1. Introduction
Interest in Bayesian analysis, generally, and Bayesian model averaging (BMA), specifically, has increased rapidly as computational power of desktops and personal laptops have expanded (
Steel 2019). With the demand for these tools comes an array of platforms with which to implement them. One of the most popular statistical softwares for any type of Bayesian analysis is the open source statistical environment R (
R Development Core Team 2013). Even with the ability to conduct Bayesian analysis in R, there exist a wide variety of packages and compiled code; a user interested in BMA or variable selection has at their fingertips over 13 packages that can do the job (
Forte et al. 2018). Given such a large menu of options, the uninitiated may not know which direction to go to start their analysis. A useful starting point is the BMS package.
1The BMS package (
Feldkircher and Zeugner 2009;
Zeugner and Feldkircher 2015) implements linear BMA with a comprehensive choice of priors, Monte Carlo Markov Chain samplers, and post-processing functions. This package provides a large degree of flexibility in the specification of the underlying features used to analyze the model and produces a wide range of easily-readable outputs including the posterior inclusion probabilities, means, and standard deviations, the number of models visited, and the number of draws from the sample. This package also takes advantage of R’s powerful graphical interface and creates useful graphs that allow the user to visualize the posterior model size distribution, posterior model probabilities, and cumulative model probabilities as well as providing plotting facilities for the marginal densities of the posterior coefficients.
Aside from the standard objects of interest in a BMA exercise (such as posterior inclusion probabilities, the highest probability model, etc.), attention has also been focused on jointness (
Doppelhofer and Weeks 2009). Jointness captures dependence between covariates across the model space for the posterior distribution. Rather than focus on an individual variable’s inclusion, jointness quantifies how likely two variables are to appear together. In the presence of model uncertainty, this joint inclusion can be important across a variety of dimensions (
Man 2018). However, jointness can take many different forms (
Doppelhofer and Weeks 2009;
Ley and Steel 2009b;
Strachan 2009) and many of the measures that have been proposed have limitations in one form or another, depending on the range of properties considered for a measure of jointness (
Hofmarcher et al. 2018). As yet, a consensus does not exist as to the best measure of jointness, nor is it well understood how robust a given jointness measure is across various user defined choices (such as choice of prior), though
Man (
2018) is one step in this direction.
This paper details both the basic functionality of the BMS package and provides an easy to deploy function that calculates eight different jointness measures. We begin with an overview of both BMA and jointness. We then detail how to install the BMS package and implement a BMA empirical exercise using this package. We describe the main features under the user’s control for this package including the set of prior probabilities and model sampling algorithms as well as the plot diagnostics available to visualize the results. We show how a user can obtain estimates, posterior inclusion probabilities, and model statistics from this package with a mock empirical example. We do this both with a set of covariates that allows for full enumeration of the model space as well as requiring the implementation of a model space search mechanism. Lastly, we follow up with an application to the equity premium from the finance literature and provide an R routine that users can implement within BMS to calculate jointness across eight different measures. Having access to these various measures allows users to quickly determine how robust alternative findings of jointness are to various changes in the setup of the BMA exercise.
2. Bayesian Model Averaging
In brief, the implementation of BMA begins by considering a set of possible models, say
.
M represents the model space the averaging will be conducted over. Once this space has been set the posterior distribution of any quantity of interest,
, given the data,
D, is
which is simply the weighted average of the posterior distributions under each model.
The most common framework for BMA is the linear regression model of the form
where
y is the
dependent variable vector and
the
matrix of covariates. Here, there are potentially
L covariates. In this case,
, where
is a subvector or
.
Using Bayes Theorem, one can rewrite the posterior probability of model
as follows:
where
is the vector of parameters from model
,
is a prior probability distribution assigned to the parameters of model
, and
is the prior probability that
is the true model. As mentioned above, in order to make BMA applicable, we need to choose prior distributions for the parameters of the model and then, based on the data, calculate posterior probabilities attached to different models and finally find the parameter distributions by averaging posterior distributions.
One should notice that, as stated in
Brock et al. (
2003, p. 270), ideally the set of prior probabilities should be informative with respect to the likelihood, meaning priors should assign relatively high probability to areas that have high likelihood. Were this not the case then the choice of priors will have a substantial effect on the posteriors. Unfortunately, the likelihood is unknown, making the choice of the prior user specific. Several studies have attempted to discern the effect that the choice of prior probabilities has on posterior probabilities, which are commonly used to gauge the ‘robustness’ of a variable. This is not to be confused with variable importance, which attempts to discern if a variable belongs to the true model.
2 Rather, robustness seeks to determine how small changes to the prior probability structure impact the posterior estimates.
Ley and Steel (
2009a) and
Steel (
2019) provide a complete review on the effect of prior assumptions on the outcome of BMA analyses. As will be important later when we discuss the BMS package, the ability of a software package to allow the user to vary the prior to assess small changes is important to allow researchers the ability to gauge robustness.
The issues with BMA highlighted here are by no means an indictment of the methods. Rather, they are to draw attention to the areas where the user must exert caution when implementing a model averaging exercise. Undoubtedly, for any model averaging investigation, the researcher will face issues based on the route taken to average across models. Furthermore, understanding the nuances of model averaging exercises allows for clearer comparisons and the ability to understand where results may differ. We counsel interested readers to consult
Moral-Benito (
2015),
Fletcher (
2018), or
Steel (
2019) for a review of the state of the art.
3. Jointness
Capturing the dependence between explanatory variables in the posterior distribution while implementing a Bayesian analysis is crucial. Taking such a dependence into account reveals the sensitivity of posterior distributions of parameters to dependence across regressors. For instance, if two specific variables are complementary over the model space, we expect relatively higher weights for the models that include both variables together than models where only one variable is present.
In this section, we discuss how the applied literature has focused on quantifying the dependence between predictive variables. The methodology behind BMA provides a measure for the
marginal posterior inclusion probability of a given regressor. However, although the marginal probability measure of variable importance has interesting policy implications and prediction, it hardly provides information on the nature of dependencies among regressors. To address this issue, we follow
Doppelhofer and Weeks (
2009) and
Ley and Steel (
2009b) and introduce the posterior joint inclusion probability of variables
and
as
where
is the
ith model, and
D is the data. This equation adds up posterior model probabilities for all the models in which the two variables are present. These posterior model probabilities are calculated as the weighted sum of the prior model probability times its marginal likelihood:
with the marginal likelihood defined as
For the linear regression model with normal priors on
and
, coupled with a gamma prior for
, it can be shown (
Steel 2019, p. 22) that the marginal likelihood is
, where
g comes from the
g-prior of
Zellner (
1986), and
is the number of covariates in model
j where
is the traditional in-sample measure of fit. Posterior model probabilities also form the basis for the calculation of posterior inclusion probabilities, which is simply the sum of the posterior model probabilities that contain a specific covariate.
From this discussion, a natural measure of dependence between variables
and
is given by
3Finally, in a detailed treatment of jointness,
Hofmarcher et al. (
2018) proposed two alternative measures:
and
They show these two statistics have formal statistical and intuitive meaning in terms of jointness, and are more likely to be well-behaved when the posterior inclusion probability of one of the regressors is either zero or very close to zero.
4 An interesting feature of
is that it maps the jointness measure of
Doppelhofer and Weeks (
2009), Equation (
8), from
to
.
Given these various proposals to measure jointness, a natural question to ask is which one should be used for applied work.
Hofmarcher et al. (
2018) lists seven key properties that jointness measures, in general, may possess
Definition: is the jointness measure defined whenever the one of the variables in included with positive probability (this is criteria C4 in
Ley and Steel (
2007));
Monotonicity/Boundedness/Maximality: is the range of association between
and
bounded; is the measure monotonically increasing between the boundaries; the jointness measure only achieves the boundaries if both variables either always or never appear together (maximality is criteria C3 in
Ley and Steel (
2007));
Limiting Behavior: The jointness measure should converge to its maximal value as the probability that and appear together increases to 1 and should converge to its minimal value as the probability that and appear separately increases to 1;
Bayesian Confirmation: the jointness measure equals 0 if and only if the inclusion of and are statistically independent events;
Non Null-Invariance: the jointness measure should not ignore model specifications where and and jointly excluded;
Commutative Symmetry: suitable measures of jointness statistics should be symmetric to the ordering of variables;
Hypothesis Symmetry: if and are complements for a given jointness measure, then and are substitutes (disjoint) by the same jointness measure.
Only the modified Yule’s Q measure of jointness, Equation (
13), satisfies all seven of these properties, whereas every jointness statistic presented here satisfies commutative symmetry.
Ley and Steel (
2007) also argue that any jointness measure should have a formal statistical meaning (what they term Interpretability), and the values that the jointness measure can take on should be calibrated against a clearly defined scale (what they term Calibration).
Positive (or large) values for jointness statistics indicate that variables
and
are
complements, reflecting that posterior probabilities of models jointly including and excluding both variables are larger than posterior probabilities of models including only one. A negative (or small) value for the statistic, on the other hand, indicates that the variables are capturing a similar underlying effect and are
disjoint; as noted in
Steel (
2019, p. 43), disjoint variables suggest that these variables are more likely to appear in a model separately from one another. Disjointness can arise when a pair of covariates are highly collinear or may be thought of as proxies/substitutes for each other. Note that, for
and
, the lower bound for jointness is 0. It is common in practice to take the logarithm of these measures, see
Ley and Steel (
2009a).
The magnitude of the jointness statistics of
Doppelhofer and Weeks (
2009) is sensitive to whether or not the posterior inclusion probability of one of the explanatory variables is zero or extremely small, a case that commonly occurs in practice. As noted in
Hofmarcher et al. (
2018), a key property of any jointness measure is that it should be ‘defined’ whenever one of the variables is included with positive probability. This property is fulfilled by the two alternative measures proposed by
Ley and Steel (
2009b) as well as those introduced by
Hofmarcher et al. (
2018) but not by the measures proposed in
Doppelhofer and Weeks (
2009) or
Strachan (
2009). R code to construct all of the jointness measures discussed here is provided in
Appendix A.
4. The BMS Package
Having now discussed both BMA and notions of jointness, we turn to how users can conduct a BMA exercise and calculate different jointness scores. Our platform for this is the BMS package.
4.1. Installation and Install Setup
Prior to invocation of the BMS package, R must be installed. R can be downloaded at no charge from
http://www.cran.r-project.org. The R statistical environment runs on all common operating systems including Linux, Unix, Windows, and Mac-OS X.
5 Once R is installed, it is preferable to install BMS directly within R simply by typing

in your R console. Then, you will be prompted to choose a CRAN repository and the package should be installed after a few seconds. The package can then be loaded into the R workspace by typing library (BMS) at the command prompt.
6 For users who prefer to work with MATLAB, the core functionality of the BMS package can be accessed via the
BMS Toolbox for Matlab. This toolbox provides MATLAB core functions that perform BMA by calling a hidden instance of R. This functionality requires a Windows operating system (NT, XP, Vista, 7, or 8) and the installation of both MATLAB (Version 6 or higher) and the R statistical environment.
7 4.2. Functionality
The main command within the BMS package is bms() which deploys a standard Bayesian normal-conjugate linear model (see Equation (
2)). Primarily, the options for the bms() command hinge on sampling from the model space and selection of both model priors and Zellner’s
g-priors. These three categories comprise the most important aspects of conducting a BMA exercise.
4.3. Controlling the BMA Exercise
4.3.1. Model Sampling
A BMA analysis begins with constructing model weights for each model within the defined model space. However, since enumerating all potential variable combinations quickly becomes infeasible for even a modest number of covariates, the BMS package uses a Markov Chain Monte Carlo (MCMC) samplers to gather results on the most important part of the posterior distribution when more than 14 covariates exist.
The BMS package offers two different MCMC samplers to probe the model space. These two methods differ in the way they propose candidate models. The first method is called the birth-death sampler (mcmc=bd). In this case, one of the potential regressors is randomly chosen; if the chosen variable is already in the current model , then the candidate model will have the same set of covariates as but drops the chosen variable. If the chosen covariate is not contained in , then the candidate model will contain all the variables from plus the chosen covariate; hence, the appearance (birth) or disappearance (death) of the chosen variable depends if it already appears in the model. The second approach is called the reversible-jump sampler (mcmc=rev.jump). This sampler draws a candidate model by the birth-death method with 50% probability and with 50% probability the candidate model randomly drops one covariate with respect to and randomly adds one random variable from the potential covariates that were not included in model .
The precision of any MCMC sampling mechanism depends on the number of draws the procedure runs through. Given that the MCMC algorithms used in the BMS package may begin using models which might not necessarily be classified as ‘good’ models, the first set of iterations do not usually draw models with high posterior model probabilities (PMP). This indicates that the sampler will only converge to spheres of models with the largest marginal likelihoods after some initial set of draws (known as the burn-in) from the candidate space. Therefore, this first set of iterations will be omitted from the computation of future results. In the BMS package, the argument (burn) specifies the number of burn-ins (models omitted), and the argument (iter) the number of subsequent iterations to be retained. The default number of burn-in draws for either MCMC sampler is 1000 and the default number of iteration draws to be sampled (excluding burn-ins) is 3000 draws.
4.3.2. Model Priors
The BMS package offers considerable freedom in the choice of model prior. One can employ the uniform model prior as the choice of prior model size
(mprior=“uniform”), the Binomial model priors
8 where the prior probability of a model is the product of inclusion and exclusion probabilities
(mprior=“fixed”), the Beta-Binomial model prior
(mprior=“random”) that puts a hyperprior on the inclusion probabilities drawn from a Beta distribution
9 or a custom model size and prior inclusion probabilities
(mprior=“customk”).
4.3.3. Alternative Zellner’s g-Priors
Different mechanisms have been proposed in the literature for specifying g priors. The options in the BMS package are as follows:
4.4. Outputs
In addition to posterior inclusion probabilities (PIP) and posterior means and standard deviations, bms() returns a list of aggregate statistics including the number of draws, burn-ins, models visited, the top models, and the size of the model space. It also returns the correlation between iteration counts and analytical PMPs for the best models, those with the highest PMPs.
4.5. Plot Diagnostics
BMS package users have access to plots of the prior and posterior model size distributions, a plot of posterior model probabilities based on the corresponding marginal likelihoods and MCMC frequencies for the best models that visualize how well the sampler has converged. A grid with signs and inclusion of coefficients vs. posterior model probabilities for the best models and plots of predictive densities for conditional forecasts are also produced.
4.6. Empirical Illustration
This section shows the results of a basic BMA exercise using the Hedonic dataset available in the plm package
Croissant and Millo (
2008). This dataset contains information aggregated across census tracts for the Boston metropolitan area in 1970, originally published in
Harrison and Rubinfeld (
1978). This cross-sectional dataset consists of 506 observations along with 13 potential determinants of median housing prices in Boston. The dependent variable (
) is the corrected median value of owner-occupied homes in
$1000s, and among the explanatory variables are the per capita crime rate (
), the pupil–teacher ratio by town school district (
), the index of accessibility to radial highways (
), the proportion of owner-occupied units built prior to 1940 (
), the proportion of non-retail business acres per town (
), the proportion of African-Americans per town (
B), and a variable reflecting the nitric oxides concentration (
). See
Harrison and Rubinfeld (
1978, Table 4) for more details.
The authors use a hedonic housing price model to generate quantitative estimates of the willingness to pay for air quality improvements. We assume there exists uncertainty about which housing attributes should be a part of the true model. The small number of covariates allows the bms() command to fully enumerate the model space, i.e., every possible model in M is estimated prior to averaging. To further demonstrate searching over the model space, we append 12 fictitious variables, generated as independent standard normal random deviates, which pushes the number of covariates beyond the threshold search level and requires MCMC methods. These 12 additional variables have no impact on median housing prices and are introduced here only to demonstrate how well the BMS package works when there are a large number of covariates. We present diagnostic plots to illustrate the flexibility of the calls within the package.
4.6.1. Enumeration of the Model Space
We first present the results of performing basic BMA with the original Hedonic dataset, which is small enough to fully enumerate the model space. First, we load the required packages and set the R options via the following commands:

Next, we load the dataset, append the 12 fictitious variables, and manipulate it using the following commands:

Now, we perform BMA via the bms() command, and retrieve the main results via the coef function. The following commands will implement the BMA analysis over the Hedonic dataset.

In this setup,
bms() enumerates all
models. The current call uses a uniform distribution for model priors and unit information priors (UIP) for the distribution of regressions coefficients.
Table 1 shows the output for model.enu.
The first column, named PIP, shows the posterior inclusion probabilities indicating the probability that each variable belongs to the true model. BMS sorts these probabilities from the highest to the lowest automatically. The second and third columns show the posterior means and standard errors of regressors calculated from this package. Several key takeaways emerge from
Table 1. Of the 13 variables in consideration, seven have PIPs of 1 and two more (Property Tax Rate and Black People Percentage) have PIPs above 0.95. Only three variables have PIPs low enough to suggest they do not belong to the true model. The magnitudes of the posterior means are also aligned with intuition.
Other additional information about the model averaging procedure can be obtained using the summary function. In our case, the output would be

As is apparent, some useful statistics including the number of models visited, the average number of regressors used, and time performance are produced.
4.6.2. Model Sampling
In this section, we present results obtained when full enumeration is computationally infeasible or undesirable. Using the Hedonic.large dataset, the following commands will implement the BMA analysis using the birth-death MCMC search algorithm (see
Section 4.3.1) with 10,000 iterations and a burn in of 2000 models.

The PIPs for this exercise are shown in the first column of
Table 2 after invocation of the coef function on the BMS object. The choices for model priors and the distribution of the model coefficients are the uniform distribution and unit information priors, respectively. As in
Table 1, the next two columns show the estimated posterior means and standard deviations of the covariates. Even with the addition of the 12 fictitious variables, the birth–death sampler provides PIPs consistent with the earlier full enumeration example. We do not list the PIPs for the 12 fictitious variables or the three variables with PIPs below 0.05 in
Table 1. Even having to search the model space (which is orders of magnitude larger than with the original dataset), we see similar posterior mean and posterior standard deviation estimates across all covariates with the same signs.
Additional statistical information is revealed via the call

Note that the MCMC search algorithm visited less than one half of one percent of the total number of models in the model space and still provided results consistent with full enumeration over the model space.
4.6.3. Plot Diagnostics
The plotting facilities within BMS are an important tool that allows the user to visualize the shape of the posterior distributions of coefficients, assess the size of the true model, compare PIPs, and investigate model complexity. The BMS package plots the marginal inclusion densities as well as images that show inclusion and exclusion of variables within models using separate colors. This package also provides graphics for both the PMPs and posterior model size distribution. The following figures are some examples of the available plots corresponding to the above example where we added 12 fictitious covariates to force the package to engage in searching across the model space.
In order to produce a plot for comparison of prior and posterior distributions of the model size, simply use

The first argument in the command is the R object where we have saved our estimation results, and the second argument defines the type of line we are going to use for our graphs.
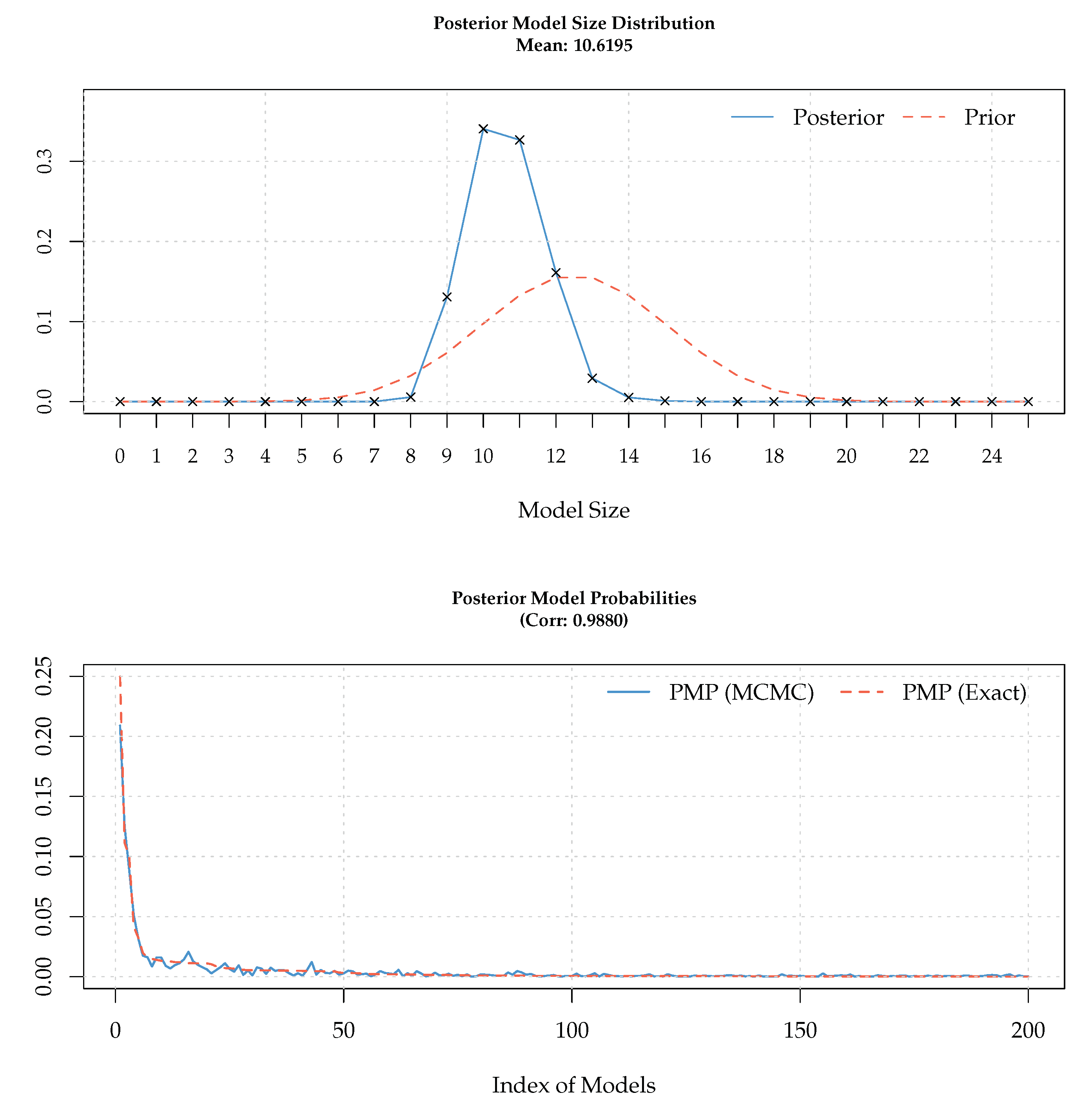
Figure 1 is a combined plot from the BMS package. The upper plot shows the prior and posterior distribution of model sizes and helps the user illustrate the impact of the model prior assumption on the estimation results. For example, the upper plot of
Figure 1 assumes a uniform distribution on model priors and, if the user wants to examine how far the posterior model size distribution matches up to the prior, he might consider other popular model priors that allow more freedom in choosing prior expected model size and other factors. The lower plot of the figure is an indicator of how well the first 200 best models encountered by BMS have converged. These plots are useful in determining the search mechanisms ability to find ‘good’ models throughout the model space.
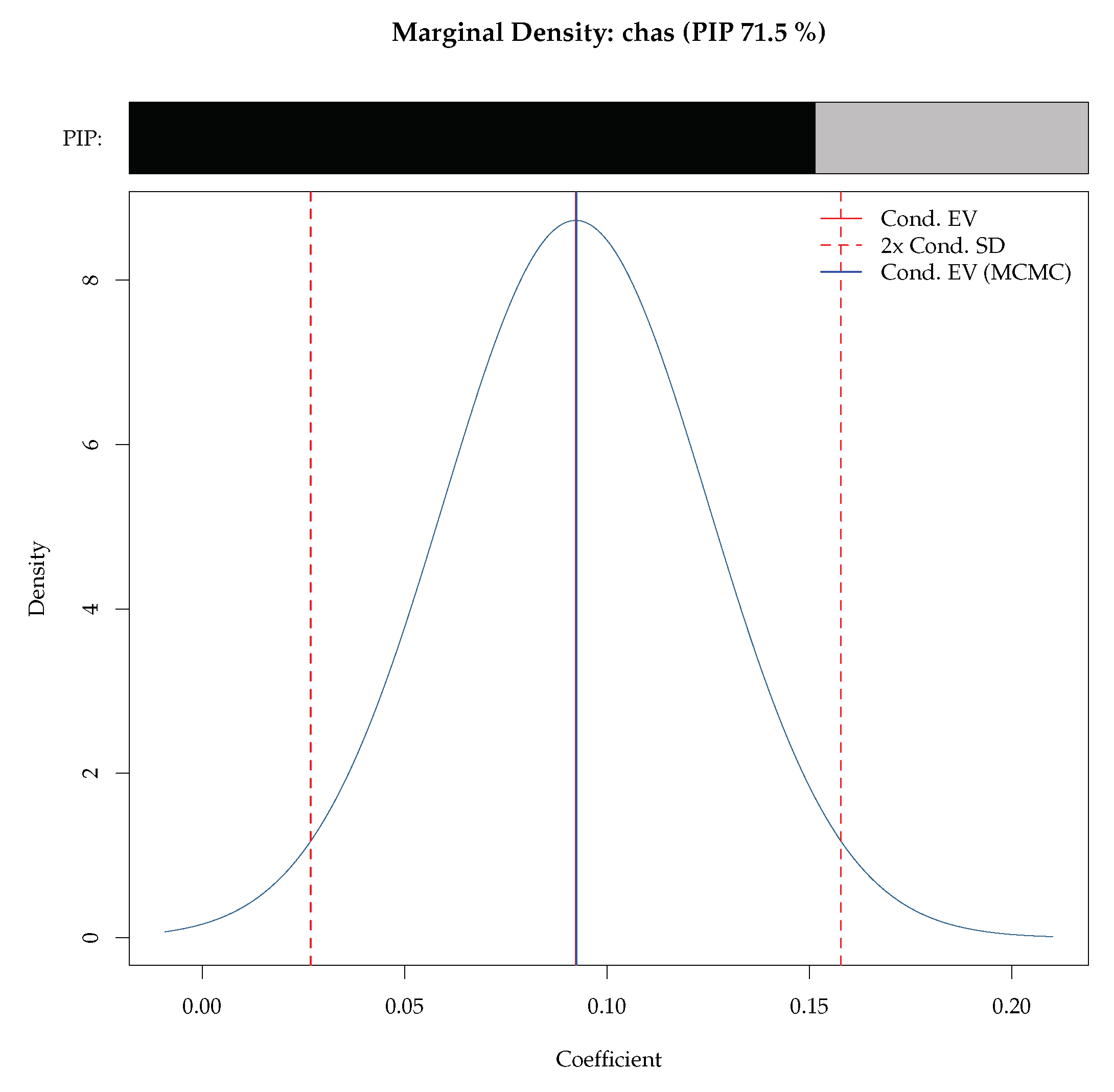
Figure 2 is a visualization of the mixture marginal posterior density for the coefficient for the Charles River Dummy produced by the BMS package. The bar above the density shows the PIP, and the dotted vertical lines show the corresponding standard deviation bounds. This figure can be generated simply via density.bma function within the BMS package

This is an extremely flexible command and provides several options for the user. Addons receives string values specifying which additional information should be added to the plot via low-level commands. To see more details, run help(density.bma) in your R console.
5. A Finance Application with Jointness
Financial economists have proposed numerous variables including dividend-price ratio, dividend yield, earnings-price ratio, dividend-payout ratio, stock variance, net equity issuance, treasury bill rate, return on long-term government bonds, term spread, book-to-market ratio, inflation, and investment-to-capital ratio, among others, along with different econometric techniques in attempts to predict the equity risk premium (
Welch and Goyal 2008). However, a lack of consensus regarding theoretical frameworks has created situations where many possible models exist to explain the effect of a particular variable on equity premium. We argue that, under this circumstance, picking a single model tends to ignore the uncertainty associated with the specification of the selected model and may result in unstable outcomes. Hence, we suggest using BMA to combine all the competing models and compute a weighted average of the estimates to mitigate the uncertainty and instability risk associated with reliance on a single model. In this section, we deploy the BMS to identify the key determinants of equity premium.
The dataset used in this section is an extended version of the dataset described in
Welch and Goyal (
2008). Our sample period is from 1927 to 2013 and includes information on the following variables:
Equity premium (eqp): Defined as the total rate of return on the stock market minus the prevailing short-term interest rate.
Dividends: Dividend yield (dy) is the difference between the log of dividends and the log of lagged prices.
Earnings: Earnings price ratio (e/p) is the difference between the log of earnings on the S&P 500 index and the log of prices. Dividend payout ratio (d/e) is the difference between the log of dividends and the log of earnings.
Volatility: Stock variance (svar) is measured as the sum of squared daily returns on the S&P 500.
Book value: Book-to-market ratio (b/m) is the ratio of book value at the end of the previous year divided by the end-of-month market value.
Corporate issuing activity: Net equity expansion (nee) is the ratio of 12-month moving sums of net issues by NYSE listed stocks divided by the total end-of-year market capitalization of NYSE stocks.
Treasury bills: T-bill rate (tbl) is the secondary market rate of three-month US treasury bills.
Long-term yield: Long-term government bond yields (lty) and long-term government bond returns (ltr) are the yields and returns of long-term US treasury bonds, respectively.
Corporate bond returns: Default return spread (dfr) is the difference between returns on long-term corporate bonds and returns on long-term government bonds. Default yield spread (dfy) is the difference between BAA-rated and AAA-rated corporate bond yields.
Inflation: Inflation (infl) is the Consumer Price Index (all urban consumers) from the Bureau of Labor Statistics, lagged by one month.
Table 3 presents summary statistics for the equity premium sample. The majority of the variables are nearly symmetric, with the earnings to price ratio and the dividend yield being slightly skewed. The long-term government bond yield has an average monthly return of 5.2%, but an average return of only 0.5%; this is also reflected in the minimum and maximum over the sample (−11.2–15.2%).
The posterior inclusion probabilities, posterior mean and standard deviation estimates of the coefficients are in
Table 4. Of the 12 variables, five have PIPs of one: dividend yield, earnings to price ratio, dividend payout ratio, stock variance and the treasury bill rate. The book-to-market ratio has a PIP of 0.5 which suggests some likelihood of inclusion in the true model, though its posterior mean is essentially 0. The remaining variables have low PIPs along with low posterior means and standard deviations. The magnitudes and signs of the five variables with PIPs of one are consistent with standard models of equity premia.
What is immediate is that, across the three tables, the jointness measure of
Doppelhofer and Weeks (
2009) cannot be calculated across many of the covariates.
10 This arises from how the jointness measure is constructed given which covariates appear in models with positive posterior probability, i.e., the lack of definition. For those covariates for which jointness is calculated, the majority of the scores are between −1 and 1. The only strong substitution/disjointness effect that is found is default yield spread and book-to-market ratio. Several other patterns of disjointness which are intuitive emerge: net equity expansion and long-term yield, long-term yield and inflation, and long-term government bond returns and inflation.
For the main jointness measure of
Ley and Steel (
2009b) presented in
Table 6, nearly all of the tabular entries show up as 0 with a large block of maximal entries due to four of the variables that have PIPs equivalent to 1 from
Table 4. Consistent with
Table 5, default yield spread and book-to-market ratio are strong substitutes. The many 0 entries in
Table 6 suggest that a majority of the 12 covariates are substitutes as it pertains to the true model of equity premia according to the jointness measure of
Ley and Steel (
2009b).
A similar pattern emerges for the modified Yule’s Q jointness measure of
Hofmarcher et al. (
2018) presented in
Table 7; many of the tabular entries show up as negative and larger in magnitude than 0.75. We also see that when
Ley and Steel’s (
2009b) measure is 0 or near 0, the modified Yule’s Q measure is close to −1.
Table 6 and
Table 7 provide the same insights regarding jointness, which do differ in some ways from
Table 5.
Aggregating across these three tables the insights of
Man (
2018, p. 846) bear relevance:
“‘
… jointness structures where virtually all variable pairs involving at least one covariate below the 50% PIP (posterior inclusion probability) threshold display significant or even strong negative jointness, that is, substitutability. Since, typically, only a small number of variables is above the 50% threshold, this implies that most variable pairs in any given dataset display negative jointness. Under the other concept due to
Ley and Steel (
2009b), in addition to the substitutability partition, there is a (strong) complementarity partition comprising variable pairs where both covariates are significant in BMA.”
This last sentence is especially true here. Both
and
suggests strong complementarity for the five variables with PIPs equal to 1 in
Table 4 and substitutability for those variables with small PIPs. It is difficult to read too much into the results stemming from
as the lack of satisfaction of the definition property of
Hofmarcher et al. (
2018) leads to many entries that are not defined.




















{kind=link}
{kind=link}