1. Introduction
Over the past few decades, numerous countries have vigorously launched various types of spacecraft for military, commercial, and other goals due to the rapid advancement of space science and technology [
1]. Spacecraft become defunct spacecraft and space debris when their service lives are coming to an end. The number of defunct spacecraft and space debris in orbit is currently immense, nearing a critical threshold [
2]. This results in increasingly scarce orbital resources and a heightened probability of collisions. Consequently, using on-orbit servicing technologies to deorbit and remove defunct spacecraft has become a focal point in the aerospace sector globally [
3]. Space robots, as effective actuators in space operations, hold significant value in satellite fault repair, space debris removal, and the assembly of large space facilities, both in theoretical research and engineering applications [
4]. Therefore, a great deal of study has been performed on space robot dynamics and control [
5]. Space robotic arms operate very differently from terrestrial robotic arms because of the microgravity environment there [
6]. This makes motion planning for space robotic systems a challenging task.
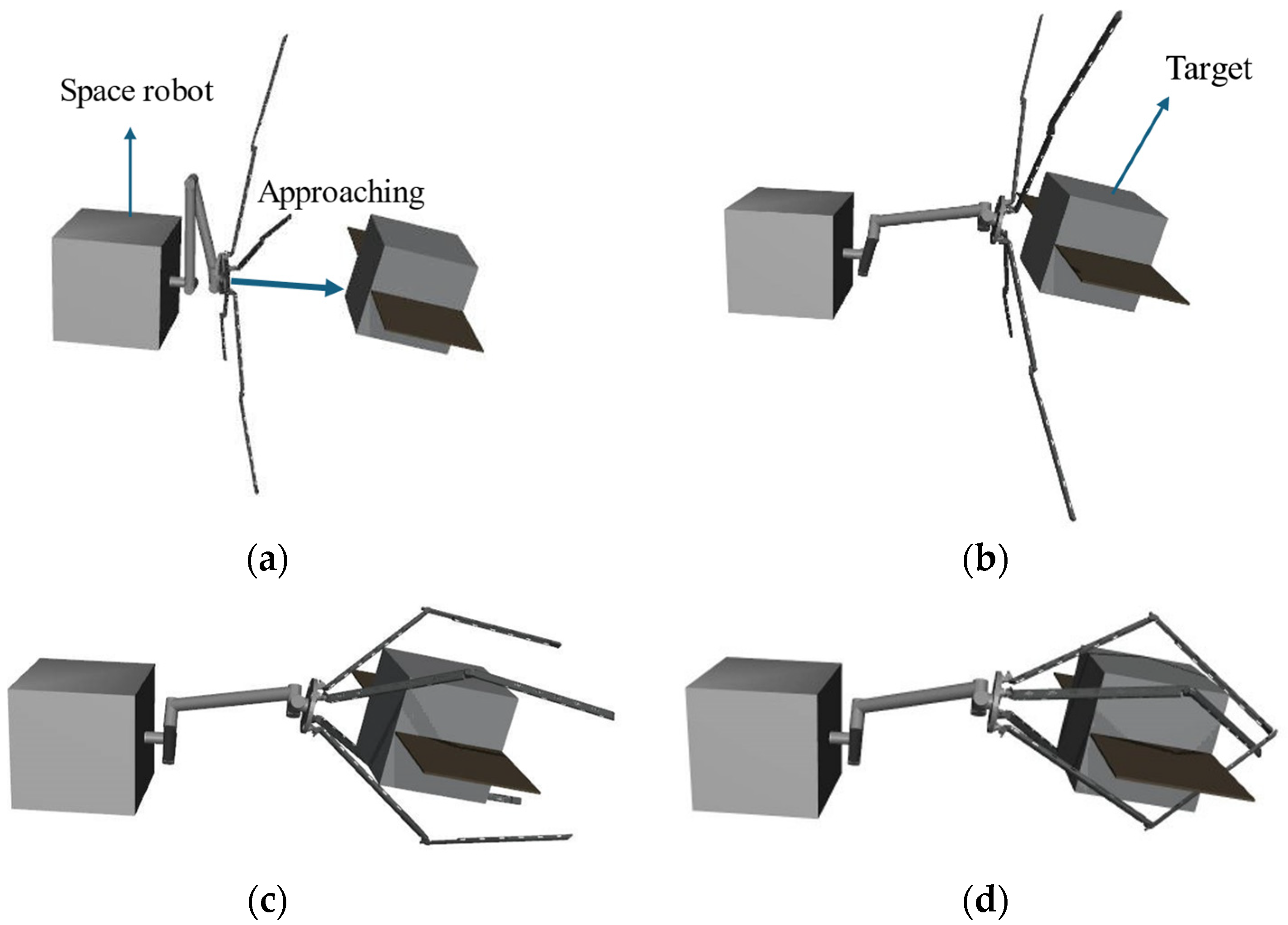
A space robotic system typically comprises three main components: a base platform, a robotic arm attached to the base, and an end-effector for capture. When performing on-orbit tasks, space robots face significant challenges due to the uncertainties in the motion of the target spacecraft, which may lead to unpredictable disturbances upon contact [
7]. Moreover, the robotic arm and the end-effector form a highly coupled dynamic system, where the movements of the arm affect the stability of the end-effector [
8]. These issues present substantial challenges for the stable control of space robots in orbit, directly impacting the success of on-orbit servicing missions. To address these challenges, numerous researchers have proposed efficient solutions for capturing tasks performed by space robots. Yu et al. [
9] investigated the dynamics modeling and capture tasks of a space-floating robotic arm with flexible solar panels when dealing with non-cooperative targets. Cai et al. [
10] addressed the contact point configuration problem in capturing non-cooperative targets using an unevenly oriented distribution joint criterion method. This approach combines virtual symmetry and geometric criteria, ensuring stable grasping through geometric calculations and optimizing the selection and distribution of contact points to enhance capture stability and efficiency. Zhang et al. [
11] proposed a pseudospectral-based trajectory optimization and reinforcement learning-based tracking control method to mitigate reaction torques induced by the robotic arm, focusing on mission constraints and base–manipulator coupling issues. Aghili et al. [
12] developed an optimal control strategy for the close-range capture of tumbling satellites, switching between different objective functions to achieve either the time-optimal control of target capture or the optimal control of the joint velocities and accelerations of the robotic arm. Richard et al. [
13] employed predictive control to forecast the motion of tumbling targets, controlling the end-effector to track and capture the target load, and limiting the acceleration of the arm joints to avoid torque oscillations due to tracking errors at the moment of capture. Jayakody et al. [
14] redefined the dynamic equations of free-flying space robots and applied a novel adaptive variable structure control method to achieve robust coordinated control, unaffected by system uncertainties. Xu et al. [
15] proposed an adaptive backstepping controller to address uncertainties in the kinematics, dynamics, and end-effector of space robotic arms, ensuring asymptotic convergence of tracking errors compared to traditional dynamic surface control methods. Hu et al. [
16] designed a decentralized robust controller using a decentralized recursive control strategy to address trajectory-tracking issues in space manipulators. The aforementioned capture strategies for space robotic arms are all based on multi-body dynamic models. However, accurately establishing such models is challenging, and strict adherence to these models can result in significant position and velocity deviations, excessive collision forces, or capture failures.
In recent years, the rapid development of artificial intelligence technology has provided new avenues for solving space capture problems, integrating the advantages of optimal control with traditional methods [
17]. The research and application of deep reinforcement learning (DRL) algorithms have progressed swiftly, finding uses in autonomous driving [
18], decision optimization [
19], and robotic control [
20]. These algorithms adjust network parameters through continuous interaction between the agent and the environment, deriving optimal strategies and thus avoiding the complex modeling and control parameter adjustment processes. Using reinforcement learning to advance capture technology has become a prominent research focus. Deep reinforcement learning algorithms such as Proximal Policy Optimization (PPO) [
21], Deep Deterministic Policy Gradient (DDPG) [
22], and Soft Actor–Critic (SAC) [
23] have been applied to solve planning problems for space robots. Yan et al. [
24] employed the Soft Q-learning algorithm to train energy-based path planning and control strategies for space robots, providing a reference for capture missions. Li et al. [
25] propose a novel motion planning approach for a 7-degree-of-freedom (DOF) free-floating space manipulator, utilizing deep reinforcement learning and artificial potential fields to ensure robust performance and self-collision avoidance in dynamic on-orbit environments. Lei et al. [
26] introduced an active target tracking scheme for free-floating space manipulators (FFSM) based on deep reinforcement learning algorithms, bypassing the complex modeling process of FFSM and eliminating the need for motion planning, making it simpler than traditional algorithms. Wu et al. [
27] addressed the problem of optimal impedance control with unknown contact dynamics and partially measured parameters in space manipulator tasks, proposing a model-free value iteration integral reinforcement learning algorithm to approximate optimal impedance parameters. Cao et al. [
28] incorporated the EfficientLPT algorithm, integrating prior knowledge into a hybrid strategy and designing a more reasonable reward function to improve planning accuracy. Wang et al. [
29] developed a reinforcement learning system for motion planning of free-floating dual-arm space manipulators when dealing with non-cooperative objects, achieving successful tracking of unknown state objects through two modules for multi-objective trajectory planning and target point prediction. These advancements in reinforcement learning algorithms represent significant strides in enhancing the performance and reliability of space capture missions, offering promising alternatives to traditional control methods.
The aforementioned research primarily focuses on the position planning of the end-effector, ignoring the importance of the end-effector’s orientation and the non-cooperative nature of the target. Considering only the motion planning of the end-effector’s position may result in a mismatch between the end-effector and the target’s orientation. Particularly when a specific orientation is required for capture, neglecting the importance of the end-effector’s orientation can result in ineffective or unstable captures, thereby affecting the overall mission success. In space capture missions, the uncertainty in parameters such as the shape, size, and motion state of non-cooperative targets significantly increases the control precision requirements for space robotic arms. Reinforcement learning algorithms face challenges in training optimal capture strategies due to these uncertainties. To overcome these limitations, this paper proposes a motion planning method that comprehensively considers both the position and orientation of the end-effector, aiming to achieve efficient, stable, and safe capture by the robotic arm’s end-effector. Specifically, the proposed approach decomposes the capture task of non-cooperative targets into two stages: the approach phase of the robotic arm and the capture phase of the end-effector. First, an orientation planning network is established to plan the capture pose of the end-effector based on the target’s orientation. Then, deep reinforcement learning methods are introduced to transform the control problems of position, torque, and velocity of the robotic arm during the capture process into a high-dimensional target approximation problem. By setting a target reward function, the end-effector’s position and motion parameters are driven to meet the capture conditions, achieving stable and reliable capture and deriving the optimal capture strategy. The main contributions of this paper are as follows:
- (1)
Constructing the structural model of the space robotic arm, defining its physical parameters, and establishing the dynamic model;
- (2)
Designing a deep reinforcement learning algorithm that integrates capture orientation planning to develop a space robotic arm controller, obtaining the optimal capture strategy to achieve stable and reliable capture;
- (3)
Establishing a simulation environment to validate the superiority of the proposed algorithm in controlling the capture of non-cooperative targets.
The rest of this paper is organized as follows:
Section 2 provides a detailed description of the problem of capturing non-cooperative targets with space robots.
Section 3 presents the proposed grasping posture planning method for common targets, establishes a reinforcement learning algorithm control framework, and designs the reward function.
Section 4 describes the simulation test environment and presents the simulation results and discussion. Additionally, the conclusions of this work are given in
Section 5.
3. Capture Control Strategy
Reinforcement learning (RL) learns through the interaction between an agent and the environment, continually attempting to obtain the optimal policy for the current task. This learning algorithm does not require an accurate dynamic model, making it widely applicable [
31]. Reinforcement learning treats the decision-making process as a Markov process, which consists of a series of state and action interactions over discrete time steps. RL guides the agent to choose the optimal policy in the future through the value function of the current state and available actions. The agent learns and gradually improves its policy in the environment to maximize cumulative future rewards. This Markov decision process-based modeling method provides RL with significant flexibility and applicability in handling real-world problems characterized by uncertainty and complex dynamics. Therefore, applying RL to the design of space robot controllers endows them with the capability of autonomous learning, and proactive adjustment of control strategies to adapt to changes in their dynamic structure and external environment. Through self-reinforcement learning amid changes, the controller continuously optimizes control strategies, enhancing the intelligence of the robotic arm’s movements and achieving optimal control performance.
3.1. DRL Algorithm Integrating Capture Pose Planning
This paper combines the grasping posture planning method with deep reinforcement learning, integrating the planned grasping posture information into the environmental state information. During the interactive learning process in the environment, the agent can more accurately perceive the pose information of the capture target. When deciding on capture actions, the agent comprehensively considers both the capture planning results and the reward information from reinforcement learning, thereby selecting the optimal capture strategy. However, traditional Actor–Critic algorithms face issues such as inefficient exploration in complex state and action spaces, susceptibility to local optima, and lengthy training times [
32]. To address these issues, the SAC algorithm [
33] employs double Q networks to estimate the lower bounds of Q values, thereby avoiding the problem of Q value overestimation that can render the agent’s learning strategy ineffective. Although double Q networks can effectively mitigate overestimation issues, the estimated Q values are approximations, leading to significant discrepancies between the estimated and true values. This discrepancy can cause the policy to concentrate, increasing the risk of the algorithm getting trapped in local optima. When applying DRL algorithms to solve the capture tasks of space robotic arms, it is essential to integrate the advantages of capture pose planning and reinforcement learning algorithms. The algorithm design should balance exploration efficiency, learning stability, and training efficiency to ensure the algorithm effectively learns the optimal control strategy. To solve the aforementioned problems, this paper adopts the OAC algorithm [
34] with an optimistic exploration strategy to avoid the local optimization problem caused by strategy concentration.
The objective of the reinforcement learning task in this paper is to guide the space robot to learn an optimal capture policy
through continuous exploration. This strategy maximizes the cumulative reward obtained by the space robot during its interactions with the environment. The policies can be expressed as follows:
where
represents the entropy of the policy taking action
in state
;
is the reward function;
is the action at time
;
is the state–action distribution formed by the policy; and
is the temperature coefficient, used to control the degree of policy exploration.
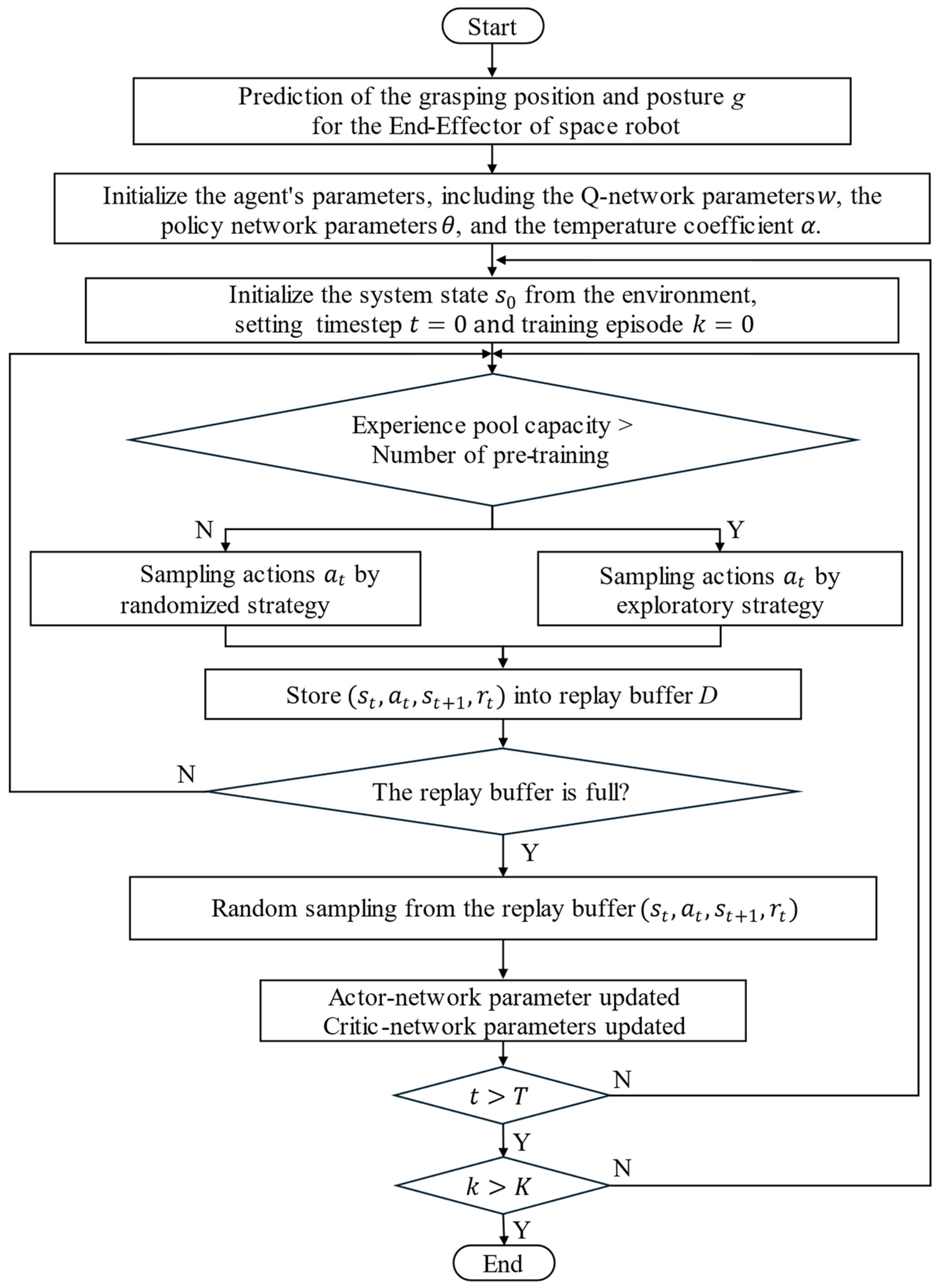
The implementation process of the DRL algorithm integrated with capture pose prediction is shown in
Figure 5, and the specific update procedure is as follows:
- (1)
Plan the capture position and pose of the end-effector based on the target satellite’s position;
- (2)
Initialize the parameters of each network;
- (3)
Initialize the state from the state space;
- (4)
If the experience pool capacity exceeds the pre-training number, calculate the exploration policy and sample action ; otherwise, sample actions using the random policy;
- (5)
Pass the given actions into the environment to update the state and reward , and store the obtained data in the replay buffer ;
- (6)
If the number of experience samples is less than the set size, go to step (4); otherwise, randomly sample data from the experience pool;
- (7)
Input the sampled data into the agent to update the network parameters;
- (8)
If the algorithm has been trained to the maximum number of episodes , terminate the training; otherwise, return to step (2).
3.2. Capture Pose Planning
The grasping posture of a space robotic arm has a crucial impact on the quality of capturing non-cooperative targets. In the space environment, due to the lack of external references and the reduced influence of gravity, the robotic arm needs to accurately determine the capture pose to ensure that the target object can be reliably captured and remain stable. A suitable capture pose not only increases the success rate of the capture but also reduces the instability of the pose generated during the capture process, thus ensuring the quality and efficiency of the capture. The capture pose is represented as
, where
P denotes the grasp center of the end-effector and
R denotes the rotational pose of the end-effector. Based on the position
and pose
of the target object, the capture pose is obtained as follows:
where
represents the planning network for the grasping posture, mapping the position and orientation of the target object to the position and rotational posture of the grasping device.
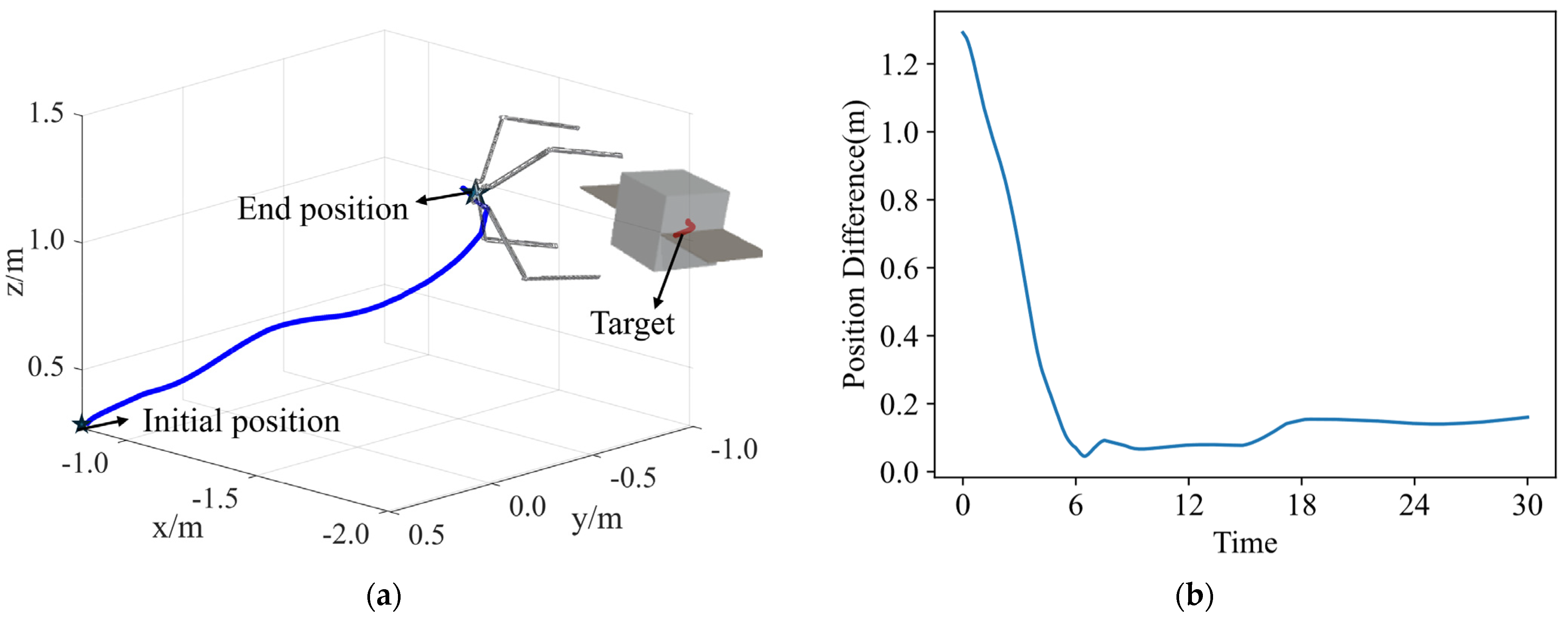
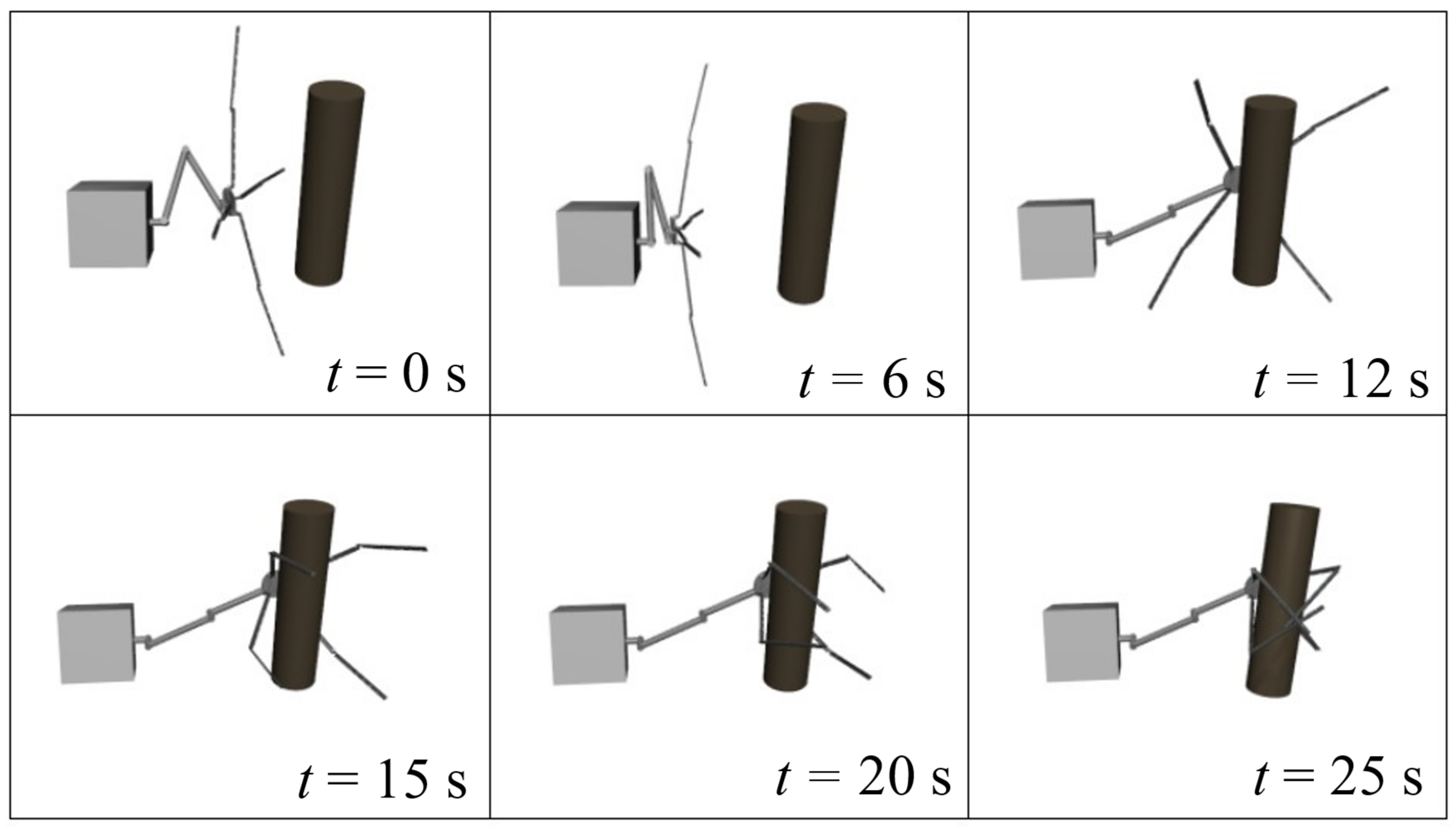
For the dataset required to train the prediction network, this paper uses the Mujoco210 physics simulation software to generate non-cooperative targets in a simulated environment. The position and pose of the non-cooperative targets within the capture range are varied, and each capture is annotated to create a capture dataset. This study targets square satellites with solar panels, planar debris, and rod-shaped space debris for capture. It considers actual gripping habits to avoid the capture mechanism pushing the target out of the capture area during the closure process, as shown in
Figure 6. The blue areas in the figure represent the reasonable capture point regions. For square satellites with solar panels and planar debris, the capture region should be selected at the center of the satellite or debris, away from protruding structures like solar panels, to minimize the impact on the target’s pose. The gripper should perform the capture operation along the main axis of the target to ensure that the applied force is uniform during the capture process, effectively controlling the target’s pose and position. For rod-shaped targets, the capture region should be chosen in the middle of the cylinder, and the capture should be performed along the axial direction to ensure stability.
3.3. Construction of the Agent Network
The network structure of the OAC algorithm primarily consists of the actor network and the critic network. The interaction process between these two networks is as follows: The agent first observes the current state information of the environment; subsequently, the actor network generates the current policy action based on this state information. After the agent executes this action, it transitions to the next state and receives a corresponding reward. This process constitutes a complete interaction with the environment. The critic network estimates the action-state value based on the current state information. Unlike traditional Actor–Critic methods, the OAC algorithm employs an optimistic initialization strategy, initializing the action value function with relatively high values to encourage the agent to explore the environment actively. Additionally, the OAC algorithm adopts a dynamic exploration mechanism, gradually decreasing the exploration rate based on the agent’s learning progress to balance exploration and exploitation during the learning process.
The entire network structure of the OAC algorithm, as shown in
Figure 7, includes six networks. The actor network consists of the exploration policy network and the target policy network. The critic network includes four Q networks: Q
1, Q
2, and their corresponding target Q networks. Although Q
1 and Q
2 are identical in structure and training methods, their initial parameters differ. When calculating the target Q value, the smaller value between Q
1 and Q
2 is used to reduce bias in the Q value estimation. Additionally, by introducing uncertainty estimation, optimistic Q values are constructed to encourage the agent to explore. The actor network is a parameterized neural network that selects an appropriate action based on the current state, updating the parameters of the exploration policy network
. The target actor network generates actions to calculate the target Q values when updating the critic network. Its network parameters
are periodically updated from
. The critic networks estimate the Q values of state–action pairs under the current policy, guiding the update of the actor network.
The Q function in the OAC algorithm establishes an approximate upper bound
and a lower bound
, each serving different purposes. The lower bound is used to update the policy, preventing overestimation by the critic network, thereby improving sample efficiency and stability. The upper bound is used to guide the exploration policy, selecting actions by maximizing the upper bound, which encourages the exploration of new and unknown regions in the action space, thus enhancing exploration efficiency. The lower bound
is calculated using the Q values obtained from two Q function neural networks,
and
. These two networks have the same structure but different initial weight values.
where
and
represent the Q values obtained by the target Q function neural networks for the state–action pair
;
is the reward discount factor; and
denotes the probability distribution of selecting action
in state
. For the upper bound
, it is defined using uncertainty estimation as follows:
where
determines the importance of the standard deviation
, effectively controlling the optimism level of the agent’s exploration.
and
are the mean and standard deviation of the estimated Q function, respectively, used to fit the true Q function.
3.4. Exploration Strategy Optimization in OAC Algorithm
To address the conservative exploration and low exploration efficiency issues in Actor–Critic algorithms, an optimistic exploration strategy
is introduced. This strategy is only used by the agent to sample actions from the environment and store the obtained information in the experience pool. The primary purpose of introducing optimistic estimation is to encourage exploration by increasing the value estimation of actions with high uncertainty, thereby avoiding local optima. The exploration strategy
is expressed as
, where
,
can be calculated by the formula:
where
is the temporal difference error, indicating the discrepancy between the exploration strategy and the target strategy;
is the mean of the exploration strategy probability distribution; and
is the covariance of the exploration strategy probability distribution. The mean and covariance obtained in this formula should satisfy the KL constraint to ensure the stability of OAC updates. Through the strategy
, the agent is encouraged to actively explore unknown action spaces, avoiding local optima caused by policy convergence.
The parameters of the Q function neural network can be updated by minimizing the Bellman residual:
where
represents the lower bound of the Q value obtained by the target Q function neural network; D represents the experience replay buffer; and
represents the policy under the network parameters
. The target policy network parameters
are updated by minimizing the following equation:
The parameters of the target Q network
are updated by:
where
is the soft update coefficient.
The temperature coefficient,
, is updated by minimizing
:
where
is updated through gradient descent to minimize this function and
is the minimum desired entropy, typically set to the dimensionality of the action space.
According to the agent network framework and strategy optimization method described above, the algorithm pseudo-code is shown in Algorithm 1.
| Algorithm 1: DRL Algorithm Integrating Capture Pose Planning |
- 1:
Predict the position and orientation of the space robotic end-effector . - 2:
Randomly initialize the agent network parameters: Q network parameters , policy network parameters , and temperature coefficient - 3:
for each episode k = 1 to K do - 4:
Initialize state s - 5:
for each timestep t = 1 to T do - 6:
Obtain the current state and sample an action - 7:
Execute action in the environment - 8:
Obtain reward , and next state - 9:
Store into the experience replay buffer D - 10:
Sample a batch from the experience replay buffer - 11:
Update policy network parameters by Equation (12) - 12:
Update Q network parameters by Equation (13) - 13:
Update temperature coefficient by Equation (14) - 14:
end for - 15:
end for
|
3.5. State Space and Action Space
The space manipulator system comprises a 6-DOF manipulator arm and an 8-DOF end-effector capture device. According to the reinforcement learning control strategy components, the state space of the system is defined as follows: , where represents the joint angles of the space manipulator and represents the corresponding joint angular velocities. , represents the position and orientation of the end-effector capture device, and represents the position and orientation of the captured target.
3.6. Reward Function Design
The design of the reward function plays a crucial role in reinforcement learning algorithms, as it aims to guide the agent in learning the optimal action strategy to accomplish the desired task. For the task of capturing non-cooperative targets in space, the reward function in this study considers the position and orientation of the manipulator’s movement as well as the capture mechanism’s grasping and enclosing of the target.
First, the position and orientation of the manipulator when moving to the capture point are considered. To ensure that the manipulator can effectively approach the target and maintain an appropriate orientation for capturing it, reward terms for the position and orientation errors are designed. The position error can be represented as the Euclidean distance between the end of the manipulator and the target, while the orientation error can be represented as the angular difference between the manipulator’s end and the target. Therefore, the reward terms for position and orientation errors are expressed as follows:
where
is the Euclidean distance between the end-effector and the target, and
is the angular difference between the end-effector and the target.
Second, the grasping and enclosing performance of the end-effector is considered. To incentivize the end-effector to perform effective grasping actions and avoid unnecessary damage, a reward term for the grasping effect is designed. The reward term for the grasping effect can be expressed as:
where the first term
is the reward for the joint enclosing effect and
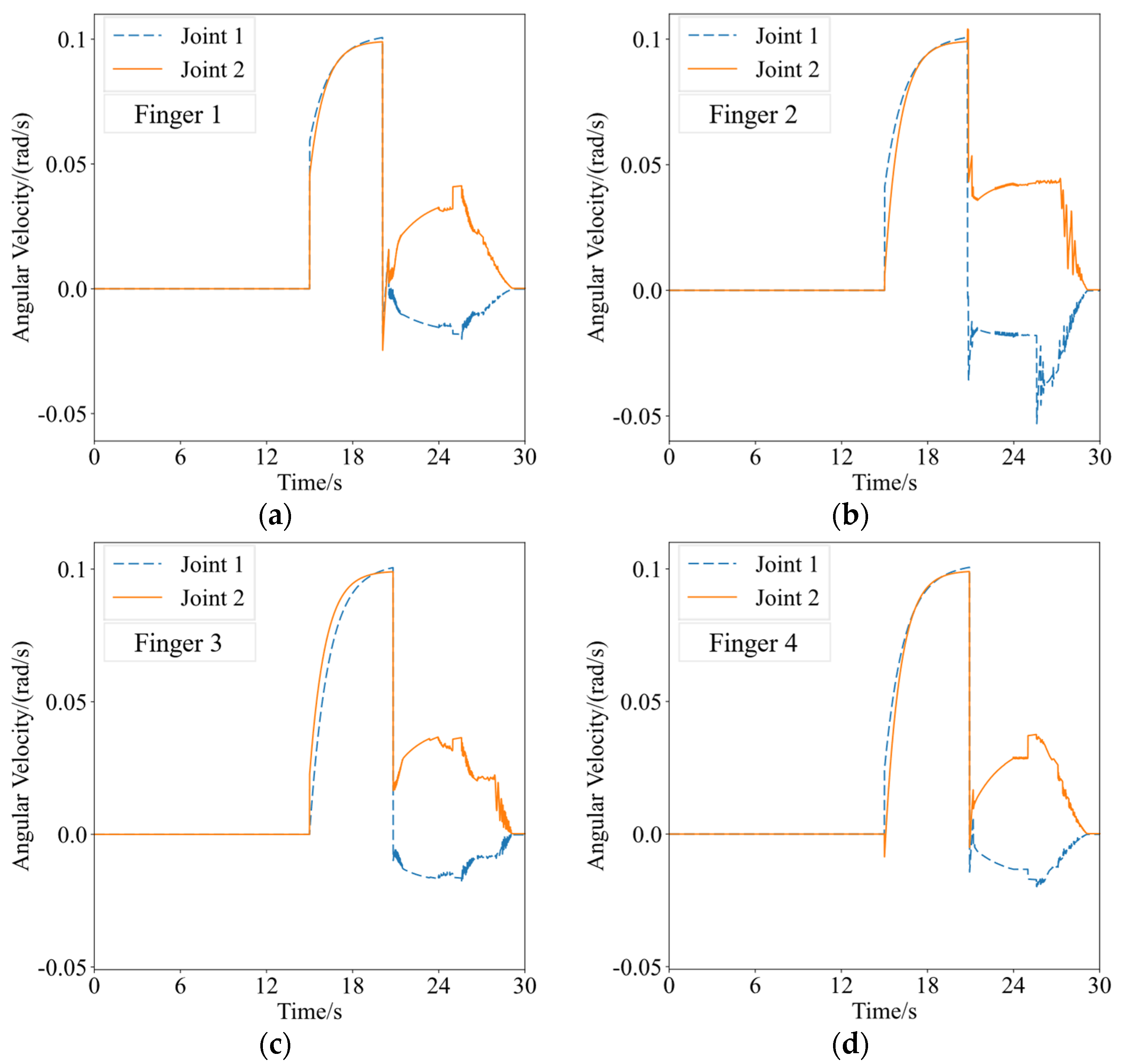
represents the angle of the j-th joint on the i-th arm of the end-effector. The second term is the reward for the grasping stability of the capture mechanism. If the four fingers simultaneously contact the target within a certain time window, a reward
is given. This setting effectively guides the agent to learn to achieve simultaneous contact with the target by all four fingers during the grasping process, thereby improving the success rate and stability of the capture task.
Finally, a time-step reward is set to keep the total training reward value within an appropriate range. The setting of this reward term does not affect the final result.
By weighting and summing all the reward terms according to their importance, the final reward function is:
where
,
, and
are the coefficients corresponding to each reward term. The coefficients represent the importance of the corresponding reward terms. Based on multiple simulation experiments, the three parameters are set to
,
, and
.
_Zhu.png)

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



