
Autonomous Trajectory Planning Method for Stratospheric Airship Regional Station-Keeping Based on Deep Reinforcement Learning


Abstract
1. Introduction
- This paper proposes a DRL-based continuous action space 2D trajectory planning method. Compared to methods with discrete action spaces, this method provides the airship with higher flexibility and smoother flight trajectories. During flight, the airship can make reasonable flight decisions by considering the wind field environment and its own state, allowing it to reach the target area and achieve long-duration station-keeping.
- Our approach is based on a time-varying wind field that reflects the dynamic characteristics of wind speed and direction changes over time. The action of the airship does not depend on past or future wind field states but is based on current real-time wind speed information. By adjusting and optimizing the flight path in real-time, the airship can automatically navigate and reduce the need for human intervention.
2. Problem Formulation
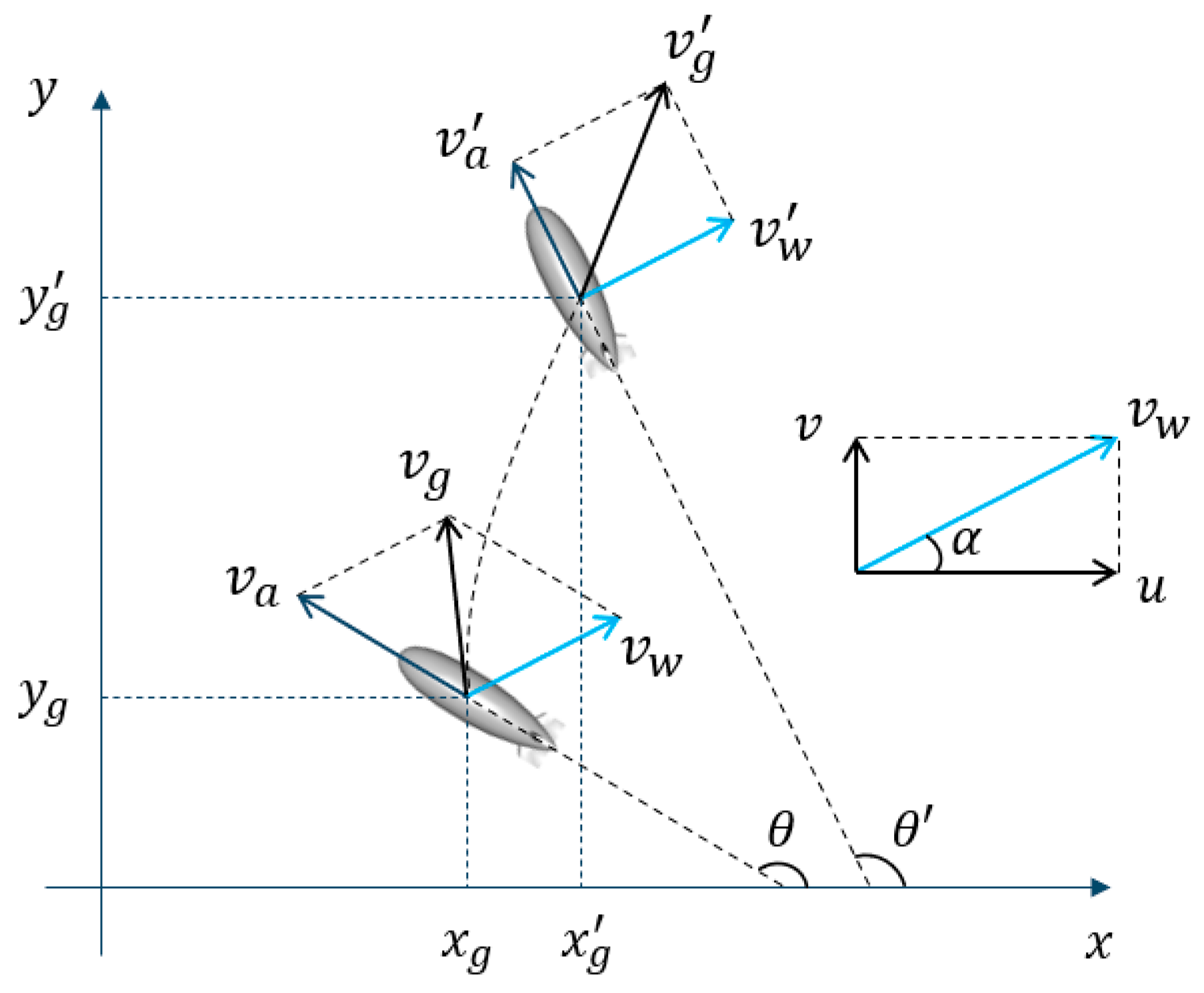
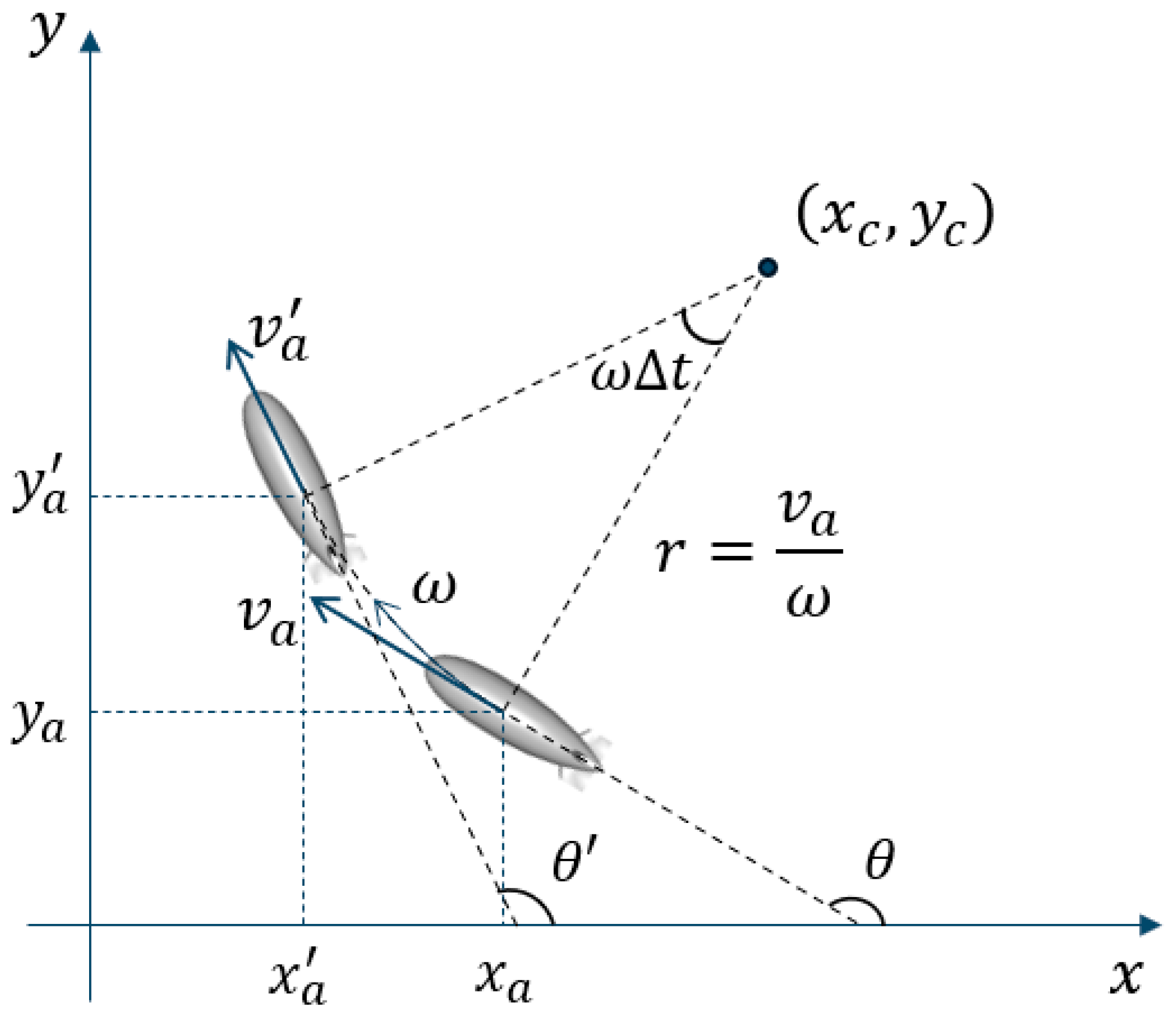
2.1. The Kinematic Airship Model
- The airship has large inertia and weak wind resistance, making it significantly susceptible to wind field effects.
- The airship is simplified as a particle.
- The airship usually does not have the ability to actively adjust its height and does not consider the vertical movement of the airship, only considering the movement of the fixed isobaric surface.
- Only the kinematic characteristics of the airship are considered.
- The wind field is assumed to be constant within a ∆t time interval, and the airship’s displacement due to the wind is equal to the wind displacement during the ∆t time interval.
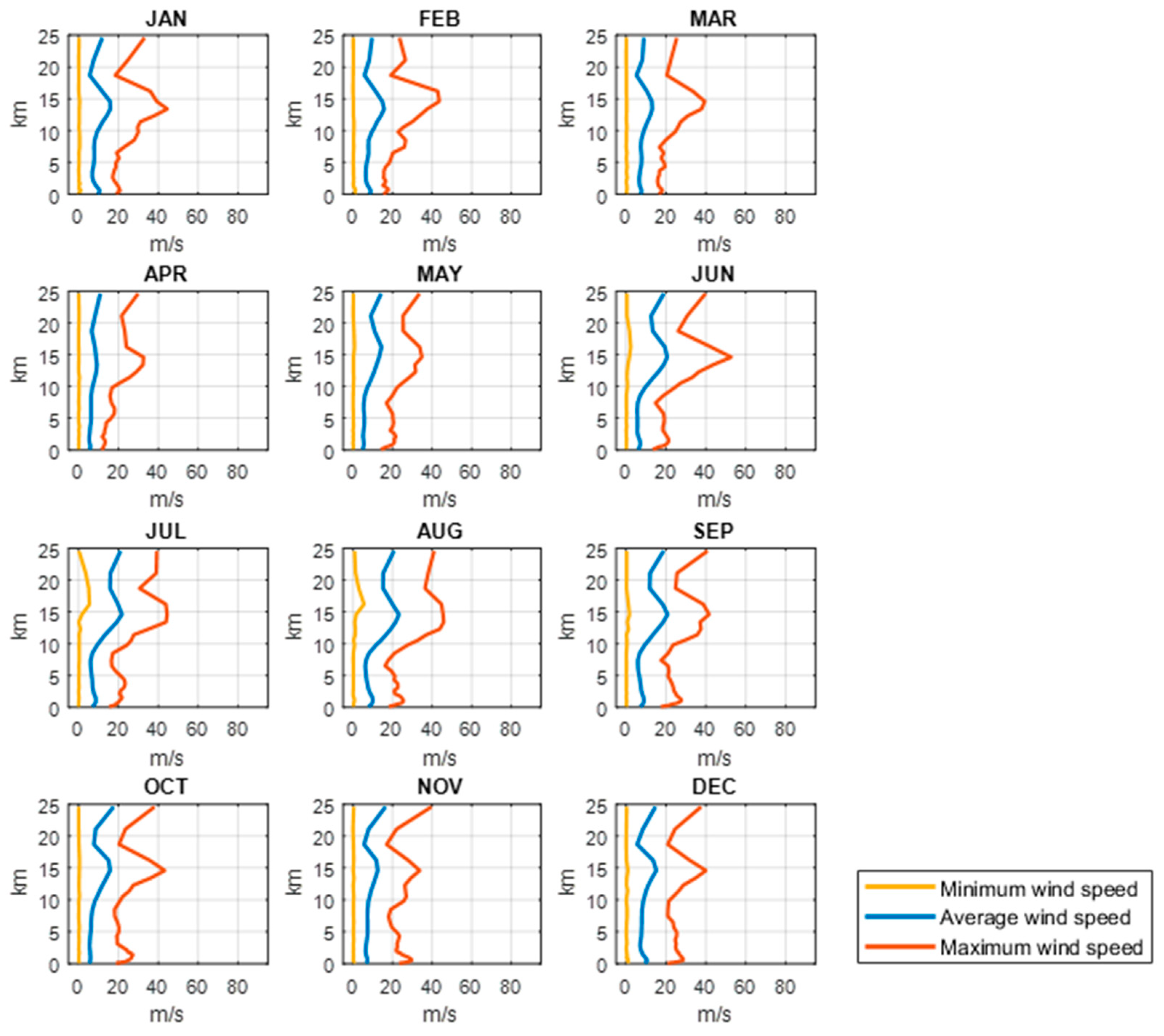
2.2. Description of Stratospheric Complex Wind Field Environment
3. DRL Model for Airship Trajectory Planning
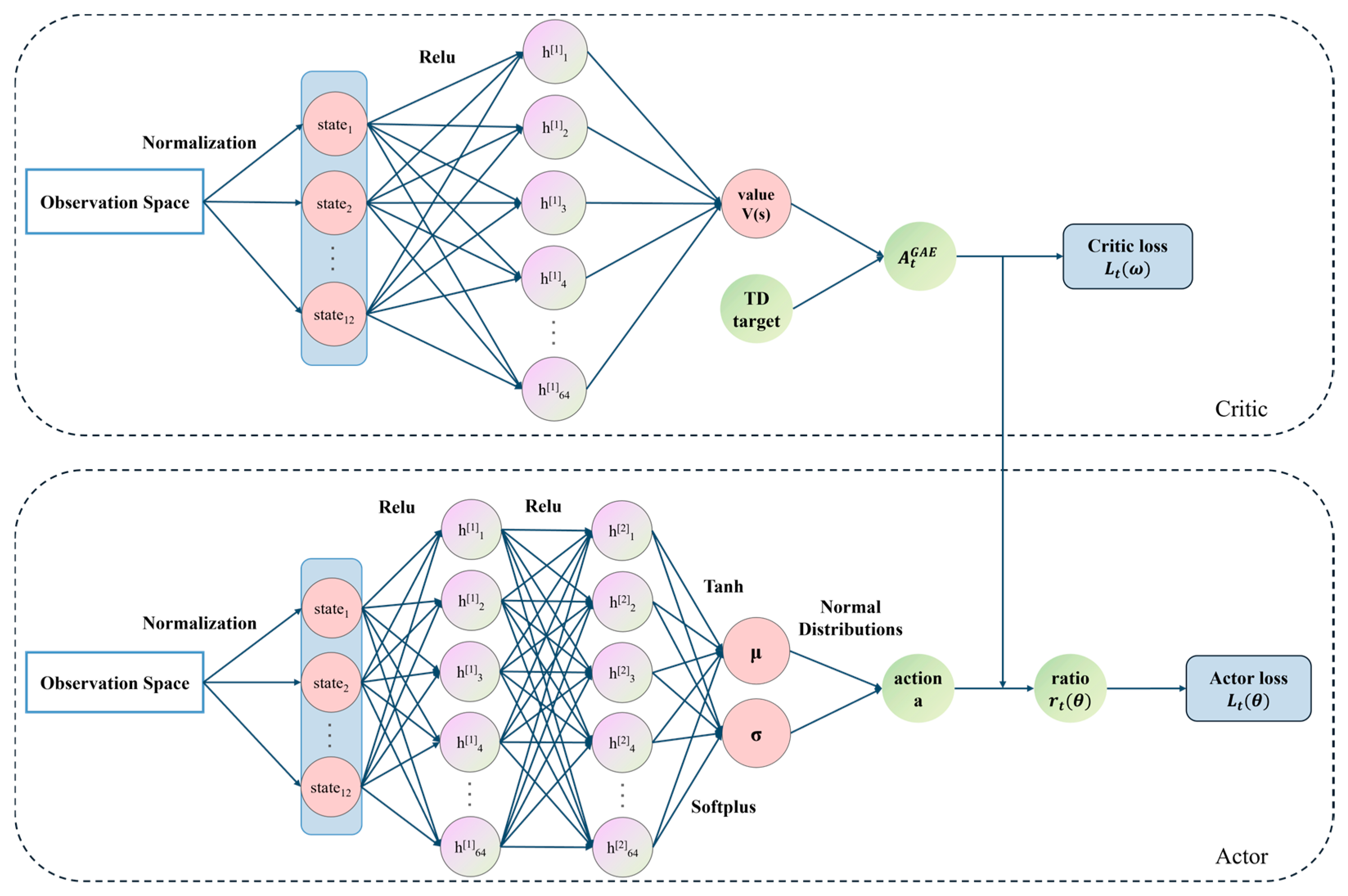
3.1. Introduction to Proximal Policy Optimization
3.2. Design of Observation Space and Action Space
3.2.1. Observation Space
3.2.2. Action Space
3.3. Reward Design
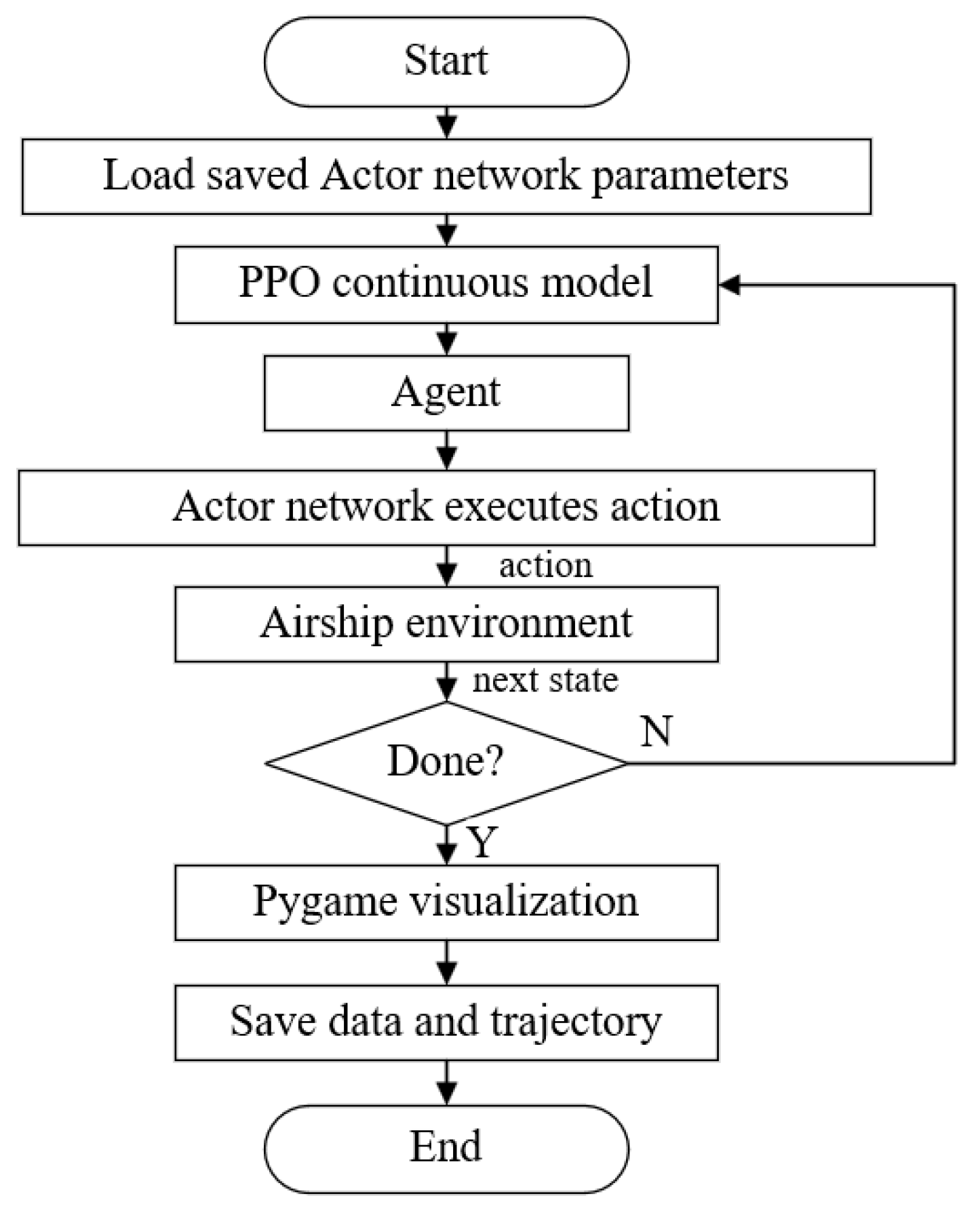
4. Experiment
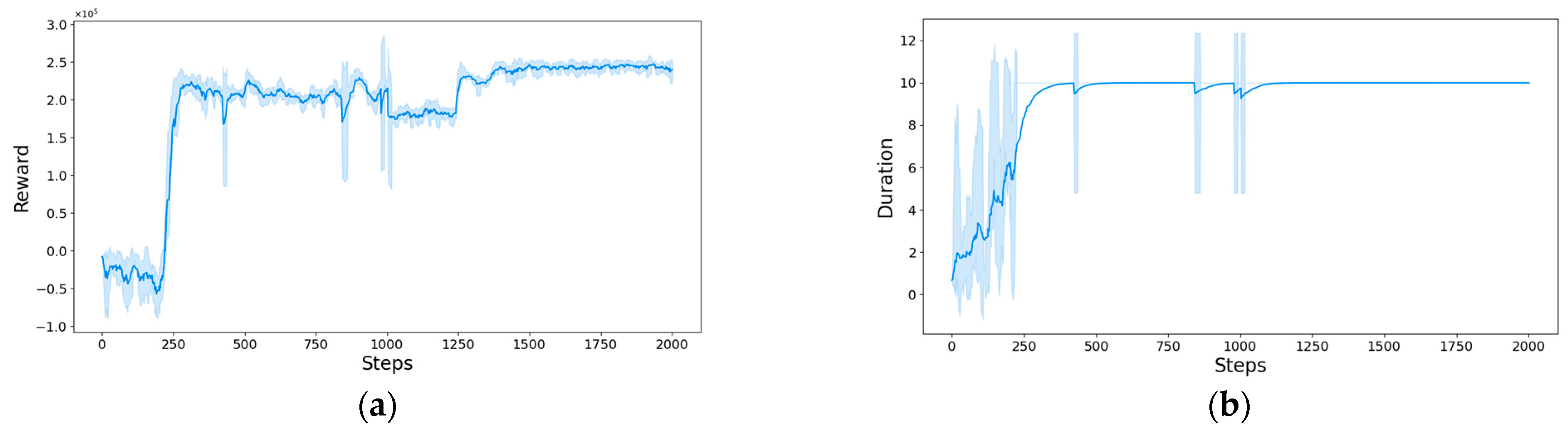
4.1. Traning
4.2. Testing
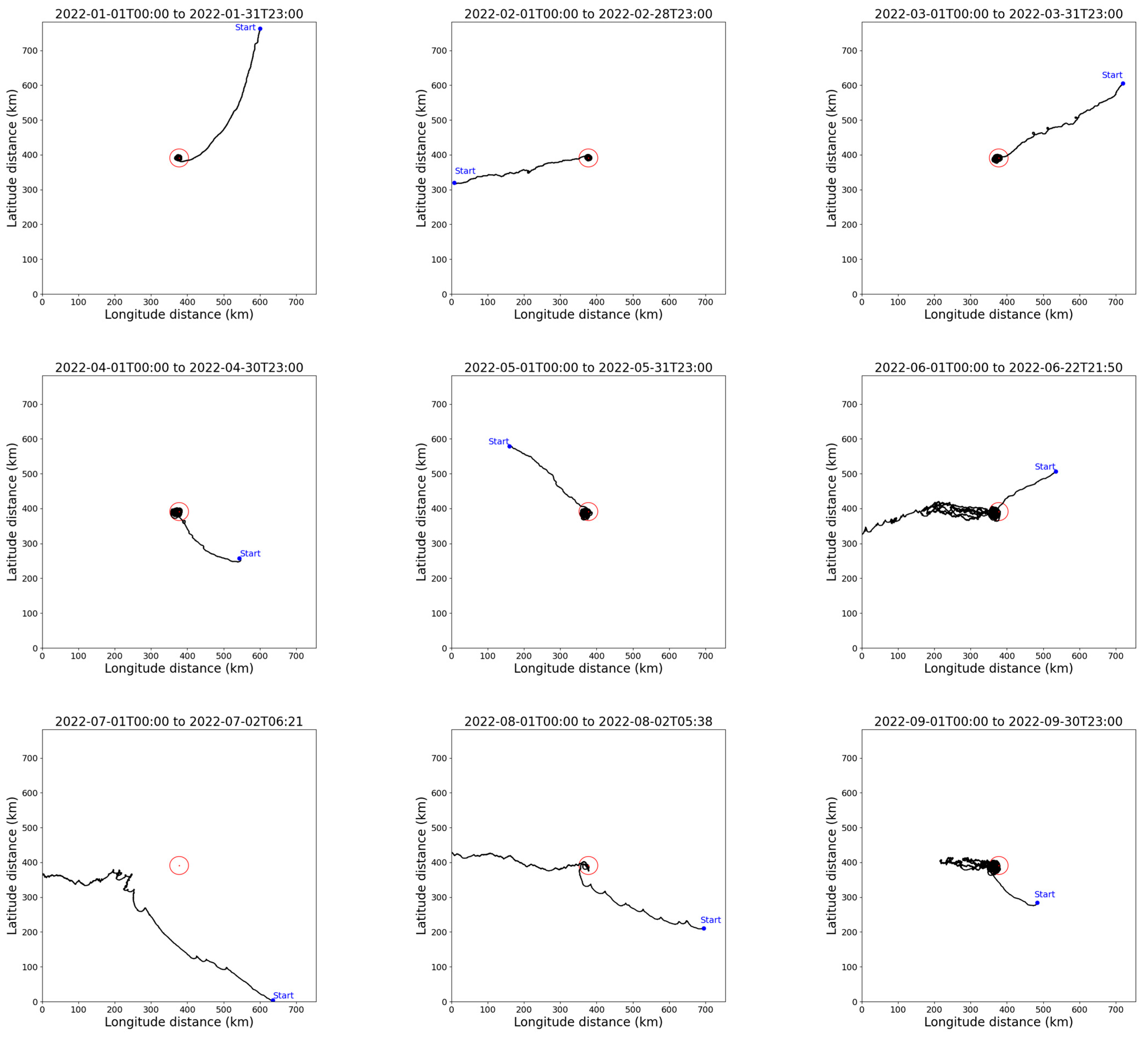
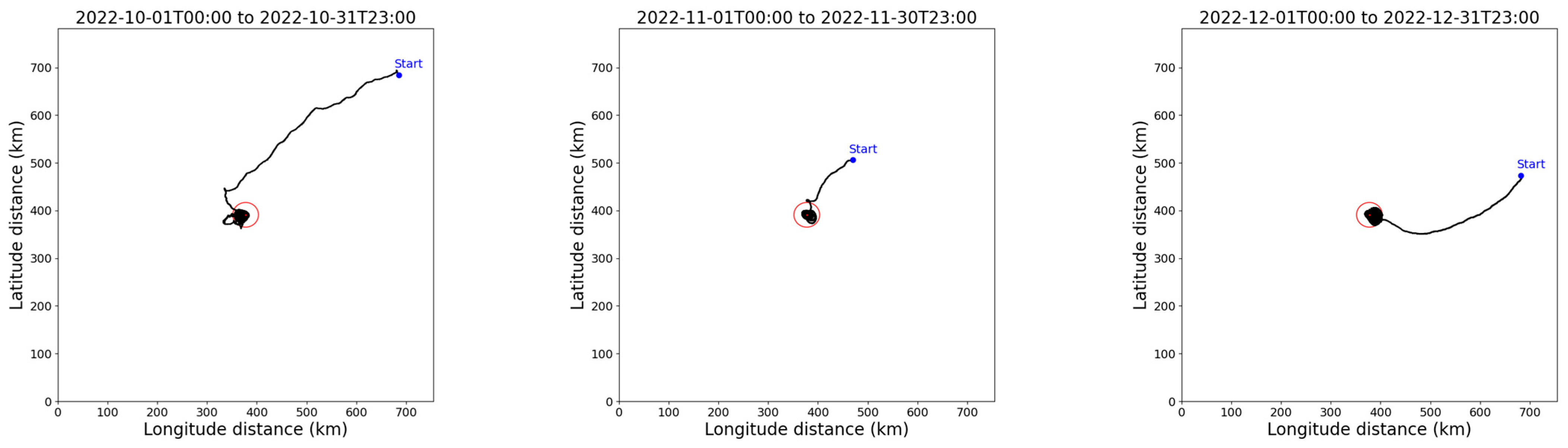
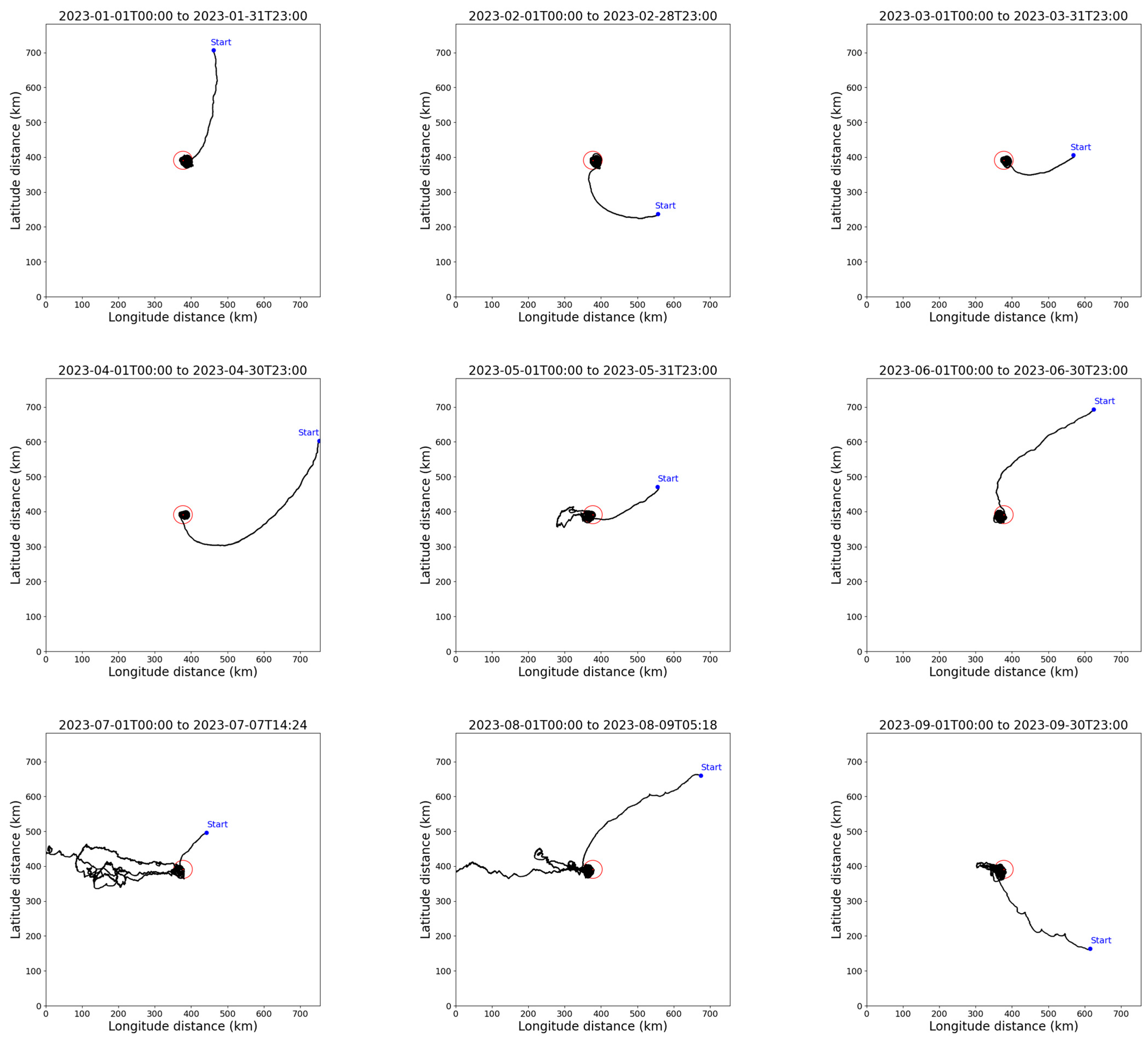
- Take-off Time (TT): The take-off time of the airship, uniformly set to the 1st of each month at 00:00 UTC.
- Flight Time (FT): The flight time of the airship within the 7° × 7° mission area.
- Time to Reach the Station-keeping Area (TRSA): The time it takes for the airship to first reach the boundary of the station-keeping area from the starting point.
- Station-keeping Time (ST): The total time the airship spends within the station-keeping area.
- Station-keeping Time Ratio (STR): The ratio of the airship’s station-keeping time to its flight time.
- The influence of wind field on station-keeping performance
- 2.
- Model performance analysis
- 3.
- Model autonomy analysis
- 4.
- Analysis of potential sources of error
5. Conclusions
- The model does not rely on past or future wind field states; it autonomously calculates and adjusts flight paths based on the current wind field conditions to achieve station-keeping, thereby reducing the need for manual intervention. In practical applications, current wind speed information can be obtained through wind speed sensors, allowing the system to respond immediately to changes in wind speed without relying on historical data or future wind field predictions.
- The results of training and testing show that the model can achieve long-term regional station-keeping effectively under stable wind field conditions, with a maximum station-keeping time ratio of 0.997. Even in months with higher average wind speeds, which typically exceed the airship’s maximum wind resistance capability and cause the airship to leave the station-keeping area, the airship still shows a tendency to drift back towards the station-keeping area. Once the wind speeds subside, the airship can return to and continue station-keeping in the designated area.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Xu, Y.; Jiang, B.; Gao, Z.; Zhang, K. Fault tolerant control for near space vehicle: A survey and some new results. J. Syst. Eng. Electron. 2011, 22, 88–94. [Google Scholar] [CrossRef]
- Young, M.; Keith, S.; Pancotti, A. An overview of advanced concepts for near space systems. In Proceedings of the 45th AIAA/ASME/SAE/ASEE Joint Propulsion Conference & Exhibit, Denver, CO, USA, 2–5 August 2009; p. 4805. [Google Scholar]
- Parsa, A.; Monfared, S.B.; Kalhor, A. Backstepping control based on sliding mode for station-keeping of stratospheric airship. In Proceedings of the 6th RSI International Conference on Robotics and Mechatronics (IcRoM), Tehran, Iran, 23–25 October 2018; pp. 554–559. [Google Scholar]
- Wu, J.; Fang, X.; Wang, Z.; Hou, Z.; Ma, Z.; Zhang, H.; Dai, Q.; Xu, Y. Thermal modeling of stratospheric airships. Prog. Aerosp. Sci. 2015, 75, 26–37. [Google Scholar] [CrossRef]
- Mueller, J.; Paluszek, M.; Zhao, Y. Development of an aerodynamic model and control law design for a high altitude airship. In Proceedings of the AIAA 3rd” Unmanned Unlimited” Technical Conference, Workshop and Exhibit, Chicago, IL, USA, 20–23 September 2004; p. 6479. [Google Scholar]
- d’Oliveira, F.A.; Melo, F.C.; Devezas, T.C. High-altitude platforms—Present situation and technology trends. J. Aerosp. Technol. Manag. 2016, 8, 249–262. [Google Scholar] [CrossRef]
- Luo, Q.C.; Sun, K.W.; Chen, T.; Zhang, Y.F.; Zheng, Z.W. Trajectory planning of stratospheric airship for station-keeping mission based on improved rapidly exploring random tree. Adv. Space Res. 2024, 73, 992–1005. [Google Scholar] [CrossRef]
- Wang, J.; Meng, X.; Li, C. Recovery trajectory optimization of the solar-powered stratospheric airship for the station-keeping mission. Acta Astronaut. 2021, 178, 159–177. [Google Scholar] [CrossRef]
- Erke, S.; Bin, D.; Yiming, N.; Qi, Z.; Liang, X.; Dawei, Z. An improved A-Star based path planning algorithm for autonomous land vehicles. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420962263. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Yuan, Q. Application of Dijkstra algorithm in robot path-planning. In Proceedings of the Second International Conference on Mechanic Automation and Control Engineering, Inner Mongolia, China, 15–17 July 2011; pp. 1067–1069. [Google Scholar]
- Noreen, I.; Khan, A.; Habib, Z. A comparison of RRT, RRT* and RRT*-smart path planning algorithms. Int. J. Comput. Sci. Netw. Secur. 2016, 16, 20. [Google Scholar]
- Li, Q.; Xu, Y.; Bu, S.; Yang, J. Smart vehicle path planning based on modified PRM algorithm. Sensors 2022, 22, 6581. [Google Scholar] [CrossRef]
- Luo, Q.; Wang, H.; Zheng, Y.; He, J. Research on path planning of mobile robot based on improved ant colony algorithm. Neural Comput. Appl. 2020, 32, 1555–1566. [Google Scholar] [CrossRef]
- Elshamli, A.; Abdullah, H.A.; Areibi, S. Genetic algorithm for dynamic path planning. In Proceedings of the Canadian Conference on Electrical and Computer Engineering, Niagara Falls, ON, Canada, 2–5 May 2004; pp. 677–680. [Google Scholar]
- Miao, H.; Tian, Y.C. Dynamic robot path planning using an enhanced simulated annealing approach. Appl. Math. Comput. 2013, 222, 420–437. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, Z.; Cheng, L.; Knoll, A.C.; Zhou, M. Deep reinforcement learning based trajectory planning under uncertain constraints. Front. Neurorobotics 2022, 16, 883562. [Google Scholar] [CrossRef] [PubMed]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Zhou, Y.; Yang, J.; Guo, Z.; Shen, Y.; Yu, K.; Lin, J.C. An indoor blind area-oriented autonomous robotic path planning approach using deep reinforcement learning. Expert Syst. Appl. 2024, 254, 124277. [Google Scholar] [CrossRef]
- Yang, L.; Bi, J.; Yuan, H. Dynamic path planning for mobile robots with deep reinforcement learning. IFAC-PapersOnLine 2022, 55, 19–24. [Google Scholar] [CrossRef]
- Chun, D.H.; Roh, M.I.; Lee, H.W.; Yu, D. Method for collision avoidance based on deep reinforcement learning with path-speed control for an autonomous ship. Int. J. Nav. Archit. Ocean. Eng. 2024, 16, 100579. [Google Scholar] [CrossRef]
- Teitgen, R.; Monsuez, B.; Kukla, R.; Pasquier, R.; Foinet, G. Dynamic trajectory planning for ships in dense environment using collision grid with deep reinforcement learning. Ocean. Eng. 2023, 281, 114807. [Google Scholar] [CrossRef]
- Guo, T.; Jiang, N.; Li, B.; Zhu, X.; Wang, Y.; Du, W. UAV navigation in high dynamic environments: A deep reinforcement learning approach. Chin. J. Aeronaut. 2021, 34, 479–489. [Google Scholar] [CrossRef]
- Yan, C.; Xiang, X.; Wang, C. Towards real-time path planning through deep reinforcement learning for a UAV in dynamic environments. J. Intell. Robot. Syst. 2020, 98, 297–309. [Google Scholar] [CrossRef]
- Aradi, S. Survey of deep reinforcement learning for motion planning of autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 23, 740–759. [Google Scholar] [CrossRef]
- Yu, L.; Shao, X.; Wei, Y.; Zhou, K. Intelligent land-vehicle model transfer trajectory planning method based on deep reinforcement learning. Sensors 2018, 18, 2905. [Google Scholar] [CrossRef] [PubMed]
- Lei, X.; Zhang, Z.; Dong, P. Dynamic path planning of unknown environment based on deep reinforcement learning. J. Robot. 2018, 2018, 5781591. [Google Scholar] [CrossRef]
- Xie, R.; Meng, Z.; Wang, L.; Li, H.; Wang, K.; Wu, Z. Unmanned aerial vehicle path planning algorithm based on deep reinforcement learning in large-scale and dynamic environments. IEEE Access 2021, 9, 24884–24900. [Google Scholar] [CrossRef]
- Ni, W.; Bi, Y.; Wu, D.; Ma, X. Energy-optimal trajectory planning for solar-powered aircraft using soft actor-critic. Chin. J. Aeronaut. 2022, 35, 337–353. [Google Scholar] [CrossRef]
- Zhu, G.; Shen, Z.; Liu, L.; Zhao, S.; Ji, F.; Ju, Z.; Sun, J. AUV dynamic obstacle avoidance method based on improved PPO algorithm. IEEE Access 2022, 10, 121340–121351. [Google Scholar] [CrossRef]
- Josef, S.; Degani, A. Deep reinforcement learning for safe local planning of a ground vehicle in unknown rough terrain. IEEE Robot. Autom. Lett. 2020, 5, 6748–6755. [Google Scholar] [CrossRef]
- Zheng, B.; Zhu, M.; Guo, X.; Ou, J.; Yuan, J. Path planning of stratospheric airship in dynamic wind field based on deep reinforcement learning. Aerosp. Sci. Technol. 2024, 150, 109173. [Google Scholar] [CrossRef]
- Yang, X.; Yang, X.; Deng, X. Horizontal trajectory control of stratospheric airships in wind field using Q-learning algorithm. Aerosp. Sci. Technol. 2020, 106, 106100. [Google Scholar] [CrossRef]
- Nie, C.; Zhu, M.; Zheng, Z.; Wu, Z. Model-free control for stratospheric airship based on reinforcement learning. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 10702–10707. [Google Scholar]
- Zhang, Y.; Yang, K.; Chen, T.; Zheng, Z.; Zhu, M. Integration of path planning and following control for the stratospheric airship with forecasted wind field data. ISA Trans. 2023, 143, 115–130. [Google Scholar] [CrossRef]
- Climate Data Store. Available online: https://cds.climate.copernicus.eu (accessed on 1 November 2023).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observation Space | Notation | Min | Max |
|---|---|---|---|
| Airspeed of the airship (m/s) | 0 | 20 | |
| Heading of the airship | 0 | ||
| Wind speed | 0 | - | |
| Wind direction | 0 | ||
| Angle between the wind direction and the airspeed direction | 0 | ||
| Distance between the airship and the station-keeping area center (km) | 0 | - | |
| Whether present in the station-keeping area | 0 | 1 | |
| Angle between the airship to the station-keeping area center line and the x-axis | 0 |
| Action Space | Notation | Min | Max |
|---|---|---|---|
| Acceleration (m/s2) | −0.3 | 0.15 | |
| Angular velocity (rad/s) | −0.0125 | 0.0125 |
| Parameters | Value |
|---|---|
| Actor learning rate | |
| Critic learning rate | |
| State dimension | 12 |
| Action dimension | 2 |
| Hidden layer dimension | 64 |
| 0.99 | |
| 0.95 | |
| 0.2 | |
| Epoch | 10 |
| Batch size | 32 |
| Time step interval | 1 min |
| Optimizer | Adam |
| TT | FT (Days) | TRSA (Min) | ST (Days) | STR | ||||
|---|---|---|---|---|---|---|---|---|
| Year | 2022 | 2023 | 2022 | 2023 | 2022 | 2023 | 2022 | 2023 |
| 01-01 00:00 | 31.0 | 31.0 | 427 | 265 | 30.7 | 30.5 | 0.990 | 0.985 |
| 02-01 00:00 | 28.0 | 28.0 | 390 | 364 | 27.7 | 27.7 | 0.990 | 0.991 |
| 03-01 00:00 | 31.0 | 31.0 | 381 | 204 | 30.7 | 30.8 | 0.991 | 0.995 |
| 04-01 00:00 | 30.0 | 30.0 | 225 | 569 | 29.8 | 29.6 | 0.995 | 0.987 |
| 05-01 00:00 | 31.0 | 31.0 | 244 | 168 | 30.8 | 30.1 | 0.994 | 0.971 |
| 06-01 00:00 | 21.9 | 30.0 | 101 | 351 | 17.3 | 29.7 | 0.792 | 0.990 |
| 07-01 00:00 | 1.3 | 6.6 | 0 | 71 | 0 | 2.3 | 0 | 0.343 |
| 08-01 00:00 | 1.2 | 8.2 | 342 | 366 | 0.5 | 5.2 | 0.444 | 0.636 |
| 09-01 00:00 | 30.0 | 30.0 | 907 | 312 | 26.4 | 28.3 | 0.880 | 0.944 |
| 10-01 00:00 | 31.0 | 31.0 | 404 | 748 | 30.5 | 30.4 | 0.986 | 0.983 |
| 11-01 00:00 | 30.0 | 30.0 | 118 | 351 | 29.9 | 29.7 | 0.997 | 0.992 |
| 12-01 00:00 | 31.0 | 31.0 | 356 | 454 | 30.6 | 30.6 | 0.990 | 0.990 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zhou, S.; Miao, J.; Shang, H.; Cui, Y.; Lu, Y. Autonomous Trajectory Planning Method for Stratospheric Airship Regional Station-Keeping Based on Deep Reinforcement Learning. Aerospace 2024, 11, 753. https://doi.org/10.3390/aerospace11090753
Liu S, Zhou S, Miao J, Shang H, Cui Y, Lu Y. Autonomous Trajectory Planning Method for Stratospheric Airship Regional Station-Keeping Based on Deep Reinforcement Learning. Aerospace. 2024; 11(9):753. https://doi.org/10.3390/aerospace11090753
Chicago/Turabian StyleLiu, Sitong, Shuyu Zhou, Jinggang Miao, Hai Shang, Yuxuan Cui, and Ying Lu. 2024. "Autonomous Trajectory Planning Method for Stratospheric Airship Regional Station-Keeping Based on Deep Reinforcement Learning" Aerospace 11, no. 9: 753. https://doi.org/10.3390/aerospace11090753
APA StyleLiu, S., Zhou, S., Miao, J., Shang, H., Cui, Y., & Lu, Y. (2024). Autonomous Trajectory Planning Method for Stratospheric Airship Regional Station-Keeping Based on Deep Reinforcement Learning. Aerospace, 11(9), 753. https://doi.org/10.3390/aerospace11090753