
Coordinated Reentry Guidance with A* and Deep Reinforcement Learning for Hypersonic Morphing Vehicles Under Multiple No-Fly Zones


Abstract
1. Introduction
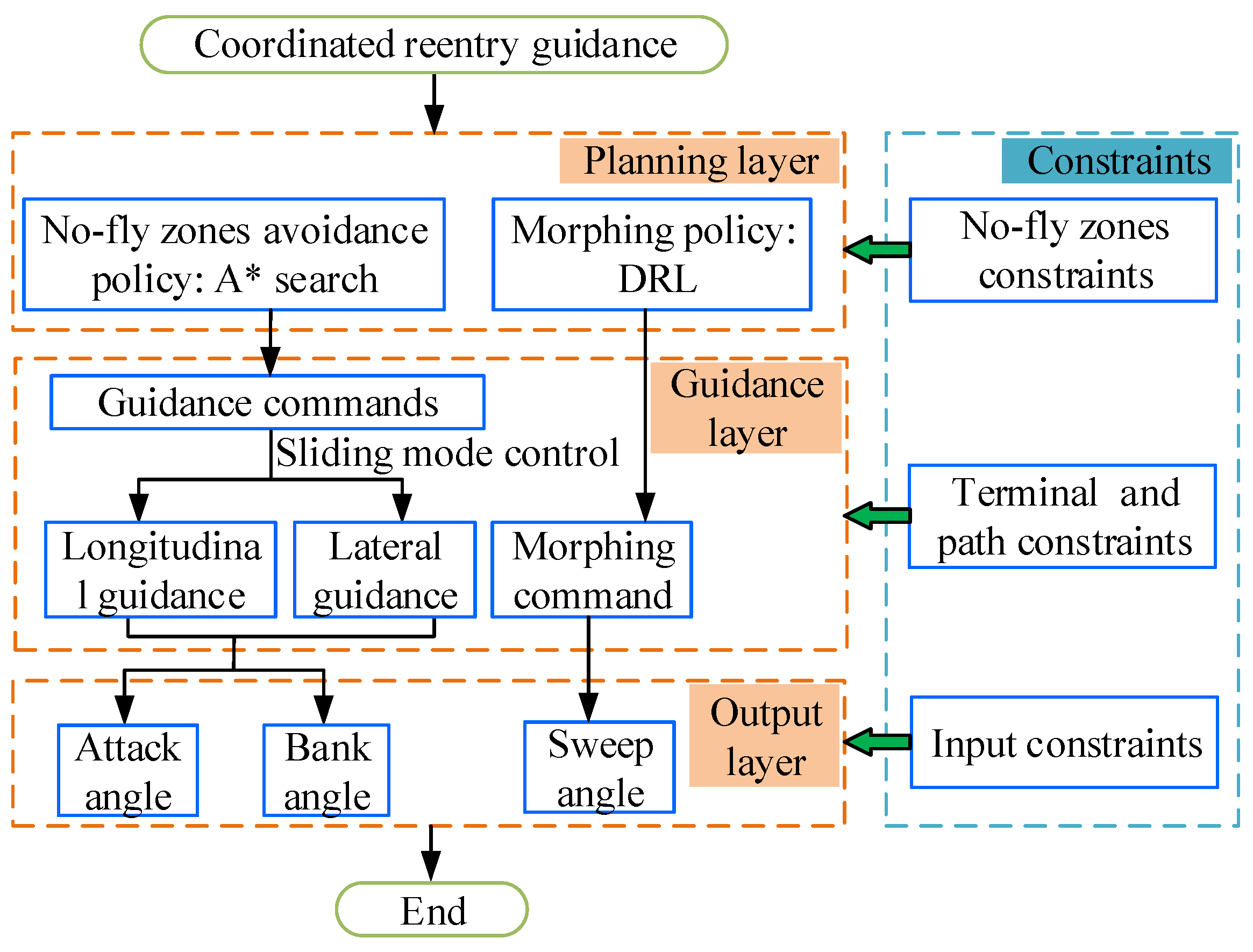
- The energy-optimal avoidance reentry trajectory search approach based on A* algorithm, effectively solves the challenge of finding optimal waypoints under the intricate constraints of multiple no-fly zones.
- Leveraging DRL algorithms, an intelligent autonomous morphing policy network for HMVs is trained. This network intelligently utilizes morphing commands to adaptively control terminal velocity, resulting in a significant optimization of reentry guidance performance.
- A QEGC guidance law that relies on a continuous switching sliding mode control is proposed. This approach transforms path constraints into direct guidance input constraints, enabling high-precision guidance with a robust performance.
2. Models of the HMV
2.1. Morphing Mode
2.2. Motion Models
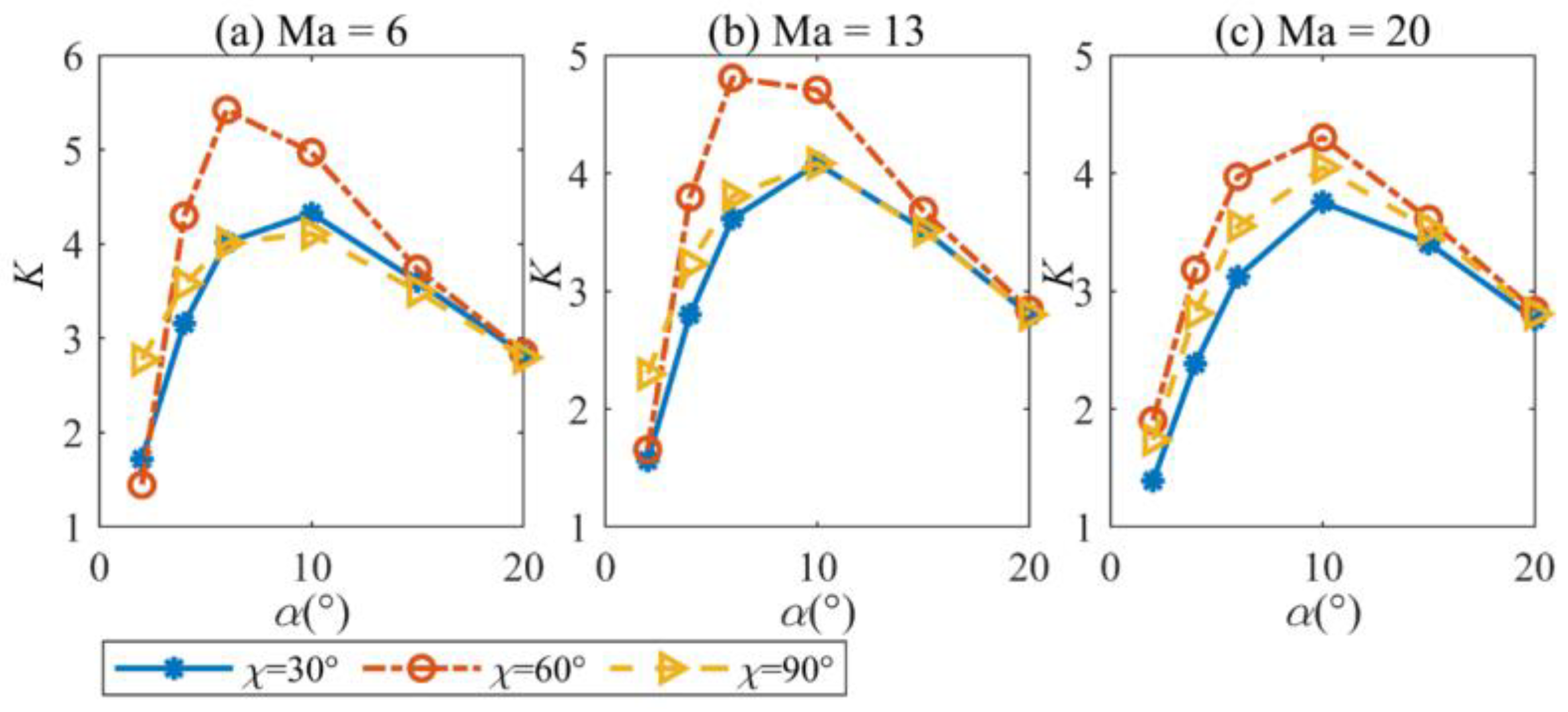
2.3. Effects of Morphing on the Aerodynamic Performance of the HMV
2.4. Modeling of Constraints
3. No-Fly Zone Avoidance Policy Based on the A* Search Algorithm
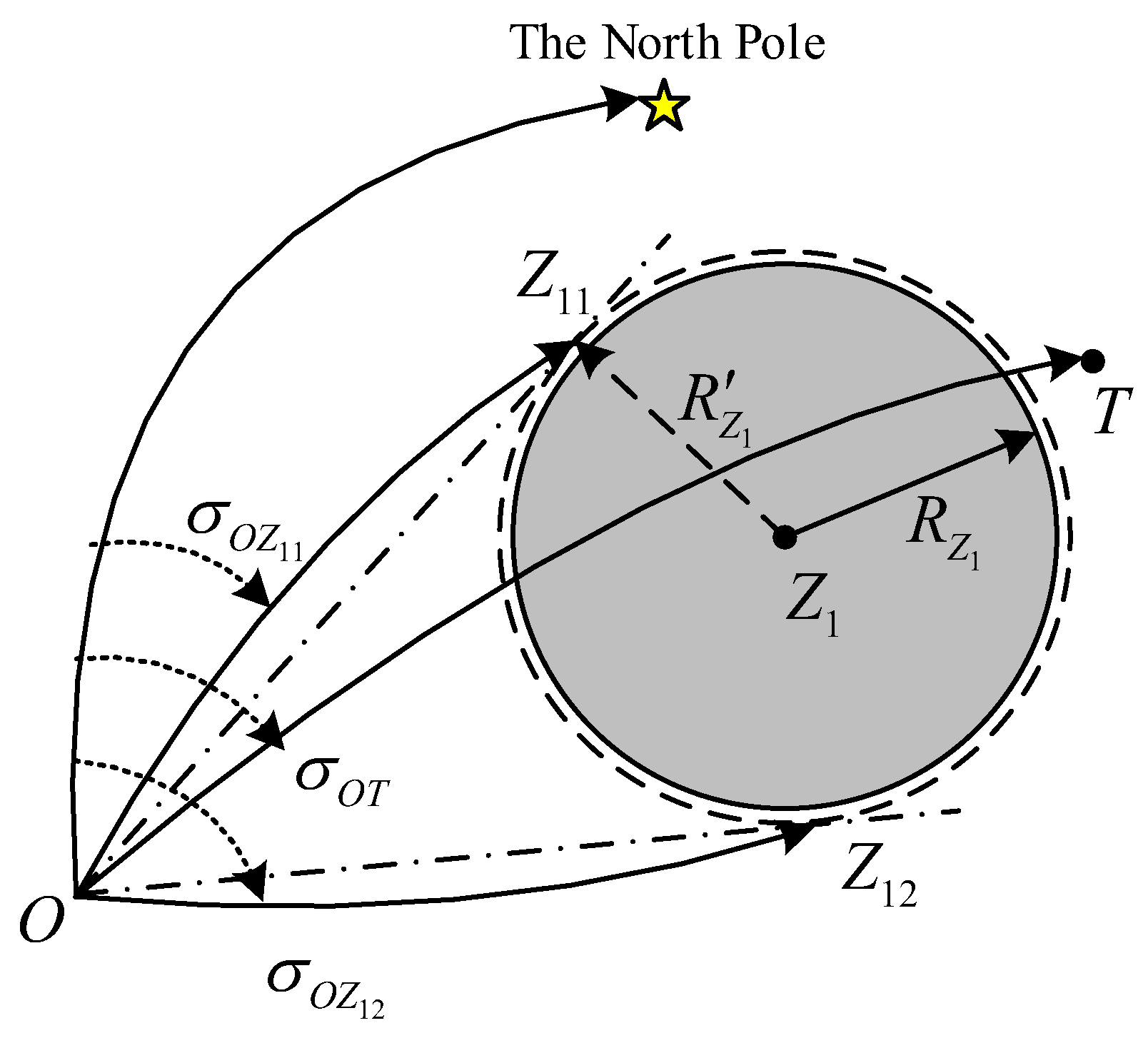
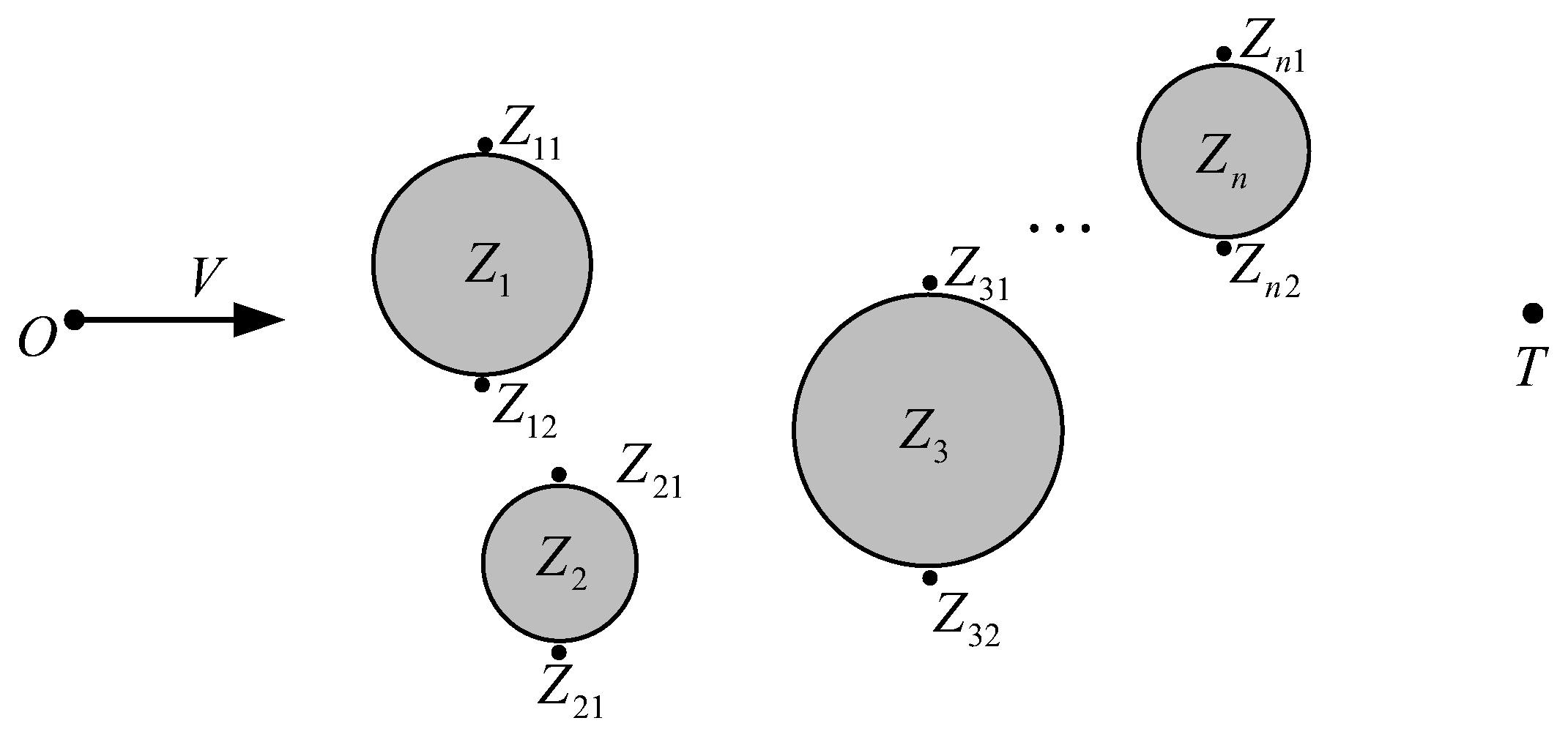
3.1. No-Fly Zone Avoidance Way
3.2. Design of Evaluation Function
3.3. The A*-Based Waypoint Search Algorithm
| Algorithm 1: A*-based multiple no-fly zones waypoint search algorithm |
| Initialization: input the starting position , target , and no-fly zones location and radius parameters, and create two empty tables A1 and A2; if : No operation. Direct flight from to . else: Store the starting position in A1 while or for ( is the number of waypoints in A1) if Calculated from Equation (10); Combine Equations (13), (15) and (16) to get end end ; Extended to the set of all waypoints satisfied ; , , is stored in A1 and the waypoints that A1 has expanded are stored in A2: , . end end Output the optimal set of the waypoints in A2 |
4. QEGC Guidance Law Based on Continuous Switching Sliding Mode
4.1. Longitudinal Guidance
4.2. Lateral Guidance
4.3. Stability Analysis
4.4. Conversion of Control Input
5. DRL-Based Morphing Policy
5.1. The MDP Model for Morphing Policy Learning
5.2. Design of Reward Functions
5.3. Policy Learning Based on the DDPG Algorithm
| Algorithm 2: DDPG algorithm |
| Initialize online Critic network and online Actor network Copy the parameters of the online Critic network and online Actor network to the corresponding target network: Initialize the capacity of replay memory For episode = 1 to do Initialize Gaussian noise distribution Initialization state for t = 1 to end do Execute the action , get the reward r and the new state Store to memory n samples are randomly selected from Calculate Update the Critic network to the minimized Critic loss: The Actor network is updated by the policy gradient ascent: Update the parameters of the Target network and end for end For |
6. Tests and Analysis
6.1. Solutions for the Path Constraint and Angle of Attack
6.2. Setup of Simulation Parameters
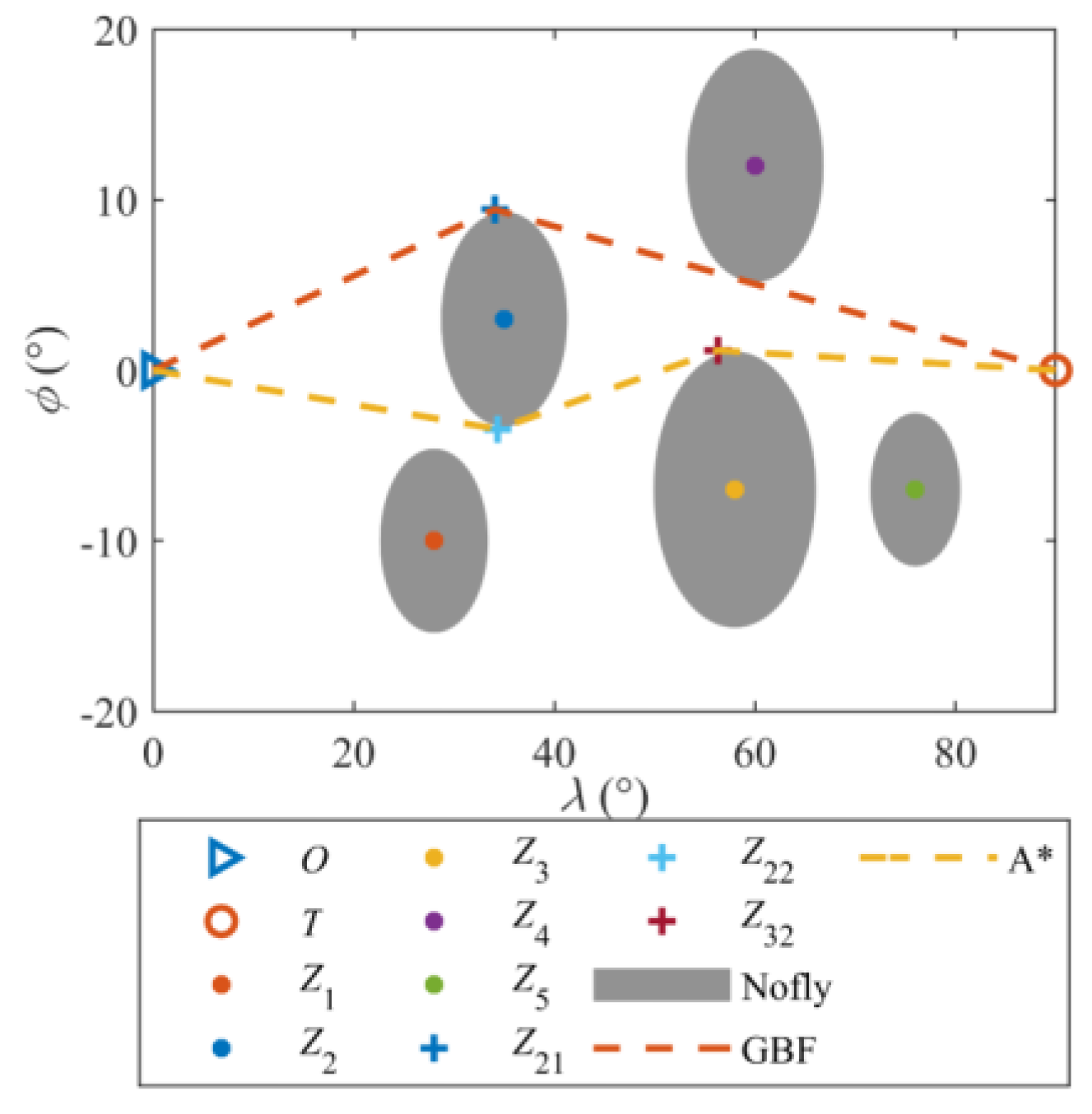
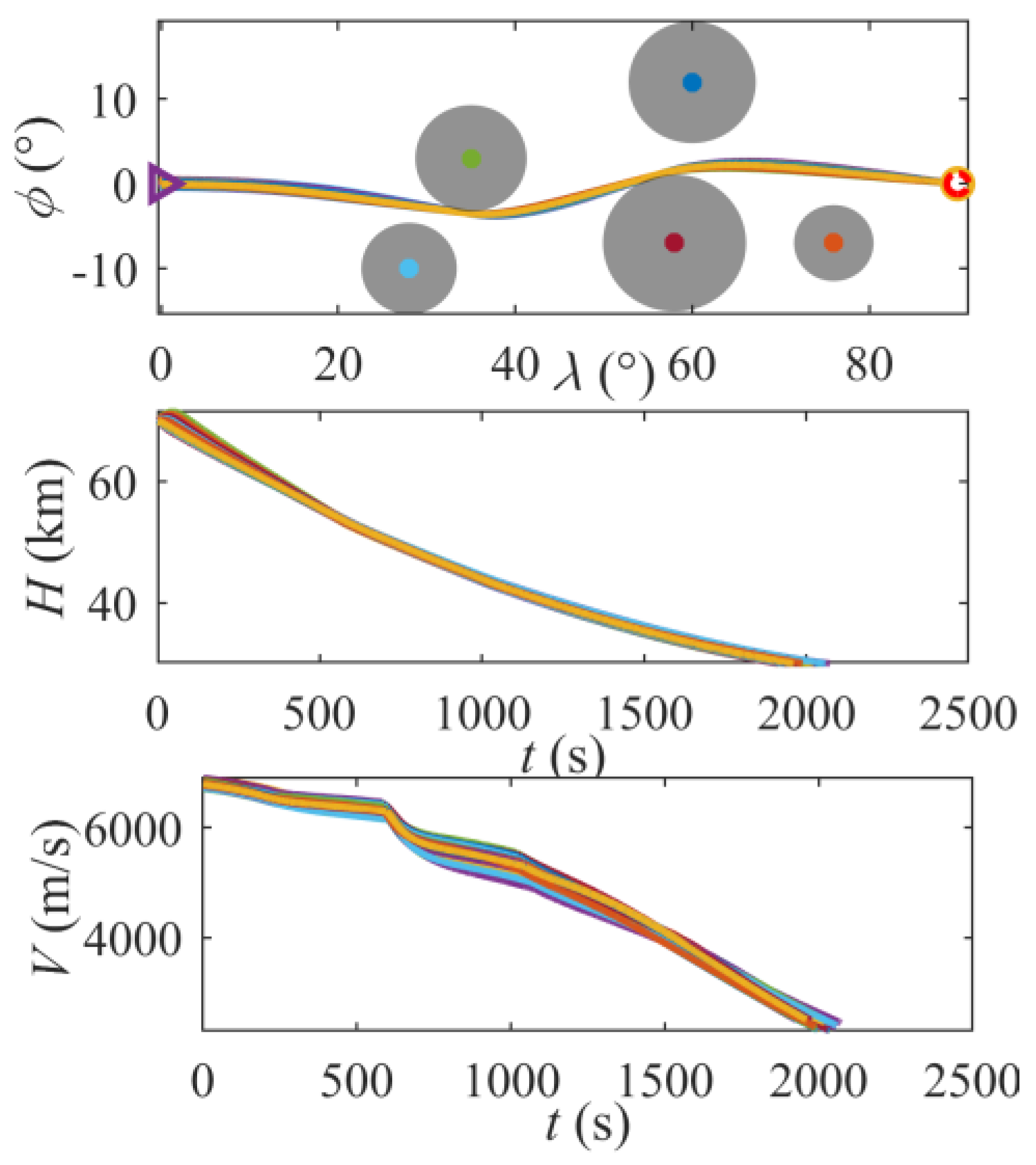
6.3. Avoidance Search Results Under Multiple No-Fly Zones
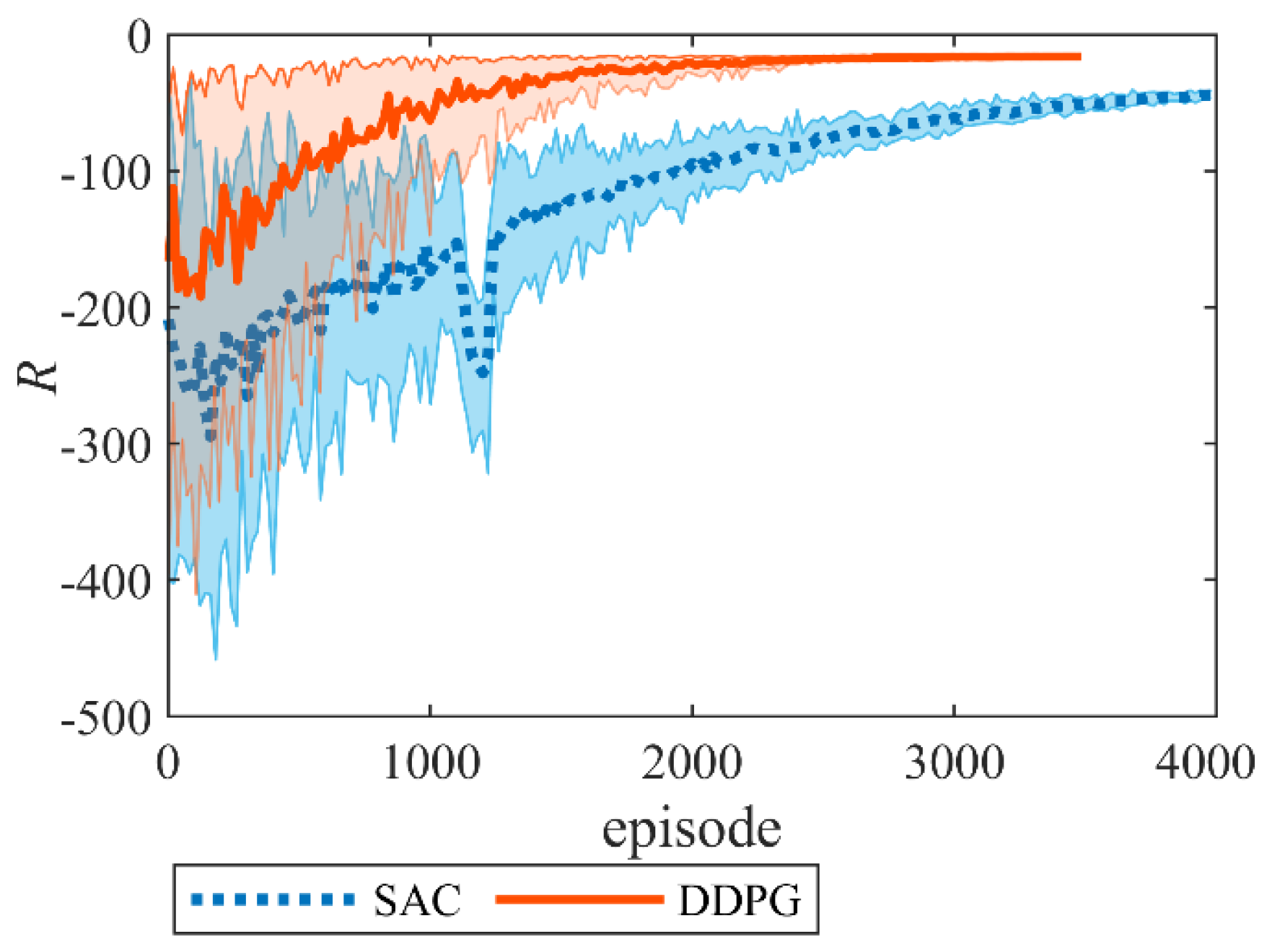
6.4. Training Results of RL
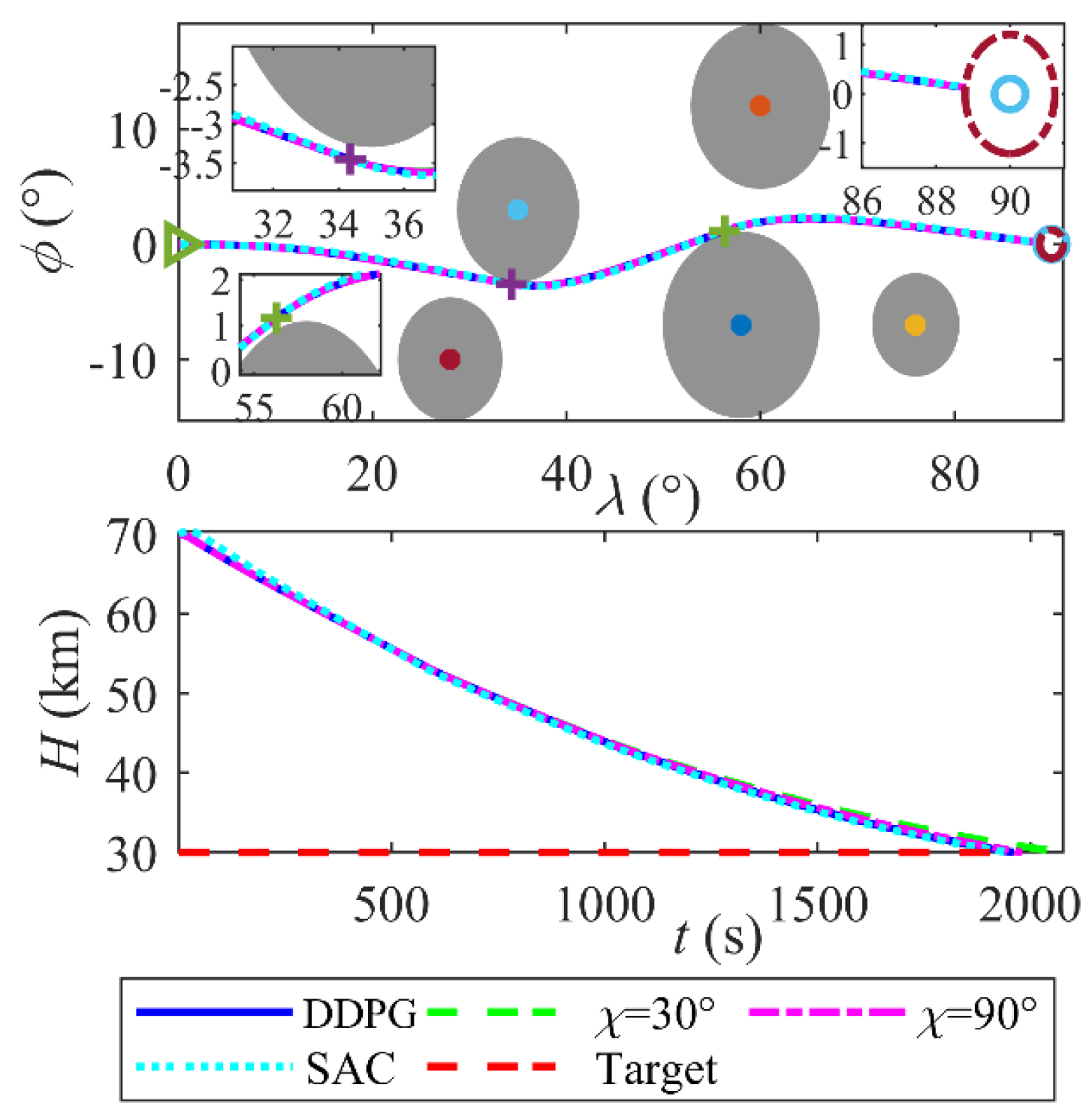
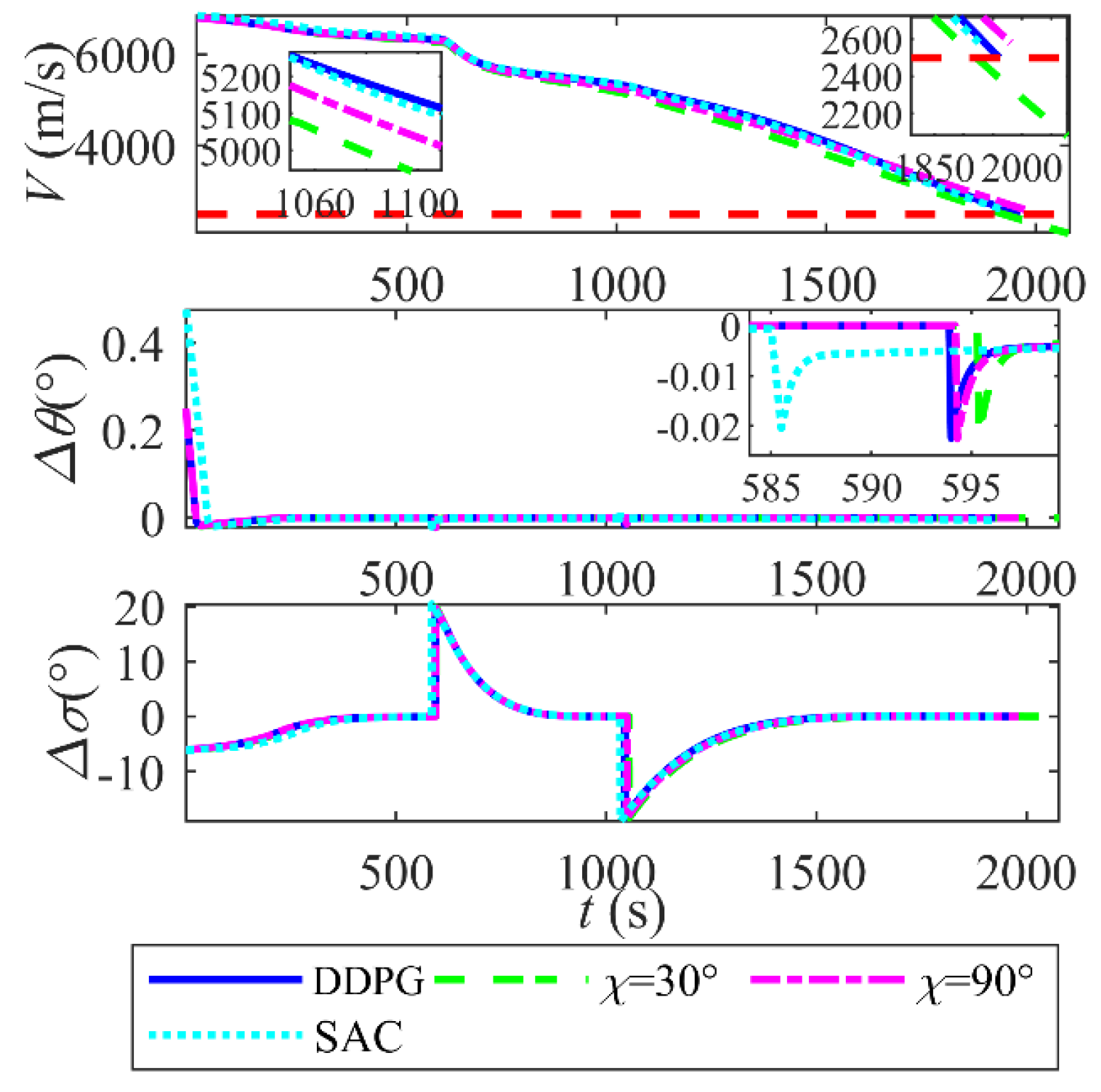
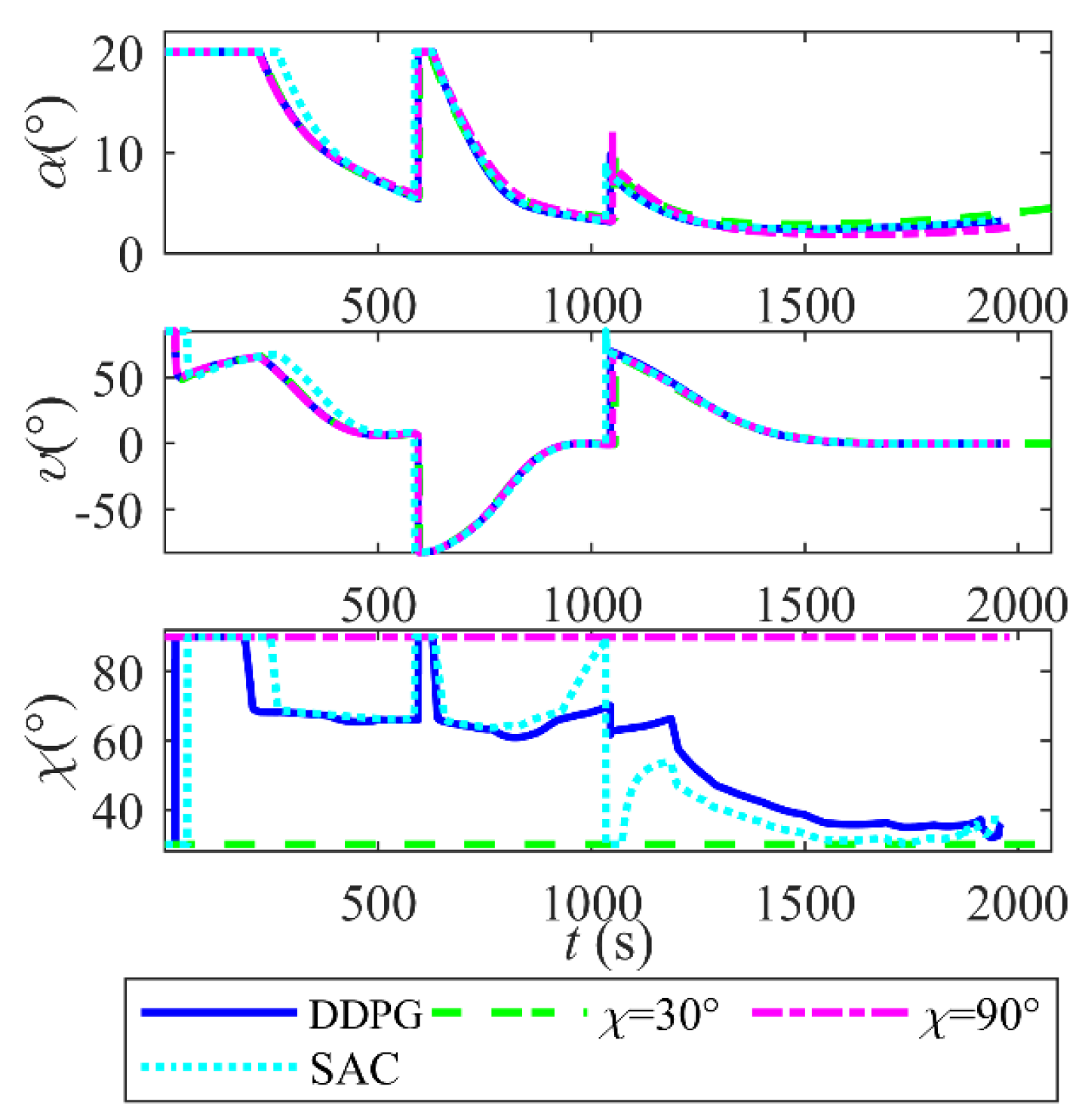
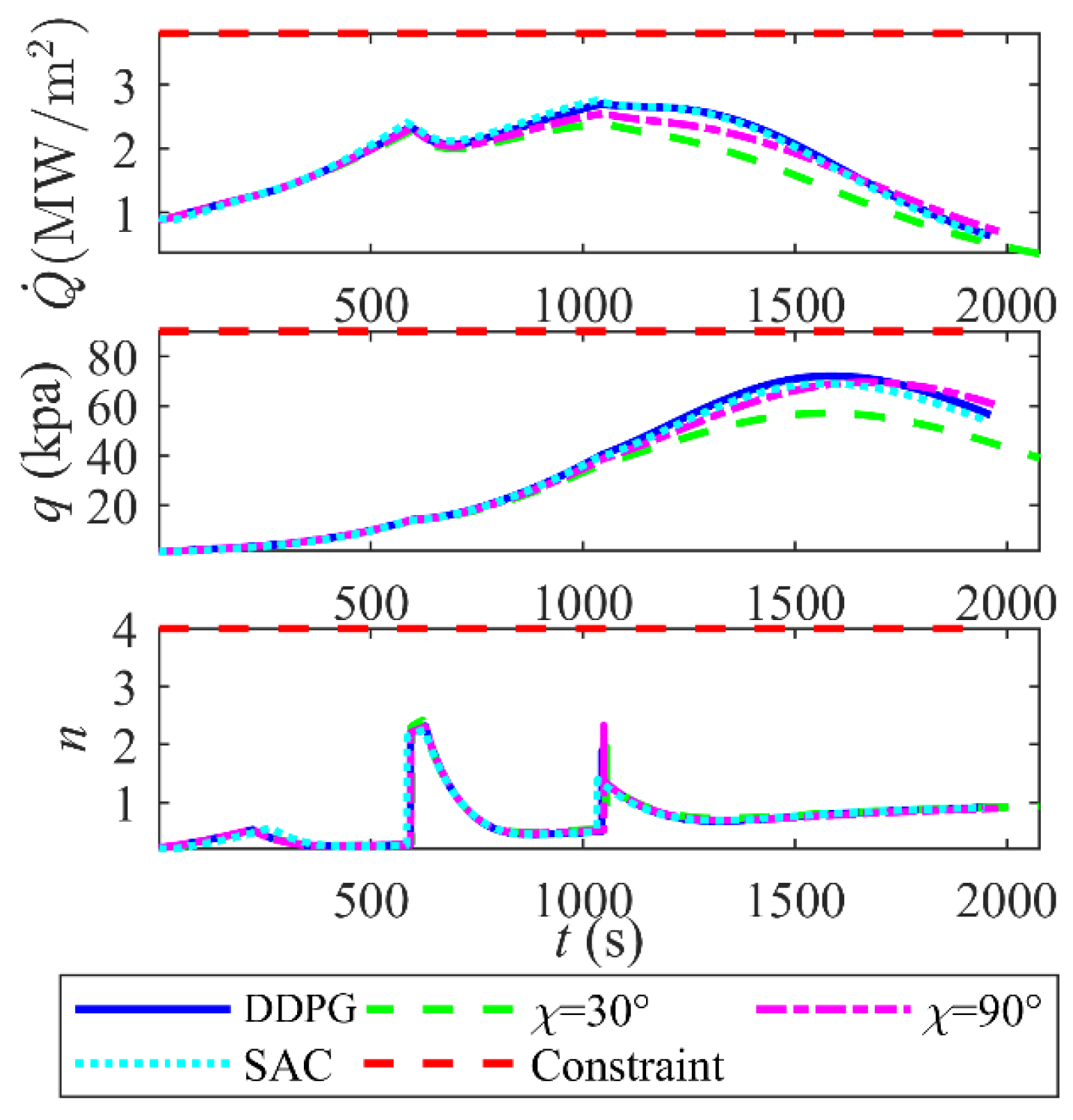
6.5. Effectiveness of the Intelligent Coordinated Guidance Method

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | DDPG | χ = 30° | χ = 90° | SAC |
|---|---|---|---|---|
| −0.09 | 0.01 | 0.24 | 0.39 | |
| 5275.0 | 5074.14 | 5181.86 | 5260.2 | |
| −0.01 | −419.39 | 80.61 | 87.23 | |
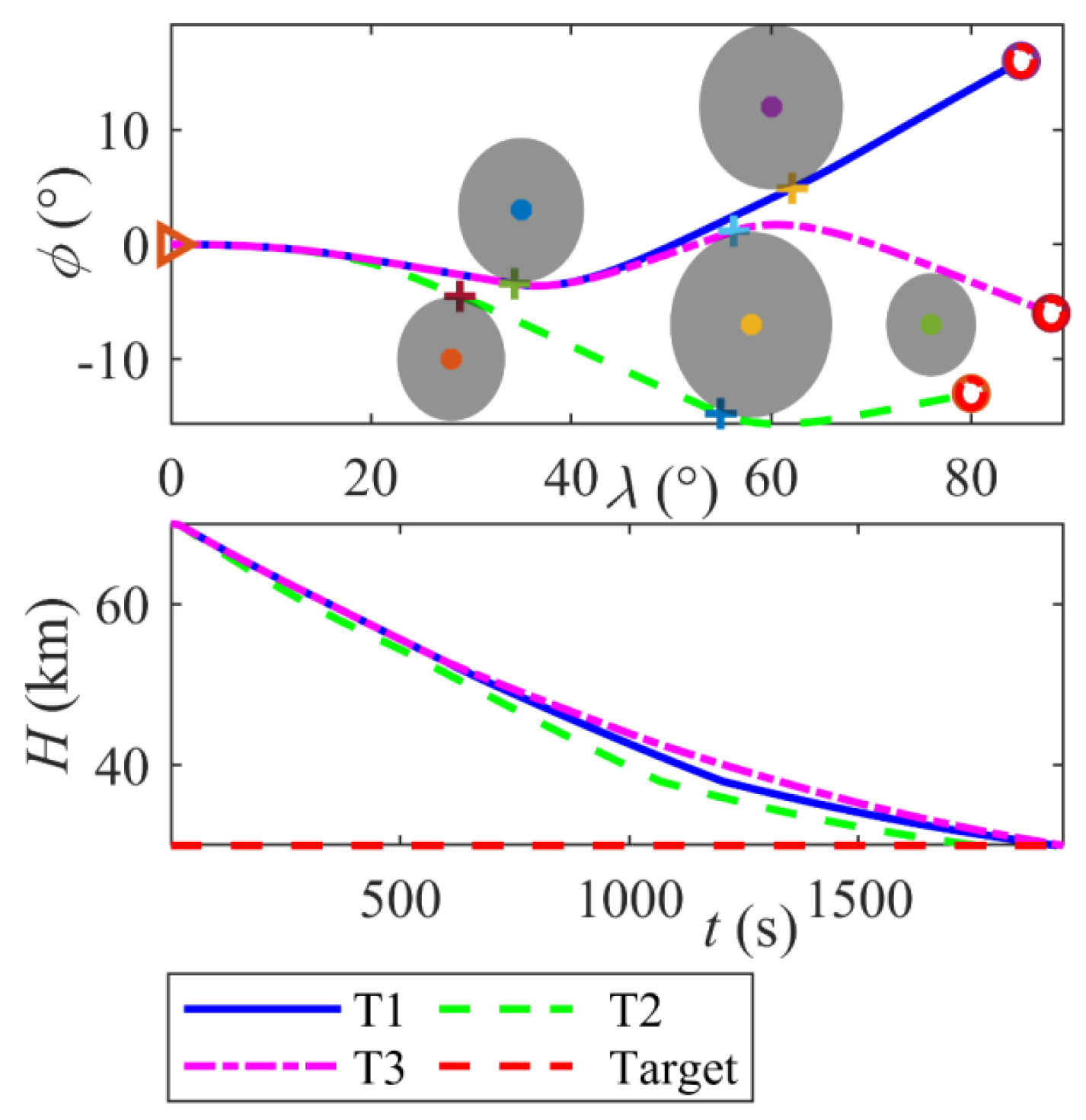
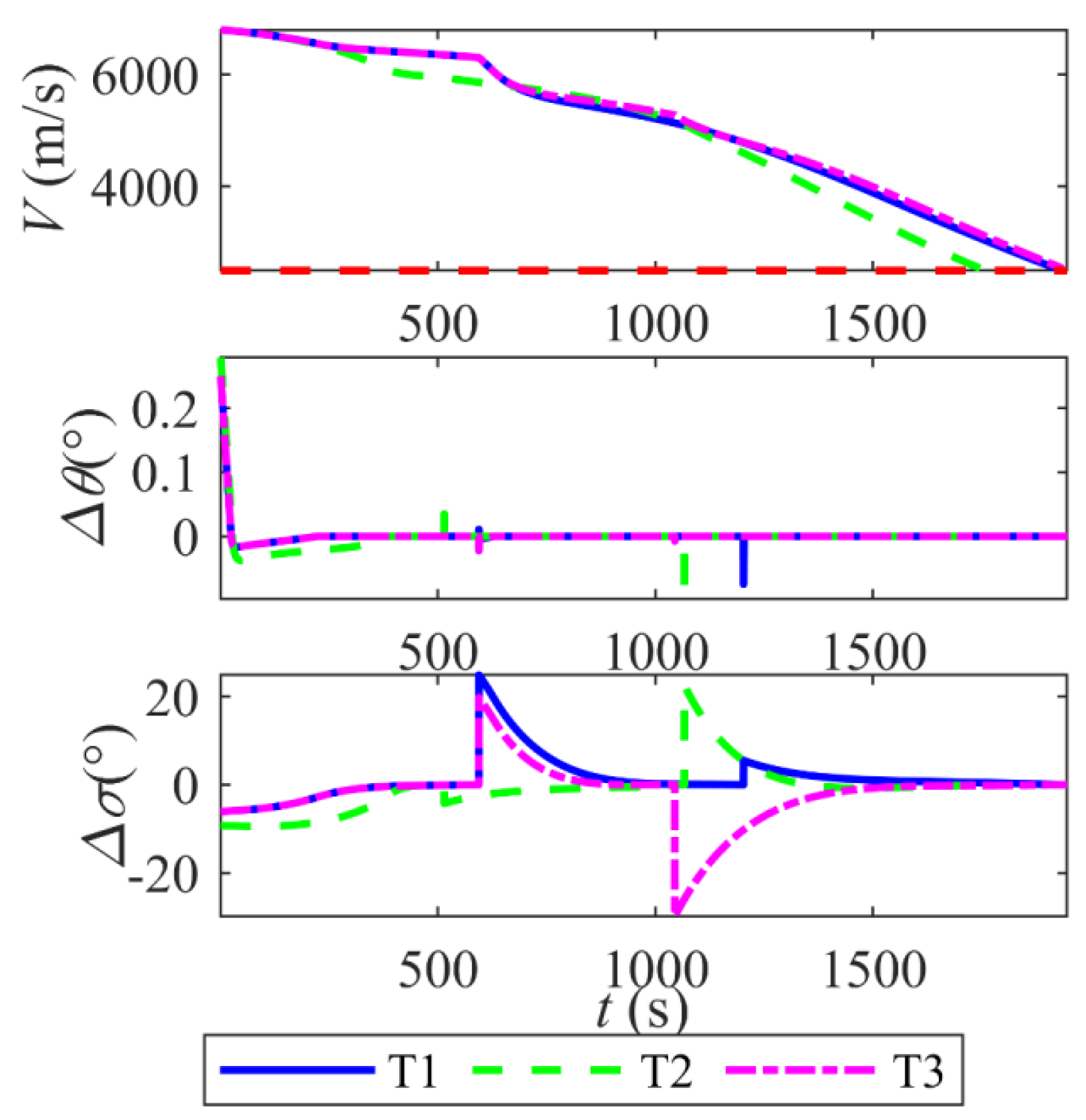
6.6. Generalization of Intelligent Coordinated Guidance Method
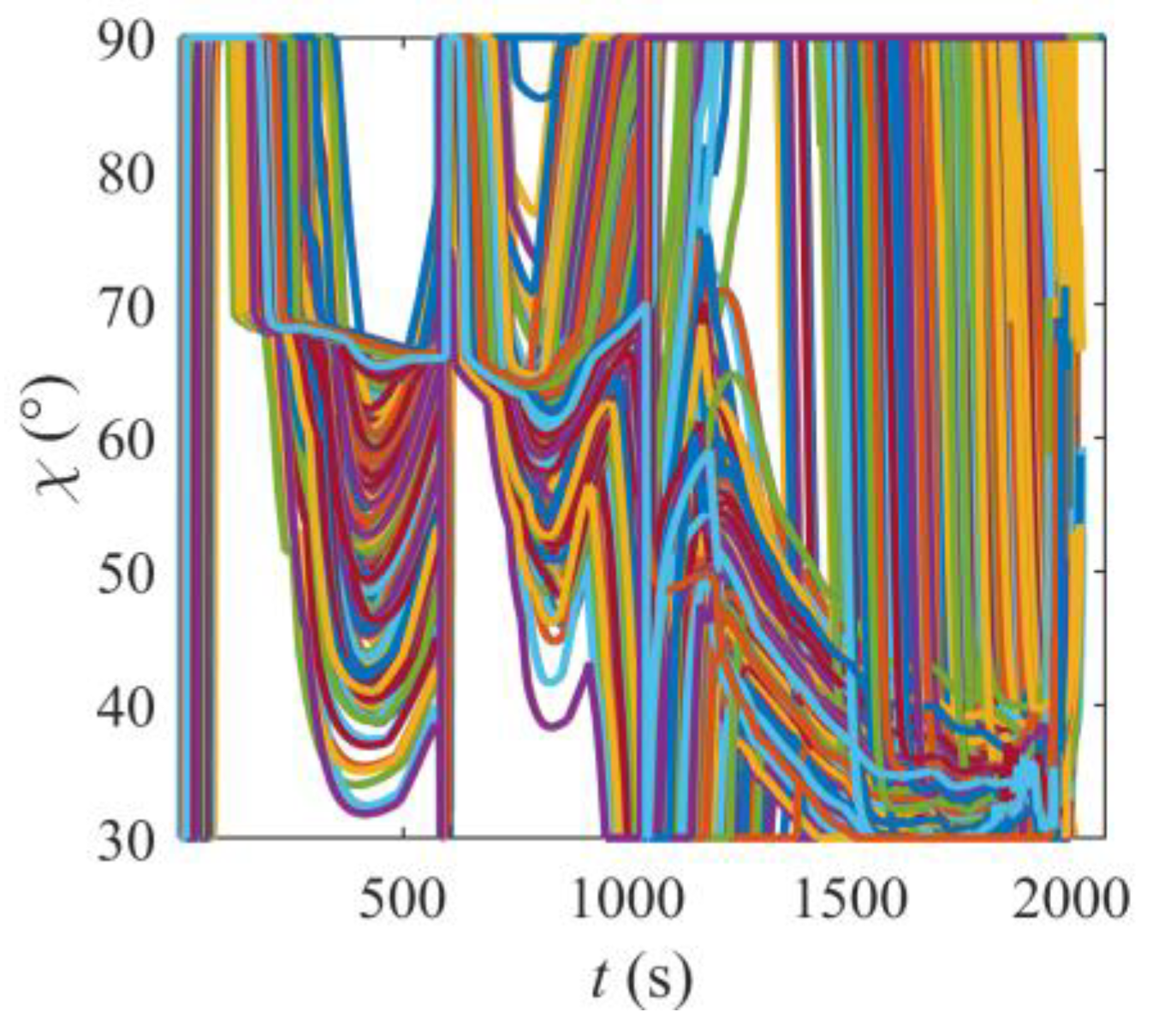
6.7. Robustness of the Intelligent Coordinated Guidance Method
7. Conclusions
- A hybrid framework integrating A* trajectory planning, DRL-based morphing control, and QEGC guidance law is proposed. The A* algorithm systematically generates energy-optimal avoidance trajectories by resolving waypoints within complex no-fly zones, outperforming the greedy best-first search method (GBF) with a 6.2% reduction in evaluation function value.
- RLs provide an online implementation of policy network solutions for autonomous optimal morphing decision. The DDPG algorithm trains a morphing policy network to adaptively adjust the sweep angle in real time. The DDPG policy requires 122.2 kB memory and a 0.1ms inference time on an Intel Core i7, meeting the 50ms guidance period time.
- The coordination guidance law of DDPG and QEGC ensures precise longitudinal and lateral tracking via continuous switching sliding mode control. Compared to fixed morphing policies and a SAC-based control, the proposed approach reduces the terminal position error to 0.09 km and terminal velocity error to 0.01m/s. The reward-driven DDPG policy optimizes velocity retention during avoidance maneuvers, achieving a terminal velocity of 5275.0 m/s and improving by at least 93m/s compared to the fixed sweep. Moreover, it maintains the minimum tracking error.
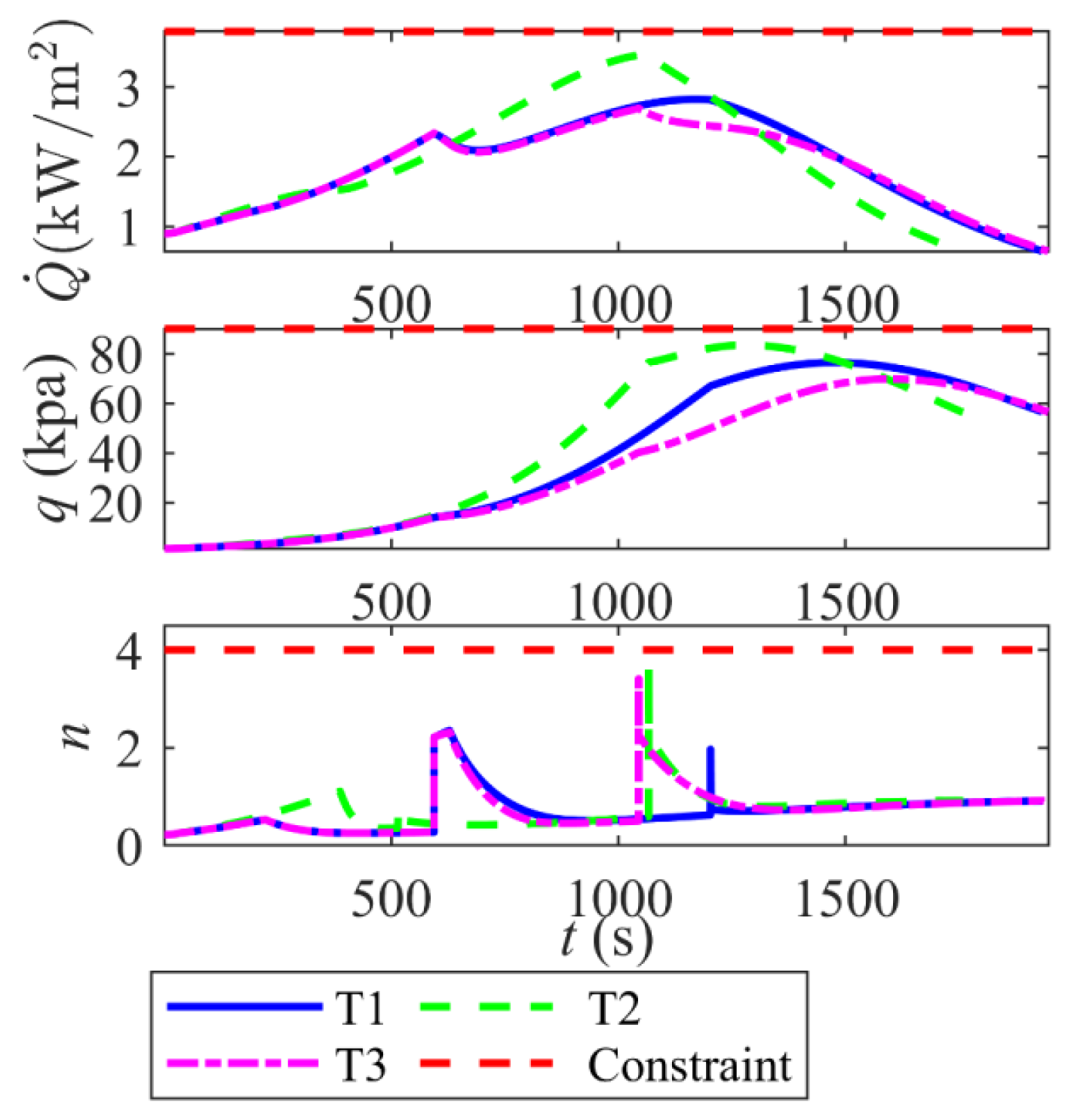
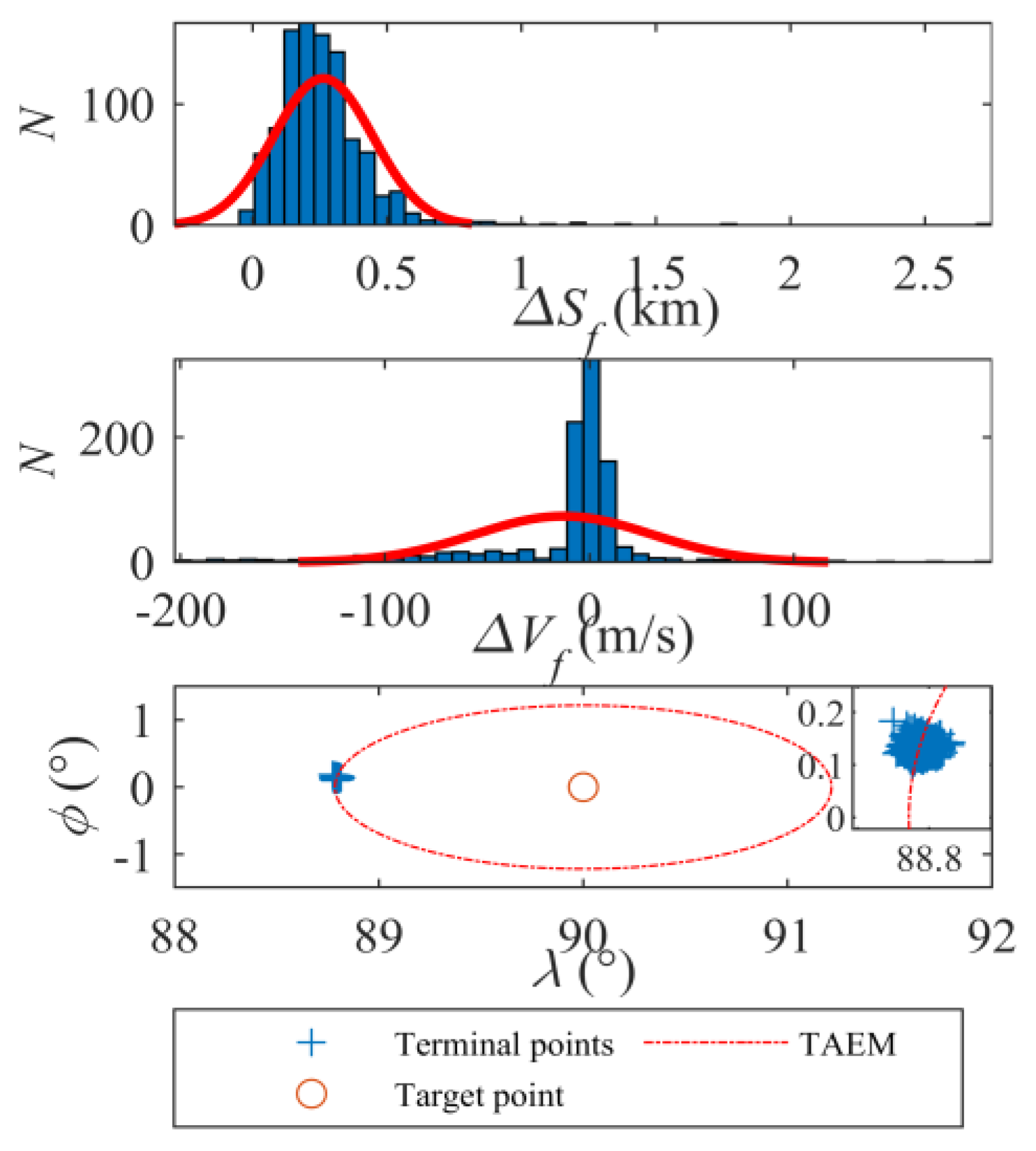
- The framework demonstrates robust generalization and adaptability. Monte Carlo simulations validate its robustness, with terminal range errors confined to 0.263 km (mean) ± 0.184 km (std) and velocity errors to −12.7 m/s (mean) ± 42.93 m/s (std). Additionally, tests across three distinct target missions (T1–T3) show consistent terminal position errors below 0.24 km and velocity errors under 5.90 m/s, confirming the method’s capability to generalize beyond training scenarios.
- This study bridges trajectory planning, adaptive morphing, and robust guidance for HMVs. By synergizing A*’s global optimization with DRL’s real-time adaptability, the method ensures safe reentry under stringent path constraints. Future work will focus on implementing model pruning and computational acceleration to further optimize the policy network for deployment on flight-grade embedded processors.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jin, Z.; Yu, Z.; Meng, F.; Zhang, W.; Cui, J.; He, X.; Lei, Y.; Musa, O. Parametric Design Method and Lift/Drag Characteristics Analysis for a Wide-Range, Wing-Morphing Glide Vehicle. Aerospace 2024, 11, 257. [Google Scholar] [CrossRef]
- Dai, P.; Yan, B.; Huang, W.; Zhen, Y.; Wang, M.; Liu, S. Design and aerodynamic performance analysis of a variable-sweep-wing morphing waverider. Aerosp. Sci. Technol. 2020, 98, 105703. [Google Scholar] [CrossRef]
- Cheng, L.; Li, Y.; Yuan, J.; Ai, J.; Dong, Y. L1 Adaptive Control Based on Dynamic Inversion for Morphing Aircraft. Aerospace 2023, 10, 786. [Google Scholar] [CrossRef]
- Li, D.; Zhao, S.; Da Ronch, A.; Xiang, J.; Drofelnik, J.; Li, Y.; Zhang, L.; Wu, Y.; Kintscher, M.; Monner, H.P.; et al. A review of modelling and analysis of morphing wings. Prog. Aeronaut. Sci. 2018, 100, 46–62. [Google Scholar] [CrossRef]
- Chu, L.; Li, Q.; Gu, F.; Du, X.; He, Y.; Deng, Y. Design, modeling, and control of morphing aircraft: A review. Chin. J. Aeronaut. 2022, 35, 220–246. [Google Scholar] [CrossRef]
- Cai, G.; Shang, Y.; Xiao, Y.; Wu, T.; Liu, H. Predefined-Time Sliding Mode Control with Neural Network Observer for Hypersonic Morphing Vehicles. IEEE Trans. Aerosp. Electron. Syst. 2025, 1–17. [Google Scholar] [CrossRef]
- Bao, C.; Wang, P.; Tang, G. Integrated guidance and control for hypersonic morphing missile based on variable span auxiliary control. Int. J. Aerosp. Eng. 2019, 2019, 6413410. [Google Scholar] [CrossRef]
- Zhou, X.; He, R.-Z.; Zhang, H.-B.; Tang, G.-J.; Bao, W.-M. Sequential convex programming method using adaptive mesh refinement for entry trajectory planning problem. Aerosp. Sci. Technol. 2021, 109, 106374. [Google Scholar] [CrossRef]
- Dai, P.; Feng, D.; Feng, W.; Cui, J.; Zhang, L. Entry trajectory optimization for hypersonic vehicles based on convex programming and neural network. Aerosp. Sci. Technol. 2023, 137, 108259. [Google Scholar] [CrossRef]
- Lu, P.; Brunner, C.W.; Stachowiak, S.J.; Mendeck, G.F.; Tigges, M.A.; Cerimele, C.J. Verification of a fully numerical entry guidance algorithm. J. Guid. Control Dyn. 2017, 40, 230–247. [Google Scholar] [CrossRef]
- Zhu, J.; Liu, L.; Tang, G.; Bao, W. Robust adaptive gliding guidance for hypersonic vehicles. Proc. Inst. Mech. Eng. Part G 2018, 232, 1272–1282. [Google Scholar] [CrossRef]
- Zhu, J.; Zhang, S. Adaptive Optimal Gliding Guidance Independent of QEGC. Aerosp. Sci. Technol. 2017, 71, 373–381. [Google Scholar] [CrossRef]
- Yao, D.; Xia, Q. Finite-Time Convergence Guidance Law for Hypersonic Morphing Vehicle. Aerospace 2024, 11, 680. [Google Scholar] [CrossRef]
- Huang, S.; Jiang, J.; Li, O. Adaptive Neural Network-Based Sliding Mode Backstepping Control for Near-Space Morphing Vehicle. Aerospace 2023, 10, 891. [Google Scholar] [CrossRef]
- Fazeliasl, S.B.; Moosapour, S.S.; Mobayen, S. Free-Will Arbitrary Time Cooperative Guidance for Simultaneous Target Interception with Impact Angle Constraint Based on Leader-Follower Strategy. IEEE Trans. Aerosp. Electron. Syst. 2025, 1–15. [Google Scholar] [CrossRef]
- Xie, Y.; Liu, L.; Liu, J.; Tang, G.; Zheng, W. Rapid generation of entry trajectories with waypoint and no-fly zone constraints. Acta Astronaut. 2012, 77, 167–181. [Google Scholar] [CrossRef]
- He, R.; Liu, L.; Tang, G.; Bao, W. Rapid generation of entry trajectory with multiple no-fly zone constraints. Adv. Space Res. 2017, 60, 1430–1442. [Google Scholar] [CrossRef]
- Hu, Y.; Gao, C.; Li, J.; Jing, W.; Chen, W. A novel adaptive lateral reentry guidance algorithm with complex distributed no-fly zones constraints. Chin. J. Aeronaut. 2022, 35, 128–143. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, L.; Wang, Y. On-line reentry guidance algorithm with both path and no-fly zone constraints. Acta Astronaut. 2015, 117, 243–253. [Google Scholar] [CrossRef]
- Wang, S.; Ma, D.; Yang, M.; Zhang, L.; Li, G. Flight strategy optimization for high-altitude long-endurance solar-powered aircraft based on Gauss pseudo-spectral method. Chin. J. Aeronaut. 2019, 32, 2286–2298. [Google Scholar] [CrossRef]
- Zhang, R.; Xie, Z.; Wei, C.; Cui, N. An enlarged polygon method without binary variables for obstacle avoidance trajectory optimization. Chin. J. Aeronaut. 2023, 36, 284–297. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, R.; Li, H. Graph-based path decision modeling for hypersonic vehicles with no-fly zone constraints. Aerosp. Sci. Technol. 2021, 116, 106857. [Google Scholar] [CrossRef]
- Radmanesh, R.; Kumar, M.; French, D.; Casbeer, D. Towards a PDE-based large-scale decentralized solution for path planning of UAVs in shared airspace. Aerosp. Sci. Technol. 2020, 105, 105965. [Google Scholar] [CrossRef]
- AlShawi, I.S.; Yan, L.; Pan, W.; Luo, B. Lifetime enhancement in wireless sensor networks using fuzzy approach and A-star algorithm. In Proceedings of the IET Conference on Wireless Sensor Systems (WSS 2012), London, UK, 18–19 June 2012; IET: London, UK, 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, Z. A multiple mobile robots path planning algorithm based on A-star and Dijkstra algorithm. Int. J. Smart Home 2014, 8, 75–86. [Google Scholar] [CrossRef]
- Dai, P.; Feng, D.; Zhao, J.; Cui, J.; Wang, C. Asymmetric integral barrier Lyapunov function-based dynamic surface control of a state-constrained morphing waverider with anti-saturation compensator. Aerosp. Sci. Technol. 2022, 131, 107975. [Google Scholar] [CrossRef]
- Dai, P.; Yan, B.; Han, T.; Liu, S. Barrier Lyapunov Function Based Model Predictive Control of a morphing waverider with input saturation and full-state constraints. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3071–3081. [Google Scholar] [CrossRef]
- Chen, X.; Li, C.; Gong, C.; Gu, L.; Ronch, A.D. A study of morphing aircraft on morphing rules along trajectory. Chin. J. Aeronaut. 2021, 34, 232–243. [Google Scholar] [CrossRef]
- Fasel, U.; Tiso, P.; Keidel, D.; Ermanni, P. Concurrent Design and Flight Mission Optimization of Morphing Airborne Wind Energy Wings. AIAA J. 2021, 59, 1254–1268. [Google Scholar] [CrossRef]
- Bao, C.; Wang, P.; Tang, G. Integrated method of guidance, control and morphing for hypersonic morphing vehicle in glide phase. Chin. J. Aeronaut. 2021, 34, 535–553. [Google Scholar] [CrossRef]
- Xu, W.; Li, Y.; Pei, B.; Yu, Z. Coordinated intelligent control of the flight control system and shape change of variable sweep morphing aircraft based on dueling-DQN. Aerosp. Sci. Technol. 2022, 130, 107898. [Google Scholar] [CrossRef]
- Xu, D.; Hui, Z.; Liu, Y.; Chen, G. Morphing control of a new bionic morphing UAV with deep reinforcement learning. Aerosp. Sci. Technol. 2019, 92, 232–243. [Google Scholar] [CrossRef]
- Hou, L.; Liu, H.; Yang, T.; An, S.; Wang, R. An Intelligent Autonomous Morphing Decision Approach for Hypersonic Boost-Glide Vehicles Based on DNNs. Aerospace 2023, 10, 1008. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Kemp, C.; Griffiths, T.L.; Goodman, N.D. How to grow a mind: Statistics, structure, and abstraction. Science 2011, 331, 1279–1285. [Google Scholar] [CrossRef] [PubMed]
- Bao, C.Y.; Zhou, X.; Wang, P.; He, R.Z.; Tang, G.J. A deep reinforcement learning-based approach to onboard trajectory generation for hypersonic vehicles. Aeronaut. J. 2023, 127, 1638–1658. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on International Conference on Machine Learning-Volume 32, Bejing, China, 21–26 June 2014; JMLR.org: Beijing, China, 2014; pp. I-387–I-395. [Google Scholar]
- Heusner, M.; Keller, T.; Helmert, M. Best-Case and Worst-Case Behavior of Greedy Best-First Search. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI 2018), Stockholm, Sweden, 13–19 July 2018; International Joint Conferences on Artificial Intelligence Organization: Stockholm, Sweden, 2018; pp. 1463–1470. [Google Scholar] [CrossRef]
- Wu, Y.; Sun, G.; Xia, X.; Xing, M.; Bao, Z. An Improved SAC Algorithm Based on the Range-Keystone Transform for Doppler Rate Estimation. IEEE Geosci. Remote Sens. Lett. 2013, 10, 741–745. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, C.; Li, X.; Xu, W.; Tang, G.; Yao, W. Coordinated Reentry Guidance with A* and Deep Reinforcement Learning for Hypersonic Morphing Vehicles Under Multiple No-Fly Zones. Aerospace 2025, 12, 591. https://doi.org/10.3390/aerospace12070591
Bao C, Li X, Xu W, Tang G, Yao W. Coordinated Reentry Guidance with A* and Deep Reinforcement Learning for Hypersonic Morphing Vehicles Under Multiple No-Fly Zones. Aerospace. 2025; 12(7):591. https://doi.org/10.3390/aerospace12070591
Chicago/Turabian StyleBao, Cunyu, Xingchen Li, Weile Xu, Guojian Tang, and Wen Yao. 2025. "Coordinated Reentry Guidance with A* and Deep Reinforcement Learning for Hypersonic Morphing Vehicles Under Multiple No-Fly Zones" Aerospace 12, no. 7: 591. https://doi.org/10.3390/aerospace12070591
APA StyleBao, C., Li, X., Xu, W., Tang, G., & Yao, W. (2025). Coordinated Reentry Guidance with A* and Deep Reinforcement Learning for Hypersonic Morphing Vehicles Under Multiple No-Fly Zones. Aerospace, 12(7), 591. https://doi.org/10.3390/aerospace12070591