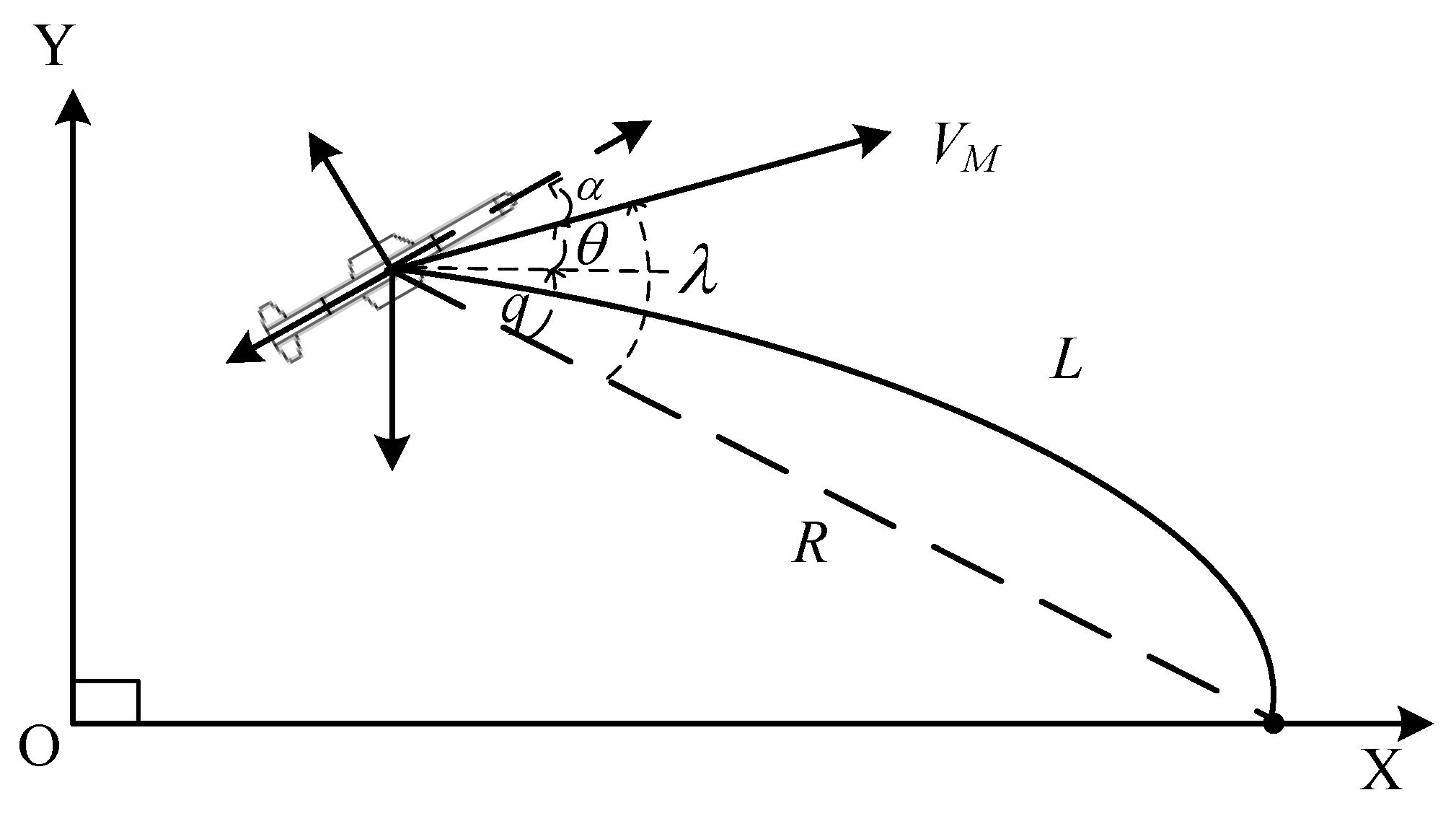
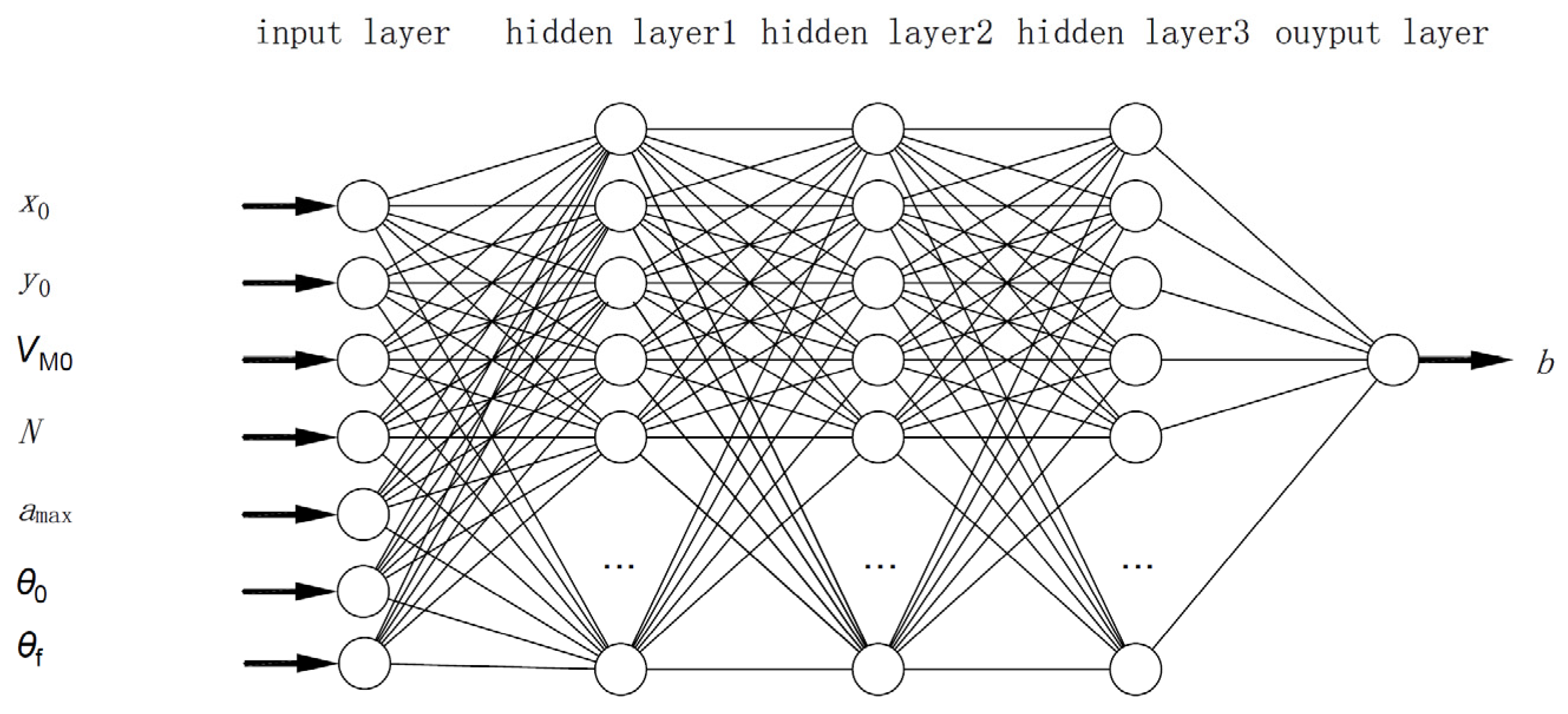
In this section, the construction of samples required for neural network training is presented. First, we conduct a mapping analysis to provide theoretical support for obtaining samples through simulation. Second, we perform a sensitivity analysis, which can achieve sample reduction while ensuring accuracy, thereby reducing computational costs during training. Finally, we establish a sample database based on the above analyses.
3.1. Mapping Analysis
From Equation (15), the relationship between the constant bias term and the terminal impact angle can be expressed as
and Equation (16) can be transformed into
The errors in the above formulas are due to the small-angle assumption and the inaccurate estimation of the flight time, and compensation can be carried out by introducing deviation terms
and
for angles and time, respectively, to account for the actual correspondence. For computational convenience, we adopt the method of Equation (15) and incorporate
and
:
where
and
are the initial distance and flight vehicle velocity, respectively. In Equation (18), the initial parameters such as
,
,
,
, and
are known and treated as constants, i.e., fixed values.
is typically taken as a negative value, such that Equation (18) becomes the following:
Even though the specific values of
and
are unknown, they do not affect the signs of the parameters. Therefore, the numerator term
is positive. From Equation (19), we infer that
is a strictly monotonic increasing function with respect to
. Exactly monotonic functions have one-to-one mapping relationships. Therefore, when the other initial parameters in Equation (19) are given, we can prove that
and
have a one-to-one mapping relationship. The relationship between
and
can be expressed as follows:
Theorem 1. Let , where is strictly increasing or decreasing. Then, function must have an inverse function , which is also a purely monotonic function with respect to within its domain.
Proof of Theorem 1. Since f is strictly increasing over , for any , there exists an such that .
Assume , where is strictly increasing. Let , and show that there exists such that
Since , there exists some such that . Since is strictly increasing, for any , . Similarly, for any , .
Consider the case where . Since , . Thus, such that .
Now, consider the case where . Since is strictly increasing, and . Since is strictly increasing, for any , . Similarly, for any , . Thus, there is an such that and .
Consider the case where . Since is strictly increasing, there exists some a such that and . Similarly, for any , . Thus, there is an such that and .
In all cases, for any , an such that exists. Therefore, function f is inverse, and it is a strictly monotonic function with respect to within its domain. This completes the proof of Theorem 1. □
According to Theorem 1, the inverse function of Equation (20) is also strictly increasing. Therefore, a one-to-one mapping relationship exists between
and
, as shown below:
Equations (20) and (21) can be approximated as inverse transformations. In ideal conditions, the inversion is exact. However, inversion errors may occur in the inverse process because of approximation transformations or parameter changes. A neural network can be used to represent this nonlinear inverse transformation. During offline training, an accurate mathematical model can provide an approximate inversion that adapts to the total flight envelope. This allows the neural network to compensate for the inversion errors online.
For
R and
in Equation (20), according to the trigonometric relationship, we replace them in the form of
and
. This has the advantage of reducing the amount of calculation. The coordinate information of the flight vehicle is directly available, while
R and
need to be calculated. Additionally, based on the analysis in the previous section, limited acceleration has a significant impact on the impact angle. Hence, the mapping relationship between
and b can be transformed as follows:
Subsequently, Equation (22) represents the mapping relationship in this paper, replacing Equation (21). Suppose all data from each dimension in the input are used as a sample. In that case, this approach results in many samples, significantly increasing computational complexity. Moreover, each dimension may have a different influence on . Therefore, conducting sensitivity analysis on each dimension, selecting appropriate sample intervals, and employing different sampling strategies can help reduce the computational burden while maintaining accuracy.
Sensitivity analysis performed on each dimension identifies those that significantly impact the mapping relationship. A smaller sample interval is selected for these dimensions to capture variations more accurately. Conversely, a larger sample interval is chosen for dimensions with a relatively minor impact, reducing the number of samples without sacrificing accuracy significantly. These strategies effectively reduce the overall sample count while capturing an accurate mapping relationship between the input dimensions and .
3.2. Sensitivity Analysis
In optimization theory, sensitivity analysis is often used to study the stability of the optimal solution when the original data are inaccurate or changes occur. The influence of parameters on the system or model can be quantified by conducting this sensitivity analysis, which helps explain how changes in input parameters affect the output or performance of the system or model. It provides insights into which parameters significantly impact the objective function or constraints and to what extent. This information is valuable for decision making, model validation, and robustness analysis. By evaluating the sensitivity of the system or model to parameter variations, we can identify critical parameters that require accurate estimation or control. Sensitivity analysis also helps identify parameters with little influence on the system, enabling simplifications or reducing the computational burden.
This subsection mainly analyzes the sensitivity of the constant bias term to variations in the parameters for sample reduction in Equation (22). To do this, Equation (22) is adjusted with respect to the parameters, resulting in the following:
Based on the analysis in the previous section, a mapping relationship exists between
and the parameters, indicating a functional relationship. Therefore, Equation (23) can be expanded as follows:
In Equation (23), the partial derivatives of the terms can be obtained through numerical integration methods. According to Equation (19), the partial derivatives of the term involve unknown parameters such as and , making an analytical solution to Equation (24) challenging. Simulation-based validation can be used to assess the impact of variations in each parameter on . By conducting simulations with different parameter values and observing the resulting changes in , the sensitivity and magnitude of each parameter’s influence on can be determined. This empirical analysis can thus provide valuable insights into the relationship between the parameters and .
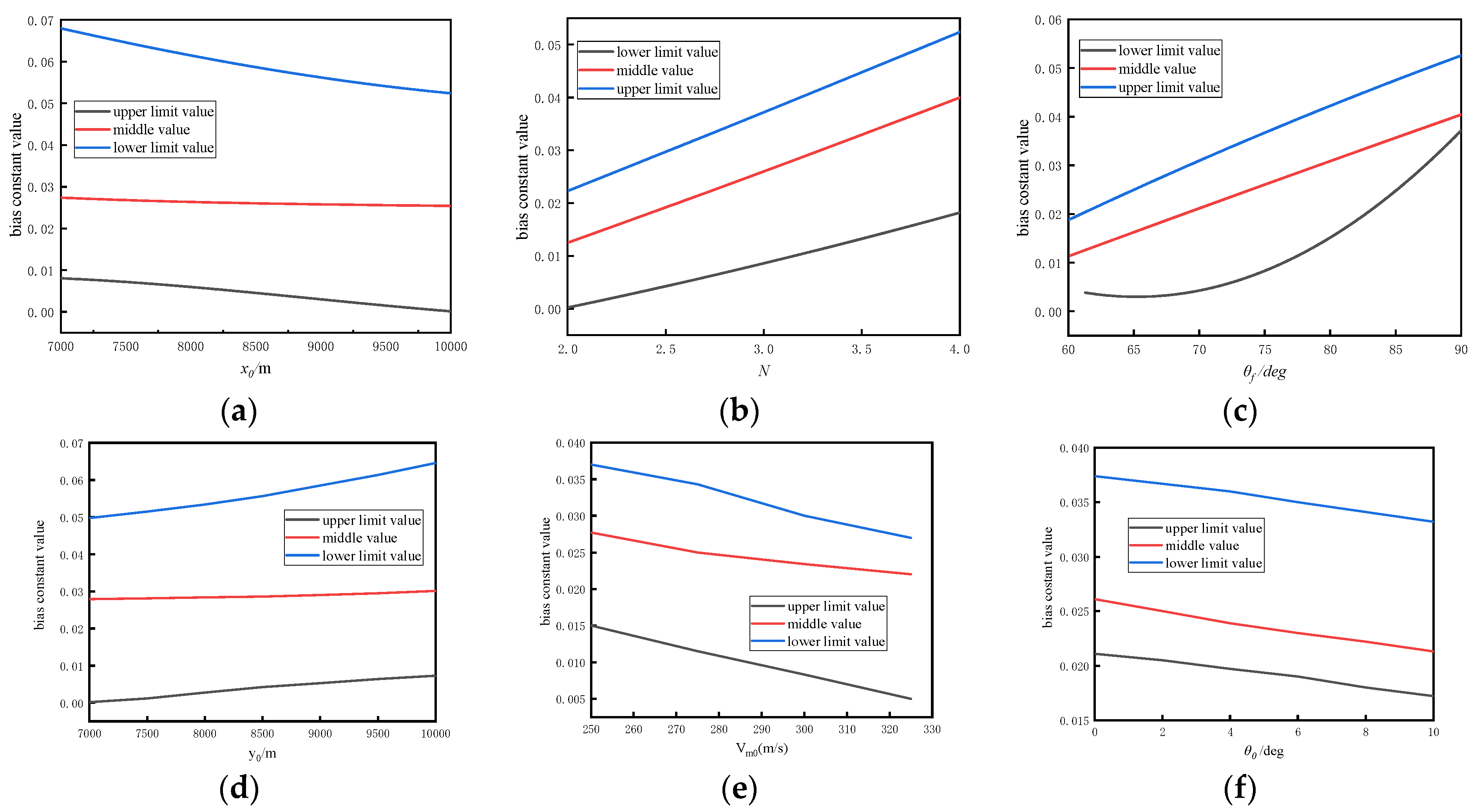
To establish a database and provide the boundaries for each dimension in Equation (22), such as , , , , , , and , we performed sensitivity analysis on each parameter on three levels: upper limit, middle value, and lower limit, which encompass the variations in all parameters and capture their trends.
First, when analyzing
and
, since both represent the influence on distance, we only need to explore one. We define the three levels as
,
, and
, with parameter values of
for the lower limit,
for the middle value, and
for the upper limit. Simulations were conducted for these three cases, and the results are shown in
Figure 2a.
Based on the figure, whether considering the lower limit, middle value, or upper limit, the variation in has a relatively small impact on , i.e., a low sensitivity. However, an overall decreasing trend is present. Therefore, when has smaller values, a larger sample interval should be chosen. On the other hand, when has larger values, a smaller sample interval should be selected.
Secondly, when analyzing
, we designated the three levels as
,
, and
, with parameter values of
for the lower limit,
for the middle value, and
for the upper limit. The results of the simulations for these three cases are shown in
Figure 2b.
Based on the figure, in consideration of the lower limit, middle value, and upper limit, the variation in has a relatively significant impact on the value of , and an overall increasing trend is present. Therefore, a smaller sample interval should be chosen, especially when is larger.
Finally, when analyzing
for ease of analysis, we select
as the analysis value. We designate the three levels as
,
, and
, with parameter values of
for the lower limit,
for the middle value, and
for the upper limit. Simulations will be conducted for these three cases, and the results are shown in
Figure 2c. The results show that regardless of the level considered, the variation in
had a relatively significant impact on
, exhibiting an overall increasing trend. Therefore, a smaller sample interval should be chosen, especially when
is larger. Additionally, from the lower limit curve, because, at larger desired impact angles, the acceleration capacity is limited, there is a slower response to the impact angle term and a steep increase in
. Hence, this experiment demonstrates the strong correlation between the desired impact angle term and acceleration capacity. Analyzing the limited acceleration and incorporating it as an input is crucial for accurate guidance.
For parameters such as and , the analysis methods are similar to those mentioned above, so these analyses are omitted. Furthermore, is already analyzed through the impact angle, resulting in the recommendation of a smaller sample interval. The analyses presented above provide a basis for establishing a strategy of evenly distributed sampling.
For sensitivity analysis, we mainly analyze its sensitivity level, because parameters with higher sensitivity have a greater impact on the output. At this point, the step size refers to the sampling step size, which is significantly different from the step size in general programs. Alternatively, it is more appropriate to use more sampling points for those that have a greater impact on the output and require more sampling points to ensure its accuracy. For those that have a smaller impact on the output, fewer sampling points can be used.




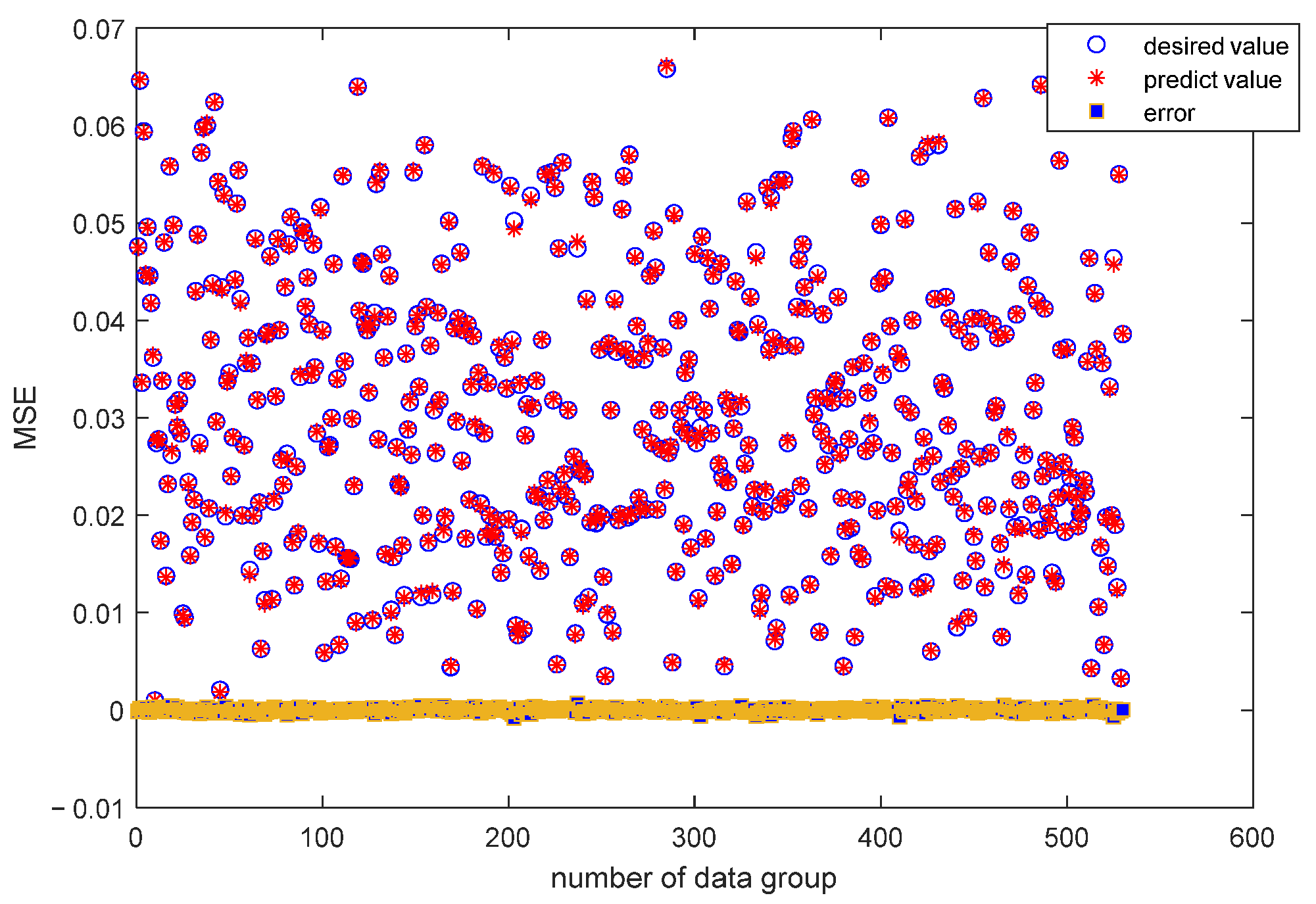


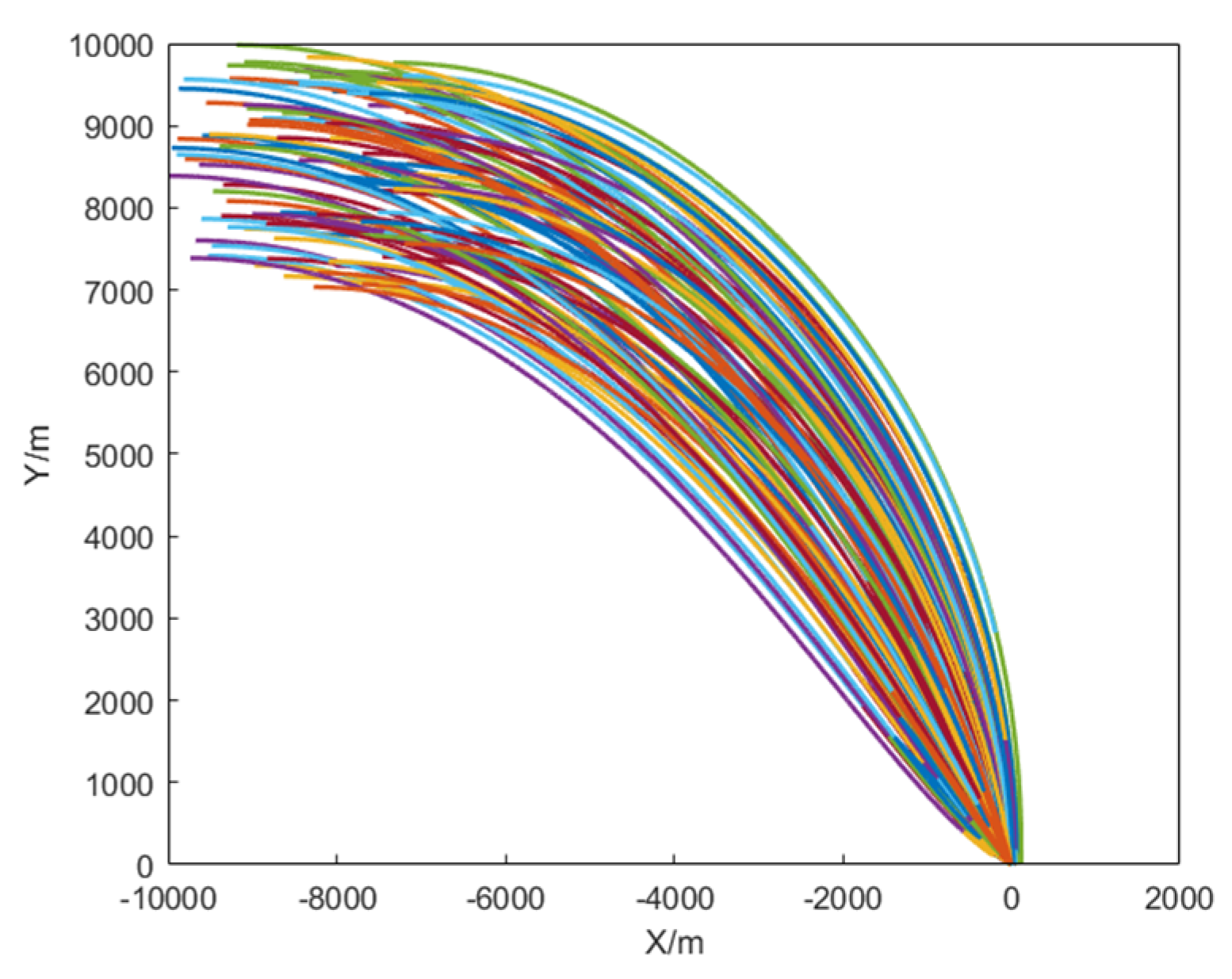

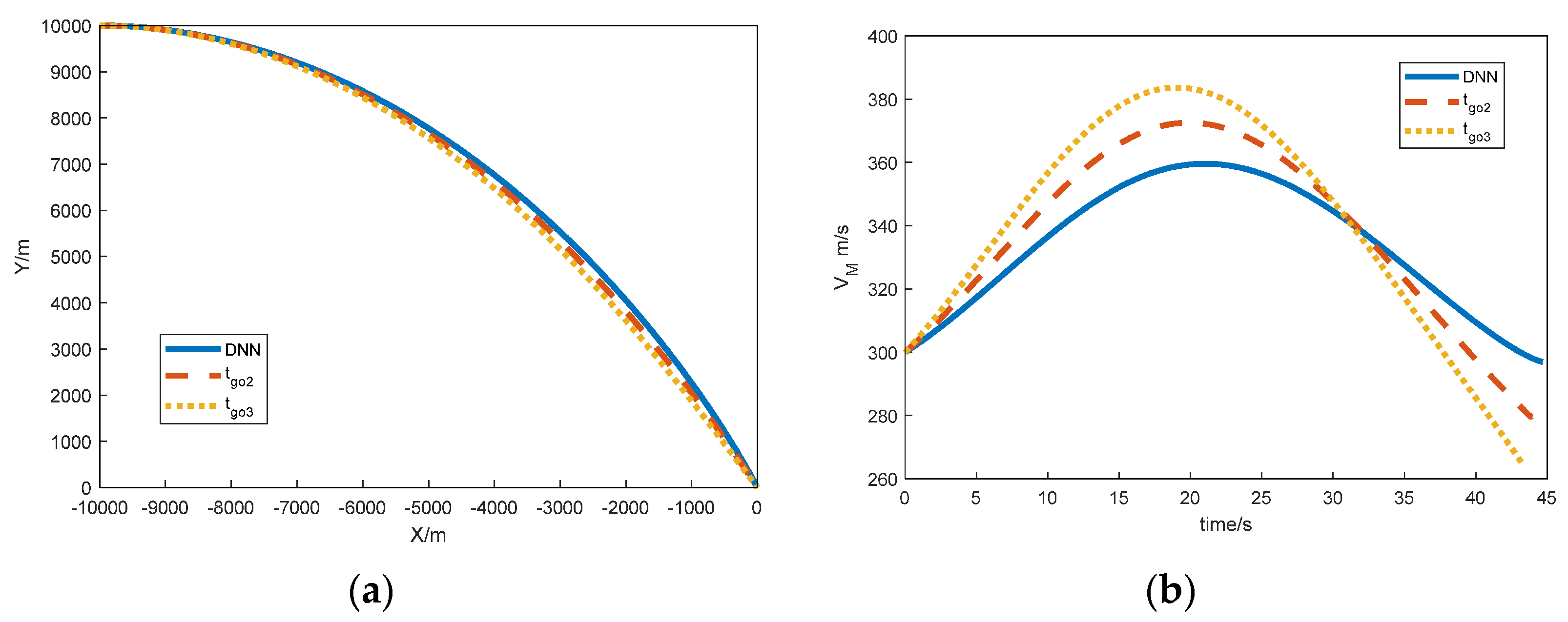
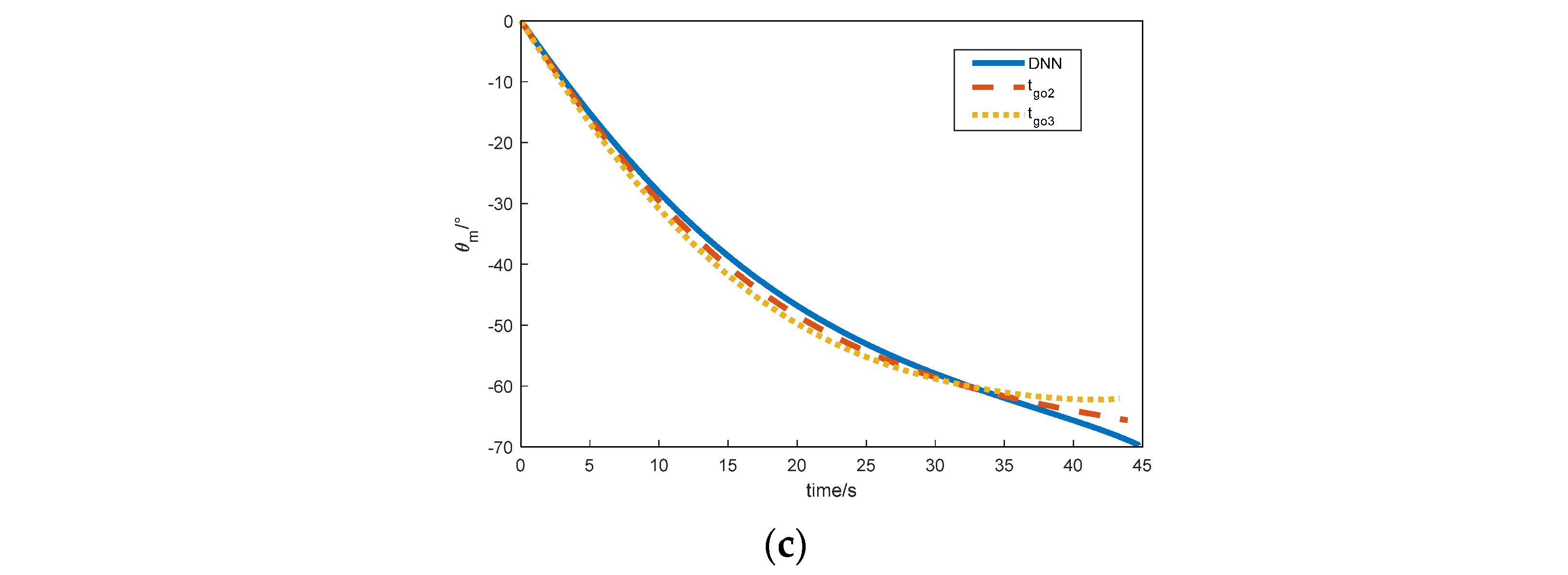

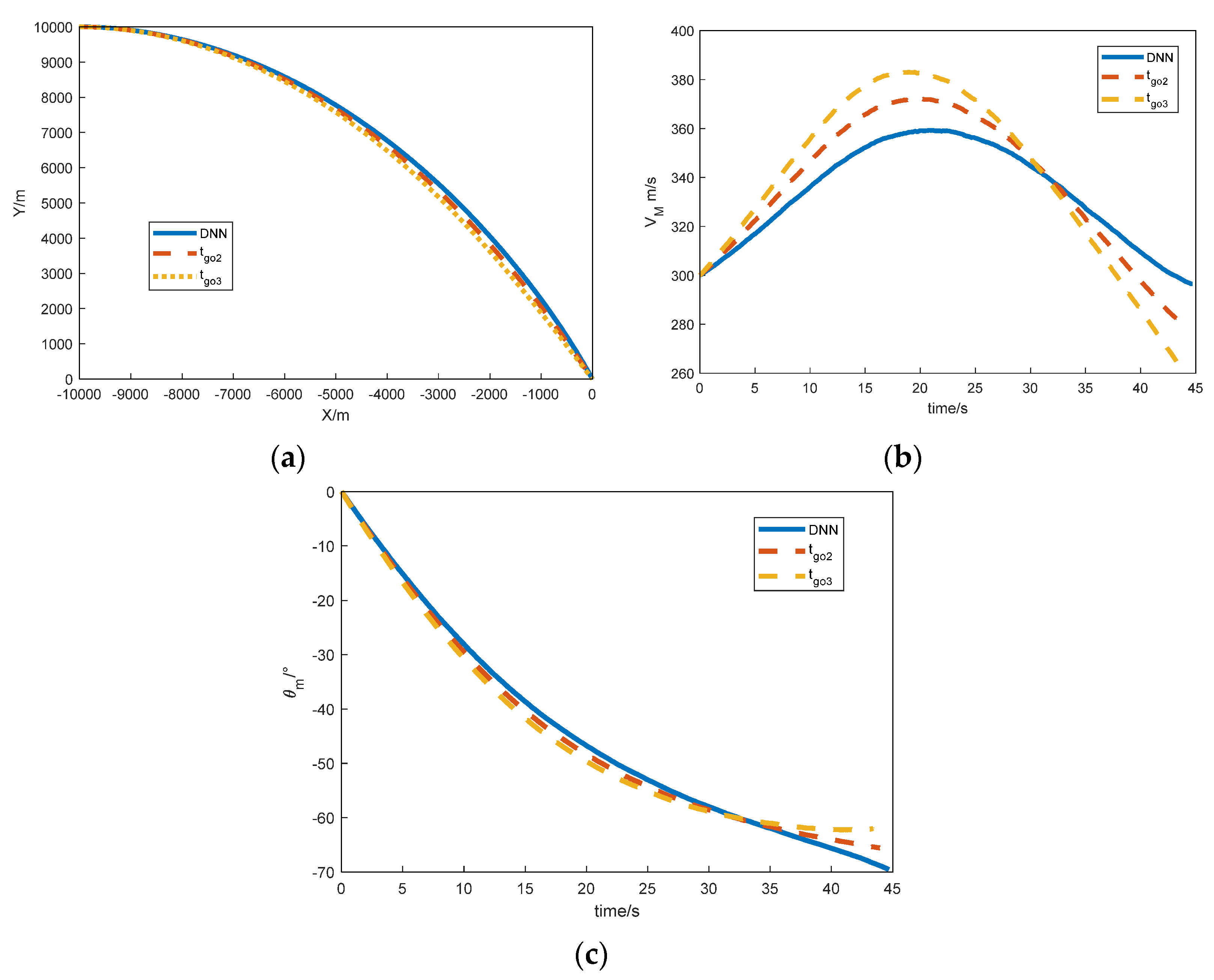

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}