1. Introduction
According to the Intergovernmental Panel on Climate Change report (IPCC, 2014), the global average temperature has increasing in the last few decades. The climate changes, associated with natural or anthropological activities, can lead to changes in the likelihood of the occurrence and/or strength of severe weather and climate events (
Allen et al. 2014). Severe events such as heat waves, droughts, tornadoes, and hurricanes may cause properties damages and death. According to the Emergency Events Database (EM-DAT) of Centre for Research on the Epidemiology of Disasters (CRED), there were 315 natural disaster events recorded, which caused 11.804 deaths and more than
$130 billion of economic losses across the world in 2018.
Tornadoes are a type of extreme weather defined by a violently rotating column of air touching the ground, usually attached to the base of a thunderstorm
1. The United States experiences more tornadoes per year than any other country, with an average of over 1000 tornadoes each year, according to the National Oceanic and Atmospheric Administration (NOAA). Tornadoes caused almost
$650 million in damages and 35 fatalities in the United States (NOAA) in 2017. Due to the impact of these events on society, understanding how tornado activity will respond to climate changes is important in order to be prepared for possible impacts.
Previous studies searched for relationships between tornado activity and global warming (
Diffenbaugh et al. 2013;
Lee 2012;
Moore and DeBoer 2019). Recent works analyzed the variability of tornadoes occurrence in the United States. As a result, some studies found that, when removing many non-meteorological factors, there are no significant changes in the annual frequency of United States tornadoes (
Kunkel et al. 2013;
Tippett et al. 2015). Some other studies have generally found that tornadoes are becoming more clustered over time. Specifically,
Tippett et al. (
2016) found that the frequency of U.S. outbreaks with many tornadoes is increasing since the 1970s and that it is increasing faster for more extreme outbreaks.
Moore (
2017) have found evidence that the number of (E)F1 and stronger tornado days has decreased while the number of high-frequency (30+) tornado days has increased, which tended to be focused further east of the Great Plains. Other empirical studies also proposed analyzing whether the spatial distribution of tornadoes shifted over time (
Gensini and Brooks 2018;
Moore and McGuire 2019). For instance,
Gensini and Brooks (
2018) found evidence that national annual frequencies of tornado reports have remained relatively constant while significant spatially varying temporal trends in tornado frequency have occurred since 1979, with negative tendencies in portion of Great Plains and positive trends in portions of the Midwest and Southeast United States. In addition,
Moore and McGuire (
2019) have found that the spatial dispersion of tornadoes in the United States have changed between 1954 and 2017, especially in spring, summer and fall. Also, their results suggest that the increased occurrence of tornado outbreaks is contributing to the decrease in dispersion.
Increases in the frequency and severity of natural catastrophes in recent decades have led to an important discussion about the role of the financial markets and institutions associated with global warming. Until the mid-1990s, only the insurance companies and the government were responsible to cover the damage caused by natural catastrophes. After hurricane Andrew, in Florida, the insurance and reinsurance industry needed to look for alternative methods to hedge their risks. The idea was to create natural disaster risk-linked securities, called catastrophe bonds (cat bonds, hereafter). The purpose of the cat bonds is to transfer natural disaster risk from an issuer/insurance company to bond market investors (
Morana and Sbrana (
2019)). In this sense,
Morana and Sbrana (
2019) investigated whether the return by unit of risk or
multiple on cat bonds pattern is consistent with the historical evolution of natural catastrophe risk. Their results show that despite the evidence that supports the global warming hypotheses, the climate change risk might not yet have been properly incorporated in cat bond multiples, since the multiple of the cat bond has decreased. The implications of natural disasters, such as hurricanes and tornadoes, and the evolution of natural catastrophes risk due to climate change on the financial market reinforces the importance to properly analyze the severe weather occurrence.
The data on which we base our work are daily tornado reports, which consists of the locations of observed tornado occurrences in the United States. The appropriated statistical models for this kind of data are spatio-temporal point process models. The Log Gaussian Cox process (LGCP) defines a class of models to handle with spatio-temporal point process due to their flexibility and the fact that these models are particularly useful in the context of modelling aggregation relative to some underlying unobserved environmental field (
Illian et al. 2010;
Simpson et al. 2016). These processes are Cox processes where the log-intensity function is a Gaussian random field (
Møller et al. 1998). Cox processes are inhomogeneous Poisson processes, where the intensity function is a stochastic process.
The LGCP formulation is attractive for theoretical and empirical reasons. In particular, it allows adding structures in the stochastic intensity function, allowing controling for omitted variables with spatial dependence. However, fitting LGCP is difficult because it is computationally expensive.
Illian et al. (
2010) proposed using integrated nested Laplace approximations (INLA) to fit LGCP models. They construct a Poisson approximation to the true LGCP likelihood to perform inference on a regular lattice over the region of interest, counting the number of points in each cell (
Simpson et al. 2016). However, this approach can be computationally wasteful since the quality of the likelihood approximation depends on the size of the grid, i.e., it is necessary to construct a fine grid. To circumvent this problem,
Simpson et al. (
2016) proposed using the stochastic partial differential equations (SPDE) approach to approximate a Gaussian Field (GF) to a Gaussian Markov Random Fields (GMRF), which is defined by sparse matrices. The main result provided by
Simpson et al. (
2016) is that it is not necessary to construct too fine grids in order to approximate LGCP likelihood, allowing computationally effective methods. Moreover, according to
Simpson et al. (
2016), the LGCP formulation fits naturally within the Bayesian hierarchical modelling framework in combination with INLA approach, proposed by
Rue et al. (
2009).
This paper discusses how to perform inference procedures for spatio-temporal processes using a dynamic representation of a LGCP. This representation is based on the modeling of the intensity function from decomposition of components in trend, cycles, covariates and spatial effects. We also assume that spatial effects are based on a dynamic formulation, which allows it to change over time, based on an autoregressive functional structure. Our model follows the approach introduced by
Laurini (
2019) which proposes a method for decomposition of trend, cycle and seasonal components in spatio-temporal models, where the spatial component is based on a continuous projections of spatial covariance functions. Indeed, our proposed model can be seen as an extension of
Laurini (
2019) approach to spatial point process, where the dynamics in point process are captured by persistent term and mean-reverting components, plus the spatial term, which is time-varying by the autoregressive group structure. The persistent term is modeled as a first order random walk for a latent component whereas the cyclic component is based on a second-order latent autoregressive structure. This formulation is useful since it allows identifying permanent changes in the intensity of occurrences over time and also to capture cyclical effects in time series. We apply this methodology to modeling the spatio-temporal distribution of the tornado occurrences in the United States, taken into account the different intensities of the occurrences, based on Fujita (prior to 2007) and Enhanced Fujita (2007 and posterior) damaging rate scales, which ranges from (E)F0 (lowest damage indicator) to (E)F5 (highest damage indicator). The results indicate that the trends in annual tornado occurrences in the United States have remained relatively constant, supporting previously reported findings, e.g.,
Kunkel et al. (
2013) and
Moore (
2017).
This article is organized as follows.
Section 2 contains a description of the statistical approach and data.
Section 3 shows the results with discussion.
Section 4 concludes.
2. Materials and Methods
To model the spatio-temporal distribution of the occurrence of tornadoes, we use the structure of point processes, which is a mathematical way of describing random events distributed in some abstract space. In our application, these point events occur in time as well as space, where the space-time region can be defined as a Cartesian product, , where S is the spatial region defined by the latitude and longitude of the tornado occurrences and T is the time interval of the event occurrence. It is possible to use more complex structures to represent the process, such as the distribution of tornadoes in the terrestrial sphere or other sample intervals, at the cost of greater computational complexity.
An essential structure for modeling point processes is the so-called spatial Poisson process. In this process the number of occurrences in a certain limited region of space is characterized by a Poisson distribution with an intensity parameter . Assuming constant we have a homogeneous Poisson process, which would generate a random but regular distribution of points in space. As this process is very restrictive, a way of making possible a non-homogeneous distribution in space is through a function of deterministic intensity, where we usually assume that the intensity of the process is a deterministic function of a set of fixed and observed covariates in the same space.
This structure is interesting, but it may have several important empirical limitations. It is necessary to have a structure of covariates observed at each point in the space to assess the likelihood of the process. This is an important limitation since for practical purposes we need covariates observed continuously for their use, and in many cases these covariates are not observed or are constructed from methods of interpolation of discrete observations in space. The second limitation is that this structure does not incorporate the possible sources of uncertainty associated with this process, such as measurement errors and omission of relevant variables in the model.
Another extremely important limitation is that the Poisson process is conditionally independent, i.e., conditional on the covariates of the process, the events are independent. This does not allow incorporating processes of spatial (or temporal) dependence generated by latent processes or dependence generated by covariates omitted from the system.
An alternative is to allow the dependency function in a point process to be stochastic, allowing incorporating spatio-temporal dependency processes in the occurrences and other forms of randomness in the process, including structures of random effects. These effects can be structured in such a way as to capture possible spatial and temporal dependency structures in the point process, allowing control for the effects of dependence generated by the omission of relevant covariates, measurement errors and also as an approximation to point processes that are truly dependent outside of the class of Poisson point process.
We use in this work the structure of Log Gaussian Cox Process (LGCP), which are point processes defined by a function of stochastic intensity defined by the class of processes known as Gaussian Markov Random Fields (GMRF) (
Rue and Held 2005). This class is defined by a structure of Gaussian latent effects, assuming a Markovian dependence structure which allows the use of efficient methods of computational representation and inference. Below we define the LGCP structure used in our work.
2.1. Spatio-Temporal Log-Gaussian Cox Process
The model used in this work is a spatio-temporal formulation of point processes with stochastic intensity, using a decomposition of the intensity function into components that vary in time and space. The central idea is to represent the possible temporal evolution through a component of stochastic tendency, which serves to identify permanent changes in the intensity function, and a cycle component, which represents persistent patterns but with reversion to the mean, in the intensity function. This interpretation is analogous to the so-called decomposition of unobserved components in time series, as discussed in
Harvey (
1989). The trend component is modeled as a local level process (first order random walk for a latent component), and thus changes in this level indicate permanent impacts.
Please note that this formulation is extremely useful for identifying possible changes in the intensity of occurrences over time, which would be associated with permanent changes in the occurrence of tornadoes associated with climate change. The mean reversion component is based on a second-order latent autoregressive structure, a parsimonious way of capturing cyclical effects in time series. This structure is important as it allows estimating the impact of non-permanent shocks on temporal patterns, being especially useful in modeling climate processes as it allows estimating the aggregate effects of phenomena such as droughts, cyclical changes in ocean temperature and other periodic patterns. A detailed discussion of this decomposition applied to climate change patterns can be found in
Laurini (
2019).
The spatial distribution of the intensity function is captured through a random effect, associated with a spatial covariance function projected continuously in space. This effect represents the spatial variation of the occurrence of tornadoes, and is a simple way to estimate regions with high and low intensities of occurrence of events. However, it is possible to make this spatial effect also time-varying, allowing estimating possible changes in the spatial distribution of the occurrence of tornadoes, which again could be associated with possible effects of climate change on the spatial distribution of tornadoes.
The decomposition proposed in this article is therefore especially useful for analyzing possible changes in the temporal and spatial patterns of the occurrence of events. It captures changes in the average number of occurrences through the trend component, and changes in the spatial distribution pattern through the time varying spatial random effect.
Following the notation adopted by
Simpson et al. (
2016), the model can be represented as a spatio-temporal point process as follows:
where
is the number of occurrences in a region
s in time
t,
is the exposure offset for the region
s,
is the intercept,
is the long term trend,
is a cycle component represented by an second-order autoregressive process with possibly complex roots,
and
are nonspatial independent innovations with
and
. The
is the spatial random effects represented by the Gaussian process
continuously projected in space and given by
where
is a covariance function of the Matérn class, which can be written as
where
is the Euclidean distance between locations
s and
,
is a spatial scale parameter,
is the smoothness parameter and
is a modified Bessel function.
The Matérn covariance function is an especially useful covariance structure in spatial modeling. It is very flexible; for example, the Gaussian and exponential covariance functions can be obtained as particular cases of that function. Additionally, it has good approximation properties for other spatial dependency structures, as discussed in
Illian et al. (
2012), and computational advantages that will be discussed later.
The marginal variance
is defined by:
where
is a scaling parameter and
d is the space dimension. Following
Lindgren et al. (
2011), we adopt a parameterization in terms of
and
for the covariance function:
where
. This representation is advantageous since, conditional on the value of
, it is necessary to estimate only two parameters.
Considering a bounded region
, it follows that the likelihood for an LGCP associated with data
is of the form
Due to the doubly stochastic property of the intensity function, the likelihood in (
6) is analytically intractable. Since the term
corresponds to a GF with Matérn covariance, it is possible to use the SPDE approach, proposed by
Lindgren et al. (
2011), to approximate the initial GF to a GMRF, which has very good computational properties due to Markov structure, providing a sparse representation of the spatial effect through a sparse precision matrix (
Krainski et al. 2018).
The first main important result, provided by
Whittle (
1954) and extensively used by
Lindgren et al. (
2011), is that a GF x(s) with the Matérn covariance function is a stationary solution to the linear fractional SPDE
where
is the Laplacian operator and
is a spatial white noise. Therefore, in order to find a GMRF approximation of a GF, we first need to find the stochastic weak solution of SPDE (
7).
Lindgren et al. (
2011) proposed using Finite Method Elements (FEM) to construct an approximated solution of SPDE. By proposing FEM,
Lindgren et al. (
2011) provided a solution for the case of irregular grids, since one of the big advantages of the FEM method is the irregularity, i.e., the domain can be divided into an irregular non-intersecting set of elements. A tutorial on the construction of this approximation can be found at
Bakka (
2013). The approximation of SPDE solution is given by
where
n is the number of vertices of the triangulation,
are the weights with Gaussian distribution and
are the basis functions defined for each node on the mesh. The idea is to calculate the weights
, which determine the values of the field at the vertices, while the values inside the triangles are determined by linear interpolation (
Lindgren et al. 2011), where the basis functions are chosen to be piecewise linear on each triangle, and the points where the weights
are evaluated are given by the function:
The stochastic weak solution of (
7) is found by requiring
where
are test functions and
denotes equality in distribution. Replacing (
8) in (
10) gives us
for
, where
m is the number of test functions. The finite dimensional solution is obtained by finding the distribution for the Gaussian weights in Equation (
8) that fulfils (
11) for only a specific set of test functions, with
. Choosing
and
2 yields
Define the
matrices,
C and
G as
then a weak solution to (
7) is given by (
8), where
and the precision of the weights,
w, is
Although
and
are sparse matrices,
is not sparse. The solution is to replace
by the diagonal matrix
, that yields a Markov approximation. Therefore,
w is a GMRF with precision matrix defined by (
15).
Replacing the GF
by the GMRF approximation
in Equation (
1), and approximating the integral in (
6) by a quadrature rule, results that the approximate likelihood consists of
independent Poisson random variables, where
n is the number of vertices and
is the number of observed point processes.
According to
Simpson et al. (
2016), the LGCP formulation fits naturally within the Bayesian hierarchical modelling framework and are latent Gaussian models, therefore, it may be fitted using the Integrated Nested Laplace Approximations (INLA) approach of
Rue et al. (
2009).
2.2. Data
We used in this work a subset of the Storm Prediction Center’s Severe Weather Database file, available at
https://www.spc.noaa.gov/wcm/. Although the database covers the 1950–2018 period, we propose to use the 1954–2018 period in order to remove the undercount of tornadoes in the first years, as discussed by
Agee and Childs (
2014). To facilitate the visualization of the results, we use a yearly aggregation of the daily data. The database also includes damage rating scales, Fujita (F)-prior to 2007- and Enhanced Fujita (EF)-beginning in 2007. Both scales range from 0 (lowest damage indicator) to 5 (highest damage indicator).
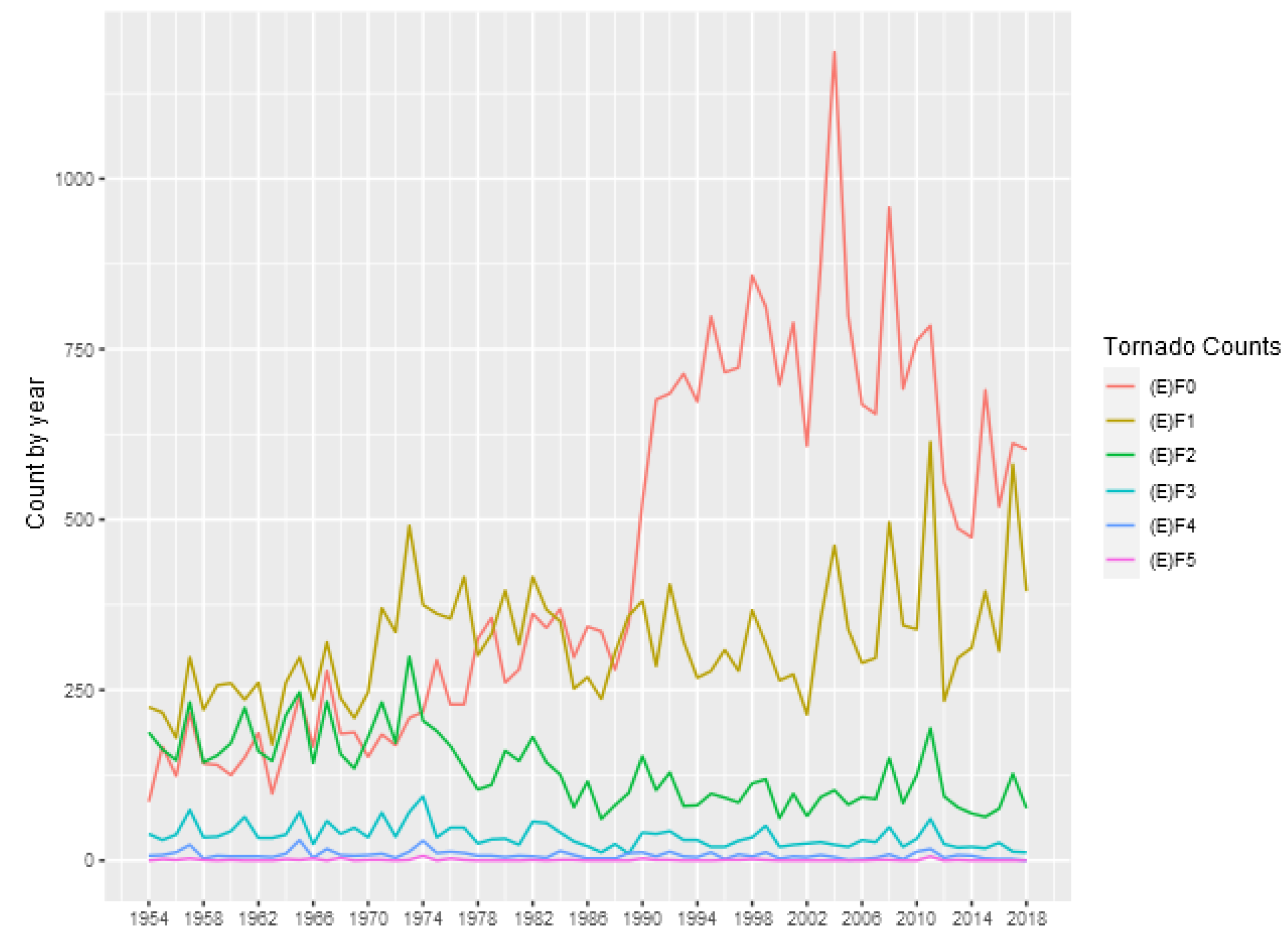
Table 1 shows some descriptive statistics for the annual counts of tornadoes in each category, and
Figure 1 show the number of tornado occurrences reported in each year and each intensity.
In this figure it is possible to observe an increasing in the number of (E)F0 tornadoes after 1990, which can be related to non-meteorological factor
Moore (
2017). On the other hand, (E)F1 and stronger tornadoes appear to be are stationary. In addition, it is possible to observe a slightly decreasing in the number of (E)F1 and (E)F2 tornadoes after 1974, which can be related to changes in tornado intensity classification adopted by National Weather Service, as discussed by
Moore (
2017). The occurrences of (E)F5 tornadoes are extremely rare, as can be seen in
Table 1, therefore, hereafter we just consider (E)F4 and weaker tornadoes.
3. Results
To apply the inference procedures discussed in
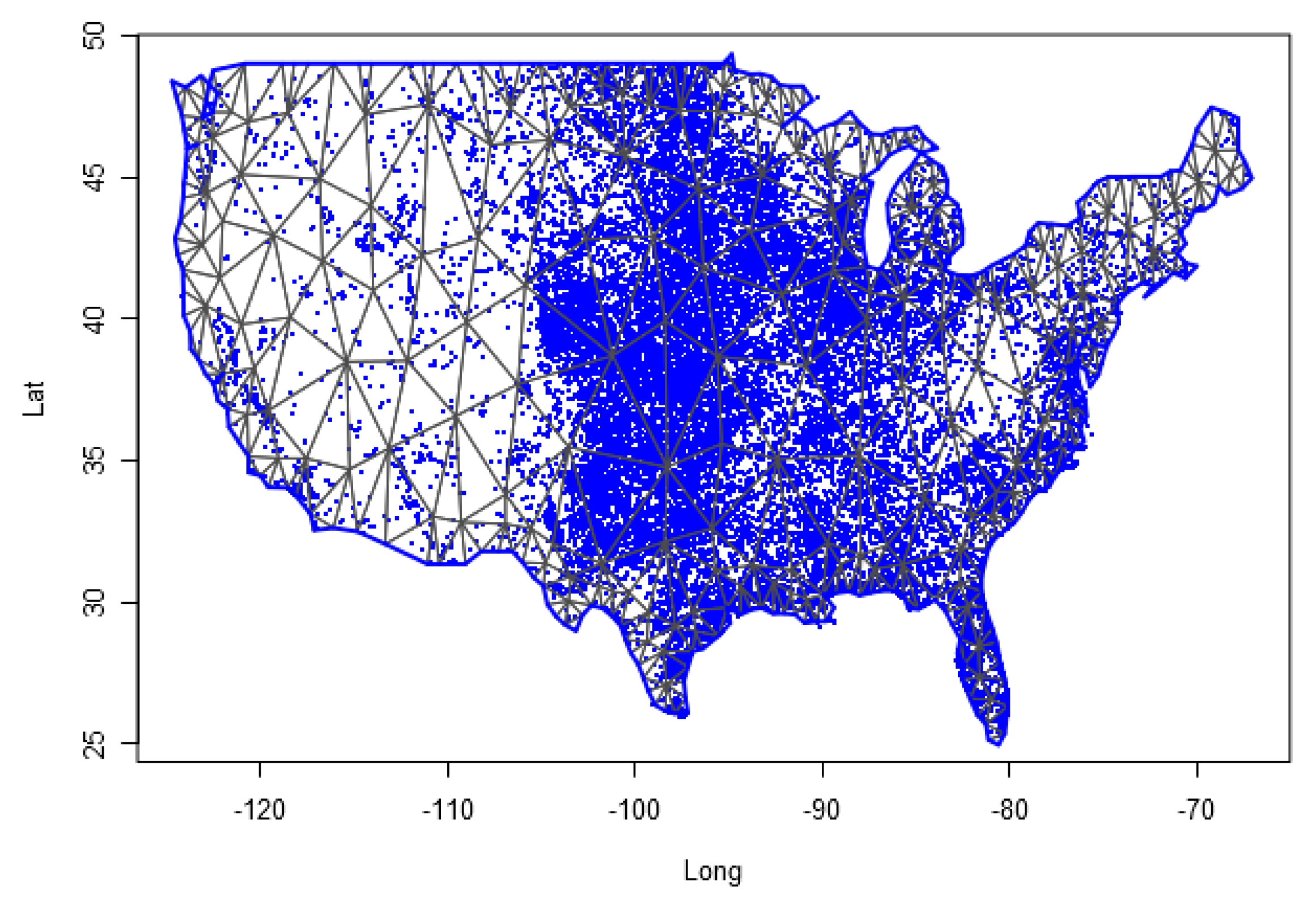
Section 2, the first step is to define a triangulation mesh of the interest region. Here, we define a triangulation mesh with 439 triangles covering all the United States area.
Figure 2 shows the spatial mesh used in the work, and as an illustration we put dots showing the occurrence of (E)F0 tornadoes for the entire sample used. A discussion of criteria for choosing mesh size in estimating LGCP models can be found in
Simpson et al. (
2016). As discussed in this work, the use of the continuous approximation for LGCP avoids the use of very thin meshes in the process approximation, and thus allows representing and estimate the parameters and random effects in a computationally efficient way. This characteristic is especially important in space-time models, where the computational representation of the process is very intensive in memory.
The second step is to define a set of knots over time to build a temporal mesh. For the time domain, we define a temporal mesh based on the number of observed years, 65. To obtain the space-time aggregation, we find to which polygon belongs each data point in the spatial mesh and to which part of the time belongs each data point. Hereafter, we use these both identification index sets to aggregate the data.
As described in Equation (
1), we estimate the parameters associated with the dynamic and spatial components. The parameters are the intercept (
), the precision of the trend component (
) and cycle component (
). The parameters of the second-order autoregressive process of the cycle are parameterized as partial autocorrelations (PACF1 and PACF2), whereas the parameters of spatial covariance are represented by
and
and the parameter of spatial time dependence (
). As previously discussed, in this work we use the estimation structure based on Integrated Nested Laplace Approximations (INLA) to estimate the parameters and random effects of the model. For reasons of space, we do not detail these procedures, and we indicate
Rue et al. (
2009) for the INLA method and the details of SPDE approximation for LGCP can be found in
Simpson et al. (
2016).
In
Table 2 we present the estimated posterior distribution for the parameters associated with the model given by Equation (
1), for the tornado classifications (E)F0-(E)F4. The intercept parameter estimates the unconditional mean of the estimated log intensity function, and we can see that the values are consistent with the observed magnitude of the number of tornadoes in each classification. The precision parameters report the variability associated with the trend and cycle processes. Greater precision is associated with less variability in the component, and again the results are consistent with the general patterns of the number of tornadoes occurring in each category analyzed. The partial correlation parameters are related to the autoregressive parameters in the AR (2) representation of the cycle. In all estimates, the results indicate the presence of a cyclic component, since the roots of the lag polynomial associated with the estimated partial correlation coefficients fall in the complex region. The estimated period for the cycle components for (E)F0, (E)F1, (E)F2, (E)F3 and (E)F4 tornadoes are, respectively, 3.98, 5.63, 5.59, 2.78, and 3.09 years. These periods are consistent with those observed for climatic phenomena associated with interactions between sea temperature and the atmosphere, such as El Niño and La Niña (ENSO), as discussed in
Cook et al. (
2017). Please note that the interpretation of this cycle component is an approximation for the effects of all shocks with persistent but non-permanent effects that affect the occurrence of tornadoes.
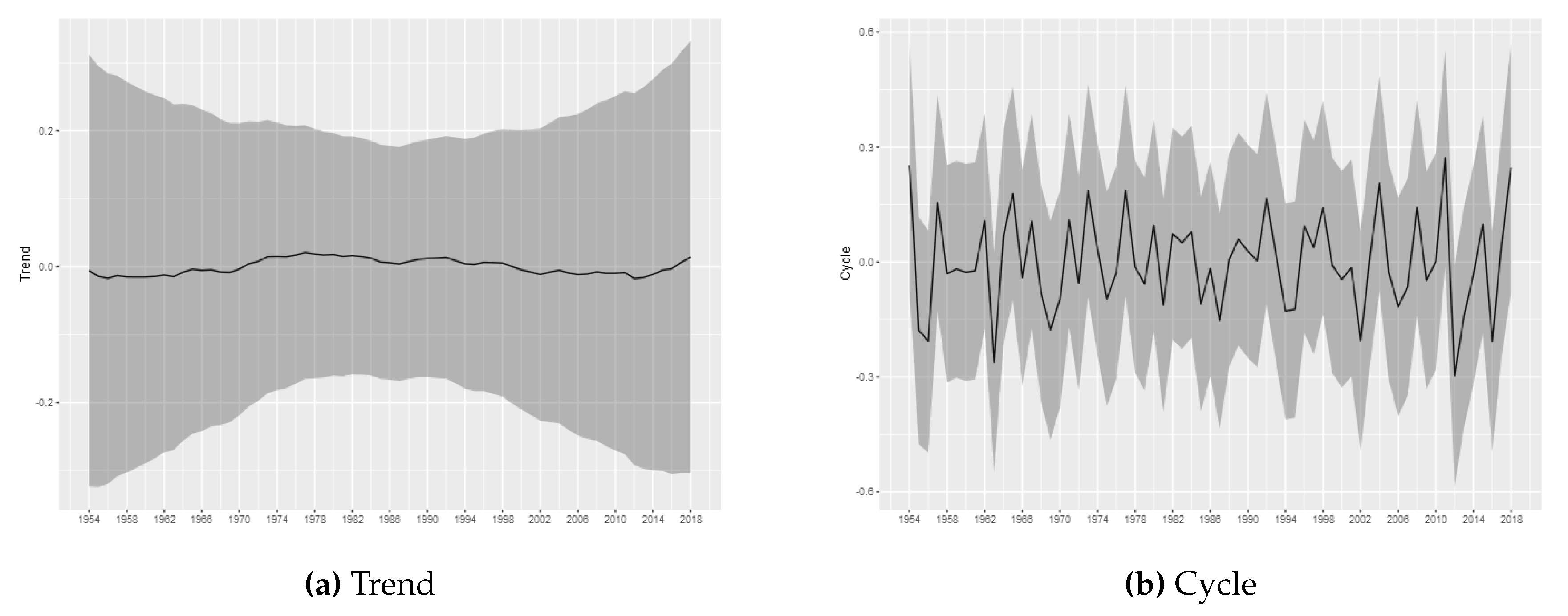
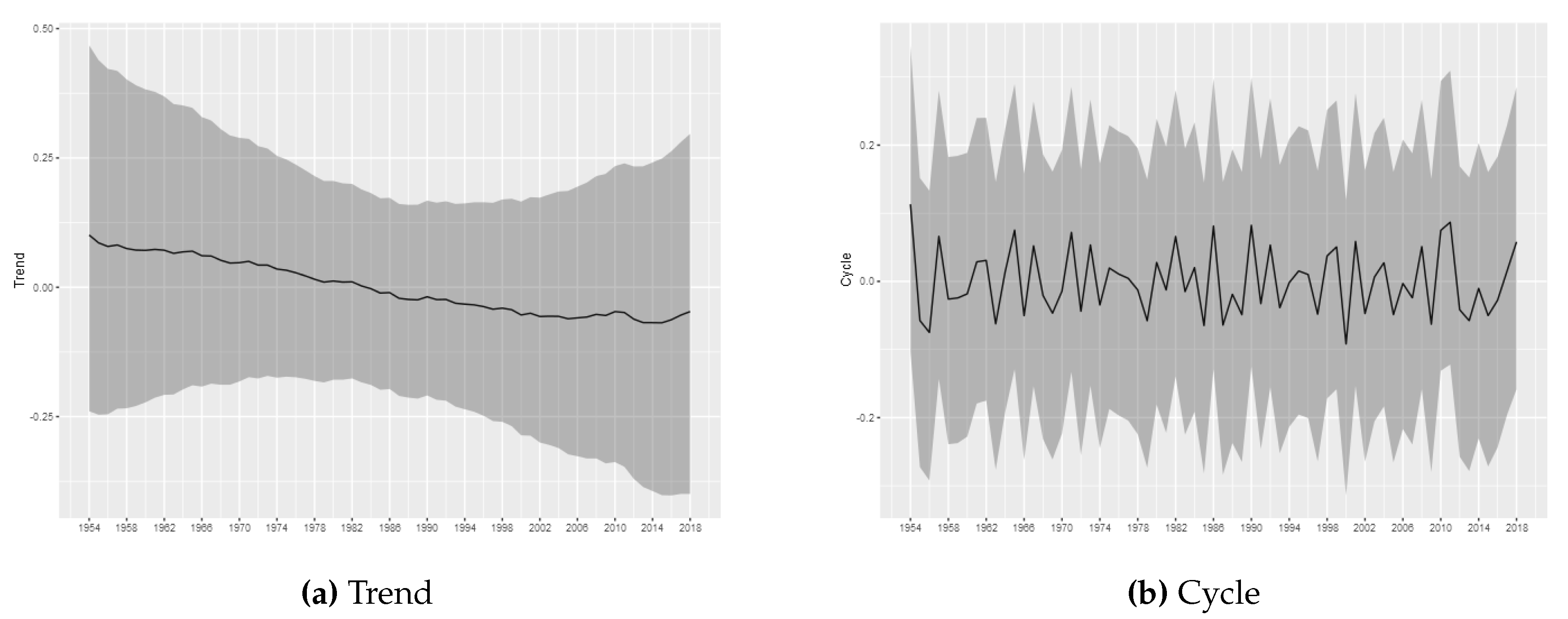
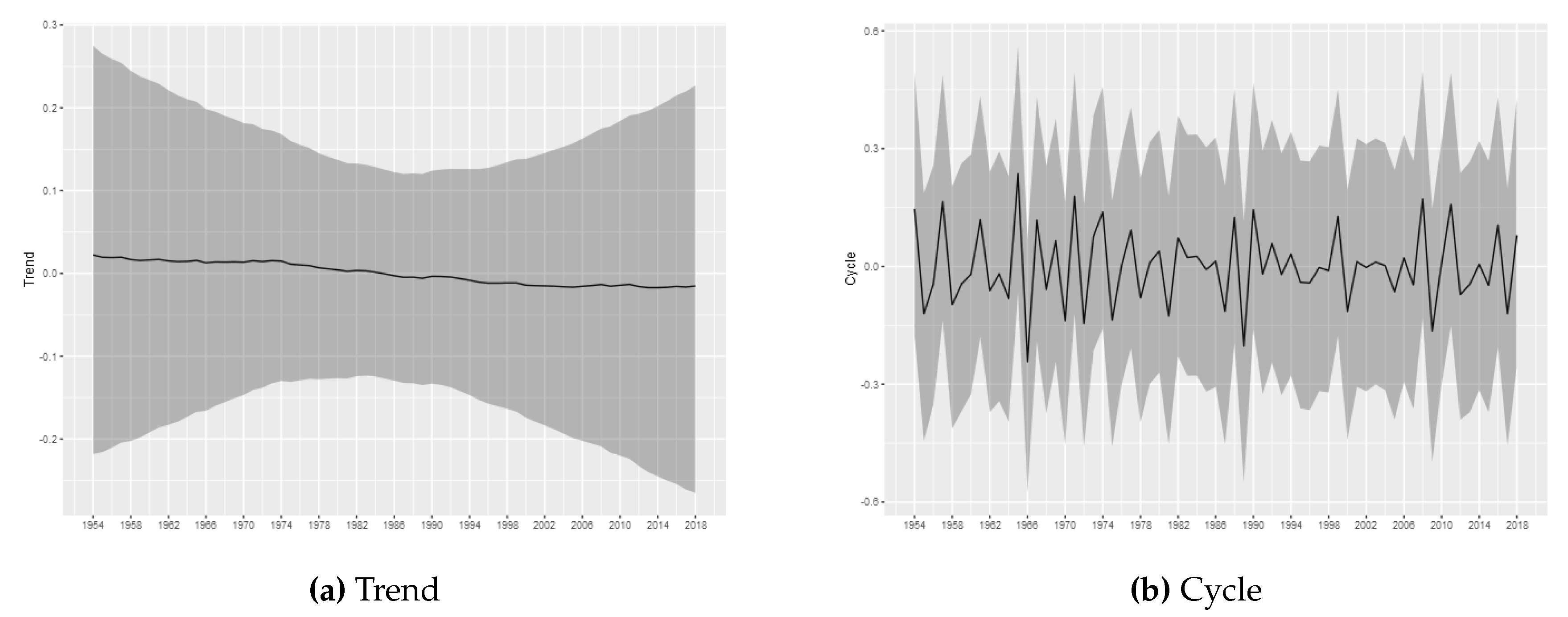
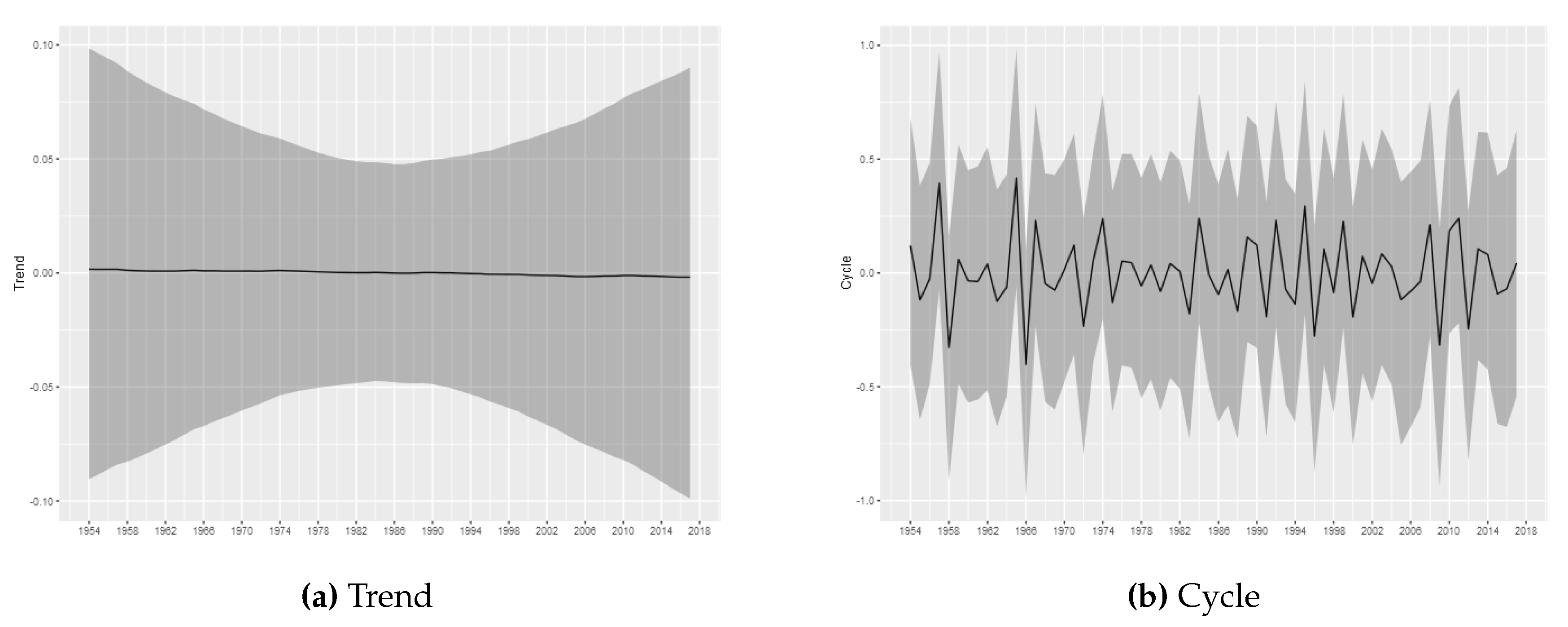
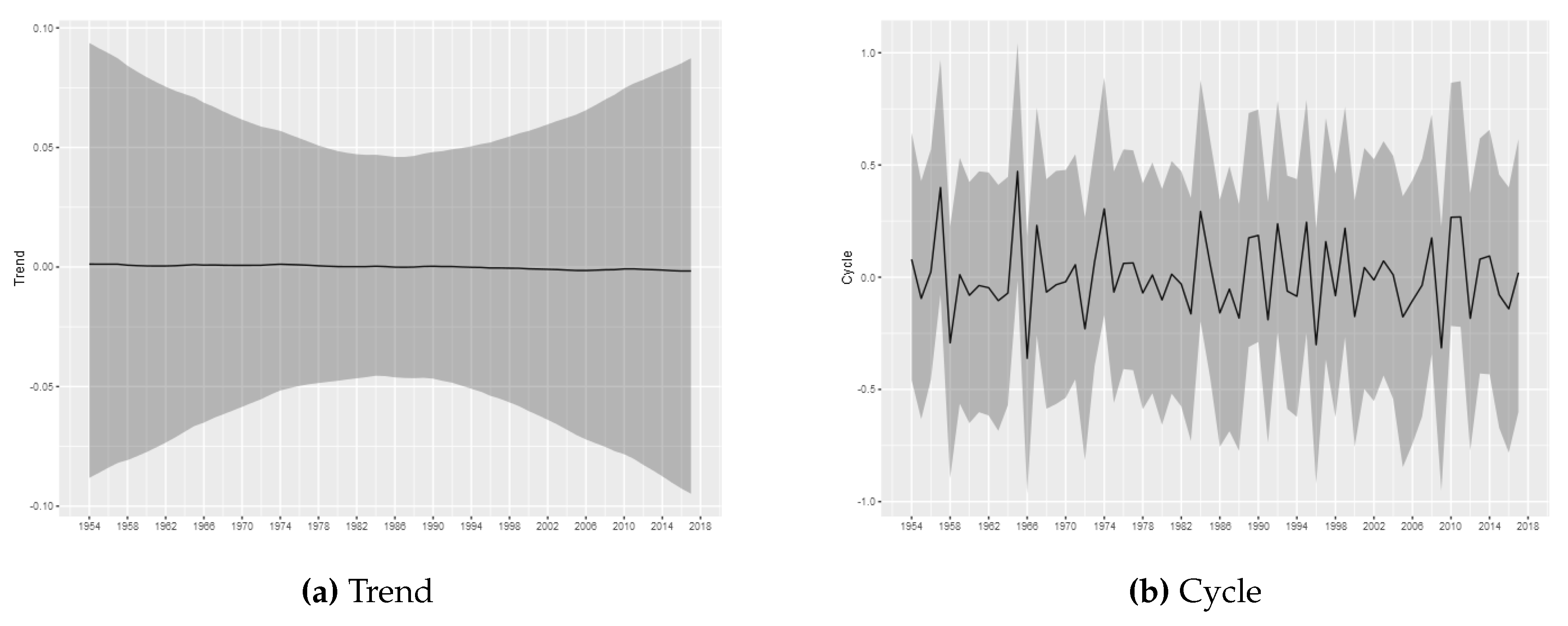
The estimated trend and cycle components for each tornado log intensity are shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, which present the posterior mean of the estimated components with 95% Bayesian credibility interval. The most important result is related to the trend component. Considering (E)F0 tornadoes, it is possible to observe a growth pattern in the trend component between 1962 and 2000, whereas between 2000 and 2016 it remains stable. From 2016 can be seen a growth pattern again. This result is consistent to results commonly found in the literature and, as discussed by
Moore (
2017), part of this effect can also be attributed to non-meteorological factors such as changes in reporting practices, reporting procedures, and observing technology. As argued by
Brooks and Doswell III (
2001), information about tornadoes comes from untrained witnesses, which may have led to basic errors in reporting practice. Weaker tornadoes are likely to be missed in the reporting since they have short lifetimes and path lengths, while stronger tornadoes may be more reliably reported (
Brooks and Doswell III 2001;
Kunkel et al. 2013;
Verbout et al. 2006). An additional component of the increase trend in the F0 tornadoes is likely due to the policy change in 1982 which have established that all tornadoes that did not have rated damage must be classified as (E)F0 (
Brooks 2004). Despite the evidence that the (E)F0 series may increases due to non-meteorological factors, it is important to note that our proposed model is able to capture the effects of exogenous changes and may capture possible changes in the spatial distribution, even if the trend is not associated with climate changes.
For the tornadoes of (E)F1-(E)F4 classification, it is not possible to infer permanent changes in the occurrence intensity. The estimated trend components do not show relevant variations, being all estimated close to zero, with the credibility intervals always covering this value. The results obtained through the modeling carried out in this article do not indicate the presence of relevant changes in the trend of occurrences for these categories of tornadoes. Considering (E)F1-(E)F4 tornadoes, the results are consistent with stationary patterns in the temporal counts of tornado occurrences, in line with the results found in
Kunkel et al. (
2013) and
Moore (
2017).
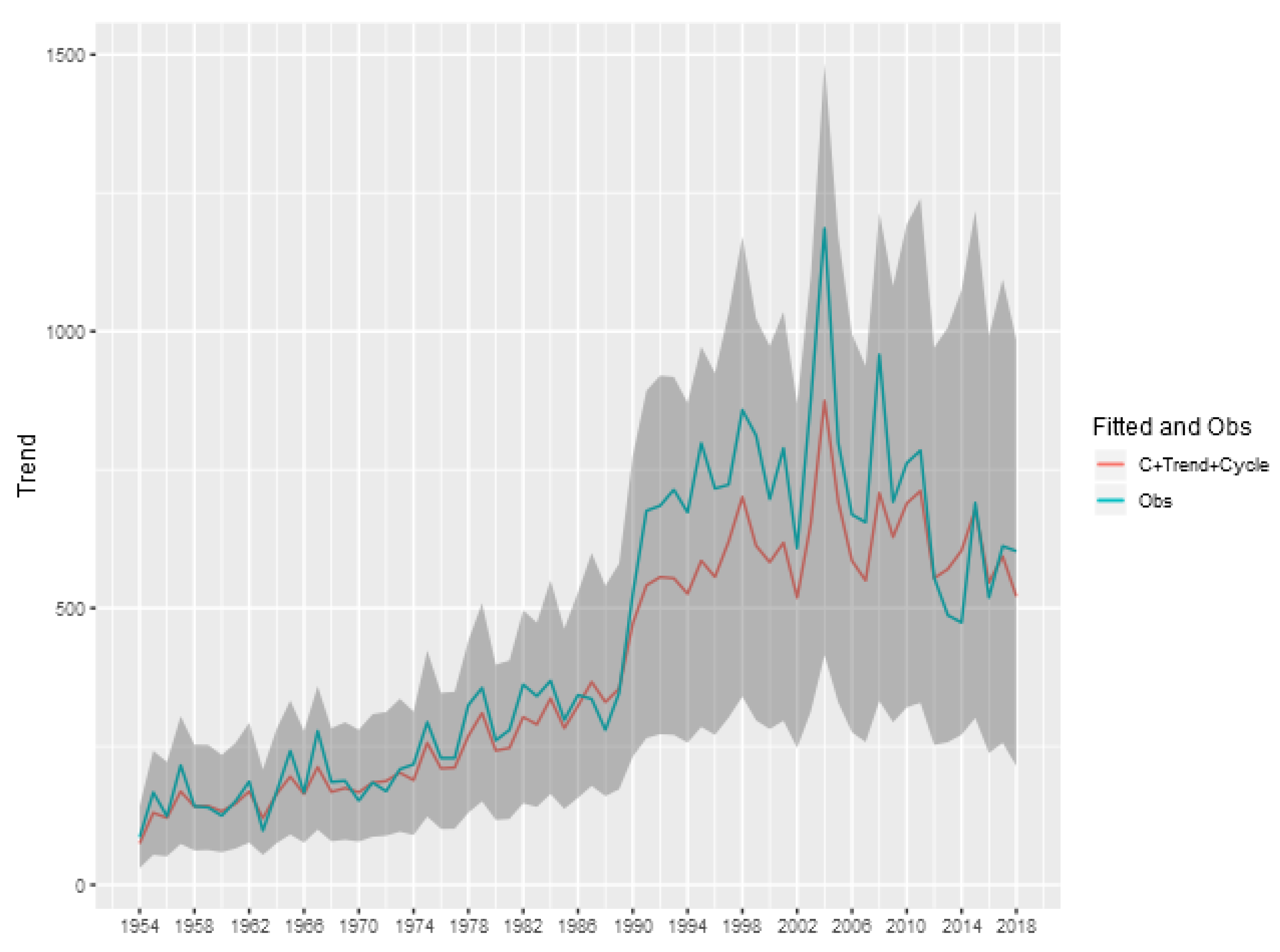
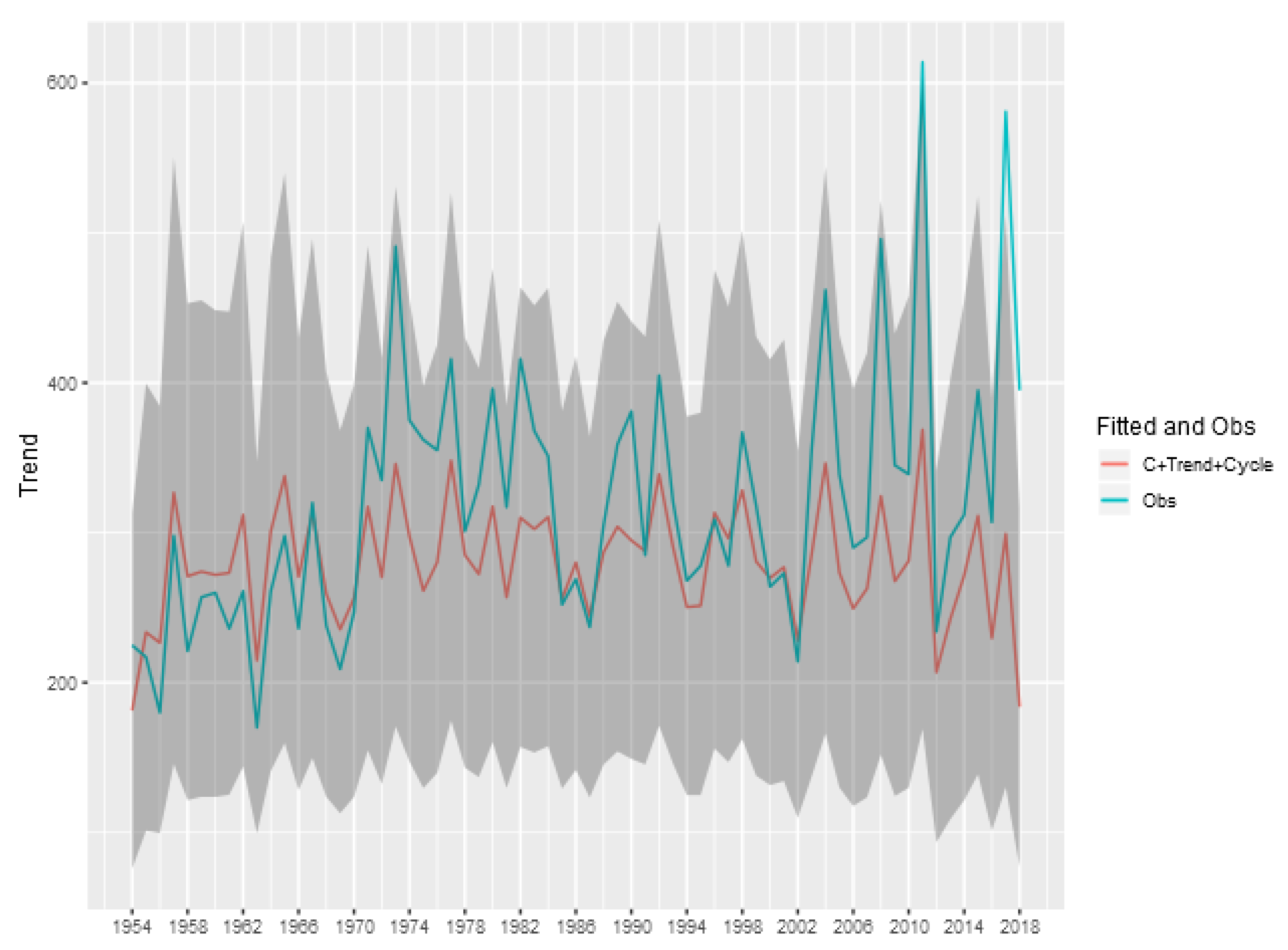
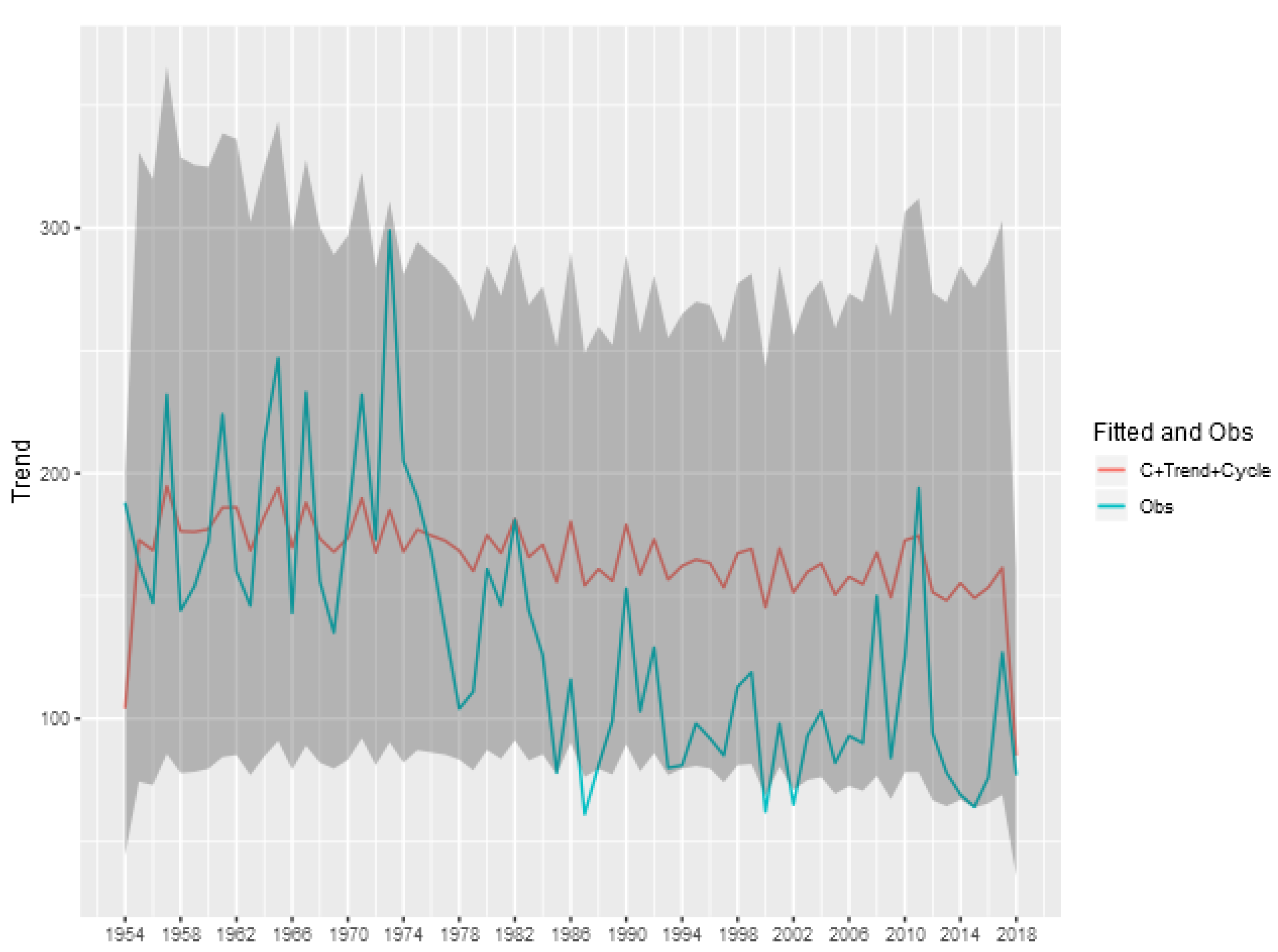
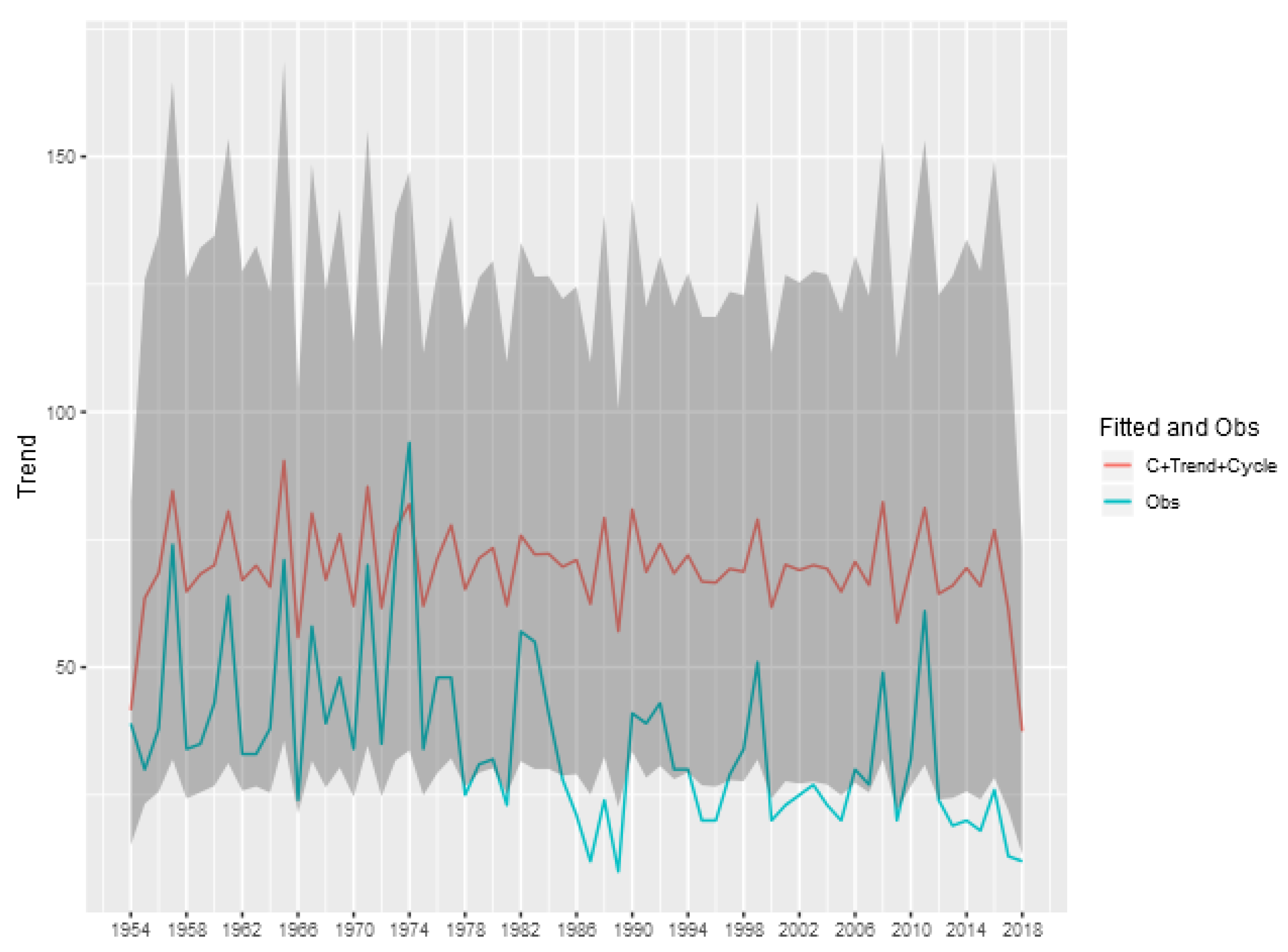
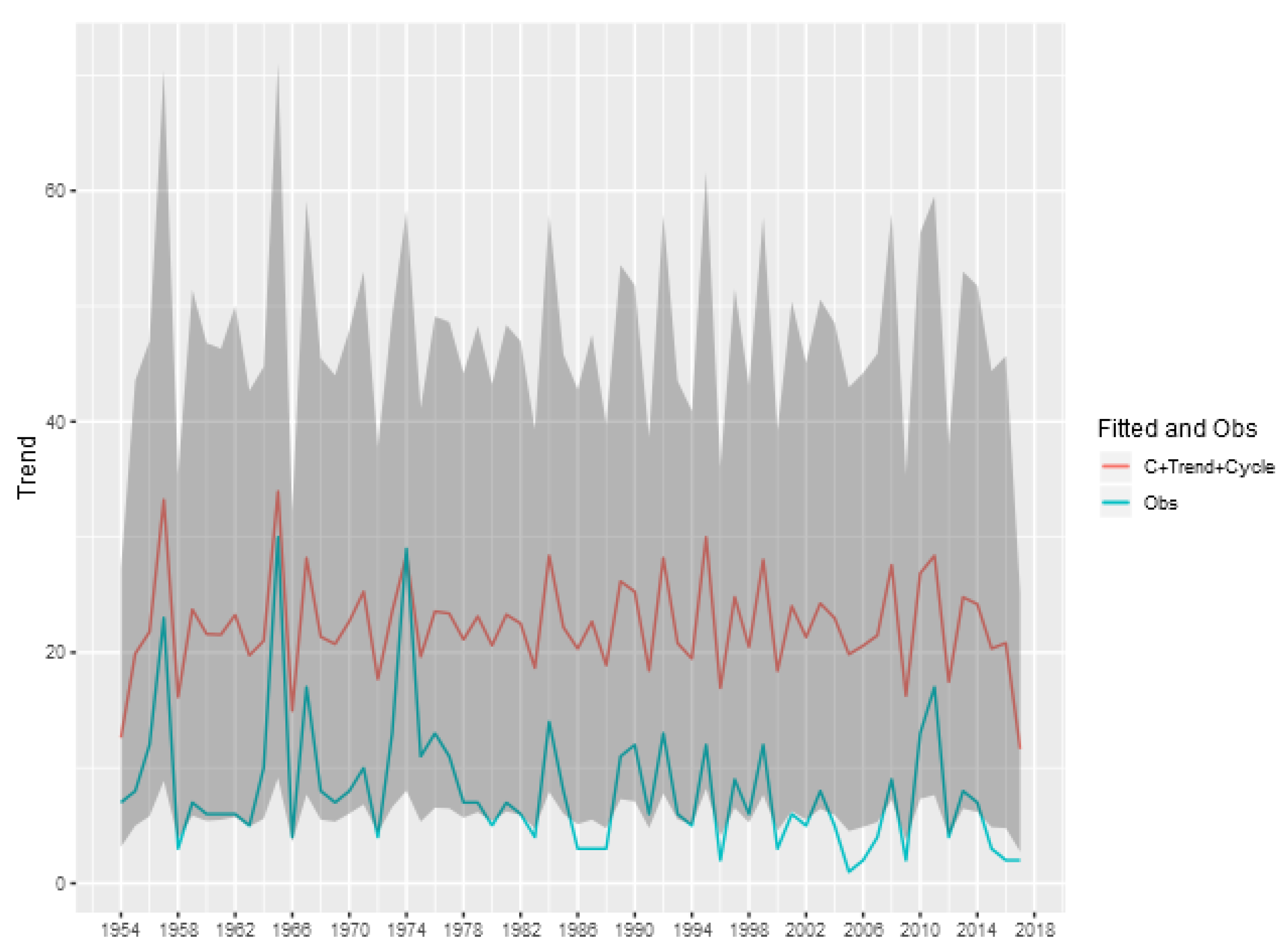
To show the importance of the trend and cycle components in the analysis of the tornado occurrence patterns, we show in
Figure 8 the predicted value for the tornado count (E)F0 in each year given by the sum of the trend, cycle and intercept components of model, and also the credibility interval of this sum. This represents the prediction of the total count ignoring the spatial random effect, obtained by aggregating the exposure of the entire area multiplied by the exponential of the sum of these components. The analogous figures for the other classifications (
Figure A1,
Figure A2,
Figure A3 and
Figure A4) are shown in the Appendix of the article.
We can see that for the (E)F0 and (E)F1 classifications, the random effects of trend and cycle explain a large part of the variability observed in the total tornado count. For the other classifications, the spatial component is more relevant in explaining the count observed each year, indicating a greater spatial heterogeneity in the intensity of occurrences.
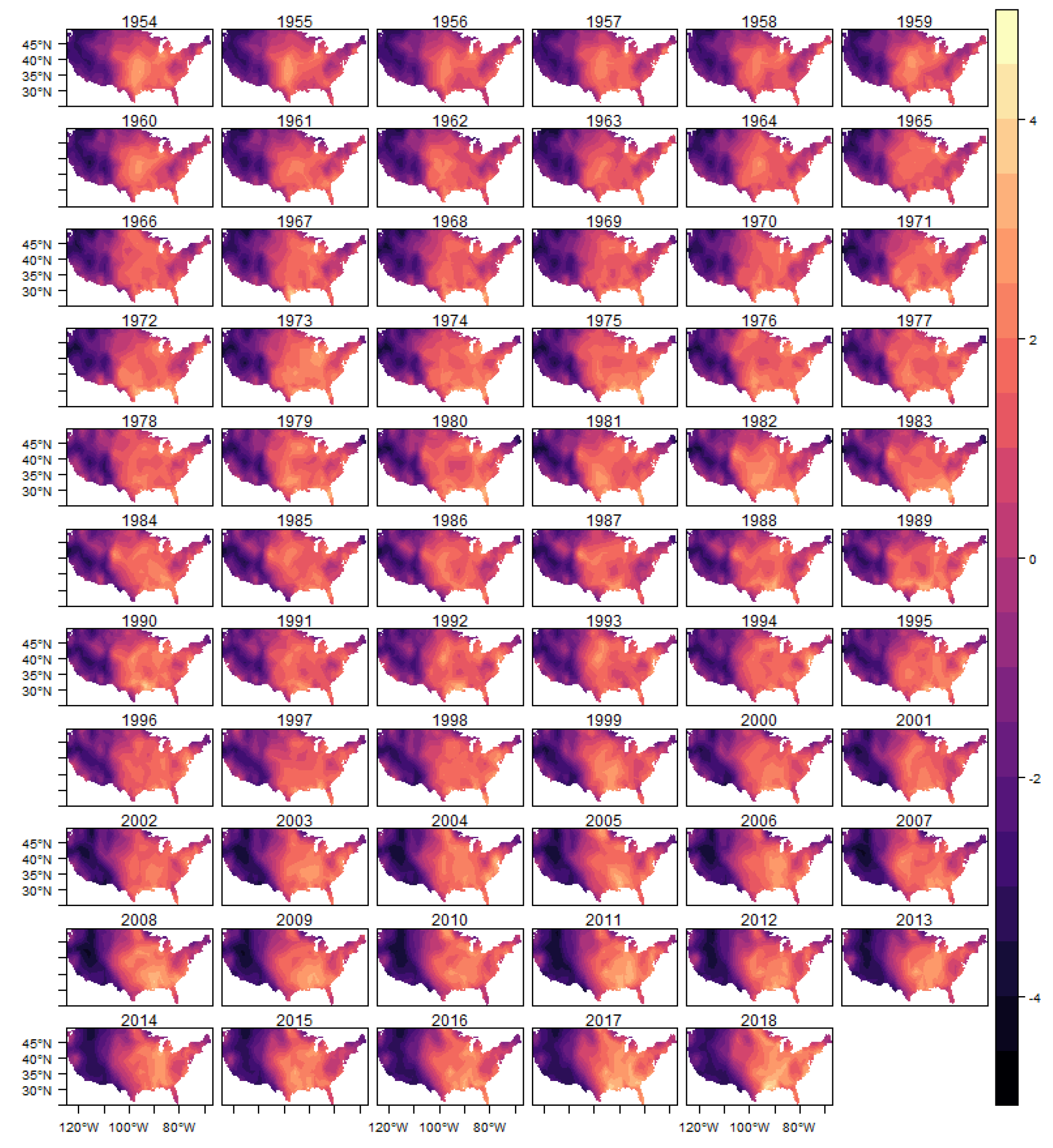
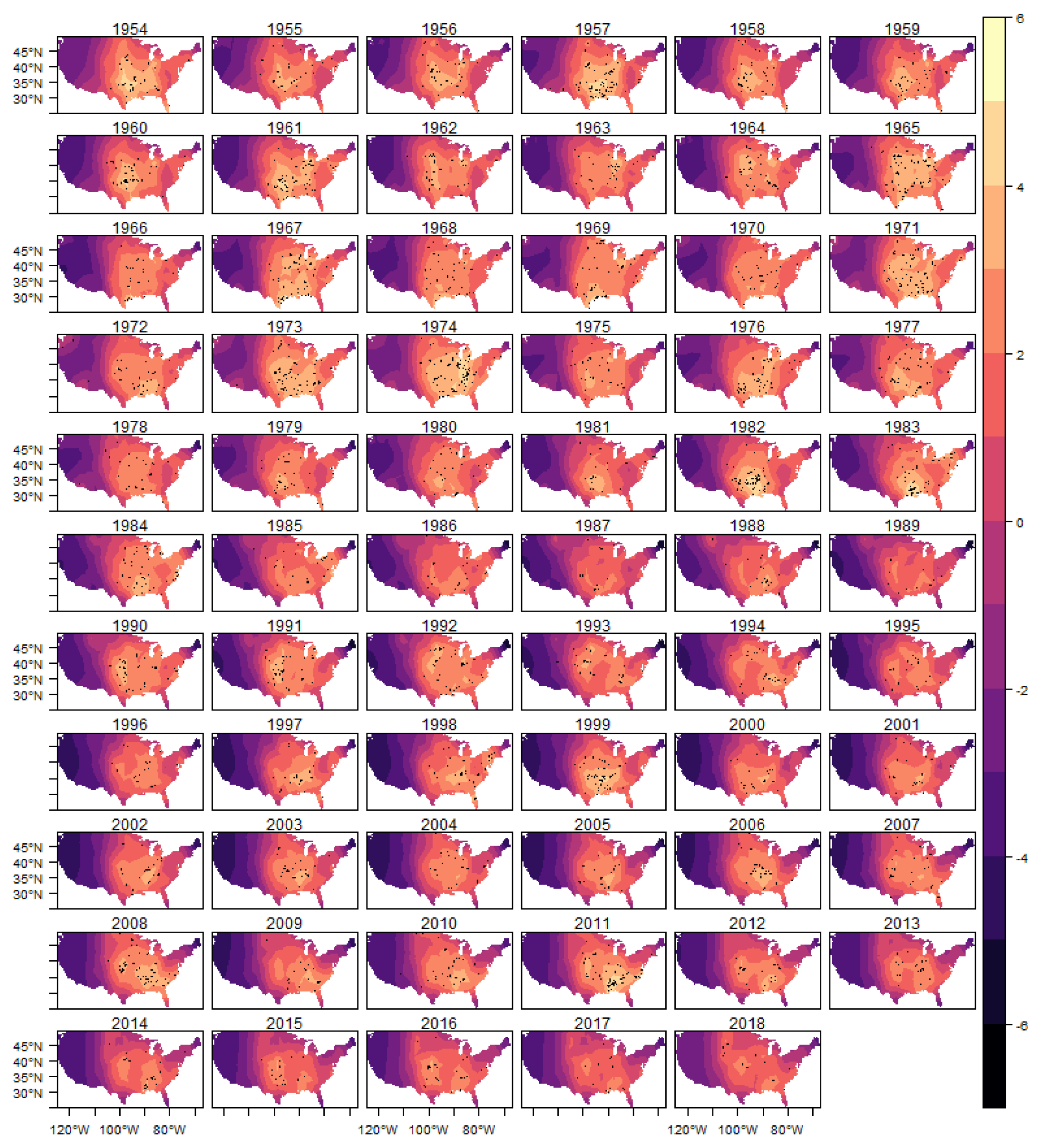
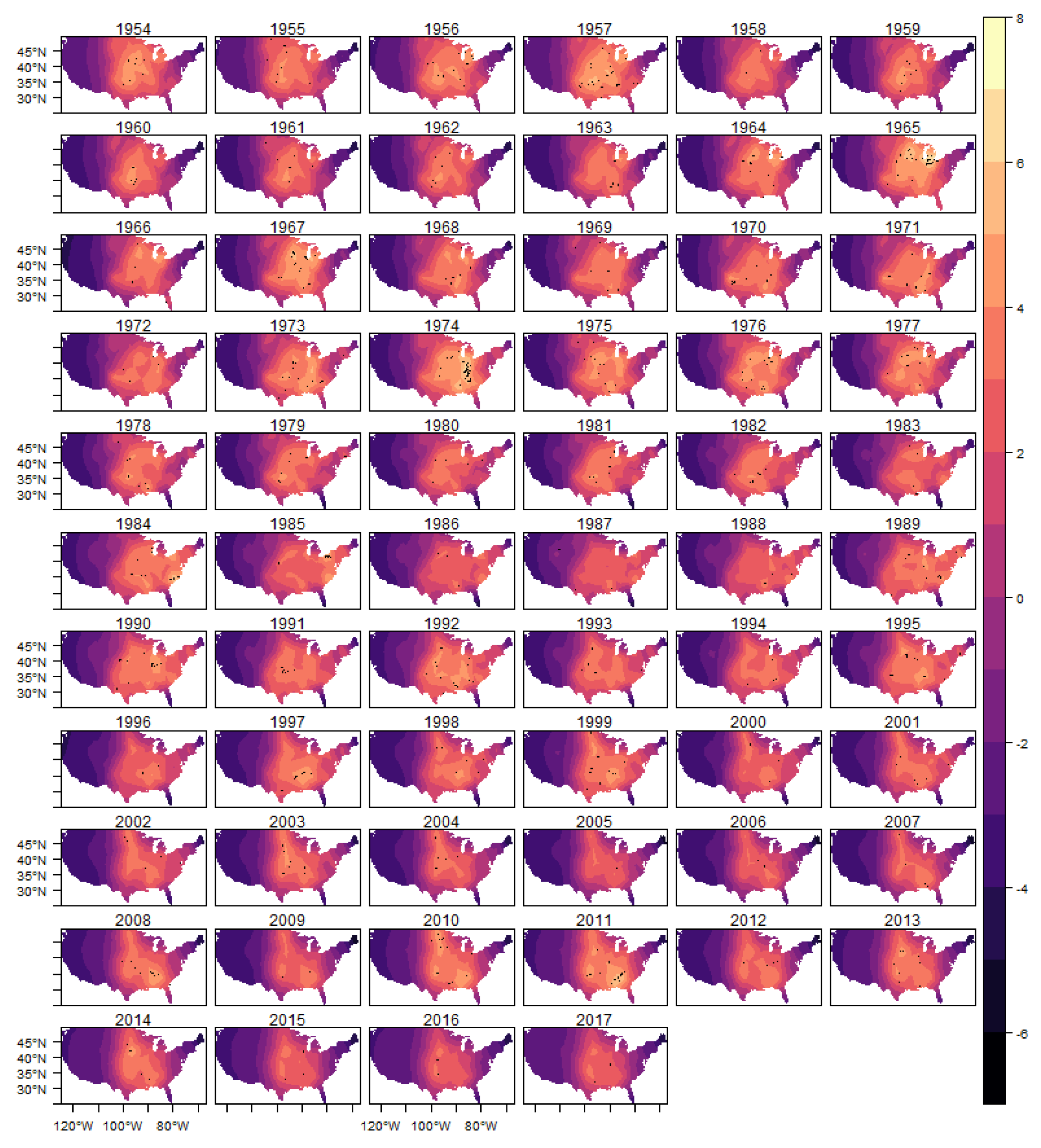
The spatial heterogeneity of the tornado occurrences can be seen through the estimated spatial random effect
. In this section, we show in
Figure 9 the estimated posterior distribution of spatial random effect for (E)F0 tornadoes, and in the appendix of the article the results for the other classifications in
Figure A5,
Figure A6,
Figure A7 and
Figure A8.
In these figures it is possible to observe the variability captured by the spatial random effects, especially in the region known as Tornado Alley, which is a nickname given to an area in the southern plains of the central United States that experiences a high frequency of tornadoes each year (NOAA). In addition, after 1980s, it is also possible to observe an increasing in the variability in the Southeast region, for all intensities considered, which is consistent with finds reported in the literature (e.g.,
Moore and DeBoer (
2019) and
Gensini and Brooks (
2018)).
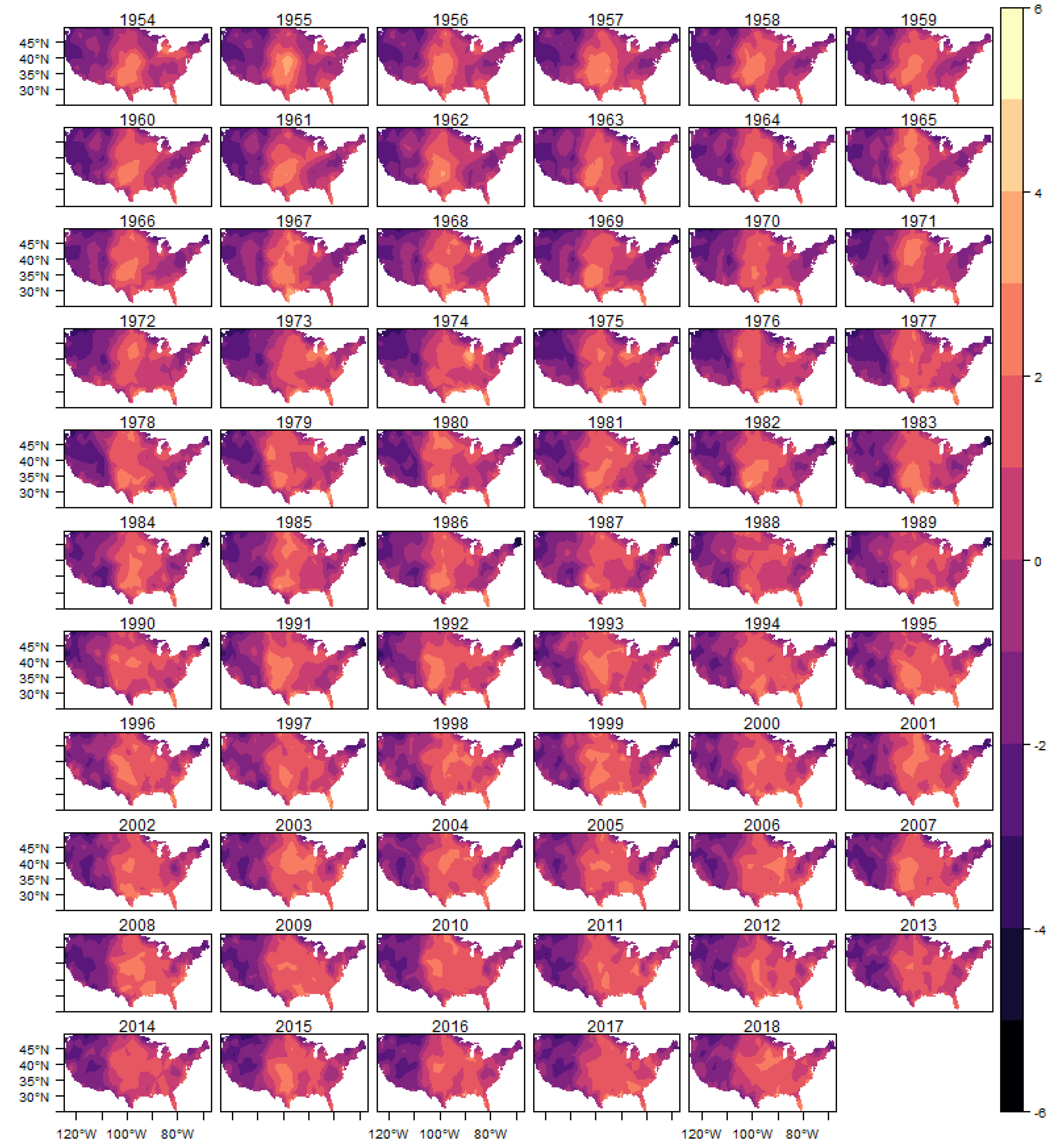
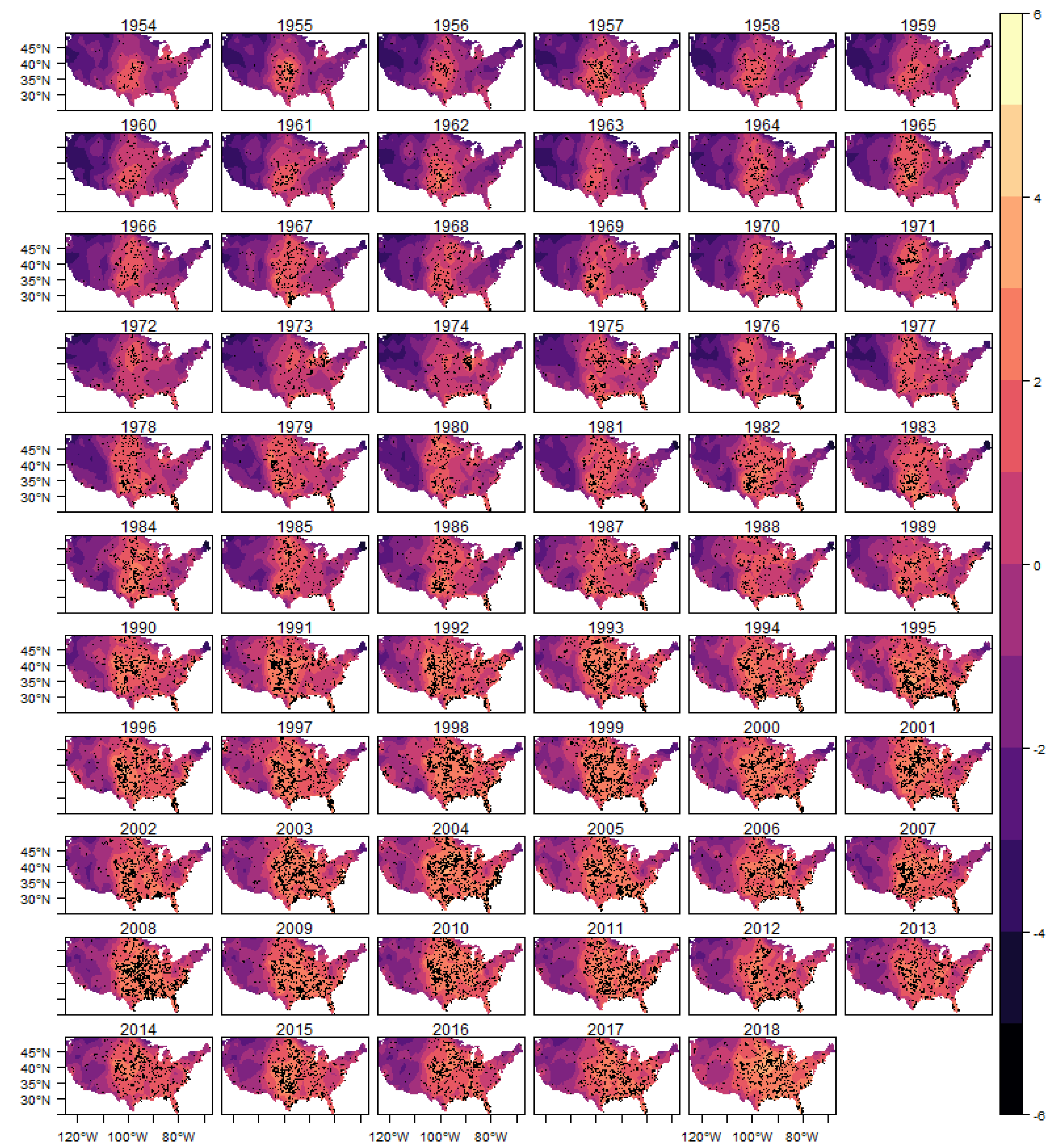
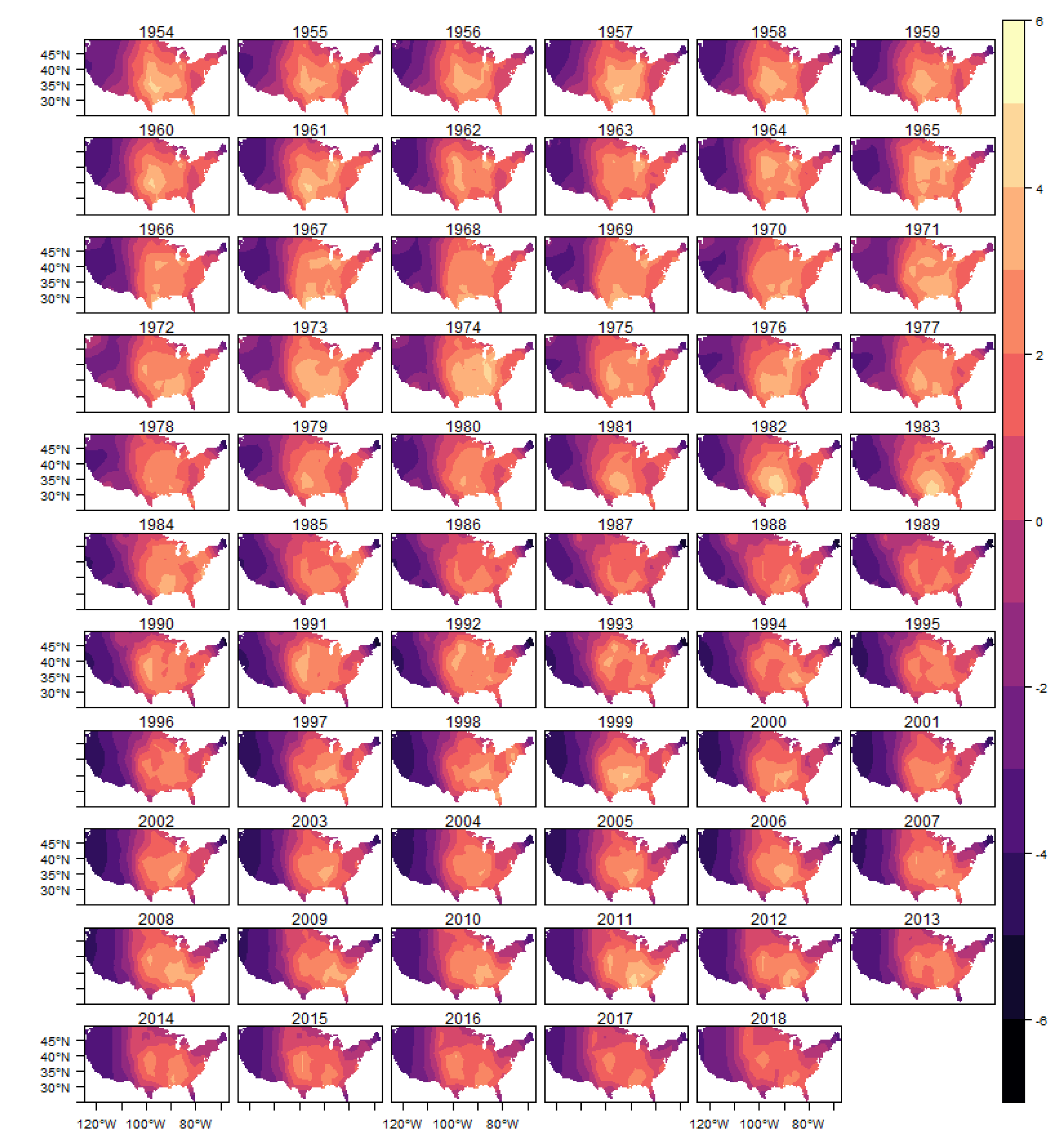
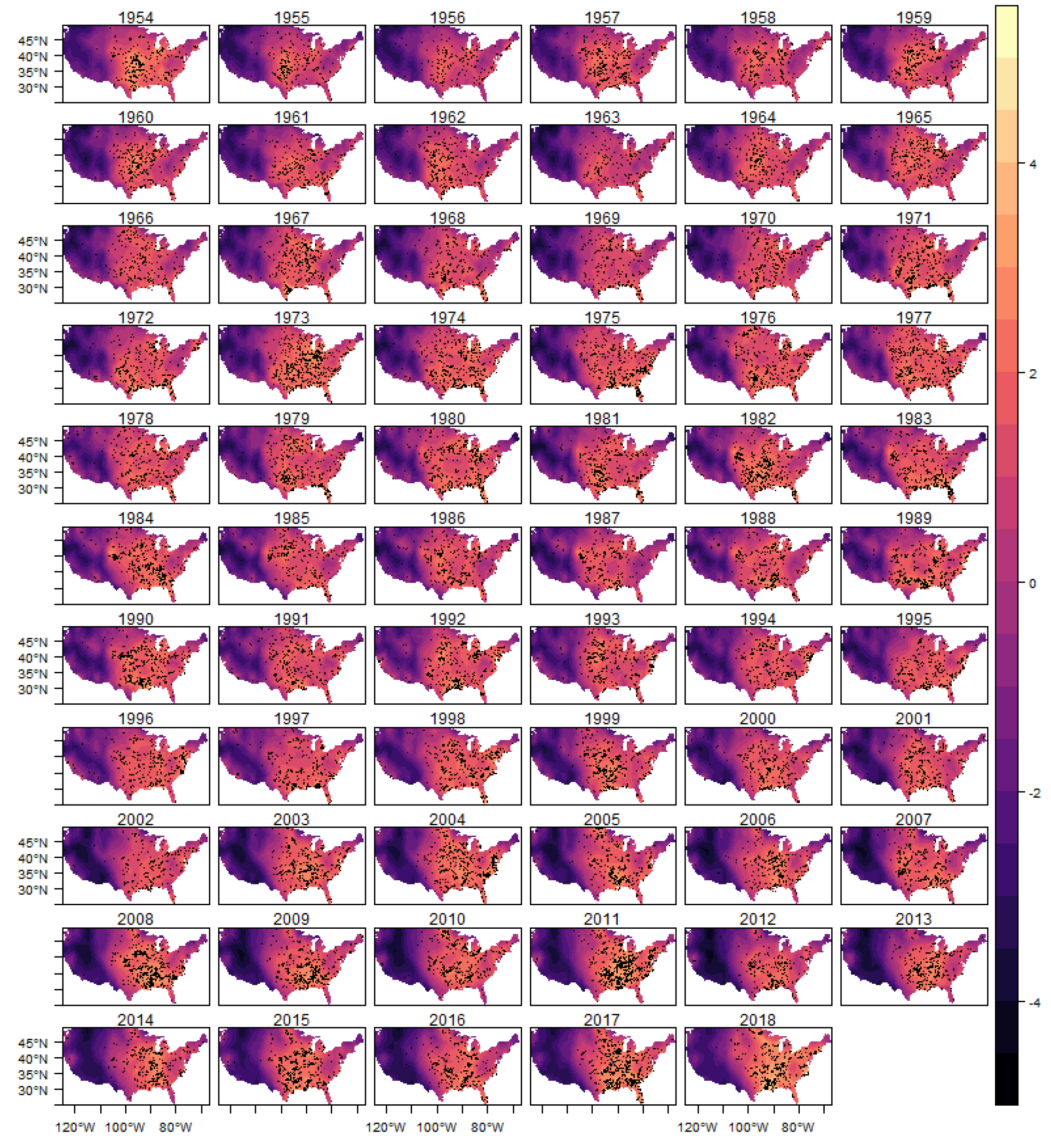
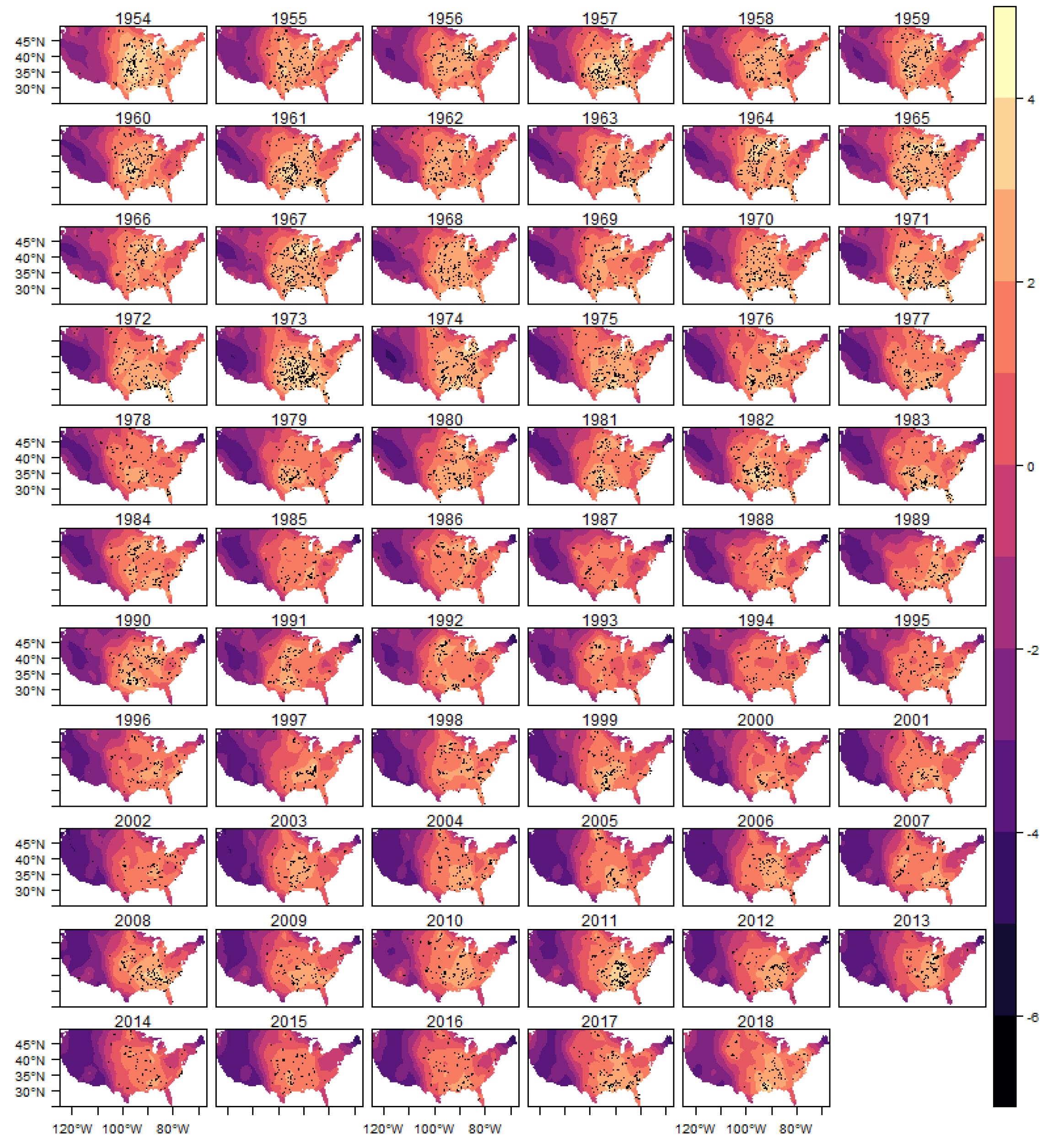
In
Figure 10 we show the estimated intensity function for the (E)F0 classification tornadoes, given by the sum of all random components (trend, cycle and spatial) in each year. The analogous results for the other classifications are shown in
Figure A9,
Figure A10,
Figure A11 and
Figure A12 in the Appendix.
In each year presented in these figures we also show the observed occurrences of tornadoes as black dots. We can observe that the estimated intensity log function adequately explains the spatio-temporal variation observed in the tornado count for all classifications, indicating that the space-time LGCP model proposed in this work has an adequate fit to the analyzed pattern of occurrences.
To verify the robustness of the results found and the importance of the estimated components, we analyzed different specifications of the model using information criteria. We compared for each classification of tornadoes four restricted versions of the model.
Table 3 shows the Deviance information criterion (DIC), a generalization of the Akaike information criterion proposed in
Spiegelhalter et al. (
2010) and the widely applicable information criterion (WAIC), also known as Watanabe–Akaike information criterion, another generalization of the Akaike information criterion, proposed in
Watanabe (
2010) and
Watanabe (
2013).
Model M0 in
Table 3 corresponds to the model with trend, cycle, and the time varying spatial random effects. The first restricted specification (M1) assumes that there is no trend component, and so there is no permanent change in the long-term average pattern for tornadoes. The second specification (M2) assumes the restriction that there is no cycle component and including the trend and time varying spatial random effects, the third specification (M3) assumes that the spatial random effects are constant over time, but including the trend and cycle components. The last specification (M4) assumes only an intercept and fixed spatial random effects.
Thus, these different specifications allow to analyze the impact of each component of the model on the spatio-temporal dynamics of tornadoes. The restricted specifications are important for the analysis of possible climate changes, since they analyze changes in long-term permanent patterns (trend) and possible changes in the spatial distribution of tornadoes over time.
In
Table 3 the best specification for each classification is marked in bold. For the (E)F0 classification, the DIC points out as the best specification M1, which includes trend, cycle and time-varying spatial effects, and WAIC selects the M2. For the (E)F1 classification the best specification is M2 by both
criteria, suggesting that for this classification the cycle effects are not relevant for the explanation of
the tornado pattern, a result consistent with the estimated magnitude of the cycles shown in
Figure 4,
and consistent with the patterns of change in the trend and the spatial component over time.
For the (E)F2 classification, the M1 model is selected by the DIC criterion, while for WAIC the M2 is selected, indicating the importance of the temporal variation pattern in the spatial component, and doubt about the inclusion of the trend. The model selected by the DIC is consistent with the results shown in
Figure 6, which indicate little variability in the trend. The results for the (E)F4 classification are substantially different, selecting the M3 model, which includes the trend and cycle components, but assumes that the spatial random effects are fixed in time. The absence of relevant variations in the spatial component is consistent with the results shown in
Figure A8. It is important to note that the lower number of occurrences in this class of tornadoes makes the identification of variations in temporal patterns less accurate. The parameters estimated in these specifications and other results are available under request from the authors.
Other alternative specifications were also tested in relation to the mesh size used, the numerical method to determine the modes in the Laplace approach and methods for the numerical integration. The results are qualitatively invariant when choosing the mesh size, and we used a mesh size that was computationally efficient in terms of memory usage and processing speed, which are especially important when comparing models. Thinner mesh construction did not produce more accurate or qualitatively different results. It is not possible to show a comparison of information criteria in this case since different mesh sizes are not directly comparable in terms of model fit, as they have different sample sizes.
Different methods of numerical optimization found the same results (modes) in the Laplace approximation. We analyzed four alternatives in the Laplace approximations. The first three forms, described in
Rue et al. (
2009), are the Gaussian, simplified and full Laplace approximations, and last form is the adaptive method, described in
Gomez-Rubio (
2020), which is computationally more efficient at the cost of greater memory usage. The results are basically the same in all approximation methods. The construction of the precision matrices (reordering) and the sparse linear algebra tools use the paradiso library which allows a great gain in numerical efficiency.
It is important to discuss some limitations of this study. A relevant point is related to model identification, given the high persistence of the autoregressive parameter of spatial random effect. To avoid a possible identification problem, we impose that the autoregressive term is time stationary in the estimation of the spatial random effect through a transformation, representing the parameter as . For finite values of this minimizes the identification problems generated by a unit root in this coefficient and the simultaneous inclusion of the trend. However, it is still possible that the value of the autoregressive coefficient is very close to one. An alternative may be to investigate a model with several common trends. However, this is not possible yet, because there are some important limitations that must be circumvented. One of these limitations is that our structure of spatial random effects is continuous in the space. Thus, there is not a straightforward way to determine what regions of the continuum would be affected by each trend in the model. In the limit we must have a coefficient that is a continuous function in the space, which has not yet been done for this class of models. To avoid this problem, an alternative would be to discretize the space and impose that each discretized region has a separated trend. The problem is that this alternative involves ad-hoc choices, since to the limit of our knowledge, there is no method developed for this problem. Another alternative may be assuming that the spatial effect is a random walk process. In this case, each location in the continuum would have a particular trend. Nonetheless, in this case, the problem would be the non-stationarity.
In this case, one may consider the use of nonstationary spatial modelling with explanatory variables in the dependence structure, as described by
Ingebrigtsen et al. (
2014), which have proposed a flexible class of non-stationary models where explanatory variables can be easily included in the dependence structure. In this specification, the covariance parameters are determined through a log-linear regression with coefficients for possible explanatory variables defined on the mesh, allowing that these coefficients spatially vary. The difficulty of this specification in the tornado modelling is due the fact that the spatial variation of tornadoes depends on air mass movements, which have a great seasonal variation, which makes this method substantially difficult to implement. The application of this methodology including fixed covariates, such as latitude, longitude, distance to coast and elevation would be considered for future papers.
Zero-Inflated Poisson
Data were taken for different intensities of tornadoes, based on Fujita (F) and Enhanced Fujita (EF) damage rating scales. Historically, stronger tornadoes are less likely to occur, which led to the database having many zero counts. For classifications with very few occurrences, a possible modification is to change the likelihood function to account for the possibility of an excess of zeros. Mixed-distribution models, such as Zero-Inflated-Poisson (ZIP) can be used in such cases. According to
Lambert (
1992), ZIP is a model for count with excess zeros, which assumes that with probability
p the observation is 0, and with probability
, a Poisson is observed.
We consider two different types of ZIP models: type 0 and type 1. The type 0 likelihood is defined as
where
p is a hyperparameter where
and
is the internal representation of
p, meaning that the initial value and prior is given by
. On the other hand, the type 1 is defined as
where
p is a hyperparameter where
where
has the same meaning above-mentioned. As discussed by
Serra et al. (
2014), the only difference between type 0 and 1 is the conditioning on
for type 0, which means that for type 0 the probability that y is equal 0 is
p, whereas for type 1, the same probability is
.
Table 4 shows the estimated posterior distribution for the parameters associated with the ZIP model for (E)F4 tornadoes, considering type 1. For space issue we show only the results obtained with type 1, which had best results, in terms of fit, in relation to type 0. The results obtained with type 0 are available with the authors. As in
Table 2, the precision parameters represent the variability associated with trend and cycle components. The results indicate great precision associated with the trend component whereas the precision of cycle component is relatively minor.
Figure 11 shows the estimated trend and cycle components for the (E)F4 tornadoes, considering the ZIP model with type 1, where it is possible to observe the absence of permanent changes in the occurrence intensity. In addition, it is important to note that the ZIP model with type 1 results do not present significant changes in the trend and cycle components, relatively to those results obtained with Poisson distribution and shown in
Figure 4,
Figure 5,
Figure 6 and
Figure 7.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}