Abstract
Several modified estimation methods of the memory parameter have been introduced in the past years. They aim to decrease the upward bias of the memory parameter in cases of low frequency contaminations or an additive noise component, especially in situations with a short-memory process being contaminated. In this paper, we provide an overview and compare the performance of nine semiparametric estimation methods. Among them are two standard methods, four modified approaches to account for low frequency contaminations and three procedures developed for perturbed fractional processes. We conduct an extensive Monte Carlo study for a variety of parameter constellations and several DGPs. Furthermore, an empirical application of the log-absolute return series of the S&P 500 shows that the estimation results combined with a long-memory test indicate a spurious long-memory process.
Keywords:
spurious long memory; semiparametric estimation; low frequency contamination; perturbation; Monte Carlo simulation JEL Classification:
C13; C14; C22
1. Introduction
Over the last decades, the long memory literature focusses on an effect called spurious long memory. This effect is characterized by a contaminated short-memory process exhibiting the typical properties of a long-memory process, such as a hyperbolically decaying autocorrelation function and an unbounded spectral density at the origin. Several types of contamination exist and we follow the classification of Hou and Perron (2014). We distinguish between short-run and additive noise components which influence the bias and efficiency of the standard estimator in finite samples. Further, low frequency contaminations modeled by time trends and level shifts can cause inconsistent estimators and are a source of the aforementioned spurious long memory (cf. Diebold and Inoue 2001; Granger and Hyung 2004). Haldrup and Nielsen (2007) present strongly biased standard estimators for contaminated processes in their simulation study and emphasize the need of modified estimators. Besides the theoretical effects of low frequency contaminations, McCloskey and Perron (2013) emphasize the relevance to macroeconomic and financial applications.
Motivated by these findings, several modified estimation methods of the memory parameter have been developed. In this survey paper, we concentrate on semiparametric estimation methods and do not consider the literature of fully parametric estimation techniques, such as McCloskey (2013) or McCloskey and Hill (2017). Further, we omit semiparametric Fourier- and wavelet-based estimation approaches and refer to a survey paper by Faÿ et al. (2009).
Generally, all modified estimation methods aim to decrease the upward bias of the memory parameter in cases of low frequency contaminations or an additive noise component, especially in situations with a short-memory process being contaminated. Several types of modifications have been proposed in the literature and we compare the effects of a trimmed periodogram and an adjusted spectral density. The order of the periodogram differs from a typical long-memory process to a contaminated process. Therefore, by adding or replacing components of the original spectral density, a so-called pseudo-spectral density function is modeled (e.g., Hou and Perron 2014). Alternatively, trimming the lower frequencies of a periodogram removes the high peak of the periodogram that is caused by the contamination. A common drawback of the modified estimators is the bias-variance trade-off which means that a bias reduction is combined with an increased variance.
To our knowledge, this is the first survey paper on semiparametric estimation methods of the memory parameter considering several types of contaminated processes. Usually, authors of modified estimation methods compare the results to the original non-modified estimation method. However, a comparison between different modified estimation methods would be of great interest. Further, the simulation studies of the modified estimation procedures are often limited to a few data generating processes (DGPs) and to a small set of parameter constellations, except for Hou and Perron (2014). We contribute to this literature by providing an extensive Monte Carlo study for a variety of parameter constellations and several DGPs. Additionally, we review the performance of the estimation methods for perturbed fractional processes since the general idea is closely related to an additive noise component as it has been considered by Hou and Perron (2014).
The idea of the paper is to give an overview of different estimation methods of pure and contaminated short and long-memory processes and to compare them under several scenarios. We aim to provide some user-guidelines in the end or a recommendation on which method should be preferred or which one is performing most stable across the wide setup in the simulation study. In the following, we briefly introduce the estimation methods. Two widespread semiparametric estimation methods are considered for pure long-memory processes, the log-periodogram estimator (also known as GPH estimator) of Geweke and Porter-Hudak (1983) and the local Whittle estimation approach of Kuensch (1987). In this survey paper, we compare the modified estimators of Smith (2005), Iacone (2010), McCloskey and Perron (2013) and Hou and Perron (2014). Smith (2005) develops a biased corrected version of the log-periodogram estimator by adding an additional regressor to the ordinary least squares regression equation. The trimming technique of Iacone (2010) is based on the local Whittle estimator, whereas McCloskey and Perron (2013) use the GPH estimator. As stated by Yamamoto and Perron (2013), the high peaks in the periodogram at low frequencies induced by the level shifts or trends are robustly removed by the trimming procedure of McCloskey and Perron (2013) and Iacone (2010). Modifying the estimator of Kuensch (1987) by adding a term to the spectral density that considers the contaminated process results in the estimator of Hou and Perron (2014).
In addition to the modified estimation methods of the memory parameter, we consider three estimation methods for perturbed fractional processes. In contrast to a pure fractional process, the short-run dynamics and long-run behavior of a perturbed fractional process are no longer driven by the same innovation. As defined in Frederiksen et al. (2012), a perturbed fractional process can be expressed by a signal-plus-noise model with the signal process being a long-memory process, which is perturbed by an additive noise term. We focus on local Whittle based estimators for perturbed fractional processes and refer to Sun and Phillips (2003) or Arteche (2006) for contributions based on the log-periodogram estimator.
Extending this survey paper by the estimators of Andrews and Sun (2004), Hurvich et al. (2005) and Frederiksen et al. (2012) we are considering an additive noise component as well as short-run effects as another form of contamination. All three estimation methods modify the form of the spectral density. Andrews and Sun (2004) replace a constant term in the spectral density by a polynomial structure to model the short-run dynamics. Hurvich et al. (2005) extend the estimator of Hurvich and Ray (2003) that is adding an additional term for capturing the effect of the noise term to the low frequency behavior of the spectral density. The estimator of Frederiksen et al. (2012) models the short-run dynamics as well as the influence of an additive noise component by a polynomial and allows for serial dependence in the noise term, in contrast to Frederiksen and Nielsen (2008).
According to our Monte Carlo results, we conclude to use either the estimator of Iacone (2010) or Hou and Perron (2014) in cases of low frequency contaminations. Although the estimator of McCloskey and Perron (2013) yields comparable estimation results, it suffers from a higher variance. The performance of the estimator of Smith (2005) in cases of high short-run dynamics or perturbation is comparable to the standard perturbation methods, although the estimator has originally been developed for low frequency contamination. However, in the latter situation, the estimator is no alternative to its competitors. Furthermore, the estimator of Hurvich et al. (2005) and Frederiksen et al. (2012) yield almost identical findings, which are in most situations better than the results of Andrews and Sun (2004). Based on the Monte Carlo results, we recommend applying the low frequency estimators when it is unclear whether a low frequency contamination or a perturbed fractional process is present.
Three out of the seven modified semiparametric estimators that we consider have been applied to empirical data in the original paper, such as the Dow Jones Industrial Average or the S&P 500 series. Smith (2005) and Frederiksen et al. (2012) find upward biased estimator suggesting a long-memory process, whereas McCloskey and Perron (2013) find evidence for a spurious long-memory process. In an empirical application, we apply the methods robust to perturbation as well as to low frequency contaminations to daily log-absolute returns of the S&P 500 which gives us additional insights which of these effects if not both are of relevance in our data set. We conclude that the analyzed time series follows rather a spurious long-memory process than a perturbed fractional process. This finding is further supported by a test of Qu (2011) that rejects the null hypothesis of a true long-memory process at the 1% significance level.
The structure of the paper is as follows. In the next section, we introduce a variety of modified semiparametric estimation methods of the memory parameter. In Section 3, we analyze the small sample performance of the different estimation approaches in a Monte Carlo study. Section 4 presents the empirical application and Section 5 concludes. Supplementary Materials with detailed Monte Carlo results are provided on the authors webpages.
2. Semiparametric Estimation Methods
In this section, we introduce several concepts of standard and modified estimation methods. We start with general long-memory definitions and briefly review the two standard estimation methods. An overview of modified local Whittle and log-periodogram estimation methods follows which have been designed to capture low frequency contaminations and to reduce the bias of the standard methods. Afterwards, we consider approaches which focus on perturbed fractional processes and therefore account for short-run and additive noise effects.
2.1. The Model and Standard Estimation Methods
A pure long-memory process is typically modeled as an process which has been developed by Granger and Joyeux (1980) and Hosking (1981). It is defined as
where , and are the autoregressive and moving average polynomials, respectively, with all roots lying outside the unit circle. The order of fractional integration is given by d, L denotes the backshift operator and with the Gamma function . The interval implies long memory and short memory exists for with an exponentially decaying autocorrelation function and a bounded spectral density function for zero frequencies. The process is stationary and invertible for the interval as well as mean reverting for . Typically, a long-memory process is defined by not summable autocovariances, . Further, the spectral density function of a stationary process is given by for frequency close to the origin and a slowly varying function G (cf. Doukhan et al. 2002).
In the following, we introduce the data generating process with a constant term c and being a short or long-memory process,
The low frequency contamination and additive noise component are captured by and , where A is a dummy variable which is 1 if we include low frequency contaminations in the DGP and zero otherwise. The dummy variable B is its respective equivalent for a possible perturbation process. We consider several types of low frequency contamination, among them are a sinus time trend and randomly (non-)stationary as well as deterministic level shifts. The perturbation process is captured by different forms of ARMA processes with varying coefficients and variances of the error term. The explicit structure of and will be discussed in Section 3 in more detail. The two standard estimation methods are designed for a process of the form . The four estimators especially designed for low frequency components consider the data generating process , except for Smith (2005) who excludes the short-memory process in . Additionally, Hou and Perron (2014) extend the process to with being a zero mean white noise process with variance . The three estimators developed for perturbed fractional processes are exhibiting the following DGP structure with being an process. Finally, a joint definition of the periodogram for the individual processes in Equation (1) with with and T being the sample size is provided by Hou and Perron (2014).
Before we compare the modified estimation methods, we briefly summarize the properties of two most commonly applied semiparametric estimation procedures of Geweke and Porter-Hudak (1983) and Kuensch (1987). They serve as benchmark approaches, since the modified versions should generally produce a smaller bias in the presence of contaminations. Further, the efficiency loss of the modified versions in situations without contaminations can be illustrated by comparing their performance to the standard methods. Geweke and Porter-Hudak (1983) propose the log-periodogram estimator as one of the earliest estimator for a semiparametric model. The GPH estimator is based on a regression model which is obtained by replacing the spectral density of a process by the logarithm of its periodogram,
with a constant term c and an error term . The explanatory variable is given by with the bandwidth parameter m and the Fourier frequency . Minimizing the sum of squared residuals of the above regression model with respect to the slope coefficient yield
with and . Robinson (1995) shows that the asymptotic distribution equals for . For the following asymptotic properties of the different estimation methods we assume the stationary interval of the memory parameter, if not stated differently. The local Whittle method of Kuensch (1987), also known as the Gaussian semiparametric estimation method, is often applied in the literature. The estimator is based on the local Whittle likelihood function
with . Minimizing with respect to G leads to the profiled likelihood function
The local Whittle estimator is given by and converges to a normal distribution according to .
2.2. Modified Log-Periodogram Estimator of Smith (2005)
The form of the spectral density is influenced by low frequency contaminations, however, standard estimation methods are not considering this change and biased estimators emerge. Smith (2005) introduces a modified log-periodogram estimator. For rare level shifts, the part of the adjusted spectral density that is mainly responsible for the high bias of the standard GPH method equals . Since the level shift probability p is unknown an estimate is introduced with . The estimation approach considers the new form of the spectral density with by including the above component of the adjusted spectral density as a regressor in Equation (2). The regression model of the log-periodogram estimator is extended by the additional regressor to
with as defined above and . The modified log-periodogram estimator is given by
with , the annihilator matrix with P denoting the projection matrix and . Simulation studies of Smith (2005) recommends to set . The limiting distribution is similar to the log-periodogram distribution with . However, the bias reduction implicates a variance increase which is captured by the scale factor , with for k=3.
2.3. Modified Local Whittle Estimator of Iacone (2010)
In contrast to modifying the form of the spectral density, Iacone (2010) proposes a trimmed version of the Gaussian semiparametric estimator of Kuensch (1987). The idea of the procedure is to balance the frequencies of the periodogram. On the one hand, enough frequencies should be considered so that the stationary process dominates in this region and on the other hand lower frequencies for which the contamination component is most influential should be excluded. Therefore, a trimming parameter l is introduced to the local Whittle likelihood function and the loss function in Equation (3) can be rewritten as,
The modified local Whittle estimator is given by and by setting the local Whittle estimator is obtained. In general, the trimming and bandwidth parameter need to be set to and with for some and . Under certain assumptions of the trimming and bandwidth parameter, the estimator of Iacone (2010) follows the limiting distribution of the local Whittle estimator without an inflated variance caused by the trimming technique, .
2.4. Modified Log-Periodogram Estimator of McCloskey and Perron (2013)
In addition to Smith (2005), who introduces a biased correction form of the GPH estimator, McCloskey and Perron (2013) provide a trimmed version of the popular log-periodogram estimator of Geweke and Porter-Hudak (1983). One major difference between these two estimation methods is the restriction on the process. The modified GPH estimator of Smith (2005) is designed for a short-memory process, whereas McCloskey and Perron (2013) extend their estimator to short or long-memory processes. The standard log-periodogram regression from Equation (2) is adjusted by the trimming parameter l and given by
with . Applying the ordinary least squares method, the modified GPH estimator can be expressed as
with and . In addition to the general requirements on the trimming and bandwidth parameter mentioned above for the previous estimator, McCloskey and Perron (2013) constrained the trimming parameter to a strictly positive value. Further, an additional condition on the two user-chosen parameters is expressed by as . To satisfy this condition is restricted to certain values depending on the memory parameter. For the interval of particular interest, , the exponent of the trimming parameter needs to be set to with . The optimal choice of the upper and lower bound of the sum in (4) is crucial for this estimation method.
Under restrictive assumptions concerning the trimming and bandwidth parameter, the limiting distribution of the trimmed GPH estimator shows no efficiency loss in cases of low frequency contaminations so that is still valid. However, in the absence of a contamination component, the variance increases and, compared to the trimmed estimator of Iacone (2010), the variance increase is sometimes extremely high.
2.5. Modified Local Whittle Estimator of Hou and Perron (2014)
This approach considers the new form of the approximated spectral density when low frequency contaminations are present. In contrast to Iacone (2010) and McCloskey and Perron (2013), this method considers all data and no trimming technique is required. Adding the new term to the standard form of the spectral density, a so-called pseudo spectral density can be written as
where is the signal-to-noise ratio. The new parameter controls the influence of contaminations at low frequencies. The pseudo spectral density aims to provide a good approximation of the true spectral density in the existence of low frequency contaminations. The pseudo likelihood function is given by
and the modified local Whittle estimator is defined as for and with
In the absence of low frequency contamination, the form of the pseudo likelihood function in Equation (5) reduces to the standard local Whittle likelihood function. Hence, no asymptotic efficiency loss exists with for . In contrast to the aforementioned authors, Hou and Perron (2014) are the first who provide an extension to account for additive noise and short-memory effects. The modifications are based on the concepts of Andrews and Sun (2004), Hurvich et al. (2005) and Frederiksen et al. (2012) which follow in the next subsections.
2.6. Local Polynomial Whittle Estimator of Andrews and Sun (2004)
In addition to the modified estimation methods of the memory parameter, we consider three estimation methods for perturbed fractional processes. Arteche (2004) shows that when the local Whittle and log-periodogram estimator are applied to perturbed fractional processes they are biased but remain consistent and asymptotical normal. Therefore, several estimation methods have been developed to account for the perturbation. The following three estimation methods modify the local Whittle estimator of Kuensch (1987).
In contrast to a pure fractional process, the short-run dynamics and long-run behavior of a perturbed fractional process are no longer driven by the same innovation. As defined in Frederiksen et al. (2012), a perturbed fractional process can be expressed by a signal-plus-noise model with the signal process being a long-memory process, which is perturbed by an additive noise term. Following the authors, we use an ARMA process for the perturbation process.
The estimation method of Andrews and Sun (2004) adjusts the form of the spectral density by providing a polynomial structure. For frequencies close to the origin the term can be approximated by with the polynomial . This leads to the following form of the spectral density and the resulting estimator is known as local polynomial Whittle (LPW). The log-likelihood function of the estimator is given by
where and . The local polynomial Whittle estimator is defined as and will be in a set of with
and, by setting in Equation (6), the standard local Whittle estimator is obtained. The polynomial degree r influences on the one hand the variance and on the other hand the convergence rate of the estimator. We are more interested in a reduced variance than in a convergence rate close to a parametric one. Therefore, we choose a small polynomial degree and set .
The variance of the LPW estimator increases by a constant that depends on the polynomial degree r since a polynomial structure of the spectral density is considered. The asymptotic properties can be summarized by where the constant term in the variance is increasing with r and equals for .
2.7. Local Whittle with Noise Estimator of Hurvich et al. (2005)
Hurvich et al. (2005) suggest to replace the constant component G in the spectral density by a more complex function . We focus on the following parameterizations of . The local Whittle with noise (LWN) estimator of Hurvich et al. (2005) is nested in the estimator of Frederiksen et al. (2012) and the additional parameter is labeled according to them. The above parameterization of excludes serial correlation between the noise term and the long-memory process, unlike the method of Frederiksen et al. (2012). With the improved form of the spectral density and the additional parameter , the log-likelihood function equals
Minimizing with respect to G leads to the profiled likelihood function
The LWN estimator is defined as for and . The standard local Whittle estimator is obtained in the case of . An important difference to the previously introduced estimation methods is the domain of the memory parameter since the short-memory case is explicitly not allowed, instead d is supposed to be greater than zero. Allowing for no correlation between the signal and noise process, the variance of the LWN estimator is depending on d with , so that the limiting distribution is expressed by .
2.8. Local Polynomial Whittle with Noise Estimator of Frederiksen et al. (2012)
Frederiksen et al. (2012) combine the approaches of Andrews and Sun (2004) and Hurvich et al. (2005) to create a new estimation method, the so-called local polynomial Whittle with noise (LPWN) estimator. In contrast to Hurvich et al. (2005), the spectral density of the LPWN estimator is locally approximated by polynomials instead of a constant near the zero frequency. Furthermore, this procedure differs from the aforementioned methods, since it considers the correlation between the signal and the noise process. Therefore, two polynomials are introduced that capture the noise, , and short-memory effects . Frederiksen et al. (2012) propose the following approximation of the spectral density . The LPWN estimator assumes an additional functional form of the spectral density that is expressed by
with and by setting the spectral density of the local Whittle estimator is obtained. The exponents in Equation (7) exhibit the polynomial structure of the earlier introduced estimator of Andrews and Sun (2004) with where and for . Additionally, by setting both polynomials and to zero the LWN estimator of Hurvich et al. (2005) is obtained with . Further, the authors distinguish between three different types of LPWN(,) estimators, the LPWN(0,1), LPWN(1,0) and LPWN(1,1). The LPWN estimator is obtained by for and with the objective function
The polynomials increase the asymptotic variance of by a multiplicative constant depending only on d and not on the parameters , with . The LPWN estimator is normally distributed with a zero mean and exhibits a more complex form of the variance compared to the aforementioned methods, which can be found in Frederiksen et al. (2012).
3. Monte Carlo Analysis
This section analyzes the performance of the previously presented estimators under different scenarios. First, we introduce the Monte Carlo setup with different kind of DGPs and parameter settings for the estimation methods. Afterwards, we present the simulation results by focusing on the bias and root mean squared error (RMSE) of the estimators.
3.1. Monte Carlo Setup
We compare the performance of the estimation methods under nine different DGPs, which are given in Table 1. The DGP types are obtained by adapting parts of the Monte Carlo structure provided by Qu (2011), Frederiksen et al. (2012) and Hou and Perron (2014). The process is modeled by an ARFIMA (1,d,0) with , where is a zero mean white noise process if not otherwise defined. We standardize the ARFIMA process by its own standard deviation and consider the following values of the autoregressive and persistence coefficient with 0.0, 0.2, 0.4, 0.6 and 0.0, 0.3, 0.6. By choosing , we violate against the stationarity assumption for a variety of estimators to check the robustness in the case of non-stationarity. The sample size is set to 256, 512, 1024, 4096 and the results are based on 1000 Monte Carlo replications.

Table 1.
Overview of data generating processes.
In the following, we provide further information on the different types of DGPs given in Table 1. Unreported simulation results of a linear trend as contamination show almost no difference to the performance of a sinus trend and are therefore omitted. The components and of the random level shift (RLS) processes are mutually independent and the shift probability equals . For the deterministic level shift process, we consider five shifts at fixed user-chosen dates with for and with . DGPs 7 and 8 are especially designed for the perturbed fractional estimation methods. The ARMA(0,0) process is basically an additive white noise process with a large variance. Unreported simulation results of an ARMA(1,0) process with are showing no clear pattern and recommendations are hard to formulate. Therefore, we omit the results and instead consider the ARMA(0,1) process. The last DGP combines the two groups of contaminations with a low frequency component, in the form of a stationary RLS, and an additive noise term as a perturbation contamination.
Following Frederiksen et al. (2012), we set the noise-to-signal ratio equal to five and by rearranging the noise-to-signal ratio the variance of the ARFIMA (1,d,0) process is obtained by
We conduct the simulation study for all three forms of the LPWN estimator of Frederiksen et al. (2012). The bias and RMSE results of the three different types are very similar, especially the LPWN(0,1) and LPWN(1,0) show no significant difference. For the Monte Carlo study and the empirical example, we present the results of the LPWN(1,1) since we are varying the autoregressive coefficient for every DGP and also analyze several noise structures as perturbation. In general, we follow the commonly used parameter settings in the literature to reflect the empirical findings in the financial volatility. For all estimation methods, we choose the following values of the bandwidth with . The additional parameter of Smith (2005) is set to . To satisfy the trimming and bandwidth condition of Iacone (2010), we choose and . We consider the adaptive procedure of McCloskey and Perron (2013), since this extension exhibits a smaller variance. The first step of the adaptive method, , applies the setting of the trimmed GPH estimator with . For the next iterations, , the trimming changes to with as a consistent estimator of d. Two different convergence criteria are used, either the procedure stops as or when with the final value of . We set and for the estimator of McCloskey and Perron (2013) and the GPH estimator is used as starting value. The numerical optimization of the Monte Carlo study is based on R using the L-BFGS-B algorithm developed by Byrd et al. (1995).
3.2. Monte Carlo Results
In the following, the DGPs are numbered consecutively according to the order in Table 1. The bias and root mean squared error results of all estimation methods and for the corresponding DGPs are given in the Supplementary Materials. Before presenting some detailed results, we are summarizing the major findings of the simulation study.
The two standard estimation methods are very robust compared to the modified methods in two cases. Considering the first DGP without contamination and the ARFIMA (1,d,0) plus GARCH (1,1), the log-periodogram and Gaussian estimator are both characterized by a smaller bias and RMSE especially for . In the case of a larger bandwidth and , the modified estimators of Andrews and Sun (2004) and Hou and Perron (2014) perform slightly better or equivalent in terms of the RMSE than the local Whittle estimator. The same results hold for the modified estimator of Smith (2005) compared to the GPH estimator.
For a sinus trend or deterministic level shift as contamination type, the modified estimator of Hou and Perron (2014) is outperforming the local Whittle estimator in terms of bias and also for the majority cases of RMSE. Additionally, for the two variations of the random level shift process, performs well, especially for lower values of the memory parameter (d ≤ 0.2).
The two trimmed versions of the local Whittle and GPH estimator are both exhibiting a very similar pattern over the DGPs. Similar to the estimator of Hou and Perron (2014), the estimators of Iacone (2010) and McCloskey and Perron (2013) also have their strength in the presence of level shifts, irrespective of whether they occur randomly (non-)stationary or deterministic. The good performance in the aforementioned situations is restricted to smaller values of d and to less short-run effects.
While the estimators of Hou and Perron (2014), Iacone (2010) and McCloskey and Perron (2013) often improve the standard estimators in the short-memory case or without short-run dynamics, the methods of Smith (2005), Andrews and Sun (2004), Hurvich et al. (2005) and Frederiksen et al. (2012) outperform their respective standard methods for larger values of the persistence parameter (d ≥ 0.4) as well as for a higher short-run parameter (). This finding is not very surprising for the three estimation methods designed for perturbation, however the good performance of in these situations is rather unexpected. In particular, the DGPs especially constructed for the perturbation setup are dominated by the perturbation estimators and by Smith (2005). Moreover, unreported simulation studies stress the robustness of the estimation method of Smith (2005) to short-run effects with values larger than .
After a broad overview of the simulation results, we focus on three different contamination types in more detail: a sinus trend, a stationary random level shift and an additive noise term. Since the parameter intervals of the Monte Carlo study are very comprehensive, we concentrate on a sample size of for the following three tables and distinguish between two bandwidths. Further, we omit the persistence value of for the first two detailed DGPs and for the third contamination type we add the memory value but exclude the short-memory case.
The results of a sinus trend as contamination are presented in Table 2. The best performance in terms of lowest bias and RMSE is obtained by the GPH and modified GPH estimator of McCloskey and Perron (2013). Further, the trimmed local Whittle estimator of Iacone (2010) exhibits a comparable small bias and RMSE for . In the next step, we compare the modified methods to the respective standard estimators. The modified estimator of Hou and Perron (2014) outperforms the local Whittle estimator for all combinations in terms of bias and RMSE. Generally, the estimator improves the performance with a larger bandwidth, except for situations with a larger autoregressive parameter of the ARFIMA model. The performance of the estimator of Iacone (2010) is very similar with an even smaller bias and RMSE for and for combined with a smaller bandwidth. Although the trimmed GPH estimator of McCloskey and Perron (2013) performs well in terms of the bias for , the inflated variance increases the RMSE compared to the GPH estimator in most cases. The estimator of Smith (2005) performs better with an increasing autoregressive parameter and for a larger bandwidth. However, the three estimation methods developed for perturbed fractional processes are not an alternative to the standard methods. For the trimmed local Whittle estimator, the reduction of the RMSE is in the range of 60–80% for and remains within 30–75% for . In contrast to the aforementioned estimator, the estimator of Hou and Perron (2014) has a smaller reduction of the RMSE for with 20–65% due to the higher bias. For , the reduction of the RMSE of is very similar to the estimator of Iacone (2010) with 35–80% and remains within 20–75% for , except for . The estimator of Smith (2005) provides a smaller reduction of the RMSE compared to the estimator of Hou and Perron (2014) for the highest value of the autoregressive parameter with 5–50%.
Table 2.
DGP2:ARFIMA (1,d,0) plus sinus trend for T = 1024.
Table 3 presents the results for a stationary random level shift as contamination. In general, the results of the non-stationary RLS in the Supplementary Materials have a similar pattern but with a larger bias due to the non-stationarity and, thus, an increased RMSE. Three out of the four modified estimators developed especially for low frequency contaminations, such as a random level shifts, improve the standard methods, especially for smaller persistence values. The highest reduction in the RMSE for the estimation methods of Hou and Perron (2014), Iacone (2010) and McCloskey and Perron (2013) is obtained for with 50–55%, 35–50% and 1–35%, respectively, and with less improvement for an increased short-run effect. The performance of is rather unexpected and shows no improvement against the GPH estimator. The poor results of Smith (2005) are stressed by the fact that the estimator of Andrews and Sun (2004) outperforms , even though the estimator of Smith (2005) has originally been developed for random level shifts, unlike . The three estimation methods not explicitly developed for low frequency contaminations are offering no improvement. Nevertheless, compared to the sinus trend above the bias and RMSE decreased and the findings are getting closer to the other modified estimators, especially for a higher short-run dynamic.
Table 3.
DGP3: ARFIMA (1,d,0) plus stationary RLS for T = 1024.
After two typical examples of low frequency contaminations in the form of a time trend and level shift, we consider the effect of an additive noise term with the results given in Table 4. Overall, the estimators of Smith (2005), Hurvich et al. (2005) and Frederiksen et al. (2012) are the three best performing estimation methods in terms of bias and RMSE. In the following, we compare the modified methods to the respective standard estimators. As expected, the three estimation methods developed for perturbed fractional processes are dominating the standard methods in terms of a lower bias and RMSE, although a RMSE reduction is restricted to larger memory values of . Additionally, the estimator of Smith (2005) performs well compared to the GPH estimator. The reduction of the RMSE for the estimators of Smith (2005) and Andrews and Sun (2004) is decreasing over the interval and ranging from 20–30% to 15–30% and finally to 10–30%. A similar but slightly larger reduction of the RMSE is obtained for the estimation methods of Hurvich et al. (2005) and Frederiksen et al. (2012) with 20–60%, 15–60% and still 5–60% for the same aforementioned region of . The largest reduction is gained for and , irrespective of the previous estimation methods. In the presence of an additive noise term, the two standard methods are more robust than the four modified estimators developed for low frequency contaminations, except for Smith (2005).
Table 4.
DGP8: ARFIMA (1,d,0) plus ARMA(0,0) for T = 1024.
The last detailed DGP in Table 5 contains two groups of contamination: a stationary random level shift and an additive noise term. The overall outcome combines the individual results of each contamination type from Table 3 and Table 4. Excluding the short-memory process, the estimators of Smith (2005) and Andrews and Sun (2004) perform best in terms of bias and RMSE. For the reduction of the RMSE to the respective standard method of Smith (2005) and Andrews and Sun (2004) equals on average , irrespectively of the short-run influence. On the contrary, the estimators of Iacone (2010) and Hou and Perron (2014) provide the best results for a short-memory process being contaminated. With an increasing influence of the short-run dynamic, the reduction of the RMSE for decreases on average from 55% to 50% and then to 30% for the estimators of Iacone (2010) and Hou and Perron (2014). Therefore, no procedure provides stable results over the whole range of the persistence parameter in the case of two contamination types.
Table 5.
DGP9: ARFIMA (1,d,0) plus stationary RLS plus additive noise for T = 1024.
In the following, we give a broad user-guideline by focusing on the RMSE. Usually, an economist is not aware of specific trends, level shifts or perturbation types when empirical data are analyzed. In the following, we compare the effects of two possible scenarios. The first situation is characterized by a perturbation process and instead of using the more appropriate estimators designed for this specific case one falsely applies estimation methods developed for low frequency contamination. The Monte Carlo results indicate a moderate increase of the RMSE for low frequency contaminated estimators, apart from . The next scenario summarizes the reverse case, which means that, for a low frequency contaminated process, the estimators developed to capture perturbation are used. Depending on the specific type of low frequency contamination, the Monte Carlo study shows mixed results. Considering a sinus trend or deterministic level shift the RMSE increases substantially for the perturbation estimators, in some cases three times as much as the estimators developed for low frequency contamination. The increase of the RMSE for a (non-)stationary RLS is lower than for the two aforementioned processes but still more than twice as high as the RMSE of low frequency contaminated estimators. The random level shift process plus an additive noise term shows slightly higher root mean squared errors. Considering the three different types of random level shifts an improvement of the RMSE is obtained for when the perturbation estimators are used instead of the methods designed for low frequency contamination. Therefore, we recommend the estimators developed for low frequency contamination, since the increase in a perturbation setup is not as severe as in the reverse case, especially in the stationary region of the memory parameter.
In summary, our results show a good performance of in situations of a high short-run dynamic and in typical perturbation situations, however, in cases of low frequency contaminations, the estimator shows some weaknesses. The estimators of Iacone (2010) and Hou and Perron (2014) perform very similar in terms of bias and RMSE, whereas is slightly better. In many situations, the estimator of McCloskey and Perron (2013) cannot compete with the other modified estimators developed for low frequency contamination in terms of RMSE due to the higher variance. Finally, the estimators of Hurvich et al. (2005) and Frederiksen et al. (2012) yield almost identical findings, which are in most situations better than the results of Andrews and Sun (2004).
4. Application
In this section, we analyze the daily log-absolute return series of the S&P 500 from 1 January 1997 to 31 October 2017 (T = 5245) to investigate the robustness of the aforementioned results to the choice of estimator. Furthermore, we apply methods robust to perturbation as well as to low frequency contaminations which gives us additional insights which of these effects if not both are of relevance in our data set. We follow the method of Xu and Perron (2014) and calculate the log-absolute returns as . The log-returns are obtained by differencing the logarithm of the price index, , and the constant 0.001 is added to avoid the problem of taking the logarithm of zero. Figure 1 displays the time series of the S&P 500 with the hyperbolically decaying autocorrelation function and the periodogram with a pole at the origin, as typical characteristics of a long-memory process.
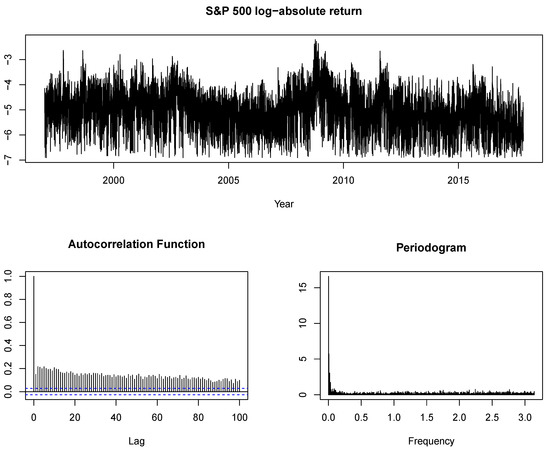
Figure 1.
The log-absolute return series of the S&P 500 with the corresponding autocorrelation function and periodogram.
We estimate the persistence parameter with nine different estimation methods and vary the bandwidth parameter according to our Monte Carlo study with and . The parameter settings of the corresponding estimation methods remain unchanged to the simulation study above. Table 6 shows the estimation results of and the standard errors which are given in brackets below. Additionally, we apply the univariate test of Qu (2011) to test the null hypothesis of a true long-memory process against spurious long memory. The test statistics are given in the last column of Table 6. We set the trimming parameter of Qu (2011) to and the critical value equals 1.517 at the 1% significance level.
Table 6.
estimates and the corresponding standard errors in brackets below for different bandwidths with * denoting significance at 1% level.
In general, the memory parameters decrease with an increased bandwidth, with the exception of and . This finding gives a first hint that the series might be contaminated since the long-memory component dominates for higher frequencies in a contaminated process (cf. Perron and Qu 2010). The estimators of Iacone (2010), Hou and Perron (2014) and McCloskey and Perron (2013) are downward biased compared to the respective non-modified standard method. Especially for the highest bandwidth (), the reduction of the memory is extremely strong with less than half of the memory value for and compared to . This downward pattern of the estimators for an increased bandwidth suggests the existence of low frequency contaminations in the log-absolute return series of the S&P 500. This interpretation is in line with the test results of Qu (2011). The test rejects the null hypothesis for and at the 1% significance level and therefore suggests that the S&P 500 series follows a spurious long-memory process.
Contrary to this finding, the four other estimation methods present upward biased estimator of in a non-stationary region compared to the local Whittle or GPH estimator. The estimator of Andrews and Sun (2004) increases less than the other estimators and lies only for in the non-stationary region. However, the estimators of Smith (2005), Frederiksen et al. (2012) and, especially, Hurvich et al. (2005) show larger memory parameters in the non-stationary region. The estimation results of Hurvich et al. (2005) and Frederiksen et al. (2012) are very similar. As expected from the simulation study, the estimator of Smith (2005) behaves rather unexpected since it is an estimator originally designed to capture low frequency contaminations instead of perturbation.
The estimators developed to capture perturbation are in the non-stationary region and combined with downward biased standard estimators and even more biased modified estimators for low frequency contamination a perturbed fractional process may be possible (cf. Wenger et al. 2017). Our findings are in line with those of McCloskey and Perron (2013) and Frederiksen et al. (2012), whereas the interpretation of the latter authors differs to our interpretation of a spurious long-memory process. We conclude that the analyzed time series follows a spurious long-memory process rather than a perturbed fractional process. In addition to the estimation results, this interpretation is supported by a formal test of Qu (2011) and the current literature of spurious long memory (cf. Lu and Perron 2010 or Qu and Perron 2013). Without the test results of Qu (2011), a perturbed fractional process would be an alternative conclusion.
In summary, the two standard methods indicate a stationary long-memory process, whereas the methods of Iacone (2010), Hou and Perron (2014) and McCloskey and Perron (2013) suggest a weakly stationary long-memory process, especially for the highest bandwidth. The four other modified estimation methods imply a non-stationary long-memory process.
5. Conclusions
In this paper, we analyze the performance of nine semiparametric estimation methods and compare them in a simulation study. The Monte Carlo study suggests to use either the estimator of Iacone (2010) or Hou and Perron (2014) in cases of low frequency contaminations. Although the estimator of McCloskey and Perron (2013) yields comparable estimation results, it suffers from a higher variance. The performance of the estimator of Smith (2005) in cases of high short-run dynamics or perturbation is comparable to the standard perturbation methods, even though the estimator has originally been developed for low frequency contamination. However, in the latter situation, the estimator is no alternative to its competitors. Furthermore, the estimators of Hurvich et al. (2005) and Frederiksen et al. (2012) yield almost identical findings, which are in most situations better than the results of Andrews and Sun (2004). Based on the Monte Carlo results, we recommend applying the low frequency estimators when its unclear whether a low frequency contamination or a perturbed fractional process is present. In our empirical example, we consider the log-absolute return series of the S&P 500. The downward pattern of Iacone (2010), Hou and Perron (2014) and McCloskey and Perron (2013) as the bandwidth increases combined with a rejection of the null hypothesis of a true long-memory process by the test of Qu (2011) suggests a spurious long-memory process. This paper presents the strengths and weaknesses of the different semiparametric estimation methods and provide some user-guidelines.
Supplementary Materials
The following are available online at http://www.mdpi.com/2225-1146/6/1/13/s1. The tables present the bias and root mean squared error (RMSE) results of nine dierent estimation methods.
Supplementary File 1Author Contributions
The authors contributed jointly to the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Andrews, Donald W.K., and Yixiao Sun. 2004. Adaptive local polynomial Whittle estimation of long-range dependence. Econometrica 72: 569–614. [Google Scholar] [CrossRef]
- Arteche, Josu. 2004. Gaussian semiparametric estimation in long memory in stochastic volatility and signal plus noise models. Journal of Econometrics 119: 131–54. [Google Scholar] [CrossRef]
- Arteche, Josu. 2006. Semiparametric estimation in perturbed long memory series. Computational Statistics & Data Analysis 51: 2118–141. [Google Scholar]
- Byrd, Richard H., Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. 1995. A limited memory algorithm for bound constrained optimization. SIAM Journal on Scientific Computing 16: 1190–208. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Atsushi Inoue. 2001. Long memory and regime switching. Journal of Econometrics 105: 131–59. [Google Scholar] [CrossRef]
- Doukhan, Paul, George Oppenheim, and Murad Taqqu. 2002. Theory and Applications of Long-Range Dependence. Berlin: Springer Science & Business Media. [Google Scholar]
- Faÿ, Gilles, Eric Moulines, François Roueff, and Murad S. Taqqu. 2009. Estimators of long-memory: Fourier versus wavelets. Journal of Econometrics 151: 159–77. [Google Scholar] [CrossRef]
- Frederiksen, Per, Frank S. Nielsen, and Morten Ørregaard Nielsen. 2012. Local polynomial Whittle estimation of perturbed fractional processes. Journal of Econometrics 167: 426–47. [Google Scholar] [CrossRef]
- Frederiksen, Per, and Morten Ørregaard Nielsen. 2008. Bias-reduced estimation of long-memory stochastic volatility. Journal of Financial Econometrics 6: 496–512. [Google Scholar] [CrossRef]
- Geweke, John, and Susan Porter-Hudak. 1983. The estimation and application of long memory time series models. Journal of Time Series Analysis 4: 221–38. [Google Scholar] [CrossRef]
- Granger, Clive W. J., and Namwon Hyung. 2004. Occasional structural breaks and long memory with an application to the S&P 500 absolute stock returns. Journal of Empirical Finance 11: 399–421. [Google Scholar]
- Granger, Clive W. J., and Roselyne Joyeux. 1980. An introduction to long-memory time series models and fractional differencing. Journal of Time Series Analysis 1: 15–29. [Google Scholar] [CrossRef]
- Haldrup, Niels, and Morten Ørregaard Nielsen. 2007. Estimation of fractional integration in the presence of data noise. Computational Statistics & Data Analysis 51: 3100–14. [Google Scholar]
- Hosking, Jonathan R. M. 1981. Fractional differencing. Biometrika 68: 165–76. [Google Scholar] [CrossRef]
- Hou, Jie, and Pierre Perron. 2014. Modified local Whittle estimator for long memory processes in the presence of low frequency (and other) contaminations. Journal of Econometrics 182: 309–28. [Google Scholar] [CrossRef]
- Hurvich, Clifford M., Eric Moulines, and Philippe Soulier. 2005. Estimating long memory in volatility. Econometrica 73: 1283–328. [Google Scholar] [CrossRef]
- Hurvich, Clifford M., and Bonnie K. Ray. 2003. The local Whittle estimator of long-memory stochastic volatility. Journal of Financial Econometrics 1: 445–70. [Google Scholar] [CrossRef]
- Iacone, Fabrizio. 2010. Local Whittle estimation of the memory parameter in presence of deterministic components. Journal of Time Series Analysis 31: 37–49. [Google Scholar] [CrossRef]
- Kuensch, Hans R. 1987. Statistical aspects of self-similar processes. Paper presented at First World Congress of the Bernoulli Society, Tashkent, Uzbekistan, September 8–14; pp. 67–74. [Google Scholar]
- Lu, Yang K., and Pierre Perron. 2010. Modeling and forecasting stock return volatility using a random level shift model. Journal of Empirical Finance 17: 138–56. [Google Scholar] [CrossRef]
- McCloskey, Adam. 2013. Estimation of the long-memory stochastic volatility model parameters that is robust to level shifts and deterministic trends. Journal of Time Series Analysis 34: 285–301. [Google Scholar] [CrossRef]
- McCloskey, Adam, and Jonathan B. Hill. 2017. Parameter estimation robust to low-frequency contamination. Journal of Business & Economic Statistics 35: 598–610. [Google Scholar]
- McCloskey, Adam, and Pierre Perron. 2013. Memory parameter estimation in the presence of level shifts and deterministic trends. Econometric Theory 29: 1196–237. [Google Scholar] [CrossRef]
- Perron, Pierre, and Zhongjun Qu. 2010. Long-memory and level shifts in the volatility of stock market return indices. Journal of Business & Economic Statistics 28: 275–90. [Google Scholar]
- Qu, Zhongjun. 2011. A test against spurious long memory. Journal of Business & Economic Statistics 29: 423–38. [Google Scholar]
- Qu, Zhongjun, and Pierre Perron. 2013. A stochastic volatility model with random level shifts and its applications to S&P 500 and NASDAQ return indices. The Econometrics Journal 16: 309–39. [Google Scholar]
- Robinson, Peter M. 1995. Log-periodogram regression of time series with long range dependence. The Annals of Statistics 23: 1048–72. [Google Scholar] [CrossRef]
- Smith, Aaron. 2005. Level shifts and the illusion of long memory in economic time series. Journal of Business & Economic Statistics 23: 321–35. [Google Scholar]
- Sun, Yixiao, and Peter C. B. Phillips. 2003. Nonlinear log-periodogram regression for perturbed fractional processes. Journal of Econometrics 115: 355–89. [Google Scholar] [CrossRef]
- Wenger, Kai, Christian Leschinski, and Philipp Sibbertsen. 2017. The Memory of Volatility. Unpublished Manuscript. Hanover, Germany: Department of Economics, University of Hannover. [Google Scholar]
- Xu, Jiawen, and Pierre Perron. 2014. Forecasting return volatility: Level shifts with varying jump probability and mean reversion. International Journal of Forecasting 30: 449–63. [Google Scholar] [CrossRef]
- Yamamoto, Yohei, and Pierre Perron. 2013. Estimating and testing multiple structural changes in linear models using band spectral regressions. The Econometrics Journal 16: 400–29. [Google Scholar] [CrossRef][Green Version]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).