? Learning Conditions and Working Memory Capacity in Ab Initio Language Development. Applied Linguistics 37: 669–92. [Google Scholar] [CrossRef]
- Schneider, Walter, Amy Eschmann, and Anthony Zuccolotto. 2012. E-Prime 2.0. Psychology Software Tools. [Google Scholar]
- Shelton, Jill, Emily Elliott, B.D. Hill, Matthew Calamia, and Wm Drew Gouvier. 2009. A comparison of laboratory and clinical working memory tests and their prediction of fluid intelligence. Intelligence 37: 283–93. [Google Scholar] [CrossRef]
- Shintani, Natsuko. 2015. The Effectiveness of Processing Instruction and Production-based Instruction on L2 Grammar Acquisition: A Meta-Analysis. Applied Linguistics 36: 306–25. [Google Scholar] [CrossRef]
- VanPatten, Bill. 2015a. Foundations of processing instruction. International Review of Applied Linguistics in Language Teaching 53: 91–109. [Google Scholar] [CrossRef]
- VanPatten, Bill. 2015b. Input processing in adult SLA. In Theories in Second Language Acquisition, 2nd ed. Edited by Bill VanPatten and Jessica Williams. Mahwah: Lawrence Erlbaum, pp. 113–34. [Google Scholar]
- VanPatten, Bill. 2017. Processing instruction. In Routledge Handbook of Instructed Second Language Acquisition. Edited by Shawn Loewen and Masatoshi Sato. London: Routledge, pp. 166–80. [Google Scholar]
- VanPatten, Bill, and Teresa Cadierno. 1993. Explicit instruction and input processing. Studies in Second Language Acquisition 15: 225. [Google Scholar] [CrossRef]
- VanPatten, Bill, and Gregory D. Keating. 2007. Getting Tense: Lexical Preference, L1 Transfer, and Native and Non-Native Processing of Temporal Reference. Paper presented at the Annual Meeting of the American Association for Applied Linguistics, Costa Mesa, CA, USA, April 21–24. [Google Scholar]
- VanPatten, Bill, Gregory D. Keating, and Michael J. Leeser. 2012. Missing verbal inflections as a representational problem: Evidence from on-line methodology. Linguistic Approaches to Bilingualism 2: 109–40. [Google Scholar] [CrossRef]
- VanPatten, Bill, and Soile Oikkenon. 1996. Explanation versus structured input in processing instruction. Studies in Second Language Acquisition 18: 495–510. [Google Scholar] [CrossRef]
- Villegas, Briana, and Kara Morgan-Short. 2019. The effect of training condition and working memory on second language development of a complex form: The Spanish subjunctive. In Selected Proceedings of the 2017 Second Language Research Forum. Edited by Hope Wilson, Nicole King, Eun Jeong Park and Kirby Childress. Sovervillee: Cascadilla Proceedings Project, pp. 185–99. [Google Scholar]
- Wechsler, David. 1997. WAIS-III Administration and Scoring Manual, 3rd ed. San Antonio: Psychological Corporation. [Google Scholar]
- Wechsler, David. 2008. WAIS-IV Administration and Scoring Manual, 4th ed. San Antonio: Psychological Corporation. [Google Scholar]
- Williams, John N. 2012. Working memory and SLA. In The Routledge Handbook of Second Language Acquisition. Edited by Susan M. Gass and Alison Mackey. New York: Routledge, pp. 427–41. [Google Scholar]
- Wong, Wynne. 2004. The nature of Processing Instruction. In Processing Instruction: Theory, Research, and Commentary. Edited by Bill VanPatten. Mahwah: Lawrence Erlbaum, pp. 33–67. [Google Scholar]
- Wong, Wynne, and Kiwako Ito. 2018. The effects of processing instruction and traditional instruction on L2 online processing of the causative construction in French: An eye-tracking study. Studies in Second Language Acquisition 40: 241–68. [Google Scholar] [CrossRef]
- Wulff, Stefanie, and Nick C. Ellis. 2018. Usage-based approaches to second language acquisition. In Bilingual Cognition and Language: The State of the Science Across Its Subfields. Edited by David Miller, Fatih Bayram, Jason Rothman and Ludovica Serratrice. Amsterdam: John Benjamins, pp. 37–56. [Google Scholar]
| 1 | The concept of “task-essentialness” was first elucidated in detail by Loschky and Bley-Vroman (1993), and there are different types of training that may be considered task essential. Here and throughout this paper, “task-essential training” refers primarily to those interventions that are comprehension-based, meaningful, and processing-oriented such as Structured Input and similar treatments like those used by Ellis and Sagarra (2010a, 2010b), Sanz (2004), or Filgueras-Gomez (2016), among others. |
| 2 | While PI interventions make explicit reference to the Input Processing model, use of Processing Instruction can be motivated by other theoretical constructs. For example, Ellis and Sagarra (2010a, 2010b), working from a usage-based perspective, ask whether PI may help learners identify cues, and overcome attentional biases to rely on morphological cues, thus optimizing acquisition. |
| 3 | Similarly, PI could target the subject information on the verb. Participants would read the same sentence and then determine the subject of the sentence. |
| 4 | Participants completed two additional complex span tasks, a reading span and an operation span task. Scores on these three WM measures were correlated, consistent with studies such as Shelton et al. (2009). LNS was selected for analysis because it is the least linguistically demanding of the three tasks and does not rely on task-specific skills (e.g, math and sentence processing). |
| 5 | Since there is no morphological distinction between the present and preterite in the 1st-person plural forms for -AR and -IR verbs, participants never saw one of these verb forms followed by a tense question. |
| 6 | An additional no-feedback group also underwent training as part of a larger study. This article does not report the results of that group because the goal of this study was not to evaluate whether feedback was a necessary component of training, and the most robust effects of training on offline tasks were found among groups who received feedback. We refer the reader to Dracos and Henry (2018). |
| 7 | Akaike Information Criterion and Bayesian Information Criterion help determine the validity and quality of the statistical models and what factors should be included in the model. See Larson-Hall (2010). |
| 8 | Although there was a main effect of Group and no Time × Group interaction, it is relevant to note that a one-way ANOVA revealed no significant between-group differences on the pretest (F2,88 = 0.452, p = 0.638). Thus, the between-group difference was not due to differences between groups prior to training. |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Verb | Person/Number | Present | Past (Preterite) | Future |
|---|---|---|---|---|
| escuchar ‘to listen’ (-AR-type verb) | 1st-sg | escucho | escuché | escucharé |
| 2nd-sg.inf | escuchas | escuchaste | escucharás | |
| 3rd-sg/2nd-sg.f | escucha | escuchó | escuchará | |
| 1st-pl | escuchamos | escuchamos | escucharemos | |
| 2nd-pl.inf | escucháis | escuchasteis | escucharéis | |
| 3rd-pl/2nd-pl.f | escuchan | escucharon | escucharán | |
| aprender ‘to learn’ (-ER-type verb) | 1st-sg | aprendo | aprendí | aprenderé |
| 2nd-sg.inf | aprendes | aprendiste | aprenderás | |
| 3rd-sg/2nd-sg.f | aprende | aprendió | aprenderá | |
| 1st-pl | aprendemos | aprendimos | aprenderemos | |
| 2nd-pl.inf | aprendéis | aprendisteis | aprenderéis | |
| 3rd-pl/2nd-pl.f | aprenden | aprendieron | aprenderán | |
| vivir ‘to live’ (-IR-type verb) | 1st-sg | vivo | viví | viviré |
| 2nd-sg.inf | vives | viviste | vivirás | |
| 3rd-sg/2nd-sg.f | vive | vivió | vivirá | |
| 1st-pl | vivimos | vivimos | viviremos | |
| 2nd-pl.inf | vivís | vivisteis | viviréis | |
| 3rd-pl/2nd-pl.f | viven | vivieron | vivirán |
| Vocab Test | Grammar Proficiency | Production: Present | Production: Preterite | Production: Future | WM: LNS task | |
|---|---|---|---|---|---|---|
| Metalinguistic Feedback | 96.78 (4.40) | 52.78 (10.90) | 81.94 (17.10) | 57.41 (19.77) | 3.94 (9.67) | 13.30 (2.91) |
| Yes–No Feedback | 98.25 (4.30) | 53.82 (10.71) | 83.85 (18.97) | 63.80 (20.52) | 7.29 (14.71) | 12.13 (2.01) |
| Control | 97.11 (5.29) | 54.06 (11.50) | 83.59 (21.54) | 56.87 (22.01) | 7.81 (11.39) | 12.83 (2.85) |
| Tense | Condition | Sample Stimuli | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Preterite | Agreement | El | año | pasado | ella | recib-ió | el | diploma | en | la | ceremonia. |
| The | year | last | she-3sg | received-3sg | the | diploma | at | the | ceremony. | ||
| ‘Last year she received the diploma at the ceremony.’ | |||||||||||
| Tense Violation | * El | próximo | año | ella | recib-ió | el | diploma | en | la | ceremonia. | |
| * The | next | year | she-3sg | received-3sg | the | diploma | at | the | ceremony. | ||
| ‘Next year she received the diploma at the ceremony.’ | |||||||||||
| SV Violation | * El | año | pasado | yo | recib-ió | el | diploma | en | la | ceremonia. | |
| * The | year | last | I-1sg | received-3sg | the | diploma | at | the | ceremony. | ||
| ‘Last year I received the diploma at the ceremony.’ | |||||||||||
| Future | Agreement | El | próximo | año | ella | recibir-á | el | diploma | en | la | ceremonia. |
| The | next | year | she-3sg | will receive-3sg | the | diploma | at | the | ceremony. | ||
| ‘Next year she will receive the diploma at the ceremony.’ | |||||||||||
| Tense Violation | * El | año | pasado | ella | recibir-á | el | diploma | en | la | ceremonia. | |
| * The | year | last | she-3sg | will receive-3sg | the | diploma | at | the | ceremony. | ||
| ‘Last year she will receive the diploma at the ceremony.’ | |||||||||||
| SV Violation | * El | próximo | año | yo | recibir-á | el | diploma | en | la | ceremonia. | |
| * The | next | year | I-1sg | will receive-3sg | the | diploma | at | the | ceremony. | ||
| ‘Next year I will receive the diploma at the ceremony.’ | |||||||||||
| Pretest | Posttest | Delayed Posttest | |
|---|---|---|---|
| Tense-Preterite | |||
| Metalinguistic Feedback | 50.00 (25.00) | 75.93 (25.46) | 71.30 (21.60) |
| Yes–No Feedback | 51.04 (34.17) | 66.67 (24.08) | 68.75 (25.80) |
| Control | 45.00 (24.81) | 54.38 (28.24) | 56.88 (24.67) |
| Tense-Future | |||
| Metalinguistic Feedback | 21.30 (24.71) | 76.85 (26.79) | 73.15 (28.53) |
| Yes–No Feedback | 23.96 (27.07) | 71.88 (25.87) | 62.50 (27.58) |
| Control | 23.75 (27.12) | 26.88 (24.93) | 21.88 (26.06) |
| Subject-Preterite | |||
| Metalinguistic Feedback | 68.52 (24.61) | 84.26 (20.97) | 81.48 (21.48) |
| Yes–No Feedback | 64.58 (26.50) | 86.46 (14.71) | 76.04 (21.47) |
| Control | 61.25 (19.57) | 70.00 (26.07) | 66.88 (24.28) |
| Subject-Future | |||
| Metalinguistic Feedback | 72.22 (20.02) | 94.44 (10.59) | 85.19 (18.68) |
| Yes–No Feedback | 66.67 (21.70) | 86.46 (18.03) | 83.33 (20.41) |
| Control | 72.50 (19.45) | 75.00 (23.34) | 73.13 (21.47) |
| Tense-Preterite | Tense-Future | Subject-Preterite | Subject-Future | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Factors | OR | SE | CI | t | OR | SE | CI | t | OR | SE | CI | t | OR | SE | CI | t |
| Group: | ||||||||||||||||
| Control (base) | ||||||||||||||||
| Y–N | 1.63 | 0.24 | 1.0, 2.6 | 2.0 * | 1.22 | 0.38 | 0.6, 2.6 | 0.5 | 1.17 | 0.27 | 0.7, 2.0 | 0.6 | 0.83 | 0.25 | 0.5, 1.3 | −0.8 |
| Meta. | 1.77 | 0.20 | 1.2, 2.6 | 3.0 ** | 1.00 | 0.38 | 0.5, 2.1 | −0.0 | 1.38 | 0.26 | 0.8, 2.3 | 1.3 | 0.91 | 0.24 | 0.6, 1.5 | −0.4 |
| Time: | ||||||||||||||||
| Pretest (base) | ||||||||||||||||
| Posttest | 2.03 | 0.16 | 1.5, 2.7 | 4.3 *** | 1.22 | 0.26 | 0.7, 2.0 | 0.76 | 1.52 | 0.19 | 1.1, 2.2 | 2.3 * | 1.14 | 0.23 | 0.7, 1.8 | 0.6 |
| Delayed | 2.00 | 0.13 | 1.6, 2.6 | 5.2 *** | 0.88 | 0.23 | 0.6, 1.4 | −0.5 | 1.37 | 0.15 | 1.0, 1.8 | 2.1 * | 1.03 | 0.18 | 0.7, 1.5 | 0.2 |
| Group × Time | ||||||||||||||||
| Y–N × Posttest | - | - | - | - | 8.04 | 0.45 | 3.3, 19.5 | 4.6 *** | 2.53 | 0.36 | 1.2, 5.1 | 2.6 * | 2.83 | 0.38 | 1.3, 6.0 | 2.7 ** |
| Y–N × Delayed | - | - | - | - | 7.01 | 0.42 | 3.0, 16.1 | 4.6 *** | 1.53 | 0.31 | 0.8, 2.9 | 1.3 | 2.44 | 0.36 | 1.2, 4.9 | 2.5 * |
| Meta × Posttest | - | - | - | - | 12.67 | 0.47 | 5.0, 32.2 | 5.4 *** | 1.60 | 0.37 | 0.8, 3.3 | 1.3 | 5.60 | 0.43 | 2.4, 13.1 | 4.0 *** |
| Meta. × Delayed | - | - | - | - | 14.14 | 0.41 | 6.3, 31.8 | 6.4 *** | 1.47 | 0.34 | 0.8, 2.9 | 1.1 | 2.18 | 0.38 | 1.0, 4.6 | 2.0 * |
| WM | 1.06 | 0.03 | 1.0, 1.1 | 2.0 * | 1.36 | 0.1 | 1.2, 1.5 | 6.0 *** | 1.02 | 0.03 | 1.0, 1.1 | 0.6 | 1.18 | 0.03 | 1.1, 1.2 | 6.0 *** |
| WM × Group: | ||||||||||||||||
| WM × Y–N | - | - | - | - | 0.79 | 0.1 | 0.6, 1.0 | −2.3 * | - | - | - | - | - | - | - | - |
| WM × Meta | - | - | - | - | 0.71 | 0.1 | 0.6, 0.9 | −3.2 ** | - | - | - | - | - | - | - | - |
| WM × Time: | ||||||||||||||||
| WM × Posttest | - | - | - | - | - | - | - | - | 1.09 | 0.05 | 1.0, 1.2 | 1.7 | - | - | - | - |
| WM × Delayed | - | - | - | - | - | - | - | - | 1.22 | 0.06 | 1.1, 1.4 | 3.6 ** | - | - | - | - |
| Intercept | 0.68 | 0.15 | 0.5, 0.9 | −2.6 * | 0.24 | 0.23 | 0.2, 0.4 | −6.2 | 1.59 | 0.13 | 1.2, 2.1 | 3.6 ** | 2.74 | 0.14 | 2.1, 3.6 | 7.0 |
| Tense-Preterite | Tense-Future | Subject-Preterite | Subject-Future | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F | df | p | F | df | p | F | df | p | F | df | p | |
| Time | 14.53 | 2, 267 | <0.001 | 40.91 | 2, 261 | <0.001 | 18.73 | 2, 261 | <0.001 | 20.28 | 2, 263 | <0.001 |
| Group | 5.14 | 2, 267 | 0.006 | 26.77 | 2, 261 | <0.001 | 6.44 | 2, 261 | 0.002 | 7.52 | 2, 263 | 0.001 |
| Time × Group | - | - | - | 13.91 | 4, 261 | <0.001 | 2.10 | 4, 261 | 0.081 | 5.51 | 4, 263 | <0.001 |
| WM | 3.92 | 1, 267 | 0.049 | 6.39 | 1, 261 | 0.012 | 13.46 | 1, 261 | <0.001 | 36.46 | 1, 263 | <0.001 |
| WM × Time | - | - | - | - | - | - | 7.48 | 2, 261 | 0.001 | - | - | - |
| WM × Group | - | - | - | 6.37 | 2, 261 | 0.002 | - | - | - | - | - | - |
| Tense-Future | Subject-Preterite | Subject-Future | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Cont. Est. | CI | p | Cont. Est. | CI | p | Cont. Est. | CI | p | |
| Pretest: | |||||||||
| Meta vs. Y–N | −0.03 | −0.18, 0.12 | 0.639 | 0.04 | −0.11, 0.18 | 0.633 | 0.02 | −0.10, 0.14 | 0.737 |
| Meta vs. Contr | 0.00 | −0.12, 0.12 | 0.997 | 0.07 | −0.04, 0.18 | 0.202 | −0.02 | −0.12, 0.08 | 0.703 |
| Y–N vs. Contr | 0.03 | −0.10, 0.16 | 0.608 | 0.04 | −0.09, 0.16 | 0.557 | −0.04 | −0.14, 0.06 | 0.453 |
| Posttest: | |||||||||
| Meta vs. Y–N | 0.05 | −0.10, 0.19 | 0.533 | −0.04 | −0.14, 0.06 | 0.471 | 0.06 | −0.01, 0.13 | 0.090 |
| Meta vs. Contr | 0.56 | 0.44, 0.68 | <0.001 | 0.13 | 0.02, 0.25 | 0.018 | 0.18 | 0.12, 0.26 | <0.001 |
| Y–N vs. Contr | 0.52 | 0.40, 0.64 | <0.001 | 0.17 | 0.08, 0.26 | <0.001 | 0.12 | 0.03, 0.21 | 0.008 |
| Delayed: | |||||||||
| Meta vs. Y–N | 0.10 | −0.06, 0.27 | 0.200 | 0.02 | −0.09, 0.12 | 0.728 | −0.00 | −0.10, 0.10 | 0.959 |
| Meta vs. Contr | 0.58 | 0.45, 0.70 | <0.001 | 0.13 | 0.03, 0.23 | 0.014 | 0.11 | 0.02, 0.20 | 0.017 |
| Y–N vs. Contr | 0.47 | 0.34, 0.60 | <0.001 | 0.11 | 0.02, 0.21 | 0.024 | 0.11 | 0.03, 0.20 | 0.011 |
| Group | Condition | Pretest RTs (ms) | Posttest RTs (ms) | Delayed RTs (ms) | |
|---|---|---|---|---|---|
| Yes–No Feedback (n = 24) | Preterite | Agreement | 729.03 (253.81) | 552.55 (278.60) | 501.26 (209.85) |
| AdvV Violation | 738.76 (302.92) | 555.55 (315.75) | 494.81 (210.00) | ||
| SV Violation | 737.72 (281.38) | 555.59 (260.34) | 458.22 (170.56) | ||
| Future | Agreement | 886.18 (366.13) | 579.48 (272.53) | 529.79 (232.54) | |
| AdvV Violation | 877.37 (374.50) | 616.14 (315.46) | 486.73 (200.15) | ||
| SV Violation | 806.63 (321.91) | 608.73 (322.23) | 513.05 (229.90) | ||
| Metalinguistic Feedback (n = 27) | Preterite | Agreement | 748.13 (252.93) | 571.81 (272.14) | 571.78 (249.31) |
| AdvV Violation | 747.29 (331.70) | 575.14 (221.79) | 603.47 (323.86) | ||
| SV Violation | 765.99 (289.76) | 642.04 (255.09) | 586.59 (296.88) | ||
| Future | Agreement | 836.42 (373.27) | 677.82 (342.81) | 595.63 (308.19) | |
| AdvV Violation | 845.63 (351.94) | 755.09 (460.81) | 607.86 (353.20) | ||
| SV Violation | 813.26 (339.56) | 701.72 (375.87) | 583.50 (303.59) | ||
| Control (n = 40) | Preterite | Agreement | 871.20 (513.94) | 592.90 (303.55) | 505.58 (217.26) |
| AdvV Violation | 825.67 (356.22) | 631.99 (289.53) | 494.75 (205.49) | ||
| SV Violation | 833.25 (393.96) | 616.43 (239.22) | 523.32 (250.82) | ||
| Future | Agreement | 876.47 (383.24) | 609.86 (262.68) | 559.40 (237.55) | |
| AdvV Violation | 921.80 (412.80) | 614.76 (254.22) | 572.05 (280.29) | ||
| SV Violation | 885.79 (398.62) | 674.17 (328.38) | 597.21 (353.47) | ||
| SV-Future (Agreement-Future Minus SV-FutureViolation) | AdvV-Future (Agreement-Future Minus AdvV-Future Violation) | |||||||
|---|---|---|---|---|---|---|---|---|
| Factors | Est | SE | t | CI | Est | SE | t | CI |
| Time: | ||||||||
| Pretest (base) | ||||||||
| Posttest | 76.1 | 42.1 | 1.8 | −7.4, 159.6 | 59.4 | 51.6 | 1.2 | −43.0, 161.9 |
| Delayed | 35.4 | 42.1 | 0.8 | −48.1, 118.9 | −13.5 | 51.6 | −0.3 | −115.9, 88.9 |
| WM | 5.5 | 7.1 | 0.8 | −8.7, 19.8 | −17.5 | 15.0 | −1.2 | −47.1, 12.2 |
| WM × Time: | ||||||||
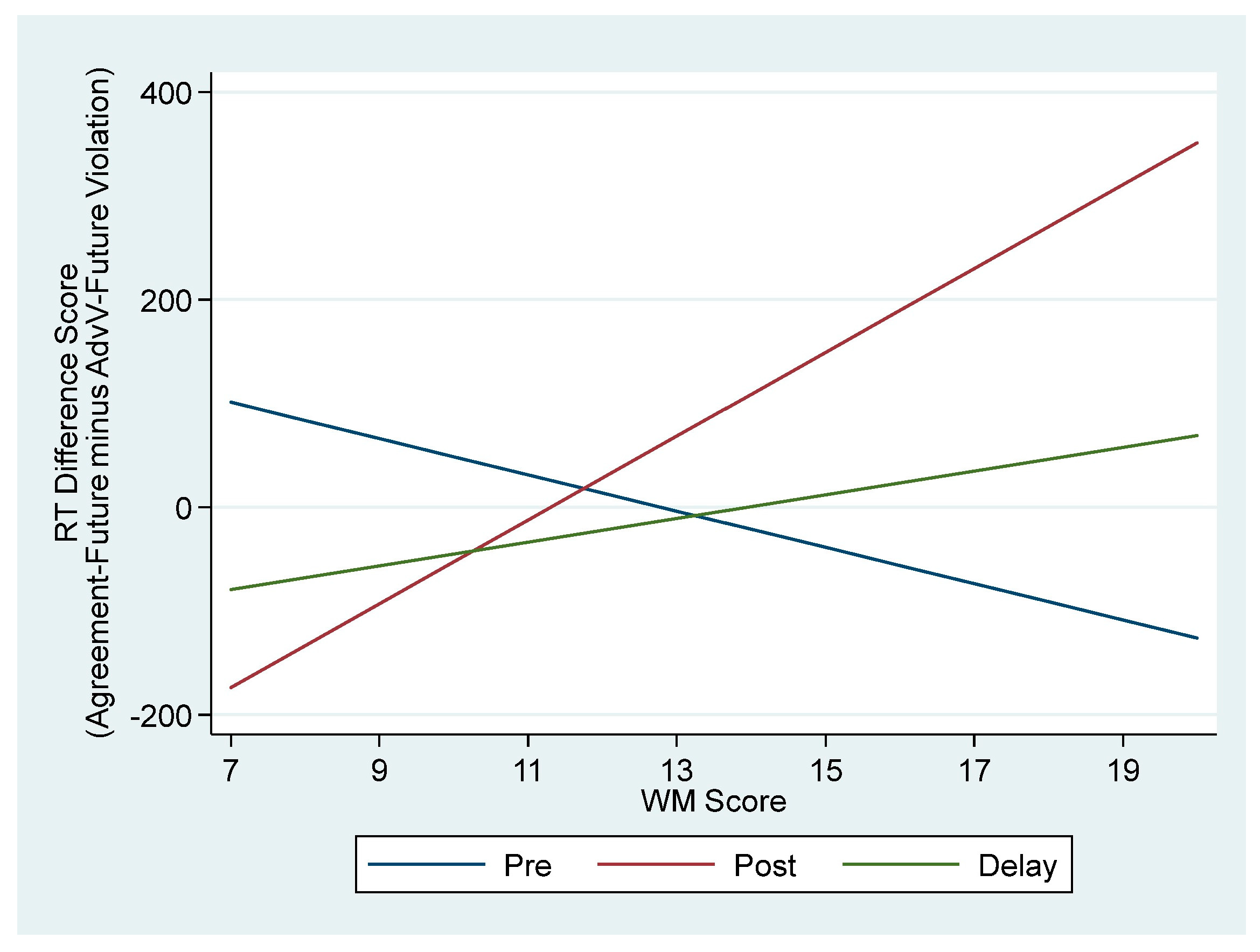
| WM × Posttest | - | - | - | - | 57.8 | 20.3 | 2.8 ** | 17.6, 98.1 |
| WM × Delayed | - | - | - | - | 28.9 | 20.3 | 1.4 | −11.4, 69.2 |
| Intercept | −49.5 | 30.3 | −1.6 | −109.3, 10.3 | 0.1 | 38.2 | 0.0 | −75.3, 75.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dracos, M.; Henry, N. The Role of Task-Essential Training and Working Memory in Offline and Online Morphological Processing. Languages 2021, 6, 24. https://doi.org/10.3390/languages6010024
Dracos M, Henry N. The Role of Task-Essential Training and Working Memory in Offline and Online Morphological Processing. Languages. 2021; 6(1):24. https://doi.org/10.3390/languages6010024
Chicago/Turabian StyleDracos, Melisa, and Nick Henry. 2021. "The Role of Task-Essential Training and Working Memory in Offline and Online Morphological Processing" Languages 6, no. 1: 24. https://doi.org/10.3390/languages6010024
APA StyleDracos, M., & Henry, N. (2021). The Role of Task-Essential Training and Working Memory in Offline and Online Morphological Processing. Languages, 6(1), 24. https://doi.org/10.3390/languages6010024