
Outliers in Semi-Parametric Estimation of Treatment Effects


Abstract
1. Introduction
2. A Brief Review of the Literature
3. Framework
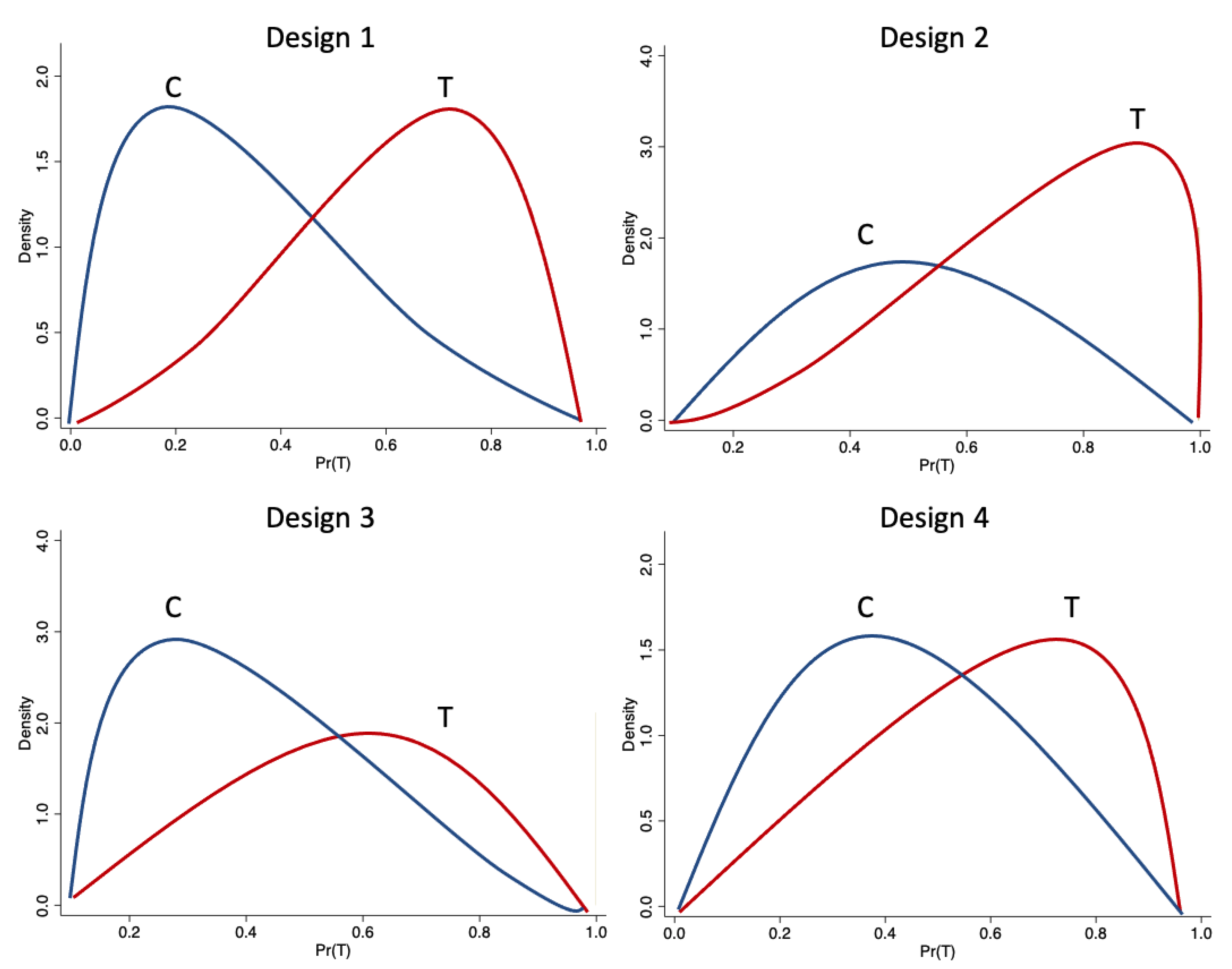
4. Monte Carlo Setup
5. The Effect of Outliers in the Estimation of Treatment Effects
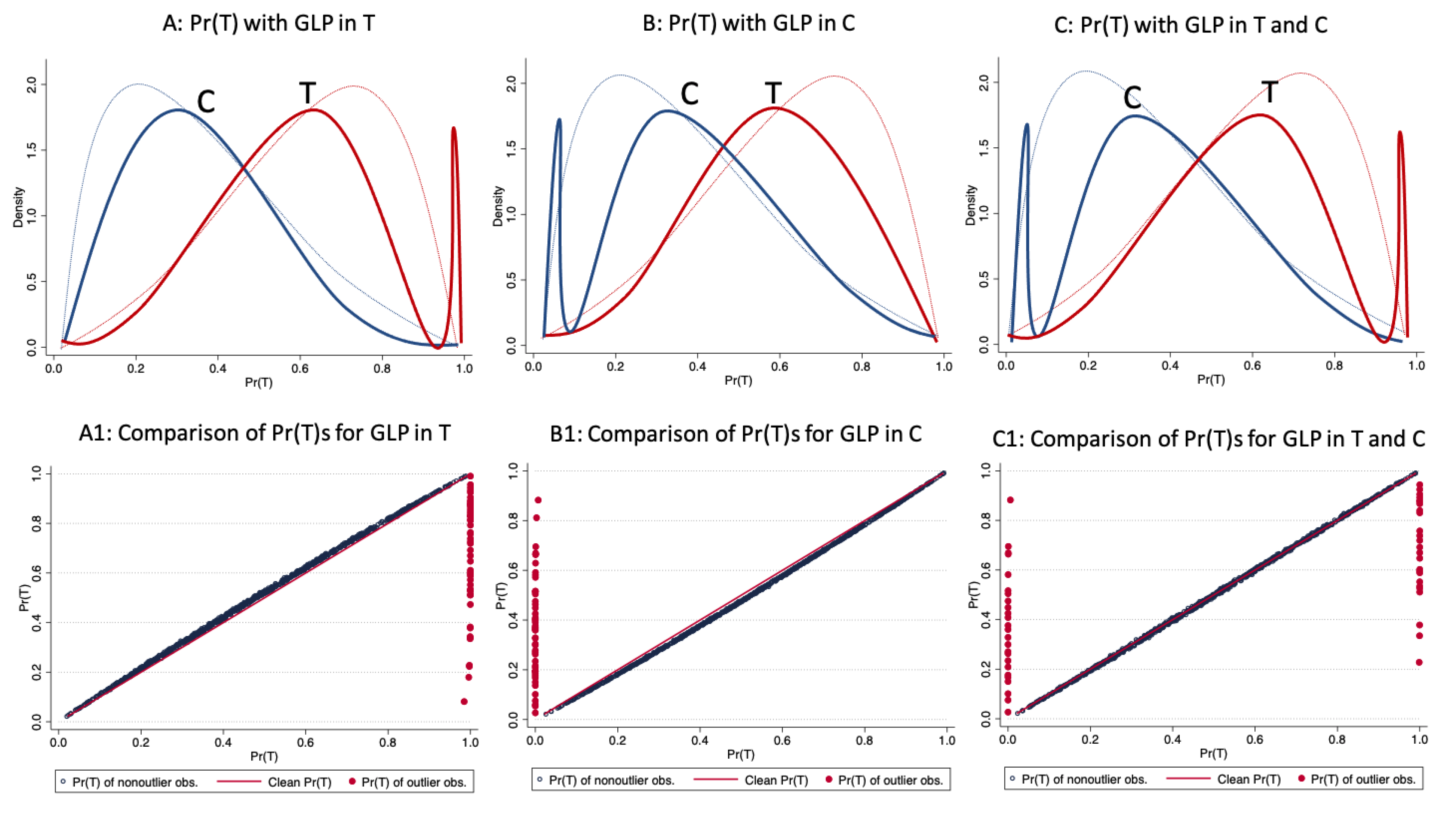
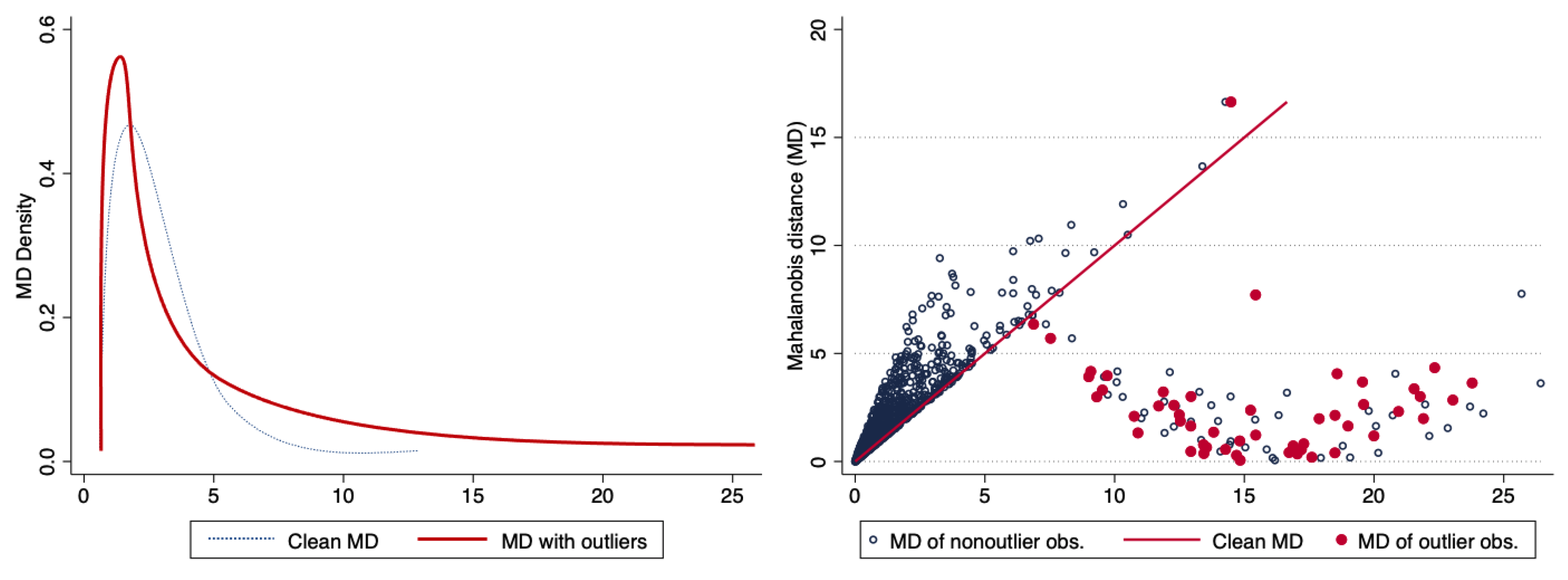
5.1. The Effect of Outliers in the Metrics
- (a) The distribution of the propensity score in presence of outliers
- (b) The distribution of the Mahalanobis distance in presence of outliers
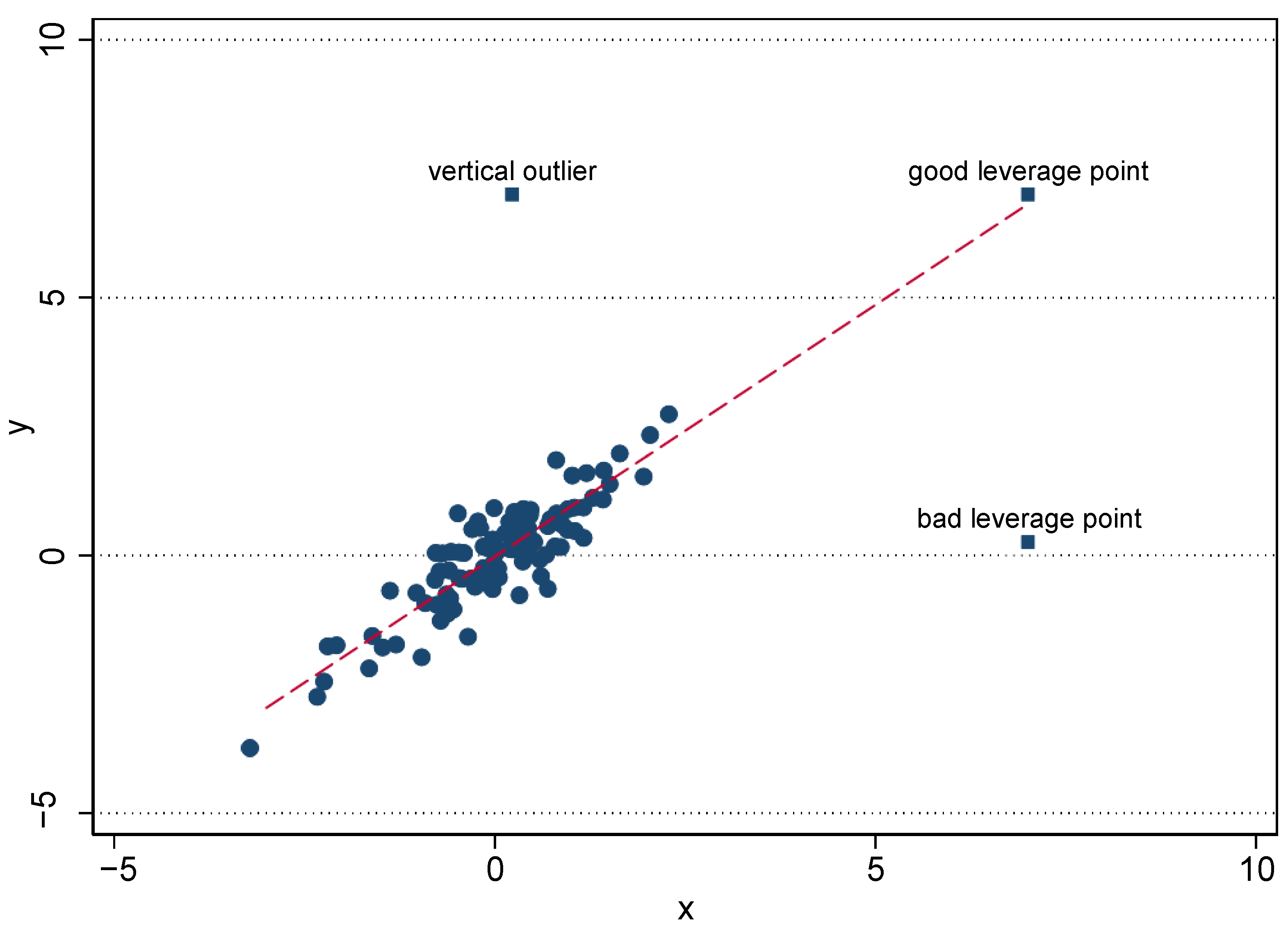
5.2. The Matching Process in the Presence of Outliers, a Toy Example
5.3. The Effect of Outliers on the Different Matching Estimators
5.4. Outliers and Balance Checking
5.5. Solving the Puzzle, Re-Weighting Treatment Effects to Correct for Outliers
6. An Analysis of the Dehejia-Wahba (2002) and Smith-Todd (2005) Debate with Regard to Outliers
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 1086.22 | 1223.63 | 1119.44 | 1172.59 | 1157.35 | 1178.44 | 1168.45 | 2668.76 | −489.12 | 1088.07 |
| Ridge M. Epan | 842.51 | 720.66 | 919.31 | 843.54 | 693.92 | 996.84 | 895.42 | 2425.10 | −740.40 | 839.84 |
| IPW | 299.37 | 634.05 | 636.05 | 632.63 | 299.32 | 300.98 | 297.69 | 1881.92 | −1264.44 | 309.81 |
| Pair Matching (bias corrected) | −0.30 | 784.72 | −4.07 | 390.26 | −794.54 | −2.97 | −398.78 | 1582.25 | −1561.61 | 5.80 |
| MSE (×1000) | ||||||||||
| Pair Matching | 1195.58 | 1512.29 | 1269.62 | 1390.48 | 1354.94 | 1405.09 | 1380.86 | 7140.02 | 389.79 | 1270.85 |
| Ridge M. Epan | 728.11 | 545.59 | 864.04 | 731.77 | 510.25 | 1012.31 | 821.86 | 5901.36 | 736.89 | 810.76 |
| IPW | 164.17 | 459.52 | 464.34 | 458.64 | 164.85 | 172.71 | 167.73 | 3619.12 | 2173.43 | 421.42 |
| Pair Matching (bias corrected) | 33.63 | 647.77 | 34.49 | 179.25 | 705.14 | 34.03 | 206.16 | 2539.83 | 3115.53 | 385.02 |
| Panel B: Severe contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 30.91 | 208.75 | 36.59 | 122.37 | −44.75 | 38.48 | −2.37 | 739.06 | −677.65 | 32.78 |
| Ridge M. Epan | 10.32 | 18.98 | 13.36 | 11.95 | −29.65 | 15.18 | 13.39 | 718.08 | −698.28 | 11.13 |
| IPW | 16.56 | 366.56 | 366.76 | 366.70 | 13.15 | 14.52 | 14.14 | 724.71 | −694.33 | 18.71 |
| Pair Matching (bias corrected) | −0.45 | 352.34 | 3.28 | 176.75 | −351.72 | 0.43 | −175.19 | 707.70 | −709.09 | 1.41 |
| MSE (×1000) | ||||||||||
| Pair Matching | 11.98 | 58.24 | 12.97 | 26.70 | 18.82 | 12.97 | 12.71 | 557.67 | 501.67 | 28.60 |
| Ridge M. Epan | 8.29 | 9.41 | 8.89 | 8.62 | 9.03 | 8.87 | 8.62 | 524.74 | 513.96 | 17.84 |
| IPW | 11.37 | 140.60 | 140.75 | 140.72 | 11.44 | 12.32 | 11.91 | 536.91 | 512.48 | 20.91 |
| Pair Matching (bias corrected) | 11.53 | 144.05 | 12.26 | 43.13 | 162.99 | 12.16 | 49.71 | 512.82 | 549.09 | 29.90 |
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 1086.22 | 1159.95 | 1082.64 | 1121.85 | 1095.43 | 1130.02 | 1112.92 | 1560.98 | 613.62 | 1086.77 |
| Ridge M. Epan | 842.51 | 834.56 | 841.42 | 837.11 | 756.97 | 924.32 | 844.29 | 1317.29 | 367.63 | 841.70 |
| IPW | 299.37 | 553.26 | 555.45 | 557.44 | 288.31 | 289.99 | 287.53 | 774.14 | −169.77 | 302.51 |
| Pair Matching (bias corrected) | −0.30 | 233.96 | 115.19 | 163.37 | −242.97 | 4.65 | −118.03 | 474.47 | −468.69 | 1.53 |
| MSE (×1000) | ||||||||||
| Pair Matching | 1195.58 | 1360.56 | 1188.79 | 1274.27 | 1215.94 | 1293.03 | 1254.26 | 2452.46 | 403.96 | 1202.47 |
| Ridge M. Epan | 728.11 | 715.45 | 727.87 | 720.04 | 593.99 | 873.91 | 732.86 | 1753.60 | 167.95 | 733.91 |
| IPW | 164.17 | 361.29 | 367.50 | 367.74 | 160.30 | 168.08 | 163.66 | 674.21 | 147.06 | 188.24 |
| Pair Matching (bias corrected) | 33.63 | 81.71 | 49.12 | 56.58 | 102.09 | 35.63 | 51.16 | 259.04 | 311.60 | 64.86 |
| Panel D: Mild contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 30.91 | 130.59 | 170.19 | 164.75 | −38.46 | 20.82 | −8.39 | 243.35 | −181.66 | 31.47 |
| Ridge M. Epan | 10.32 | 107.76 | 151.50 | 141.35 | −50.88 | −1.65 | −21.12 | 222.65 | −202.26 | 10.57 |
| IPW | 16.56 | 166.69 | 166.07 | 168.93 | −16.22 | −14.88 | −13.95 | 229.01 | −196.71 | 17.21 |
| Pair Matching (bias corrected) | −0.45 | 105.94 | 156.04 | 148.67 | −104.89 | −12.24 | −58.01 | 212.00 | −213.04 | 0.11 |
| MSE (×1000) | ||||||||||
| Pair Matching | 11.98 | 27.17 | 39.59 | 37.51 | 15.41 | 12.14 | 12.50 | 70.27 | 46.86 | 13.48 |
| Ridge M. Epan | 8.29 | 19.21 | 31.03 | 27.80 | 11.83 | 8.77 | 9.22 | 57.82 | 50.73 | 9.11 |
| IPW | 11.37 | 35.14 | 36.07 | 36.43 | 12.83 | 13.38 | 13.05 | 63.62 | 51.76 | 12.18 |
| Pair Matching (bias corrected) | 11.53 | 21.63 | 35.20 | 32.71 | 26.99 | 12.51 | 16.96 | 56.51 | 60.10 | 13.21 |
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 157.33 | 555.59 | 554.08 | 549.96 | 104.26 | 106.62 | 102.91 | 1766.01 | −1425.13 | 178.94 |
| Ridge M. Epan | 147.88 | 515.87 | 513.57 | 513.06 | 104.64 | 104.81 | 109.83 | 1755.33 | −1429.67 | 173.25 |
| IPW | 302.65 | 638.80 | 638.05 | 637.00 | 305.49 | 303.68 | 303.62 | 1900.85 | −1270.70 | 320.41 |
| Pair Matching (bias corrected) | −1.46 | 610.43 | 613.04 | 463.74 | −400.41 | −397.05 | −397.35 | 1599.17 | −1577.66 | 15.82 |
| MSE (×1000) | ||||||||||
| Pair Matching | 71.59 | 343.59 | 342.04 | 337.37 | 70.16 | 72.50 | 69.81 | 3603.22 | 2511.61 | 556.46 |
| Ridge M. Epan | 61.16 | 293.04 | 291.05 | 290.18 | 59.08 | 59.91 | 60.06 | 3463.70 | 2415.09 | 436.35 |
| IPW | 127.18 | 438.55 | 437.76 | 436.00 | 129.61 | 129.60 | 128.99 | 3804.20 | 1777.43 | 290.78 |
| Pair Matching (bias corrected) | 33.22 | 400.58 | 402.54 | 240.62 | 236.94 | 233.46 | 224.63 | 2918.21 | 2843.96 | 389.60 |
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 6.77 | 365.94 | 367.44 | 363.69 | −52.71 | −53.61 | −52.90 | 715.82 | −704.41 | 9.01 |
| Ridge M. Epan | −1.26 | 361.99 | 362.35 | 361.20 | −39.69 | −38.78 | −1.32 | 707.99 | −710.25 | 0.59 |
| IPW | 15.14 | 366.01 | 365.67 | 365.88 | 11.74 | 12.45 | 12.60 | 724.58 | −694.08 | 16.83 |
| Pair Matching (bias corrected) | −2.53 | 357.08 | 359.43 | 358.67 | −178.27 | −180.27 | −179.55 | 706.65 | −713.44 | −0.06 |
| MSE (×1000) | ||||||||||
| Pair Matching | 8.93 | 141.38 | 142.58 | 139.63 | 16.61 | 16.57 | 15.16 | 532.34 | 517.66 | 21.31 |
| Ridge M. Epan | 6.56 | 137.26 | 137.50 | 136.73 | 11.45 | 11.32 | 6.99 | 513.77 | 517.40 | 12.91 |
| IPW | 7.49 | 139.29 | 139.04 | 139.22 | 7.77 | 7.71 | 7.69 | 537.06 | 494.29 | 12.61 |
| Pair Matching (bias corrected) | 8.98 | 134.52 | 136.12 | 135.97 | 53.05 | 53.97 | 48.70 | 519.86 | 530.76 | 21.61 |
| Panel C: Mild contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 157.33 | 463.05 | 462.51 | 465.78 | 106.34 | 109.70 | 105.85 | 639.93 | −317.41 | 163.81 |
| Ridge M. Epan | 147.88 | 421.79 | 420.59 | 423.28 | 105.66 | 106.37 | 109.36 | 630.12 | −325.38 | 155.49 |
| IPW | 302.65 | 557.12 | 555.97 | 558.83 | 294.72 | 293.01 | 293.63 | 782.11 | −169.35 | 307.98 |
| Pair Matching (bias corrected) | −1.46 | 308.67 | 305.55 | 352.88 | −120.19 | −119.79 | −118.44 | 478.73 | −474.32 | 3.72 |
| MSE (×1000) | ||||||||||
| Pair Matching | 71.59 | 247.91 | 247.32 | 249.98 | 70.09 | 72.02 | 68.68 | 492.73 | 188.26 | 116.46 |
| Ridge M. Epan | 61.16 | 203.29 | 202.74 | 204.07 | 58.90 | 59.87 | 59.55 | 465.08 | 175.98 | 96.51 |
| IPW | 127.18 | 339.96 | 338.72 | 342.15 | 123.97 | 124.03 | 123.85 | 659.32 | 75.26 | 143.62 |
| Pair Matching (bias corrected) | 33.22 | 119.82 | 118.23 | 149.90 | 58.48 | 58.29 | 56.14 | 289.87 | 288.91 | 64.86 |
| Panel D: Mild contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 6.77 | 166.49 | 165.31 | 176.44 | −43.12 | −43.16 | −42.81 | 219.49 | −206.58 | 7.44 |
| Ridge M. Epan | −1.26 | 155.43 | 153.36 | 160.93 | −42.85 | −42.41 | −39.68 | 211.52 | −213.96 | −0.70 |
| IPW | 15.14 | 166.26 | 164.94 | 167.79 | −17.68 | −16.96 | −15.55 | 227.97 | −197.63 | 15.64 |
| Pair Matching (bias corrected) | −2.53 | 153.08 | 151.58 | 173.31 | −61.94 | −62.04 | −60.94 | 210.22 | −215.81 | −1.79 |
| MSE (×1000) | ||||||||||
| Pair Matching | 8.93 | 35.45 | 35.23 | 39.21 | 12.64 | 12.98 | 12.27 | 58.07 | 52.79 | 10.18 |
| Ridge M. Epan | 6.56 | 30.34 | 29.67 | 32.10 | 9.13 | 9.16 | 8.72 | 51.85 | 52.98 | 7.20 |
| IPW | 7.49 | 33.43 | 33.06 | 34.04 | 8.57 | 8.42 | 8.35 | 59.68 | 46.86 | 7.94 |
| Pair Matching (bias corrected) | 8.98 | 31.11 | 30.81 | 38.08 | 14.93 | 15.24 | 14.31 | 54.25 | 56.78 | 10.23 |
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 155.72 | 536.54 | 568.73 | 547.42 | 43.91 | 162.42 | 100.70 | 1738.27 | −1425.95 | 160.84 |
| Nearest-Neighbor matching (M = 5) | 241.55 | 595.71 | 623.69 | 607.70 | 156.59 | 252.63 | 203.82 | 1824.10 | −1333.56 | 245.78 |
| Nearest-Neighbor matching (bias corrected, M = 1) | −1.48 | 785.56 | 433.26 | 461.78 | −797.19 | −4.43 | −398.52 | 1581.07 | −1570.68 | 9.77 |
| Nearest-Neighbor matching (bias corrected, M = 5) | −3.95 | 787.35 | 433.81 | 465.12 | −807.07 | −3.41 | −406.21 | 1578.59 | −1557.95 | 8.98 |
| MSE (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 112.73 | 353.53 | 384.21 | 361.60 | 134.13 | 121.73 | 122.59 | 3113.71 | 3808.92 | 1005.98 |
| Nearest-Neighbor matching (M = 5) | 98.98 | 390.64 | 421.90 | 403.38 | 76.79 | 106.41 | 88.37 | 3370.40 | 2524.73 | 469.56 |
| Nearest-Neighbor matching (bias corrected, M = 1) | 61.73 | 669.61 | 234.13 | 258.86 | 857.37 | 65.18 | 283.12 | 2564.56 | 3774.03 | 735.33 |
| Nearest-Neighbor matching (bias corrected, M = 5) | 49.99 | 663.59 | 224.75 | 253.07 | 848.14 | 53.36 | 270.56 | 2544.56 | 3446.37 | 557.36 |
| Panel B: Severe contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 9.13 | 367.76 | 367.39 | 364.36 | −112.22 | 10.93 | −50.59 | 717.27 | −705.47 | 12.48 |
| Nearest-Neighbor matching (M = 5) | 21.41 | 370.20 | 370.50 | 370.52 | −77.89 | 23.46 | −25.64 | 729.56 | −687.38 | 24.62 |
| Nearest-Neighbor matching (bias corrected, M = 1) | −0.05 | 354.12 | 363.51 | 359.18 | −353.72 | 1.14 | −176.80 | 708.10 | −714.09 | 3.67 |
| Nearest-Neighbor matching (bias corrected, M = 5) | 0.50 | 354.69 | 364.89 | 363.61 | −355.22 | 1.02 | −175.60 | 708.65 | −707.78 | 4.04 |
| MSE (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 13.17 | 145.73 | 145.98 | 143.36 | 42.97 | 14.28 | 22.53 | 528.13 | 557.91 | 36.83 |
| Nearest-Neighbor matching (M = 5) | 9.42 | 143.94 | 144.39 | 144.41 | 20.01 | 10.32 | 12.02 | 541.71 | 504.42 | 21.16 |
| Nearest-Neighbor matching (bias corrected, M = 1) | 13.17 | 134.87 | 143.09 | 139.57 | 184.52 | 14.30 | 59.37 | 515.14 | 571.01 | 37.00 |
| Nearest-Neighbor matching (bias corrected, M = 5) | 9.24 | 132.05 | 140.45 | 139.38 | 154.80 | 10.11 | 47.13 | 511.91 | 535.13 | 21.87 |
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 155.72 | 446.02 | 478.72 | 465.70 | 49.10 | 163.02 | 104.01 | 630.48 | −318.78 | 157.26 |
| Nearest-Neighbor matching (M = 5) | 241.55 | 501.66 | 529.56 | 519.54 | 158.63 | 249.52 | 203.33 | 716.31 | −230.98 | 242.82 |
| Nearest-Neighbor matching (bias corrected, M = 1) | −1.48 | 236.68 | 376.49 | 350.68 | −240.05 | −2.05 | −118.73 | 473.28 | −472.24 | 1.89 |
| Nearest-Neighbor matching (bias corrected, M = 5) | −3.95 | 232.97 | 374.53 | 348.82 | −246.06 | −4.13 | −124.34 | 470.81 | −470.15 | −0.07 |
| MSE (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 112.73 | 262.10 | 289.80 | 278.70 | 130.69 | 120.45 | 119.56 | 486.58 | 342.40 | 193.33 |
| Nearest-Neighbor matching (M = 5) | 98.98 | 283.71 | 312.46 | 302.20 | 76.94 | 104.75 | 87.36 | 553.96 | 158.56 | 132.95 |
| Nearest-Neighbor matching (bias corrected, M = 1) | 61.73 | 100.48 | 187.36 | 170.06 | 151.11 | 66.23 | 90.72 | 286.13 | 398.70 | 121.23 |
| Nearest-Neighbor matching (bias corrected, M = 5) | 49.99 | 89.78 | 176.80 | 159.20 | 141.52 | 53.69 | 79.69 | 271.91 | 361.58 | 95.43 |
| Panel D: Mild contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 9.13 | 127.38 | 204.31 | 175.95 | −79.71 | −3.21 | −40.49 | 221.57 | −205.25 | 10.13 |
| Nearest-Neighbor matching (M = 5) | 21.41 | 138.25 | 206.59 | 180.88 | −57.49 | 7.10 | −24.41 | 233.86 | −191.22 | 22.38 |
| Nearest-Neighbor matching (bias corrected, M = 1) | −0.05 | 105.04 | 199.85 | 172.82 | −106.54 | −13.39 | −58.22 | 212.40 | −214.26 | 1.07 |
| Nearest-Neighbor matching (bias corrected, M = 5) | 0.50 | 105.91 | 198.37 | 172.22 | −106.76 | −15.38 | −59.53 | 212.95 | −211.98 | 1.57 |
| MSE (×1000) | ||||||||||
| Nearest-Neighbor matching (M = 1) | 13.17 | 27.84 | 52.39 | 43.02 | 25.87 | 13.98 | 17.67 | 62.24 | 59.63 | 15.40 |
| Nearest-Neighbor matching (M = 5) | 9.42 | 26.96 | 49.90 | 40.25 | 15.54 | 9.87 | 11.38 | 63.69 | 47.69 | 10.51 |
| Nearest-Neighbor matching (bias corrected, M = 1) | 13.17 | 22.53 | 50.49 | 41.89 | 31.93 | 14.24 | 19.74 | 58.35 | 63.53 | 15.40 |
| Nearest-Neighbor matching (bias corrected, M = 5) | 9.24 | 19.18 | 46.53 | 37.23 | 24.93 | 10.41 | 15.00 | 54.63 | 56.53 | 10.39 |
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 153.23 | 161.46 | 166.61 | 164.65 | 159.53 | 166.83 | 164.22 | 161.13 | 166.63 | 165.69 |
| Ridge M. Epan | 143.85 | 151.25 | 161.14 | 155.85 | 150.92 | 160.83 | 155.94 | 151.11 | 161.07 | 155.66 |
| IPW | 299.39 | 310.16 | 310.98 | 310.18 | 310.06 | 311.04 | 310.27 | 310.22 | 311.04 | 310.06 |
| Pair Matching (bias corrected) | −3.42 | −1.91 | −0.18 | 2.80 | −3.54 | 0.80 | 2.34 | −2.49 | −0.39 | 3.92 |
| MSE (×1000) | ||||||||||
| Pair Matching | 110.00 | 114.79 | 122.35 | 120.16 | 114.20 | 122.54 | 119.51 | 114.38 | 123.05 | 120.32 |
| Ridge M. Epan | 93.27 | 97.21 | 106.22 | 101.66 | 97.08 | 106.01 | 101.65 | 97.18 | 106.12 | 101.62 |
| IPW | 176.78 | 183.69 | 192.95 | 188.56 | 183.54 | 192.92 | 188.52 | 183.68 | 192.88 | 188.53 |
| Pair Matching (bias corrected) | 59.26 | 61.07 | 66.69 | 63.52 | 61.14 | 66.75 | 63.75 | 60.61 | 67.25 | 63.39 |
| Panel B: Severe contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 0.64 | 13.14 | 12.80 | 13.64 | 12.67 | 13.41 | 14.03 | 14.01 | −4.53 | 6.56 |
| Ridge M. Epan | −5.81 | 5.85 | 3.79 | 4.62 | 5.80 | 3.53 | 4.50 | 6.97 | −14.32 | −2.43 |
| IPW | 5.00 | 17.44 | 17.15 | 17.44 | 17.46 | 17.20 | 17.25 | 18.55 | 0.04 | 9.96 |
| Pair Matching (bias corrected) | −8.05 | 4.19 | 2.93 | 4.24 | 3.76 | 3.28 | 4.43 | 5.10 | −14.81 | −3.20 |
| MSE (×1000) | ||||||||||
| Pair Matching | 13.48 | 14.59 | 14.33 | 14.32 | 14.53 | 14.23 | 14.27 | 14.56 | 15.21 | 14.62 |
| Ridge M. Epan | 8.69 | 9.16 | 9.68 | 9.32 | 9.15 | 9.66 | 9.30 | 9.26 | 10.26 | 9.41 |
| IPW | 10.51 | 11.13 | 12.02 | 11.56 | 11.14 | 11.99 | 11.54 | 11.24 | 11.93 | 11.38 |
| Pair Matching (bias corrected) | 13.50 | 14.43 | 14.21 | 14.13 | 14.41 | 14.05 | 14.06 | 14.40 | 15.47 | 14.56 |
| Panel C: Mild contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 153.35 | 372.82 | 448.04 | 404.06 | 81.00 | 160.58 | 119.21 | 572.72 | −279.06 | 125.27 |
| Ridge M. Epan | 142.75 | 341.86 | 407.26 | 368.73 | 86.30 | 155.08 | 125.86 | 560.98 | −288.90 | 115.28 |
| IPW | 298.74 | 512.04 | 505.90 | 497.75 | 296.01 | 300.50 | 300.04 | 716.64 | −132.98 | 273.76 |
| Pair Matching (bias corrected) | −6.88 | 159.64 | 332.41 | 286.55 | −161.82 | −2.89 | −74.90 | 412.20 | −443.64 | −33.62 |
| MSE (×1000) | ||||||||||
| Pair Matching | 112.55 | 214.29 | 267.55 | 234.91 | 125.43 | 120.77 | 117.19 | 421.68 | 296.76 | 184.73 |
| Ridge M. Epan | 93.86 | 174.62 | 216.32 | 191.14 | 102.58 | 103.93 | 103.34 | 392.40 | 258.90 | 146.59 |
| IPW | 178.51 | 328.55 | 327.55 | 319.77 | 177.27 | 185.24 | 181.27 | 604.96 | 157.50 | 198.96 |
| Pair Matching (bias corrected) | 59.45 | 76.73 | 160.90 | 132.77 | 109.02 | 65.43 | 75.90 | 234.83 | 354.43 | 117.85 |
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | −0.21 | 105.36 | 173.82 | 145.27 | −73.17 | −9.80 | −39.24 | 198.55 | −202.15 | −6.85 |
| Ridge M. Epan | −7.54 | 103.37 | 159.17 | 135.36 | −66.00 | −19.15 | −39.54 | 192.80 | −211.98 | −13.43 |
| IPW | 5.90 | 141.82 | 137.88 | 138.21 | −20.45 | −20.49 | −18.14 | 205.01 | −199.09 | −0.81 |
| Pair Matching (bias corrected) | −8.79 | 86.96 | 170.39 | 142.58 | −94.95 | −19.95 | −54.20 | 189.74 | −210.86 | −15.76 |
| MSE (×1000) | ||||||||||
| Pair Matching | 13.79 | 22.60 | 41.57 | 32.63 | 23.57 | 14.18 | 16.99 | 53.79 | 57.78 | 16.10 |
| Ridge M. Epan | 8.82 | 18.63 | 33.51 | 26.57 | 14.72 | 9.66 | 11.09 | 46.28 | 55.22 | 9.81 |
| IPW | 10.74 | 28.30 | 27.67 | 27.78 | 12.16 | 13.04 | 12.47 | 53.14 | 51.33 | 11.32 |
| Pair Matching (bias corrected) | 13.96 | 19.01 | 40.39 | 31.84 | 27.59 | 14.58 | 18.39 | 50.41 | 61.52 | 16.34 |
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 152.34 | 149.75 | 156.83 | 151.28 | 149.75 | 156.19 | 151.28 | 163.71 | 153.86 | 142.29 |
| Ridge M. Epan | 138.48 | 137.02 | 147.56 | 142.11 | 137.02 | 146.91 | 142.11 | 150.40 | 143.65 | 132.93 |
| IPW | 287.92 | 288.30 | 291.06 | 287.58 | 288.29 | 290.29 | 287.58 | 304.14 | 285.32 | 276.17 |
| Pair Matching (bias corrected) | 0.72 | −0.55 | −2.12 | −2.97 | −0.56 | −2.40 | −2.97 | 13.34 | −1.44 | −0.13 |
| MSE (×1000) | ||||||||||
| Pair Matching | 110.27 | 109.94 | 119.95 | 114.58 | 109.94 | 118.23 | 114.58 | 114.02 | 116.67 | 113.05 |
| Ridge M. Epan | 90.46 | 89.46 | 99.95 | 94.09 | 89.46 | 98.28 | 94.09 | 93.36 | 96.94 | 91.24 |
| IPW | 158.59 | 160.06 | 170.16 | 163.64 | 160.06 | 167.97 | 163.64 | 168.70 | 164.99 | 156.69 |
| Pair Matching (bias corrected) | 60.60 | 60.63 | 65.44 | 62.81 | 60.64 | 65.28 | 62.81 | 60.95 | 64.68 | 63.21 |
| Panel B: Severe contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 5.84 | 60.79 | 115.17 | 75.98 | −7.27 | 9.59 | 5.22 | 168.07 | −182.60 | −85.43 |
| Ridge M. Epan | −0.35 | 38.97 | 72.88 | 37.08 | 0.82 | 1.23 | 1.17 | 168.72 | −200.15 | −97.69 |
| IPW | 15.25 | 113.44 | 380.97 | 214.43 | 8.32 | 16.07 | 13.91 | 175.00 | −175.32 | −77.65 |
| Pair Matching (bias corrected) | −2.05 | 48.24 | 104.91 | 68.79 | −28.77 | 0.39 | −7.03 | 160.14 | −189.36 | −92.39 |
| MSE (×1000) | ||||||||||
| Pair Matching | 12.82 | 17.45 | 30.02 | 21.03 | 14.12 | 13.93 | 13.94 | 42.33 | 52.56 | 26.01 |
| Ridge M. Epan | 8.62 | 10.68 | 16.89 | 11.03 | 8.84 | 9.20 | 9.06 | 38.30 | 52.19 | 21.24 |
| IPW | 10.71 | 22.08 | 189.59 | 84.18 | 11.10 | 12.07 | 11.63 | 41.91 | 43.09 | 18.24 |
| Pair Matching (bias corrected) | 12.92 | 15.87 | 26.01 | 19.06 | 15.54 | 13.95 | 14.21 | 39.89 | 55.21 | 27.41 |
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 152.34 | 307.84 | 546.35 | 447.56 | 94.94 | 155.58 | 130.00 | 545.29 | −286.20 | 98.49 |
| Ridge M. Epan | 138.48 | 278.68 | 502.11 | 411.40 | 96.21 | 144.93 | 125.60 | 533.17 | −293.85 | 88.63 |
| IPW | 287.92 | 473.48 | 518.67 | 491.40 | 271.91 | 284.70 | 278.17 | 671.22 | −142.53 | 233.00 |
| Pair Matching (bias corrected) | 0.72 | 113.34 | 351.41 | 289.74 | −96.44 | −0.35 | −39.81 | 401.63 | −430.23 | −44.21 |
| MSE (×1000) | ||||||||||
| Pair Matching | 110.27 | 168.85 | 367.38 | 281.25 | 110.64 | 117.79 | 113.33 | 381.69 | 293.79 | 160.86 |
| Ridge M. Epan | 90.46 | 133.96 | 305.60 | 231.58 | 90.70 | 97.72 | 93.70 | 352.70 | 250.72 | 128.20 |
| IPW | 158.59 | 281.51 | 361.13 | 324.48 | 151.63 | 165.62 | 158.94 | 527.29 | 120.48 | 147.94 |
| Pair Matching (bias corrected) | 60.60 | 63.81 | 171.62 | 138.51 | 78.57 | 64.94 | 67.13 | 220.79 | 343.86 | 115.39 |
| Panel D: Mild contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 5.84 | 119.67 | 202.83 | 169.20 | −73.65 | −6.12 | −37.15 | 196.41 | −204.66 | −7.11 |
| Ridge M. Epan | −0.35 | 116.59 | 181.51 | 153.11 | −63.08 | −15.09 | −36.10 | 195.20 | −210.36 | −10.70 |
| IPW | 15.25 | 156.44 | 170.36 | 165.59 | −24.20 | −13.84 | −17.50 | 204.99 | −194.20 | 1.85 |
| Pair Matching (bias corrected) | −2.05 | 100.85 | 197.21 | 165.58 | −92.41 | −15.47 | −50.13 | 188.88 | −212.26 | −14.77 |
| MSE (×1000) | ||||||||||
| Pair Matching | 12.82 | 26.27 | 51.74 | 39.84 | 23.27 | 14.22 | 16.69 | 51.73 | 58.05 | 14.26 |
| Ridge M. Epan | 8.62 | 21.25 | 41.09 | 31.18 | 14.10 | 9.54 | 10.76 | 46.90 | 54.63 | 9.57 |
| IPW | 10.71 | 31.83 | 37.04 | 35.31 | 12.93 | 12.75 | 12.86 | 52.66 | 49.25 | 11.09 |
| Pair Matching (bias corrected) | 12.92 | 22.08 | 49.40 | 38.58 | 26.81 | 14.38 | 17.98 | 48.93 | 61.36 | 14.60 |
References
- Abadie, Alberto, and Guido W. Imbens. 2006. Large sample properties of matching estimators for average treatment effects. Econometrica 74: 235–67. [Google Scholar] [CrossRef]
- Abadie, Alberto, and Guido W. Imbens. 2011. Bias-corrected matching estimators for average treatment effects. Journal of Business & Economic Statistics 29: 1–11. [Google Scholar]
- Angiulli, Fabrizio, and Clara Pizzuti. 2002. Fast outlier detection in high dimensional spaces. In European Conference on Principles of Data Mining and Knowledge Discovery. Berlin/Heidelberg: Springer, pp. 15–27. [Google Scholar]
- Ashenfelter, Orley. 1978. Estimating the effect of training programs on earnings. The Review of Economics and Statistics 60: 47–57. [Google Scholar] [CrossRef]
- Ashenfelter, Orley, and David Card. 1985. Using the Longitudinal Structure of Earnings to Estimate the Effect of Training Programs. The Review of Economics and Statistics 67: 648–60. [Google Scholar] [CrossRef]
- Bassi, Laurie J. 1983. The Effect of CETA on the Postprogram Earnings of Participants. The Journal of Human Resources 18: 539–56. [Google Scholar] [CrossRef]
- Bassi, Laurie J. 1984. Estimating the effect of training programs with non-random selection. The Review of Economics and Statistics 66: 36–43. [Google Scholar] [CrossRef]
- Breunig, Markus M., Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. 2000. LOF: Identifying density-based local outliers. In ACM Sigmod Record. New York: ACM, vol. 29, pp. 93–104. [Google Scholar]
- Busso, Matias, John DiNardo, and Justin McCrary. 2009. Finite sample properties of semiparametric estimators of average treatment effects. Journal of Business and Economic Statistics. Forthcoming. [Google Scholar]
- Busso, Matias, John DiNardo, and Justin McCrary. 2014. New evidence on the finite sample properties of propensity score reweighting and matching estimators. The Review of Economics and Statistics 96: 885–97. [Google Scholar] [CrossRef]
- Canavire-Bacarreza, Gustavo, and Merlin M. Hanauer. 2013. Estimating the impacts of bolivia’s protected areas on poverty. World Development 41: 265–85. [Google Scholar] [CrossRef]
- Croux, Christophe, and Gentiane Haesbroeck. 2003. Implementing the Bianco and Yohai estimator for logistic regression. Computational Statistics & Data Analysis 44: 273–95. [Google Scholar]
- Croux, Christophe, Cécile Flandre, and Gentiane Haesbroeck. 2002. The breakdown behavior of the maximum likelihood estimator in the logistic regression model. Statistics & Probability Letters 60: 377–86. [Google Scholar]
- De Vries, Timothy, Sanjay Chawla, and Michael E. Houle. 2010. Finding local anomalies in very high dimensional space. Paper presented at the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, December 13–17; pp. 128–37. [Google Scholar]
- Dehejia, Rajeev. 2005. Practical propensity score matching: A reply to Smith and Todd. Journal of Econometrics 125: 355–64. [Google Scholar] [CrossRef]
- Dehejia, Rajeev H., and Sadek Wahba. 1999. Causal effects in nonexperimental studies: Reevaluating the evaluation of training programs. Journal of the American Statistical Association 94: 1053–62. [Google Scholar] [CrossRef]
- Dehejia, Rajeev H., and Sadek Wahba. 2002. Propensity score-matching methods for nonexperimental causal studies. The Review of Economics and Statistics 84: 151–61. [Google Scholar] [CrossRef]
- Donoho, David L. 1982. Breakdown Properties of Multivariate Location Estimators. Technical report. Boston: Harvard University. [Google Scholar]
- Frölich, Markus. 2004. Finite-sample properties of propensity-score matching and weighting estimators. The Review of Economics and Statistics 86: 77–90. [Google Scholar] [CrossRef]
- Hadi, Ali S., AHM Rahmatullah Imon, and Mark Werner. 2009. Detection of outliers. Wiley Interdisciplinary Reviews: Computational Statistics 1: 57–70. [Google Scholar] [CrossRef]
- Hausman, Jerry A., and David A. Wise. 1985. Social Experimentation. Chicago: University of Chicago Press for National Bureau of Economic Research. [Google Scholar]
- Heckman, James J., and Edward Vytlacil. 2005. Structural equations, treatment effects, and econometric policy evaluation1. Econometrica 73: 669–738. [Google Scholar] [CrossRef]
- Heckman, James J., Hidehiko Ichimura, and Petra E. Todd. 1997a. Matching as an econometric evaluation estimator: Evidence from evaluating a job training programme. The Review of Economic Studies 64: 605–54. [Google Scholar] [CrossRef]
- Heckman, James J., Jeffrey Smith, and Nancy Clements. 1997b. Making the most out of programme evaluations and social experiments: Accounting for heterogeneity in programme impacts. The Review of Economic Studies 64: 487–535. [Google Scholar] [CrossRef]
- Hirano, Keisuke, Guido W. Imbens, and Geert Ridder. 2003. Efficient estimation of average treatment effects using the estimated propensity score. Econometrica 71: 1161–89. [Google Scholar] [CrossRef]
- Imbens, Guido W. 2004. Nonparametric estimation of average treatment effects under exogeneity: A review. The Review of Economics and Statistics 86: 4–29. [Google Scholar] [CrossRef]
- Jarrell, Michele Glanker. 1994. A comparison of two procedures, the Mahalanobis distance and the Andrews-Pregibon statistic, for identifying multivariate outliers. Research in the Schools 1: 49–58. [Google Scholar]
- Keller, Fabian, Emmanuel Muller, and Klemens Bohm. 2012. HiCS: High contrast subspaces for density-based outlier ranking. Paper presented at the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, April 1–5; pp. 1037–48. [Google Scholar]
- Khan, Shakeeb, and Elie Tamer. 2010. Irregular identification, support conditions, and inverse weight estimation. Econometrica 78: 2021–42. [Google Scholar]
- Khandker, Shahidur R., Gayatri B. Koolwal, and Hussain A. Samad. 2009. Handbook on Impact Evaluation: Quantitative Methods and Practices. Washington, DC: World Bank Publications. [Google Scholar]
- King, Gary, Christopher Lucas, and Richard A. Nielsen. 2017. The Balance-Sample Size Frontier in Matching Methods for Causal Inference. American Journal of Political Science 61: 473–89. [Google Scholar] [CrossRef]
- Knorr, Edwin M., Raymond T. Ng, and Vladimir Tucakov. 2000. Distance-based outliers: Algorithms and applications. The VLDB Journal—The International Journal on Very Large Data Bases 8: 237–53. [Google Scholar] [CrossRef]
- LaLonde, Robert J. 1986. Evaluating the econometric evaluations of training programs with experimental data. The American Economic Review 76: 604–20. [Google Scholar]
- Maronna, Ricardo A., R. Douglas Martin, and Victor Yohai. 2006. Robust Statistics. Chichester: John Wiley & Sons. [Google Scholar]
- Orair, Gustavo H., Carlos H. C. Teixeira, Wagner Meira, Jr., Ye Wang, and Srinivasan Parthasarathy. 2010. Distance-based outlier detection: Consolidation and renewed bearing. Proceedings of the VLDB Endowment 3: 1469–80. [Google Scholar] [CrossRef]
- Osborne, Jason W., and Amy Overbay. 2004. The power of outliers (and why researchers should always check for them). Practical Assessment, Research & Evaluation 9: 1–12. [Google Scholar]
- Rasmussen, Jeffrey Lee. 1988. Evaluating outlier identification tests: Mahalanobis D squared and Comrey Dk. Multivariate Behavioral Research 23: 189–202. [Google Scholar] [CrossRef] [PubMed]
- Rousseeuw, Peter J., and Annick M. Leroy. 2005. Robust Regression and Outlier Detection. Hoboken: John Wiley & Sons, vol. 589. [Google Scholar]
- Rousseeuw, Peter J., and Bert C. Van Zomeren. 1990. Unmasking multivariate outliers and leverage points. Journal of the American Statistical Association 85: 633–39. [Google Scholar] [CrossRef]
- Rubin, Donald B. 1974. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology 66: 688. [Google Scholar] [CrossRef]
- Schwager, Steven J., and Barry H. Margolin. 1982. Detection of multivariate normal outliers. The Annals of Statistics 10: 943–54. [Google Scholar] [CrossRef]
- Seifert, Burkhardt, and Theo Gasser. 2000. Data adaptive ridging in local polynomial regression. Journal of Computational and Graphical Statistics 9: 338–60. [Google Scholar]
- Smith, Jeffrey A., and Petra E. Todd. 2005. Does matching overcome LaLonde’s critique of nonexperimental estimators? Journal of Econometrics 125: 305–53. [Google Scholar] [CrossRef]
- Stahel, Werner A. 1981. Robuste Schätzungen: Infinitesimale optimalität und Schätzungen von Kovarianzmatrizen. Zürich: Eidgenössische Technische Hochschule [ETH]. [Google Scholar]
- Stevens, James P. 1984. Outliers and influential data points in regression analysis. Psychological Bulletin 95: 334. [Google Scholar] [CrossRef]
- Stuart, Elizabeth A., Brian K. Lee, and Finbarr P. Leacy. 2013. Prognostic score–based balance measures can be a useful diagnostic for propensity score methods in comparative effectiveness research. Journal of Clinical Epidemiology 66 Suppl. 8: S84–S90.e1. [Google Scholar] [CrossRef] [PubMed]
- Verardi, Vincenzo, and Alice McCathie. 2012. The S-Estimator of Multivariate Location and Scatter in Stata. The Stata Journal: Promoting Communications on Statistics and Stata 12: 299–307. [Google Scholar] [CrossRef]
- Verardi, Vincenzo, and Christophe Croux. 2009. Robust Regression in Stata. The Stata Journal 9: 439–53. [Google Scholar] [CrossRef]
- Verardi, Vincenzo, Marjorie Gassner, and Darwin Ugarte. 2012. Robustness for Dummies. ECARES Working Papers. Brussels: ECARES. [Google Scholar]
- Zimmerman, Donald W. 1994. A note on the influence of outliers on parametric and nonparametric tests. The Journal of General Psychology 121: 391–401. [Google Scholar] [CrossRef]
| 1. | For a complete discussion and examples of the relationship between randomized and non-randomized experiments and their bias, see LaLonde (1986); Heckman et al. (1997a); Heckman et al. (1997b). |
| 2. | |
| 3. | In the regression analysis framework these type of outliers affects the coefficients of the regression. |
| 4. | Recall that the Mahalanobis distance is calculated using the squared distances to the centroid; that is:
|
| 5. | For specific details about this method, see Verardi et al. (2012) and Maronna et al. (2006). A Stata code to implement this tool is available upon request. |
| 6. | Since dummies are partialled out in these strategies, they do not represent an issue for the estimators. |
| 7. | Verardi et al. (2012) also propose a weighted regression using the weighting function in order to preserve the original sample: where . |
| 8. | For a brief explanation of matching techniques see Canavire-Bacarreza and Hanauer (2013). |
| 9. | When there is more than one covariate, is a vector of coefficients equal to for each covariate. |
| 10. | Since and , then is also normally distributed with mean 0, thus, on average half the population will receive the treatment. |
| 11. | All the overlap plots are based on density estimation. |
| 12. | Results for the remaining designs are available from the corresponding author upon request. |
| 13. | In this case the correlation for the clean data should be equal to 1. |
| 14. | Results for the remaining designs are available from the corresponding author upon request. |
| 15. | Note that although we searched for the single closest match, as will be shown below, the illustration discussed above holds for different matching methods. |
| 16. | Recall that the true effect of the treatment is equal to one. |
| 17. | Since the Pair Matching estimator in Table 4 uses 1 nearest neighbor for the matching process, we tested two cases and for nearest-neighbor matching and bias adjusted nearest-neighbor matching. The results are depicted in Table A3 in Appendix A and show that, in general, increasing the number of matching neighbors, slightly increases the bias of the estimator and decreases its variance (whether it is biased corrected or not). |
| 18. | |
| 19. | Similar results were obtained when applying the SD tool to other estimators (see Verardi et al. (2012)). |
| 20. | Similar results are obtained when using the Smultiv/SD algorithms to check for outliers when estimating the Average Treatment Effect (ATE) and also when changing the number of neighbors in nearest neighbor matching. |
| 21. | DW applied propensity score matching estimators to subsamples of the same experimental data from the National Supported Work (NSW) Demonstration and the same non-experimental data from the Current Population Survey (CPS) and the Panel Study of Income Dynamics (PSID) analyzed by LaLonde (1986). ST re-estimated DW’s model using three samples: LaLonde’s full sample, DW’s sub-sample, and a third sub-sample (ST-sample). See Dehejia and Wahba (1999, 2002), and Smith and Todd (2005) for details. |
| 22. | We would like to thank professor Smith for kindly sharing his data with us. |
| 23. | |
| 24. | The specifications for the PSID comparison group are age, age squared, schooling, schooling squared, no high school degree, married, black, Hispanic, real earnings in 1974, real earnings in 1974 squared, real earnings in 1975, real earnings in 1975 squared, dummy zero earning in 1974, dummy zero earning in 1975, and Hispanic * dummy zero earning in 1974. The specifications for the CPS group are age, age squared, age cubed, schooling, schooling squared, no high school degree, married, black, Hispanic, real earnings in 1974, real earnings in 1975, dummy zero earning in 1974, dummy zero earning in 1975, and Hispanic * dummy zero earnings in 1974. |





| Panel A: Severe contamination, ten covariates (p = 10) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Coefficient (beta) | 0.51 | −0.05 | −0.04 | −0.04 | 0.51 | 0.51 | 0.51 |
| MSE (×1000) | 3.57 | 297.54 | 296.84 | 295.30 | 3.74 | 3.72 | 3.72 |
| Propensity Score | |||||||
| Mean | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 |
| Growth in Variance | −11.0% | −11.0% | −11.1% | 5.0% | 5.0% | 4.8% | |
| Growth in Kurtosis | 5.7% | 5.7% | 5.8% | −1.9% | −1.8% | −1.8% | |
| Loss in Correlation | −7.9% | −7.8% | −7.8% | −2.4% | −2.4% | −2.3% | |
| Panel B: Severe contamination, two covariates (p = 2) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Coefficient (beta) | 0.50 | 0.00 | 0.00 | 0.00 | 0.51 | 0.51 | 0.51 |
| MSE (×1000) | 2.28 | 246.01 | 245.58 | 245.82 | 2.29 | 2.33 | 2.36 |
| Propensity Score | |||||||
| Mean | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 |
| Growth in Variance | −50.9% | −50.9% | −50.9% | 19.3% | 19.3% | 18.4% | |
| Growth in Kurtosis | 18.0% | 18.0% | 18.0% | 4.4% | 4.3% | 4.9% | |
| Loss in Correlation | −29.7% | −29.6% | −29.6% | −8.3% | −8.3% | −8.0% | |
| Panel C: Mild contamination, ten covariates (p = 10) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Coefficient (beta) | 0.51 | 0.09 | 0.09 | 0.09 | 0.53 | 0.53 | 0.52 |
| MSE (×1000) | 3.57 | 170.62 | 169.52 | 172.47 | 3.68 | 3.67 | 3.63 |
| Propensity Score | |||||||
| Mean | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 |
| Growth in Variance | −11.3% | −11.3% | −11.3% | 5.0% | 5.0% | 4.8% | |
| Growth in Kurtosis | 6.1% | 6.1% | 6.1% | −2.1% | −2.1% | −2.0% | |
| Loss in Correlation | −29.7% | −29.6% | −29.6% | −8.3% | −8.3% | −8.0% | |
| Panel D: Mild contamination, two covariates (p = 2) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Coefficient (beta) | 0.50 | 0.29 | 0.29 | 0.28 | 0.55 | 0.55 | 0.55 |
| MSE (×1000) | 2.28 | 46.35 | 46.33 | 47.86 | 4.32 | 4.40 | 4.19 |
| Propensity Score | |||||||
| Mean | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 |
| Growth in Variance | −29.3% | −29.3% | −29.6% | 17.1% | 17.1% | 16.7% | |
| Growth in Kurtosis | 9.3% | 9.4% | 9.4% | −3.0% | −3.0% | −2.6% | |
| Loss in Correlation | −6.3% | −6.2% | −6.5% | −3.8% | −3.8% | −3.9% | |
| Panel A: Severe contamination, ten covariates (p = 10) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Mahalanobis Distance | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Mean | 2.00 | 2.04 | 2.04 | 2.00 | 2.04 | 2.04 | 2.00 |
| Growth in Variance | 395.0% | 394.5% | 361.0% | 398.8% | 398.6% | 364.2% | |
| Growth in Asymmetry | 89.6% | 89.5% | 87.7% | 89.6% | 89.6% | 87.7% | |
| Growth in Kurtosis | 95.9% | 95.6% | 93.1% | 95.7% | 95.4% | 92.7% | |
| Loss in Correlation | −76.3% | −76.3% | −75.6% | −75.4% | −75.4% | −74.7% | |
| Panel B: Severe contamination, two covariates (p = 2) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Mahalanobis Distance | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Mean | 2.00 | 2.02 | 2.02 | 2.00 | 2.03 | 2.03 | 2.00 |
| Growth in Variance | 206.6% | 207.5% | 199.2% | 234.6% | 234.9% | 222.7% | |
| Growth in Asymmetry | 86.7% | 87.0% | 85.6% | 88.3% | 88.4% | 87.0% | |
| Growth in Kurtosis | 112.4% | 112.9% | 110.1% | 111.1% | 111.4% | 108.9% | |
| Loss in Correlation | −64.3% | −64.0% | −64.0% | −63.8% | −63.5% | −63.3% | |
| Panel C: Mild contamination, ten covariates (p = 10) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Mahalanobis Distance | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Mean | 2.00 | 2.01 | 2.01 | 2.00 | 2.02 | 2.02 | 2.00 |
| Growth in Variance | 106.6% | 106.2% | 106.3% | 129.7% | 129.6% | 127.1% | |
| Growth in Asymmetry | 76.5% | 75.8% | 76.3% | 81.5% | 81.0% | 80.3% | |
| Growth in Kurtosis | 118.8% | 116.5% | 117.1% | 121.8% | 120.5% | 118.3% | |
| Loss in Correlation | −49.2% | −49.1% | −49.6% | −50.4% | −50.3% | −50.7% | |
| Panel D: Mild contamination, two covariates (p = 2) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Mahalanobis Distance | Clean | in T | in C | in T and C | in T | in C | in T and C |
| Mean | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| Growth in Variance | 1.7% | 2.0% | 2.3% | 19.2% | 19.2% | 19.8% | |
| Growth in Asymmetry | 3.4% | 3.5% | 4.4% | 21.6% | 21.3% | 22.2% | |
| Growth in Kurtosis | 7.0% | 6.9% | 9.0% | 37.6% | 36.9% | 38.1% | |
| Loss in Correlation | −7.8% | −7.8% | −8.3% | −17.7% | −17.6% | −18.2% | |
| Col: | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | (15) | (16) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Propensity Score | Covariate Matches | |||||||||||||||
| Original Data | Propensity Score | Matches (ID) | Mahalanobis Distance | (ID) | ||||||||||||
| ID | y | x1 | x2 | T | P(T)o | P(T)blp | P(T)glp | mo | mblp | mglp | MDo | MDblp | MDglp | mo | mblp | mglp |
| 1 | 0.94 | 0.35 | −1.14 | T | 0.27 | 0.30 | 0.28 | 14 | 11 | 14 | 0.62 | 0.62 | 0.61 | 12 | 11 | 11 |
| 2 | 2.58 | 0.58 | −0.06 | T | 0.78 | 0.47 | 0.75 | 12 | 15 | 12 | 0.51 | 0.02 | 0.26 | 12 | 12 | 12 |
| 3 | 2.29 | 1.41 | 0.67 | T | 0.99 | 0.55 | 0.99 | 12 | 9 | 12 | 4.40 | 0.90 | 1.78 | 15 | 13 | 8 |
| 4 | 1.45 | −0.79 | 0.68 | T | 0.52 | 0.65 | 0.56 | 8 | 8 | 8 | 0.66 | 1.19 | 0.55 | 12 | 14 | 11 |
| 5 | 1.27 | −0.83 | 0.04 | T | 0.25 | 0.55 | 0.30 | 14 | 9 | 14 | 0.63 | 0.78 | 0.04 | 12 | 11 | 9 |
| 6 | 1.08 | 0.87 | 0.36 | T | 0.93 | 0.52 | 0.92 | 12 | 9 | 12 | 1.73 | 0.28 | 0.82 | 13 | 9 | 11 |
| 7 | 2.21 | 0.35 | 1.15 | T | 0.96 | 0.68 | 0.95 | 12 | 8 | 12 | 2.37 | 1.21 | 1.98 | 8 | 14 | 8 |
| 8 | −0.72 | −1.58 | 1.50 | C | 0.51 | 0.79 | 0.59 | 2.60 | 3.74 | 1.94 | ||||||
| 9 | 1.26 | −0.17 | −0.08 | C | 0.47 | 0.50 | 0.49 | 0.02 | 0.18 | 0.04 | ||||||
| 10 | −1.47 | 1.74 | −3.12 | C | 0.13 | 0.06 | 0.10 | 5.98 | 6.52 | 5.88 | ||||||
| 11 | 0.52 | −0.25 | −1.00 | C | 0.13 | 0.35 | 0.16 | 0.91 | 0.69 | 0.50 | ||||||
| 12 | 0.04 | 0.75 | −0.51 | C | 0.68 | 0.38 | 0.66 | 0.50 | 0.11 | 0.23 | ||||||
| 13 | −0.10 | −0.61 | −0.90 | C | 0.08 | 0.38 | 0.11 | 1.39 | 0.88 | 0.46 | ||||||
| 14 | −0.08 | 0.30 | −1.48 | C | 0.16 | 0.26 | 0.16 | 1.24 | 1.14 | 1.16 | ||||||
| 15 | −1.53 | −2.30 | 1.16 | C | 0.14 | 0.49 | 0.00 | 4.42 | 9.75 | 11.74 | ||||||
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 155.72 | 536.54 | 568.73 | 547.42 | 43.91 | 162.42 | 100.70 | 1738.27 | −1425.95 | 160.84 |
| Ridge M. Epan | 143.49 | 501.50 | 525.45 | 511.43 | 48.85 | 151.99 | 105.46 | 1725.28 | −1428.19 | 153.34 |
| IPW | 299.37 | 634.05 | 636.05 | 632.63 | 299.32 | 300.98 | 297.69 | 1881.92 | −1264.44 | 309.81 |
| Pair Matching (bias corrected) | −1.48 | 785.56 | 433.26 | 461.78 | −797.19 | −4.43 | −398.52 | 1581.07 | −1570.68 | 9.77 |
| MSE (×1000) | ||||||||||
| Pair Matching | 112.73 | 353.53 | 384.21 | 361.60 | 134.13 | 121.73 | 122.59 | 3113.71 | 3808.92 | 1005.98 |
| Ridge M. Epan | 93.06 | 301.00 | 320.69 | 308.11 | 106.14 | 100.44 | 100.95 | 3053.33 | 3406.23 | 760.11 |
| IPW | 164.17 | 459.52 | 464.34 | 458.64 | 164.85 | 172.71 | 167.73 | 3619.12 | 2173.43 | 421.42 |
| Pair Matching (bias corrected) | 61.73 | 669.61 | 234.13 | 258.86 | 857.37 | 65.18 | 283.12 | 2564.56 | 3774.03 | 735.33 |
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 9.13 | 367.76 | 367.39 | 364.36 | −112.22 | 10.93 | −50.59 | 717.27 | −705.47 | 12.48 |
| Ridge M. Epan | 0.29 | 362.47 | 362.71 | 361.51 | −74.07 | 1.11 | 1.80 | 709.29 | −710.40 | 2.20 |
| IPW | 16.56 | 366.56 | 366.76 | 366.70 | 13.15 | 14.52 | 14.14 | 724.71 | −694.33 | 18.71 |
| Pair Matching (bias corrected) | −0.05 | 354.12 | 363.51 | 359.18 | −353.72 | 1.14 | −176.80 | 708.10 | −714.09 | 3.67 |
| MSE (×1000) | ||||||||||
| Pair Matching | 13.17 | 145.73 | 145.98 | 143.36 | 42.97 | 14.28 | 22.53 | 528.13 | 557.91 | 36.83 |
| Ridge M. Epan | 8.70 | 138.96 | 139.35 | 138.48 | 26.19 | 9.39 | 9.22 | 512.84 | 535.14 | 19.80 |
| IPW | 11.37 | 140.60 | 140.75 | 140.72 | 11.44 | 12.32 | 11.91 | 536.91 | 512.48 | 20.91 |
| Pair Matching (bias corrected) | 13.17 | 134.87 | 143.09 | 139.57 | 184.52 | 14.30 | 59.37 | 515.14 | 571.01 | 37.00 |
| Panel C: Mild contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 155.72 | 446.02 | 478.72 | 465.70 | 49.10 | 163.02 | 104.01 | 630.48 | −318.78 | 157.26 |
| Ridge M. Epan | 143.49 | 407.01 | 434.69 | 422.19 | 52.56 | 150.44 | 104.68 | 618.03 | −328.02 | 146.44 |
| IPW | 299.37 | 553.26 | 555.45 | 557.44 | 288.31 | 289.99 | 287.53 | 774.14 | −169.77 | 302.51 |
| Pair Matching (bias corrected) | −1.48 | 236.68 | 376.49 | 350.68 | −240.05 | −2.05 | −118.73 | 473.28 | −472.24 | 1.89 |
| MSE (×1000) | ||||||||||
| Pair Matching | 112.73 | 262.10 | 289.80 | 278.70 | 130.69 | 120.45 | 119.56 | 486.58 | 342.40 | 193.33 |
| Ridge M. Epan | 93.06 | 212.60 | 234.28 | 223.57 | 104.30 | 100.14 | 99.52 | 455.07 | 297.76 | 153.73 |
| IPW | 164.17 | 361.29 | 367.50 | 367.74 | 160.30 | 168.08 | 163.66 | 674.21 | 147.06 | 188.24 |
| Pair Matching (bias corrected) | 61.73 | 100.48 | 187.36 | 170.06 | 151.11 | 66.23 | 90.72 | 286.13 | 398.70 | 121.23 |
| Panel D: Mild contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 9.13 | 127.38 | 204.31 | 175.95 | −79.71 | −3.21 | −40.49 | 221.57 | −205.25 | 10.13 |
| Ridge M. Epan | 0.29 | 125.16 | 183.86 | 160.66 | −67.73 | −14.64 | −38.13 | 212.99 | −212.92 | 0.86 |
| IPW | 16.56 | 166.69 | 166.07 | 168.93 | −16.22 | −14.88 | −13.95 | 229.01 | −196.71 | 17.21 |
| Pair Matching (bias corrected) | −0.05 | 105.04 | 199.85 | 172.82 | −106.54 | −13.39 | −58.22 | 212.40 | −214.26 | 1.07 |
| MSE (×1000) | ||||||||||
| Pair Matching | 13.17 | 27.84 | 52.39 | 43.02 | 25.87 | 13.98 | 17.67 | 62.24 | 59.63 | 15.40 |
| Ridge M. Epan | 8.70 | 23.30 | 41.90 | 33.80 | 15.14 | 9.56 | 11.09 | 54.14 | 56.18 | 9.77 |
| IPW | 11.37 | 35.14 | 36.07 | 36.43 | 12.83 | 13.38 | 13.05 | 63.62 | 51.76 | 12.18 |
| Pair Matching (bias corrected) | 13.17 | 22.53 | 50.49 | 41.89 | 31.93 | 14.24 | 19.74 | 58.35 | 63.53 | 15.40 |
| Panel A: Severe contamination, ten covariates (p = 10) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Clean | in T | in C | in T and C | in T | in C | in T and C | |
| Contaminated variable | |||||||
| Percentage Bias | 0.20 | 0.19 | 0.25 | 0.07 | 0.46 | 0.21 | 0.31 |
| Variance ratio | 1.21 | 28.45 | 0.14 | 3.87 | 31.94 | 1.22 | 16.86 |
| Remaining variables | |||||||
| Percentage Bias | 0.21 | 0.17 | 0.16 | 0.16 | 0.26 | 0.21 | 0.23 |
| Variance ratio | 1.21 | 1.15 | 1.14 | 1.14 | 1.29 | 1.22 | 1.25 |
| Panel B: Severe contamination, two covariates (p = 2) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Clean | in T | in C | in T and C | in T | in C | in T and C | |
| Contaminated variable | |||||||
| Percentage Bias | 0.05 | 0.04 | 0.07 | 0.05 | 0.33 | 0.06 | 0.21 |
| Variance ratio | 1.05 | 6.25 | 0.17 | 1.02 | 6.00 | 1.06 | 3.73 |
| Remaining variables | |||||||
| Percentage Bias | 0.05 | 0.01 | 0.01 | 0.01 | 0.13 | 0.06 | 0.08 |
| Variance ratio | 1.06 | 1.02 | 1.03 | 1.03 | 1.00 | 1.07 | 1.02 |
| Panel C: Mild contamination, ten covariates (p = 10) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Clean | in T | in C | in T and C | in T | in C | in T and C | |
| Contaminated variable | |||||||
| Percentage Bias | 0.20 | 0.18 | 0.23 | 0.19 | 0.35 | 0.20 | 0.24 |
| Variance ratio | 1.22 | 3.63 | 0.25 | 0.87 | 4.02 | 1.19 | 2.62 |
| Remaining variables | |||||||
| Percentage Bias | 0.20 | 0.17 | 0.16 | 0.16 | 0.25 | 0.21 | 0.23 |
| Variance ratio | 1.20 | 1.15 | 1.14 | 1.14 | 1.28 | 1.22 | 1.24 |
| Panel D: Mild contamination, two covariates (p = 2) | |||||||
| Bad Leverage Point | Good Leverage Point | ||||||
| Clean | in T | in C | in T and C | in T | in C | in T and C | |
| Contaminated variable | |||||||
| Percentage Bias | 0.05 | 0.09 | 0.09 | 0.06 | 0.10 | 0.05 | 0.07 |
| Variance ratio | 1.06 | 1.48 | 0.60 | 0.87 | 1.47 | 1.01 | 1.25 |
| Remaining variables | |||||||
| Percentage Bias | 0.05 | 0.05 | 0.07 | 0.04 | 0.08 | 0.06 | 0.06 |
| Variance ratio | 1.06 | 0.95 | 1.15 | 1.07 | 1.02 | 1.08 | 1.04 |
| Panel A: Severe contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 158.08 | 157.10 | 162.57 | 160.13 | 157.10 | 162.57 | 160.13 | 157.10 | 162.57 | 160.13 |
| Ridge M. Epan | 155.01 | 153.21 | 163.61 | 157.12 | 153.21 | 163.61 | 157.12 | 153.21 | 163.61 | 157.12 |
| IPW | 326.35 | 322.38 | 327.74 | 325.20 | 322.38 | 327.74 | 325.20 | 322.38 | 327.74 | 325.20 |
| Pair Matching (bias corrected) | −4.61 | −1.71 | −1.50 | −2.46 | −1.71 | −1.50 | −2.46 | −1.71 | −1.50 | −2.46 |
| MSE (×1000) | ||||||||||
| Pair Matching | 103.35 | 103.17 | 109.20 | 106.19 | 103.17 | 109.20 | 106.19 | 103.17 | 109.20 | 106.19 |
| Ridge M. Epan | 89.68 | 89.20 | 96.04 | 92.18 | 89.20 | 96.04 | 92.18 | 89.20 | 96.04 | 92.18 |
| IPW | 168.24 | 165.36 | 173.85 | 170.05 | 165.36 | 173.85 | 170.05 | 165.36 | 173.85 | 170.05 |
| Pair Matching (bias corrected) | 57.22 | 59.24 | 59.53 | 60.21 | 59.24 | 59.53 | 60.21 | 59.24 | 59.53 | 60.21 |
| Panel B: Severe contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 13.98 | 14.40 | 17.01 | 18.32 | 14.40 | 17.01 | 18.32 | 14.40 | 17.03 | 18.31 |
| Ridge M. Epan | 0.06 | 1.22 | 1.74 | 2.33 | 1.22 | 1.74 | 2.33 | 1.22 | 1.73 | 2.33 |
| IPW | 50.56 | 44.67 | 50.43 | 47.75 | 44.67 | 50.43 | 47.75 | 44.67 | 50.43 | 47.75 |
| Pair Matching (bias corrected) | −1.37 | 0.50 | 1.29 | 3.65 | 0.50 | 1.29 | 3.65 | 0.50 | 1.30 | 3.65 |
| MSE (×1000) | ||||||||||
| Pair Matching | 12.89 | 13.15 | 13.87 | 13.39 | 13.15 | 13.87 | 13.39 | 13.15 | 13.88 | 13.38 |
| Ridge M. Epan | 8.51 | 8.94 | 9.03 | 8.95 | 8.94 | 9.03 | 8.95 | 8.94 | 9.02 | 8.95 |
| IPW | 10.94 | 10.81 | 11.39 | 11.13 | 10.81 | 11.39 | 11.13 | 10.81 | 11.39 | 11.13 |
| Pair Matching (bias corrected) | 13.08 | 13.19 | 14.03 | 13.35 | 13.19 | 14.03 | 13.35 | 13.19 | 14.03 | 13.35 |
| Panel C: Mild contamination, ten covariates (p = 10) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 158.08 | 159.37 | 184.47 | 170.38 | 155.57 | 162.66 | 159.47 | 187.90 | 143.09 | 165.59 |
| Ridge M. Epan | 155.01 | 156.83 | 182.20 | 169.61 | 151.49 | 163.50 | 156.27 | 186.61 | 142.49 | 163.68 |
| IPW | 326.35 | 327.93 | 340.40 | 334.92 | 321.77 | 327.41 | 324.76 | 354.28 | 305.75 | 330.53 |
| Pair Matching (bias corrected) | −4.61 | 1.95 | 22.80 | 8.90 | −5.46 | −1.03 | −3.61 | 30.80 | −20.01 | 3.87 |
| MSE (×1000) | ||||||||||
| Pair Matching | 103.35 | 102.88 | 119.55 | 109.51 | 103.60 | 109.63 | 106.28 | 114.93 | 106.79 | 110.93 |
| Ridge M. Epan | 89.68 | 89.81 | 103.87 | 96.26 | 89.18 | 96.02 | 92.12 | 101.21 | 92.07 | 95.36 |
| IPW | 168.24 | 168.47 | 181.48 | 176.14 | 165.14 | 173.69 | 169.86 | 187.75 | 160.26 | 173.85 |
| Pair Matching (bias corrected) | 57.22 | 58.22 | 62.05 | 60.18 | 59.71 | 59.57 | 60.54 | 60.01 | 63.42 | 61.48 |
| Panel D: Mild contamination, two covariates (p = 2) | ||||||||||
| Bad Leverage Point | Good Leverage Point | Vertical Outliers in Y | ||||||||
| Estimator | Clean | in T | in C | in T and C | in T | in C | in T and C | in T | in C | in T and C |
| BIAS (×1000) | ||||||||||
| Pair Matching | 13.98 | 66.06 | 112.49 | 87.75 | −21.00 | 9.60 | −3.57 | 143.83 | −99.29 | 22.02 |
| Ridge M. Epan | 0.06 | 55.77 | 94.40 | 75.45 | −29.71 | −6.86 | −17.36 | 129.81 | −118.99 | 5.99 |
| IPW | 50.56 | 105.41 | 126.67 | 114.80 | 29.92 | 37.12 | 34.51 | 172.36 | −64.94 | 54.20 |
| Pair Matching (bias corrected) | −1.37 | 50.92 | 101.49 | 76.23 | −40.72 | −6.36 | −21.52 | 129.50 | −115.00 | 6.88 |
| MSE (×1000) | ||||||||||
| Pair Matching | 12.89 | 17.33 | 24.93 | 20.25 | 15.36 | 13.29 | 13.76 | 34.25 | 23.69 | 14.21 |
| Ridge M. Epan | 8.51 | 12.25 | 17.88 | 14.90 | 10.49 | 9.21 | 9.49 | 26.14 | 24.02 | 9.65 |
| IPW | 10.94 | 19.35 | 24.18 | 21.40 | 9.86 | 10.25 | 10.20 | 38.89 | 13.44 | 12.07 |
| Pair Matching (bias corrected) | 13.08 | 15.82 | 22.72 | 18.61 | 17.18 | 13.73 | 14.75 | 30.58 | 27.48 | 14.18 |
| Comparison Group | Treatment Group | Experimental TOT | Estimated TOT | Estimated SD-TOT | Estimated Smultiv-TOT |
|---|---|---|---|---|---|
| PSID [2490 obs] | LaLonde [297 obs] | 886 | −1390 (966) | −870 (1012) | −514 (1116) |
| PSID [2490 obs] | Dehejia-Wahba [185 obs] | 1794 | 990 (1255) | 1306 (1662) | 2135 (1325) |
| CPS [15992 obs] | LaLonde [297 obs] | 886 | −4001 (563) | −2884 (713) | −3130 (1070) |
| CPS [15992 obs] | Dehejia-Wahba [185 obs] | 1794 | 1566 (770) | 1824 (890) | 1849 (819) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Canavire-Bacarreza, G.; Castro Peñarrieta, L.; Ugarte Ontiveros, D. Outliers in Semi-Parametric Estimation of Treatment Effects. Econometrics 2021, 9, 19. https://doi.org/10.3390/econometrics9020019
Canavire-Bacarreza G, Castro Peñarrieta L, Ugarte Ontiveros D. Outliers in Semi-Parametric Estimation of Treatment Effects. Econometrics. 2021; 9(2):19. https://doi.org/10.3390/econometrics9020019
Chicago/Turabian StyleCanavire-Bacarreza, Gustavo, Luis Castro Peñarrieta, and Darwin Ugarte Ontiveros. 2021. "Outliers in Semi-Parametric Estimation of Treatment Effects" Econometrics 9, no. 2: 19. https://doi.org/10.3390/econometrics9020019
APA StyleCanavire-Bacarreza, G., Castro Peñarrieta, L., & Ugarte Ontiveros, D. (2021). Outliers in Semi-Parametric Estimation of Treatment Effects. Econometrics, 9(2), 19. https://doi.org/10.3390/econometrics9020019