Abstract
This paper provides a new statistical model for repeated voluntary contribution mechanism games. In a repeated public goods experiment, contributions in the first round are cross-sectionally independent simply because subjects are randomly selected. Meanwhile, contributions to a public account over rounds are serially and cross-sectionally correlated. Furthermore, the cross-sectional average of the contributions across subjects usually decreases over rounds. By considering this non-stationary initial condition—the initial contribution has a different distribution from the rest of the contributions—we model statistically the time varying patterns of the average contribution in repeated public goods experiments and then propose a simple but efficient method to test for treatment effects. The suggested method has good finite sample performance and works well in practice.
JEL Classification:
C91; C92; C33
1. Introduction
Experimental data from the laboratory have unique features. The most well known statistical benefit from laboratory experiments is the randomized outcome: by selecting subjects randomly, the difference between the treated and controlled groups can be directly measured. However, data from laboratory experiments have properties that sometimes make the information contained in them difficult to extract. Decisions in lab experiments are often repeated in order to give the subjects time to gain familiarity with the environment and strategic context. As subjects learn, responses may change considerably between the first and final periods of play. With repetition, subjects’ responses are highly persistent and cross-sectionally correlated. The question is how to estimate the treatment effects from such complicated data.
This paper aims to provide a simple and novel estimation method to analyze the treatment effect in repeated public goods games with voluntary contribution mechanism (VCM). A VCM game is one of the most popular experimental games, and its use has increased exponentially in the social and natural sciences. Applications to economics, political sciences, marketing, finance, psychology, biology and behavioral sciences are common. In each round, individuals are given a fixed amount of tokens and asked to invest in either a private or group account. The invested tokens in the public account are multiplied by a factor—which is usually greater than unity—and then are distributed evenly to all individuals. The overall outcome or the fraction of tokens contributed to the public account becomes the prime objective of experimentalists.
Let be the fraction of contributed tokens to a public account of the i-th subject at the round As Ledyard (1995) points out, there are some common agreements among experimental studies: (i) the total amount of tokens does not influence on the overall outcomes. Hence, rather than the total amount of contributed tokens, the fraction of contributed tokens, becomes of interest. In other words, is a bounded series between zero and unity; (ii) the average of initial contributions to a public account is around half of endowed tokens; (iii) as a game repeats, the cross-sectional average of contributions decreases usually over rounds; (iv) Even though an initial contribution, is not cross-sectionally dependent—since subjects are randomly selected—, as a game repeats, is dependent on the previous group account. In other words, is cross-sectionally correlated; (v) Lastly, is serially dependent as well.
Another interesting feature is the existence of different subject types. Commonly assumed types are free-riders, selfish contributors (or strategists), reciprocators, and altruists. Usually, it is not feasible to identify each type statistically because subjects change their own types over rounds. Instead, following Ambrus and Greiner (2012), we attempt to approximate heterogeneous behaviors econometrically into three groups: increasing, decreasing and fluctuating. The increasing and fluctuating groups are obtained by changing parameters in the decreasing model, which we propose in this paper. If experimental outcomes are generated from a single group, the cross-sectional dispersion of the outcome should not diverge over rounds. We will discuss how to test the homogeneity restriction by using the notion of weak —convergence developed by Kong et al. (2018).
The purpose of this paper is to provide a simple but efficient method to analyze treatment effects by utilizing stylized facts. To achieve this goal, we first build a simple time series model with a nonstationary initial condition: the distribution of the first round outcomes is different from the rest of outcomes. The nonstationary initial condition model generates a temporal time decaying function. When experimental outcomes are generated from a decreasing (or increasing) group, the unknown mean of the initial outcome and decay rate for each experiment can be measured directly from estimating the following trend regression in the logarithm of the cross-sectional averages of individual experimental outcomes, .1 That is,
where i and t index subject and round, denotes the true log mean of the initial outcome, and represents the log decay rate of the repeated experimental outcomes. After obtaining the estimates of and by running a regression of (1) for each experiment, the overall outcome in the long run, can be estimated by
The remainder of the paper is organized as follows: Section 2 presents empirical examples in detail in order to motivate key issues and identify statistical problems. Section 3 builds a new statistical model for repeated experiments. This section also explains how the trend regression in Label (1) and the measurement of treatment effects in Label (2) are created, and provides the justification for why such measures can be used in practice. Section 4 provides asymptotic properties of the trend regression and discusses how to measure and test the treatment effects. Section 5 presents empirical evidence establishing the effectiveness of the new regression and measures in practice. Section 6 examines the finite sample performance of the suggested methods. Section 7 provides conclusions. The appendix includes technical derivations.
2. Canonical Examples
Throughout the paper, we use two sets of experimental data from Croson (1996) and Keser and Van Winden (2000). The design of these experiments are very similar to each other. Both papers aim to test the difference between Strangers Group and Partners Group in a repeated public goods game. In a standard repeated public goods game, several subjects play the game together as a group and the game is usually repeated for T rounds. The size of the group (number of subjects in a group) is denoted as G. At the beginning of each round, every subject is given some endowment tokens e to divide between a public account and a private account. Each token contributed to the public account will be multiplied by M and then divided among all members in the group. In this environment, the payoff function at each round for the subject i can be written as , where is the amount subject i contributes to the public account. is called marginal per capita return (MPCR). If subjects are rematched randomly into groups for each iteration of the game, then it is a Strangers Group. If the composition of the group does not change through all the rounds, then it is a Partners Group.
Since Andreoni (1988) found that the average contribution from Strangers group was relatively larger than that from Partners group, there are lots of papers investigating the difference between Strangers and Partners group, but the results are inconclusive. Andreoni and Croson (2008) summarize the results from many replications and studies that have explored this question: ‘Nonetheless, this summary of results does little to clear up the picture. In all, four studies find more cooperation among Strangers, five find more by Partners, and four fail to find any difference at all.’ The answer to whether partners group or strangers group contribute more is really mixed. We will re-examine the treatment effect of rematching in this paper. Among all the replications of Partners vs. Strangers Game, the experiments from Croson (1996) and Keser and Van Winden (2000) are identical except for the number of rounds. Interestingly, both papers found that the average contribution from Partners group was higher than that from Strangers group. Table 1 describes the data and various features of the experiments, and Figure 1 shows the average contribution for each round in Croson (1996). Note that it seems to be straightforward to compare two samples in Figure 1 if all samples are independently distributed. In many experimental studies, however, this assumption is violated: usually, is cross-sectionally and serially correlated. Under this circumstance, a conventional z-score test with for each or with time series averages of becomes invalid unless the cross sectional dependence is considered properly. For the same reason, other statistics used in practice become invalid as well.2

Table 1.
Data description.
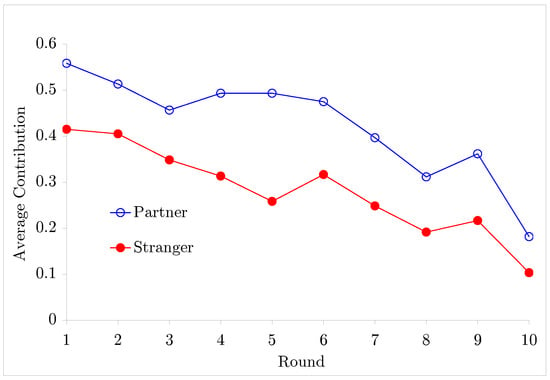
Figure 1.
Average contributions over rounds from Croson (1996).
For each study, controlled and treated groups may be defined and then the treatment effects can be measured. For all cases, the null hypothesis of interest becomes no treatment effect or the same overall outcomes given by
where and are controlled and treated overall outcomes, respectively. Under the null hypothesis, the overall outcomes become the same regardless of the number of rounds.
The overall outcomes can be measured by the area below of the cross sectional averages. Let be the true, but unknown decay function for the sth experiment. Then, the overall outcome can be defined as 4 When the treated experimental outcome at time t is always greater or equal to the controlled one for all that is, then the overall treatment effects, becomes positive. However, when is crossing over , it is hard to judge whether or not the treatment effects become positive or negative. Figure 2 demonstrates such an artificial case where the null hypothesis is not easy to be tested.5 Panel A in Figure 2 shows the hypothetical average of the controlled and treated outcomes for each round. The decay rate for the controlled group is faster than that for the treated group, but the initial average outcome for the controlled group is higher than that for the treated group. The overall effects can be measured by the areas below the average of the outcomes which are displayed in Panel B in Figure 2. Evidently, the treatment effect is depending on the number of rounds. The treatment effect becomes negative, zero and positive when the final round T becomes and
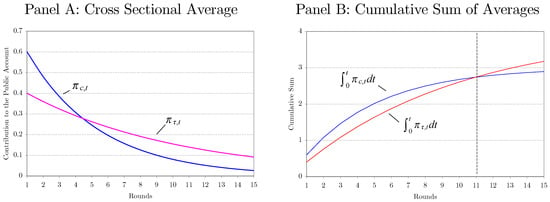
Figure 2.
Overall treatment effects.
3. Statistical Model
There is one important and distinctive feature of the repeated lab-experimental data: a nonstationary initial condition. This unique feature is rarely seen in conventional data, and, more importantly, the estimation without accounting for this feature is invalid, which consequently leads to wrong judgements. This section provides a new statistical model for this nonstationary initial condition.
3.1. Statistical Modelling Nonstationary Initial Condition
Here, we statistically approximate the decay rate in Figure 1 and Figure 2 as an exponential decay function. We do not aim to model or explain the unknown decay function theoretically but rather approximate it. In other words, we model it statistically. In repeated experiments, subjects are randomly selected but exhibit common behavior. Typically, responses decrease over successive rounds as shown in Figure 1. Interestingly, such common behavior, or highly cross-sectionally correlated behavior, can be generated if the true mean of the initial contributions is different from the mean of the contributions in the long run. Note that, in this subsection, we will ignore the subscript s for notational convenience.
Define to be the cross-sectional average of at time When we let
Meanwhile, we assume that the cross-sectionally aggregated series follows AR(1) process:
where a can be treated as the long run value of in the sense that
so that
since Usually, the expected value of initial outcome is not the same as the long run outcome. That is, Statistically, the transitory behavior of due to the nonstationary initial condition in (4) can be modeled by
where the error follows an AR(1) process with the nonstationary initial condition.
If the initial mean, is different from the long run mean, then have a time decay function as it is shown in (8).
One of the most interesting features of the repeated games is the convergent behavior. As t approaches the last round, the fraction of free riders increases and, for some games, this fraction becomes one.6 That is, the average outcome, is converging to the long run equilibrium. This implies that the variance of the random error should be decreasing over time as well. Otherwise, the fraction of free riders does not converge to unity as t increases. To reflect this fact, we assume that the variance of is shrinking at the rate over time.7
This implies that at Since is bounded between zero and one, the initial error term, should be bounded between and We assume that this restricted condition holds with as well. That is, is independently distributed but bounded between and Statistically, we write as
where stands for ‘independently distributed’, B implies boundedness, and the superscript and subscript show the upper and lower bounds.
3.2. Features of New Statistical Model
In the previous subsection, we assume that the nonstationary initial condition model can approximate well the cross-sectional average of individual outcomes. In this subsection, we consider the possibility that the aggregated model in (8) through (10) holds for all subjects. That is, we further assume that the stochastic process for can be written as
where the experimental outcome is normalized by the maximum number of tokens so that always for all i and The long run value of is is the unknown initial mean of is the decay rate and is the approximation error. Note that is a bounded, but independent random variable with mean zero and variance or As t increases, the unconditional mean of individual outcome, converges which can be interpreted as a long run steady state.
If the assumption in (11) holds, then the simple stochastic process for may explain the temporal cross-sectional dependence. When (initial round), the individual outcome, is not cross sectionally dependent since subjects are randomly selected. However, when the individual outcome becomes cross-sectionally dependent due to the time varying mean part, The common factor model captures the kind of behavior described in Ashley et al. (2010): the previous group outcome affects the experimental outcome for each subject. To see this, consider the fact that the group means excluding the ith subject outcome, is similar to the group mean of In addition, the group mean is similar to the cross sectional average: where and are the cross-sectional averages of and Note that with large N, is close to zero, so that this term can be ignored. Statistically for any Hence, the subject’s outcome at time t can be rewritten as
The first term represents the marginal rate of the relative contribution of each subject, and the second term is the group average in the previous round, and the last two terms are random errors.
Nonetheless, we do not attempt to model the implicit behaviors of individuals, such as selfish, reciprocal and altruistic behaviors. Instead, we model the time varying patterns of the outcome (contribution to group account) statistically. By following Ambrus and Greiner (2012), we approximate heterogeneous behaviors of subjects econometrically into three groups: increasing, decreasing and fluctuating. The increasing group includes two subgroups of subjects: subjects contribute all tokens to the public account for all rounds or contribute more tokens over successive rounds. Similarly, the decreasing group includes the two subgroups of subjects: Subjects do not contribute at all, or subjects contribute fewer tokens over rounds. Lastly, a fluctuating or confused subject is neither in the decreasing or increasing group.
In public goods games, if the long run Nash equilibrium occurs (or if and ), the fraction of free riders increases over rounds. Meanwhile, if and then the unconditional mean of the individual outcome, converges to the Pareto optimum . Furthermore, except for the initial round, the experimental outcomes are cross-sectionally dependent so that individual’s decision depends on the overall group outcome. Lastly, if the decay rate becomes unity or , then the individual outcome becomes purely random.
To be specific, we can consider the following three dynamic patterns:
For groups and , the contribution is decaying each round at the same rate, If a subject belongs to , the contribution is decreasing over rounds and, if she belongs to , the contribution is increasing. The remaining subjects are classified together in a ‘fluctuating’ group. For non-fluctuating groups ( and ), the random errors can be rewritten as for Hence, as round increases, the variance of decreases and eventually converges to zero. Meanwhile, the random error for is not time varying since is always unity.
Let be the number of subjects in and Similarly, we can define and as the numbers of subjects in and and and as their fractions, respectively. The sample cross-sectional averages for each round under homogeneity (only exists) and heterogeneity can be written as
where , and
Therefore, the time varying behavior of the cross-sectional averages under homogeneity become very different from those under heterogeneity. First, under homogeneity, the average outcome decreases each round and converges to zero. However under heterogeneity, depending on the value of the average outcome may decrease , increase or does not change at all over rounds. Second, the variance of the random part of the cross-sectional average, under homogeneity is much smaller than that under heterogeneity. In other words, the cross-sectional averages under heterogeneity become much more volatile than those under homogeneity. Third, both random errors, and are serially correlated. However, the serial correlation of the random errors under homogeneity, goes away quickly as s increases, meanwhile the serial correlation under heterogeneity, never goes to zero even when as long as
It is not hard to show that under heterogeneity the cross-sectional variance of diverges over rounds. In this case, the estimation of the treatment effects is not straightforward since and in (13) cannot be identified in some cases.8 We leave the case of heterogeneity for future work, and mainly focus on the estimation of the treatment effects under homogeneity. The homogeneity assumption is testable. One may test the convergence directly by using Phillips and Sul (2007) or Kong et al. (2018). Particularly the weak —convergence test proposed by Kong et al. (2018) is more suitable for the convergence test since the relative convergence test by Phillips and Sul (2007) requires somewhat more restrictive conditions than the weak convergence test by Kong et al. (2018).
The contributions to the public account up to the last round T can be measured by the following statistic.
where
since the sum of over T is 9 The estimation of the overall treatment can be done simply by comparing the two means, provided the subjects in the two experiments are independently and randomly selected. Let where and are the total numbers of subjects for the controlled and treated experiments, respectively. Then, from (11), the probability limit of the average difference becomes the treatments effect (TE) given by
where and are the cross-sectional mean of the initial contributions. When the overall treatment effect with the slower decay rate is higher than the treatment effect with the faster decay rate. When two experimental outcomes cross over each other, the overall effect becomes ambiguous. Mathematically, this case can be written as but . Suppose that, with a fixed T (say the overall effect in the crossing-over case is identical between the two experiments. Then, such a result does not become robust since, with more repetitions, the experimental outcome with the slower decay rate must be higher than that with the faster decay rate. Hence, for a such case, the following asymptotic treatment effect can measure the two outcomes robustly and effectively:
3.3. Estimation of Overall Treatment Effects
The experimental outcomes will converge to zero when the dominant strategy is Nash bargaining.10 It is better to use this convergence result in the estimation of the asymptotic treatment effect. That is, the percentage of free-riding is assumed to become one as the total number of rounds increases.11 If there are multiple dominant strategies in a game, then the experimental outcomes do not need to converge to a certain value. In this case, the outcome for each round may be volatile and, more importantly, the cross-sectional variance will increase over rounds.
The estimation of the asymptotic treatment effects requires the estimation of two unknown parameters; and There are two ways to estimate both parameters jointly: nonlinear least squares estimators (NLS) and log transformed least squares estimation with the cross-sectionally averaged data. Below, we first discuss the potential problems associated with NLS estimation, and then go on to show the simple log trend regression.
Nonlinear Least Squares (NLS) Estimation
To estimate one may consider estimating first by running the following NLS regression for each i:
It is well known that the NLS estimators for and are inconsistent as because for and See Malinvaud (1970) and Wu (1981) for more detailed discussions. However, there is a way to estimate and by using cross sectional averages. Consider the following regression with cross-sectional averages
For a given as for and Therefore, both and can be estimated consistently as Denote the resulting estimators as and We will discuss the underlying asymptotic theory in the next section, but, in the meantime, we want to emphasize here that the fastest convergence rate for is even when jointly.
Logarithm Transformation
Alternatively, the nonlinear regression in (16) can be transformed into a linear regression by taking the logarithm in .12 Observe this:
From (9), the last term can be rewritten as
where Hence, the following simple trend regression can be used to estimate and :
Taking the exponential function of and provides consistent estimators for and , respectively. The asymptotic properties of the trend regression in (19) will be discussed in detail shortly, but here note that the convergence rate for is much faster than However, this does not always imply that is more accurate than , especially with small It is possible that the minimum value of the cross-sectional averages of can be near-zero or zero. In this case, the dependent variable in (19) is not well-defined.
4. Asymptotic Theory
This section provides the asymptotic theory for the proposed estimators in (16) and (19). We make the following assumptions.
Assumption A: Bounded Distributions
- (A.1)
- is independent and identically distributed with meanand variance, but it is bounded between 0 and 1:
- (A.2)
- forwhereis independently distributed with mean zero and variance, but it is bounded betweenandThat is,
Assumption B: Data Generating Process
The data generating process is given by
Under Assumptions A and B, it is easy to show that, if all subjects’ outcomes become zero in the long run:
In other words, converges to zero. Assumption A.2 implies no serial dependence in for the sake of simplicity. We will show later that we cannot find any empirical evidence suggesting that is serially correlated. In addition, see Remark 5 and 6 for more discussion of the ramifications of the violation of Assumption A.2.
Define the nonlinear least squares estimator in (16) as the minimizer of the following loss function:
Meanwhile, the ordinary least squares estimator in (19) is defined as
Since the point estimates are obtained by running either nonlinear or linear time series regression, the initial mean, for each subject is not directly estimated, but the cross-sectional mean, is estimated. Define as an estimator for Then, the deviation from its true mean can be decomposed as
Since also becomes as long as for There are two ways to derive the limiting distribution for , depending on the definition of the regression errors or the definition of the regression coefficients. First, the error terms can be defined as in (16) and (19). Then, the limiting distribution of can be derived, which is the first term in (21). After that, the limiting distribution of can be obtained by adding the limiting distribution of to that of
Second, the error terms or the coefficient terms may be re-defined as follows:
Of course, the limiting distributions of the estimators in (16) and (19) are identical to those in (22) and (23). Nonetheless, it is important to address how to estimate the variance of consistently. We will discuss this later but now provide the limiting distributions for the estimators of and in (22) and (23) here first. Let and where and are LS estimators of the coefficients given in (23).
Theorem 1.
Limiting Distributions
Under Assumption A and B, as jointly,
(ii) The limiting distributions of the LS estimators in (23) are given by
See Appendix A for the detailed proof of Theorem 1. Here, we provide an intuitive explanation of the results, especially regarding the convergence rate. The convergence rate of the NLS estimators is even under the condition of jointly. The underlying reason is as follows. The first derivative of with respect to is so that since However, the order in probability of the regression errors is , which determines the convergence rate of Meanwhile, the LS estimators with the logged cross-sectional averages in (23) are free from this problem. That is why the convergence rate of the estimator for is From the delta method, Hence, the convergence rate of is also As we discussed under (21), the convergence rate of is totally dependent on that of which is We will show later by means of Monte Carlo simulation that the LS estimators have better finite sample performance than NLS estimators.
Here are some important remarks regarding the properties of the considered estimators.
Remark 1.
Limiting Distributions for Fixed T
Define and Under Assumption A and B, as with fixed the limiting distributions are given by
The variances and are finite constants but are not expressed explicitly since their formulae are very complicated. To evaluate and compare the two variances analytically, we set and .13 With these values, the relative variance, becomes a function of the relative variance of Figure 3 displays the relative variance of to Obviously, the LS estimators are more efficient than the NLS estimators because the variance of the LS estimator is always smaller than that of the NLS estimator for all . Interestingly, as increases, also increases.
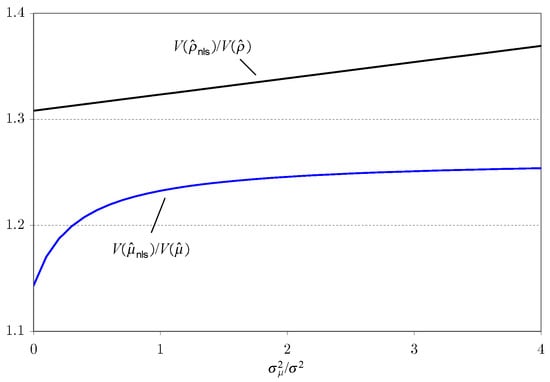
Figure 3.
Overall treatment effects.
Remark 2.
Consistent Estimator of
There are several ways to construct consistent estimators for by utilizing the LS estimator To save space, we do not report all consistent estimators. By means of (unreported) Monte Carlo simulation, we find that the following estimator for provides the smallest variance among several estimators. The individual fixed effects, can be estimated by running on Note that, for any
so that can be rewritten as
Rewrite the LS estimator of in (26) as
By direct calculation, it is easy to show that this estimator is almost unbiased. Specifically,
Note that the convergence rate of over T is not but since the denominator term, becomes However, the sample variance of estimates consistently. As the probability limit of the sample mean of becomes
In addition, the probability limit of its variance is given by
Remark 3.
Limiting Distribution of Asymptotic Treatment Effects
Let the overall average individual outcome be
To derive its limiting distribution, define . Then, by using the delta method, the limiting distribution of can be obtained from (25) directly:
where and Σ is defined in (25). The variance can be estimated by replacing the true parameters by the point estimates since
Further note that the average treatment effect between the controlled and treated outcomes, can be estimated by and its limiting distribution is
Remark 4.
Heterogeneity of ρ
If the decay rate is heterogeneous across subjects, both parameters should be estimated for each i. However, as the NLS estimators are inconsistent, as we discussed before. In addition, the logarithm approximation for each subject’s outcome cannot be calculated for any i such that for some Moreover, the cross-sectional average of yields
even when is assumed to be independent from To see this, let and take Taylor expansion of around
where is the higher order term. Since the second term does not have zero mean, for
Remark 5.
Violation of Assumption A.2 and Serial Dependence in Error
The error term can be serially dependent if subjects do not form rational expectation. In addition, if Assumption A.2 does not hold, then the logarithm approximation in (17) and (18) does not hold. To accommodate such situations, we change Assumption A.2 as follows:
Assumption A.3:
for and where has a finite fourth moment over i for each t and follows autoregressive process of order 1. In particular for where and
Under Assumption A.3, the convergence rate of is slower than that of since for all and In this case, the error should be re-defined as Therefore, the variance of diverges to infinity since as . This problem can be avoided by considering only N asymptotics with fixed Under Assumption A.3, as with fixed the limiting distribution is given by
The definition of is given in Appendix B.
Remark 6.
Violation of Assumption A.2 under Local to Unity
Next, consider the local to unity setting which allows as In this case, the faster convergence rate can be restored. We replace Assumption A.3 with
Assumption A.4:
has a finite fourth moment over i for each and is weakly dependent and stationary over Define the autocovariance sequence of as where Partial sums of over t satisfy the panel functional limit laws
where is an independent Brownian motion with variance over Moreover, the limit, = The decay rate becomes a function of Particularly, where for any small
Under Assumption A.1, A.4 and B, as jointly the limiting distribution is given by
where is the long run variance of See Appendix C for the detailed proof.
5. Return to Empirical Examples
As we discussed early, the estimation of the treatment effects based on (27) requires the pretesting for homogeneity. We use the weak convergence test proposed by Kong et al. (2018) to examine the homogeneity restriction. Here, we briefly discuss how to test the weak convergence. Define as the sample cross-sectional variance of at time That is,
Next, run on a constant and a linear trend
Denote the t-ratio of as
where is the heteroskedasticity autocorrelation consistent (HAC) estimator for the long run variance of Kong et al. (2018) suggest to use Newey and West (1987)’s HAC estimator with the window length of int where int is an integer function.
Table 2 reports the number of pure altruistic subjects—those who contribute all tokens for all rounds—for each experimental setting, the homogeneity test, and the estimation of the trend regression. It is important to note that the weak convergence holds even when a few does not converge into the cross-sectional average. For example, in Croson (1996)’s data, one subject in the Partner game always contributes all tokens, so that the fraction of pure altruistic subjects is around 4%. In addition to Keser and Van Winden (2000)’s data, one subject in the Stranger game always contributes all tokens as well. Since the fraction of the pure altruistic subjects is too small, the homogeneity test is influenced very little. The estimation of the treatment effects is influenced very little by an outlier as well. In all cases, the point estimates of become significantly negative statistically, which implies that there is only a single group of subjects asymptotically.
Table 2.
Estimation of trend regressions and homogeneity Tests.
Table 2 also reports the point estimates of and and their standard errors. These estimates can be used to construct the long run treatment effects, In addition, note that the point estimates of and their standard errors can be used to test the treatment effect in the initial round. Here, we show how to calculate them. Consider Croson’s case as example. The treatment effect in the initial round becomes where the control group becomes Strangers, but the treated group becomes Partners. Then, the difference becomes
but its standard error becomes
Hence, the t-ratio is not big enough to conclude that the Partners game provides more contributions. Meanwhile, the initial treatment in Keser and Van Winden (2000)’s case becomes significant. The resulting t-ratio becomes . Hence, the Partners game provides more contributions in the first round.
Next, we estimate the long run treatment effects, and the null hypothesis of the same asymptotic treatment of Strangers and Partners:
where and stand for the asymptotic contribution from Strangers and Partners groups, respectively. Note that the asymptotic or long run contribution can be calculated by summing up all contributions across rounds as it shown in Figure 2.
The estimates of and are given in Table 3. As it is shown in Figure 1, in both cases, the asymptotic contribution from Partners game () is larger than that from Strangers game (). The difference between and is the treatment effect. In Croson’s case, the estimated asymptotic treatment effect is around 3.1, but its standard error is too big, so that the null hypothesis of no difference cannot be rejected. In Keser and Winden’s case, the estimated asymptotic treatment effect becomes around 15, but again its standard error is also very large. Hence, in both cases, the null hypothesis cannot be rejected. Partners appear to contribute more than Strangers in both of the studies, but large standard errors result in insignificant differences.
Table 3.
Asymptotic treatment effects.
6. Monte Carlo Study
This section examines the finite sample performance of the proposed estimators and tests. The data generating process is given by
In addition, we impose the restriction of The parameters are set based on the results in Table 2, as follows: , [ ], , and . All errors are generated from a truncated normal distribution. The total number of replications is 2000. Note that is assumed to be serially independent here, but allowing serial dependence does not alter the main findings in this section. To be specific, we allow where . Under this setting, the results of the Monte Carlo simulation become slightly better compared to those under serial independence. To save space, only a few highlighted results under serial independence are reported here, but the rest of results are available on the authors’ website.
Table 4 reports the finite sample performance of the NLS and LS estimators given in (16) and (19). Both estimators do not show any bias at all. The variances of and are similar, but the variance of is slightly smaller than that of as our theory predicts. Meanwhile, the variance of is much smaller than that of , and the efficiency gain of over becomes dominant as T becomes bigger. When the variance of NLS estimator is approximately 1.3 times larger than that of the LS estimator. However, as T approaches 20, the variance of the NLS estimator becomes about three times larger than that of the LS estimator. Hence, asymptotic theory established in Theorem 1 also explains the finite sample properties of both estimators very well.
Table 4.
Comparison between NLS and LS estimators.
Table 5 exhibits the size and power of the test. Under the null of no treatment effect, we set and but and Overall, when T is small or is large, the proposed test suffers from a mild size distortion. However, the distortion goes away very quickly either as T increases or if is small. Under the alternative, we decrease the decay rate for the second game from 0.9 to 0.85: . Even with such a small change, the proposed test captures the treatment effects very well. Regardless of the values of and the power of the test becomes perfect as long as Even with the power of the test approximately reaches 90%.
Table 5.
Size and power of test.
7. Conclusions
This paper deals with the repeated public donation games and provides a simple but efficient method to test overall treatment effects. We assume that the cross-sectional average of experimental outcomes follows AR(1) process. In the initial round, subjects do not have any information on other players. Over rounds, subjects are learning about the game and other subjects’ behaviors. Hence, the distribution of the initial average differs from the rest of averages. When the initial average differs from the long run mean, this nonstationary initial condition model generates a temporal time decay function. We use the simple nonstationary initial condition model to approximate the cross-sectional averages over time. The nonstationary initial condition model is a nonlinear function of three key parameters: initial average ( time decay rate or AR(1) coefficient and long run average The long run average is not identifiable unless a game repeats many times. Hence, we had to assume that this value is known. Under this restrictive assumption, we provide a logarithm approximation of the nonlinear function, which becomes a simple log trend regression. Comparing with previous methods, the newly suggested method takes statistical inference very seriously.
By means of Monte Carlo simulations, we showed that the finite sample performance of the suggested method is reasonably good. We applied the new estimation method to Croson (1996) and Keser and Van Winden (2000)’s experiments. The estimates of the overall outcomes in Partners games are larger than those in Strangers games. However, due to large standard errors, which come from persistent values of the time decay functions, the difference between the two games is not statistically significant.
Author Contributions
All authors contributed equally to the paper.
Funding
This research received no external funding.
Acknowledgments
We thank Ryan Greenaway-McGrevy for editorial assistance. In addition, we are grateful to Eunyi Chung, Joon Park and Yoosoon Chang for thoughtful comments, and thank Catherine Eckel, Rachel Croson, Daniel Houser, Sherry Li, James Walker and Arlington Williams for helpful discussions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs of Theorem
Theorem 1 (i)
Let Then, the first derivatives with respect to and are given by
Next, consider the following covariance and variance matrix:
where
Hence, it is straightforward to show that as jointly, the limiting distribution of NLS estimators are given by
where
Theorem 1 (ii)
Let
where
Let the expectation of the covariance and variance matrix as
where
Therefore, the limiting distribution of the LS estimators in the logged trend regression is given by
By using Delta method, it is easy to show that
Alternatively, the same limiting distribution can be derived by redefining the regression parameters as
where
Note that
so that the limiting distributions can be rewritten as
By using the delta method, the limiting distributions of and can be rewritten as
Finally, since the limiting distributions of and are given by (25).
Appendix B. Proof of Remark 5
Note that the initial condition for the expectation error is nonstationary. That is, the second moments of become dependent on
Define
where
Each element of the covariance matrix is defined as
since
In addition,
Then, the limiting distribution of is given by
Hence, the joint limiting distribution can be written as
Appendix C. Proof of Remark 6
As the effect of the nonstationary initial condition, or the term, goes away very quickly. Assumption B1 ensures that the decay rate does not go away even when The following two lemmas are helpful in deriving the limiting distribution. Let and then as
Lemma A1.
Let for for any small Then, .
Proof of Lemma A1.
By definition, so that the following hold:
Hence,
☐
Proof of Remark 6.
Let
Since is independent of the asymptotic variances of the denominator term are given by
since
In addition,
Therefore,
☐
References
- Ambrus, Attila, and Ben Greiner. 2012. Imperfect Public Monitoring with Costly Punishment: An Experimental Study. American Economic Review 102: 3317–32. [Google Scholar] [CrossRef]
- Andreoni, James. 1988. Why Free Ride? Strategies and Learning in Public Goods Experiments. Journal of Public Economics 37: 291–304. [Google Scholar] [CrossRef]
- Andreoni, James, and Rachel Croson. 2008. Partners versus Strangers: Random Rematching in Public Goods Experiments. In Handbook of Experimental Economics Results. Amsterdam: Elsevier. [Google Scholar]
- Ashley, Richard, Sheryl Ball, and Catherine Eckel. 2010. Motives for Giving: A Reanalysis of Two Classic Public Goods Experiments. Southern Economic Journal 77: 15–26. [Google Scholar] [CrossRef]
- Chao, John, Myungsup Kim, and Donggyu Sul. 2014. Mean Average Estimation of Dynamic Panel Models with Nonstationary Initial Condition. In Advances in Econometrics. Bingley: Emerald Group Publishing Limited, vol. 33, pp. 241–79. [Google Scholar]
- Croson, Rachel. 1996. Partners and Strangers Revisited. Economics Letters 53: 25–32. [Google Scholar] [CrossRef]
- Dal Bó, Pedro, and Guillaume R. Fréchette. 2011. The Evolution of Cooperation in Infinitely Repeated Games: Experimental Evidence. American Economic Review 101: 411–29. [Google Scholar] [CrossRef]
- Keser, Claudia, and Frans Van Winden. 2000. Conditional Cooperation and Voluntary Contributions to Public Goods. Scandinavian Journal of Economics 102: 23–39. [Google Scholar] [CrossRef]
- Kong, Jianning, and Donggyu Sul. 2013. Estimation of Treatment Effects under Multiple Equilibria in Repeated Public Good Experiments. New York: mimeo. Richardson: University of Texas at Dallas. [Google Scholar]
- Kong, Jianning, Peter C. B. Phillips, and Donggyu Sul. 2018. Weak σ- Convergence: Theory and Applications. New York: mimeo. Richardson: University of Texas at Dallas. [Google Scholar]
- Ledyard, John O. 1995. Public Goods: A Survey of Experimental Research. In The Handbook of Experimental Economics. Edited by John H. Kagel and Alvin E. Roth. Princeton: Princeton University Press. [Google Scholar]
- Malinvaud, Edmond. 1970. The Consistency of Nonlinear Regressions. Annals of Mathematical Statistics 41: 956–69. [Google Scholar] [CrossRef]
- Newey, Whitney K., and Kenneth D. West. 1987. A Simple, Positive Semi-definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix. Econometrica 55: 703–8. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Donggyu Sul. 2007. Transition modeling and econometric convergence tests. Econometrica 75: 1771–855. [Google Scholar] [CrossRef]
- Wu, Chien-Fu. 1981. Asymptotic Theory of Nonlinear Least Squares Estimation. Annals of Statistics 9: 501–13. [Google Scholar] [CrossRef]
| 1 | When the cross-sectional average is increasing over rounds, (but is weakly -converging), the trend regression needs to be modified as = + + error. Furthermore, the long run overall outcome becomes |
| 2 | Note that dynamic panel regressions or dynamic truncated regressions are invalid since usually the decay rate—AR(1) coefficient—is assumed to be homogeneous across different games. In addition, see Chao et al. (2014) for additional issues regarding the estimation of the dynamic panel regression under non-stationary initial conditions. |
| 3 | Croson (1996) designed two sequences for partners and strangers game. There were ten rounds for each sequence. In this paper, only the data from first sequence are used for the consistent comparison. |
| 4 | Assume that the sample cross-sectional average estimates the unknown common stochastic function consistently for every t as Then, by using a conventional spline method, we can approximate the unknown The overall effects can be estimated by the sum of the approximated function and statistically evaluate it by using an HAC estimator defined by Newey and West (1987). However, this technical approach does not provide any statistical advantage over the AR(1) fitting, which we will discuss in the next section. |
| 5 | The decay function for the controlled and treated experiments are set as and respectively. |
| 6 | However, it is not always the case. More recent experimental studies show widely heterogeneous divergent behaviors. See Kong and Sul (2013) for detailed discussion. |
| 7 | Note that if the condition in (9) does not hold, then it implies that the variance of is increasing over time if the variance of is time invariant. To be specific, let for all t. Then which is an increasing function over |
| 8 | If , can be identified as long as is known, but cannot be identified. If both and cannot be identified jointly. |
| 9 | Since = where under (11), as jointly. |
| 10 | If subjects do not know the number of repeated games, the dominant strategy could change to Pareto-optimum in an infinitely repeated game. See Dal Bó and Fréchette (2011) for a more detailed discussion. |
| 11 | More precisely speaking, we assume that the fraction of free riders in the long run becomes unity as the number of subjects goes to infinity. This assumption allows a few outliers such as altruists. As long as the number of altruists does not increase as the number of subjects increases, the asymptotics studied in the next section are valid. |
| 12 | Taking logarithm in both sides of Equation (16) yields |
| 13 | We will show later that the point estimates of for all three empirical examples are around 0.9. However, the choice of does not matter much when comparing the two variances. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).