
Aviation-BERT-NER: Named Entity Recognition for Aviation Safety Reports




Abstract
:1. Introduction
2. Literature Review and Problem Definition
2.1. Domain-Specific NER Models
2.2. Data Preparation Methods
2.3. Related Work
2.4. Problem Definition
- 1
- Improved generalizability: This work enhances template-based NER by directly generating training data from templates populated with diverse entities drawn from structured datasets, reflecting the complexity of aviation safety reports. This ensures the domain-specific synthetic training data accurately represent the multifaceted nature of aviation entities, reducing the risk of overfitting.
- 2
- Enhanced flexibility and customization: This work improves flexibility of domain-specific NER systems, enabling rapid updates and customization of entity types and formats to align with specific domain requirements or evolving stakeholder feedback. This adaptability ensures that the NER system remains current and effective, even as aviation safety standards and practices evolve.
- 3
- Independence from existing models and manual labeling: The presented methodology eliminates reliance on pre-existing NER models and the intensive labor of manual data labeling. By leveraging structured datasets for template filling, a more efficient, scalable, and error-resistant approach is offered for generating training data, ensuring high-quality inputs from the start.
- 4
- Ease of adjustments for real-world texts: In response to testing feedback and real-world application, this system provides swift and precise model adjustments. Whether refining entity definitions or modifying template wording, these changes can be implemented without the need for comprehensive model retraining, facilitating continuous improvement and adaptability to real-world needs.
3. Data Preparation
3.1. Named Entity Data Preparation
3.2. Template Preparation
- During a routine surveillance flight {DATE} at {TIME}, a {AIRCRAFT_NAME}({AIRCRAFT_ICAO}) operated by {AIRLINE_NAME} ({AIRLINE_IATA}) experienced technical difficulties shortly after takeoff from {AIRPORT_NAME}({AIRPORT_SYMBOL}) in {CITY}, {STATE_NAME}, {COUNTRY_NAME}.
- The pilot of a {MANUFACTURER} {AIRCRAFT_ICAO} noted that the wind was about {SPEED} and favored a {DISTANCE} turf runway.
- An unexpected {WEIGHT} shift prompted {AIRCRAFT_NAME}’s crew to reroute via {TAXIWAY} for an emergency inspection.
- {AIRLINE_NAME} encountered unexpected {TEMPERATURE} fluctuations while cruising at {SPEED}, leading to an unscheduled maintenance check upon landing at {AIRPORT_NAME}.
- Visibility challenges due to a low {TEMPERATURE} at {AIRPORT_NAME} led the {AIRCRAFT_NAME} to modify its course to an alternate {TAXIWAY}, under guidance from air traffic control.
“Using the information provided for entity placeholders, aviation safety reports, and example templates, generate 10 new templates based on aviation safety data, covering a range of possible incidents and scenarios. Do not add placeholders beyond the list already provided. Templates must be single sentences.”
“Generate 10 more templates. Increase the occurrence of placeholders {DURATION}, {WEIGHT}, and {TEMPERATURE}. Do not repeat any previously generated templates.”
3.3. Labeled Synthetic Dataset Generation for Training
3.4. Labeled Dataset Generation for Testing
4. Fine-Tuning
4.1. Training
4.2. Testing
5. Results and Discussion
5.1. Scores and Predictions
5.2. Model Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Category | Data Format/Variation | Variable Range | Comments |
|---|---|---|---|
| DATE | y
-m-d m-d-y d/m/y on the of in of on the | d = 01–31 m = 01–12 y = 2010–2023 = 1st–31st (appropriate suffix for each day) = January–December, Jan.–Dec. = 2010–2023 | All dates generated were practical values. Example, 30th Feb. is not possible and thus not used. |
| TIME | HM H:M HM H:M | H = 00–23 M = 00–59 = time zone names, abbreviations, offsets | List of world time zones was obtained from [47]. |
| WAY | runway rwy rw taxiway txy txwy | = 01–36, 01L–36L, 01C–36C, 01R–36R = A–Z, A1–Z5, AA–ZZ | Taxiway letters I, O, X, II, OO, and XX were excluded. |
| SPEED | kts knots kilometers per hour km/h km/hr miles per hour mph | = 1–600 = 1–1200 = 1–745 | Both integers and floating point to 1 decimal values were used. |
| ALTITUDE | feet ft ’ meters m FL | = 50–60,000 = no suffix, ‘agl’, ‘above ground level’, ‘msl’, ‘mean sea level’ = 20–18,300 = 100–600 | Only integers were used for numbers. Multiples of 10 were used for flight level. |
| DISTANCE | nautical miles NM kilometers km miles feet ft foot meters m | = 10–7500 = 10–14,000 = 10–8700 = 50–9000 = 10–3000 | Both integers and floating point to 1 decimal values were used. |
| TEMPERATURE | Celsius C °C degrees Celsius degrees C Fahrenheit F °F degrees Fahrenheit degrees F | = −60 to 70 = −76 to 150 | Both integers and floating point to 1 decimal values were used. |
| PRESSURE | inches of mercury inHG hectopascals hPa millibars mb pascal Pa pounds per square inch psi | = 2–33 = 800–1014 = 72–1014 = 7240–101,400 = 1–16 | Both integers and floating point to 1 decimal values were used. |
| DURATION | seconds sec secs hours h hr hrs minutes m min mins | = 1–1000 = 1–24 = 1–300 | Both integers and floating point to 1 decimal values were used. |
| WEIGHT | pounds lb lbs kilograms kg tons tonnes | = 1–1,000,000 = 1–453,592 = 1–453 | Both integers and floating point to 1 decimal values were used. |
Appendix B
| Model # | Dataset Size | Training Epochs | F1 Score | F1 Score (without BIO) |
|---|---|---|---|---|
| 1 | 50,337 | 3 | 94.45% | 95.86% |
| 2 | 50,337 | 4 | 95.03% | 96.12% |
| 3 | 54,990 | 3 | 93.03% | 94.20% |
| 4 | 54,990 | 4 | 94.28% | 95.43% |
| 5 | 60,066 | 3 | 93.84% | 95.28% |
| 6 | 60,066 | 4 | 94.11% | 95.26% |
| 7 | 60,066 | 5 | 93.98% | 95.13% |
| 8 | 65,142 | 3 | 94.26% | 95.53% |
| 9 | 65,142 | 4 | 93.94% | 95.14% |
| 10 | 70,218 | 3 | 94.78% | 96.14% |
| 11 | 70,218 | 4 | 93.60% | 95.19% |
| 12 | 80,370 | 3 | 92.54% | 93.65% |
| 13 | 80,370 | 4 | 93.79% | 95.20% |
| 14 | 80,370 | 5 | 93.47% | 94.69% |
| 15 | 100,251 | 3 | 93.83% | 95.47% |
| 16 | 100,251 | 4 | 93.27% | 94.82% |
| 17 | 100,251 | 5 | 93.38% | 94.68% |
| 18 | 120,132 | 3 | 93.45% | 94.60% |
| 19 | 120,132 | 4 | 93.30% | 94.49% |
| 20 | 120,132 | 5 | 92.57% | 93.87% |

References
- International Air Transport Association. IATA Annual Review 2024. Available online: https://www.iata.org/contentassets/c81222d96c9a4e0bb4ff6ced0126f0bb/iata-annual-review-2024.pdf (accessed on 12 September 2024).
- Oster, C.V., Jr.; Strong, J.S.; Zorn, C.K. Analyzing aviation safety: Problems, challenges, opportunities. Res. Transp. Econ. 2013, 43, 148–164. [Google Scholar] [CrossRef]
- Zhang, X.; Mahadevan, S. Bayesian Network Modeling of Accident Investigation Reports for Aviation Safety Assessment. Reliab. Eng. Syst. Saf. 2021, 209, 107371. [Google Scholar] [CrossRef]
- Zhong, K.; Jackson, T.; West, A.; Cosma, G. Natural Language Processing Approaches in Industrial Maintenance: A Systematic Literature Review. Procedia Comput. Sci. 2024, 232, 2082–2097. [Google Scholar] [CrossRef]
- Amin, N.; Yother, T.L.; Johnson, M.E.; Rayz, J. Exploration of Natural Language Processing (NLP) applications in aviation. Coll. Aviat. Rev. Int. 2022, 40, 203–216. [Google Scholar] [CrossRef]
- Rose, R.L.; Puranik, T.G.; Mavris, D.N.; Rao, A.H. Application of structural topic modeling to aviation safety data. Reliab. Eng. Syst. Saf. 2022, 224, 108522. [Google Scholar] [CrossRef]
- NASA. ASRS Program Briefing. 2023. Available online: https://asrs.arc.nasa.gov/docs/ASRS_ProgramBriefing.pdf (accessed on 22 October 2024).
- NTSB. National Transportation Safety Board–Aviation Investigation Search. 2024. Available online: https://www.ntsb.gov/Pages/AviationQueryv2.aspx (accessed on 22 October 2024).
- Yang, C.; Huang, C. Natural Language Processing (NLP) in Aviation Safety: Systematic Review of Research and Outlook into the Future. Aerospace 2023, 10, 600. [Google Scholar] [CrossRef]
- Liu, Y. Large language models for air transportation: A critical review. J. Air Transp. Res. Soc. 2024, 2, 100024. [Google Scholar] [CrossRef]
- Perboli, G.; Gajetti, M.; Fedorov, S.; Giudice, S.L. Natural Language Processing for the identification of Human factors in aviation accidents causes: An application to the SHEL methodology. Expert Syst. Appl. 2021, 186, 115694. [Google Scholar] [CrossRef]
- Madeira, T.; Melício, R.; Valério, D.; Santos, L. Machine Learning and Natural Language Processing for Prediction of Human Factors in Aviation Incident Reports. Aerospace 2021, 8, 47. [Google Scholar] [CrossRef]
- Miyamoto, A.; Bendarkar, M.V.; Mavris, D.N. Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns. Aerospace 2022, 9, 450. [Google Scholar] [CrossRef]
- Zhang, X.; Srinivasan, P.; Mahadevan, S. Sequential deep learning from NTSB reports for aviation safety prognosis. Saf. Sci. 2021, 142, 105390. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Kierszbaum, S.; Lapasset, L. Applying Distilled BERT for Question Answering on ASRS Reports. In Proceedings of the 2020 New Trends in Civil Aviation (NTCA), Prague, Czech Republic, 23–24 November 2020; pp. 33–38. [Google Scholar] [CrossRef]
- Kierszbaum, S.; Klein, T.; Lapasset, L. ASRS-CMFS vs. RoBERTa: Comparing Two Pre-Trained Language Models to Predict Anomalies in Aviation Occurrence Reports with a Low Volume of In-Domain Data Available. Aerospace 2022, 9, 591. [Google Scholar] [CrossRef]
- Wang, L.; Chou, J.; Tien, A.; Zhou, X.; Baumgartner, D. AviationGPT: A Large Language Model for the Aviation Domain. In Proceedings of the AIAA Aviation Forum and Ascend 2024, Las Vegas, NV, USA, 29 July–2 August 2024. [Google Scholar] [CrossRef]
- Ricketts, J.; Barry, D.; Guo, W.; Pelham, J. A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports. Safety 2023, 9, 22. [Google Scholar] [CrossRef]
- Chandra, C.; Jing, X.; Bendarkar, M.; Sawant, K.; Elias, L.; Kirby, M.; Mavris, D. Aviation-BERT: A Preliminary Aviation-Specific Natural Language Model. In Proceedings of the AIAA AVIATION 2023 Forum, San Diego, CA, USA, 12–16 June 2023. [Google Scholar] [CrossRef]
- Jing, X.; Chennakesavan, A.; Chandra, C.; Bendarkar, M.V.; Kirby, M.; Mavris, D.N. BERT for Aviation Text Classification. In Proceedings of the AIAA AVIATION 2023 Forum, San Diego, CA, USA, 12–16 June 2023. [Google Scholar] [CrossRef]
- Jing, X.; Sawant, K.; Bendarkar, M.V.; Elias, L.R.; Mavris, D. Expanding Aviation Knowledge Graph Using Deep Learning for Safety Analysis. In Proceedings of the AIAA Aviation Forum and Ascend 2024, Las Vegas, NV, USA, 29 July–2 August 2024. [Google Scholar] [CrossRef]
- Agarwal, A.; Gite, R.; Laddha, S.; Bhattacharyya, P.; Kar, S.; Ekbal, A.; Thind, P.; Zele, R.; Shankar, R. Knowledge Graph - Deep Learning: A Case Study in Question Answering in Aviation Safety Domain. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 6260–6270. [Google Scholar]
- Sanmartin, D. KG-RAG: Bridging the Gap Between Knowledge and Creativity. arXiv 2024, arXiv:2405.12035. [Google Scholar] [CrossRef]
- Mollá, D.; Van Zaanen, M.; Smith, D. Named entity recognition for question answering. In Proceedings of the Australasian Language Technology Association Workshop, Sydney, Australia, 30 November–1 December 2006; Australasian Language Technology Association: Sydney, Australia, 2006; pp. 51–58. [Google Scholar]
- Shah, A.; Gullapalli, A.; Vithani, R.; Galarnyk, M.; Chava, S. FiNER-ORD: Financial Named Entity Recognition Open Research Dataset. arXiv 2024, arXiv:2302.11157. [Google Scholar] [CrossRef]
- Durango, M.C.; Torres-Silva, E.A.; Orozco-Duque, A. Named Entity Recognition in Electronic Health Records: A Methodological Review. Healthc. Inform. Res. 2023, 29, 286–300. [Google Scholar] [CrossRef]
- Wang, X.; Gan, Z.; Xu, Y.; Liu, B.; Zheng, T. Extracting Domain-Specific Chinese Named Entities for Aviation Safety Reports: A Case Study. Appl. Sci. 2023, 13, 11003. [Google Scholar] [CrossRef]
- Chu, J.; Liu, Y.; Yue, Q.; Zheng, Z.; Han, X. Named entity recognition in aerospace based on multi-feature fusion transformer. Sci. Rep. 2024, 14, 827. [Google Scholar] [CrossRef]
- Bharathi, A.; Ramdin, R.; Babu, P.; Menon, V.K.; Jayaramakrishnan, C.; Lakshmikumar, S. A hybrid named entity recognition system for aviation text. EAI Endorsed Trans. Scalable Inf. Syst. 2024, 11, 1–10. [Google Scholar]
- Andrade, S.R.; Walsh, H.S. What Went Wrong: A Survey of Wildfire UAS Mishaps through Named Entity Recognition. In Proceedings of the 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18–22 September 2022; pp. 1–10. [Google Scholar] [CrossRef]
- Ray, A.T.; Pinon-Fischer, O.J.; Mavris, D.N.; White, R.T.; Cole, B.F. aeroBERT-NER: Named-Entity Recognition for Aerospace Requirements Engineering using BERT. In Proceedings of the AIAA SCITECH 2023 Forum, National Harbor, MD, USA, 23–27 January 2023. [Google Scholar] [CrossRef]
- Pai, R.; Clarke, S.S.; Kalyanam, K.; Zhu, Z. Deep Learning based Modeling and Inference for Extracting Airspace Constraints for Planning. In Proceedings of the AIAA AVIATION 2022 Forum, Online, 27 June–1 July 2022. [Google Scholar] [CrossRef]
- Aarsen, T. SpanMarker for Named Entity Recognition. Available online: https://github.com/tomaarsen/SpanMarkerNER (accessed on 13 September 2024).
- Aarsen, T. SpanMarker with Bert-Base-Cased on FewNERD. Available online: https://huggingface.co/tomaarsen/span-marker-bert-base-fewnerd-fine-super (accessed on 13 September 2024).
- Li, Z.Z.; Feng, D.W.; Li, D.S.; Lu, X.C. Learning to select pseudo labels: A semi-supervised method for named entity recognition. Front. Inf. Technol. Electron. Eng. 2020, 21, 903–916. [Google Scholar] [CrossRef]
- Jehangir, B.; Radhakrishnan, S.; Agarwal, R. A survey on Named Entity Recognition—Datasets, tools, and methodologies. Nat. Lang. Process. J. 2023, 3, 100017. [Google Scholar] [CrossRef]
- Nadeau, D.; Turney, P.D.; Matwin, S. Unsupervised named-entity recognition: Generating gazetteers and resolving ambiguity. In Proceedings of the Advances in Artificial Intelligence: 19th Conference of the Canadian Society for Computational Studies of Intelligence, Canadian AI 2006, Québec City, QC, Canada, 7–9 June 2006; Proceedings 19. Springer: Cham, Switzerland, 2006; pp. 266–277. [Google Scholar] [CrossRef]
- Iovine, A.; Fang, A.; Fetahu, B.; Rokhlenko, O.; Malmasi, S. CycleNER: An unsupervised training approach for named entity recognition. In Proceedings of the The Web Conference 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-Based Named Entity Recognition Using BART. arXiv, 2021. [Google Scholar] [CrossRef]
- Palt, K. ICAO Aircraft Codes—Flugzeuginfo.net. 2019. Available online: https://www.flugzeuginfo.net/table_accodes_en.php (accessed on 19 March 2024).
- Gacsal, C. airport-codes.csv—GitHub Gist. 2021. Available online: https://gist.github.com/chrisgacsal/070379c59d25c235baaa88ec61472b28 (accessed on 19 March 2024).
- Bansard International. Airlines IATA and ICAO Codes Table. 2024. Available online: https://www.bansard.com/sites/default/files/download_documents/Bansard-airlines-codes-IATA-ICAO.xlsx (accessed on 19 March 2024).
- OpenAI. ChatGPT (GPT-4). Large Language Model. 2024. Available online: https://openai.com/chatgpt (accessed on 19 March 2024).
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:1711.05101. [Google Scholar] [CrossRef]
- Time and Date AS. Time Zone Abbreviations—Worldwide List. 2024. Available online: https://www.timeanddate.com/time/zones/ (accessed on 19 March 2024).





| Entity Category | Unique Count | Entity Examples | Source |
|---|---|---|---|
| MANUFACTURER | 272 | ‘Bell Helicopter’, ‘Aerospatiale’, ‘Piaggio’, ‘Boeing’, ‘EMBRAER’ | flugzeuginfo.net [42] |
| AIRCRAFT | 2720 | ‘A330-200’, ‘707-100’, ‘DH-115 Vampire’, ‘PA38’, ‘MD11’ | |
| AIRPORT | 58,632 | ‘Caffrey Heliport’, ‘Regina General Hospital Helipad’, ‘Wilsche Glider Field’, ‘41WA’, ‘SAN’ | GitHub Gist [43] |
| CITY | 15,507 | ‘New Brighton’, ‘Hortonville’, ‘Wiesbaden’, ‘Dimapur’, ‘Marietta’ | |
| STATE | 1893 | ‘Michigan’, ‘Sipaliwini District’, ‘Saarland’, ‘SO’, ‘QLD’, ‘ME’ | |
| COUNTRY | 115 | ‘United States of America’, ‘Ghana’, ‘South Africa’, ‘Brazil’, ‘France’ | |
| AIRLINE | 759 | ‘Gulf Air’, ‘Air Moldova’, ‘Etihad Airways’, ‘S7’, ‘NCA’ | Bansard International [44] |
| DATE | 22,115 | ‘in October of 2022 on the 5th’, ‘02-04-2016 ’, ‘22/07/2016’, ‘on the 6th of Aug. 2022’ | See Appendix A |
| TIME | 14,360 | ‘05:37 CST’, ‘0031 UTC + 6’, ‘11:47’, ‘11:56 Central Europe Time’, ‘0945’ | |
| WAY | 915 | ‘runway 09’, ‘rwy 25R’, ‘taxiway D’, ‘txwy A4’ | |
| SPEED | 800 | ‘120 kts’, ‘107.2 knots’, ‘514.6 mph’, ‘87 miles per hour’, ‘217 km/h’ | |
| ALTITUDE | 2650 | ‘12,422 m’, ‘38,800 feet agl’, ‘10,132 ft’, ‘FL210’, ‘5541 m’ | |
| DISTANCE | 500 | ‘11,981 km’, ‘182.9 miles’, ‘496.7 kilometers’, ‘995 NM’, ‘2000 ft’ | |
| TEMPERATURE | 1500 | ‘9 degree C’, ‘31 Fahrenheit’, ‘−2.5 F’, ‘54 °F’, ‘25 C’ | |
| PRESSURE | 900 | ‘101,263.6 Pa’, ‘24.2 inches of mercury’, ‘20.5 inHg’, ‘1117 hPa’, ‘1026.2 millibars’ | |
| DURATION | 1100 | ‘35 s’, ‘11.6 h’, ‘1.5 h’, ‘9 h’, ‘10 mins’ | |
| WEIGHT | 700 | ‘56,667 kg’, ‘503,385 pounds’, ‘1200 kilograms’, ‘22,476.3 lbs’, ‘179.1 tonnes’ |
| Template | Sentence | Entity | Entity with BIO |
|---|---|---|---|
| During | During | O | O |
| a | a | O | O |
| routine | routine | O | O |
| surveillance | surveillance | O | O |
| flight | flight | O | O |
| {DATE} | on | DATE | B-DATE |
| the | DATE | I-DATE | |
| 12th | DATE | I-DATE | |
| of | DATE | I-DATE | |
| May | DATE | I-DATE | |
| 2012 | DATE | I-DATE | |
| at | at | O | O |
| {TIME} | 0821 | TIME | B-TIME |
| , | , | O | O |
| a | a | O | O |
| {AIRCRAFT_NAME} | 100 | AIRCRAFT | B-AIRCRAFT |
| King | AIRCRAFT | I-AIRCRAFT | |
| Air | AIRCRAFT | I-AIRCRAFT | |
| ( | ( | O | O |
| {AIRCRAFT_ICAO} | BE10 | AIRCRAFT | B-AIRCRAFT |
| ) | ) | O | O |
| operated | operated | O | O |
| by | by | O | O |
| {AIRLINE_NAME} | SATA | AIRLINE | B-AIRLINE |
| Internacional | AIRLINE | I-AIRLINE | |
| ( | ( | O | O |
| {AIRLINE_IATA} | S4 | AIRLINE | B-AIRLINE |
| ) | ) | O | O |
| experienced | experienced | O | O |
| technical | technical | O | O |
| difficulties | difficulties | O | O |
| shortly | shortly | O | O |
| after | after | O | O |
| takeoff | takeoff | O | O |
| from | from | O | O |
| {AIRPORT_NAME} | Andrews | AIRPORT | B-AIRPORT |
| University | AIRPORT | I-AIRPORT | |
| Airpark | AIRPORT | I-AIRPORT | |
| ( | ( | O | O |
| {AIRPORT_SYMBOL} | C20 | AIRPORT | B-AIRPORT |
| ) | ) | O | O |
| in | in | O | O |
| {CITY} | Berrien | CITY | B-CITY |
| Springs | CITY | I-CITY | |
| , | , | O | O |
| {STATE_NAME} | Michigan | STATE | B-STATE |
| , | , | O | O |
| {COUNTRY_NAME} | United | COUNTRY | B-COUNTRY |
| States | COUNTRY | I-COUNTRY | |
| of | COUNTRY | I-COUNTRY | |
| America | COUNTRY | I-COUNTRY | |
| . | . | O | O |
| Test Dataset | Precision | Recall | F1 Score |
|---|---|---|---|
| 50 paragraphs | 95.34% | 94.62% | 94.78% |
| 848 sentences | 95.59% | 94.90% | 95.08% |
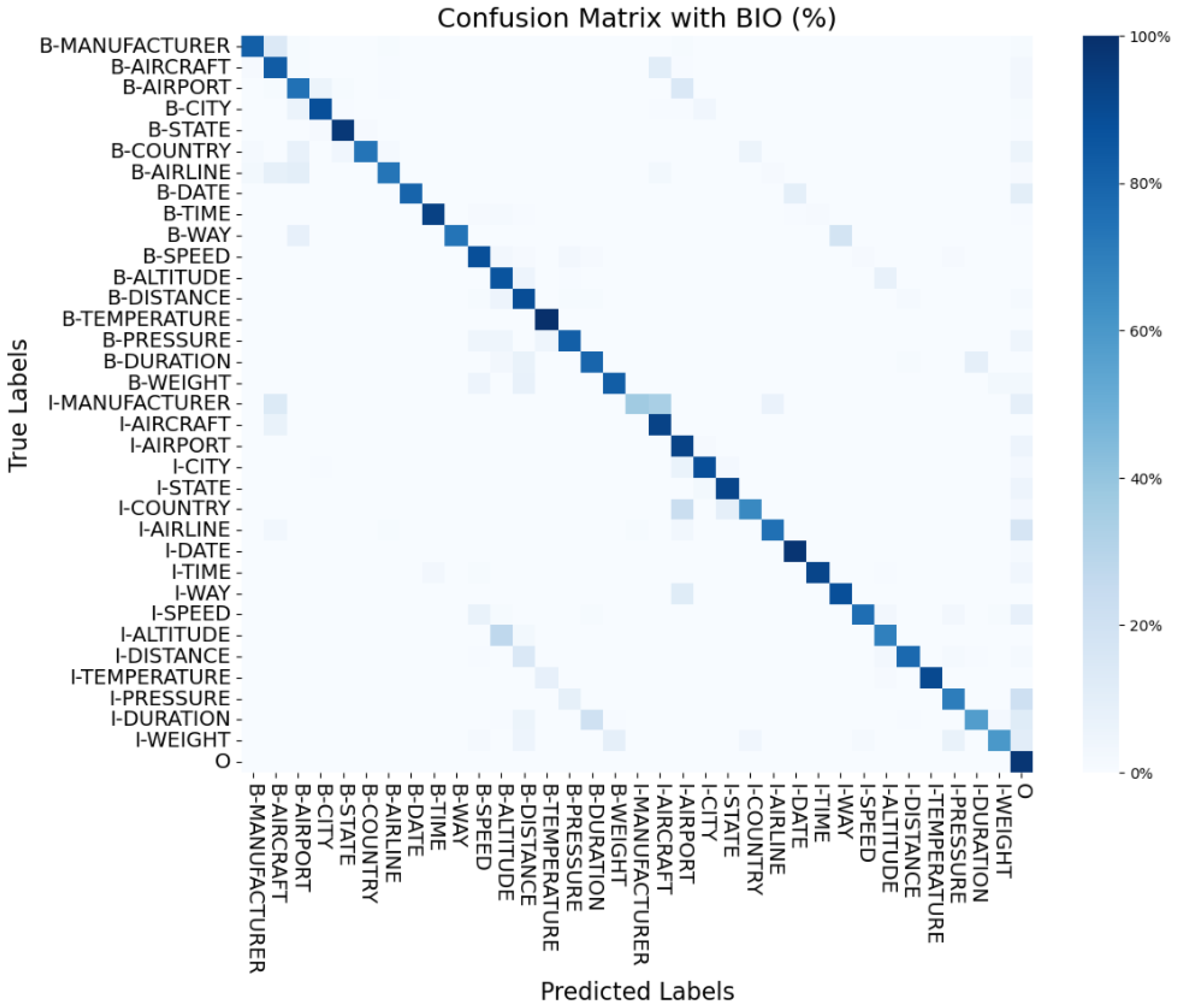
| Entity Label | % Correct Predictions | Entity Label | % Correct Predictions | ||
|---|---|---|---|---|---|
| 50 Paragraphs | 848 Sentences | 50 Paragraphs | 848 Sentences | ||
| B-MANUFACTURER | 82.00 | 88.00 | I-MANUFACTURER | 36.36 | 63.64 |
| B-AIRCRAFT | 82.86 | 88.10 | I-AIRCRAFT | 92.79 | 92.79 |
| B-AIRPORT | 74.80 | 73.60 | I-AIRPORT | 92.75 | 89.12 |
| B-CITY | 88.14 | 86.02 | I-CITY | 88.41 | 85.51 |
| B-STATE | 96.67 | 95.33 | I-STATE | 91.89 | 91.89 |
| B-COUNTRY | 73.59 | 73.59 | I-COUNTRY | 65.91 | 70.46 |
| B-AIRLINE | 73.08 | 85.90 | I-AIRLINE | 75.20 | 85.60 |
| B-DATE | 80.00 | 87.62 | I-DATE | 97.78 | 99.72 |
| B-TIME | 93.71 | 94.34 | I-TIME | 92.06 | 97.20 |
| B-WAY | 73.49 | 75.90 | I-WAY | 88.06 | 88.06 |
| B-SPEED | 88.06 | 91.05 | I-SPEED | 76.15 | 78.90 |
| B-ALTITUDE | 86.15 | 90.00 | I-ALTITUDE | 69.44 | 72.70 |
| B-DISTANCE | 88.89 | 93.16 | I-DISTANCE | 78.02 | 79.12 |
| B-TEMPERATURE | 100.00 | 100.00 | I-TEMPERATURE | 90.36 | 91.57 |
| B-PRESSURE | 81.82 | 95.46 | I-PRESSURE | 70.37 | 80.25 |
| B-DURATION | 79.38 | 79.38 | I-DURATION | 57.45 | 56.74 |
| B-WEIGHT | 82.05 | 84.62 | I-WEIGHT | 60.00 | 60.00 |
| O | 97.55 | 97.35 | |||
| Test Dataset | Precision | Recall | F1 Score |
|---|---|---|---|
| 50 paragraphs | 96.37% | 96.07% | 96.14% |
| 848 sentences | 96.55% | 96.23% | 96.32% |
| Model | Focus Area | Language | Identified Entities | F1 Score |
|---|---|---|---|---|
| Chinese IDCNN-BiGRU-CRF [29] | Aviation Safety Reports | Chinese | 1. Aircraft Type, 2. Aircraft Registration, 3. Aircraft Part, 4. Flight Number, 5. Company, 6. Operation, 7. Event, 8. Personnel, 9. City, 10. Date | 97.93% |
| Chinese MFT-BERT [30] | Aerospace Documents | Chinese | 1. Companies & Organizations, 2. Airports & Spacecraft Launch Sites, 3. Vehicle Type, 4. Constellations & Satellites, 5. Space Missions & Projects, 6. Scientists & Astronauts, 7. Technology & Equipment | 86.10% |
| Singapore’s SpaCy NER [31] | Aviation Safety Reports | English | 1. Aircraft Model, 2. Aircraft Registration, 3. Manufacturer, 4. Airline, 5. Flight Number, 6. Departure Location, 7. Destination Location | 93.73% |
| Custom BERT NER model [32] | Aviation Safety Reports | English | 1. Failure Mode, 2. Failure Cause, 3. Failure Effect, 4. Control Processes, 5. Recommendations | 33% * |
| aeroBERT-NER [33] | Aerospace Design Requirements | English | 1. System, 2. Organization, 3. Resource, 4. Values, 5. Date/Time | 92% |
| Aviation-BERT-NER | Aviation Safety Reports | English | 1. Manufacturer, 2. Aircraft, 3. Airport, 4. City, 5. State, 6. Country, 7. Airline, 8. Date, 9. Time, 10. Way, 11. Speed, 12. Altitude, 13. Distance, 14. Temperature, 15. Pressure, 16. Duration, 17. Weight | 94.78% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chandra, C.; Ojima, Y.; Bendarkar, M.V.; Mavris, D.N. Aviation-BERT-NER: Named Entity Recognition for Aviation Safety Reports. Aerospace 2024, 11, 890. https://doi.org/10.3390/aerospace11110890
Chandra C, Ojima Y, Bendarkar MV, Mavris DN. Aviation-BERT-NER: Named Entity Recognition for Aviation Safety Reports. Aerospace. 2024; 11(11):890. https://doi.org/10.3390/aerospace11110890
Chicago/Turabian StyleChandra, Chetan, Yuga Ojima, Mayank V. Bendarkar, and Dimitri N. Mavris. 2024. "Aviation-BERT-NER: Named Entity Recognition for Aviation Safety Reports" Aerospace 11, no. 11: 890. https://doi.org/10.3390/aerospace11110890
APA StyleChandra, C., Ojima, Y., Bendarkar, M. V., & Mavris, D. N. (2024). Aviation-BERT-NER: Named Entity Recognition for Aviation Safety Reports. Aerospace, 11(11), 890. https://doi.org/10.3390/aerospace11110890