
Effects of Input Consistency on Children’s Cross-Situational Statistical Learning of Words and Morphophonological Rules


 , ,
, , 
Abstract
1. Introduction
1.1. Input Variability and Statistical Language Learning
1.2. The Present Study
- (1)
- Does inconsistent language input hinder children’s cross-situational statistical language learning, and does this depend on (a) the amount of inconsistent input (12.5% or 25% inconsistent input), and (b) the linguistic level (words vs. rules) at which learning takes place?
- (2)
- Do different levels of inconsistent input affect the type of errors (i.e., random errors vs. substitution errors that may have occurred in the input) that children make in their generalization of the morphophonological rules?
2. Materials and Methods
2.1. Participants
2.2. Materials
2.3. Procedure
2.4. Data Analysis
3. Results
3.1. Background Measures: Group Comparisons in Language Proficiency
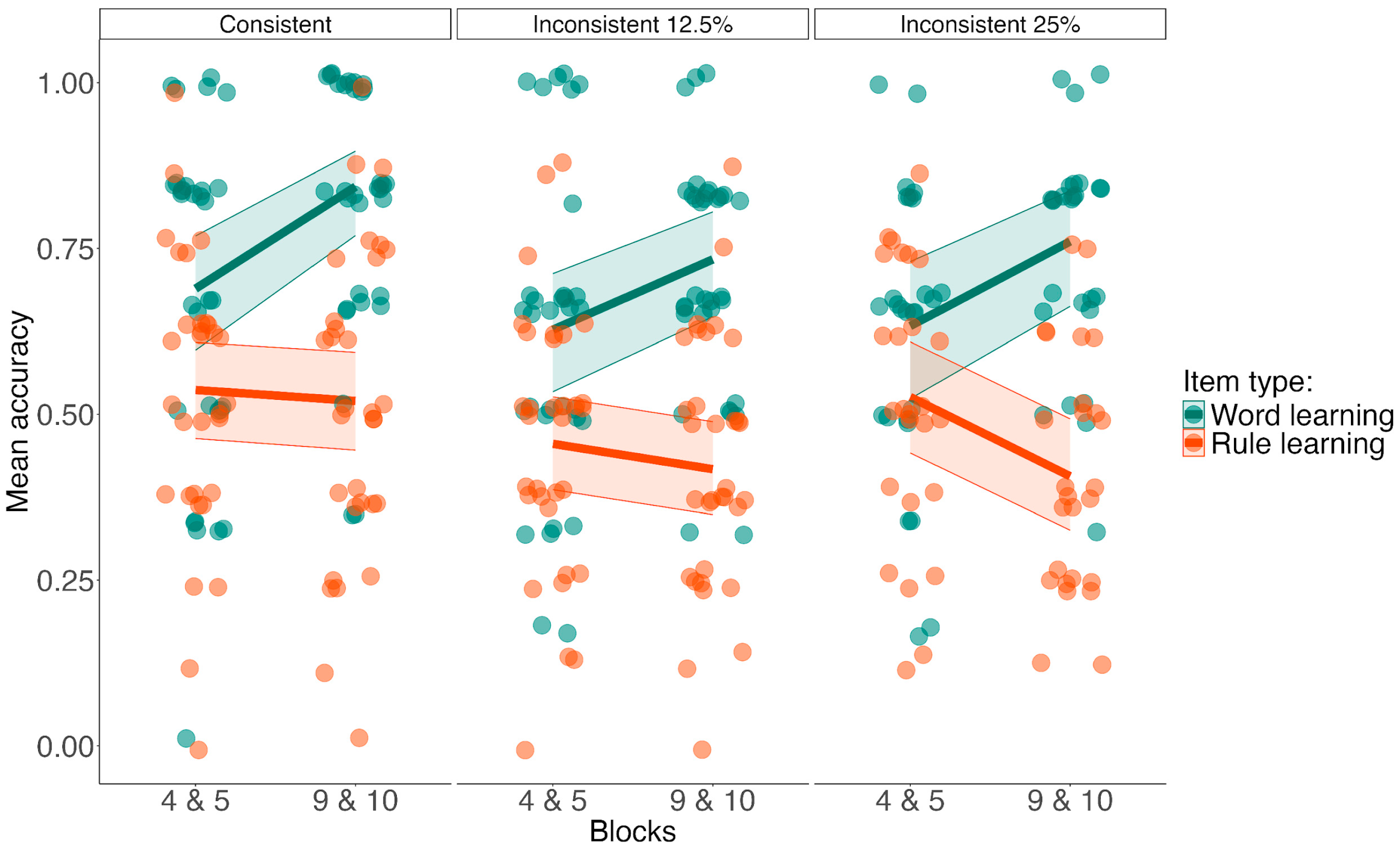
3.2. Research Question 1: Confirmatory Results
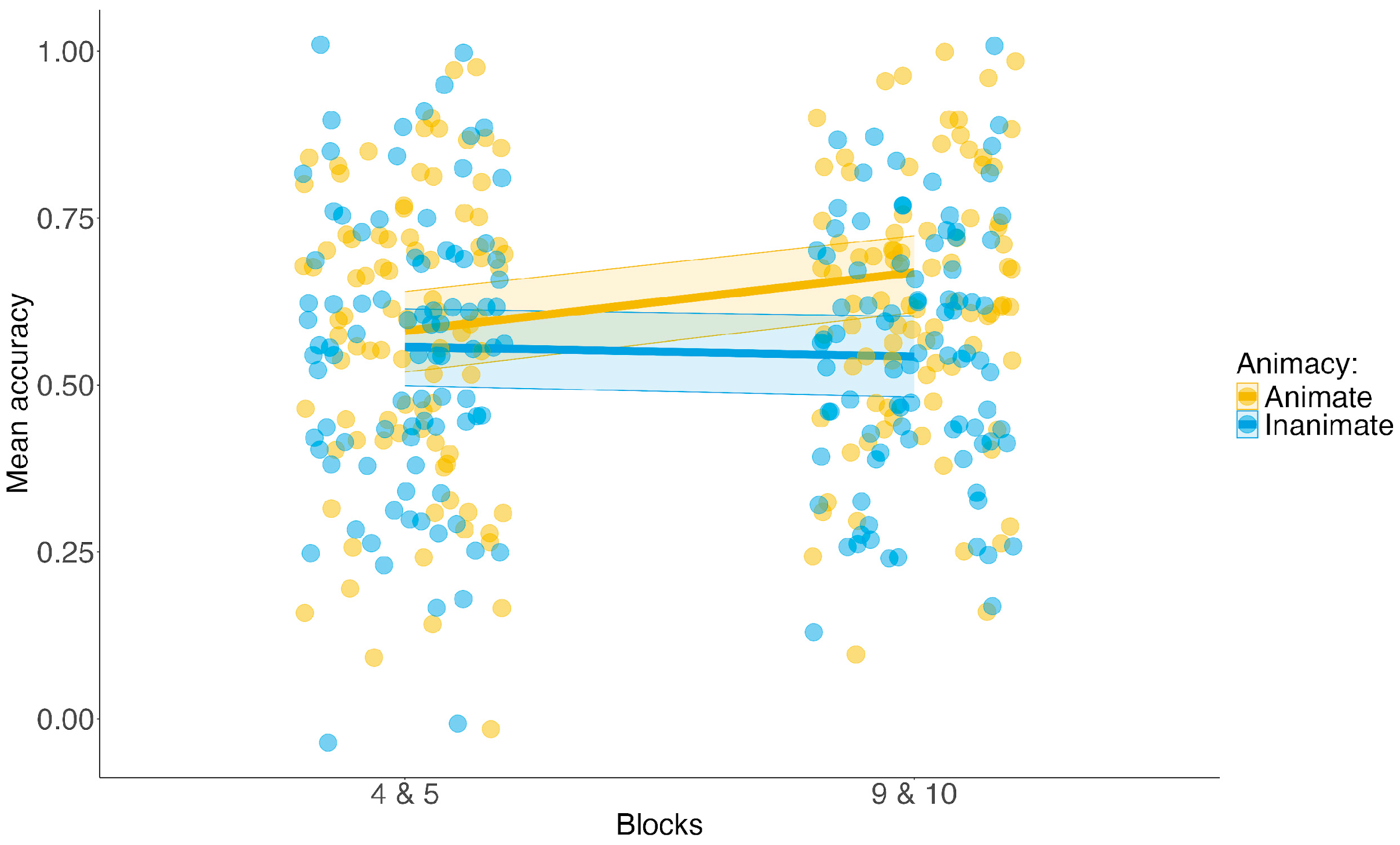
3.3. Research Question 1: Exploratory Results
3.4. Research Question 2: Confirmatory Results
3.5. Research Question 2: Exploratory Results
4. Discussion
Limitations and Future Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | The second part of cross-situational statistical task requires reading. |
| 2 | That is, for these children, at least one of their parents was a native speaker of another language than Dutch and, during a regular week, this parent used their native language at least 10% of the time with their child. We originally planned to explore the differences between multilingual and monolingual children as well, but because of difficulties with the recruitment, we ended up with a relatively low number of multilingual children, and decided not to explore this question further. |
| 3 | Reviewers noted an unequal distribution of boys and girls across our three input conditions, and wondered whether this may have impacted the group comparisons, given that girls may have relatively higher language proficiencies than boys. We therefore first checked for differences in language proficiency and phonological memory skills between the children in our three input conditions. If differences in language proficiencies and phonological memory were found between our three groups, then we would have controlled for these differences by adding children’s scores on the tasks that measure these variables to our statistical models. |
| 4 | To check whether our cross-situational statistical learning task can be used to learn this type of rule, we (post hoc) decided to run the experiment in adults as well. A total of 97 adults participated (consistent condition: n = 31; inconsistent 12.5%: n = 33; inconsistent 25% condition: n = 32). For adults, the re-referenced models estimated that adults learned the morphophonoligical marking rules. That is, for both the word learning model (estimate log-odds = 1.6; probability = 83%; p-value < .001; 95% Wald CI probability = [78%, 86%]) and rule generalization model (estimate log-odds = 0.43; probability = 60%; p-value = .0040, 95% Wald CI probability = [52%, 68%]), the intercepts were statistically significantly different from chance performance of 50%. Furthermore, the main model estimated that adults’ accuracy was lower for the inconsistent input conditions and compared to the consistent input condition (estimate log-odds = −0.46, odds ratio = 0.62, p = .039, 95% Wald CI odds ratio = [0.4,1.0]). This difference became larger in the second part of the training (blocks 9, 10) as compared to the first part of the training (blocks 10, 11; estimate log-odds = −0.55, odds ratio = 0.58, p = .011, 95% Wald CI odds ratio = [0.4, 0.9]). The complete set of outcomes for the adult data can be found at our Radboud Data Sharing Collection (Savarino et al., 2025). |
| 5 | For adults (see also Note 3), the model estimated that the likelihood that adults made a substitution error as compared to a random error was higher for adults in the inconsistent input conditions as compared to adults in the consistent input condition (estimate log-odds = 1.1, odds ratio = 3.1, p = .0018, 95% Wald CI odds ratio = [1.5, 6.2]). Please see the Supplementary Materials at our Radboud Data Sharing Collection (Savarino et al., 2025) for more details. |
References
- Anderson, N. J., Graham, S. A., Prime, H., Jenkins, J. M., & Madigan, S. (2021). linking quality and quantity of parental linguistic input to child language skills: A meta-analysis. Child Development, 92(2), 484–501. [Google Scholar] [CrossRef] [PubMed]
- Austin, A. C., Schuler, K. D., Furlong, S., & Newport, E. L. (2022). Learning a language from inconsistent input: Regularization in child and adult learners. Language Learning and Development, 18(3), 249–277. [Google Scholar] [CrossRef]
- Benitez, V. L., & Li, Y. (2023). Cross-situational word learning in children and adults: The case of lexical overlap. Language Learning and Development, 20(3), 195–218. [Google Scholar] [CrossRef]
- Chen, C., Gershkoff-Stowe, L., Wu, C.-Y., Cheung, H., & Yu, C. (2017). Tracking multiple statistics: Simultaneous learning of object names and categories in English and Mandarin speakers. Cognitive Science, 41(6), 1485–1509. [Google Scholar] [CrossRef] [PubMed]
- Chen, J., Justice, L. M., Tambyraja, S. R., & Sawyer, B. (2020). Exploring the mechanism through which peer effects operate in preschool classrooms to influence language growth. Early Childhood Research Quarterly, 53, 1–10. [Google Scholar] [CrossRef]
- De Bree, E., Verhagen, J., Kerkhoff, A., Doedens, W., & Unsworth, S. (2017). Language learning from inconsistent input: Bilingual and monolingual toddlers compared. Infant and Child Development, 26(4), e1996. [Google Scholar] [CrossRef]
- de Cat, C., Kašćelan, D., Prevost, P., Serratrice, L., Tuller, L., & Unsworth, S. (2021). Manual and design documentation for the Q-BEx questionnaire (dataset and materials). Available online: https://osf.io/v7ec8/ (accessed on 4 March 2025). [CrossRef]
- Dunn, K. J., Frost, R. L. A., & Monaghan, P. (2024). Infants’ attention during cross-situational word learning: Environmental variability promotes novelty preference. Journal of Experimental Child Psychology, 241, 105859. [Google Scholar] [CrossRef] [PubMed]
- Gómez, R. L., & Lakusta, L. (2004). A first step in form-based category abstraction by 12-month-old infants. Developmental Science, 7(5), 567–580. [Google Scholar] [CrossRef]
- Hoff, E. (2006). How social contexts support and shape language development. Developmental Review, 26(1), 55–88. [Google Scholar] [CrossRef]
- Hoff, E., Core, C., & Shanks, K. F. (2020). The quality of child-directed speech depends on the speaker’s language proficiency. Journal of Child Language, 47(1), 132–145. [Google Scholar] [CrossRef]
- Horst, J. S., & Hout, M. C. (2016). The Novel Object and Unusual Name (NOUN) Database: A collection of novel images for use in experimental research. Behavior Research Methods, 48(4), 1393–1409. [Google Scholar] [CrossRef] [PubMed]
- Hudson Kam, C. L. (2015). The impact of conditioning variables on the acquisition of variation in adult and child learners. Language, 91(4), 906–937. [Google Scholar] [CrossRef]
- Hudson Kam, C. L., & Newport, E. L. (2005). Regularizing unpredictable variation: The roles of adult and child learners in language formation and change. Language Learning and Development, 1(2), 151–195. [Google Scholar] [CrossRef]
- Isbilen, E. S., & Christiansen, M. H. (2022). Statistical learning of language: A meta-analysis into 25 years of research. Cognitive Science, 46(9), e13198. [Google Scholar] [CrossRef] [PubMed]
- Kachergis, G., Yu, C., & Shiffrin, R. M. (2009). Frequency and contextual diversity effects in cross-situational word learning. Proceedings of the Annual Meeting of the Cognitive Science Society, 31(31), 2220–2225. Available online: https://escholarship.org/uc/item/1jh968zh (accessed on 4 March 2025).
- Keogh, A., & Lupyan, G. (2024). Who benefits from redundancy in learning noun class systems? In J. Nölle, L. Raviv, K. E. Graham, S. Hartmann, Y. Jadoul, M. Josserand, T. Matzinger, K. Mudd, M. Pleyer, A. Slonimska, S. Wacewicz, & S. Watson (Eds.), The evolution of language: Proceedings of the 15th international conference (EVOLANG XV). The Evolution of Language Conferences. [Google Scholar] [CrossRef]
- Lammertink, I. (2021). Stats and structure: Their presence and role in the peer language environment of children with developmental language disorder. (Project No. VI.Veni.211C.054) [Grant]. Dutch Research Council Talent Programme. Available online: https://www.nwo.nl/en/researchprogrammes/nwo-talent-programme/projects-veni/veni-2021 (accessed on 4 March 2025).
- Lammertink, I., Boersma, P., Wijnen, F., & Rispens, J. (2020). Children with developmental language disorder have an auditory verbal statistical learning deficit: Evidence from an online measure. Language Learning, 70(1), 137–178. [Google Scholar] [CrossRef]
- Lammertink, I., Van Witteloostuijn, M., Verhagen, J., & Rispens, J. (2024, July 15–19). The effects of input consistency on children’s statistical language learning [Poster presentation]. International Congress for the Study of Child Language (IASCL), Prague, Czech. Available online: https://iascl2024.com/program/schedule/ (accessed on 4 March 2025).
- Lany, J. (2014). Judging words by their covers and the company they keep: Probabilistic cues support word learning. Child Development, 85(4), 1727–1739. [Google Scholar] [CrossRef]
- Lhoste, E., Bonin, P., Bard, P., Poulin-Charronnat, B., & Vinter, A. (2024). A processing advantage in favor of animate entities in incidental word learning in young children. Journal of Experimental Child Psychology, 243, 105913. [Google Scholar] [CrossRef]
- Poepsel, T. J., & Weiss, D. J. (2016). The influence of bilingualism on statistical word learning. Cognition, 152, 9–19. [Google Scholar] [CrossRef]
- Quine, W. (1960). Word and object: An inquiry into the linguistic mechanisms of objective reference. John Wiley. [Google Scholar]
- Raviv, L., & Arnon, I. (2018). The developmental trajectory of children’s auditory and visual statistical learning abilities: Modality-based differences in the effect of age. Developmental Science, 21(4), e12593. [Google Scholar] [CrossRef]
- Rispens, J. E., Abrahamse, R., Broedelet, I., & Monaghan, P. (2023, September 6–9). Linguistic rule learning through cross-situational word learning in DLD and typical language development [Paper presentation]. 23th Conference on the European Society for Cognitive Psychology (Escop), Porto, Portugal. Available online: https://boa.unimib.it/retrieve/dfceab10-51a3-4542-96fe-d23ad11fdc38/Maisto-2023-ESCop-VoR.pdf (accessed on 4 March 2025).
- Rispens, J. E., & de Bree, E. (2014). Past tense productivity in Dutch children with and without SLI: The role of morphophonology and frequency. Journal of Child Language, 41(1), 200–225. [Google Scholar] [CrossRef]
- Rowe, M. L. (2012). A Longitudinal investigation of the role of quantity and quality of child-directed speech in vocabulary development. Child Development, 83(5), 1762–1774. [Google Scholar] [CrossRef]
- Saffran, J. R., & Kirkham, N. Z. (2018). Infant statistical learning. Annual Review of Psychology, 69(1), 181–203. [Google Scholar] [CrossRef]
- Samara, A., Smith, K., Brown, H., & Wonnacott, E. (2017). Acquiring variation in an artificial language: Children and adults are sensitive to socially conditioned linguistic variation. Cognitive Psychology, 94, 85–114. [Google Scholar] [CrossRef]
- Savarino, M., van Witteloostuijn, M., Verhagen, J., Rispens, J., & Lammertink, I. (2025). Effects of input consistency on children’s cross-situational statistical language learning (Version 1) [dataset]. Radboud University. Available online: https://data.ru.nl/collections/ru/cls/effects_input_consistency_children_cross-situational_statistical_language_learning_dsc_167 (accessed on 4 March 2025). [CrossRef]
- Schlichting, L. (2005). PPVT-III-NL: Peabody picture vocabulary test-III-NL. Harcourt test Publishers. [Google Scholar]
- Semel, E., Wiig, E., & Secord, W. (2003). Clinical evaluation of language fundamentals: Dutch version (W. Kort, E. Compaan, M. Schittekatte, & P. Dekker, Trans.; 4th ed.). [Measurement instrument]. Pearson. [Google Scholar]
- Smith, K., Smith, A. D. M., & Blythe, R. A. (2011). Cross-situational learning: An experimental study of word-learning mechanisms. Cognitive Science, 35(3), 480–498. [Google Scholar] [CrossRef]
- Smith, L., & Yu, C. (2008). Infants rapidly learn word-referent mappings via cross-situational statistics. Cognition, 106(3), 1558–1568. [Google Scholar] [CrossRef] [PubMed]
- Spit, S., Andringa, S., Rispens, J., & Aboh, E. O. (2022). Kindergarteners use cross-situational statistics to infer the meaning of grammatical elements. Journal of Psycholinguistic Research, 51(6), 1311–1333. [Google Scholar] [CrossRef] [PubMed]
- Suanda, S. H., Mugwanya, N., & Namy, L. L. (2014). Cross-situational statistical word learning in young children. Journal of Experimental Child Psychology, 126, 395–411. [Google Scholar] [CrossRef]
- Suanda, S. H., & Namy, L. L. (2012). Detailed behavioral analysis as a window into cross-situational word learning. Cognitive Science, 36(3), 545–559. [Google Scholar] [CrossRef] [PubMed]
- Vet, D. J. (2024). ED—Experiment designer. Available online: https://www.fon.hum.uva.nl/dirk/ed.php (accessed on 4 March 2025).
- Yu, C., & Smith, L. B. (2007). Rapid word learning under uncertainty via cross-situational statistics. Psychological Science, 18(5), 414–420. [Google Scholar] [CrossRef]
- Yurovsky, D., Fricker, D. C., Yu, C., & Smith, L. B. (2014). The role of partial knowledge in statistical word learning. Psychonomic Bulletin & Review, 21(1), 1–22. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Input Condition | Number of Children | Gender | Age in Years:Months | Maternal Education a | ||||
|---|---|---|---|---|---|---|---|---|
| M | Range | SD | M | Range | SD | |||
| Consistent | n = 31 | Girls (n = 20) Boys (n = 11) | 9:1 | 7:6–11:0 | 0:7 | 3.5 | 1–4 | 0.79 |
| Inconsistent 12.5% | n = 32 | Girls (n = 16) Boys (n = 16) | 9:0 | 8:0–10:9 | 0:7 | 3.7 | 2–4 | 0.53 |
| Inconsistent 25% | n = 26 | Girls (n = 8) Boys (n = 18) | 9:5 | 7:6–10:7 | 0:8 | 3.6 | 2–4 | 0.62 |
| Predictor | Contrast-Coding | Operationalization | Model | |
|---|---|---|---|---|
| Input | ||||
| ConsvsIncons (constrast 1) | Consistent: Inconsistent 12.5%: Inconsistent 25%: + | Accuracy difference between consistent and inconsistent input conditions. | 1, 2 | |
| Incons (contrast 2) | Inconsistent 12.5%: Inconsistent 25%: | Accuracy difference between the inconsistent 12.5% and inconsistent 25% condition. | ||
| ItemType | Words: Rules: | Accuracy difference between items that assess word learning (trained items) vs. items that assess morphophonological rule generalization (novel/untrained). | 1 | |
| Time | Timepoint 1: Timepoint 2: | Accuracy difference between first part of training (blocks 4, 5) and second part of training (blocks 9, 10). | 1 | |
| Animacy | Animate: Inanimate: | Accuracy difference between animate and inanimate label–referent pairs. | 1, 2 | |
| Input Condition | Sentence Recall a | Receptive Vocabulary b | Phonological Memory a | |||
|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | |
| Consistent | 10 | 3.2 | 106 | 10 | 10 | 2.8 |
| Inconsistent 12.5% | 10 | 2.8 | 106 | 9.7 | 10 | 3.3 |
| Inconsistent 25% | 9 | 3.1 | 108 | 11 | 11 | 3.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Savarino, M.; van Witteloostuijn, M.; Verhagen, J.; Rispens, J.; Lammertink, I. Effects of Input Consistency on Children’s Cross-Situational Statistical Learning of Words and Morphophonological Rules. Languages 2025, 10, 52. https://doi.org/10.3390/languages10030052
Savarino M, van Witteloostuijn M, Verhagen J, Rispens J, Lammertink I. Effects of Input Consistency on Children’s Cross-Situational Statistical Learning of Words and Morphophonological Rules. Languages. 2025; 10(3):52. https://doi.org/10.3390/languages10030052
Chicago/Turabian StyleSavarino, Marica, Merel van Witteloostuijn, Josje Verhagen, Judith Rispens, and Imme Lammertink. 2025. "Effects of Input Consistency on Children’s Cross-Situational Statistical Learning of Words and Morphophonological Rules" Languages 10, no. 3: 52. https://doi.org/10.3390/languages10030052
APA StyleSavarino, M., van Witteloostuijn, M., Verhagen, J., Rispens, J., & Lammertink, I. (2025). Effects of Input Consistency on Children’s Cross-Situational Statistical Learning of Words and Morphophonological Rules. Languages, 10(3), 52. https://doi.org/10.3390/languages10030052