Headedness and the Lexicon: The Case of Verb-to-Noun Ratios



Abstract
1. The Starting Point
2. Basic Notions
2.1. Verbs and Nouns
- s-jə-pəj1sg-poss-enemy”my enemy”
- *s-jə-kwa-ʁe1sg-poss-go-pst”my departed”
2.2. Headedness and Headedness Types
3. Data Collection
3.1. General Remarks
3.2. Dictionary or Corpus?
4. Head-Initial and Head-Final Types
- Null hypothesis: head-final and head-initial languages have comparable distribution of nouns and verbs;
- Alternative hypothesis: Head-final languages have a smaller number of simplex verbs.
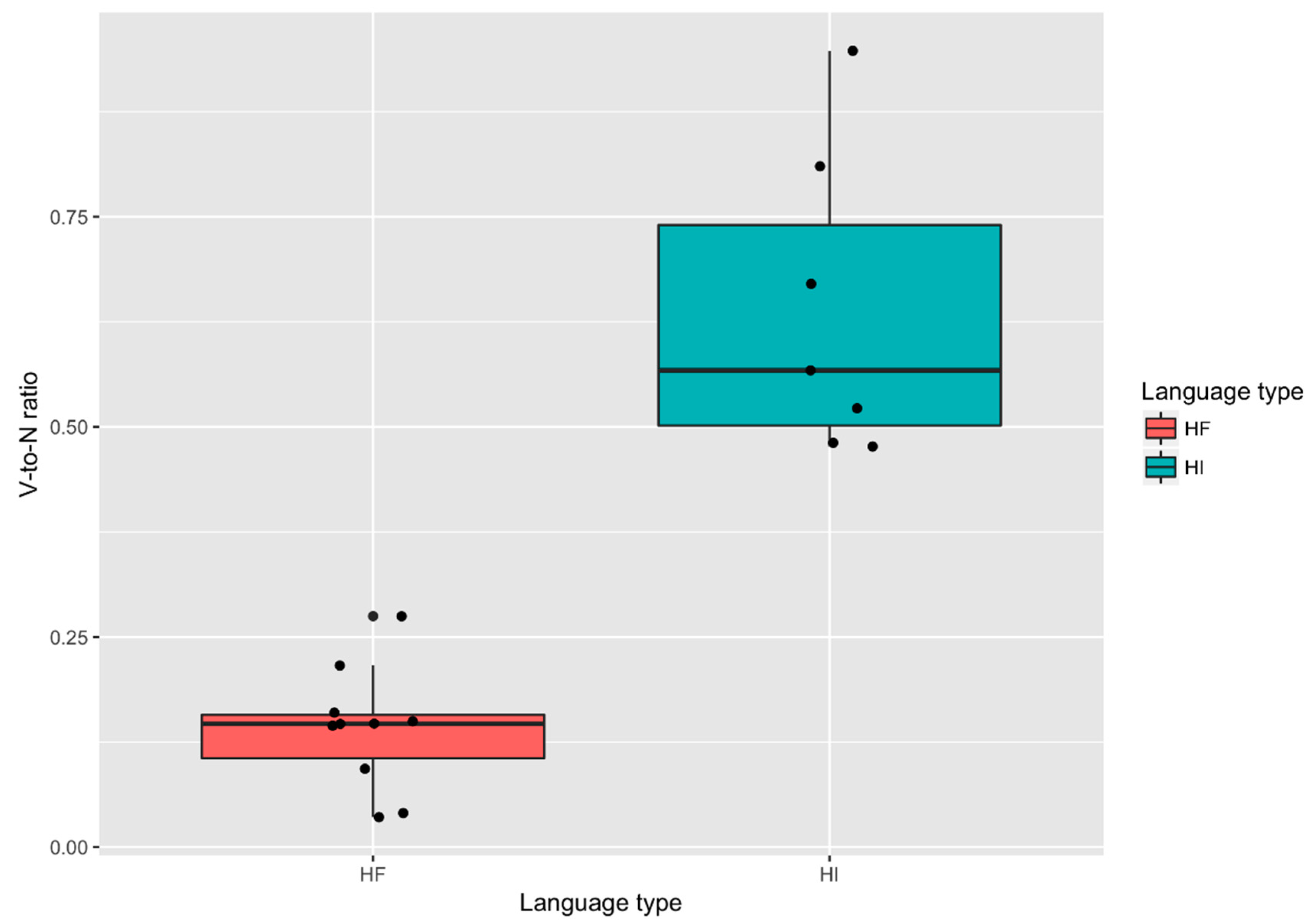
4.1. Head-Initial and Head-Final Types: Quantitative Data
4.2. Testing the Predictions
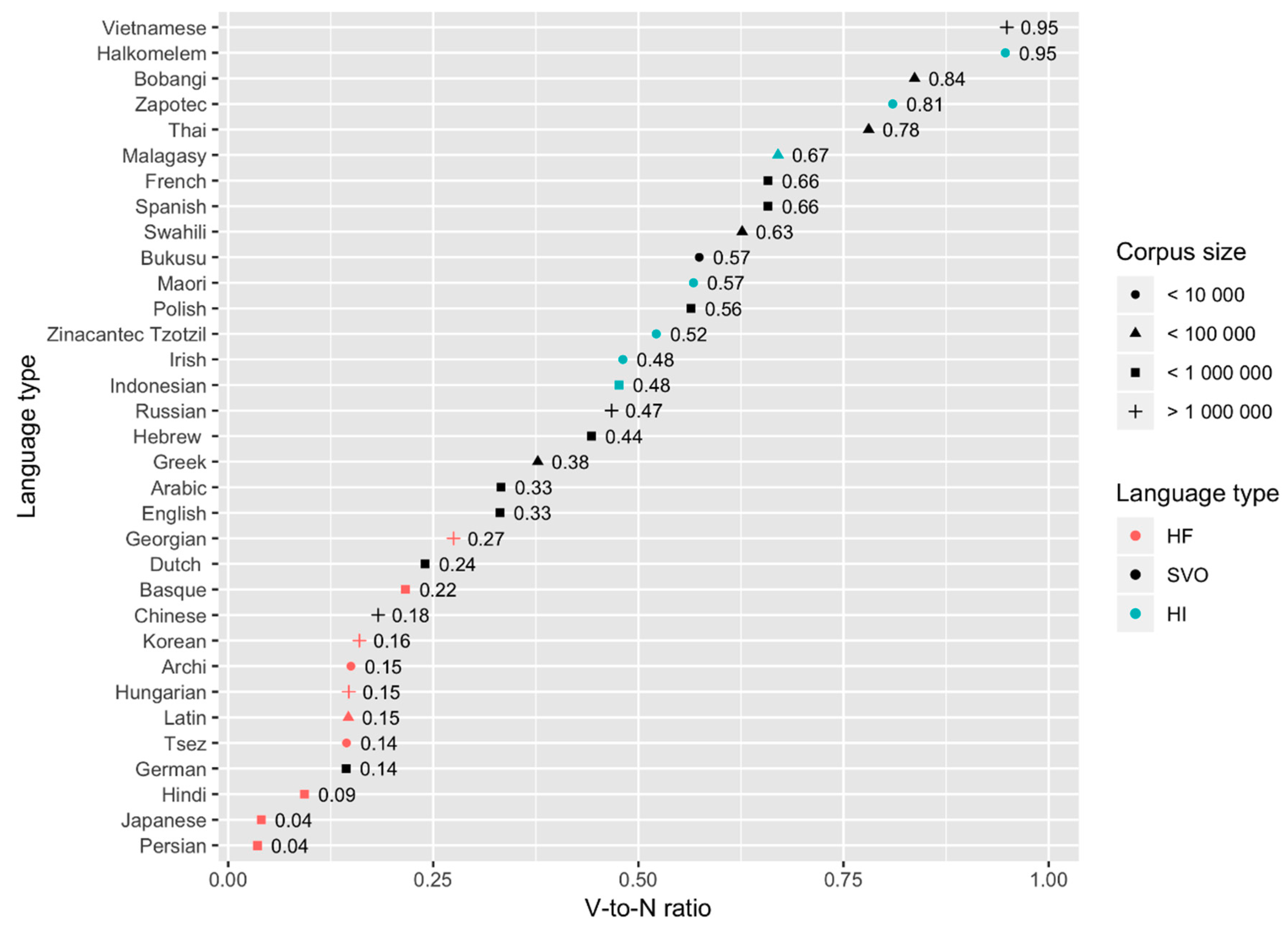
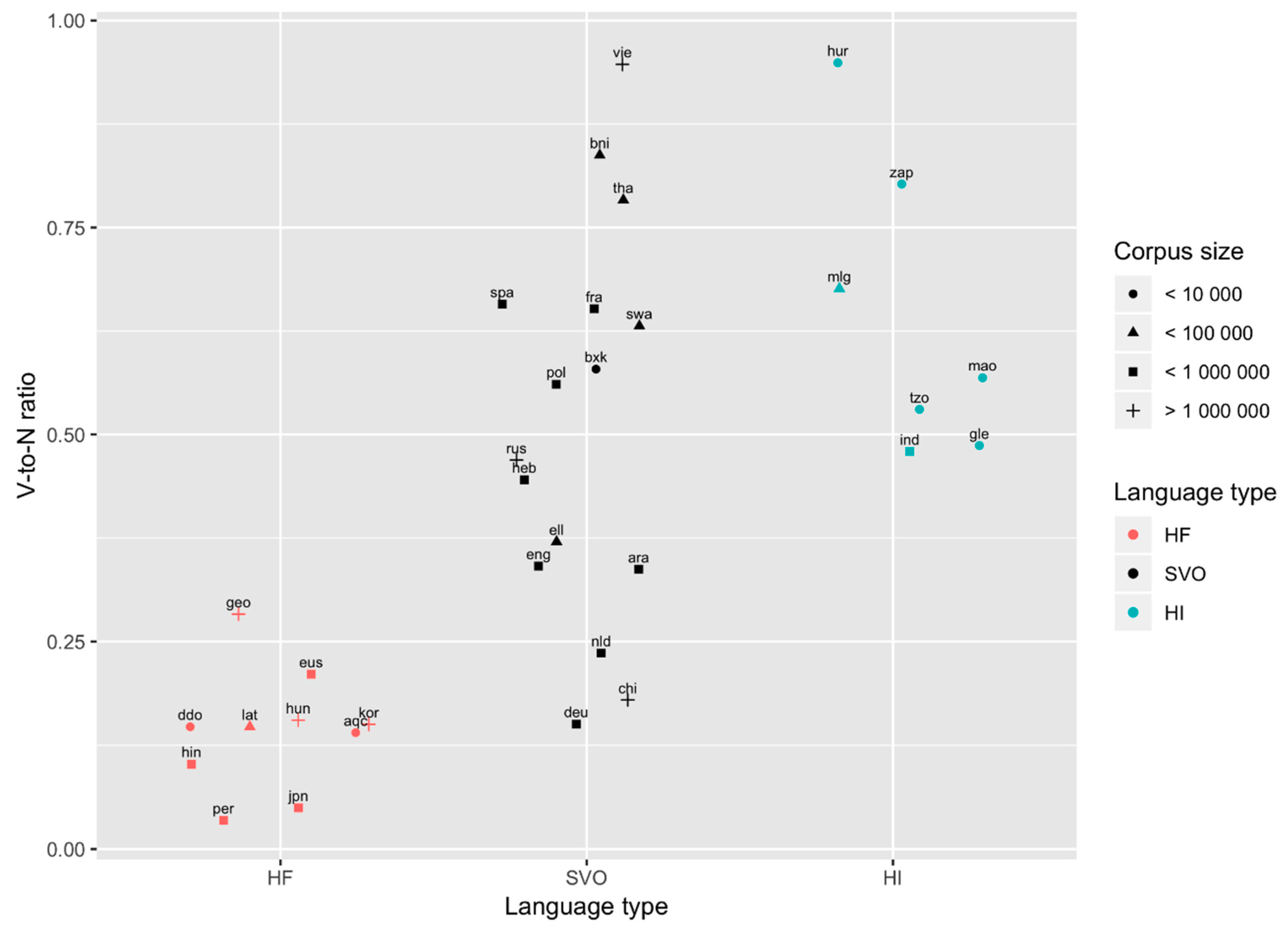
4.3. The Pattern of Results: Verb-Rich and Verb-Poor Languages
5. What about SVO Languages?
- Order of noun and adjective
safari njema trip good ”good trip; bon voyage" - Order of noun and possessive modifier
jina langu name my ”my name” - Order of noun and numeral
matunda manane fruit six ”six pieces of fruit” - Order of verb and adverb
njoo haraka come.imp quickly “come quickly” - Structure of teen numerals
kumi na saba ten with seven ”seventeen” - Inflected verb
hawa-ta-fanya 3pl.neg-fut-make ”they won’t make”.
the outstanding issues that Slavic lexicographers need to deal with: verb aspect; reflexive verbs; verb prefixation (single, double, triple)…. For instance, the number of verbs could go up or down depending on how the lexicographer approaches Slavic aspectual pairs: does one count verbs in the perfective and imperfective as separate lemmas or as members of the same lemma? Counting all verbs twice obviously inflates the size of the verbal lexicon…. These … factors alone are more than sufficient to force an even greater discrepancy than the one we observe.
6. In Search of an Explanation
6.1. General Remarks
6.2. Establishing the Baseline
- wädiya;
- wädäzziya;
- wädäzzih;
- wädih.
6.3. Where Have All the Verbs Gone?
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Language Sample, Adposition Study
| Language | Pr and/or Po |
| Adyghe | Po |
| Amharic | Po |
| Armenian | Pr/Po |
| Basque | Po |
| Bulgarian | Pr |
| Dutch | Pr |
| English | Pr |
| Finnish | Pr/Po |
| French | Pr |
| Georgian | Po |
| German | Pr/Po |
| Gombe Fula | Pr |
| Hungarian | Po |
| Hunzib | Po |
| Ingush | Po |
| Irish | Pr |
| Japanese | Po |
| Korean | Po |
| Latin | Pr/Po |
| Lezgian | Po |
| Mandarin Chinese | Po |
| Marathi | Po |
| Modern Greek | Pr |
| Modern Irish | Pr |
| Musqueam | Pr |
| Ndyuka | Pr |
| Ossetic (Digor) | Pr/Po |
| Russian | Pr |
| Spanish | Pr |
| Turkish | Po |
Appendix B. Analysis of Adpositional Data

{kind=link}
{kind=link}
{kind=link}
| Coefficient | Estimate | Std. Error | z Value | p |
|---|---|---|---|---|
| (Intercept) | 2.9485 | 0.1205 | 24.460 | <2 × 10−16 *** |
| Pr ~ Po | 0.1001 | 0.2977 | 0.336 | 0.737 (n.s.) |
References
- Abinal, Antoine, and Victorin Malzac. 1899. Dictionnaire Malgache-Français. Tananarive: Mission catholique. [Google Scholar]
- Amberer, Mengistu, Brett Baker, and Mark Harvey, eds. 2001. Complex Predicates in Cross-Linguistic Perspective. Cambridge: Cambridge University Press. [Google Scholar]
- Arad, Maya. 2003. Locality constraints on the interpretation of roots: The case of Hebrew denominal verbs. Natural Language and Linguistic Theory 21: 737–78. [Google Scholar] [CrossRef]
- Aranovich, Raúl. 2013. Transitivity and polysynthesis in Fijian. Language 89: 465–500. [Google Scholar] [CrossRef]
- Arkadiev, Peter, Yury Lander, Alexander Letuchiy, Nina Sumbatova, and Yakov Testelets. 2009. Vvedenie. Osnovnye svedenija ob adygejskom jazyke. In Aspekty polisintetizma: Očerki po grammatike adygejskogo jazyka. Edited by Yakov Testelets. Moscow: Russian University for the Humanities, pp. 17–120. [Google Scholar]
- Aronoff, Mark. 1994. Morphology by Itself: Stems and Inflectional Classes. Cambridge: MIT Press. [Google Scholar]
- Asbury, Ana. 2008. The Morphosyntax of Case and Adpositions. Utrecht: LOT Dissertation Series. [Google Scholar]
- Baker, Mark C. 2003. Lexical Categories: Verbs, Nouns, and Adjectives. Cambridge: Cambridge University Press. [Google Scholar]
- Baker, Mark C., and Ruth Kramer. 2014. Rethinking Amharic prepositions as case markers inserted at PF. Lingua 145: 141–72. [Google Scholar] [CrossRef][Green Version]
- Biberauer, Theresa, and Ian Roberts. 2005. Changing EPP parameters in the history of English: Accounting for variation and change. English Language and Linguistics 9: 5–46. [Google Scholar] [CrossRef]
- Biberauer, Theresa, and Ian Roberts. 2009. The return of the Subset Principle. In Historical Syntax and Linguistic Theory. Edited by Paola Crisma and Giuseppe Longobardi. Oxford: Oxford University Press, pp. 58–74. [Google Scholar]
- Biberauer, Theresa, and Michelle Sheehan. 2013. Theoretical Approaches to Disharmonic Word Order. Oxford: Oxford University Press. [Google Scholar]
- Blake, Barry. 1994. Case. Cambridge: Cambridge University Press. [Google Scholar]
- Borik, Olga. 2006. Aspect and Reference Time. Oxford: Oxford University Press. [Google Scholar]
- Briceño, Fidencio. 2002. Topicalización, enfoque, énfasis y adelantamiento en el maya yukateco. In La organización social entre los mayas prehispánicos, coloniales y modernos. Edited by V. Tiesler Blos, R. Cobos and M. Greene Robertson. Mexico City/Mérida: INAH/UADY, pp. 374–87. [Google Scholar]
- Broschart, Jürgen. 1997. Why Tongan does it differently: Categorial distinctions in a language without nouns and verbs. Linguistic Typology 1: 123–65. [Google Scholar] [CrossRef]
- Brugman, Claudia. 2001. Lights verbs and polysemy. Language Sciences 23: 551–78. [Google Scholar] [CrossRef]
- Bybee, Joan. 1995. Regular morphology and the lexicon. Language and Cognitive Processes 10: 425–51. [Google Scholar] [CrossRef]
- Chao, Yuen Ren. 1968. A Grammar of Spoken Chinese. Berkeley: University of California Press. [Google Scholar]
- Chung, Sandra. 2012. Are lexical categories universal? The view from Chamorro. Theoretical Linguistics 53: 1–56. [Google Scholar] [CrossRef]
- Diksionera. 1973. Diksionera Malagasy–Englisy. Antananarivo: Trano Printy Loterana. [Google Scholar]
- Dixon, Robert M. W. 1982. Where Have All the Adjectives Gone? Berlin: Moutin de Gruyter. [Google Scholar]
- Dryer, Matthew. 1991. SVO languages and the OV:VO typology. Journal of Linguistics 27: 443–82. [Google Scholar] [CrossRef]
- Dryer, Matthew. 2013a. Order of subject, object and verb. In The World Atlas of Language Structures Online. Edited by M. S. Dryer and M. Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. Available online: http://wals.info/chapter/81 (accessed on 23 July 2018).
- Dryer, Matthew. 2013b. Order of relative clause and noun. In The World Atlas of Language Structures Online. Edited by M. S. Dryer and M. Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. Available online: http://wals.info/chapter/90 (accessed on 23 July 2018).
- Dryer, Matthew. 2013c. Relationship between the order of object and verb and the order of adposition and noun phrase. In The World Atlas of Language Structures Online. Edited by M. S. Dryer and M. Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. Available online: http://wals.info/chapter/95 (accessed on 23 July 2018).
- Dryer, Matthew. 2013d. relationship between the order of object and verb and the order of relative clause and noun. In The World Atlas of Language Structures Online. Edited by M. S. Dryer and M. Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. Available online: http://wals.info/chapter/96 (accessed on 23 July 2018).
- Dryer, Matthew. 2013e. Order of object and verb. In The World Atlas of Language Structures Online. Edited by M. S. Dryer and M. Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. Available online: http://wals.info/chapter/83 (accessed on 23 July 2018).
- Durbin, Marshall, and Fernando Ojeda. 1978. Basic word order in Yucatec Maya. In Papers in Mayan Linguistics. Edited by Nora England. Columbia: University of Missouri, pp. 69–77. [Google Scholar]
- Filip, Hana. 2012. Lexical aspect. In The Oxford Handbook of Tense and Aspect. Edited by R. I. Binnick. Oxford: Oxford University Press, pp. 721–51. [Google Scholar]
- Folli, Raffaella, and Heidi Harley. 2013. The syntax of argument structure: Evidence from Italian complex predicates. Journal of Linguistics 49: 93–125. [Google Scholar] [CrossRef]
- Galloway, Brent Douglas. 2009. Dictionary of Upriver Halkomelem. Berkeley: University of California Press, vol. 104. [Google Scholar]
- Gentner, Dedre. 1981. Some interesting differences between verbs and nouns. Cognition and Brain Theory 4: 161–78. [Google Scholar]
- Gil, David. 2005. Word order without syntactic categories: How Riau Indonesian does it. In Verb First: On the Syntax of Verb-Initial Languages. Edited by Andrew Carnie, Heide Harley and Sheila Dooley. Amsterdam: John Benjamins, pp. 243–63. [Google Scholar]
- Greenberg, Joseph H. 1963. Some universals of grammar with particular reference to the order of meaningful elements. In Universals of Language. Edited by Joseph H. Greenberg. Cambridge: MIT Press, pp. 73–113. [Google Scholar]
- Grimshaw, Jane, and Armin Mester. 1988. Light verbs and ɵ-Marking. Linguistic Inquiry 19: 205–32. [Google Scholar]
- Gutiérrez Bravo, Rodrigo, and Jorge Monforte. 2008. La alternancia sujeto-inicial/verbo-inicial y la Teoría de Optimidad. In Teoría de Optimidad: Estudios de Sintaxis y Fonología. Edited by Rodrigo Gutiérrez-Bravo and Evelina Herrera. Mexico City: El Colegio de México, pp. 61–99. [Google Scholar]
- Gutiérrez-Bravo, Rodrigo, and Jorge Monforte. 2009. Focus, Agent Focus, and relative clauses in Yucatec Maya. In New Perspectives on Mayan Linguistics. Edited by Heriberto Avelino, Jessica Coon and Elisabeth Norcliffe. Cambridge: MIT Working Papers in Linguistics, pp. 83–95. [Google Scholar]
- Gutiérrez-Bravo, Rodrigo, and Jorge Monforte. 2010. On the nature of word order in Yucatec Maya. In Information structure in Indigenous Languages of the Americas. Edited by Jose Camacho, Rodrigo Gutiérrez-Bravo and Liliana Sánchez. Berlin: Mouton de Gruyter, pp. 139–70. [Google Scholar]
- Gvozdanović, Jadranka. 2012. Perfective and imperfective aspect. In The Oxford Handbook of Tense and Aspect. Edited by Robert. I. Binnick. Oxford: Oxford University Press, pp. 781–802. [Google Scholar]
- Hagège, Claude. 2010. Adpositions. New York: Oxford University Press. [Google Scholar]
- Harley, Heidi. 2014. On the identity of roots. Theoretical Linguistics 40: 225–76. [Google Scholar] [CrossRef]
- Haviland, John. 1994. “Te xa setel xulem” [The buzzards were circling]: Categories of verbal roots in (Zinacantec) Tzotzil. Linguistics 32: 691–741. [Google Scholar] [CrossRef]
- Hawkins, John A. 1983. Word Order Universals. New York: Academic Press. [Google Scholar]
- Hofling, Charles Andrew. 1984. On proto-Yucatecan word order. Journal of Mayan Linguistics 2: 35–64. [Google Scholar]
- Jacobsen, William. 1992. The transitive structure of events in Japanese. Tokyo: Kurosio. [Google Scholar]
- Kaufman, Daniel. 2009. Austronesian nominalism and its consequences: A Tagalog case study. Theoretical Linguistics 35: 1–49. [Google Scholar] [CrossRef]
- Kayne, Richard. 1994. The Antisymmetry of Syntax. Cambridge: MIT Press. [Google Scholar]
- Khalilov, Majid X. 1999. Cezsko-Russkij Slovar’. Moscow: Akademia. [Google Scholar]
- Kiss, Katalin É. 2002. The Syntax of Hungarian. Oxford: Oxford University Press. [Google Scholar]
- Kracht, Markus. 2002. On the semantics of locatives. Linguistics and Philosophy 25: 157–232. [Google Scholar] [CrossRef]
- Kuroda, S.-Y. 1972. The categorical and the thetic judgment. Foundations of Language 9: 153–85. [Google Scholar]
- Langacker, Ronald W. 1987. Nouns and verbs. Language 63: 53–94. [Google Scholar] [CrossRef]
- Langacker, Ronald W. 2002. Concept, Image and Symbol: The Cognitive Basis of Grammar, 2nd ed. Berlin: de Gruyter. [Google Scholar]
- Lehmann, Winfred. 1973. A structural principle of language and its implications. Language 49: 42–66. [Google Scholar] [CrossRef]
- Lehmann, Winfred. 1978. The great underlying ground-plans. In Syntactic Typology. Edited by Winifred Lehmann. Austin: University of Texas Press, pp. 3–55. [Google Scholar]
- Lois, Ximena, and Valentina Vapnarsky. 2006. Root indeterminacy and polyvalence in Yukatecan Mayan languages. In Lexical Categories and Root Classes in Amerindian Languages. Edited by Ximena Lois and Valentina Vapnarsky. Bern: Peter Lang, pp. 69–116. [Google Scholar]
- Long, Rebecca, and Sofronio Cruz. 1999. Diccionario Zapoteco de San Bartolomé Zoogocho Oaxaca. Coyoacán, D.F.: Instituto Lingüístico de Verano. [Google Scholar]
- Mahajan, Anoop. 2000. Relative asymmetries and Hindi correlatives. In The Syntax of Relative Clauses. Edited by Artemis Alexiadou, Paul Law, André Meinunger and Chris Wilder. Amsterdam: John Benjamins, pp. 201–30. [Google Scholar]
- Malvestitti, Marisa. 2006. Polyvalence in Mapuzungun: Contributions from a Patagonian variety of language. In Lexical categories and root classes in Amerindian languages. Edited by Ximena Lois and Valentina Vapnarsky. Bern: Peter Lang, pp. 189–210. [Google Scholar]
- Marácz, László. 1989. Asymmetries in Hungarian. Groningen: Rijksuniversiteit Groningen. [Google Scholar]
- Miller, George, Richard Beckwith, Christiane Fellbaum, Derek Gross, and Katherine Miller. 1990. WordNet: An online lexical database. International Journal of Lexicography 3: 235–44. [Google Scholar] [CrossRef]
- Minozzi, Stefano. 2009. The Latin Wordnet project. Paper Presented at the 15th International Colloquium on Latin Linguistics (ICLL), Innsbrucker Beiträge zur Sprachwissenschaft, Innsbruck, Austria, April 4–8. [Google Scholar]
- Miyagawa, Shigeru. 1989. Structure and Case Marking in Japanese. San Diego: Academic Press. [Google Scholar]
- Osborne, Timothy, and Thomas Groß. 2012. Constructions are catenae: Construction Grammar meets Dependency Grammar. Cognitive Linguistics 23: 163–214. [Google Scholar] [CrossRef]
- Pawley, Andrew. 2006. Where have all the verbs gone? Remarks on the organisation of languages with small, closed verb classes. Paper Presented at the 11th Biennial Rice University Linguistics Symposium, Houston, TX, USA, March 16–18. [Google Scholar]
- Pham, Giang, Kathryn Kohnert, and Edward Carney. 2008. Corpora of Vietnamese texts: Lexical effects of intended audience and publication place. Behavior Research Methods 40: 154–63. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Philippova, Tatiana. 2018. Prepositional Repercussions in Russian: Pronouns, Comparatives and Ellipsis. Ph.D. dissertation, Ben-Gurion University, Beersheba, Israel. [Google Scholar]
- Polinsky, Maria. 2012. Headedness, again. In Theories of Everything. (UCLA Working Papers in Linguistics). Edited by Thomas Graf, Denis Paperno and Anna Szabolcsi. Los Angeles: UCLA Department of Linguistics, vol. 17, Article 40. pp. 348–59. [Google Scholar]
- Sasse, Hans-Jürgen. 1987. The thetic/categorical distinction revisited. Linguistics 25: 511–80. [Google Scholar] [CrossRef]
- Sasse, Hans-Jürgen. 1993. Syntactic categories and subcategories. In Syntax: An International Handbook of Contemporary Research. Edited by Joachim Jacobs, Arnim von Stechow, Wolfgang Sternefeld and Theo Vennemann. Berlin: Mouton de Gruyter, pp. 646–85. [Google Scholar]
- Schachter, Paul. 1985. Parts-of-speech systems. In Language Typology and Syntactic Description, I: Clause Structure. Edited by Timothy Shopen. Cambridge: Cambridge University Press, pp. 3–61. [Google Scholar]
- Schoorlemmer, Maaike. 1995. Participial passive and aspect in Russian. Utrecht: LOT. [Google Scholar]
- Seifart, Frank, Jan Strunk, Balthasar Bickel, Brigitte Pakendorf, Alena Witzlack-Makarevich, Iren Hartmann, Swintha Danielsen, Søren Wichmann, and Taras Zakharko. 2014. Noun to verb ratio and word order. Paper Presented at the CHLING8 Conference, Zurich, Switzerland, May 3; Available online: http://www.linguistik.uzh.ch/whatsup/activities/chling8/Seifart-NTVR-Word-Order.pdf (accessed on 18 November 2019).
- Seifart, Frank, Jan Strunk, Swintha Danielsen, Iren Hartmann, Brigitte Pakendorf, Søren Wichmann, Alena Witzlack-Makarevich, Nivja H. de Jong, and Balthasar Bickel. 2018. Nouns slow down speech across structurally and culturally diverse languages. PNAS 115: 5720–25. [Google Scholar] [CrossRef]
- Sheehan, Michelle, Theresa Biberauer, Ian Roberts, and Anders Holmberg. 2017. The Final-Over-Final Condition: A Syntactic Universal. Cambridge: MIT Press. [Google Scholar]
- Siewierska, Anna. 1997. Variation in major constituent order: a global and a European perspective. In Constituent Order in the Languages of Europe: Eurotyp 20-1. Edited by Anna Siewierska. Berlin and New York: Mouton de Gruyter, pp. 475–551. [Google Scholar]
- Strunk, Jan, Balthasar Bickel, Swintha Danielsen, Iren Hartmann, Brigitte Pakendorf, Søren Wichmann, Alena Witzlack-Makarevich, Taras Zakharko, and Frank Seifart. 2015. Noun-to-verb ratio and word order. Paper Presented at the “Diversity Linguistics: Retrospect and Prospect”, Leipzig, Germany; May. Available online: https://www.eva.mpg.de/fileadmin/content_files/linguistics/conferences/2015-diversity-linguistics/Strunketal_slides.pdf (accessed on 12 September 2019).
- Szekely, Anna, Simonetta D’Amico, Antonella Devescovi, Kara Federmeier, Dan Herron, Gowri Iyer, Thomas Jacobsen, Anal’a Arévalo, Andras Vargha, and Elizabeth Bates. 2005. Timed action and object naming. Cortex 41: 7–25. [Google Scholar] [CrossRef]
- Talmy, Len. 1975. Figure and Ground in complex sentences. In Proceedings of the First Annual Meeting of the Berkeley Linguistics Society. Berkeley: Berkeley Linguistic Society, pp. 419–30. [Google Scholar]
- Talmy, Len. 2000. Toward a Cognitive Semantics. Cambridge: MIT Press, vol. I. [Google Scholar]
- Tao, Hongyin, and Richard Z. Xiao. 2007. The UCLA Chinese corpus. Lancaster: UCREL. [Google Scholar]
- Thivierge, Sigwan. 2018. On the syntactic nature of Nishnaabemwin roots. In Proceedings of the Workshop on Structure and Constituency in Languages of the Americas 23. (University of British Columbia Working Papers in Linguistics 40). Edited by N. Weber, E. Guntly, Z. Lam and S. Chen. Vancouver: University of British Columbia. [Google Scholar]
- Trommer, Jochen. 2008. Case suffixes, postpositions and the phonological word in Hungarian. Linguistics 46: 403–38. [Google Scholar] [CrossRef]
- Ueno, M., and Maria Polinsky. 2009. Does headedness affect processing? A new look at the VO-OV contrast. Journal of Linguistics 45: 675–710. [Google Scholar] [CrossRef]
- Van Riemsdijk, Henk. 1997. Push chains and drag chains: Complex predicate split in Dutch. In Scrambling. Edited by S. Tonoike. Tokyo: Kurosio Publishers, pp. 7–33. [Google Scholar]
- Vennemann, Theo. 1974. Analogy in generative grammar: The origin of word order. In Proceedings of the Eleventh International Congress of Linguists (1972). Bologna: il Mulino, pp. 79–83. [Google Scholar]
- Vennemann, Theo. 1976. Categorial grammar and the order of meaningful elements. In Linguistic Studies Offered to Joseph Greenberg on the Occasion of His Sixtieth Birthday. Edited by Alphonse Juilland. Saratoga: Anma Libri, pp. 615–34. [Google Scholar]
- Vigliocco, Gabriella, David P. Vinson, Judit Druks, Horacio Barber, and Stefano F. Cappa. 2011. Nouns and verbs in the brain: A review of behavioural, electrophysiological, neuropsychological and imaging studies. Neuroscience and Biobehavioral Reviews 35: 407–26. [Google Scholar] [CrossRef]
- Vikner, Sven. 1994. Scandinavian object shift and West Germanic scrambling. In Studies on Scrambling: Movement and Non-Movement Approaches to Free Word-Order Phenomena. Edited by N. Corver and H. van Riemsdijk. Berlin: Mouton de Gruyter, pp. 487–517. [Google Scholar]
- Watanabe, Akira. 2009. Seisei-Bunpo [Syntax in Generative Grammar]. Tokyo: University of Tokyo Press. [Google Scholar]
- Williams, Herbert W. 1957. A Dictionary of the Maori Language, 6th ed. Wellington: Government Printer. [Google Scholar]
- Xue, Nianwen. 2001. Defining and Automatically Identifying Words in Chinese. Ph.D. dissertation, University of Delaware, Newark, DE, USA. [Google Scholar]
- Zaliznjak, Andrey A. 1977. Grammatičeskij slovar’ russkogo jazyka: Slovoizmenenie. Moscow: Russkij jazyk. [Google Scholar]
| 1 | The Mandarin Chinese borrowings are so numerous that it would take a number of pages to list just part of them; see (Jacobsen 1992, chp. 7) for representative examples. | ||||||||||||||||||||
| 2 | The abbreviations follow the Leipzig Glossing Rules. Additional abbreviations: LVC—light verb construction, POS—part of speech. | ||||||||||||||||||||
| 3 | It is often stated that nouns are easier to process than verbs (Vigliocco et al. 2011; Szekely et al. 2005). However, in a recent paper, Seifart et al. (2018) show that in eight languages out of nine in their sample, pauses are longer before nouns than before verbs, which they interpret as a sign of additional processing difficulty associated with nouns. English, the ninth language in their sample, shows the opposite trend (more pauses before verbs). The eight other languages in their sample are pro-drop, which may be a confounding factor in the results. | ||||||||||||||||||||
| 4 | We will return to the issue of diagnostics and numerical estimates in Section 3. | ||||||||||||||||||||
| 5 | Previous studies (Polinsky 2012; Seifart et al. 2014; Strunk et al. 2015) presented the noun-to-verb ratio. Here we reverse it, primarily for expository purposes—as a reflection of the relative stability of the class of nouns across languages (see Section 4.2). | ||||||||||||||||||||
| 6 | Dictionaries are probably more reliable for a study like ours, because the parts of speech are annotated by hand and do not depend on the vagaries of morphological analyzers or genre distribution. | ||||||||||||||||||||
| 7 | A crucial difference between corpora and dictionaries has to do with the percentage of parts of speech in the relevant collection. To continue with our side-by-side evaluation of corpora and dictionaries, compare the percentages of nouns and verbs in corpora and dictionaries of Russian and English (percentages rounded off to integers).
In this percentage count, the size of a corpus seems to play a significant role. For some languages in the UD corpus, the corpora are very small (for instance, the Irish corpus has 23,964 tokens, the Greek corpus, 61,773 tokens). With such small tagged corpora, it may be more expeditious to rely on dictionaries. In the representation of the quantitative data below, we will be showing the size of the corpus/dictionary as well. | ||||||||||||||||||||
| 8 | To reiterate, our study is based on types, however, corpus size is normally indicated in tokens, as shown in this table. | ||||||||||||||||||||
| 9 | Persian seems to be an outlier in the UD corpora; in the Persian counts, nouns are at 62%. That may have something to do with the relatively small corpus size or with the particulars of morphological analysis for Persian. We do not have a clear explanation of this fact. | ||||||||||||||||||||
| 10 | The exponentiated coefficient for the intercept will correspond to the average verb-to-noun ratio for the base level (in this case, HF); the exponentiated coefficients for the other levels of the predictor will correspond to the proportional change in the verb-to-noun ratio change relative to the base level. | ||||||||||||||||||||
| 11 | These results pose an interesting challenge to existing analyses of Hungarian and possibly, other languages. Although Hungarian is described as head-final in typological literature (e.g., Dryer 2013a), É. Kiss (2002) considers its head-final order derived from a head-initial base. Positing a particular underlying word order is often associated with specific theoretical assumptions, and those may not be shared by all other researchers. It is however possible that our generalizations reflect the output of particular syntactic derivations, and that output can be arrived at by different routes. | ||||||||||||||||||||
| 12 | We will return to the headedness properties of the Middle group shortly. | ||||||||||||||||||||
| 13 | The exponentiated coefficient for the intercept will correspond to the average verb-to-noun ratio for the base level (in this case, HF); the exponentiated coefficients for the other levels of the predictor will correspond to the proportional change in the verb-to-noun ratio change relative to the base level. | ||||||||||||||||||||
| 14 | The z-value for the comparison between HF and M is not reported in Table 6; it can easily be obtained by refitting the model with M as baseline level. The following R command will do it: glm(cbind(v_count, n_count) ~ relevel(langtype, “M”), data = data, family = “binomial”). | ||||||||||||||||||||
| 15 | As a result, researchers are often at a loss as to how to fit Mandarin Chinese in the word order typology (see Dryer 1991, pp. 447, 476 for different, sometimes even conflicting approaches). | ||||||||||||||||||||
| 16 | We would like to underscore that this cross-linguistic distribution should be taken seriously primarily because of the structural principles just mentioned. Without those principles, it could have been less dramatic and could be due to historical accidents or extralinguistic factors. | ||||||||||||||||||||
| 17 | In the UD corpora, the reliability of tagging may vary—it is as good as the underlying analyzer is. For example, one of the tagged corpora for Japanese, GSD, lists 63 lemmas for postpositions (tag ADP), and another, corpus BCCWJ, lists one! | ||||||||||||||||||||
| 18 | We counted English and Russian, which have very few postpositions, in the Pr-language class. | ||||||||||||||||||||
| 19 | We would like to thank Bert Vaux for this example of historical change and helpful discussion. | ||||||||||||||||||||
| 20 | In fact, many speakers of American English strengthen this sound to [dʒ] in the onset position. | ||||||||||||||||||||



| Head-Final | Head-Initial | ||
|---|---|---|---|
| Rigid | Non-Rigid | ||
| Example languages | Japanese, Korean | Basque, Latin, Persian | Irish, Malagasy, Tzotzil |
| Verbs (%) | Nouns (%) | Verb-to-Noun Ratio | Corpus Size, Tokens | Genres |
|---|---|---|---|---|
| 11 | 33 | 0.33 | 254,829 | news, wiki |
| 15 | 36 | 0.41 | 80,041 | blog, social, reviews, email |
| 16 | 38 | 0.41 | 49,616 | academic, fiction, nonfiction, news, spoken, web, wiki |
| 15 | 36 | 0.41 | 21,540 | news, wiki |
| Language | Headedness | Verbs, Raw Numbers (Types) | Nouns, Raw Numbers (Types) | Source |
|---|---|---|---|---|
| Archi (aqc) | HF | 362 | 2419 | dictionary |
| Basque (eus) | HF | 1017 | 4707 | UD corpus |
| Georgian (geo) | HF | 25,467 | 92,691 | Georgian National Corpus |
| Hindi (hin) | HF | 601 | 6463 | UD corpus |
| Hungarian (hun) | HF | 2765 | 18,799 | Hungarian National Corpus |
| Japanese (jpn) | HF | 361 | 8952 | NINJAL |
| Korean (kor) | HF | 5308 | 33,172 | Seojeong Corpus, grammatically tagged |
| Latin, Classical (lat) | HF | 700 | 4777 | Aronoff (1994); Minozzi (2009) |
| Persian (per) | HF | 184 | 5163 | UD corpus |
| Tsez (ddo) | HF | 506 | 3508 | dictionary (Khalilov 1999) |
| Halkomelem (hur) | HI | 916 | 967 | dictionary (Galloway 2009) |
| Irish, Modern (gle) | HI | 890 | 1850 | Corpas na Gaeilge Comhaimseartha |
| Malagasy (mlg) | HI | 3643 | 5436 | dictionary (Diksionera 1973) |
| Mãori (mao) | HI | 1656 | 2920 | dictionary (Williams 1957) |
| Zapotec (zap) | HI | 439 | 542 | dictionary (Long and Cruz 1999) |
| Zinacantec Tzotzil (tzo) | HI | 850 | 1629 | dictionary (Haviland 1994) |
| Coefficient | Estimate | Std. Error | z Value | p |
|---|---|---|---|---|
| (Intercept) | −1.58 | 0.006 | −277.43 | <2 × 10−16 |
| HI | 1.04 | 0.013 | 78.64 | <2 × 10−16 |
| Language | Verbs, Raw Numbers | Nouns, Raw Numbers | Source |
|---|---|---|---|
| Arabic (ara) | 1551 | 4662 | UD |
| Bobangi (bni) | 3324 | 3973 | dictionary |
| Bukusu (bxk) | 1653 | 2879 | dictionary |
| Chinese, Mandarin (chi) | 3430 | 18,764 | Tao and Xiao (2007) |
| Dutch (nld) | 2436 | 10,152 | UD |
| English (eng) | 2102 | 6342 | UD |
| French (fra) | 302 | 459 | UD |
| German (deu) | 2669 | 18,559 | UD |
| Greek, Modern (ell) | 956 | 2533 | UD |
| Hebrew, Modern (heb) | 1861 | 4202 | UD |
| Indonesian (ind) | 2742 | 5754 | UD |
| Polish (pol) | 3519 | 6238 | UD |
| Russian (rus) | 7832 | 16,761 | UD |
| Spanish (spa) | 5034 | 7652 | Corpus del español actual |
| Swahili (swa) | 3853 | 6150 | dictionary |
| Thai (tha) | 20,415 | 26,150 | dictionary |
| Vietnamese (vie) | 20,766 | 21,879 | Pham et al. (2008) |
| Coefficient | Estimate | Std. Error | z Value | p |
|---|---|---|---|---|
| (Intercept) | −1.61 | 0.005 | −313.57 | <2 × 10−16 |
| HI | 1.31 | 0.007 | 181.33 | <2 × 10−16 |
| M | 0.79 | 0.011 | 74.54 | <2 × 10−16 |
| Head-Final Type | Head-Initial Type | |
|---|---|---|
| Preposition | possible | possible |
| Postposition | possible | impossible |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Polinsky, M.; Magyar, L. Headedness and the Lexicon: The Case of Verb-to-Noun Ratios. Languages 2020, 5, 9. https://doi.org/10.3390/languages5010009
Polinsky M, Magyar L. Headedness and the Lexicon: The Case of Verb-to-Noun Ratios. Languages. 2020; 5(1):9. https://doi.org/10.3390/languages5010009
Chicago/Turabian StylePolinsky, Maria, and Lilla Magyar. 2020. "Headedness and the Lexicon: The Case of Verb-to-Noun Ratios" Languages 5, no. 1: 9. https://doi.org/10.3390/languages5010009
APA StylePolinsky, M., & Magyar, L. (2020). Headedness and the Lexicon: The Case of Verb-to-Noun Ratios. Languages, 5(1), 9. https://doi.org/10.3390/languages5010009