In this section, results of the forecasting competition between the nowcasting model developed at the NY FED and simple benchmark models are presented. In the main text, we report the results based on second GDP releases. We verify the robustness of the conclusions using such alternative GDP releases as advance, final, and the latest ones, which are reported in the
Appendix A. This section is divided in two parts. The first part discusses the predictive ability of the models in terms of the traditional measures based on squared forecast errors averaged over the full evaluation sample or its recessionary and expansionary sub-samples. The second part applies the recursive measures of the forecast accuracy dissecting differences in the predictive ability observation by observation.
6.1. Point Estimates of the Relative Forecasting Accuracy
The point estimates of the forecast accuracy (MSFE and relative MSFE) are reported in
Table 1 and
Table 2, respectively. These two tables are organized in the following way. The left panel reports the measures of the forecasting accuracy for the pre-COVID period, 2002Q1–2019Q4. In the left panel of
Table 1, we report the MSFE for the full sample as well as separately for the expansionary period (2002Q1–2007Q3 and 2009Q3–2019Q4) and the period of the Great Financial Crisis (2007Q4–2009Q2). The left panel of
Table 2 correspondingly contains the derived relative MSFEs of the DFM and ARM with respect to the benchmark HMM model. The right panel of each table contains the nominal and relative MSFEs for the full sample at our disposal (2002Q1–2020Q2) and the two recessionary periods (2007Q4–2009Q2 and 2020Q1–2020Q2). Since the expansionary period for the full sample is the same as for the pre-COVID sample, the relevant column was omitted from the right panel in
Table 1 and
Table 2.
The results presented in this way allow us to disentangle the effect of extending the forecasting exercise with the two COVID quarters on the nominal and relative forecast accuracy measures reported for the full sample, i.e., averaging across expansionary and recessionary quarters, as well as for the case when one is interested in differences in the models’ predictive ability across the expansionary and recessionary phases.
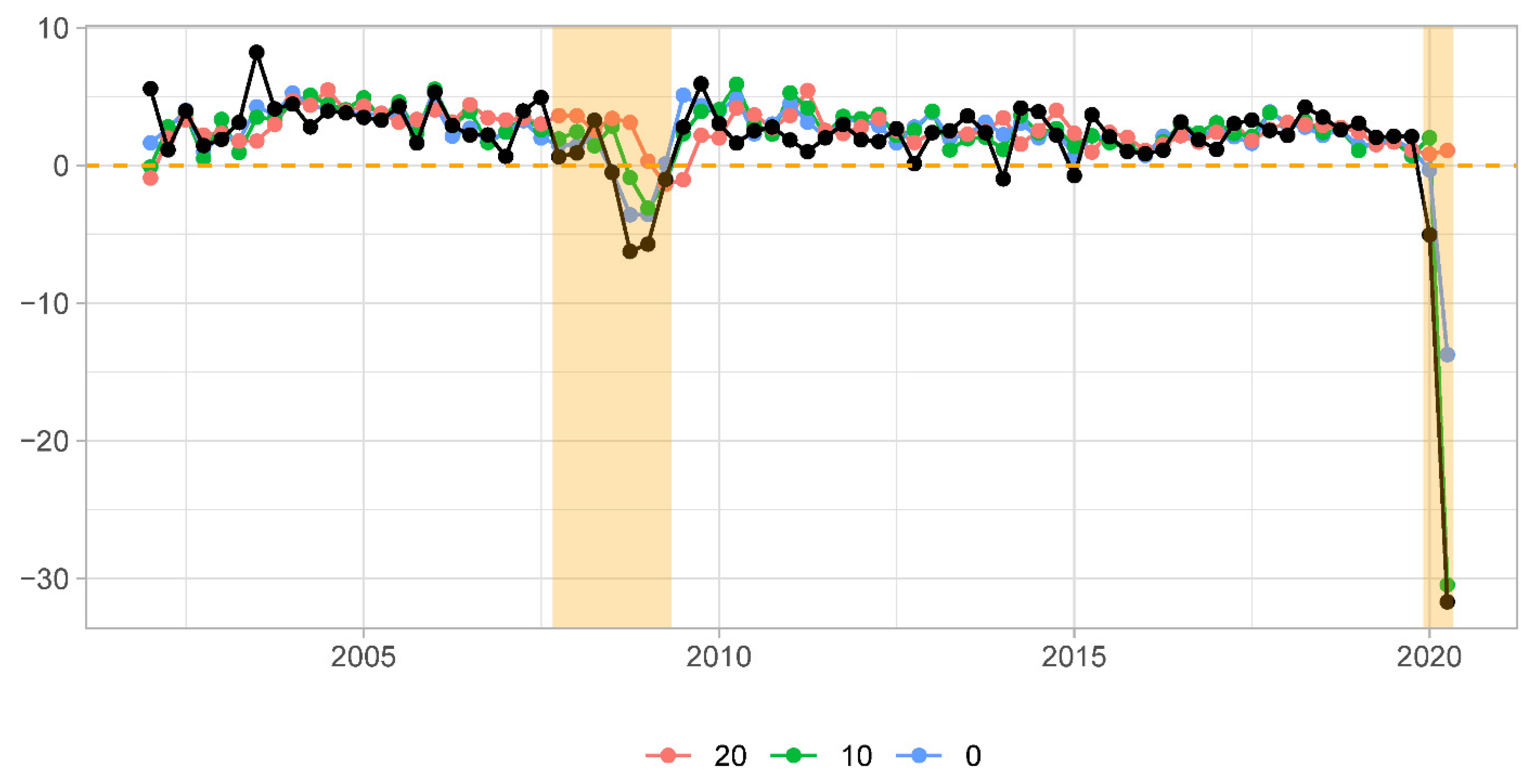
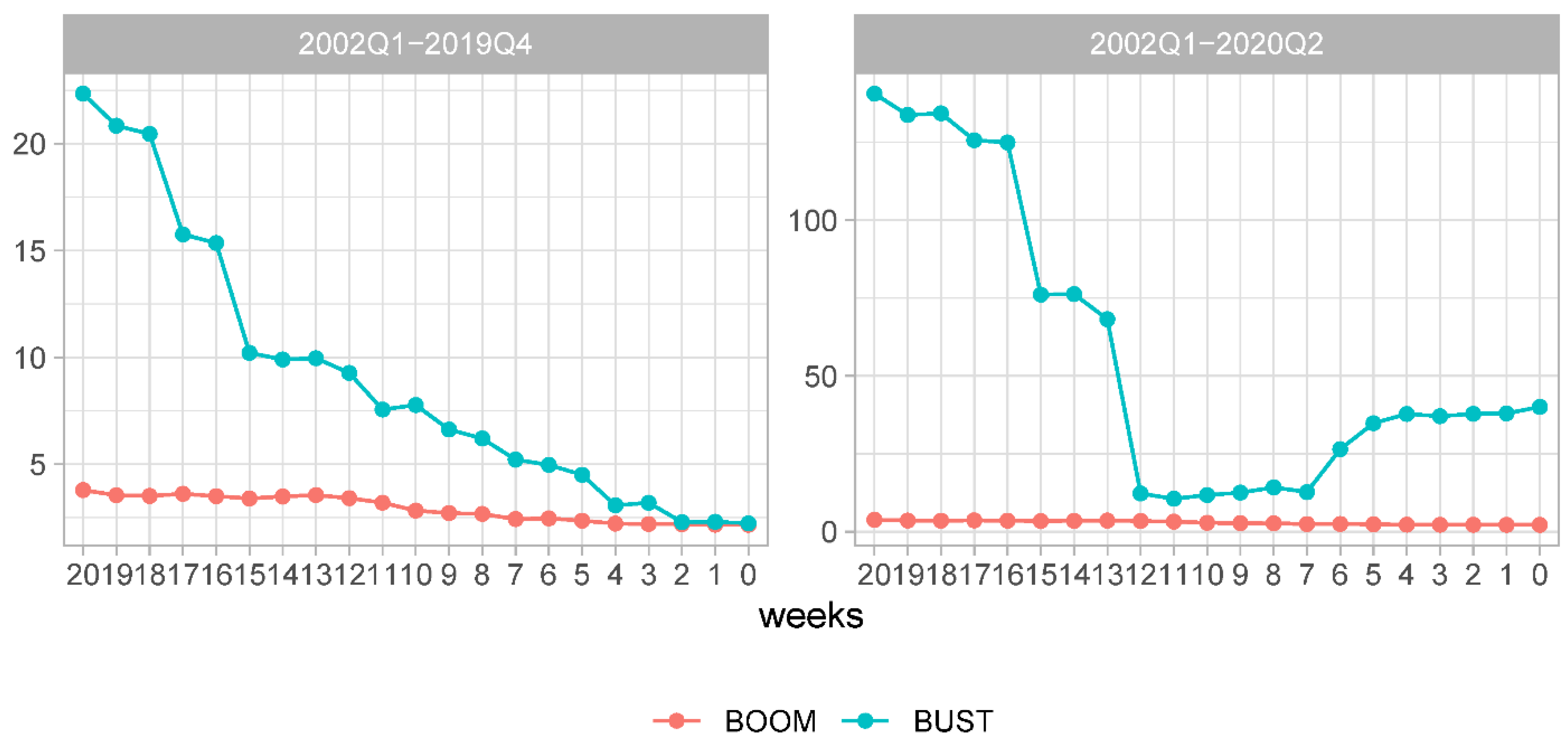
First, we address differences in MSFEs brought about by extending the sample by the COVID recessionary period. The evolution of MSFE at each forecast origin for each of the three models under scrutiny is shown for the pre-COVID and full samples in the left and right panels in
Figure 4, respectively. Upon comparing these two plots, it becomes evident that the average squared forecast error substantially increased at every forecast origin and for every model. We also observe that at the earlier forecast origins the relative model ranking has changed. In the pre-COVID period, the univariate benchmark models were characterized by lower MSFE than the NY FED model. In the full sample, this advantage in forecast accuracy of the benchmark models disappeared.
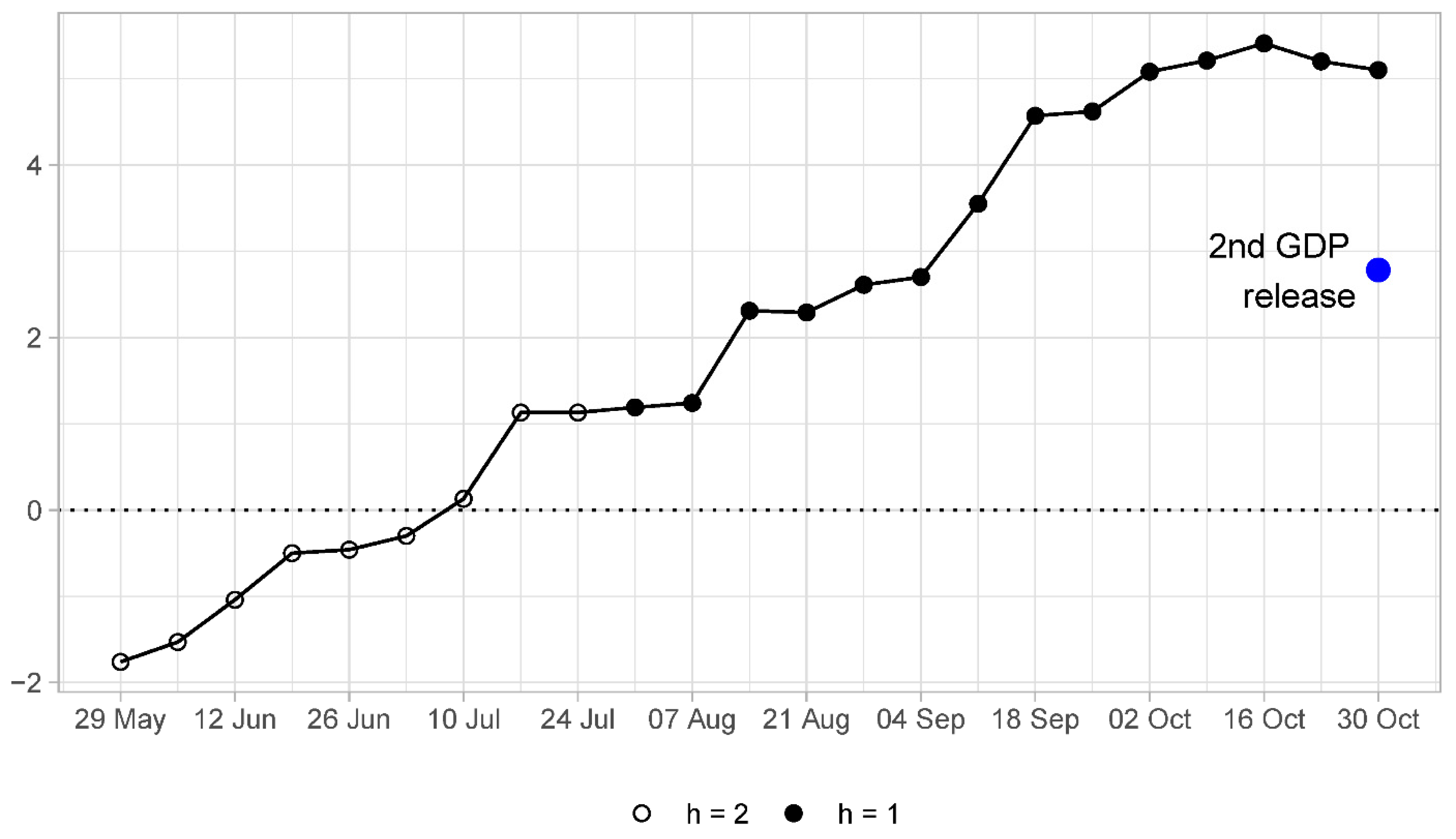
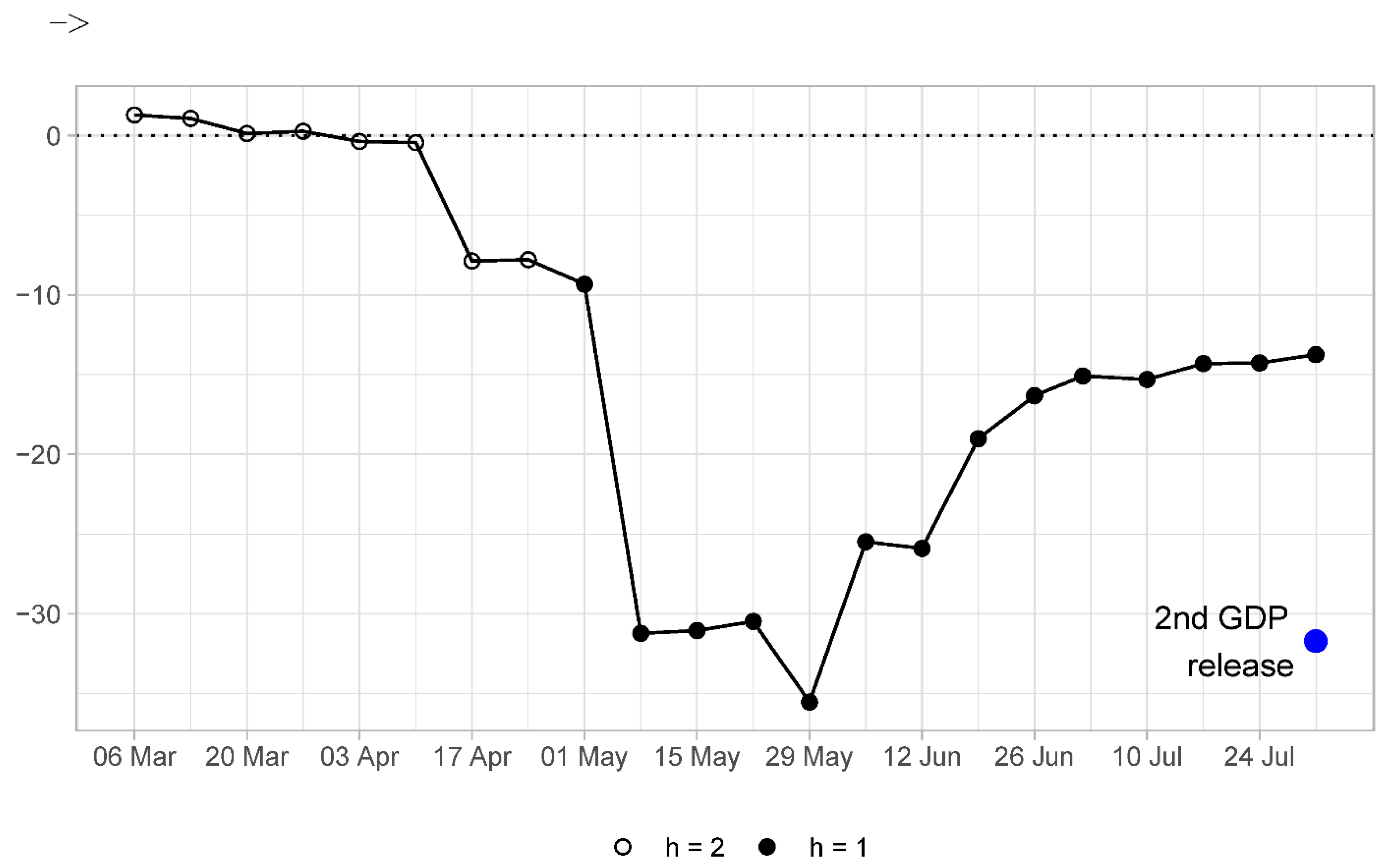
One more detail deserves attention. In the pre-COVID period, the MSFE of the DFM showed a clear downward trending behavior, implying increasing forecast accuracy as more information was incorporated into the model. In the full sample, this pattern is no longer observed. In fact, the most accurate predictions are made for the forecasts made about 7–12 weeks before advance GDP releases. Forecasts made at shorter forecast horizons are characterized by increasing MSFE values. An explanation for such observation can be found in
Figure 2 where the sequence of nowcasts for 2020Q2 is presented. One can observe that, at the forecast origins of 7–12 weeks, the nowcasts are very close to the GDP outturn, whereas this is not the case for nowcasts made either earlier or later than that. In short, this example illustrates that a single data point can have a rather large influence on the measures of forecast accuracy based on averages of squared forecast errors.
Comparative forecasting performance of the benchmark models deserves a special mention. As can be seen in
Figure 4, when evaluated for the full sample (either with or without the COVID period), the ARM produces lower MSFE values than the HMM. At first glance, this observation should support the choice of the autoregressive model as the harder-to-beat benchmark model. However, when one examines the relative MSFE
ARM/HMM reported in
Table 2, it becomes evident that during the expansionary phase the MSFE values of the ARM are up to 20% higher than those of the HMM. It is only during recessions when losses in forecast accuracy during expansions relative to the historical mean model are overcompensated by the respective gains for the autoregressive model. This implies that the HMM is a harder-to-beat benchmark during the expansions that take a lion’s share of observations in our sample. This is actually the main reason why the relative measures of forecast accuracy are reported with respect to the historical mean model in this study.
Motivated by this conclusion, we present evolution rMSFE DFM/HMM for the samples without and with COVID observations in
Figure 5. The overall conclusion that can be tentatively made is very comforting for the NY FED nowcasting model. The reduction in MSFEs, when compared to that of the HMM, is up to 55% for the pre-COVID forecast evaluation sample and about 80% for the full sample under scrutiny.
Another dimension for the analysis of the predictive ability of the NY FED nowcasting model is to compare the MSFE values for the expansionary and recessionary periods.
Chauvet and Potter (
2013) observe that during recessions it is harder to make forecasts in the sense that forecast errors tend to be larger than those observed during expansions. The corresponding MSFE values are shown in
Figure 6. In the left panel of the figure, we report the evolution of the MSFE for expansionary (2002Q1–2007Q3 and 2009Q3–2019Q4) and recessionary samples (2007Q4–2009Q2) in the pre-COVID period. In the right panel of the figure, we report the evolution of the MSFE for the expansionary (2002Q1–2007Q3 and 2009Q3–2019Q4) and recessionary samples (2007Q4–2009Q2 and 2020Q1–2020Q2) in the full period.
For the pre-COVID sample, one can observe the pattern that largely conforms to the observation made by
Chauvet and Potter (
2013). At the earlier forecast origins, the forecasts are less precise during the GFC than during the expansionary phases. At the same time, for the forecasts made less than three weeks ahead of the advance GDP estimate releases, the forecasting accuracy during the GFC and expansions is very similar. However, the latter observation can no longer be confirmed when one compares the MSFEs computed for both the GFC and COVID recessionary periods with the MSFE computed for the expansionary period. As can be seen from the right panel of
Figure 6, at all forecast origins, forecasts of GDP growth during the recessions are less precise than those during the expansions.
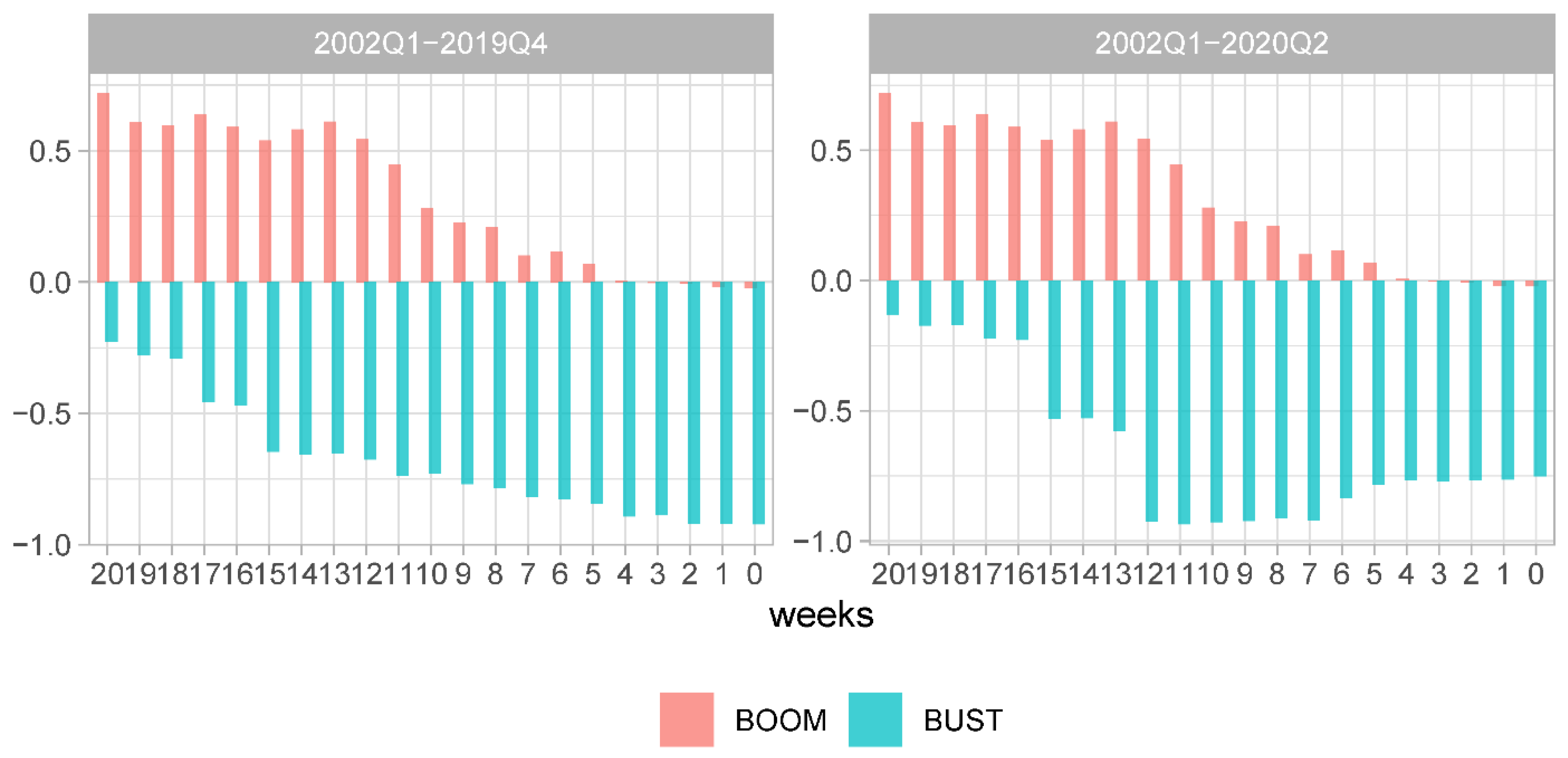
More importantly, given such large differences in nominal measures of forecast accuracy during recessions and expansions, it is worthwhile verifying whether there are noticeable differences in the relative measures. In
Figure 7, we plot the evolution of the relative MSFE of the NY FED model and the historical mean model rMSFE
DFM/HMM separately for the recessionary and expansionary periods. The left panel shows the results for the pre-COVID sample and the right panel—for the sample extended with the COVID recessionary period.
In both panels of
Figure 7, one can observe a very pronounced asymmetry in the relative forecast accuracy between the DFM and HMM. During expansions, the HMM model produces more precise forecasts made at forecast origins longer than four weeks ahead of advance GDP releases. Only where forecasts are made less than four weeks ahead of advance GDP releases, the forecast accuracy of both models becomes very similar. Given the timing of a typical advance GDP release, this corresponds to the forecast origins at the end of the last month of a targeted quarter and during the weeks of the first month after the end of the targeted quarter. This observation is consistent with that made by
Chauvet and Potter (
2013), i.e., simple univariate models are robust forecasting devices during expansions; see also
Siliverstovs (
2020a) for an assessment of the predictive ability of the model of
Carriero et al. (
2015) for US GDP growth during expansions and recessions. At the same time, during economic crisis periods, the NY FED nowcasting model produces much more accurate forecasts than the historical mean model.
At this point, it is instructive to compare rMSFE
DFM/HMM shown in
Figure 5 for the full sample (excluding or including the COVID recession) with the above values of rMSFE
DFM/HMM shown in
Figure 7. As can be seen, the advantages of the more sophisticated model over the very simple benchmark model reported for the full sample are brought about by rather few observations during economic crises, be it only the Great Financial Crisis or both the GFC and COVID pandemic. Hence, when one ignores this asymmetry in the forecasting performance of the models during business cycles, the forecasting ability of a more sophisticated model tends to be severely overstated during expansions. In this sense, recessions serve as the breadwinner for forecasters devoted to developing evolved models—a point that was made by
Siliverstovs and Wochner (
2021)/
Siliverstovs and Wochner (
2019) after a comprehensive and systematic evaluation of forecastability of more than 200 US time series during expansions and recessions.
6.2. Recursive Estimates of the Relative Forecasting Accuracy
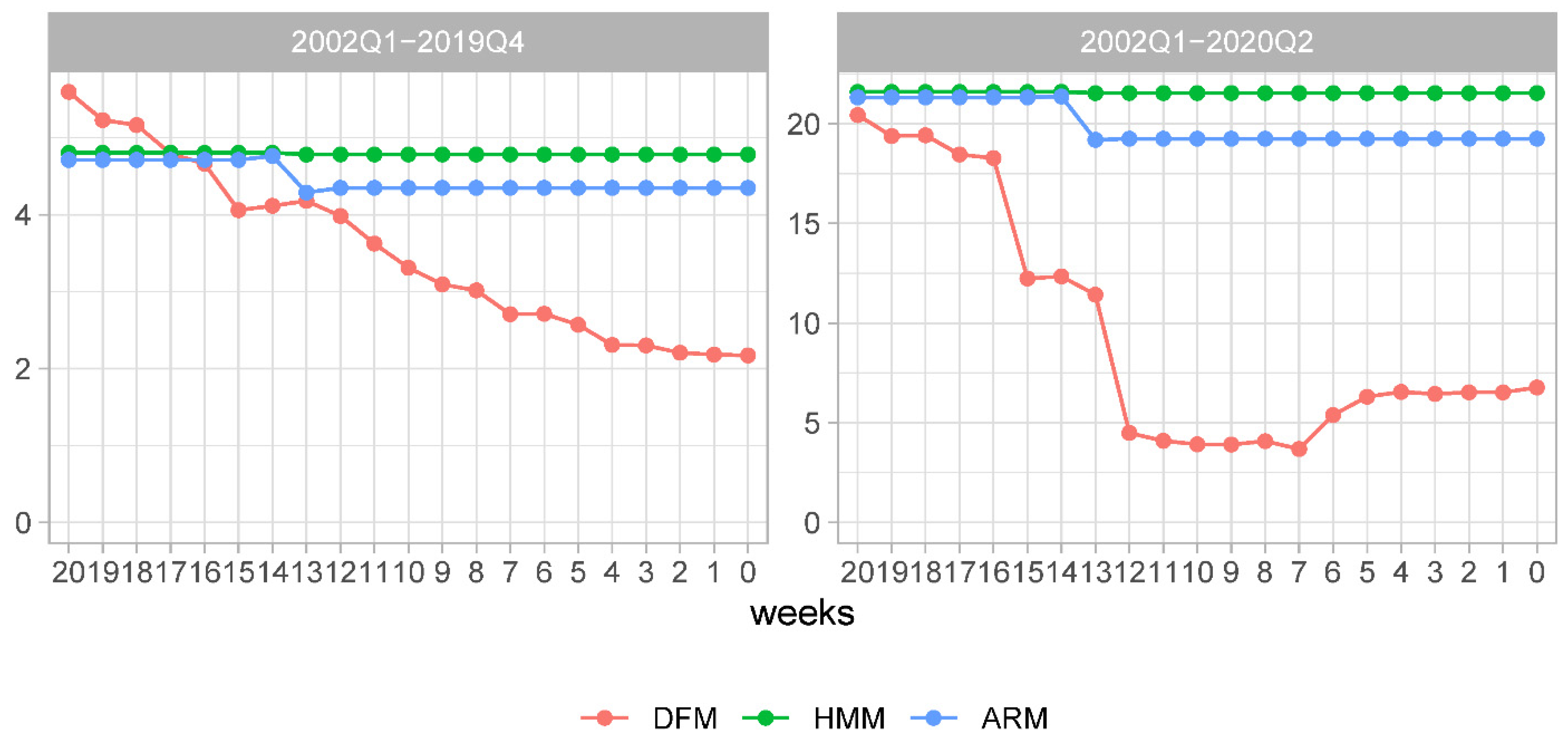
In this section, we present an analysis of the relative forecasting accuracy of the NY FED dynamic factor model (DFM) and the historical mean model (HMM). The main focus of our analysis is centered around Figures 9 and 11 representing CSSFED DFM/HMM and R2MSFE(+R) recursive measures. The auxiliary plots depicting SFED DFM/HMM in its natural temporal ordering and rearranged by its absolute value within each sub-period (expansionary, GFC, and CVD) are represented in Figures 8 and 10, respectively.
For the sake of brevity and without loss of generalization, we will concentrate on the forecasts made at the three selected forecast origins, namely 20, 10, and 0 weeks ahead of advance GDP estimate releases.
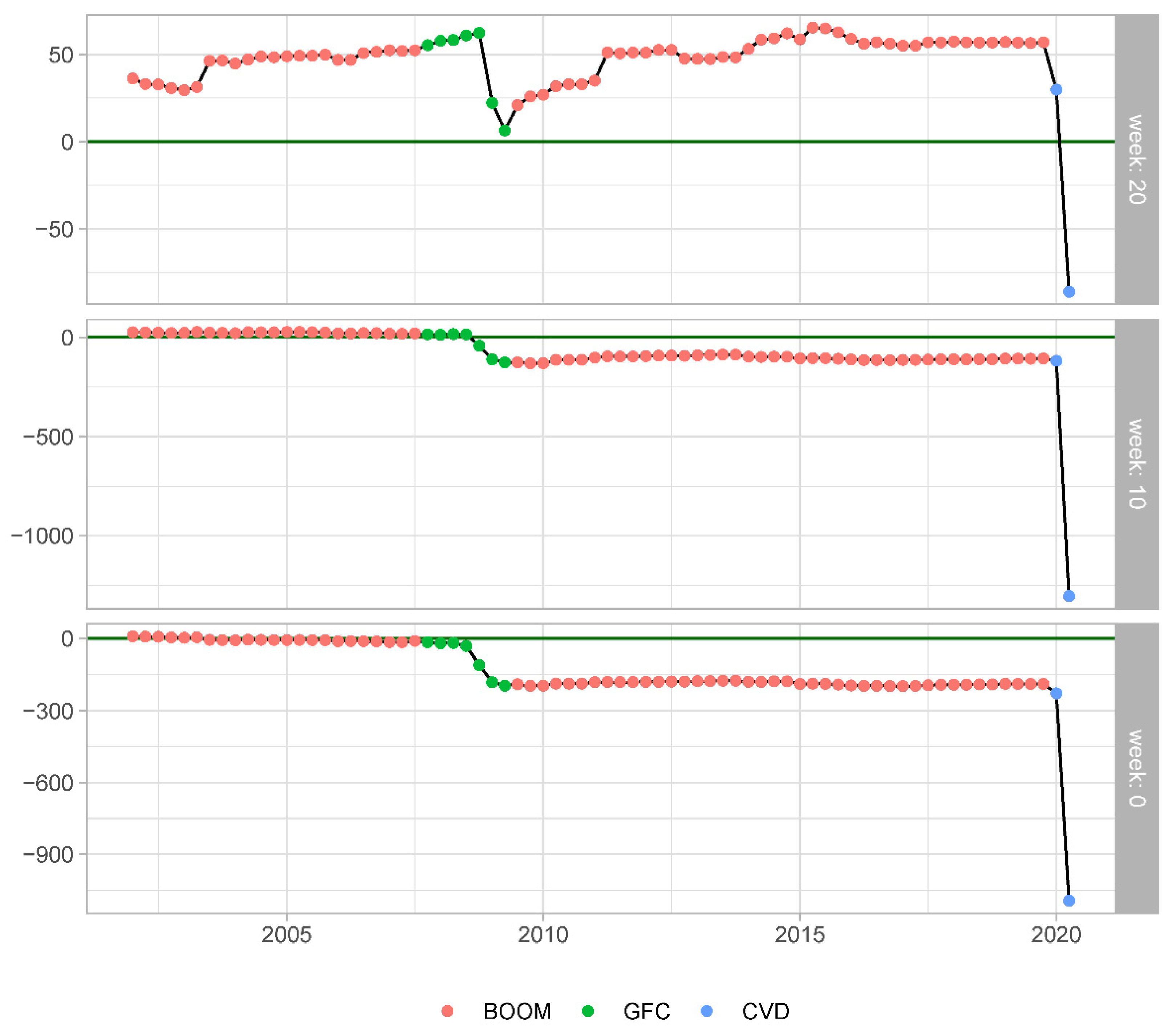
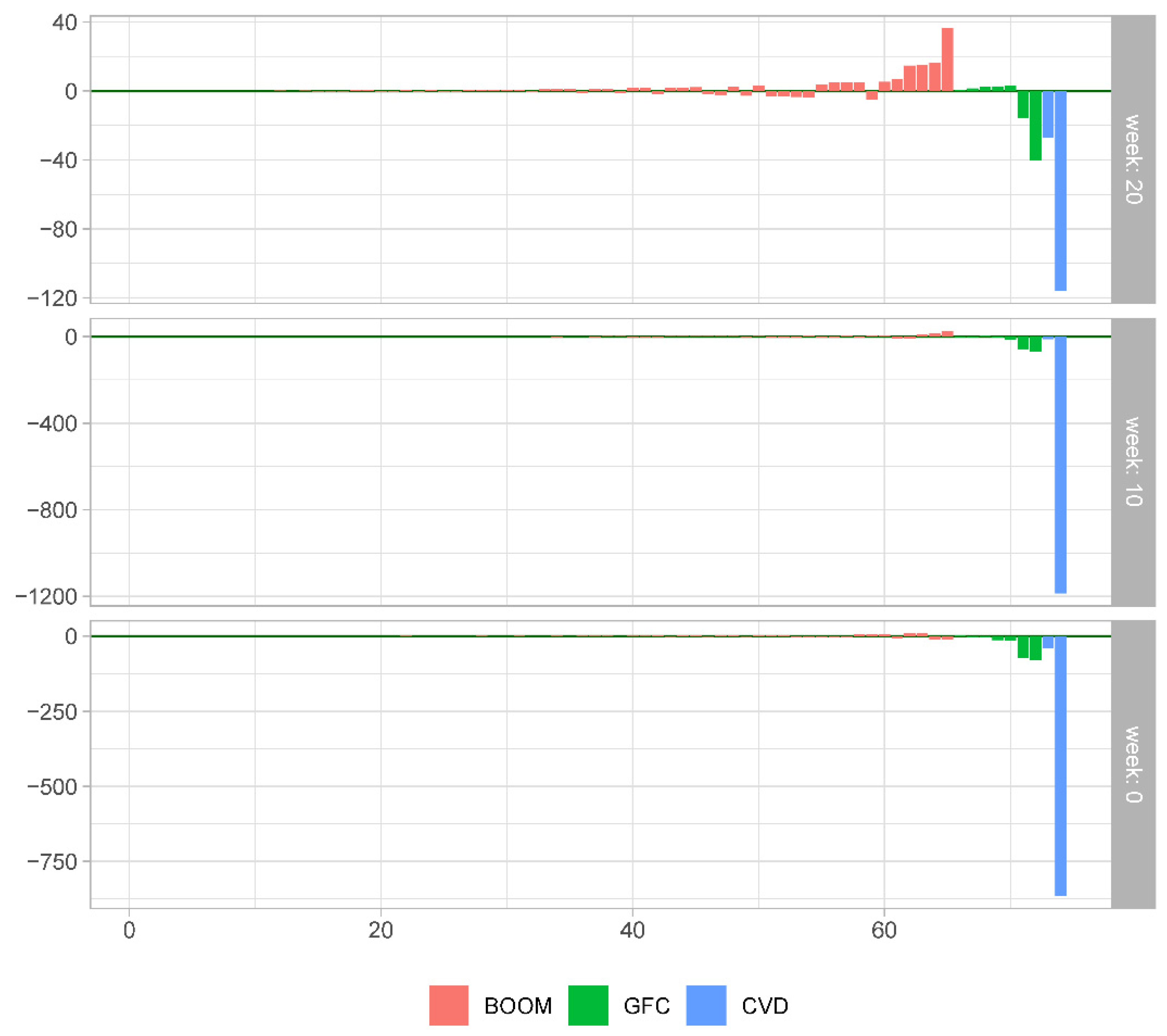
Figure 8 depicts the SFED DFM/HMM computed for each out-of-sample forecast evaluation period. As can be seen, there are rather few observations for which we observe substantial differences in the forecast accuracy at the 20-week forecast origin. Less so at the other two forecast origins. Please note that during the COVID pandemic in 2020Q2 there is the largest SFED in our sample. As expected during the GFC, we also observe substantial differences in forecast accuracy between these two models.
The raw plots of SFED DFM/HMM are informative in pointing out that the models’ forecasting accuracy varies from observation to observation and it tends to be more pronounced during periods of economic distress. However, a simple operation makes these differences informative about changes in the relative ranking of the models, based on their forecasting performance. The resulting cumulative sums of these SFED DFM/HMM are shown in the respective panels of
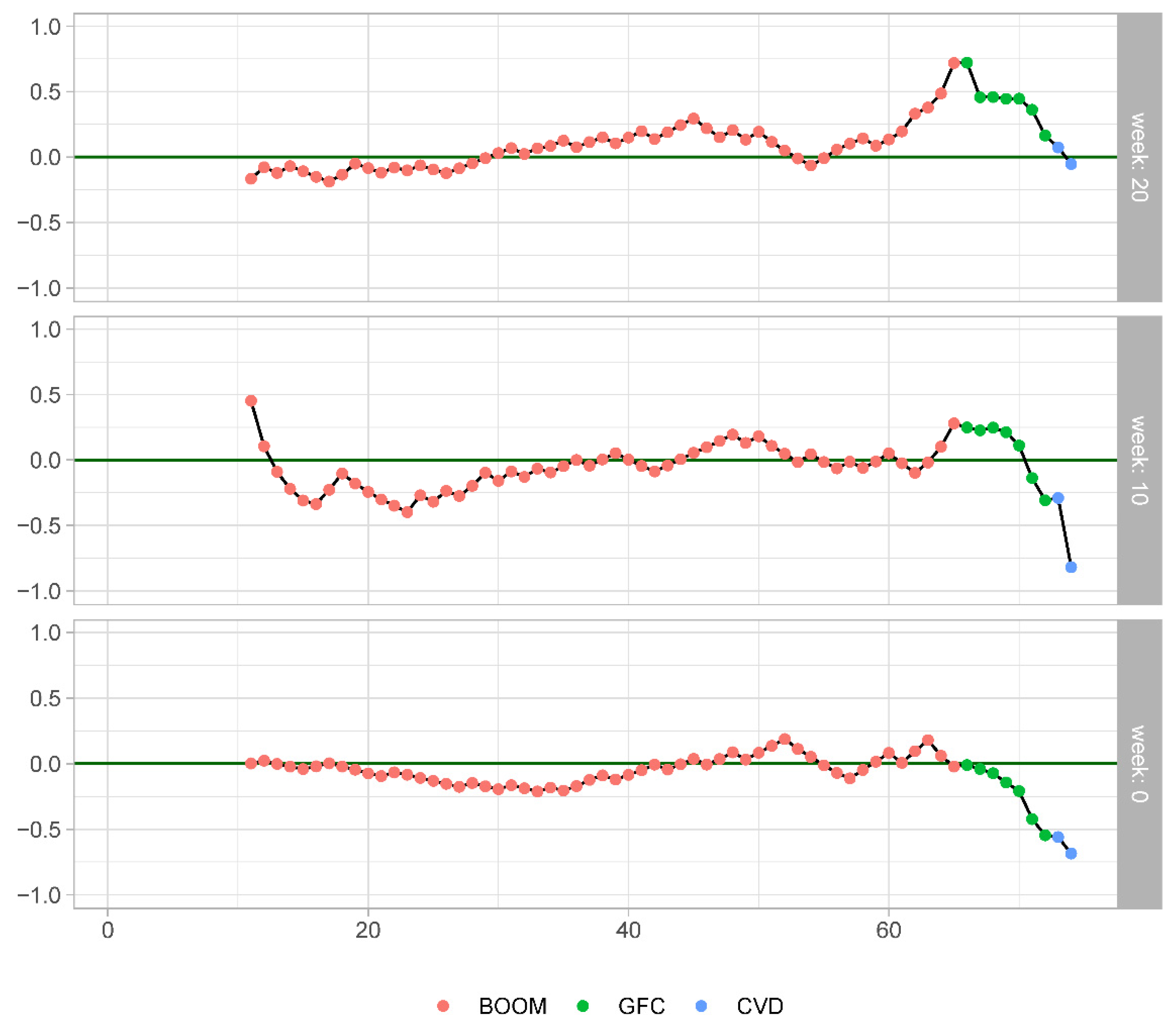
Figure 9. Points above the zero line indicate that up until this observation the DFM produced on average higher squared forecast errors than the HMM. Points below the zero line indicate the opposite.
As for the forecasts made at the 20-week origin (see the upper panel of
Figure 9), we can conclude that, based on the evidence from all but one observation (2020Q2), the forecast accuracy produced by the HMM was superior to that of the DFM. It was only the latest observation in our forecast evaluation sample that was the game changer reversing the conclusion in favour of the DFM over the HMM. This is a good example when one observation leads to complete overhaul of the models’ relative ranking based on their average forecasting performance. From the middle panel of
Figure 9, we can infer that the conclusion on the superior average forecasting ability of the HMM over DFM reversed much earlier, i.e., during the GFC period. In any case, for the 10- and 0-week forecast origins, the observation in 2020Q2 strongly reinforces the evidence of the superior average forecasting accuracy of the NY FED nowcasting model that first surfaced during the GFC.
Last but not least, we conclude the analysis of relative predictive ability using the R
2MSFE(+R) of
Siliverstovs (
2020b). The R
2MSFE(+R) allows to directly track the evolution of the rMSFE DFM/HMM, as for its computation one adds more and more observations of increasing intensity that is measured in terms of absolute values of SFED, |SFED
t|. One option is to report R
2MSFE(+R) based on the reordered observations purely by the magnitude of |SFED
t| in the ascending order. We, however, apply a slight modification in rearranging the observations capitalising on the knowledge of the expansionary and recessionary phases of the business cycle in our data. We present the R
2MSFE(+R) in
Figure 10 that is based on the observations rearranged by the magnitude of |SFED
t| in ascending order within each of the three sub-samples: the expansions (2002Q1–2007Q3 and2009Q3–2019Q4), the GFC period (2007Q4–2009Q2), and the COVID period (2020Q1–2020Q2). The main advantage of visually presenting the results in this way is that they are directly comparable to the numerical results reported in
Table 2. The underlying SFEDs, rearranged in the ascending order according to its modulus within the three sub-periods (expansionary, the GFC, and COVID periods), are shown in
Figure 11.
The R
2MSFE(+R) calculated using the forecasts for the three selected forecast origins are shown in
Figure 10. These sequences visually display asymmetry in the relative forecasting ability of the dynamic factor and historical mean models during different sub-samples. As for the expansionary period, we can clearly observe that the HMM, on average, produces lower squared forecast errors than its sophisticated counterpart at the forecast origins that are 20- and 10-weeks ahead of advance GDP releases. The last point in the red sequence in the upper and middle panels of the figures corresponds to the rMSFE reported in Column (3) of
Table 2. These values indicate that the MSFE of the DFM model is 71.8% and 28.0% higher than that of the HMM for the forecasts made 20 and 10 weeks before the releases of advance GDP estimates. We can infer from the lower panel of the figure that the rMSFE
DFM/HMM is very close to zero for the forecasts released during the same week when advance GDP estimates are published. In fact, the corresponding entry of −0.022 in
Table 2 indicates that the MSFE
DFM is only about 2% lower than the MSFE
HMM during expansions.
The sequence of the green dots shows how the relative MSFE changes if we add observations from the GFC period. The last green dot corresponds to the value of rMSFE reported in Column (1) in
Table 2. For the 20-week-ahead forecasts, we can read off the corresponding value of 0.165 which indicates that the HMM average forecast accuracy is superior to that of the DFM, even when the observations from the GFC are taken into account. However, for the shorter forecast horizon of 10 weeks, the corresponding entry is −0.308 indicating changes in the models’ relative ranking brought about by the observations during the GFC period. This perfectly illustrates how excessive gains in the forecasting ability during the Great Recession, accrued by the more sophisticated model, can overcompensate for the forecast accuracy losses during much longer periods of economic expansion. As for the forecasts released during the same week as advance GDP releases, the relevant value of −0.546 in
Table 2 signals a reduction of about 55% in MSFE brought about by the DFM.
Finally, the blue dots indicate how rMSFE
DFM/HMM changes if the two remaining observations (2020Q1–2020Q2) are added to the sample. The last dots in these sequences correspond to the entries in Column (7) of
Table 2 for the DFM model. As discussed above, addition of these observations changes the relative ranking of the models for 20-week-ahead forecasts, now indicating a reduction of about 5.4% in MSFE brought about by the DFM, and substantially lowers the relative MSFE for the forecasts made at shorter forecast horizons. The corresponding reductions in MSFE are 81.8% and 68.6% relative to those of the HMM.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










