
Stacked Multiscale Densely Connected Temporal Convolutional Attention Network for Multi-Objective Speech Enhancement in an Airborne Environment


Abstract
1. Introduction
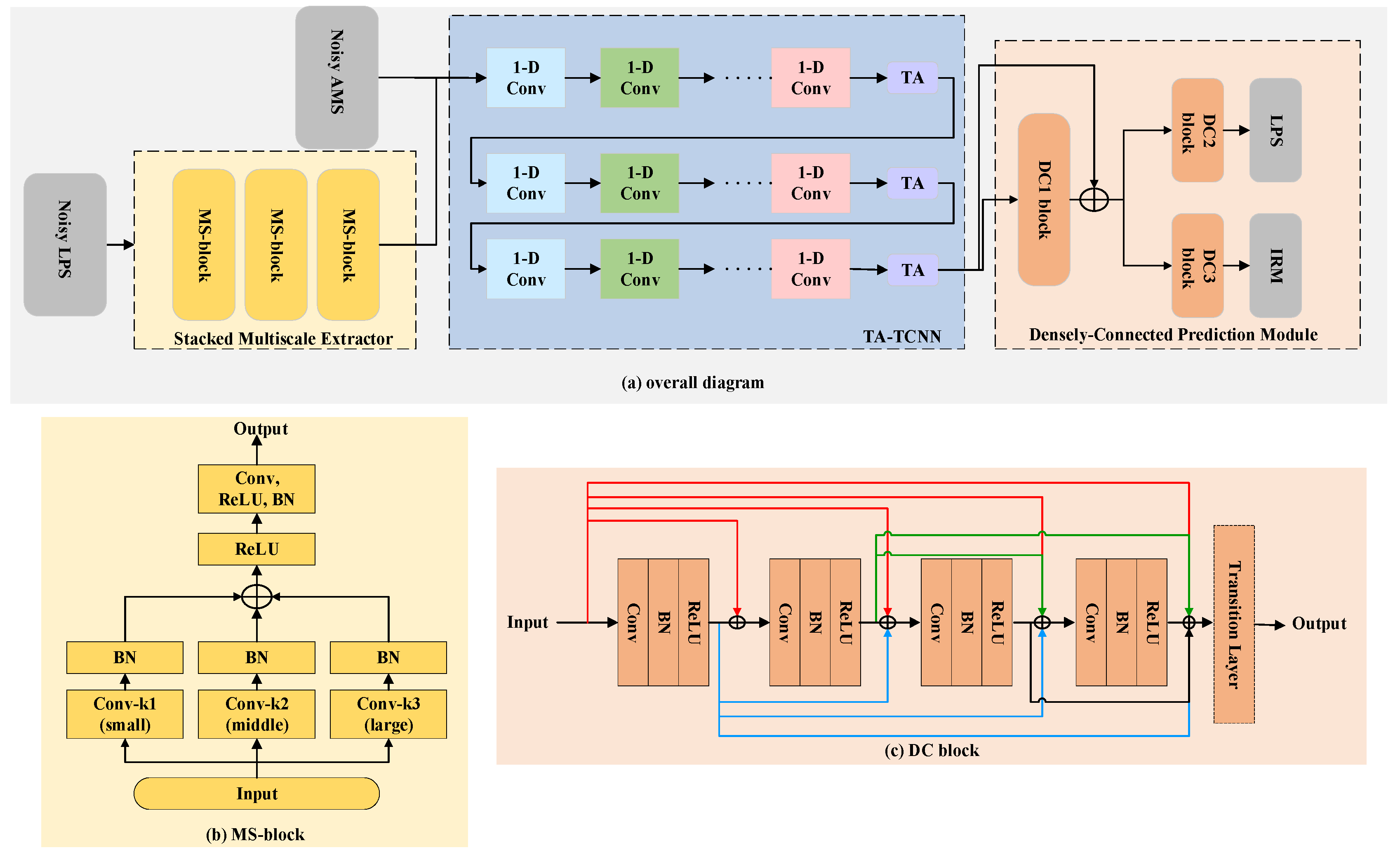
- A stacked multiscale feature extractor is proposed to improve the abstract feature extraction ability. By stacking multiple multiscale blocks, our feature extractor can garner much larger receptive fields and provide discriminative information of different scales for obtaining better speech enhancement performance.
- A triple-attention block is designed to optimize the TCNN, enabling it to focus simultaneously on regions of interest in the channel, spatial, and T-F dimensions, thereby enhancing its ability to model the temporal dependencies of speech signals.
- Constructed with two dense connection convolution blocks, a densely connected prediction module is built which can strengthen feature propagations and enhance the information flow of the network to produce a more robust enhancement performance.
- To fully leverage the advantages of MA and MSA loss functions for learning mask targets, a new joint-weighted loss function is proposed, which can make SMDTANet optimize the masking subtask in both the TF magnitude and masking domains simultaneously.
2. Related Work
2.1. Multi-Objective Speech Enhancement
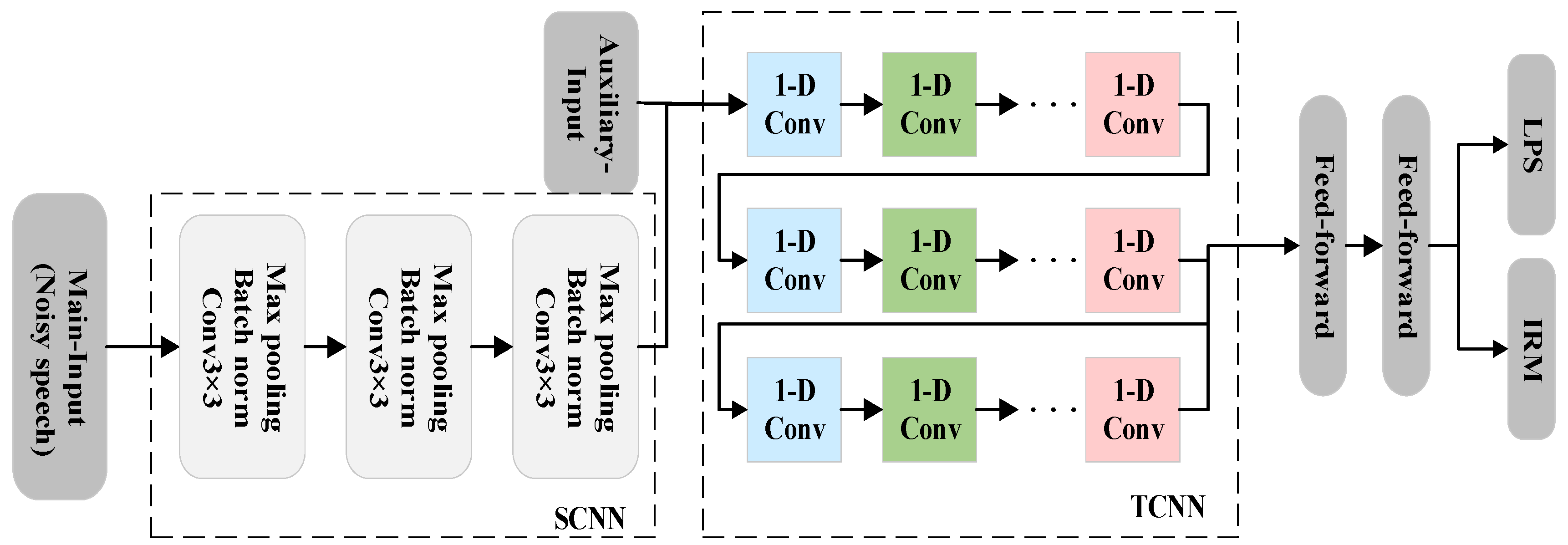
2.2. Baseline STCNN Network Topology
3. Proposed System Description
3.1. Stacked Multiscale Feature Extraction
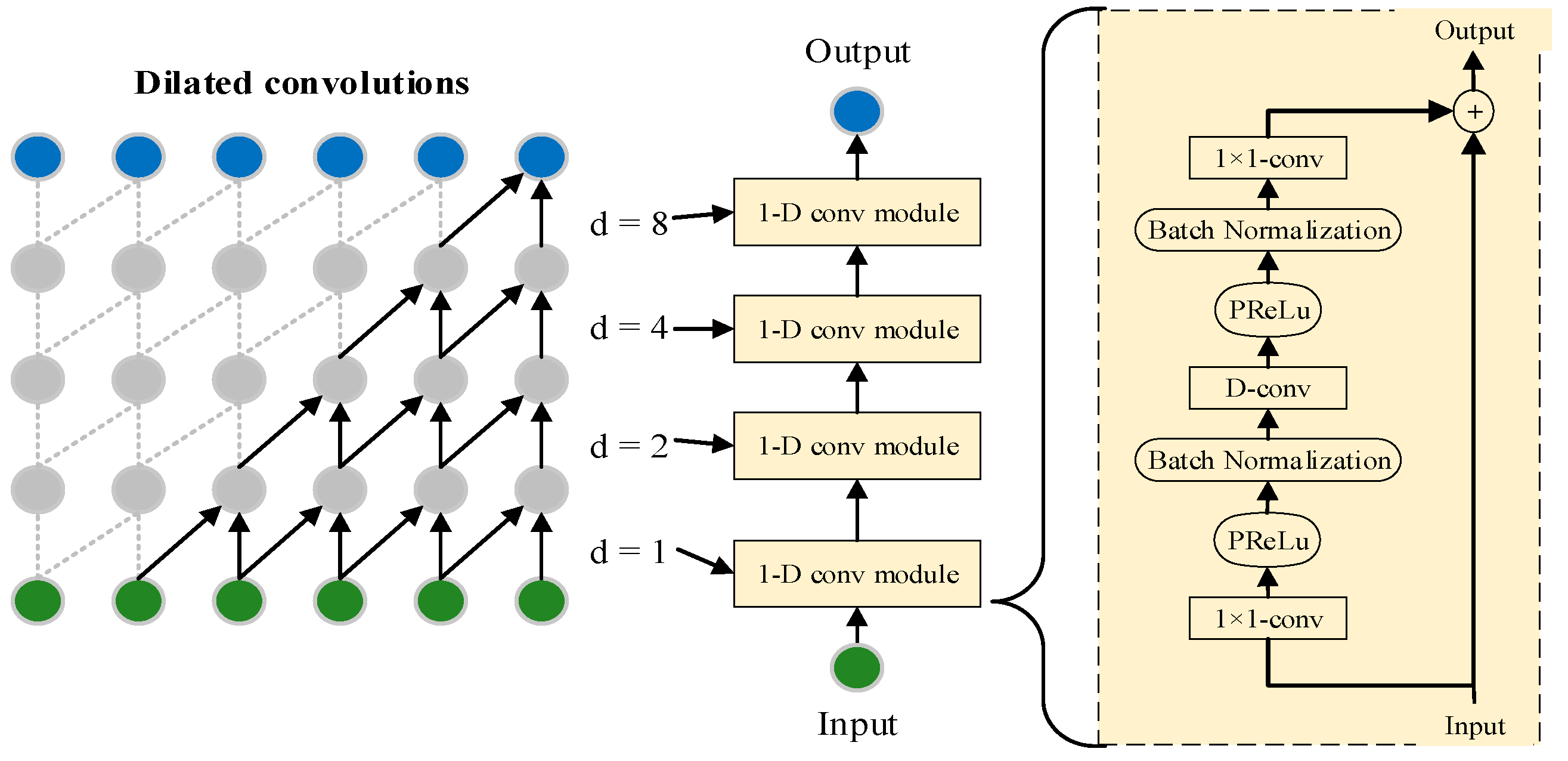
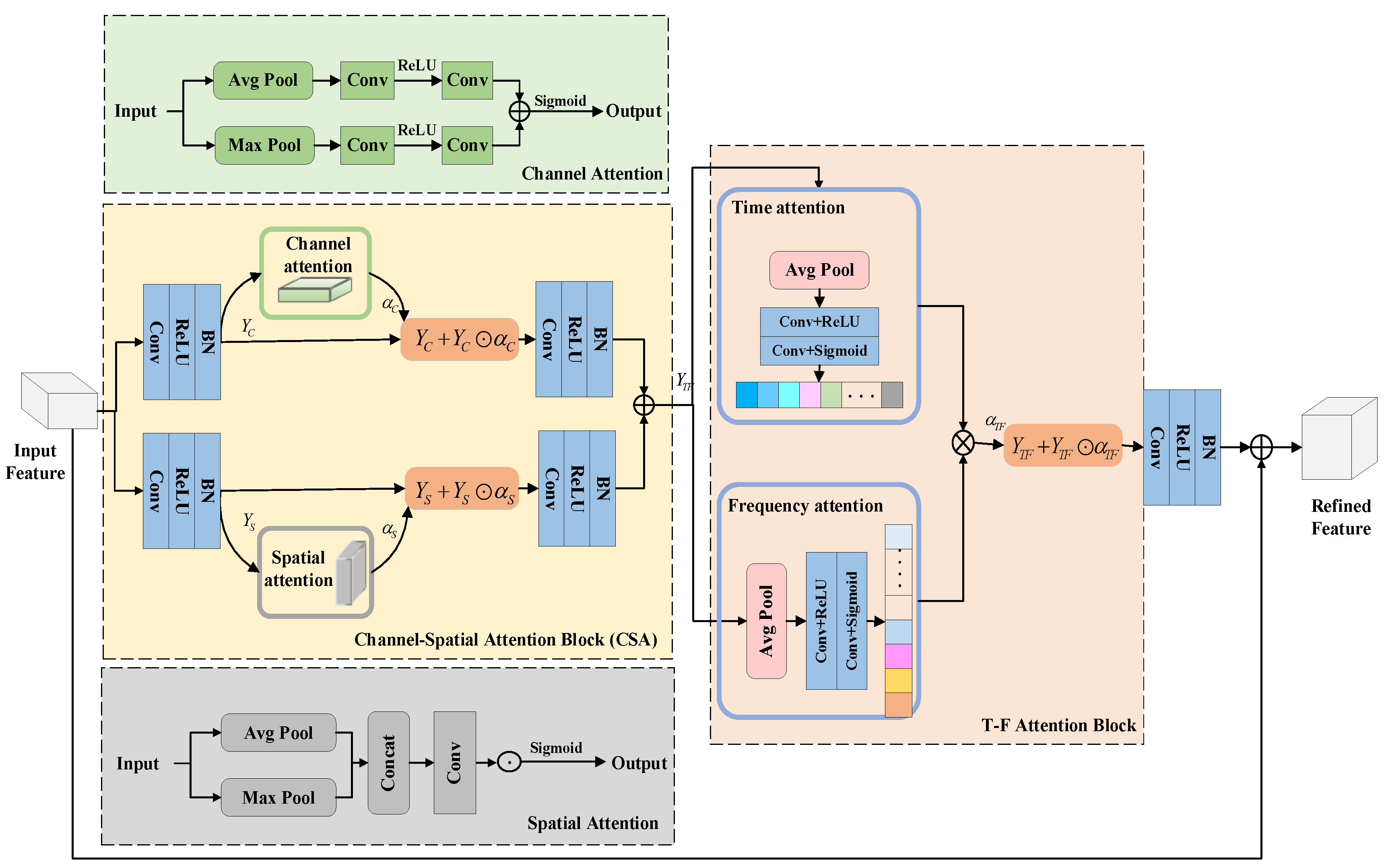
3.2. Triple-Attention-Based TCNN (TA-TCNN)
3.2.1. Channel Attention
3.2.2. Spatial Attention
3.2.3. Time–Frequency (T-F) Attention
3.3. Densely Connected Prediction Module
3.4. Joint-Weighted (JW) Loss Function
4. Experimental Setup
4.1. Datasets
4.2. Experimental Setup and Baselines
4.3. Evaluation Metrics
5. Experimental Results and Analysis
5.1. Ablation Study
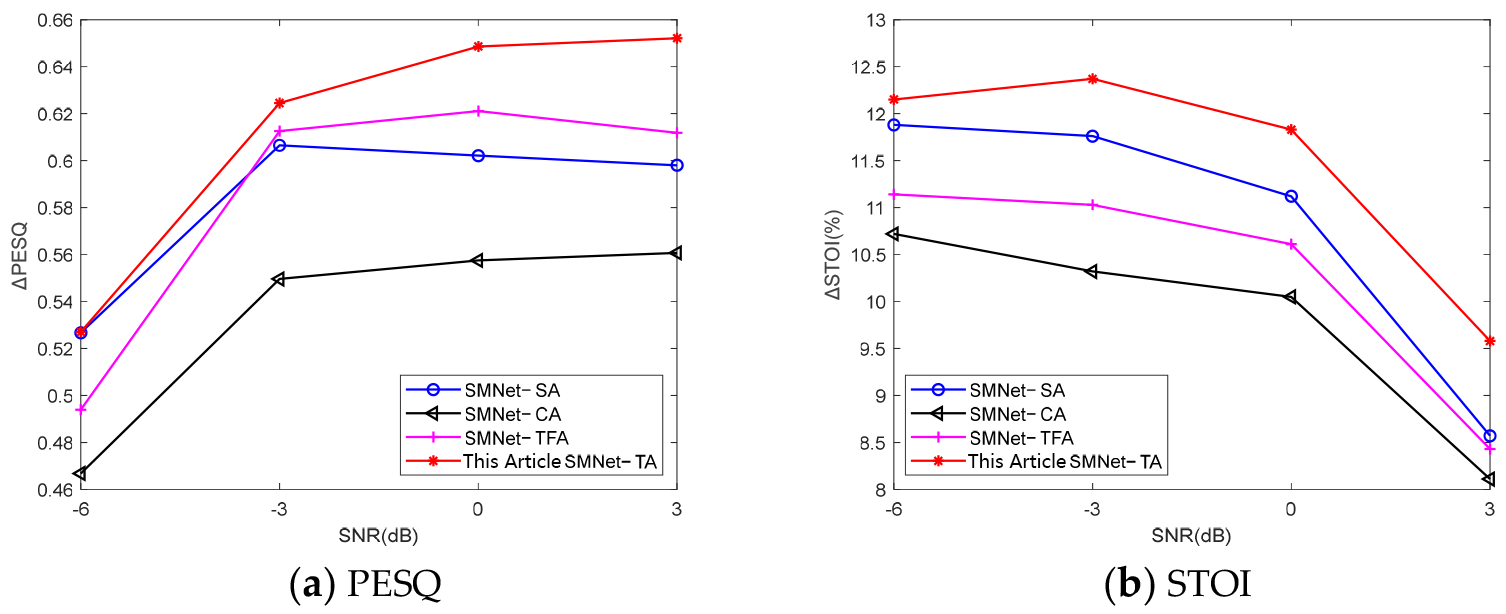
5.1.1. The Effectiveness of Network Components in SMDTANet
5.1.2. The Effectiveness of the Loss Function in SMDTANet
5.2. Comparison with Other Attention Types
5.3. Overall Performance Comparison
5.4. Enhanced Spectrogram Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| T-F | Time–frequency |
| LPS | Log-power spectra |
| AMS | Amplitude modulation spectrogram |
| IRM | Ideal ratio mask |
| MOL | Multi-objective learning |
| DFT | Discrete Fourier transform |
| DNN | Deep neural network |
| MLP | Multi-layer perception |
| RNN | Recurrent neural network |
| CNN | Convolutional neural network |
| LSTM | Long short-term memory |
| TCNN | Temporal convolutional neural network |
| STCNN | Stacked and temporal convolutional neural network |
| CRN | Convolutional recurrent network |
| GCRN | Gated convolutional recurrent network |
| FullSubNet | Full-band and sub-band fusion network |
| GaGNet | Glance and gaze network |
| D-conv | Depth-wise convolution |
| SMDTANet | Stacked multiscale densely connected temporal convolutional attention network |
| MS-block | Multiscale convolution block |
| TA-TCNN | Triple-attention-based temporal convolutional neural network |
| CSA | Channel–spatial attention |
| DC | Densely connected |
| ERB | Equivalent rectangular bandwidth |
| ReLU | Rectifying linear unit |
| BN | Batch normalization |
| MSE | Mean-square error |
| MA | Mask approximation |
| MSA | Mask-based signal approximation |
| JW | Joint weighted |
| M | Million |
| GFLOPs | Giga-floating-point operations per second |
| SNR | Signal-to-noise ratio |
| PESQ | Perceptual evaluation of speech quality |
| STOI | Short-time objective intelligibility |
| RTF | Real-time factor |
References
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Lim, J.; Oppenheim, A. All-pole modeling of degraded speech. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 197–210. [Google Scholar] [CrossRef]
- Ephraim, Y.; Van Trees, H.L. A signal subspace approach for speech enhancement. IEEE Trans. Speech Audio Process. 1995, 3, 251–266. [Google Scholar] [CrossRef]
- Li, A.; Yuan, M.; Zheng, C.; Li, X. Speech enhancement using progressive learning-based convolutional recurrent neural network. Appl. Acoust. 2020, 166, 107347. [Google Scholar] [CrossRef]
- Ren, X.; Chen, L.; Zheng, X.; Xu, C.; Zhang, X.; Zhang, C.; Guo, L.; Yu, B. A neural beamforming network for b-format 3d speech enhancement and recognition. In Proceedings of the 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), Gold Coast, Australia, 25–28 October 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Xiang, X.; Zhang, X. Joint waveform and magnitude processing for monaural speech enhancement. Appl. Acoust. 2022, 200, 109077. [Google Scholar] [CrossRef]
- Saleem, N.; Khattak, M.I.; Al-Hasan, M.; Qazi, A.B. On learning spectral masking for single channel speech enhancement using feedforward and recurrent neural networks. IEEE Access 2020, 8, 160581–160595. [Google Scholar] [CrossRef]
- Taherian, H.; Wang, Z.Q.; Chang, J.; Wang, D. Robust speaker recognition based on single-channel and multi-channel speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1293–1302. [Google Scholar] [CrossRef]
- Wang, Y.; Han, J.; Zhang, T.; Qing, D. Speech enhancement from fused features based on deep neural network and gated recurrent unit network. EURASIP J. Adv. Signal Process. 2021, 2021, 104. [Google Scholar] [CrossRef]
- Jia, X.; Li, D. TFCN: Temporal-frequential convolutional network for single-channel speech enhancement. arXiv 2022, arXiv:2201.00480. [Google Scholar]
- Wang, Q.; Du, J.; Dai, L.R.; Lee, C.H. A Multiobjective Learning and Ensembling Approach to High-Performance Speech Enhancement with Compact Neural Network Architectures. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1185–1197. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, X.; Wu, C.; Zhong, Q.; Cheng, X.; Tang, Y. Speech Enhancement via Residual Dense Generative Adversarial Network. Comput. Syst. Sci. Eng. 2021, 38, 279–289. [Google Scholar] [CrossRef]
- Haridas, A.V.; Marimuthu, R.; Chakraborty, B. A novel approach to improve the speech intelligibility using fractional delta-amplitude modulation spectrogram. Cybern. Syst. 2018, 49, 421–451. [Google Scholar] [CrossRef]
- Wang, X.; Bao, F.; Bao, C. IRM estimation based on data field of cochleagram for speech enhancement. Speech Commun. 2018, 97, 19–31. [Google Scholar] [CrossRef]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 7–19. [Google Scholar] [CrossRef]
- Fujimura, T.; Koizumi, Y.; Yatabe, K.; Miyazaki, R. Noisy-target training: A training strategy for DNN-based speech enhancement without clean speech. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; IEEE: New York, NY, USA, 2021; pp. 436–440. [Google Scholar]
- Chen, J.; Wang, D.L. Long short-term memory for speaker generalization in supervised speech separation. J. Acoust. Soc. Am. 2017, 141, 4705–4714. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Du, J.; Dai, L.R.; Lee, C.H. Multiple-target deep learning for LSTM-RNN based speech enhancement. In Proceedings of the 2017 Hands-Free Speech Communications and Microphone Arrays (HSCMA), San Francisco, CA, USA, 1–3 March 2017; IEEE: New York, NY, USA, 2017; pp. 136–140. [Google Scholar]
- Pandey, A.; Wang, D.L. TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 6875–6879. [Google Scholar]
- Li, R.; Sun, X.; Li, T.; Zhao, F. A multi-objective learning speech enhancement algorithm based on IRM post-processing with joint estimation of SCNN and TCNN. Digit. Signal Process. 2020, 101, 102731. [Google Scholar] [CrossRef]
- Weninger, F.; Hershey, J.R.; Le Roux, J.; Schuller, B. Discriminatively trained recurrent neural networks for single-channel speech separation. In Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Atlanta, GA, USA, 3–5 December 2014; IEEE: New York, NY, USA, 2014; pp. 577–581. [Google Scholar]
- Liu, Y.; Zhang, H.; Zhang, X.; Yang, L. Supervised speech enhancement with real spectrum approximation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 5746–5750. [Google Scholar]
- Xu, C.; Rao, W.; Chng, E.S.; Li, H. Spex: Multi-scale time domain speaker extraction network. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1370–1384. [Google Scholar] [CrossRef]
- Ye, J.X.; Wen, X.C.; Wang, X.Z.; Xu, Y.; Luo, Y.; Wu, C.L.; Chen, L.Y.; Liu, K. HGM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition. Speech Commun. 2022, 145, 21–35. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Q.; Qian, X.; Ni, Z.; Nicolson, A.; Ambikairajah, E.; Li, H. A Time-Frequency Attention Module for Neural Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 31, 462–475. [Google Scholar] [CrossRef]
- Jeihouni, P.; Dehzangi, O.; Amireskandari, A.; Dabouei, A.; Rezai, A.; Nasrabadi, N.M. Superresolution and Segmentation of OCT Scans Using Multi-Stage Adversarial Guided Attention Training. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 1106–1110. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xie, J.; He, N.; Fang, L.; Ghamisi, P. Multiscale densely-connected fusion networks for hyperspectral images classification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 246–259. [Google Scholar] [CrossRef]
- Zhou, T.; Ye, X.; Lu, H.; Zheng, X.; Qiu, S.; Liu, Y. Dense convolutional network and its application in medical image analysis. BioMed Res. Int. 2022, 2022, 2384830. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus CD-ROM; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1993. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Hu, G. 100 Nonspeech Environmental Sounds. 2004. Available online: http://www.cse.ohio.state.edu/pnl/corpus/HuCorpus.html (accessed on 1 May 2021).
- Hirsch, H.G.; Pearce, D. The AURORA experimental framework for the performance evaluations of speech recognition systems under noisy conditions. In Proceedings of the ASR2000-Automatic Speech Recognition: Challenges for the New Millenium International, Speech Communication Association (ISCA) Tutorial and Research Workshop (ITRW), Paris, France, 18–20 September 2000; pp. 181–188. [Google Scholar]
- Tan, K.; Wang, D.L. A convolutional recurrent neural network for real-time speech enhancement. Interspeech 2018, 2018, 3229–3233. [Google Scholar]
- Tan, K.; Wang, D.L. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 380–390. [Google Scholar] [CrossRef]
- Hao, X.; Su, X.; Horaud, R.; Li, X. Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 6633–6637. [Google Scholar]
- Li, A.; Zheng, C.; Zhang, L.; Li, X. Glance and gaze: A collaborative learning framework for single-channel speech enhancement. Appl. Acoust. 2022, 187, 108499. [Google Scholar] [CrossRef]
- Schröter, H.; Rosenkranz, T.; Maier, A. DeepFilterNet: Perceptually Motivated Real-Time Speech Enhancement. arXiv 2023, arXiv:2305.08227. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- ARix, W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Lu, Z.; Rallapalli, S.; Chan, K.; La Porta, T. Modeling the resource requirements of convolutional neural networks on mobile devices. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1663–1671. [Google Scholar]
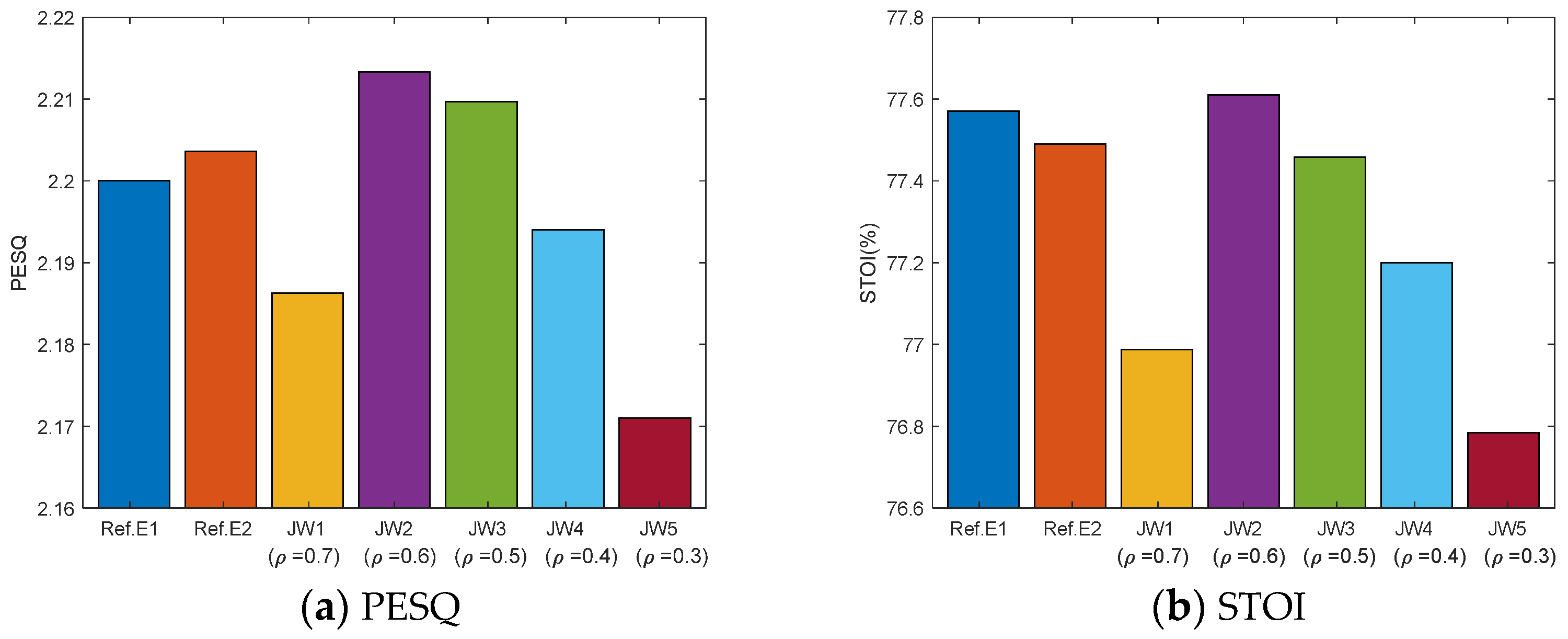

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Noise Source | Noise Type | Total Number |
|---|---|---|---|
| Training set | Real-time acquisition in the cockpit of aircraft A | Engine fire alarms, aircraft taxiing noise, aircraft take-off noise, aircraft landing noise, aircraft fault noise, and stall alarm noise. | 8 |
| Test set | Real-time acquisition in the cockpit of aircraft B | Aircraft tail noise, high-frequency metal scratching noise, propeller noise, and space noise in the aircraft cabin. | 4 |
| Method | Model Size (M) | GFLOPs | RTF | PESQ (Score) | STOI (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR Level (dB) | Avg | SNR Level (dB) | Avg | ||||||||||
| 3 | 0 | −3 | −6 | 3 | 0 | −3 | −6 | ||||||
| Noisy | - | - | - | 1.858 | 1.6398 | 1.4226 | 1.2556 | 1.544 | 75.47 | 69.07 | 62.52 | 55.21 | 65.57 |
| STCNN | - | - | - | 2.4187 | 2.1917 | 1.9507 | 1.7145 | 2.0689 | 84.81 | 79.42 | 72.73 | 65.01 | 75.49 |
| SMNet | 7.46 | 8.04 | 0.0369 | 2.4727 | 2.2278 | 1.9852 | 1.7599 | 2.11 | 84.85 | 79.91 | 73.39 | 65.89 | 76.01 |
| SMNet-TA | +0.8 | +0.71 | 0.0567 | 2.5101 | 2.2884 | 2.0471 | 1.7826 | 2.157 | 85.05 | 80.9 | 74.89 | 67.36 | 77.05 |
| SMDTANet | +3.84 | +3.31 | 0.086 | 2.551 | 2.3304 | 2.0977 | 1.8337 | 2.20 | 85.46 | 81.2 | 75.24 | 68.37 | 77.57 |
| Noise Type | PESQ (Score) | |||||||
|---|---|---|---|---|---|---|---|---|
| LSTM | STCNN | CRN | GCRN | FullSubNet | GaGNet | DeepFilterNet | SMDTANet | |
| b1 | 2.6327 | 2.6800 | 2.7158 | 2.6957 | 2.7596 | 2.7366 | 2.8011 | 2.8232 |
| restaurant | 1.8861 | 1.9614 | 1.9468 | 1.9956 | 2.0118 | 2.0033 | 2.0619 | 2.0948 |
| car | 1.9855 | 2.1000 | 2.0332 | 1.9989 | 2.1786 | 2.2238 | 2.2653 | 2.2990 |
| b2 | 2.1092 | 2.3296 | 2.1025 | 2.1502 | 2.2620 | 2.3656 | 2.466 | 2.4896 |
| b3 | 1.8697 | 1.9620 | 1.9500 | 1.9486 | 2.1052 | 2.1079 | 2.1501 | 2.1376 |
| airport | 2.1052 | 2.1591 | 2.1444 | 2.0920 | 2.2027 | 2.2099 | 2.2454 | 2.2753 |
| train | 2.5627 | 2.5698 | 2.5762 | 2.6380 | 2.6772 | 2.6507 | 2.7204 | 2.7518 |
| exhibition | 1.5373 | 1.6571 | 1.6237 | 1.7853 | 1.8066 | 1.8728 | 1.9055 | 1.9227 |
| b4 | 1.7467 | 1.5409 | 1.5804 | 1.4919 | 1.2047 | 1.4901 | 1.3306 | 1.3355 |
| subway | 2.1975 | 2.2799 | 2.2727 | 2.2616 | 2.3114 | 2.3089 | 2.3822 | 2.4050 |
| street | 1.3713 | 1.5184 | 1.4464 | 1.6472 | 1.5602 | 1.7531 | 1.7905 | 1.8120 |
| Average | 2.0003 | 2.0689 | 2.0356 | 2.0641 | 2.0982 | 2.1566 | 2.1926 | 2.2133 |
| Noise Type | STOI (%) | |||||||
| LSTM | STCNN | CRN | GCRN | FullSubNet | GaGNet | DeepFilterNet | SMDTANet | |
| b1 | 84.50 | 86.48 | 85.74 | 85.19 | 86.24 | 86.39 | 87.56 | 87.34 |
| restaurant | 69.90 | 72.57 | 72.02 | 75.68 | 72.00 | 72.37 | 74.02 | 74.58 |
| car | 72.87 | 76.15 | 74.78 | 74.21 | 76.45 | 77.40 | 78.88 | 79.18 |
| b2 | 79.08 | 83.53 | 80.22 | 82.82 | 81.63 | 82.91 | 84.21 | 84.64 |
| b3 | 65.66 | 69.44 | 68.21 | 70.45 | 73.05 | 72.61 | 73.22 | 72.95 |
| airport | 75.66 | 77.97 | 77.34 | 82.52 | 76.76 | 77.37 | 78.74 | 79.38 |
| train | 86.17 | 87.32 | 86.05 | 86.45 | 86.68 | 86.67 | 87.13 | 87.97 |
| exhibition | 65.59 | 68.00 | 66.80 | 70.63 | 72.01 | 72.28 | 72.66 | 72.78 |
| b4 | 64.21 | 65.21 | 63.23 | 69.29 | 60.87 | 66.03 | 65.01 | 64.75 |
| subway | 78.42 | 80.70 | 79.40 | 78.35 | 79.64 | 79.63 | 81.71 | 81.30 |
| street | 59.71 | 63.02 | 60.85 | 63.45 | 63.62 | 67.75 | 68.6 | 68.86 |
| Average | 72.89 | 75.49 | 74.06 | 76.28 | 75.36 | 76.49 | 77.43 | 77.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, P.; Wu, Y. Stacked Multiscale Densely Connected Temporal Convolutional Attention Network for Multi-Objective Speech Enhancement in an Airborne Environment. Aerospace 2024, 11, 156. https://doi.org/10.3390/aerospace11020156
Huang P, Wu Y. Stacked Multiscale Densely Connected Temporal Convolutional Attention Network for Multi-Objective Speech Enhancement in an Airborne Environment. Aerospace. 2024; 11(2):156. https://doi.org/10.3390/aerospace11020156
Chicago/Turabian StyleHuang, Ping, and Yafeng Wu. 2024. "Stacked Multiscale Densely Connected Temporal Convolutional Attention Network for Multi-Objective Speech Enhancement in an Airborne Environment" Aerospace 11, no. 2: 156. https://doi.org/10.3390/aerospace11020156
APA StyleHuang, P., & Wu, Y. (2024). Stacked Multiscale Densely Connected Temporal Convolutional Attention Network for Multi-Objective Speech Enhancement in an Airborne Environment. Aerospace, 11(2), 156. https://doi.org/10.3390/aerospace11020156