
Automatic Marine Debris Inspection


Abstract
1. Introduction
2. Methods
- Dataset
- B.
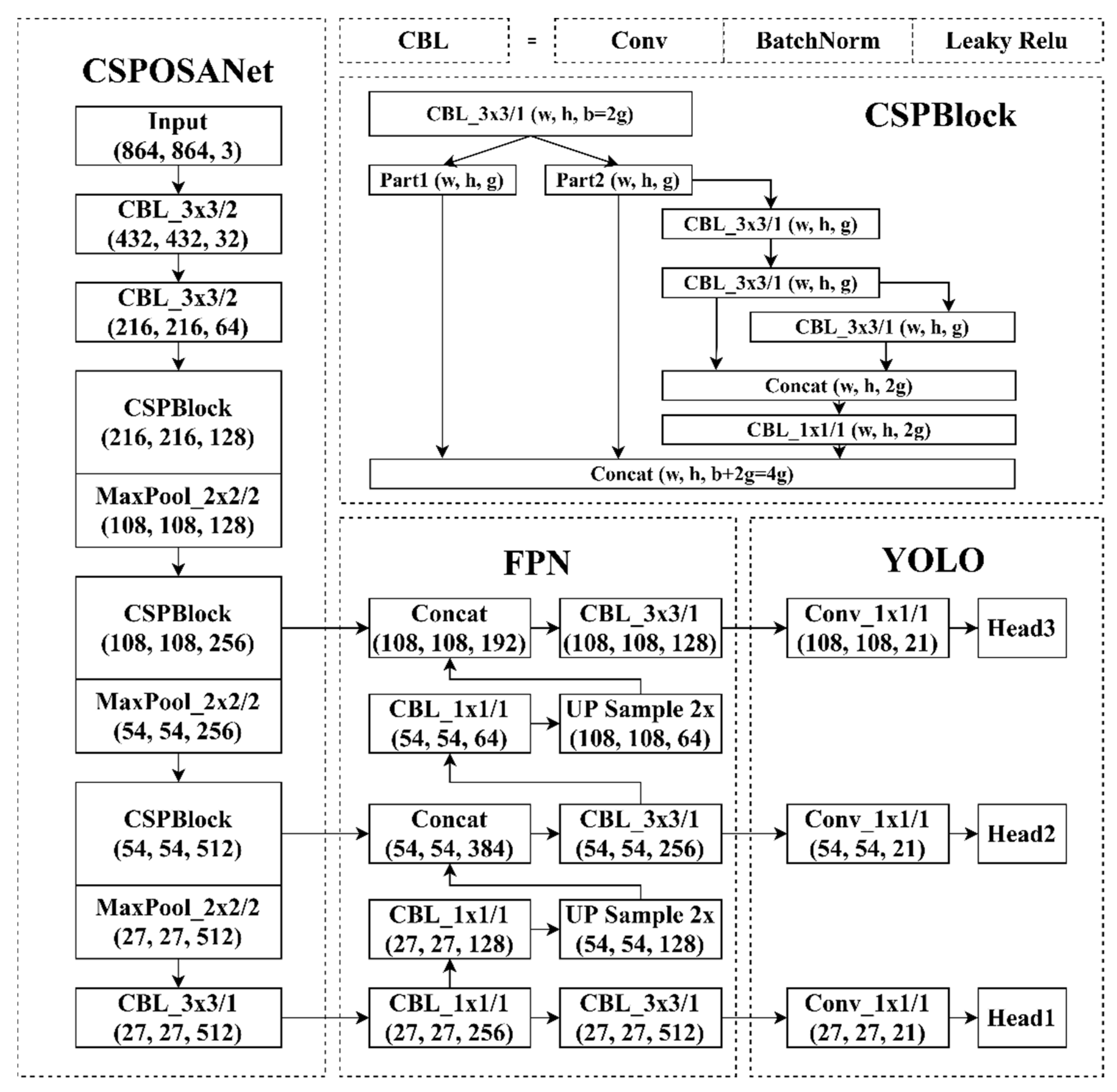
- Object Detectors
- C.
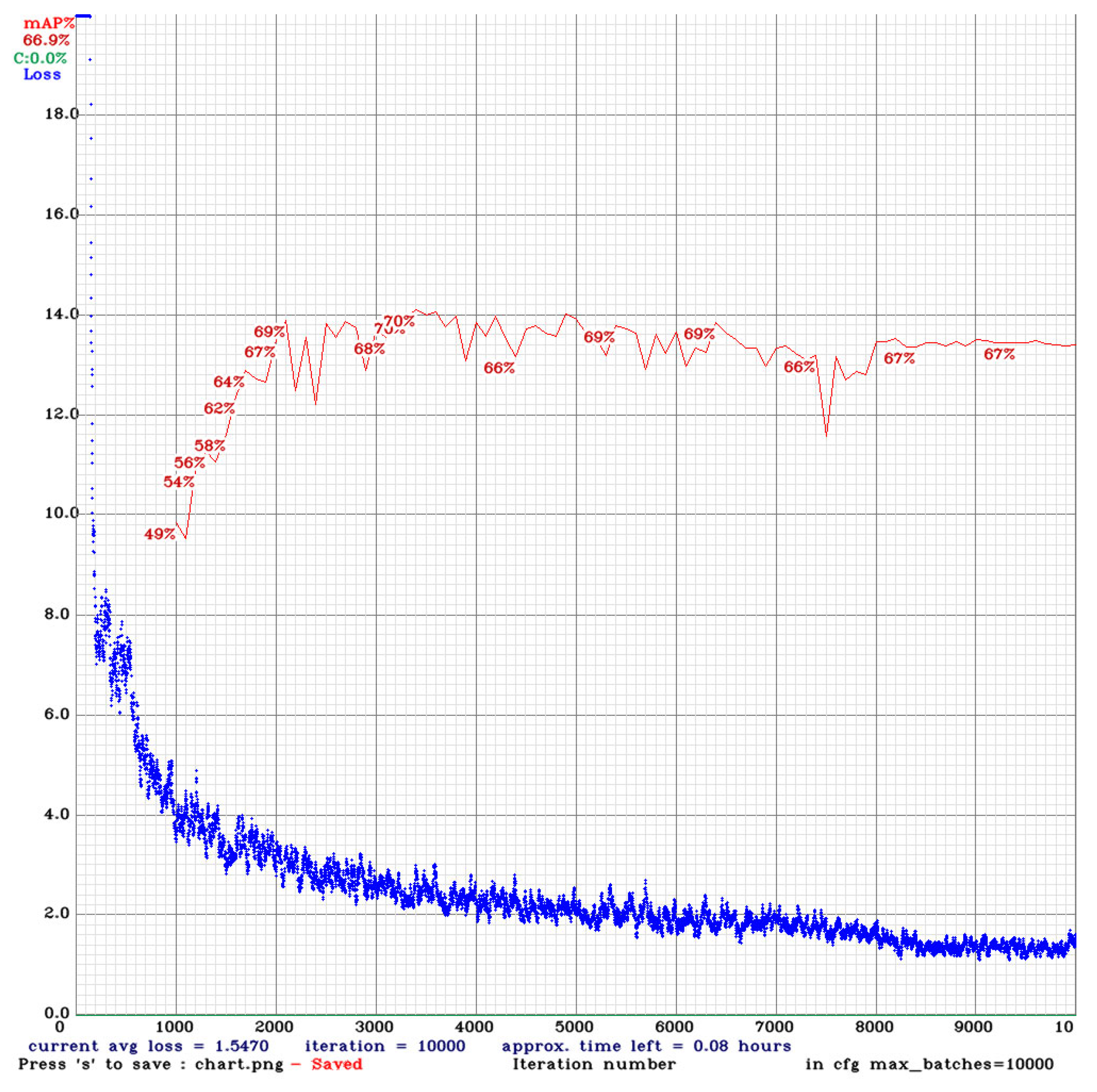
- Holdout Method and Hyperparameter Tuning
- D.
- K-Fold Cross-Validation
- E.
- Nested Cross-Validation
3. Experimental Results
- The NTOU Campus
- B.
- Badouzi Fishing Port
- C.
- Wanghai Xiang Beach
- D.
- Data Mining
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Greenpeace. 2019. Available online: https://www.greenpeace.org/taiwan/update/15198 (accessed on 15 August 2020).
- 422 Earth Day. 2021. Available online: https://www.businesstoday.com.tw/article/category/183027/post/202104210017 (accessed on 5 May 2021).
- Schölkopf, B. SVMs-A Practical Consequence of Learning Theory. Proc. IEEE Intell. Syst. Appl. 1998, 13, 18–21. [Google Scholar]
- Gongde, G.; Hui, W.; David, B.; Yaxin, B.; Kieran, G. KNN Model-Based Approach in Classification. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2888, pp. 986–996. [Google Scholar] [CrossRef]
- Nielsen, H. Theory of the Backpropagation Neural Network. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 17–21 June 1989; Volume 1, pp. 593–605. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, W.; Wei, J.; Meng, Q. Comparisons on KNN, SVM, BP and the CNN for Handwritten Digit Recognition. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications, Dalian, China, 25–27 August 2020; pp. 587–590. [Google Scholar]
- Ruchi; Singla, J.; Singh, A.; Kaur, H. Review on Artificial Intelligence Techniques for Medical Diagnosis. In Proceedings of the 3rd International Conference on Intelligent Sustainable Systems, Thoothukudi, India, 3–5 December 2020; pp. 735–738. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. In Proceedings of the 2nd International Conference on Learning Representations, Scottsdale, Arizona, 15–17 December 2013. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: http://arxiv.org/abs/1804.02767 (accessed on 5 August 2020).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Mountain View, CA, USA, 6–11 July 2015; Volume 1, pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. Available online: http://arxiv.org/abs/1908.08681 (accessed on 25 July 2020).
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. DropBlock: A Regularization Method for Convolutional Networks. Adv. Neural Inf. Process. Syst. 2018, 31, 10727–10737. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018-Conference Track Proceedings, Vancouver, BA, Canada, 30 April–3 May 2017. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. Available online: http://arxiv.org/abs/1708.04552 (accessed on 12 July 2020).
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE International Conference on Computer Vision, 27–28 October 2019; pp. 6022–6031. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 12993–13000. [Google Scholar]
- Lee, Y.; Hwang, J.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 752–760. [Google Scholar]
- Bak, S.H.; Hwang, D.H.; Kim, H.M.; Yoon, H.J. Detection and Monitoring of Beach Litter using UAV Image and Deep Neural Network. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2019, 42, 55–58. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Merlino, S.; Paterni, M.; Berton, A.; Massetti, L. Unmanned Aerial Vehicles for Debris Survey in Coastal Areas: Long-Term Monitoring Programme to Study Spatial and Temporal Accumulation of the Dynamics of Beached Marine Litter. Remote Sens. 2020, 12, 1260. [Google Scholar] [CrossRef]
- Escobar-Sánchez, G.; Haseler, M.; Oppelt, N.; Schernewski, G. Efficiency of Aerial Drones for Macrolitter Monitoring on Baltic Sea Beaches. Front. Environ. Sci. 2021, 8, 560237. [Google Scholar] [CrossRef]
- Tharani, M.; Amin, A.W.; Maaz, M.; Taj, M. Attention Neural Network for Trash Detection on Water Channels. arXiv 2020, arXiv:2007.04639. [Google Scholar]
- Proença, P.F.; Simões, P. TACO: Trash Annotations in Context for Litter Detection. arXiv 2020, arXiv:2003.06975. Available online: http://arxiv.org/abs/2003.06975 (accessed on 22 January 2021).
- Flickr. pedropro/TACO: Trash Annotations in Context Dataset Toolkit. Available online: https://github.com/pedropro/TACO (accessed on 21 March 2021).
- Liu, Y.; Ge, Z.; Lv, G.; Wang, S. Research on automatic garbage detection system based on deep learning and narrowband internet of things. J. Phys. 2018, 1069, 12032. [Google Scholar] [CrossRef]
- Niu, G.; Li, J.; Guo, S.; Pun, M.O.; Hou, L.; Yang, L. SuperDock: A deep learning-based automated floating trash monitoring system. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 1035–1040. [Google Scholar]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2018, arXiv:1811.12808. Available online: http://arxiv.org/abs/1811.12808 (accessed on 5 August 2020).
- Ca, B.U.; Fr, Y.G. No Unbiased Estimator of the Variance of K-Fold Cross-Validation Yoshua Bengio Yves Grandvalet. J. Mach. Learn. Res. 2004, 16, 1–17. [Google Scholar]
- Wainer, J.; Cawley, G. Nested Cross-Validation When Selecting Classifiers Is Overzealous for Most Practical Applications. arXiv 2018, arXiv:1809.09446. Available online: http://arxiv.org/abs/1809.09446 (accessed on 23 July 2020). [CrossRef]
- Liao, Y.; Juang, J. Real-Time UAV Trash Monitoring System. Appl. Sci. 2022, 12, 1838. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size | FPS1080ti | FPSTX2 | AP |
|---|---|---|---|---|
| YOLOv4-tiny | 416 | 371 | 42 | 21.7% |
| YOLOv4-tiny(31) | 320 | 252 | 41 | 28.7% |
| ThunderS146 | 320 | 248 | - | 23.6% |
| CSPPeleeRef | 320 | 205 | 41 | 23.5% |
| YOLOv3-tiny | 416 | 368 | 37 | 16.6% |
| Method | Size | FPS 2080Ti | FPS NX | BFLOPs | AP30 (Val) | AP50 (Val) | AP75 (Val) | AP50 (Test) | AP50 (Train) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv4-Tiny-3l | 416 | 470 | 72 | 8.022 | 75.76% | 67.42% | 23.53% | 71.65% | 92.48% |
| YOLOv3-Tiny | 864 | 231 | 28 | 23.506 | - | 64.46% | - | 68.50% | 91.22% |
| YOLOv4-Tiny | 864 | 204 | 25 | 29.284 | - | 69.75% | - | 72.48% | 91.80% |
| YOLOv3-Tiny-3l | 864 | 194 | 24 | 30.639 | - | 66.15% | - | 69.85% | 91.97% |
| YOLOv4-Tiny-3l | 864 | 177 | 22 | 34.602 | 78.17% | 71.46% | 28.27% | 73.37% | 97.41% |
| YOLOv3 | 416 | 118 | 12 | 65.312 | - | 66.27% | - | 69.24% | 94.61% |
| YOLOv3-SPP | 416 | 116 | 12 | 65.69 | - | 64.66% | - | 66.86% | 90.88% |
| YOLOv4 | 416 | 92 | 10 | 59.57 | 78.36% | 70.29% | 29.15% | 74.20% | 90.65% |
| YOLOv4-CSP | 512 | 88 | 9 | 76.144 | - | 58.12% | - | 61.76% | 58.08% |
| YOLOv4 | 512 | 80 | 7 | 90.237 | 79.83% | 72% | 27.49% | 74.41% | 93.43% |
| YOLOv4 | 608 | 63 | 5 | 127.248 | 80.04% | 72.20% | 28.81% | 72.70% | 94.28% |
| YOLOv4x-MISH | 640 | 41 | 3 | 220.309 | 74.07% | 66.10% | 26.49% | 71.35% | 96.06% |
| Hyperparameter. | Size | Batch | Iteration | lr | Steps | Scales | Multi-Scale | Act. | Mosaic | SAT | IOU | NMS | Pretrain | AP50 (Val) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 864 | 16 | 10,000 | 0.00261 | 4500; 7000 | 0.1; 0.1 | - | leaky | - | - | ciou | greedy | imageNet | 69.71% |
| 2 | 864 | 16 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | - | leaky | - | - | ciou | greedy | imageNet | 69.33% |
| 3 | 864 | 16 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | - | leaky | yes | - | ciou | greedy | imageNet | 70.69% |
| 4 | 864 | 16 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | - | leaky | yes | - | ciou | greedy | - | 68.07% |
| 5 | 864 | 8 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | yes | leaky | yes | - | ciou | greedy | imageNet | 71.15% |
| 6 | 864 | 8 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | yes | leaky | - | - | ciou | greedy | imageNet | 71.46% |
| 7 | 864 | 16 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | - | leaky | yes | - | ciou | greedy | imageNet | 70.32% |
| 8 | 864 | 8 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | - | leaky | yes | - | ciou | greedy | imageNet | 69.55% |
| 9 | 864 | 8 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | yes | leaky | - | - | ciou | diou | imageNet | 71.16% |
| 10 | 864 | 8 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | yes | leaky | - | yes | ciou | greedy | imageNet | 70.73% |
| 11 | 864 | 6 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | yes | mish | - | - | ciou | greedy | imageNet | 70.58% |
| 12 | 864 | 8 | 10,000 | 0.002 | 8000; 9000 | 0.1; 0.1 | yes | leaky | - | - | ciou | greedy | imageNet | 71.18% |
| 13 | 864 | 8 | 10,000 | 0.00261 | 8000; 9000 | 0.1; 0.1 | yes | leaky | - | - | ciou | greedy | TACO | 70.38% |
| 14 | 864 | 8 | 10,000 | 0.004 | 4500; 6000 | 0.1; 0.1 | - | leaky | - | - | ciou | greedy | imageNet | 71.25% |
| Method | Size | AP50 (Test Fold) | |||||
|---|---|---|---|---|---|---|---|
| 5–1 | 5–2 | 5–3 | 5–4 | 5–5 | Avg. | ||
| YOLOv4-Tiny-3l | 864 | 73.61% | 71.28% | 68.89% | 73.72% | 69.76% | 71.45% |
| YOLOv4 | 416 | 72.56% | 72.48% | 70.80% | 72.45% | 70.58% | 71.77% |
| YOLOv4 | 512 | 72.63% | 71.31% | 70.18% | 73.58% | 70.67% | 71.67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, Y.-H.; Juang, J.-G. Automatic Marine Debris Inspection. Aerospace 2023, 10, 84. https://doi.org/10.3390/aerospace10010084
Liao Y-H, Juang J-G. Automatic Marine Debris Inspection. Aerospace. 2023; 10(1):84. https://doi.org/10.3390/aerospace10010084
Chicago/Turabian StyleLiao, Yu-Hsien, and Jih-Gau Juang. 2023. "Automatic Marine Debris Inspection" Aerospace 10, no. 1: 84. https://doi.org/10.3390/aerospace10010084
APA StyleLiao, Y.-H., & Juang, J.-G. (2023). Automatic Marine Debris Inspection. Aerospace, 10(1), 84. https://doi.org/10.3390/aerospace10010084