
Remote Sensing Image Super-Resolution for the Visual System of a Flight Simulator: Dataset and Baseline

Abstract
1. Introduction
- Due to the lack of a dataset for the super-resolution task in the research field of the visual system of a flight simulator, we present a new dataset named Airport80, which contains 80 ultra-high-resolution remote sensing images captured from the airspace near airports.
- We propose a neural network based on the GAN framework to serve as a baseline model of this dataset, in which some of the latest network designs are integrated into the model to improve the SISR performance. The proposed method is capable of generating realistic textures during a single remote sensing image super-resolution.
- Experimental results for the proposed benchmark demonstrate the effectiveness of the proposed method and show it has reached satisfactory performances. We hope that this work can bring better quality data for the visual system of a flight simulator.
2. Related Work
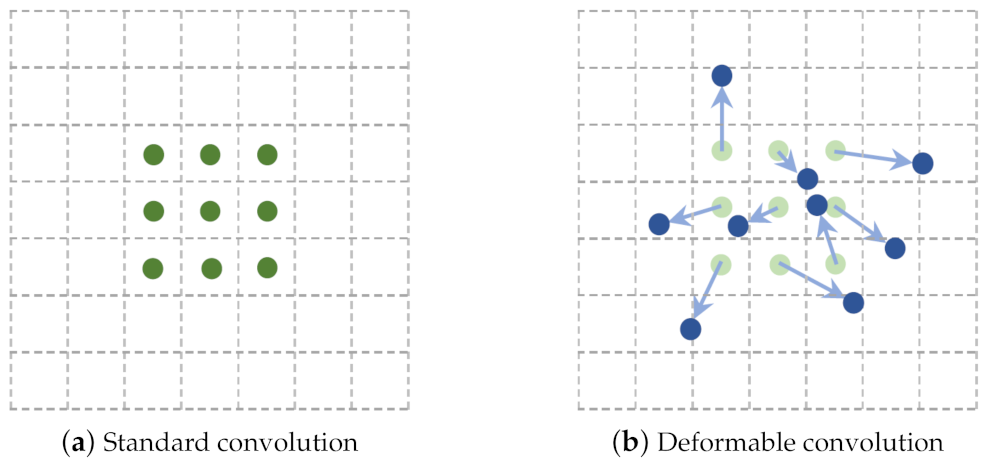
3. Methodology
3.1. Airport80 Dataset
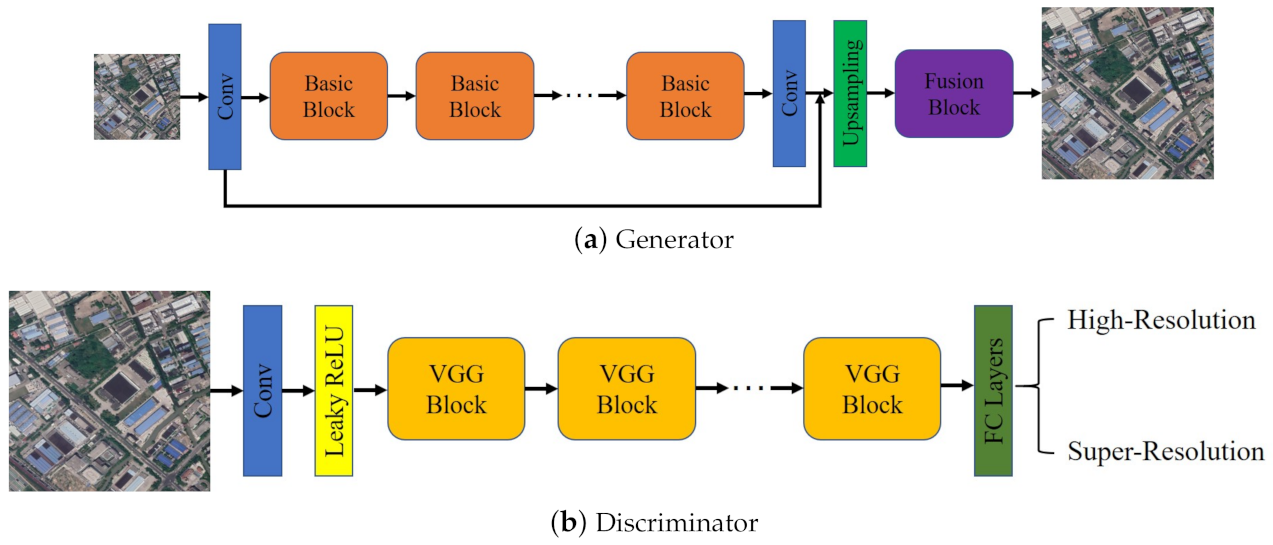
3.2. Network Architecture
3.2.1. Baseline Model
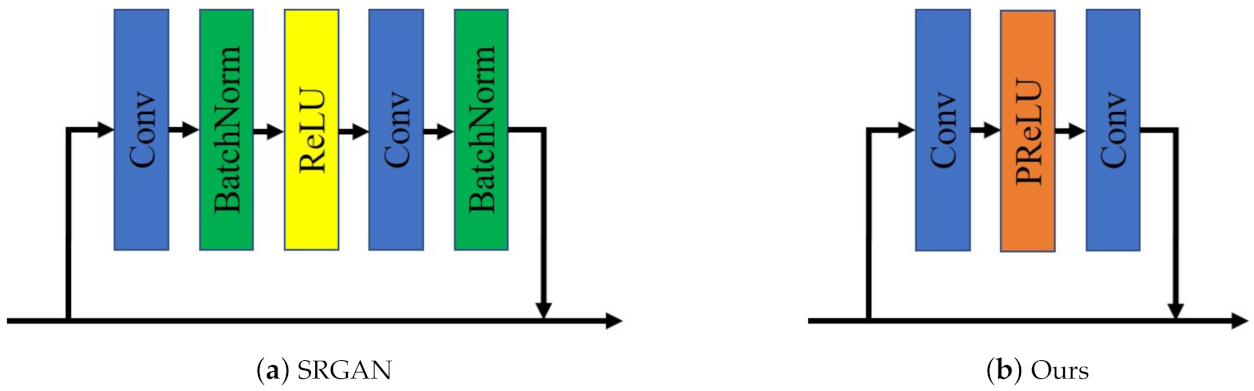
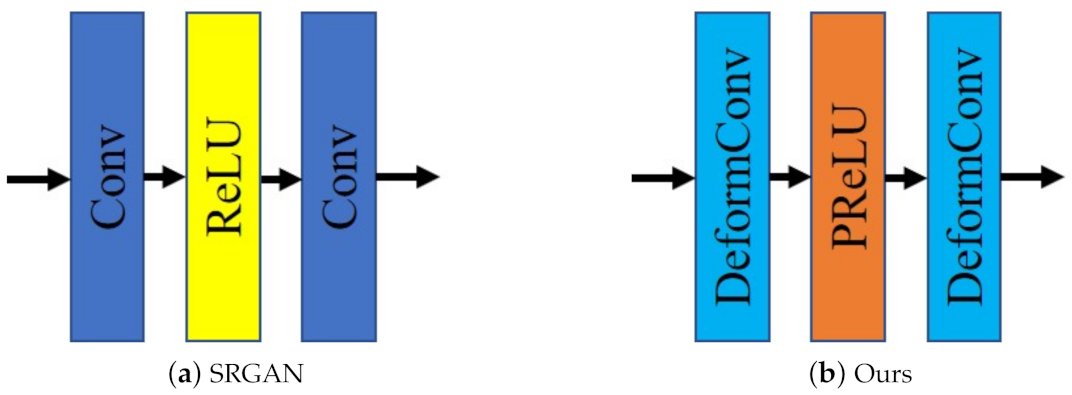
3.2.2. Incremental Details
3.3. Loss Function
4. Experiments
4.1. Training Details
4.2. Ablation Study
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A Real-Time ATC Safety Monitoring Framework Using a Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2019, 4572–4581. [Google Scholar] [CrossRef]
- Lin, Y.; Guo, D.; Zhang, J.; Chen, Z.; Yang, B. A Unified Framework for Multilingual Speech Recognition in Air Traffic Control Systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Li, L.; Jing, H.; Ran, B.; Sun, D. Automated traffic incident detection with a smaller dataset based on generative adversarial networks. Accid. Anal. Prev. 2020, 144, 105628. [Google Scholar] [CrossRef]
- Li, L.; Lin, Y.; Du, B.; Yang, F.; Ran, B. Real-time traffic incident detection based on a hybrid deep learning model. Transportmetrica 2020, 1–21. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Aitken, P.A.; Tejani, A.; Totz, J.; Wang, Z.; Shi, W. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the ICCV, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Xu, X.; Xiong, X.; Wang, J.; Li, X. Deformable Kernel Convolutional Network for Video Extreme Super-Resolution. In Proceedings of the ECCV Workshops, Glasgow, UK, 23–28 August 2020; pp. 82–98. [Google Scholar]
- Freeman, T.W.; Jones, R.T.; Pasztor, C.E. Example-Based Super-Resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the CVPR, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Yang, J.; Wright, J.; Huang, S.T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the CVPR, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, K.J.; Lee, M.K. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, P.A.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, M.K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the CVPR Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the CVPR, Anchorage, AK, USA, 24–26 June 2018; pp. 2472–2481. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Timofte, R. Unsupervised Learning for Real-World Super-Resolution. In Proceedings of the ICCV Workshops, Seoul, Korea, 27 October–2 November 2019; pp. 3408–3416. [Google Scholar]
- Lugmayr, A.; Joon, H.N.; Won, S.Y.; Kim, G.; Kwon, D.; Hsu, C.C.; Lin, C.H.; Huang, Y.; Sun, X.; Lu, W.; et al. AIM 2019 Challenge on Real-World Image Super-Resolution—Methods and Results. In Proceedings of the ICCV Workshops, Seoul, Korea, 27 October–2 November 2019; pp. 3575–3583. [Google Scholar]
- Fritsche, M.; Gu, S.; Timofte, R. Frequency Separation for Real-World Super-Resolution. In Proceedings of the ICCV Workshops, Seoul, Korea, 27 October–2 November 2019; pp. 3599–3608. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; pp. 1–10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Curves and Surfaces; Springer: Berlin/Heisenberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, Z.; Bovik, C.A.; Sheikh, R.H.; Simoncelli, P.E. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, J.I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, C.A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, C.H.S. Deep Learning for Image Super-resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
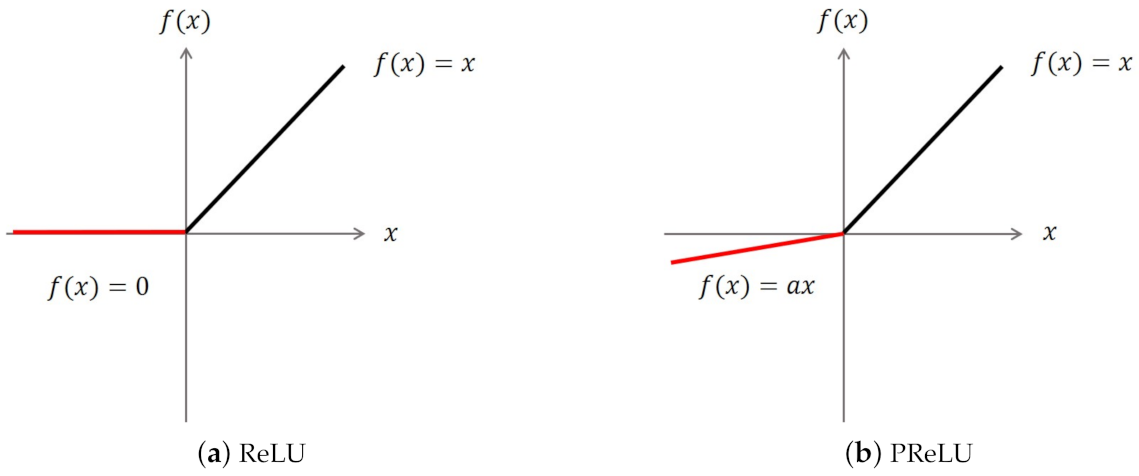{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BN Removal | PReLU | DeformConv | PSNR | SSIM |
|---|---|---|---|---|
| 26.08 | 0.7054 | |||
| √ | 26.75 () | 0.7251 () | ||
| √ | 26.34 () | 0.7156 () | ||
| √ | 26.68 () | 0.7215 () | ||
| √ | √ | √ | 27.01 () | 0.7292 () |
| Metric | Nearest | Bicubic | SRCNN | SRGAN | SRResNet | Ours* | Ours |
|---|---|---|---|---|---|---|---|
| PSNR | 23.47 | 25.12 | 25.74 | 23.22 | 26.08 | 27.01 | 24.59 |
| SSIM | 0.6109 | 0.6744 | 0.6896 | 0.6184 | 0.7054 | 0.7292 | 0.6375 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, W.; Wang, Z.; Wang, G.; Tan, S.; Zhang, J. Remote Sensing Image Super-Resolution for the Visual System of a Flight Simulator: Dataset and Baseline. Aerospace 2021, 8, 76. https://doi.org/10.3390/aerospace8030076
Ge W, Wang Z, Wang G, Tan S, Zhang J. Remote Sensing Image Super-Resolution for the Visual System of a Flight Simulator: Dataset and Baseline. Aerospace. 2021; 8(3):76. https://doi.org/10.3390/aerospace8030076
Chicago/Turabian StyleGe, Wenyi, Zhitao Wang, Guigui Wang, Shihan Tan, and Jianwei Zhang. 2021. "Remote Sensing Image Super-Resolution for the Visual System of a Flight Simulator: Dataset and Baseline" Aerospace 8, no. 3: 76. https://doi.org/10.3390/aerospace8030076
APA StyleGe, W., Wang, Z., Wang, G., Tan, S., & Zhang, J. (2021). Remote Sensing Image Super-Resolution for the Visual System of a Flight Simulator: Dataset and Baseline. Aerospace, 8(3), 76. https://doi.org/10.3390/aerospace8030076