1. Introduction
The aircraft anti-skid braking system (AABS) is an essential airborne utilities system to ensure the safe and smooth landing of aircraft [
1]. With the development of aircraft towards high speed and large tonnage, the performance requirements of AABS are increasing. Moreover, AABS is a complex system with strong nonlinearity, strong coupling, and time-varying parameters, and is sensitive to the runway environment [
2]. These characteristics make AABS controller design an interesting and challenging topic.
The most widely used control method in practice is PID + PBM, which is a speed differential control law. However, it suffers from low-speed slipping and underutilization of ground bonding forces, making it difficult to meet high performance requirements. To this end, researchers have proposed many advanced control methods to improve the AABS performance, such as mixed slip deceleration PID control [
3], model predictive control [
4], extremum-seeking control [
5], sliding mode control [
6], reinforcement Q-learning control [
7], and so on. Zhang et al. [
8] proposed a feedback linearization controller with a prescribed performance function to ensure the transient and steady-state braking performance. Qiu et al. [
9] combined backstepping dynamic surface control with an asymmetric barrier Lyapunov function to obtain a robust tracking response in the presence of disturbance and runway surface transitions. Mirzaei et al. [
10] developed a fuzzy braking controller optimized by a genetic algorithm and introduced an error-based global optimization approach for fast convergence near the optimum point. The above-mentioned works provide an in-depth study on AABS control; however, the adverse effects caused by typical component faults such as actuator faults are neglected. Since most AABS are designed based on hydraulic control systems, the long hydraulic pipes create an enormous risk of air mixing with oil, and internal leakage. Without regular maintenance, it is easy to cause functional degradation or even failure, which raises many security concerns [
11,
12]. How to ensure the stability and the acceptable braking performance of AABS after actuator faults becomes a key issue.
In order to actually improve the safety and reliability of AABS, the fault probability can be reduced by reliability design and redundant technology on the one hand [
13]. However, due to the production factors (cost/weight/technological level), the redundancy of aircraft components is so limited that the system reliability is hard to increase. On the other hand, fault-tolerant control (FTC) technology can be introduced into the AABS controller design, which is the future development direction of AABS and the key technology that needs urgent attention [
14]. Reconfiguration control is a popular branch of FTC that has been widely used in many safety-critical systems, especially in aerospace engineering [
15,
16]. The essence of reconfiguration control is to consider the possible faults of the plant in the controller design process. When component faults occur, the fault system information is used to reconfigure the controller structure or parameters automatically [
17]. In this way, the adverse effects caused by faults can be restrained or eliminated, thus realizing an asymptotically stable and acceptable performance of the closed-loop system. A number of common reconfiguration control methods can be classified as follows: adaptive control [
18,
19], multi-model switching control [
20], sliding mode control [
21], fuzzy control [
22], other robust control [
23], etc. In addition, the characteristics of AABS increase the difficulty of accurate modeling, and many nonlinear reconfiguration control methods are complex and relatively hard to apply in engineering. Therefore, it is crucial to design a reconfiguration controller with a clear structure, and which is model-independent, strong fault-perturbation resistant, and easy to implement.
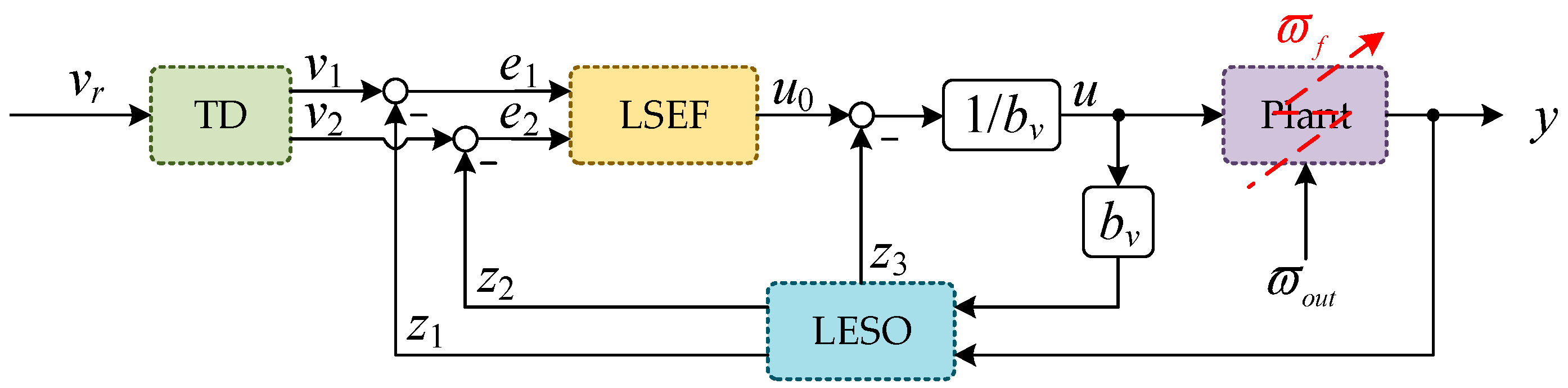
Han retained the essence of PID control and proposed an active disturbance rejection control (ADRC) technique that requires low model accuracy and shows good control performance [
24]. ADRC can estimate disturbances in internal and external systems and compensate for them [
25]. Furthermore, ADRC has been widely used in FTC system design because of its obvious advantages in solving control problems of nonlinear models with uncertainty and strong disturbances [
26,
27,
28]. Although the structure is not difficult to implement with modern digital computer technology, ADRC needs to tune a bunch of parameters which makes it hard to use in practice [
29]. To overcome the difficulty, Gao proposed linear active disturbance rejection control (LADRC), which is based on linear extended state observer (LESO) and linear state error feedback (LSEF) [
30,
31]. The bandwidth tuning method greatly reduced the number of LADRC parameters. LADRC has been applied to solve various control problems [
32,
33,
34].
However, it is well known that a controller with fixed parameters may not be able to maintain the acceptable (rated or degraded) performance of a fault system. For this reason, some advanced algorithms with parameter adaptive capabilities have been introduced by researchers that further improve the robustness and environmental adaptability of ADRC, such as neural networks [
35,
36], fuzzy logic [
37,
38], and the sliding mode [
39,
40]. With the development of artificial intelligence techniques, reinforcement learning has been applied to control science and engineering [
41,
42], and good results have been achieved. Yuan et al. proposed a novel online control algorithm for a thickener which is based on reinforcement learning [
43]. Pang et al. studied the infinite-horizon adaptive optimal control of continuous-time linear periodic systems, using reinforcement learning techniques [
44]. A Q-learning-based adaptive method for ADRC parameters was proposed by Chen et al. and has been applied to the ship course control [
45].
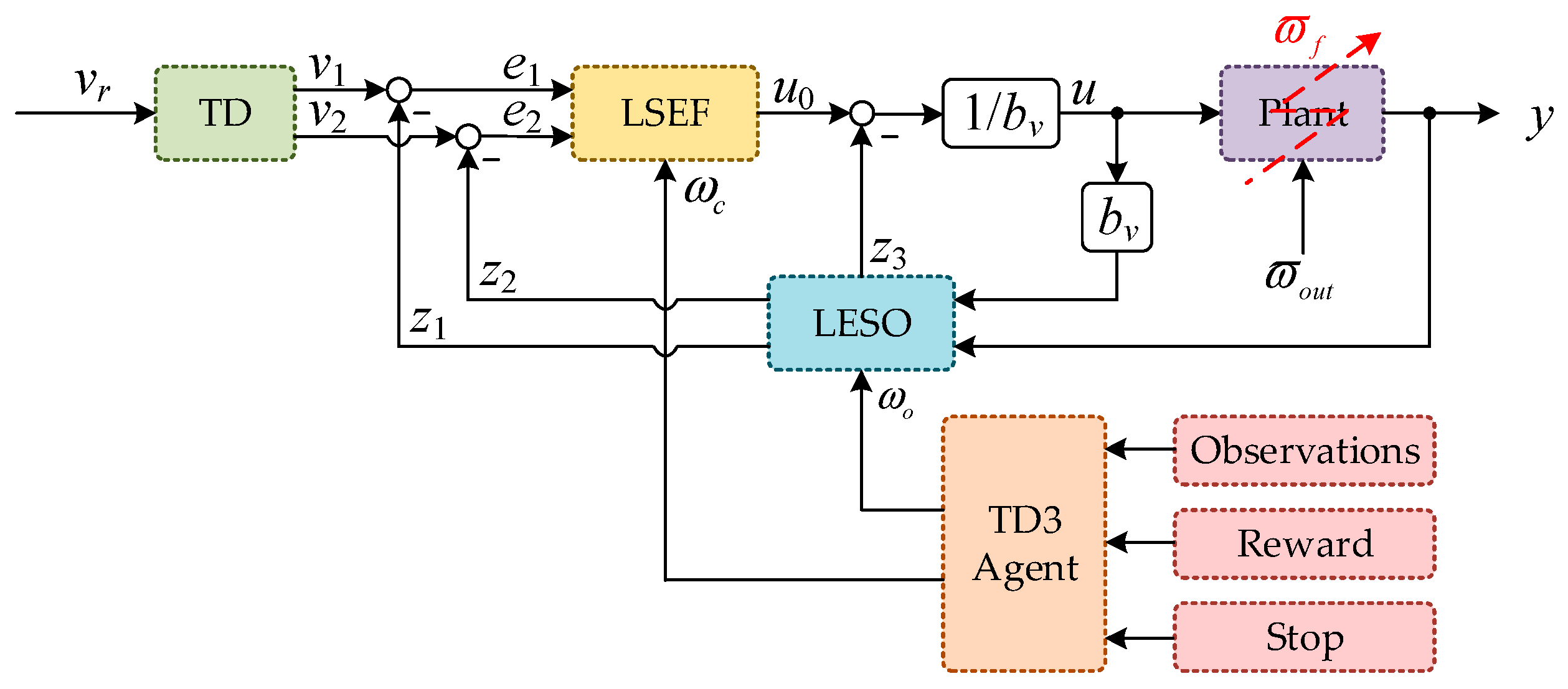
Motivated by the above observations, in this paper, a reconfiguration control scheme via LADRC combined with deep reinforcement learning was developed for AABS which is subject to various fault perturbations. The proposed reconfiguration control method is a remarkable control strategy compared to previous methods for three reasons:
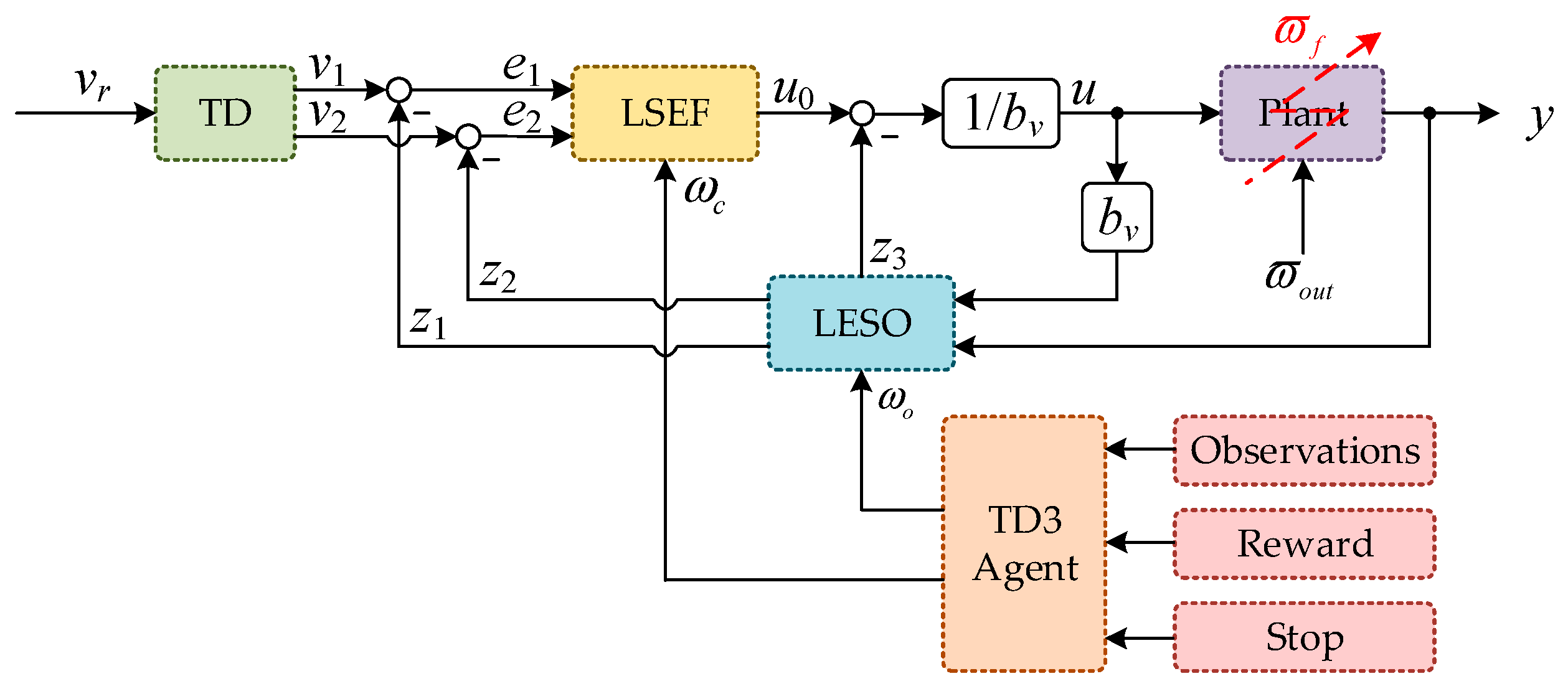
(1) AABS is extended with a new state variable, which is the sum of all unknown dynamics and disturbances not noticed in the fault-free system description. This state variable can be estimated using LESO. It indirectly simplifies the AABS modeling;
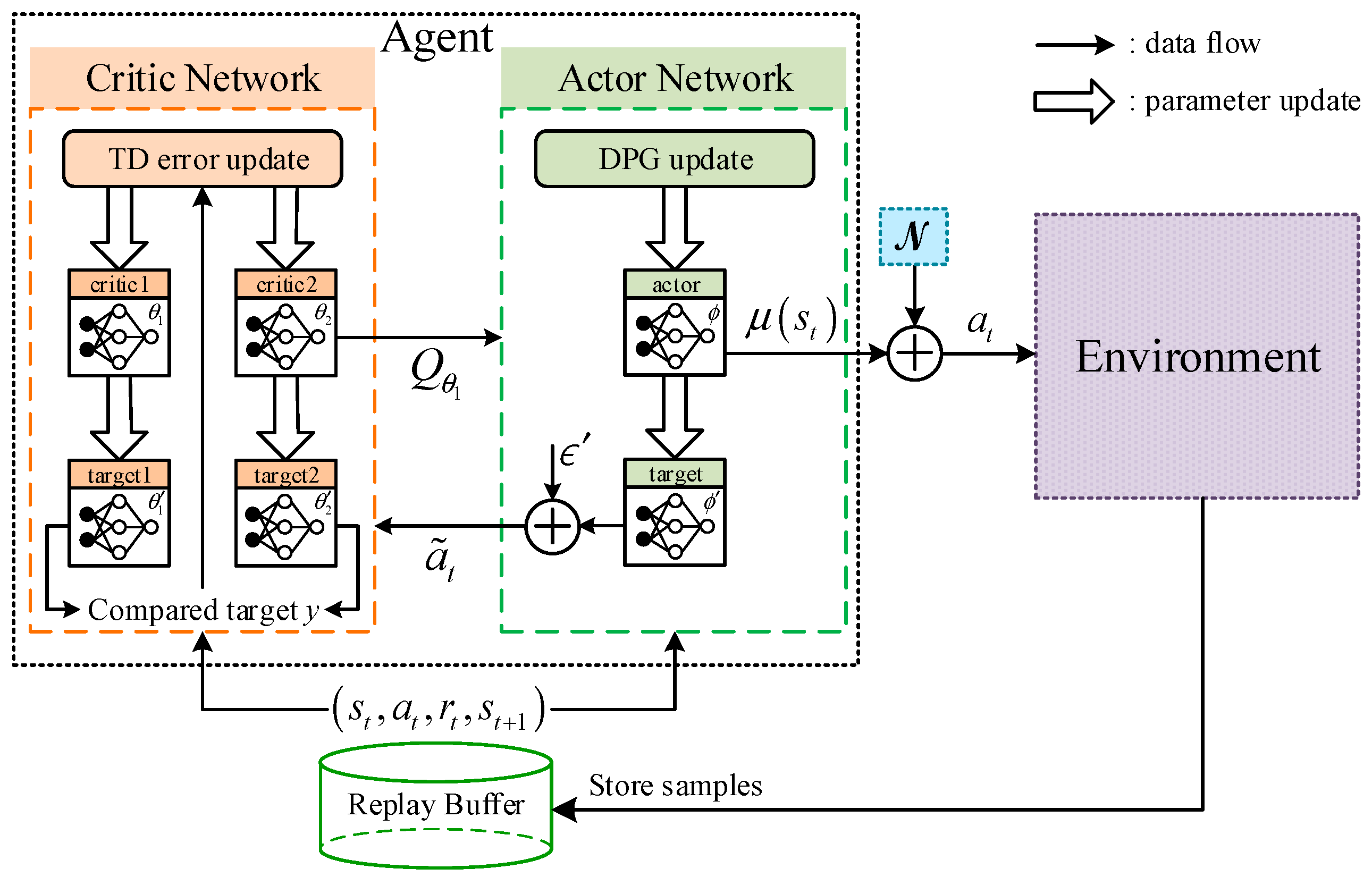
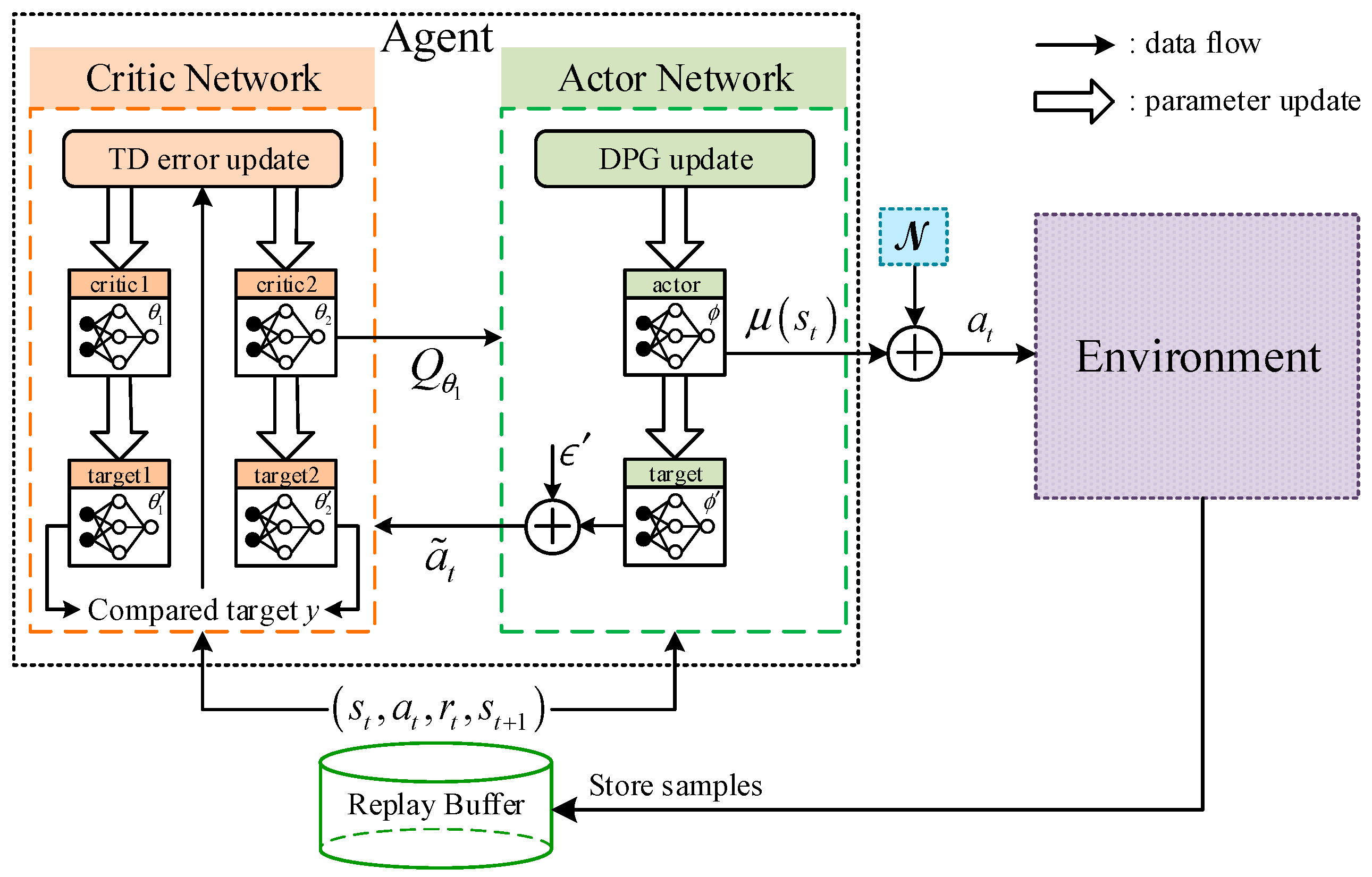
(2) Artificial intelligence technology is introduced and combined with the traditional control method to solve special control problems. By combining LADRC with the deep reinforcement learning TD3 algorithm, the selection of controller parameters is equivalent to the choice of agent actions. The parameter adaptive capabilities of LESO and LSEF are endowed through the continuous interaction between the agent and the environment, which not only eliminates the tedious manual tuning of the parameters, but also results in more accurate estimation and compensation for the adverse effects of fault perturbations;
(3) It is a data-driven robust control strategy that does not require any additional fault detection or identification (FDI) module, while the controller parameters are adaptive. Therefore, the proposed method corresponds to a novel combination of active reconfiguration control and FDI-free reconfiguration control, which makes it an interesting solution under unknown fault conditions.
The paper is organized as follows.
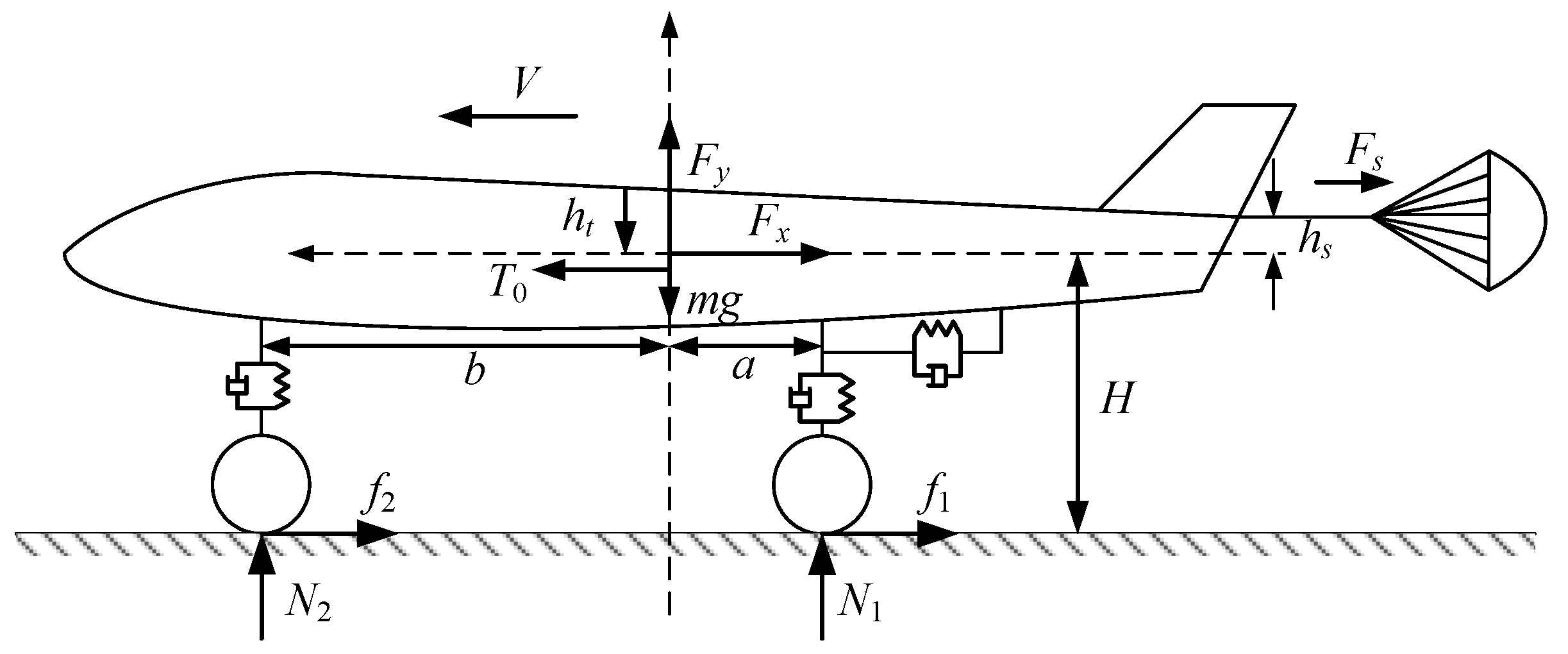
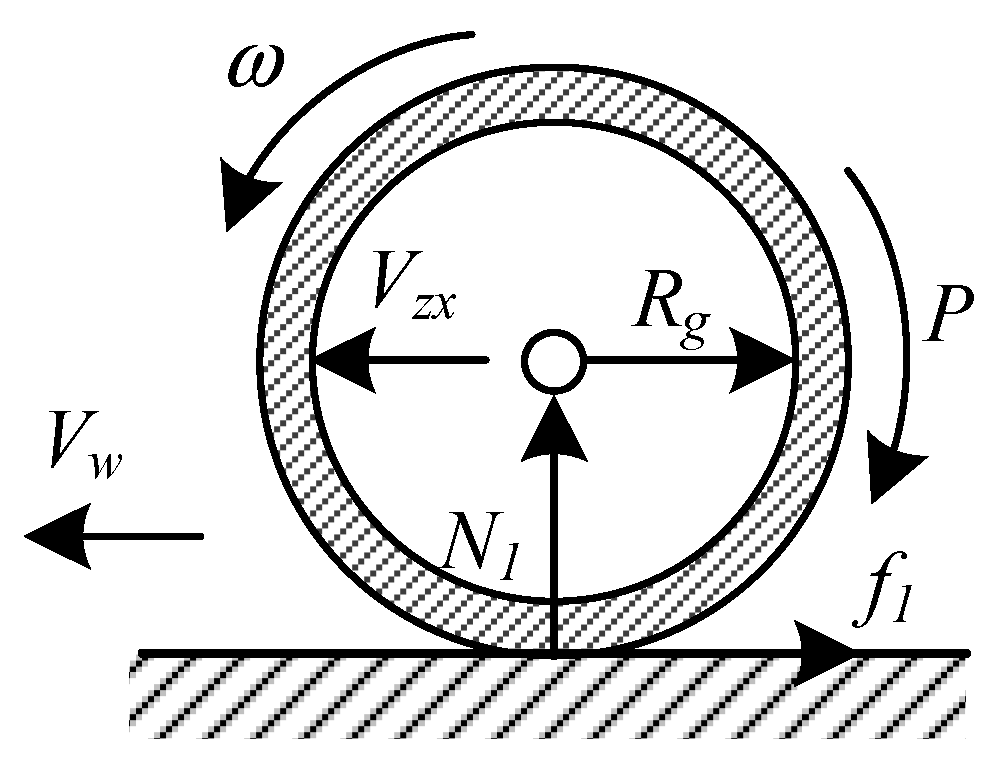
Section 2 describes AABS dynamics with an actuator fault factor. The reconfiguration controller is presented in
Section 3. The simulation results are presented to demonstrate the merits of the proposed method in
Section 4, and conclusions are drawn in
Section 5.
4. Simulation Results
In order to verify the reconfiguration capability and disturbance rejection capabilities of the proposed method, the corresponding simulations are carried out in this section and compared with conventional PID + PBM and LADRC.
The initial states of the aircraft are set as follows:
- (1)
The initial speed of aircraft landing ;
- (2)
The initial height of the center of gravity .
To prevent deep wheel slippage as well as tire blowout, the wheel speed was kept following the aircraft speed quickly at first, and the brake pressure was applied only after 1.5 s. The anti-skid brake control was considered to be over when was less than 2 m/s.
In the experiment, both the critic networks and the actor networks were realized by a fully connected neural network with three hidden layers. The number of neurons in the hidden layer was (50,25,25). The activation function of the hidden layer was selected as the ReLU function, and the activation function of the output layer of the actor network was selected as the tanh function. In addition, the parameters of the actor network and the critic network were tuned by an Adam optimizer. The remaining parameters of TD3-LADRC are shown in
Table 7.
Remark 5. It is noted that the braking time t and braking distance x are selected as the criteria for braking efficiency, and the system stability is observed by slip rate .
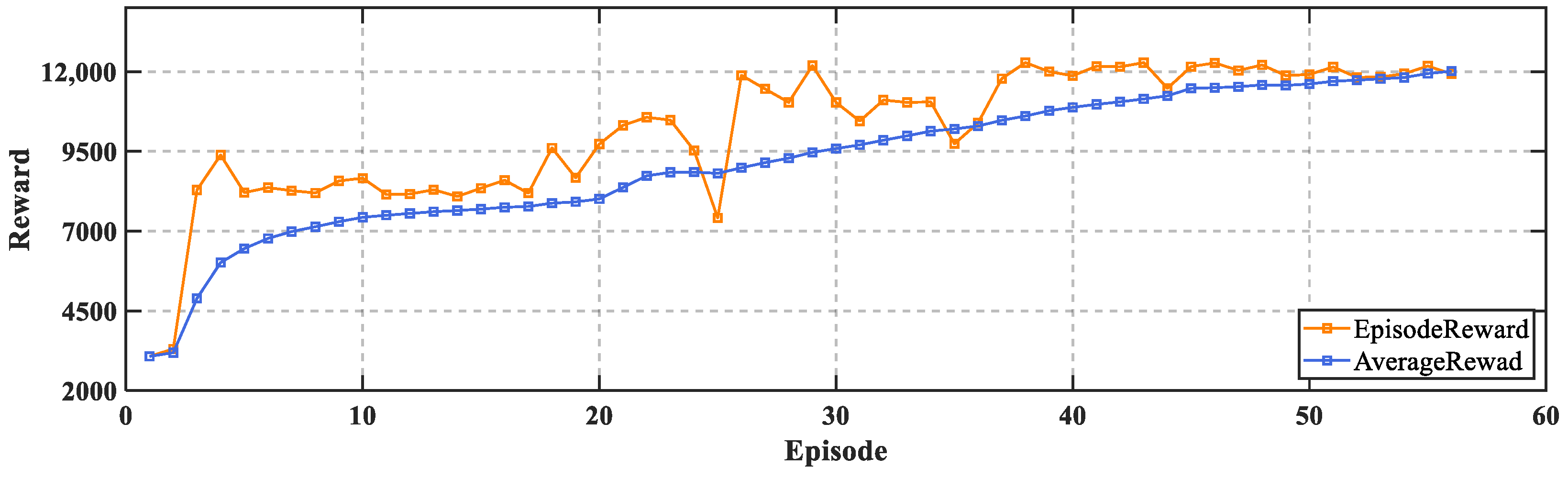
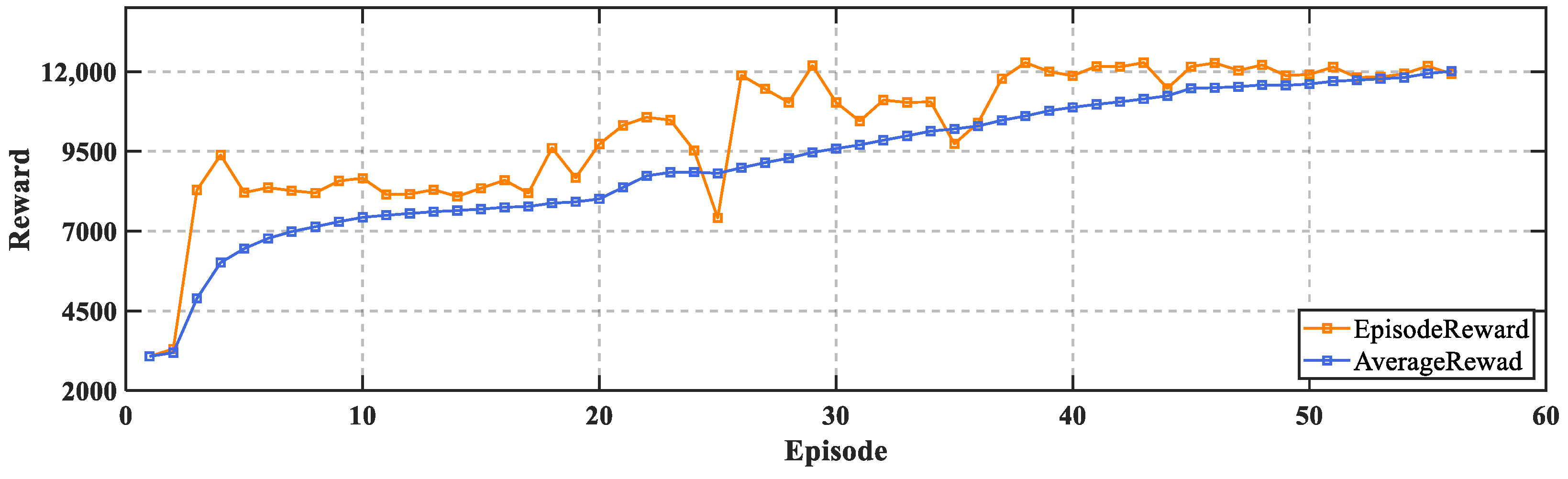
The model simulation was carried out in MATLAB 2022a, and the TD3 algorithm was realized through the reinforcement learning toolbox. The simulation time was 20 s, the sampling time was 0.001 s. The training stopped when the average reward reached 12,000. The training took about 6 h to complete. The learning curves of the reward obtained by the agent for each interaction with the environment during the training process are shown in
Figure 6.
It can be seen that at the beginning of the training, the agent was in the exploration phase and the reward obtained was relatively low. Later, the reward gradually increased, and after 40 episodes, the reward was steadily maintained at a high level and the algorithm gradually converges.
4.1. Case 1: Fault-Free and External Disturbance-Free in Dry Runway Condition
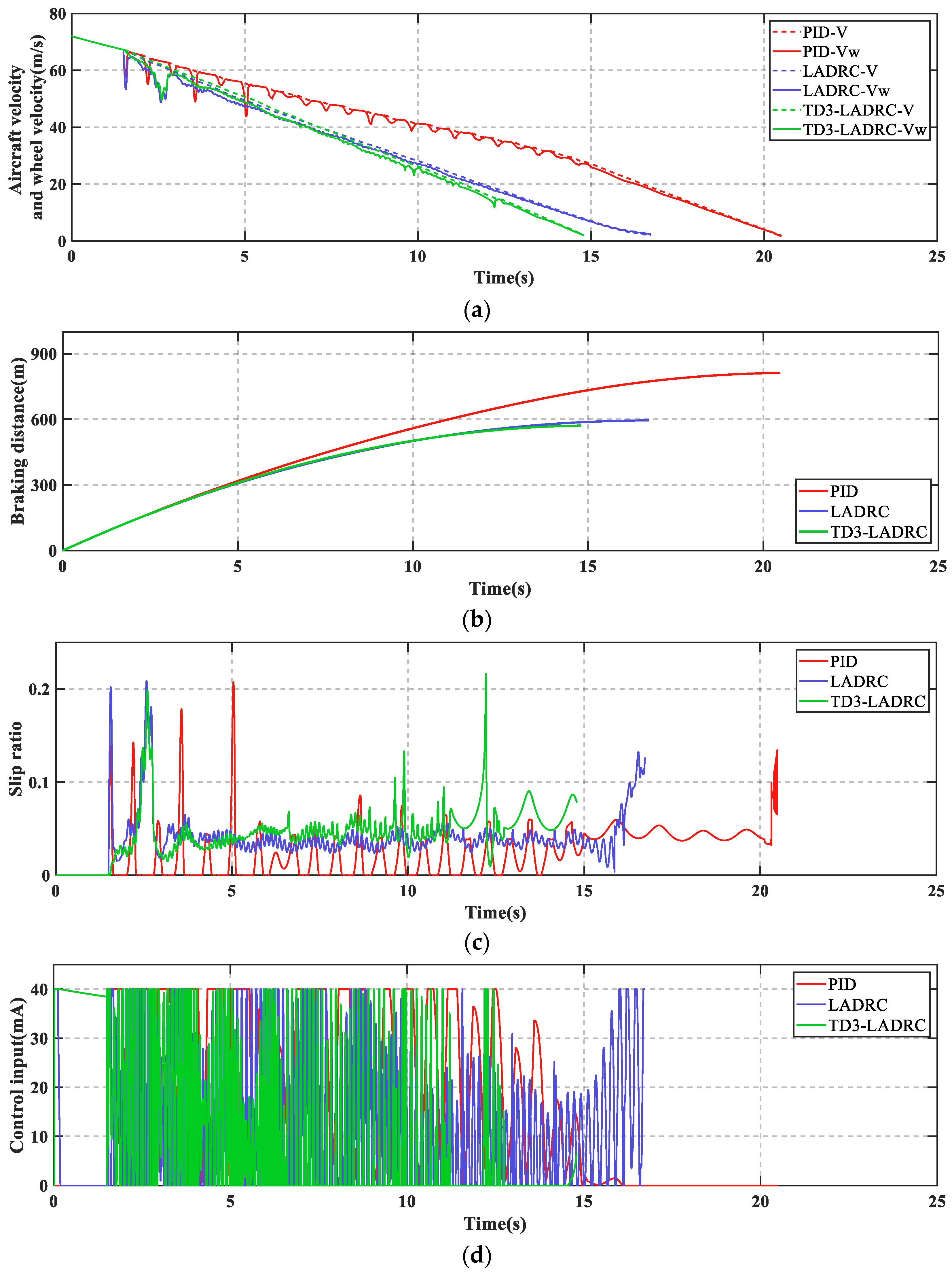
The simulation results of the dynamic braking process for different control schemes are shown in
Figure 7 and
Figure 8 and
Table 8.
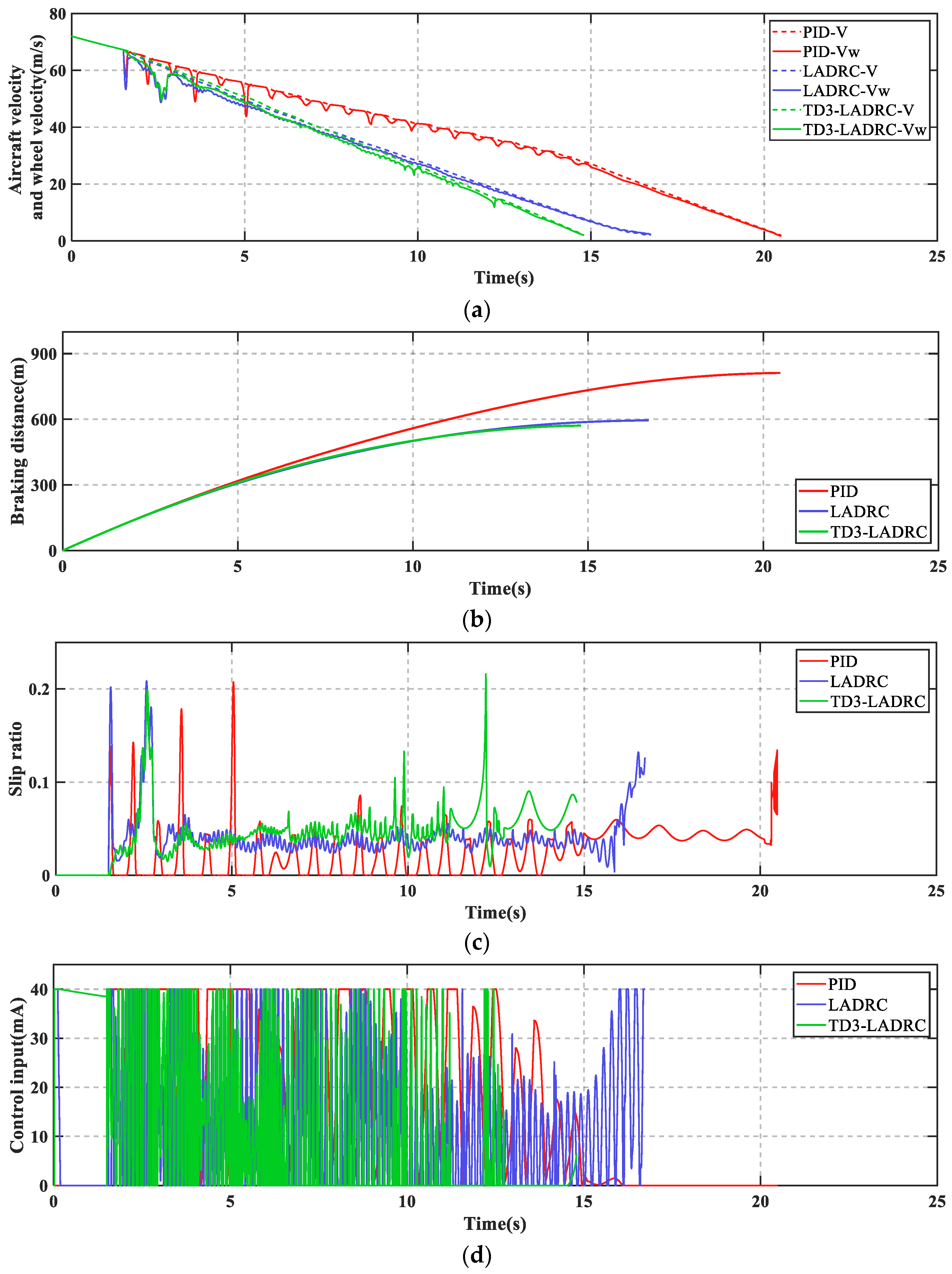
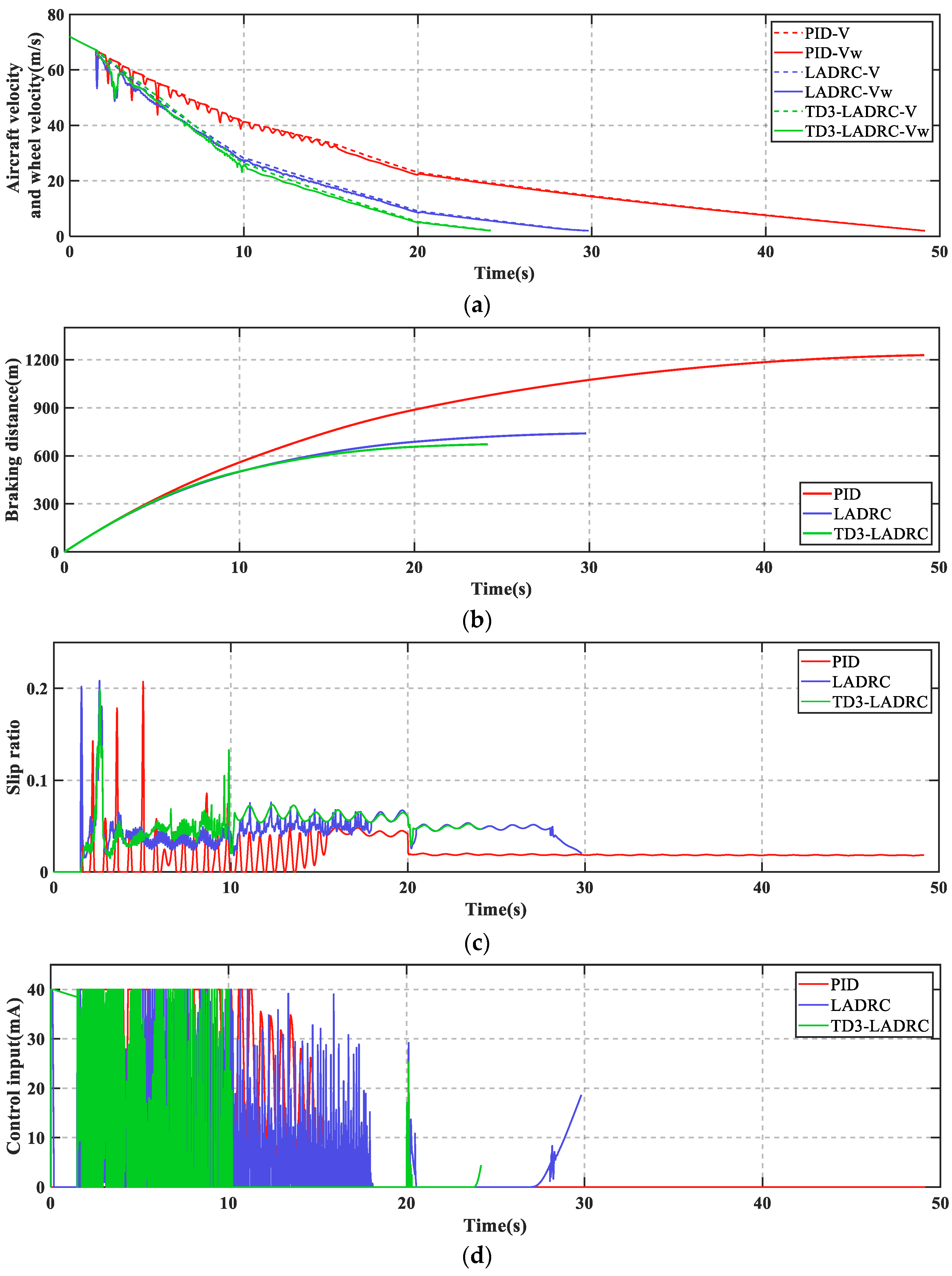
As can be seen from
Figure 7, PID + PBM leads to numerous skids during braking, which may cause serious loss to the tires. In contrast, LADRC and TD3-LADRC not only skid less frequently, but also have shorter braking time and braking distance. Moreover, the control effect of TD3-LADRC is better than LADRC.
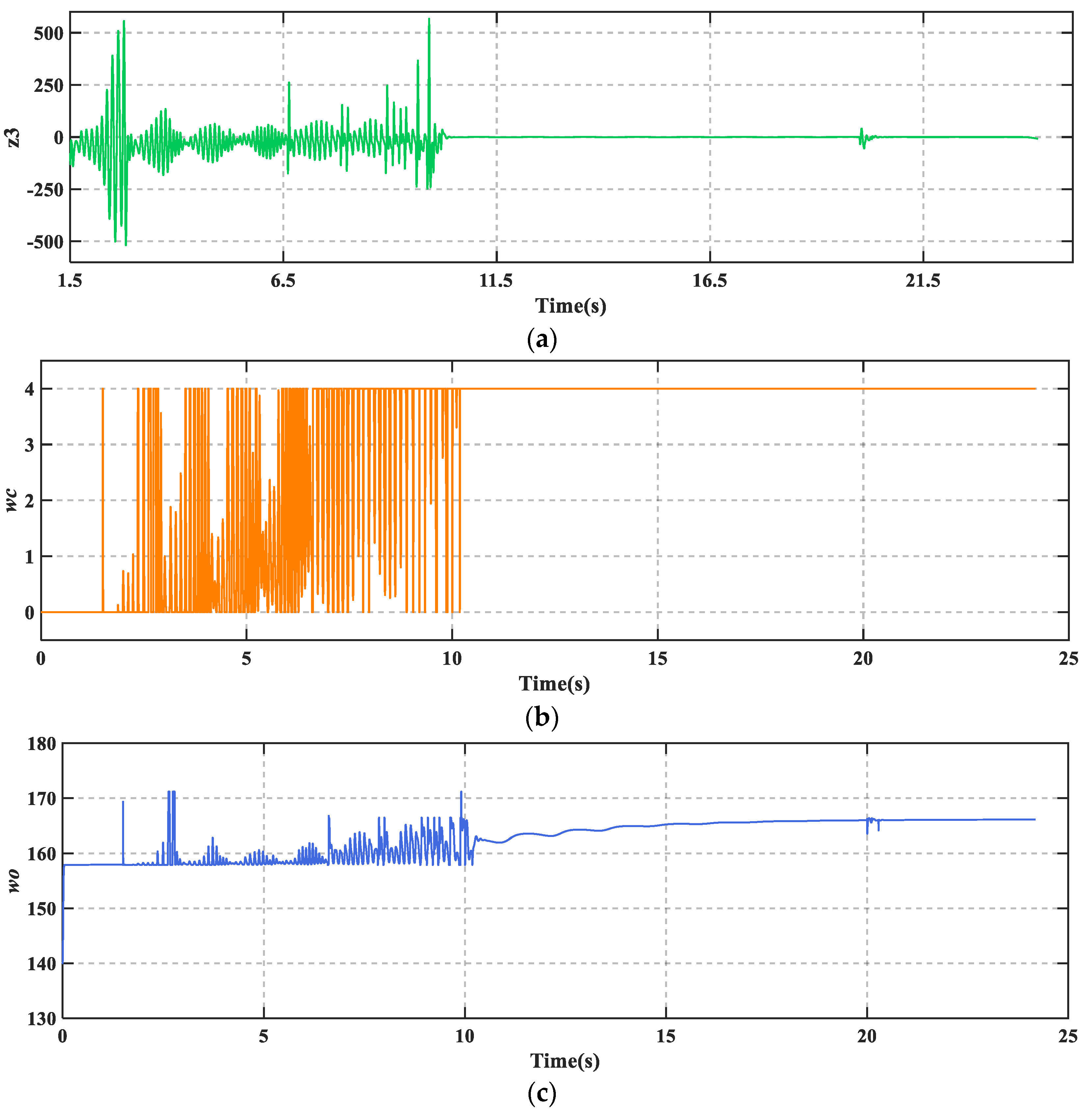
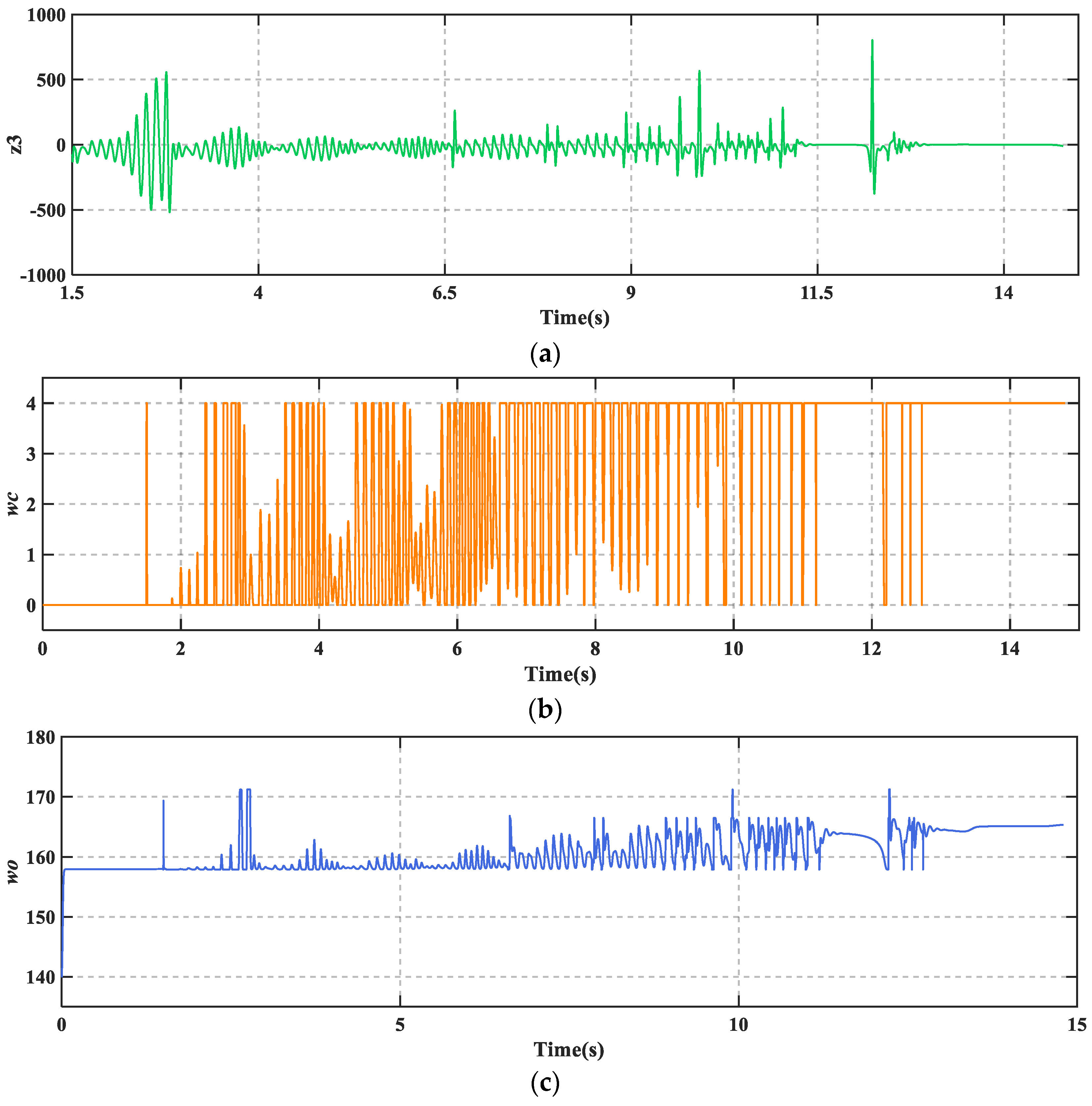
Figure 8 shows that TD3-LADRC can dynamically tune the controller parameters to accurately observe and compensate for the total disturbances, and thus improve the AABS performance.
Remark 6. During the braking process, it is observed that in some instants. It may not affect the stability of the whole system. On the one hand, the value of does not change the fact that is Hurwitz (see Proof of Theorem 2 for details). On the other hand, is constantly changed by the agent through a continuous interaction with the environment, and in these instants the agent considers as optimal, i.e., no anti-skid braking control leads to better braking results.
4.2. Case 2: Actuator LOE Fault in Dry Runway Condition
The fault considered here assumed a 20% actuator LOE at 5 s and escalated to 40% LOE at 10 s. The simulation results are shown in
Figure 9 and
Figure 10 and
Table 9.
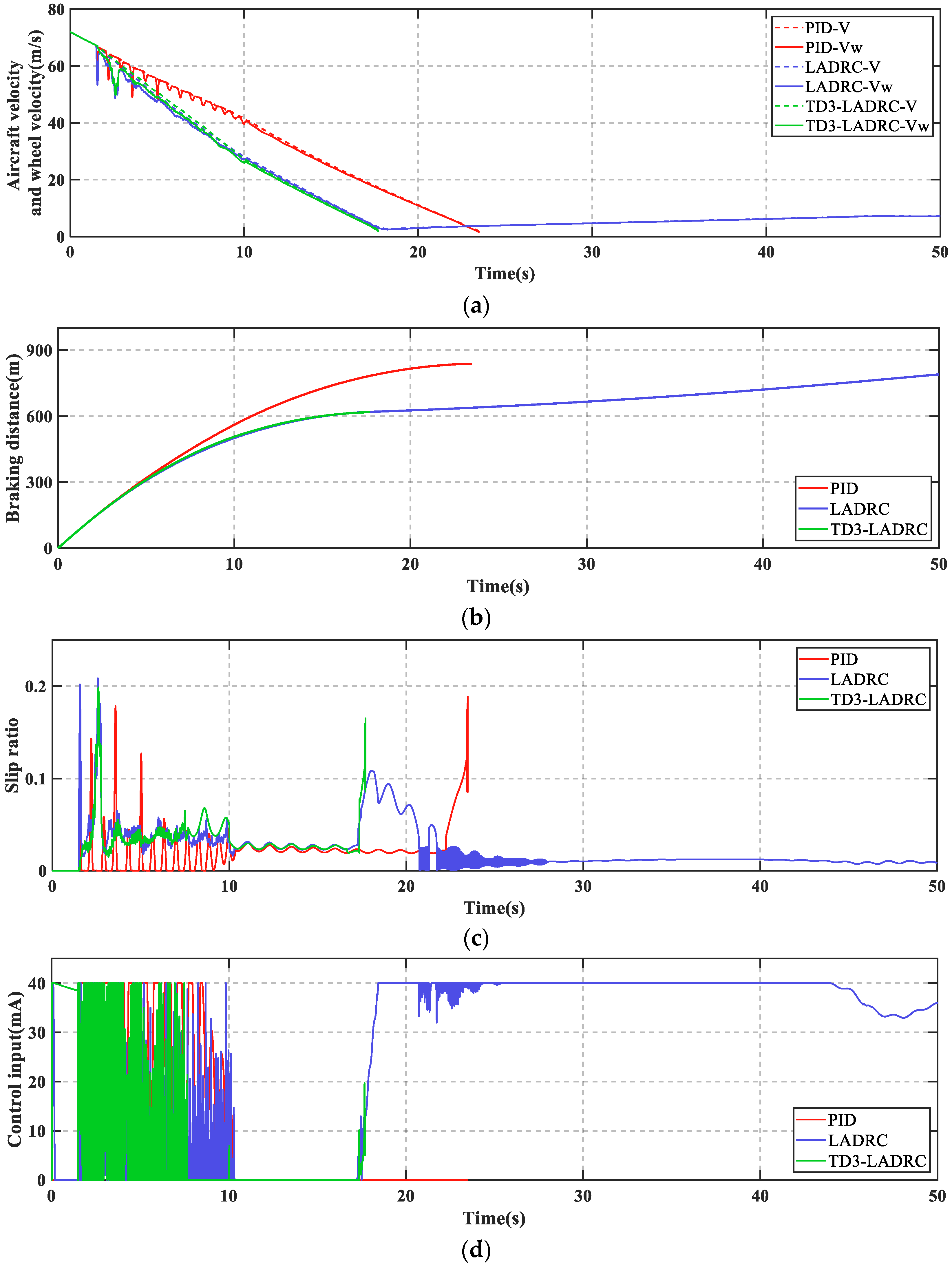
As can be seen in
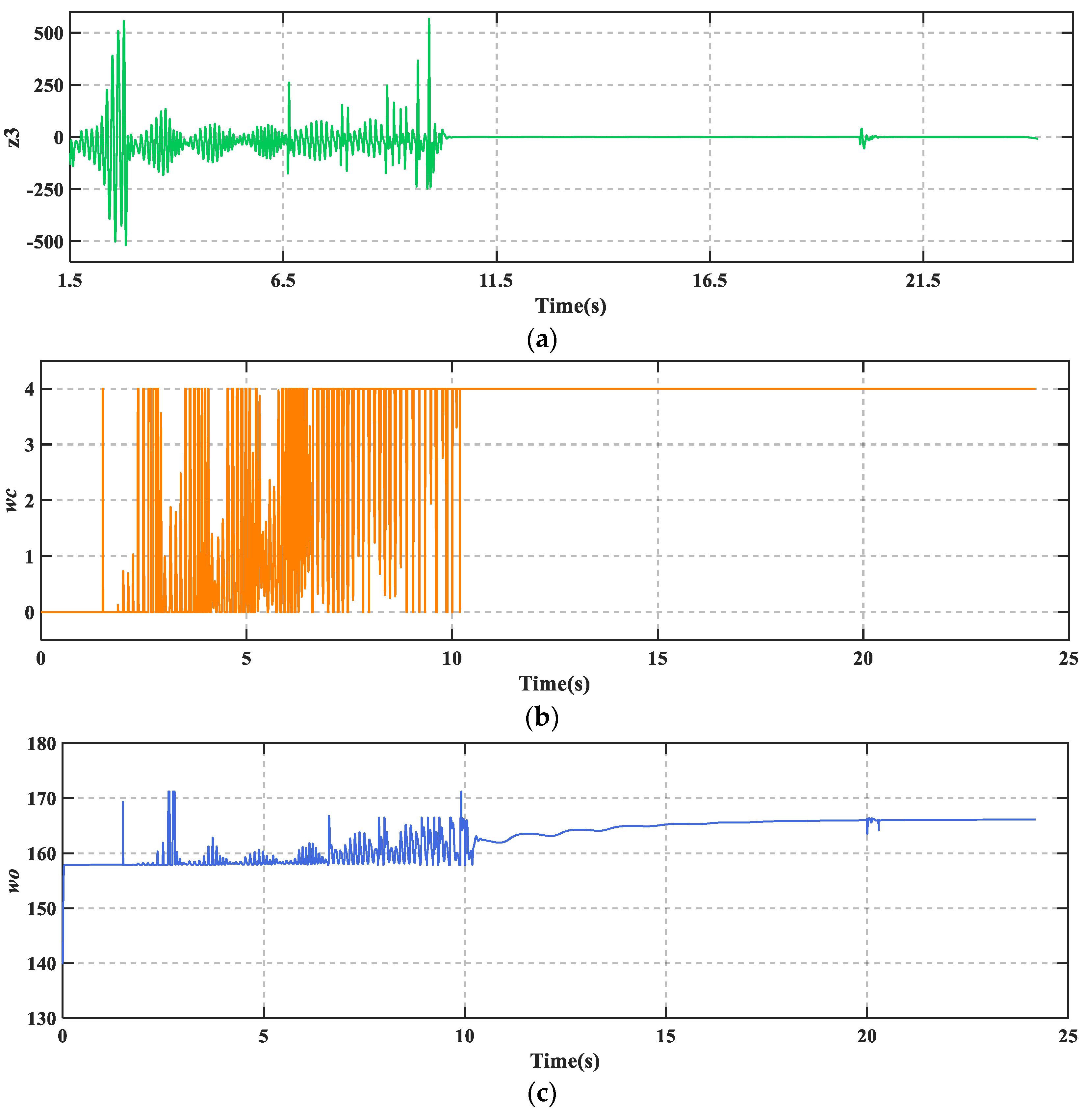
Figure 9, PID + PBM continuously performed a large braking and releasing operation under the combined effect of fault and disturbance. This makes braking much less efficient and risks dragging and flat tires. In addition, LADRC cannot brake the aircraft to a stop which is not allowed in practice.
Figure 9c shows that there is a high frequency of wheel slip in the low-speed phase of the aircraft. In contrast, TD3-LADRC retains the experience gained from the agent’s prior training and continuously adjusts the controller parameters online based on the plant states, which ultimately allows the aircraft to brake smoothly. From
Figure 10a, it can be seen that the total fault perturbations are estimated fast and accurately based on the adaptive LESO. Overall, TD3-LADRC not only improves the robustness and immunity of the controller in fault-perturbed conditions, but also greatly significantly improves the safety and reliability of AABS.
4.3. Case 3: Actuator LOE Fault in Mixed Runway Condition
The mixed runway structure is as follows: dry runway in the interval of 0–10 s, wet runway in the interval of 10–20 s, and snow runway after 20 s. The fault considered here assumed a 10% actuator LOE at 10 s. The simulation results are shown in
Figure 11 and
Figure 12 and
Table 10.
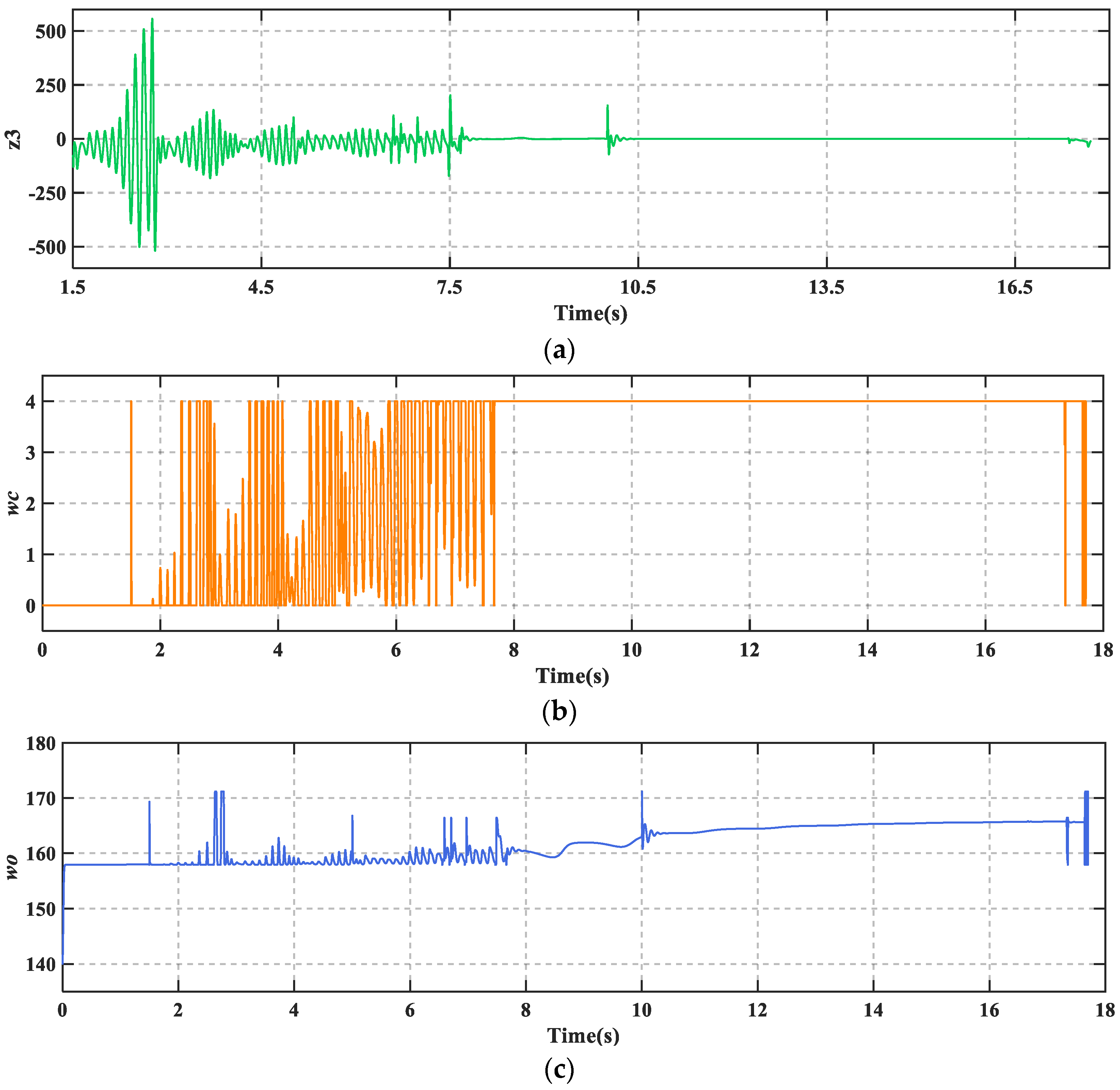
The deterioration of the runway conditions has resulted in a very poor tire–ground bond. It can be seen from
Figure 11 that both braking time and braking distance have increased compared to the dry runway.
Figure 12 shows that TD3-LADRC is still able to achieve controller parameters adaption, accurately observe the total fault perturbations, and effectively compensate for the adverse effects. The whole reconfiguration control system adapts well to runway changes. The environmental adaptability of AABS is improved.


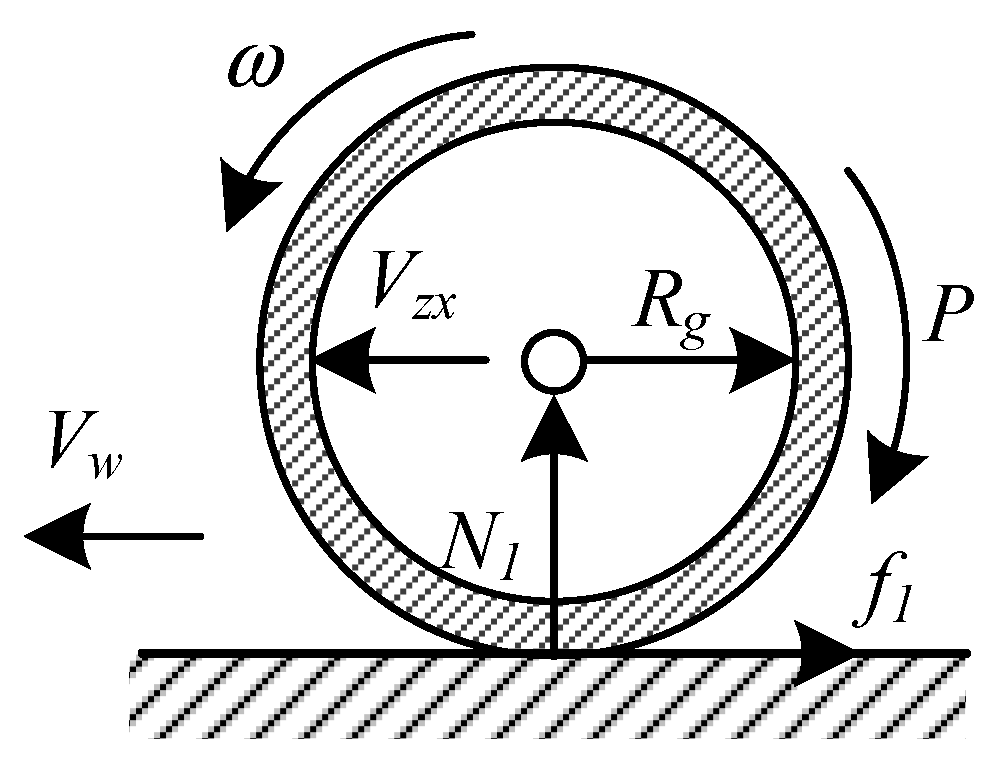
 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}