
Tactical Conflict Solver Assisting Air Traffic Controllers Using Deep Reinforcement Learning


Abstract
1. Introduction
2. Previous Related Works
3. Methodology
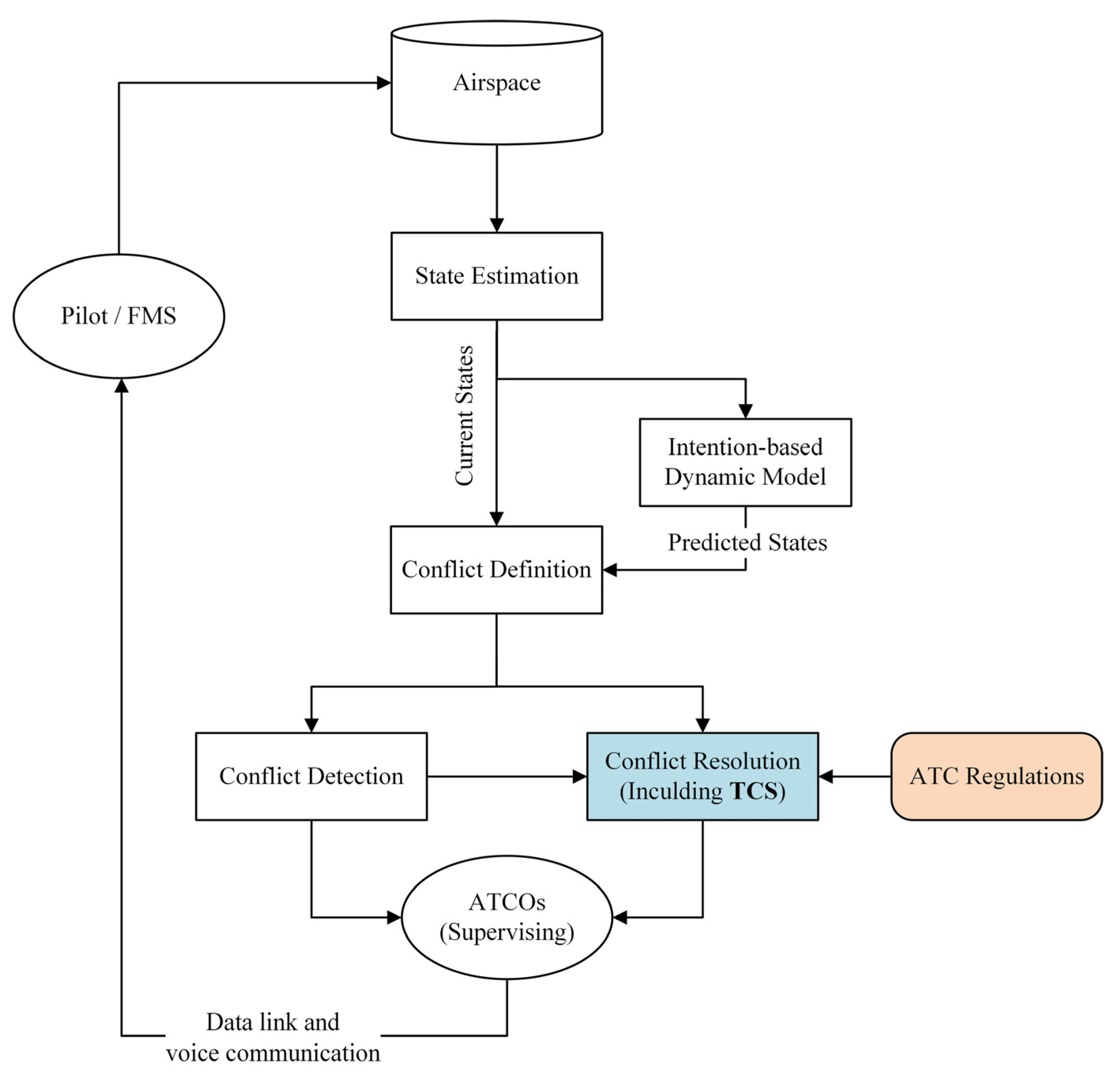
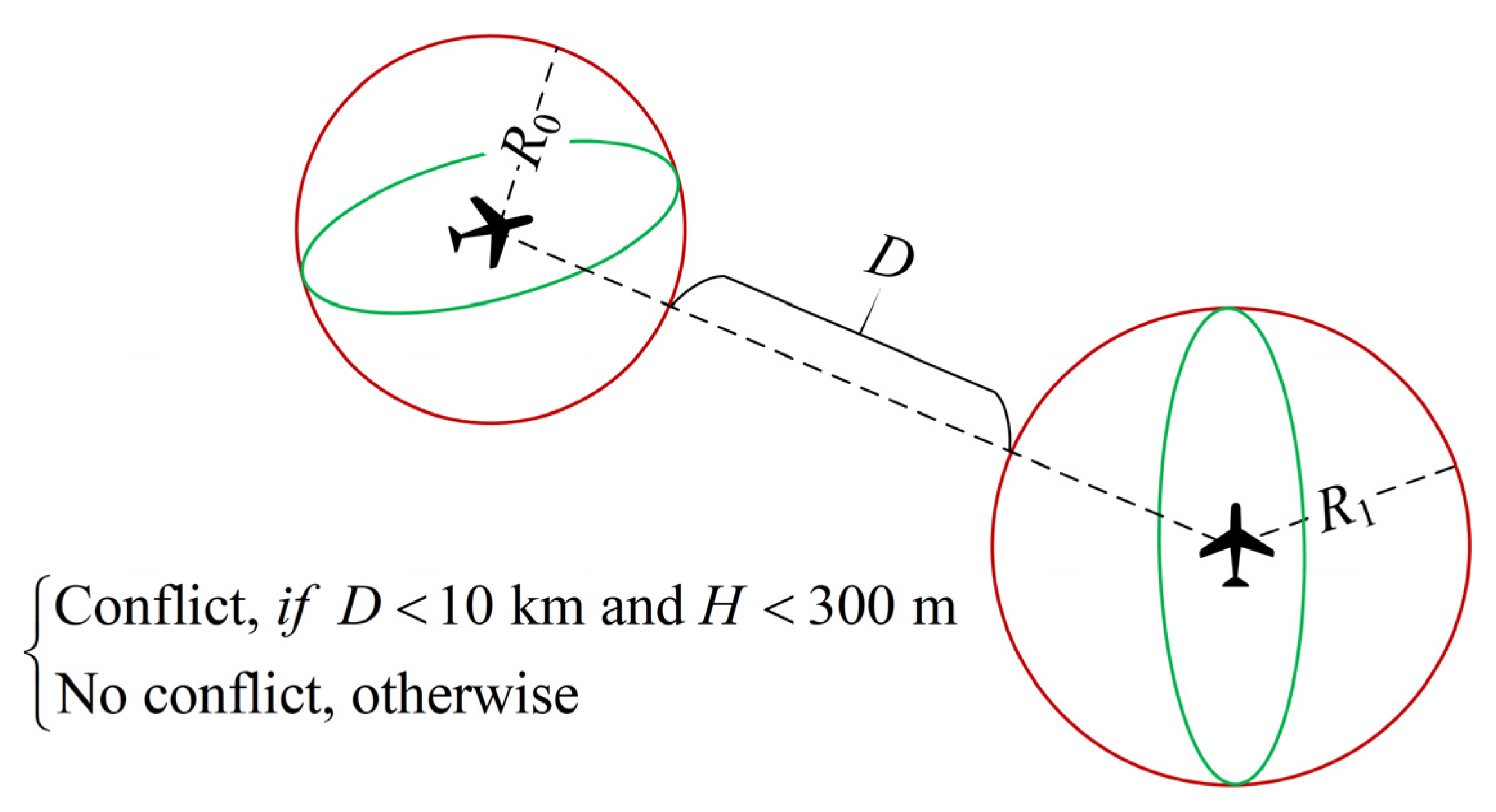
3.1. Conflict Detection and Resolution Framework
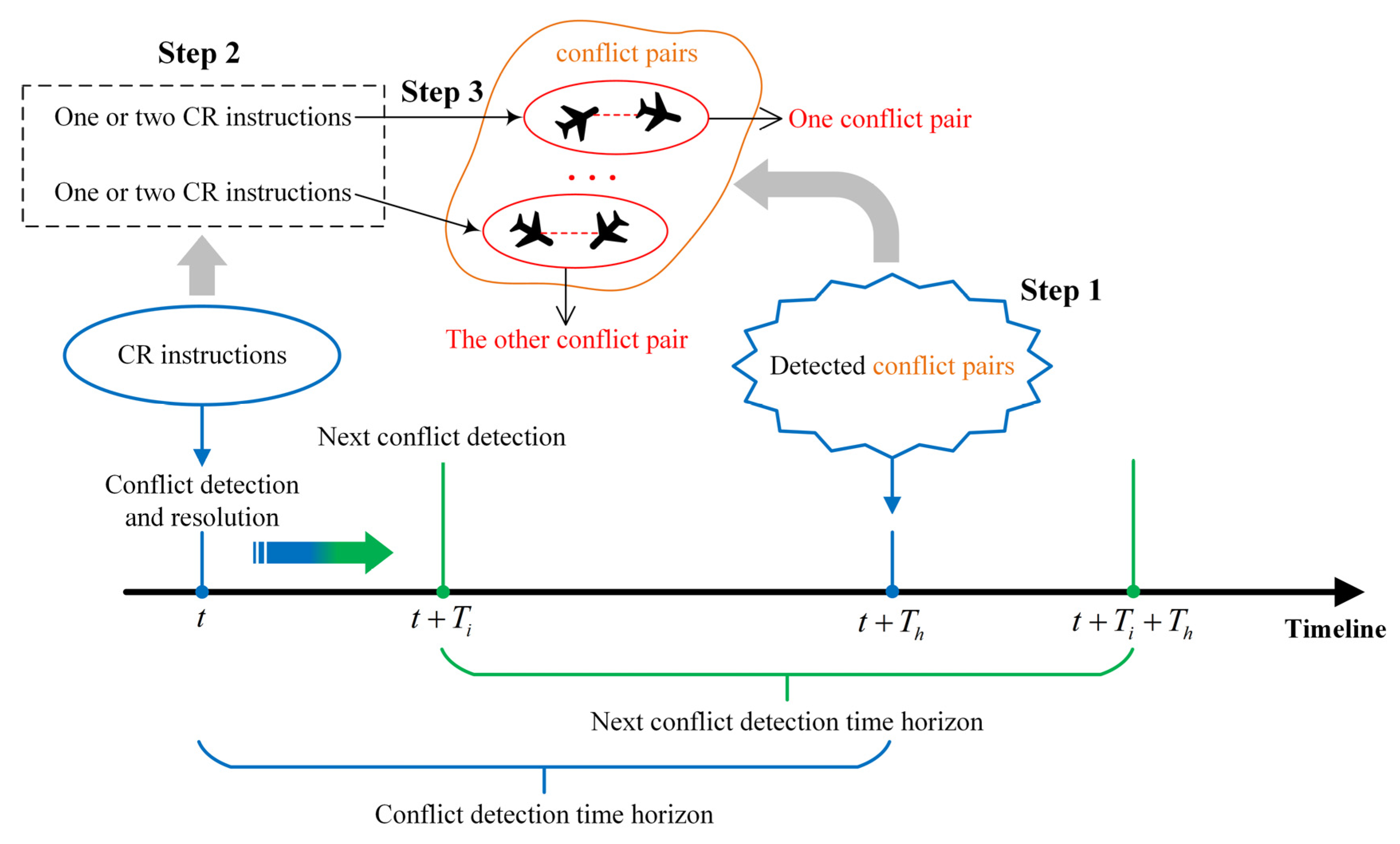
- Step 1: Conflict detection. At , the proposed mechanism detects whether there are conflict pairs at (a conflict pair is an aircraft conflict involving two aircraft). If there are no conflict pairs, the subsequent conflict detection is performed after . If there are conflict pairs, the conflict resolution session is initiated.
- Step 2: Conflict resolution. One or two CR instructions are generated for each conflict pair in turn at time (if a single CR instruction cannot resolve the conflict pair, two CR instructions are generated for each of the conflicting aircraft to execute).
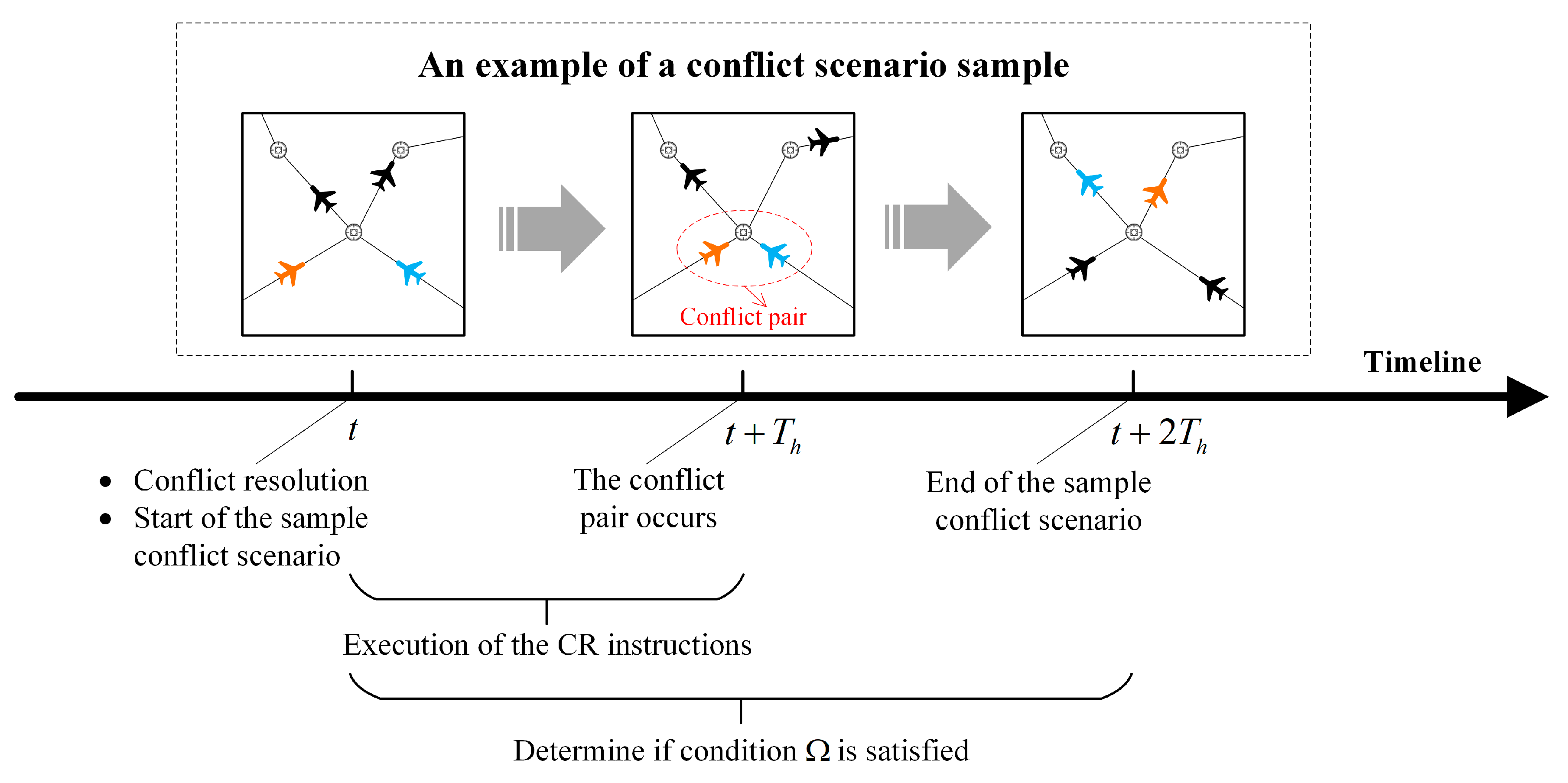
- Step 3: Scheme selection. Let CONDITION be the condition for successfully resolving a conflict pair, i.e., the given CR instructions need to ensure that there is no conflict between the two aircraft in the conflict pair at and that there is no conflict between the two conflicting aircraft and the neighbouring aircraft at . CONDITION involves the time horizon and neighbouring aircraft in order to avoid secondary conflicts. If the CR instructions satisfy CONDITION , they are sent to the controller; otherwise, the controller resolves the conflict manually. The subsequent conflict detection is then started after .For example, at , the detection conflicts occur at : aircraft A and B are in conflict, and aircraft A and C are in conflict. Thus, two conflict pairs can be formed: A–B and A–C. Depending on the severity of the conflict pairs (measured, for example, by the distance between conflicting aircraft), A–B is assumed to be a high priority, and A–C is the next highest priority. At , CR instructions are first generated to resolve the A–B conflict pair, and then additional CR instructions are generated to resolve the A–C conflict pair. It is then determined whether the CR instructions satisfy CONDITION to determine whether they can be sent to the controller. Finally, after , the subsequent conflict detection is started.
3.2. Conflict Resolution Model
3.2.1. Conflict Resolution Model Based on Markov Decision Process
- Based on the state (), the TCS agent generates and executes an action () (giving the CR instruction corresponding to ) and then receives the reward (). contains the airspace situation at and the predicted airspace situation a while after for the agent to receive sufficiently comprehensive information. The trajectory prediction determines whether CONDITION is satisfied after executes the CR instruction. If the condition is met, the conflict pair is successfully resolved, and the terminal state is reached.
- Suppose the conflict pair is not successfully resolved. In that case, the state is transferred from to ( contains the airspace situation at and the predicted airspace situation for a while after the CR instruction has been executed by ). The TCS agent generates and executes an action () (giving the CR instruction corresponding to ) based on the latest state () and then receives the reward (). Subsequently, a terminal state is reached. If CONDITION is satisfied, the TCS agent successfully resolves the conflict pair; otherwise, the conflict resolution fails.
3.2.2. MDP Description
- (1)
- State space
- (2)
- Action space
- (3)
- Reward function
- (a)
- The primary goal is to ensure that the conflict pair is resolved; therefore, if it succeeds in resolving the conflict pair, the agent should be rewarded heavily. Conversely, if it fails, it should be given a substantial penalty. A conflict resolution failure occurs when the TCS agent cannot satisfy condition , even after giving CR instructions to the two aircraft in the conflict pair. Accordingly, the reward function () can be expressed as:where the constant is .
- (b)
- The actions given by the TCS agent must be executable. If these actions breach the ATC regulations, the agent will be punished; otherwise, it will be rewarded. The ATC regulations are defined in the second paragraph of Section 3.1. Therefore, the reward function is expressed as:where the constant is . The value of should be set lower than that of because the primary goal is to resolve the conflict pair.
- (c)
- Let be the number of conflicts between the aircraft in the conflict pair plus the number of conflicts between the aircraft in the conflict pair and the neighbouring aircraft during ; then:where the negative coefficient is . By punishing the agent with , the agent can learn to reduce conflicts in the future and improve its ability to satisfy condition .
3.3. Training Environment
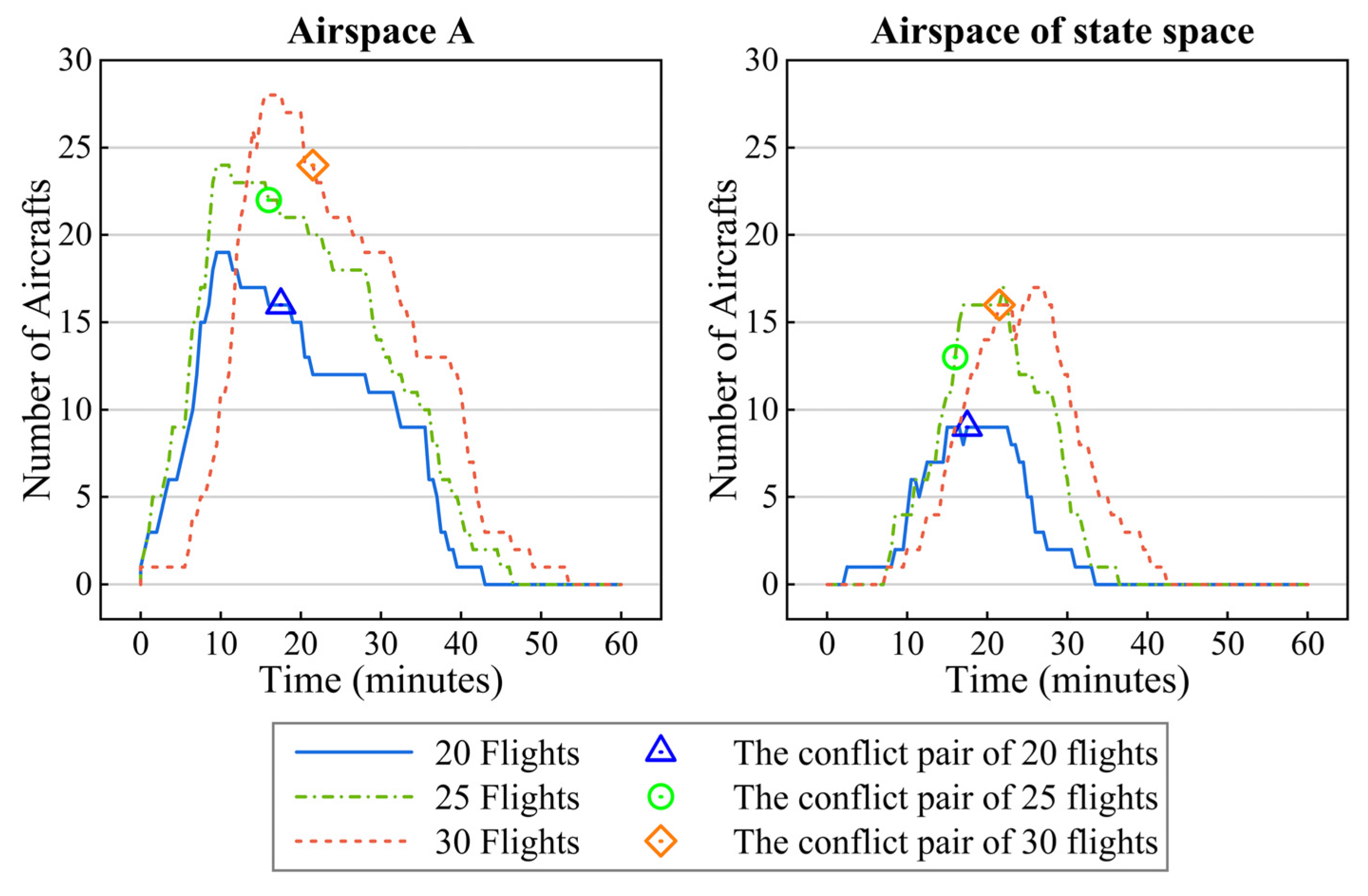
3.3.1. Conflict Scenario Samples
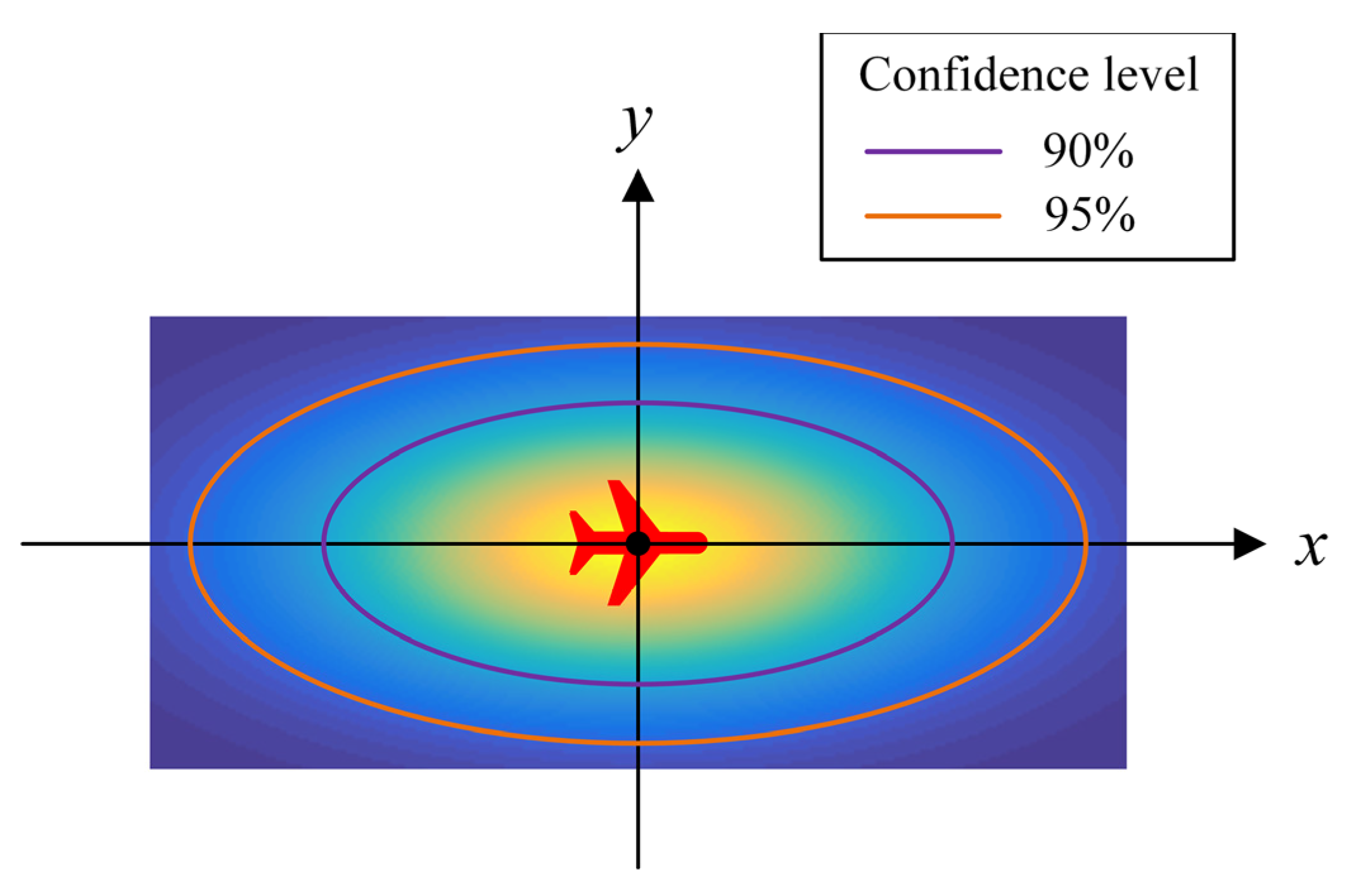
3.3.2. Uncertainty of Prediction
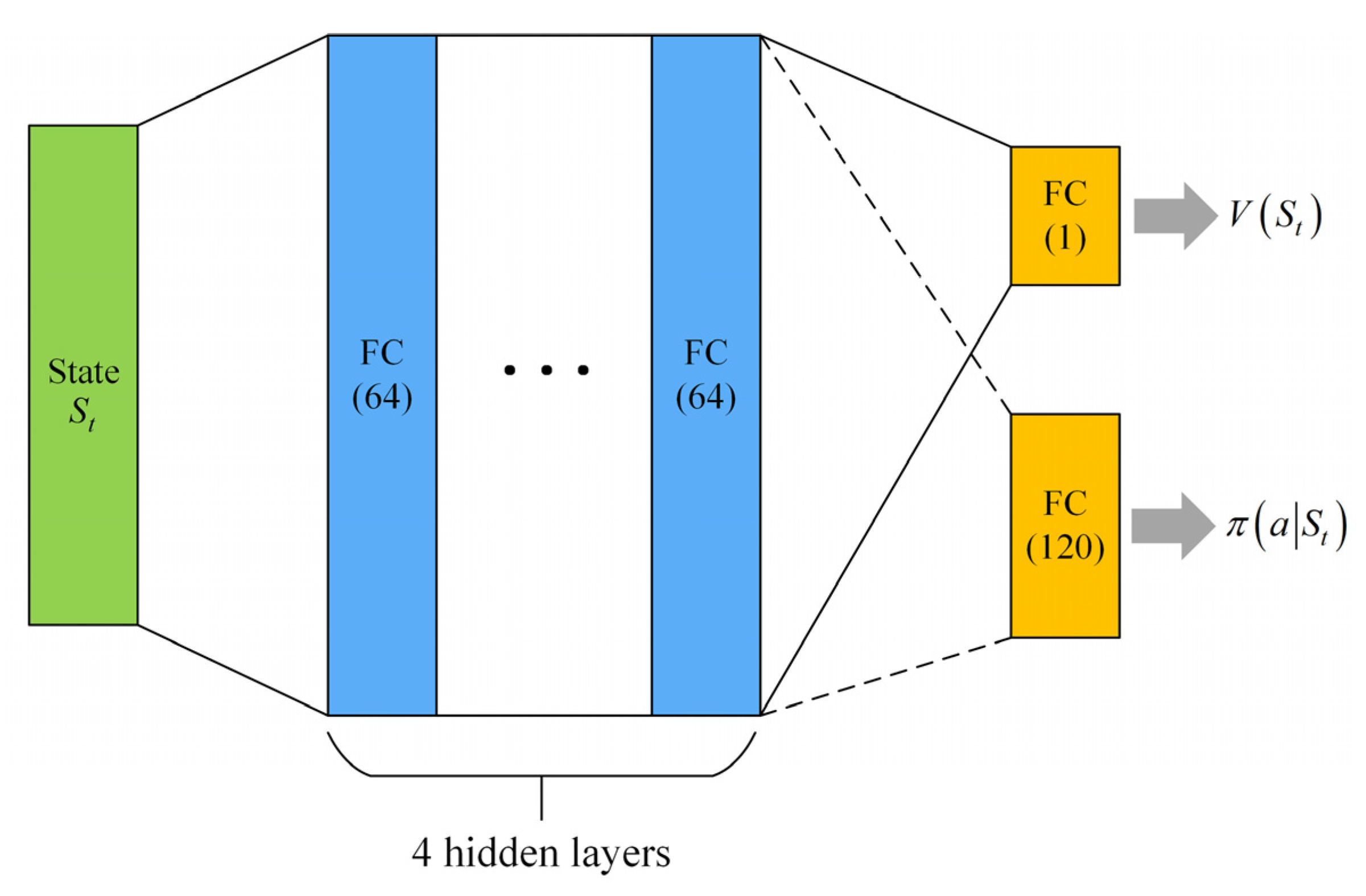
3.4. Resolution Scheme Based on ACKTR
3.4.1. Actor–Critic Using Kronecker-Factored Trust Region (ACKTR)
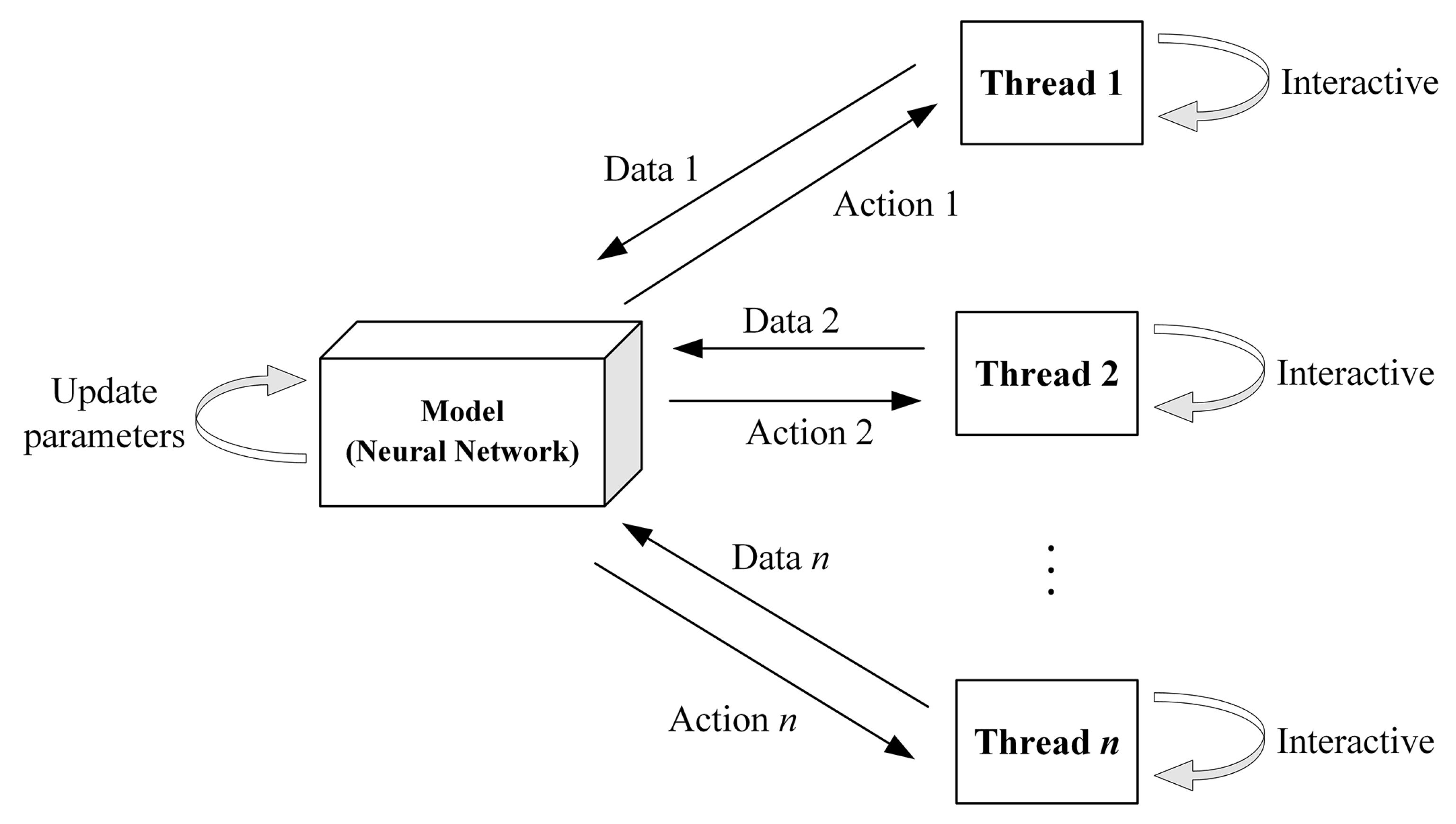
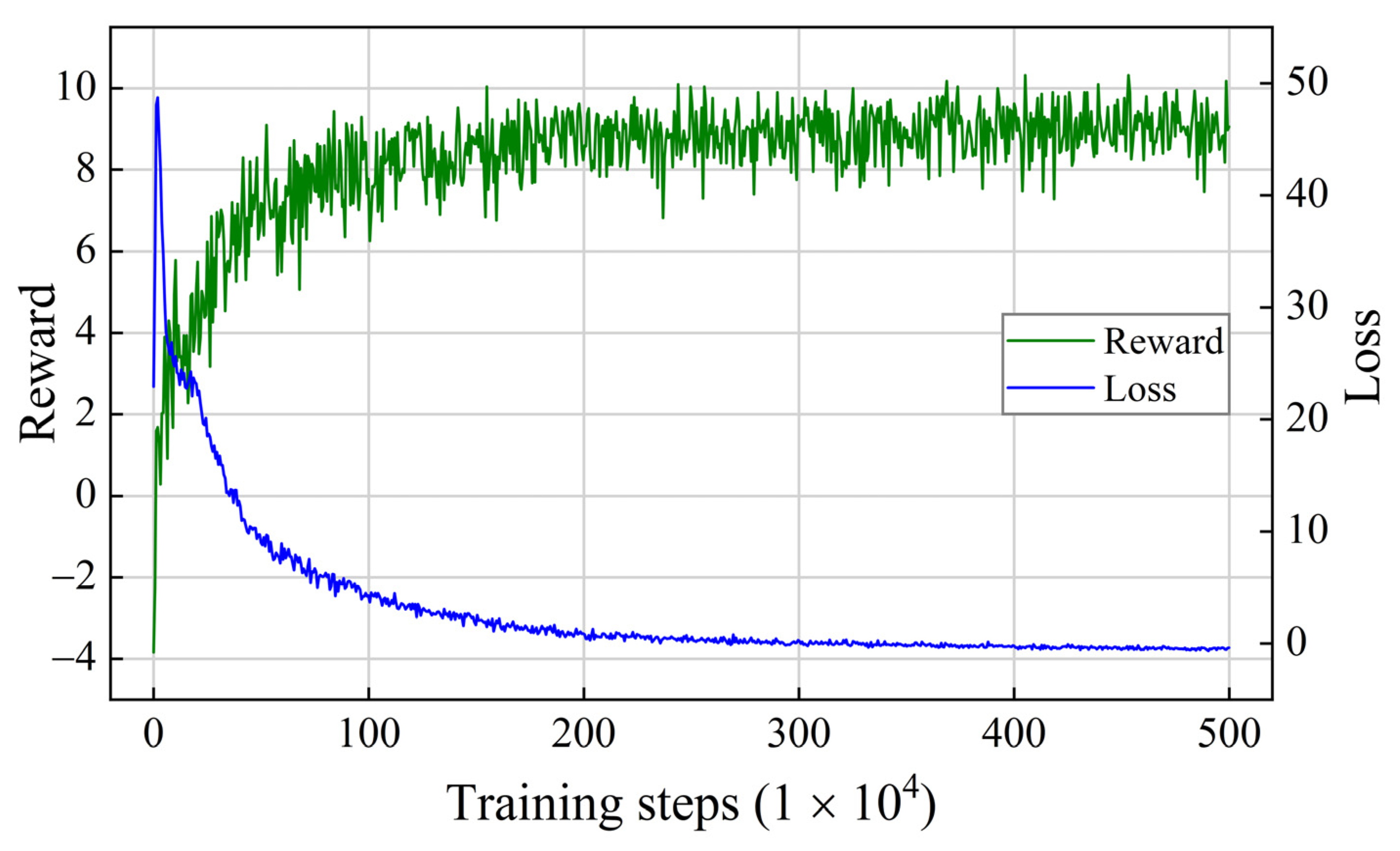
3.4.2. Training Process
| Algorithm 1: ACKTR Algorithm for Training the TCS Agent | |
| 1: | Initialize the parameter of the global network. |
| 2: | Loop through iterations . |
| 3: | Each thread selects a conflict scenario sample randomly and initializes the state . |
| 4: | Loop through the steps . |
| 5: | Each thread generates its own trajectory with its policy . |
| 6: | Until the steps end. |
| 7: | Summarise the trajectory of each thread and calculate the loss function according to Equation (13). |
| 8: | For the layer of the global network, do: |
| 9: | , in the calculation of and , . |
| 10: | End for. |
| 11: | Use K-FAC to approximate the natural gradient to update the parameters of the global network: . |
| 12: | Until the iterations end. |
4. Results
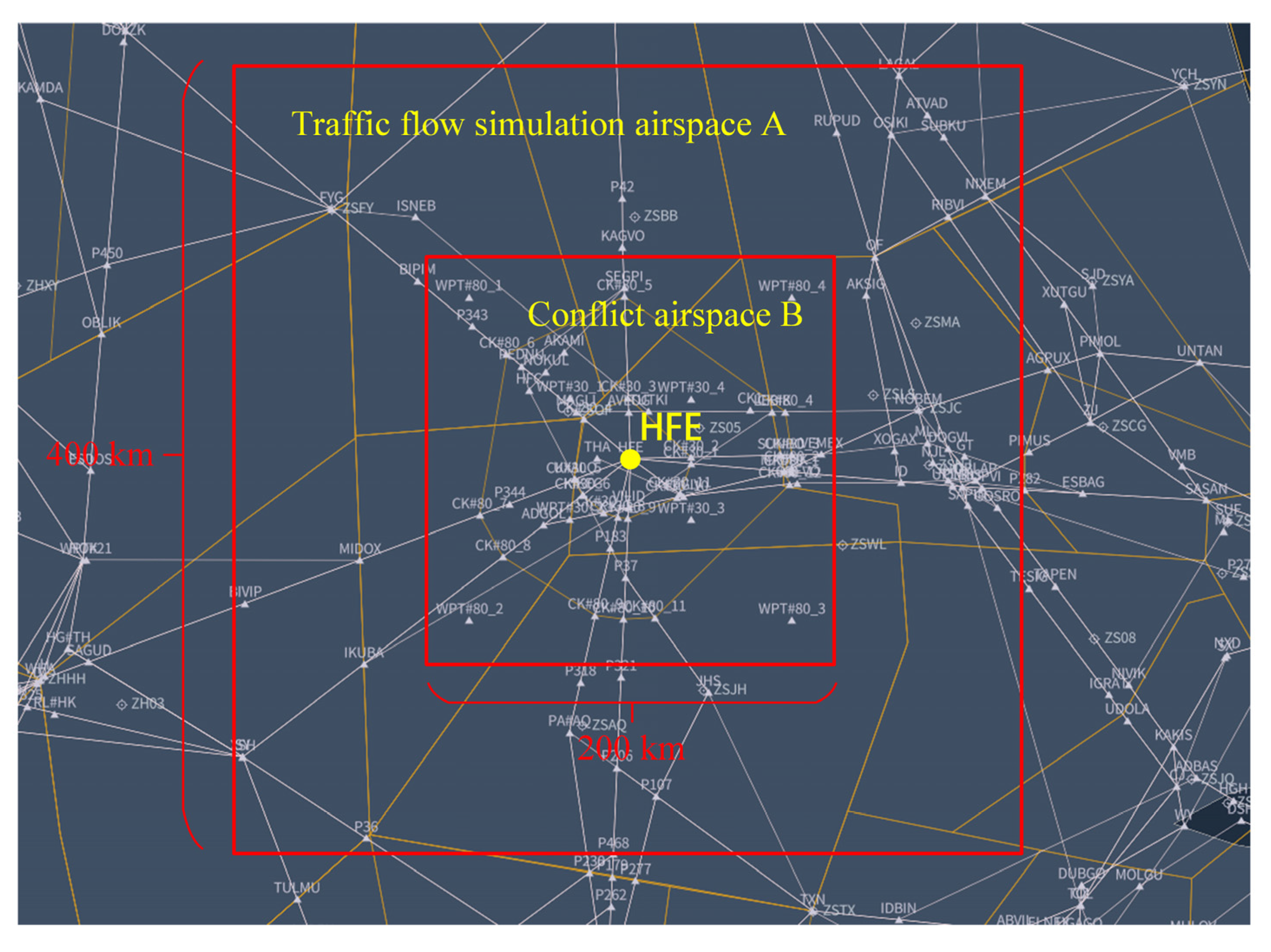
4.1. Experimental Setup
- (1)
- Experiment and simulation environment
- (2)
- Conflict scenario samples
- Step 1: From the simulation flight plan set, 20–30 flights were randomly loaded, and the departure times of the flights were changed by adding random amounts to ensure that the flights arrived at airspace A within the 10 min window;
- Step 2: The detected conflict pairs in airspace B were recorded during the simulation. For each conflict pair, we determined whether the conflict scenario construction condition described in Section 3.3.1 was met. If so, a conflict scenario sample was generated for the period in which the conflict occurred;
- Step 3: Steps 1 and 2 were repeated until the number of conflict scenario samples satisfied the requirements.
- (3)
- Baseline algorithms
4.2. Experimental Analysis
- (1)
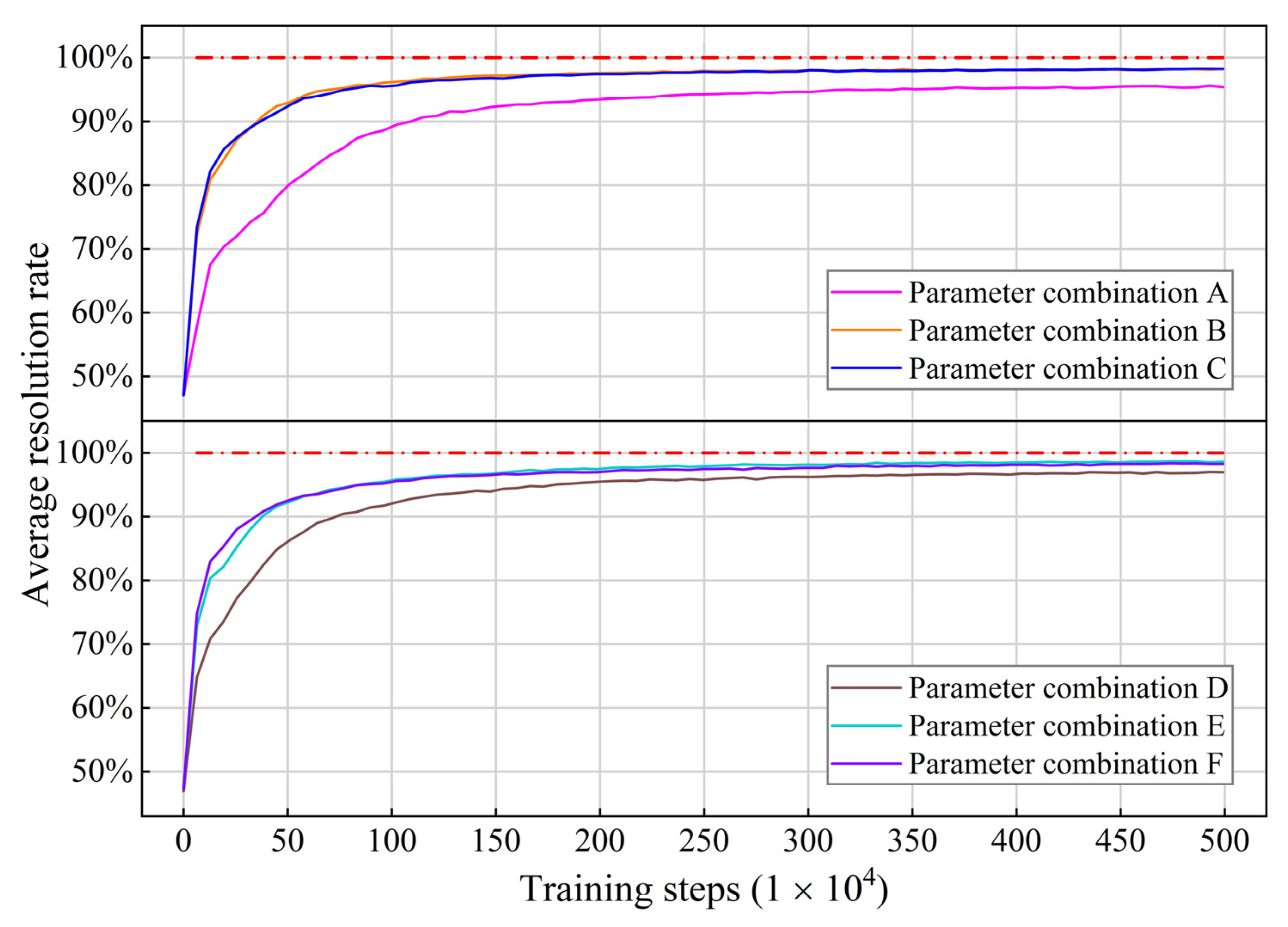
- Determining the parameter combination
- (2)
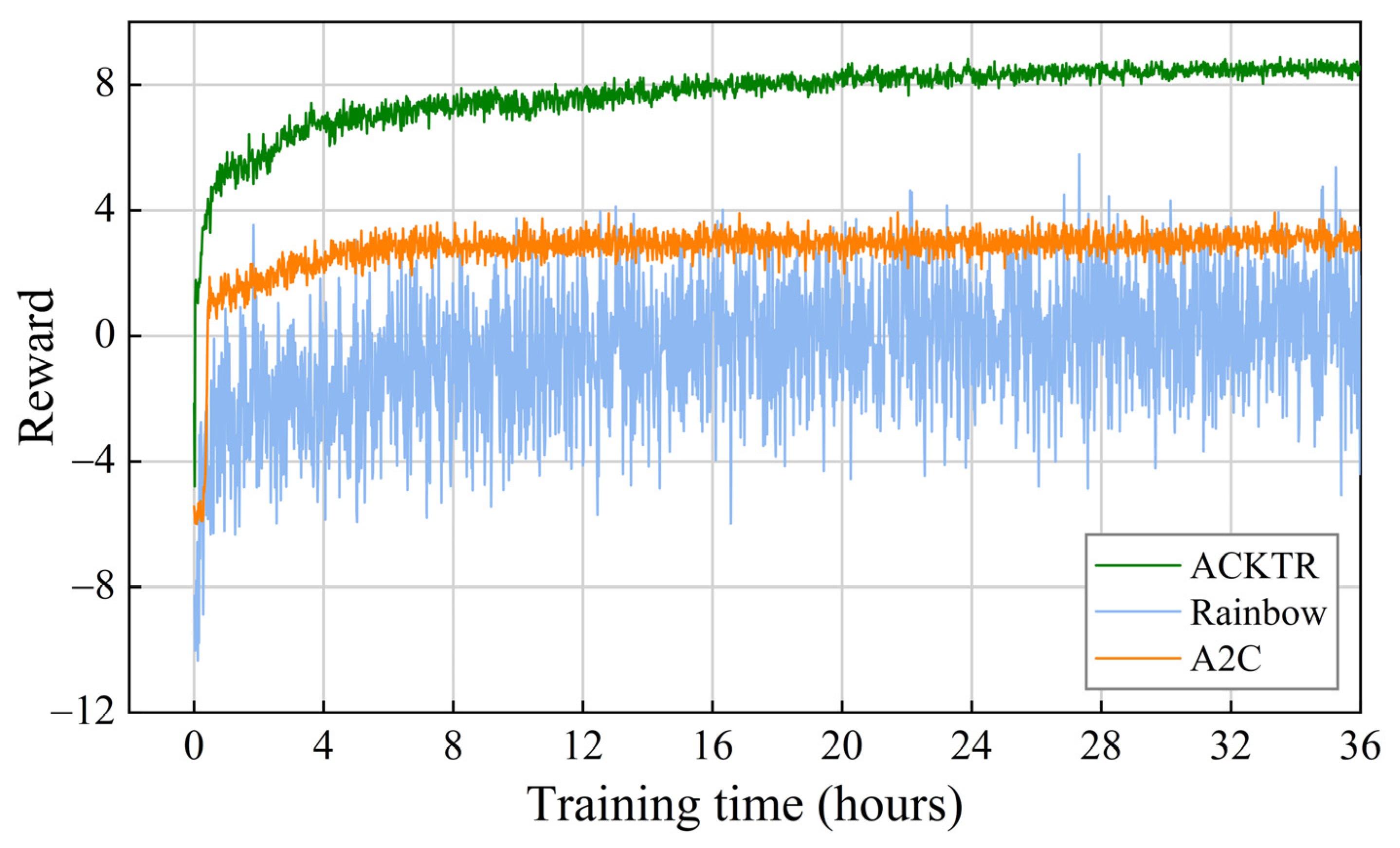
- Comparison with the baseline algorithms
- (3)
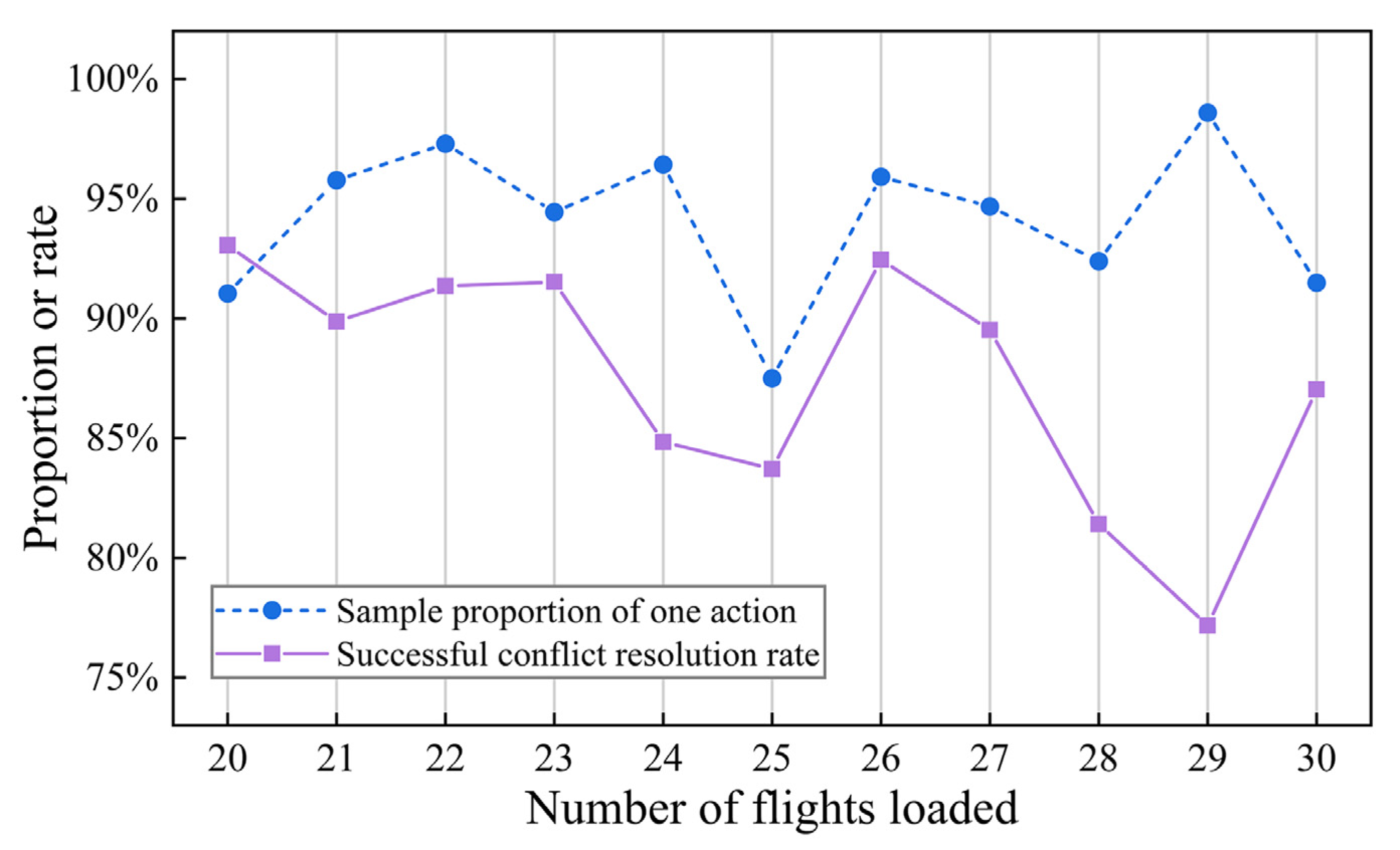
- Model performance based on the testing set
- (4)
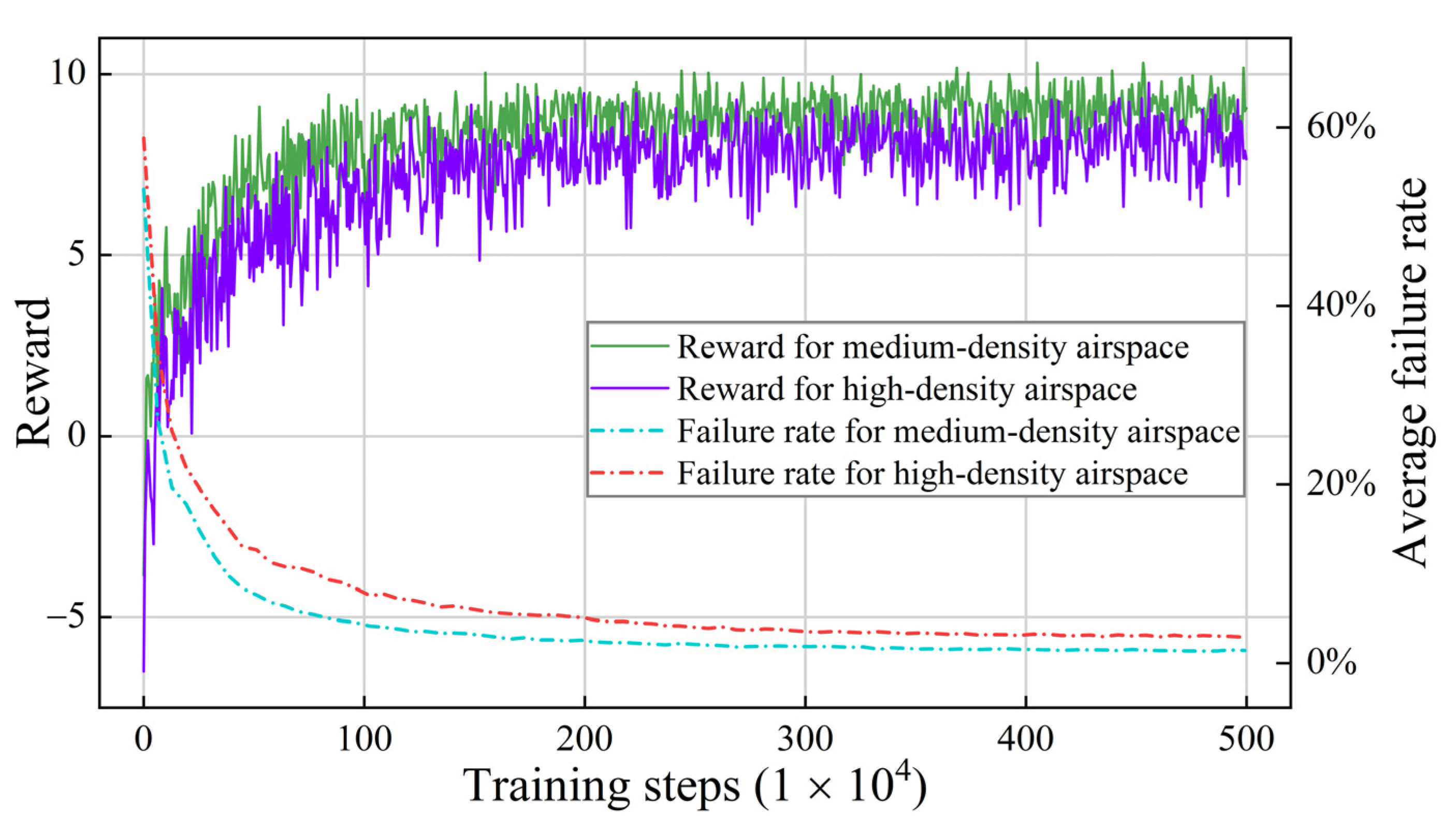
- Performance of the model in higher-density airspace
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Walker, C. All-Causes Delay and Cancellations to Air Transport in Europe: Annual Report for 2019; Eurocontrol: Brussels, Belgium, 2019; Available online: https://www.eurocontrol.int/publication/all-causes-delay-and-cancellations-air-transport-europe-2019 (accessed on 23 October 2022).
- Federal Aviation Administration. Air Traffic by the Numbers [Internet]; Federal Aviation Administration: Washington, DC, USA, 2022. Available online: https://www.faa.gov/air_traffic/by_the_numbers/media/Air_Traffic_by_the_Numbers_2022.pdf (accessed on 23 October 2022).
- Civil Aviation Administration of China. Statistical Bulletin of Civil Aviation Industry Development in 2020 [Internet]; Civil Aviation Administration of China: Beijing, China, 2022. Available online: http://www.caac.gov.cn/en/HYYJ/NDBG/202202/P020220222322799646163.pdf (accessed on 23 October 2022).
- Isaacson, D.R.; Erzberger, H. Design of a conflict detection algorithm for the Center/TRACON automation system. In Proceedings of the 16th DASC, AIAA/IEEE Digital Avionics Systems Conference: Reflections to the Future, Irvine, CA, USA, 30 October 1997. [Google Scholar]
- Brudnicki, D.J.; Lindsay, K.S.; McFarland, A.L. Assessment of field trials, algorithmic performance, and benefits of the user request evaluation tool (uret) conflict probe. In Proceedings of the 16th DASC, AIAA/IEEE Digital Avionics Systems Conference: Reflections to the Future, Irvine, CA, USA, 30 October 1997. [Google Scholar]
- Torres, S.; Dehn, J.; McKay, E.; Paglione, M.M.; Schnitzer, B.S. En-Route Automation Modernization (ERAM) trajectory model evolution to support trajectory-based operations (TBO). In Proceedings of the Digital Avionics Systems Conference. IEEE/AIAA. 34th 2015. (DASC 2015) (3 VOLS), Prague, Czech Republic, 13–17 September 2015; p. 1A6-1. [Google Scholar]
- Brooker, P. Airborne Separation Assurance Systems: Towards a work programme to prove safety. Saf. Sci. 2004, 42, 723–754. [Google Scholar] [CrossRef]
- Kuchar, J.E.; Drumm, A.C. The traffic alert and collision avoidance system. Linc. Lab. J. 2007, 16, 277. [Google Scholar]
- Kochenderfer Mykel, J.; Jessica EHolland James, P. Chryssanthacopoulos: ‘Next-Generation Airborne Collision Avoidance System’; Massachusetts Institute of Technology-Lincoln Laboratory: Lexington, MA, USA, 2012. [Google Scholar]
- Owen, M.P.; Panken, A.; Moss, R.; Alvarez, L.; Leeper, C. ‘ACAS Xu: Integrated collision avoidance and detect and avoid capability for UAS’. In Proceedings of the AIAA 2019 38th Digital Avionics System Conference (DASC), San Diego, CA, USA, 8–12 September 2019; pp. 1–10. [Google Scholar]
- Eurocontrol. European ATM Master Plan [Internet]; Eurocontrol: Brussels, Belgium, 2020; Available online: https://www.sesarju.eu/sites/default/files/documents/reports/European%20ATM%20Master%20Plan%202020%20Exec%20View.pdf (accessed on 23 October 2022).
- International Civil Aviation Organization. Doc 9854, Global Air Traffic Management Operational Concept; International Civil Aviation Organization: Montreal, QC, Canada, 2005. [Google Scholar]
- Kuchar, J.K.; Yang, L.C. A review of conflict detection and resolution modeling methods. IEEE Trans. Intell. Transp. Syst. 2000, 1, 179–189. [Google Scholar] [CrossRef]
- Ribeiro, M.; Ellerbroek, J.; Hoekstra, J. Review of conflict resolution methods for manned and unmanned aviation. Aerospace 2020, 7, 79. [Google Scholar] [CrossRef]
- Tang, J. Conflict detection and resolution for civil aviation: A literature survey. IEEE Aerosp. Electron. Syst. Mag. 2019, 34, 20–35. [Google Scholar] [CrossRef]
- Soler, M.; Kamgarpour, M.; Lloret, J.; Lygeros, J. A hybrid optimal control approach to fuel-efficient aircraft conflict avoidance. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1826–1838. [Google Scholar] [CrossRef]
- Matsuno, Y.; Tsuchiya, T.; Matayoshi, N. Near-optimal control for aircraft conflict resolution in the presence of uncertainty. J. Guid. Control Dyn. 2016, 39, 326–338. [Google Scholar] [CrossRef]
- Liu, W.; Liang, X.; Ma, Y.; Liu, W. Aircraft trajectory optimisation for collision avoidance using stochastic optimal control. Asian J. Control 2019, 21, 2308–2320. [Google Scholar] [CrossRef]
- Cafieri, S.; Omheni, R. Mixed-integer nonlinear programming for aircraft conflict avoidance by sequentially applying velocity and heading angle changes. Eur. J. Oper. Res. 2017, 260, 283–290. [Google Scholar] [CrossRef]
- Cai, J.; Zhang, N. Mixed integer nonlinear programming for aircraft conflict avoidance by applying velocity and altitude changes. Arab. J. Sci. Eng. 2019, 44, 8893–8903. [Google Scholar] [CrossRef]
- Alonso-Ayuso, A.; Escudero, L.F.; Martín-Campo, F.J. Multiobjective optimisation for aircraft conflict resolution. A metaheuristic approach. Eur. J. Oper. Res. 2016, 248, 691–702. [Google Scholar] [CrossRef]
- Omer, J. A space-discretized mixed-integer linear model for air-conflict resolution with speed and heading maneuvers. Comput. Oper. Res. 2015, 58, 75–86. [Google Scholar] [CrossRef]
- Cecen, R.K.; Cetek, C. Conflict-free en-route operations with horizontal resolution manoeuvers using a heuristic algorithm. Aeronaut J. 2020, 124, 767–785. [Google Scholar] [CrossRef]
- Hong, Y.; Choi, B.; Oh, G.; Lee, K.; Kim, Y. Nonlinear conflict resolution and flow management using particle swarm optimisation. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3378–3387. [Google Scholar] [CrossRef]
- Cecen, R.K.; Saraç, T.; Cetek, C. Meta-heuristic algorithm for aircraft pre-tactical conflict resolution with altitude and heading angle change maneuvers. Top 2021, 29, 629–647. [Google Scholar] [CrossRef]
- Durand, N.; Alliot, J.; Noailles, J. Automatic aircraft conflict resolution using genetic algorithms. In Proceedings of the SAC ’96-ACM Symposium on Applied Computing, Philadelphia, PA, USA, 17–19 February 1996; pp. 289–298. [Google Scholar]
- Ma, Y.; Ni, Y.; Liu, P. Aircraft conflict resolution method based on ADS-B and genetic algorithm. In Proceedings of the 2013 Sixth International Symposium on Computational Intelligence and Design, Washington, DC, USA, 28–29 October 2013. [Google Scholar]
- Emami, H.; Derakhshan, F. Multi-agent based solution for free flight conflict detection and resolution using particle swarm optimisation algorithm. UPB Sci. Bull. Ser. C Electr. Eng. 2014, 76, 49–64. [Google Scholar]
- Sui, D.; Zhang, K. A tactical conflict detection and resolution method for en route conflicts in trajectory-based operations. J. Adv. Transp. 2022, 2022, 1–16. [Google Scholar] [CrossRef]
- Durand, N.; Guleria, Y.; Tran, P.; Pham, D.T.; Alam, S. A machine learning framework for predicting ATC conflict resolution strategies for conformal automation. In Proceedings of the 11th SESAR Innovation Days, Virtual, 7–9 December 2021. [Google Scholar]
- Kim, K.; Deshmukh, R.; Hwang, I. Development of data-driven conflict resolution generator for en-route airspace. Aerosp. Sci. Technol. 2021, 114, 106744. [Google Scholar] [CrossRef]
- Van Rooijen, S.J.; Ellerbroek, J.; Borst, C.; van Kampen, E. Toward individual-sensitive automation for air traffic control using convolutional neural networks. J. Air. Transp. 2020, 28, 105–113. [Google Scholar] [CrossRef]
- Wang, Z.; Li, H.; Wang, J.; Shen, F. Deep reinforcement learning based conflict detection and resolution in air traffic control. IET Intell. Transp. Syst. 2019, 13, 1041–1047. [Google Scholar] [CrossRef]
- Pham, D.T.; Tran, N.P.; Goh, S.K.; Alam, S.; Duong, V. Reinforcement learning for two-aircraft conflict resolution in the presence of uncertainty. In Proceedings of the 2019 IEEE-RIVF International Conference on Computing and Communication Technologies (RIVF), Danang, Vietnam, 20–22 March 2019; pp. 1–6. [Google Scholar]
- Tran, P.N.; Pham, D.T.; Goh, S.K.; Alam, S.; Duong, V. An interactive conflict solver for learning air traffic conflict resolutions. J. Aerosp. Inf. Syst. 2020, 17, 271–277. [Google Scholar] [CrossRef]
- Sui, D.; Xu, W.; Zhang, K. Study on the resolution of multi-aircraft flight conflicts based on an IDQN. Chin. J. Aeronaut. 2022, 35, 195–213. [Google Scholar] [CrossRef]
- Dalmau-Codina, R.; Allard, E. Air traffic control using message passing neural networks and multi-agent reinforcement learning. In Proceedings of the 10th SESAR Innovation Days (SID), Virtual, 7–10 December 2020. [Google Scholar]
- Brittain, M.; Wei, P. One to any: Distributed conflict resolution with deep multi-agent reinforcement learning and long short-term memory. In Proceedings of the AIAA Scitech 2021, Virtual, 11–15 & 19–21 January 2021; p. 1952. [Google Scholar]
- Brittain, M.; Wei, P.; Brittain, M. Scalable autonomous separation assurance with heterogeneous multi-agent reinforcement learning. IEEE Trans. Autom. Sci. Eng. 2022, 19, 2837–2848. [Google Scholar] [CrossRef]
- Isufaj, R.; Aranega Sebastia, D.; Angel Piera, M. Toward conflict resolution with deep multi-agent reinforcement learning. J. Air Transp. 2022, 30, 71–80. [Google Scholar] [CrossRef]
- Ribeiro, M.; Ellerbroek, J.; Hoekstra, J. Determining optimal conflict avoidance manoeuvres at high densities with reinforcement learning. In Proceedings of the Tenth SESAR Innovation Days Virtual Conference, Virtual, 7–10 December 2020; pp. 7–10. [Google Scholar]
- Ribeiro, M.; Ellerbroek, J.; Hoekstra, J. Improvement of conflict detection and resolution at high densities through reinforcement learning. In Proceedings of the ICRAT 2020: International Conference on Research in Air Transportation, Tampa, FL, USA, 23–26 June 2020. [Google Scholar]
- International Civil Aviation Organization. Doc 4444, Procedures for Air Navigation Services—Air Traffic Management; International Civil Aviation Organization: Montreal, QC, Canada, 2016. [Google Scholar]
- Lauderdale, T. Probabilistic conflict detection for robust detection and resolution. In Proceedings of the 12th AIAA Aviation Technology, Integration, and Operations (ATIO) Conference and 2012 14th AIAA/ISSMO Multidisciplinary Analysis and Optimisation Conference, Indianpolis, IN, USA, 17–19 September 2012; p. 5643. [Google Scholar]
- Wu, Y.; Mansimov, E.; Grosse, R.B.; Liao, S.; Ba, J. Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation. Adv. Neural Inf. Process. Syst. 2017, 30, 1–14. [Google Scholar]
- Martens, J.; Grosse, R. Optimizing neural networks with kronecker-factored approximate curvature. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; pp. 2408–2417. [Google Scholar]
- Ba, J.; Grosse, R.; Martens, J. Distributed second-order optimisation using Kronecker-Factored approximations. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Civil Aviation Administration of China. Report of Civil Aviation Airspace Development in China 2019; Civil Aviation Administration of China: Beijing, China, 2020. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: Palo Alto, CA, USA, 2018. [Google Scholar]
- OpenAI, Inc., San Francisco. Openai.com/blog/baselines-acktr-a2c. Available online: https://openai.com/blog/baselines-acktr-a2c/ (accessed on 23 October 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Scholars | Specific Methods | Assisting ATCOs | CR Manoeuvres | Uncertainty | Complete and Detailed CD&R | Solution Time |
|---|---|---|---|---|---|---|---|
| Optimal control | Soler [16] | Hybrid optimal control | ✕ | 2D | ✕ | ✕ | 474 s |
| Matsuno [17] | Stochastic near-optimal control | ✕ | 2D | ◯ | ✕ | 38–231 s | |
| Liu [18] | Stochastic optimal control | ✕ | 2D | ◯ | ✕ | 115.3 s | |
| Mathematical programming | Cafieri [19] | MINLP | ◯ | 2D | ✕ | ✕ | 0.04–2561.98 s |
| Cai [20] | MINLP | ◯ | 3D | ✕ | ✕ | 3.131–75.102 s | |
| Alonso-Ayuso [21] | MINLP | ◯ | 3D | ✕ | ✕ | 0.32–24.00 s | |
| Omer [22] | MILP | ◯ | 2D | ✕ | ✕ | Within 8.3 s | |
| Cecen [23] | MILP | ✕ | 2D | ✕ | ✕ | 3.8–17 s | |
| Hong [24] | Nonlinear programming | ◯ | 2D | ✕ | ✕ | Within 11 s | |
| Cecen [25] | Two-step optimisation | ✕ | 3D | ✕ | ✕ | Within 240 s | |
| Swarm intelligence optimisation or search methods | Durand [26] | GA | ◯ | 2D | ◯ | ✕ | - |
| Ma [27] | GA | ✕ | 2D | ✕ | ✕ | - | |
| Emami [28] | PSO | ✕ | 3D | ✕ | ✕ | - | |
| Sui [29] | MCTS | ◯ | 3D | ✕ | ◯ | Average 12.44 s | |
| Supervised learning | Durand [30] | Random forests | ◯ | 2D | ✕ | ✕ | - |
| Kim [31] | Hierarchical classification | ◯ | 3D | ✕ | ✕ | Within 0.1 s | |
| Van Rooijen [32] | Convolutional neural networks | ◯ | 2D | ✕ | ✕ | - | |
| DRL | Wang [33] | KCAC | ◯ | 2D | ✕ | ✕ | 0.762 s |
| Pham [34] | DDPG | ◯ | 2D | ◯ | ✕ | - | |
| Tran [35] | DDPG | ◯ | 2D | ✕ | ✕ | - | |
| Sui [36] | IDQN | ◯ | 3D | ✕ | ✕ | Average 0.011 s | |
| Dalmau-Codina [37] | MARL | ◯ | 2D | ✕ | ✕ | - | |
| Brittain [38] | PPO | ✕ | 2D | ✕ | ◯ | - | |
| Brittain [39] | PPO | ✕ | 2D | ✕ | ◯ | - | |
| Isufaj [40] | MADDPG | ✕ | 2D | ✕ | ✕ | - | |
| Ribeiro [41] | DDPG and MVP | ✕ | 3D | ✕ | ✕ | - | |
| Ribeiro [42] | DDPG and MVP | ✕ | 2D | ✕ | ✕ | - |
| CR Manoeuvre | Resolution Action | Adjustment Value | Waiting Time |
|---|---|---|---|
| Altitude adjustment | Climbing or descending/m | 300, 600, 900 | 20x s |
| Speed adjustment | Acceleration or deceleration/kt | 10, 20 | |
| Heading adjustment | Right or left offset/nm | 6 |
| Hyperparameter | Parameter Value | Hyperparameter | Parameter Value |
|---|---|---|---|
| Total training steps | 5,000,000 | 0.0005 | |
| Discount factor | 0.99 | 0.6 | |
| Number of threads | 32 | 0.3 | |
| Interaction steps per thread | 2 | Learning rate |
| Combination Name | Learning Rate | |||
|---|---|---|---|---|
| Combination A | 5.0 × 10−4 | 5 | 0.2 | |
| Combination B | 5.0 × 10−4 | 10 | 0.6 | |
| Combination C | 5.0 × 10−4 | 20 | 1 | |
| Combination D | 1.0 × 10−3 | 5 | 0.2 | |
| Combination E | 1.0 × 10−3 | 10 | 0.6 | |
| Combination F | 1.0 × 10−3 | 20 | 1 |
| Combination Name | Average Reward after Four Million Steps Divided by Optimal Reward | Average Resolution Rate after Four Million Steps |
|---|---|---|
| A | 72.19% | 95.39% |
| B | 84.31% | 98.14% |
| C | 87.13% | 98.15% |
| D | 73.16% | 96.86% |
| E | 85.16% | 98.58% |
| F | 86.20% | 98.21% |
| Algorithm | Average Reward after 30 h | Average Resolution Rate after 30 h |
|---|---|---|
| ACKTR | 9.03 | 98.58% |
| A2C | 3.07 | 79.32% |
| Rainbow | 0.16 | 67.82% |
| Algorithm | Conflict Resolution Rate | Average Reward | Median Reward |
|---|---|---|---|
| ACKTR | 87.10% | 6.54 | 10.60 |
| Rainbow | 75.30% | 2.73 | 10.60 |
| A2C | 83.60% | 5.29 | 10.60 |
| Random agent | 46.00% |
| CR Manoeuvre | Frequency | CR Manoeuvre | Frequency |
|---|---|---|---|
| Climbing (300 m) | 188 | Acceleration (10 kt) | 0 |
| Climbing (600 m) | 116 | Acceleration (20 kt) | 0 |
| Climbing (900 m) | 11 | Deceleration (10 kt) | 0 |
| Descending (300 m) | 253 | Deceleration (20 kt) | 3 |
| Descending (600 m) | 486 | Right offset (6 nm) | 6 |
| Descending (900 m) | 117 | Left offset (6 nm) | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sui, D.; Ma, C.; Wei, C. Tactical Conflict Solver Assisting Air Traffic Controllers Using Deep Reinforcement Learning. Aerospace 2023, 10, 182. https://doi.org/10.3390/aerospace10020182
Sui D, Ma C, Wei C. Tactical Conflict Solver Assisting Air Traffic Controllers Using Deep Reinforcement Learning. Aerospace. 2023; 10(2):182. https://doi.org/10.3390/aerospace10020182
Chicago/Turabian StyleSui, Dong, Chenyu Ma, and Chunjie Wei. 2023. "Tactical Conflict Solver Assisting Air Traffic Controllers Using Deep Reinforcement Learning" Aerospace 10, no. 2: 182. https://doi.org/10.3390/aerospace10020182
APA StyleSui, D., Ma, C., & Wei, C. (2023). Tactical Conflict Solver Assisting Air Traffic Controllers Using Deep Reinforcement Learning. Aerospace, 10(2), 182. https://doi.org/10.3390/aerospace10020182