_Zhu.png)
Redundant Space Manipulator Autonomous Guidance for In-Orbit Servicing via Deep Reinforcement Learning




Abstract
1. Introduction
2. Problem Statement
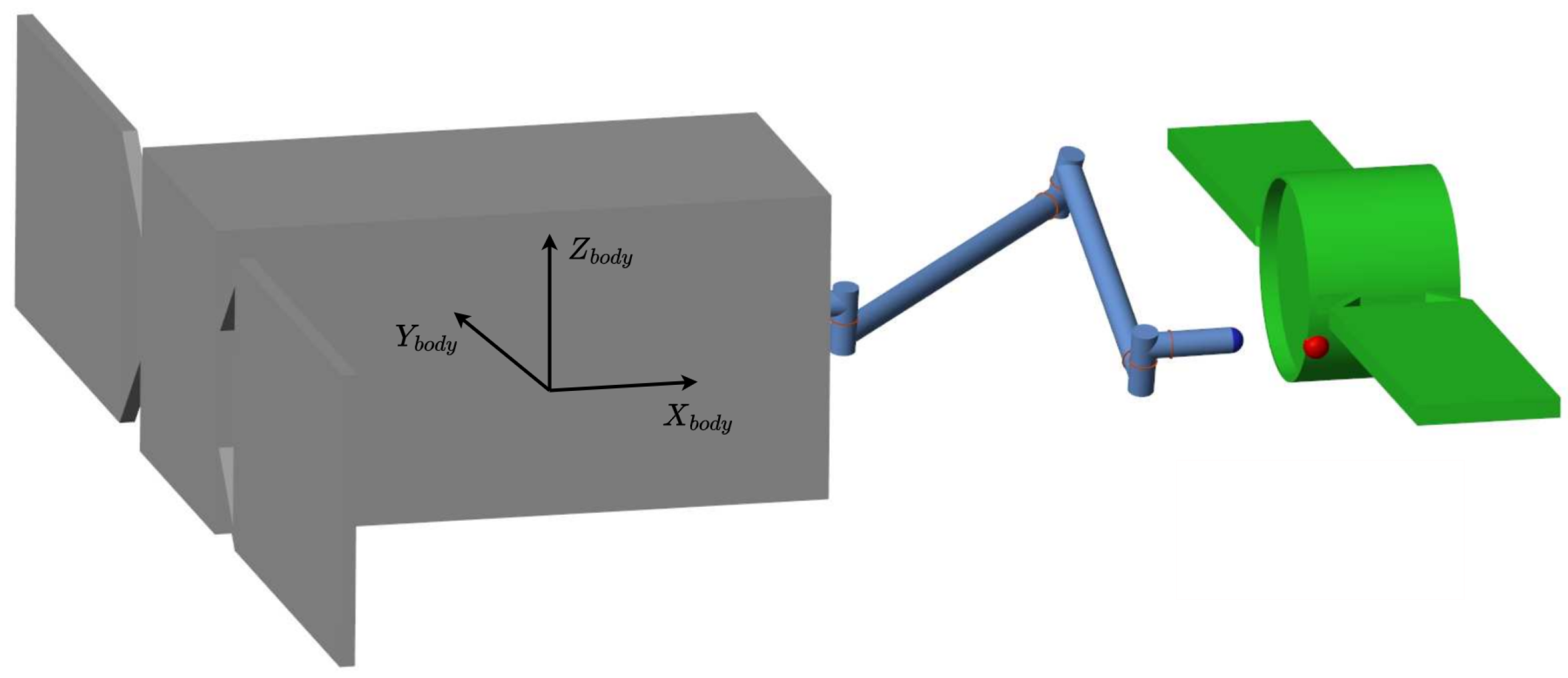
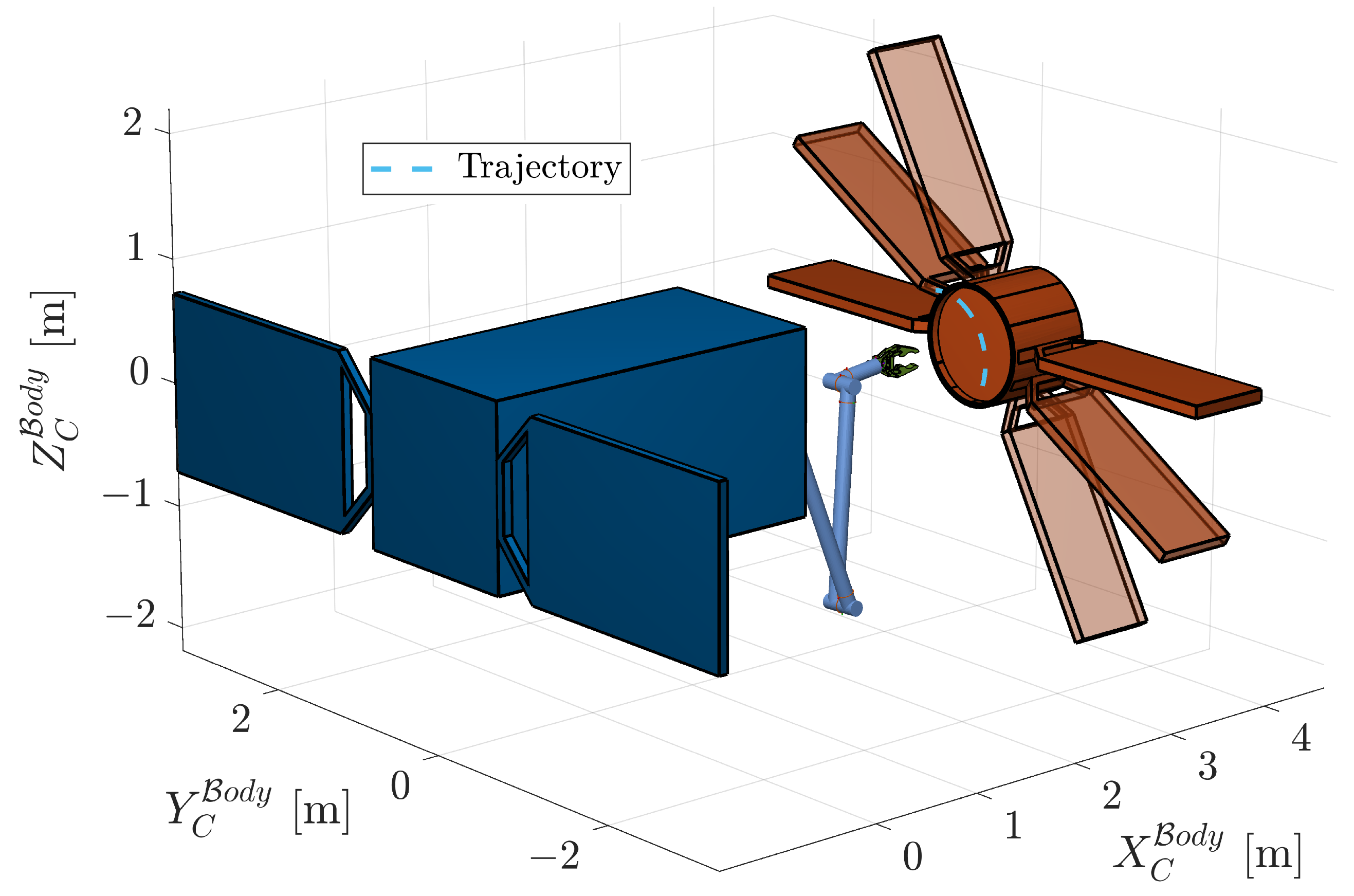
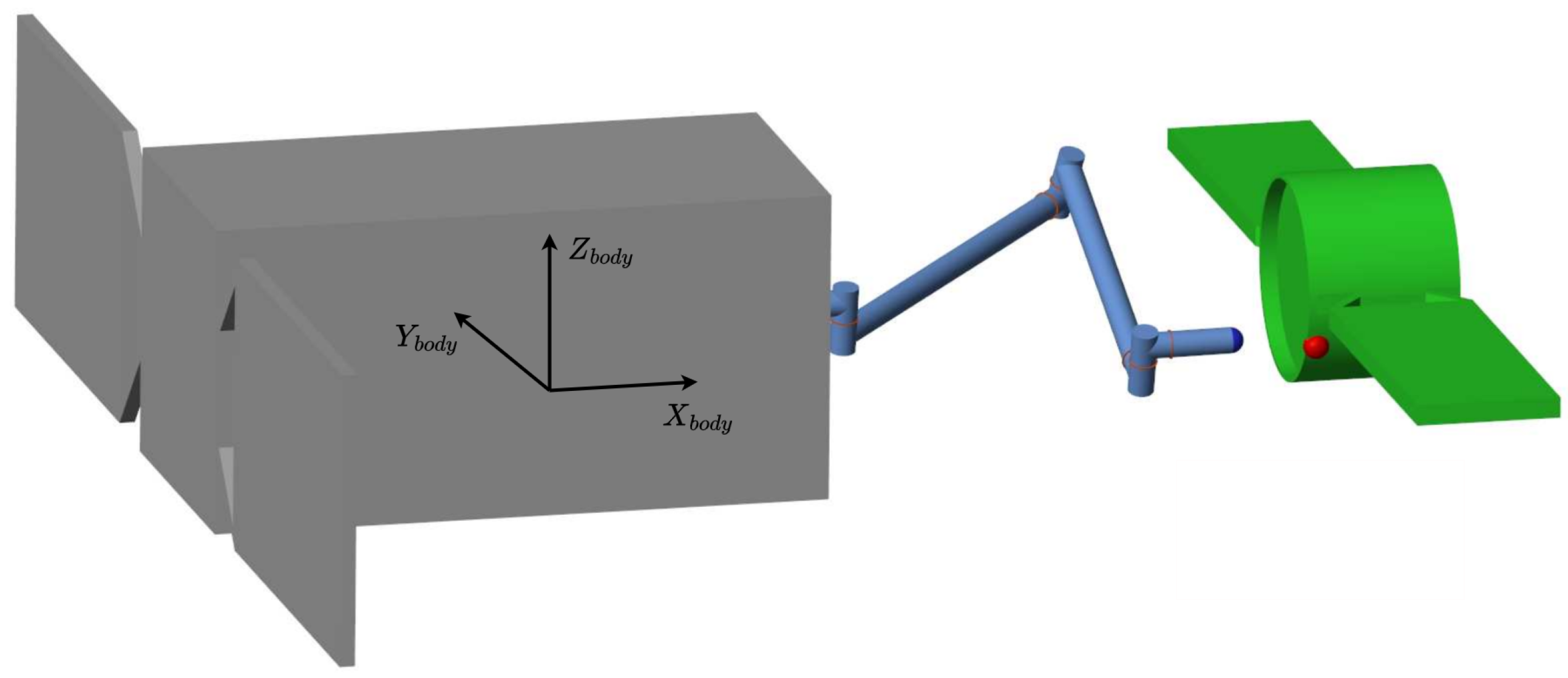
2.1. Space Manipulator Dynamics
2.2. Target Dynamics
3. Reinforcement Learning Guidance
3.1. Proximal Policy Optimization
- An agent is initially situated at a state s and perceives its environment through observations o.
- Based on o, the Actor autonomously decides the action a to take and applies it in the environment to move to a new state .
- Depending on the definition of the reward , the Critic evaluates the action that has been taken and guides the parameter updates of the Actor through a stochastic gradient descent on a loss function.
3.2. GNC Implementation and Environment
3.3. Action Space and Observation Space
3.4. Reward
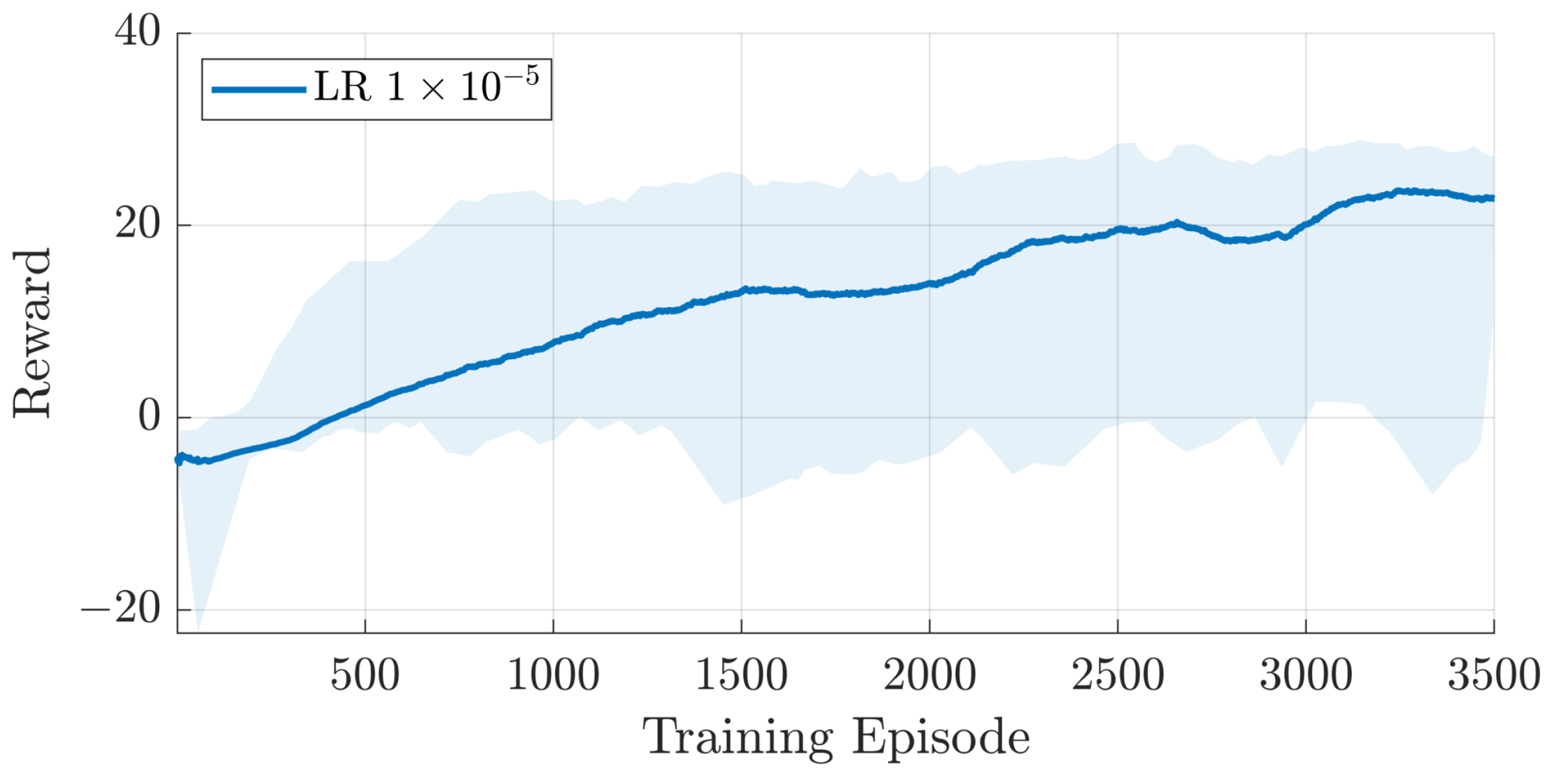
4. Training and Results
- Target’s major-axis spin rate deg/s.
- Each initial manipulator joint angle is perturbed by a random value deg.
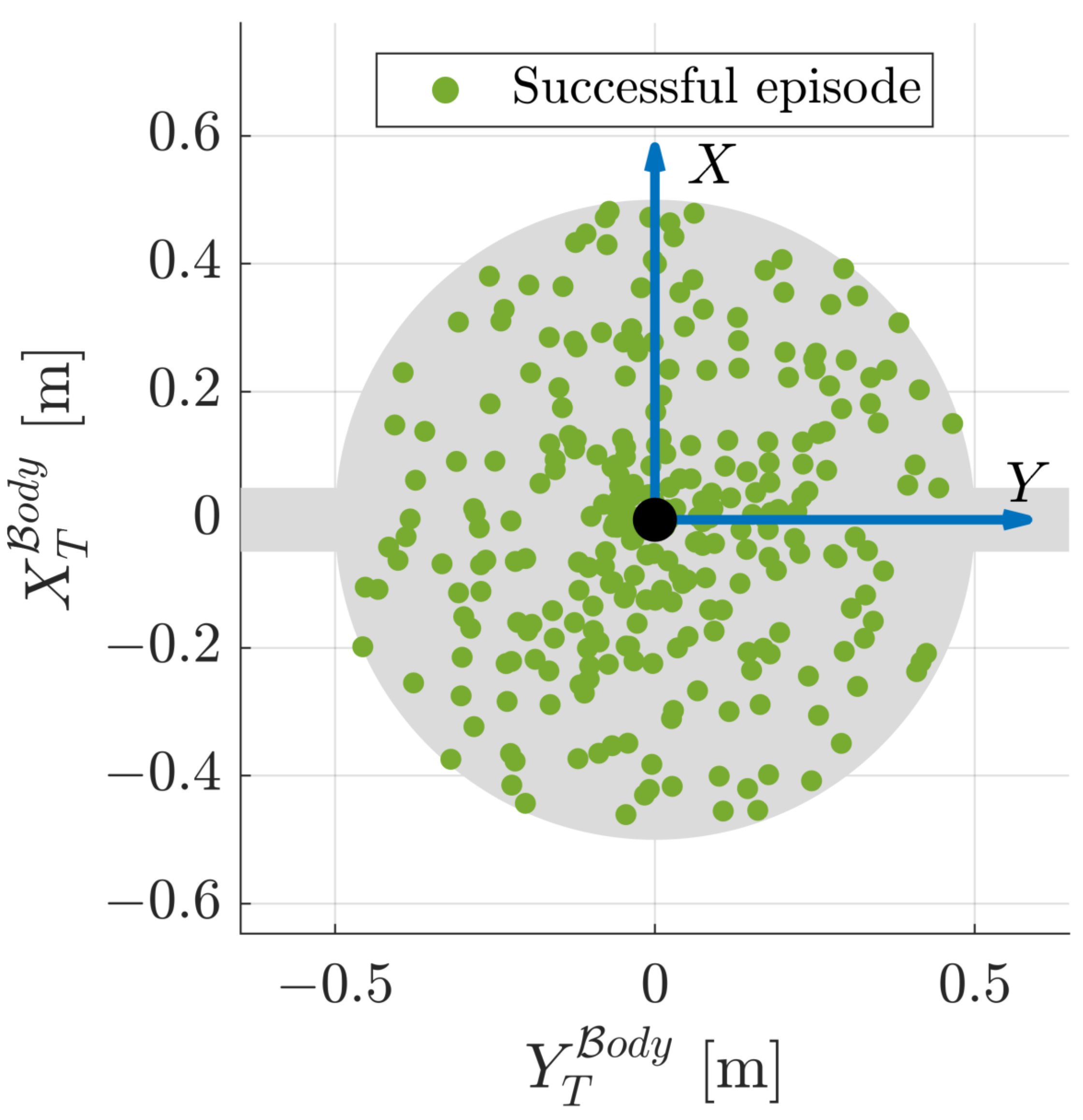
- Desired end effector state is randomized on the whole SR-facing side of the target, both in terms of position and attitude.
- Distance between SR and target is perturbed by a random value cm.
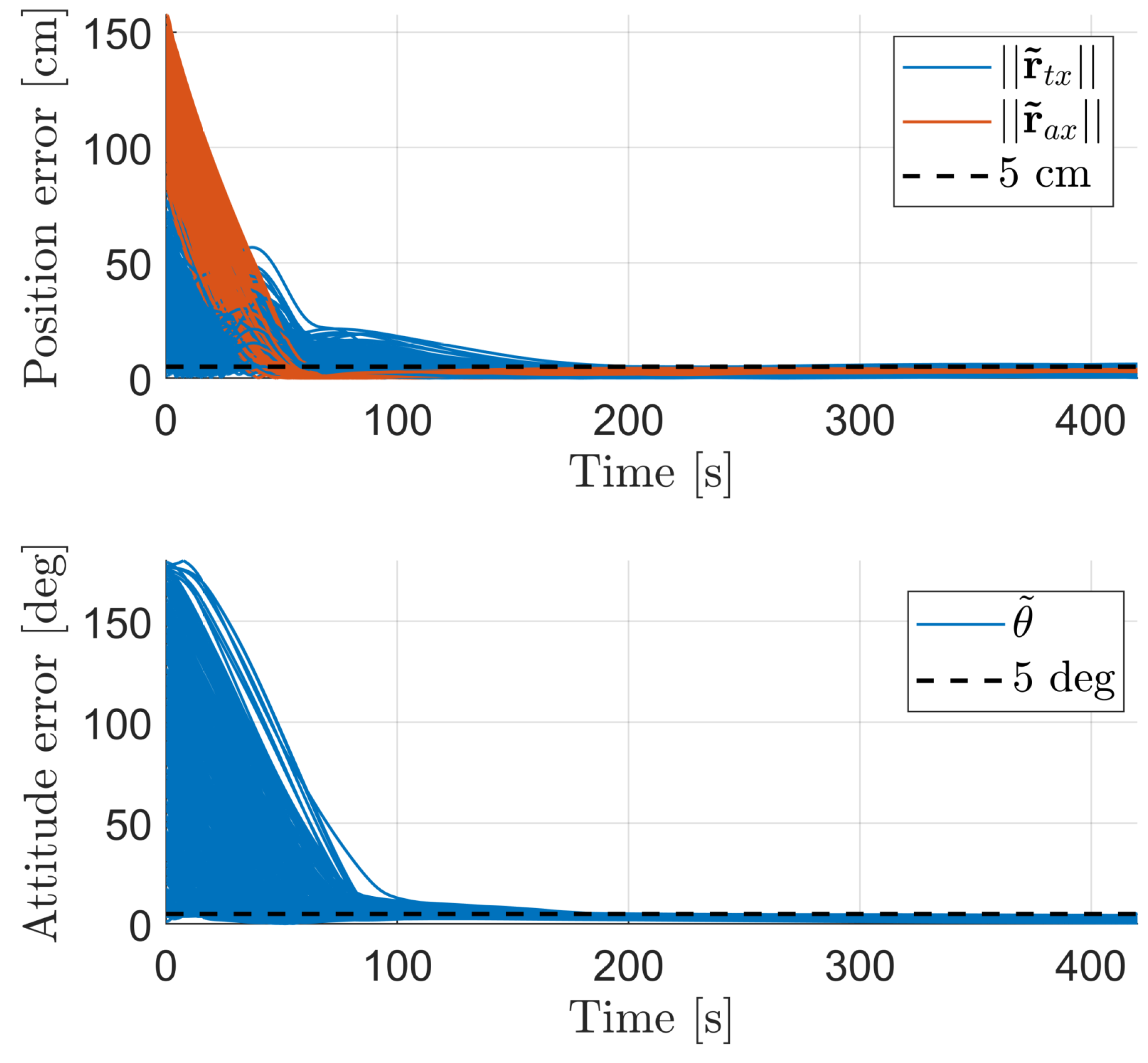
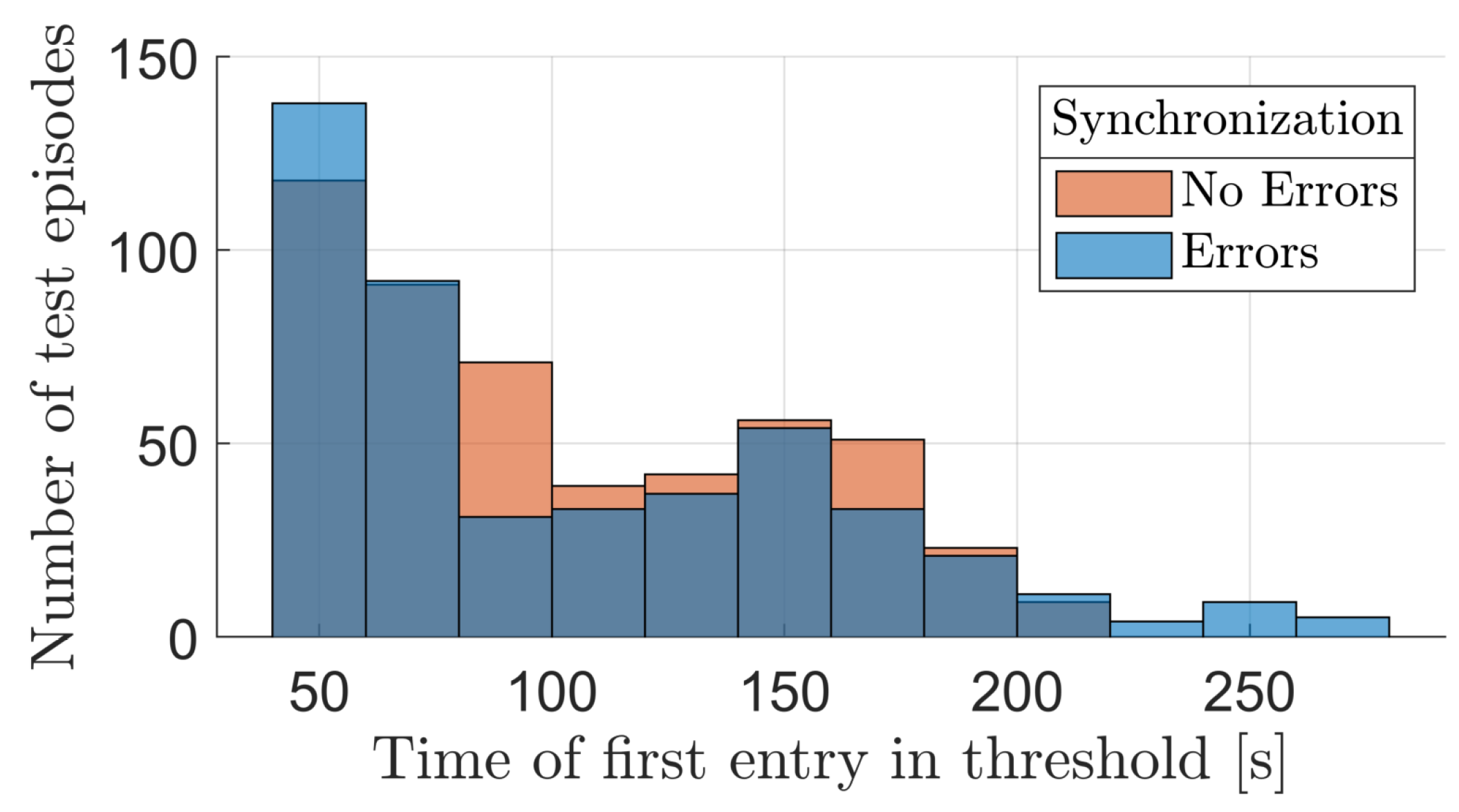
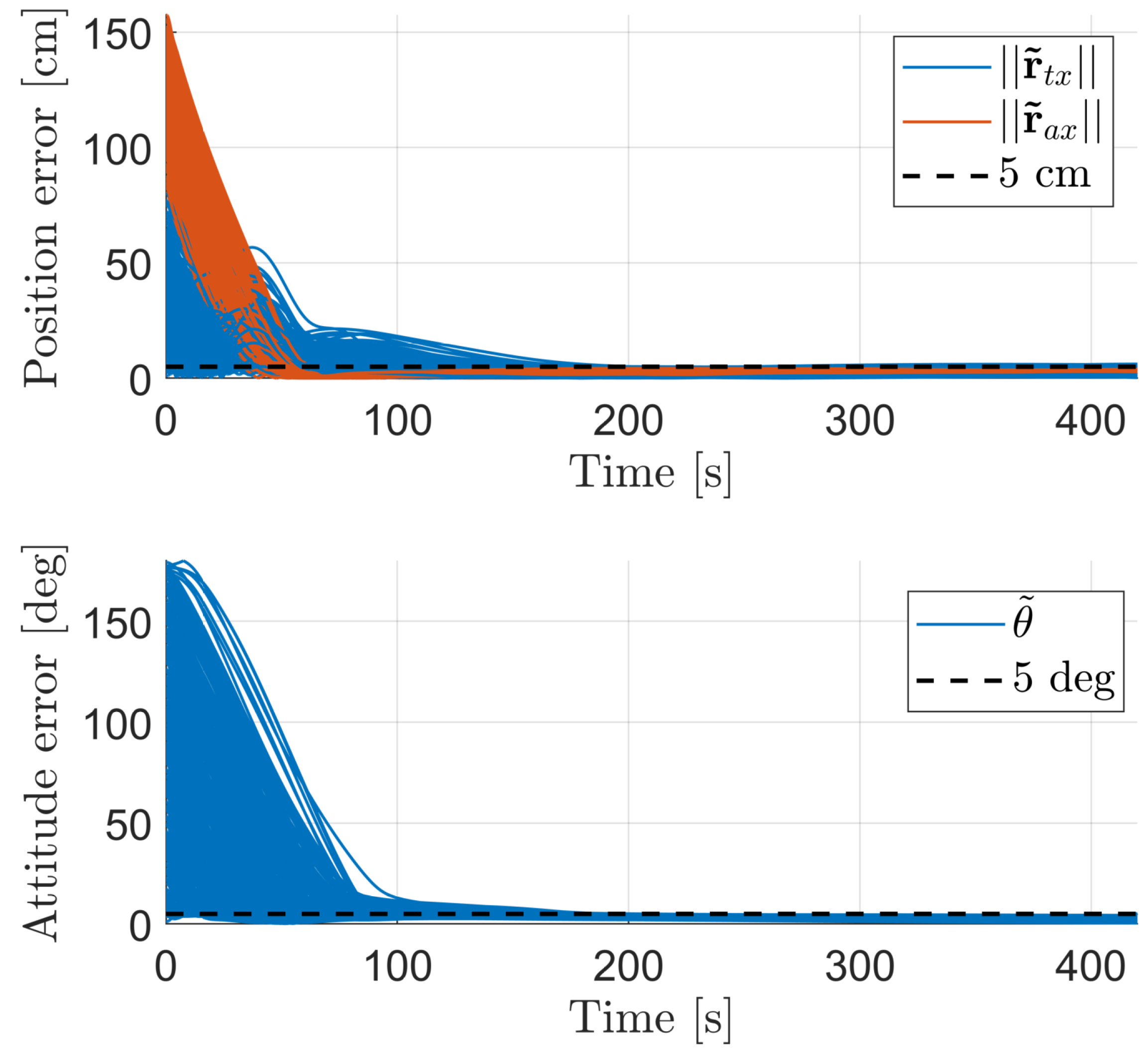
4.1. Agent Performance
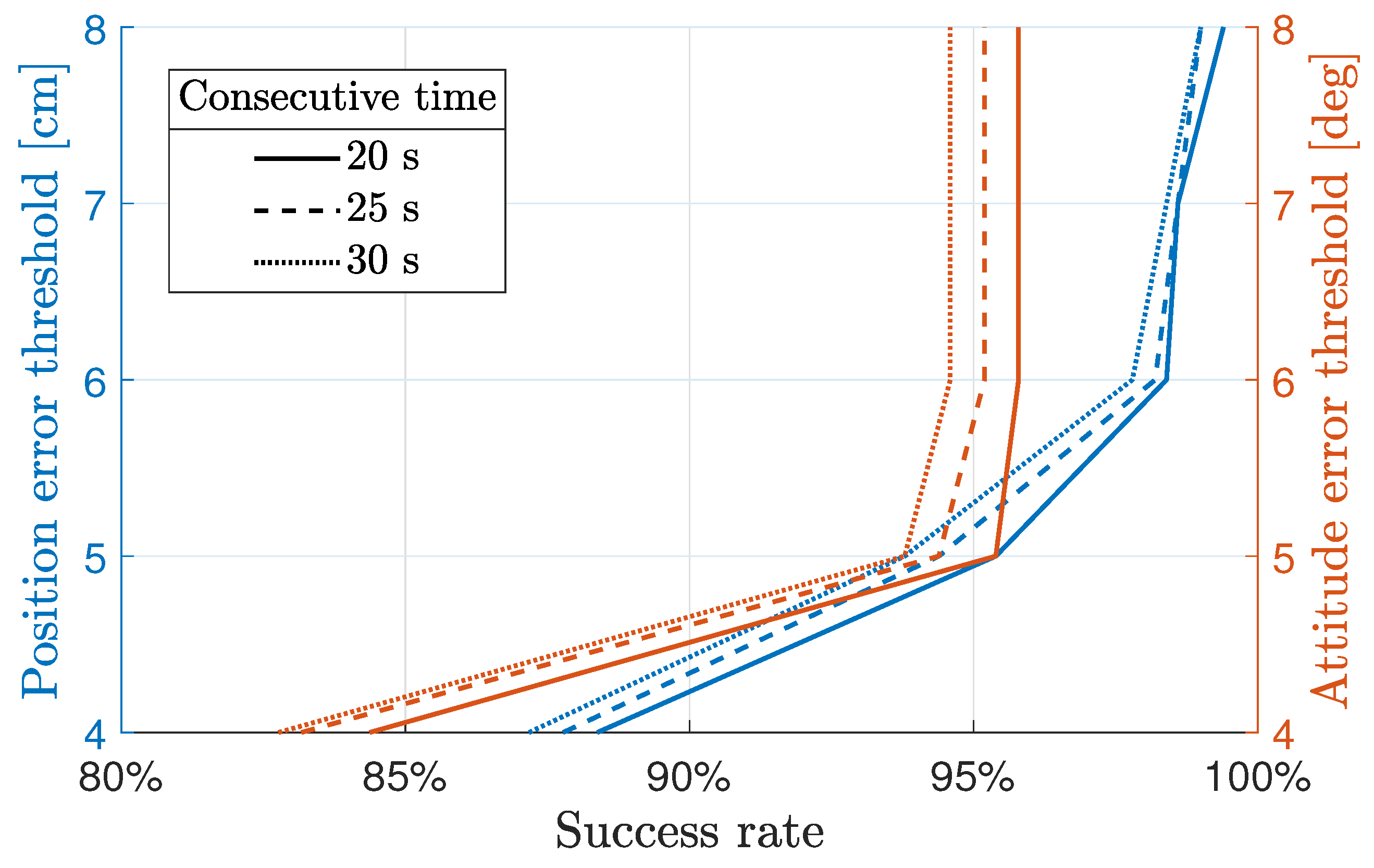
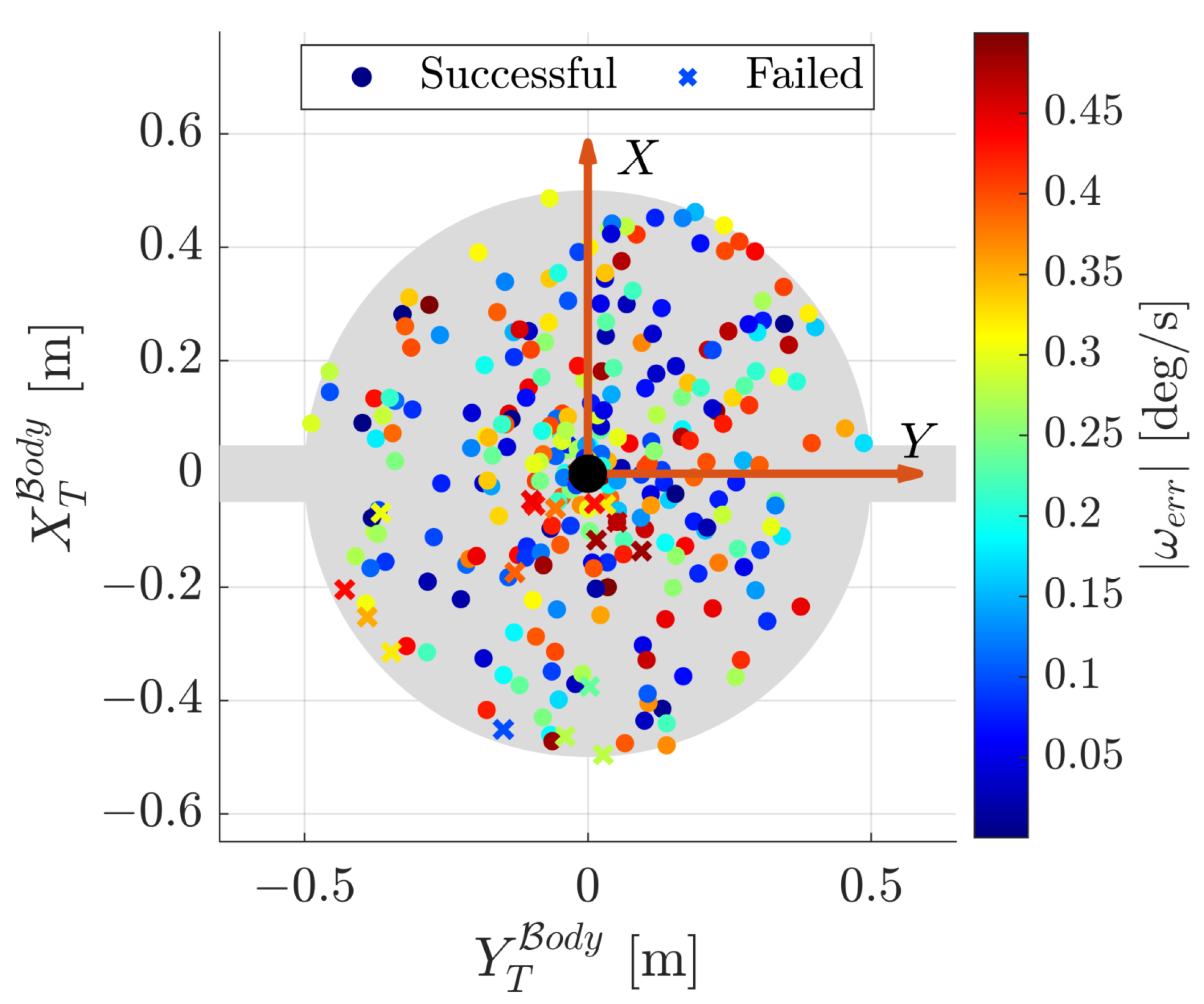
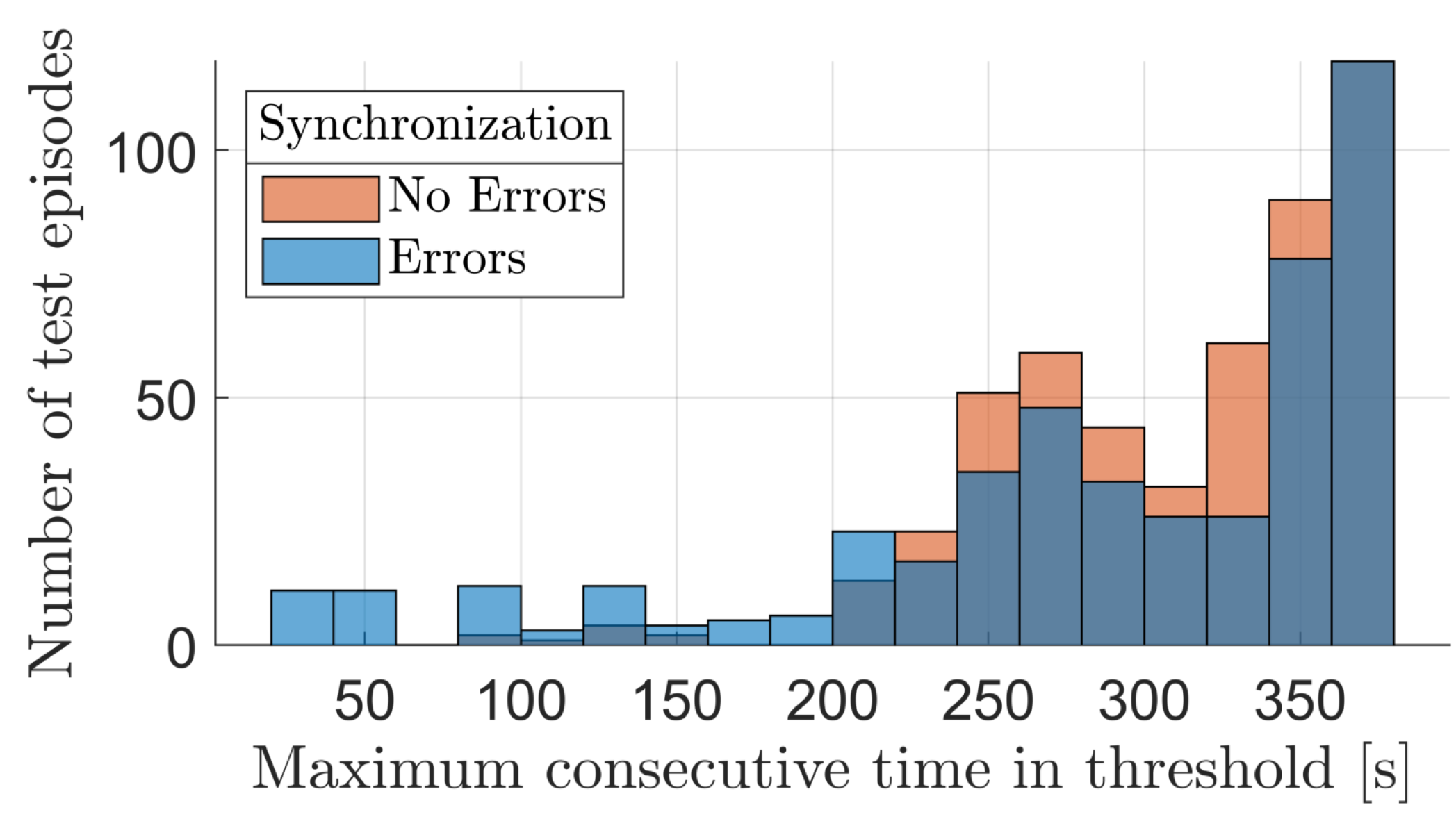
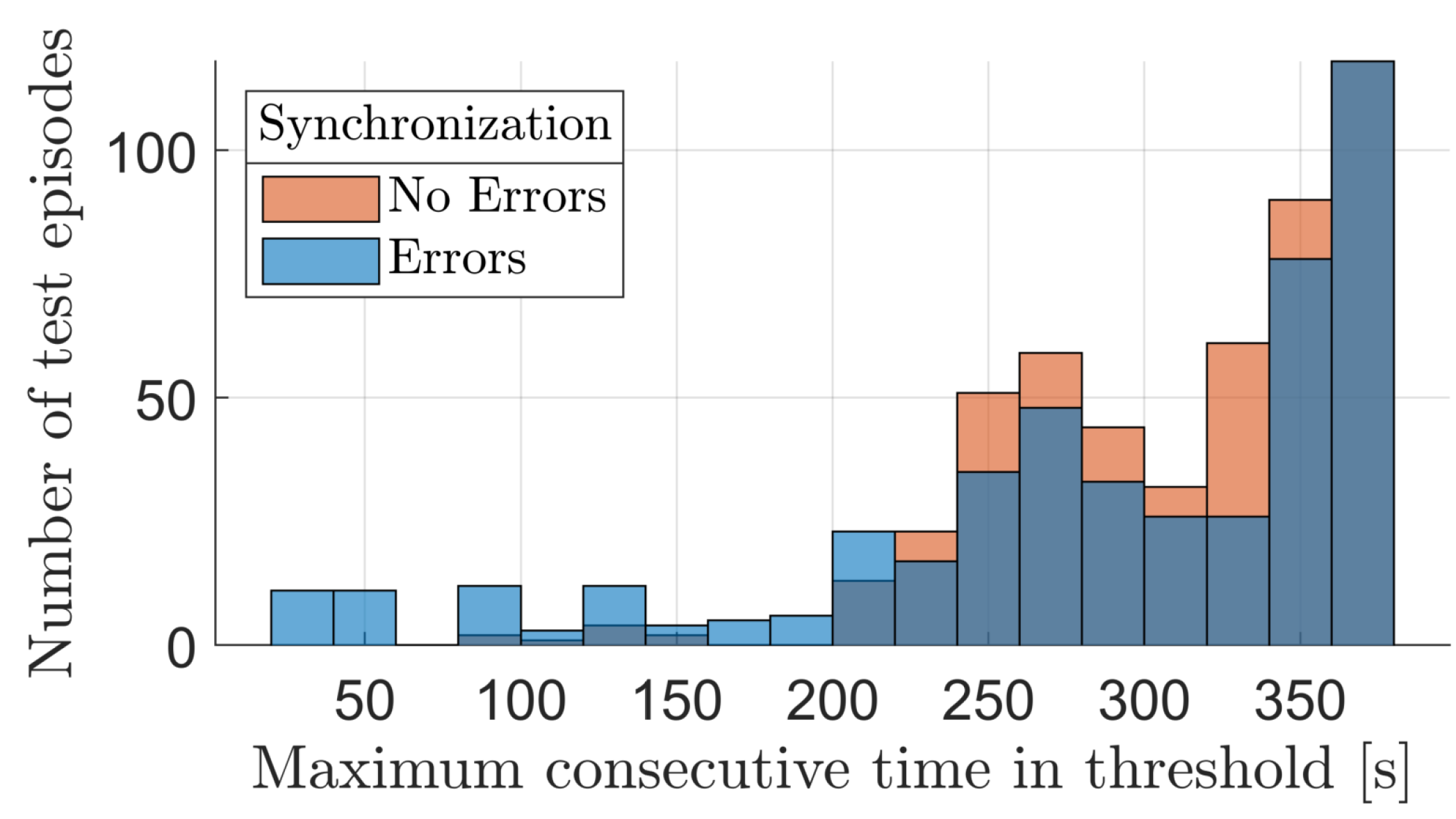
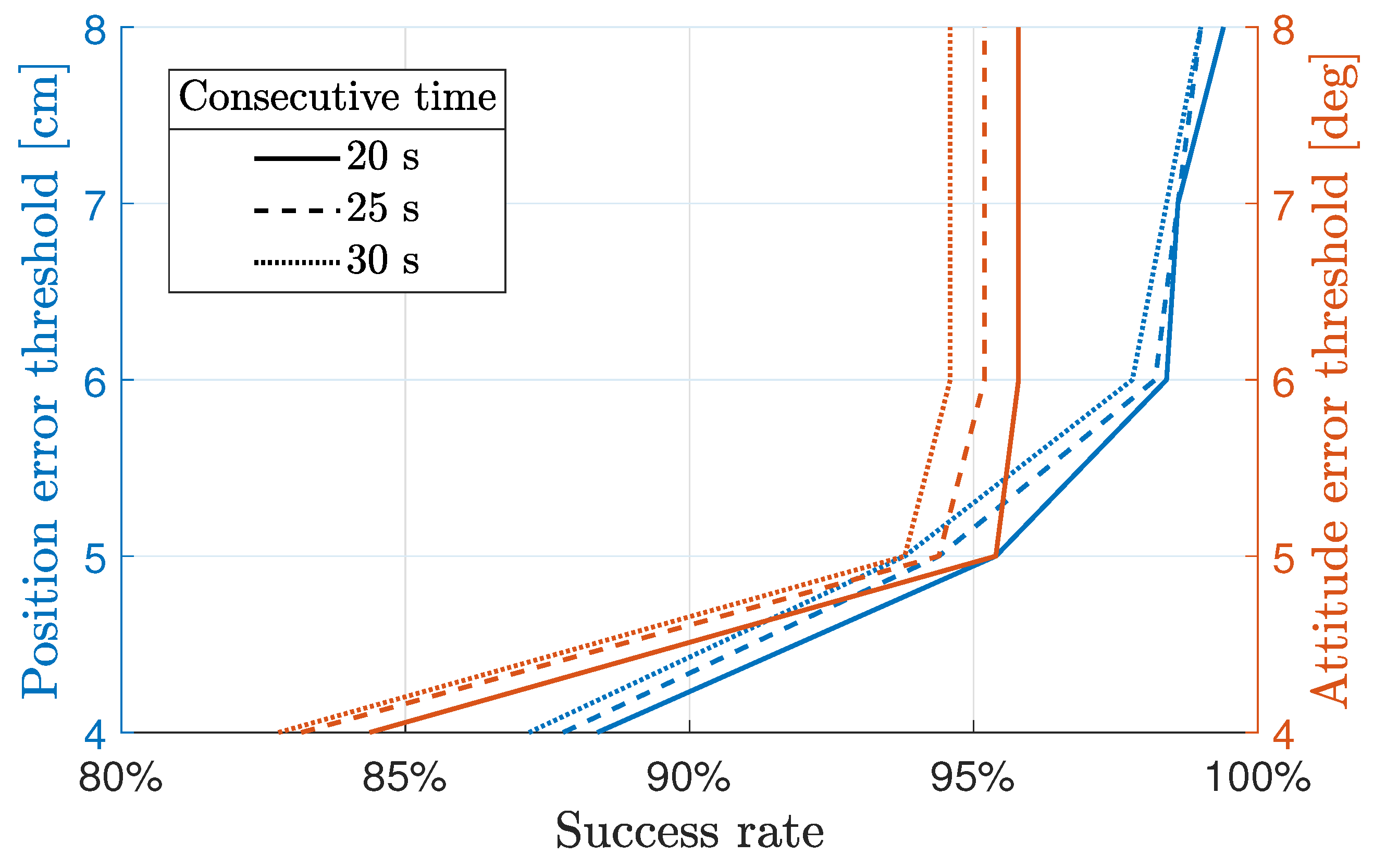
4.2. Agent Robustness
- The curves associated to the left axis show how the success rate varied in function of the thresholds on , , and while keeping the one on fixed.
- The curves associated with the right axis show how the success rate varied in function of the thresholds on and while keeping the ones on and fixed:
5. Conclusions
Further Developments
- A possible strategy is to develop new reward functions to train the agent, that inherently take into account the end effector’s position and attitude. Indeed, the majority of reward functions found in the literature only consider the positioning component and are unfit to achieve goals similar to those set in this work. Detailed analyses on alternative reward functions is a topic often overlooked, but could be one of the main strategies to improve the convergence properties of the DRL algorithm and the manipulator’s performance at end effector level.
- Another approach to increasing the agent’s performance and robustness would be to focus on the neural network architectures themselves, to see which ones provide the greatest benefits to the manipulator’s guidance. For example, Recurrent Neural Networks (RNN) have been demonstrated to provide increased robustness against autonomous DRL agents [1,2] when subject to environments with large domain gaps with respect to training, and their evaluation could provide insightful extensions to this work.
- Finally, methods are being explored in the literature to ease policy convergence during optimization, which is often hindered by a difficult selection and the tuning of the reward function and hyperparameters, especially in environments with large observation spaces. Among these is the use of offline data to pre-train the neural networks, which has been shown [19] to provide considerable benefits to the subsequent online optimization process, achieved through agent–environment interactions. Considering the current computational limitations of space-rated hardware, running complete agent training in space is unrealistic, and deploying agents that have been pre-trained on the ground seems to be one of the most promising approaches. To this extent, many research lines are emerging within the so-called Sim2Real DRL transfer [20,21], which are aimed at finding ways to limit the discrepancies between the performances of agents tested both in a simulated environment and the real world.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| APF | Artificial Potential Field |
| CIM | Convective Inertia Matrix |
| DNN | Deep Neural Network |
| DoF | Degrees of Freedom |
| DRL | Deep Reinforcement Learning |
| FNN | Feedforward Neural Network |
| GIM | Generalized Inertia Matrix |
| GNC | Guidance, Navigation, and Control |
| IOS | In-Orbit Servicing |
| LR | Learning Rate |
| MDP | Markov Decision Process |
| ORM | Orbital Robotics Mission |
| POMDP | Partially Observable Markov Decision Process |
| PPO | Proximal Policy Optimization |
| RL | Reinforcement Learning |
| SR | Space Robot |
| TRPO | Trust Region Policy Optimization |
References
- Brandonisio, A.; Capra, L.; Lavagna, M. Deep reinforcement learning spacecraft guidance with state uncertainty for autonomous shape reconstruction of uncooperative target. Adv. Space Res. 2023, in press. [Google Scholar] [CrossRef]
- Capra, L.; Brandonisio, A.; Lavagna, M. Network architecture and action space analysis for deep reinforcement learning towards spacecraft autonomous guidance. Adv. Space Res. 2023, 71, 3787–3802. [Google Scholar] [CrossRef]
- Gaudet, B.; Furfaro, R. Integrated and Adaptive Guidance and Control for Endoatmospheric Missiles via Reinforcement Meta-Learning. arXiv 2023, arXiv:2109.03880. [Google Scholar]
- Gaudet, B.; Linares, R.; Furfaro, R. Deep reinforcement learning for six degree-of-freedom planetary landing. Adv. Space Res. 2020, 65, 1723–1741. [Google Scholar] [CrossRef]
- Gaudet, B.; Linares, R.; Furfaro, R. Terminal adaptive guidance via reinforcement meta-learning: Applications to autonomous asteroid close-proximity operations. Acta Astronaut. 2020, 171, 1–13. [Google Scholar] [CrossRef]
- Moghaddam, B.M.; Chhabra, R. On the guidance, navigation and control of in-orbit space robotic missions: A survey and prospective vision. Acta Astronautica 2021, 184, 70–100. [Google Scholar] [CrossRef]
- Li, Y.; Li, D.; Zhu, W.; Sun, J.; Zhang, X.; Li, S. Constrained Motion Planning of 7-DOF Space Manipulator via Deep Reinforcement Learning Combined with Artificial Potential Field. Aerospace 2022, 9, 163. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, X.; Cao, Y.; Zhang, T. A Multi-Target Trajectory Planning of a 6-DoF Free-Floating Space Robot via Reinforcement Learning. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Prague, Czech Republic, 27 September–1 October 2021; pp. 3724–3730. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, Q.; Liu, Z.; Wang, X.; Liang, B. Control of Free-floating Space Robots to Capture Targets using Soft Q-learning. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Kuala Lumpur, Malaysia, 12–15 December 2018. [Google Scholar]
- Papadopoulos, E.; Aghili, F.; Ma, O.; Lampariello, R. Robotic Manipulation and Capture in Space: A Survey. Front. Robot. AI 2021, 8, 686723. [Google Scholar] [CrossRef] [PubMed]
- Virgili-Llop, J.; Drew, D.V.; Romano, M. SPART SPAcecraft Robotics Toolkit: An Open-Source Simulator for Spacecraft Robotic Arm Dynamic Modeling And Control. In Proceedings of the 6th International Conference on Astrodynamics Tools and Techniques, Darmstadt, Germany, 14–17 March 2016. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; Westchester Publishing Services: Danbury, CT, USA, 2018; p. 526. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms (PPO). arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.I.; Abbeel, P. Trust Region Policy Optimization. arXiv 2015, arXiv:1502.05477. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Kumar, V.; Hoeller, D.; Sundaralingam, B.; Tremblay, J.; Birchfield, S. Joint Space Control via Deep Reinforcement Learning. arXiv 2020, arXiv:2011.06332. [Google Scholar]
- Wu, Y.H.; Yu, Z.C.; Li, C.Y.; He, M.J.; Hua, B.; Chen, Z.M. Reinforcement learning in dual-arm trajectory planning for a free-floating space robot. Aerosp. Sci. Technol. 2020, 98, 105657. [Google Scholar] [CrossRef]
- Colmenarejo, P.; Branco, J.; Santos, N.; Serra, P.; Telaar, J.; Strauch, H.; Fruhnert, M.; Giordano, A.M.; Stefano, M.D.; Ott, C.; et al. Methods and outcomes of the COMRADE project-Design of robust Combined control for robotic spacecraft and manipulator in servicing missions: Comparison between between Hinf and nonlinear Lyapunov-based approaches. In Proceedings of the 69th International Astronautical Congress (IAC), Bremen, Germany, 1–5 October 2018; pp. 1–5. [Google Scholar]
- Ball, P.J.; Smith, L.; Kostrikov, I.; Levine, S. Efficient Online Reinforcement Learning with Offline Data. arXiv 2023, arXiv:2302.02948. [Google Scholar]
- Miao, Q.; Lv, Y.; Huang, M.; Wang, X.; Wang, F.Y. Parallel Learning: Overview and Perspective for Computational Learning Across Syn2Real and Sim2Real. IEEE CAA J. Autom. Sin. 2023, 10, 603–631. [Google Scholar] [CrossRef]
- Kaspar, M.; Osorio, J.D.M.; Bock, J. Sim2Real transfer for reinforcement learning without dynamics randomization. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4383–4388. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DoF | Proportional Gain 1 | Derivative Gain 1 |
|---|---|---|
| Base | 0.4 | 0.3 |
| Manipulator | 2.5 | 1.25 |
| Layers | Actor Neurons | Critic Neurons |
|---|---|---|
| Input | 32 | 32 |
| 1st hidden | 300 | 300 |
| 2nd hidden | 300 | 300 |
| 3rd hidden | 300 | 300 |
| Output | 14 | 1 |
| Learning Rate | 1 × 10−5 | 1 × 10−5 |
| Activation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Ambrosio, M.; Capra, L.; Brandonisio, A.; Silvestrini, S.; Lavagna, M. Redundant Space Manipulator Autonomous Guidance for In-Orbit Servicing via Deep Reinforcement Learning. Aerospace 2024, 11, 341. https://doi.org/10.3390/aerospace11050341
D’Ambrosio M, Capra L, Brandonisio A, Silvestrini S, Lavagna M. Redundant Space Manipulator Autonomous Guidance for In-Orbit Servicing via Deep Reinforcement Learning. Aerospace. 2024; 11(5):341. https://doi.org/10.3390/aerospace11050341
Chicago/Turabian StyleD’Ambrosio, Matteo, Lorenzo Capra, Andrea Brandonisio, Stefano Silvestrini, and Michèle Lavagna. 2024. "Redundant Space Manipulator Autonomous Guidance for In-Orbit Servicing via Deep Reinforcement Learning" Aerospace 11, no. 5: 341. https://doi.org/10.3390/aerospace11050341
APA StyleD’Ambrosio, M., Capra, L., Brandonisio, A., Silvestrini, S., & Lavagna, M. (2024). Redundant Space Manipulator Autonomous Guidance for In-Orbit Servicing via Deep Reinforcement Learning. Aerospace, 11(5), 341. https://doi.org/10.3390/aerospace11050341