
Statistical Metamodel of Liner Acoustic Impedance Based on Neural Network and Probabilistic Learning for Small Datasets


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
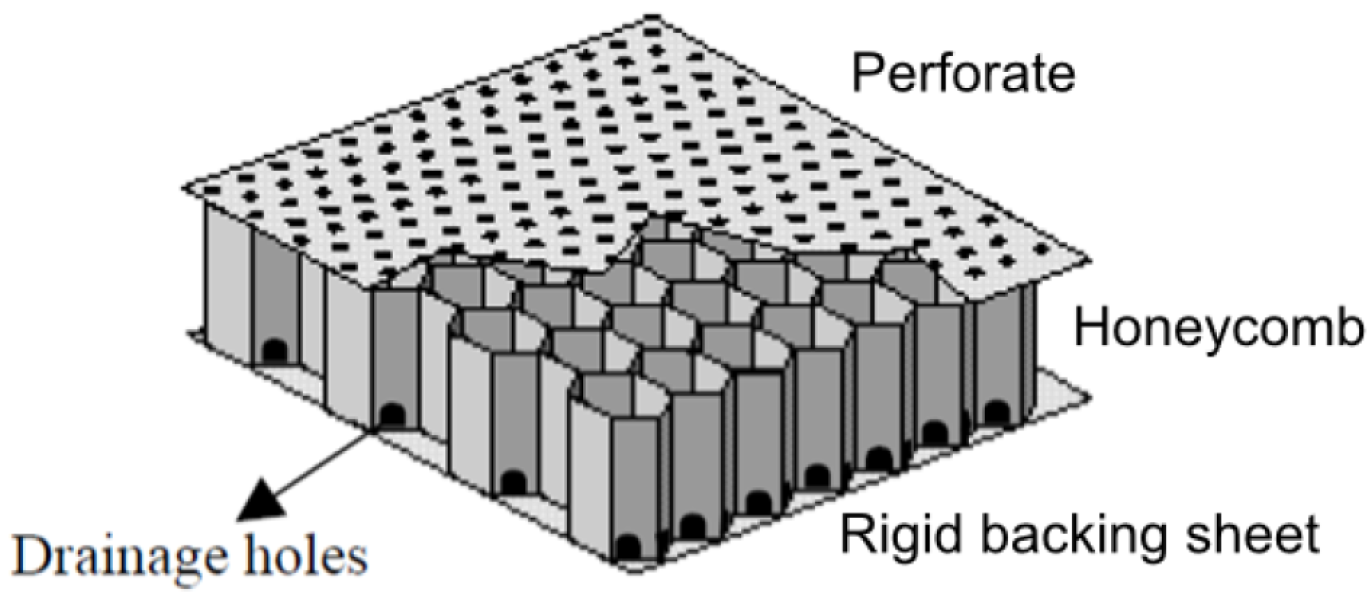
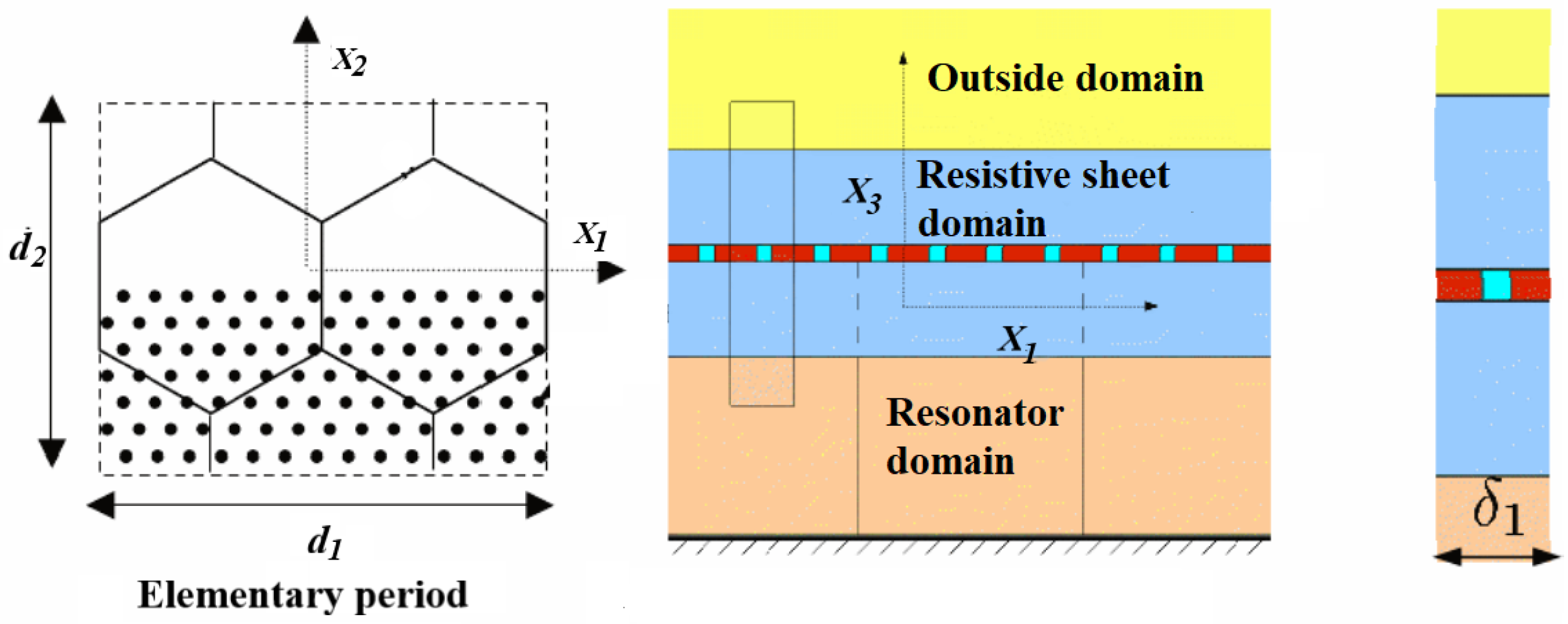
2. Control Parameters and ACM Dataset
3. Prior Probabilistic Model of the Frequency-Sampled Impedance Vector
3.1. PCA-Based Statistical Reduction of
3.2. Prior Conditional Probabilistic Density Function of Given
3.3. Statistically Independent Realizations of and Given
4. Statistical ANN-Based Metamodel
4.1. Fully Connected Feedforward Neural Network
4.2. Statistical ANN-Based Metamodel for Regression with the Learned Dataset
4.3. Statistical ANN-Based Metamodel for Regression with a Learned GKDE-Based Estimates’ Dataset
5. Numerical Applications
5.1. Architecture of the Statistical ANN-Based Metamodel
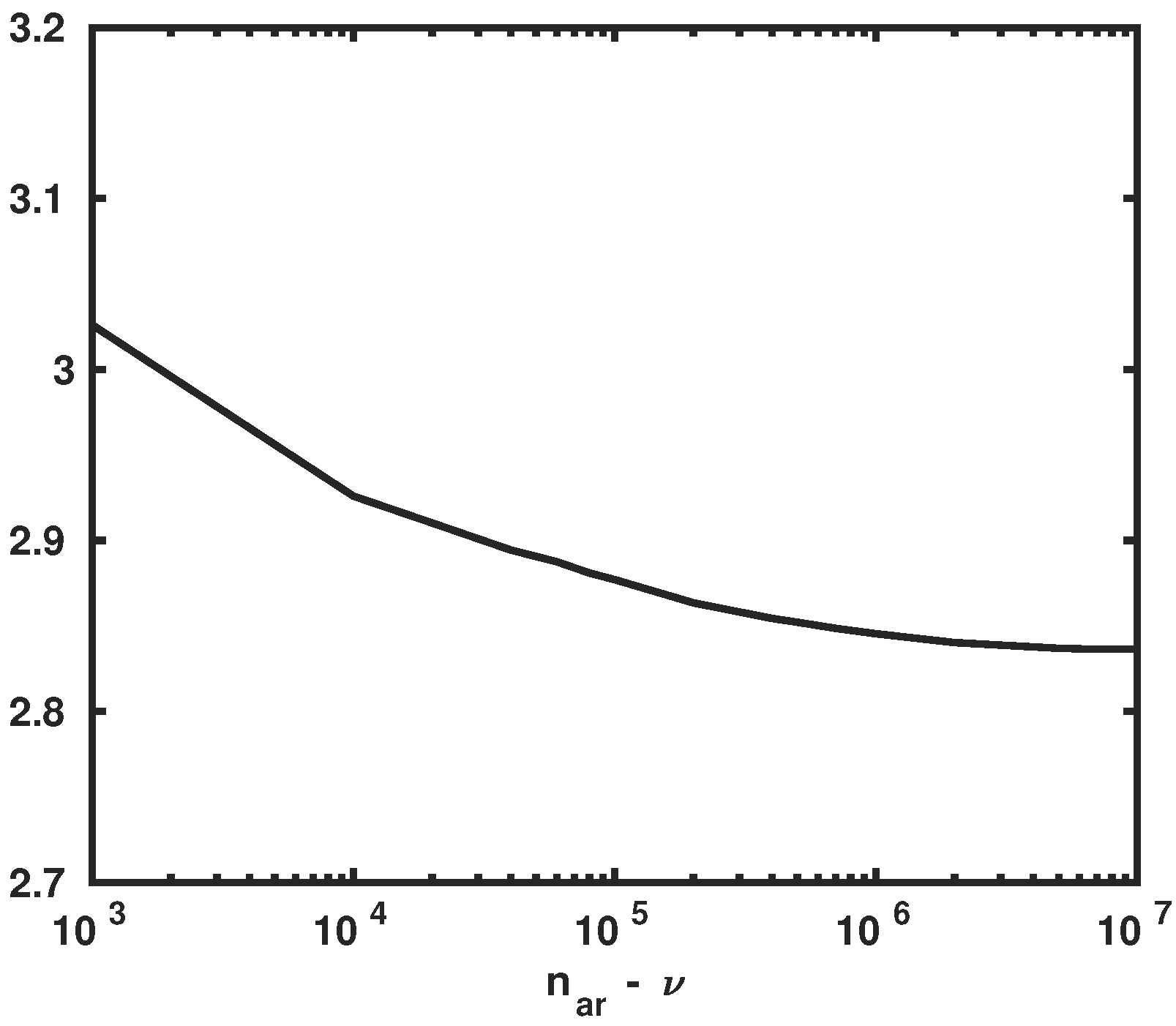
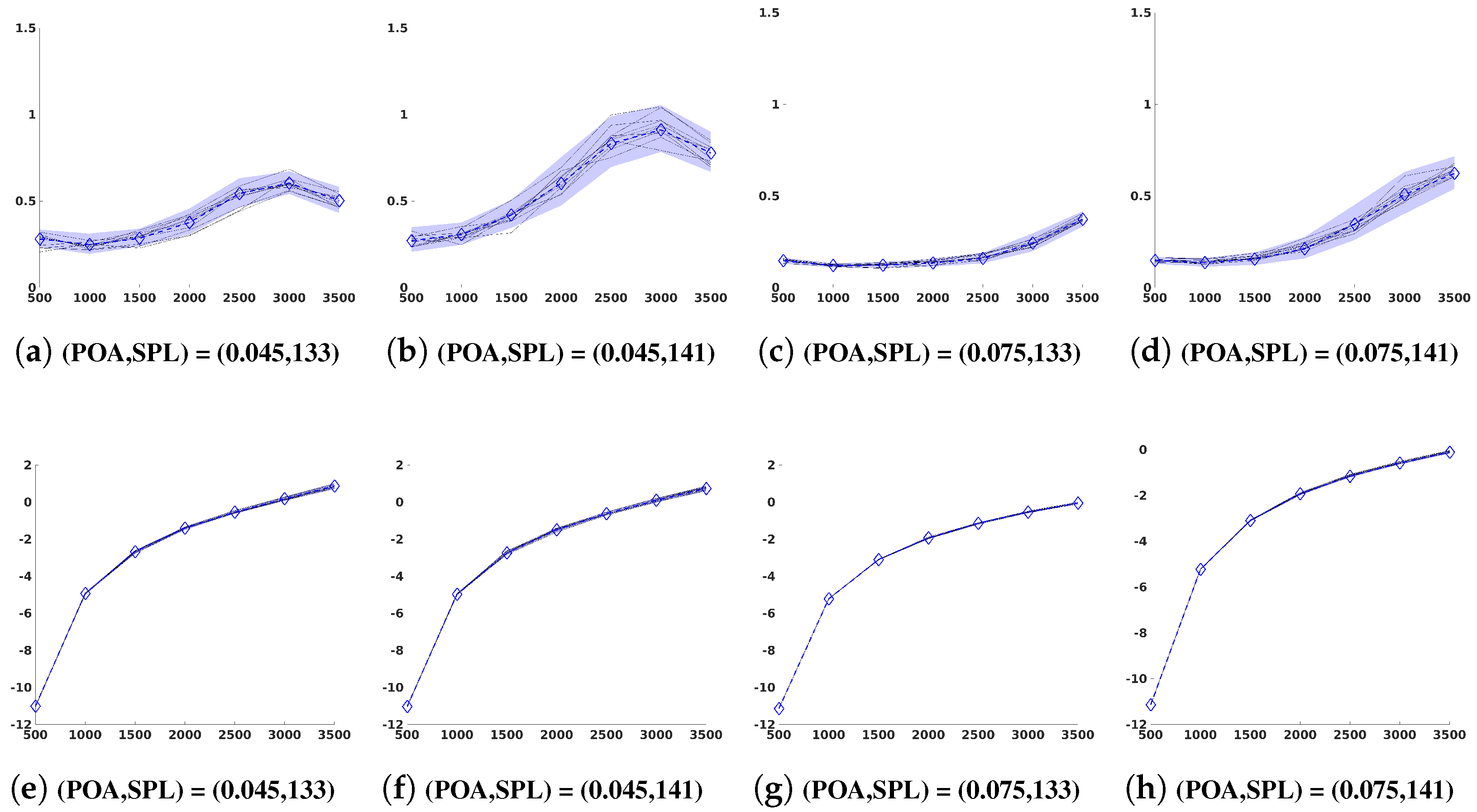
5.2. Statistical Convergence Analysis for the Learned GKDE-Based Estimates’ Dataset
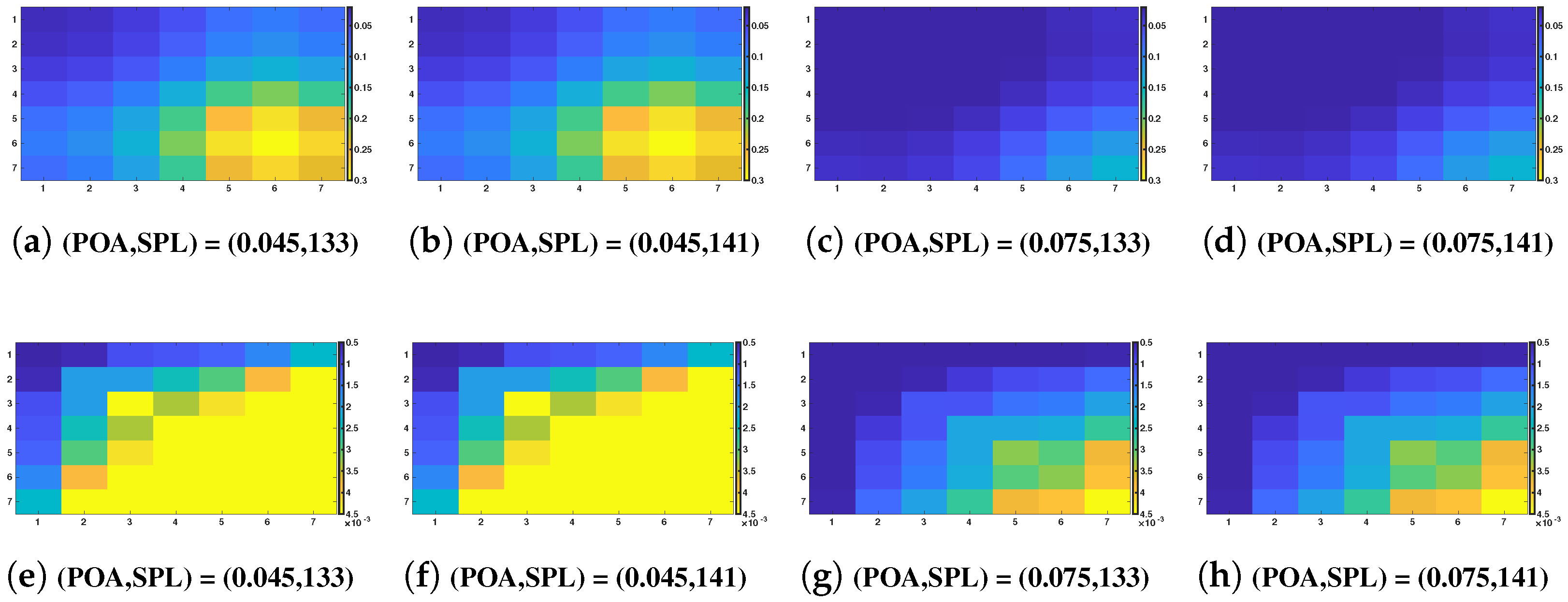
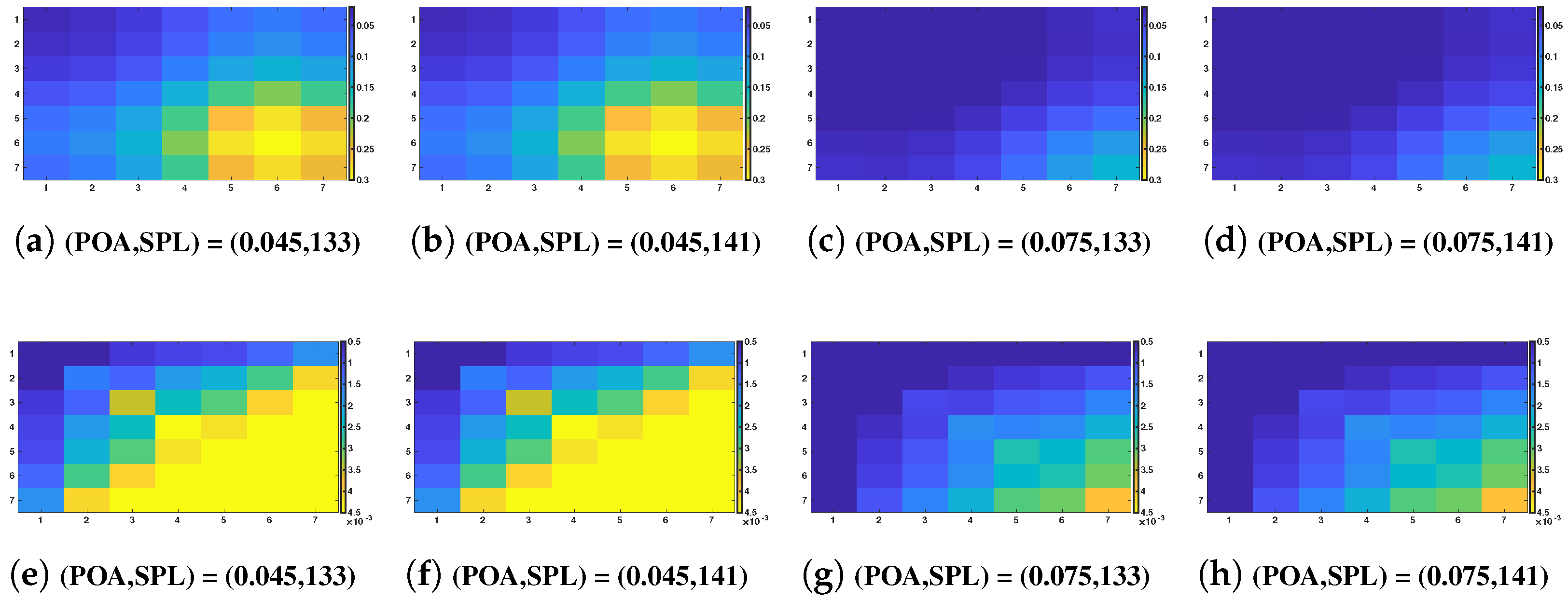
5.3. Conditional Covariance Matrices of and Given
5.4. Frequency-Sampled Impedance Using the Statistical ANN-Based Metamodel
6. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Conditional covariance matrix of given | |
| Covariance matrix of | |
| Conditional covariance matrix of given | |
| Conditional covariance matrix of given | |
| Mathematical expectation operator | |
| Cost function for ANN training | |
| Number of values in | |
| Number of control parameters | |
| Number of sampled frequencies | |
| Conditional probability density functions | |
| Probability density function of | |
| Resistance from the ACM | |
| s | Silverman bandwidth |
| Reactance from the ACM | |
| j-th realization of conditional mean | |
| Random vectors for impedance, resistance, and reactance | |
| Empirical mean value of | |
| j-th frequency-sampled impedance from the ACM | |
| k-th realization of frequency-sampled impedance given | |
| ℓ-th additional realization of frequency-sampled impedance | |
| j-th frequency-sampled resistance from the ACM | |
| Control parameters (POA and SPL) | |
| j-th realization of control parameters | |
| Rewriting (with repetition) of | |
| ℓ-th additional realization of control parameters | |
| Random vector of control parameters | |
| Frequency-dependent acoustic impedance from the ACM | |
| j-th realization of covariance matrix parameters | |
| Diagonal matrix of eigenvalues | |
| Matrix of eigenvectors | |
| Normalized random vector from PCA | |
| ANN output for conditional mean of given | |
| ANN output for vectorized upper triangular elements of the matrix logarithm of | |
| Negative log-likelihood | |
| Frequency (rad/s) | |
| Parameters of the ANN | |
| ACM | Aeroacoustic computational model |
| ANN | Artificial neural network |
| BPF | Blade passing frequency |
| GKDE | Gaussian kernel density estimation |
| MaxEnt | Maximum entropy |
| PCA | Principal component analysis |
| PLoM | Probabilistic learning on manifolds |
| POA | Percentage of open area |
| SPL | Sound pressure level |
| UHBR | Ultra-high bypass ratio |
| ACM dataset | |
| Training dataset | |
| Learned dataset | |
| GKDE-based estimates’ dataset | |
| Set of control parameter values |
References
- van Den Nieuwenhof, B.; Detandt, Y.; Lielens, G.; Rosseel, E.; Soize, C.; Dangla, V.; Kassem, M.; Mosson, A. Optimal design of the acoustic treatments damping the noise radiated by a turbo-fan engine. In Proceedings of the 23rd AIAA/CEAS Aeroacoustics Conference, Denver, CO, USA, 5–9 June 2017; p. 4035. [Google Scholar] [CrossRef]
- Nark, D.M.; Jones, M.G. Design of an advanced inlet liner for the quiet technology demonstrator 3. In Proceedings of the 25th AIAA/CEAS Aeroacoustics Conference, Delft, The Netherlands, 20–23 May 2019; p. 2764. [Google Scholar] [CrossRef]
- Sutliff, D.L.; Nark, D.M.; Jones, M.G.; Schiller, N.H. Design and acoustic efficacy of a broadband liner for the inlet of the DGEN aero-propulsion research turbofan. In Proceedings of the 25th AIAA/CEAS Aeroacoustics Conference, Delft, The Netherlands, 20–23 May 2019; p. 2582. [Google Scholar] [CrossRef]
- Chambers, A.T.; Manimala, J.M.; Jones, M.G. Design and optimization of 3D folded-core acoustic liners for enhanced low-frequency performance. AIAA J. 2020, 58, 206–218. [Google Scholar] [CrossRef]
- Özkaya, E.; Gauger, N.R.; Hay, J.A.; Thiele, F. Efficient Design Optimization of Acoustic Liners for Engine Noise Reduction. AIAA J. 2020, 58, 1140–1156. [Google Scholar] [CrossRef]
- Dangla, V.; Soize, C.; Cunha, G.; Mosson, A.; Kassem, M.; Van den Nieuwenhof, B. Robust three-dimensional acoustic performance probabilistic model for nacelle liners. AIAA J. 2021, 59, 4195–4211. [Google Scholar] [CrossRef]
- Spillere, A.M.; Braga, D.S.; Seki, L.A.; Bonomo, L.A.; Cordioli, J.A.; Rocamora, B.M., Jr.; Greco, P.C., Jr.; dos Reis, D.C.; Coelho, E.L. Design of a single degree of freedom acoustic liner for a fan noise test rig. Int. J. Aeroacoust. 2021, 20, 708–736. [Google Scholar] [CrossRef]
- Lavieille, M.; Abboud, T.; Bennani, A.; Balin, N. Numerical simulations of perforate liners: Part I—Model description and impedance validation. In Proceedings of the 19th AIAA/CEAS Aeroacoustics Conference, Berlin, Germany, 27–29 May 2013. [Google Scholar] [CrossRef]
- Van Antwerpen, B.; Detandt, Y.; Copiello, D.; Rosseel, E.; Gaudry, E. Performance improvements and new solution strategies of Actran/TM for nacelle simulations. In Proceedings of the 20th AIAA/CEAS Aeroacoustics Conference, Atlanta, GA, USA, 16–20 June 2014; p. 2315. [Google Scholar] [CrossRef]
- Pascal, L.; Piot, E.; Casalis, G. A new implementation of the extended Helmholtz resonator acoustic liner impedance model in time domain CAA. J. Comput. Acoust. 2016, 24, 1663–1674. [Google Scholar] [CrossRef]
- Casadei, L.; Deniau, H.; Piot, E.; Node-Langlois, T. Time-domain impedance boundary condition implementation in a CFD solver and validation against experimental data of acoustical liners. In Proceedings of the eForum Acusticum, Digital Event, 7–11 December 2020; pp. 359–366. [Google Scholar] [CrossRef]
- Dangla, V.; Soize, C.; Cunha, G.; Mosson, A.; Kassem, M.; Van Den Nieuwenhof, B. Stochastic computational model of 3D acoustic noise predictions for nacelle liners. In Proceedings of the AIAA Aviation 2020 Forum, Virtual Event, 15–19 June 2020; p. 2545. [Google Scholar] [CrossRef]
- Winkler, J.; Mendoza, J.M.; Reimann, C.A.; Homma, K.; Alonso, J.S. High fidelity modeling tools for engine liner design and screening of advanced concepts. Int. J. Aeroacoust. 2021, 20, 530–560. [Google Scholar] [CrossRef]
- Soize, C.; Ghanem, R. Data-driven probability concentration and sampling on manifold. J. Comput. Phys. 2016, 321, 242–258. [Google Scholar] [CrossRef]
- Soize, C.; Ghanem, R. Probabilistic learning on manifolds. Found. Data Sci. 2020, 2, 279–307. [Google Scholar] [CrossRef]
- Soize, C.; Ghanem, R. Probabilistic learning on manifolds (PLoM) with partition. Int. J. Numer. Methods Eng. 2022, 123, 268–290. [Google Scholar] [CrossRef]
- Soize, C. Software_PLoM_with_PARTITION_2021_06_24, 2021.
- Sinha, A.; Soize, C.; Desceliers, C.; Cunha, G. Aeroacoustic liner impedance metamodel from simulation and experimental data using probabilistic learning. AIAA J. 2023, 61, 4926–4934. [Google Scholar] [CrossRef]
- Soize, C. Uncertainty Quantification; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Constrained Optimization and Lagrange Multiplier Methods; Academic Press: Cambridge, MA, USA, 1982. [Google Scholar]
- Luenberger, D. Optimization by Vector Space Methods; John Wiley & Sons: Hoboken, NJ, USA, 1997. [Google Scholar]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Calamai, P.H.; Moré, J.J. Projected gradient methods for linearly constrained problems. Math. Program. 1987, 39, 93–116. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; Proceedings of Machine Learning Research. Teh, Y.W., Titterington, M., Eds.; Volume 9, pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sinha, A.; Desceliers, C.; Soize, C.; Cunha, G. Statistical Metamodel of Liner Acoustic Impedance Based on Neural Network and Probabilistic Learning for Small Datasets. Aerospace 2024, 11, 717. https://doi.org/10.3390/aerospace11090717
Sinha A, Desceliers C, Soize C, Cunha G. Statistical Metamodel of Liner Acoustic Impedance Based on Neural Network and Probabilistic Learning for Small Datasets. Aerospace. 2024; 11(9):717. https://doi.org/10.3390/aerospace11090717
Chicago/Turabian StyleSinha, Amritesh, Christophe Desceliers, Christian Soize, and Guilherme Cunha. 2024. "Statistical Metamodel of Liner Acoustic Impedance Based on Neural Network and Probabilistic Learning for Small Datasets" Aerospace 11, no. 9: 717. https://doi.org/10.3390/aerospace11090717
APA StyleSinha, A., Desceliers, C., Soize, C., & Cunha, G. (2024). Statistical Metamodel of Liner Acoustic Impedance Based on Neural Network and Probabilistic Learning for Small Datasets. Aerospace, 11(9), 717. https://doi.org/10.3390/aerospace11090717