A Phonetic Account of Spanish-English Bilinguals’ Divergence with Agreement

 , ,
, , 
 and
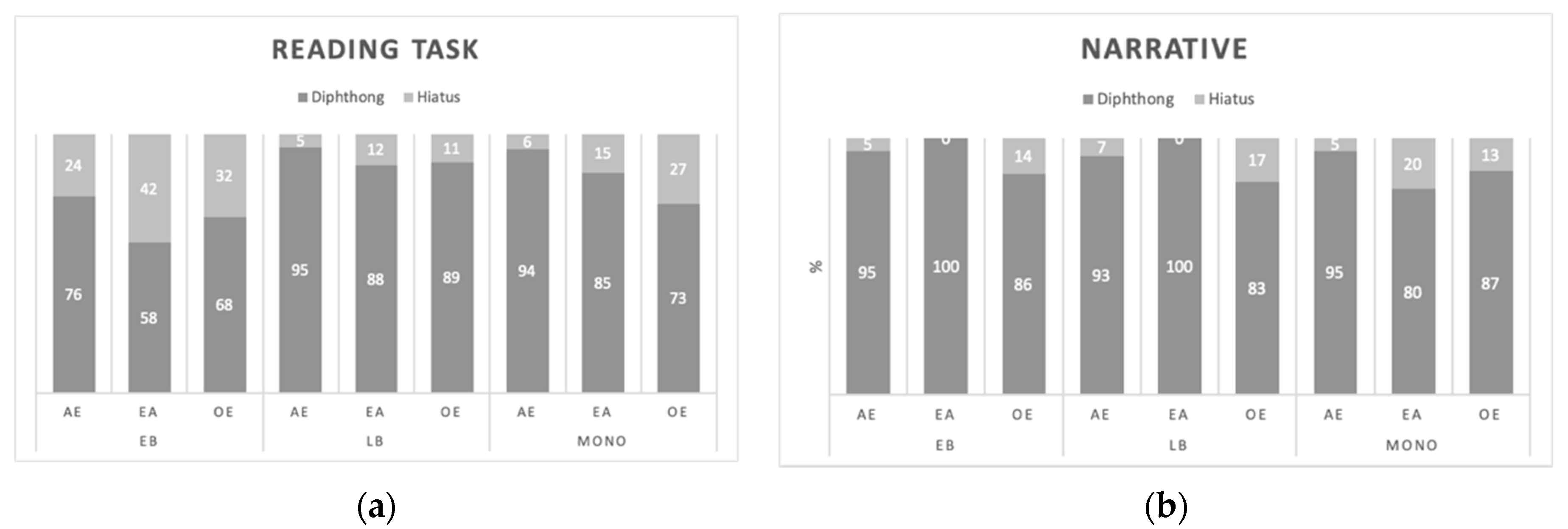
and
Abstract
1. Introduction
1.1. Acquisition of Gender in Spanish-English Bilinguals
1.2. Acquisition of Vowels in Spanish-English Bilinguals
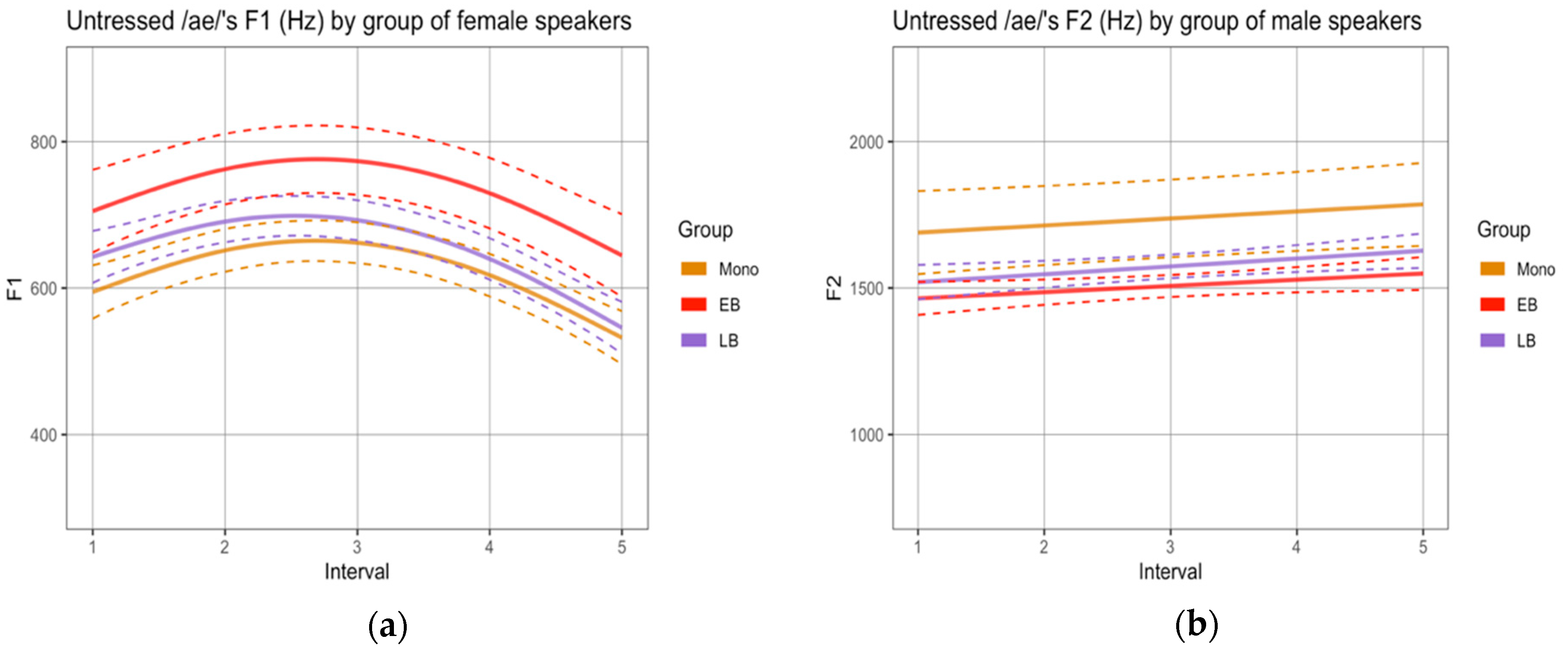
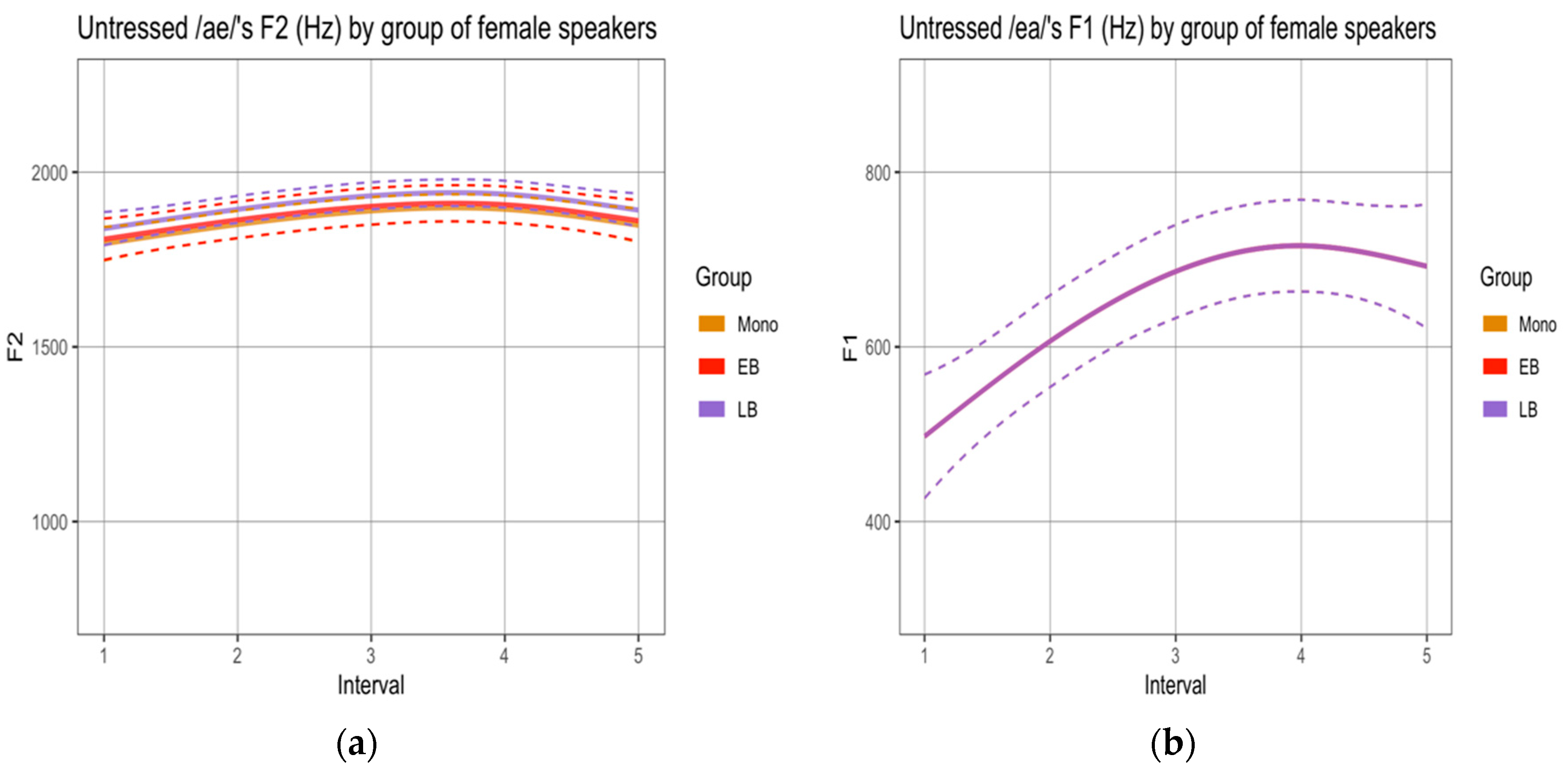
1.3. Phonetics and Morphosyntax
1.4. Research Questions and Hypotheses
2. Materials and Methods
2.1. Participants
2.2. Materials and Tasks
2.3. Analysis
- (1)
- DP configuration
Noun: lobo ‘wolf’ Adjective + Noun gran lobo ‘big wolf-mas’ Determiner + Noun: el lobo ‘the-mas wolf-mas’ Determiner + Covert Noun + Adjective: el grande ‘the-mas big’ Determiner + Adjective + Noun: el gran lobo ‘the-mas big wolf-mas’ Determiner + Noun + Adjective: el lobo grande ‘the-mas wolf-mas big’ - (2)
- Agreement: match for agreement features (number or gender) with determiners and/or adjectives, and with target gender of the noun
Correct: las casas bonitas ‘the-fem pretty-fem houses-fem’ Incorrect: la casa bonito ‘the-fem pretty-mas house-fem’ - (3)
- Noun semantic type: semantic features of the noun under analysis
Abstract: paz ‘peace’ Concrete: coche ‘car’ Animate: gato ‘cat’ Human: chica ‘girl’ Event: fiesta ‘party’ - (4)
- Individuation
Mass: arena ‘sand’ Individual: coche ‘car’ Collective: equipo ‘team’ Ambiguous (used as individual): la policía ‘female police officer’ Ambiguous (used as collective): la policía ‘police’ Both (mass or individual): fruta ‘fruit’
- (5)
- Gender visibility
[nouns with formally visible gender] word marker: niño (m) ‘boy’ niña (f) ‘girl’ transparent suffix: educación (f) ‘education’ cazador (m) ‘hunter’ [nouns with no visible gender marking] -e: padre (m) ‘father’ -i / -u: espíritu (m) ‘spirit’ consonant: amor (m) ‘love’ inverted (-o for fem. /-a for masc.): mano (f), foto (m) ‘hand, photo’ - (6)
- Gender alternation: whether or not there exists an opposite word to pair with the noun in terms of gender and the nature of the lexical relationship between the alternants
Transparent: gato (m)/gata (f) ‘male cat, female cat’ Unmarked masculine: jefe/jefa (m)/(f) ‘male boss, female boss’ Lexical root gender: hombre (m), mujer (f) ‘man, woman’ Derivational: cerezo/cereza (m)/(f) ‘cherry tree, cherry’ Free variation (alternating forms with minimal or no semantic change): canasta (f)/canasto(m) ‘basket’ Unrelated: plato (m)/plata (f) ‘plate, silver’ Invisible gender (semantically alternating but marked only in article): estudiante (f)/(m) ‘male or female student’ Unique (only one gender per root): carro (cf *carra) ‘car’ Epicene (one grammatical gendered semantically unspecified gender): víctima (f) ‘male or female victim’
3. Results
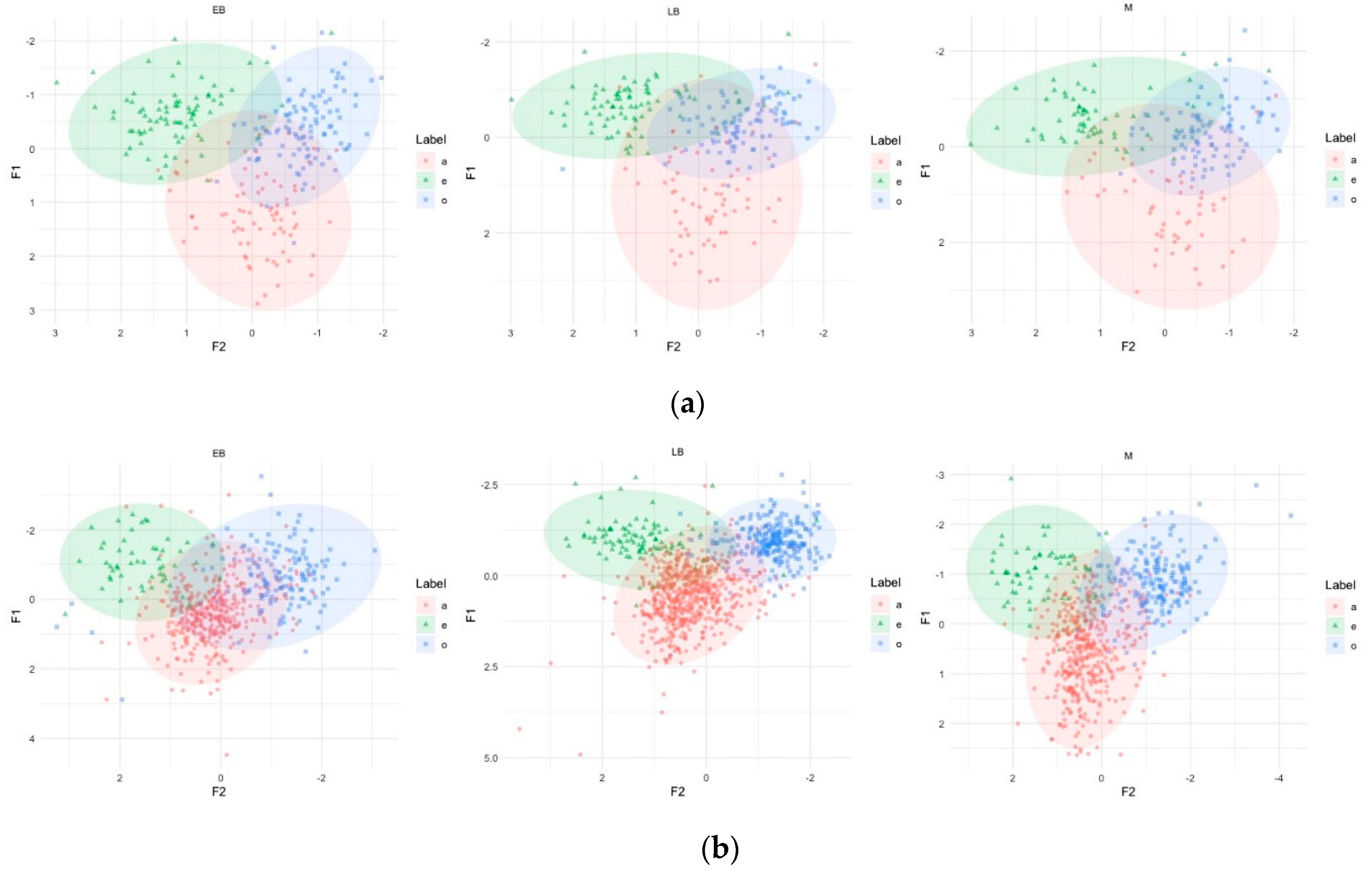
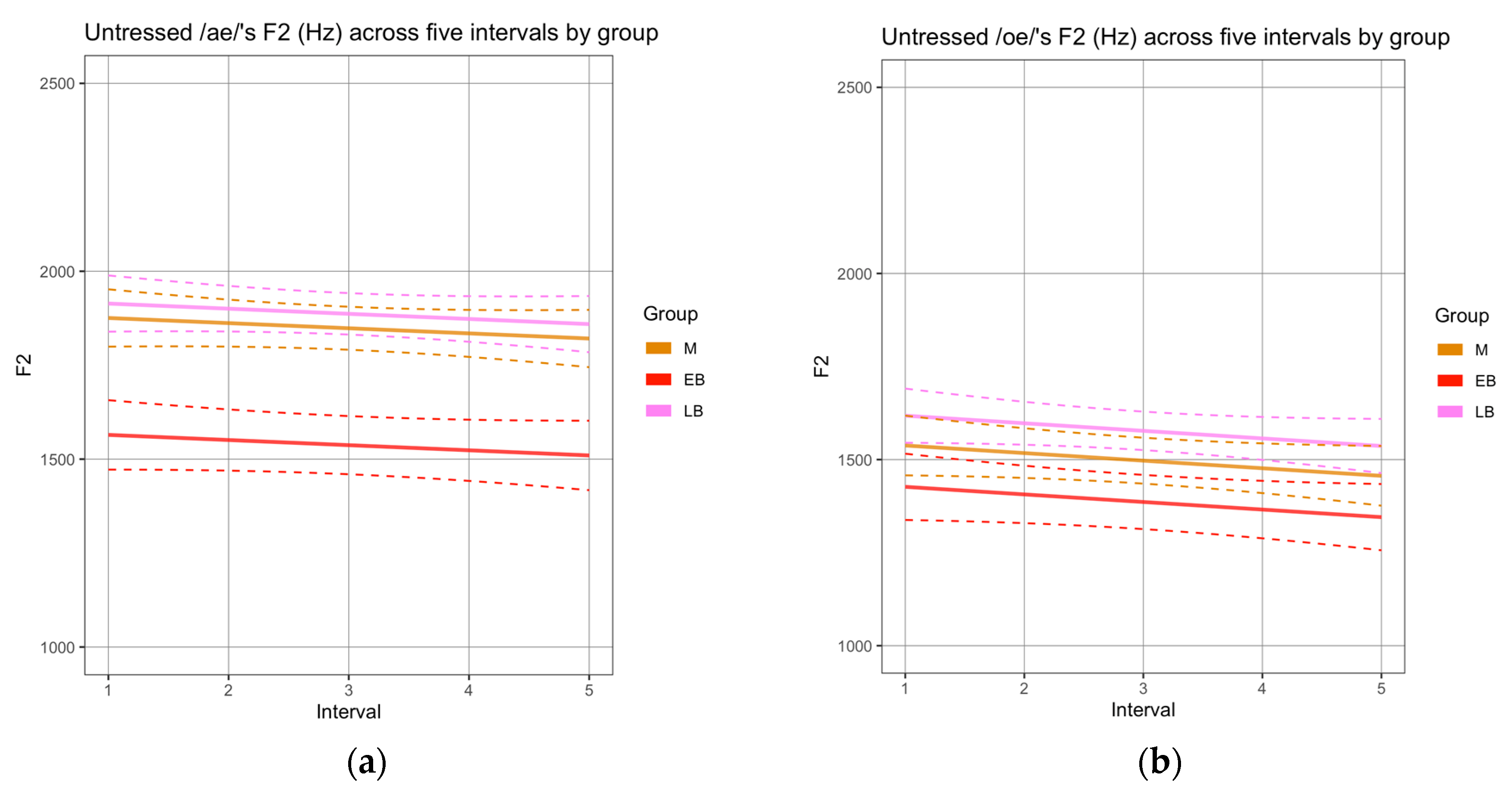
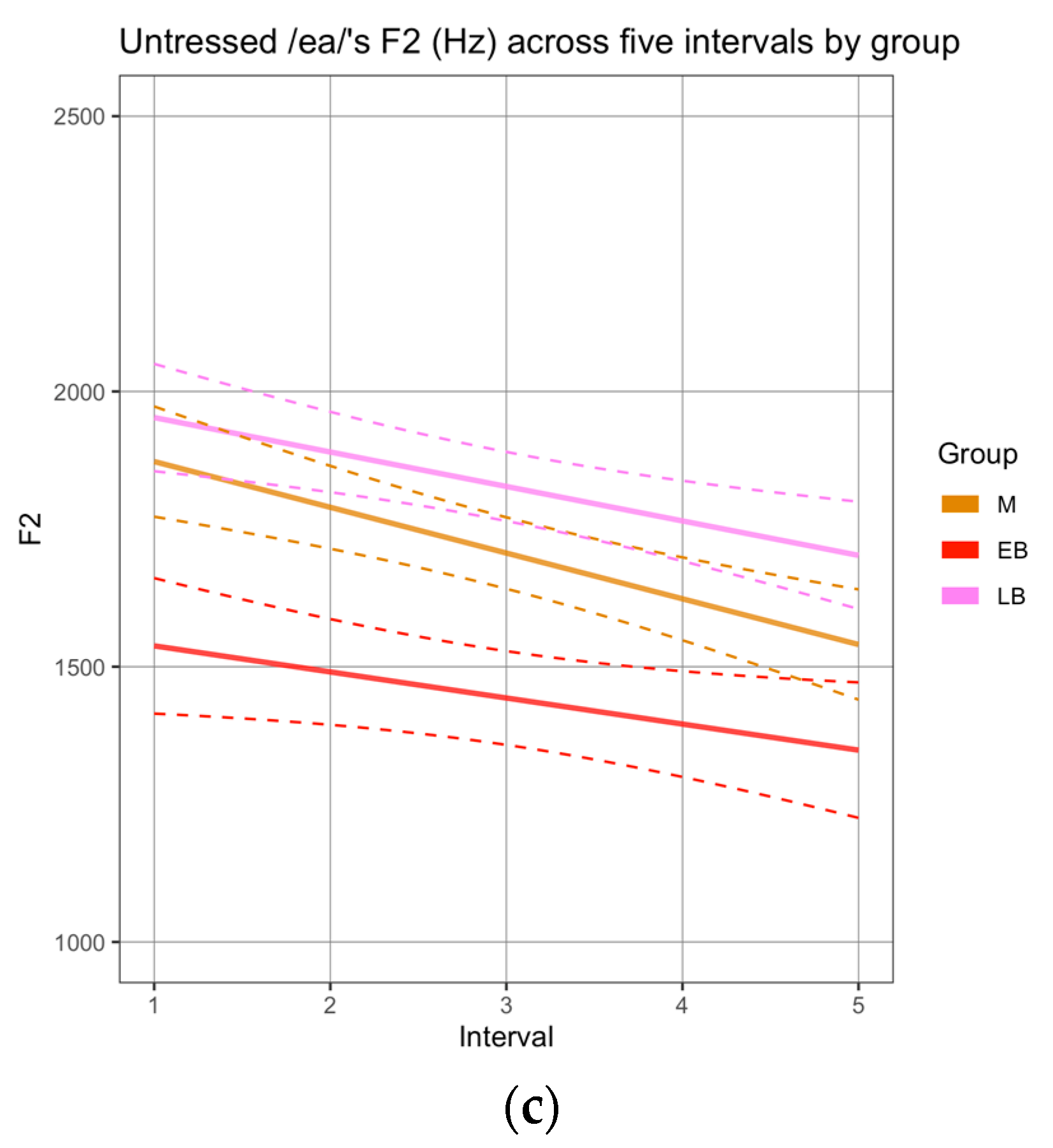
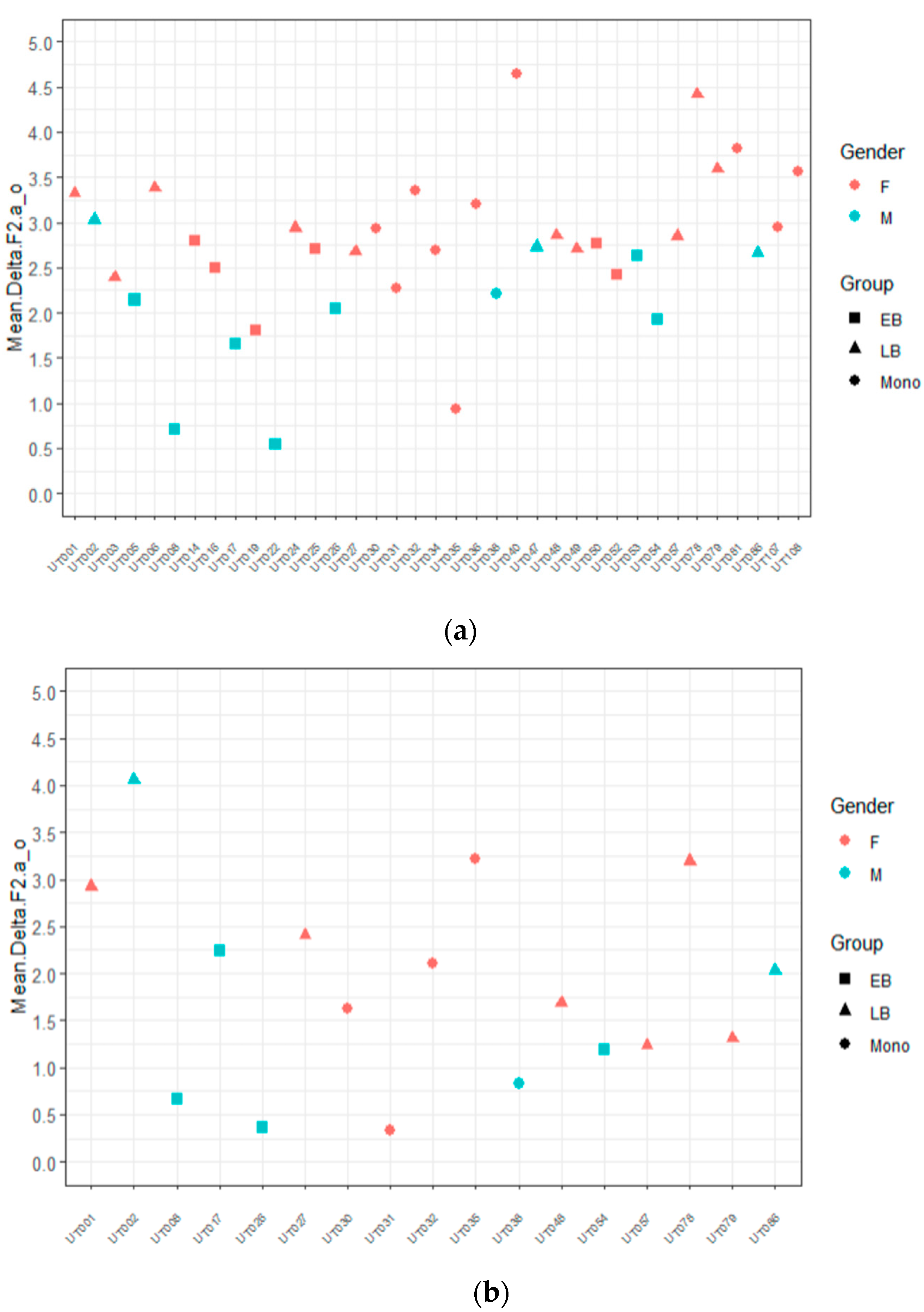
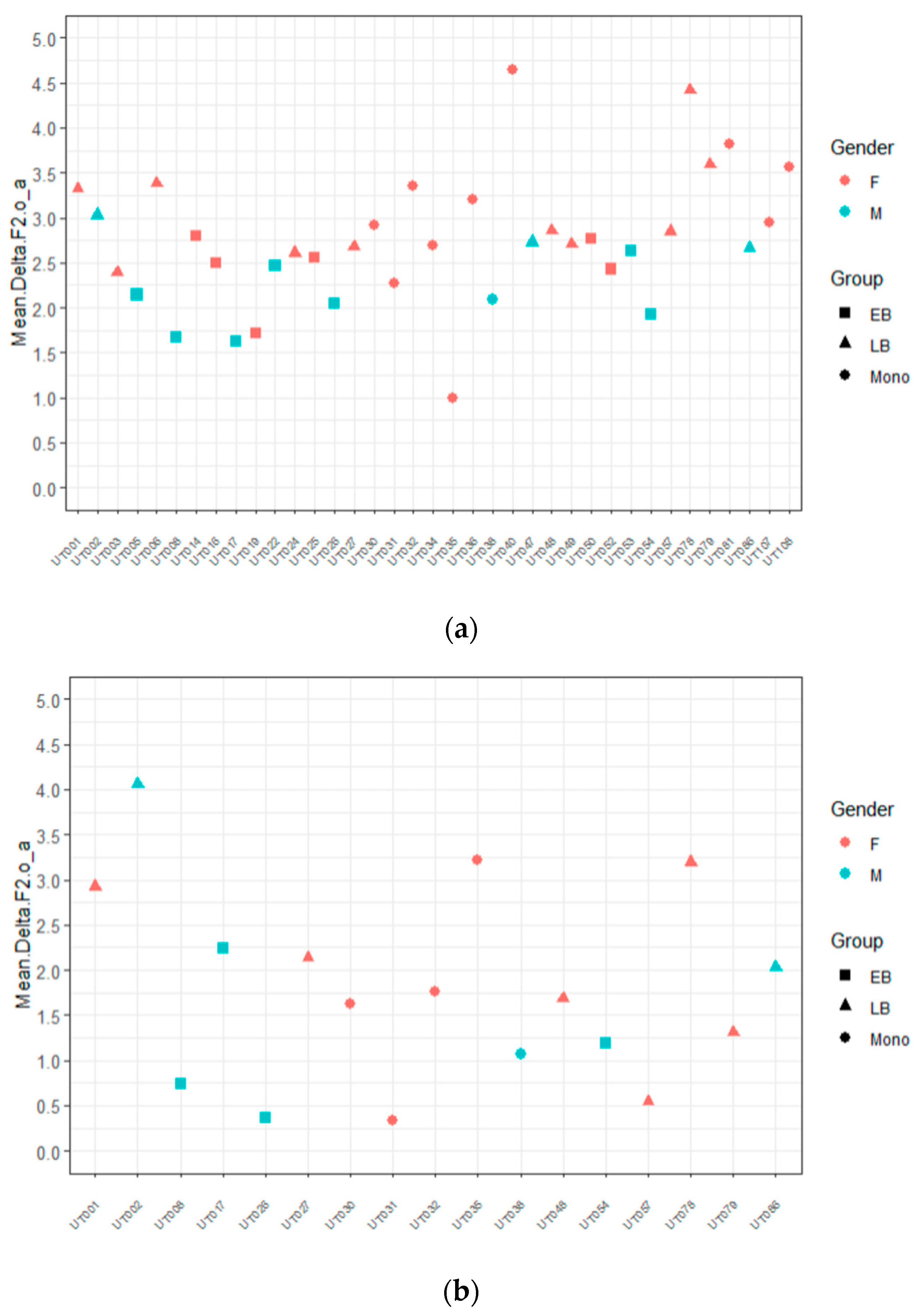
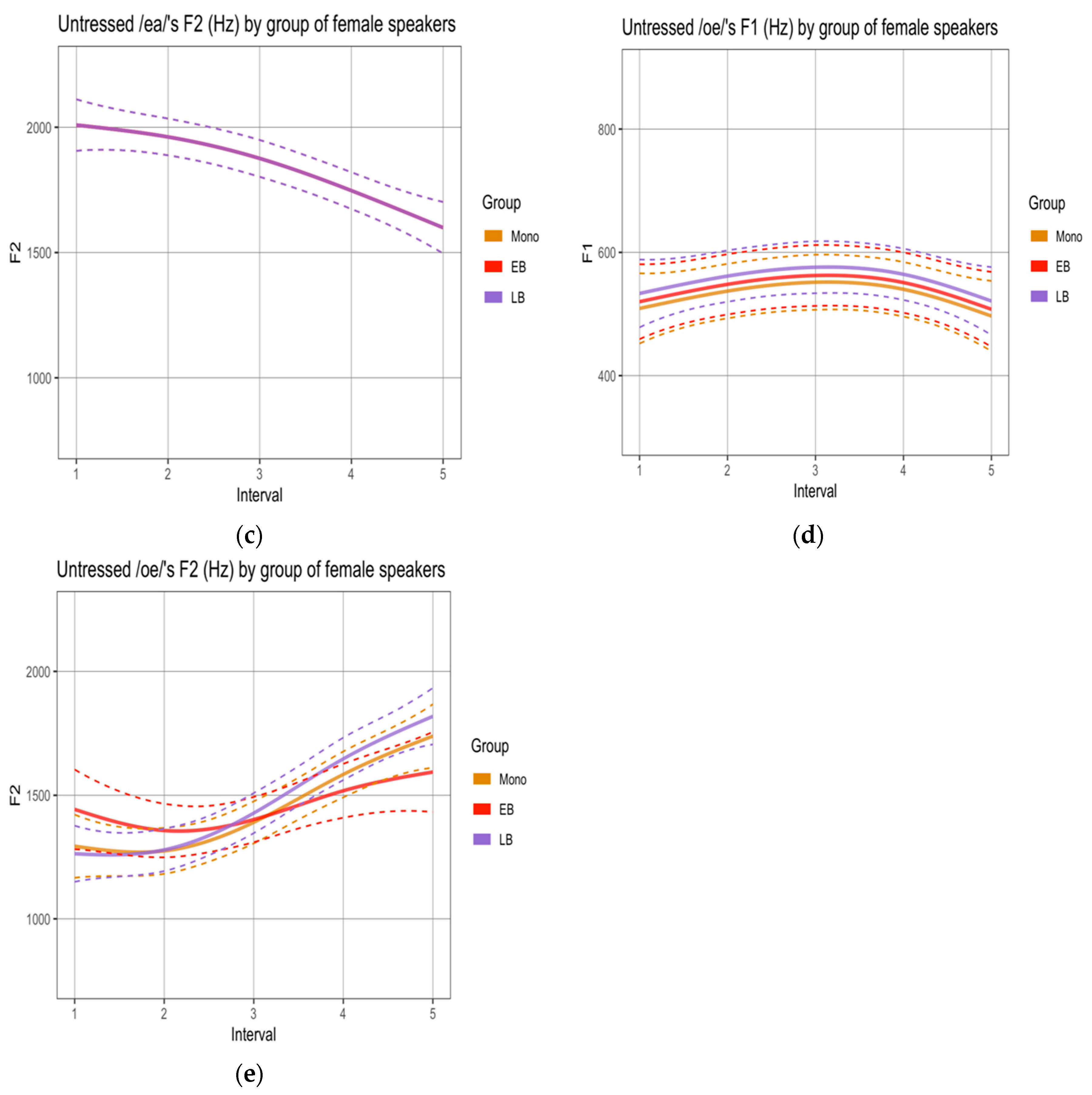
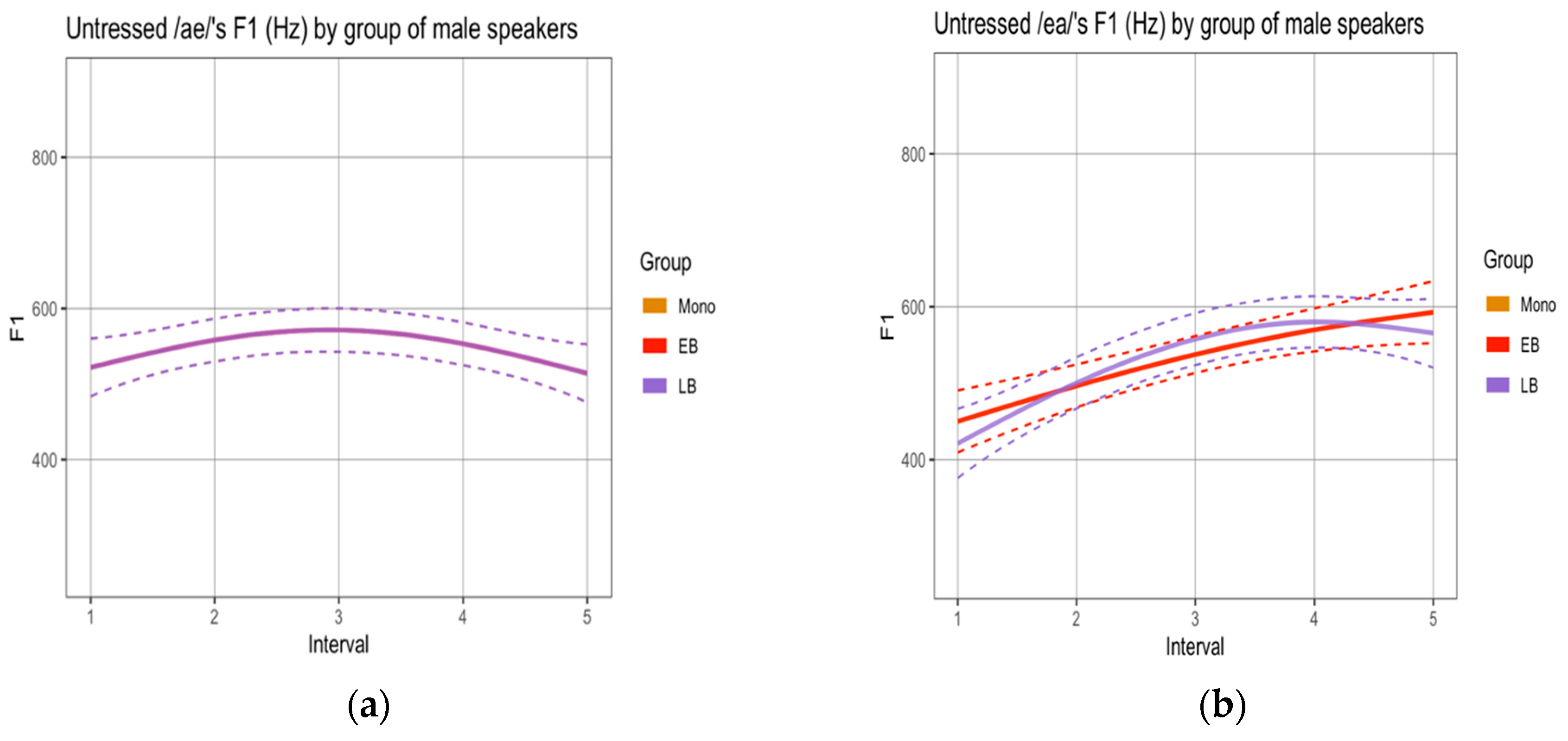
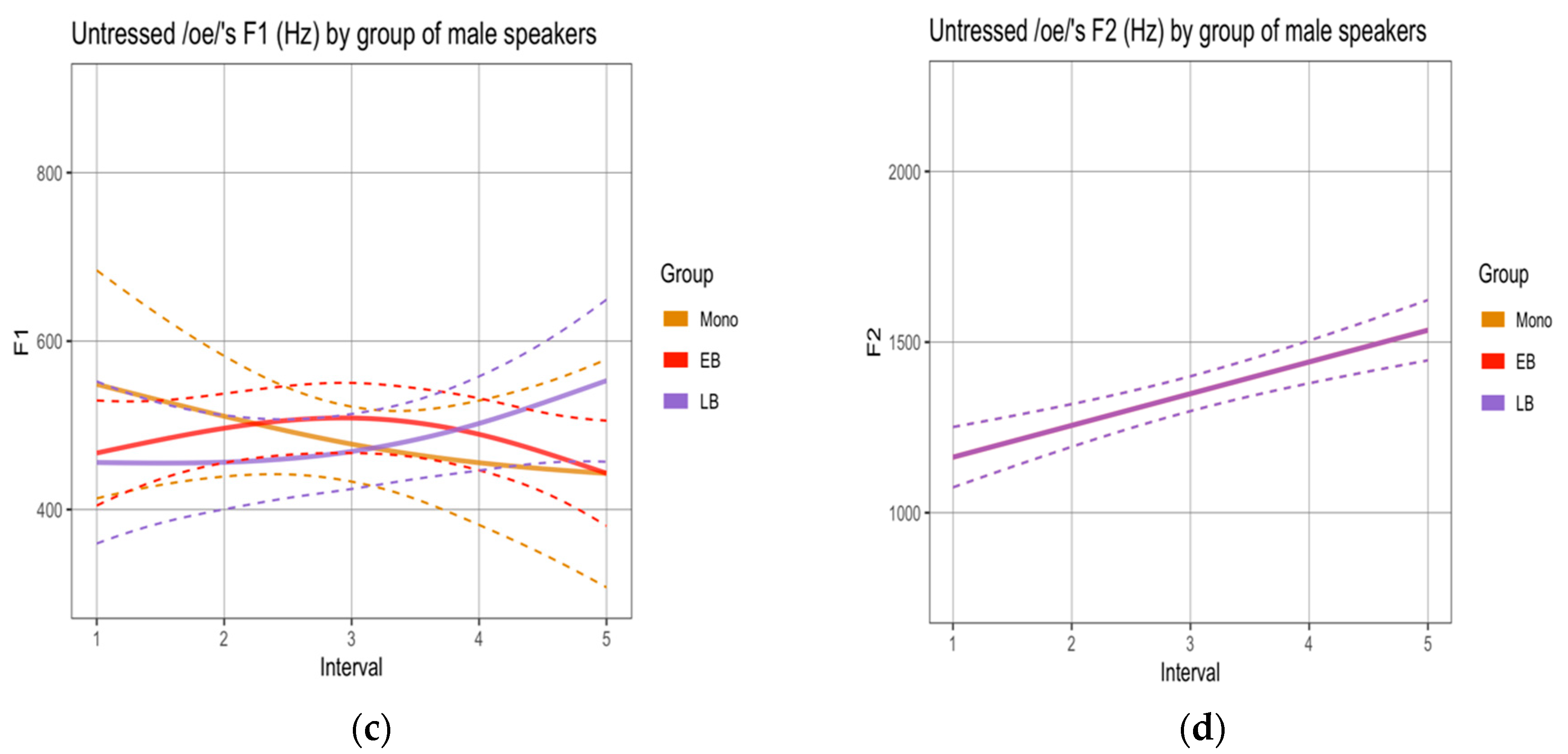
3.1. Phonetic Analysis
3.2. Morphosyntactic Analysis
- (7)
- la abuelita y la caperucita rojo … (Speaker UT052, EB)The-fem grandmother-fem and the-fem little-riding-hood- fem red-masc
- (8)
- Y la niña la caperucita rojo … (Speaker UT052, EB)And the-fem girl-fem the-fem little-riding-hood-fem red-masc
- (9)
- con ello y a a le hablaba y … (Speaker UT054, EB)With him and ah ah her-dat spoke and [intended reference to “with her”]
- (10)
- bueno su abuelo la había … (Speaker UT107, M)Well her grandparent-masc her-dat had
- (11)
- todas las alimentos … (Speaker UT086, LB)All-fem the-fem food-masc
- (12)
- tanto zozobra … (Speaker UT002, LB)So-much-masc unstability-fem
- (13)
- este caperucita está entrando … (Speaker UT030, M)This-masc little-riding-hood-fem is entering
- (14)
- y eso cosas como eso … (Speaker UT054, EB)And this-masc things-fem like this-masc
3.3. Combined Results
4. Discussion
4.1. Hypothesis Evaluation
4.2. General Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A





References
- Adank, Patti M., Roel Smits, and Roeland van Hout. 2004. A comparison of vowel normalization procedures for language variation research. Journal of the Acoustical Society of America 116: 3099–107. [Google Scholar] [CrossRef]
- Aguilar, Lourdes. 1999. Differences. Speech Communication 28: 57–74. [Google Scholar] [CrossRef]
- Aguilar, Lourdes. 2010. Vocales en Grupo. Madrid: Arco/Libros. [Google Scholar]
- Alba, Matthew C. 2006. Accounting for variability in the production of Spanish vowel sequences. In Selected Proceedings of the 9th Hispanic Linguistics Symposium. Edited by Nuria Sagarra and Almeida. J. Toribio. Somerville: Cascadilla Press, pp. 273–85. [Google Scholar]
- Barreña, Andoni. 1997. Desarrollo diferenciado de sistemas gramaticales en un niño vasco-español bilingüe. In Contemporary perspectives on the acquisition of Spanish. Edited by Ana T. Pérez-Leroux and W. Glass. Somerville: Cascadilla Press, vol. 1, pp. 55–74. [Google Scholar]
- Bedore, Lisa M., and Laurence B. Leonard. 2001. Grammatical morphology deficits in Spanish-speaking children with specific language impairment. Journal of Speech, Language, and Hearing Research 44: 905–24. [Google Scholar] [CrossRef]
- Bernhardt, Barbara H., and Joseph P. Stemberger. 1998. Handbook of Phonological Development. San Diego: Academic Press. [Google Scholar]
- Boersma, Paul, and David Weenink. 2001. Praat: Doing Phonetics by Computer [Computer Program]. Available online: http://www.praat.org/ (accessed on 15 June 2020).
- Borzone de Manrique, Ana M. 1976. Acoustic study of /i, u/ in the Spanish diphthongs. Language and Speech 19: 121–28. [Google Scholar] [CrossRef]
- Calabrese, Andrea. 2012. Auditory representations and phonological illusions: A linguist’s perspective on the neuropsychological bases of speech perception. Journal of Neurolinguistics 25: 355–81. [Google Scholar] [CrossRef]
- Calenge, Clément. 2006. The package adehabitat for the R software: A tool for the analysis of space and habitat use by animals. Ecological Modelling 197: 516–19. [Google Scholar] [CrossRef]
- Castilla, Anny P., and Ana T. Pérez-Leroux. 2010. Omissions and substitutions in Spanish object clitics: Developmental optionality as a property of the representational system. Language Acquisition 17: 2–25. [Google Scholar] [CrossRef]
- Colantoni, Laura, and José. I. Hualde. 2016. Constraints on front-mid vowel gliding in Spanish. In The syllable and Stress. Edited by R. Nuñez Cedeño. The Hague: Mouton de Gruyter, pp. 1–28. [Google Scholar]
- Colantoni, L., and A. Limanni. 2010. Where are hiatuses left? A comparative study of vocalic sequences in Argentine Spanish. In Selected Proceedings of the 38th Linguistic Symposium on Romance Languages. Edited by En K. Arregi, Z. Fagyal, S. Montrul and A. Tremblay. Amsterdam: John Benjamins, pp. 23–38. [Google Scholar]
- Culberston, Jennifer, Hanna Jarvinen, Frances Heggarty, and Kenny Smith. 2019. Children’s sensitivity to phonological and semantic cues during noun class learning evidence for a phonological bias. Language 95: 268–93. [Google Scholar] [CrossRef]
- Cuza, Alejandro, and Roció Pérez-Tattam. 2016. Grammatical gender selection and phrasal word order in child heritage Spanish: A feature re-assembly approach. Bilingualism: Language and Cognition 19: 50–68. [Google Scholar] [CrossRef]
- Cuza, Alejandro, Ana T. Pérez-Leroux, and Liliana Sánchez. 2013. The role of semantic transfer in clitic-drop among Chinese L1-Spanish L2 bilinguals. Studies in Second Language Acquisition 35: 93–125. [Google Scholar] [CrossRef]
- D’Imperio, Mariapaola, Gorka Elordieta, Sónia Frota, Pilar Prieto, and Marina Viga’rio. 2005. Intonational phrasing in Romance: The role of syntactic and prosodic structure. In Prosodies. Edited by Sónia Frota, Marina Viga’rio and Maria J. Freitas. Berlin: Mouton de Gruyter, pp. 59–98. [Google Scholar]
- Davidson, Lisa, and Daniel Erker. 2014. Hiatus resolution in American English: The case against glide insertion. Language 90: 482–514. [Google Scholar] [CrossRef]
- Delattre, Pierre. 1965. Comparing the Phonetic Features of English, French, German and Spanish: An Interim Report. Philadelphia: Julius Groos Verlag. [Google Scholar]
- Durvasula, Karthik, and Jimin Kahng. 2015a. Illusory vowels in perceptual epenthesis: The role of phonological alternations. Phonology 32: 385–416. [Google Scholar] [CrossRef]
- Durvasula, Karthik, and Jimin Kahng. 2015b. Phonological Alternations Modulate Illusory Vowels in Perceptual Epenthesis. Tromso: Universitetet i Tromsoe. [Google Scholar]
- Eichler, Nadine, Veronika Jansen, and Natascha Müller. 2013. Gender acquisition in bilingual children: French–German, Italian–German, Spanish–German and Italian–French. International Journal of Bilingualism 17: 550–72. [Google Scholar] [CrossRef]
- Ettlinger, Marc, and Jennifer Zapf. 2011. The role of phonology in children’s acquisition of the plural. Language Acquisition 18: 294–313. [Google Scholar] [CrossRef] [PubMed]
- Fox, Robert A., James E. Flege, and Murray J. Munro. 1994. The perception of English and Spanish vowels by native English and Spanish listeners: A multidimensional scaling analysis. Journal of the Acoustic Society of America 97: 2540–51. [Google Scholar] [CrossRef] [PubMed]
- Frota, Sonia, Mariapaola D’Imperio, Gorka Elordieta, Pilar Prieto, and Marina Viga’rio. 2007. The phonetics and phonology of intonational phrasing in Romance. In Prosodic and Segmental Issues in (Romance) Phonology. Edited by Pilar Prieto, Joan Mascaro and Maria-Josep Sole. Amsterdam: John Benjamins, pp. 131–53. [Google Scholar]
- Gathercole, Virginia. C. Mueller. 2002. Grammatical gender in bilingual and monolingual children: A Spanish morphosyntactic distinction. In Language and Literacy in Bilingual Children. Edited by D. Kimbrough Oller and Rebecca E. Eilers. Clevedon: Multilingual Matters, pp. 207–19. [Google Scholar]
- Gilbert, Harvey R., Michael P. Robb, and Yang Chen. 1997. Formant frequency development: 15 to 36 months. Journal of Voice 11: 260–66. [Google Scholar] [CrossRef]
- Gildersleeve-Neumann, Christina E., Elizabeth D. Pen˜a, Barbara L. Davis, and Ellen S. Kester. 2009. Effects on L1 during early acquisition of L2: Speech changes in Spanish at first English contact. Bilingualism: Language and Cognition 12: 259–72. [Google Scholar] [CrossRef]
- Goebel-Mahrle, Thomas, and Naomi L. Shin. 2020. A corpus study of child heritage speakers’ Spanish gender agreement. International Journal of Bilingualism 2020: 1–17. [Google Scholar] [CrossRef]
- Goldstein, Brian A., and Karen E. Pollock. 2000. Vowel errors in Spanish-speaking children with phonological disorders: A retrospective comparative study. Clinical Linguistics and Phonetics 14: 217–34. [Google Scholar]
- Grinstead, John, Myriam Cantú-Sánchez, and Blanca Flores-Ávalos. 2008. Canonical and epenthetic plural marking in Spanish-speaking children with specific language impairment. Language Acquisition 15: 329–49. [Google Scholar] [CrossRef]
- Gu, Chong. 2014. Smoothing Spline ANOVA Models: R Package Gss. Journal of Statistical Software 58: 1–25. Available online: http://www.jstatsoft.org/v58/i05/ (accessed on 1 July 2020).
- Guasti, Maria. T., Anna Gavarro, Joke De Lange, and Claudia Caprin. 2008. Article omission across child languages. Language Acquisition 15: 89–119. [Google Scholar] [CrossRef]
- Hawkins, Sarah. 2010. Phonological features, auditory objects, and illusions. Journal of Phonetics 38: 60–89. [Google Scholar] [CrossRef]
- Haynes, Erin F., and Michael Taylor. 2014. An assessment of acoustic contrasts between short and long vowels using convex hulls. Journal of the Acoustical Society of America 136: 883–91. [Google Scholar] [CrossRef]
- Hualde, José I. 2014. Los sonidos del Espan˜ol. Cambridge: Cambridge University Press. [Google Scholar]
- Hualde, José I., Miquel Simonet, and Francisco Torreira. 2008. Postlexical contraction of nonhigh vowels in Spanish. Lingua 118: 1906–25. [Google Scholar] [CrossRef]
- Hutchinson, Sandra P. 1974. Spanish vowel sandhi. In Parasession on Natural Phonology of the Regional Meeting of the Chicago Linguistic Society. Chicago: Chicago Linguistic Society, pp. 752–62. [Google Scholar]
- Johnson, Daniel E. 2015. Quantifying Overlap with Bhattacharyya’s Affinity. Paper presented at NWAV 44, Toronto, ON, Canada, October 25. Available online: https://danielezrajohnson.shinyapps.io/nwav_44 (accessed on 28 August 2020).
- Kehoe, Margaret M., and Conxita Lleó. 2017. Vowel reduction in German-Spanish bilinguals. In Romance-Germanic Bilingual Phonology. Edited by Mehmet Yavas, Margaret M. Kehoe and Walcir C. Cardoso. London: Equinox, pp. 14–37. [Google Scholar]
- Kent, Raymond D., and Ann. D. Murray. 1982. Acoustic features of infant vocalic utterances at 3, 6 and 9 months. Journal of the Acoustic Society of America 72: 353–65. [Google Scholar] [CrossRef]
- Kuchenbrandt, Imme. 2005. Gender acquisition in bilingual Spanish. In Proceedings of the 4th International Symposium on Bilingualism. Edited by James Cohen, Kara T. McAlister, Kellie Rolstad and Jeff MacSwan. Somerville: Cascadilla Press, pp. 1252–63. [Google Scholar]
- Ladefoged, Peter. 2001. Vowels and Consonants: An Introduction to the Sounds of Language. Oxford: Blackwell. [Google Scholar]
- Larran˜aga, Pilar, uijarro-Fuentes, and edro. 2012. Clitics in L1 bilingual acquisition. First Language 32: 151–75. [Google Scholar] [CrossRef]
- Lleo’, Conxita, and Katherine Demuth. 1999. Prosodic constraints on the emergence of grammatical morphemes: Crosslinguistic evidence from Germanic and romance languages. In Proceedings of the 23rd annual Boston University Conference on Language Development. Edited by Annabel Greenhill, Heather Littlefield and Cheryl Tano. Somerville: Cascadilla Press, pp. 407–18. [Google Scholar]
- Lopez Ornat, Susana. 1997. What lies in between a pre-grammatical and a grammatical representation? In Contemporary Perspectives on the Acquisition of Spanish, Volume 1: Developing Grammars. Edited by Ana T. Pérez-Leroux and W. Glass. Somerville: Cascadilla Press, vol. 1, pp. 3–20. [Google Scholar]
- Lobanov, Boris M. 1971. Classification of Russian vowels spoken by different listeners. Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Mak Brian, Etienne Barnard. 1996. Phone clustering using the Bhattacharyya distance. In Proceeding of Fourth International Conference on Spoken Language Processing. ICSLP ’96. Philadelphia: IEEE, vol. 4, pp. 2005–8. [Google Scholar]
- Martínez-Gibson, Elizabeth. A. 2011. A comparative study on gender agreement errors in the spoken Spanish of heritage speakers and second language learners. Porta Linguarum 15: 177–93. [Google Scholar]
- Mateu, Victoria E. 2015. Object Clitic Omission in Child Spanish: Evaluating Representational and Processing Accounts. Language Acquisition 22: 240–84. [Google Scholar] [CrossRef]
- Mazzaro, Natalia, Laura Colantoni, and Alejandro Cuza. 2016. Age effects and the discrimination of consonantal and vocalic contrasts in heritage and native Spanish. In Romance Linguistics. Edited by Christina Tortora, Marcel den Dikken, Ignacio L. Montoya and Teresa O’Neill. Amsterdam: John Benjamins, pp. 277–300. [Google Scholar]
- McCloy, Daniel R. 2016. phonR: Tools for Phoneticians and Phonologists. R Package Version 1.0–7. Available online: http://drammock.github.io/phonR/ (accessed on 25 June 2020).
- Menke, Mandy. 2010. Examination of the Spanish vowels produced by Spanish-English bilingual children. Southwest Journal of Linguistics 28: 98–135. [Google Scholar]
- Miller, Karen, and Cristina Schmitt. 2010. Effects of variable input in the acquisition of plural in two dialects of Spanish. Lingua 120: 1178–93. [Google Scholar] [CrossRef]
- Mohaghegh, Mercedeh. 2016. Connected Speech Processes and Lexical Access in Real-Time Comprehension. Unpublished Ph.D. dissertation, University of Toronto, Toronto, ON, Canada. [Google Scholar]
- Montrul, Silvina. 2011. Morphological errors in Spanish second language learners and heritage speakers. Studies in Second Language Acquisition 33: 155–61. [Google Scholar] [CrossRef]
- Montrul, Silvina, and Kim Potowski. 2007. Command of gender agreement in school-age Spanish-English bilingual children. International Journal of Bilingualism 11: 301–28. [Google Scholar] [CrossRef]
- Montrul, Silvina, labakova, and oumyana. 2003. Competence similarities between native and near-native speakers: An investigation of the preterite/imperfect contrast in Spanish. Studies in Second Language Acquisition 25: 351–98. [Google Scholar] [CrossRef]
- Montrul, Silvina, Rebecca Foote, and Silvia Perpiñán. 2008. Gender agreement in adult second language learners and Spanish heritage speakers: The effects of age and context of acquisition. Language Learning 58: 503–53. [Google Scholar] [CrossRef]
- Montrul, Silvina, Justin Davidson, Israel de la Fuente, and Rebecca Foote. 2014. Early language experience facilitates the processing of gender agreement in Spanish heritage speakers. Bilingualism: Language and Cognition 17: 118–38. [Google Scholar] [CrossRef]
- Morgan, Gareth P., M. Adelaida Restrepo, and Alejandra Auza. 2013. Comparison of Spanish morphology in monolingual and Spanish-English bilingual children with and without language impairment. Bilingualism: Language and Cognition 16: 578–96. [Google Scholar] [CrossRef]
- Morrison, Geoffrey S. 2003. Perception and production of Spanish vowels by English speakers. In Proceedings of the 15th International Congress of Phonetic Sciences. Edited by Maria-Josep Sole’, Daniel Recasens and Joaquin Romero. Adelaide: Causal Productions, pp. 1533–36. [Google Scholar]
- Morrison, Geoffrey S. 2006. L1 and L2 Production and Perception of English and Spanish Vowels: A Statistical Modelling Approach. Unpublished Ph.D. dissertation, University of Alberta, Edmonton, AB, Canada. [Google Scholar]
- Navarro Toma’s, Tomás. 1970. La pronunciacio’n del espan˜ol. Madrid: CSIC. [Google Scholar]
- Nearey, Terrance M. 1977. Phonetic Feature Systems for Vowels. Ph.D. dissertation, University of Alberta, Edmonton, AB, Canada. [Google Scholar]
- Nevins, Andrew. 2014. Misheard lyrics Introduction: ABBA’s Super Trouper. Available online: https://youtu.be/dBnhkwRmYuQ (accessed on 10 October 2020).
- Nicoladis, Elena, and Kristan Marchak. 2011. Le carte blanc or la carte blanche? bilingual children’s acquisition of french adjective agreement. Language Learning 61: 734–58. [Google Scholar] [CrossRef]
- Ohala, John J. 1989. Sound change is drawn from a pool of synchronic variation. In Language Change: Contributions to the Study of Its Causes. Edited by Leiv Breivik and Ernst Jahr. New York: Mouton de Gruyter, pp. 173–98. [Google Scholar]
- Ohala, John J. 1993. The phonetics of sound change. In Historical Linguistics: Problems and Perspectives. Edited by Charles Jones. London: Longman, pp. 237–78. [Google Scholar]
- Pérez-Pereira, Miguel. 1991. The acquisition of gender: What Spanish children tell us. Journal of Child Language 18: 571–90. [Google Scholar] [CrossRef] [PubMed]
- R Studio Team. 2020. RStudio: Integrated Development for R. RStudio, PBC, Boston, MA. Available online: http://www.rstudio.com/ (accessed on 25 May 2020).
- Repp, Bruno H. 1992. Perceptual Restoration of a “Missing” Speech Sound: Auditory Induction or Illusion? Perception & Psychophysics 51: 14–32. Available online: http://myaccess.library.utoronto.ca/login?qurl=https%3A%2F%2Fsearch.proquest.com%2Fdocview%2F58231001%3Faccountid%3D14771 (accessed on 28 August 2020).
- Rogers, Henry. 2000. The Sounds of Language: An Introduction to Phonetics. London: Longman. [Google Scholar]
- Rogers, Brandon M. 2012. Vowel Quality and Language Contact in Miami Cuban Spanish. Ph.D. dissertation, Brigham Young University, Provo, UT, USA. [Google Scholar]
- Romanelli, Sofía, Andrea Menegotto, and Ron Smyth. 2018. Stress-induced acoustic variation in L2 and L1 Spanish vowels. Phonetica 75: 190–218. [Google Scholar] [CrossRef] [PubMed]
- Ronquest, Rebecca. 2016. Stylistic variation in heritage Spanish vowel production. Heritage Language Journal 13: 275–96. [Google Scholar] [CrossRef]
- Ronquest, Rebecca, and Rajiv Rao. 2018. Heritage Spanish phonetics and phonology. In The Routledge Handbook of Spanish as a Heritage Language. Edited by Kim Potowski and Javier Muñoz-Basols. Abingdon: Routledge, pp. 164–77. [Google Scholar]
- Rvachew, Susan, Elzbieta. B. Slavinski, Megan Williams, and Carol L. Green. 1996. Formant frequencies of vowels produced by infants with and without early onset otitis media. Canadian Acoustical Society 24: 19–28. [Google Scholar]
- Rvachew, Susan, Karen Mattock, Linda Polka, and Lucie Me’nard. 2006. Developmental and cross-linguistic variation in the infant vowel space: The case of Canadian English and Canadian French. Journal of the Acoustic Society of America 120: 2250–59. [Google Scholar] [CrossRef]
- Schnitzer, Marc L., and Emily Krasinski. 1994. The development of segmental and phonological production in a bilingual child. Journal of Child Language 21: 585–622. [Google Scholar] [CrossRef]
- Scontras, Gregory, Zuzanna Fuchs, and Maria Polinsky. 2015. Heritage language and linguistic theory. Frontiers in Psychology 6: 15–45. [Google Scholar] [CrossRef]
- Scontras, Gregory, Maria Polinsky, and Zuzanna Fuchs. 2018. In support of representational economy: Agreement in heritage Spanish. Glossa: A Journal of General Linguistics 3: 1–28. [Google Scholar] [CrossRef]
- Shoemaker, Ellenor, and Rebekah Rast. 2013. Extracting words from the speech stream at first exposure. Second Language Research 29: 165–83. [Google Scholar] [CrossRef]
- Silva-Corvala’n, Carmen. 2014. Bilingual Language Acquisition: Spanish and English in the First Six Years. Cambridge: Cambridge University Press. [Google Scholar]
- Snyder, William, Ann Senghas, and Kelly Inman. 2001. Agreement morphology and the acquisition of noun-drop in Spanish. Language Acquisition 9: 157–73. [Google Scholar] [CrossRef]
- Song, Jae Y., Megha Sundara, and Katherine Demuth. 2009. Phonological constraints on children’s production of English third person singular–s. Journal of Speech, Language, and Hearing Research 52: 623–64. [Google Scholar] [CrossRef]
- Stoel-Gammon, Carol, and Karen Pollock. 2009. Vowel development and disorders. In The handbook of Clinical Linguistics. Edited by Martin J. Ball, Michael R. Perkins, Nicole Mu¨ller and Sara Howard. Hoboken: Blackwell, pp. 525–548. [Google Scholar]
- Stoel-Gammon, Carol, and Anna Vogel Sosa. 2008. Phonological development. In Language Development. Edited by Erika Hoff and Marilyn Shatz. Oxford: Blackwell, pp. 238–56. [Google Scholar]
- Strelluf, Christopher. 2016. Overlap among back vowels before /l/ in Kansas City. Language Variation and Change 28: 379–407. [Google Scholar] [CrossRef]
- Vokic, Gabriela, and Jorge M. Guitart. 2009. On the realization of non-high Spanish vowels in contact within sequences of more than three vocoids: Spectrographic evidence and theoretical implications. Southwest Journal of Linguistics 28: 71–102. [Google Scholar]
- Willis, Erik W. 2005. An initial examination of southwest Spanish vowels. Southwest Journal of Linguistics 24: 185–98. [Google Scholar]
- Winter, Bodo. 2020. Statistics for Linguists: An Introduction Using R. New York and London: Routledge. [Google Scholar]
| 1 | Kehoe and Lleó (2017) report similar results for German-Spanish bilinguals. |
| 2 | Although no tokens had to be discarded from the reading task, we excluded 72 single vowel tokens from the narrative which were produced with creaky voice. |
| 3 | As explained by Haynes and Taylor (2014), these are measurements of overlap and not of statistical significance. As in Haynes and Taylor’s study, we are not interested in statistical differences but in the extent to which vocalic spaces overlap, because a greater degree of overlap suggests that the vowels are articulated similarly. |
| 4 | Hiatus also differ from diphthongs in the duration and trajectory of formant transitions (e.g., Aguilar 1999). |
| 5 | Only these sequences were analyzed because (i) the first vowel was unstressed and (ii) they appeared in the reading task and in the narrative. |
| 6 | Frozen expressions such as Fin, Colorín Colorado (‘the end’) and lugar (‘place’) in the prepositional locution en lugar de (‘in lieu of’) were excluded from the analysis. |
| 7 | The morphosyntactic coding was conducted by one of the authors and then was verified by another author. As concerns the error count, this was first checked by one investigator, then re-checked by a second author, and discrepancies (N = 2) were solved by a third author. |
| 8 | The combined analysis only included data from the narrative because we are interested in comparing vowel quality and gender accuracy. The reading task, instead, is not clearly reflecting participants’ grammatical knowledge. |
| 9 | Results regarding the vowel [e] in the narrative should be interpreted with caution, because this vowel represents only 10% of the total tokens. |
| 10 | Note that only sequences that were realized as diphthongs in all groups were analyzed. |
| 11 | |
| 12 | We focus on these two vowels, given that we had a larger number of tokens than for /e/ and that 80% of the nouns that were marked for gender in the story had these vowels. |
| 13 | |
| 14 | EB_predictable = 2.15; EB_non-predictable = 1.33; LB_predictable = 3.08; LB_non-predictable = 2.43; mono_predictable = 2.91; mono_non-predictable = 1.80. |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Early Bilinguals (EB) (n = 13; Female = 7) | Late Bilinguals (LB) (n = 13; Female = 9) | Monolinguals (M) (n = 11; Female = 10) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean age at testing (SD) | 23 (2.64) | 38 (13.46) | 25 (11.13) | ||||||
| Mean AOA (SD) | 2.5 (3.6) | 23 (9.37) | 20 (4.23) | ||||||
| Mean LOR (SD) | 21 (2.95) | 16 (9.6) | 08 (0.8) | ||||||
| Self-Proficiency | English = 3.73/4 Spanish = 2.9/4 | English = 2.9/4 Spanish = 3.9/4 | English = 1.43/4 Spanish = 4/4 | ||||||
| DELE score | 40/50 | 45/50 | 45/50 | ||||||
| Language use | SPAN | ENG | BOTH | SPAN | ENG | BOTH | SPAN | ENG | BOTH |
| Home | 15% | 23% | 62% | 77% | 8% | 15% | 100% | 0% | 0% |
| School | 8% | 77% | 15% | 42% | 17% | 41% | 90% | 0% | 10% |
| Work | 9% | 64% | 27% | 10% | 40% | 50% | 100% | 0% | 0% |
| Social situations | 23% | 46% | 31% | 58% | 0% | 42% | 100% | 0% | 10% |
| SPAN | ENG | BOTH | SPAN | ENG | BOTH | SPAN | ENG | BOTH | |
| Most comfortable in | 8% | 46% | 46% | 77% | 0% | 23% | 100% | 0% | 0% |
| Group | Affinity (0–1) | (Convex Hulls) Overlap (%) | ||||
|---|---|---|---|---|---|---|
| a–e | a–o | e–o | a–e | a–o | e–o | |
| EB | 0.23 | 0.49 | 0.21 | 13.8 | 10.2 | 11.8 |
| LB | 0.35 | 0.48 | 0.28 | 15.4 | 11.9 | 11.5 |
| M | 0.31 | 0.40 | 0.36 | 15.8 | 10.5 | 9.8 |
| Group | Affinity (0–1) | (Convex Hulls) Overlap (%) | ||||
|---|---|---|---|---|---|---|
| a–e | a–o | e–o | a–e | a–o | e–o | |
| EB | 0.36 | 0.52 | 0.17 | 26 | 32.1 | 21.3 |
| LB | 0.35 | 0.24 | 0.17 | 27.4 | 25.1 | 15 |
| M | 0.36 | 0.41 | 0.16 | 17.5 | 18.9 | 17.8 |
| Determiner | Plural | Singular | Total |
|---|---|---|---|
| def | 68 | 1011 | 1079 |
| dem | 35 | 52 | 87 |
| indef | 20 | 279 | 299 |
| null | 94 | 535 | 629 |
| poss | 13 | 292 | 305 |
| quant | 15 | 27 | 42 |
| wh | 10 | 7 | 17 |
| All DPs | 255 | 2203 | 2458 |
| Determiner | All Gendered Nouns | Only Alternating Nouns | ||
|---|---|---|---|---|
| Plural | Singular | Plural | Singular | |
| Definite | 50 | 838 | 10 | 651 |
| Indefinite | 15 | 184 | 6 | 111 |
| Demonstrative | 25 | 44 | 13 | |
| Contextual | Concrete | Abstract | Event | Anim | Hum |
|---|---|---|---|---|---|
| Previous mention | 19 | 243 | 755 | ||
| Known | 2 | 29 | 141 | ||
| Neither | 931 | 163 | 3 | 29 | 129 |
| Grand Total | 952 | 163 | 3 | 301 | 1025 |
| Context | All Nouns | Only Gendered Nouns in Alternation | ||
|---|---|---|---|---|
| Preceding Article | No Syntactic Cues | Preceding Article | No Syntactic Cues | |
| Previous mention | 553 | 465 | 459 | 7 |
| Known | 80 | 92 | 40 | 1 |
| Neither | 669 | 586 | 256 | 24 |
| Fixed Effects | Estimate | SE | t | p(>|t|) |
|---|---|---|---|---|
| Intercept | 5.05 | 0.18 | 27.52 | <0.001 |
| Vowel(e) | −3.03 | 0.12 | 24.16 | <0.001 |
| Vowel(o) | −0.97 | 0.07 | −13.38 | <0.001 |
| EBs | −0.10 | 0.22 | 0.047 | 0.63 |
| LBs | −0.11 | 0.22 | −0.50 | 0.61 |
| Predictability(yes) | 0.17 | 0.09 | 1.94 | 0.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colantoni, L.; Martínez, R.; Mazzaro, N.; Pérez-Leroux, A.T.; Rinaldi, N. A Phonetic Account of Spanish-English Bilinguals’ Divergence with Agreement. Languages 2020, 5, 58. https://doi.org/10.3390/languages5040058
Colantoni L, Martínez R, Mazzaro N, Pérez-Leroux AT, Rinaldi N. A Phonetic Account of Spanish-English Bilinguals’ Divergence with Agreement. Languages. 2020; 5(4):58. https://doi.org/10.3390/languages5040058
Chicago/Turabian StyleColantoni, Laura, Ruth Martínez, Natalia Mazzaro, Ana T. Pérez-Leroux, and Natalia Rinaldi. 2020. "A Phonetic Account of Spanish-English Bilinguals’ Divergence with Agreement" Languages 5, no. 4: 58. https://doi.org/10.3390/languages5040058
APA StyleColantoni, L., Martínez, R., Mazzaro, N., Pérez-Leroux, A. T., & Rinaldi, N. (2020). A Phonetic Account of Spanish-English Bilinguals’ Divergence with Agreement. Languages, 5(4), 58. https://doi.org/10.3390/languages5040058