2.1. Spacecraft Pose Estimation
Pose determination/estimation is the capability of an active spacecraft (chaser) to accurately estimate its relative position and attitude (orientation) with respect to an active or inactive target in close-proximity in space. The position is usually in Cartesian coordinates and it can be expressed as a position vector as in Equation (
1), where
,
and
are the base vectors in the Cartesian plane.
On the other hand, orientation in three-dimensional (3D) can be represented in various ways such as use of Euler angles, rotational matrices and quaternions. In Euler angles, an orientation can be represented with 3 numbers (Euler angles) in 12 possible Euler angle sequences such as
xyz,
xzy,
zxy etc. One shortcoming of Euler angle approach is that they suffer from gimbal lock whereby two axes effectively line up leading to loss of a degree of freedom. They also require extensive trigonometry operations when converting between different rotational matrices [
12]. Quaternions offer a more effective way of representing 3D orientations [
13,
14]. They are four-dimensional with one real component and three components in the
ijk imaginary space, as expressed in Equation (
2).
where
i,
j,
k satisfy the conditions in Equation (
3)
Whereas, rotations in Euler Angles are obtained by specific angle sequences, quaternions offer an analogous single rotation around a unique axis that results in the same rotation. The quaternion embeds this possibility i.e., angle and axis of rotation within its four-element vector. A rotation of a vector
v in
to
w by the quaternion
is given by:
The above equations represent the fundamental concepts of position and orientation determination (pose estimation) while using Cartesian coordinates and Quaternions.
There are two major categories in pose estimation techniques: cooperative and uncooperative spacecraft [
15]. In the former, the target has inbuilt capacity to provide the chaser with information suitable for pose estimation. This capacity can be in the form of dedicated radio-link to interact with the chaser (active) or artificial markers that are easily recognized (passive). In uncooperative targets, there is minimal (known target) or no information (unknown targets) available to facilitate pose estimation. Spacecraft pose determination is achieved by relying mainly on electro-optical sensors, such as stereo cameras, monocular vision/infrared cameras, and Light Detection and Ranging (LIDAR) systems. The advantages of the latter over the other two is that LIDAR systems are robust in poorly illuminated conditions and, hence, the target can be easily segmented from the background. They also offer very large operational ranges with constant accuracy levels. The main disadvantage is the hardware complexity and cost of such systems. Hence, monocular and stereo cameras are preferred for spacecraft pose determination. They have low power, mass, and cost requirements. However, they require additional algorithms to extract pose information, since they cannot provide direct measurements of the relative range [
16].
These additional algorithms have been based on image processing techniques while using hand-engineered features. Consequently, the pose is estimated utilizing the target’s image and its 3D model. However, such feature-based pose estimation is not scalable to spacecraft of different structural and physical properties. Improvements to such approaches have been proposed, with deep learning-based algorithms emerging as the preferred approaches. Such deep learning methods achieve pose estimation by two main ways. One approach is to discretize the pose space and solve the resulting classification problem. The other approach is to directly regress the relative pose from the input image. This becomes a regression problem for the deep learning network to solve. CNN-based algorithms that use single monochrome images for pose estimation have been studied with satisfactory results. Hirano, in [
17], demonstrates a CNN-based pose estimator for a spacecraft. The training data were obtained by use of a software simulator to generate synthesized images from a 3D model of the target object. This pose estimator directly estimates the 3D keypoints of the model from which the pose is determined. Sharma, in [
18], combines CNN with a Gauss–Newton algorithm. The CNN allows for feature detection without need for manual tuning of hyper-parameters whilst the Gauss-Newton algorithm provides the perspective equations for quantifying uncertainty in the estimated pose. Thaweerath et al. in [
19] presented a CNN-based pose estimation for noncooperative docking operations. The position and orientation were predicted by directly regressing them from the input image.
The ESA Pose Estimation Challenge is based on the SPEED dataset from [
20] that is comprised of synthetic and real images of a spacecraft model. A 3D model of the Tango spacecraft was used in order to generate synthetic images that were grouped into different categories representing different pose labels. AlexNet CNN architecture was used in training a deep learning algorithm that could classify spacecraft image into one of the pose labels. The study noted that pose estimation increased with higher levels of discretization, i.e., more pose labels. Other approaches used in the challenge include [
21], where a CNN-based algorithm is used to estimate 6-DoF (Degree of Freedom) pose of the satellite from a single image. The algorithm first detects the two-dimensional (2D) landmarks on the input image, performs 2D-to-3D landmarks mapping and finally obtains the pose via non-linear optimization. In other CNN-based pose estimation approaches, CNN is used as a pose initializer. In [
22], CNN is proposed as a corrective mechanism to feature based pose tracking during the initialization phase. Synthetic data of monocular images is used to train two models based on VGG-19 architecture. It is noted that CNN-based models have an advantage over feature-based ones in that they can be adapted for different spacecraft by training the model with huge datasets of the new spacecraft.
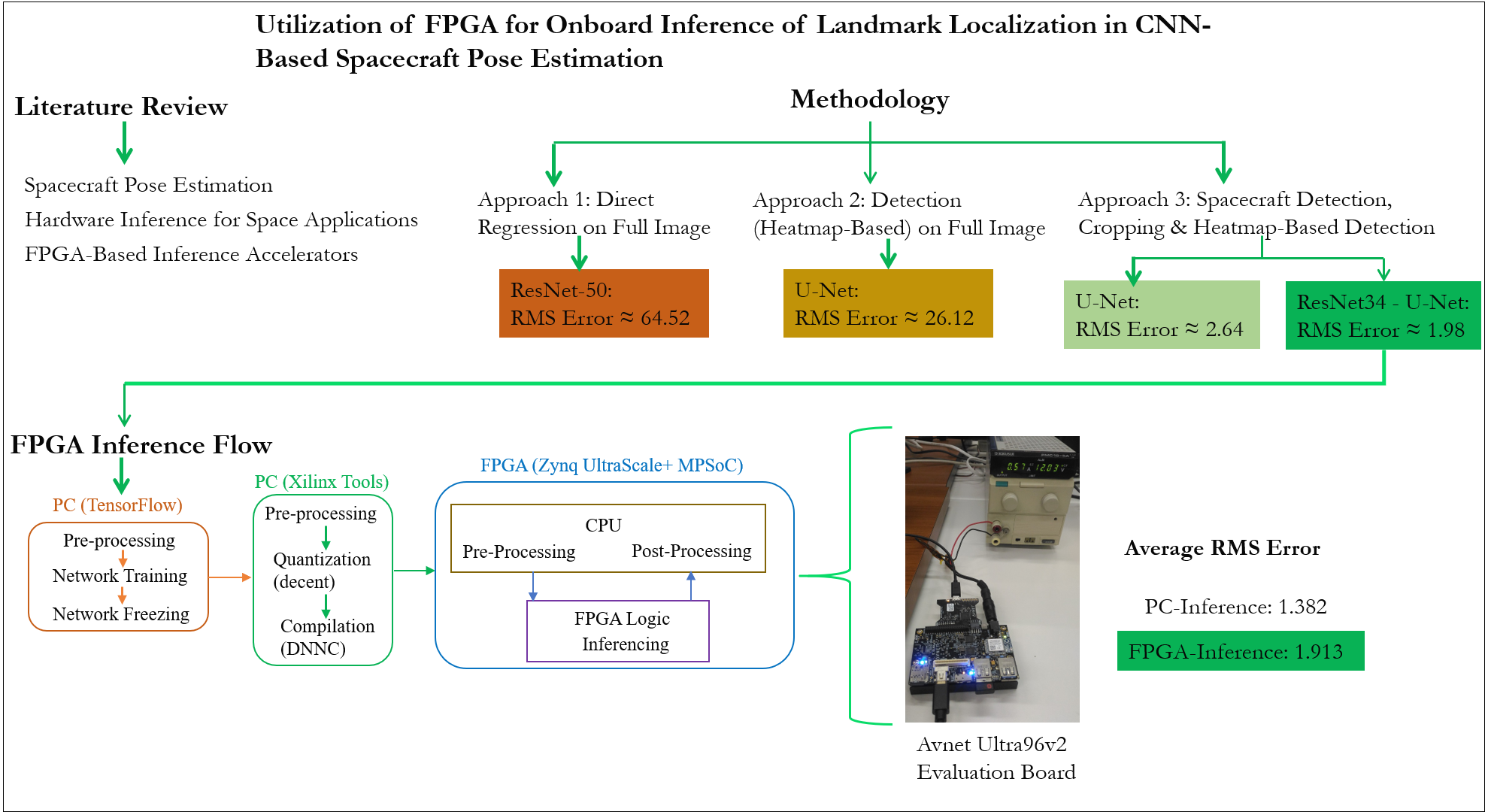
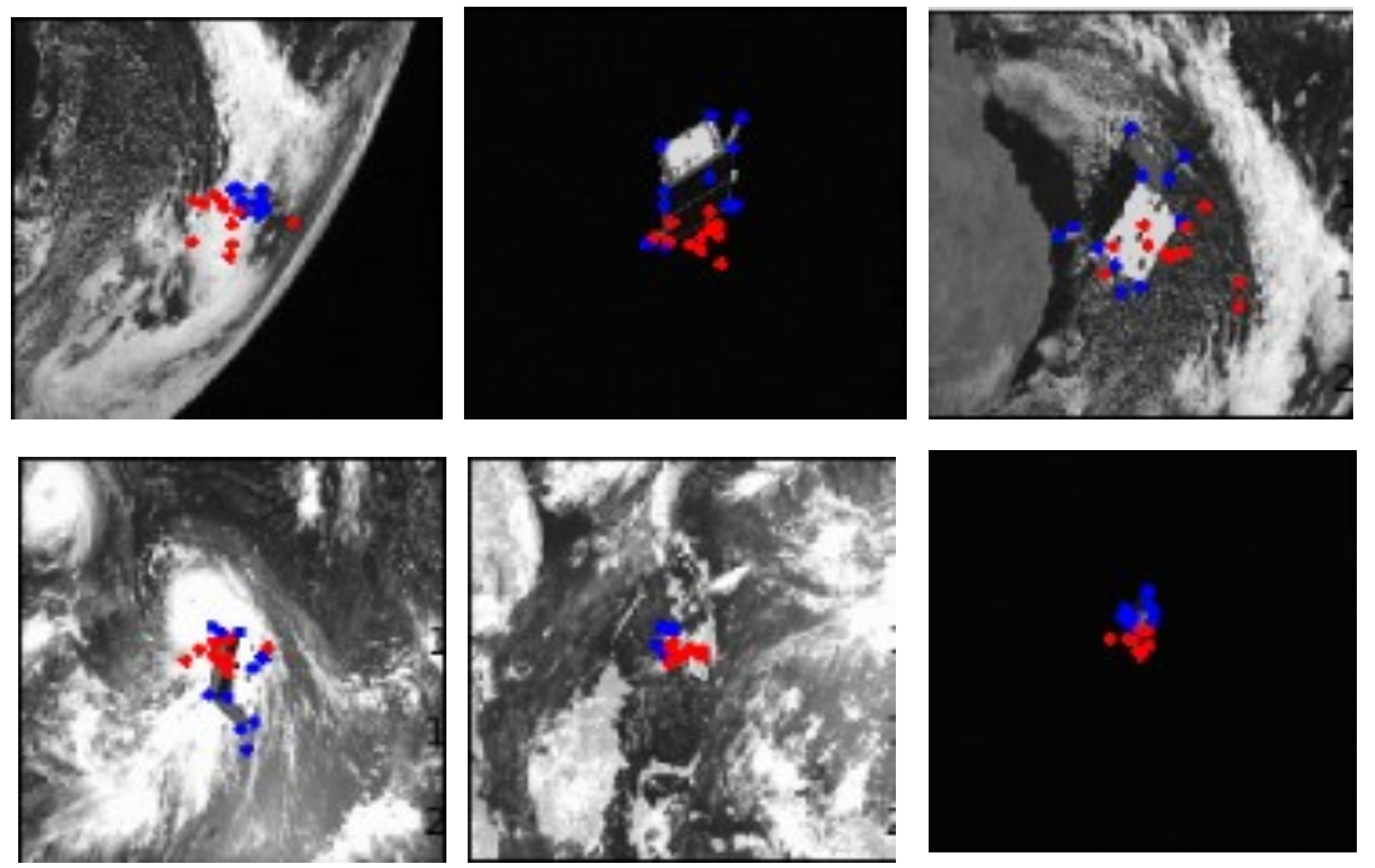
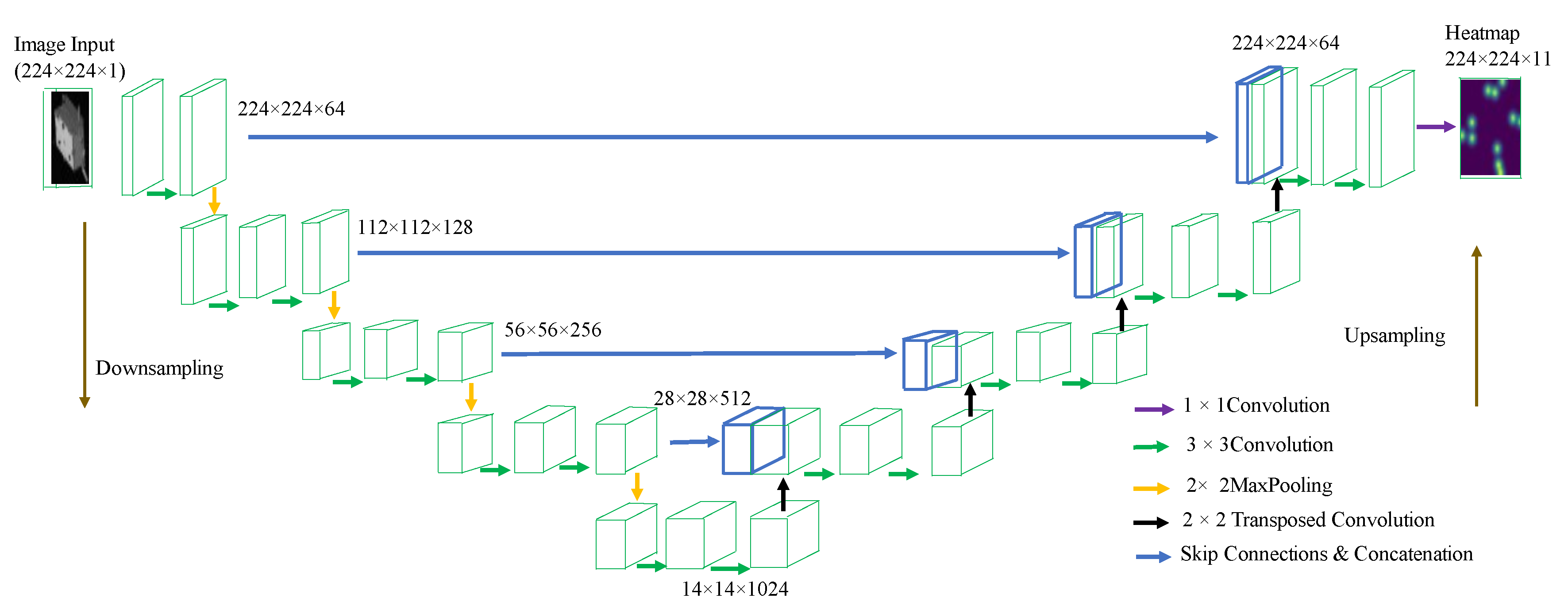
Figure 1 shows a typical CNN-based pose estimation flow.
2.2. Hardware Inference for Space Applications
While various space applications, including pose estimation, can benefit from deep learning, they face challenge in suitable hardware for inference. Small satellites have limited power, mass, and cost budgets, which poses computing power challenges compared to terrestrial applications. The space environment also offers challenging conditions for the operation of electronics. Lu et al. in [
23] review the effects of space environment in different orbits. They observe that a spacecraft is mainly affected by the following space components: neutral atmosphere, plasma, radiation, macroscopic particles, geomagnetic, and temperature fields. LEO is predominantly influenced by radiation and macroscopic particles, whilst MEO and GEO are greatly exposed to solar activities, plasma environment, and radiation. Approximately, radiation anomalies and temperature-induced anomalies account for 40% and 11% of spacecraft failures in the space environment, respectively [
23].The main radiation sources in space include trapped radiation, galactic cosmic rays, and solar energy particles.
Damage to electronic devices on board spacecraft due to radiation is mainly categorized into ionizing and non-ionizing (displacement) damage. Displacement damage is the cumulative long term non-ionizing damage due to protons, electrons, and neutrons. Ionization damage is the creation of electron-hole pairs and it can be further categorized into total ionizing dose (TID) and single event effects (SEE). The former is the cumulative long term ionizing damage due to protons and electrons, whilst the latter is caused by a single charged particle such as heavy ions and protons [
24,
25]. The Tenkoh satellite that was developed at Kyushu Institute of Technology and launched in October 2018 was analyzed to have suffered SEEs after passing over the South Atlantic Anomaly [
26].
Due to these harsh conditions in space, radiation-tolerant, radiation-hardened, and space-grade computing hardware is desirable for space operations. This has limited the options available for hardware suitable for inference in space. Nevertheless, there is hardware with flight heritage that is very amenable to on-board inference. This section explores such computing hardware that is based on flight heritage or planned missions, support for CNN inference, and other factors, such as low power consumption. These are summarized in
Table 1.
This survey reveals that hybrid computing devices comprising FPGAs and Systems-on-Chips (SoCs) are preferred for implementing machine and deep learning algorithms onboard spacecraft. However, most of these are not space-grade devices. George et al. in [
27] identified hybrid and reconfigurable computing as driving the revolutionary capabilities of small satellites such as cubesats. Lentaris et al. in [
28] conducted a review of high-performance embedded computing for vision-based navigation in space based on four categories: FPGA, CPU, GPU, and DSP. They found that FPGAs achieved the highest performance per watt of all platforms by at least one order of magnitude. GPUs are power hungry when compared to FPGAs and CPUs for comparable operation and accuracy [
28]. CPUs performance fade in comparison to FPGAs in DL inference. Consequently, FPGAs are more suitable for space inference-based applications. Additionally, they are already being used in mission-specific and satellite subsystem operations. They are also reconfigurable and, therefore, can be adopted for different tasks on the fly.
In May 2020, Xilinx unveiled the Xilinx
® Radiation Tolerant (RT) Kintex
® UltraScale™ XQRKU060 FPGA. The device is optimized for various computational-intensive space applications. It is the first 20 nm space-grade FPGA optimized for machine learning inference coupled with unlimited on-orbit reconfiguration for real time on-board-processing. Some of its key applications include on-board AI for autonomous space exploration, real-time streaming of earth observation, remote sensing video, and for flexible, digital beam-forming telecommunication satellites [
29]. In September 2020, ESA launched the Phi-sat-1 satellite that incorporated AI for Earth observation. Intel’s Myriad 2 Vision Processing Unit was used as the onboard inference platform, although it is not space-grade. This hardware was incorporated to utilize deep CNN in automatic cloud cover identification. Synthetic data from existing missions were used as the training data. It is the first European satellite to demonstrate how onboard artificial intelligence can improve the efficiency of sending EO data back to Earth. Initial data downlinked from the satellite showed successful assortment of the hyperspectral imagery into cloudy and non-cloudy pixels [
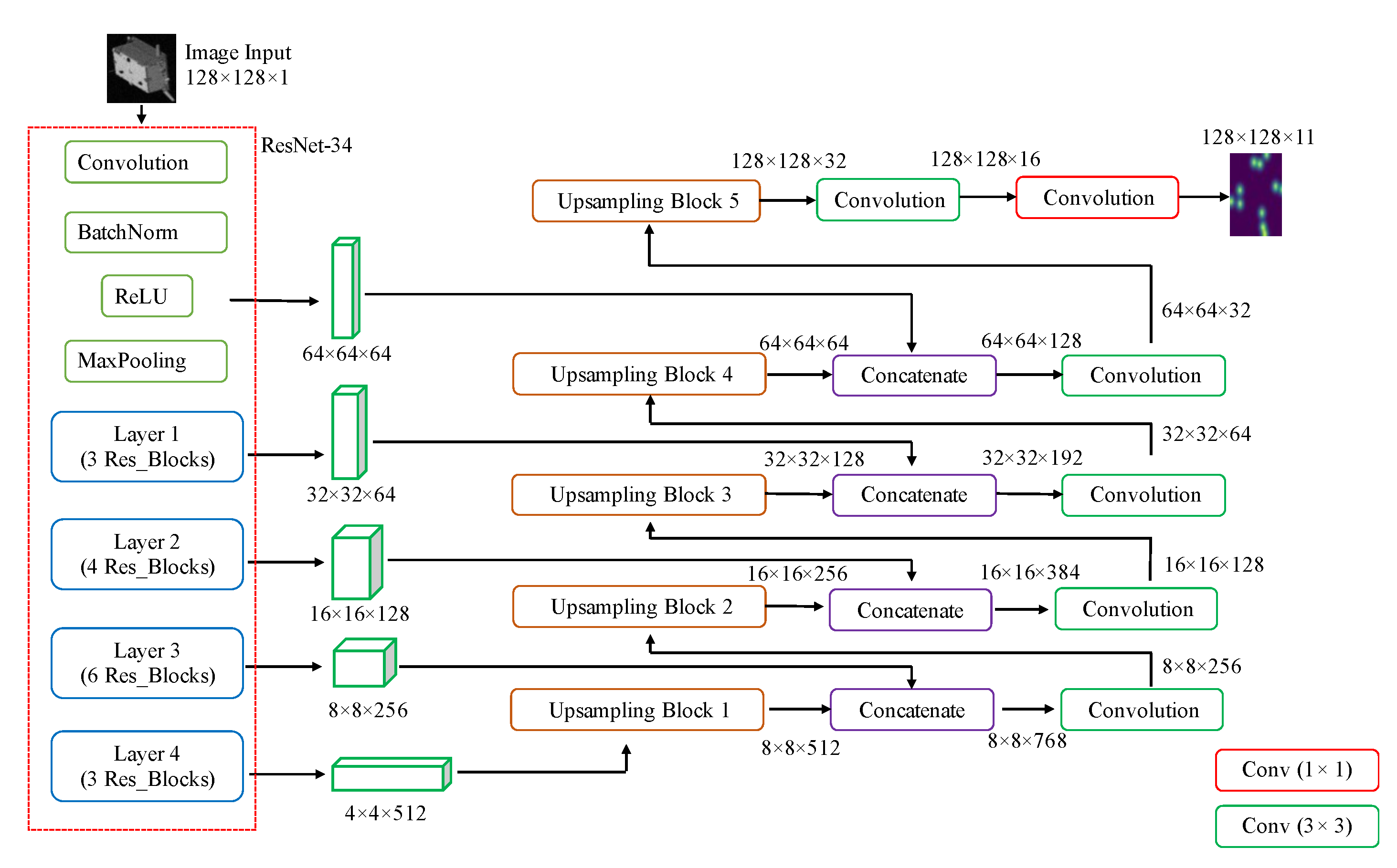
30]. This preceding hardware survey informed the decision to pick the Xilinx Zynq UltraScale+ MPSoC for onboard CNN inference. This is because its programmable logic can be comparable to the XQRKU060 FPGA logic, as presented later in Table 6.
2.3. FPGA-Based Inference Accelerators
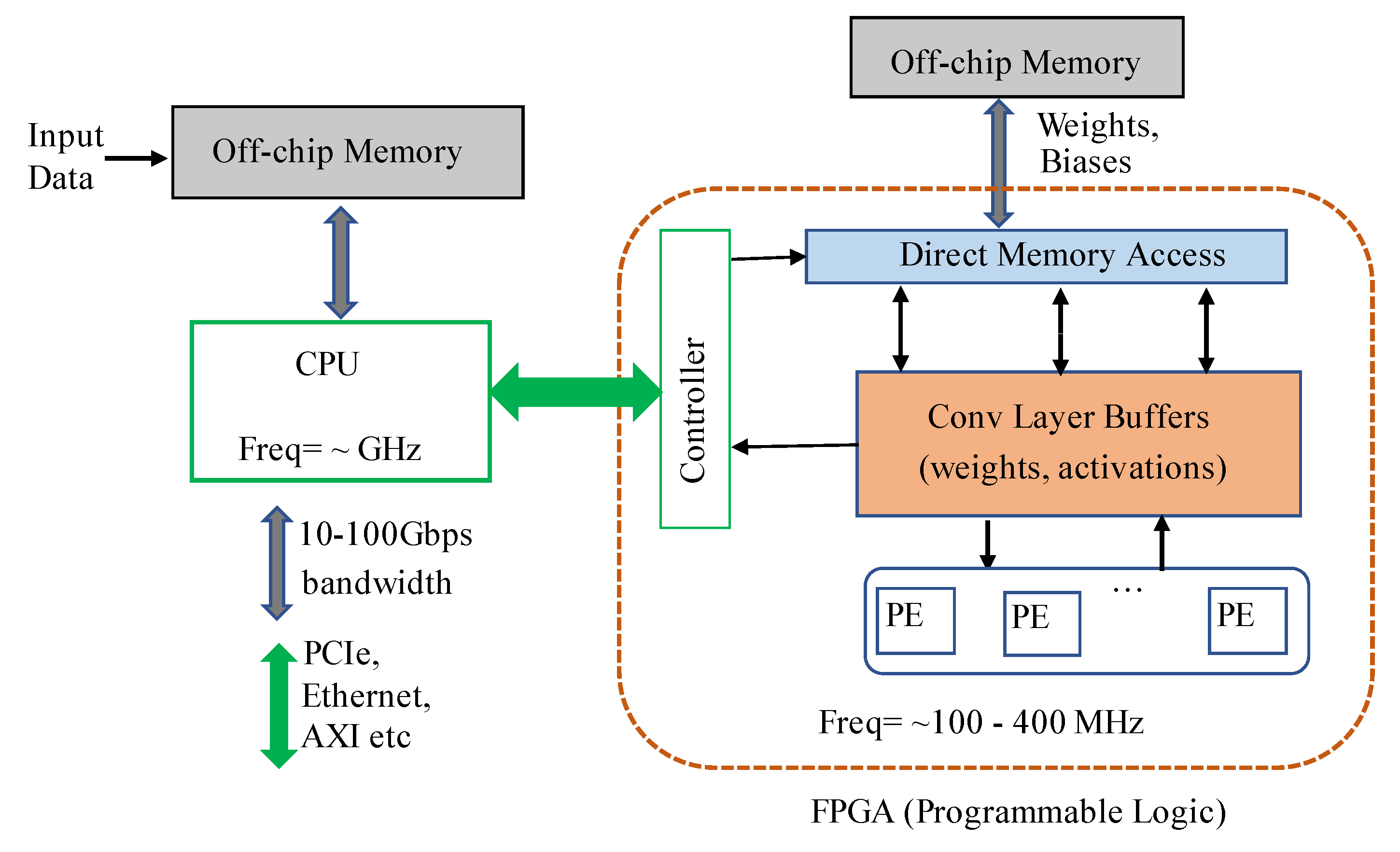
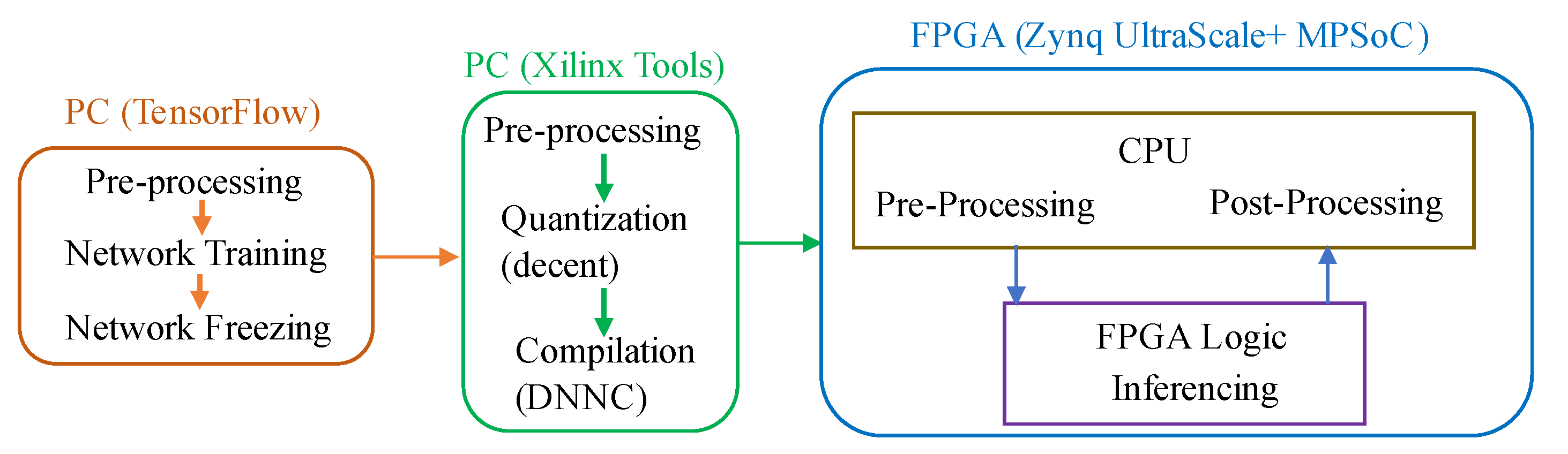
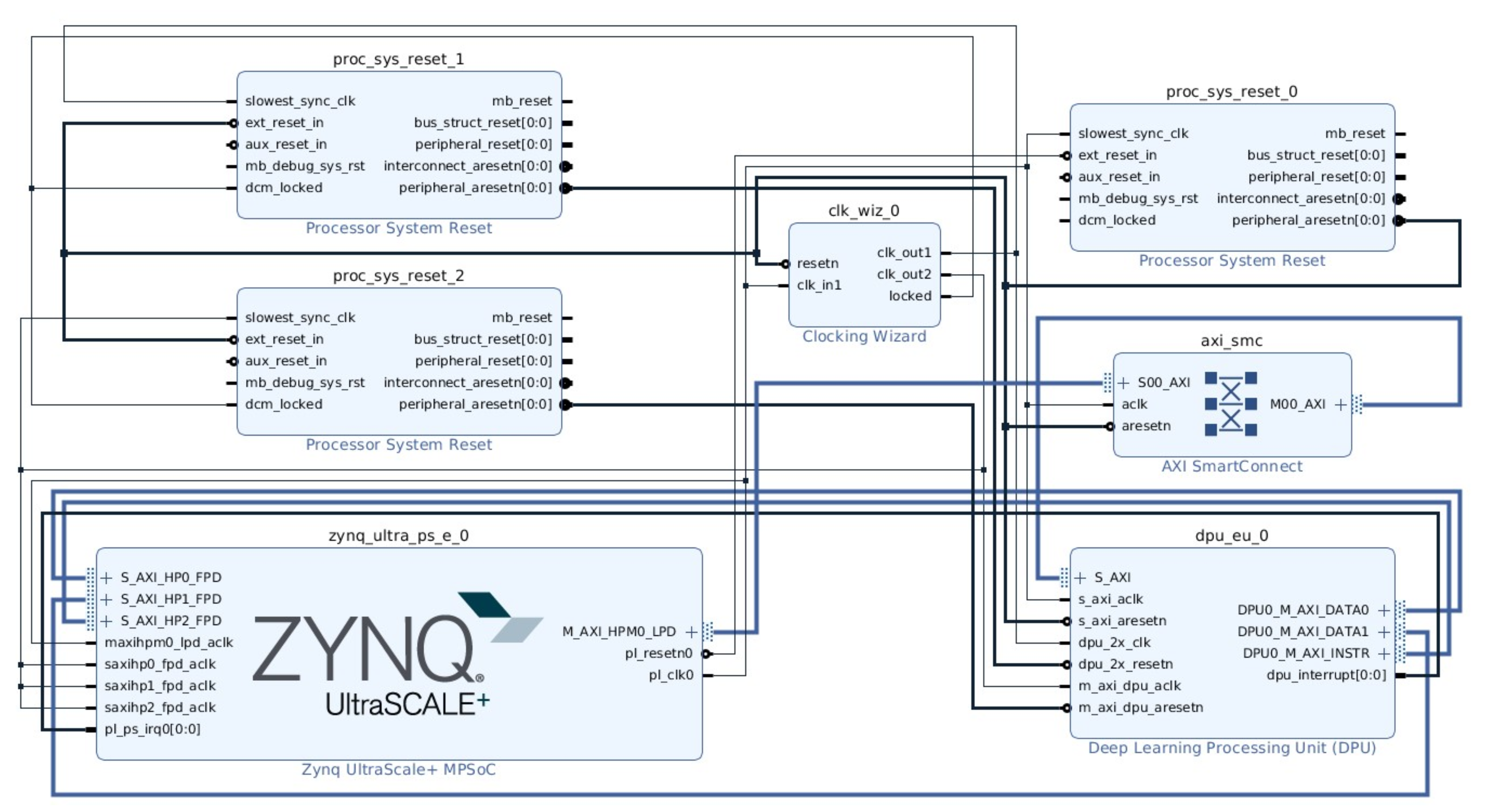
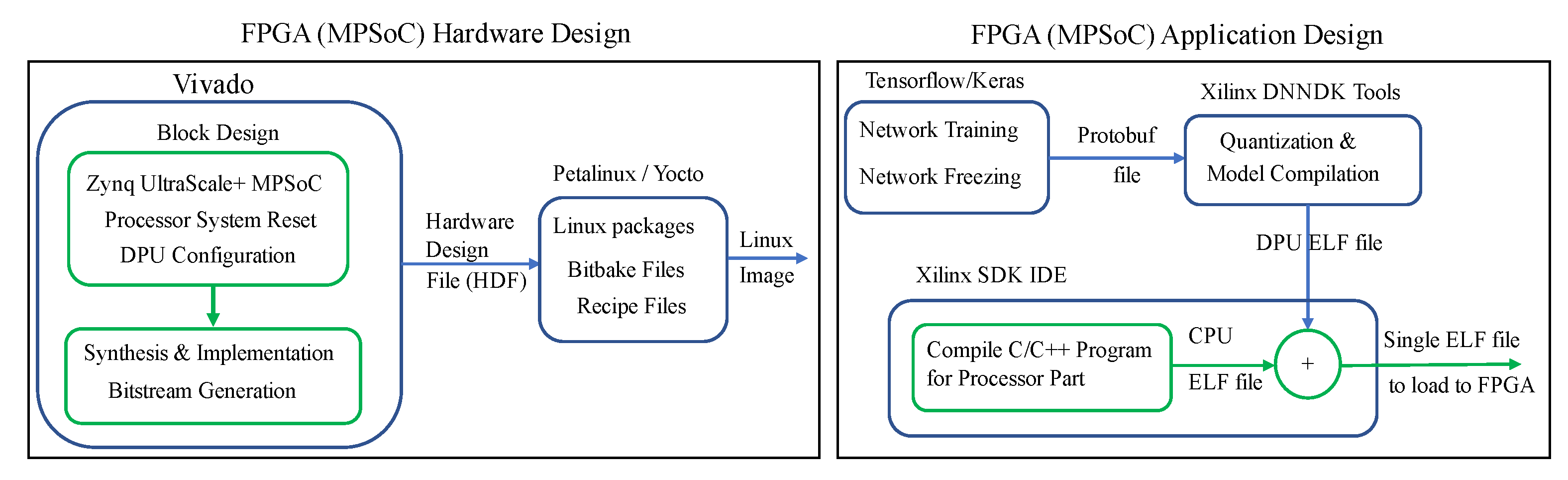
In terrestrial applications, FPGAs have been investigated and utilized as inference accelerators in deep and machine learning applications. The inherent parallelism of FPGAs has been instrumental in achieving real-time inference for such applications. The evaluation boards used in FPGA-based inference have hybrid CPU + FPGA heterogeneous architecture. The Programmable Logic (PL) is the FPGA chip and it contains the computing complex, processing elements, on-chip buffers, controller, and the DMAs. The Processing System (PS) consists of the CPU and external memory. Most of the FPGA-based accelerators have been specific to different CNN architectures and models.
Figure 2 shows a typical accelerator that is based on FPGA. The CNN inference is performed in the PL side, whilst a CPU is required for pre-and post-processing and scheduling tasks. An external memory is required to store the CNN model parameters, data, and instructions. A full CNN model comprises of both convolutional (CONV) and fully-connected (FC) layers. The former are computational-intensive, whilst FC layers are memory-centric, as they typically contain millions of weights. Basic architectures of FPGA-based accelerators can be grouped in three categories: (i) single processing engine, usually in the form of a systolic array that processes each layer sequentially; (ii) streaming architecture that consists of one Processing Element (PE) per network layer; and, (iii) vector processor with instructions that are specific to accelerating the primitive operations of convolutions.
Guo et al., in [
31], conducted a survey on FPGA-based NN inference accelerators. They note that the main considerations for such accelerators is high speed (high throughput and low latency) and high energy efficiency. One of the key steps in adopting models for FPGA inferencing is reducing the network size i.e., model compression. This can be achieved by approaches. such as data quantization and weight reduction, via methods such as pruning. The survey also explores the various hardware design methodologies that have been adopted for efficient architecture, including computation unit designs, loop unrolling strategies and the overall system design taking into account CPU, FPGA and memory configurations. It also investigates the different automation approaches for mapping networks to hardware i.e., hardware and software design automation.
Dinelli et al. presented one example of hardware design methodology in [
32], where they implemented a MEM-OPT system to address the on-chip memory bottleneck of FPGA-based hardware accelerators. The MEM-OPT system is composed of three design aspects: a scheduling algorithm, a Secondary Cache System (SCS) for data re-use and support for different configurations. The scheduler determines the number of elements read out of the Input Cache (IC) for efficient on-chip memory usage. The SCS memory enables IC data re-use, hence reducing the amount of data read out the IC, because successive convolution operations share part of the input data previously read. The MEM-OPT does not require output buffer, because each processing element computes only one output value at a time. This system showed considerable reduction of on-chip memory (BRAMs) usage when compared to other scheduling algorithms.
Wei et al., in [
33], implemented CNN on FPGA while using systolic array architecture for high throughput. This approach ensures low global data transfer since the processing elements (PEs) do not need to access the on-chip memory. Instead, connections are only required between different computation units for data transfer. This systolic architecture enables achievement of high frequency even in massive parallelization with hundreds of PEs. They also implemented an automated flow to map CNN architectures from high-level C code to FPGA, with no hardware-related, low-level considerations necessary for end-users. Lian et al. in [
34] implemented an FPGA-based CNN model by adopting an optimized block floating-point (BFP) arithmetic. The BFP is composed of a mantissa part, whose bit length is defined as 8 for typical CNN models, and an exponent part. Quantization involves both FP2BFP and BFP2FP conversions.
Earlier quantization strategies had gone to as low as binary representation. Courbariaux et al., in [
35], introduced a method of training such Binarized Neural Networks (BNNs). This enabled the use of binary weights and activations for computing the parameters gradients. This enables replacement of arithmetic operations with bit-wise operations, even during train-time, hence reducing training time, memory consumption, and increasing power-efficiency. During training, the weights and activations are constrained to either +1 or −1. Rastegari et al., in [
36], implemented two efficient binary variations of convolutional neural networks. The first one, Binary Weight Networks, had all the weight values approximated with binary values whilst the second one, XNOR Networks, had both weight and input with binary values. The former led to 32x smaller networks when compared to equivalent networks with single-precision weight values and resulted in 2x speed up. The XNOR-Nets resulted in 58x speed up, whilst offering accurate approximation of CNNs. Umuroglu, in [
37], presented a framework (named FINN) for building scalable and fast inference accelerators on FPGAs. They provide an end-to-end mapping of BNNs onto FPGAs. The FINN implementation uses separate compute engines that were dedicated to each layer and which communicate via on-chip data streams. Each engine starts to compute as soon as the previous engine starts to produce output. This framework was further improved into FINN-R that automated the creation of fully customized inference engines for quantized neural networks [
38].
One of the seminal works on FPGA-based inference accelerators was presented by Qiu et al. in [
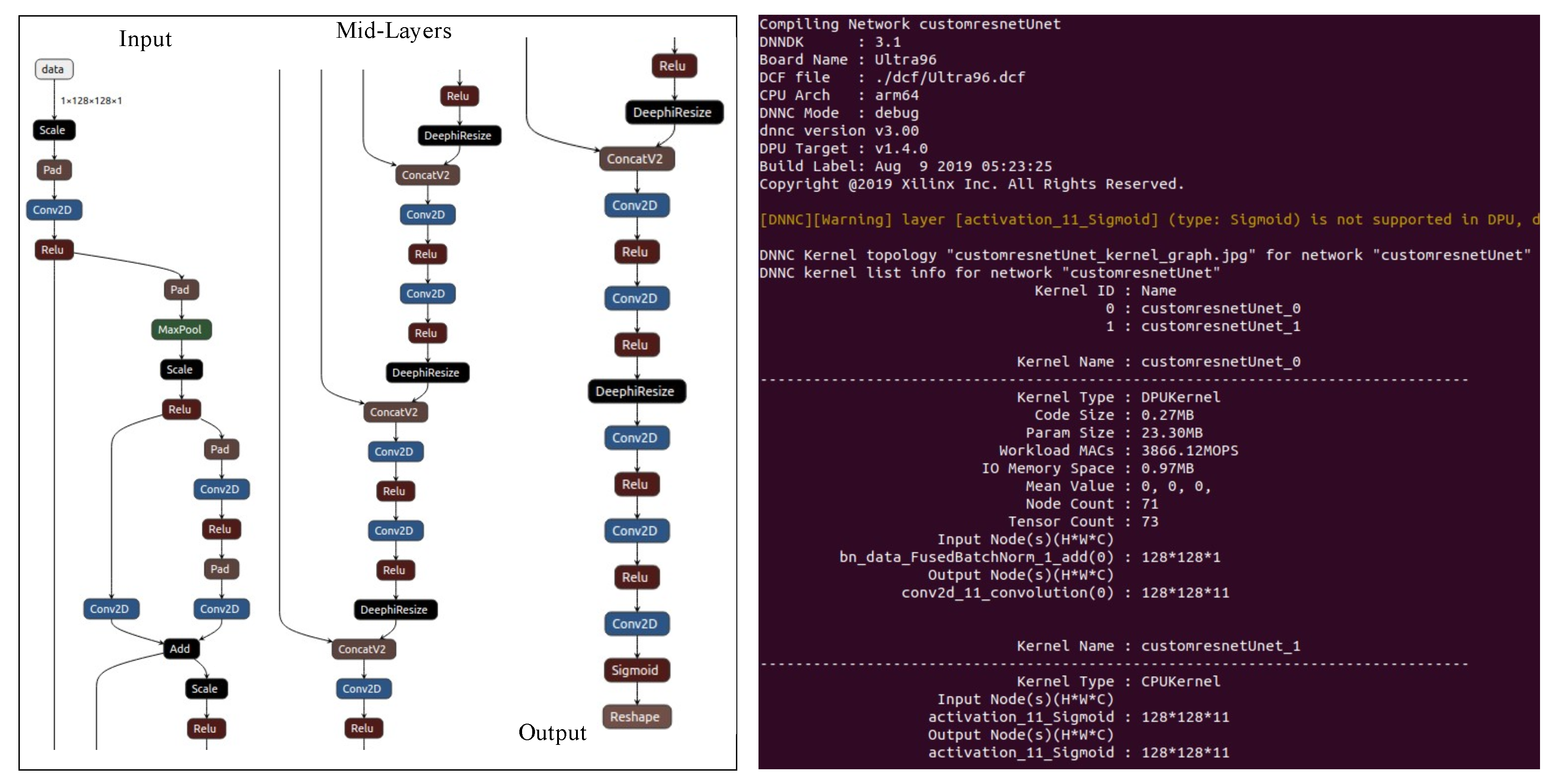
39]. They implemented a CNN accelerator for the Image-Net large-scale image classification on the Xilinx Zynq ZC706 board.A major contribution was an automatic flow for 8/4 bit dynamic-precision data quantization. They used 8-bit and 16-bit fixed-point numbers for the onboard inference and achieved comparable results to floating-point implementations. This set the foundation for their next contribution in [
40], where they present a hardware/software co-design flow for FPGA-based CNN implementation. The original network is compressed to fixed-point representation by optimizing the choice of the radix point positions for the network parameters in every layer. They also implement a parameterized and run-time configurable hardware architecture that supports various networks and that can be adopted on different hardware platforms. They also propose a compiler to map a CNN model to the hardware platform. This work led to the commercial FPGA accelerator engine, DeePhi [
41], which was later acquired by Xilinx and improved into the Deep Neural Network Development Kit (DNNDK) package [
42].
Previous accelerator engines had to be custom-designed for various networks and model applications. This had made the adoption of FPGAs as inference engine in real-world applications limited. However, the DNNDK package led to Xilinx introducing an Intellectual Property (IP) core, the Xilinx Deep Learning Processing Unit (DPU) [
43]. This enhances the implementation of inference engines that are easily adaptable for different CNN architectures and models. Zhu et al., in [
44], explored the DPU architecture and design flow by implementing an efficient task assignment framework to maximize performance on DPU-based CNN acceleration. They explored the optimization of task scheduling between the heterogeneous ARM CPU and multiple DPUs. The optimization strategy aims to utilize the DPU in otherwise unused interval time between multiple inference problems running on multiple threads.The optimization strategy also aimed to ensure that the inference tasks of different networks are controllable. The use of DPU has greatly been enhanced by Xilinx’s machine learning ecosystem that includes the Vitis-AI and model zoo.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
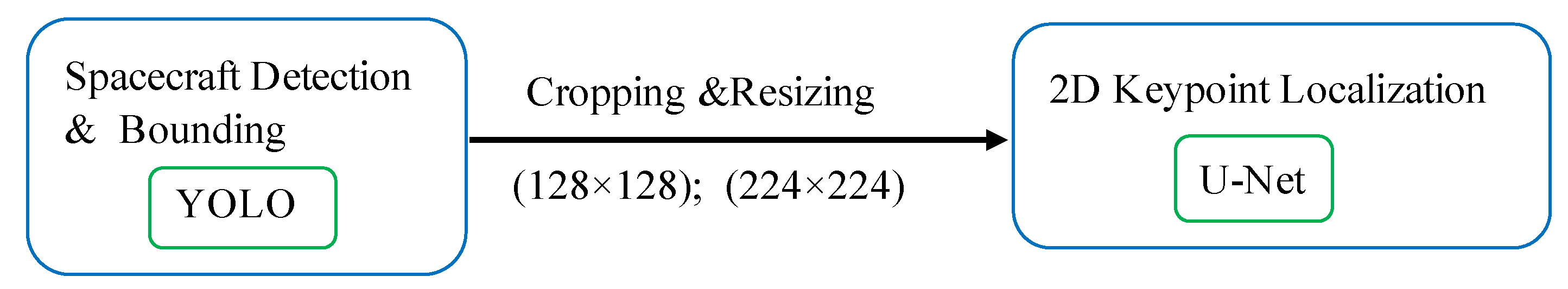{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}