
Fault-Tolerant Control for Multi-UAV Exploration System via Reinforcement Learning Algorithm

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (1)
- We simulate a Multi-UAV exploration scenario in a grid world. Faulty UAVs will occur in the scenario, which are used to verify the performance of our algorithm.
- (2)
- We propose a novel network model named Error-Resilience Graph Network (ERGN); it can receive the agent health status and conduct a scheduling policy to reduce the impact that faulty agents bring to the swarm target.
- (3)
- We integrate a temporal convolution module into the algorithm, which enables the agents to capture the temporal information and achieve better performance.
2. Methods
2.1. Dependence
2.1.1. Multi-Agent Reinforcement Learning (MARL)
2.1.2. Deep Q Network (DQN)
2.1.3. Graph Attention Networks (GATs)
2.1.4. Long Short-Term Memory (LSTM)
2.2. System Model
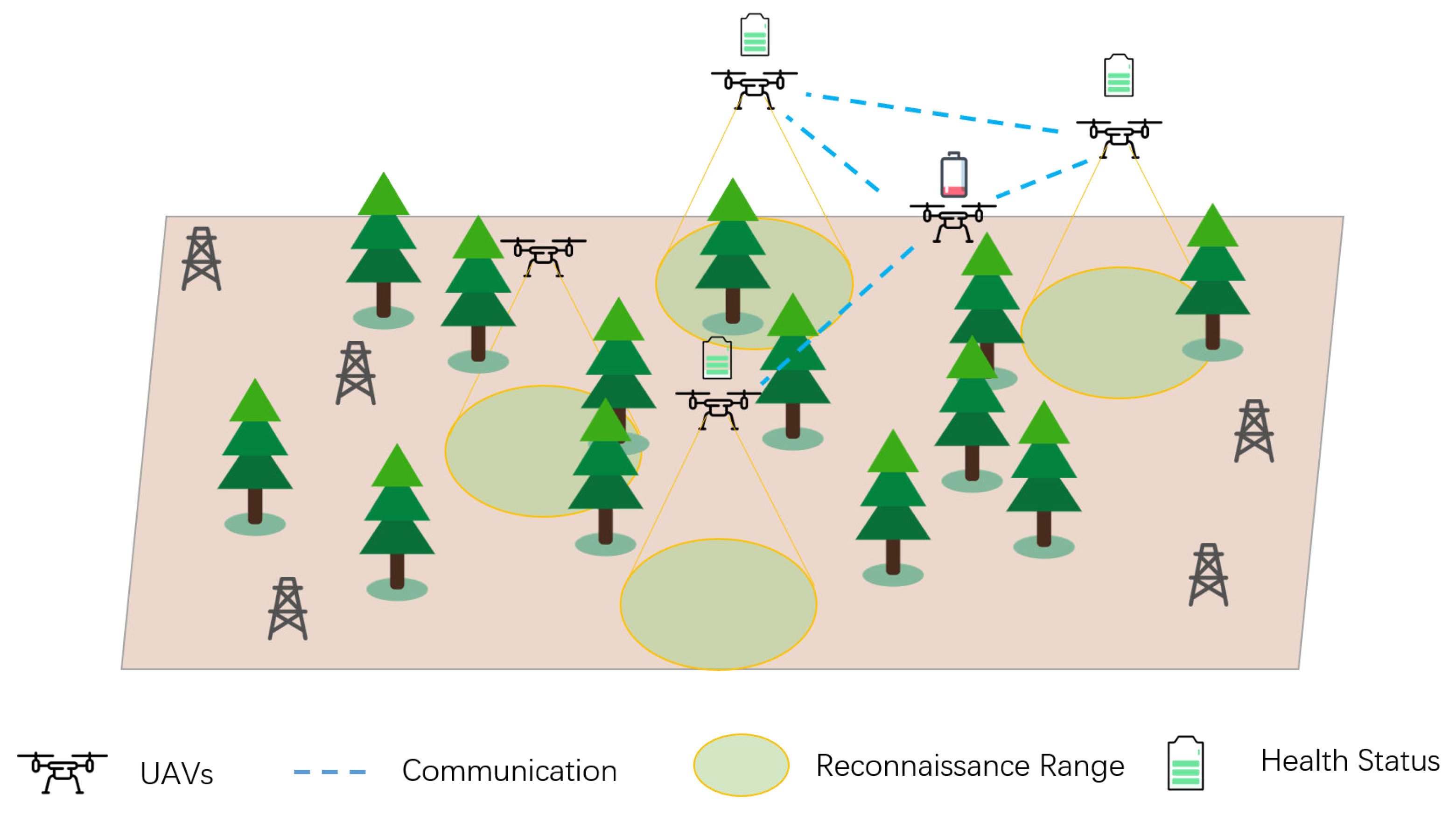
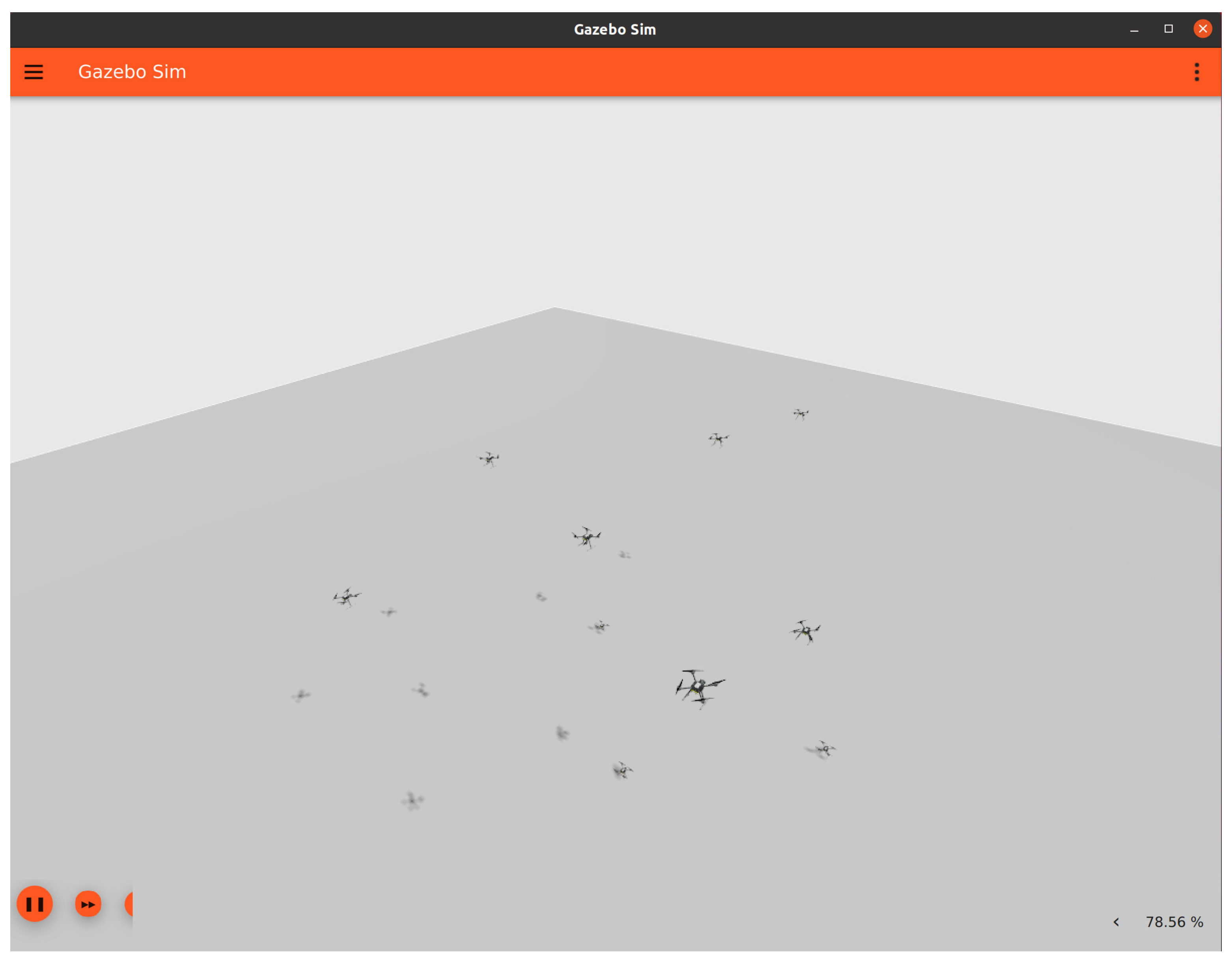
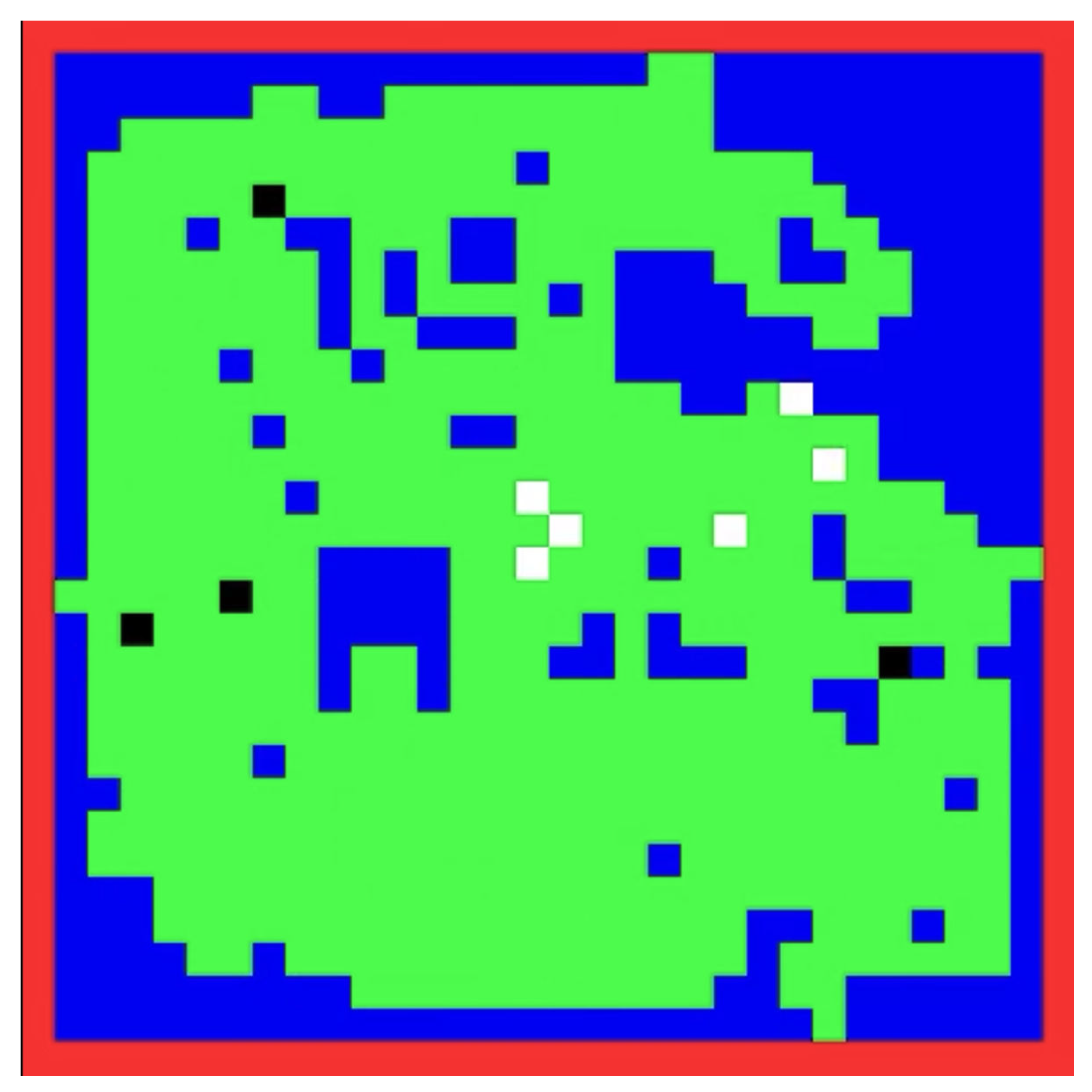
2.2.1. Ground Exploration Scenario
2.2.2. Observation Space and Action Space
2.2.3. Evaluation Metrics
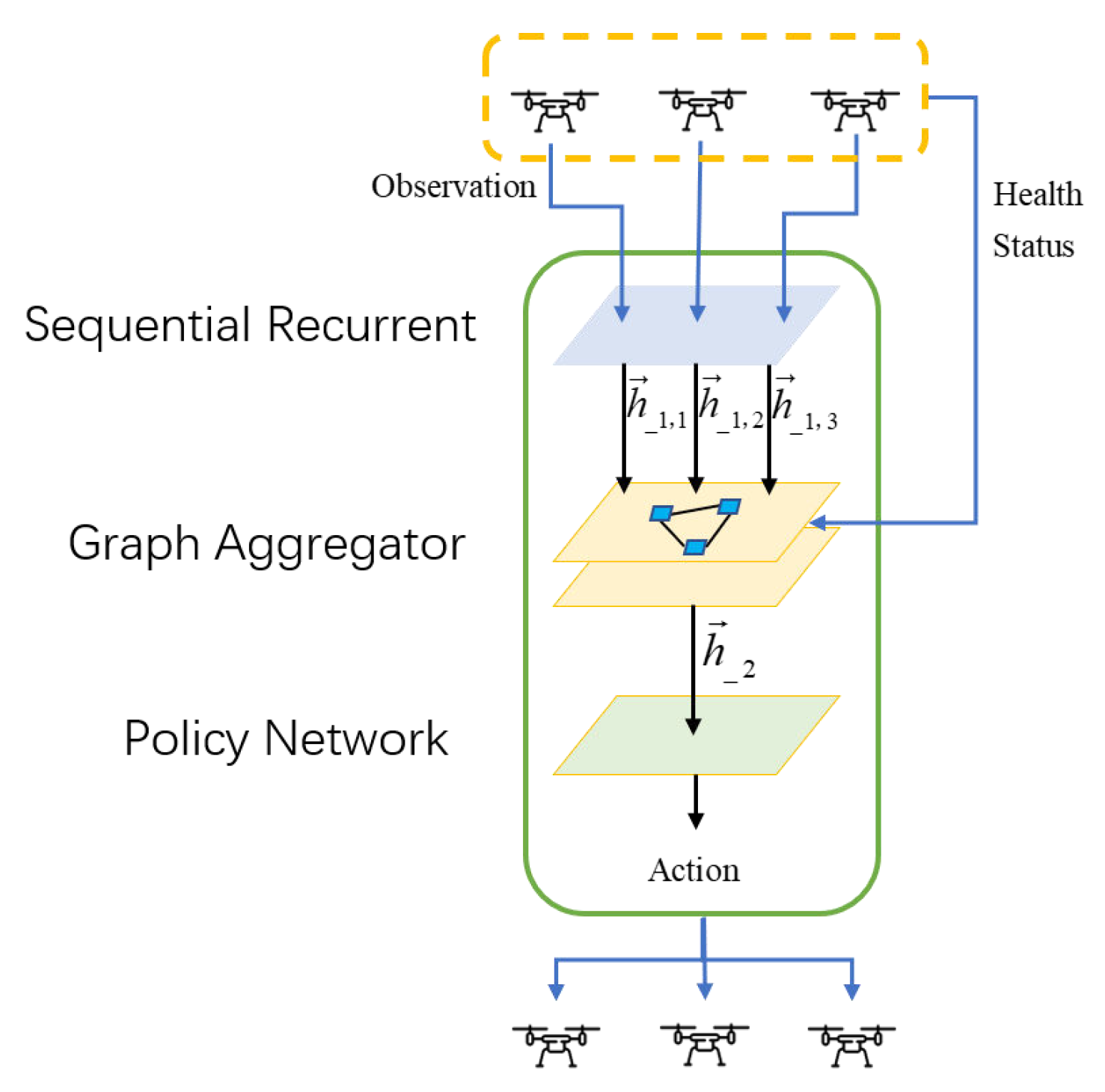
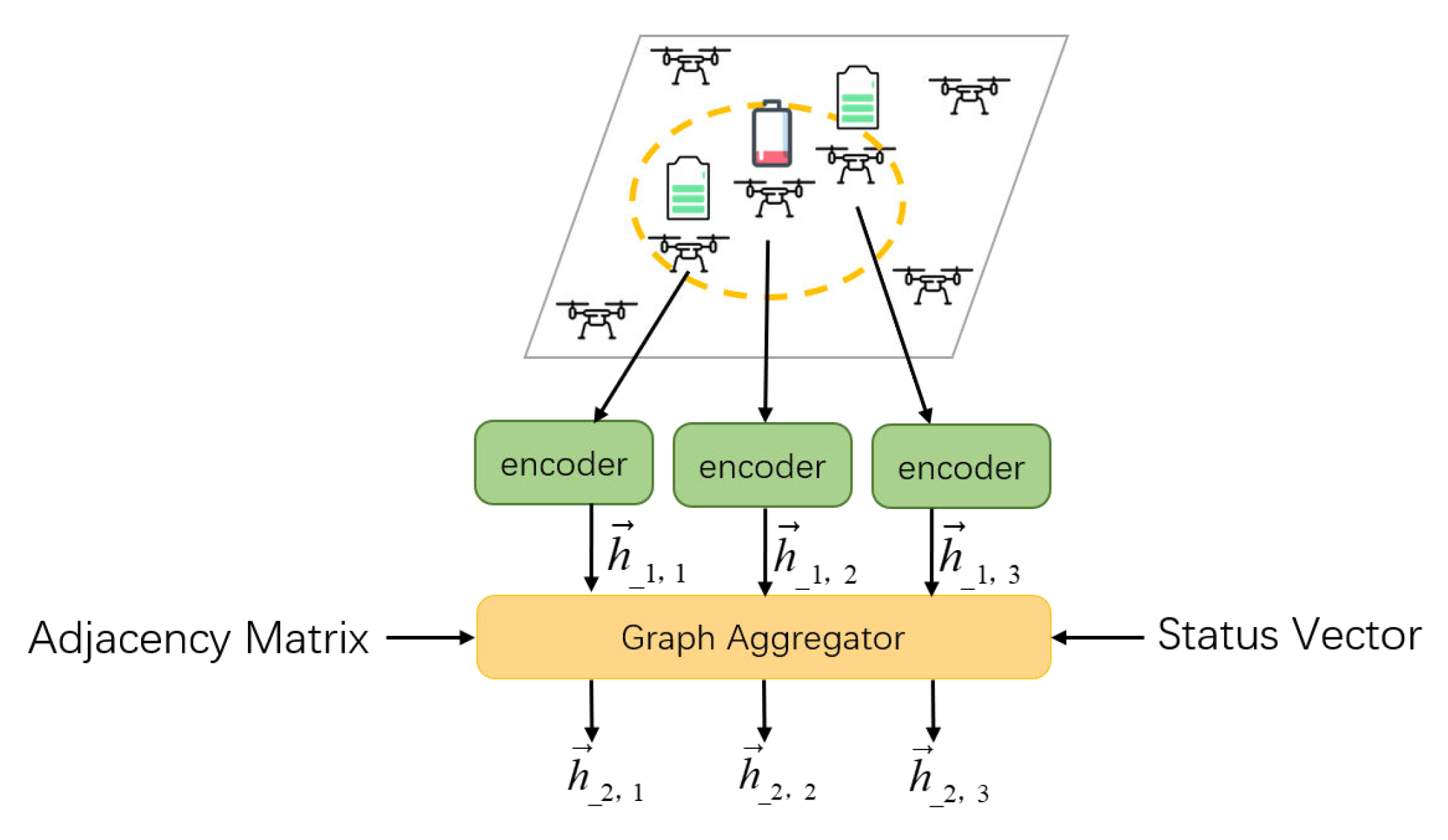
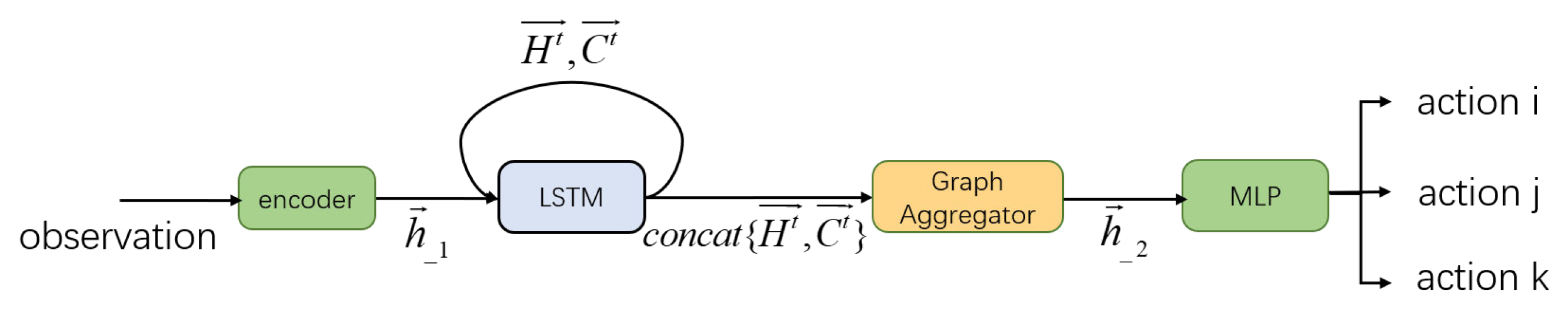
2.3. Error-Resilient Graph Network
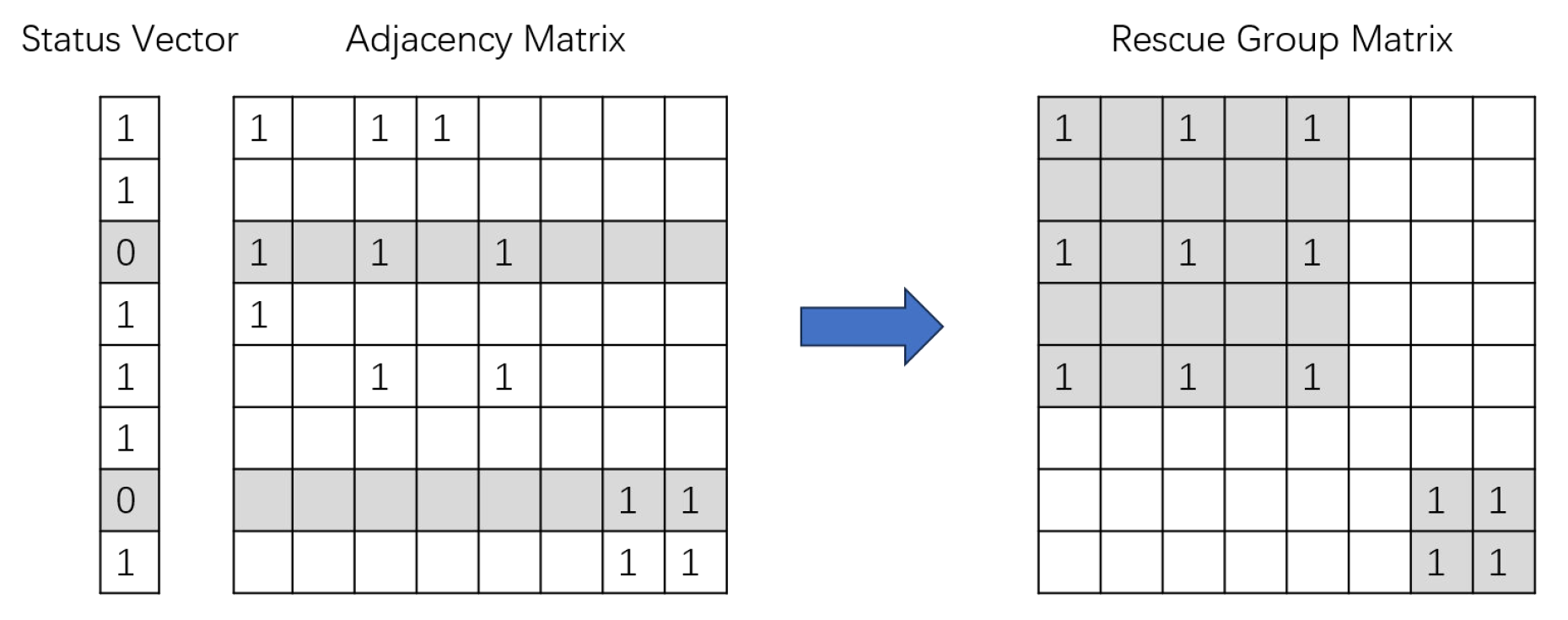
2.3.1. Spatial Information Aggregation
2.3.2. Temporal Information Aggregation
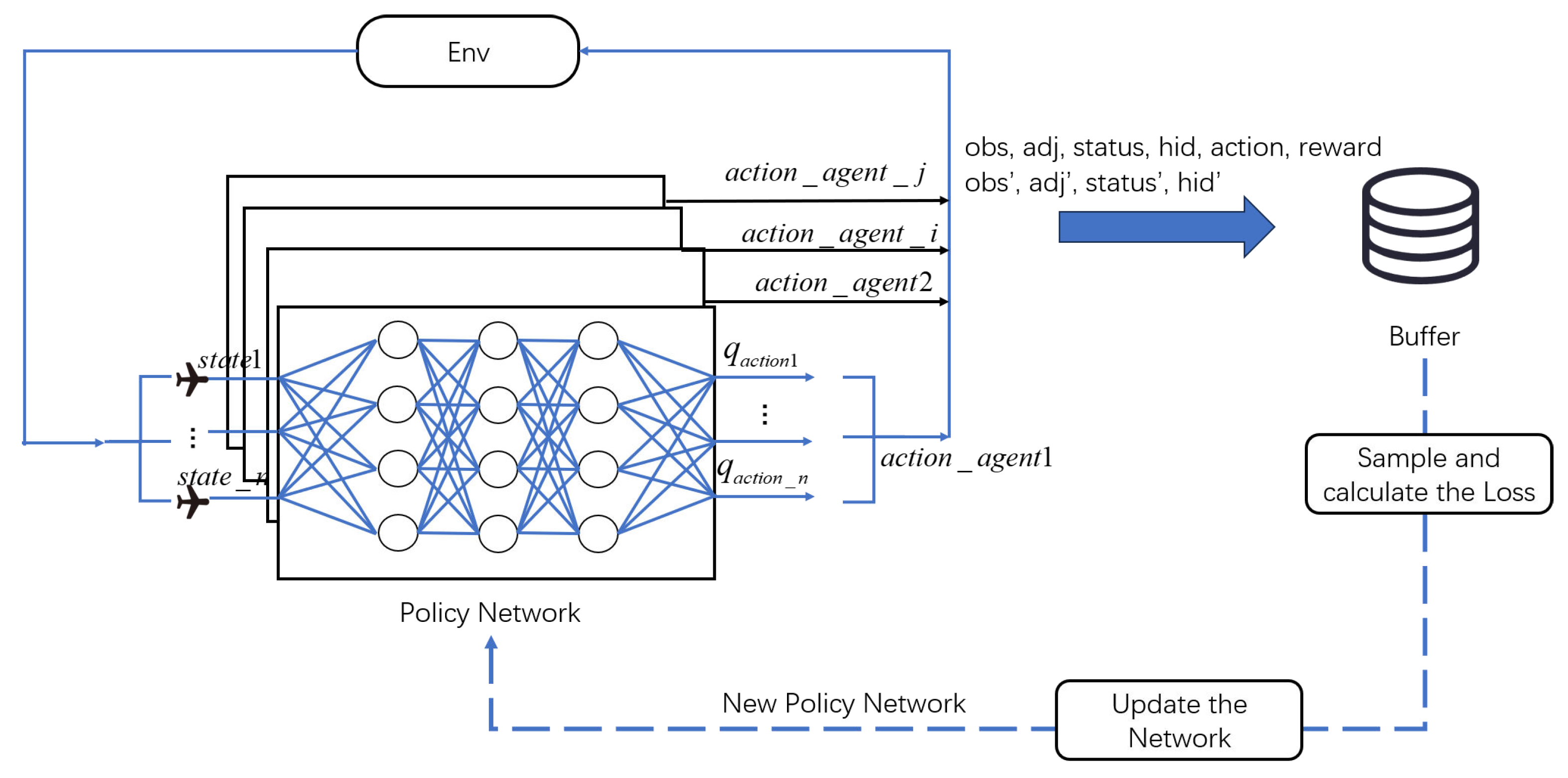
2.4. Training Process
| Algorithm 1 Error-Resilient Graph Network |
|
2.5. Training Settings
2.6. Training Scenarios
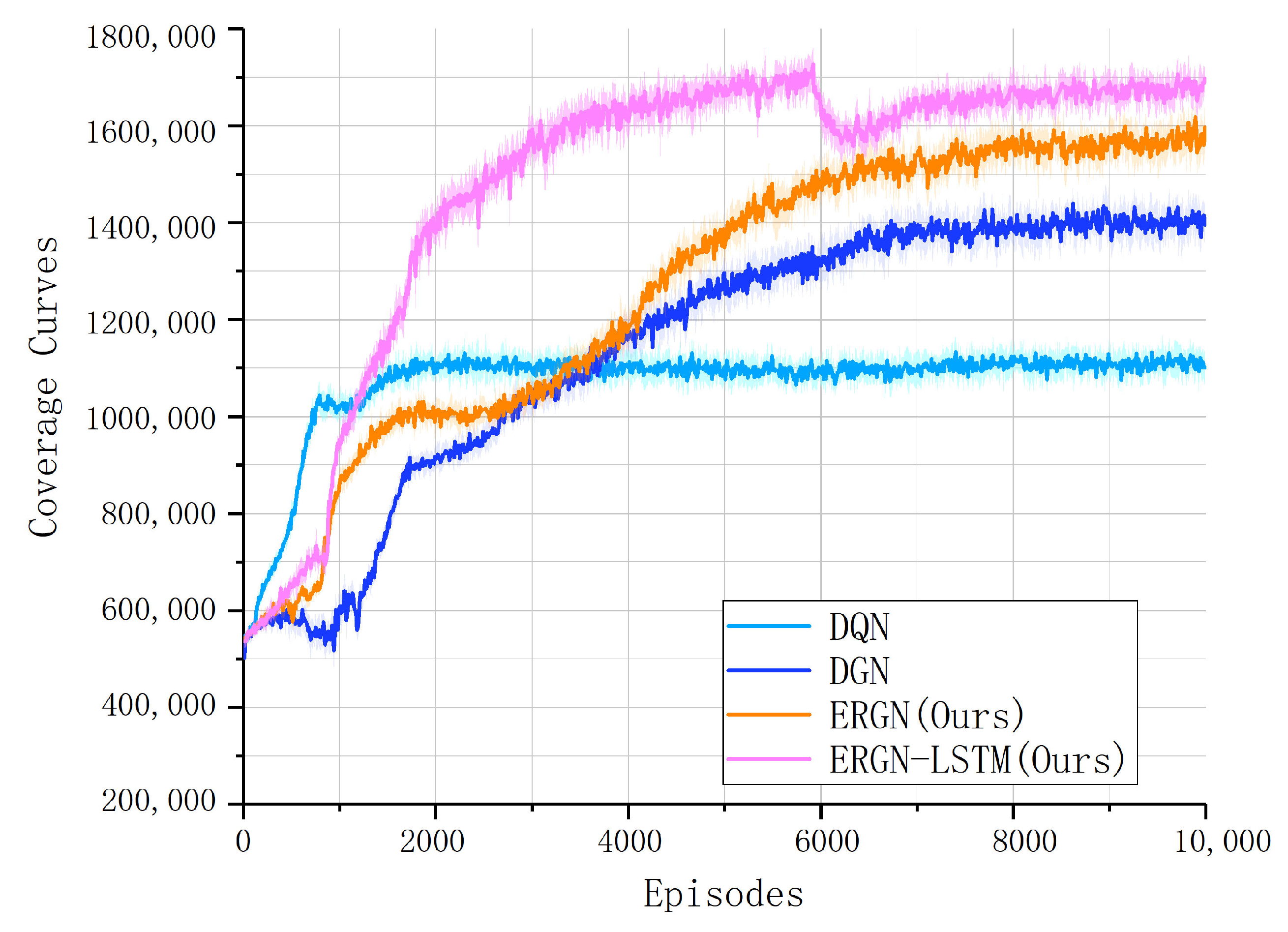
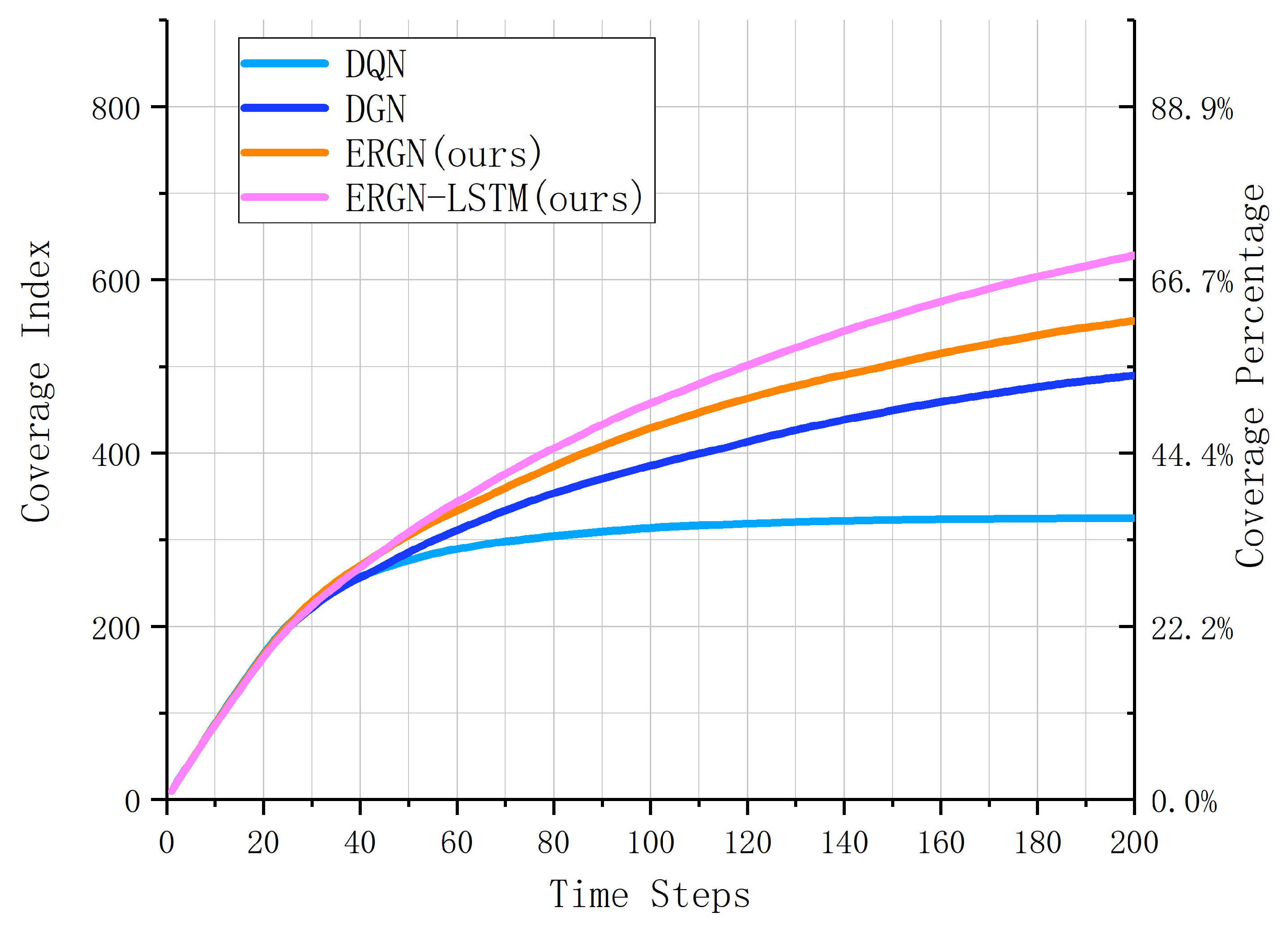
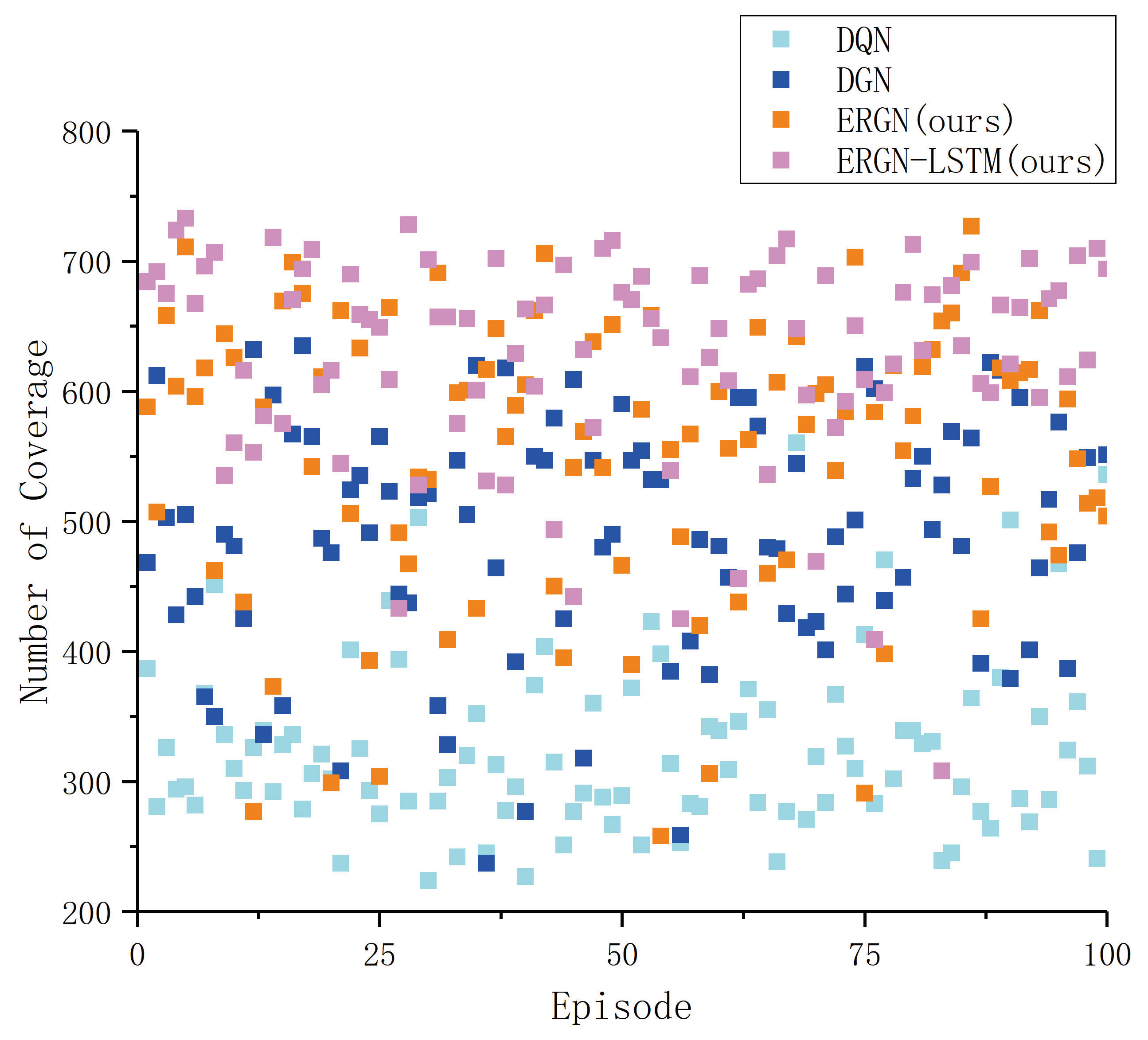
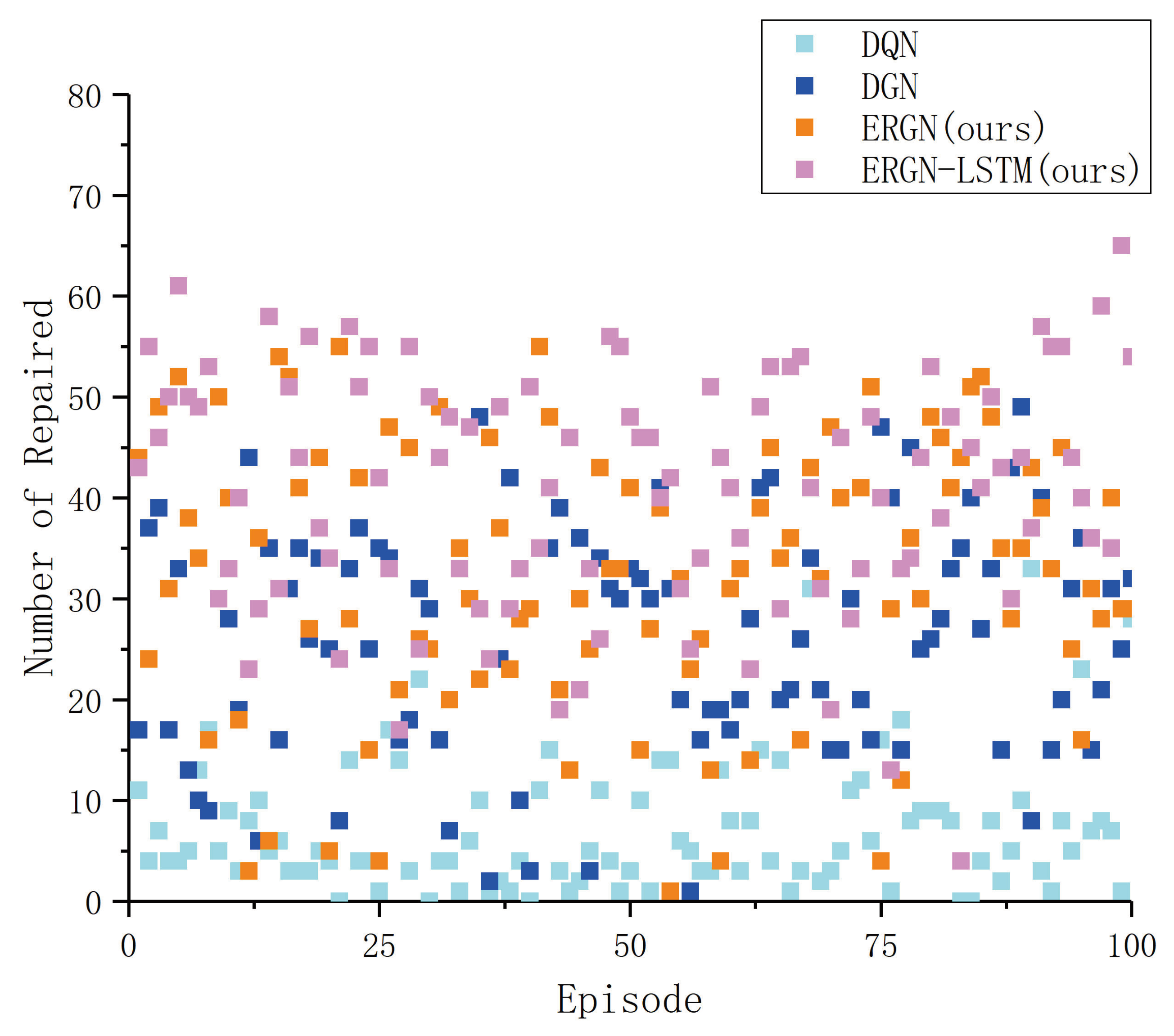
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MARL | Multi-Agent Reinforcement Learning |
| UAV | Unmanned Aerial Vehicle |
| DQN | Deep Q Network |
| DGN | Deep Graph Network |
| ERGN | Error-Resilient Graph Network |
| GATs | Graph Attention Networks |
| LSTM | Long Short-Term Memory |
| MLP | Multi-Layer Perceptron |
References
- Fan, B.; Li, Y.; Zhang, R.; Fu, Q. Review on the technological development and application of UAV systems. Chin. J. Electron. 2020, 29, 199–207. [Google Scholar] [CrossRef]
- Ravankar, A.A.; Ravankar, A.; Kobayashi, Y.; Emaru, T. Autonomous mapping and exploration with unmanned aerial vehicles using low cost sensors. Multidiscip. Digit. Publ. Inst. Proc. 2018, 4, 44. [Google Scholar]
- Zhou, B.; Xu, H.; Shen, S. Racer: Rapid collaborative exploration with a decentralized multi-uav system. IEEE Trans. Robot. 2023, 39, 1816–1835. [Google Scholar] [CrossRef]
- Jiang, Z.; Chen, Y.; Wang, K.; Yang, B.; Song, G. A Graph-Based PPO Approach in Multi-UAV Navigation for Communication Coverage. Int. J. Comput. Commun. Control 2023, 18, 5505. [Google Scholar] [CrossRef]
- Jiang, Z.; Chen, Y.; Song, G.; Yang, B.; Jiang, X. Cooperative planning of multi-UAV logistics delivery by multi-graph reinforcement learning. In Proceedings of the International Conference on Computer Application and Information Security (ICCAIS 2022), Wuhan, China, 23–24 December 2022; Volume 12609, pp. 129–137. [Google Scholar]
- Zhan, G.; Zhang, X.; Li, Z.; Xu, L.; Zhou, D.; Yang, Z. Multiple-uav reinforcement learning algorithm based on improved ppo in ray framework. Drones 2022, 6, 166. [Google Scholar] [CrossRef]
- Rezaee, H.; Parisini, T.; Polycarpou, M.M. Almost sure resilient consensus under stochastic interaction: Links failure and noisy channels. IEEE Trans. Autom. Control 2020, 66, 5727–5741. [Google Scholar] [CrossRef]
- Jiang, H.; Shi, D.; Xue, C.; Wang, Y.; Wang, G.; Zhang, Y. Multi-agent deep reinforcement learning with type-based hierarchical group communication. Appl. Intell. 2021, 51, 5793–5808. [Google Scholar] [CrossRef]
- Mann, V.; Sivaram, A.; Das, L.; Venkatasubramanian, V. Robust and efficient swarm communication topologies for hostile environments. Swarm Evol. Comput. 2021, 62, 100848. [Google Scholar] [CrossRef]
- Gu, S.; Geng, M.; Lan, L. Attention-based fault-tolerant approach for multi-agent reinforcement learning systems. Entropy 2021, 23, 1133. [Google Scholar] [CrossRef]
- Xing, Z.; Jia, J.; Guo, K.; Jia, W.; Yu, X. Fast active fault-tolerant control for a quadrotor uav against multiple actuator faults. Guid. Navig. Control 2022, 2, 2250007. [Google Scholar] [CrossRef]
- Muslimov, T. Adaptation Strategy for a Distributed Autonomous UAV Formation in Case of Aircraft Loss. In Proceedings of the International Symposium on Distributed Autonomous Robotic Systems, Montbéliard, France, 28–30 November 2022; pp. 231–242. [Google Scholar]
- Bianchi, D.; Di Gennaro, S.; Di Ferdinando, M.; Acosta Lùa, C. Robust control of uav with disturbances and uncertainty estimation. Machines 2023, 11, 352. [Google Scholar] [CrossRef]
- Kilinc, O.; Montana, G. Multi-agent deep reinforcement learning with extremely noisy observations. arXiv 2018, arXiv:1812.00922. [Google Scholar]
- Luo, C.; Liu, X.; Chen, X.; Luo, J. Multi-agent Fault-tolerant Reinforcement Learning with Noisy Environments. In Proceedings of the 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), Hong Kong, China, 2–4 December 2020; pp. 164–171. [Google Scholar]
- Abel, R.O.; Dasgupta, S.; Kuhl, J.G. The relation between redundancy and convergence rate in distributed multi-agent formation control. In Proceedings of the 2008 47th IEEE Conference on Decision and Control, Cancun, Mexico, 9–11 December 2008; pp. 3977–3982. [Google Scholar]
- Wang, G.; Luo, H.; Hu, X.; Ma, H.; Yang, S. Fault-tolerant communication topology management based on minimum cost arborescence for leader–follower UAV formation under communication faults. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417693965. [Google Scholar] [CrossRef]
- Han, B.; Jiang, J.; Yu, C. Distributed fault-tolerant formation control for multiple unmanned aerial vehicles under actuator fault and intermittent communication interrupt. Proc. Inst. Mech. Eng. Part I J. Syst. Control Eng. 2021, 235, 1064–1083. [Google Scholar] [CrossRef]
- Hu, J.; Niu, H.; Carrasco, J.; Lennox, B.; Arvin, F. Fault-tolerant cooperative navigation of networked UAV swarms for forest fire monitoring. Aerosp. Sci. Technol. 2022, 123, 107494. [Google Scholar] [CrossRef]
- Ghamry, K.A.; Zhang, Y. Fault-tolerant cooperative control of multiple UAVs for forest fire detection and tracking mission. In Proceedings of the 2016 3rd Conference on Control and Fault-Tolerant Systems (SysTol), Barcelona, Spain, 7–9 September 2016; pp. 133–138. [Google Scholar]
- Huang, S.; Teo, R.S.H.; Kwan, J.L.P.; Liu, W.; Dymkou, S.M. Distributed UAV loss detection and auto-replacement protocol with guaranteed properties. J. Intell. Robot. Syst. 2019, 93, 303–316. [Google Scholar] [CrossRef]
- Oroojlooy, A.; Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl. Intell. 2023, 53, 13677–13722. [Google Scholar] [CrossRef]
- Kim, W.; Park, J.; Sung, Y. Communication in multi-agent reinforcement learning: Intention sharing. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Berlin/Heidelberg, Germany, 2021; pp. 321–384. [Google Scholar]
- Zhang, Y.; Yang, Q.; An, D.; Zhang, C. Coordination between individual agents in multi-agent reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, virtually, 2–9 February 2021; Volume 35, pp. 11387–11394. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Gao, J.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of ppo in cooperative multi-agent games. Adv. Neural Inf. Process. Syst. 2022, 35, 24611–24624. [Google Scholar]
- Yang, X.; Huang, S.; Sun, Y.; Yang, Y.; Yu, C.; Tu, W.W.; Yang, H.; Wang, Y. Learning Graph-Enhanced Commander-Executor for Multi-Agent Navigation. arXiv 2023, arXiv:2302.04094. [Google Scholar]
- Egorov, M. Multi-agent deep reinforcement learning. In CS231n: Convolutional Neural Networks for Visual Recognition; Stanford.edu: Stanford, CA, USA, 2016; pp. 1–8. [Google Scholar]
- de Witt, C.S.; Gupta, T.; Makoviichuk, D.; Makoviychuk, V.; Torr, P.H.; Sun, M.; Whiteson, S. Is independent learning all you need in the starcraft multi-agent challenge? arXiv 2020, arXiv:2011.09533. [Google Scholar]
- Tan, M. Multi-agent reinforcement learning: Independent vs. cooperative agents. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 June 1993; pp. 330–337. [Google Scholar]
- Chu, X.; Ye, H. Parameter sharing deep deterministic policy gradient for cooperative multi-agent reinforcement learning. arXiv 2017, arXiv:1710.00336. [Google Scholar]
- Brody, S.; Alon, U.; Yahav, E. How attentive are graph attention networks? arXiv 2021, arXiv:2105.14491. [Google Scholar]
- Liu, Y.; Wang, W.; Hu, Y.; Hao, J.; Chen, X.; Gao, Y. Multi-agent game abstraction via graph attention neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7211–7218. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1025–1035. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Song, T.; Yang, B.; Song, G. Fault-Tolerant Control for Multi-UAV Exploration System via Reinforcement Learning Algorithm. Aerospace 2024, 11, 372. https://doi.org/10.3390/aerospace11050372
Jiang Z, Song T, Yang B, Song G. Fault-Tolerant Control for Multi-UAV Exploration System via Reinforcement Learning Algorithm. Aerospace. 2024; 11(5):372. https://doi.org/10.3390/aerospace11050372
Chicago/Turabian StyleJiang, Zhiling, Tiantian Song, Bowei Yang, and Guanghua Song. 2024. "Fault-Tolerant Control for Multi-UAV Exploration System via Reinforcement Learning Algorithm" Aerospace 11, no. 5: 372. https://doi.org/10.3390/aerospace11050372
APA StyleJiang, Z., Song, T., Yang, B., & Song, G. (2024). Fault-Tolerant Control for Multi-UAV Exploration System via Reinforcement Learning Algorithm. Aerospace, 11(5), 372. https://doi.org/10.3390/aerospace11050372