1. Introduction
The cognitive capacity for language, like any other brain function, develops as individuals progress in cognition and social development, creating an interplay between linguistic processes and other cognitive abilities. This development is shaped by various internal and external factors that influence both the acquisition and refinement of linguistic competence. Optimal expression of this capacity requires specific social and cognitive conditions (
Lytle & Kuhl, 2018). When these conditions are different, disorders related to language, speech, and/or communication may arise. Such disorders may manifest in acquired conditions, such as aphasia, or in developmental disorders, including autism, Down syndrome or Williams syndrome (
Penke, 2015).
This study investigates the morphosyntactic productions of individuals with Williams syndrome (
Williams et al., 1961; hereafter referred to as WS). Specifically, it focuses on gender and number agreement relations in Spanish to determine whether these align with those of typically developing (TD) speakers.
WS results from the deletion of genetic material (
Kozel et al., 2021;
Ewart et al., 1993a,
1993b), resulting in a characteristic facial phenotype, congenital cardiac conditions, neurological challenges, and global cognitive alterations. Although most individuals with WS present moderate intellectual disabilities, a minority has cognitive levels that are in a range similar to that of people with TD of the same chronological age. WS has often been considered a paradoxical condition. Generally, individuals with WS exhibit a distinctive cognitive development characterized by delayed temporalization and difficulties in processing and comprehending complex information, along with impairments in visuospatial skills, such as depth perception, object recognition, and motor coordination. However, they typically display optimal social behaviors. WS thus offers an opportunity to explore the interconnections between genetics, cognition, and language, even though interpreting linguistic profiles might be challenging in such conditions. Research on the linguistic abilities of individuals with WS has produced mixed findings, leaving open the question of whether the linguistic productions of people with WS significantly diverge from those of TD individuals.
Considering these contrasting perspectives, this study is grounded in the opposing positions on the linguistic performances of individuals with WS. Specifically, it focuses on studying the potential atypicalities in their linguistic productions compared to those of TD speakers. By analyzing a linguistic dataset, this research aims to make a well-founded contribution to the ongoing debate on language in WS.
The primary goal of this study is to analyze whether the production of gender and number agreement in the spontaneous spoken discourse of individuals with WS significantly differs from that of TD individuals, so as to provide more linguistic evidence on the morphosyntactic abilities of individuals with WS. This involves addressing the following questions:
Do the gender and number agreement relations produced in the spontaneous spoken discourse of individuals with WS differ from those of TD individuals? Are those differences, if existent, significant?
If atypicalities are present in the agreement relations produced by individuals with WS, are these atypicalities systematic?
To this end, this paper is structured as follows:
Section 2 provides an overview of WS and its characteristics, with an emphasis on linguistic aspects;
Section 3 presents the theoretical linguistic frameworks considered in this study;
Section 4 outlines the methodology used for data analysis, leading to the presentation of results in
Section 5 and the discussion in
Section 6. Finally, the paper concludes with a summary of the main findings.
3. The Study of Morphosyntax and Dependency Grammar (DG)
Morphosyntactic analysis can be approached from various theoretical perspectives. Before describing the approach chosen for this study, it is essential to clarify some key concepts that will be used. This study focuses on gender and number agreement relations, particularly among determiners, nouns, and adjectives.
This research is therefore centered on analyzing grammatical morphemes, defined as units containing morphosyntactic information derived from lexical processes (e.g., the Catalan case for bou ‘bull’ → vaca ‘cow’) or morphological processes (e.g., in Catalan, alumne ‘male pupil’ → alumna ‘female pupil’). In all cases, the analysis starts with inflectional morphemes that display the characteristics under investigation. Although derivation and inflection might initially appear similar, we clearly distinguish between them in this paper.
On one hand, inflection is a context-sensitive grammatical mechanism that facilitates agreement among elements. Through inflection, morphosyntactic information—such as aspect, number, person, and modality—is conveyed, generally guided by sentence structure. For example, in Catalan, the forms som, ets, and són, represent inflected forms of the lexeme ser (‘to be’). On the other hand, derivation is a productive morphological process that allows for the creation of new words or changes in grammatical category. For instance, the Catalan verb pagar (‘to pay’) combined with the derivational suffix -dor forms the noun pagador (‘payer’).
Thus, unlike derivation, inflection does not produce new words. As a result, inflection does not alter lexical category, argument structure, aspectual structure, or intrinsic word features. Inflection applies across all forms within a grammatical category, while derivation may present exceptions. From this perspective, the primary difference between these two processes is functional: derivation encodes lexical–semantic relations, while inflection encodes properties and relationships within the clause.
This distinction leads to other important concepts, such as the notions of lexeme and morpheme. While a lexeme is an abstract unit representing a set of grammatical words, a morpheme is the language unit that conveys morphosyntactic information.
To classify inflectional grammatical morphemes, we adopt
Matthews’ (
1991) definition distinguishing between simple and cumulative exponents. Simple exponents fulfill a single morphosyntactic function, whereas cumulative exponents combine multiple morphosyntactic functions in a single form. For example, in the Spanish word
plantas (‘plants’), the morpheme
-s is a simple exponent indicating the plural, while in the Czech word
holky (‘girls’),
-y is a cumulative morpheme denoting nominative/accusative, feminine, and plural.
Languages express agreement relationships through inflectional morphemes in diverse ways. For example, Swahili, Hindustani, and Czech show gender agreement between the verb and its external argument (e.g., Czech Holka přišla ‘the girl came’; Chlapec přišel ‘the boy came’), while in French, gender agreement is internal to nominal categories, with the article and the adjective agreeing with the noun (les petits enfants ‘the little children’). Spanish, the language studied in this paper, resembles French and other Romance languages in this regard, as agreement between determiner, noun, and adjective is also sensitive to gender and number. Additionally, Spanish subject–verb relationships are sensitive to number.
Agreement relationships follow a dependency pattern rather than occurring arbitrarily. Typically, the phrase or clause head determines the properties that other elements must encode. For instance, in the Catalan noun phrase nines altes (‘tall girls’), nines (‘girls’) serves as the head, dictating that the phrase encodes feminine and plural properties. These are simple morphemes since each one expresses only one morphosyntactic property. Furthermore, in languages like Catalan or Spanish, these properties are sometimes represented by morphemes without phonological realization. In phrases like el gato blanco (‘the white cat’), the singular property is not morpho-phonetically materialized but rather encoded by a null morpheme (i.e., without specific sounds encoding meaning).
In summary, agreement is understood as an asymmetric relationship, as elements within the relationship depend on others based on morphosyntactic properties. This perspective leads us to adopt Dependency Grammar as the framework for our analysis.
The Dependency Grammar (DG) model emerged from structural linguistics, as proposed by
Tesnière (
1959). DG posits that language consists of syntactic structures shaped by a network of syntactic dependencies, without distinctions between terminal and non-terminal nodes.
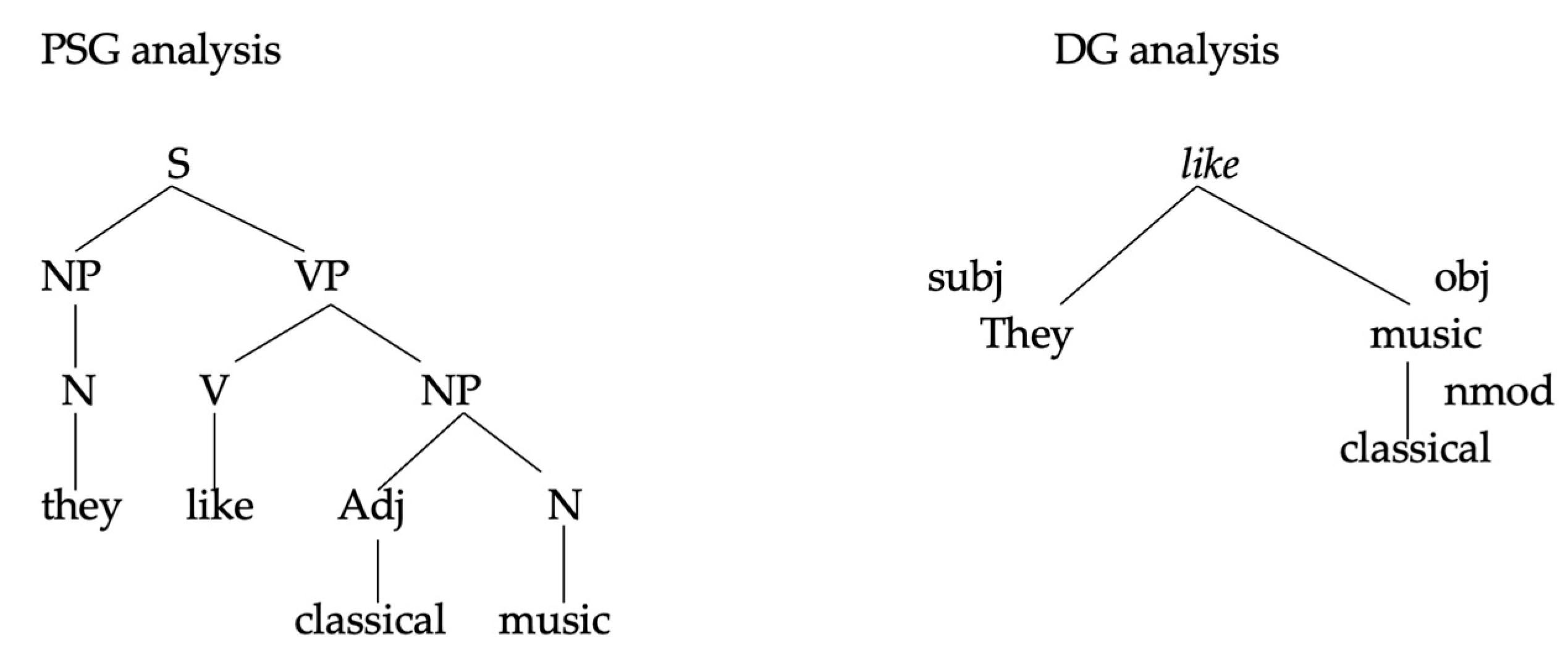
From a syntactic perspective, DG treats the word as the minimal unit of analysis and assumes that syntactic constructions consist of combinations of at least two words. In DG, words are linked through binary dependency relations between nodes (A → B), where node A (the dependent) syntactically depends on node B (the governor). In other words, dependency relations are structured as unique pairings, where each element in the syntactic structure depends on only one node. These word-to-word dependency relations are the foundation of DG, represented in tree-like structures where words are nodes and lines indicate dependency relationships between them (see
Figure 1). This approach relies on antisymmetric and intransitive relationships. In the field of psycholinguistics, DG establishes short-term memory as a factor limiting syntactic chains.
DG is not the only system for describing syntactic structures in language. It has often been contrasted with the phrase structure grammar (PSG) model, formulated by
Bloomfield (
1933), which presents an alternative way of representing dependency relations. According to
Mel’čuk (
1988), PSG describes how linguistic items combine to form larger units, while DG illustrates how items relate to each other. Unlike DG, PSG allows dependency relations between multiple elements, meaning each element may project more than one node. PSG also introduces an initial distinction in clauses between noun phrases and verb phrases, whereas in DG, the verb serves as the root of the entire structure. A crucial aspect is the preservation of the hierarchy between dependent and governor (
Hudson, 1990). These characteristics have been considered as common points between the notion of ‘Dependency’ and the ‘Merge’ operation in generativist proposals (
Ninio, 2014).
Figure 1 provides an example analysis comparing the two frameworks.
For this study DG was selected as the reference framework for its capacity to represent these relationships concisely. Since the focus is solely on agreement relationships rather than derived units, DG is sufficient for an in-depth analysis. Additionally, a morphosyntactic annotator based on DG (see
Section 4) is used in this analysis. Thus, DG will be the sole syntactic model discussed in the following sections.
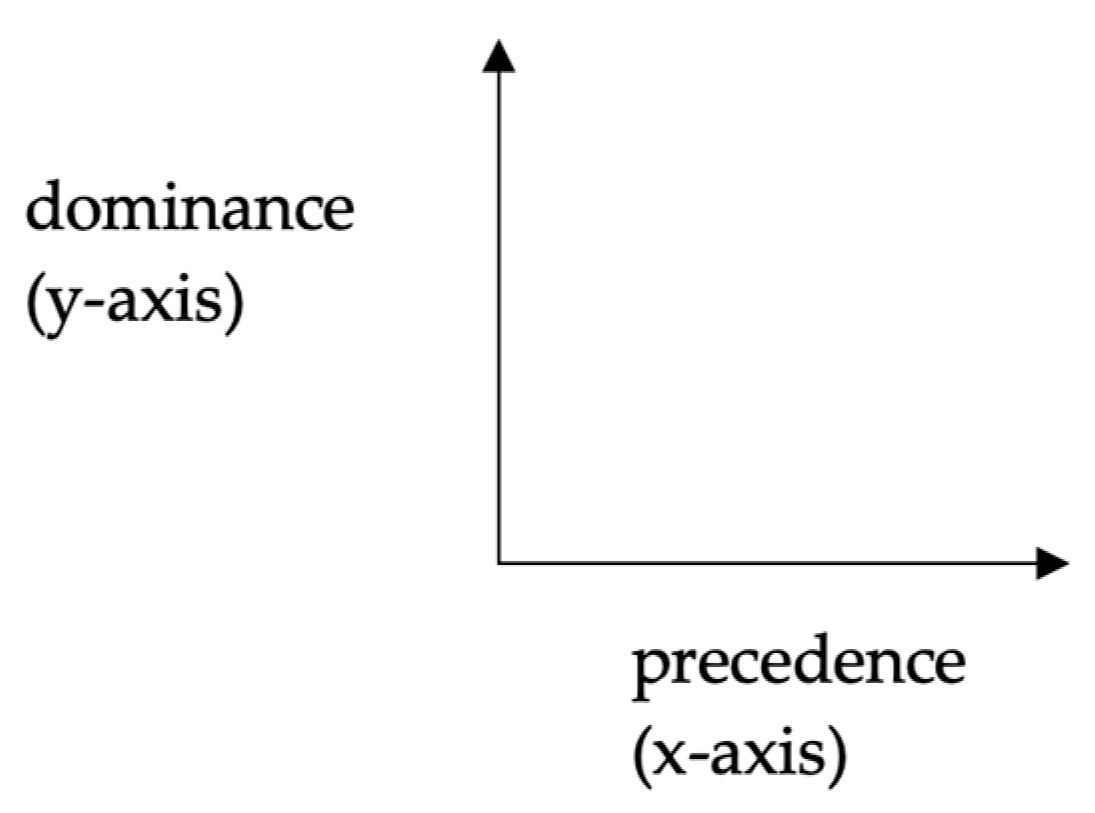
In common with other syntactic approaches, DG assumes that words are organized in a structured, non-random way. According to this theory, word order in language is explained by the principles of precedence and dominance. While precedence organizes elements horizontally, dominance arranges them vertically (see
Figure 2). Precedence is explicitly observed in any spoken or written language, as words follow a specific order. For example, in the determiner phrase
the girl, the determiner
the precedes the noun
girl.
Tesnière (
1959) describes dominance as an abstract principle determining how words combine to convey specific meanings.
The roles of these two principles vary by syntactic theory. Some approaches consider precedence as a derivative of dominance. DG, however, posits that both principles hold equal status, with neither derived from the other.
These relations generate two items in constructions (C): the head (H) and the dependent (D). To maintain unified criteria, this study follows
Hudson’s (
1990) contributions, specifying that each syntactic relation consists of an H, which determines the grammatical category, and a D that is subordinate to it. Consequently, based on binary relationships between nodes, DG focuses directly on syntactic relations between words rather than grouping them into constituents. The criteria outlined by Hudson to determine dependency relations and distinguish between H and D in a construction are generally as follows:
The H establishes the syntactic and semantic category of C.
The H is obligatory; the D is optional.
The D contains specific semantic information.
The H selects the D and determines its obligatory presence.
The form of the D depends on the H (agreement and linkage).
The D’s position is specified in reference to the H.
While DG does not typically define explicit criteria for handling agreement relations, Criterion 5 is particularly relevant, as it frames the agreement relations analyzed in this study. This has been combined with
Mel’čuk’s (
1988) description of three types of dependency relations: morphological, syntactic, and semantic. For example, in the phrase
paper blanc (‘white paper’),
paper is the H and
blanc the D. In terms of dependency,
paper as the H establishes the agreement criteria applied to the adjective
blanc (masculine, singular).
DG is an analytical perspective that has had a significant influence in the European syntactic tradition as well as in computational linguistics. Today, many morphological and syntactic analysis systems process languages using this model, including corpus annotation software such as FreeLing, Stanford Parser, and Netlang—the latter of which is used in this study.
4. Materials and Methods
4.1. Corpus Configuration
The corpus for this study consists of 16 recordings of natural, spontaneous speech, each approximately 5 min long. These recordings were collected from interviews recorded and transcribed orthographically. The interviews used open-ended questions on familiar topics for the interviewee (all related to their daily life). All interviews were conducted in Spanish, the primary language of all participants. Half of the sample spoke Mexican Spanish, and the other half spoke northern Peninsular Spanish. These two geographic varieties were chosen because they were the most represented in the corpus of speakers with Williams syndrome (WS).
The corpus was divided into two sub-corpora: one for speakers with WS (CWS) and a control group corpus of TD speakers (CTD), with each sub-corpus containing 8 recordings.
All participants in the sample were adults, ranging from 17 to 49 years of age. Obtaining a sample with more similar ages, which would allow age to be analyzed as a variable, was not feasible given that WS is a minority condition. To ensure valid group comparisons, only individuals who were considered linguistically adults were selected.
As detailed in the following subsections, the Laboratory of Research in Complexity and Experimental Linguistics (LICLE) at the University of the Balearic Islands provided some of these recordings, along with transcriptions for certain ones. Additional recordings were gathered by the study’s researcher, who conducted interviews with participants and produced orthographic transcriptions for both newly recorded material and any recordings from LICLE that had not been previously transcribed.
4.1.1. Corpus of Individuals with WS
LICLE formalized an agreement between the University of the Balearic Islands and the Williams Syndrome Association in Spain on 12 November 2020 to develop joint study programs aimed at promoting and facilitating communication, participation, and cooperation among professionals, families, and people with WS. Through the project PID2021-128404NA-I00, and in collaboration with other research centers, a database was created: the Àncora project.
1 This project collects corpora of spontaneous speech from individuals with WS to transcribe and analyze them.
4.1.2. Corpus of Individuals with TD
Part of this corpus, specifically that of Spanish speakers, was extracted from LICLE’s database. The other part, corresponding to Mexican Spanish, was compiled as part of this study.
The spontaneous speech segments in this corpus were extracted from interviews that aimed to obtain spontaneous speech samples, therefore using open-ended questions that explored various aspects of the participant’s life (for instance, their occupational roles, daily routines, residence, or activities). This aimed to obtain comparable samples to those that already existed. The interviews were then transcribed orthographically for analysis using Netlang, as explained in
Section 4.3.
4.2. Variables
Table 1 shows the dependent, independent, and categorical variables.
It is important to note that informants’ gender was not considered as a variable in this study. Given that this study involves a clinically rare condition, the sample size is small. Consequently, segmenting data by gender was deemed inappropriate, as it would divide the dataset and prevent meaningful data extraction. While this could be considered a limitation of the study and measuring this variable might have yielded valuable insights, a larger sample than the one available in this research would be necessary for a valid analysis.
4.3. Analysis with Netlang
Netlang is a piece of corpus annotation software (
Barceló-Coblijn et al., 2017) with the primary function of providing support to linguistic analysis of corpora, with the added capability of representing this analysis within complex networks.
The interface allows users to input texts in free format to accommodate the unique features of each language, while mapping out syntactic relationships through a set of customizable tags. It also enables the tagging of lexical content and other relevant information as considered necessary by the researcher. Although Netlang provides built-in tags for dependency relations and grammatical categories, researchers can add or modify tags to suit their needs.
To utilize these functions, the user needs to select the text fragment to be analyzed and, if necessary, edit its content in a pop-up window. Once done, the content can be analyzed. Importantly, the analysis is performed manually, giving the researcher complete control over the process and data generation.
As explained in
Barceló-Coblijn et al. (
2017), Netlang operates on graph theory principles, where its interface organizes information through a system of nodes, each capable of containing different types of data depending on the study. The relationships established between nodes, along with additional morphosyntactic information added by the researcher, can be saved in multiple formats—such as .netlang, .sif, .svc, or .xml—enabling different types of data analysis. For instance, data can be processed in spreadsheets or visualized in network applications like Cytoscape 3.10.3, which represent data as complex networks.
2As the researcher establishes dependency relations between nodes, Netlang visualizes them in the Graph window as networks that expand based on the tags applied to the corpus. Simultaneously, related tags and nodes are displayed in the Relationship window, providing a detailed view of connections within the corpus.
The features and functionality of Netlang make it an ideal tool for researching language acquisition and development processes in clinical and typical environments. In this study, Netlang has proven to be useful especially thanks to the ability to manually tag and edit texts. For instance, specific codes could be manually added to the text to analyze agreement relationships in cases involving null morphemes. This in-line editing allowed us to add these codes directly during corpus analysis, eliminating the need to pre-edit the document before using Netlang. All this improved the efficiency of the analysis process, enabling real-time corrections if any errors were detected.
The data extracted from the spontaneous speech transcriptions were labeled to allow for a systematic analysis. In line with the criteria outlined in
Table 2, labels were created for the two variables under analysis (gender and number) as well as their variants (masculine/feminine/invariant and singular/plural/invariant). These labels display the relationships between variants, enabling us to determine whether they exhibit gender and number agreement.
The labels were applied specifically to the inflectional morphemes of the analyzed words. To achieve this, the lexeme and each morpheme were separated using Netlang’s text editing function, allowing for the selection and tagging of each morpheme with the appropriate label. Codes were created to represent empty morphemes, enabling systematic marking of agreement relationships when the morpheme lacked phonological representation. Specifically, for gender, code “0” was designated for unmarked morphemes (i.e., masculine) and “1” for marked morphemes (i.e., feminine). For number, “00” was used for unmarked morphemes (singular) and “01” for marked ones (plural). Additionally, elements with invariant agreement—those that do not change morphological form based on gender (e.g.,
inteligente ‘intelligent’,
feroz ‘fierce’) or number (e.g.,
lunes, ‘Monday’)—were labeled as “GINV” and “NINV”, as shown in
Table 3.
It was also necessary to create labels to define cases of disagreement between variants, presented in
Table 4. When a disagreement between the element of a phrase or clause and its head was detected, it was marked using these labels.
Statistical calculations were conducted using JASP 0.17.1 (
JASP Team, 2023).
The following section will show how these labels were applied in the different corpora to extract the results that allowed us to provide an answer to the research questions.
5. Results
Table 5 shows the results for each participant, expressed in both absolute values and percentual values. Absolute values reflect the sum of analyzed items, while percentual values represent the relative frequency of a specific agreement relation (singular, plural, masculine, etc.) with respect to the total word count. This proportion, expressed as a percentage, is obtained by dividing the specific relation count by the total word count and multiplying by 100. For instance, in the CTD-Mex_01 corpus, there are 509 agreement relations, and the whole text had 718 words, resulting in a percentual value of 70.8% agreement relations out of the total number of words contained in the text. This measure enables comparisons across different corpora. Finally, mean values were calculated for gender and number variables to represent these proportions in graphs.
The table includes the absolute number of transcribed words and agreement relations, as well as the proportional percentage of agreement relations over the total word count. The data reveal that discourses from individuals with TD tend to be longer and contain more absolute agreement relations (values between 358 and 515) than those from individuals with WS (values between 94 and 423).
Below are the figures that analyze data based on individuals’ clinical condition (WS or TD).
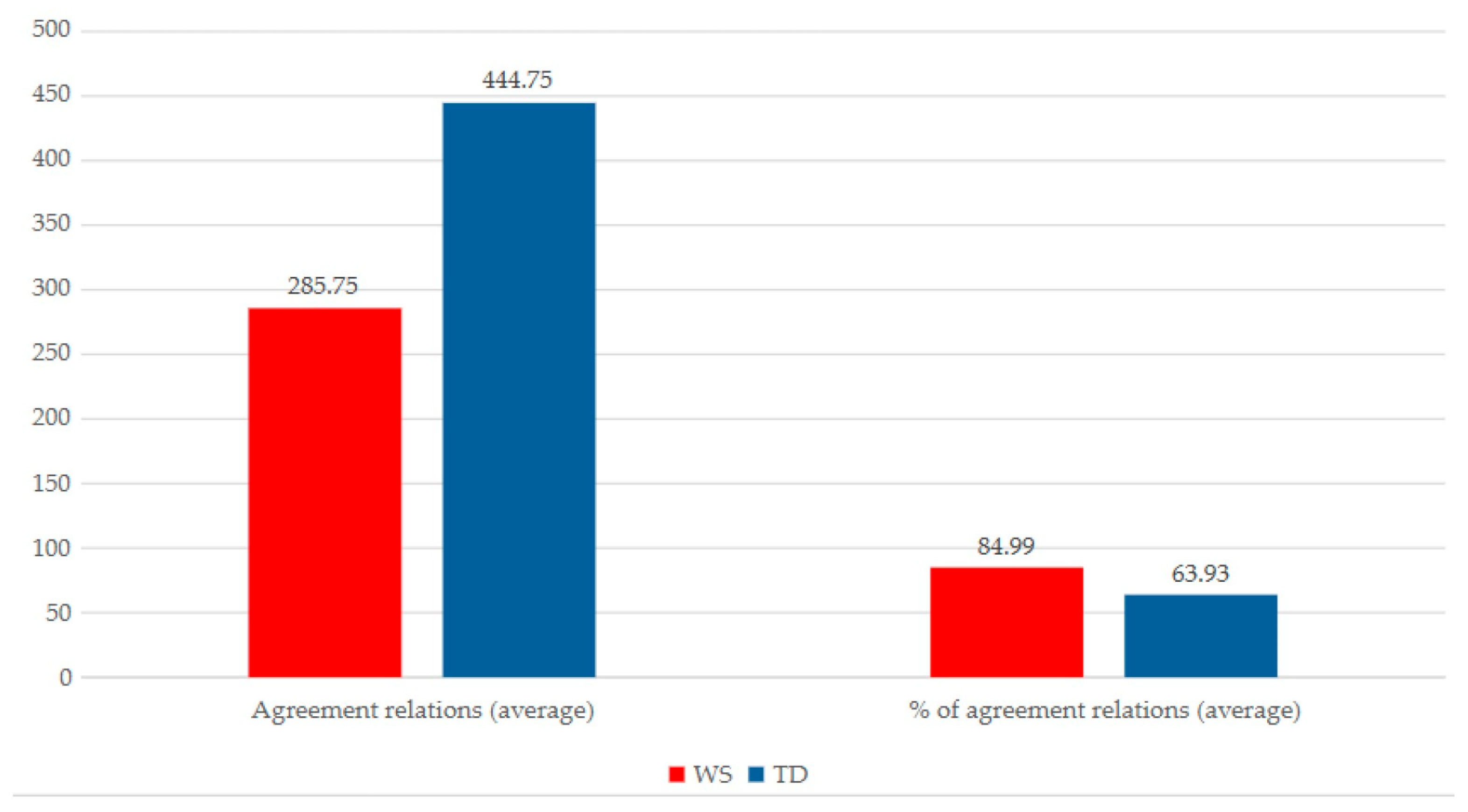
Figure 3 shows the mean number of agreement relations according to clinical conditions, in both absolute values and percentages. As we can see, even though the absolute number of relations of individuals with WS is lower than that of individuals with TD, when we look at percentages, there is evidence that, proportionally, individuals with WS produce more relations. However, the differences are not notable in any case.
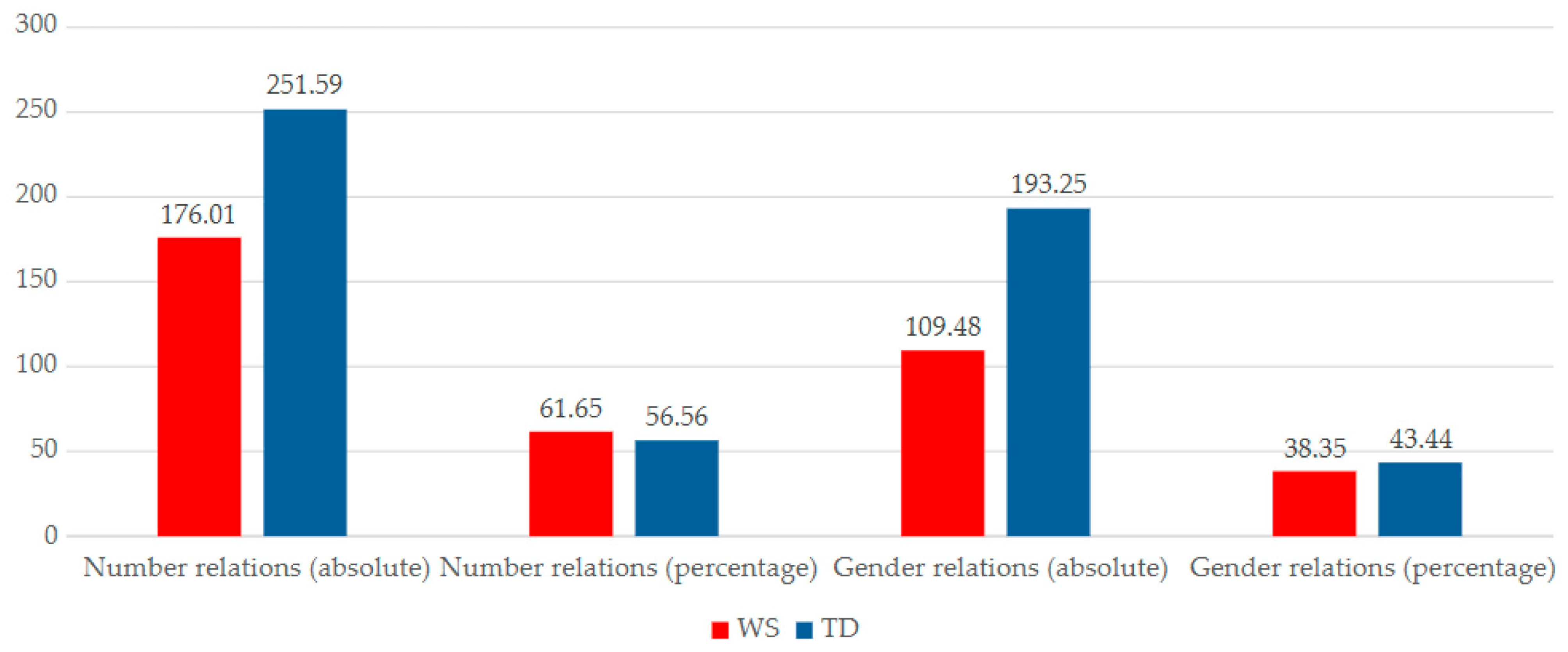
Figure 4 shows all the relationships in terms of number and gender (including the erroneous ones), both in absolute values and in percentages. Here, the absolute value represents the sum of all instances of each variable’s agreement relations, while the proportional value indicates the percentage of each variable regarding the total number of observed relations. As we could observe in the previous figure, the differences between the WS and TD groups lessen when comparing absolute values with proportional ones. Individuals with TD produce both more gender-related and number-related agreement relations, but the discrepancies between values are minimal, with divergences not exceeding 4 percentage points.
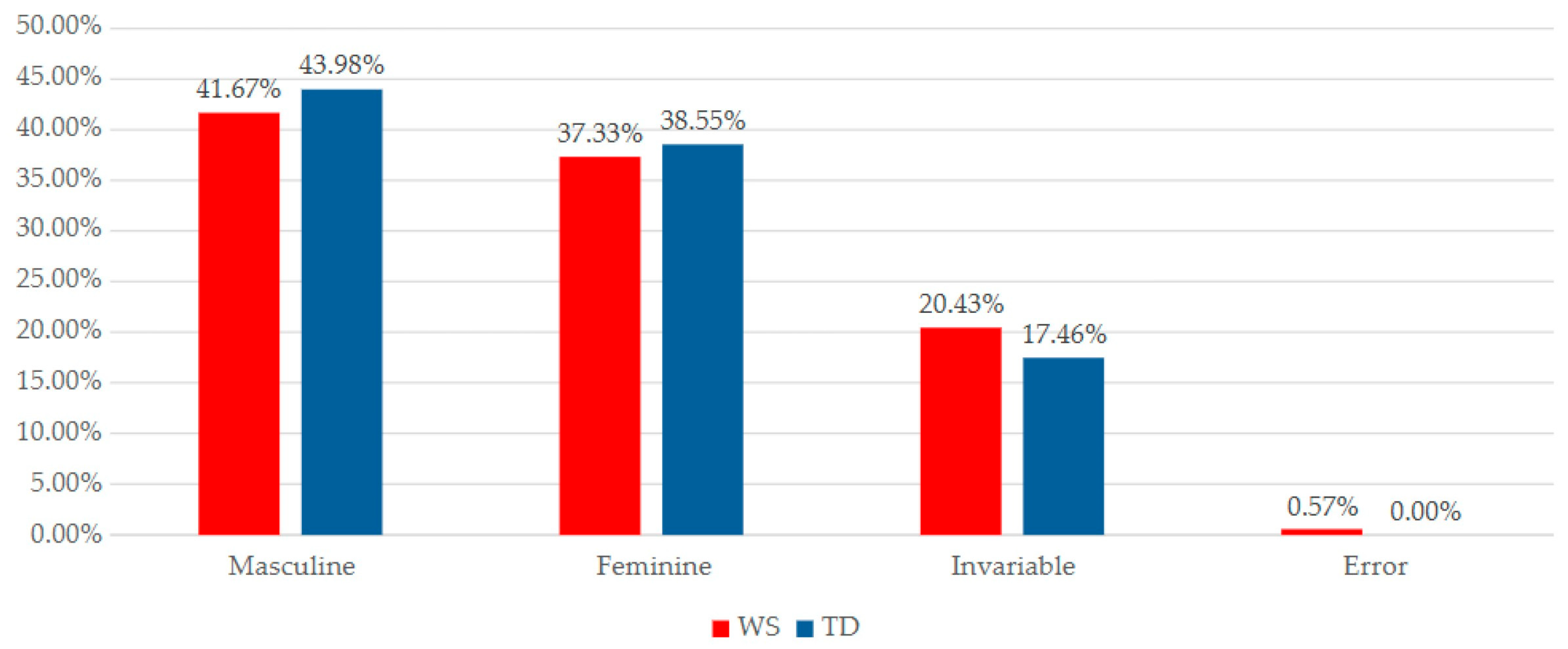
5.1. Gender Variable
If we take a closer look at the gender variable, we can see, as detailed in
Figure 5 and
Figure 6, that, although the absolute values reveal differences between WS and TD (
Figure 5), these disparities become smaller when viewed as percentual values (
Figure 6). In fact, the differences between the TD and WS groups in producing feminine, invariant, or even gender-related errors are less than 1%.
In terms of absolute values, both groups display a tendency to generate unmarked (masculine) relationships. However,
Figure 6 indicates that these differences are minimal, when we look into the percentages.
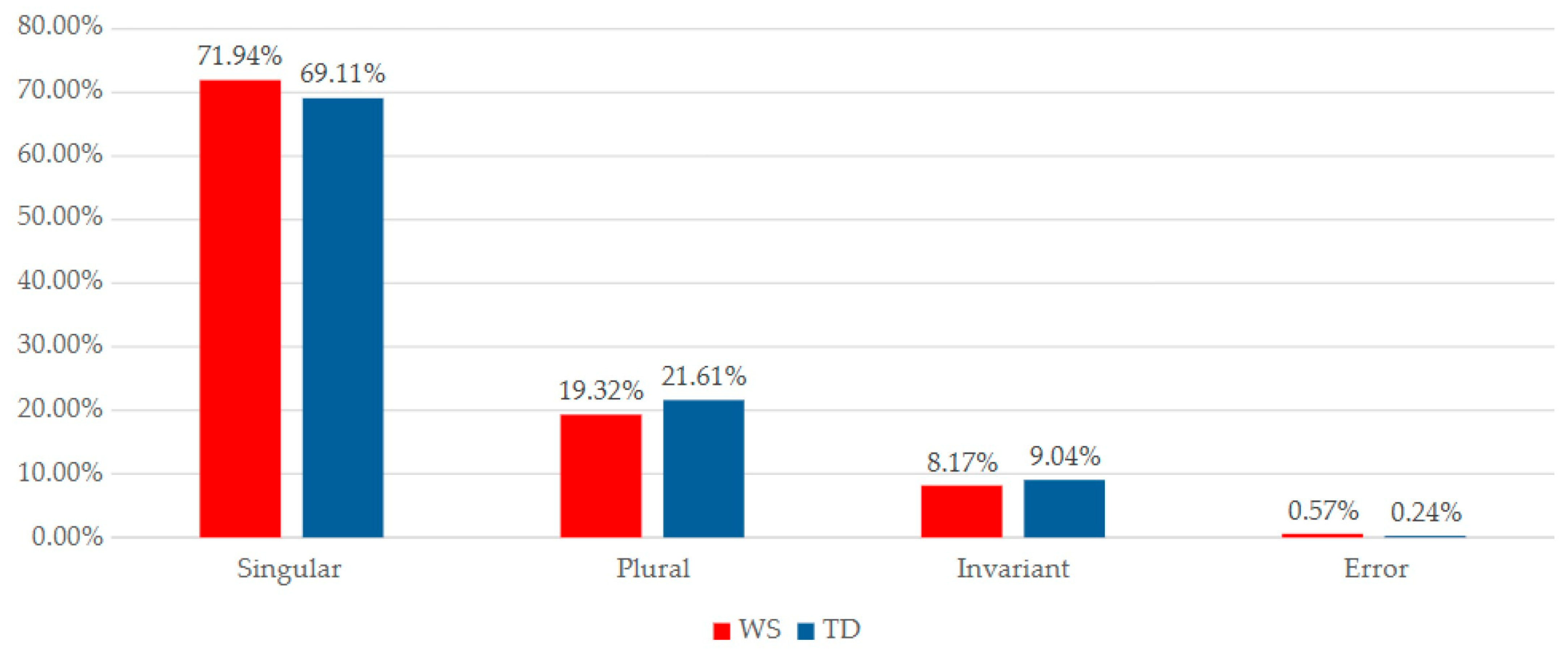
5.2. Number Variable
In this section the results regarding the variable number are presented, with data summarized in the figures displayed below.
Figure 7 details the values for this variable according to clinical condition. The figures indicate that both groups show a preference for the unmarked value, which in this case is singular.
Parallel to the gender variable analysis, the absolute values show that the TD group produces more matches across all categories. However, when viewed in percentages (
Figure 8) the WS group demonstrates a higher frequency of singular and invariant number agreement relations than the TD group. Comparing these values by clinical condition, the largest discrepancy appears in the plural. An independent samples
t-test showed that there are significant differences between the groups (
p = 0.050,
g = 0.594).
5.3. Errors in Gender and Number
Apart from the production of agreement relations themselves, it is important, for this study, to address whether the clinical condition (WS or TD) of individuals can determine the production of errors in both gender and number.
Table 6 reveals that the difference between values remains low overall. However, both in absolute and percentual terms, individuals with WS produce more errors than individuals with TD. Proportionally, however, error rates in each group do not exceed 1% of the total agreement relations.
Focusing on errors in the variable number, differences between clinical conditions are minor, even in the absolute values. For the WS group, errors are concentrated within three individuals, resulting in an average of one in absolute terms. In the TD group, errors are distributed across four corpora, with an average of 0.75. Remarkably, 50% of number errors in the WS group are concentrated within a single individual’s production (CWS-Mex_01), while the TD group’s errors are more evenly spread. In the WS group, a maximum of four errors per individual was produced, while the TD group does not exceed two errors per production. Additionally, it is noteworthy that three out of the four individuals in the WS group who make number errors also make gender errors.
For gender errors, the WS group has an average absolute error rate of 0.63, compared to 0.12 for the TD group. This discrepancy highlights two key differences: first, in the distribution of errors—spread across five corpora for the WS group and concentrated in just one for the TD group; and second, in the frequency of errors, with the WS group producing more than the TD group.
The analysis compared grammatical processing between Williams syndrome (SW, n = 8) and typically developing (TD, n = 8) groups using Mann–Whitney U tests (see
Table 7 and
Table 8). This non-parametric approach was justified by both the small sample size and violations of normality in key variables: Shapiro–Wilk tests revealed significant non-normality (
p < 0.05) for NUM_Error in both groups (TD:
p = 0.004; SW:
p = 0.032) and for GEN_Error in the SW group (
p = 0.056), with other variables showing marginal or non-significant deviations (all other
p > 0.05). The conservative nature of Mann–Whitney tests reduces Type I error risk but may inflate Type II error rates, making the significant gender effects—feminine (W = 53.50,
p = 0.027, rank-biserial r = 0.67 [95% CI: 0.23, 0.89]) and masculine (W = 60.50,
p = 0.003, r = 0.89 [0.69, 0.97])—particularly noteworthy. In contrast, non-significant results in number processing (e.g., NUM_Error:
p = 0.449) may reflect either true null effects or reduced power from the combined limitations of sample size and conservative methods. Levene’s test (
Table 9) indicated homogeneity of variances for most measures (all
p > 0.05), except marginal heteroscedasticity in NUM_Error (
p = 0.099). These findings should be replicated with larger samples to mitigate the constraints of the current design.
6. Discussion
The main findings of this study pertain to the production of morphosyntactic relations—among determiners, nouns, and adjectives—and a comparative analysis between a group with TD and another with WS. Far from being mutually exclusive, the production-centered approach, which provides a more descriptive account of how individuals with Williams syndrome speak, can complement the processing-centered approach. The latter offers greater control over experimental tasks and allows for the exploration of the limits of the speaker’s syntactic capacity. Before moving on to the discussion, however, it is important to note that the sample consists of only 16 participants, 8 per condition. While this is larger than some other studies on speakers with WS included in the literature review for this paper, it remains a small sample for statistically significant or broadly generalizable results. Therefore, the collected data can only suggest potential trends, discussed as follows.
The initial data, covering word production and agreement relations, show that the TD group produces more words overall, and thus more agreement relations when we look at the absolute values. To compare them, all variables were equalized using percentages. Interestingly, these proportional values indicate the reverse trend: the group with the highest production rates was the WS group, even though differences are relatively small. This finding suggests that the speech of individuals with WS, compared to those with TD, is unimpaired concerning agreement relations. This perspective would thus favor the view that individuals with WS show good grammatical abilities, as stated in some of the reviewed literature (
Brock, 2007;
Miezah et al., 2021).
The tendency for the two variables under study (gender and number) confirms this. When examining gender and number by clinical condition, production values for agreement relations were nearly identical across groups. Regarding gender, individuals with WS used masculine and feminine forms almost equally, whereas those with TD showed a higher number of relations for the unmarked gender (masculine), which could be simply due to the semantic field of the discourse or the topics covered (they were all spontaneous speech, and therefore might have conducted the conversations towards slightly different—but comparable—topics). For number, both groups showed a marked preference for singular over plural or invariant forms. Among all gender and number values, singularity exhibited the largest difference, but the difference is too small to claim that individuals with WS favor singularity differently from those with TD. This trend could simply reflect the higher occurrence frequency of singular over plural words in general. Moreover, a proportional trend between singular and plural was observed in both groups, as singular usage decreased in tandem with plural usage. In summary, given the observed similarities in usage patterns and values for gender and number, the WS group seems to demonstrate typical discourse in these areas, even though the reduced size of the sample makes it complex to establish generalizations.
Contrary to
Clahsen and Almazan (
2001) for English, the data here do not indicate a higher rate of ungrammatical forms or agreement errors in individuals with WS compared to those with TD. Similarly, no evidence of morphological overgeneralization, noted by
Bartke (
2004) for English and by
Benítez-Burraco et al. (
2017) for Spanish, was found in this sample—even though, as said, it is reduced. Unlike these studies, this sample consists of an adult group, which may explain the absence of such forms, as they appear more commonly in younger groups.
Aligned with this study’s focus, previous research by
Krause and Penke (
2002) for German and
Lukács et al. (
2004) for Hungarian observed (generally) typical plural use by WS speakers. Similarly, the frequency of errors in irregular plural forms noted by these authors does not align with patterns in the corpus analyzed here. However, we consider the current data insufficient to generalize these findings to Spanish speakers with WS.
Indeed, a closer examination of individual data points within the WS group shows that a small number of participants account for a high share of the observed agreement errors. These outlier cases, while few, is proof of the heterogeneity of the WS population. Most notably, individuals who exhibited gender errors often also displayed number agreement issues, suggesting a possible link between broader morphosyntactic vulnerability and specific cognitive-linguistic profiles. While the sample size limits strong statistical conclusions, this concentration of errors in particular individuals indicates the need for more fine-grained analyses that move beyond group averages. Longitudinal or case study methodologies may be particularly well-suited to exploring how individual cognitive and linguistic profiles interact with grammatical development in WS. More studies, with a larger amount of data, are needed to confirm these results.
It is also important to note that the current study relies on Dependency Grammar as the theoretical framework for identifying and analyzing agreement relations. While this framework offers a structured and economical way of mapping syntactic dependencies—especially in spontaneous speech data—it may also impose certain limitations. For example, its focus on hierarchical binary relations might obscure more fluid or gradient phenomena in spoken language, particularly in clinical populations where atypical structures may not neatly align with standard dependency rules. Moreover, the identification of errors within this model assumes a normative syntactic baseline, which may not fully capture the developmental or compensatory strategies employed by individuals with WS. A critical reflection on this point highlights the need to triangulate findings using complementary syntactic models or error typologies, especially in clinical linguistics.
7. Conclusions
The reviewed literature reveals contrasting perspectives on the linguistic capabilities of individuals with WS. On one side, some researchers suggest that linguistic ability is relatively preserved in comparison to other cognitive skills (which were not tested in this study since it was not the main goal); on the other, some studies highlight significant linguistic deficiencies. The only point of consensus between these views seems to be the asynchronous development of cognitive abilities in individuals with WS.
Considering the different perspectives, the current study intended to shed light on the morphosyntactic abilities in the spoken language of individuals with WS, specifically regarding gender and number agreement. The results suggest that the morphosyntactic ability of the WS group is comparable to that of the TD group. Indeed, differences in gender and number usage across clinical groups were minimal. The most noticeable variations were in the use of masculine and singular forms, yet these might be more closely tied to word frequency rather than clinical condition. Supporting this interpretation, both the WS and TD groups showed similarly low error rates in agreement, suggesting that mistakes could hypothetically be attributable to slips of the tongue rather than cognitive impairments.
However, this does not rule out the possibility of specific types of errors unique to WS individuals. While this study includes a relatively larger sample size than other studies, the corpus remains limited, making it difficult to draw statistically significant or generalizable conclusions. The data suggest certain trends but would benefit from further validation with a larger sample. Additionally, the findings underscore the importance of recognizing individual variability within the WS group, suggesting that observed differences might originate from individual cases. Further research is therefore needed to understand the language production of individuals with WS. Specifically, studies should explore how other cognitive skills, such as short- and long-term memory, influence language development, as, according to the literature, individuals with WS have shown both deficits and strengths in these areas.
In summary, the findings of this study, even though limited regarding the size of the sample, indicate that the morphosyntactic abilities of individuals with WS regarding gender and number agreement have certain similarities to those of TD individuals. Nonetheless, much remains to be explored to fully understand language in WS individuals. Further studies are needed to examine their linguistic abilities through a theoretical, interdisciplinary lens (with experimental analyses, for instance, or taking into account other factors related to cognition), and a robust corpus that enables statistically significant data extraction while capturing individual differences for stronger conclusions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}