1. Introduction
The Air Traffic Management (ATM) system undergoes a change of paradigm. Current control techniques are surveillance based, meaning that aircraft are monitored using measured positions, mainly obtained by radars. Only in some very specific areas, like oceanic airspaces, procedure based control is applied with separations between aircraft ensured by the compliance to the flight plan and large enough safety margins. In both cases, Air Traffic Controllers (ATC) are using aircraft positions and filed flight plans to avoid conflicts but have no knowledge about the real trajectory. To cope with the increase in air traffic, trajectory based operations will be gradually introduced in the ATM, along with partial delegation of the separation task to on-board systems. Using the improved capabilities of next generation Flight Management Systems (FMS), aircraft will be bound to follow pre-negotiated trajectories designed to minimize interactions, thus alleviating the control workload in low to medium density airspaces. However, uncertainties must be identified and quantified in order to make the overall design resilient and avoid unexpected situations where conflict solving has to be handed out to a human operator in addition to its affected traffic.
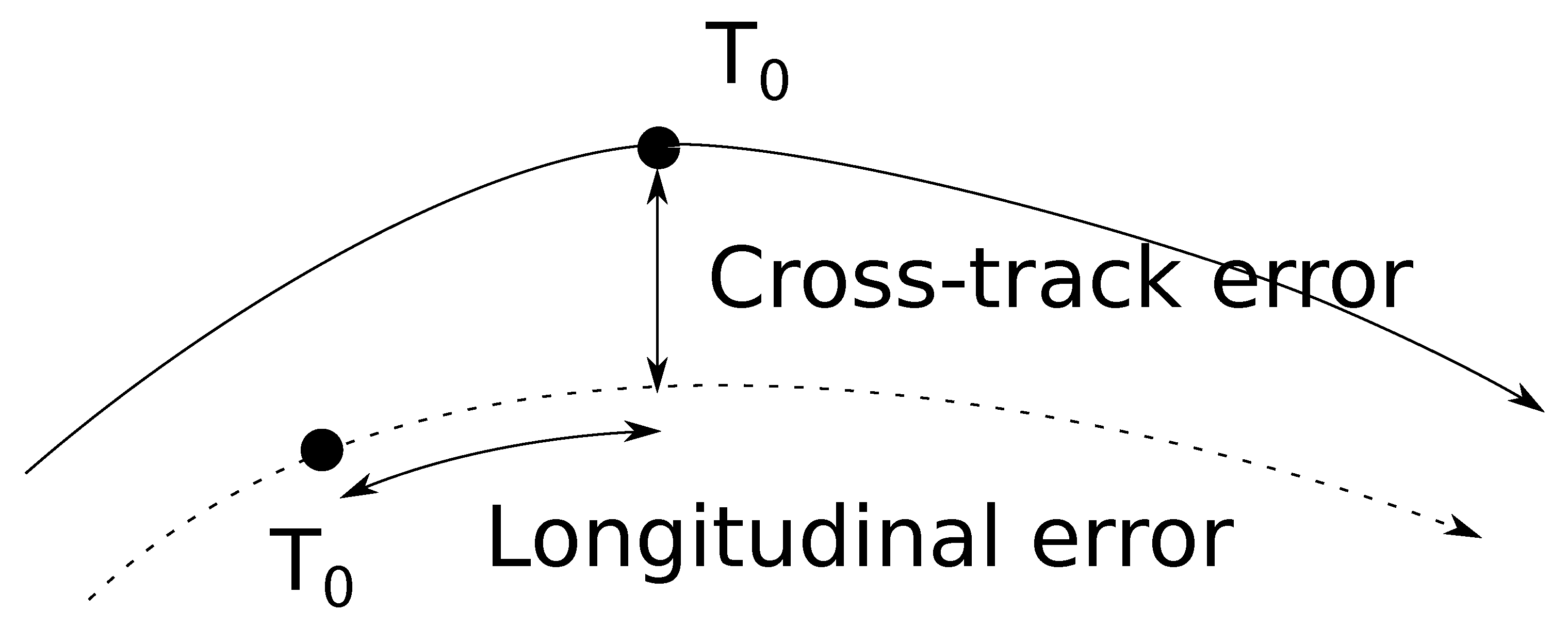
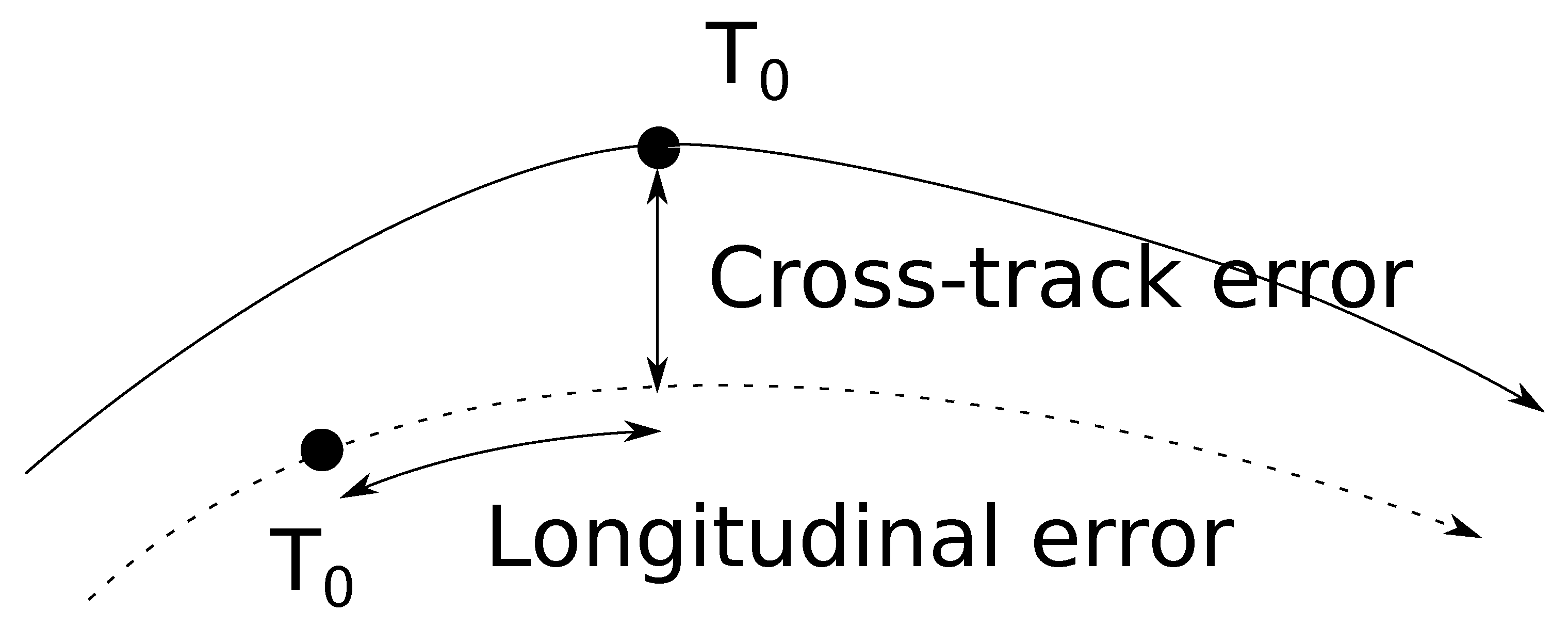
One of the most important sources of uncertainties in the ATM system comes from the wind. When flying a given path, an aircraft can experience two kinds of errors: a cross-track error that describes the lateral deviation from the intended trajectory and a longitudinal error that describes the distance between the current and the expected position at a given time.
Figure 1 summarizes these two measures.
FMS are able to deal efficiently with the cross-track error that can be reduced to very low values so that they are generally not a concern, at least during en-route flight phase. Managing the longitudinal error relies on changing the aircraft velocity, mainly by engine thrust adjustment. Such an operation impairs fuel consumption and may not even be possible since during the cruise phase aircraft are operated close to the maximal altitude, significantly reducing the safe interval of speed variation.
As a consequence, keeping an aircraft on a 4D trajectory, that is bound to a given position at a given time, is not realistic, even in the context of future ATM systems like SESAR (Single European Sky ATM Research) or Nextgen. In a real operational context, the flight will fly a sample path of an underlying stochastic process, that is obtained from the reference trajectory by applying a random time change.
To gain a wide social acceptance of the concept, all automated systems must be proven safe, even under uncertainties on aircraft positions and thus must take the above effect into account.
Several automated trajectory planners exist [
1], most of them being adapted from their counterparts in robotics, but are generally very sensitive to random perturbations. Navigation functions are of current use for autonomous robots and have been extended to air traffic problems [
2]. They offer built-in collision avoidance and are fast to compute. Furthermore, relying basically on a gradient path following algorithm, it is quite easy to derive convergence properties. An interesting approach to design navigation functions is the use of harmonic potentials and recently bi-harmonic ones. The computation is reduced to an elliptic partial differential equation solving, that can be done readily using off-the-shelf software. The STARGATE project, funded by the French agency ANR (Agence Nationale de la Recherche), was initiated to extend harmonic and bi-harmonic navigation functions to a stochastic setting. Within this frame, a mean of simulating random events is required, in order to quantify the probability of failure. As mentioned above, only the longitudinal error along the track is a concern, and it comes from two main sources:
Airport or ATC delays may be somewhat anticipated, but an important variability still exists. Concerning the wind, meteorological models are not accurate enough to ensure a good predictability: the best possible description of a wind field is as the sum of a mean component, generally taken to be the output of the atmosphere models, and a random perturbation. Conflict detection under stochastic wind assumption has been addressed for example in [
3], where a Monte-Carlo approach was taken to estimate conflict probabilities. The importance of random events in simulation for assessing the robustness of conflict resolution algorithms is pointed out in [
4].
Section 3 of this article will be devoted to the means of generating random wind fields, that will be processed within a fast time air traffic simulator. The resulting synthetic flight paths can be used to assess the performance of the conflict solving algorithms and to test the resilience of the planning schemes produced.
In
Section 4, a statistical analysis of airport and ATC delays will be presented, and a simple delay generator will be detailed.
In
Section 5, numerical implementation issues will be discussed and finally a conclusion will be drawn, along with perspectives for future work.
2. Fast-Time Simulations
Experiments in ATC are often conducted using simulated traffic, as setting up even a small scale real traffic campaign is difficult and expensive. Furthermore, the safety issue of using flying aircraft for studies is barely compatible with a quick assessment of the performance of new concepts. When dealing with simulation, the degree of realism needed depends heavily on the kind of study conducted: investigating flight performance at the aircraft level requires a simulator based on flight dynamics and aerodynamics and will involve realistic physical models. On the other hand, new concepts in ATC can be studied with global, less accurate models that only mimic the expected behavior of the aircraft. In this last case, the execution time and the ability to simulate a large number of flights is more important than the knowledge of the individual states of aircraft. Simulators complying with these needs are called fast-time simulators, in reference to the ability to release trajectories orders of magnitude faster than the actual flight time.
Within the class of fast time simulators, six degrees of freedom (6DOF) ones have the highest accuracy and are closest to the true physics of the aircraft. At the other end of the scale, tabular simulators use precomputed, tabulated performance data that describe an average behavior for a given flight phase: climb, descent, approach, cruise. In the middle, point-mass simulators based on total energy models offer a good compromise between accuracy and ease of implementation. A standard fast-time off the shelf simulator is AirTOp [
5], that offers an integrated environment including airports and rule based conflict resolution. For the purpose of the study however, a full control on the simulator code was needed so that this option was not feasible.
The open source fast-time simulator CATS [
6] is a lightweight tabular simulator using BADA tables [
7] written in CAML (Categorical abstract machine language). It was developed with research applications in mind and is easily configurable. However, since the core software of the STARGATE project was written in Java, interfacing with it is a little bit tricky. Furthermore, it is now quite an old tool, not actively maintained.
A recent (2015) BADA based simulation tool, is Bluesky [
8] from TU Delft. It is fully open source and active. It allows for taking a wind field into account, but not with a stochastic component. Being written in Python, it is not easily interfaced with the core part of STARGATE.
Due to the limitations of the aforementioned tools, the development of a complete simulation environment was planned within the frame of the STARGATE project. It was coded almost entirely in pure Java, with only a small portion written in C++ for performance issues. The simulator was nicknamed -rats, and includes a very accurate physical model for the taxi part of the flight. The two stochastic components presented below are used respectively to model the uncertainties during the flight and the random take-off delay.
3. Random Wind Field Simulation
Wind fields generally exhibit an organized structure, along with more chaotic behavior in some areas, as shown in
Figure 2.
Meteorological models forecast wind speed on a sampling grid, with angular increments that can be as low as 0.01 degrees (e.g., the AROME model from the French weather service). The temporal resolution is not so high, typically in the hour range. Due to the requirements of future ATM systems, providers are working on an order of magnitude improvement, but such data is not yet available.
Even with the best available resolution, the characteristic mesh size is about 1 km, which is not enough to ensure a very high quality trajectory prediction: an interpolation error will add to the predicted position. The same is true for the time interpolation point of view and both effects may be modeled as a random variable. Finally, inherent model inaccuracies can be incorporated, so that the wind field X may be represented as the sum of a deterministic mean value and a stochastic field . While is a vector valued field, it will be described in coordinates and only scalar fields will be considered in the sequel.
3.1. Spectral Representation
In order to be able to simulate a random wind field, a mathematical model of it must be found. This kind of problem pertains to the field of geostatistics [
9] and has been investigated in many contexts ranging from mining to economics and weather science. From an intuitive point of view, one wants to construct a random function that maps a position to a vector.
At the most abstract level, a random field is thus a measurable mapping
where
is the domain of definition and
is a probability space that describes the possible outcomes [
10]. For a given point
x in
U, the random variable
is the (stochastic) value of the field at position
x. It describes the variations of the velocity at
x and will be denoted by
in the sequel. According to a theorem of Kolmogorov [
10], the knowledge of the probability space
is not required. In fact, a random field is fully characterized by the distribution of its finite samples
for any possible choice of the sampling points. When these distributions are normal, the field is said to be Gaussian. It is a very common assumption in geostatistics, backed by the central limit theorem when the randomness of the data comes from a physical noise.
Taking the expectation of and letting x vary over U defines the so-called mean function of the field.
Definition 1. Let η be a Gaussian field on a domain U of . Its mean function is the mapping defined as: The covariance function of the field describes the correlation between velocities:
Definition 2. Let η be a Gaussian field on a domain U of . Its covariance function is the mapping defined as:
with
the set of square positive definite matrices of dimension
d.
The mean and covariance functions fully characterize the Gaussian field
[
11]. In many cases, the covariance function is translation invariant, meaning that it depends only on the difference between the two measure points and not on their absolute positions. This property is known as spatial stationarity and is expressed as follows:
Definition 3. Let η be a Gaussian field. It is said to be second order stationary if it exists a mapping such that: The next proposition is classical and can be found in [
12] in a more general form.
Proposition 1. For any finite sequence of points in , the vector is Gaussian, with meanand covariance The covariance function is positive definite [
11] and satisfies:
The Bochner theorem [
13] gives a characterization of positive definite functions:
Theorem 1. A continuous mapping is positive definite if and only if it exists a finite positive measure F such that: It is often easier to check that a given mapping is positive definite through the use of Theorem 1 than with a direct proof. In the case of covariance functions, F is known as the spectral measure of the random field and when it admits a density , one can compute a numerical approximation of it using a discrete Fourier transform. This property is the key ingredient of many efficient random field generators. The spectral density can be proved to be even and positive.
3.2. Gaussian Field Generation
Algorithms for scalar Gaussian field generation can be direct or spectral. In the first case, the Proposition 1 is invoked to generate Gaussian vectors on a mesh of points that is generally structured as a rectangular, evenly spaced grid.
Proposition 2. Let be a sample of independent, normally distributed real numbers. Let v be a vector in and C a symmetric, positive definite matrix. The vector is Gaussian, with mean v and covariance C.
Proof. It is a very classical result that comes at once from the properties of mathematical expectation. Since
u has zero mean:
The covariance is then given by:
☐
The computation of the square root is not required: the Cholesky decomposition will give the same result and is much easier to obtain. The algorithmic complexity of the process is dominated by the Cholesky decomposition, that is an process. Once done, sampling the vector u and performing the combination is of order . In many cases, the covariance will quickly drop for distant pairs of points: the matrix C is often nearly sparse, and adapted algorithms for the Cholesky decomposition exist. However, this stage remains the bottleneck of the Gaussian field generation procedure.
Spectral algorithms rely on a fast Fourier transform to let computations occur in the frequency domain. In [
14], some methods for sampling Gaussian fields based on this approach are detailed.
The general principle underlying these methods is the use of Bochner theorem and Itô isometry formula. While almost never stated in references related to numerical Gaussian field simulations, it is a very important point that may be used as a basis to derive algorithms. The approach taken in this work is to directly approximate the spectral representation of the field instead of using it only as a convenient tool for lowering the computational cost. A benefit is that optimal quadrature rules may be used in the Fourier domain to improve the reconstruction of the simulated field.
Let us first start with some basic facts about spectral representation of processes as exposed in the reference work [
15].
Definition 4. Let be a probability space and let be the space of finite variance complex random variables over it. An orthogonal stochastic measure on is a mapping μ from to such that:
For all couples in such that : P-almost surely.
It exists a measure m on such that for all couples in :
The measure m occurring in the Definition 4 is called the structural measure of The definition can be extended straightforwardly to vector valued, finite variance random variables by requiring that the covariance matrix is a -additive function on with diagonal entries ordinary measures.
Given a simple function
, one can define its
-integral as:
which is an
random variable by definition of
. Given the fact that random variables in
are limits of such functions, one can define the
-integral of an arbitrary
random variable.
A very important isometry theorem holds for -integrals.
Theorem 2. Let be random variables. Then: An important special case arises when is obtained from a left mean-square continuous process F with orthogonal increments. In such a case, one can construct on intervals by and extend to the Borel -algebra on . The resulting -integral is a stochastic Stieltjes integral. Extension to can be done component-wise, using independent processes in each coordinate and take as the stochastic measure of a rectangle the product of the stochastic measures of its sides. Itô integral is recovered when F is the Wiener process, the Theorem 2 being the Itô isometry.
Theorem 3. Let X be a complex stochastic process on with a well defined covariance function . If it exists a measure space and measurable functions such that: Then it exists a stochastic orthogonal measure μ on with structure measure m such that: The previous two theorems can be extended to vector-value stochastic processes [
15].
The following special case will be the one used in the sequel:
Theorem 4. Let X be a complex vector valued continuous, stationary random process defined on with zero mean. Then it exists a vector-valued stochastic orthogonal measure μ such that almost surely: 3.3. Principles of Gaussian Fields Simulation
If
is the covariance function of the field that must be simulated, then it can be written according to Theorem 1 as:
and if
is absolutely continuous with respect to the Lebesgue measure as:
with
a density. Let
Z be the centered random field given by:
with
the
d-dimensional complex Wiener process. By the Itô isometry it comes;
Finally, the process has covariance and mean as required.
For numerical simulations, the above stochastic processes need to generate samples at fixed positions, which may be done using a very simple approximation of the integral as a finite sum. First of all, the domain of integration has to be reduced to a bounded region
U of
in order to make it amenable to numerical implementation. Since in the spectral representation the density
is even, it makes sense to let
U be a product of centered rectangles:
(here
or
). An elementary cell in the grid,
, indexed by the vector
with integer coordinates, will be written accordingly as:
where for each
i,
is a subdivision of the interval
. Please note that the index coordinates
are for each
i in the set
. The discretization of the integral in (
3) over the partition given by the cells
using the rectangle quadrature formula gives:
with:
In the computation of the volume element (
7),
are independent one-dimensional Wiener processes. Due to the fact that
has normally distributed increments, it appears that
follows a
d-dimensional centered Gaussian distribution with diagonal covariance matrix and variance
in dimension
i: generating samples according to such a law is easily done using for example the Box-Muller algorithm [
16].
In practice, only regular grids are used, and we may further assume that discretization steps are equal to a fixed value in each direction. The random number generator is then calibrated once for all to draw samples according to a . Please note that the algorithm takes place in the Fourier domain, so characteristic dimensions must be inverted when going to the space domain, as it will be made more precise in the sequel, when dealing with numerical implementation.
3.4. Finding a Covariance Function
Model covariance functions must comply with the requirements already mentioned above, namely they must be a symmetric and of positive type function. Finding a good covariance function is quite a common question arising within the frame of spatial statistics. A good account on the subject is [
17] that covers many aspects of covariance functions estimates. As usual with estimators, available methods fall within two categories. In the first one, covariance candidates are selected from a fixed family, whose parameters are adjusted so as to best fit the observations. A classical choice is exponential functions, either in spatial or the Fourier domain: in such a case the transformed function in the dual domain will be a slowly decreasing mapping, behaving roughly as
at infinity. Another option is to use a Gaussian function, that is of positive type and exhibits fast decrease in both the spatial and Fourier domain. Parameters are estimated using a maximum likelihood procedure. Finally, the Matern function [
18] is a popular class within the geostatistics community and is defined as:
where
is the modified Bessel function of order
.
a is a scale parameter that tunes the model characteristic distance while
tunes the smoothness. Large
yield very smooth fields while low
produce rough ones. While being more accurate for wind field or temperature field simulations, the Matern covariance has the drawback of not having an easily computable Fourier transform. When using the spectral approach for simulations, it must be first evaluated on the same grid as the field to be simulated, then a FFT must be performed in order to have its approximate Fourier transform. Please note that this has to be done only once, regardless of the number of random fields that will be simulated. It has been implemented in the simulator, along with the exponential and Gaussian covariance functions.
The second class of covariance functions, known as non-parametric estimates, is mentioned here for the sake of completeness as it was not implemented for the study. The idea is to build the covariance from the observations themselves, without any assumption about an underlying model. The most commonly used estimators are:
where
is the observed field at position
and:
K is a kernel function that is compactly supported most of the time: as a consequence, the summation takes place on a reduced set of the observation, making the method nearly constant in time if the samples are not too concentrated. As before, computing the Fourier transform requires sampling the covariance function
C on a grid. Its main drawback is the number of samples required to get a good estimate and the need to adjust the scale of the kernel in order to get the best possible results.
4. Airport and ATC Delays: A Statistical Study
For the purpose of the STARGATE project, only a coarse modeling is needed for the airport delays, as simulations involving ground side are done at a strategical time horizon, namely weeks to days from real departure dates. Given the uncertainties in the weather at this time scale, only very conservative planning may be designed, which will serve as a basis for reference business trajectories negotiation. A statistical study was conducted on sample data coming from flight plans data in France over the years 2012–2015. A python parser was designed in order to transform the original data in COURAGE format (used by the French civil aviation authorities) into a csv file readable in R. The code is made available at the project website [
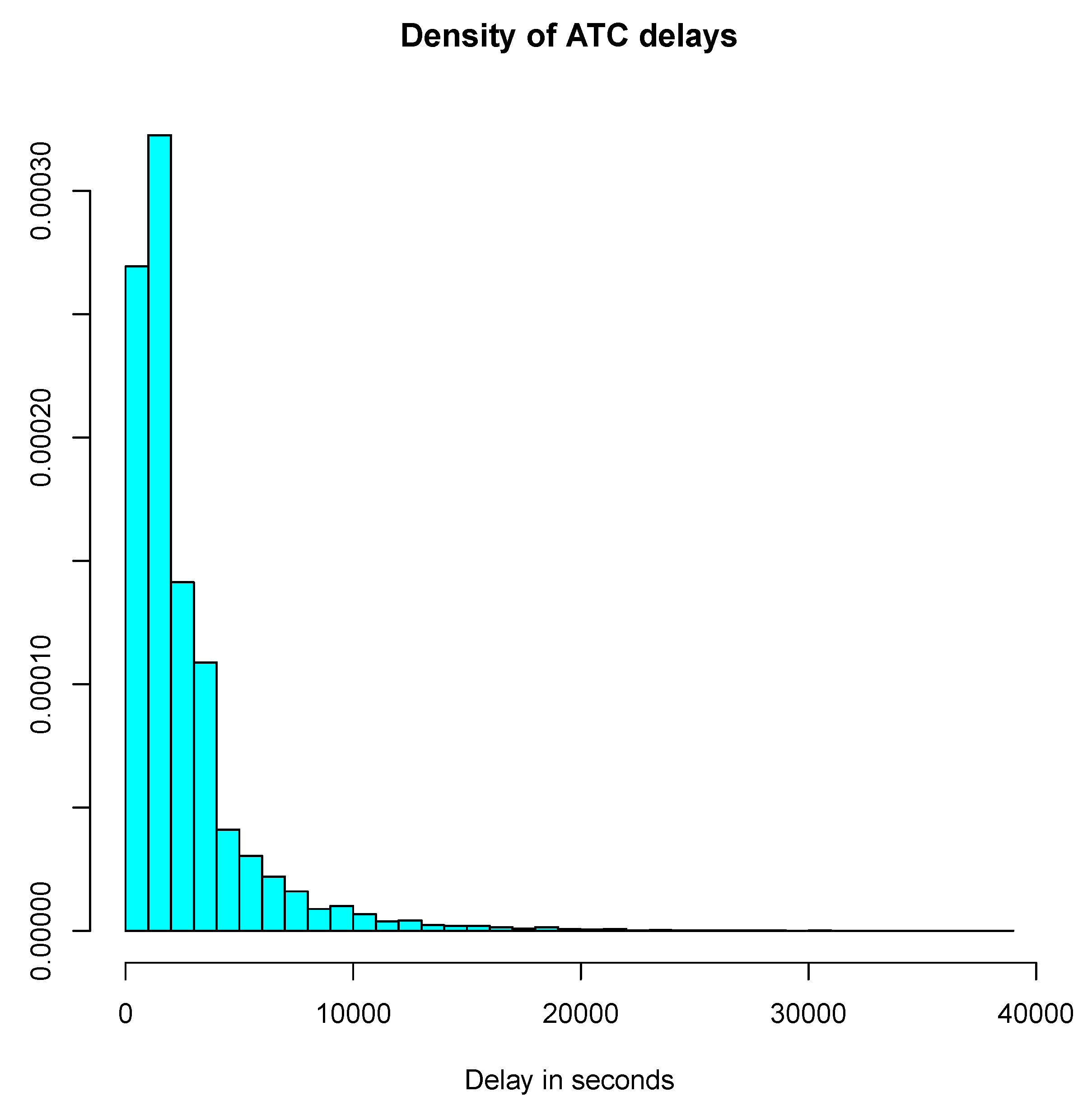
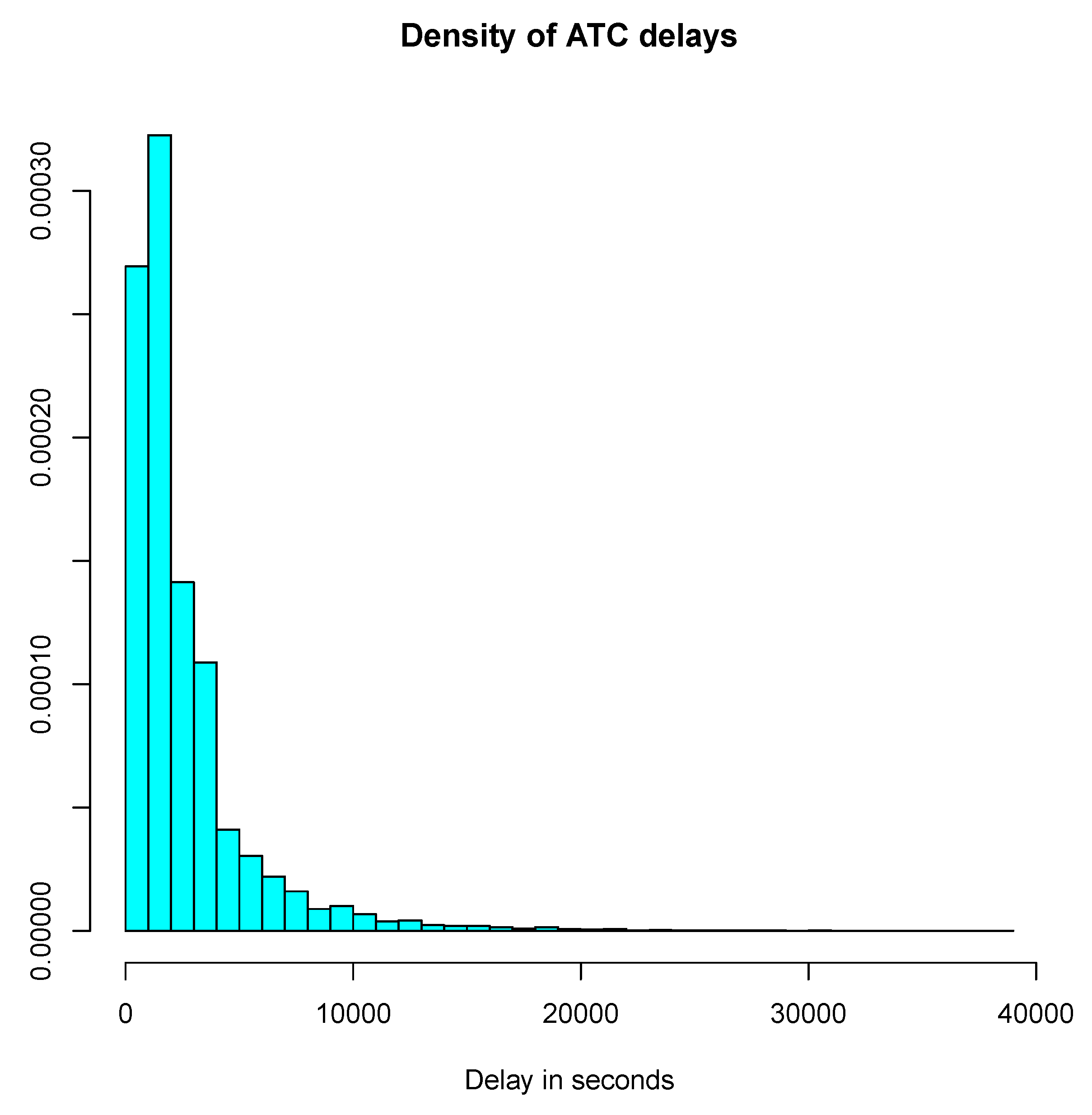
19]. A simple pre-processing step is needed to get rid of aberrant values due to flights erroneously classified on a day, while departing one day before or after. This situation occurs on long-haul flights when part of the trajectory is made over the French airspace, but departure or arrival take place on another day. All flights with high delays are thus processed in order to check for such an event and are discarded from the initial set of samples. Furthermore, negative delays may occur but are uncommon and not useful for the application in mind: only flights with positive ones have been retained in the final sample. The density histogram on the cleaned data is shown on
Figure 3.
From classical queuing theory, it is common to fit an exponential distribution on delays. Based on the histogram, other candidates are the Weibull and gamma distributions. Using the function
fitdistr from the R package MASS (Modern Applied Statistics with S). the maximum likelihood estimates in
Table 1 were found.
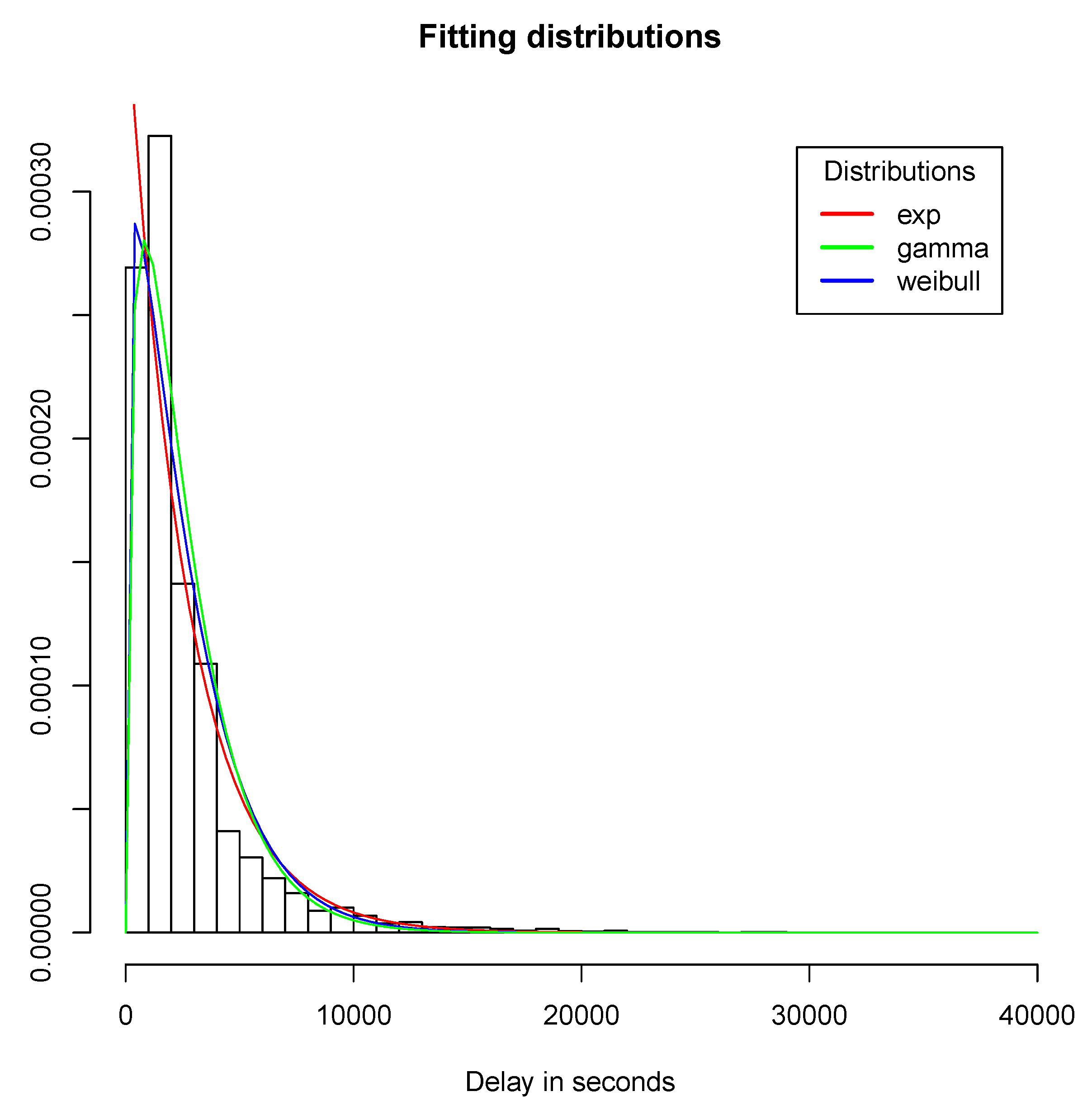
The resulting densities are plotted against the sample histogram in
Figure 4.
Only the initial part of the curve makes a real difference, especially for the exponential distribution that will not vanish at the origin. The best fitted distribution is the gamma one, and in fact the exponential distribution is a special case, with the shape parameter equal to 1. For simulation purposes, the generation of exponentially distributed values is easy using either a transformation or the fast ziggurat algorithm [
20], making it a first choice from the computational point of view. The exponential distribution yields easier theoretical derivations. It is not a real issue for simulations, but the stochastic delay model is intended to be used also for resilient automatic conflict resolution algorithms. In this context, the ability to derive provable results is mandatory.
The well known absence of memory of the exponential law is questionable in the context of airport or ATC delays as one can expect them to be highly correlated in time. This is true at small time scales, say hours, but no longer verified at the larger time horizons. Depending on the accuracy needed for the model, it may not be an issue. On the other hand, the general gamma distribution is a better choice from the modeling accuracy point of view. The flexibility given by the shape parameter allows a decrease in the likelihood of observing zero delays, which is close to the operational reality. In fact, it is a common practice to allow several aircraft to take-off at the same time. In this case, only one of them will experience zero delay, while the others will be slightly delayed.
Simulating a gamma distribution can be done in a very efficient manner using the reject algorithm presented in [
21] since the estimated shape parameter is larger than 1. Let us recall briefly the principle of the rejection method for random variable generation [
22]. Let
be the target distribution and let
be a reference distribution. Let
and
be two positive functions satisfying
. Putting
the rejection procedure is given in Algorithm 1.
| Algorithm 1 Rejection sampling. |
while not accepted do
y is sampled from
u is sampled from
if then
Accept
end if
end while |
The computational efficiency of the algorithm may be low if
is large: finding a reference
as close as possible to
is the key ingredient of the method. For shape parameters less than 2, which is the case for the delay samples observed so far, the choice made is to use a reference exponential distribution. Following [
23], the optimal rate for this distribution equals the ratio rate/shape of the target gamma distribution, which is
with the above sample of delays. The comparison functions are:
A simulation was conducted with the generation of gamma distributed random variables, yielding an acceptance rate of , which is extremely good in such a context. Please note that the computation of the special function is not needed for the rejection method: only exponentials and powers are required.
The overall conclusion for the delays simulation is to use the gamma distribution with the rejection algorithm. It yields close to operational values, with only a small increase in computational cost when compared to the exponential distribution. For theoretical derivations, the exponential distribution is the best suited, but the above result shows that it is a close approximation of the gamma.
Finally, it is worth mentioning that gamma distributions can be represented as points on a two dimensional Riemannian manifold [
24]. Using this geometrical framework will pave the way to a very accurate description of the structure of delays, by performing clustering on the gamma manifold. The final result will be an empirical distribution of gamma distributions, allowing for the generation of different delays structure, possibly taking into account spatial informations. This extension is currently under investigation, the main issue being the availability of the delays at the airport level.
5. Numerical Implementation
The purpose of this section is to detail the way random wind fields are generated. It is split into two parts: acquisition of weather data, with an emphasis on publicly accessible sources and stochastic simulation.
5.1. Weather Data
The overall simulation process starts with prior information about the deterministic component of the field. It is available from weather services as a grid of values computed from a numerical model. Depending on the reference time, real measurements may be part of the data, but will not cover the entire grid: an interpolation is realized implicitly by the model used. The French weather agency provides two ways for accessing the data:
Direct download of files encoded in the GRIB (GRIdded Binary) format [
25].
Access through a web service complying with the European INSPIRE (Infrastructure for spatial information in Europe) directive [
26].
The highest resolutions can be obtained only using the first procedure.
Table 2 summarizes the data downloadable with the associated grid spacing and coverage, expressed in latitude-longitude coordinates.
Nearly all atmospheric parameters are available. The complete description of the AROME and ARPEGE models is available at [
27].
Figure 5 is an example of wind data acquired from the 0.01 deg AROME model.
Unfortunately, high resolution data cannot be accessed from the web service at the time where this article was written, only the 2.5 deg world coverage was implemented. It is expected that all models will soon be ported to this platform, which will then become the preferred data source. Due to the resolution limitations and the fact that fine step samples are needed to accurately implement the random field generation, only the outputs from the AROME model were used in the present work. The relevant atmospheric parameters were the wind components, associated respectively to projections onto local longitude and latitude coordinates and with an altitude-pressure of 250 hPa, roughly equal to the flight level 340, which is the mean cruise altitude for commercial aircraft (one must note that resolution is reduced at this altitude compared to the original 0.01 deg).
5.2. Gaussian Field Simulation
As indicated in
Section 3, the simulation will be conducted by means of a spectral representation. The fast Fourier transform (FFT) is an
algorithm for efficiently computing sums like the one appearing in (
6). The software library used for that purpose is FFTW [
28,
29], a very efficient implementation that is able to operate on sequences of arbitrary lengths (The original FFT algorithms requires lengths in powers of two).
Let us first recall the definition of a discrete Fourier transform (DFT), that is computed by the FFT algorithm. Given a sequence
, its DFT is the sequence
given by:
Looking at expression (
12), it appears immediately that
is a periodic sequence, of period
N. Furthermore, if the DFT is interpreted as an approximation of a Fourier integral, then the domain of integration has length 1, due to the
appearing in the complex exponential. The inverse DFT is defined pretty much the same way:
The DFT can be used to approximate an integral if considered as a Riemann sum. In such a case, it is easy to see that if the points
are considered as samples at positions
in the interval
, so that the time period is
T, then the corresponding sample positions in the frequency domain are located at
. Introducing the so-called sampling frequency
, the samples in the frequency domain are expressed as
. Going back to formula (
7), the points
appearing in the expression correspond to a subdivision of the interval
where
is the sampling frequency in the dimension
i (with corresponding number of samples
). This fact is important and often overlooked: the frequency domain depends on the sampling rate, and thus if the time (or spatial) interval is fixed, on the number of discretization points. On the other hand, the frequency resolution, that is the difference between two samples in the Fourier domain depends only on
T, the length of the time interval. As a consequence, the respective variances of the Gaussian increments occurring in the expression (
7) are
, where
is the length of the spatial domain in dimension
i, and are not dependent on the number of sampling points. The same remark applies for the function
appearing in (
7) where care must be taken to use the points
. When using the inverse DFT for computing, it is important to note that the term
present in the expression must be scaled out in order to get an approximate integral. Finally, the procedure described above will generate a complex valued random field, which is not needed in practice, unless one wants to obtain two independent samples in one step. It is possible to get a real valued field by generating only half of the Gaussian random variables and taking the complex conjugate of them for the remaining ones. Gathering things, a 2D-field generation algorithm on a evenly spaced grid with
points in each coordinate, can be summarized as indicated below.
Algorithm 2 returns a field with energy proportional to the product . This can be understood intuitively by recalling that the DFT approximates an integral over . If a unit energy is needed, then an inverse scaling must be applied or a normalization performed: this last option is preferred as it removes any inaccuracy coming from the finite precision computation of the FFT, at the expense of a higher computational cost.
| Algorithm 2 2D Gaussian field generation. |
Require:M is a complex matrix
Require: are the respective sample frequencies in
Require: is the required spectral density
Require: generates independent random normally distributed real numbers with mean and variance
for do
for do
▹ Endpoints are handled differently: they have a vanishing imaginary part
if or or or then
else
end if
end for
end for
▹ X is the generated real field |
5.3. Hardware and Software Architecture
The complete -rats framework is a fast-time simulator written in Java and able to perform parallel computations on a grid of computers. Each compute node hosts a simulation process and communicates with a master node using MPICH3 and the Java Native Interface (JNI) API. In the current implementation, nodes are Fujitsu Celsius workstations with gigabyte links, a dual XEON E5-2609 at 2.5 GHz and 16 GB of RAM memory. The master workstation is also used for sandbox development and has a Pascal Titan X GPU card attached. Future releases of the simulation environment, including the random wind field simulator, will make use of GPU computing power when available.
The random delay generator does not significantly impact the overall computation cost since it is used only when a flight is scheduled for departure. It was implanted in pure Java, without any third-party library. Its performance was assessed both on qualitative and quantitative aspects using a database of flight plans filled and realized in the French airspace and covering the 2016–2017 period. According to French Civil Aviation School (ENAC) operational experts, the simulated departure delays are coherent with their experience on French airports.
The bottleneck of the wind field simulator is the two dimensional Fourier transform. It is performed using the FFTW v3.3.7 library, which is one of the most efficient software implementations of the FFT algorithm available today. It has the ability to exploit all the cores and processors available on the compute platform. On the master node described above, the simulation of a day of traffic over France (approx. 8000 flights), with refreshing rate of 4 s, takes less than 10 min. One day of world traffic can be simulated on a grid of six nodes in 20 min. A snapshot of simulated traffic is given in
Figure 6.
6. Conclusions and Future Work
The present work describes means of simulating random events occurring in the context of the air traffic system. ATC and airports delays can be modeled according to a gamma distribution, taking into account the large time horizon considered. This choice was backed by expert advice, which justifies its use in a research oriented simulator. For the meteorological uncertainties, a simple random Gaussian field model is assumed. Generating such samples can be done efficiently using a spectral algorithm. This approach is based on the spectral representation of the process and its discretization in the Fourier domain, which contrasts with the usual spatial discretization. The resulting algorithm is similar to the ones described in the literature, but relies on a different principle and allows more flexibility. A direct extension can be done to deal with multiscale simulation of wind fields, effectively representing turbulent phenomenons, like those occurring in approach phases. While not implemented in the current release of the simulator, the use of wavelets for representing the covariance functions will be introduced in a future work to cope with multiscale modeling. Finally, it is worth mentioning that a UAV extension of the
-rats simulator is under development and will be made available on [
19] at the beginning of 2019.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}