English Focus Perception by Mandarin Listeners


Abstract
:1. Introduction
2. Intonation, Information Structure, Focus, and Prominence
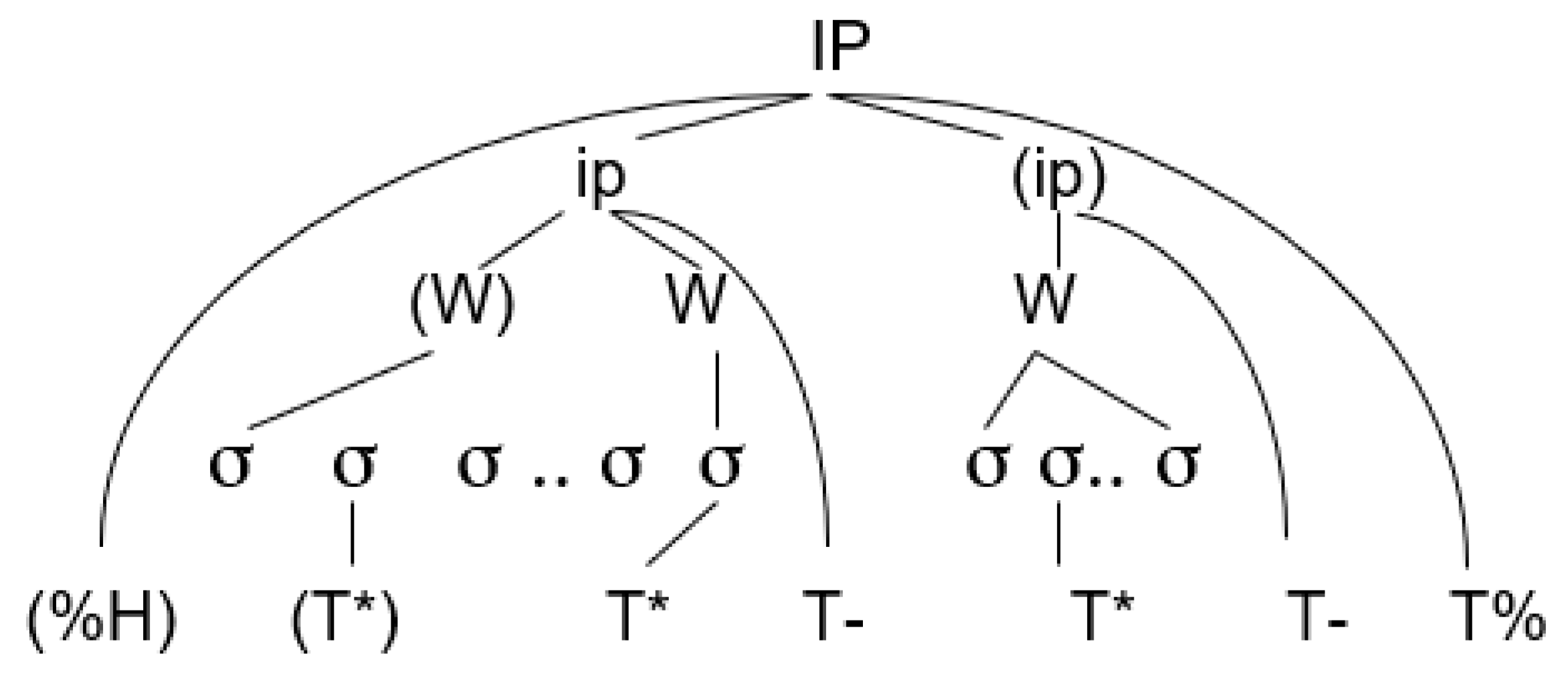
2.1. English Focus Marking
2.2. Mandarin Focus Marking
2.3. Non-Native Perception of Phrasal Prosody
3. This Study
3.1. Methods
3.1.1. Participants
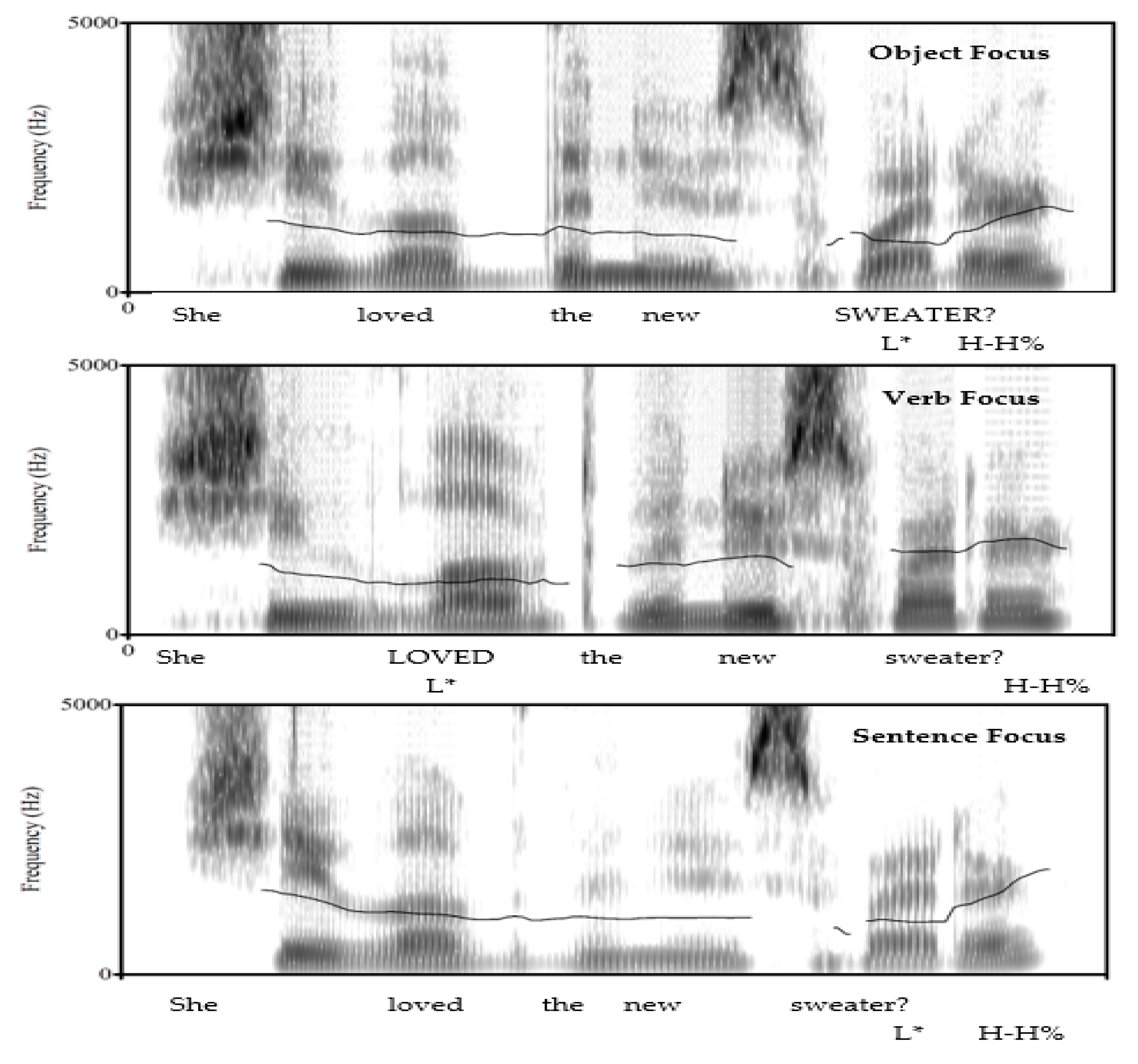
3.1.2. Materials
3.1.3. Procedures
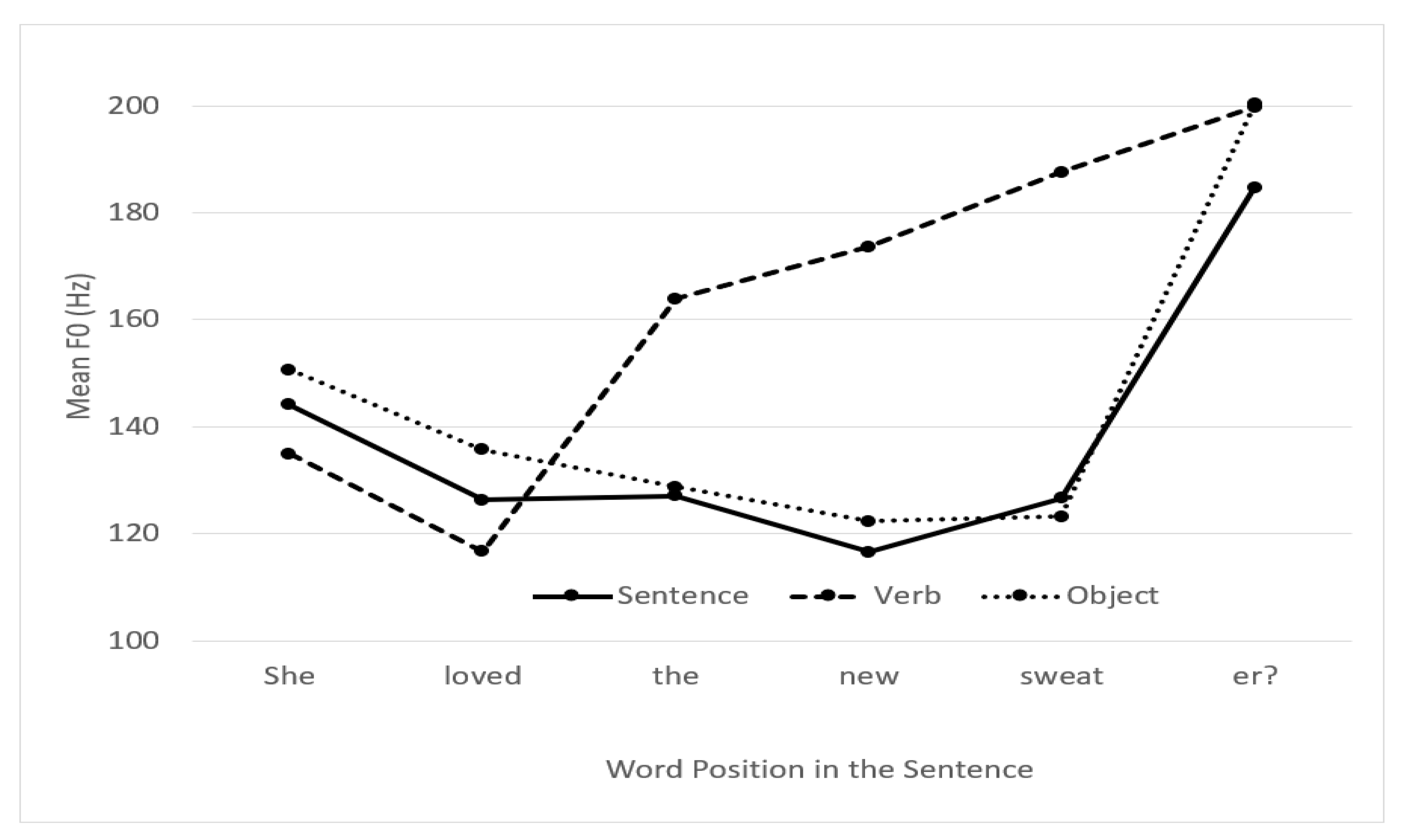
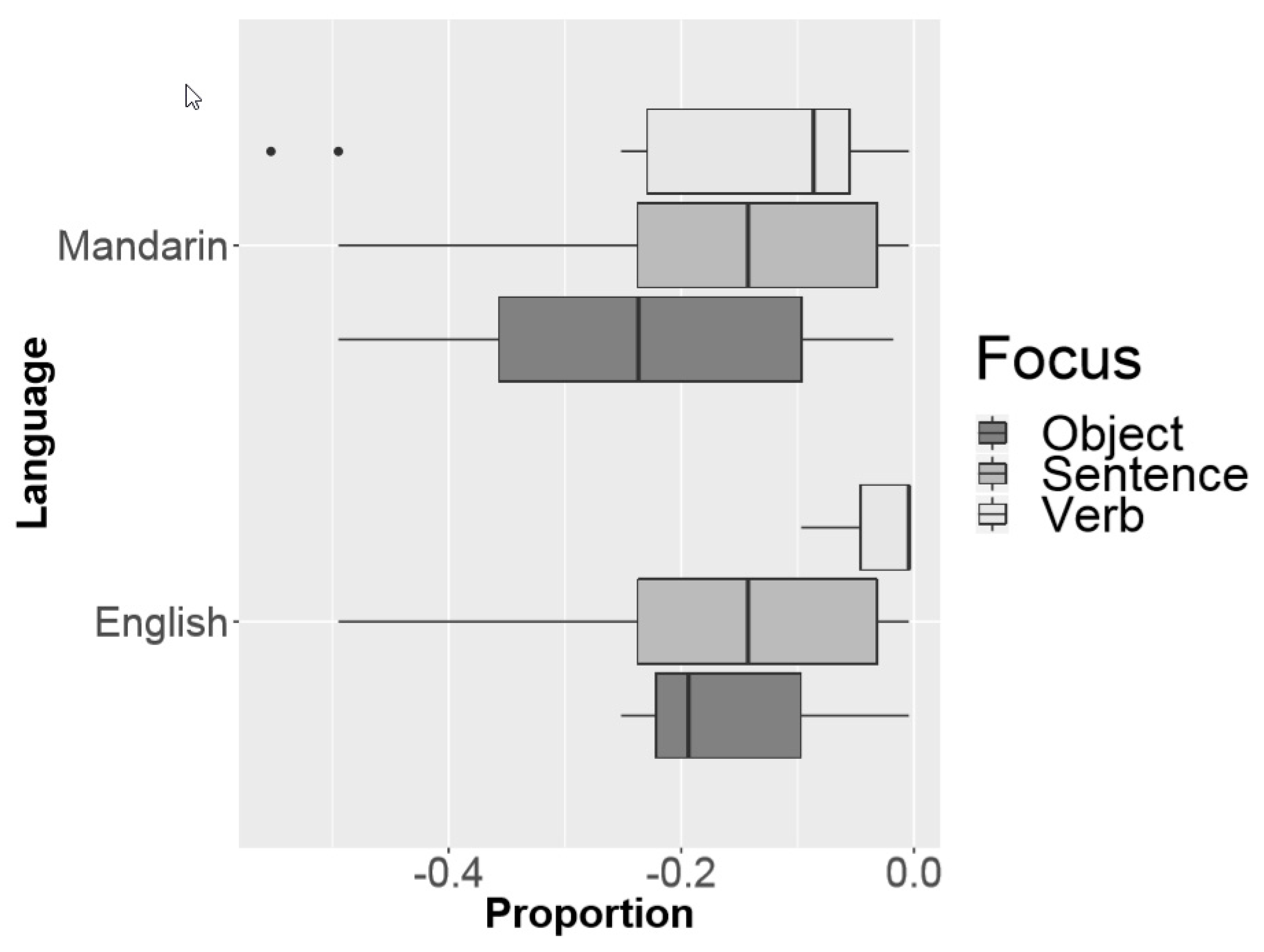
4. Results
5. Discussion
6. Summary and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Akker, Evelien, and Anne Cutler. 2003. Prosodic cues to semantic structure in native and nonnative listening. Bilingualism: Language and Cognition 6: 81–96. [Google Scholar] [CrossRef]
- Artstein, Ron. 2002. A focus semantics for echo questions. In Workshop on Information Structure in Context. Stuttgart: IMS, University of Stuttgart, vol. 98, p. 107. [Google Scholar]
- Avesani, Cinzia, and Mario Vayra. 2003. Broad, narrow and contrastive focus in Florentine Italian. Paper presented at 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9; Rome: Consiglio Nazionale delle Ricerche, vol. 2, pp. 1803–6. [Google Scholar]
- Ayers, Gayle. 1996. Nuclear accent types and prominence: Some psycholinguistics experiments. Ph.D. thesis, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Baker, Rachel. E. 2010. Non-native perception of native English prominence. Paper presented at Speech Prosody 2010—Fifth International Conference, Chicago, IL, USA, May 10–14. [Google Scholar]
- Bates, Douglas, Martin Maechler, Ben Bolker, and Steven Walker. 2015. lme4: Linear mixed-effects models using Eigen and S4. R package version 1.1-8. Available online: http://CRAN.R-project.org/package=lme4 (accessed on 1 September 2019).
- Baumann, Stefan, Johannes Becker, Martine Grice, and Doris Mücke. 2007. Tonal and articulatory marking of focus in German. Paper presented at 16th International Congress of Phonetic Sciences, Saarbrücken, Germany, August 6–10; Saarbrücken: Pirrot GmbH Dudweiler, pp. 1029–32. [Google Scholar]
- Beckman, Mary, and Gayle Ayers. 1994. Guidelines for ToBI Labelling. Version 2.0. Manuscript and Accompanying Speech Materials. Columbus: Ohio State University. [Google Scholar]
- Beckman, Mary E., and Janet B. Pierrehumbert. 1986. Intonational structure in Japanese and English. Phonology 3: 255–309. [Google Scholar] [CrossRef]
- Beckman, Mary E., and Julia Hirschberg. 1994. The ToBI Annotation Conventions. Manuscript and Accompanying Speech Materials. Columbus: Ohio State University. [Google Scholar]
- Bishop, Jason. 2012. Information structural expectations in the perception of prosodic prominence. In Prosody and Meaning. Edited by G. Elordieta and P. Prieto. Berlin: Mouton de Gruyter, pp. 239–70. [Google Scholar]
- Birch, Stacy, and Charles Clifton. 1995. Focus, accent, and argument structure: Effects on language comprehension. Language and Speech 38: 365–91. [Google Scholar] [CrossRef] [PubMed]
- Boersma, Paul, and David Weenink. 2018. Praat: Doing Phonetics by Computer. Version 6.0.37. Available online: http://www.praat.org/ (accessed on 1 March 2018).
- Bolinger, Dwight. 1972. Accent is predictable (if you’re a mind-reader). Language 48: 633–44. [Google Scholar] [CrossRef]
- Breen, Mara, Evelina Fedorenko, Michael Wagner, and Edward Gibson. 2010. Acoustic correlates of information structure. Language and Cognitive Processes 25: 1044–98. [Google Scholar] [CrossRef]
- Bunnell, H. Timothy, Steven R. Hoskins, and Debra Yarrington. 1997. Interactions among F0, Duration, and Amplitude in the Perception of Focus. The Journal of the Acoustical Society of America 102: 3203. [Google Scholar] [CrossRef]
- Büring, Daniel. 2009. Towards a typology of focus realization. In Information Structure. Oxford: Oxford University Press, pp. 177–205. [Google Scholar]
- Chafe, Wallace. L. 1974. Language and consciousness. Language 50: 111–33. [Google Scholar] [CrossRef]
- Chen, Yiya, and Carlos Gussenhoven. 2008. Emphasis and tonal implementation in Standard Chinese. Journal of Phonetics 36: 724–46. [Google Scholar] [CrossRef]
- Chen, Szu-Wei, Bei Wang, and Yi Xu. 2009. Closely related languages, different ways of realizing focus. Paper Presented at Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, September 6–10. [Google Scholar]
- Cole, Jennifer, Yansook Mo, and Mark Hasegawa-Johnson. 2010. Signal-based and expectation-based factors in the perception of prosodic prominence. Laboratory Phonology 1: 425–52. [Google Scholar] [CrossRef]
- Cooper, William E., Stephen J. Eady, and Pamela R. Mueller. 1985. Acoustical aspects of contrastive stress in question–answer contexts. The Journal of the Acoustical Society of America 77: 2142–56. [Google Scholar] [CrossRef]
- Cruz-Ferreira, Madalena. 1987. Non-native interpretive strategies for intonational meaning: An experimental study. Sound Patterns in Second Language Acquisition 36: 103–20. [Google Scholar]
- Cutler, Anne, Delphine Oahan, and Wilma van Donselaar. 1997. Prosody in the comprehension of spoken language: A literature review. Language and Speech 40: 141–201. [Google Scholar] [CrossRef]
- Eady, Stephen J., William E. Cooper, Gayle V. Klouda, Pamela R. Mueller, and Dan W. Lotts. 1986. Acoustical characteristics of sentential focus: Narrow vs. broad and single vs. dual focus environments. Language and Speech 29: 233–51. [Google Scholar] [CrossRef]
- Eady, Stephen J., and William E. Cooper. 1986. Speech intonation and focus location in matched statements and questions. The Journal of the Acoustical Society of America 80: 402–15. [Google Scholar] [CrossRef]
- Frota, Sonia. 1997. On the prosody and intonation of focus in European Portuguese. In Issues in the Phonology and Morphology of the Major Iberian Languages. Washington: Georgetown University Press, pp. 359–92. [Google Scholar]
- Grice, Martine. 2006. Intonation. In Encyclopedia of Language and Linguistics, 2nd ed. Edited by Brown Keith. Oxford: Elsevier, vol. 5, pp. 778–88. [Google Scholar]
- Gussenhoven, Carlos. 1983a. Focus, mode and the nucleus. Journal of Linguistics 19: 377–417. [Google Scholar] [CrossRef]
- Gussenhoven, Carlos. 1983b. Testing the reality of focus domains. Language and Speech 26: 61–80. [Google Scholar] [CrossRef]
- Gussenhoven, Carlos. 1999. On the limits of focus projection in English. In Focus: Linguistic, Cognitive, and Computational Perspectives. Edited by Peter Bosch and Rob van der Sandt. Cambridge: Cambridge University Press, pp. 43–55. [Google Scholar]
- Gussenhoven, Carlos. 2008. Notions and subnotions in information structure. Acta Linguistica Hungarica 55: 381–95. [Google Scholar] [CrossRef]
- Hagoort, Peter. 2019. The neurobiology of language beyond single-word processing. Science 366: 55–58. [Google Scholar] [CrossRef]
- Hanssen, Judith, Jörg Peters, and Carlos Gussenhoven. 2008. Prosodic effects of focus in Dutch declaratives. Paper presented at Speech Prosody, Boston, MA, USA, May 31–June 3; Campiñas: Editora RG/CNPq, pp. 609–12. [Google Scholar]
- Jin, Shunde. 1996. An Acoustic Study of Sentence Stress in Mandarin Chinese. Ph.D. dissertation, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Jun, Sun-Ah. 1993. The Phonetics and Phonology of Korean Prosody. Ph.D. dissertation, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Jun, Sun-Ah. 1998. The accentual phrase in the Korean prosodic hierarchy. Phonology 15: 189–226. [Google Scholar] [CrossRef]
- Jun, Sun-Ah. 2005. Prosody in sentence processing: Korean vs. English. UCLA Working Papers in Phonetics 104: 26–45. [Google Scholar]
- Jun, Sun-Ah, ed. 2006. Prosodic typology. In Prosodic Typology: The Phonology of Intonation and Phrasing. Oxford: Oxford University Press, vol. 1, pp. 430–48. [Google Scholar]
- Krifka, Manfred. 2008. Basic notions of information structure. Acta Linguistica Hungarica 55: 243–76. [Google Scholar] [CrossRef]
- Ladd, Robert. 1980. The Structure of Intonational Meaning: Evidence from English. Bloomington: Indiana University Press. [Google Scholar]
- Ladd, D. Robert. 2012. Intonational Phonology. Cambridge: Cambridge University Press. [Google Scholar]
- Lee, Yong-Cheol, Ting Wang, and Mark Liberman. 2016. Production and perception of tone 3 focus in Mandarin Chinese. Frontiers in Psychology 7: 1058. [Google Scholar] [CrossRef] [PubMed]
- Lee, Yong-Choel, Bei Wang, Sisi Chen, Martine Adda-Decker, Angélique Amelot, Satoshi Nambu, and Mark Liberman. 2015. A crosslinguistic study of prosodic focus. Paper presented at 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, April 19–24; Piscataway: IEEE, pp. 4754–58. [Google Scholar]
- Liu, Fang, and Yi Xu. 2005. Parallel encoding of focus and interrogative meaning in Mandarin intonation. Phonetica 62: 70–87. [Google Scholar] [CrossRef] [PubMed]
- Nespor, Marina, and Irene Vogel. 1983. Prosodic structure above the word. In Prosody: Models and Measurements. Springer: Berlin/Heidelberg, pp. 123–40. [Google Scholar]
- Nooteboom, Sieb G., and Johanna G. Kruyt. 1987. Accents, focus distribution, and the perceived distribution of given and new information: An experiment. The Journal of the Acoustical Society of America 82: 1512–24. [Google Scholar] [CrossRef] [PubMed]
- Paris, Marie- Claude. 1998. Focus operators and types of predication in Mandarin. Cahiers de Linguistique-Asie Orientale 27: 139–59. [Google Scholar] [CrossRef]
- Paul, Waltraud, and John Whitman. 2008. Shi… de focus clefts in Mandarin Chinese. The Linguistic Review 25: 413–51. [Google Scholar] [CrossRef]
- Pierrehumbert, Janet B. 1980. The Phonology and Phonetics of English Intonation. Ph.D. dissertation, Massachusetts Institute of Technology, Boston, MA, USA, September 9. [Google Scholar]
- Pierrehumbert, Janet, and Julia Hirschberg. 1990. The meaning of intonational contours in the interpretation of discourse. In Intentions in Communication. Edited by Philip Cohen, Jerry Morgan and Martha Pollack. Cambridge: MIT Press, pp. 271–311. [Google Scholar]
- Reis, Marga. 2012. On the analysis of echo questions. Tampa Papers in Linguistics 3: 1–24. [Google Scholar]
- Repp, Sophie, and Lena Rosin. 2015. The intonation of echo wh-questions. Paper Presented at 16th Annual Conference of the International Speech Communication Association, ISCA speech, Dresden, Germany, September 6–10; Red Hook: Curran Associates, pp. 938–42. [Google Scholar]
- Rooth, Mats. 1992. A theory of focus interpretation. Natural Language Semantics 1: 75–116. [Google Scholar] [CrossRef]
- R Development Core Team. 2008. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Rump, Hans H., and Rene Collier. 1996. Focus conditions and the prominence of pitch-accented syllables. Language and Speech 39: 1–17. [Google Scholar] [CrossRef]
- Selkirk, Elizabeth. 1978. On prosodic structure and its relation to syntactic structure. In Nordic Prosody II. Trondheim: TAPIR. [Google Scholar]
- Selkirk, Elizabeth. 1980. Prosodic domains in phonology: Sanskrit revisited. Juncture 7: 107–29. [Google Scholar]
- Selkirk, Elizabeth O. 1981. On the nature of phonological representation. Advances in Psychology 7: 379–88. [Google Scholar]
- Selkirk, Elizabeth. 1984. Phonology and Syntax: The Relation between Sound and Structure. Cambridge: MIT Press. [Google Scholar]
- Selkirk, Elizabeth. 1995. Sentence prosody: Intonation, stress, and phrasing. In The Handbook of Phonological Theory. Edited by J. A. Goldsmith. Oxford: Blackwell Sci, pp. 550–69. [Google Scholar]
- Seuren, Pieter A. 2009. Language from Within: Vol. 1. Language in Cognition. Oxford: Oxford University Press. [Google Scholar]
- Shih, Chilin. 1988. Tone and intonation in Mandarin. In Working Papers of the Cornell Phonetics Laboratory. Ithaca: Cornell University, vol. 3, pp. 83–109. [Google Scholar]
- Shattuck-Hufnagel, Stephanie, and Alice. E. Turk. 1996. A prosody tutorial for investigators of auditory sentence processing. Journal of Psycholinguistic Research 25: 193–47. [Google Scholar] [CrossRef] [PubMed]
- Sityaev, Dmitry, and Jill House. 2003. Phonetic and phonological correlates of broad, narrow and contrastive focus in English. Paper Presented at 15th International Congress of Phonetic Sciences ICPhS, Barcelona, Spain, August 3–9. [Google Scholar]
- Yuan, Jiahong. 2004. Intonation in Mandarin Chinese: Acoustics, Perception, and Computational Modeling. Ph.D. thesis, Cornell University, Ithaca, NY, USA. [Google Scholar]
- Wang, Bei, and Yi Xu. 2006. Prosodic encoding of topic and focus in Mandarin. Paper Presented at Speech Prosody: 3rd International Conference, Dresden, Germany, May 2–5. [Google Scholar]
- Welby, Pauline. 2003. Effects of pitch accent position, type, and status on focus projection. Language and Speech 46: 53–81. [Google Scholar] [CrossRef] [PubMed]
- Xu, Yi, Szu-wei Chen, and Bei Wang. 2012. Prosodic focus with and without post-focus compression: A typological divide within the same language family? The Linguistic Review 29: 131–47. [Google Scholar] [CrossRef]
- Xu, Yi. 1999. Effects of tone and focus on the formation and alignment of f0 contours. Journal of Phonetics 27: 55–105. [Google Scholar] [CrossRef]
- Xu, Yi, Ching X. Xu, and Xuejing Sun. 2004. On the temporal domain of focus. Paper Presented at International Conference on Speech Prosody, Nara, Japan, March 23–26. [Google Scholar]
- Xu, Yi. 2004. Transmitting tone and intonation simultaneously-the parallel encoding and target approximation (PENTA) model. Paper Presented at International Symposium on Tonal Aspects of Languages: With Emphasis on Tone Languages, Beijing, China, March 28–31. [Google Scholar]
- Xu, Yi, and Ching X. Xu. 2005. Phonetic realization of focus in English declarative intonation. Journal of Phonetics 33: 159–97. [Google Scholar] [CrossRef]
- Xu, Yi. 2005. Speech melody as articulatorily implemented communicative functions. Speech Communication 46: 220–51. [Google Scholar] [CrossRef]
- Xu, Yi. 2013. ProsodyPro—A Tool for Large-Scale Systematic Prosody Analysis. Aix-en-Provence: Laboratoire Parole et Language. [Google Scholar]
- Zubizarreta, Maria L. 2014. Nuclear stress and information structure. In The Oxford Handbook of Information Structure. Oxford: Oxford University Press. [Google Scholar]
- Zimmermann, Malte, and Edgar Onea. 2011. Focus marking and focus interpretation. Lingua 121: 1651–70. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Focus Type | Verb | Object | Sentence |
|---|---|---|---|
| Verb | 260 (94.54%) | 8 (2.91%) | 7 (2.55%) |
| Object | 22 (8%) | 197 (71.64%) | 56 (14%) |
| Sentence | 15 (3.75%) | 60 (21.82%) | 200 (72.73%) |
| Focus Type | Verb | Object | Sentence |
|---|---|---|---|
| Verb | 292 (73%) | 39 (9.25%) | 71 (17.75%) |
| Object | 38 (9.5%) | 241 (60.25%) | 121 (30.25%) |
| Sentence | 30 (7.5%) | 85 (21.25%) | 285 (71.25%) |
| Estimate | Std. Error | z Value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | 1.16 | 0.30 | 3.86 | <0.001 ** |
| (L1 background) English | 0.06 | 0.45 | 0.12 | 0.90 |
| (Focus type) Object | −0.60 | 0.17 | −3.63 | <0.001 ** |
| (Focus type) Verb | 0.10 | 0.17 | 0.61 | 0.54 |
| (L1 background) English: (focus type) Object | 0.54 | 0.27 | 2.02 | 0.043 * |
| (L1 background) English: (focus type) Verb | 2.01 | 0.36 | 5.64 | <0.001 * |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wayland, R.; Guerra, C.; Chen, S.; Zhu, Y. English Focus Perception by Mandarin Listeners. Languages 2019, 4, 91. https://doi.org/10.3390/languages4040091
Wayland R, Guerra C, Chen S, Zhu Y. English Focus Perception by Mandarin Listeners. Languages. 2019; 4(4):91. https://doi.org/10.3390/languages4040091
Chicago/Turabian StyleWayland, Ratree, Chelsea Guerra, Si Chen, and Yiqing Zhu. 2019. "English Focus Perception by Mandarin Listeners" Languages 4, no. 4: 91. https://doi.org/10.3390/languages4040091
APA StyleWayland, R., Guerra, C., Chen, S., & Zhu, Y. (2019). English Focus Perception by Mandarin Listeners. Languages, 4(4), 91. https://doi.org/10.3390/languages4040091