The results presented in this section determined whether the proposed conceptual prioritization pipeline could enable effective NLP-based prioritization on nanosatellites with improved flexibility compared to existing methods. By evaluating the two approaches presented in the previous section, the viability of the conceptual prioritization pipeline was confirmed.
An important metric considered was the top-k accuracy score. This metric computes the number of times where the correct label or description is among the top
k labels or descriptions predicted, ranked by predicted scores. The scikit-learn [
22] implementation of the top-k accuracy score was used and can be expressed as follows:
where
is the predicted class for the
ith sample corresponding to the
jth largest predicted score,
is the corresponding true value, and
k is the number of guesses allowed. The top-k score was used to quantify how well each approach could prioritize the data, by illustrating numerically how likely it was that the satellite would downlink RS images scientists requested within
k downlinked images.
Top-k accuracy, along with average cosine similarity score, was used to evaluate each approach. The average cosine similarity score provided a good indication of how confident each approach was when predicting the correct description or class.
3.1. Oriented Bounding-Box Approach
The OBB approach implemented separately trained image and text encoders. To determine the performance of each encoder in producing an accurate intermediate representation, the cosine similarity of the encoder outputs and the ground-truth intermediate representations, generated from the DOTA-v1.5 OBB definitions, were considered.
Table 7 presents the average cosine similarity compared to the ground-truth intermediate representation for each encoder-produced intermediate representation.
The YOLOv8 models saw a cosine similarity of 0.75 for intermediate representations generated from input images. Meanwhile, Llama2 produced intermediate representations from text descriptions with a cosine accuracy of 0.99. However, it should be noted that three descriptions resulted in errors when trying to produce the JSON intermediate representation from the LLM output. This was due to the Llama2 model not correctly outputting in the JSON format.
The YOLO and Llama2 outputs were compared to test the performance of the OBB approach in associating the input image with the correct description. The approach made a prediction by assigning the description whose intermediate representation was most similar to the one produced from the YOLO output of a given image.
Table 8 presents the average cosine similarity for the correct description of a given image. This shows that on average, the intermediate representation produced by Llama2 from the correct description had a cosine similarity of 0.76 compared to the intermediate representation produced from the output of YOLO given the corresponding image as input.
To determine how well the OBB approach could filter and prioritize images, the top-k accuracies for individual description matching were determined and are given in
Table 9.
These results can be interpreted as follows: for both YOLO models, in 71% of cases, the OBB approach assigned the correct description to an image within the top-30 descriptions. While the top-1 scores were not nearly as high,
Table 9 shows that the OBB approach could still be used to filter and prioritize images; however, a number of downlinks may be required to get the images requested by scientists. The low top-k scores may be a result of similar image descriptions causing misclassifications with similar counterparts.
While both YOLO models performed similarly, the sizes of the models differed slightly due to the different image input sizes. As a result, the runtime performance and inference time of each model would differ. Therefore, the consideration of both models will prove useful for evaluating the performance of this approach on the target hardware and understanding the effect of model size on inference time and runtime performance.
3.2. CLIP Approach
CLIP provided both the image and text encoders for this approach. Since the NWPU-Captions dataset provided overall class labels for each image, both the individual description and class description results were presented. Individual description results took each description as a unique classification for each image. Images with duplicate descriptions were removed so that each image had only one unique description. This resulted in 2821 image and description pairs. Class description results took one random description from each image class as the true description for all images in that same class. This was performed 10 times to calculate an average result and performance. All 3150 test images were considered in that case.
To evaluate the confidence of the correct image and description pairs,
Table 10 presents the average cosine similarity for the correct description for each image, considering both individual descriptions and class descriptions. It is clear that the ResNet50-based model produced more confident predictions compared to the ViT-B-16-based model.
To determine how well the CLIP approach could filter and prioritize images, the top-k accuracies for both individual descriptions and class descriptions were determined and are presented in
Table 11.
While the individual description top-k scores were far lower than the class description scores, they still indicated that the CLIP approach was useful for initial filtering and prioritization of the RS images. The low scores may be a result of images scoring highly on descriptions of similar counterparts. The class description scores were much higher and showed that the CLIP approach could confidently classify images according to general class descriptions. This means that scientists can describe the RS scenes they desire, and the CLIP method will be able to filter and prioritize the correct images efficiently. The ViT-B-16-based model appeared to perform better in the individual description case, while the ResNet50-based model appeared to perform better in the class description case.
3.3. Prioritization Test
The prioritization test assessed the performance of the OBB and CLIP approaches on the target hardware, the VERTECS CCB, using the types of images expected in a practical application of these approaches. The PrioEval dataset, which contains four common classes with 25 images each, was used for this test. The two approaches were assessed based on how well they classified and prioritized images with respect to the appropriate class descriptions written for this dataset. The runtime performance of these approaches on the Raspberry Pi CM4 was also considered.
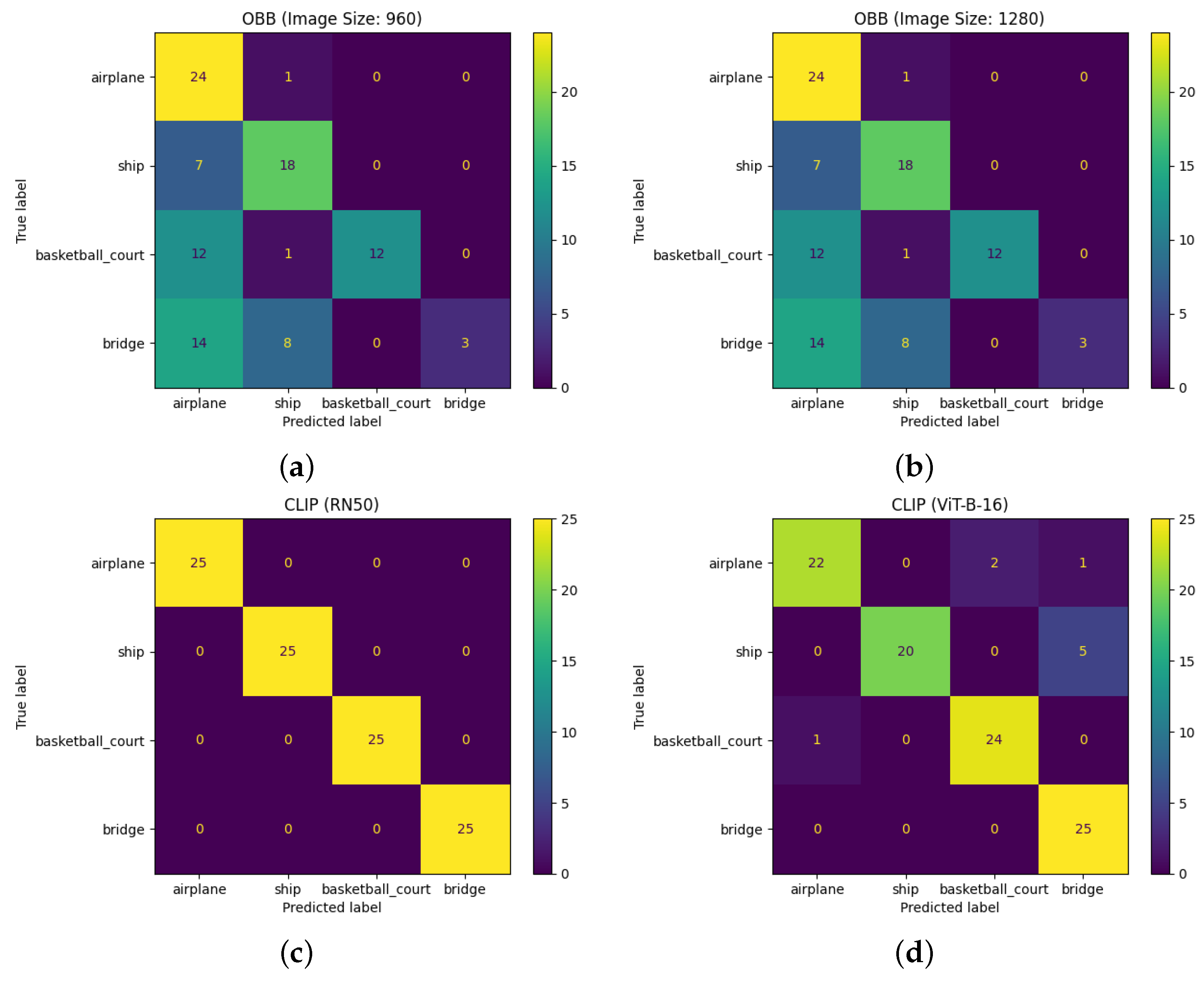
Figure 7 presents the confusion matrices produced from the classifications predicted by the OBB and CLIP approaches. Classifications for a given image were predicted by determining the class description with which it had the highest cosine similarity score. This provided a good indication of the performance of each approach in making correct image–description associations.
The CLIP models performed the best by far, with the ResNet50-based model showing 100% accuracy for classification. Meanwhile, the OBB methods appeared to struggle with the class classifications, perhaps due to the performance of the YOLOv8 models on this dataset. This was especially evident in the “bridge” class, a class on which both YOLOv8 models performed poorly.
The goal of these approaches was to prioritize the downlink of data so that the most desirable data were downlinked first; therefore, it was important to visualize the effect of prioritization on data downlink.
Figure 8 presents the simulated effect on the downlink from each approach when a specific class was requested. Prioritization for a given class was performed by sorting the class similarities from high to low and downlinking the images with the highest similarities to the given class first. The perfect case would see the 25 images in a class downlinked within 25 image downlinks.
Figure 8a presents the case of a randomly sorted baseline where no prioritization was applied. An efficiently prioritized result would see a straight line to the total number of images in a class, as no undesirable images were downlinked. Horizontal movement in the plot indicated that the downlink of an image from an undesired class took place. Visually, an improvement in performance can be seen in most cases where prioritization was performed. The most improvement was seen with the CLIP models, specifically with the ResNet50-based model in
Figure 8d, with perfect downlink prioritization for almost all classes.
Another method to quantify prioritization performance is to consider the prioritization error, calculated as:
where
m is the regression line fit to the plots in
Figure 8 using the polyfit function from the Numpy Python library [
28]. A lower error means better prioritization performance.
Table 12 presents the prioritization error for the OBB and CLIP approaches for each class in the PrioEval dataset. A baseline case where no prioritization is performed is, once again, provided.
The ResNet50-based CLIP model provided the lowest error rate for all classes, showing that it efficiently prioritized the downlink of RS images. The ViT-B-16-based CLIP model was impacted by sequencing the last few images in each class later on in the downlink process, resulting in a higher prioritization error. The OBB models seemed to perform relatively well on vehicles; however, they too were severely impacted from prioritizing the last few images in a class much later in the downlink process, also resulting in a higher prioritization error.
Finally, the runtime performance and memory requirements of each approach on the VERTECS CCB must be considered.
Table 13 presents the size of the intermediate representation files for each approach, which include representations for the four different text class descriptions. These are the files which must be uplinked to the satellite for similarity score calculation. In this case, a smaller file is best, as this would require less bandwidth to uplink to a nanosatellite in orbit.
The OBB approach featured the smallest file size due to being a simple JSON object. The CLIP models had a larger file size as they were text embeddings output by their respective text encoders.
Figure 9 presents the CPU usage, memory usage, maximum memory consumed, and total runtime of each model evaluated on the VERTECS CCB.
The majority of the runtime for both approaches was taken by image processing, with actual similarity score calculation taking a fraction of the time. The average image processing time for a single image and the similarity calculation time for 100 images are presented in
Table 14 for each model.
CLIP appeared to process images more efficiently due to processing them as a batch, while for the OBB approach, YOLO needed to make predictions one image at a time. The same was the case for calculating the similarity score as CLIP made one dot product calculation for all images and text descriptions considered, while the OBB approach calculated similarity class-by-class before obtaining an average, performing this one image at a time.
While the OBB approach had lower CPU and memory utilization, the total runtime of the algorithms was longer compared to those of the CLIP approach. This means that the CCB had to operate for a longer time, consuming more power in the process. This is clear in
Figure 10, which presents the power consumption over time of the VERTECS CCB, at 5 V, when running the main program code of each approach. A uniform filter was applied over the data to increase the clarity of the plots. While the CLIP approach experienced higher peak power usage, the power consumption over time in watt hours for the CLIP approach was lower compared to that of the OBB approach.
Table 15 presents these values for each variant of each approach. The values show that less energy was consumed overall by running the CLIP algorithms on the VERTECS CCB compared to the OBB algorithms.
Therefore, despite having increased CPU and memory utilization, if the memory requirement can be met, the CLIP approach is more desirable since the required hardware up-time and total power consumption are lower.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}