
Understanding Dialectal Variation in Contact Scenarios Through Dialectometry: Insights from Inner Asia Minor Greek

Abstract
1. Introduction
2. Materials and Methods
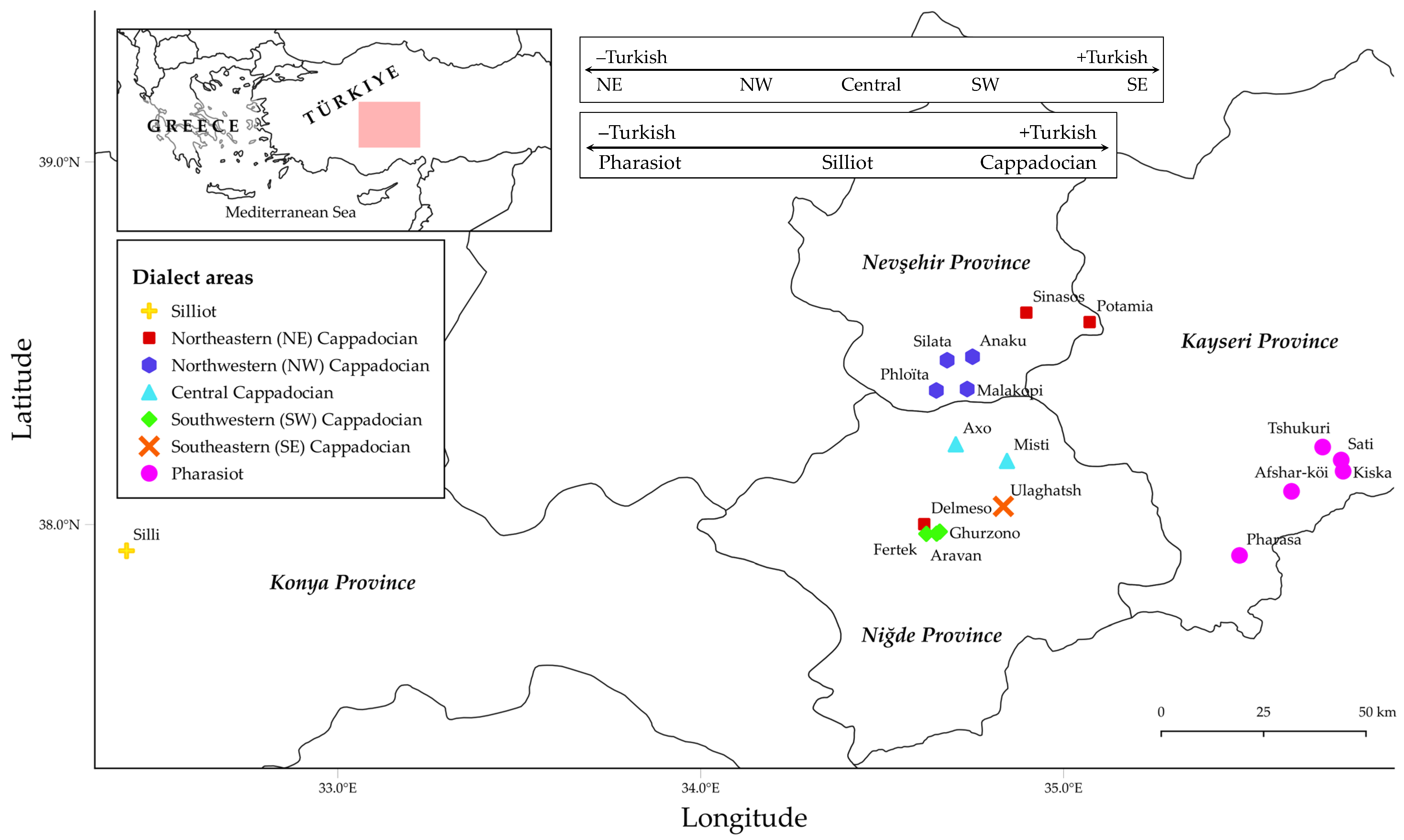
2.1. The Inner Asia Minor Greek Dialect Continuum
- borrowing of Turkish idioms;
- use of Turkish word order;
- effects of Turkish vowel harmony;
- unvoiced final consonants;
- unchanged velars in paradigms;
- pronunciation of [ɣ] as [q];
- failure to pronounce /θ/ and /ð/;
- loss of genders;
- partial disuse of the article;
- use of the accusative ending -ον/-on/ only after the article and generalization using -ς/-s/;
- agglutinative declension;
- comparative of adjectives based on the Turkish model;
- use of Turkish numerals;
- use of Turkish derivative verbal suffixes in Greek;
- addition of Turkish personal endings to the Greek verb;
- agglutinative formation of the imperfect passive;
- pluperfect on the Turkish model;
- position of the enclitic substantive verb.
- the preservation vs. loss of the Greek interdental fricatives /θ, ð/ and their replacement by dental stops;
- the preservation vs. loss of traces of the Greek gender system;
- the absence vs. presence of (Turkish) ‘agglutinative’ patterns in noun inflection; and
- the degree of use of Turkish syntactic structures.
2.2. Linguistic Data
2.2.1. Grammatical Data
2.2.2. Lexical Data
2.3. Parameterization of Linguistic Data
2.3.1. Parameterization of Grammatical Data
2.3.2. Parameterization of Lexical Data
2.4. Limitations of Linguistic Data
2.5. Extra-Linguistic Data
2.5.1. Geographic Data
2.5.2. Demographic Data
2.5.3. Proximity to Urban Centers
2.5.4. Variety Type
2.5.5. Education
2.5.6. Migration
2.6. Parameterization of Extra-Linguistic Data
2.7. Computational Analysis
2.7.1. Linguistic Distances (Dependent Variables)
2.7.2. Extra-Linguistic Distances (Independent Variables)
2.8. Statistical Analysis
3. Results
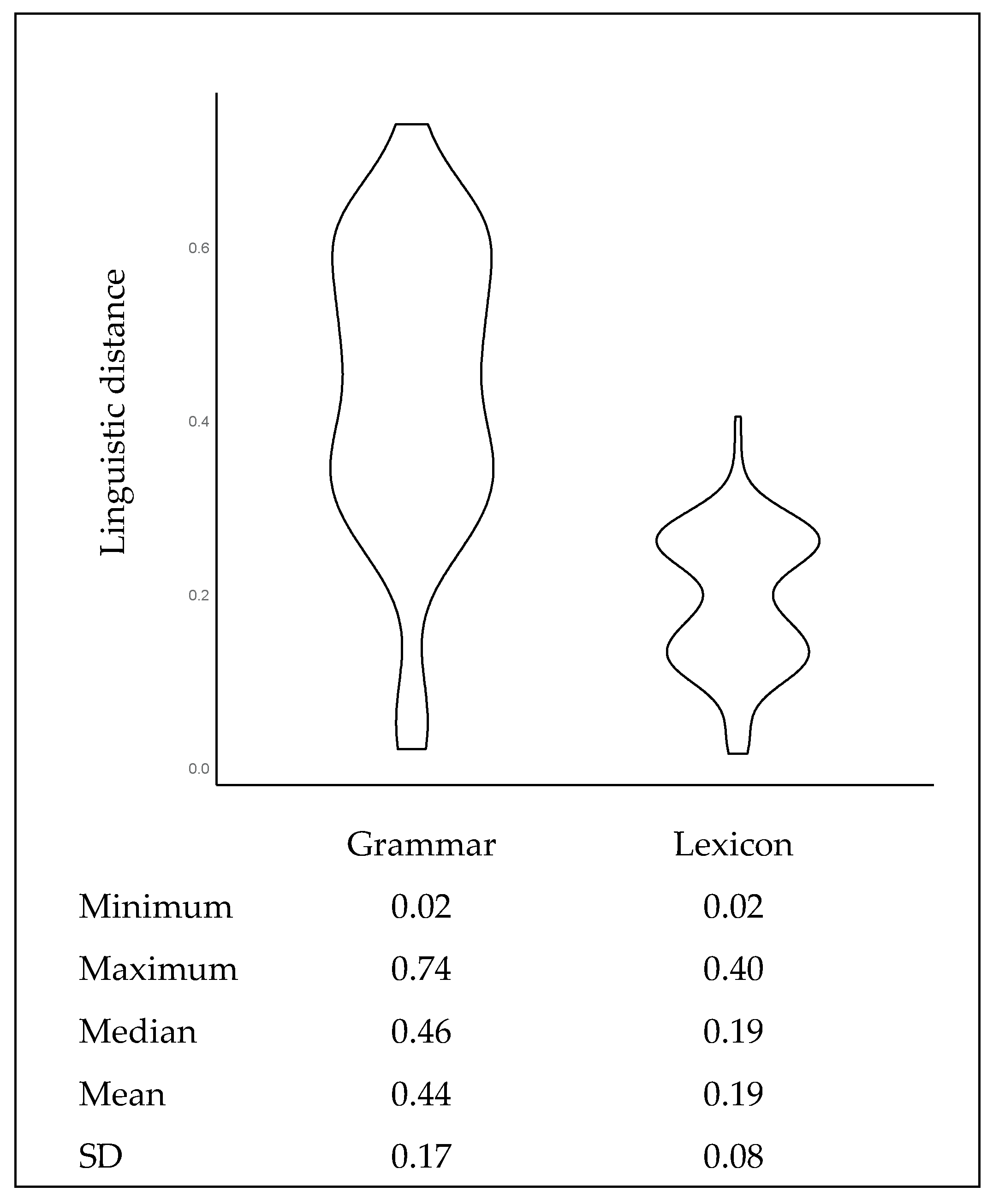
3.1. Overview
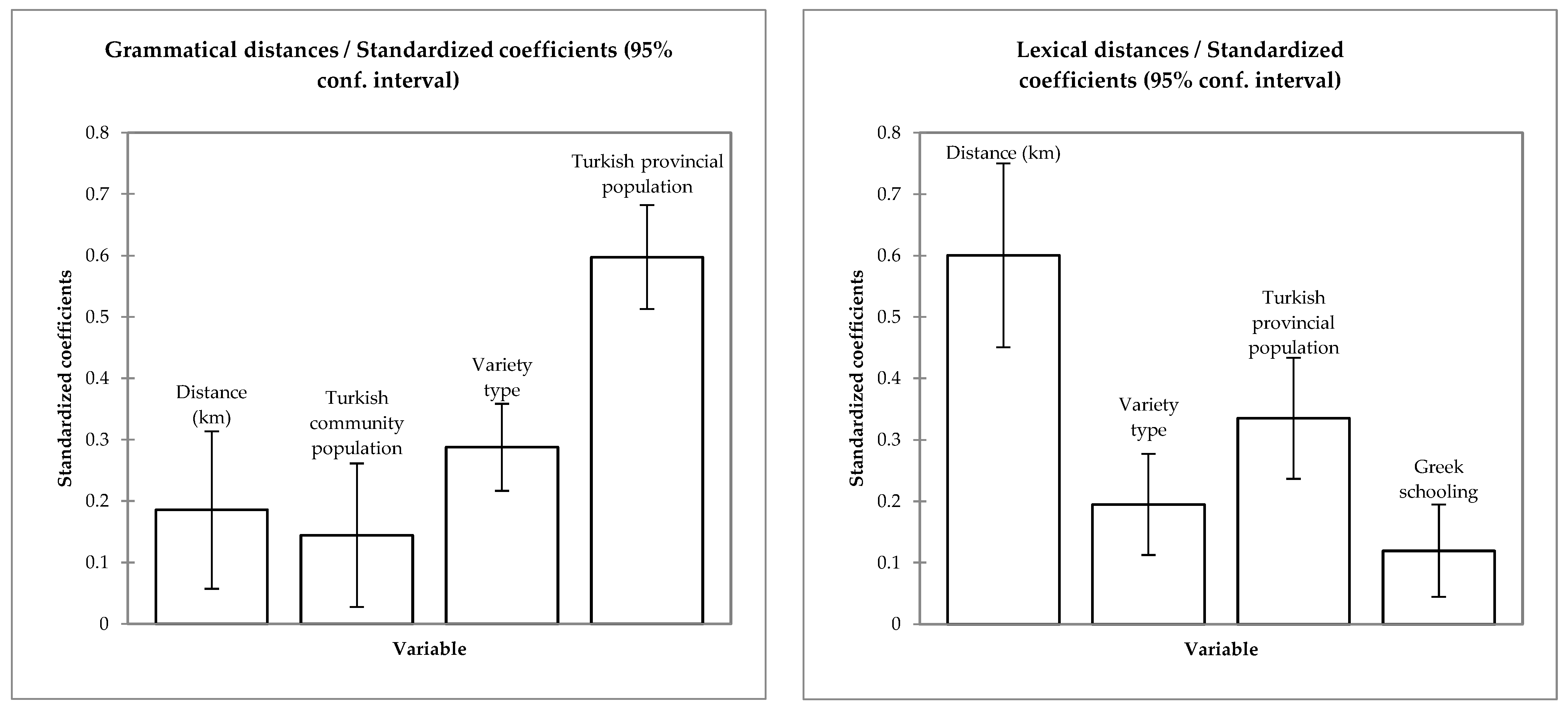
3.2. Multiple Regression on Distance Matrices
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | The FDP states that “geographically proximate varieties tend to be more similar than distant ones” (Nerbonne & Kleiweg, 2007, p. 154). |
| 2 | This paper investigates the Cappadocian, Pharasiot, and Silliot (sub)varieties of the iAMGr subgroup within the broader Asia Minor Greek dialect continuum (cf. Manolessou, 2019). The term ‘inner Asia Minor Greek’ (iAMGr) is used as a convenient cover term for these varieties in line with Kontosopoulos’ (1981/2008, pp. 6–10) without assuming a specific genetic affiliation among them in the exclusion of Pontic (Manolessou, 2019, pp. 20–21, 29–40), although belonging to the iAMGr group, which is not the focus of this study. |
| 3 | The underlying causes of language change in iAMGr have been a subject of debate among scholars. Some argue that language change is driven by inherent linguistic forces (e.g., Karatsareas, 2011). Others argue that language change is primarily the result of language contact (e.g., Thomason & Kaufman, 1988; Janse, 2001, 2019; Melissaropoulou, 2012; Melissaropoulou, 2016a, 2016b). According to this perspective, the main distinction lies in the source of the change. In contact-induced change, the source is the influence of another language, whereas, for language-internal change, the source is the structural asymmetries within a single linguistic system (Thomason, 2001, p. 86). The objective of this paper is not to take a stance in this debate but rather to examine the intricate interactions between the extralinguistic factors and the dialect distances. |
| 4 | Given this lack of evidence, more recent studies draw material from refugees’ interviews carried out between 1930 and 1975 in Greece (Theodoridi, 2017; Theodoridi & Karantzola, 2019; Karantzola et al., 2021). |
| 5 | The Greco-Turkish War (1920–1922) led to the end of the Greek presence in Asia Minor. In the aftermath of the war, the Convention Concerning the Exchange of Greek and Turkish Populations was signed by the Greek and Turkish governments in Lausanne (Switzerland) on 30 January 1923. This convention mandated a compulsory population exchange based on the religious affiliation of Turkish nationals of the Greek Orthodox faith residing in Turkey and Greek nationals of the Muslim faith residing in Greece. These individuals were prohibited from returning to live in Turkey or Greece, respectively, without authorization from their respective governments. Consequently, the Greek speakers of Asia Minor were displaced from their eastern homelands and relocated mainly to the newly acquired northern parts of Greece as refugees. |
| 6 | Lexical distances in this study refer to the variation observed at the level of lexical items, encompassing, among others, phonetic variants, morphophonological adaptations, and the integration of borrowings, while also including comparisons of both cognate and non-cognate items. This approach goes beyond simple measures of vocabulary overlap, such as Hamming distance, which is limited to binary comparisons based on specific lexical forms. By employing PMI Levenshtein distance, we effectively capture these variations by quantifying differences in the phonetic and morphophonological structure of lexical (and sub-lexical) items. This provides a precise measure of lexical variation that reflects the linguistic complexities of iAMGr. |
| 7 | As argued by Karatsareas (2020, pp. 184–185) present-day Modern Greek and Turkish, especially their standard forms, may not be the suitable reference varieties to compare when attempting to determine the causes of change observed in iAMG. What is more, Greek and Turkish were not the only languages constituting the so-called ‘(Graeco-)Anatolian Sprachbund’ (for an overview, see Donabedian & Sitaridou, 2021). Therefore, one would ideally want to compare the iAMGr data with data derived from varieties of Greek and Turkish that are closer to iAMGr from a historical and/or geographical perspective. However, the almost complete absence of texts written in iAMGr in dialectal Greek or Turkish in the period before the 19th century makes this type of comparison unfeasible. |
| 8 | We addressed the possibility of collinearity between the two population variables by employing the Mantel test to assess the correlation between their matrices. The results (r = −0.0005, p = 0.9871, α = 0.05) indicate no significant collinearity, affirming the independence of the variables. |
References
- Adamou, E. (2016). A corpus-driven approach to language contact: Endangered languages in a comparative perspective. De Gruyter. [Google Scholar] [CrossRef]
- Alektoridis, A. S. (1883). Λεξιλόγιον τοῦ Ἐν Φερτακαίνοις τῆς Καππαδοκίας γλωσσικοῦ Ἰδιώματος [Vocabulary of the linguistic variety spoken in Fertakena of Cappadocia]. Deltion Istorikis Ethnologikis Etaireias. [Google Scholar]
- Anastasiadis, V. K. (1976). Ἡ σύνταξη στὸ Φαρασιώτικο Ἰδίωμα τῆς Καππαδοκίας σὲ σύγκριση πρὸς τὰ Ὑπόλοιπα Ἰδιώματα τῆς Μικρᾶς Ἀσίας, καθὼς καὶ πρὸς τὴν Ἀρχαία, τὴ Μεσαιωνικὴ καὶ τὴ Νέα Ἑλληνικὴ γλῶσσα [Syntax in the Pharasiot variety of Cappadocia in comparison to the other varieties of Asia Minor, as well as to Ancient, Medieval, and Modern Greek language]. University of Ioannina. [Google Scholar]
- Bağrıaçık, M. (2018). Pharasiot Greek: Word order and clause structure [Ph.D. thesis, Ghent University]. [Google Scholar]
- Bloomfield, L. (1933). Language. Holt, Rinehart & Winston. [Google Scholar]
- Bompolas, S. (2023). Computational dialectology in the linguistic varieties of Cappadocian, Pharasiot, and Silliot [Ph.D. thesis, University of Patras]. [Google Scholar] [CrossRef]
- Bompolas, S., & Melissaropoulou, D. (2023a). A dialectometric approach to inner Asia Minor Greek: Comparisons and associations between linguistic levels. Digital Scholarship in the Humanities, 38(4), 1389–1403. [Google Scholar] [CrossRef]
- Bompolas, S., & Melissaropoulou, D. (2023b). A first dialectometric approach to contact-induced vs language-internal variation in inner Asia Minor Greek. Studies in Greek Linguistics, 42, 51–62. [Google Scholar]
- Britain, D. (2012). Varieties of English: Diffusion. In A. Bergs, & L. Brinton (Eds.), Handbücher zur sprach- und kommunikationswissenschaft [Handbooks of linguistics and communication science 34.2] (pp. 2031–2043). De Gruyter. [Google Scholar] [CrossRef]
- Chambers, J. K., & Trudgill, P. (1998). Dialectology (2nd ed.). Cambridge Textbooks in Linguistics. Cambridge University Press. [Google Scholar]
- Dawkins, R. M. (1916). Modern Greek in Asia minor: A study of the dialects of Sílli, Cappadocia and Phárasa with grammar, texts, translations and glossary. Cambridge University Press. [Google Scholar]
- Donabedian, A., & Sitaridou, I. (2021). Anatolia. In E. Adamou, & Y. Matras (Eds.), The Routledge handbook of language contact (1st ed., pp. 404–433). Series: Routledge handbooks in linguistics: Routledge. Routledge. [Google Scholar] [CrossRef]
- Farasopoulos, S. (1895). Τὰ Σύλατα. Μελέτη Τοῦ Νομοῦ Ἰκονίου Ὑπὸ Γεωγραφικήν, Φιλολογικὴν Καὶ Ἐθνολογικὴν Ἔποψιν [Sylata. A study of the region of Ikonio from a geographical, philological, and ethnological perspective]. Deligianni’s and Kalergis’ Print Shop. [Google Scholar]
- Foley, W. A. (2010). Language contact in the New Guinea region. In R. Hickey (Ed.), The handbook of language contact (1st ed., pp. 795–813). Wiley. [Google Scholar] [CrossRef]
- Goebl, H. (2006). Recent Advances in Salzburg Dialectometry. Literary and Linguistic Computing, 21(4), 411–435. [Google Scholar] [CrossRef]
- Goebl, H. (2017). Dialectometry. In C. Boberg, J. Nerbonne, & D. Watt (Eds.), The handbook of dialectology (1st ed., pp. 123–142). Wiley. [Google Scholar] [CrossRef]
- Gooskens, C. (2005). Travel time as a predictor of linguistic distance. Dig, 2005(13), 38–62. [Google Scholar] [CrossRef]
- Gooskens, C., & Heeringa, W. (2004). Perceptive evaluation of levenshtein dialect distance measurements using norwegian dialect data. Language Variation and Change, 3, 189–207. [Google Scholar] [CrossRef]
- Goslee, S. C. (2010). Correlation analysis of dissimilarity matrices. Plant Ecology, 206(2), 279–286. [Google Scholar] [CrossRef]
- Goslee, S. C., & Urban, D. L. (2007). The ecodist package for dissimilarity-based analysis of ecological data. Journal of Statistical Software, 22(7), i07. [Google Scholar] [CrossRef]
- Grenoble, L. A., & Whaley, L. J. (1998). Toward a typology of language endangerment. In L. A. Grenoble, & L. J. Whaley (Eds.), Endangered languages (1st ed., pp. 22–54). Cambridge University Press. [Google Scholar] [CrossRef]
- Grieve, J. (2014). A comparison of statistical methods for the aggregation of regional linguistic variation. In B. Szmrecsanyi, & B. Wälchli (Eds.), Aggregating dialectology, typology, and register analysis (pp. 53–88). De Gruyter. [Google Scholar] [CrossRef]
- Guillot, G., & Rousset, F. (2013). Dismantling the Mantel tests. Edited by Luke Harmon. Methods in Ecology and Evolution, 4(4), 336–344. [Google Scholar] [CrossRef]
- Heeringa, W. (2024). PMI Levenshtein distance. Available online: https://www.led-a.org/docs/PMI.pdf (accessed on 2 January 2025).
- Heeringa, W. J. (2004). Measuring dialect pronunciation differences using Levenshtein distance [Ph.D. thesis, University of Groningen]. [Google Scholar]
- Heeringa, W., Kleiweg, P., Gooskens, C., & Nerbonne, J. (2006). Evaluation of string distance algorithms for dialectology. In Proceedings of the workshop on linguistic distances (pp. 51–62). Association for Computational Linguistics. Available online: https://aclanthology.org/W06-1108 (accessed on 2 January 2025).
- Heeringa, W., Nerbonne, J., Niebaum, H., Nieuweboer, R., & Kleiweg, P. (2000). Dutch-German Contact in and around Bentheim. Studies in Slavic and General Linguistics, 28, 145–156. [Google Scholar]
- Heeringa, W., Nerbonne, J., & Osenova, P. (2010). Detecting contact effects in pronunciation. In M. Norde, B. de Jonge, & C. Hasselblatt (Eds.), IMPACT: Studies in language and society (Vol. 28, pp. 131–154). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Heeringa, W., & Prokić, J. (2017). Computational Dialectology. In C. Boberg, J. Nerbonne, & D. Watt (Eds.), The handbook of dialectology (1st ed., pp. 330–347). Wiley. [Google Scholar] [CrossRef]
- Heeringa, W., van Heuven, V., & Van de Velde, H. (2022, August 1–5). LED-A: A web app for measuring distances in the sound components among local dialects. Seventeenth International Conference on Methods in Dialectology (Methods XVII), Johannes Gutenberg-University Mainz, Mainz, Germany. Available online: https://www.led-a.org/slides.pdf (accessed on 2 January 2025).
- Heeringa, W., Van Heuven, V., & Van de Velde, H. (2023). LED-A: Levenshtein edit distance app [Computer Program]. Available online: https://www.led-a.org/ (accessed on 2 January 2025).
- Honkola, T., Ruokolainen, K., Syrjänen, K. J. J., Leino, U.-P., Tammi, I., Wahlberg, N., & Vesakoski, O. (2018). Evolution within a language: Environmental differences contribute to divergence of dialect groups. BMC Evolutionary Biology, 18(1), 132. [Google Scholar] [CrossRef]
- Huisman, J. L. A., Franco, K., & van Hout, R. (2021). Linking linguistic and geographic distance in four semantic domains: Computational geo-analyses of internal and external factors in a dialect continuum. Frontiers in Artificial Intelligence, 4, 668035. [Google Scholar] [CrossRef] [PubMed]
- ILIK. (2024). Ιστορικό Λεξικό Των Ιδιωμάτων Της Καππαδοκίας [Historical dictionary of Cappadocian varieties]. Athens Academy. [Google Scholar]
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An introduction to statistical learning: With applications in R [Springer texts in statistics]. Springer. [Google Scholar] [CrossRef]
- Janse, M. (2001). Morphological borrowing in Asia Minor. In International conference on Greek Linguistics, 4th, proceedings (pp. 473–479). University Studio Press. [Google Scholar]
- Janse, M. (2008). Clitic Doubling from ancient to Asia Minor Greek. In D. Kallulli, & L. Tasmowski (Eds.), Linguistik aktuell/Linguistics today (Vol. 130, pp. 165–202). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Janse, M. (2019). Agglutinative noun inflection in Cappadocian. In A. Ralli (Ed.), The morphology of Asia Minor Greek (pp. 66–115). Brill. [Google Scholar] [CrossRef]
- Jeszenszky, P., Hikosaka, Y., Imamura, S., & Yano, K. (2019). Japanese lexical variation explained by spatial contact patterns. ISPRS International Journal of Geo-Information, 8(9), 400. [Google Scholar] [CrossRef]
- Jeszenszky, P., Stoeckle, P., Glaser, E., & Weibel, R. (2017). Exploring global and local patterns in the correlation of geographic distances and morphosyntactic variation in Swiss German. Journal of Linguistic Geography, 5(2), 86–108. [Google Scholar] [CrossRef]
- Karantzola, T., Theodoridi, A., & Sampanis, K. (2021). The interplay of external and sociolinguistic factors in contact-induced language change: Cappadocian Greek as a case study. Mediterranean Language Review, 28, 21. [Google Scholar] [CrossRef]
- Karasimos, A., Manolessou, I., & Melissaropoulou, D. (2020). Creating a DTD template for Greek dialectal lexicography: The case of the historical dictionary of the Cappadocian dialect. In Z. Gavriilidou, M. Mitsiaki, & A. Fliatouras (Eds.), Lexicography for inclusion: Proceedings of the 19th EURALEX international congress, 7–9 September 2021, Alexandro upolis (Vol. 1, pp. 305–314). Democritus University of Thrace. Available online: https://www.euralex.org/elx_proceedings/Euralex2020-2021/EURALEX2020-2021_Vol1-p305-314.pdf (accessed on 2 January 2025).
- Karatsareas, P. (2011). A study of Cappadocian Greek nominal morphology from a diachronic and dialectological perspective [Ph.D. thesis, University of Cambridge]. [Google Scholar] [CrossRef]
- Karatsareas, P. (2020). The development, preservation and loss of differential case marking in inner Asia Minor Greek. Journal of Language Contact, 13(1), 177–226. [Google Scholar] [CrossRef]
- Kholopoulos, S. (1905). Μονογραφική Ἱστορία Ζήλης ἢ Σύλατας [Monographic history of Zili or Sylata]. Xenophánis, II, 92–96. [Google Scholar]
- Kitromilidis, P., & Mourelos, G. (Eds.). (1982). H Έξοδος, Τόμος Β. Μαρτυρίες Aπό Τις Επαρχίες Της Κεντρικής Και Νότιας Μικρασίας [The Exodus, volume b. Testimonies from the provinces of Central and Southern Asia Minor]. Kentro Mikrasiatikōn Spoudōn. [Google Scholar]
- Kontosopoulos, N. (2008). Διάλεκτοι Καὶ Ἰδιώματα Τῆς Νέας Ἑλληνικῆς [Dialects and idioms of Modern Greek]. Grigoris. (Original work published 1981). [Google Scholar]
- Kortmann, B. (2013). How powerful is geography as an explanatory factor in morphosyntactic variation? Areal features in the anglophone world. In P. Auer, M. Hilpert, A. Stukenbrock, & B. Szmrecsanyi (Eds.), Space in language and linguistics (pp. 165–194). De Gruyter. [Google Scholar] [CrossRef]
- Leinonen, T., Çöltekin, Ç., & Nerbonne, J. (2016). Using Gabmap. Lingua, 178, 71–83. [Google Scholar] [CrossRef]
- Lichstein, J. W. (2007). Multiple regression on distance matrices: A multivariate spatial analysis tool. Plant Ecology, 188(2), 117–131. [Google Scholar] [CrossRef]
- List, J.-M. (2019). Automated Methods for the Investigation of Language Contact, with a Focus on Lexical Borrowing. Language and Linguistics Compass, 13(10), e12355. [Google Scholar] [CrossRef]
- Logotheti-Merlier, M. (1977). Oι Ελληνικές Κοινότητες Στη Σύγχρονη Καππαδοκία [The Greek communities in Modern Cappadocia]. Bulletin of the Centre for Asia Minor Studies, 1, 29–74. [Google Scholar] [CrossRef]
- Manolessou, I. (2019). The Historical Background of the Asia Minor Dialects. In A. Ralli (Ed.), The morphology of Asia Minor Greek (pp. 20–65). Brill. [Google Scholar] [CrossRef]
- Manolessou, I., Karasimos, A., & Katsouda, G. (2022). Retro-digitization in Greek dialectology and lexicography: Challenges of morpho-phonetic representation of the Cappadocian dialect. Modern Greek Dialects and Linguistics Theory, 9, 322–336. [Google Scholar]
- Mantel, N. (1967). The detection of disease clustering and a generalized regression approach. Cancer Research, 27(2), 209–220. [Google Scholar] [PubMed]
- Melissaropoulou, D. (2012). Reorganization of grammar in the light of the language contact factor: A case study on Grico and Cappadocian. Modern Greek Dialects and Linguistics Theory, 5, 311–334. [Google Scholar] [CrossRef]
- Melissaropoulou, D. (2016a). Loanwords integration as evidence for the realization of gender and inflection class: Greek in Asia Minor. In A. Ralli (Ed.), Contact morphology in modern Greek dialects (pp. 145–177). Cambridge Scholars Publishing. [Google Scholar]
- Melissaropoulou, D. (2016b). Variation in word formation in situations of language contact: The case of Cappadocian Greek. Language Sciences, 55, 55–67. [Google Scholar] [CrossRef]
- Melissaropoulou, D. (2024). Γλωσσικός Άτλαντας Των Διαλεκτικών Ποικιλιών Της Καππαδοκίας (5 Τόμ.) [Linguistic atlas of the dialectal varieties of Cappadocia] (Vol. 5). Academy of Athens. [Google Scholar]
- Melissaropoulou, D., & Bompolas, S. (2022). Μια Υπολογιστική Γεωγλωσσολογική Προσέγγιση Στις Γλωσσικές Ποικιλίες Της Καππαδοκίας [A computational geolinguistic approach to the linguistic varieties of Cappadocia]. Modern Greek Dialects and Linguistics Theory, 9, 221–244. [Google Scholar] [CrossRef]
- Melissaropoulou, D., Bompolas, S., & Tsimpouris, C. (2022). Digital cartography in the service of preservation of cultural linguistic heritage: Implementing the electronic dialectal atlas of Cappadocian Greek. Scientific Culture, 8(2), 135–146. [Google Scholar] [CrossRef]
- Nerbonne, J. (2010). Measuring the diffusion of linguistic change. Philosophical Transactions of the Royal Society B: Biological Sciences, 365(1559), 3821–3828. [Google Scholar] [CrossRef]
- Nerbonne, J. (2013). How much does geography influence language variation? In P. Auer, M. Hilpert, A. Stukenbrock, & B. Szmrecsanyi (Eds.), Space in language and linguistics (pp. 222–239). De Gruyter. [Google Scholar] [CrossRef]
- Nerbonne, J., & Heeringa, W. (2001). Computational comparison and classification of dialects. Dig, 2001(9), 69–84. [Google Scholar] [CrossRef]
- Nerbonne, J., & Heeringa, W. (2007). Geographic distributions of linguistic variation reflect dynamics of differentiation. Studies in Generative Grammar, 96, 267–298. [Google Scholar]
- Nerbonne, J., & Kleiweg, P. (2003). Lexical distance in LAMSAS. Computers and the Humanities, 37(3), 339–357. [Google Scholar] [CrossRef]
- Nerbonne, J., & Kleiweg, P. (2007). Toward a dialectological yardstick. Journal of Quantitative Linguistics, 14(2–3), 148–166. [Google Scholar] [CrossRef]
- Nerbonne, J., & Wieling, M. (2017). Statistics for aggregate variationist analyses. In C. Boberg, J. Nerbonne, & D. Watt (Eds.), The Handbook of dialectology (1st ed., pp. 400–414). Wiley. [Google Scholar] [CrossRef]
- Nerbonne, J., Colen, R., Gooskens, C. S., Leinonen, T., & Kleiweg, P. (2011). Gabmap—A web application for dialectology. Dialectologia, SI II, 65–89. [Google Scholar]
- Prokić, J., & Nerbonne, J. (2008). Recognising groups among dialects. International Journal of Humanities and Arts Computing, 2(1–2), 153–172. [Google Scholar] [CrossRef]
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 2 January 2025).
- Sarantidis, A. I. (1899). Ἡ Σινασός, Ἤτοι Θέσις, Ἱστορία, Ἠθικὴ Καὶ Διανοητικὴ Κατάστασις, Ἤθη, Ἔθιμα Καὶ Γλῶσσα Τῆς Ἐν Καππαδοκίᾳ Κωμοπόλεως Σινασοῦ. Ἐν Ἐπιμέτρῳ Δὲ Καὶ Σύντομος Περιγραφὴ Τῶν Ἐν Ταῖς Ἐπαρχίαις Καισαρείας Καὶ Ἰκονίου Ἑλληνικῶν Κοινοτήτων Ὡς Καὶ Τῶν Ἐν Aὐταῖς Σῳζομένων Ἑλληνικῶν Διαλέκτων Ἐν Σχέσει Πρὸς Τὴν Ἐν Σινασῷ Λαλουμένην [Sinasos, or the position, history, ethical and intellectual state, customs, traditions, and language of the town of Sinasos in Cappadocia. Additionally, a brief description of the Greek communities in the provinces of Caesarea and Iconium, as well as the preserved Greek dialects spoken in them in relation to the dialect spoken in Sinasos]. Ioannis Nikolaidis. [Google Scholar]
- Scherrer, Y., & Stoeckle, P. (2016). A quantitative approach to Swiss German—Dialectometric Analyses and comparisons of linguistic levels. Dialectologia et Geolinguistica, 24(1), 92–125. [Google Scholar] [CrossRef]
- Séguy, J. (1971). La relation entre la distance spatiale et la distance lexicale. Imprimerie Protat Frères. [Google Scholar] [CrossRef]
- Shackleton, R. G. (2005). English-American speech relationships: A quantitative approach. Journal of English Linguistics, 33(2), 99–160. [Google Scholar] [CrossRef]
- Shackleton, R. G. (2007). Phonetic variation in the traditional English dialects: A computational analysis. Journal of English Linguistics, 35(1), 30–102. [Google Scholar] [CrossRef]
- Smouse, P. E., Long, J. C., & Sokal, R. R. (1986). Multiple regression and correlation extensions of the Mantel test of matrix correspondence. Systematic Zoology, 35(4), 627. [Google Scholar] [CrossRef]
- Snoek, C. (2014). Review of Gabmap: Doing dialect analysis on the web. Language Documentation & Conservation, 8, 192–208. [Google Scholar]
- Sousa, X., & García, F. D. (2020). Measuring language contact in geographical space—Sprachkontakt im geographischen raum messen. Zeitschrift Für Dialektologie Und Linguistik, 87(2), 285–306. [Google Scholar] [CrossRef]
- Spruit, M. R., Heeringa, W., & Nerbonne, J. (2009). Associations among linguistic levels. Lingua, 119(11), 1624–1642. [Google Scholar] [CrossRef]
- Stanford, J. N. (2012). One size fits all? Dialectometry in a small clan-based indigenous society. Language Variation and Change, 24(2), 247–278. [Google Scholar] [CrossRef]
- Szmrecsanyi, B. (2012). Geography is overrated. In S. Hansen, C. Schwarz, P. Stoeckle, & T. Streck (Eds.), Dialectological and folk dialectological concepts of space (pp. 215–231). De Gruyter. [Google Scholar] [CrossRef]
- Theodoridi, A. (2017). Καππαδοκικές Διάλεκτοι και Φαρασιωτική: Κοινωνιογλωσσικά και Δομικά Στοιχεία της Γλωσσικής Επαφής τους με την Τουρκική [Cappadocian dialects and Pharasiot: Sociolinguistic and structural elements of their linguistic contact with turkish] [Ph.D. thesis, University of Aegean]. [Google Scholar] [CrossRef]
- Theodoridi, A., & Karantzola, E. (2019). Επαφή Των Καππαδοκικών Διαλέκτων Με Την Τουρκική: Τα Πεδία Της Εκπαίδευσης Και Της Θρησκείας [Contact of Cappadocian dialects with Turkish: The fields of education and religion]. In C. Tzitzilis, & G. Papanastasiou (Eds.), Language contact in the Balkans and Asia Minor (Vol. 1, pp. 92–110). Institute of Modern Greek Studies [Manolis Triandaphyllidis Foundation]. [Google Scholar]
- Thomason, S. (2008). Social and linguistic factors as predictors of contact-induced change. Journal of Language Contact, 2(1), 42–56. [Google Scholar] [CrossRef]
- Thomason, S. G. (2001). Language contact. Edinburgh Univ. Press. [Google Scholar]
- Thomason, S. G., & Kaufman, T. (1988). Language contact, creolization, and genetic linguistics. University of California Press. [Google Scholar]
- Trudgill, P. (1974). Linguistic change and diffusion: Description and explanation in sociolinguistic dialect geography. Language in Society, 3(2), 215–246. [Google Scholar] [CrossRef]
- Trudgill, P. (1986). Dialects in contact. B. Blackwell. [Google Scholar]
- Vittinghoff, E., Glidden, D. V., Shiboski, S. C., & McCulloch, C. E. (2012). Regression methods in biostatistics: Linear, logistic, survival, and repeated measures models (Statistics for biology and health). Springer. [Google Scholar] [CrossRef]
- Wieling, M. B. (2012). A quantitative approach to social and geographical dialect variation [Ph.D. thesis, University of Groningen]. [Google Scholar]
- Wieling, M., & Nerbonne, J. (2015). Advances in dialectometry. Annual Review of Linguistics, 1(1), 243–264. [Google Scholar] [CrossRef]
- Wieling, M., Montemagni, S., Nerbonne, J., & Baayen, R. H. (2014). Lexical differences between Tuscan dialects and standard Italian: Accounting for geographic and sociodemographic variation using generalized additive mixed modeling. Language, 90(3), 669–692. [Google Scholar] [CrossRef]
- Wieling, M., Valls, E., Baayen, R. H., & Nerbonne, J. (2018). Border effects among Catalan dialects. In D. Speelman, K. Heylen, & D. Geeraerts (Eds.), Mixed-effects regression models in linguistics (pp. 71–97). Quantitative methods in the humanities and social sciences. Springer International Publishing. [Google Scholar] [CrossRef]
- Wolfram, W., & Schilling-Estes, N. (2017). Dialectology and linguistic diffusion. In B. D. Joseph, & R. D. Janda (Eds.), The handbook of historical linguistics (pp. 713–735). Blackwell Publishing Ltd. [Google Scholar] [CrossRef]
- Yakpo, K. (2021). Social factors. In E. Adamou, & Y. Matras (Eds.), The Routledge handbook of language contact (1st ed., pp. 129–146). Series: Routledge handbooks in linguistics: Routledge. Routledge. [Google Scholar] [CrossRef]
- Zhang, L., Fabri, R., Nerbonne, J., & Nerbonne, J. (2021). Detecting loan words computationally. In E. O. Aboh, & C. B. Vigouroux (Eds.), Contact language library (Vol. 59, pp. 269–288). John Benjamins Publishing Company. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grammatical Domain | Type of Data | Sum of Features in Group | % of Total Features | |
|---|---|---|---|---|
| Phonetics—(Morpho)phonology | Vowels | Categorical | 19 | 4.43% |
| Consonants | 24 | 5.59% | ||
| Stress | 1 | 0.23% | ||
| Morphophonology | 5 | 1.17% | ||
| Morphology | Articles | 27 | 6.29% | |
| Gender | 16 | 3.73% | ||
| Nominal Morphology | 68 | 15.85% | ||
| Pronouns | String | 103 | 24.01% | |
| Numerals | 34 | 7.93% | ||
| Verbal Morphology | Categorical | 61 | 14.22% | |
| Derivational Morphology | 5 | 1.17% | ||
| (Morpho)syntax | Verb Morphosyntax | 3 | 0.70% | |
| Noun Phrase | 25 | 5.83% | ||
| Verb Phrase | 7 | 1.63% | ||
| Adverbial Phrase | 2 | 0.47% | ||
| Comparative Structures | 4 | 0.93% | ||
| Sentence | 25 | 5.83% | ||
| Setting Level | Extra-Linguistic Variable |
|---|---|
| Local | Number of Turkish-speaking people within the community |
| Distance between communities | |
| Regional | Variety type (high-/low-contact variety; based on Dawkins’ dialectal division) |
| Number of Turkish-speaking people within the province | |
| Distance between communities and urban centers within the province | |
| National | Contact with/migration to Constantinople |
| Extra-national | Presence/absence of (semi-)organized Greek school |
| Province | Center | Greek-Orthodox Communities | Language |
|---|---|---|---|
| Pharasa | Pharasa | Pharasa | Pharasiot |
| Pharasa colonies | Kiska | Tshukuri, Fkosi, Sati, Ashar-köi, Kiska | |
| Kurumza (Ghariptsas), Beskardas, Tastsi, Khostsa | Turkish | ||
| Iconium | Iconium | Silli | Silliot |
| Neapoli | Neapoli | Anaku, Arabison, Dila, Malakopi, Silata, Phloïta | Cappadocian |
| Neapoli | Turkish | ||
| Nigdi | Nigdi | Axo, Aravan, Ghurzono, Misti, Ulaghatsh, Semendere, T’ Axenu to khorio, Delmeso, Trokho, Tsharakly, Fertek | Cappadocian |
| Andaval, Enekhil, Iloson, Kitsaghats, Limna/Limnos, Matala, Nigdi, Poros, Sazaldza, Suludzova, Teneï | Turkish | ||
| Prokopi | Prokopi | Potamia, Sinasos, Zalela | Cappadocian |
| Prokopi | Turkish |
| Variables | VIF |
|---|---|
| Distances (km) | 4.33 |
| Turkish community population | 3.61 |
| Variety type | 1.32 |
| Turkish regional population | 1.88 |
| Greek schooling | 1.10 |
| Lexical Distances | Grammatical Distances | |||
|---|---|---|---|---|
| Estimate | p | Estimate | p | |
| Intercept | 0.00 | <0.0001 | 0.00 | <0.0001 |
| Geographic Distance (km) | 0.60 | <0.0001 | 0.19 | <0.0001 |
| Variety Type | 0.19 | <0.0001 | 0.29 | <0.0001 |
| Turkish Population in the Communities | −0.10 | 0.16 | 0.14 | 0.02 |
| Turkish Population in the Provinces | 0.34 | <0.0001 | 0.60 | <0.0001 |
| Greek Schooling | 0.12 | <0.0001 | 0.02 | 0.57 |
| R2 | 0.78 | 0.84 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bompolas, S.; Melissaropoulou, D. Understanding Dialectal Variation in Contact Scenarios Through Dialectometry: Insights from Inner Asia Minor Greek. Languages 2025, 10, 13. https://doi.org/10.3390/languages10010013
Bompolas S, Melissaropoulou D. Understanding Dialectal Variation in Contact Scenarios Through Dialectometry: Insights from Inner Asia Minor Greek. Languages. 2025; 10(1):13. https://doi.org/10.3390/languages10010013
Chicago/Turabian StyleBompolas, Stavros, and Dimitra Melissaropoulou. 2025. "Understanding Dialectal Variation in Contact Scenarios Through Dialectometry: Insights from Inner Asia Minor Greek" Languages 10, no. 1: 13. https://doi.org/10.3390/languages10010013
APA StyleBompolas, S., & Melissaropoulou, D. (2025). Understanding Dialectal Variation in Contact Scenarios Through Dialectometry: Insights from Inner Asia Minor Greek. Languages, 10(1), 13. https://doi.org/10.3390/languages10010013