1. Introduction
With the rapid development of the global aviation industry, air traffic management (ATM) is facing unprecedented pressure. The increasing complexity of air traffic control (ATC) systems has made it a pressing issue in the aviation field to enhance the efficiency of air traffic control while ensuring flight safety. As the most fundamental means of communication in air traffic control, the accuracy and timeliness of ATC instructions directly affect both flight safety and operational efficiency. However, the large volume of ATC instruction data and the complexity of its syntactic structure make it a technical challenge to efficiently and accurately extract key information from such data [
1].
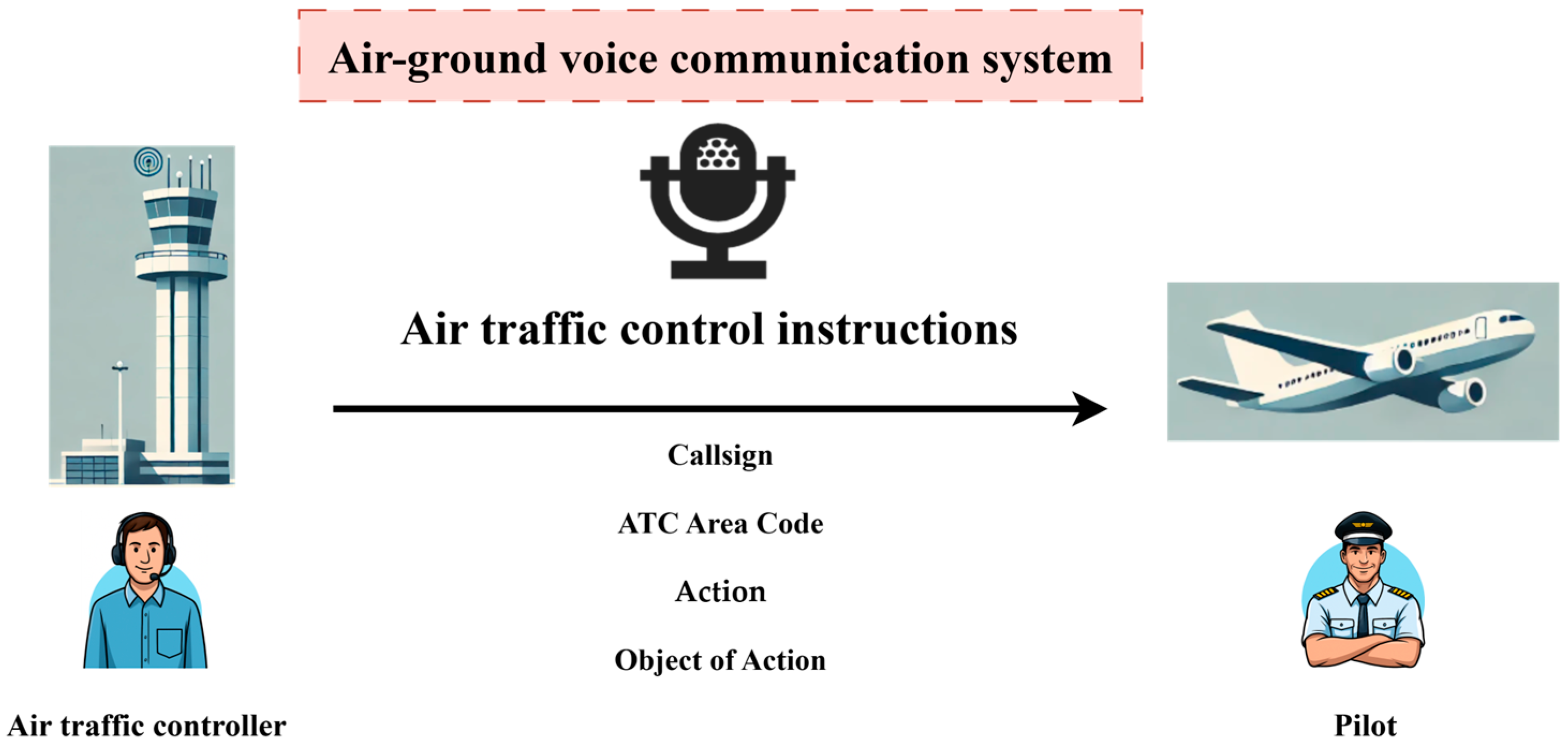
Air traffic control (ATC) instructions are typically directives issued by air traffic controllers to pilots to guide the operation of aircraft. The purpose of these instructions is to ensure that aircraft follow designated routes, speeds, altitudes, and directions during flight, thereby maintaining flight safety, avoiding conflicts, and improving operational efficiency. The “keywords” in ATC instructions usually refer to the terms or phrases that reveal the core content of the instructions, including aircraft callsigns, ATC Area Codes, actions, and objects of action. These keywords carry the critical information necessary for pilots to execute the corresponding operations. Accurate transmission and interpretation of these keywords are essential to prevent misunderstandings that may jeopardize flight safety. As such, efficient keyword extraction is not merely a technical challenge, but a fundamental prerequisite for real-time decision-making and automation in air traffic control. A schematic diagram of air–ground communication is shown in
Figure 1.
The primary task of keyword extraction technology is to identify the terms or phrases that best reflect the subject and core content of a given text. This not only facilitates an efficient text search for users but also plays an important role in document management and content recommendation [
2]. Existing keyword extraction methods primarily include statistical approaches such as Term Frequency-Inverse Document Frequency (TF-IDF), graph-based algorithms such as TextRank, and deep learning-based models. Although these methods have achieved certain successes in some scenarios, they often perform unsatisfactorily when applied to ATC instruction texts, which typically consist of multiple segments containing different types of directive information. Different instruction segments may include distinct important information, making it difficult for existing methods to effectively identify and extract keywords from multi-segment ATC instructions.
Moreover, ATC instructions often contain multiple layers of information, such as aircraft callsigns, control zone numbers, instruction actions, and action objects, which are frequently presented within a single sentence. Extracting the key information accurately from such complex sentence structures remains a technical challenge. Existing models or neural networks often fail to capture the internal dependencies among words within a single sentence when processing multi-segment instructions, which can lead to a reduced accuracy in keyword extraction.
In ATC instructions, directives are usually composed of multiple components that exhibit complex sequential relationships within a sentence. Existing keyword extraction methods tend to focus on independently extracting keywords, overlooking the syntactic and semantic dependencies among them. However, in actual ATC instructions, the order of keywords often reflects the execution flow and grammatical structure of the instruction. Any error in the sequence could lead to misinterpretation of the air traffic control instruction, thereby compromising flight safety.
The inherent complexity of ATC instructions gives rise to three interrelated challenges: (1) semantic correlation across multiple segments—existing methods often fail to capture contextual dependencies between distinct instruction segments, resulting in incomplete or fragmented keyword extraction; (2) fine-grained intra-sentence semantic understanding—the hierarchical and layered structure within individual sentences demands precise modeling of contextual and syntactic relationships; and (3) preservation of operational logic—the extracted keywords must maintain the correct sequential order to accurately reflect the intended operational flow of ATC directives. In response to these challenges, this study poses three research questions: (i) How can semantic correlations across multi-segment ATC instructions be effectively modeled? (ii) How can fine-grained semantic parsing within single sentences be enhanced? (iii) How can the sequential logic of ATC operations be preserved during keyword extraction?
In addressing these questions, the primary goal of this study was to design a robust and domain-adaptive keyword extraction model that can (1) integrate contextual dependencies across instruction segments, (2) accurately capture fine-grained semantic features within individual sentences, and (3) ensure sequence-consistent keyword prediction aligned with ATC operational intent.
In this paper, we propose a Roberta-Attention-BiLSTM-CRF-based model (RBAC-KET) for keyword extraction from air traffic control (ATC) instructions. Unlike the existing RoBERTa-BiLSTM-CRF model, which primarily captures semantic dependencies within individual sentences or single instruction segments, the proposed RABC model introduces an attention mechanism that significantly enhances the model’s ability to capture semantic relevance across multiple instruction segments—a critical challenge that prior models often overlook. Furthermore, while traditional RoBERTa-BiLSTM-CRF approaches rely on the implicit sequential structure of the text, RABC explicitly ensures that the extracted keywords not only reflect fine-grained semantic understanding within sentences but also preserve the correct sequential order across segments, thereby aligning more closely with the operational logic of ATC instructions. To the best of our knowledge, no prior research has applied the RABC model to the domain of keyword extraction from air traffic control (ATC) instructions. The inherent structural complexity and operational sensitivity of ATC communications introduce domain-specific challenges that have not been sufficiently addressed by existing approaches. Therefore, this study makes a novel contribution by adapting and optimizing the RABC model to meet the semantic precision and sequence-preservation requirements essential for ATC instruction processing. First, the Roberta model, as a pretrained language model, leverages its strong language understanding capability to capture the implicit contextual information within ATC instruction texts, thereby providing a rich semantic foundation for keyword extraction. Second, the model incorporates an attention mechanism, which allows the model to focus on the most important parts of multi-segment ATC instructions. This mechanism helps the model effectively filter out keywords from large volumes of text by concentrating on the informative segments of the instructions. To further enhance the accuracy of keyword extraction, we introduce a BiLSTM module, which captures both forward and backward dependencies within a single sentence. This enables the model to understand the contextual relationships of each word more precisely, thereby improving the identification of key information within individual sentences. Finally, to ensure that the extracted keywords are predicted in the correct order, the model integrates a Conditional Random Field (CRF) layer. The CRF layer leverages its global sequence optimization capability to establish sequential dependencies among multiple keywords, addressing the limitations of existing methods in maintaining sequence consistency during extraction. Through this global optimization, the model can accurately predict and extract keywords from ATC instructions while preserving their correct order. We conducted experiments on a real-world ATC instruction dataset and compared the proposed model with various baseline models. The results demonstrate that the Roberta-Attention-BiLSTM-CRF model effectively improves the performance of keyword extraction from ATC instructions.
The main contributions of this paper are as follows:
Addressing the semantic correlation between multi-segment ATC instruction texts: This paper introduces an attention mechanism into the model, which effectively captures the contextual information between different text segments. This mechanism strengthens the semantic connections between different instruction segments, thereby ensuring the accuracy and semantic coherence of keyword extraction;
Enhancing the fine-grained extraction of semantic information within individual sentences: To address the challenge of extracting detailed semantic information, this paper incorporates a BiLSTM module. Leveraging its ability to capture bidirectional dependencies, the model can accurately extract keywords within each sentence across multiple instruction segments;
Ensuring sequence consistency during keyword extraction: To maintain the correct order of extracted keywords, the model integrates a Conditional Random Field (CRF) layer. Through its global sequence optimization capability, the model can accurately predict multiple keywords in the correct order, ensuring sequential consistency in complex ATC instructions.
In
Section 2, this paper reviews and discusses related work in the field of keyword extraction, including keyword extraction techniques based on traditional statistical models, graph-based models, and deep learning models. It also provides a comparative analysis of the limitations of existing methods when applied to air traffic control (ATC) speech data. Next, in
Section 3, this paper presents a Roberta-Attention-BiLSTM-CRF model, which combines an attention mechanism to focus on the critical parts of multi-segment ATC speech texts, enhances the accuracy of single-sentence keyword extraction using the BiLSTM module, and ensures the correct sequential extraction of keywords through the CRF layer. In
Section 4, detailed experiments are conducted on multiple ATC instruction datasets, and the proposed model is compared with existing baseline models. The results demonstrate the superior performance of the proposed model in terms of both keyword extraction accuracy and sequence consistency. Finally, in
Section 5, the paper summarizes the main contributions of this study and suggests directions for future research.
2. Related Work
In the field of keyword extraction, related research primarily focuses on three core directions: (1) semantic modeling of long texts based on attention mechanisms; (2) enhancing fine-grained semantic representation within individual sentences by integrating contextual features to improve the capture of local dependencies; and (3) ensuring sequence consistency during the keyword extraction process.
2.1. Attention Mechanism-Based Text-Processing Research
In recent years, the attention mechanism has been widely applied in various tasks due to its strong capability in capturing long-distance dependencies and contextual relationships, particularly in the fields of natural language processing (NLP) and keyword extraction. Modeling the semantic relationships between multi-segment texts, especially in specialized domains such as air traffic control (ATC), presents unique challenges.
Originally introduced in the context of machine translation, attention mechanisms enable models to dynamically focus on the most relevant parts of an input sequence when making predictions. In natural language processing (NLP), these mechanisms capture dependencies between words, regardless of their distance within a sentence. Specifically, attention mechanisms assign greater weight to semantically important tokens, allowing the model to better identify which parts of the input are critical for keyword extraction. In 2017, Vaswani et al. proposed a novel network architecture called Transformer, which relies entirely on the attention mechanism without the need for recurrence or convolution. The self-attention mechanism enables the model to capture relationships among all tokens within a sequence, regardless of their positional distance, significantly advancing sequence-to-sequence prediction and semantic relationship modeling tasks [
3]. Subsequently, the introduction of the BERT model (bidirectional encoder representations from transformers language model) further improved the performance of NLP tasks, especially in contextual understanding and keyword extraction. Through bidirectional contextual pretraining, BERT demonstrated an exceptional performance in multitask learning, becoming a key tool in keyword extraction. Devlin et al. employed large-scale pretraining and fine-tuning strategies, which were widely applied to various NLP tasks, including keyword extraction and sentiment analysis [
4]. However, BERT’s ability to model relationships between segments remains limited when dealing with complex multi-segment texts, particularly in high-volume ATC instructions. In 2021, Liu et al. proposed an attention-based Transformer model focused on keyword extraction from short texts. This model effectively captured contextual dependencies within short sentences, significantly improving keyword extraction accuracy in short texts [
5]. However, its performance was limited when applied to long texts, especially in tasks involving multi-segment information and cross-segment dependencies, where semantic information degradation remained an issue. Additionally, Sun et al. proposed a multi-head self-attention network with an enhanced attention mechanism for short text keyword extraction. This method effectively captured semantic dependencies within short texts, improving the quality of keyword extraction [
6]. However, when applied to long texts, this method struggled with modeling cross-segment semantic associations, failing to effectively integrate multi-segment information. To address these issues, Pan et al. proposed an improved Transformer model for short-text keyword extraction. By enhancing the attention mechanism, the model was able to focus on more fine-grained contextual information [
7].
Although this method improved keyword accuracy in short texts, it failed to adequately capture semantic associations in multi-segment long texts, resulting in the loss of information from certain segments. Zhang et al. proposed a model that combines Long Short-Term Memory (LSTM) and attention mechanisms, specifically designed for keyword extraction from long texts. This model integrated the sequential modeling capability of LSTM with the contextual modeling ability of the attention mechanism, effectively addressing the challenge of processing multi-segment information in long texts and improving semantic coherence across segments [
8]. However, the model still exhibited limitations in the weighting and optimization of cross-segment information. In long-text keyword extraction tasks, Zhao et al. introduced a BERT-based long-text modeling method that combines a multi-head self-attention mechanism to strengthen associations between multi-segment texts [
9]. While this method performed well on short texts, it faced issues with information overflow and omission when processing complex multi-segment long texts, particularly when large semantic gaps existed between long sentences. To overcome these challenges, Yan et al. proposed a novel attention mechanism specifically designed to improve keyword extraction in long texts. This method adopted a dynamic attention allocation strategy to enhance cross-segment information modeling in long texts [
10].
However, it failed to effectively handle the high level of specialization and complex structure of domain-specific texts, such as ATC instructions. In this paper, we introduce an attention mechanism-based model capable of effectively capturing contextual information between multi-segment texts, reinforcing semantic connections across different instruction segments, and ensuring both the accuracy and semantic coherence of keyword extraction.
2.2. Fine-Grained Semantic Information Extraction Within a Single Sentence
On the other hand, the extraction of semantic information within a single sentence remains another challenge in text understanding. Although the aforementioned Transformer-based models perform well in processing long texts, accurately capturing fine-grained semantic information within a single sentence for keyword extraction remains a technical difficulty.
In 2020, Li adopted a method based on Bidirectional Long Short-Term Memory (BiLSTM) combined with multi-channel features to improve the accuracy of keyword extraction by learning contextual dependencies within sentences [
11]. Xu proposed a keyword extraction method based on improved Term Frequency-Inverse Document Frequency (TF-IDF) weighted word vectors and BiLSTM to enhance model performance in keyword extraction tasks [
12]. Tan applied a deep learning framework based on LSTM that combines Convolutional Neural Networks (CNNs) and the attention mechanism to improve the performance of question-answering tasks, achieving significant performance gains [
13]. Although these methods have made some progress in keyword extraction, they still have limitations when processing semantic information within a single sentence. These features are often designed based on heuristic rules and are vulnerable to the size limitations of input datasets. Specifically, in long-text keyword extraction tasks, models often fail to handle the complex implicit relationships embedded in long texts effectively. To address these issues, researchers have proposed various deep learning-based solutions. Luo proposed a BiLSTM-based keyword extraction method that successfully improved single-sentence keyword extraction by learning contextual relationships within sentences [
14]. Zhang further combined the attention mechanism with BiLSTM, strengthening the model’s focus on key semantic elements and enhancing its ability to capture semantic information within a single sentence [
15]. Wu developed an end-to-end unified grid labeling task to achieve aspect-oriented fine-grained opinion extraction, designing an effective inference strategy to leverage mutual indications between different opinion factors, thereby improving the accuracy of keyword extraction within a single sentence [
16]. In addition to sentence-level semantic understanding, task scheduling in sentences is also a key factor in air traffic control (ATC) systems, which directly affects how various instructions are interpreted and executed in time-sensitive and resource-constrained environments. Accurate keyword extraction from ATC instructions depends not only on the semantic parsing of the text but also on the effective scheduling and execution of control tasks. Recent research in the field of intelligent transportation and networked systems has explored advanced task scheduling techniques. For example, the Du-Bus system [
17] uses multi-source data fusion to improve real-time bus arrival predictions, addressing challenges similar to estimating ATC operational intentions without direct sensor input. In another study, Sun et al. [
18] proposed a task scheduling algorithm for air–ground integrated networks based on proportional fairness-aware auction. The method uses deep reinforcement learning to integrate task offloading and resource allocation decisions, thereby improving system profit, fairness, and load balancing. These insights are highly relevant to the ATC environment, where keyword extraction models can enhance semantic understanding and operational decisions by integrating task priority and scheduling awareness.
These methods have demonstrated a high keyword extraction accuracy across various text types, especially in short texts. However, in the air traffic control (ATC) domain, due to the professional and diverse nature of ATC instructions, the text often contains complex semantic structures. Existing methods frequently fail to effectively capture the deep semantic relationships across sentences and segments. In this study, we introduce a BiLSTM module, and the model can leverage its bidirectional dependency-capturing capability to ensure the accurate extraction of keywords from single sentences across multiple segments.
2.3. Research on Sequential Consistency in Keyword Extraction
For air traffic control (ATC) instructions, the sequence of extracted keywords not only affects the accuracy of understanding but also impacts the safety and precision of flight operations. An incorrect sequence may lead to misinterpretation or improper execution of instructions, thereby increasing flight risks.
To address this issue, Conditional Random Fields (CRFs) have been widely applied in sequence labeling tasks due to their global sequence optimization capability, which allows the model to consider dependencies between labels and ensures that multiple keywords are extracted in the correct order from a given input sequence. Ma proposed a neural network architecture that combines Bidirectional Long Short-Term Memory (BiLSTM), Convolutional Neural Networks (CNNs), and CRF for automatic word- and character-level representation, avoiding the reliance on manual feature engineering [
19]. Huang employed a BiLSTM-CRF model for sequence labeling tasks in natural language processing, achieving a high performance [
20]. However, this method’s limitation lies in its relatively weak ability to model sequence consistency in long texts. To solve this problem, a BERT-CRF combined model was proposed for Chinese keyword extraction, which leveraged adversarial training and distributed computation methods to overcome the issue of limited annotated data [
21]. This method improved the accuracy of sequential keyword extraction from long texts to some extent. However, the BERT model, while effective at capturing local contextual information, still faces challenges in modeling cross-segment semantic associations. Additionally, a corpus classification-based keyword extraction method was introduced, which simulates the thought process of human reviewers to improve the sequence consistency and efficiency of keyword extraction from long texts [
22]. Jiang enhanced keyword extraction performance in Chinese sports news by introducing a character-level BiLSTM-CRF model [
23]. L proposed a Multi-source Entity Integration Model (MEIM), which integrates BiLSTM-CRF, template matching, and abstract syntax tree methods to address the problem of insufficient keyword annotation data [
24]. Furthermore, the Named Entity Recognition and Rapid Automatic Keyword Extraction (NER-RAKE) method was developed to tackle keyword extraction issues in long texts [
25]. While these methods addressed some issues related to semantic association, they still face challenges when processing long texts with cross-segment information and complex syntactic structures, often leading to information loss. Zhang proposed an ALBERT-BiGRU-CRF model for Chinese keyword extraction based on the ALBERT pretrained model to solve the limitations of traditional word vector models, significantly improving extraction performance [
26]. Lee integrated the BiLSTM-CRF model with fully connected layers and pretrained natural language models, using fine-tuning techniques to prevent keyword loss [
27].
Although existing research has made some progress in keyword extraction and sequence consistency, in the ATC domain, any mistake could lead to misinterpretation or incorrect execution of instructions, thereby increasing flight risks. In this study, we combine CRF with the model to leverage its global sequence optimization capability, ensuring that multiple keywords are predicted in the correct order and maintaining sequence consistency in complex ATC instructions.
3. Model
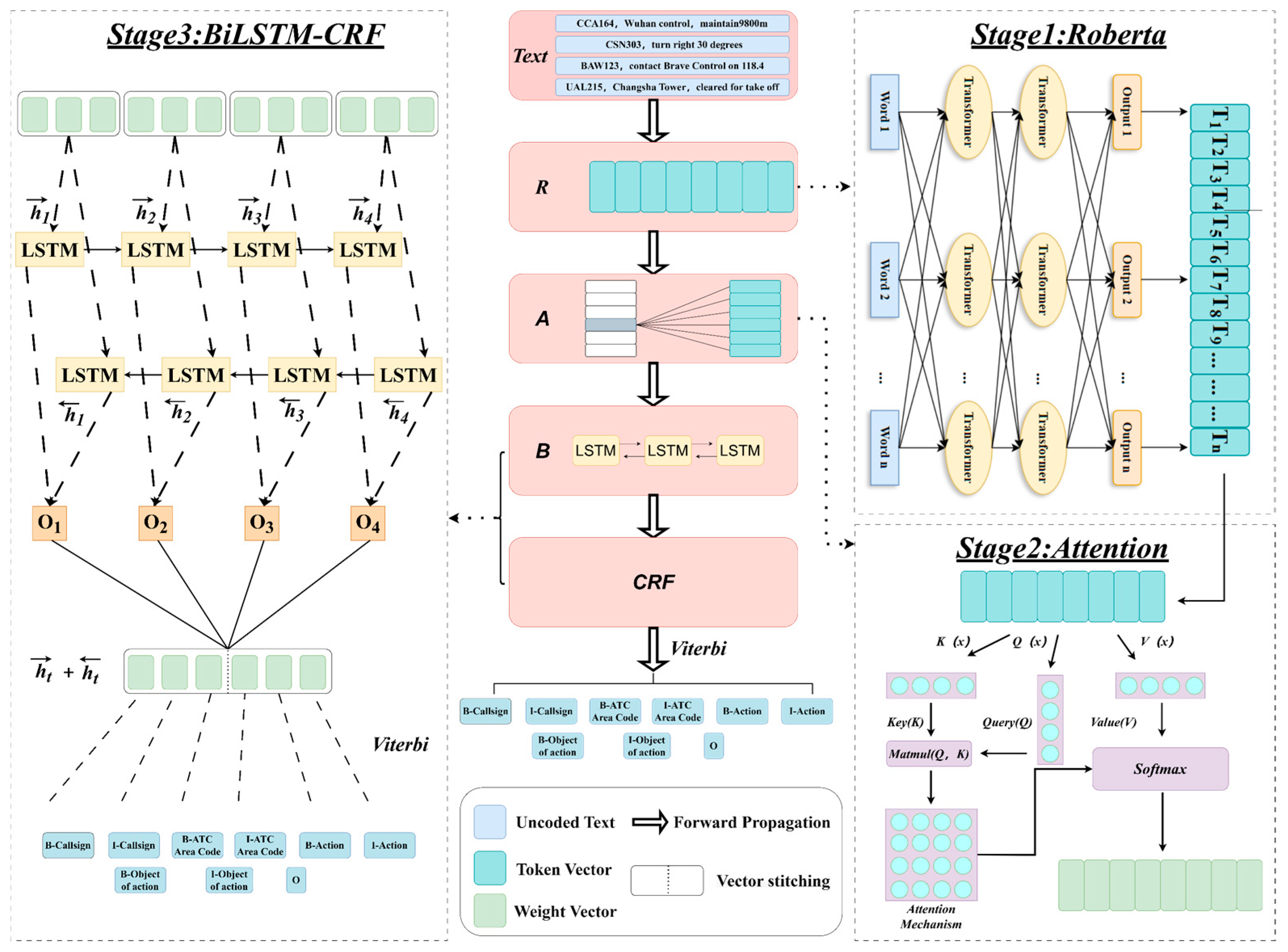
To address the issues of semantic correlation between multi-segment air traffic control (ATC) texts, the refinement of single-sentence semantic information extraction, and the consistency of keyword extraction order, we propose a model based on Roberta -Attention-BiLSTM-CRF. The model architecture is shown in
Figure 2. The pretrained Roberta model is used to generate high-quality semantic representations of the text. Through large-scale self-supervised pretraining, Roberta optimizes the language model’s understanding capability.
First, the input long-text ATC instructions are encoded, converting each word in the instruction into a contextually relevant word embedding. These embeddings capture semantic and syntactic information, enabling the model to deeply understand the meaning of the instructions. In addition, the attention mechanism is introduced to effectively model the contextual information across multi-segment texts, reinforcing semantic connections between different segments.
Next, the encoded text representations are fed into the BiLSTM module. The BiLSTM module further extracts single-sentence semantic information through a bidirectional recurrent neural network, enhancing the model’s ability to capture forward and backward dependencies within sentences.
Finally, a Conditional Random Field (CRF) layer is applied for global sequence optimization. We adopt the BIO annotation scheme, where each token is labeled as the beginning (B), inside (I), or outside (O) of a keyword. These labels are generated based on the emission scores produced by the BiLSTM layer, and subsequently refined by the CRF layer, which selects the most probable sequence of tags through global sequence optimization. The resulting label sequence is then mapped back to the corresponding keyword spans in the original ATC instruction text, enabling precise and order-preserving keyword extraction. The Viterbi algorithm is used for decoding, ensuring that the extracted keywords maintain the original order of the input text.
3.1. Roberta Module
The Roberta module plays a crucial role in the model architecture. Based on the BERT structure, the Roberta model leverages its powerful semantic understanding and contextual modeling capabilities to provide high-quality input representations for the subsequent keyword extraction tasks [
28,
29,
30]. The input to the Roberta module consists of multi-sentence control instructions, where each instruction is composed of a series of lexical units (tokens). Each token is first converted into a word vector, typically using the embedding layer of the pretrained Roberta model, which transforms the tokens into high-dimensional embeddings. The input format of the Roberta model is as follows:
represents the word embedding vector of the
token, and
denotes the dimension of the word embedding. The embedding vector of each input token not only contains information about the token itself but also encodes contextual and semantic relationships. The input sequence undergoes feature extraction through stacked Transformer encoders, and the model ultimately outputs a context-aware semantic representation.
represents the contextual semantic representation matrix,
denotes the context-aware hidden representation of the
input token, and
is the dimension of the hidden layer in Roberta. The detailed structure of the model is shown in
Figure 3.
The input refers to the original text input, where [CLS] represents a special token indicating the beginning of the entire sentence, and [SEP] serves as a special marker to separate sentences. The model’s embedding consists of three components: Token Embedding, Segment Embedding, and Position Embedding. Token Embeddings convert the input text into word vectors. Segment Embeddings are used to differentiate between the representations of preceding and succeeding sentences. Position Embeddings encode the positional information of each token. Roberta employs a Transformer encoder module to perform contextual semantic modeling on the input representation using pretrained parameters. Finally, the model output contains a sequence of vector representations that capture global language features.
3.2. Attention Module
To capture the logical relationships between preceding and succeeding sentences in multi-segment air traffic control instructions, this study introduces an attention mechanism designed to flexibly focus on details based on task requirements, thereby effectively mitigating the issue of information loss caused by excessively long time sequences. The mechanism achieves this by connecting the encoded hidden states with the input data, highlighting key information within the text. The core of the attention mechanism lies in the interactive computation among the query vector
, key vector
, and value vector
. Through the combination of these three elements, the model can intelligently focus on important keywords [
31]. For each token in the input sequence from Roberta, the corresponding query vector
, key vector
, and value vector
are first generated. These vectors are typically obtained by applying different linear transformations (matrix multiplications) to the input token embeddings.
The similarity between the query vector of each token and the key vector of all tokens in the sequence is measured using their dot product to calculate the attention score. To stabilize the computation and prevent gradient issues caused by large numerical values, the score is normalized by dividing it by the square root of the dimension of the query vector and key vector , denoted as . The attention scores are then normalized using the softmax function to produce the attention weights.
Next, the obtained attention weights
are used to compute a weighted sum over the value vectors
in the sequence, generating the final attention output [
32]. By focusing on value vectors with higher weights, the model can dynamically attend to key information in the input sequence.
The corresponding schematic diagram is shown in
Figure 4.
The specific calculation process is as follows:
represents the query vector, represents the key vector, represents the query vector at the position, represents the key vector at the position, and represents the value vector at the position. denotes the dimension of the vectors and . represents the attention weight of the query on the key , and the sum of all the attention weights equals 1. The function calculates the relevance score between the query vector and the key vector . The function maps the unnormalized attention scores to a probability distribution. The function serves as the expectation function.
3.3. BiLSTM-CRF Module
To address the challenges of fine-grained semantic information extraction within a single sentence and the issue of sequence consistency in keyword extraction, this paper proposes a joint modeling approach based on a Bidirectional Long Short-Term Memory network (BiLSTM) and a Conditional Random Field (CRF). This method employs hierarchical feature encoding and global sequence optimization to achieve accurate keyword extraction and sequence consistency control under complex contexts [
33,
34]. The BiLSTM processes the input attention sequence from both forward and backward directions, effectively capturing the contextual information and long-term dependencies of words within a single sentence [
35,
36]. Subsequently, the CRF layer considers the dependency between labels, ensuring the consistency and rationality of the output label sequence. The BiLSTM generates emission scores (label vectors), and the CRF decodes the optimal label path based on the emission scores using the Viterbi algorithm. The model structure is shown in
Figure 5.
Based on the attention output sequence, the BiLSTM performs forward and backward propagation on the input to capture the bidirectional dependency information within the text sequence.
denotes the hidden state at time step during forward propagation, represents the hidden state at the previous time step, and denotes the attention output.
denotes the hidden state at time step
during backward propagation,
represents the hidden state at the next time step, and
denotes the attention output. The bidirectional hidden states are concatenated and transformed through a linear projection to generate label emission scores, resulting in the BiLSTM output representation as follows:
represents the vector concatenation operation, and denotes the emission scores of the labeled tags.
Next, based on the emission scores generated by the BiLSTM, the CRF layer predicts the corresponding label sequence for the given input sequence. During the inference phase, the trained model computes the conditional probability distribution of the output sequence based on the input sequence features. Finally, the Viterbi algorithm is used for decoding, producing an air traffic control instruction text that aligns with the order of the input text. The calculation formula is as follows:
represents the output label sequence, denotes the emission scores of the labeled tags, is the transition matrix, represents the score of transitioning from label to label , denotes the score of assigning label at the position, and is a scoring function in the conditional random field.
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
Structured Air Traffic Control (ATC) Voice Commands refer to aviation communication phrases organized according to a fixed format and strict rules, aiming to ensure clear, accurate, and efficient information transmission, thereby minimizing ambiguity and enhancing flight safety. According to the specifications outlined in the Civil Aviation Administration of China (CAAC) Air Traffic Radio Communication Phraseology Standard (MH/T4014-2003) [
37], ATC instructions primarily consist of four key elements: aircraft callsign, ATC area code, instruction action, and object of action.
The aircraft callsign constitutes the first part of the instruction, typically used to identify the target aircraft. The ATC area code specifies the airspace or control area, such as approach, tower, or en-route sectors, providing contextual information about the control scenario. The instruction action represents the operational command issued by the controller to the aircraft, such as “take off”, “turn left”, or “maintain altitude”. The object of action provides further details about the action, including altitude, speed, heading, runway number, and other key parameters.
These elements are arranged in a strict order, forming concise and efficient ATC command statements. In this study, authentic multi-segment air–ground communication transcripts were processed and annotated using the BIO (Beginning, Inside, Outside) tagging scheme. The annotation follows the structured order of callsign, ATC area code, action, and object of action to ensure accurate identification and sequencing of ATC instruction elements. The classification examples of the ATC instruction dataset are shown in
Table 1, and the annotated examples of the ATC instruction dataset are presented in
Table 2.
There is no publicly available ATC speech corpus in the field of air traffic control. Therefore, the ATC instruction texts constructed in this study are derived from authentic air–ground communication transcripts. A total of 9200 samples have been manually annotated. To ensure fair evaluation and generalization of the model, we divided the dataset into training, validation, and test sets. Specifically, 5760 samples were used for training, 1440 samples for validation, and 2000 samples for final testing. The distribution of text lengths in the dataset is shown in
Figure 6.
4.1.2. Experimental Platform
The experiment was conducted on a Windows operating system. The computer configuration is as follows: 13th Gen Intel(R) Core(TM) i5-13500 2.50 GHz processor, 32 GB of RAM, NVIDIA RTX 4090 24 GB graphics card, 512 GB SSD, and a 2.0 TB HDD. The RABC model was implemented using the PyTorch 3.9.0 framework. The specific model hyperparameter configuration is shown in
Table 3.
4.2. Model Comparison Experiment
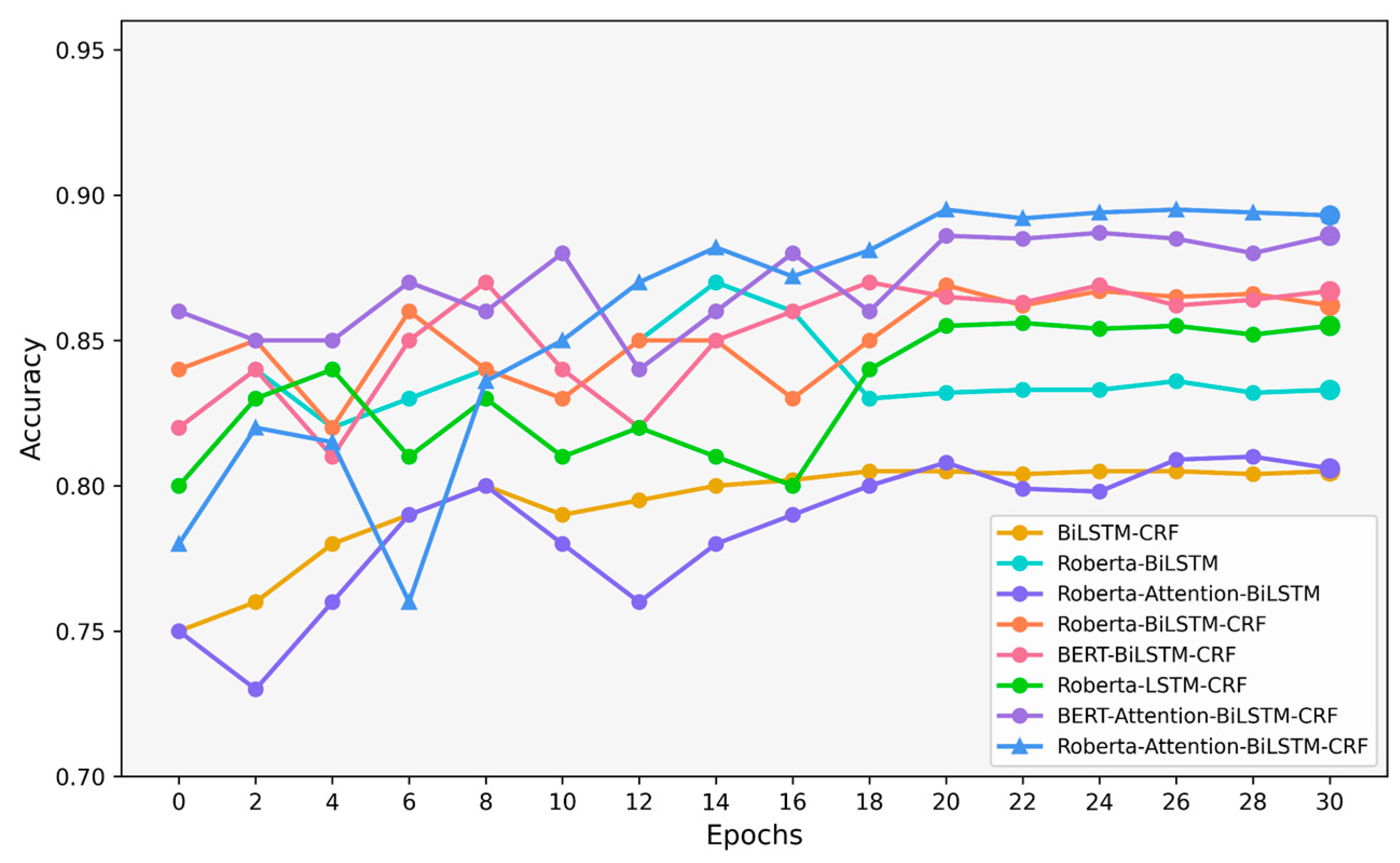
The Roberta pre-trained model was employed as the foundational architecture. While keeping the pre-trained parameters unchanged, the model was optimized by dynamically adjusting the parameters of the attention, BiLSTM, and CRF layers. The model’s performance was systematically validated over 20 training epochs. The final performance of various evaluation metrics after 20 training rounds is detailed in
Table 4, while
Figure 7 dynamically illustrates the accuracy convergence trend during training.
In terms of the evaluation framework, four core metrics were used for comprehensive assessment: accuracy, precision, recall, and F1 score [
38]. Additionally, a confusion matrix was constructed to conduct a fine-grained analysis of the accuracy in extracting keyword sequences. The calculation methods for these evaluation metrics are presented as follows:
represents accuracy, denotes precision, stands for recall, and refers to the F1 score. TP (True Positive) indicates the number of samples correctly predicted as positive by the model. TN (True Negative) represents the number of samples correctly predicted as negative. FP (False Positive) refers to the number of samples incorrectly predicted as positive. FN (False Negative) indicates the number of samples incorrectly predicted as negative.
At the beginning of model training, we set the number of training epochs to 30 to ensure model convergence and stability. The initial experimental results did not achieve the expected optimal performance and exhibited some degree of fluctuation. However, after multiple rounds of experimentation and observation, the accuracy of the RABC model steadily improved, reaching 0.895 at the 20th epoch, after which the model’s performance tended to stabilize.
Figure 7 illustrates the impact of different model combinations on the accuracy of ATC keyword recognition. The introduction of the attention mechanism significantly enhanced recognition performance, demonstrating higher accuracy and reduced fluctuation compared to other models. In contrast, the traditional combination of LSTM and CRF showed relatively weaker performance during the initial training stages but exhibited greater stability in the later phases. Overall, the high accuracy and stability of the proposed RBAC model confirm the effectiveness of the attention mechanism in keyword recognition tasks.
In
Table 4, the Roberta-Attention-BiLSTM-CRF model demonstrates the best performance in the ATC speech recognition task, achieving an accuracy of 0.895 and an F1 score of 0.882, both significantly higher than those of other models. Compared to the BERT-BiLSTM-CRF model (Acc 0.865), the Roberta-based models exhibited a clear performance advantage. Notably, the introduction of the attention mechanism further improved performance, with the Roberta-Attention-BiLSTM-CRF model achieving a 7.6% increase in accuracy over the baseline Roberta-BiLSTM model (Acc 0.832). This improvement highlights Roberta’s superior ability as a pre-trained model to effectively capture domain-specific features in ATC speech. Moreover, the integration of the CRF layer significantly enhanced model performance. For instance, the Roberta-BiLSTM-CRF model (Acc 0.869) achieved a 4.4% improvement in accuracy compared to the baseline model without the CRF layer (Acc 0.832), confirming the CRF layer’s effectiveness in optimizing label transition constraints within sequential data. It is noteworthy that the effectiveness of the attention mechanism is model-dependent. In the Roberta-Attention-BiLSTM model, using the attention mechanism alone resulted in a performance drop (Acc 0.808). However, when combined with the CRF layer (Acc 0.895), it emerged as the optimal model. This finding underscores that the attention mechanism requires joint optimization with sequence constraints to enhance feature weighting effectively. In the bidirectional structural comparison experiments, the Roberta-BiLSTM-CRF model (Acc 0.869) outperformed the Roberta-LSTM-CRF model (Acc 0.855) by 1.6%, confirming that the bidirectional structure more effectively captures contextual semantic information. Furthermore, although the baseline BiLSTM-CRF model (Acc 0.805) does not perform as well as the more advanced variants, it still shows a stable performance during training. This highlights the inherent strength of the BiLSTM-CRF architecture in handling sequence labeling tasks, even without leveraging pre-trained models, providing a strong baseline.
4.3. Ablation Study
To validate the effectiveness of the RABC model, four sets of ablation experiments were designed. The results are shown in
Table 5.
Figure 8 illustrates the relationship between F1 score and model complexity
Among the models, RB represents the Roberta-BiLSTM baseline model, RAB denotes the Roberta-Attention-BiLSTM model, RBC refers to the Roberta-BiLSTM-CRF model, and RBAC is the proposed model in this study.
In the table, the strategy of multi-model fusion, which involves progressively extracting and effectively integrating different features from the text, enables more accurate and detailed results in the keyword extraction task. As shown in
Figure 8, our proposed RABC model achieves the highest F1 score while maintaining a reasonable number of parameters compared to deeper or more resource-intensive architectures.
4.4. Confusion Matrix
To evaluate the model’s ability to handle the sequential output of keywords, 2000 ATC instruction text samples were selected as the test set for the experiment. The horizontal and vertical axes represent the ATC instruction categories.
In
Figure 9, the rectangular areas represent the number of samples corresponding to each category. The confusion matrix demonstrates that the model exhibits significant classification advantages in the task of sequential extraction of ATC instruction keywords, achieving an accuracy of 91.3% in extracting keywords in the correct input order.
The number of correctly classified callsign samples is slightly higher than that of other categories, which may be attributed to overfitting of the model to specific category sample features. This reveals the potential for improvement in the model’s ability to distinguish semantic boundaries and maintain label continuity. In future work, increasing the volume of data containing typical confusing category samples will help the model better differentiate between similar categories.
5. Conclusions
This study primarily focuses on the problem of keyword extraction from air traffic control (ATC) instructions based on deep learning, particularly the accurate extraction and classification of instruction keywords from ATC speech. By analyzing and processing ATC instruction text data, this paper proposes a multi-task keyword extraction model that integrates Roberta, Attention, BiLSTM, and CRF.
A dataset of 9200 ATC instruction text samples was constructed from authentic air–ground communication data, with annotations following strict standards and arranged in the correct sequence. This dataset can serve as a valuable resource for future research in various fields, including intent recognition, instruction correction, and other applications in speech recognition and natural language processing (NLP). The proposed multi-task model achieved a keyword extraction accuracy of 89.5% and a sequence accuracy of 91.3% on the multi-segment ATC instruction text dataset, with the extracted keywords correctly arranged in the intended order. These results confirm the model’s ability to effectively address the core challenges of keyword extraction in ATC instructions. Specifically, the attention mechanism successfully captures semantic dependencies across multiple instruction segments; the BiLSTM component improves fine-grained contextual understanding within a sentence; and the CRF layer preserves the correct sequence of keywords in line with operational logic. Importantly, the effectiveness of ATC keyword extraction should be assessed not only through technical performance but also in terms of compliance with operational standards and regulatory frameworks. International organizations such as the International Civil Aviation Organization (ICAO) and regional air navigation service providers enforce stringent communication protocols to ensure clarity, consistency, and safety. The proposed RABC model aligns with these standards by accurately extracting structured keywords—such as callsigns, ATC area codes, actions, and objects of action—thereby supporting automated decision-making, compliance monitoring, and real-time operational assistance. Moreover, the model’s enhanced accuracy and efficiency have the potential to reduce controller workload, improve situational awareness, and strengthen both the safety and operational capacity of ATC systems in increasingly complex airspace environments. Future research will continue to explore the intelligent development of the ATC domain, focusing on optimizing instruction recognition and correction systems. Special attention will be given to developing intelligent pilot systems to reduce human error, improve the accuracy of instruction execution, and ensure that ATC systems can effectively respond to dynamic changes in the air traffic environment. In addition, future work will focus on integrating the proposed RABC model into real-time ATC communication systems to enhance its adaptability and effectiveness in operational environments. To enable practical deployment, efforts will be directed toward optimizing the model to meet the computational constraints of real-time applications. This includes reducing model complexity and inference time through techniques such as model pruning, quantization, and knowledge distillation. These optimizations aim to minimize latency and memory usage, facilitating deployment on embedded systems or edge devices without sacrificing accuracy. Furthermore, adaptive learning strategies may be explored to allow the model to dynamically update in response to evolving communication patterns and operational requirements, ensuring a sustained performance in complex and changing ATC scenarios.
Author Contributions
Conceptualization, W.P. and S.C. (Sheng Chen); methodology, S.C. (Sheng Chen); software, S.C. (Sheng Chen); validation, S.C. (Sheng Chen) and W.P.; formal analysis, S.C. (Sheng Chen); investigation, S.C. (Sheng Chen); resources, W.P.; data curation, S.C. (Shenhao Chen); writing—original draft preparation, S.C. (Sheng Chen); writing—review and editing, W.P., S.C. (Sheng Chen) and X.W.; visualization, S.C. (Sheng Chen); supervision, S.C. (Sheng Chen) and Y.W.; project administration, S.C. (Sheng Chen); funding acquisition, W.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (U2333209), National Key Research and Development Program of China (No. 2021YFF0603904), National Natural Science Foundation of China (U2333207), Independent Project of Sichuan Provincial Key Laboratory (MZ2024JB01), Sichuan Provincial Civil Aviation Flight Technology and Flight Safety Engineering Technology Research Center (GY2024-48E), Sichuan Provincial Civil Aviation Flight Technology and Flight Safety Engineering Technology Research Center (GY2024-46E) and Fundamental Research Funds for the Central Universities Grant Number (24CAFUC03046).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RABC | Roberta-Attention-BiLSTM-CRF |
| ATC | Air Traffic Control |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CRF | Conditional Random Field |
| ATM | Air Traffic Management |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| NLP | Natural Language Processing |
| LSTM | Long Short-term Memory |
| CNN | Convolutional Neural Network |
| MEIM | Multi-source Entity Integration Model |
| NER-RAKE | Named Entity Recognition and Rapid Automatic Keyword Extraction |
| ALBERT | A Lite BERT for Self-supervised Learning of Language Representations |
| BiGRU | Bidirectional Gate Recurrent Unit |
| CAAC | Civil Aviation Administration of China |
| RB | Roberta-BiLSTM |
| RAB | Roberta-Attention-BiLSTM |
| RBC | Roberta-BiLSTM-CRF |
References
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Firoozeh, N.; Nazarenko, A.; Alizon, F.; Daille, B. Keyword Extraction: Issues and Methods. Nat. Lang. Eng. 2020, 26, 259–291. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, S.; Cao, J.; Yang, R.; Wen, Z. Key Phrase Aware Transformer for Abstractive Summarization. Inf. Process. Manag. 2022, 59, 102913. [Google Scholar] [CrossRef]
- Sun, W.; Liu, S.; Liu, Y.; Kong, L.; Jian, Z. Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning. Sensors 2023, 23, 4250. [Google Scholar] [CrossRef]
- Pan, W.; Jiang, P.; Wang, Z.; Li, Y.; Liao, Z. Ernie-Gram BiGRU Attention: An Improved Multi-Intention Recognition Model for Air Traffic Control. Aerospace 2023, 10, 349. [Google Scholar] [CrossRef]
- Zhang, Y.; Tuo, M.; Yin, Q.; Qi, L.; Wang, X.; Liu, T. Keywords Extraction with Deep Neural Network Model. Neurocomputing 2020, 383, 113–121. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Yan, H.; Jin, X.; Meng, X.; Guo, J.; Cheng, X. Event Detection with Multi-Order Graph Convolution and Aggregated Attention. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), Hong Kong, China, 3–7 November 2019; pp. 5766–5770. [Google Scholar]
- Li, W.; Qi, F.; Tang, M.; Yu, Z. Bidirectional LSTM with Self-Attention Mechanism and Multi-Channel Features for Sentiment Classification. Neurocomputing 2020, 387, 63–77. [Google Scholar] [CrossRef]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Tan, M.; dos Santos, C.; Xiang, B.; Zhou, B. Lstm-Based Deep Learning Models for Non-Factoid Answer Selection. arXiv 2015, arXiv:1511.04108. [Google Scholar]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An Attention-Based BiLSTM-CRF Approach to Document-Level Chemical Named Entity Recognition. Bioinformatics 2018, 34, 1381–1388. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Q.; Song, L. Sentence-State LSTM for Text Representation. arXiv 2018, arXiv:1805.02474. [Google Scholar]
- Wu, Z.; Ying, C.; Zhao, F.; Fan, Z.; Dai, X.; Xia, R. Grid Tagging Scheme for Aspect-Oriented Fine-Grained Opinion Extraction. arXiv 2020, arXiv:2010.04640. [Google Scholar]
- Rong, Y.; Xu, Z.; Liu, J.; Liu, H.; Ding, J.; Liu, X.; Luo, W.; Zhang, C.; Gao, J. Du-Bus: A Realtime Bus Waiting Time Estimation System Based on Multi-Source Data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24524–24539. [Google Scholar] [CrossRef]
- Sun, G.; Wang, Y.; Yu, H.; Guizani, M. Proportional Fairness-Aware Task Scheduling in Space-Air-Ground Integrated Networks. IEEE Trans. Serv. Comput. 2024, 17, 4125–4137. [Google Scholar] [CrossRef]
- Ma, X.; Hovy, E. End-to-End Sequence Labeling via Bi-Directional Lstm-Cnns-Crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Ding, T.; Yang, W.; Wei, F.; Ding, C.; Kang, P.; Bu, W. Chinese Keyword Extraction Model with Distributed Computing. Comput. Electr. Eng. 2022, 97, 107639. [Google Scholar] [CrossRef]
- Sun, C.; Chen, W.; Zhang, Z.; Zhang, T. A Patent Keyword Extraction Method Based on Corpus Classification. Mathematics 2024, 12, 1068. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, T.; Chai, Y.; Gao, P. Bidirectional LSTM-CRF Models for Keyword Extraction in Chinese Sport News. In Proceedings of the 11th International Conference on Multispectral Image Processing and Pattern Recognition (MIPPR 2019), Wuhan, China, 2–3 November 2019; SPIE: Bellingham, WA, USA, 2020; Volume 11430, pp. 114300H–114300H–7. [Google Scholar]
- Lv, W.; Liao, Z.; Liu, S.; Zhang, Y. MEIM: A Multi-Source Software Knowledge Entity Extraction Integration Model. Comput. Mater. Contin. 2021, 66, 1027–1042. [Google Scholar] [CrossRef]
- Huang, H.; Wang, X.; Wang, H. NER-RAKE: An Improved Rapid Automatic Keyword Extraction Method for Scientific Literatures Based on Named Entity Recognition. Proc. Assoc. Inf. Sci. Technol. 2020, 57, e374. [Google Scholar] [CrossRef]
- Zhang, X.; Cui, J.; Zhang, X. Research on Chinese Keyword Extraction Based on the ALBERT Pre-Training Model. In Proceedings of the 2022 4th International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Shanghai, China, 28–30 October 2022; pp. 20–27. [Google Scholar]
- Lee, S.-S.; Cha, S.-M.; Ko, B.; Park, J.J. Extracting Fallen Objects on the Road From Accident Reports Using a Natural Language Processing Model-Based Approach. IEEE Access 2023, 11, 139521–139533. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Delobelle, P.; Winters, T.; Berendt, B. Robbert: A Dutch Roberta-Based Language Model. arXiv 2020, arXiv:2001.06286. [Google Scholar]
- Briskilal, J.; Subalalitha, C. An Ensemble Model for Classifying Idioms and Literal Texts Using BERT and RoBERTa. Inf. Process. Manag. 2022, 59, 102756. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An Attentive Survey of Attention Models. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- An, Y.; Xia, X.; Chen, X.; Wu, F.-X.; Wang, J. Chinese Clinical Named Entity Recognition via Multi-Head Self-Attention Based BiLSTM-CRF. Artif. Intell. Med. 2022, 127, 102282. [Google Scholar] [CrossRef]
- Ke, J.; Wang, W.; Chen, X.; Gou, J.; Gao, Y.; Jin, S. Medical Entity Recognition and Knowledge Map Relationship Analysis of Chinese EMRs Based on Improved BiLSTM-CRF. Comput. Electr. Eng. 2023, 108, 108709. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The Performance of LSTM and BiLSTM in Forecasting Time Series. In Proceedings of the 2019 IEEE International conference on big data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]
- Li, Y.; Wang, L. Human Activity Recognition Based on Residual Network and BiLSTM. Sensors 2022, 22, 635. [Google Scholar] [CrossRef]
- MHT4014-2003; Phraseology for Air Traffic Control Radiotelephony. Civil Aviation Administration of China (CAAC): Beijing, China, 2003.
- Kici, D.; Malik, G.; Cevik, M.; Parikh, D.; Basar, A. A BERT-Based Transfer Learning Approach to Text Classification on Software Requirements Specifications. In Proceedings of the Canadian AI, Vancouver, BC, Canada, 25–28 May 2021. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}